Python 爬虫开发
文章目录
- 1. 常用库安装
- 2. 基础爬虫开发
- 2.1. 使用 requests 获取网页内容
- 2.2. 使用 BeautifulSoup 解析 HTML
- 2.3. 处理登录与会话
- 3. 进阶爬虫开发
- 3.1. 处理动态加载内容(Selenium)
- 3.2. 使用Scrapy框架
- 3.3. 分布式爬虫(Scrapy-Redis)
- 4. 爬虫优化与反反爬策略
- 4.1. 常见反爬机制及应对
- 4.2. 代理IP使用示例
- 4.3. 随机延迟与请求头
BeautifulSoup 官方文档
https://beautifulsoup.readthedocs.io/zh-cn/v4.4.0/
https://cloud.tencent.com/developer/article/1193258
https://blog.csdn.net/zcs2312852665/article/details/144804553
参考:
https://blog.51cto.com/haiyongblog/13806452
1. 常用库安装
pip install requests beautifulsoup4 scrapy selenium pandas
2. 基础爬虫开发
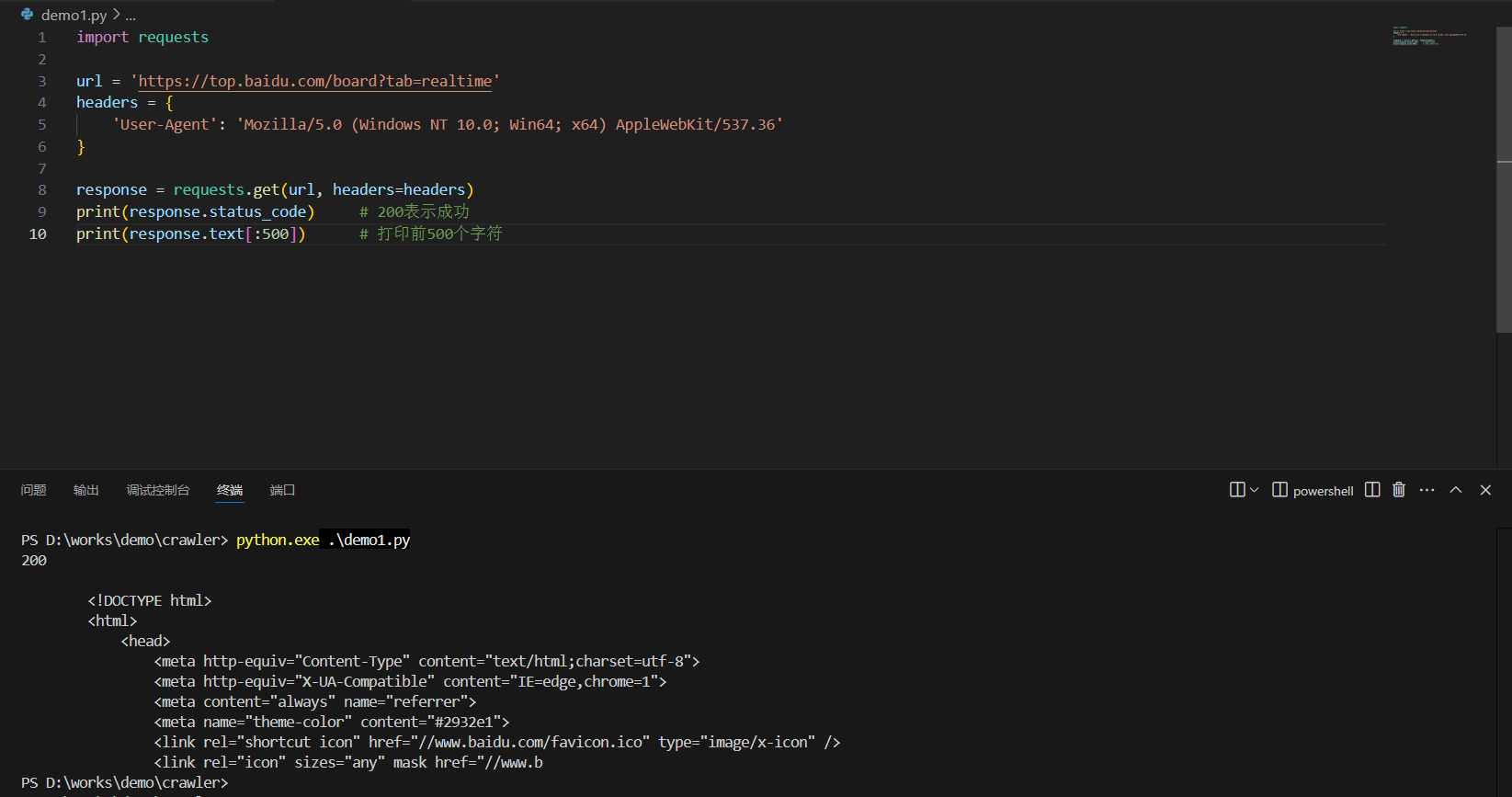
2.1. 使用 requests 获取网页内容
import requestsurl = 'https://top.baidu.com/board?tab=realtime'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}response = requests.get(url, headers=headers)
print(response.status_code) # 200表示成功
print(response.text[:500]) # 打印前500个字符
2.2. 使用 BeautifulSoup 解析 HTML
from bs4 import BeautifulSouphtml_doc = """<html><head><title>测试页面</title></head><body><p class="title"><b>示例网站</b></p><p class="story">这是一个示例页面<a href="http://example.com/1" class="link" id="link1">链接1</a><a href="http://example.com/2" class="link" id="link2">链接2</a></p>"""soup = BeautifulSoup(html_doc, 'html.parser')# 获取标题
print(soup.title.string)# 获取所有链接
for link in soup.find_all('a'):print(link.get('href'), link.string)# 通过CSS类查找
print(soup.find('p', class_='title').text)
2.3. 处理登录与会话
import requestslogin_url = 'https://example.com/login'
target_url = 'https://example.com/dashboard'session = requests.Session()# 登录请求
login_data = {'username': 'your_username','password': 'your_password'
}response = session.post(login_url, data=login_data)if response.status_code == 200:# 访问需要登录的页面dashboard = session.get(target_url)print(dashboard.text)
else:print('登录失败')
3. 进阶爬虫开发
3.1. 处理动态加载内容(Selenium)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager# 设置无头浏览器
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无界面模式
options.add_argument('--disable-gpu')# 自动下载chromedriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)url = 'https://dynamic-website.com'
driver.get(url)# 等待元素加载(隐式等待)
driver.implicitly_wait(10)# 获取动态内容
dynamic_content = driver.find_element(By.CLASS_NAME, 'dynamic-content')
print(dynamic_content.text)driver.quit()
3.2. 使用Scrapy框架
# 创建Scrapy项目
# scrapy startproject example_project
# cd example_project
# scrapy genspider example example.com# 示例spider代码
import scrapyclass ExampleSpider(scrapy.Spider):name = 'example'allowed_domains = ['example.com']start_urls = ['http://example.com/']def parse(self, response):# 提取数据title = response.css('title::text').get()links = response.css('a::attr(href)').getall()yield {'title': title,'links': links}# 运行爬虫
# scrapy crawl example -o output.json
3.3. 分布式爬虫(Scrapy-Redis)
# settings.py配置
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = 'redis://localhost:6379'# spider代码
from scrapy_redis.spiders import RedisSpiderclass MyDistributedSpider(RedisSpider):name = 'distributed_spider'redis_key = 'spider:start_urls'def parse(self, response):# 解析逻辑pass
4. 爬虫优化与反反爬策略
4.1. 常见反爬机制及应对
User-Agent检测 :随机切换User-Agent
IP限制:使用代理IP池
验证码:OCR识别或打码平台
行为分析:模拟人类操作间隔
JavaScript渲染:使用Selenium或Pyppeteer
4.2. 代理IP使用示例
import requestsproxies = {'http': 'http://proxy_ip:port','https': 'https://proxy_ip:port'
}try:response = requests.get('https://example.com', proxies=proxies, timeout=5)print(response.text)
except Exception as e:print(f'请求失败: {e}')
4.3. 随机延迟与请求头
import random
import time
import requests
from fake_useragent import UserAgentua = UserAgent()def random_delay():time.sleep(random.uniform(0.5, 2.5))def get_with_random_headers(url):headers = {'User-Agent': ua.random,'Accept-Language': 'en-US,en;q=0.5','Referer': 'https://www.google.com/'}random_delay()return requests.get(url, headers=headers)
相关文章:
Python 爬虫开发
文章目录 1. 常用库安装2. 基础爬虫开发2.1. 使用 requests 获取网页内容2.2. 使用 BeautifulSoup 解析 HTML2.3. 处理登录与会话 3. 进阶爬虫开发3.1. 处理动态加载内容(Selenium)3.2. 使用Scrapy框架3.3. 分布式爬虫(Scrapy-Redisÿ…...
第十一周作业
一、实现bluecms旁注,并解释为什么旁站攻击可以拿下主站?跨库的意思是什么? 1、为什么旁站攻击可以拿下主站 因为主站业务和旁站业务共处于同一个服务器上面,当我们无法攻破主站业务时,可以通过攻破旁站业务…...
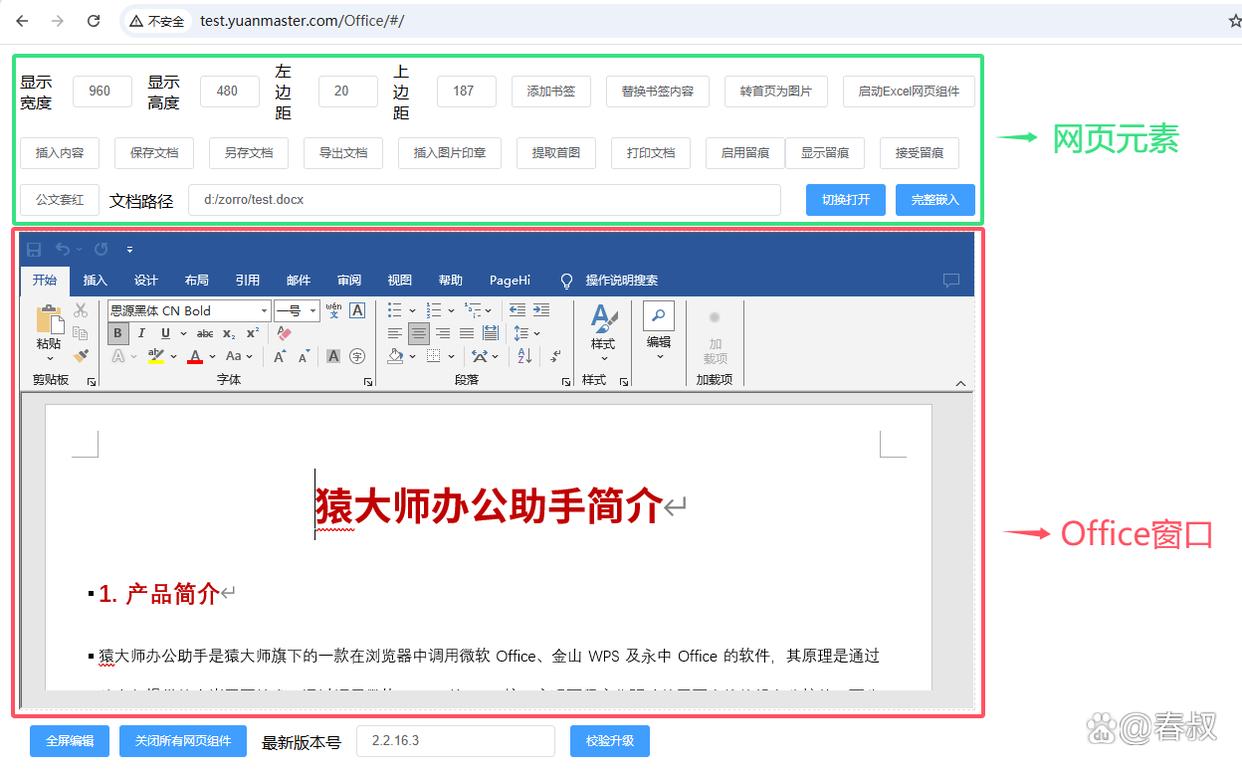
猿大师办公助手网页编辑Office/wps支持服务器文件多线程下载吗?
浏览器兼容性割裂、信创替代迫切的2025年,传统WebOffice控件因依赖NPAPI/PPAPI插件已无法适配Chrome 107等高版本浏览器。猿大师办公助手通过系统级窗口嵌入技术,直接调用本地Office/WPS内核,实现: 真内嵌非弹窗:将Of…...

英码科技携带 “无感知AI数字课堂”解决方案,亮相第22届广东教育装备展
5月23日至25日,第22届广东教育装备展览会在广州国际采购中心盛大举行。作为华为生态重要合作伙伴,英码科技携“无感知AI数字课堂解决方案”重磅登场,聚焦教学提质增效,为教育数字化转型注入新动能。 聚焦课堂真实场景,…...

各个链接集合
golang学习~~_从数组中取一个相同大小的slice有成本吗?-CSDN博客 框架 golang学习~~_从数组中取一个相同大小的slice有成本吗?-CSDN博客 golang k8s学习_容器化部署和传统部署区别-CSDN博客 K8S rabbitmq_rabbitmq 广播-CSD…...

【R语言科研绘图】
R语言在绘制SCI期刊图像时具有显著优势,以下从功能、灵活性和学术适配性三个方面分析其适用性: 数据可视化库丰富 R语言拥有ggplot2、lattice、ggpubr等专业绘图包,支持生成符合SCI期刊要求的高分辨率图像(如TIFF/PDF格式&#…...

Linux Shell 切换
在 Linux 系统中,切换至 Bash Shell 在 Linux 系统中,切换至 Bash Shell 的方法如下: 临时切换到 Bash 直接在终端输入以下命令,启动一个新的 Bash 会话: bash 退出时输入 exit 或按 CtrlD 返回原 Shell。 永久切换…...

ProfiNet转Ethernet/IP网关选型策略适配西门子S7-1500与罗克韦尔ControlLogix5580的关键指标对比
一、行业背景 新能源汽车电池制造是当前工业自动化领域增长最快的细分市场之一。随着动力电池产能扩张与技术迭代,产线对高精度装配、实时数据交互和系统兼容性提出了更高要求。在某头部电池企业的模组装配线中,面临着不同品牌设备通信协议不兼容的问题&…...

AWS WebRTC:获取信令服务节点和ICE服务节点
建立WebRTC的第一步是获取信令服务节点和ICE服务节点。 前提条件是有访问AWS的密钥,主要是ak,sk,token,我这边是业务云有接口可以返回这些信息,所以我直接从业务云获取。 先介绍一下什么是ak,skÿ…...
[图文]图6.3会计事项-Fowler分析模式的剖析和实现
1 00:00:02,090 --> 00:00:05,160 Fowler在书里面也说了,6.4 2 00:00:05,290 --> 00:00:07,540 这里也说了 3 00:00:08,030 --> 00:00:11,340 不是常用的 4 00:00:12,520 --> 00:00:15,060 更倾向用6.2,实际上就是6.3了 5 00:00:15,760 …...
)
[Linux] 利用systemd实现周期性执行任务(DDNS设置案例)
利用systemd实现周期性执行任务 文章目录 利用systemd实现周期性执行任务一、引言二、systemd定时任务基础1. systemd.timer单元的基本概念和工作原理2. systemd.timer与cron的异同对比3. systemd.timer支持的时间规范格式 三、创建systemd定时任务四、管理与监控定时任务1. 定…...

maven 3.0多线程编译提高编译速度
mvn package 默认只使用 单线程 来执行构建生命周期(即顺序地构建每一个模块)。 如果你使用的是多模块项目,Maven 从 3.0 开始提供了**并行构建(parallel build)**的能力,但它不是默认开启的。 如何启用多…...

Dalvik虚拟机、ART虚拟机与JVM的核心区别
一、架构设计差异 指令集架构 JVM:基于栈结构,所有操作(如算术运算、方法调用)均依赖操作数栈完成,指令集紧凑但执行效率较低(需频繁内存交互)。Dalvik&#x…...

Unity 3D AssetBundle加密解密教程
前言 在Unity中加密和解密AssetBundle可以保护你的资源不被未经授权的访问或篡改。以下是详细的步骤和示例代码: 对惹,这里有一个游戏开发交流小组,希望大家可以点击进来一起交流一下开发经验呀! 1. 加密AssetBundle 步骤&…...
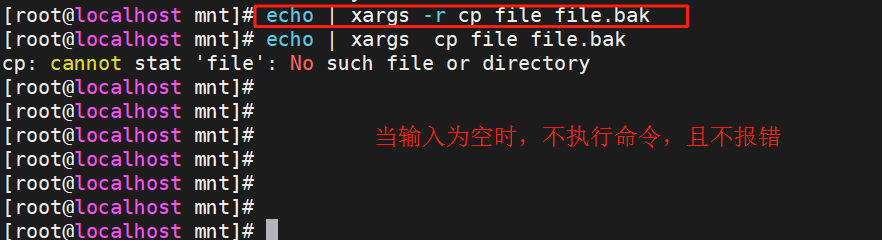
【Linux】shell脚本的常用命令
目录 简介 一.设置主机名称 1.1通过文件修改 1.2通过命令修改 二.网络管理命令nmcli 2.1查看网卡 2.2设置网卡 三.简单处理字符 3.1seq打印连续字符 3.2printf,echo打印字符 3.3sort排序 3.4uniq冗余处理 3.5cut对字符的截取 四.xargs输入转参 简介 以下命令都是…...

Netty应用:从零搭建Java游戏服务器网络框架
在游戏开发领域,服务器网络框架是连接玩家与游戏世界的桥梁,其稳定性和高效性直接影响玩家的游戏体验。本文将详细介绍如何使用Java语言和Netty框架,搭建一个兼具TCP和UDP协议支持的游戏服务器网络框架,并配套开发客户端,助你快速掌握游戏网络开发的核心技术。 1.项目概览…...
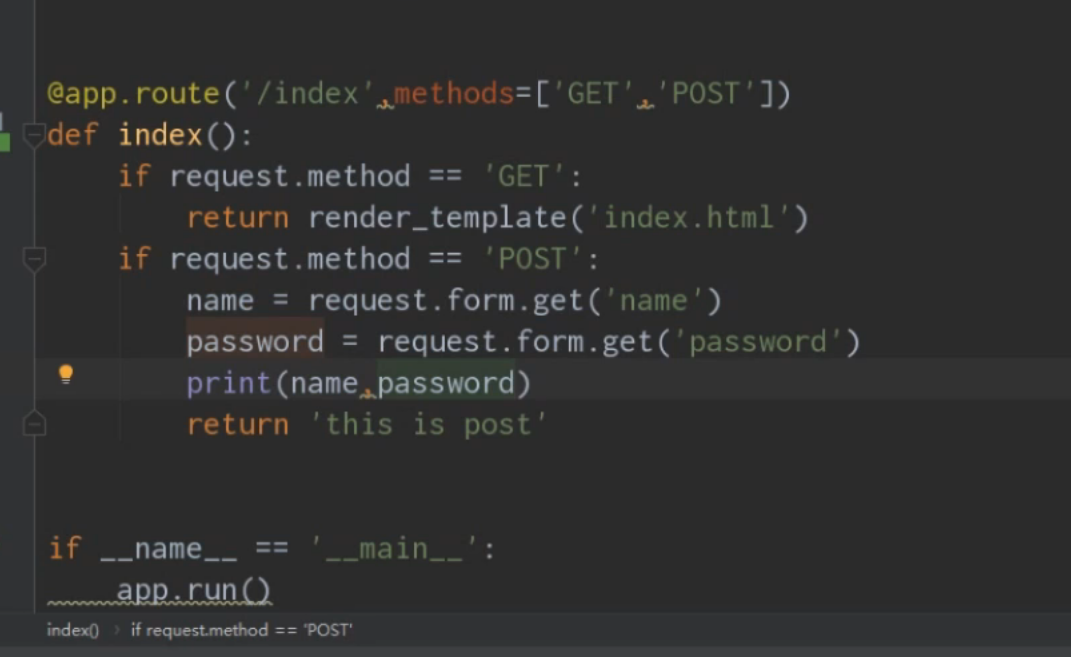
Pycharm and Flask 的学习心得(9)
request对象: 1. request包含前端发送过来的所有请求数据 将from表单里的内容CV到request里面,可以添加if语句来做判断出请求类型后的操作 在网页上的表单上input的数据,后端如何获取呢? request对象获取前端发送来的数据 // …...
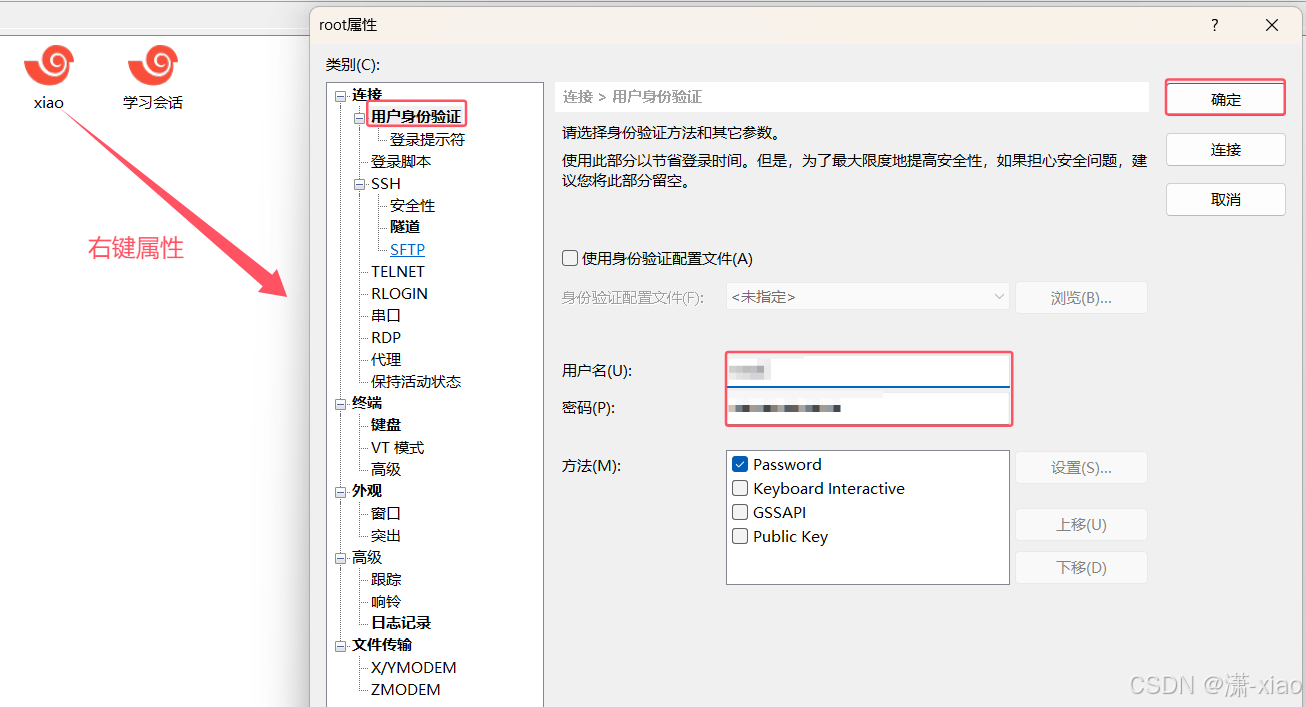
Linux初始-环境安装(2)
文章目录 安装问题(1-1.51.39)xshell的下载和登录步骤xshell创建多用户与删除用户xshell免密码登录 简介:这篇文章我认为对于初学Linux还是非常重要的,正所谓磨刀不误砍柴工,工具环境准备好了,后面的学习才…...

Nginx 安全防护与 HTTPS 部署实战笔记
Nginx 安全防护与 HTTPS 部署实战笔记 一、核心安全配置 (一)编译安装 Nginx 安装支持软件 dnf install -y gcc make pcre-devel zlib-devel openssl-devel perl-ExtUtils-MakeMaker git wget tar作用:安装 Nginx 编译所需的开发包&#…...

Python Day34 学习
今日内容 通过“心脏病数据集”对之前的内容进行复习,再进行新内容“元组和OS模块”的学习。 机器学习模型建模和评估(先不考虑调参) 基于之前已经预处理过的心脏病数据集 划分数据值 模型训练与模型评估 # 随机森林 rf_model RandomFo…...

【ASR】基于分块非自回归模型的流式端到端语音识别
论文地址:https://arxiv.org/abs/2107.09428 摘要 非自回归 (NAR) 模型在语音处理中越来越受到关注。 凭借最新的基于注意力的自动语音识别 (ASR) 结构,与自回归 (AR) 模型相比,NAR 可以在仅精度略有下降的情况下实现有前景的实时因子 (RTF) 提升。 然而,识别推理需要等待…...
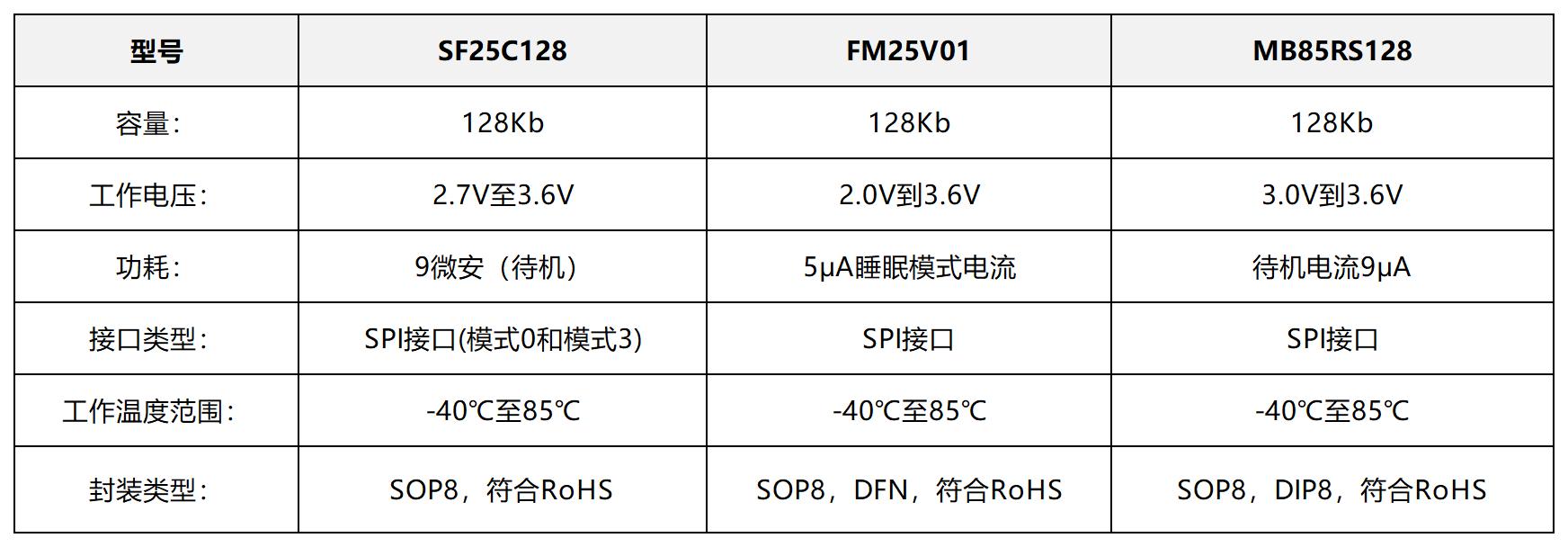
国芯思辰|国产FRAM SF25C128助力监控系统高效低功耗解决方案,对标MB85RS128/FM25V01
监控系统已成为保障公共安全、维护社会秩序的重要工具。随着监控系统的不断发展,对数据存储的要求也越来越高,不仅需要大容量、高速度的存储设备,还要求其具备高可靠性和低功耗等特性。国产铁电存储器 SF25C128作为一种新型非易失性存储器&am…...

攻防世界逆向刷题笔记(新手模式9-1?)
bad_python 看样子是pyc文件损坏了。利用工具打开,发现是MAGIC坏了。搜下也没有头绪。 攻防世界-难度1- bad_python - _rainyday - 博客园 python Magic Number对照表以及pyc修复方法 - iPlayForSG - 博客园 看WP才知道36已经提示了pyc版本了。参考第二个文章&am…...

【golang】能否在遍历map的同时删除元素
Go 团队在设计时确实允许在迭代时删除当前元素,但是不建议直接使用 for k, v : range m 删除。对于单线程读写情况: 主要原因如下: 1. 迭代变量重用问题 Go 的 range 循环会重用迭代变量的内存地址。当你使用 for k, v : range m 时…...
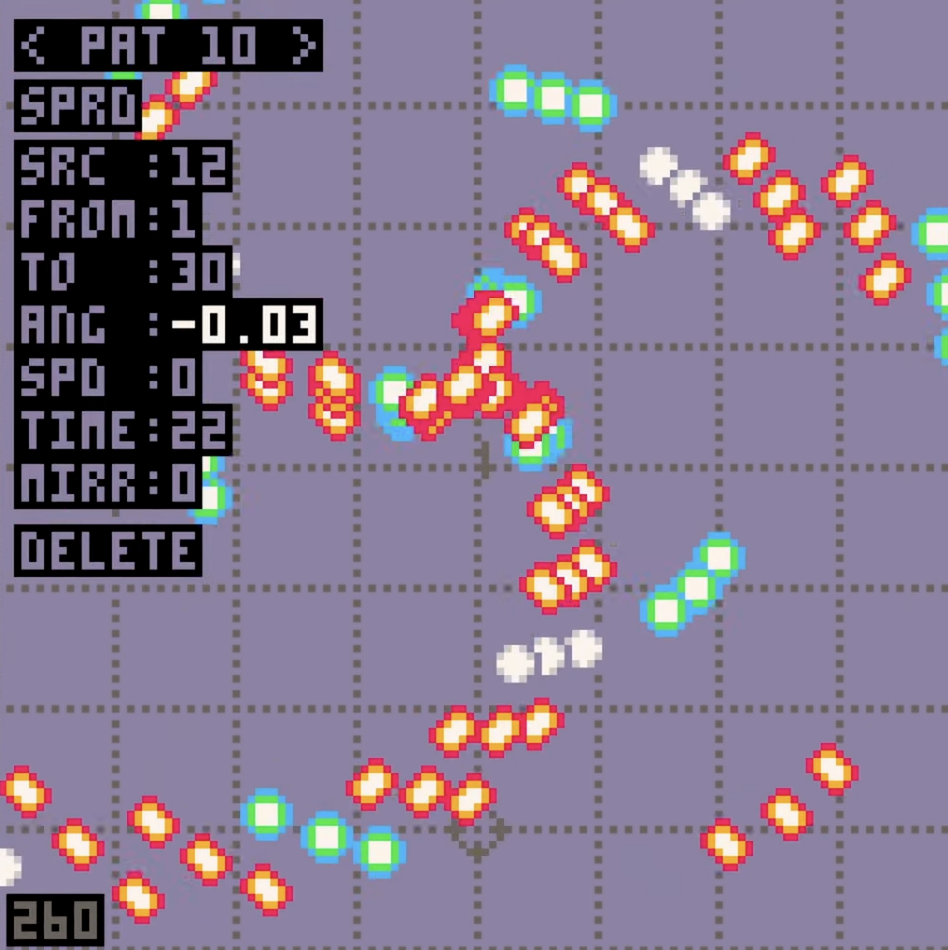
制作一款打飞机游戏58:子弹模式组合
今天我们将继续深入探讨子弹模式系统,并在我们的模式编辑器上做一些收尾工作。 子弹模式系统的乐趣 首先,我想说,这个子弹模式系统真的非常有趣。看着屏幕上不断喷射的子弹,感觉真是太棒了! 合并修饰符 今天&#…...
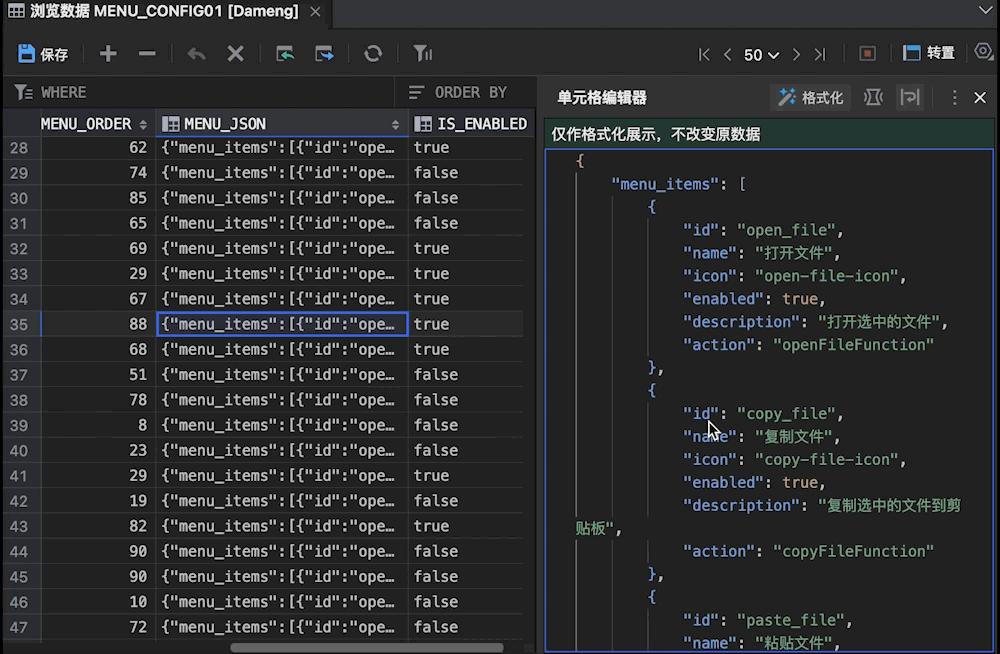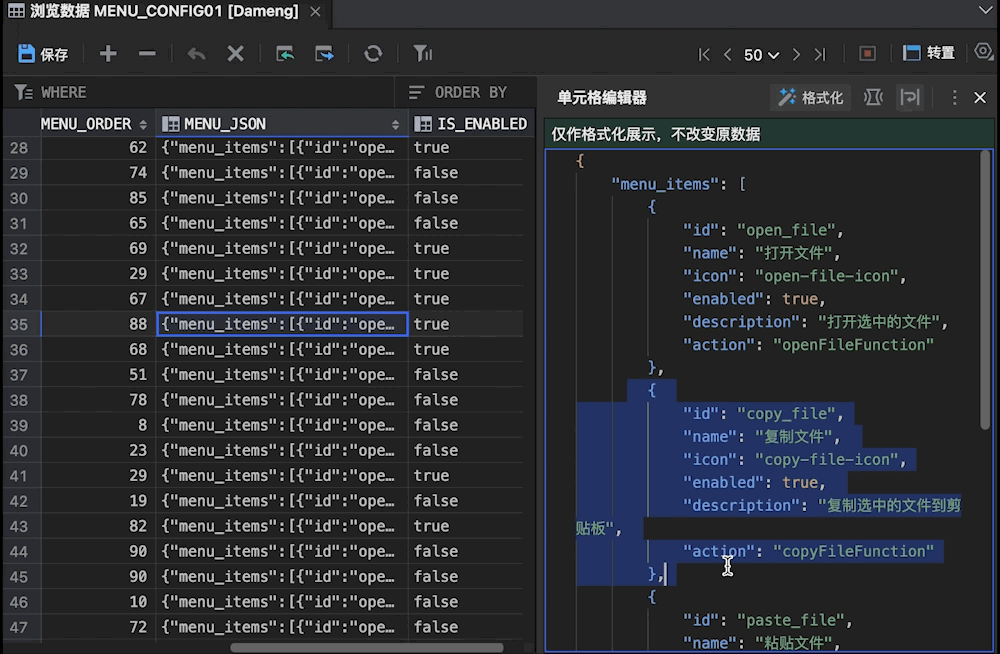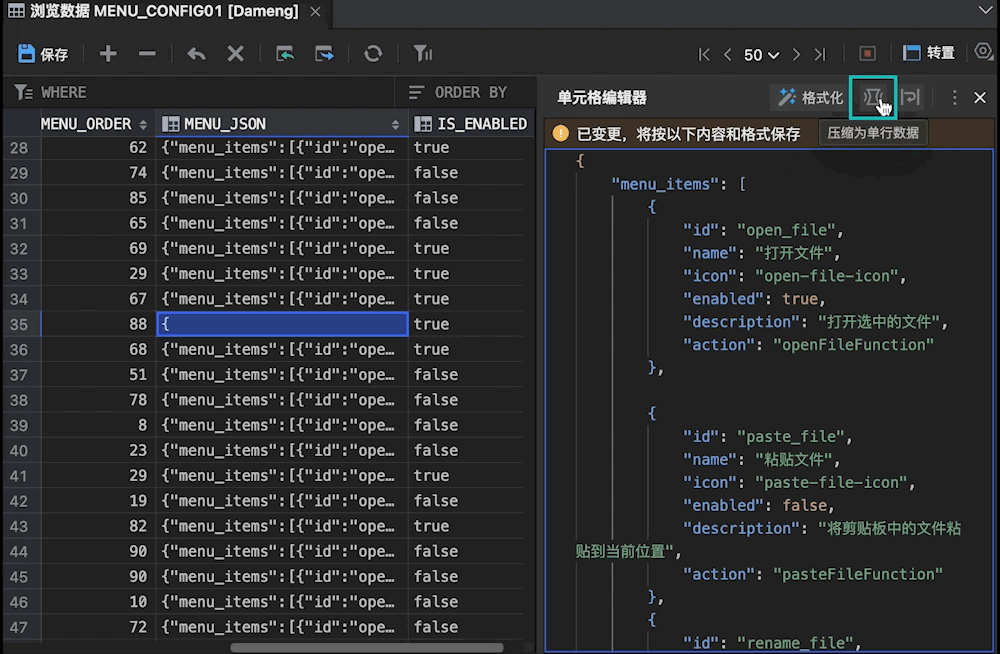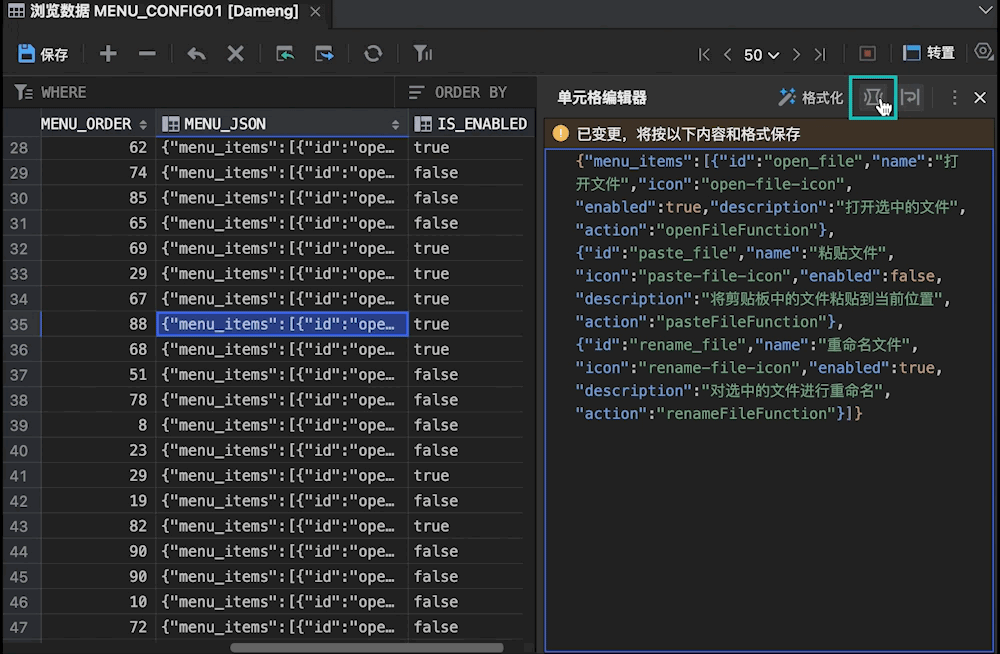
使用新一代达梦管理工具SQLark,高效处理 JSON/XML 数据!
在应用开发领域,JSON/XML数据结构因其灵活性和通用性,成为开发者存储和交换数据的首选。然而,传统管理工具在处理这些半结构化数据时,往往存在可视化效果差、编辑效率低等问题,严重影响开发者的工作效率。 现在&#…...

Qt基础:数据容器类
数据容器类 1. QList1.1 使用创建和初始化添加和删除元素访问和修改元素查找和判断元素遍历列表排序和筛选与其他容器的转换 1.2 完整示例 1. QList 在Qt中,QList 是一个动态数组容器类,用于存储和管理相同类型的元素。它提供了快速随机访问、动态扩展和…...

Vue3监听对象数组属性变化方法
在Vue3中,监听对象数组中某个属性的变化可以通过以下几种方法实现: 方法一:深度监听整个数组并比较属性变化 使用 watch 函数并启用 deep: true,在回调中遍历比较新旧数组的特定属性。 javascript 复制 下载 import { ref, …...
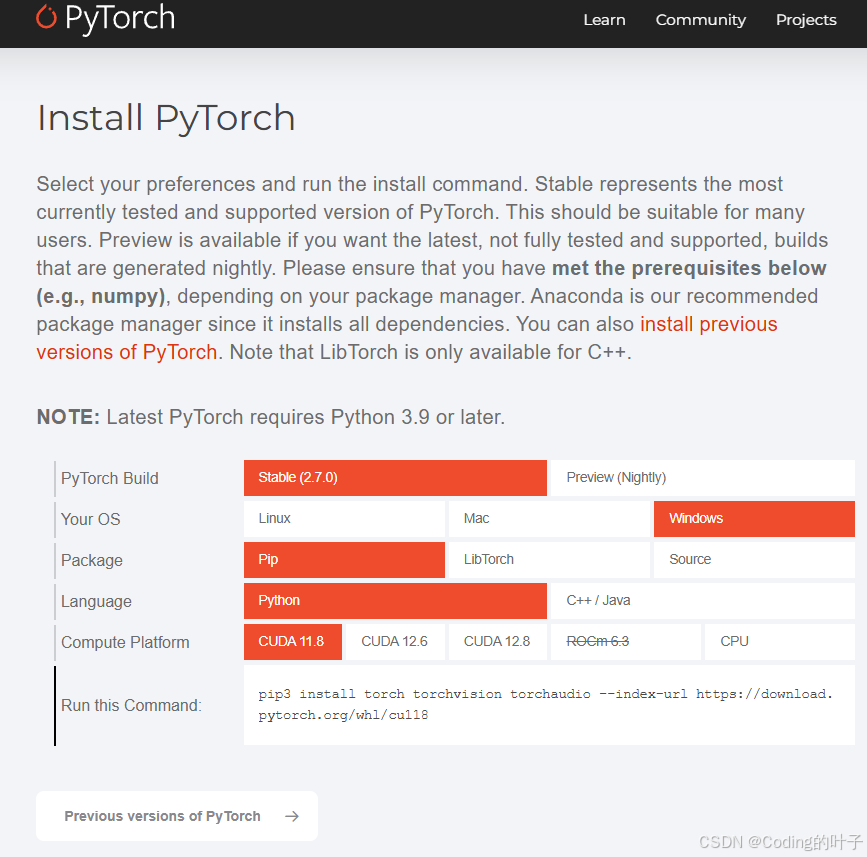
深入了解PyTorch:起源、优势、发展与安装指南
深入了解PyTorch:起源、优势、发展与安装指南 目录 引言PyTorch简介PyTorch的优势 动态计算图直观易用的API强大的社区支持丰富的生态系统高性能与可扩展性 PyTorch的发展历程PyTorch的主要组件 Torch.TensorAutograd自动求导nn模块TorchvisionTorchText和TorchAu…...
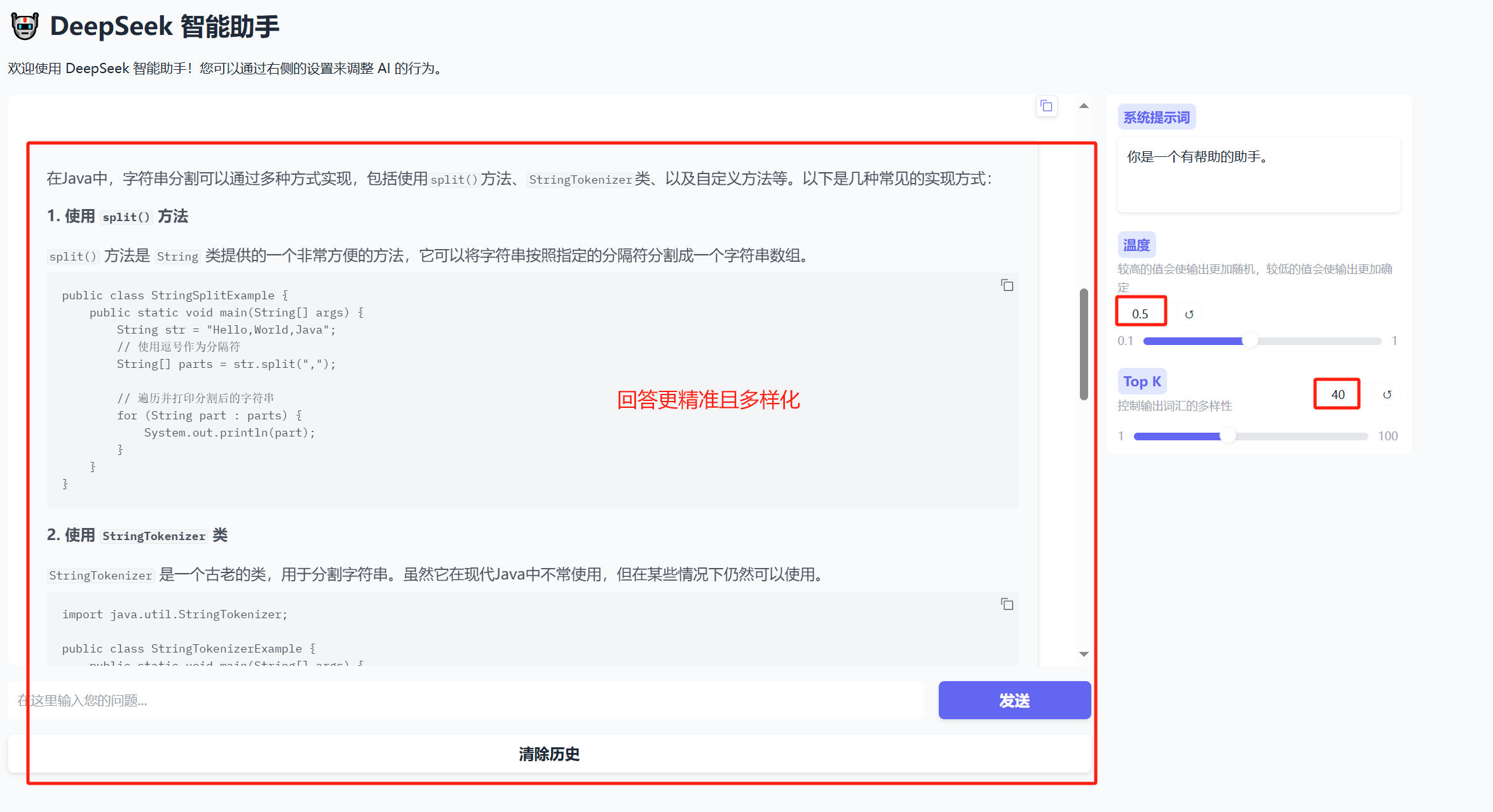
DeepSeek智能对话助手项目
目录: 1、效果图2、实现代码3、温度和TopK的作用对比 1、效果图 2、实现代码 # import gradio as gr# def reverse_text(text): # return text[::-1]# demogr.Interface(fnreverse_text,inputs"text",outputs"text")# demo.launch(share&q…...