深入了解PyTorch:起源、优势、发展与安装指南
深入了解PyTorch:起源、优势、发展与安装指南
目录
- 引言
- PyTorch简介
- PyTorch的优势
- 动态计算图
- 直观易用的API
- 强大的社区支持
- 丰富的生态系统
- 高性能与可扩展性
- PyTorch的发展历程
- PyTorch的主要组件
- Torch.Tensor
- Autograd自动求导
- nn模块
- Torchvision
- TorchText和TorchAudio
- PyTorch的安装方式
- 在Windows上安装PyTorch
- 在Linux上安装PyTorch
- 在macOS上安装PyTorch
- 使用Anaconda安装PyTorch
- 从源码安装PyTorch
- PyTorch的应用场景
- 计算机视觉
- 自然语言处理
- 强化学习
- 语音识别与生成
- PyTorch与其他深度学习框架的比较
- 结论
- 参考资料
引言
随着人工智能和深度学习的迅猛发展,越来越多的深度学习框架被开发出来,旨在简化模型的构建和训练过程。其中,PyTorch作为近年来备受瞩目的开源深度学习框架,凭借其直观易用的接口、灵活的动态计算图和强大的社区支持,迅速赢得了研究者和工程师的青睐。本文将深入探讨PyTorch的起源、优势、发展历程、主要组件、安装方法以及应用场景,帮助读者全面了解这一强大的深度学习工具。
PyTorch简介
PyTorch是一个基于Python的开源深度学习框架,由Facebook的人工智能研究团队(FAIR)于2016年开发并发布。PyTorch提供了丰富且灵活的工具集,支持从学术研究到生产环境的各类深度学习应用。其核心特性包括:
- 动态计算图:允许在运行时改变计算图结构,提供了更大的灵活性,特别适合于需要动态变化结构的模型,如递归神经网络和树状结构模型。
- 直观的API设计:PyTorch的API设计简洁明了,符合Python的编码习惯,降低了学习和使用的门槛。
- 强大的GPU加速:通过与NVIDIA的CUDA深度集成,PyTorch能够充分利用GPU的计算能力,加速深度学习模型的训练和推理过程。
- 丰富的生态系统:PyTorch拥有大量的扩展库和工具,如Torchvision、TorchText和TorchAudio,覆盖了计算机视觉、自然语言处理和音频处理等领域。
- 活跃的社区支持:全球范围内的开发者和研究者积极贡献,使得PyTorch不断演进和完善。
自发布以来,PyTorch已经在学术研究和工业应用中广泛使用,成为深度学习领域的主流框架之一。
PyTorch的优势
PyTorch能够在众多深度学习框架中脱颖而出,得益于其独特的优势和特性。下面我们详细探讨PyTorch的主要优势。
动态计算图
动态计算图是PyTorch最具标志性的特性之一。与早期的静态计算图框架(如TensorFlow 1.x)不同,PyTorch在每次前向传播时都会动态构建计算图,这带来了以下好处:
- 灵活性高:动态计算图允许根据输入数据的不同实时改变模型的结构,适用于处理变长序列、树状结构等复杂数据。
- 易于调试:由于计算图是在运行时构建的,开发者可以像调试普通Python代码一样调试模型,使用断点、打印输出等传统方法,极大地方便了开发和错误定位。
- 更自然的编码体验:动态计算图的构建过程与Python的控制流(如循环、条件判断)无缝结合,使得代码更直观、更易读。
这种动态性使得PyTorch在研究和实验阶段具有巨大的优势,能够快速实现和测试各种创新模型。
直观易用的API
PyTorch的API设计充分考虑了简洁性和可读性,具有以下特点:
- Pythonic风格:API设计遵循Python的编码习惯,变量命名和函数设计直观明了,降低了学习曲线。
- 丰富的文档和示例:PyTorch提供了详尽的官方文档和大量的代码示例,帮助新手快速上手。
- 一致性高:各模块之间的接口设计保持一致,减少了跨模块使用时的理解成本。
- 支持自定义:开发者可以轻松定义自定义的层和函数,满足特定的需求。
这种友好的API设计使得PyTorch不仅适合资深开发者,也非常适合初学者和教学用途。
强大的社区支持
PyTorch拥有一个活跃且充满活力的社区,这为其持续发展提供了强大的推动力:
- 全球贡献者:来自世界各地的开发者和研究者不断为PyTorch贡献代码、文档和示例,丰富了其功能和生态。
- 定期更新和改进:PyTorch团队积极响应社区反馈,定期发布版本更新,修复问题并添加新特性。
- 丰富的第三方库和工具:社区开发了大量基于PyTorch的扩展库,如PyTorch Lightning、fastai等,提供了更高层次的抽象和功能。
- 活跃的讨论和支持:在论坛、GitHub、StackOverflow等平台上,开发者可以迅速获得问题的解答和技术支持。
强大的社区支持确保了PyTorch的稳定性和持续改进,为用户提供了良好的使用体验。
丰富的生态系统
PyTorch的生态系统涵盖了深度学习的各个方面,提供了多种工具和库,支持不同的应用领域:
- Torchvision:专注于计算机视觉,提供了常用的数据集、模型和图像处理工具。
- TorchText:用于自然语言处理,提供了文本数据的预处理、加载和常用模型。
- TorchAudio:用于音频处理,支持音频数据的加载、预处理和模型构建。
- PyTorch Geometric:用于图神经网络,支持处理图结构数据。
- PyTorch Lightning:提供高层次的API,简化模型训练过程,提高代码可复用性。
这些丰富的生态工具使得开发者可以快速构建和部署复杂的深度学习模型,满足各种应用需求。
高性能与可扩展性
PyTorch在性能和可扩展性方面同样表现出色:
- GPU加速:通过与CUDA和cuDNN的深度集成,PyTorch能够充分利用GPU的计算能力,加速训练和推理过程。
- 分布式训练:PyTorch支持多GPU和多节点的分布式训练,适用于大规模模型和数据集的训练需求。
- 混合精度训练:支持FP16等低精度训练方式,减少显存占用,提高训练速度。
- 自定义运算符:允许开发者使用C++或CUDA编写自定义的高性能运算符,满足特殊的性能需求。
- 移动端部署:通过PyTorch Mobile,支持在Android和iOS设备上部署模型,实现边缘计算。
这些特性确保了PyTorch在各种场景下都能提供高效、可靠的性能表现。
PyTorch的发展历程
PyTorch自2016年发布以来,经历了快速的发展和迭代,逐渐成为深度学习领域的主流框架之一。下面回顾一下PyTorch的发展历程:
-
2016年:
- 发布初版:PyTorch由Facebook AI Research(FAIR)团队发布,最初的版本基于Torch框架的核心理念,但使用Python语言,实现了动态计算图的特性。
- 引起关注:由于其灵活性和易用性,PyTorch很快在研究社区中引起广泛关注,许多研究者开始采用PyTorch进行模型开发和实验。
-
2017年:
- 社区扩张:随着用户数量的增长,PyTorch社区开始迅速扩张,出现了大量的教程、示例和第三方扩展库。
- 功能完善:持续的版本更新中,PyTorch添加了更多的功能和优化,包括更丰富的神经网络模块和更高效的计算性能。
-
2018年:
- 1.0版本发布:PyTorch发布了1.0版本,引入了
TorchScript和JIT编译器,增强了模型的可部署性和性能。 - 与Caffe2合并:PyTorch与Facebook的另一个深度学习框架Caffe2合并,整合了两者的优势,进一步提升了性能和生产环境的适用性。
- 1.0版本发布:PyTorch发布了1.0版本,引入了
-
2019年:
- PyTorch Hub推出:PyTorch发布了PyTorch Hub,提供了预训练模型的集中存储和访问,方便开发者快速使用和分享模型。
- 分布式训练支持加强:引入了更完善的分布式训练支持,包括
DistributedDataParallel和混合精度训练等特性。
-
2020年:
- PyTorch Lightning等高层库兴起:社区开发了诸如PyTorch Lightning的高层次抽象库,简化了模型训练和管理过程。
- PyTorch Mobile发布:引入了移动端部署支持,允许开发者将模型部署到Android和iOS设备上,实现边缘计算。
-
2021年及之后:
- 持续优化与扩展:PyTorch持续优化性能,改进API设计,引入更多的功能,如支持新的硬件后端、改进的自动混合精度等。
- 生态系统扩大:越来越多的公司和组织采用PyTorch作为主要的深度学习框架,生态系统不断扩大,应用范围更加广泛。
PyTorch在短短几年内取得的成就,得益于其出色的设计理念、强大的技术支持和活跃的社区参与。未来,PyTorch有望在人工智能领域继续发挥重要作用。
PyTorch的主要组件
PyTorch由多个核心组件构成,每个组件在不同的层面上提供了支持,帮助开发者构建和训练各种复杂的深度学习模型。下面详细介绍PyTorch的主要组件。
Torch.Tensor
**Torch.Tensor**是PyTorch的核心数据结构,类似于NumPy的ndarray,但具有以下独特特性:
-
支持GPU加速:
Tensor可以在CPU和GPU之间自由转换,利用GPU的并行计算能力大幅加速计算。import torch# 创建一个张量 x = torch.rand(5, 3)# 将张量移动到GPU if torch.cuda.is_available():x = x.cuda() -
自动求导集成:
Tensor与PyTorch的自动求导机制(autograd)无缝结合,支持对复杂操作进行梯度计算。# 创建一个可求导的张量 x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) y = x ** 2 y.backward(torch.tensor([1.0, 1.0, 1.0])) print(x.grad) # 输出:tensor([2., 4., 6.]) -
丰富的操作支持:提供了大量的数学运算和操作,支持线性代数、随机数生成、索引、切片等功能,操作方式与NumPy类似。
a = torch.randn(2, 3) b = torch.randn(2, 3) c = a + b # 张量相加 d = torch.matmul(a, b.T) # 矩阵乘法 -
与NumPy互操作:
Tensor和ndarray之间可以轻松转换,方便在PyTorch和其他Python库之间共享数据。import numpy as np# Tensor转为NumPy数组 a = torch.ones(5) b = a.numpy()# NumPy数组转为Tensor c = np.array([1, 2, 3]) d = torch.from_numpy(c)
Torch.Tensor的设计使得PyTorch的数值计算既高效又灵活,满足各种深度学习任务的需求。
Autograd自动求导
**Autograd**是PyTorch中负责自动计算梯度的核心组件,它为神经网络的训练过程提供了强大的支持。Autograd的主要特点包括:
-
动态计算图:
Autograd在每次前向传播时动态构建计算图,根据张量的操作记录节点,支持复杂和动态的模型结构。x = torch.tensor(1.0, requires_grad=True) y = torch.tensor(2.0, requires_grad=True) z = x * y + y ** 2 z.backward() print(x.grad) # 输出:2.0 print(y.grad) # 输出:5.0 -
简单易用:通过设置
requires_grad=True,PyTorch会自动跟踪张量的操作,计算梯度时只需调用backward()方法,无需手动推导和实现。# 示例:计算函数 f(x) = x^3 的梯度 x = torch.tensor(2.0, requires_grad=True) y = x ** 3 y.backward() print(x.grad) # 输出:12.0 -
支持复杂操作:
Autograd能够处理各种复杂的张量操作,包括矩阵乘法、卷积、非线性激活等,自动计算相应的梯度。# 示例:卷积操作的梯度计算 import torch.nn.functional as F input = torch.randn(1, 1, 5, 5, requires_grad=True) weight = torch.randn(1, 1, 3, 3, requires_grad=True) output = F.conv2d(input, weight) output.backward(torch.ones_like(output)) print(input.grad.size()) # 输出:torch.Size([1, 1, 5, 5]) print(weight.grad.size()) # 输出:torch.Size([1, 1, 3, 3]) -
高效性:
Autograd在计算梯度时采用高效的反向传播算法,能够在较短时间内完成大规模模型的梯度计算。
Autograd的存在大大简化了深度学习模型训练中的梯度计算过程,使得开发者可以专注于模型设计和优化,而无需关心底层的数学推导。
nn模块
nn模块是PyTorch中用于构建神经网络的高级模块,提供了丰富的预定义层和损失函数,帮助开发者快速搭建各类深度学习模型。nn模块的主要特点包括:
-
预定义层:包含了大量常用的神经网络层,如全连接层、卷积层、池化层、循环神经网络层、归一化层等。
import torch.nn as nn# 构建一个简单的卷积神经网络 class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3)self.relu = nn.ReLU()self.fc1 = nn.Linear(32 * 26 * 26, 10)def forward(self, x):x = self.relu(self.conv1(x))x = x.view(x.size(0), -1)x = self.fc1(x)return x -
损失函数:提供了各种常用的损失函数,如均方误差(MSE)、交叉熵损失、负对数似然损失等,方便在训练过程中计算损失。
criterion = nn.CrossEntropyLoss() output = model(input) loss = criterion(output, target) -
优化器集成:结合
torch.optim模块,可以方便地定义和使用各种优化算法,如SGD、Adam、RMSprop等。optimizer = torch.optim.Adam(model.parameters(), lr=0.001) optimizer.zero_grad() loss.backward() optimizer.step() -
模块化设计:
nn.Module采用面向对象的设计方式,支持模块的嵌套和复用,方便构建复杂的模型结构。# 组合多个子模块 class ComplexModel(nn.Module):def __init__(self):super(ComplexModel, self).__init__()self.layer1 = SimpleCNN()self.layer2 = AnotherModule()def forward(self, x):x = self.layer1(x)x = self.layer2(x)return x -
易于扩展:开发者可以根据需要自定义新的层和模块,继承自
nn.Module,满足特定的模型需求。# 自定义激活函数 class Swish(nn.Module):def forward(self, x):return x * torch.sigmoid(x)
nn模块的丰富性和灵活性使得构建神经网络模型变得简洁高效,大大提高了开发和实验的效率。
Torchvision
**Torchvision**是PyTorch的官方视觉工具包,专为计算机视觉任务设计,提供了多种实用功能,包括:
-
数据集加载:内置了多个常用的视觉数据集,如MNIST、CIFAR-10、ImageNet、COCO等,支持自动下载和预处理。
import torchvision.datasets as datasets import torchvision.transforms as transformstransform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]), ])train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True) -
预训练模型:提供了多种预训练的深度学习模型,如ResNet、VGG、AlexNet、MobileNet等,方便进行迁移学习和快速实验。
import torchvision.models as models# 加载预训练的ResNet50模型 model = models.resnet50(pretrained=True) -
图像转换:
transforms模块提供了丰富的图像转换和增强功能,如缩放、裁剪、旋转、翻转、归一化等,方便数据预处理。transform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomRotation(10),transforms.ToTensor(), ]) -
可视化工具:支持将图像和模型结果可视化,方便调试和结果展示。
Torchvision的存在极大地方便了计算机视觉任务的开发流程,使得从数据准备到模型训练的过程更加流畅。
TorchText和TorchAudio
除了Torchvision,PyTorch还提供了针对自然语言处理和音频处理的专用工具包:TorchText和TorchAudio。
TorchText
TorchText专注于自然语言处理,提供了以下功能:
-
文本数据加载和预处理:支持从多种格式加载文本数据,提供了分词、标记化、词汇表构建等预处理功能。
import torchtext from torchtext.data.utils import get_tokenizer from torchtext.vocab import build_vocab_from_iteratortokenizer = get_tokenizer('basic_english') train_iter = torchtext.datasets.AG_NEWS(split='train')def yield_tokens(data_iter):for _, text in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"]) vocab.set_default_index(vocab["<unk>"]) -
常用数据集:内置了多个常用的NLP数据集,如IMDB、AG_NEWS、SST等,支持快速加载。
train_dataset, test_dataset = torchtext.datasets.IMDB() -
嵌入向量:提供了预训练的词向量,如GloVe、FastText等,方便在模型中直接使用。
from torchtext.vocab import GloVeglove = GloVe(name='6B', dim=100) embedding = glove.get_vecs_by_tokens(['hello', 'world'])
TorchAudio
TorchAudio专注于音频处理,提供了以下功能:
-
音频数据加载和预处理:支持加载多种格式的音频文件,提供了滤波、变换、增益等预处理操作。
import torchaudiowaveform, sample_rate = torchaudio.load('audio.wav')# 应用梅尔频谱变换 mel_spectrogram = torchaudio.transforms.MelSpectrogram(sample_rate=sample_rate)(waveform) -
常用数据集:内置了多个音频数据集,如LIBRISPEECH、YESNO等,支持快速加载。
train_dataset = torchaudio.datasets.LIBRISPEECH("./data", url="train-clean-100", download=True) -
预训练模型:提供了预训练的音频模型,如Wav2Vec2.0,方便进行语音识别等任务。
bundle = torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H model = bundle.get_model()
这两个工具包扩展了PyTorch在自然语言处理和音频处理领域的能力,为多模态深度学习应用提供了强大的支持。
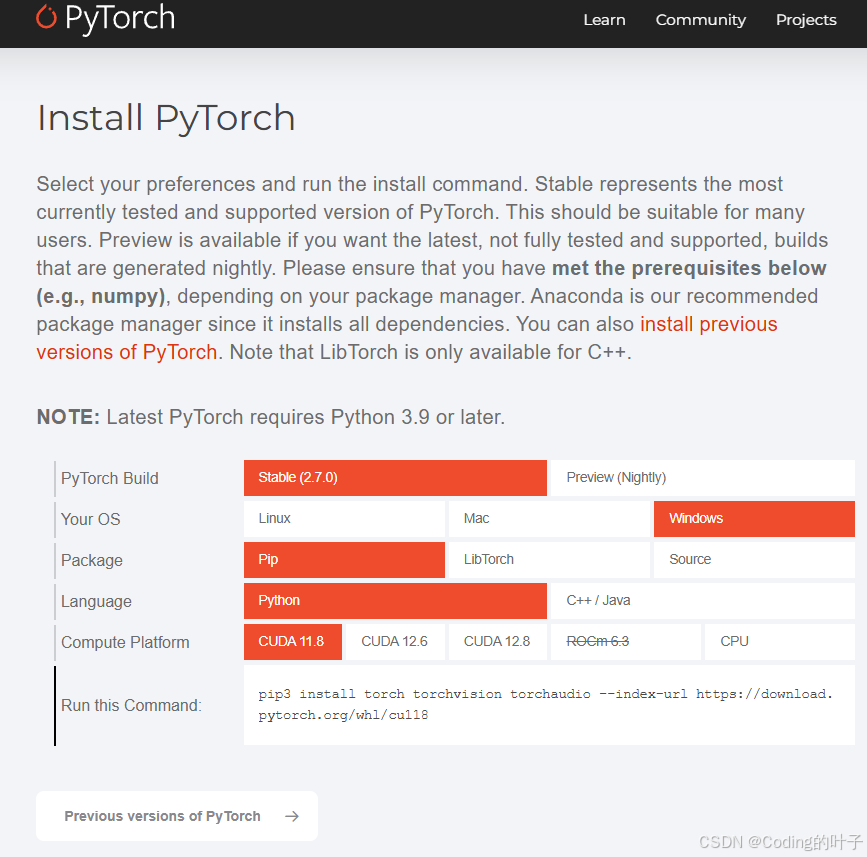
PyTorch的安装方式
PyTorch的安装过程相对简单,支持多种操作系统和安装方式,下面我们分别介绍在不同平台和环境下安装PyTorch的方法。
在Windows上安装PyTorch
1. 使用Conda安装
步骤:
-
确保已安装Anaconda或Miniconda:如果未安装,请从Anaconda官网下载并安装。
-
打开Anaconda Prompt:在开始菜单中搜索并打开。
-
选择安装配置:根据需要选择CUDA支持或CPU版本。以CUDA 11.3为例:
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch -
验证安装:
import torch print(torch.__version__) print(torch.cuda.is_available())
2. 使用pip安装
步骤:
-
确保已安装Python和pip:可从Python官网下载。
-
打开命令提示符。
-
安装PyTorch:以CUDA 11.3为例:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu113 -
验证安装:
import torch print(torch.__version__) print(torch.cuda.is_available())
在Linux上安装PyTorch
1. 使用Conda安装
步骤:
-
确保已安装Anaconda或Miniconda。
-
打开终端。
-
安装PyTorch:以CUDA 11.3为例:
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch -
验证安装:
import torch print(torch.__version__) print(torch.cuda.is_available())
2. 使用pip安装
步骤:
-
确保已安装Python和pip。
-
打开终端。
-
安装PyTorch:以CUDA 11.3为例:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu113 -
验证安装:
import torch print(torch.__version__) print(torch.cuda.is_available())
在macOS上安装PyTorch
由于macOS不支持CUDA加速,因此只能安装CPU版本。
1. 使用Conda安装
步骤:
-
确保已安装Anaconda或Miniconda。
-
打开终端。
-
安装PyTorch:
conda install pytorch torchvision torchaudio -c pytorch -
验证安装:
import torch print(torch.__version__) print(torch.cuda.is_available()) # 应该返回False
2. 使用pip安装
步骤:
-
确保已安装Python和pip。
-
打开终端。
-
安装PyTorch:
pip install torch torchvision torchaudio -
验证安装:
import torch print(torch.__version__) print(torch.cuda.is_available()) # 应该返回False
使用Anaconda安装PyTorch
优势:
- 依赖管理方便:Conda会自动处理相关依赖包,减少冲突。
- 环境隔离:可创建独立的环境,避免不同项目之间的包冲突。
安装步骤:
-
安装Anaconda或Miniconda:从Anaconda官网下载并安装。
-
创建新环境:
conda create -n pytorch_env python=3.8 conda activate pytorch_env -
安装PyTorch:根据需要选择CUDA版本。
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch -
验证安装:
import torch print(torch.__version__) print(torch.cuda.is_available())
从源码安装PyTorch
适用于:
- 需要修改PyTorch源码或使用最新的开发版本。
步骤:
-
克隆PyTorch仓库:
git clone --recursive https://github.com/pytorch/pytorch cd pytorch -
安装依赖项:
pip install -r requirements.txt -
设置环境变量(可选):
export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"} -
编译安装:
python setup.py install -
验证安装:
import torch print(torch.__version__) print(torch.cuda.is_available())
注意事项:
- 编译时间较长:从源码编译可能需要较长时间,取决于系统配置。
- 确保环境配置正确:需要正确配置编译器和相关库。
通过以上方式,开发者可以根据自己的需求和环境选择合适的安装方式,快速开始使用PyTorch进行深度学习开发。
PyTorch的应用场景
PyTorch凭借其灵活性和强大功能,被广泛应用于各种深度学习领域。下面介绍PyTorch在几个主要应用场景中的表现。
计算机视觉
应用领域:
- 图像分类:识别图像中所属的类别,如猫狗分类。
- 目标检测:在图像中识别并定位多个目标物体,如自动驾驶中的行人检测。
- 图像分割:将图像分割成不同的区域,如医学影像中的肿瘤分割。
- 图像生成:生成逼真的图像,如GAN生成的人脸图像。
- 风格迁移:将一种艺术风格应用到另一张图像上。
PyTorch优势:
- Torchvision支持:提供了丰富的预训练模型和数据集,方便快速构建和实验。
- 灵活的模型构建:动态计算图方便实现复杂的模型结构,如Attention机制、GAN等。
- 高效的训练性能:支持多GPU和分布式训练,加速大规模数据集的训练。
- 社区贡献:大量的开源项目和教程,方便学习和借鉴。
示例:
import torch
import torchvision.models as models# 加载预训练的ResNet模型
model = models.resnet50(pretrained=True)# 替换最后一层以适应新任务
num_features = model.fc.in_features
model.fc = torch.nn.Linear(num_features, 10) # 10分类任务# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
自然语言处理
应用领域:
- 文本分类:如情感分析、垃圾邮件检测。
- 机器翻译:将一种语言翻译成另一种语言。
- 问答系统:从文本中提取并回答问题。
- 文本生成:如自动写作、对话生成。
- 命名实体识别:识别文本中的人名、地名、组织名等。
PyTorch优势:
- TorchText支持:提供了文本预处理、词嵌入等工具。
- 灵活的序列建模:方便实现RNN、LSTM、Transformer等模型。
- 强大的动态性:适合处理变长序列和复杂的文本结构。
- 预训练模型:社区提供了大量的预训练模型,如BERT、GPT等,方便进行微调。
示例:
import torch
from transformers import BertTokenizer, BertForSequenceClassification# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')# 准备输入
text = "This is a great movie!"
inputs = tokenizer(text, return_tensors='pt')# 前向传播
outputs = model(**inputs)
logits = outputs.logits# 预测
prediction = torch.argmax(logits, dim=1)
强化学习
应用领域:
- 游戏AI:如AlphaGo、OpenAI Five等。
- 机器人控制:优化机器人的动作策略。
- 推荐系统:根据用户反馈优化推荐内容。
- 自动驾驶:学习最优的驾驶策略。
PyTorch优势:
- 动态计算图:适合实现复杂的策略网络和价值网络。
- 高效的梯度计算:支持在线学习和大规模模拟。
- 丰富的社区资源:如OpenAI Baselines、Stable Baselines等库提供了基于PyTorch的实现。
示例:
import torch
import torch.nn as nn# 定义策略网络
class PolicyNetwork(nn.Module):def __init__(self, state_size, action_size):super(PolicyNetwork, self).__init__()self.fc1 = nn.Linear(state_size, 128)self.relu = nn.ReLU()self.fc2 = nn.Linear(128, action_size)self.softmax = nn.Softmax(dim=-1)def forward(self, x):x = self.relu(self.fc1(x))x = self.softmax(self.fc2(x))return x# 初始化网络
policy_net = PolicyNetwork(state_size=4, action_size=2)# 定义优化器
optimizer = torch.optim.Adam(policy_net.parameters(), lr=0.01)
语音识别与生成
应用领域:
- 语音转文本(ASR):将语音信号转换为文本,如语音助手。
- 文本转语音(TTS):将文本转换为语音,如语音播报。
- 语音情感分析:识别语音中的情感状态。
- 语音分离:从混合音频中分离出单独的声音源。
PyTorch优势:
- TorchAudio支持:提供了音频数据的加载和预处理工具。
- 高效的序列建模:适合实现CTC、Transformer等模型结构。
- 丰富的预训练模型:如Wav2Vec、DeepSpeech等,方便进行下游任务的微调。
示例:
import torch
import torchaudio
from torchaudio.models import DeepSpeech# 加载音频
waveform, sample_rate = torchaudio.load('audio.wav')# 加载预训练模型
model = DeepSpeech(pretrained=True)# 进行语音识别
transcript = model(waveform)
print(transcript)
PyTorch与其他深度学习框架的比较
在深度学习领域,除了PyTorch,还有其他知名的框架,如TensorFlow、Keras、MXNet等。下面对PyTorch与这些框架进行比较。
1. PyTorch vs TensorFlow
-
动态 vs 静态计算图:
- 早期的TensorFlow采用静态计算图,需要先定义整个计算图再运行,修改不便。
- PyTorch采用动态计算图,灵活性高,易于调试。
- TensorFlow 2.x引入了
Eager Execution,也支持动态计算图,缩小了差距。
-
易用性:
- PyTorch的API更符合Python习惯,学习曲线较平缓。
- TensorFlow的API较为复杂,但拥有更完善的高层API(如Keras)。
-
部署和生产环境:
- TensorFlow在生产部署上有更成熟的支持,如TensorFlow Serving、TensorFlow Lite。
- PyTorch近年来也加强了部署支持,如TorchServe、PyTorch Mobile。
-
社区和生态:
- 两者都有庞大的社区和生态系统,各有优势。
2. PyTorch vs Keras
-
抽象层次:
- Keras提供了高层次的API,适合快速原型和简单模型。
- PyTorch提供更底层的控制,适合复杂和自定义的模型。
-
灵活性:
- PyTorch更灵活,适合研究和实验。
- Keras限制较多,但易于上手。
-
性能:
- PyTorch通常在性能上更优,特别是在复杂模型和大规模数据上。
3. PyTorch vs MXNet
-
开发者支持:
- PyTorch由Facebook支持,社区活跃度高。
- MXNet由Apache基金会管理,曾受到亚马逊的支持,但目前活跃度略低。
-
性能和可扩展性:
- MXNet在分布式训练和多语言支持上表现出色。
- PyTorch在易用性和社区支持上更有优势。
4. PyTorch vs JAX
-
自动微分:
- JAX以其先进的自动微分和函数式编程特性而著称。
- PyTorch的
Autograd也很强大,但JAX在某些数学计算上更高效。
-
易用性:
- PyTorch的API更成熟,社区资源更多。
- JAX相对较新,生态系统尚在发展中。
总结:
每个深度学习框架都有其独特的优势和适用场景。PyTorch凭借其动态计算图、易用性和强大的社区支持,成为研究和实验领域的首选。同时,随着部署支持的加强,PyTorch在生产环境中的应用也日益增多。开发者应根据具体需求和项目特点选择最适合的框架。
结论
PyTorch作为当今最流行的深度学习框架之一,凭借其动态计算图、直观的API设计、强大的性能和丰富的生态系统,广泛应用于学术研究和工业实践中。无论是计算机视觉、自然语言处理、强化学习还是语音处理,PyTorch都提供了强有力的支持。
随着人工智能技术的不断发展和演进,PyTorch也在持续更新和优化,不断引入新的功能和特性,满足日益复杂和多样化的深度学习需求。对于开发者和研究者来说,熟练掌握PyTorch将为他们在人工智能领域的探索和创新提供坚实的基础。
希望本文能够帮助读者全面了解PyTorch的起源、优势、发展历程和实际应用,激发更多的创新和实践。
参考资料
- PyTorch官方文档
- PyTorch教程
- Torchvision文档
- TorchText文档
- TorchAudio文档
- PyTorch GitHub仓库
- PyTorch社区论坛
- 深度学习框架比较
相关文章:
深入了解PyTorch:起源、优势、发展与安装指南
深入了解PyTorch:起源、优势、发展与安装指南 目录 引言PyTorch简介PyTorch的优势 动态计算图直观易用的API强大的社区支持丰富的生态系统高性能与可扩展性 PyTorch的发展历程PyTorch的主要组件 Torch.TensorAutograd自动求导nn模块TorchvisionTorchText和TorchAu…...
DeepSeek智能对话助手项目
目录: 1、效果图2、实现代码3、温度和TopK的作用对比 1、效果图 2、实现代码 # import gradio as gr# def reverse_text(text): # return text[::-1]# demogr.Interface(fnreverse_text,inputs"text",outputs"text")# demo.launch(share&q…...
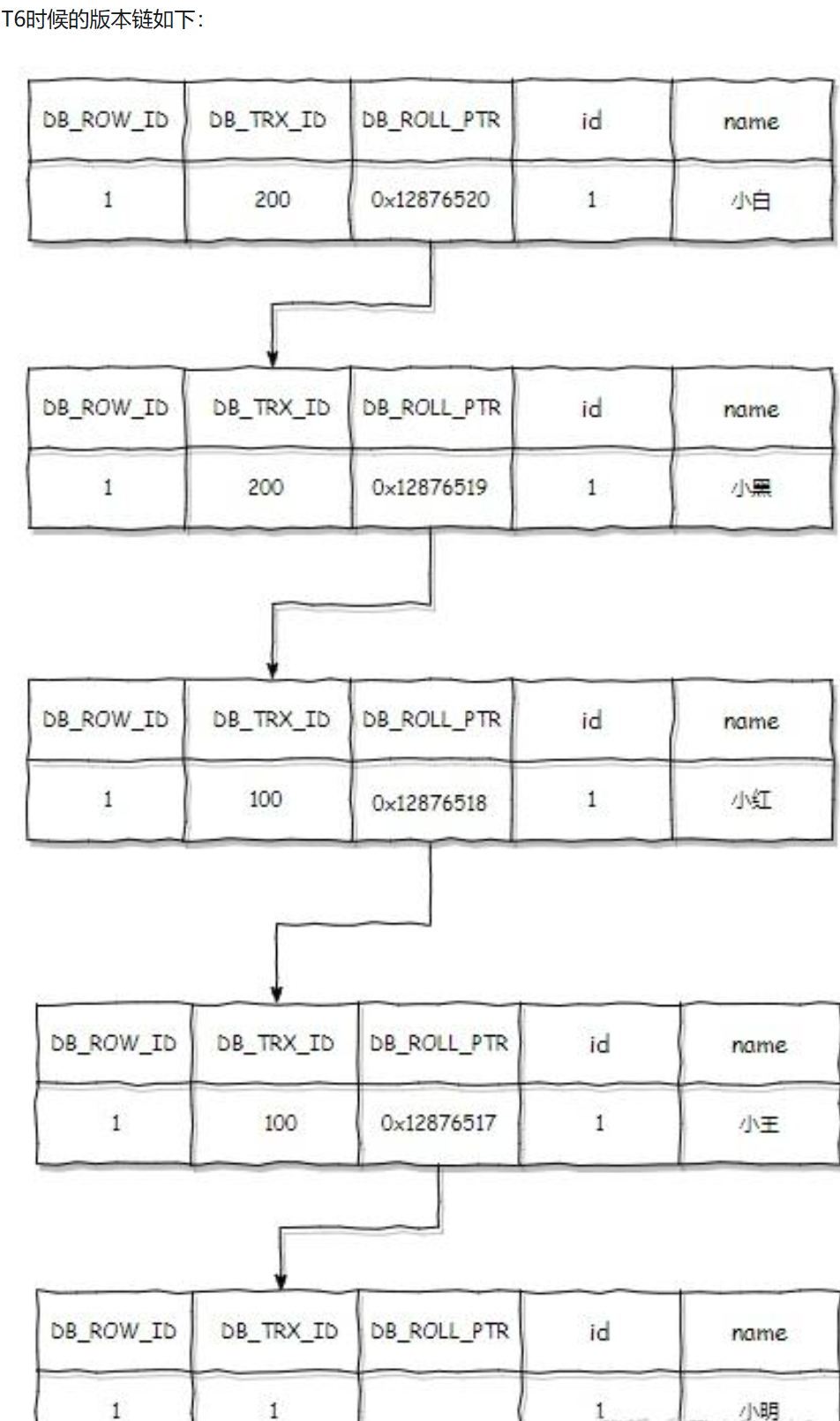
浅谈Mysql的MVCC机制(RC与RR隔离级别)
MVCC(Multi-Version Concurrency Control)多版本并发控制 说这个我们先来了解一下Mysql的隔离级别,因为MVCC和Mysql的隔离级别是有关的。 Mysql默认的隔离级别是RR(可重复读) 其他的隔离级别是读未提交(…...
uniapp-商城-72-shop(5-商品列表,购物车实现回顾)
我们通过前面的章节已经将数据添加到了购物车,但实际上购物车的处理还有很多东西需要完成。 我们看看如何将商品添加到购物车。 本文介绍了购物车功能的实现方式,重点讲解了如何将商品添加到购物车以及购物车状态管理的处理机制。主要内容包括:1. 通过Vuex管理购物车状态,包…...

【git】 pull + rebase 或 pull + merge什么区别?
在Git中,pull + rebase 和 pull + merge 是两种整合远程分支更新的方式,其核心区别在于如何处理提交历史。以下是详细对比: 核心区别 操作提交历史结构合并方式冲突处理适用场景pull + merge保留分支分叉和合并节点创建新的合并提交(Merge Commit)一次性解决所有冲突公共…...

1. 编程语言进化史与JavaScript
引言 作为一名开发者,理解编程语言的演进历史和核心特性是至关重要的。接下来将从编程语言的三个历史阶段入手,重点解析JavaScript的起源、特性及其与相关技术的关系,同时补充进制转换的基础知识,为初学者构建完整的知识体系。 一、编程语言的三大历史阶段 1. 机器语言(…...

Vue3 中 Axios 深度整合指南:从基础到高级实践引言
在现代前端开发中,与后端API的交互是构建动态应用的核心环节。Axios作为最流行的HTTP客户端之一,以其简洁的API和强大的功能在前端生态中占据重要地位。本文将全面探讨如何在Vue3项目中高效整合Axios,从基础配置到高级封装,从性能…...
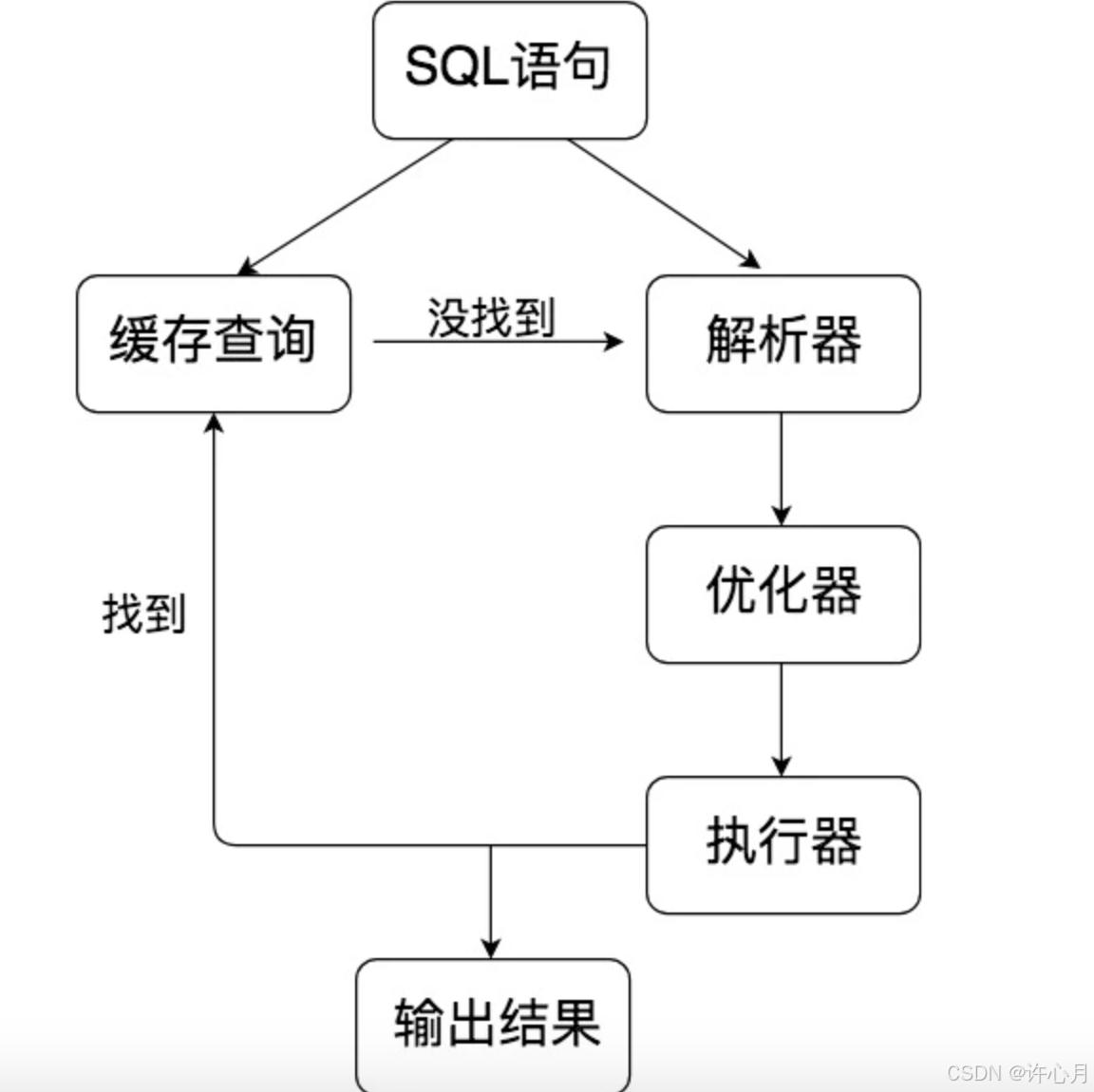
MySQL#Select语句执行过程
服务端程序架构 MySQL 是典型的 C/S 架构,即 Client/Server 架构,服务器端程序mysqld。 Select语句执行过程 连接层 客户端和服务器端建立连接,客户端发送 SQL 至服务器端 SQL层 SQL语句处理 查询缓存: 缓存命中该SQL执行结果直…...
hbuilder中h5转为小程序提交发布审核
【注意】 [HBuilder] 11:59:15.179 此应用 DCloud appid 为 __UNI__9F9CC77 ,您不是这个应用的项目成员。1、联系这个应用的所有者,请求加入项目成员(https://dev.dcloud.net.cn "成员管理"-"添加项目成员")…...

文档注释:删还是不删
问题:代码中存在大量的文档注释,占用大量篇幅,一次难以看完整个文件,于是诞生了一个想法:删除所有文档注释,于是问了下 DeepWiki 文档注释对tree - sitter有影响吗?文档注释对Roocode大模型理解…...
【数据结构】单链表练习
1.链表的中间节点 https://leetcode.cn/problems/middle-of-the-linked-list/description/ 用快慢指针来解决 /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/ struct ListNode* middleNode(struct ListNode* he…...

JVM 性能优化终极指南:全版本兼容、参数公式与场景实战
一、引言 JVM 优化的核心难点在于版本兼容性与场景适配性。从 Java 8 到 Java 21,JVM 的内存模型、GC 策略和默认参数发生了巨大变化;从高并发 Web 到大数据批处理,不同业务场景对延迟、吞吐量的要求也截然不同。本文基于历史会话中用户关注…...

分布式爬虫监控架构设计
1. 监控架构核心组件 1.1 日志集中管理 设计目标:聚合所有节点的运行日志,支持实时查询与异常分析。 实现方式: 日志采集:各节点通过 logging 模块将日志发送至中央存储(如Elasticsearch或Redis)。 日志…...

MySQL的参数 innodb_force_recovery 详解
MySQL的参数 innodb_force_recovery 详解 innodb_force_recovery 是 InnoDB 存储引擎的一个重要参数,用于在数据库崩溃恢复时控制恢复行为的级别。这个参数主要在数据库无法正常启动时使用,可以帮助我们从损坏的数据库中恢复数据。 一 参数概述 参数名…...
学习vue3:跨组件通信(provide+inject)
目录 一,关于跨组件通信概述 二,跨组件传值 案例1(爷传孙) 三,跨组件传函数 案例2(爷传孙) 疑问:孙子传给爷爷是否可行呢? 一,关于跨组件通信概述 之前我们学习了父子组件的传…...

Alibaba Sentinel 入门教程:从理论到实战
文章目录 第一部分:理论篇1. Sentinel 简介2. Sentinel 核心原理2.1 资源与规则2.2 Sentinel 工作主流程2.3 核心类解析 3. Sentinel 功能支持与使用流程3.1 流量控制3.2 熔断降级3.3 系统自适应保护3.4 热点参数限流3.5 黑白名单控制3.6 使用流程 4. Sentinel 架构…...
详解)
2.3 TypeScript 非空断言操作符(后缀 !)详解
在 TypeScript 中,当你开启了严格的空值检查(strictNullChecks)后,变量如果可能是 null 或 undefined,就必须在使用前进行显式的判断。为了在某些场景下简化代码,TypeScript 提供了非空断言操作符ÿ…...
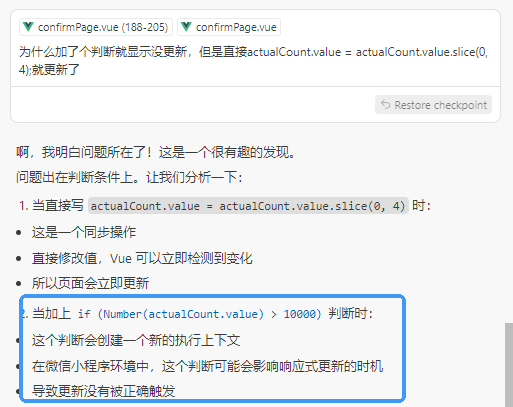
【菜狗work前端】小程序加if判断时不及时刷新 vs Web
零、前提: 实现input输入数字不大于10000(需要配合typenumber,maxlength5,这里没写) 一、探究代码: <input v-model"model1" input"changeModel1" placeholder"请输入拒收件…...

01 NLP的发展历程和挑战
1.人工智能行业介绍 ANI、AGI、ASI 以下是弱人工智能(ANI)、强人工智能(AGI)和超强人工智能(ASI)的对比表格: 类型定义当前状态弱人工智能(ANI)专注于特定任务&#x…...
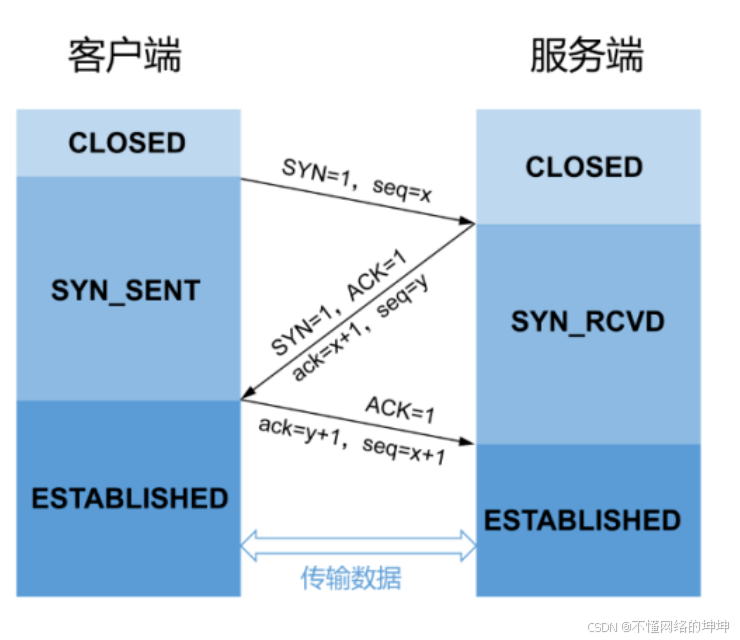
TCP 三次握手:详解与原理
无图、长文警告!!!! 文章目录 一、引言二、TCP 三次握手的过程(一)第一次握手:SYN(同步序列号)(二)第二次握手:SYN-ACK(同…...
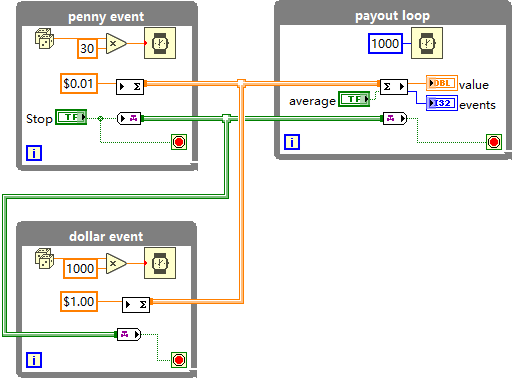
LabVIEW累加器标签通道
主要展示了 Accumulator Tag 通道的使用,通过三个并行运行的循环模拟不同数值的多个随机序列,分别以不同频率向累加器写入数值,右侧循环每秒读取累加器值,同时可切换查看每秒内每次事件的平均值,用于演示多线程数据交互…...
在 Unity 中,Start 方法直接设置 RectTransform 的位置,时出现问题,与预计位置不匹配。
改动之前的源代码:发现组件的位置,与设计的位置不一样,但是如果把这段代码,交给一个按钮按下回调,就不会出现问题。 void Start(){//初始化Text 行//读取配置文件;StaticDataObj obj Resources.Load<St…...

永磁同步电机控制算法--IP调节器
一、基本原理 在电机控制领域,现今普遍使用的是比例-积分(PI)控制器。然而,PI控制器有一些缺点,可能会在某些应用中产生一些问题,例如:一个非常快的响应,也同时具有过大的超调量。虽然设计PI控制器时,可以…...
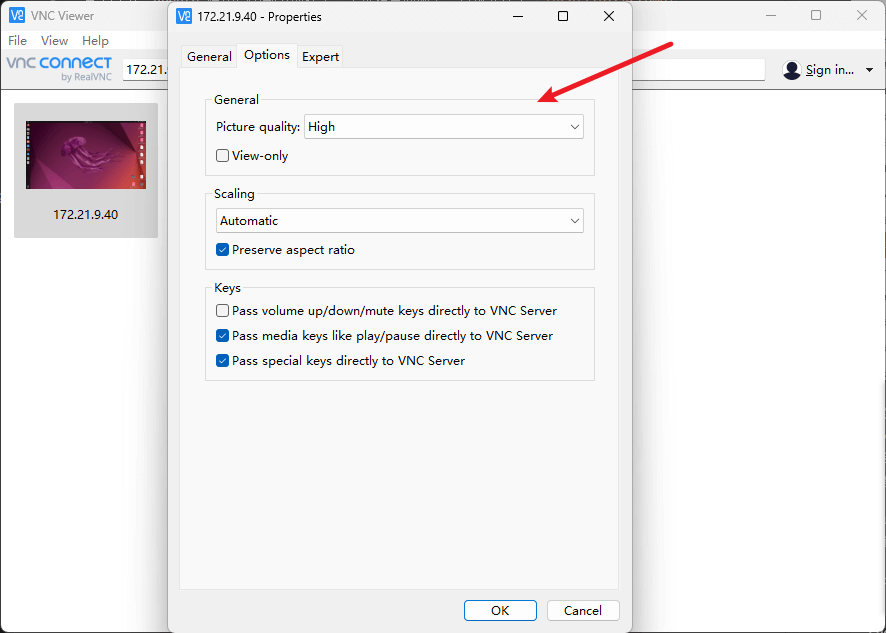
Ubuntu 25.04 锁屏不能远程连接的解决方案
最近安装了一个 Ubuntu 25.04,偶然发现可以通过 windows 自带的 rdp 远程工具进行连接,内心狂喜。此外,还支持启动 VNC 协议,也就是默认支持了 rdp 和 vnc 连接。 看了以下,ubuntu 在用户级别下创建了一个远程桌面服务…...
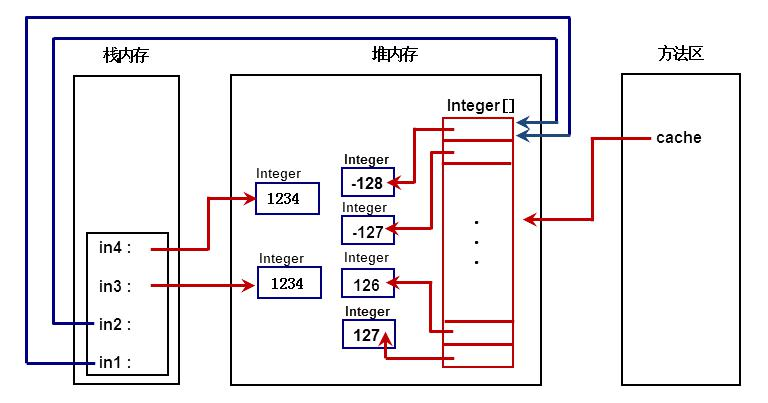
Java 自动装箱和拆箱还有包装类的缓存问题
自动装箱和拆箱就是将基本数据类型和包装类之间进行自动的互相转换。JDK1.5 后, Java 引入了自动装箱(autoboxing)/拆箱(unboxing)。 自动装箱: 基本类型的数据处于需要对象的环境中时,会自动转为“对象”。 我们以 Integer 为例:…...
java-jdk8新特性Stream流
一、Stream流 是专业用于对集合或者数组进行便捷操作的。 1.1 Stream流的创建 主要分为Collection(List与Set)、Map、数组三种创建方式: //1.Collection集合的创建List<String> names new ArrayList<>();Collections.addAll(…...
大语言模型 21 - MCP 自动操作 Figma+Cursor 实现将原型转换为代码
MCP 基本介绍 官方地址: https://modelcontextprotocol.io/introduction “MCP 是一种开放协议,旨在标准化应用程序向大型语言模型(LLM)提供上下文的方式。可以把 MCP 想象成 AI 应用程序的 USB-C 接口。就像 USB-C 提供了一种…...
QNAP NEXTCLOUD 域名访问
我是用docker compose方式安装的,虽然不知道是不是这么个叫法,废话不多说。 背景:威联通container station安装了nextcloud和lucky,lucky进行的域名解析和反代 先在想安装的路径、数据存储路径、数据库路径等新建文件夹。再新建…...

Spring MVC深度解析:控制器与视图解析及RESTful API设计最佳实践
引言 在现代Java Web开发领域,Spring MVC框架凭借其优雅的设计和强大的功能,已成为构建企业级Web应用的首选框架。本文将深入探讨Spring MVC的核心机制——控制器与视图解析,并详细讲解如何设计符合RESTful风格的API。无论你是刚接触Spring …...

华为OD机试真题——信道分配(2025B卷:200分)Java/python/JavaScript/C/C++/GO最佳实现
2025 B卷 200分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...