01 NLP的发展历程和挑战
1.人工智能行业介绍
ANI、AGI、ASI
以下是弱人工智能(ANI)、强人工智能(AGI)和超强人工智能(ASI)的对比表格:
| 类型 | 定义 | 当前状态 |
|---|---|---|
| 弱人工智能(ANI) | 专注于特定任务,在限定领域内表现接近或超越人类,但无法泛化到其他任务。 | 已广泛应用(如语音识别、推荐系统)。 |
| 强人工智能(AGI) | 具备与人类相当的通用智能,可自主学习、适应多种任务和环境。 | 尚未实现,处于理论研究阶段。 |
| 超强人工智能(ASI) | 在所有领域全面超越人类智能,能自我改进并可能引发不可预知的影响。 | 纯理论概念,存在伦理争议。 |
以下为整合实现步骤的增强版人工智能研究方向解析表:
人工智能研究方向与技术实现
| 研究方向 | 英文 | 定义 | 核心功能 | 主要步骤 | 典型应用场景 | 面临问题或注意事项 |
|---|---|---|---|---|---|---|
| 语音合成 | Text - to - Speech(TTS) | 将文字转化为语音的过程,也称为文本转语音 | 将文本转换为自然语音输出 | 1. 文本预处理:分词、标注词性、确定语调等 2. 语音合成模型选择:如基于规则、统计、深度学习的模型等 3. 参数生成:生成音素序列、音高、音量、语速等参数 4. 合成声音:根据参数生成声音信号 5. 后处理:去噪、降噪、音量调整等 细化: 1. 文本预处理(分词/正则化) 2. 声学模型训练(WaveNet/Tacotron) 3. 语音合成引擎输出 | 智能音箱、智能客服、智能助手、教育、医疗等 | 随着技术发展不断进步 |
| 语音识别 | Automatic Speech Recognition(ASR) | 将语音信号转换为文字或命令的技术 | 将语音信号转换为文本或指令 | 1. 音频采集:使用麦克风等设备采集语音信号 2. 预处理:降噪、去除杂音等 3. 特征提取:提取如MFCC等语音特征 4. 建模:用语音和文本数据训练模型,如HMM、RNNs等 5. 解码:将语音信号转换为文本或命令 6. 后处理:语言模型校正、错误修正等 细化: 1. 声学特征提取(MFCC) 2. 声学模型训练(DNN/HMM) 3. 语言模型解码(n - gram/RNN - T) | 语音助手、电话客服、语音翻译等 | 不同场景表现不同,需选合适模型算法;面临口音识别、多说话人识别、噪声干扰等问题 |
| 字符识别 | Optical Character Recognition(OCR) | 将图像或印刷体文字转换为可编辑电子文本的技术 | 从图像中提取可编辑文本 | 1. 预处理:图像增强、二值化、去噪等 2. 分割:将图像分割为单个字符 3. 特征提取:提取字符形状、大小、线条等特征 4. 分类:用分类算法将字符分配到对应类别 5. 后处理:错误纠正、格式化、语言处理等 细化: 1. 图像预处理(二值化/去噪) 2. 文字检测(CTPN/EAST) 3. 文字识别(CRNN/Transformer) | 扫描文档自动识别、车牌识别、身份证识别、手写字识别等 | 实际应用可能存在识别错误,需调整优化 |
| 机器翻译 | Machine Translation(MT) | 使用计算机和相关技术对一种自然语言文本自动翻译成另一种自然语言的过程 | 自动将一种语言翻译为另一种语言 | 1. 基于规则的机器翻译(RBMT):利用专家制定的语言规则和规则库翻译 2. 基于统计的机器翻译(SMT):利用双语语料库和统计模型翻译 3. 基于神经网络的机器翻译(NMT):利用深度学习技术端到端翻译 4. 基于混合方法的机器翻译(HMT):结合多种方法实现更高质量翻译 细化: 1. 语料对齐处理 2. 序列模型训练(Transformer) 3. 后编辑优化(BLEU评估) | 跨语言信息检索、多语言机器翻译、智能客服、智能语音交互等 | 存在语言差异、多义性、语法结构等问题,需不断改进优化 |
| 声纹识别 | Voiceprint Recognition | 利用说话人的语音信号识别和验证个人身份的生物识别技术 | 通过语音特征进行身份验证 | 1. 语音信号采集:用麦克风采集语音信号 2. 特征提取:对语音信号预处理、提取特征向量并降维 3. 特征匹配:将提取的特征向量与模板比对匹配 细化: 1. 声纹特征提取(i - vector/x - vector) 2. 模式匹配(GMM/CNN) 3. 动态阈值验证 | 语音识别、安全认证、金融交易等 | - |
| 指纹识别 | Fingerprint Recognition | 根据人体指纹独特纹路和特征识别个体身份的生物识别技术 | 利用指纹生物特征进行身份识别 | 1. 图像采集:用指纹传感器采集并预处理指纹图像 2. 特征提取:提取指纹纹路特征信息,如特征点等 3. 特征匹配:将提取的指纹特征与数据库中特征匹配 4. 判决:根据匹配结果确定个体身份 细化: 1. 图像增强(Gabor滤波) 2. 特征点提取(minutiae) 3. 模板匹配(FingerJet算法) | 手机解锁、门禁系统、考勤管理 | - |
| 语义理解 | Natural Language Understanding(NLU) | 通过计算机技术对自然语言进行理解和解释的过程 | 解析自然语言背后的意图和上下文 | 1. 词法分析:分词、词性标注、命名实体识别等 2. 句法分析:分析句子结构和语法规则 3. 语义分析:识别语义信息,如主语、谓语、宾语等 4. 语言模型:利用统计模型、深度学习等技术建模 5. 对话管理:实现对话流程控制、意图识别等功能 细化: 1. 词向量表示(Word2Vec/BERT) 2. 意图分类(BiLSTM) 3. 槽位填充(CRF) | 智能客服、机器翻译、信息提取、语音识别等 | - |
| 图像识别 | Image Recognition | 通过计算机对图像进行分析处理,识别出图像中物体、场景、人物等内容 | 识别图像中的物体、场景或人物 | 1. 图像预处理:调整亮度、对比度、去噪等 2. 特征提取:提取如边缘、角点、纹理等特征 3. 特征匹配:将提取特征与模板匹配 4. 物体检测:确定是否包含特定物体或场景 5. 分类识别:将图像分类,如动物、植物等 细化: 1. 特征提取(ResNet/ViT) 2. 目标检测(YOLO/Faster R - CNN) 3. 分类预测(Softmax) | 自动驾驶、智能监控、人脸识别、医学影像分析等 | - |
人工智能(AI)、机器学习(ML)、深度学习(DL) 的对比
| 对比维度 | 人工智能(AI) | 机器学习(ML) | 深度学习(DL) |
|---|---|---|---|
| 定义范围 | 模拟人类智能的终极目标,涵盖所有技术路径(符号逻辑、规则系统、强化学习等) | AI的子集,通过数据驱动算法实现学习(如监督学习、无监督学习) | ML的子集,基于多层神经网络的复杂模式学习 |
| 核心方法 | 符号逻辑、专家系统、进化算法、强化学习 | 统计学习、优化算法(如梯度下降)、特征工程 | 神经网络(CNN、RNN、Transformer)、反向传播、注意力机制 |
| 数据依赖 | 不一定依赖大量数据(如规则系统) | 需中等规模标注或结构化数据(如监督学习) | 高度依赖大规模非结构化数据(如图像、文本) |
| 特征处理 | 依赖人工规则或算法自动提取(如专家系统设计特征) | 部分依赖人工特征工程(如SVM需手工设计特征) | 完全自动分层提取特征(如CNN自动学习图像边缘→纹理→形状) |
| 计算成本 | 因方法而异(规则系统低,强化学习高) | 中低(线性模型、树模型) | 高(需GPU/TPU加速训练深层网络) |
| 典型应用 | 专家系统、自动驾驶决策、智能客服 | 垃圾邮件分类、推荐系统、金融风控 | 图像生成(GAN)、语音识别(ASR)、大语言模型(LLM) |
| 技术演进 | 从符号AI到连接主义(如神经网络) | 从传统算法到集成学习(如随机森林) | 从浅层网络到Transformer架构(如BERT、GPT) |
| 应用场景特点 | 规则明确、可解释性强(如医疗诊断规则) | 需平衡数据与模型复杂度(如预测房价) | 数据驱动、端到端学习(如自动驾驶感知) |
| 优缺点 | 优点:可解释性强;缺点:灵活性低(依赖人工规则) | 优点:适应性强;缺点:依赖特征工程 | 优点:自动特征学习;缺点:黑箱问题、算力需求高 |
- 层次关系:
AI > ML > DL,三者是包含关系,技术路径逐渐细化。 - 技术演进:
- AI早期依赖规则,ML引入数据驱动,DL实现端到端学习。
- DL通过Transformer等架构推动多模态大模型发展。
人工智能“三驾马车”——算法、算力、数据
| 维度 | 算法 | 算力 | 数据 |
|---|---|---|---|
| 定义 | 指导AI模型决策的规则与方法(如深度学习、强化学习) | 支撑AI计算的硬件能力(如GPU、TPU、分布式集群) | 训练与优化AI模型的原始信息(结构化/非结构化数据) |
| 核心作用 | 决定模型性能上限(如识别图像、生成文本) | 加速模型训练与推理(如千亿参数模型需万卡集群) | 提供学习样本与验证基础(如ImageNet推动计算机视觉) |
| 技术挑战 | 可解释性差、泛化能力不足 | 能耗高、算力成本攀升 | 质量参差、隐私泄露 |
| 典型应用 | 图像分类(ResNet)、自然语言处理(Transformer) | 云计算(AWS GPU集群)、自动驾驶实时决策 | 医疗诊断(病历分析)、金融风控(用户行为建模) |
| 关键突破 | Transformer架构(GPT系列)、自监督学习 | 量子计算、边缘计算 | 联邦学习、多模态数据集 |
- 算法是AI的“大脑”,算力是“引擎”,数据是“燃料”。
- 三者协同:算法依赖算力加速,算力释放数据价值,数据优化算法性能。
- 未来趋势:算法轻量化、算力普惠化、数据合规化。
2.自然语言处理(Natural Language Processing,NLP)方向的基本介绍
一、自然语言处理基本介绍
| 类别 | 详情 |
|---|---|
| 定义 | 计算机科学和人工智能领域的分支,旨在帮助计算机理解、处理和生成人类语言 |
| 主要涉及技术 | 语言分析:分词、词性标注、句法分析、语义分析等,将文本转换为结构化数据 语言生成:文本生成、机器翻译、对话生成等,将结构化数据转换为自然语言文本 信息检索:信息抽取、关键词提取、文本分类、情感分析等,从文本数据提取有用信息 |
| 应用示例 | 机器翻译:将一种语言文本自动翻译成另一种语言 智能客服:利用技术实现自动问答和客服服务 情感分析:分析文本情感倾向用于舆情监测等 文本生成:自动生成新闻、评论等文本内容 |
二、自然语言处理处理方向分类
| 处理方向 | 描述 |
|---|---|
| 语言理解 | 让计算机理解人类语言意思,包括语义理解、语法分析、文本分类、命名实体识别、情感分析等 |
| 语言生成 | 使计算机自动生成自然语言,如机器翻译、摘要生成、对话系统、文本生成等 |
| 机器翻译 | 将一种语言自动转化为另一种语言,方法有基于规则、统计、深度学习等 |
| 信息检索 | 通过搜索引擎等获取所需信息,包含文本检索、信息过滤等 |
| 问答系统 | 能根据用户提问自动回答问题,方法有基于规则、统计、深度学习等 |
| 语音识别 | 将语音信号转化为文本,方法有基于隐马尔可夫模型、深度学习等 |
| 语音合成 | 将文本转化为语音,方法有基于规则、统计、深度学习等 |
三、自然语言处理面临的困难
| 困难点 | 描述 |
|---|---|
| 语言多样性 | 不同语言形式和语法结构不同,处理方法需有差异 |
| 大规模语料库问题 | 获取和处理大规模语料库需大量人力和计算资源 |
| 歧义和多义性 | 自然语言存在歧义和多义性,需结合上下文和语境处理 |
| 数据稀疏性 | 自然语言词汇和语法结构多,导致数据稀疏,影响模型泛化能力和准确性 |
| 模型复杂度 | 常需深度学习等复杂模型,增加训练和调整难度 |
| 语言文化差异 | 不同语言文化差异大,影响NLP模型适应性和效果 |
四、自然语言处理发展历程
| 时间阶段 | 发展详情 | 主要研究路线及方法 | 代表性成果或技术发展 |
|---|---|---|---|
| 20世纪50年代 - 60年代 | NLP概念诞生,探索语言学、逻辑学与计算机科学交叉领域 | 经验主义主导,同时存在基于规则的理性主义和基于统计的经验主义两种路线 | 诞生NLP概念;Shannon和Weaver的信息论、Chomsky的语言学理论、Turing测试;人们在研究语言应用规律时进行统计、分析和归纳,并建立相应处理系统 |
| 20世纪70年代 | 开始运用统计模型处理自然语言 | 基于统计的经验主义路线进一步发展 | 基于统计语言模型的机器翻译和语音识别系统 |
| 20世纪80年代 - 90年代 | 基于知识的方法流行,机器学习方法开始发展 | 基于规则的理性主义(基于规则和专家系统)与基于统计的经验主义(机器学习方法,如神经网络、决策树分类器)并行发展,后期两者从对立走向融合 | 基于规则和专家系统的NLP系统;基于神经网络和决策树的分类器;经验主义与理性主义激烈争论后逐渐融合 |
| 21世纪00年代 | 随着互联网发展和大数据产生,运用统计机器学习方法处理大规模文本数据,基于语料库的方法出现 | 基于统计的机器学习方法成为主流,结合基于语料库的方法 | 支持向量机、最大熵模型、条件随机场等统计机器学习方法用于处理大规模文本数据;词向量、主题模型等基于语料库的方法出现 |
| 2010年代至今 | 大力发展深度学习技术,预训练语言模型出现 | 以深度学习技术为主导 | 卷积神经网络、循环神经网络、注意力机制等深度学习技术在多项NLP任务中取得显著效果;BERT、GPT等预训练语言模型出现 |
3.人工智能和深度学习的发展历程
| 发展阶段 | 时间范围 | 主要特点 | 关键事件及发展 | 面临问题或局限 |
|---|---|---|---|---|
| 第一代神经网络 | 1958 - 1969年 | 用计算机模拟神经元反应过程,将神经元简化为输入信号线性加权、求和、非线性激活(阈值法)三个过程 | - | 1969年,Minsky证明感知器本质为线性模型,只能处理线性分类问题 |
| 第二代神经网络 | 1986 - 1998年 | Hinton发明适用于多层感知器(MLP)的BP算法,采用Sigmoid进行非线性映射 | 1986年,Hinton发明BP算法解决非线性分类和学习问题 1991年,BP算法被指出存在梯度消失问题 1997年,LSTM模型发明,但未受足够重视 | BP算法存在梯度消失问题,影响前层有效学习 |
| 统计学习方法的春天 | 1986 - 2006年 | 决策树、支持向量机、随机森林等算法先后提出,并在实际场景取得不错效果 | 决策树、支持向量机、随机森林等算法出现并应用 | - |
| 第三代神经网络 - DL | 快速发展期(2006 - 2012年) 爆发期(2012年 - 至今) | 深度学习技术快速发展并在各算法任务上取得显著成果 | 2012年,Hinton课题组构建的CNN网络AlexNet参加ImageNet图像识别比赛夺冠,碾压第二名(SVM方法)的分类性能,之后深度学习模型在各种算法任务上表现出色,带动人工智能产业崛起 | - |
4.一些常用的工具和框架介绍
| 工具类别 | 工具名称 | 特点及功能 | 推荐场景 |
|---|---|---|---|
| 机器学习相关Python框架 | Tensorflow | 大名鼎鼎,工程配套完善 | 适用于大规模工业级深度学习项目 |
| 机器学习相关Python框架 | Pytorch | 学术界宠儿,调试方便 | 学术研究、快速迭代模型开发 |
| 机器学习相关Python框架 | Keras | 高级封装,简单好用,现已和Tensorflow合体 | 初学者快速搭建模型,简单项目开发 |
| 机器学习相关Python框架 | Gensim | 支持训练词向量、bm25等算法 | 文本向量表示、主题建模等文本处理任务 |
| 机器学习相关Python框架 | Sklearn | 集成大量机器学习算法,如逻辑回归、决策树等,具备数据集划分和多种评价指标实现功能 | 传统机器学习任务,如分类、聚类、回归等 |
| 机器学习相关Python框架 | Numpy | 专注各种向量矩阵操作 | 为机器学习算法提供基础的数值计算支持 |
| Python数据处理常用库 | Jieba | 可进行分词、词性标注等 | 中文文本的基础处理 |
| Python数据处理常用库 | Pandas | 擅长数据处理,能读取excel、csv等格式文件,执行按列去重、排序、去除无效值等操作 | 结构化数据处理,尤其是与表格数据相关任务 |
| Python数据处理常用库 | Matplotlib | 用于画图,实现数据可视化 | 了解数据集分布、展示数据分析结果 |
| Python数据处理常用库 | Nltk | 英文预处理工具佼佼者,词性还原、去停用词等功能完善,对中文也有一定支持 | 英文文本处理,兼顾少量中文处理需求 |
| Python数据处理常用库 | Re | 正则表达式库 | 文本模式匹配、信息提取等任务 |
| Python数据处理常用库 | Json | 用于读取json格式数据 | 处理以json格式存储的数据 |
| Python数据处理常用库 | Pickle | 可进行文件读写自定义的任意变量或数据结构,如自建索引 | 保存和加载自定义数据对象 |
| NLP常用工具 | NLTK | Python中受欢迎的NLP工具包,提供分词、标注、词干提取、词形还原、句法分析等多种文本处理功能 | Python环境下通用的文本处理,特别是教学和快速原型开发 |
| NLP常用工具 | Stanford CoreNLP | 斯坦福大学开发,支持多语言,涵盖分词、句法分析、命名实体识别等功能 | 多语言NLP任务,对多种语言有统一处理需求时 |
| NLP常用工具 | SpaCy | Python中的NLP工具包,具备分词、句法分析、命名实体识别功能,实体关系抽取功能强大 | 需要深入挖掘文本中实体关系的NLP任务 |
| NLP常用工具 | Gensim | 提供主题建模、文本相似度计算等文本处理和语言模型相关功能 | 主题分析、文本相似性度量等任务 |
| NLP常用工具 | Word2Vec | 生成词向量,将文本中单词表示为高维向量,助力文本分类、信息检索等任务 | 以词向量为基础的文本分析任务 |
| NLP常用工具 | TensorFlow | Google开发的机器学习框架,提供RNN、CNN等多种自然语言处理工具和模型 | 深度学习驱动的NLP任务,特别是大规模模型训练 |
关于GPU
GPU能够为深度学习训练加速
对于算法学习本身而言,GPU不是必须的
有需要可以尝试租卡用
相关文章:

01 NLP的发展历程和挑战
1.人工智能行业介绍 ANI、AGI、ASI 以下是弱人工智能(ANI)、强人工智能(AGI)和超强人工智能(ASI)的对比表格: 类型定义当前状态弱人工智能(ANI)专注于特定任务&#x…...
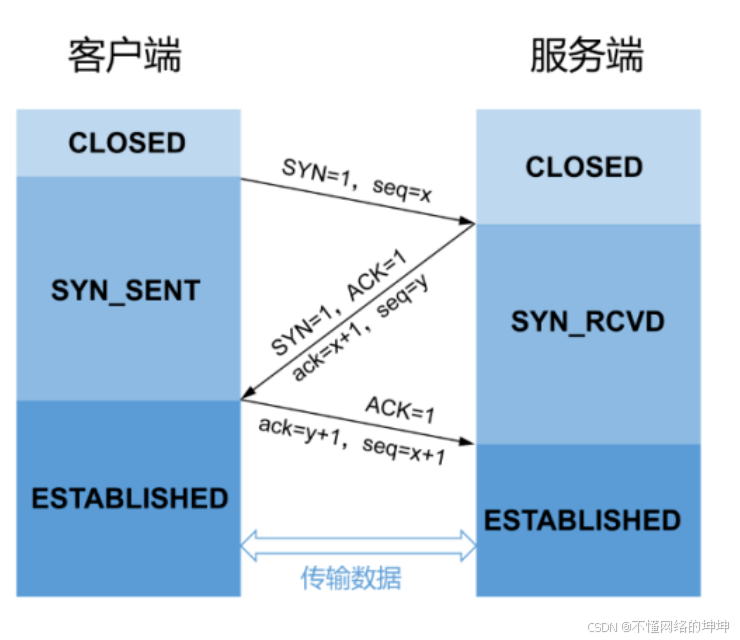
TCP 三次握手:详解与原理
无图、长文警告!!!! 文章目录 一、引言二、TCP 三次握手的过程(一)第一次握手:SYN(同步序列号)(二)第二次握手:SYN-ACK(同…...
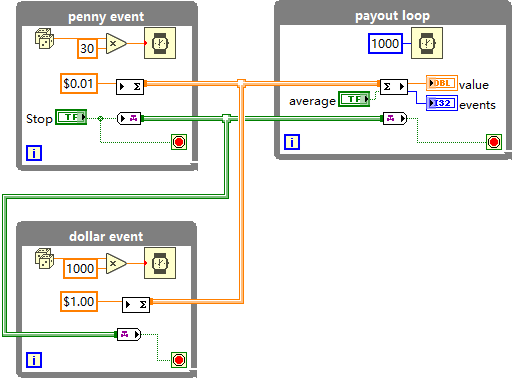
LabVIEW累加器标签通道
主要展示了 Accumulator Tag 通道的使用,通过三个并行运行的循环模拟不同数值的多个随机序列,分别以不同频率向累加器写入数值,右侧循环每秒读取累加器值,同时可切换查看每秒内每次事件的平均值,用于演示多线程数据交互…...
在 Unity 中,Start 方法直接设置 RectTransform 的位置,时出现问题,与预计位置不匹配。
改动之前的源代码:发现组件的位置,与设计的位置不一样,但是如果把这段代码,交给一个按钮按下回调,就不会出现问题。 void Start(){//初始化Text 行//读取配置文件;StaticDataObj obj Resources.Load<St…...

永磁同步电机控制算法--IP调节器
一、基本原理 在电机控制领域,现今普遍使用的是比例-积分(PI)控制器。然而,PI控制器有一些缺点,可能会在某些应用中产生一些问题,例如:一个非常快的响应,也同时具有过大的超调量。虽然设计PI控制器时,可以…...
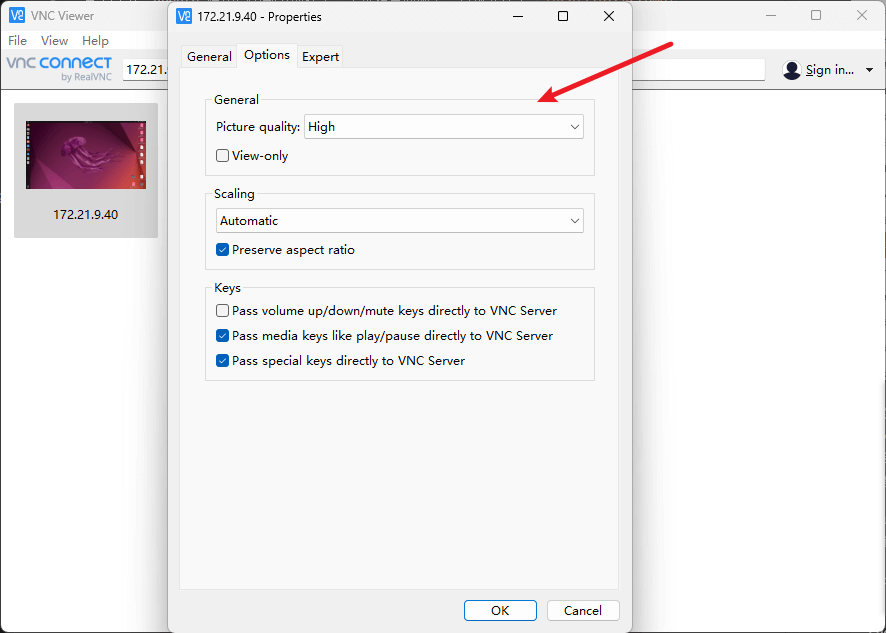
Ubuntu 25.04 锁屏不能远程连接的解决方案
最近安装了一个 Ubuntu 25.04,偶然发现可以通过 windows 自带的 rdp 远程工具进行连接,内心狂喜。此外,还支持启动 VNC 协议,也就是默认支持了 rdp 和 vnc 连接。 看了以下,ubuntu 在用户级别下创建了一个远程桌面服务…...
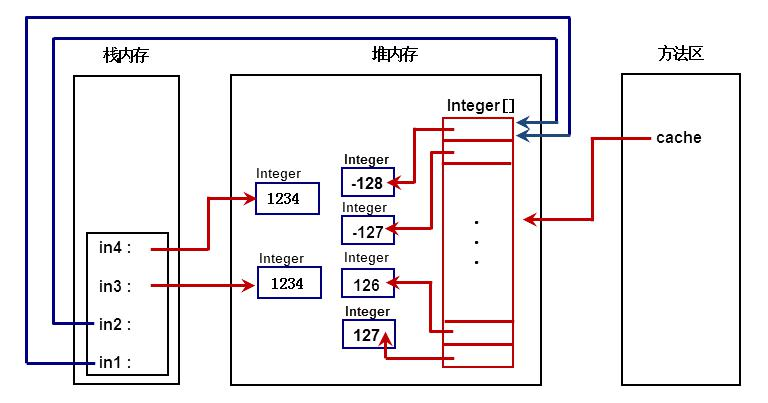
Java 自动装箱和拆箱还有包装类的缓存问题
自动装箱和拆箱就是将基本数据类型和包装类之间进行自动的互相转换。JDK1.5 后, Java 引入了自动装箱(autoboxing)/拆箱(unboxing)。 自动装箱: 基本类型的数据处于需要对象的环境中时,会自动转为“对象”。 我们以 Integer 为例:…...
java-jdk8新特性Stream流
一、Stream流 是专业用于对集合或者数组进行便捷操作的。 1.1 Stream流的创建 主要分为Collection(List与Set)、Map、数组三种创建方式: //1.Collection集合的创建List<String> names new ArrayList<>();Collections.addAll(…...
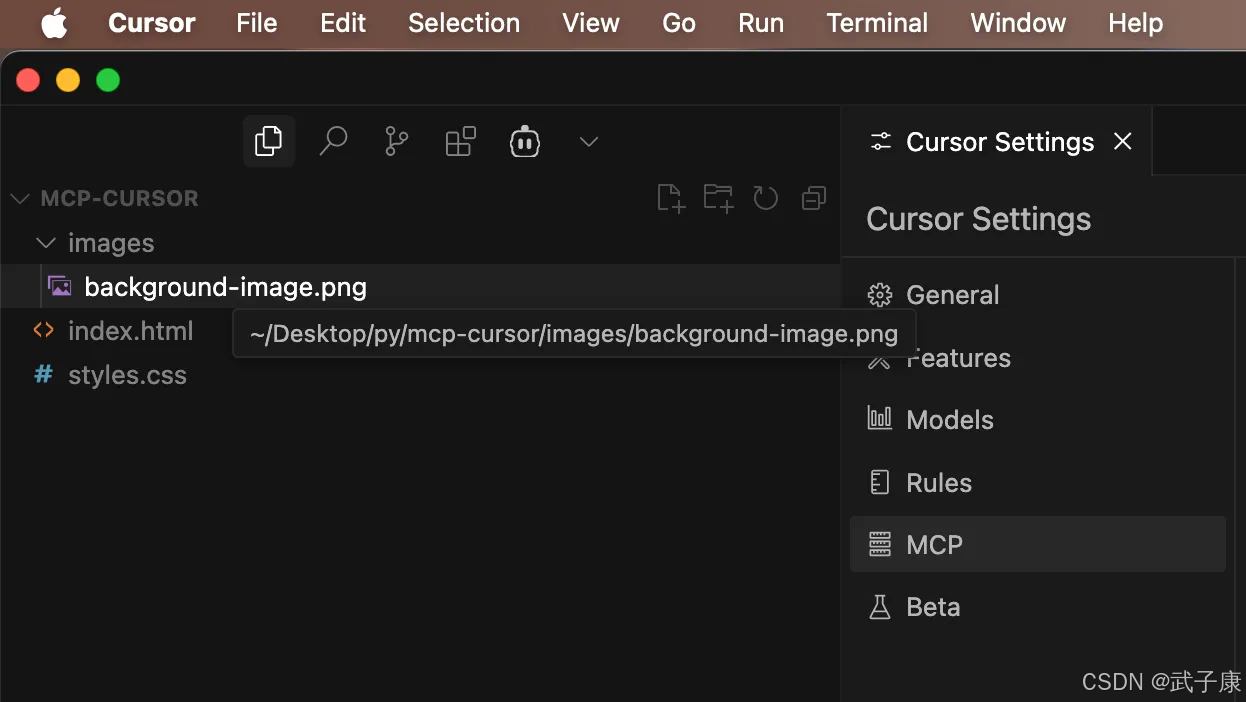
大语言模型 21 - MCP 自动操作 Figma+Cursor 实现将原型转换为代码
MCP 基本介绍 官方地址: https://modelcontextprotocol.io/introduction “MCP 是一种开放协议,旨在标准化应用程序向大型语言模型(LLM)提供上下文的方式。可以把 MCP 想象成 AI 应用程序的 USB-C 接口。就像 USB-C 提供了一种…...
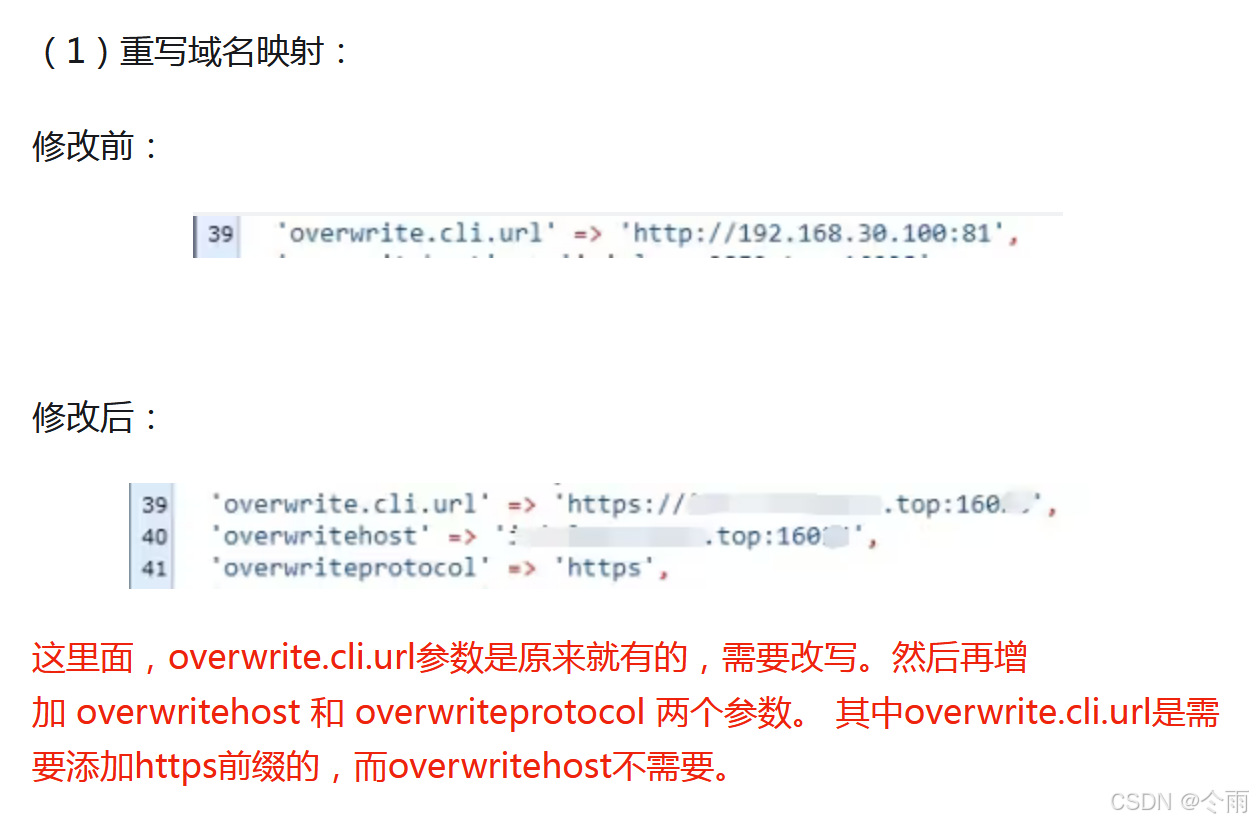
QNAP NEXTCLOUD 域名访问
我是用docker compose方式安装的,虽然不知道是不是这么个叫法,废话不多说。 背景:威联通container station安装了nextcloud和lucky,lucky进行的域名解析和反代 先在想安装的路径、数据存储路径、数据库路径等新建文件夹。再新建…...

Spring MVC深度解析:控制器与视图解析及RESTful API设计最佳实践
引言 在现代Java Web开发领域,Spring MVC框架凭借其优雅的设计和强大的功能,已成为构建企业级Web应用的首选框架。本文将深入探讨Spring MVC的核心机制——控制器与视图解析,并详细讲解如何设计符合RESTful风格的API。无论你是刚接触Spring …...

华为OD机试真题——信道分配(2025B卷:200分)Java/python/JavaScript/C/C++/GO最佳实现
2025 B卷 200分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...

比亚迪“双剑”电池获中汽中心权威认证,堪称“移动安全堡垒”。
在新能源汽车发展中,电池安全是重中之重。比亚迪的刀片电池与闪充刀片电池提前通过电池新国标全项检测,获中汽中心权威认证,堪称“移动安全堡垒”。 传统电池极端条件下易热失控,而刀片电池独特长条形设计,似刀片般&am…...
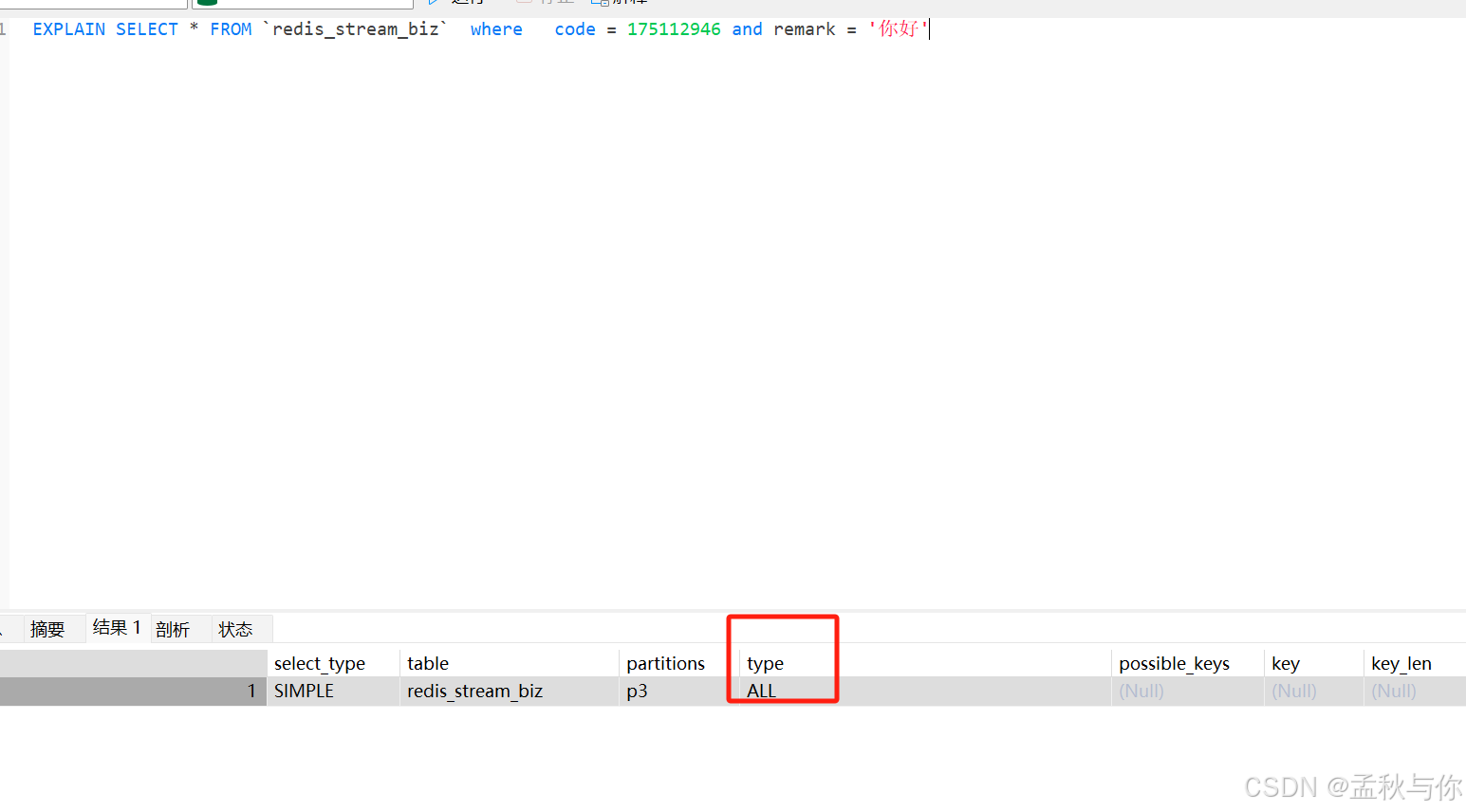
【mysql】mysql的高级函数、高级用法
mysql是最常用的数据库之一,常见的函数用法大家应该都很熟悉,本文主要例举一些相对出现频率比较少的高级用法 (注:需注意mysql版本,大部分高级特性都是mysql8才有的) 多值索引与虚拟列 主要是解决字符串索引问题,光说…...

了解一下C#的SortedSet
基础概念 SortedSet 是 C# 中的一个集合类型,位于 System.Collections.Generic 命名空间下。它是一个自动排序的集合,用于存储不重复的元素,并且会根据元素的自然顺序(默认排序)或自定义比较器进行排序,内…...
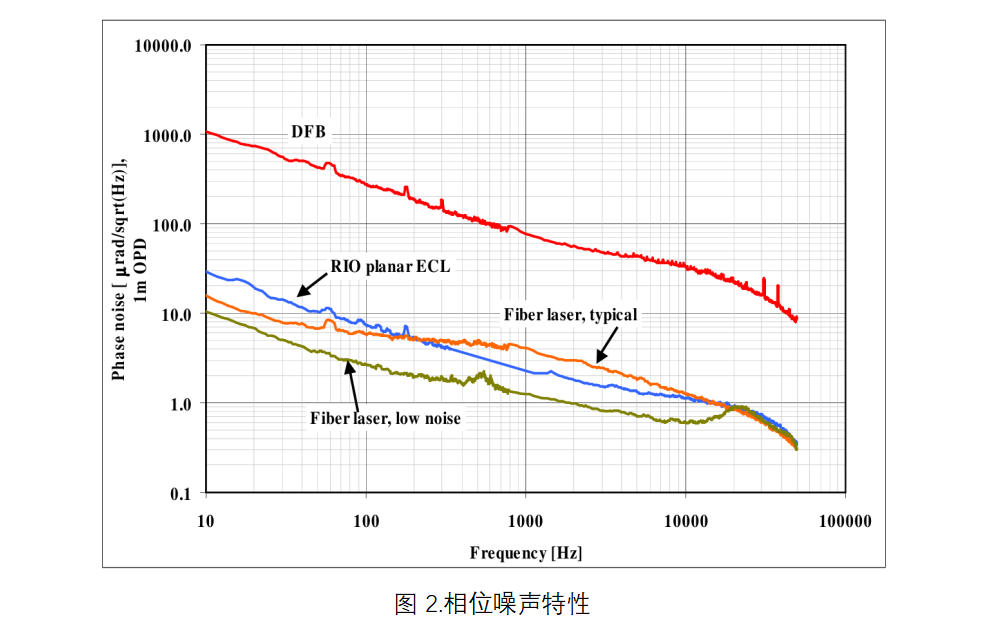
【平面波导外腔激光器专题系列】用于光纤传感的低噪声PLC外腔窄线宽激光器
----翻译自Mazin Alalusi等人的文章 摘要 高性价比的 1550 nm DWDM平面外腔 (PLANEX) 激光器是干涉测量、布里渊、LIDAR 和其他光传感应用的最佳选择。其线宽<3kHz、低相位/频率噪声和极低的RIN。 简介 高性能光纤分布式传感技术是在过去几年中开发…...
Pytorch里面多任务Loss是加起来还是分别backward? | Pytorch | 深度学习
当你在深度学习中进入“多任务学习(Multi-task Learning)”的领域,第一道关卡可能不是设计网络结构,也不是准备数据集,而是:多个Loss到底是加起来一起backward,还是分别backward? 这个问题看似简单,却涉及PyTorch计算图的构建逻辑、自动求导机制、内存管理、任务耦合…...

K8S Pod调度方法实例
以下是一篇面向企业用户、兼具通俗易懂和实战深度的 Kubernetes Pod 调度方法详解博文大纲与正文示例。全文采用“图文(代码块)并茂 问答穿插 类比”方式,模拟了真实终端操作及输出,便于读者快速上手。 一、引言 为什么要关注 P…...

【mindspore系列】- 算子源码分析
本文会介绍mindspore的算子源码结构、执行过程以及如何编写一个自定义的mindspore算子。 源码介绍 首先,我们先从https://gitee.com/mindspore/mindspore/ 官网中clone源代码下来。 clone好代码后,可以看到源码的文件夹结构如下(只列出比较重要的文件夹): docsmindspore…...

学习日记-day17-5.27
完成目标: 知识点: 1.日期相关类_Calendar日历类 常用方法:int get(int field) ->返回给定日历字段的值void set(int field, int value) :将给定的日历字段设置为指定的值void add(int field, int amount) :根据日历的规则,为给定的日历字段添加或…...
一种比较精简的协议
链接地址为:ctLink: 一个比较精简的支持C/C的嵌入式通信的中间协议。 本文采用的协议格式如下 *帧头 uint8_t 起始字节:0XAF\ *协议版本 uint8_t 使用的协议版本号:当前为0X01\ *负载长度 uint8_t 数据段内容长…...

网络常识:网线和光纤的区别
网络常识:网线和光纤的区别 一. 介绍二. 网线2.1 什么是网线?2.2 网线的主要类别2.3 网线的优势2.4 网线的劣势 三. 光纤3.1 什么是光纤?3.2 光纤的主要类别3.3 光纤的优势3.4 光纤的劣势 四. 网线 vs 光纤:谁更适合你?…...

OpenCV CUDA模块图像过滤------创建一个 Scharr 滤波器函数createScharrFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数用于创建一个 Scharr 滤波器(基于 CUDA 加速),用于图像的一阶导数计算。它常用于边缘检测任务中&#…...
html css js网页制作成品——HTML+CSS+js醇香咖啡屋网页设计(5页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

[特殊字符] 构建高内聚低耦合的接口架构:从数据校验到后置通知的分层实践
在现代企业系统开发中,接口结构设计的质量直接影响系统的稳定性、扩展性与可维护性。随着业务复杂度上升,单一层次的接口实现往往难以应对功能膨胀、事务一致性、后置扩展等需求。因此,我们提出一种面向复杂业务场景的接口分层模型࿰…...

brep2seq 源码笔记2
数学公式是什么def forward(self, noise_1, noise_2, real_z_pNone): if(real_z_p): z_p_ self.downsample(real_z_p) input_2 z_p_ noise_2 z_f self.gen_z_f(input_2) output real_z_p z_f else: …...
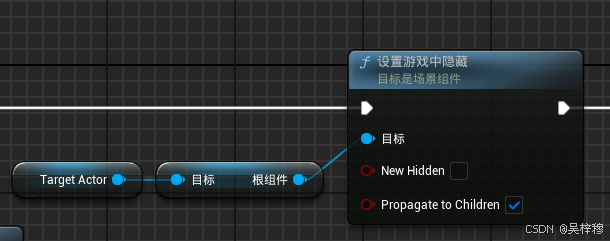
UE5 蓝图,隐藏一个Actor,同时隐藏它的所有子物体
直接用actor.sethideningame是不行的 要先找到根组件,这样就有覆盖子物体的选项了...

人工智能AI之机器学习基石系列 第 2 篇:数据为王——机器学习的燃料与预处理
专栏系列:《人工智能AI之机器学习基石》② 高质量的数据是驱动机器学习模型的强大燃料 🚀 引言:无米之炊与数据的重要性 在上一篇文章《什么是机器学习?——开启智能之门》中,我们一起揭开了机器学习的神秘面纱&…...
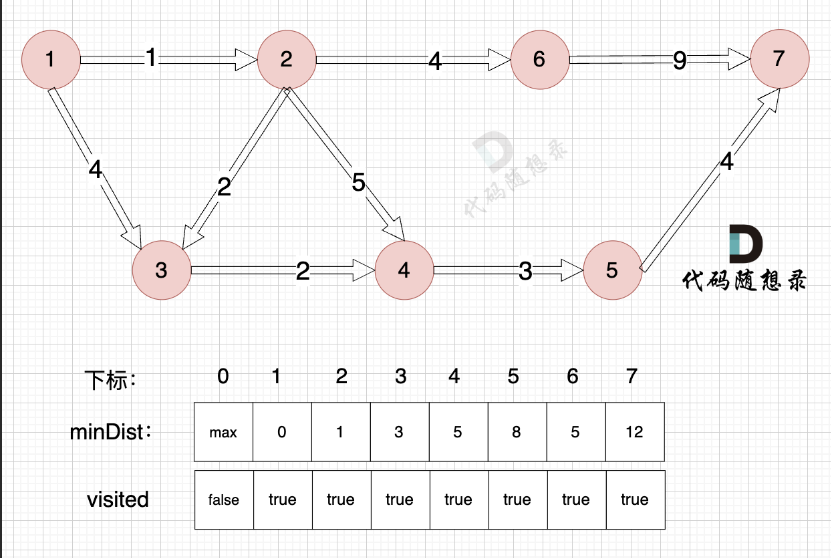
代码随想录算法训练营 Day58 图论Ⅷ 拓扑排序 Dijkstra
图论 题目 117. 软件构建 拓扑排序:给出一个有向图,把这个有向图转成线性的排序就叫拓扑排序。 当然拓扑排序也要检测这个有向图是否有环,即存在循环依赖的情况,因为这种情况是不能做线性排序的。所以拓扑排序也是图论中判断有向…...

实现单例模式的6种方法(Python)
目录 一. 基于模块的实现(简单,易用) 二. 重新创建时报错(不好用) 三. 只靠方法获取实例(不好用) 四. 类装饰器 五. 重写__new__方法 六. 元类 七. 总结 单例模式(Singleton Pattern)是一种设计模式,其核心目标是确保一个类…...