Python的分布式网络爬虫系统实现
1. 系统架构概述
一个典型的分布式网络爬虫系统通常包含以下几个核心组件:
1.主节点(Master Node):
- 任务调度:负责将抓取任务分配给各个工作节点。
- URL 管理:维护待抓取的 URL 队列和已抓取的 URL 集合,避免重复抓取。
- 数据存储:存储抓取到的数据,通常使用数据库或分布式存储系统。
- 监控与日志:监控各个工作节点的状态,记录系统日志以便故障排查。
2.工作节点(Worker Nodes):
- 数据抓取:执行实际的网页抓取任务。
- 数据解析:解析抓取到的网页内容,提取所需的信息。
- 数据存储:将解析后的数据发送到主节点或直接存储到数据库。
3.消息队列(Message Queue):
- 任务队列:用于在主节点和工作节点之间传递抓取任务。
- 结果队列:用于在工作节点和主节点之间传递抓取结果。
4.数据库(Database):
- 存储抓取数据:如 MongoDB、Elasticsearch、MySQL 等。
- 存储 URL 队列:可以使用 Redis 等内存数据库来存储待抓取的 URL。
5.配置与部署:
- 配置管理:集中管理系统的配置参数,如抓取频率、并发数等。
- 容器化与编排:使用 Docker、Kubernetes 等工具进行容器化和编排,简化部署和管理。
2. 关键技术选型
2.1 Python 库与框架
- Scrapy:一个功能强大的 Python 爬虫框架,支持异步抓取、扩展性强。
- Scrapy-Redis:基于 Redis 的 Scrapy 分布式扩展,用于分布式任务调度。
- Celery:一个异步任务队列,可以与 Scrapy 结合使用,实现更灵活的任务调度。
- Redis:用作消息队列和缓存,存储待抓取的 URL 和抓取结果。
- SQLAlchemy / Django ORM:用于数据库操作(如果使用关系型数据库)。
- BeautifulSoup / lxml:用于网页解析和内容提取。
2.2 数据库
- 关系型数据库:如 MySQL、PostgreSQL,适用于结构化数据存储。
- NoSQL 数据库:
- MongoDB:适用于存储非结构化或半结构化数据,支持灵活的文档模型。
- Elasticsearch:适用于全文检索和分析。
2.3 消息队列
- Redis:作为轻量级消息队列,支持发布/订阅模式。
- RabbitMQ:功能强大的消息队列,支持多种消息协议。
3. 详细实现步骤
3.1 环境准备
1.安装必要的库:
bash
pip install scrapy scrapy-redis celery redis
2.安装数据库:
- 安装 Redis 并启动 Redis 服务器。
- 安装 MongoDB 或其他选择的数据库并启动。
3.2 配置 Scrapy 项目
1.创建 Scrapy 项目:
bash
scrapy startproject myspider
2.配置 Scrapy-Redis:
在 settings.py 中添加以下配置:
python
# settings.py# 使用 Scrapy-Redis 的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"# 使用 Redis 作为去重存储
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"# 设置 Redis 主机和端口
REDIS_HOST = 'localhost'
REDIS_PORT = 6379# 启用管道
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 300,
}# 启用分布式请求
SCHEDULER_PERSIST = True
3.3 定义爬虫
1.创建爬虫:
bash
scrapy genspider example example.com
2.编辑爬虫:
python
# myspider/spiders/example.pyimport scrapy
from scrapy_redis.spiders import RedisSpiderclass ExampleSpider(RedisSpider):name = 'example'redis_key = 'myspider:start_urls'def parse(self, response):# 解析网页内容,提取数据title = response.xpath('//title/text()').get()yield {'url': response.url,'title': title,}# 获取页面中的所有链接,并添加到 Redis 队列中links = response.xpath('//a/@href').getall()for link in links:yield scrapy.Request(url=link, callback=self.parse)
3.4 配置 Celery(可选)
如果需要更灵活的任务调度,可以使用 Celery。以下是一个简单的配置示例:
1.创建 Celery 实例:
python
# myspider/celery_app.pyfrom celery import Celeryapp = Celery('myspider',broker='redis://localhost:6379/0',backend='redis://localhost:6379/1')app.conf.update(task_serializer='json',accept_content=['json'],result_serializer='json',timezone='Europe/Paris',enable_utc=True,
)
2.定义抓取任务:
python
# myspider/tasks.pyfrom celery_app import app
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings@app.task
def run_spider(url):process = CrawlerProcess(get_project_settings())process.crawl('example', start_urls=[url])process.start()
3.5 启动服务
1.启动 Redis 服务器:
bash
redis-server
2.启动 Celery worker(如果使用 Celery):
bash
celery -A myspider.celery_app worker --loglevel=info
3.启动 Scrapy 爬虫:
bash
scrapy crawl example
或者,如果使用 Celery,可以通过调用 Celery 任务来启动爬虫:
python
from tasks import run_spiderrun_spider.delay('http://example.com')
3.6 数据存储
1.使用 Scrapy-Redis 管道:
Scrapy-Redis 提供了 RedisPipeline,可以将抓取到的数据存储到 Redis 中。
2.自定义管道:
如果需要将数据存储到其他数据库(如 MongoDB),可以编写自定义管道。例如:
python
# myspider/pipelines.pyimport pymongoclass MongoPipeline:def __init__(self, mongo_uri, mongo_db, mongo_collection):self.mongo_uri = mongo_uriself.mongo_db = mongo_dbself.mongo_collection = mongo_collection@classmethoddef from_crawler(cls, crawler):return cls(mongo_uri=crawler.settings.get('MONGO_URI'),mongo_db=crawler.settings.get('MONGO_DB'),mongo_collection=crawler.settings.get('MONGO_COLLECTION'))def open_spider(self, spider):self.client = pymongo.MongoClient(self.mongo_uri)self.db = self.client[self.mongo_db]def close_spider(self, spider):self.client.close()def process_item(self, item, spider):self.db[self.mongo_collection].insert_one(dict(item))return item
在 settings.py 中添加配置:
python
MONGO_URI = 'mongodb://localhost:27017'
MONGO_DB = 'mydatabase'
MONGO_COLLECTION = 'mycollection'
ITEM_PIPELINES = {'myspider.pipelines.MongoPipeline': 300,
}
4. 任务调度与负载均衡
4.1 使用 Scrapy-Redis 进行任务调度
Scrapy-Redis 利用 Redis 的发布/订阅机制,实现分布式任务调度。主节点将 URL 推送到 Redis 的 start_urls 队列,工作节点从队列中获取 URL 并进行抓取。
4.2 使用 Celery 进行任务调度(可选)
如果需要更复杂的任务调度策略,如定时任务、任务优先级等,可以使用 Celery。Celery 可以与 Scrapy 结合使用,提供更灵活的任务管理。
4.3 负载均衡
- 动态分配任务:通过 Redis 队列实现动态任务分配,确保工作节点之间的负载均衡。
- 自动扩展:使用 Kubernetes 或其他容器编排工具,根据负载自动扩展工作节点的数量。
5. 错误处理与容错
5.1 异常处理
- 抓取失败:记录失败的 URL,稍后重试。
- 解析错误:处理解析异常,确保系统的稳定性。
5.2 重试机制
- 自动重试:配置 Scrapy 的重试机制,自动重试失败的请求。
- 自定义重试策略:根据具体需求,实现自定义的重试策略,如指数退避。
5.3 断点续爬
- 持久化队列:使用 Redis 持久化队列,确保在系统重启后能够继续抓取未完成的任务。
- 状态恢复:记录抓取状态,在系统恢复后从上次的状态继续。
6. 性能优化
6.1 并发控制
- 限制并发数:根据系统资源和目标网站的承载能力,限制并发请求的数量。
- 连接池:使用连接池管理 HTTP 连接,提高性能。
6.2 数据抓取优化
- 异步抓取:使用 Scrapy 的异步特性,提高抓取效率。
- 分布式抓取:通过分布式架构,分散抓取负载,提高整体性能。
6.3 缓存机制
- 缓存 DNS 解析:减少 DNS 解析时间。
- 缓存静态资源:减少重复请求,提高抓取速度。
7. 安全性与合规性
7.1 遵守网站的 robots.txt
- 遵守爬虫协议:在抓取前检查目标网站的
robots.txt,确保遵守其爬虫政策。 - 合法合规:确保抓取行为符合相关法律法规,避免侵犯隐私或知识产权。
7.2 反爬虫机制
- IP 轮换:使用代理池,轮换 IP 地址,防止被封禁。
- 请求头伪装:设置合适的请求头,模拟浏览器行为。
- 验证码处理:处理网站可能出现的验证码机制。
8. 监控与日志
8.1 实时监控
- 系统监控:使用 Prometheus 和 Grafana 监控系统的性能指标,如 CPU、内存、磁盘使用等。
- 爬虫监控:监控抓取任务的进度、成功率、失败率等。
8.2 日志管理
- 集中日志管理:使用 ELK(Elasticsearch, Logstash, Kibana)堆栈,集中管理和分析日志。
- 错误日志:记录详细的错误日志,便于故障排查。
9. 总结
基于 Python 的分布式网络爬虫系统可以通过结合 Scrapy、Redis、Celery 等技术,实现高效、可扩展且稳定的抓取任务。
通过合理的架构设计、任务调度、错误处理和性能优化,可以构建一个强大的爬虫系统,满足各种抓取需求。以下是一个简单的项目结构示例:
myspider/
├── myspider/
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders/
│ ├── __init__.py
│ └── example.py
├── celery_app.py
├── tasks.py
└── scrapy.cfg
联系方式:https://t.me/XMOhost26
交流技术群:https://t.me/owolai008
相关文章:

Python的分布式网络爬虫系统实现
1. 系统架构概述 一个典型的分布式网络爬虫系统通常包含以下几个核心组件: 1.主节点(Master Node): 任务调度:负责将抓取任务分配给各个工作节点。URL 管理:维护待抓取的 URL 队列和已抓取的 URL 集合&a…...
)
Vue快速上手(业务、技术、报错)
Vue 技术业务报错 技术 业务 Vueelement-ui,实现表格渲染缩略图,鼠标悬浮缩略图放大,点击缩略图播放视频(一) 报错 vue修改配置文件.env.development不生效 vue前端downloadFile报错:Error parsing HT…...

taro + vue3 实现小程序sse长连接实时对话
前言 taro.request是可以实现sse长连接的,但是呢其中有俩大坑,找了许多资料也没解决,后续解决办法也与后端商量改用WebSocket来实现。 代码实现 SSEManager.js: import { getAccessToken } from "../xx/xx"; import { TextDecode…...
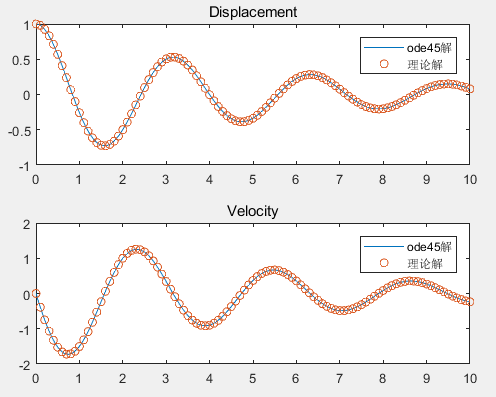
使用MATLAB求解微分方程:从基础到实践
使用MATLAB求解微分方程:从基础到实践 微分方程是描述自然界和工程领域中许多现象的重要数学工具。MATLAB提供了强大的工具来求解各种类型的微分方程。本文将介绍如何使用MATLAB求解常微分方程(ODE)。 1. 基本ODE求解器 MATLAB提供了多种ODE求解器,最…...

基于MATLAB的大规模MIMO信道仿真
1. 系统模型与参数设置 以下是一个单小区大规模MIMO系统的参数配置示例,适用于多发多收和单发单收场景。 % 参数配置 params.N_cell 1; % 小区数量(单小区仿真) params.cell_radius 500; % 小区半径(米)…...
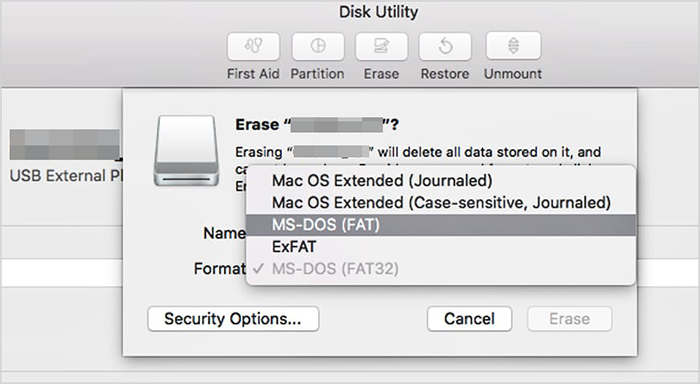
如何在 Windows 和 Mac 上擦拭和清洁希捷外置硬盘
希捷外置硬盘广泛用于存储目的,但有时您可能出于多种目的需要擦除或清洁希捷外置硬盘,例如转售、重复使用、捐赠等。为了释放硬盘上的存储空间或确保没有人可以从硬盘中恢复您的信息,擦除硬盘是必要的步骤。无论您使用的是 Windows 还是 Mac&…...

Vue 3.0 中状态管理Vuex 与 Pinia 的区别
在 Vue.js 应用开发中,状态管理是构建复杂应用的关键环节。随着 Vue 3 的普及和 Composition API 的引入,开发者面临着状态管理库的选择问题:是继续使用经典的 Vuex,还是转向新兴的 Pinia?本文将从设计理念、API 设计、…...
第三届黄河流域网安技能挑战赛复现
Web 奶龙牌图片处理器2.0 这题,之前只了解过 .user.ini 文件,并为遇到实操题 但赛前差点就做到下面这题了,不多说,复现之前先看看下面这题 靶场: 攻防世界 没错,又做上文件上传题了,别看…...
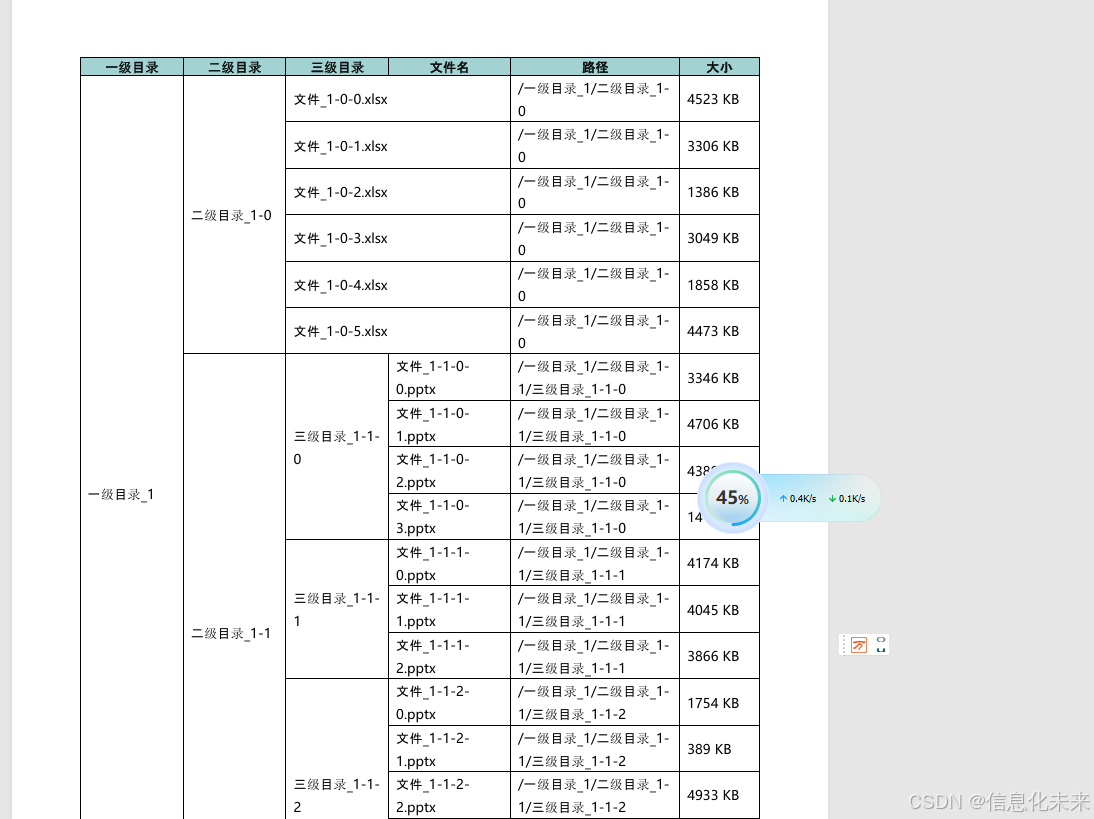
python 生成复杂表格,自动分页等功能
python 生成复杂表格,自动分页等功能 解决将Python中的树形目录数据转换为Word表格,并生成带有合并单元格的检测报告的问题。首先,要解决“tree目录数据”和“Word表格互换”,指将树…...

2025年高防IP与游戏盾深度对比:如何选择最佳防护方案?
2025年,随着DDoS攻击规模的指数级增长和混合攻击的常态化,高防IP与游戏盾成为企业网络安全的核心选择。然而,两者在功能定位、技术实现及适用场景上存在显著差异。本文结合最新行业实践与技术趋势,全面解析两者的优劣,…...

在 Vue + Vite 项目中,直接使用相对路径或绝对路径引用本地图片资源时,图片无法正确显示。
Vue 项目中静态资源引用问题 1.问题描述 在 Vue Vite 项目中,直接使用相对路径或绝对路径引用本地图片资源时,图片无法正确显示。 错误示例 javascript // 错误方式1:使用相对路径 const products [ { name: iPhone 14 Pro, image: .…...
)
判断手机屏幕上的横向滑动(左滑和右滑)
在JavaScript中,你可以通过监听触摸事件(touch events)来判断用户在手机屏幕上的横向滑动方向。以下是实现方法: 基本实现方案 let touchStartX 0; let touchEndX 0;function handleTouchStart(event) {touchStartX event.ch…...

用户有一个Django模型没有设置主键,现在需要设置主键。
用户有一个Django模型没有设置主键,现在需要设置主键。 from django.db import modelsclass CategoryAssistentModel(models.Model):second_level_category models.CharField(max_length100, nullTrue, blankTrue)third_level_category models.CharField(max_len…...
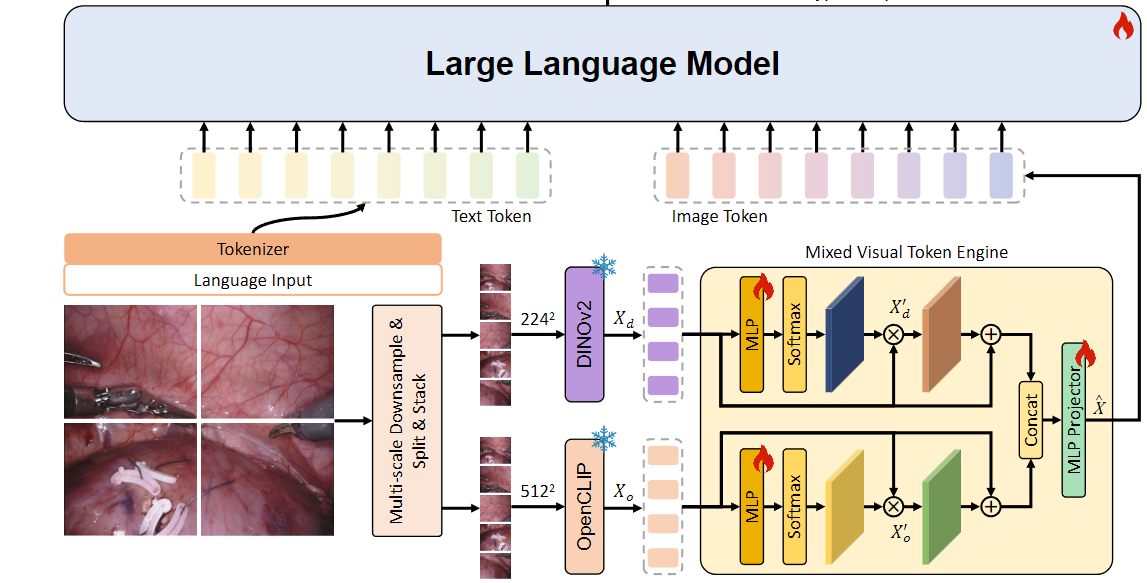
【文献阅读】EndoChat: Grounded Multimodal Large Language Model for Endoscopic Surgery
[2501.11347] EndoChat: Grounded Multimodal Large Language Model for Endoscopic Surgery 2025年1月 数据可用性 Surg-396K 数据集可在 GitHub - gkw0010/EndoChat 公开获取。 代码可用性 EndoChat 的代码可在 GitHub - gkw0010/EndoChat 下载。 摘要 近年来ÿ…...
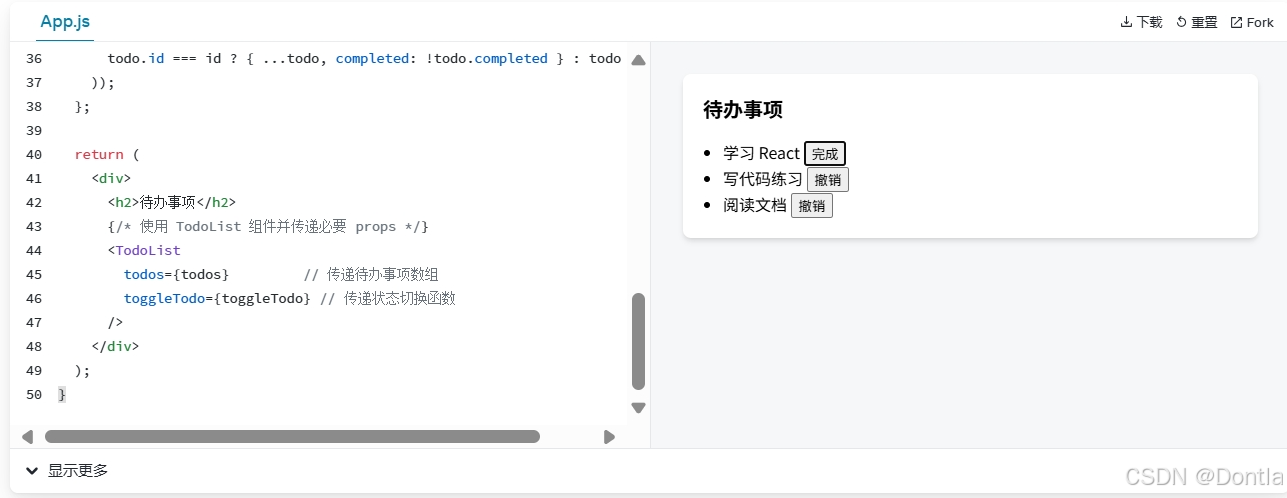
React JSX语法介绍(JS XML)(一种JS语法扩展,允许在JS代码中编写类似HTML的标记语言)Babel编译
在线调试网站:https://zh-hans.react.dev/learn 文章目录 JSX:现代前端开发的声明式语法概述JSX的本质与工作原理什么是JSXJSX转换流程 JSX语法特性表达式嵌入(JSX允许在大括号内嵌入任何有效的JavaScript表达式)属性传递…...

【R语言编程绘图-箱线图】
基本箱线图绘制 使用ggplot2绘制箱线图的核心函数是geom_boxplot()。以下是一个基础示例,展示如何用iris数据集绘制不同物种(Species)的萼片长度(Sepal.Length)分布: library(ggplot2) ggplot(iris, aes(…...

【elasticsearch 7 或8 的安装及配置SSL 操作指引】
1.标题获取安装文件 cd /opt/tools wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.11.4-linux-x86_64.tar.gz tar -zxvf elasticsearch-8.11.4-linux-x86_64.tar.gz mv /opt/tools/elasticsearch-8.11.4 /opt/elasticsearch #配置vm.max_map_co…...
)
GitHub 趋势日报 (2025年05月23日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1All-Hands-AI/OpenHands🙌开放式:少代码,做…...

MongoDB索引:原理、实践与优化指南
为什么索引对数据库如此重要? 在现代应用开发中,数据库性能往往是决定用户体验的关键因素。想象一下,当你在电商平台搜索商品时,如果每次搜索都需要等待5-10秒才能看到结果,这种体验是多么令人沮丧。MongoDB作为最流行…...

SQL实战之索引优化(单表、双表、三表、索引失效)
文章目录 单表优化双表优化三表优化结论索引失效 单表优化 总体原则:建立索引并合理使用,避免索引失效 案例说明:查询category_ id 为1且comments大于1的情况下,views最多的article_ id: 传统方案: explain select id, author_ id…...
[7-1] ADC模数转换器 江协科技学习笔记(14个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 DMA(Direct Memory Access,直接内存访问)是一种硬件特性,它允许某些硬件子系统直接访问系统的内存,而无需CPU的介入。这样,CPU就可以处理其他任务,从而提高系…...

SSM整合:Spring+SpringMVC+MyBatis完美融合实战指南
前言 在Java企业级开发领域,SSM(SpringSpringMVCMyBatis)框架组合一直占据着重要地位。这三个轻量级框架各司其职又相互配合,为开发者提供了高效、灵活的开发体验。本文将深入探讨SSM框架的整合过程,揭示整合背后的原…...

Spring Boot分页查询进阶:整合Spring Data REST实现高效数据导航
目录: 引言分页查询基础回顾 2.1 Spring Data JPA分页接口 2.2 Pageable与Page的使用 2.3 常见分页参数设计Spring Data REST简介 3.1 HATEOAS与超媒体驱动API 3.2 Spring Data REST核心功能 3.3 自动暴露Repository接口整合Spring Boot与Spring Data REST 4.1 项目…...
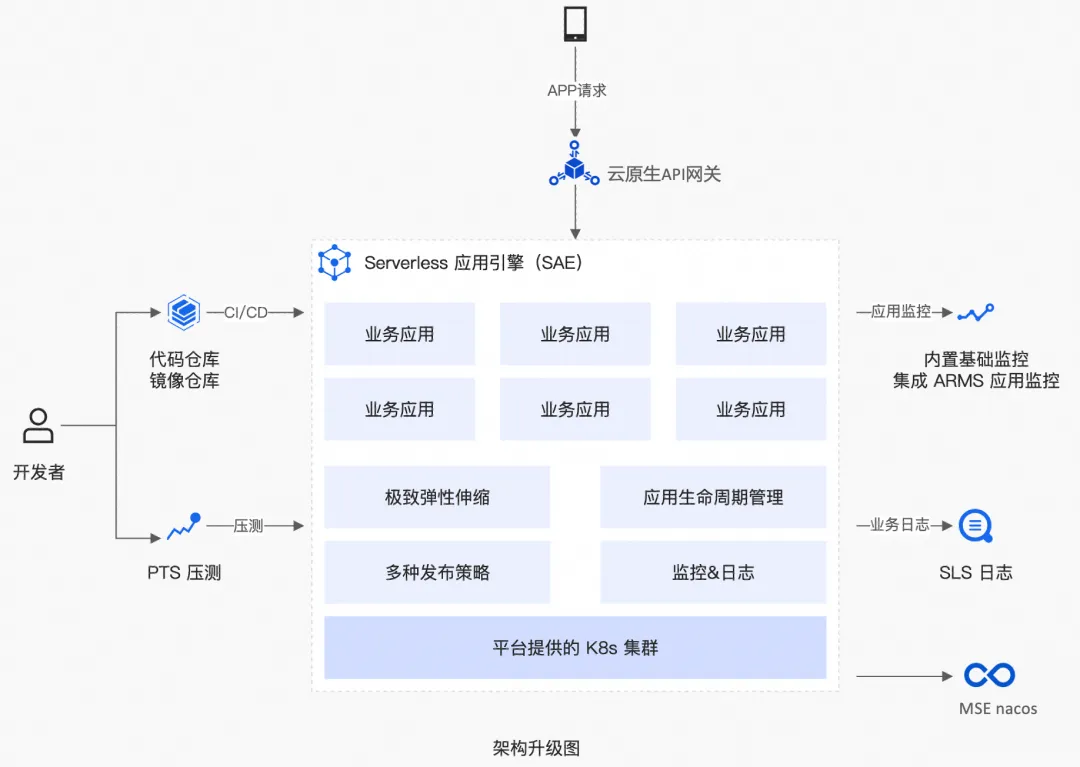
阿里云 Serverless 助力海牙湾构建弹性、高效、智能的 AI 数字化平台
作者:赵世振、十眠、修省 “通过阿里云 Serverless 架构,我们成功解决了弹性能力不足、资源浪费与运维低效的痛点。SAE 的全托管特性大幅降低技术复杂度。未来,我们将进一步探索 Serverless 与 AI 的结合,为客户提供更智能的数字…...

升级node@22后运行npm install报错 distutils not found
从node20升级到node22后,在运行 npm install 的时候报了很多 gyp 错误,其中包括 npm error npm error ModuleNotFoundError: No module named distutils。 问题原因是我在使用 brew install node22 的过程中自动把 python 升级到了 3.13。而 distutils …...

一个开源的多播放源自动采集在线影视网站
这里写自定义目录标题 欢迎使用Markdown编辑器GoFilm简介项目部署1、前置环境准备1.2 redis 配置 film-api 后端服务配置将 GoFilm 项目根目录下的 film 文件夹上传到 linux 服务器的 /opt 目录下 2. 构建运行1. docker 部署1.1 安装 docker , docker compose 环境 注意事项: 2…...
)
【PhysUnits】10 减一操作(sub1.rs)
一、源码 代码实现了一个类型级别的减一操作(Sub1 trait),通过Rust的类型系统在编译期完成数值减一的计算。 //! 减一操作特质实现 / Decrement operation trait implementation //! //! 提供类型级别的减一计算 / Provides type-level decrement operationuse su…...
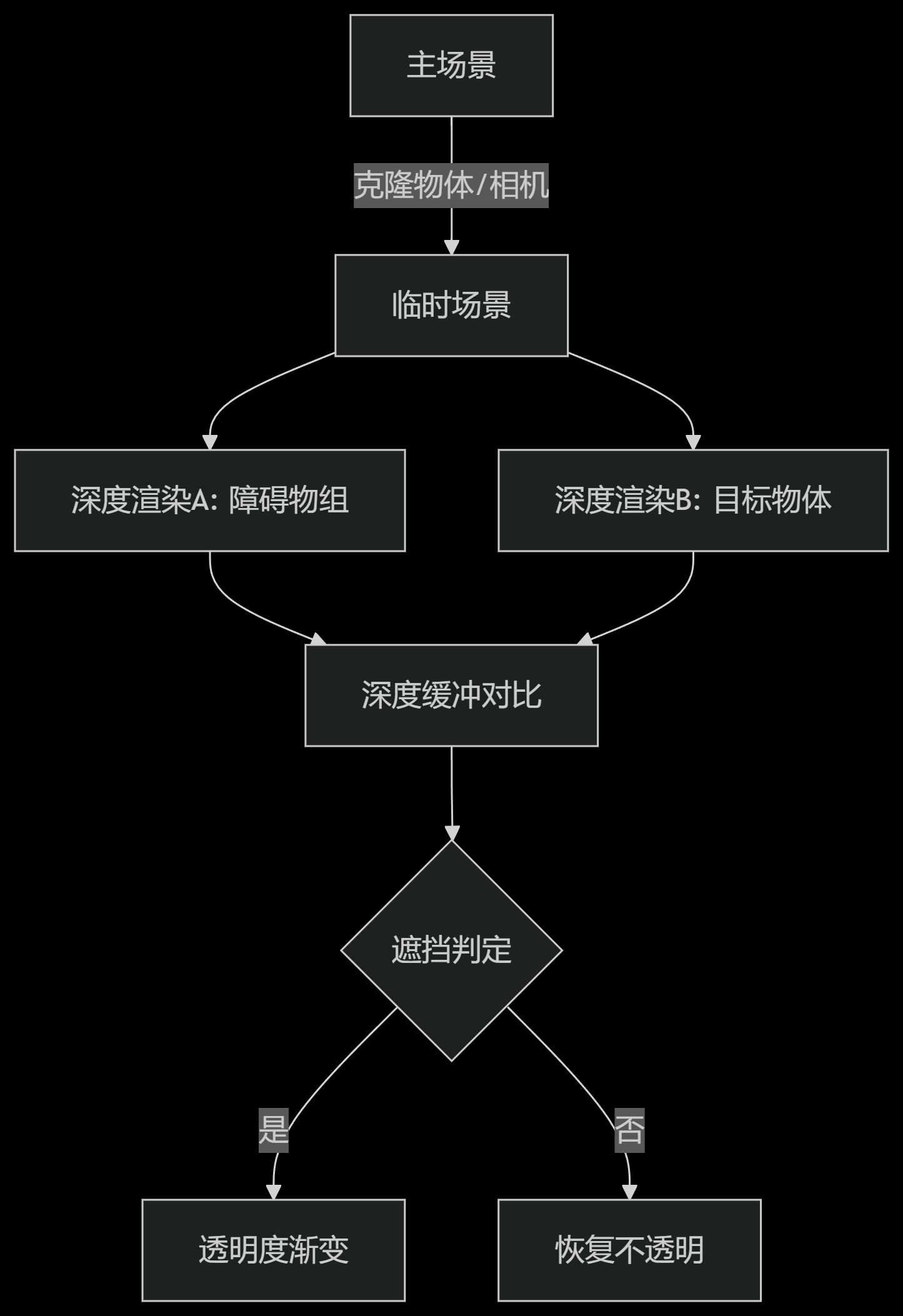
深度检测与动态透明度控制 - 基于Babylon.js的遮挡检测实现解析
首先贴出实现代码: OcclusionFader.ts import { AbstractEngine, Material, type Behavior, type Mesh, type PBRMetallicRoughnessMaterial, type Scene } from "babylonjs/core"; import { OcclusionTester } from "../../OcclusionTester"…...

Linux下使用socat将TCP服务转为虚拟串口设备
Linux下使用socat将TCP服务转为虚拟串口设备 socat是一个强大的网络工具,可以将TCP连接转换为虚拟串口设备,这在嵌入式开发、工业控制等领域非常有用。下面详细介绍如何实现这一功能。 基本原理 socat可以通过创建伪终端(PTY)来模拟串口设备ÿ…...
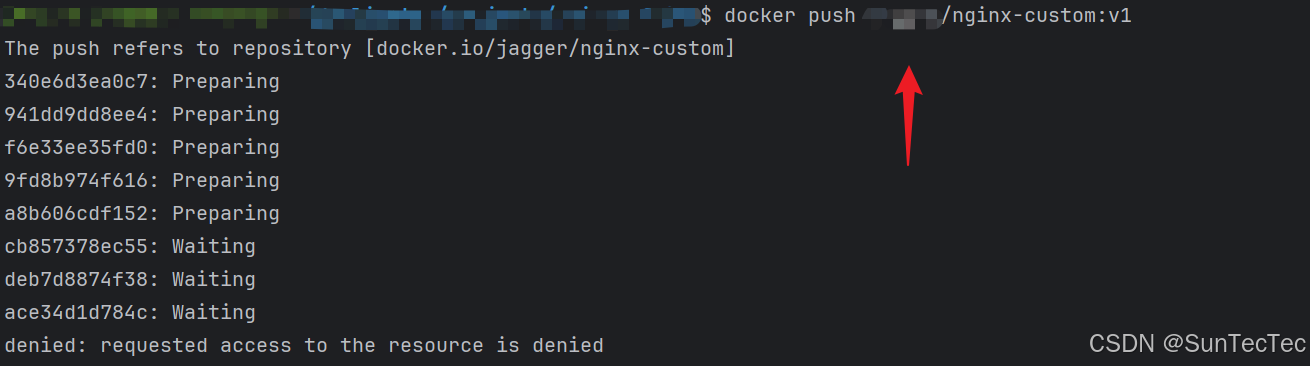
docker push 报错 denied: requested access to the resource is denied
问题:当 docker logout -> docker login 用户登录,但仍然无法 docker push $ docker push <username>/nginx-custom:v1 The push refers to repository [docker.io/jagger/nginx-custom] 340e6d3ea0c7: Preparing 941dd9dd8ee4: Preparing f6…...