Hive 分桶(Bucketing)深度解析:原理、实战与核心概念对比
一、分桶的意义:比分区更细的粒度管理
1.1 解决分区数据不均匀问题
分区的局限性:分区基于表外字段(如时间字段)划分数据,但可能导致部分分区数据量过大,部分过小,无法进一步细化。
分桶的定位:通过表内字段(如用户 ID、订单 ID)将数据划分为更细的 “桶”(Bucket),每个桶是数据文件的子集,实现数据的均衡分布与精细化管理。
1.2 分桶与分区的关系
两者均为数据分治技术,分区是粗粒度划分(如按天分区),分桶是细粒度划分(如每个分区内再按用户 ID 分桶)。
分桶可与分区结合使用,进一步提升查询效率。
二、分桶原理:哈希算法的应用
2.1 核心逻辑:哈希取余
对分桶字段的值进行哈希计算,再通过公式 hash(value) % num_buckets 确定数据所属的桶。
示例:若分桶字段为id,桶数为 4,则id=5的哈希值hash(5)=1234,1234 % 4=2,该数据存入第 2 个桶。
2.2 与 MapReduce 分区的关联
分桶原理类似 MapReduce 中Partitioner的分区逻辑,通过哈希算法将数据分配到不同 Reducer,实现并行处理。
三、分桶的核心优势
3.1 大表 JOIN 性能优化
当两张分桶表按相同字段分桶时,JOIN 操作可仅在相同桶内进行,减少跨节点数据 Shuffle,大幅提升查询速度。
原理:相同分桶字段的记录必然分布在相同桶中,无需全表扫描。
3.2 高效数据抽样
通过桶编号直接定位数据子集,支持TABLESAMPLE语法快速抽样(如抽取第 1 个桶的数据)。
3.3 数据均衡分布
避免分区数据倾斜,每个桶的数据量相对均衡,提升任务并行性。
四、实战操作:从建表到数据加载
4.1 建表语法:指定分桶字段与桶数
CREATE TABLE stu_bucket (id INT,name STRING
)
CLUSTERED BY (id) -- 指定分桶字段
SORTED BY (id DESC) -- 每个桶内数据按id降序排序
INTO 4 BUCKETS -- 分为4个桶
ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ';
4.2 数据加载:使用CLUSTER BY或DISTRIBUTE BY + SORT BY
方式 1:CLUSTER BY(分桶 + 默认升序排序)
INSERT INTO TABLE stu_bucket
SELECT * FROM student CLUSTER BY (id);
INSERT INTO TABLE stu_bucket
SELECT * FROM student DISTRIBUTE BY (id) SORT BY (id);
方式 2:自定义排序字段
INSERT INTO TABLE stu_bucket
SELECT * FROM student DISTRIBUTE BY (id) SORT BY (name ASC);
4.3 关键配置与注意事项
- 设置 Reduce 数量:
- 确保 Reduce 数≥桶数,或设为
-1让 Hive 自动决定(推荐)。
SET mapreduce.job.reduces = -1; -- 自动确定Reduce数 - 确保 Reduce 数≥桶数,或设为
- 关闭本地模式:
SET hive.exec.mode.local.auto = false; -- 避免本地模式影响分桶 - 配置 Hive 分桶属性(在
hive-site.xml中):<property><name>hive.enforce.bucketing</name><value>true</value> -- 强制启用分桶 </property>
五、分桶查询:抽样与 JOIN 优化
5.1 数据抽样:按桶编号快速获取子集
-- 抽取第1个桶的数据(桶编号从0开始)
SELECT * FROM stu_bucket TABLESAMPLE(BUCKET 1 OUT OF 4 ON id);
5.2 分桶表 JOIN 优化
-- 两张表按id分桶,JOIN时仅在相同桶内操作
SELECT a.id, a.name, b.age
FROM stu_bucket a
JOIN stu_score_bucket b ON a.id = b.id;
六、核心概念对比
6.1 分桶 vs 分区
| 维度 | 分桶(Bucketing) | 分区(Partitioning) |
|---|---|---|
| 字段类型 | 表内字段(如 id、name) | 表外字段(如日期、地域) |
| 粒度 | 细粒度(单个分区可包含多个桶) | 粗粒度(每个分区是独立目录) |
| 核心作用 | 数据均衡分布、JOIN 优化、抽样 | 数据过滤、层级管理 |
6.2 相关命令对比
| 命令 | 作用 |
|---|---|
CLUSTER BY | 分桶 + 默认升序排序(等价于DISTRIBUTE BY + SORT BY同一字段) |
DISTRIBUTE BY | 仅分桶(控制数据分布),不排序 |
SORT BY | 局部排序(每个 Reducer 内排序) |
ORDER BY | 全局排序(仅允许 1 个 Reducer,数据量大时慎用) |
PARTITIONED BY | 建表时定义分区字段 |
PARTITION BY | 开窗函数中用于分区(与分桶无关) |
相关文章:
深度解析:原理、实战与核心概念对比)
Hive 分桶(Bucketing)深度解析:原理、实战与核心概念对比
一、分桶的意义:比分区更细的粒度管理 1.1 解决分区数据不均匀问题 分区的局限性:分区基于表外字段(如时间字段)划分数据,但可能导致部分分区数据量过大,部分过小,无法进一步细化。 分桶的定…...

网络协议DHCP
DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)是一种网络协议,用于自动给网络中的设备分配 IP 地址、子网掩码、默认网关、DNS 服务器等网络配置参数。 ✅ 一、DHCP 的作用 自动为客户端分配网络信息,…...

什么是可重组机器人?
可重组机器人是一种具有高度灵活性和适应性的新型机器人系统,能够根据不同任务需求,快速改变自身结构和功能。下面我从概念、结构、特点、应用领域、发展趋势等方面,为你详细介绍: 概念:可重组机器人是由多个标准化、模…...
4、docker compose
1、介绍 Docker Compose 是 Docker 官方提供的容器编排工具,用于简化多容器应用的开发、部署和管理。它通过声明式配置文件(YAML格式)定义容器化应用的服务、网络、存储等组件及其依赖关系,使用户能够通过单一命令快速启动、停止…...

Node.js全局对象详解:console、process与核心功能
在Node.js开发中,全局对象是一类无需引入即可直接访问的对象,它们为开发者提供了与运行时环境、系统交互和调试相关的核心功能。本文将深入解析Node.js中两个最常用的全局对象 console 和 process,并简要介绍其他全局对象的作用。通过代码示例…...

测试策略:AI模型接口的单元测试与稳定性测试
测试策略:AI模型接口的单元测试与稳定性测试 在构建支持AI能力的系统中,开发者不仅要关注业务逻辑的正确性,也必须保障AI模型接口在各种环境下都能稳定运行。这就要求我们在开发阶段制定清晰的测试策略,从功能验证到性能保障,逐步推进系统可用性、可维护性与可扩展性的提…...
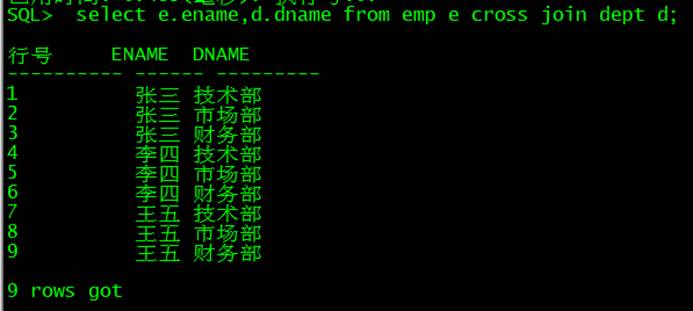
SQL里几种JOIN连接
数据信息: 员工表EMP 部门表DEPT 一、INNER JOIN(内连接) 作用:只返回两个表中完全匹配的行,相当于取交集。 场景:查询「有部门的员工信息」。 示例: SELECT 员工.姓名, 部门.部门名称 FR…...
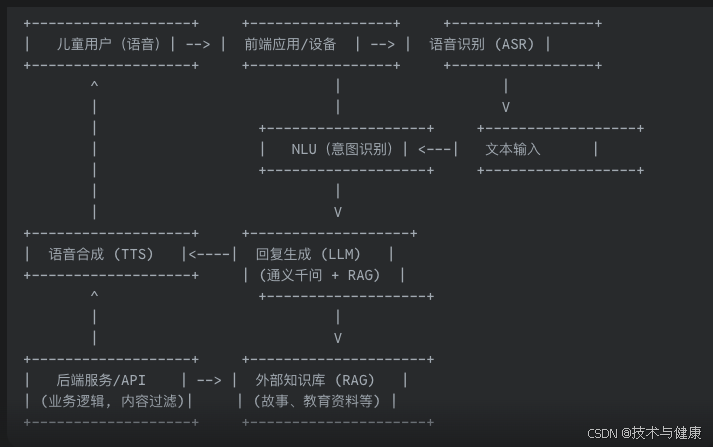
基于通义千问的儿童陪伴学习和成长的智能应用架构。
1.整体架构概览 我们的儿童聊天助手将采用典型的语音交互系统架构,结合大模型能力和外部知识库: 2. 技术方案分解 2.1. 前端应用/设备 选择: 移动App(iOS/Android)、Web应用,或者集成到智能音箱/平板等硬件设备中。技术栈: 移动App: React Native / Flutter (跨平台…...

生产环境Mysql推荐配置参数
以下是针对生产环境的 MySQL 配置(my.cnf 或 mysqld.cnf)推荐配置及说明。请根据实际硬件资源(如内存、CPU、磁盘类型)和应用场景调整参数。 核心配置模板(InnoDB 优化) [mysqld] #---------------------- 基础设置 ---------------------- datadir = /var/lib…...
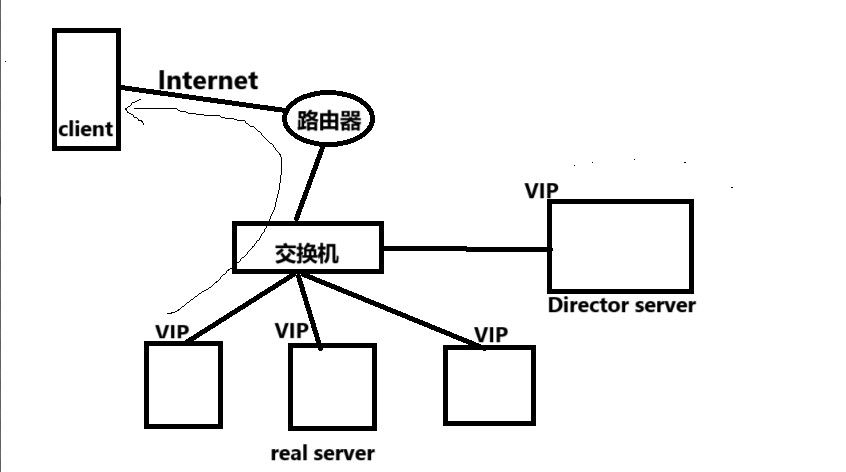
LVS-DR 负载均衡群集
目录 一、LVS-DR集群 1、LVS-DR 工作原理 2、数据包流向分析 3、LVS-DR 模式特点 二、直接路由模式(LVS-DR) 1、准备案例环境 2、配置负载调度器(101) (1)配置虚拟IP 地址(VIPÿ…...

理解并解决高丢包率问题,构建清晰流畅的实时音视频通话
丢包作为数字通信中的重要干扰因素,常常潜伏在表面之下,却严重影响性能,将清晰的对话变的模糊不清,将连贯的演示变的断断续续。因此,对音视频通话相关应用的开发者来说,理解丢包率非常重要。 什么是丢包&am…...

Ubuntu系统Todesk进度卡在100%
1 : 修改配置文件,关闭wayland sudo nano /etc/gdm3/custom.conf2 : 把#WaylandEnablefalse前的#号删掉 按图片删除注释 3 : 按Ctrl X ,离开(会问你要不要保存,输入 Y 回车保存) 4 : 重启系统 或在命令行输入 r…...

[Dify] 如何应对明道云API数据过长带来的Token超限问题
在集成明道云与大型语言模型(LLM)如ChatGPT或本地部署的Dify时,开发者经常会面临一个核心问题:API获取的数据太长,超出LLM支持的Token数限制,导致无法直接处理。本文将深入探讨这个问题的成因,并提供几种可行的解决方案,包括分段处理、外部知识库构建等策略。 明道云AP…...

Axure动态面板学习笔记
一、动态面板概述 动态面板(Dynamic Panel)是Axure中一个强大的交互组件,它本质上是多页面的集合,可以实现更丰富的页面交互功能。 主要特点: 可以包含多个状态(State),每个状态相当于一个独立页面 支持在不同状态间切换&#…...
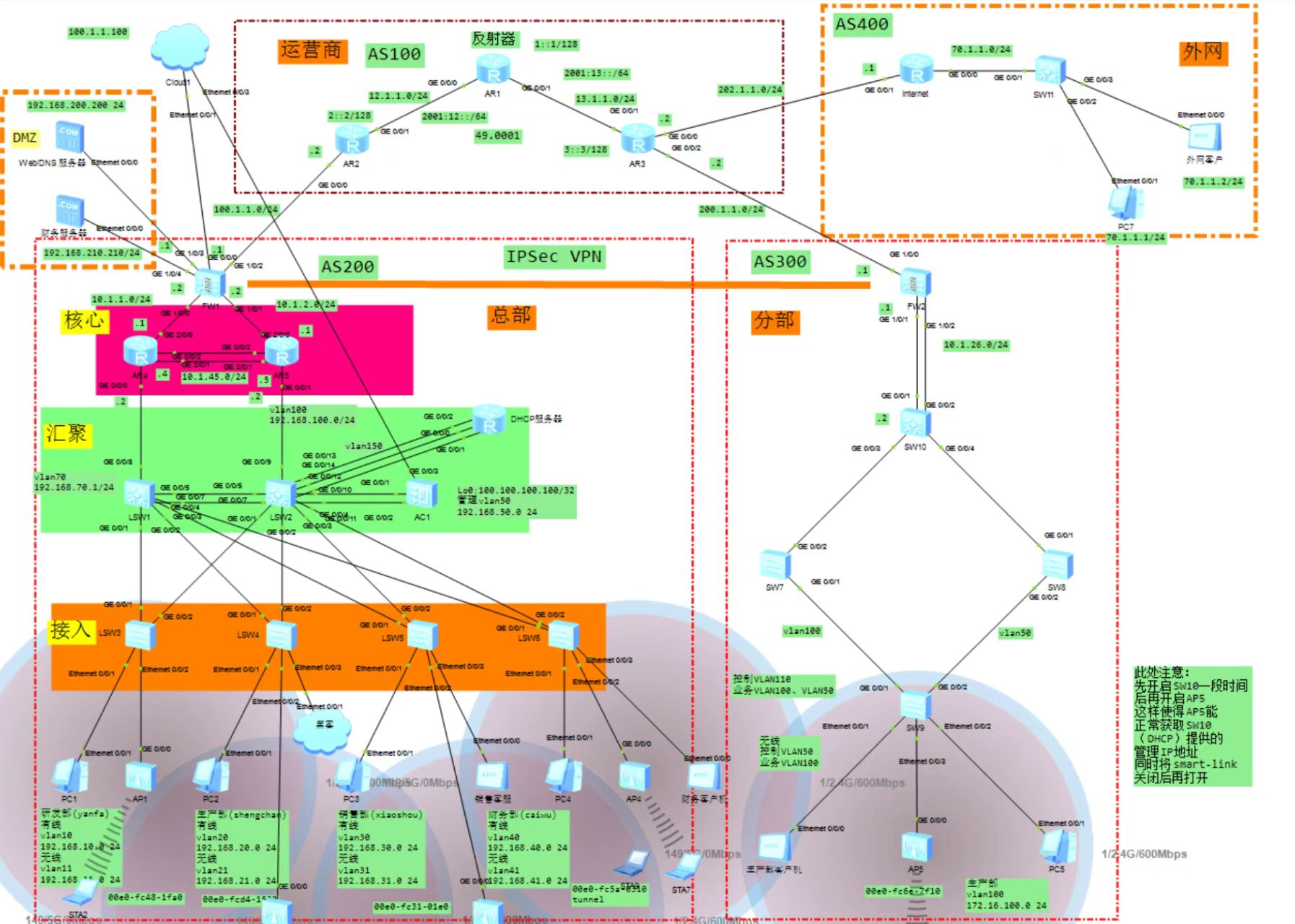
eNSP企业综合网络设计拓扑图
1.拓扑图 2.拓扑配置 此拓扑还有一些瑕疵,仅做参考和技术提升使用。 想要配置的可以关注下载 大型网络综合实验拓扑图(eNSP)资源-CSDN文库...

工程化架构设计:Monorepo 实战与现代化前端工程体系构建
三、核心架构实践:从模块管理到微前端落地 1. Monorepo 进阶:依赖治理与性能优化 痛点深化 依赖提升冲突:不同包对同一依赖的版本要求冲突幽灵依赖治理:未声明依赖被非法引用巨型仓库构建慢:全量构建耗时随项目增长线…...

BugKu Web渗透之备份是个好习惯
启动场景后,网页显示一段字符串。 看起来像md5值,但是又过长了。 步骤一:右键查看源代码,没有发现任何异常。 步骤二:使用dirsearch去查看是否有其他可疑文件。 在终端输入: dirsearch -u http://117.72.…...
华为AP6050DN无线接入点瘦模式转胖模式
引言 华为AP6050DN是一款企业级商用的无线接入点。由于产品定位原因,其默认工作在瘦模式下,即须经AC统一控制和管理,是不能直接充当普通的无线路由器来使用的。 而本文的目的,就是让其能脱离AC的统一控制和管理,当作普通无线路由器来使用。 硬件准备 华为AP6050DN无线接…...
)
uniapp 配置本地 https 开发环境(基于 Vue2 的 uniapp)
1、生成本地 HTTPS 证书(mac)打开终端,运行以下命令: mkdir ~/ssl-cert && cd ~/ssl-cert2、生成私钥: openssl genrsa -out localhost.key 20483、生成自签名证书(有效期365天)&…...
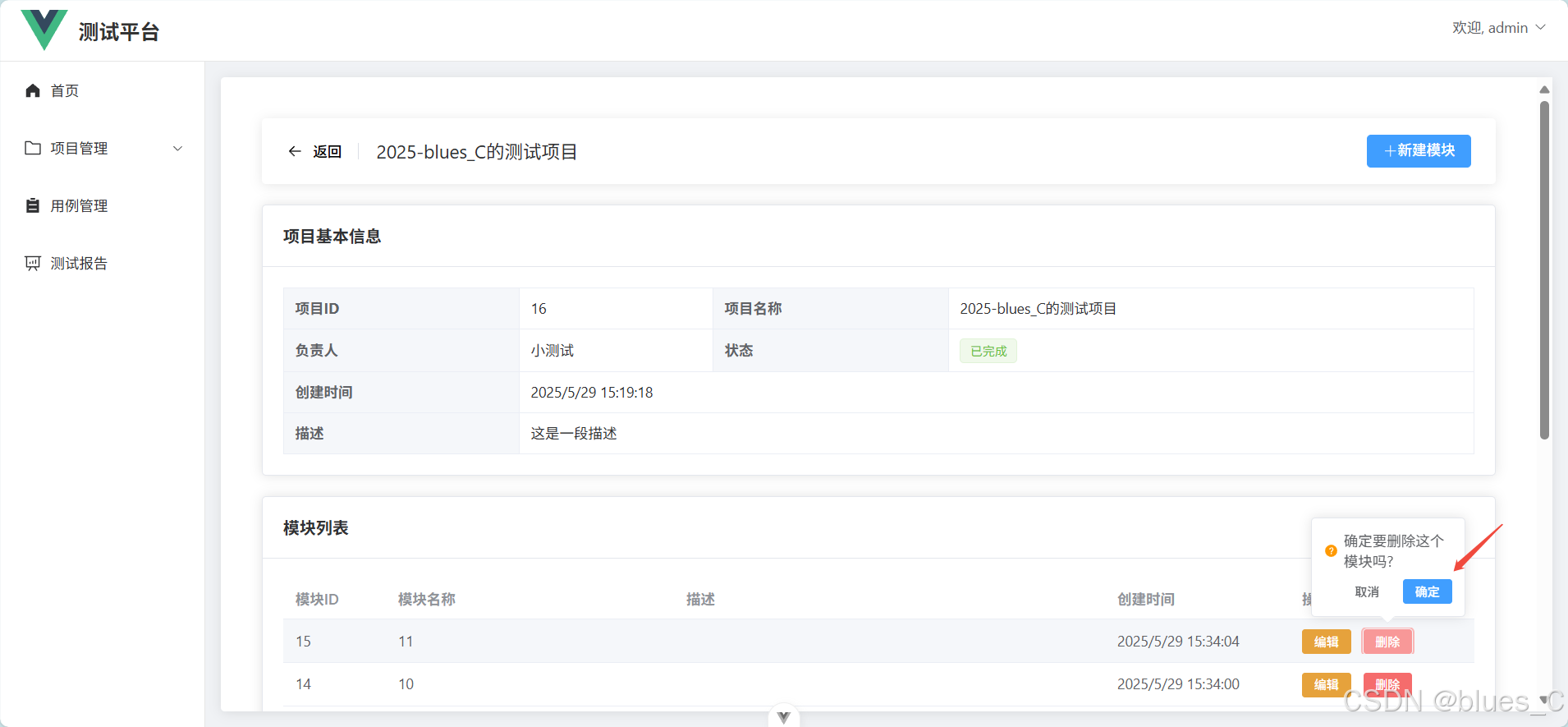
十、【核心功能篇】项目与模块管理:前端页面开发与后端 API 联调实战
【核心功能篇】项目与模块管理:前端页面开发与后端 API 联调实战 前言准备工作第一部分:完善项目管理功能 (Project)1. 创建/编辑项目的表单对话框组件 第二部分:模块管理功能 (集成到项目详情页)1. 创建模块相关的 API 服务 (src/api/module…...
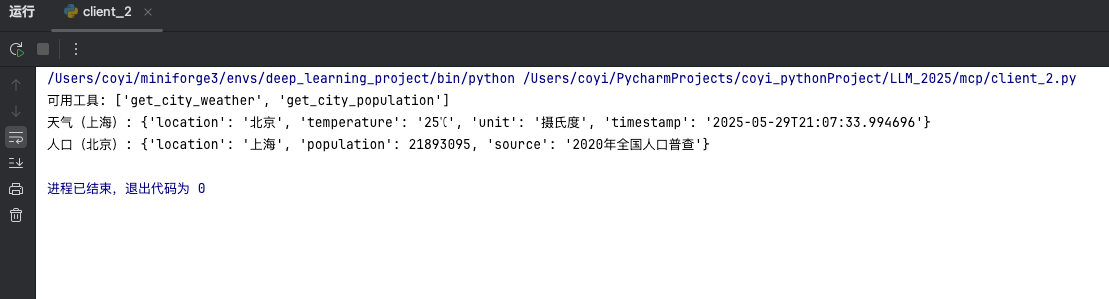
【大模型/MCP】MCP简介
一句话总结 如果你打算让 LLM 像人一样“随手”调用脚本、数据库、搜索引擎或 CI/CD 流水线,而又不想为每个工具分别写 REST 插件或轮询接口,那么把它们包进 MCP 服务器是当前最省心、延迟最低、可复用最高的做法——正因如此 OpenAI、Google DeepMind、…...
[Godot][游戏开发] 如何在 Godot 中配置 Android 环境(适配新版 Android Studio)
在使用 Godot 进行 Android 项目的开发与导出时,配置 Android 环境是一项必要步骤。随着 Android Studio 的更新(特别是自 Arctic Fox 版本起),安装方式发生了变化,默认不再引导用户手动配置 SDK/JDK/NDK,而…...

Vue-Router中的三种路由历史模式详解
在最新版的 Vue-Router 中,我们使用createRouter和createWebHashHistory、createwebHistory、createMemoryHistory等方法来配置路由。 下面详细介绍这几种历史记录栈的使用与场景,并结合实际代码说明。 1. createWebHashHistory 原理: 1.…...
机器学习多分类逻辑回归和二分类神经网络实践
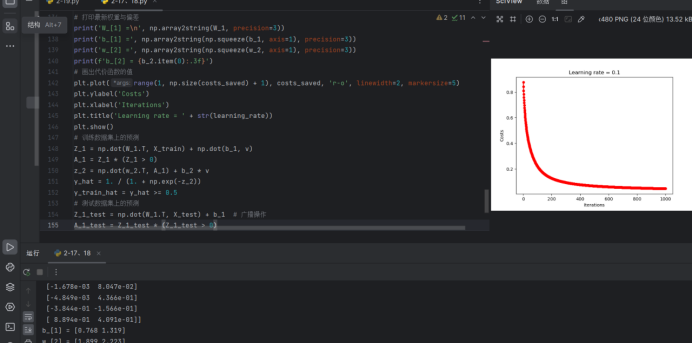
1、2-17 实现多分类逻辑回归 代码 # 2-17 实现多分类逻辑回归 import pandas as pd import numpy as np import matplotlib.pyplot as plt# 参数设置 iterations 5400 # 迭代次数 learning_rate 0.1 # 学习率 m_train 200 # 训练样本数量# 整数索引值转one-hot向量 def…...
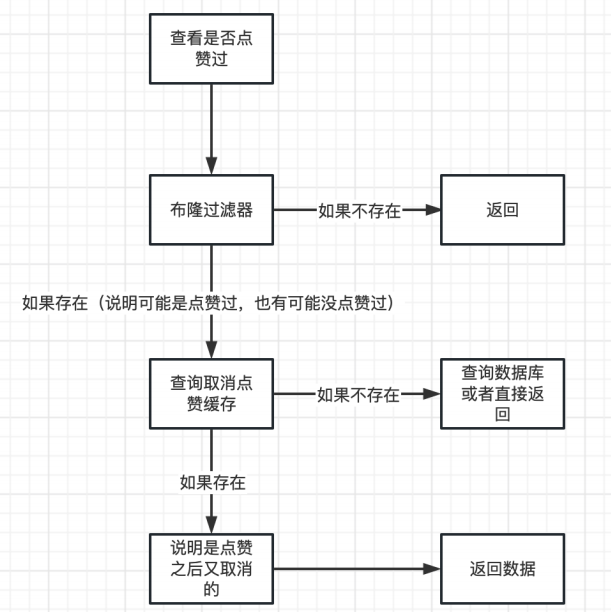
社交类网站设计:经典feed流系统架构详细设计(小红书微博等)
文章目录 一、关注服务1、粉丝、关注数架构设计(1)数据库实现方案1(2)数据库实现方案2(3)基于redis缓存优化(4)使用专用计数服务(5)近似计数(牺牲…...

K6 是什么
K6 是一款现代化的 开源性能测试工具,专注于开发者和 DevOps 团队的易用性,用于对 Web 应用、API 和微服务 进行高性能的负载测试。它采用 JavaScript 脚本编写测试用例,结合命令行工具和云原生设计,特别适合 CI/CD 集成 和 自动化…...

RISC-V PMA、PMP机制深入分析
1 PMA PMA(Physical Memory Attributes),物理内存属性,顾名思义就是用来设置物理内存属性的,但这里说“设置”,并不合理,因为一般情况下各存储的属性,在芯片设计时就固定了…...

git常见命令说明
git branch -avv -a 显示 所有分支-vv (--verbose 的缩写) 额外显示本地分支跟踪的远程分支(如 [origin/main])及其状态对比。 # git branch -v * main abc1234 修复登录bugdev def5678 更新文档# git branch -vv * main abc1234 …...

深入解析 Tomcat 线程管理机制:从设计思想到性能调优
一、Tomcat 线程模型的核心架构 Tomcat 的线程管理机制是其高性能的核心支撑,其设计围绕 Connector(连接器) 和 Executor(执行器) 两大组件展开。以下为架构分层解析: 1. Connector 的线程模型 Tomcat 的…...
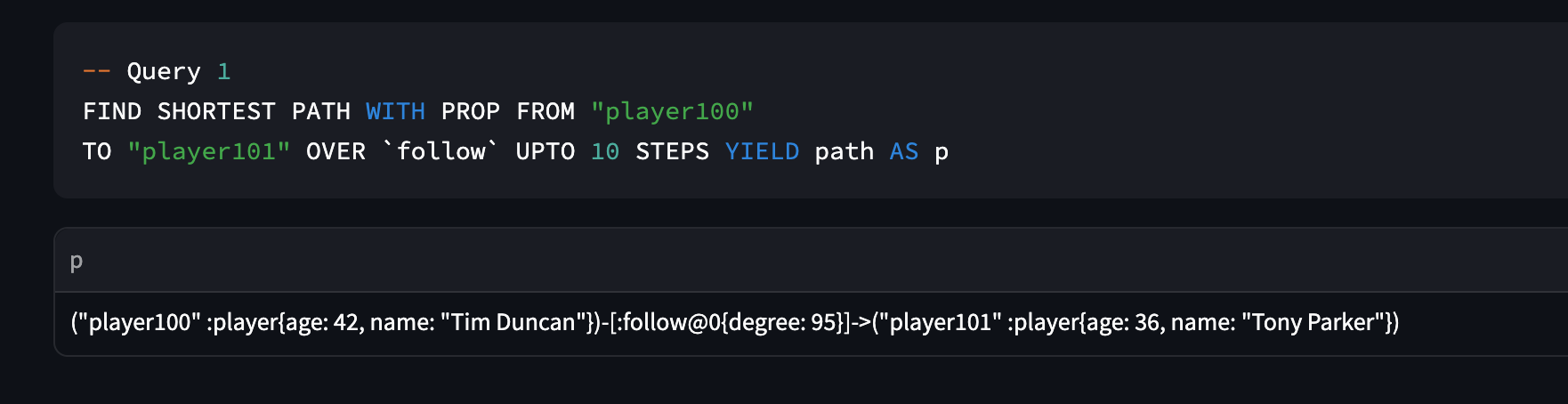
【NebulaGraph】查询案例(七)
【NebulaGraph】查询案例 七 1. 查询语句12. 查询语句23. 查询语句34. 查询语句4 1. 查询语句1 GO FROM "player100" OVER * YIELD type(edge) AS link, properties($$) AS properties,tostring(src(edge)) AS src,tostring(dst(edge)) AS dst, tags($$) AS tagLi…...