Python开发AI智能体(九)———构建RAG对话应用
前言
上篇文章我们介绍了如何在Langchain中构建代理
这篇文章我们将带领大家构建一个RAG对话应用
一、什么是RAG对话应用?
RAG(Retrieval-Augmented Generation,检索增强生成)技术通过从外部知识库检索相关信息,并将其与用户输入合并后传入大语言模型(LLM),从而增强模型在私有领域知识问答方面的能力。EAS提供场景化部署方式,支持灵活选择大语言模型和向量检索库,实现RAG对话系统的快速构建与部署。
我们这里通过爬虫的方式获取外部数据然后存到向量数据库当中。
二、编写代码
1.API调用
由于我们要使用爬虫,所以这里要引入第三方库bs4,然后设置爬虫浏览器伪装
#安装第三方库 bs4
pip install bs4# 调用AI检测平台(langSmith)
import os
import sysos.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = 'xxxxxxxxx'
os.environ["LANGCHAIN_PROJECT"] = "智谱AI"
#调用智谱AI API
os.environ["ZHIPUAI_API_KEY"] = "xxxxxxxxx"
#引入爬虫解析工具BS4
import bs4
#设置爬虫浏览器伪装(这一步是如果不写,只是报错,并不影响程序运行)
os.environ["USER_AGENT"]='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0'
2.调用第三方库
from langchain_community.chat_models import ChatZhipuAI
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import ZhipuAIEmbeddings
from langchain_chroma import Chroma
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains.retrieval import create_retrieval_chain
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain.chains.history_aware_retriever import create_history_aware_retriever
from langchain_core.runnables import RunnableWithMessageHistory3.调用大预言模型
model = ChatZhipuAI(model_name='glm-4-flash')4.加载数据
加载数据(本地数据库,或者或互联网数据)这里用一篇博客内容为例(爬虫)
文章连接:https://kib.cas.cn/kxcb/kpwz/202112/t20211230_6330472.html
这篇文章是介绍豆类植物的
loader = WebBaseLoader(web_paths=['https://kib.cas.cn/kxcb/kpwz/202112/t20211230_6330472.html']bs_kwargs=dict(parse_only =bs4.SoupStrainer(class_='TRS_Editor') ))-
WebBaseLoader: 是LangChain 提供的一个强大工具,用于从网页中提取文本并将其转换为结构化文档格式。它支持多页面加载、并发处理、自定义解析器以及代理配置,非常适合需要从网页提取大量数据的场景。
-
web_paths:可以存放一个或多个网址,多个网址要放在列表或者元组当中
-
parse_only:解析我们需要的内容。通过检查网页发现,文章的内容是放在一个类名叫'TRS_Editor'的盒子当中,所以我们这里的class类名里面要写'TRS_Editor'
5.转换文档
docs = loader.load()6.大文本切割(新建一个切割器)
1.为什么要使用文本切割器
大语言模型通常受到可以传递给它们的文本数量的限制,因此将文本分割为较小的块是必要的。
文本分割器是一种将大段文本拆分成较小块或片段的算法或方法。其目标是创建可单独处理的可管理的片段,这在处理大型文档或数据集时通常是必要的。
2.编写代码
splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200)
splits = splitter.split_documents(docs)
RecursiveCharacterTextSplitter:递归字符文本分割器,用于将长文本递归地分割成更小的片段。
该类里面一共有三个参数
-
第一个切割符号一般情况不用
-
chunk_size:每次分割的字数
-
chunk_overlap:重复次数
7.存储向量空间
#实例化一个向量空间
vectorstore =Chroma.from_documents(documents=splits,embedding=ZhipuAIEmbeddings())
#4、检索器
retriever = vectorstore.as_retriever()8.创建模板
system_prompt = '''
你是一个专业回答问题的助手。
你要用下面检索器检索出来的内容回答问题。
如果不知道就回答,数据中没有提供信息。\n
{context}
'''
prompt = ChatPromptTemplate.from_messages([ #提问和问答的历史记录("system", system_prompt),MessagesPlaceholder('chat_history'),("human", "{input}"),
])这部分代码不理解的可以移步
Python开发AI智能体(五)———构建聊天机器人智能体
9.创建提问的链
chain1 =create_stuff_documents_chain(model, prompt)10.创建子链
注意:一般情况下,我们构建的链(chain)直接使用输入问答记录来关联上下文。但是在此案例当中,查询检索器也需要对话上下文才能破译
解决办法:添加一个子链(chain),它采用最新用户的问题和聊天历史,并在它引用历史信息中的任何信息时重新表述问题
retriever_history_temp =ChatPromptTemplate.from_messages(
[('system',son_system_promot),MessagesPlaceholder('chat_history'),("human", "{input}"),
]
)
son_history_chain = create_history_aware_retriever(model,retriever,retriever_history_temp
)create_history_aware_retriever:创建一个获取对话历史记录并返回文档的链(检索器对话历史)。
11.保存问答历史记录
store={}def get_session_history(session_id:str):if session_id not in store:store[session_id] = ChatMessageHistory()return store[session_id]这部分代码不理解的可以移步
Python开发AI智能体(五)———构建聊天机器人智能体
12.创建父链
创建一个父链chain:把前两个链整合起来
chain = create_retrieval_chain(son_history_chain,chain1)13.创建最终链
result_chain = RunnableWithMessageHistory(chain,get_session_history,input_messages_key='input',history_messages_key='chat_history',output_messages_key ='answer'
)-
RunnableWithMessageHistory():允许我们为某些类型的链添加消息历史。它包装另一个可运行对象,并管理其聊天消息历史。具体来说,它在将之前的消息传递给可运行对象之前加载对话中的先前消息,并在调用可运行对象后将生成的响应保存为消息。该类还通过使用 session_id 保存每个对话来支持多个对话 - 然后在调用可运行对象时期望在配置中传递 session_id,并使用它查找相关的对话历史。
-
input_messages_key:用于指定输入的哪个部分应该在聊天历史中被跟踪和存储。在此示例中,我们希望跟踪作为输入传递的字符串。
-
history_messages_key:用于指定以前的消息应如何注入到提示中。我们的提示中有一个名为 chat_history 的 MessagesPlaceholder,因此我们指定此属性以匹配。
-
output_messages_key(对于有多个输出的链):指定要将哪个输出存储为历史记录。这是 input_messages_key 的反向
14.运行部分
def run():question = input('请输入你的问题')question = '"' + question + '"'resp1 = result_chain.invoke({'input': question,},config={'configurable': {'session_id': 'zx1234567'}})print(resp1['answer'])num = int(input('请输入你的选择 1.提问 2.退出系统'))if num == 1:run()else:sys.exit()if __name__ == "__main__":print('--------欢迎来自定义智能体---------')run()
15.运行结果


通过和博客内容对比得出,大模型给出的答案是基于文章内容的

16.完整代码
# 调用AI检测平台(langSmith)
import os
import sysos.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = 'xxxxxxxx'
os.environ["LANGCHAIN_PROJECT"] = "智谱AI"
#调用智谱AI API
os.environ["ZHIPUAI_API_KEY"] = "xxxxxxxxx"
#引入爬虫解析工具BS4
import bs4
#设置爬虫浏览器伪装(这一步是如果不写,只是报错,并不影响程序运行)
os.environ["USER_AGENT"]='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0'#调用第三方库
from langchain_community.chat_models import ChatZhipuAI
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import ZhipuAIEmbeddings
from langchain_chroma import Chroma
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains.retrieval import create_retrieval_chain
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain.chains.history_aware_retriever import create_history_aware_retriever
from langchain_core.runnables import RunnableWithMessageHistory#调用大语言模型
model = ChatZhipuAI(model_name='glm-4-flash')#1、加载数据
loader = WebBaseLoader(web_paths=['https://kib.cas.cn/kxcb/kpwz/202112/t20211230_6330472.html'],#可以存放一个或多个网址,多个网址要放在列表或者元组当中bs_kwargs=dict(parse_only =bs4.SoupStrainer(class_='TRS_Editor') #解析HTML文档 parse_only只是解析我们需要的内容))docs = loader.load() #转换文档
#2大文本的切割
splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200)
splits = splitter.split_documents(docs)#3、存储向量空间
#实例化一个向量空间
vectorstore =Chroma.from_documents(documents=splits,embedding=ZhipuAIEmbeddings())
#4、检索器
retriever = vectorstore.as_retriever()#6、创建一个AI模板
system_prompt = '''
你是一个专业回答问题的助手。
你要用下面检索器检索出来的内容回答问题。
如果不知道就回答,数据中没有提供信息。\n
{context}
'''
prompt = ChatPromptTemplate.from_messages([ #提问和问答的历史记录("system", system_prompt),MessagesPlaceholder('chat_history'),("human", "{input}"),
])#7.创建链
#提问的chain
chain1 =create_stuff_documents_chain(model, prompt)#创建一个子链
#子链的提示模板
son_system_promot="""
给我一个历史的聊天记录以即用户最新提出的问题。
在我们的聊天记录中引用我们的上下文内容,
得到一个独立的问题。
当没有聊天记录的时候,不需要回答这个问题。
直接返回问题就可以了。
"""retriever_history_temp =ChatPromptTemplate.from_messages(
[('system',son_system_promot),MessagesPlaceholder('chat_history'),("human", "{input}"),
]
)
son_history_chain = create_history_aware_retriever(model,retriever,retriever_history_temp
)#保存问答历史记录
store={}def get_session_history(session_id:str):if session_id not in store:store[session_id] = ChatMessageHistory()return store[session_id]#创建一个父链chain:把前两个链整合起来
chain = create_retrieval_chain(son_history_chain,chain1)result_chain = RunnableWithMessageHistory(chain,get_session_history,input_messages_key='input',history_messages_key='chat_history',output_messages_key ='answer'
)def run():question = input('请输入你的问题')question = '"' + question + '"'resp1 = result_chain.invoke({'input': question,},config={'configurable': {'session_id': 'zx1234567'}})print(resp1['answer'])num = int(input('请输入你的选择 1.提问 2.退出系统'))if num == 1:run()else:sys.exit()if __name__ == "__main__":print('--------欢迎来自定义智能体---------')run()相关文章:
Python开发AI智能体(九)———构建RAG对话应用
前言 上篇文章我们介绍了如何在Langchain中构建代理 这篇文章我们将带领大家构建一个RAG对话应用 一、什么是RAG对话应用? RAG(Retrieval-Augmented Generation,检索增强生成)技术通过从外部知识库检索相关信息,并将…...

NW907NW918美光固态闪存NW920NW930
NW907NW918美光固态闪存NW920NW930 技术解析:美光NW系列固态闪存的核心突破 美光NW907、NW918、NW920、NW930四款固态闪存产品,代表了当前存储技术的顶尖水平。其核心创新在于G9 NAND架构的深度优化,采用更先进的5纳米制程工艺,…...

【Deepseek 学网络互联】跨节点通信global 和节点内通信CLAN保序
Clan模式下的源端保序与Global类似,目的端保序则退化成通道保序,此时仅支持网络单路径保序。”这里的通道保序怎么理解? 用户可能正在阅读某种硬件架构文档(比如NVIDIA的NVLink或InfiniBand规范),因为"…...

Python 迭代器:从基础到高级
在 Python 中,迭代器(Iterator)是一种非常重要的概念,它允许我们逐个访问集合中的元素,而无需暴露其内部的表示形式。迭代器是实现迭代协议(Iterator Protocol)的对象,通过这种方式&…...
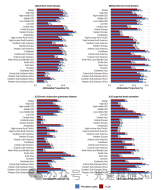
9.5 Q1 | 北京协和医学院GBD发文 | 1990-2021 年全球、区域和国家心力衰竭负担及其根本原因
1.第一段-文章基本信息 文章题目:Global, regional, and national burden of heart failure and its underlying causes, 1990-2021: results from the global burden of disease study 2021 中文标题:1990-2021 年全球、区域和国家心力衰竭负担及其根本…...

软件工程 3.0:智能驱动的软件新时代
在科技飞速发展的当下,软件工程领域正经历着深刻变革,软件工程 3.0 应运而生。这一全新阶段以 “智能增强” 为核心特征,将人工智能(AI)深度融入软件开发的全流程,为行业带来前所未有的机遇与挑战。 一、…...

从C++编程入手设计模式1——单例模式
从C编程入手设计模式 在这之前,为什么要有设计模式 Design Pattern是一个非常贴近工程化的一个议题,我们首先再开始之前(尽管有一些朋友可能已经早早就掌握了设计模式,但是出于看乐子的心态还是进来看看我写的有多烂…...
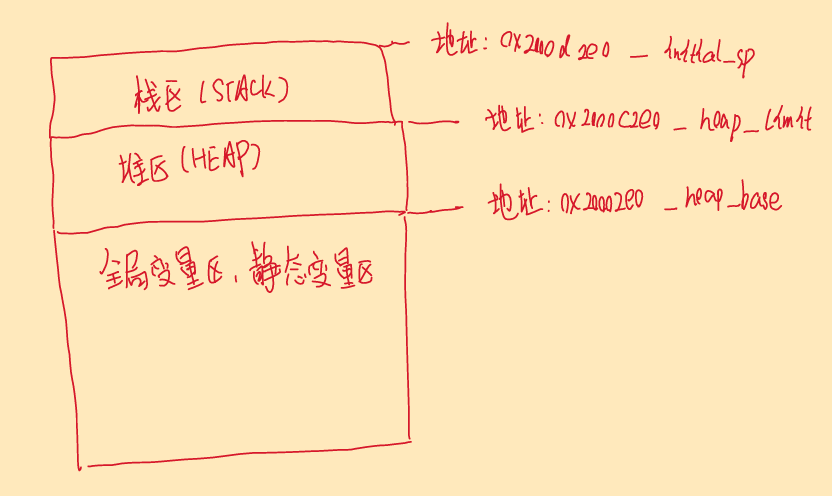
根据Cortex-M3(包括STM32F1)权威指南讲解MCU内存架构与如何查看编译器生成的地址具体位置
首先我们先查看官方对于Cortex-M3预定义的存储器映射 1.存储器映射 1.1 Cortex-M3架构的存储器结构 内部私有外设总线:即AHB总线,包括NVIC中断,ITM硬件调试,FPB, DWT。 外部私有外设总线:即APB总线,用于…...
理解)
vue的h函数(在 Vue 2中也称为 createElement)理解
官方定义 定义: 返回一个“虚拟节点” ,通常缩写为 VNode: 一个普通对象,其中包含向 Vue 描述它应该在页面上呈现哪种节点的信息,包括对任何子节点的描述。用于手动编写render h函数格式说明及使用 h 接收三个参数 type: 必需,…...
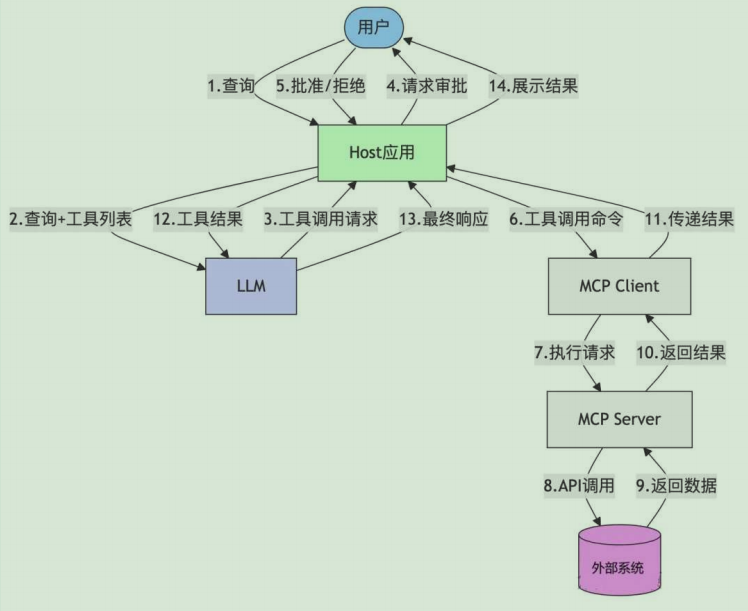
MCP入门实战(极简案例)
MCP简介 MCP(Model Context Protocol,模型上下文协议)2024年11月底由 Antbropic 推出的一种开放标准,旨在统一大型语言模型(LLM)与外部数据源和工具之间的通信协议。 Function Calling是AI模型调用函数的机制,MCP是一个标准协议,使AI模型与API无缝交互,而Al Agent是一个…...

STM32中,如何理解看门狗
在STM32微控制器中,看门狗(Watchdog)是一种硬件计时器,用于监控系统运行状态,防止软件死锁或跑飞。其核心机制是:系统需定期“喂狗”(复位看门狗计数器),若未及时喂狗&am…...
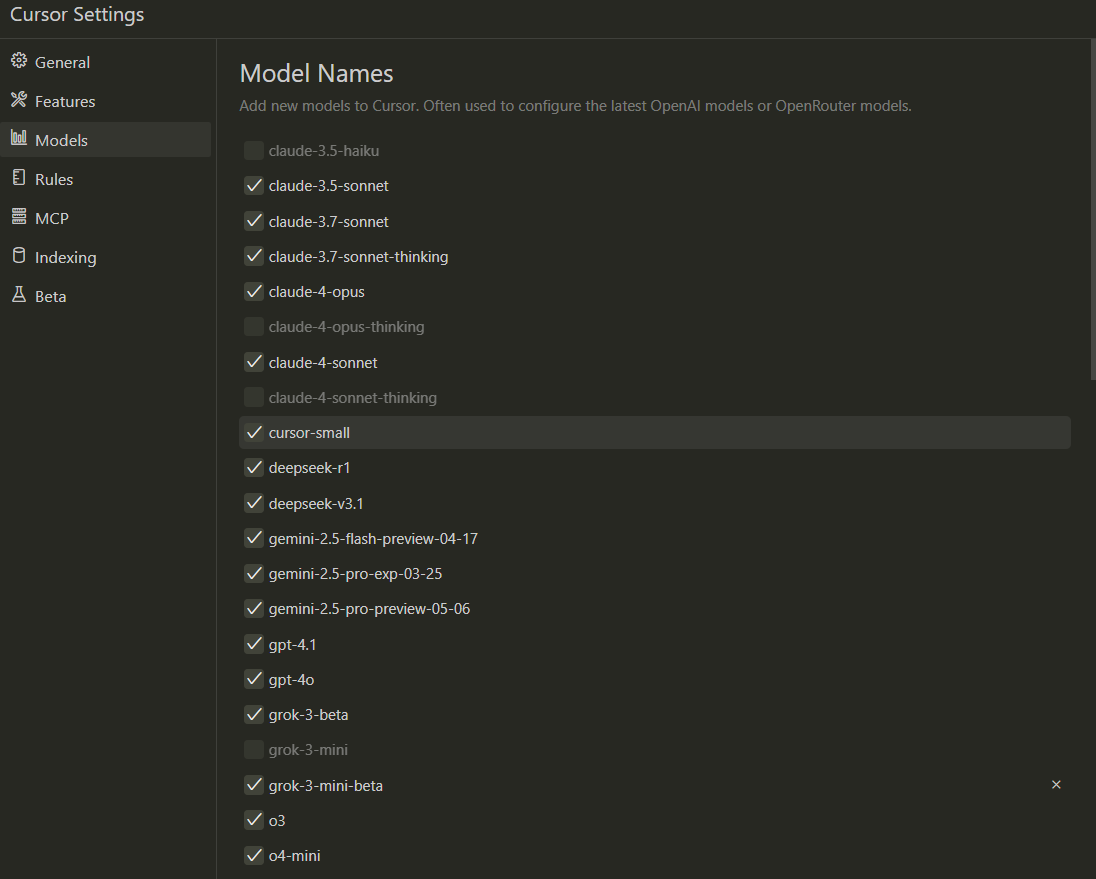
Cursor从入门到精通实战指南(一):开始使用Cursor
一、简介与核心优势 Cursor是一款基于VSCode开发的AI编程工具,集成了GPT-4、Claude 3.5等先进大语言模型,支持代码补全、生成、重构、调试等功能。其核心优势包括: 高效协作:通过自然语言对话实现代码开发,支持跨文件…...

麒麟v10+信创x86处理器离线搭建k8s集群完整过程
前言 最近为某客户搭建内网的信创环境下的x8s集群,走了一些弯路,客户提供的环境完全与互联网分离,通过yum、apt这些直接拉依赖就别想了,用的操作系统和cpu都是国产版本,好在仍然是x86的,不是其他架构&…...
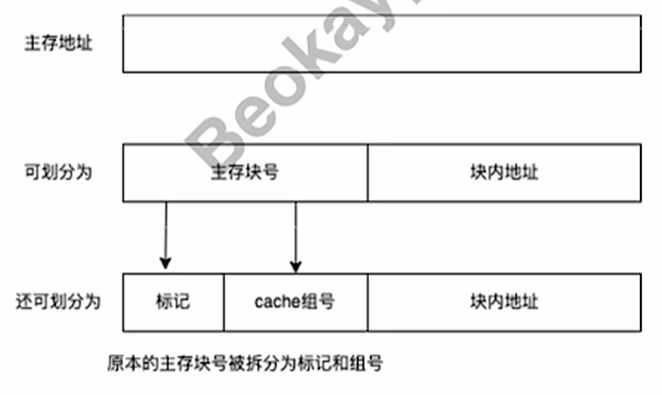
计算机组成原理——cache
3.4cache 出自up主Beokayy传送门 1.局部性原理 时间局部性: 在最近的未来要用到的信息,很可能是现在正在使用的信息,因为程序中存在循环。 空间局部性: 在最近的未来要用到的信息,很可能与现在正在使用的信息在存储…...
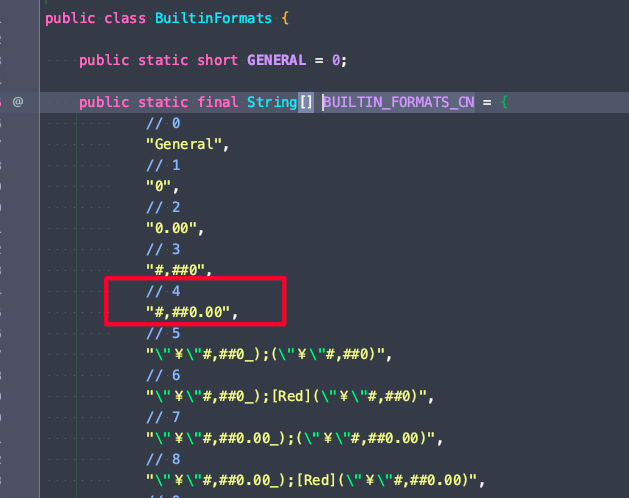
EasyExcel使用导出模版后设置 CellStyle失效问题解决
EasyExcel使用导出模版后在CellWriteHandler的afterCellDispose方法设置 CellStyle失效问题解决方法 问题描述:excel 模版塞入数据后,需要设置单元格的个性化设置时失效,本文以设置数据格式为例(设置列的数据展示时需要加上千分位…...

关于AWESOME-DIGITAL-HUMAN的部署
AWESOME-DIGITAL-HUMAN是一个开源数字人项目,可以容器化部署,资源占用少,可以对接dify,使用起来也很方便,非常感谢开发者。 容器化部署后,其实是有两个容器,分别启动两个服务,一个前…...

WebAssembly 及 HTML Streaming:重塑前端性能与用户体验
WebAssembly 及 HTML Streaming:重塑前端性能与用户体验 引言 在移动互联网时代,用户对 Web 应用的性能和体验要求日益苛刻。白屏时间、首屏渲染速度、交互流畅度,甚至 SEO 优化,都成为前端工程师必须面对的挑战。传统的前端技术…...

python同步mysql数据
python写了一个简单的mysql数据同步脚本,只作为学习练习,大佬勿喷 # -*- coding: utf-8 -*- """ Time:2025/5/29 14:38 Auth:HEhandsome """ import pymysql from pymysql import Connectclass Mysql:def __init__(self):#源数据库self.sou_hos…...

shell之通配符及正则表达式,grep参数
通配符与正则表达式 通配符(Globbing) 通配符是由 Shell 处理的特殊字符,用于路径或文件名匹配。当 Shell 在命令参数中遇到通配符时,会将其扩展为匹配的文件路径;若没有匹配项,则作为普通字符传递给命令…...
之后端篇)
RuoYi前后端分离框架集成手机短信验证码(一)之后端篇
一、背景 本项目基于RuoYi 3.8.9前后端分离框架构建,采用Spring Security实现系统权限管理。作为企业级应用架构的子模块,系统需要与顶层项目实现用户数据无缝对接(以手机号作为统一用户标识),同时承担用户信息采集的重要职能。为此,我们在保留原有账号密码登录方式的基…...
Knife4j框架的使用
文章目录 引入依赖配置Knife4j使用Knife4j 访问 SpringBoot 生成的文档 Knife4j 是基于 Swagger 的增强工具,对 Swagger 进行了拓展和优化,从而有更美观的界面设计和更强的功能 引入依赖 Spring Boot 2.7.18 版本 <dependency> <groupId>c…...

深兰科技陈海波率队考察南京,加速AI医诊大模型区域落地应用
近日,深兰科技创始人、董事长陈海波受邀率队赴南京市,先后考察了南京江宁滨江经济开发区与鼓楼区,就推进深兰AI医诊大模型在南京的落地应用,与当地政府及相关部门进行了深入交流与合作探讨。 此次考察聚焦于深兰科技自主研发的AI医…...

【芯片设计中的交通网络革命:Crossbar与NoC架构的博弈C架构的博弈】
在芯片设计领域,总线架构如同城市交通网,决定了数据流的通行效率。随着AI芯片、车载芯片等复杂场景的爆发式增长,传统总线架构正面临前所未有的挑战。本文将深入解析两大主流互连架构——Crossbar与NoC的优劣,揭示芯片"交通网…...
deepseek告诉您http与https有何区别?
有用户经常问什么是Http , 什么是Https ? 两者有什么区别,下面为大家介绍一下两者的区别 一、什么是HTTP HTTP是一种无状态的应用层协议,用于在客户端浏览器和服务器之间传输网页信息,默认使用80端口 二、HTTP协议的特点 HTTP协议…...
mac将自己网络暴露到公网
安装服务 brew tap probezy/core && brew install cpolar// 安装cpolar sudo cpolar service install // 启动服务 sudo cpolar service start访问管理网站 http://127.0.0.1:9200/#/tunnels/list 菜单“隧道列表” 》 编辑 自定义暴露的端口 再到在线列表中查看公网…...

考研政治资料分享 百度网盘
考研资料分享考研资料合集 百度网盘(仅供参考学习) 通过网盘分享的文件:2026考研英语数学政治最新等3个文件 链接: https://pan.baidu.com/s/1iK2LvbkoreNxHZ7fmOkcyQ?pwd4drt 提取码: 4drt 链接: https://pan.baidu.com/s/1FuNV…...

拓扑排序算法剖析与py/cpp/Java语言实现
拓扑排序算法深度剖析与py/cpp/Java语言实现 一、拓扑排序算法的基本概念1.1 有向无环图(DAG)1.2 拓扑排序的定义1.3 拓扑排序的性质 二、拓扑排序算法的原理与流程2.1 核心原理2.2 算法流程 三、拓扑排序算法的代码实现3.1 Python实现3.2 C实现3.3 Java…...
罗马-华为
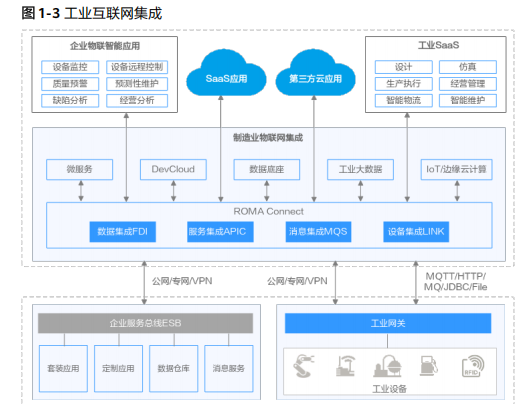
SPA应用:single-page application:单页应用SPA是一种网络应用程序或网站的模型,它通过动态重写当前页面来与用户交互,这种方法避免了页面之间切换打断用户体验在单页应用中 集成 ROMA Connect 主要包含四个组件:数据集成( FDI )、服务集成( APIC )、消息集成 ( MQS …...

单例模式的隐秘危机
引言 单例模式作为设计模式中的基石,广泛应用于配置管理、线程池、缓存系统等关键场景。然而,许多开发者误以为“私有构造函数”足以保障其唯一性,却忽视了反射机制、对象克隆、序列化反序列化这三把“隐形利刃”——它们能绕过常规防御&…...

微信小程序常用方法
微信小程序 常用方法 setData() https://developers.weixin.qq.com/miniprogram/dev/reference/api/Page.html#%E7%BB%84%E4%BB%B6%E4%BA%8B%E4%BB%B6%E5%A4%84%E7%90%86%E5%87%BD%E6%95%B0 在微信小程序中,setData 是一个非常重要的方法,主要用于更新…...