智警杯备赛--数据库管理与优化及数据库对象创建与管理
sql操作
插入数据
如果要操作数据表中的数据,首先应该确保表中存在数据。没有插入数据之前的表只是一张空表,需要使用insert语句向表中插入数据。插入数据有4种不同的方式:为所有字段插入数据、为指定字段插入数据、同时插入多条数据以及插入查询结果
知识点
为所有字段插入数据
insert [into] table_name [(column_name1, column_name2, ···)] values|value (value1, value2, ···);insert为插入数据用到的关键字
into为可选项,增加可读性
table_name表示要插入数据的表名
column_name1和column_name2分别表示表中的字段名,表中的字段可写可不写
values和value二选一,后面跟要插入的字段的值
value1和value2则分别表示对应字段的值
为指定字段插入数据
在实际开发中,有时设置了自动增加约束的字段和设置了默认值的字段不需要插入值,因为MySQL会为其插入自增后的数值或在建表时规定的默认值,所以在插入数据时没有必要为所有字段插入数据,只需为指定的部分字段插入数据即可
insert [into] table_name (column_name1, column_name2, ···) values|value (value1, value2, ···);
column_name1和column_name2分别指定添加数据的字段名
value1和value2分别表示column_name1字段和column_name2字段的值
在此需要注意的是,value值要和指定字段的顺序、数据类型相对应,即value1对应的column_name1字段,value2对应column_name2字段
使用set关键字作为字段插入数据
insert [into] table_name set column_name1 = value1[, column_name2 = value2, ···];
column_name1和column_name2分别指定添加数据的字段名
value1和value2分别表示column_name1字段和column_name2字段的值
在set关键字后面使用column_name=value这种键/值对的方式指定字段的值,每对之间使用逗号“,”隔开
如果要为所有字段插入数据,则需要列举出所有字段
如果要为指定字段插入数据,则只需要列举出部分字段即可
同时插入多条数据
如果在数据表中需要插入大量数据,那么选择一条一条地插入记录会相当麻烦,因此MySQL中提供了同时插入多条数据的SQL语句,其可以实现为所有字段或指定字段同时插入多条数据
为所有字段同时插入多条数据
insert [into] table_name [(column_name1, column_name2, ···)]
values|value (value11, value21, ···),
(value12, value22, ···),
···;为指定字段同时插入多条数据
insert [into] table_name (column_name1, column_name2, ···)
values|value (value11, value21, ···),
(value12, value22, ···),
···;插入查询结果
在MySQL中还可以通过insert语句将从一张表中查询到的结果直接插入到另一张表中,这样就间接地实现了数据的复制功能
insert [into] table_name1(column_list1)
select column_list2 from table_name2 where where_condition;table_name1为插入新数据记录的表名
column_list1为字段列表,表示要为哪些字段插入值
select为查询语句用到的关键字
column_list2也是字段列表,表示要从表中查询哪些字段的值
table_name2为要查询的表,即要插入数据的来源
where where_condition为where子句,用来指定查询条件
实训
建表
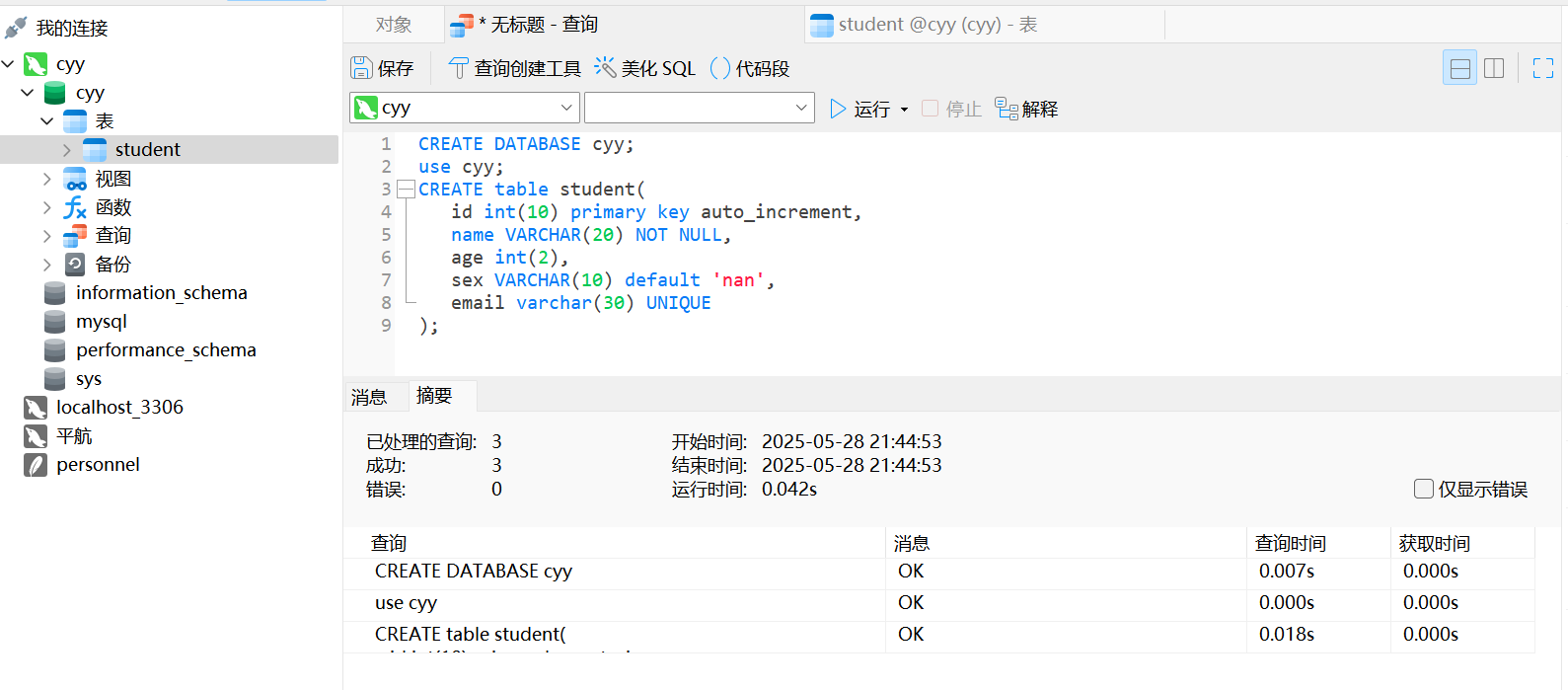
先创建一个新的数据库cyy,并在数据库中创建一张名为student的表
create database test;
use test;
create table student(
stu_id int(10) primary key auto_increment,
stu_name varchar(20) not null,
stu_age int(2),
stu_sex varchar(10) default 'nan',
stu_email varchar(30) unique
);primary key key auto_increment:
primary key将id设为主键,这列不能为空
auto_increment自增
stu_name varchar(20) not null:
not null这一列的所有值都不能为空值
stu_sex varchar(10) default 'nan':
default 'nan'插入数据时,如果stu_sex列没有指定值,将自动使用'nan'作为它的值
stu_email varchar(30) unique:
unique强制该列中的所有值都必须是唯一的,不能有重复
为所有字段插入数据
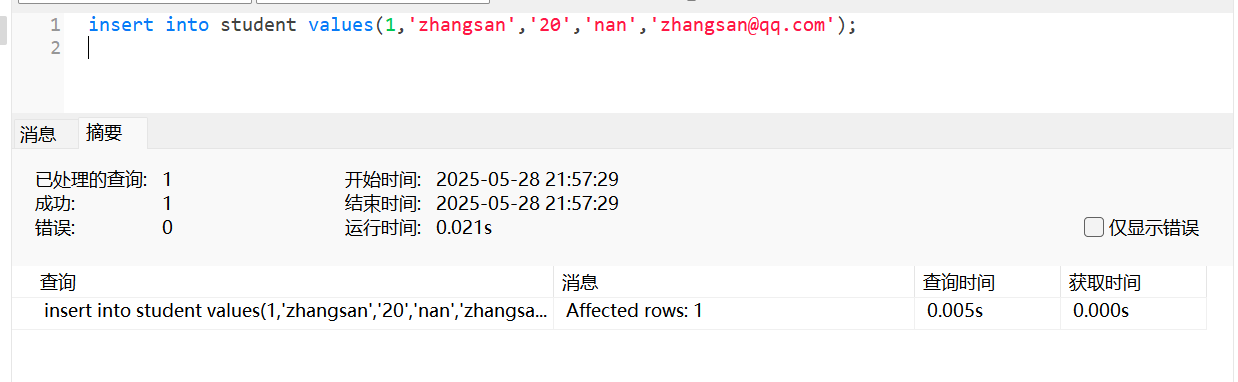
insert into student values(1, 'zhangsan', 18, 'nan', 'zhangsan@163.com');
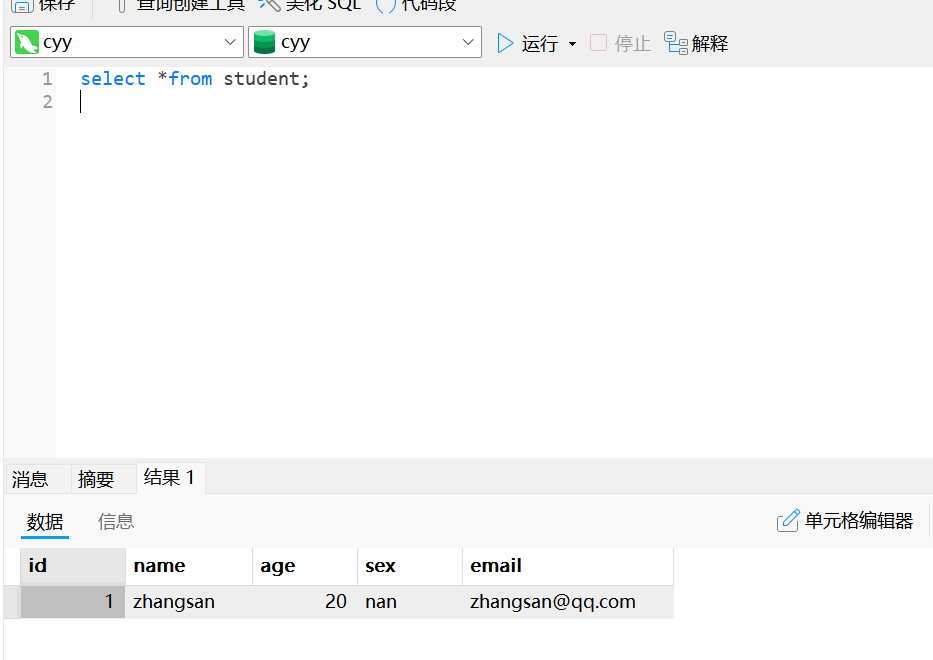
select * from student;查询表中所有存在的记录
使用set关键字为所有字段插入数据
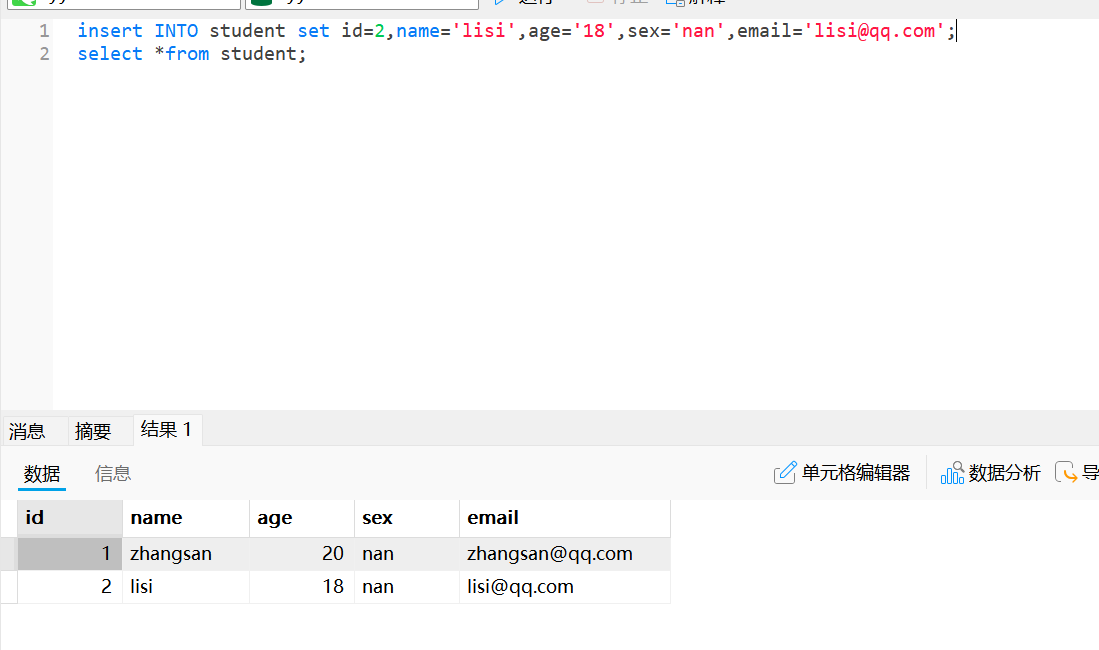
insert into student set stu_id = 4, stu_name = 'zhaoliu', stu_age = 20, stu_sex = 'nv', stu_email = 'zhaoliu@163.com';为所有字段同时插入多条数据
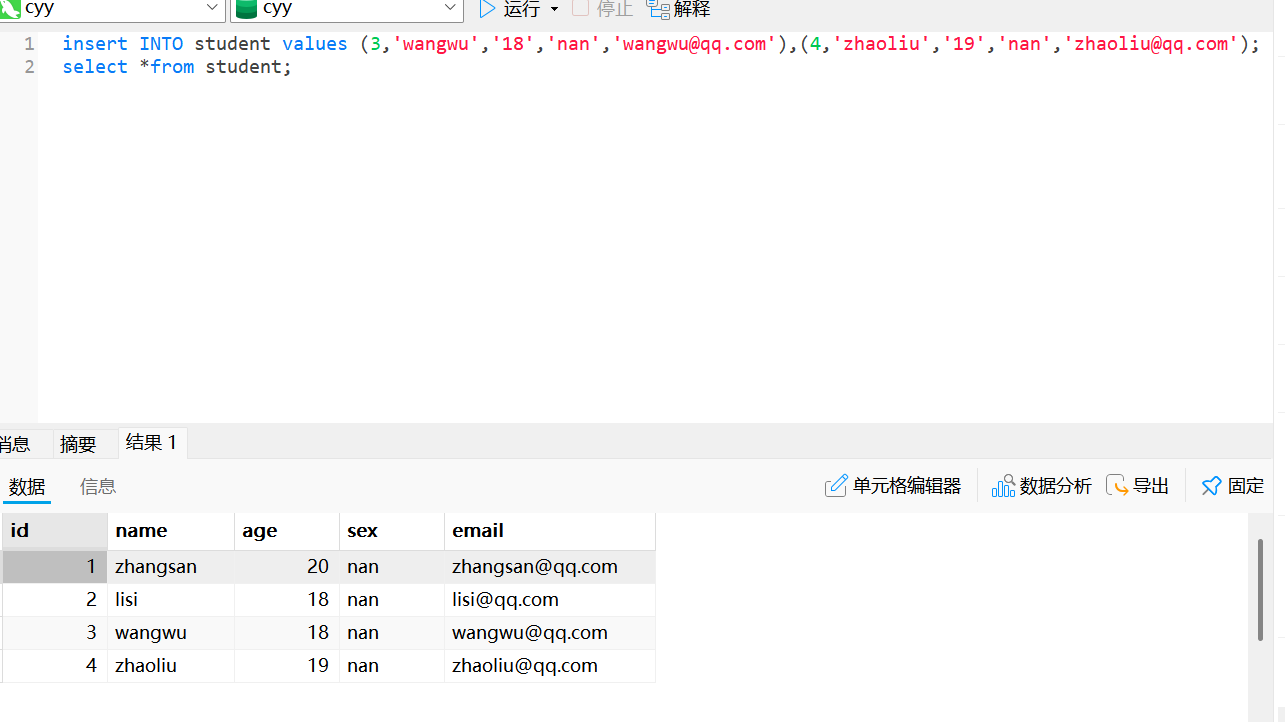
insert into student values (6, 'zhouba', 19, 'nv', 'zhouba@163.com'),
(7, 'wujiu', 18, 'nan', 'wujiu@163.com');为指定字段插入数据
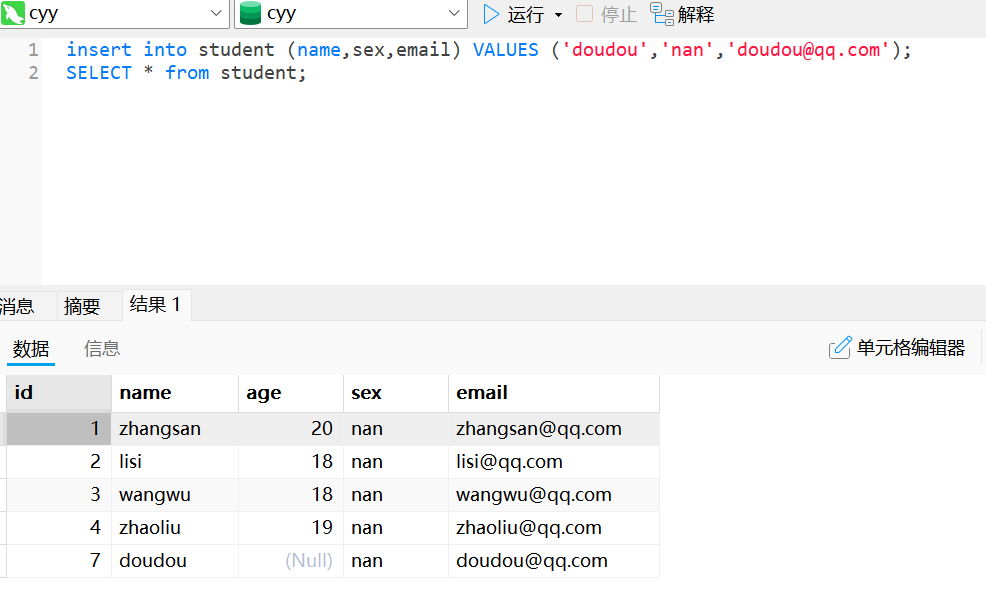
insert into student(stu_name, stu_age, stu_email) values('lisi', 19, 'lisi@163.com');使用set做关键字为指定字段插入数据
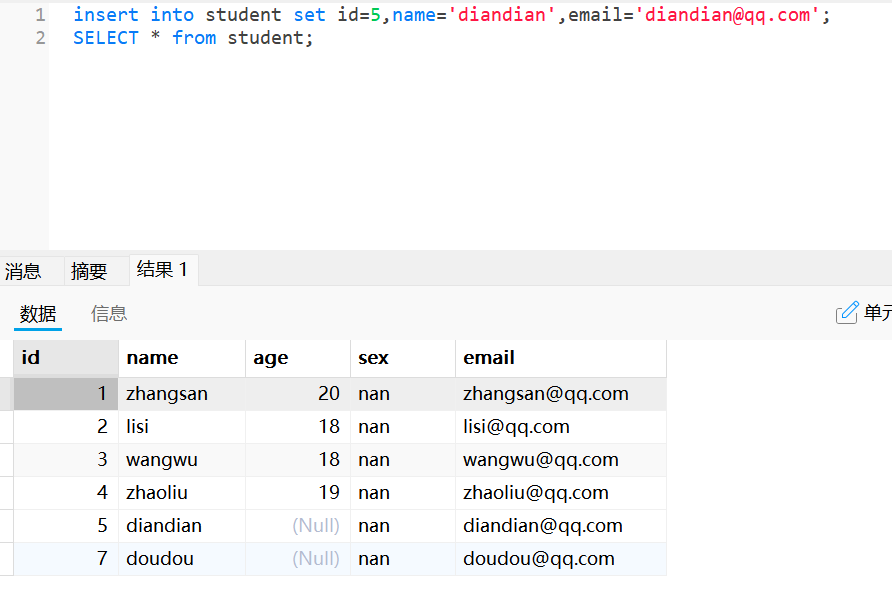
insert into student set stu_name = 'sunqi', stu_age = 19, stu_email = 'sunqi@163.com';这个跟上面所有是一样的,只是不需要的不写就可以了
同时插入多条数据
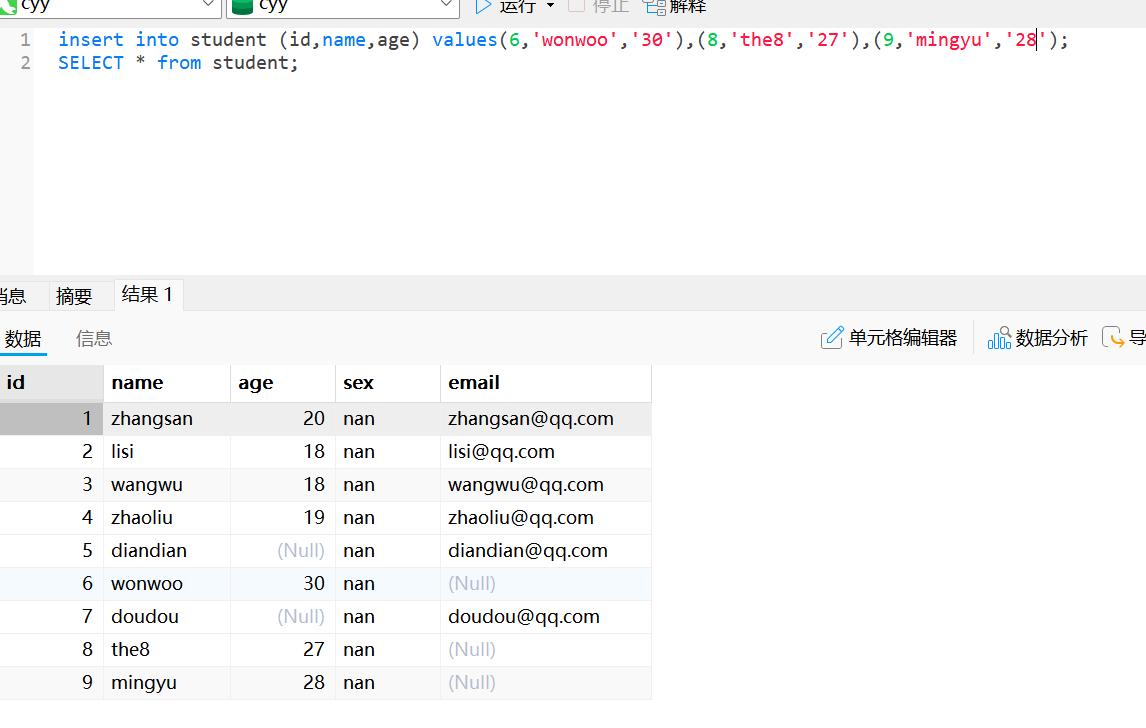
insert into student (stu_name, stu_age, stu_email) values ('zhengshi', 20, 'zhengshi@163.com'),('songshiyi', 17, 'songshiyi@163.com');插入查询结果
创建female_student的表
现在有这样一个需求,将student表中性别为女的学生信息提取出来存储到另外一张名为female_student的表中
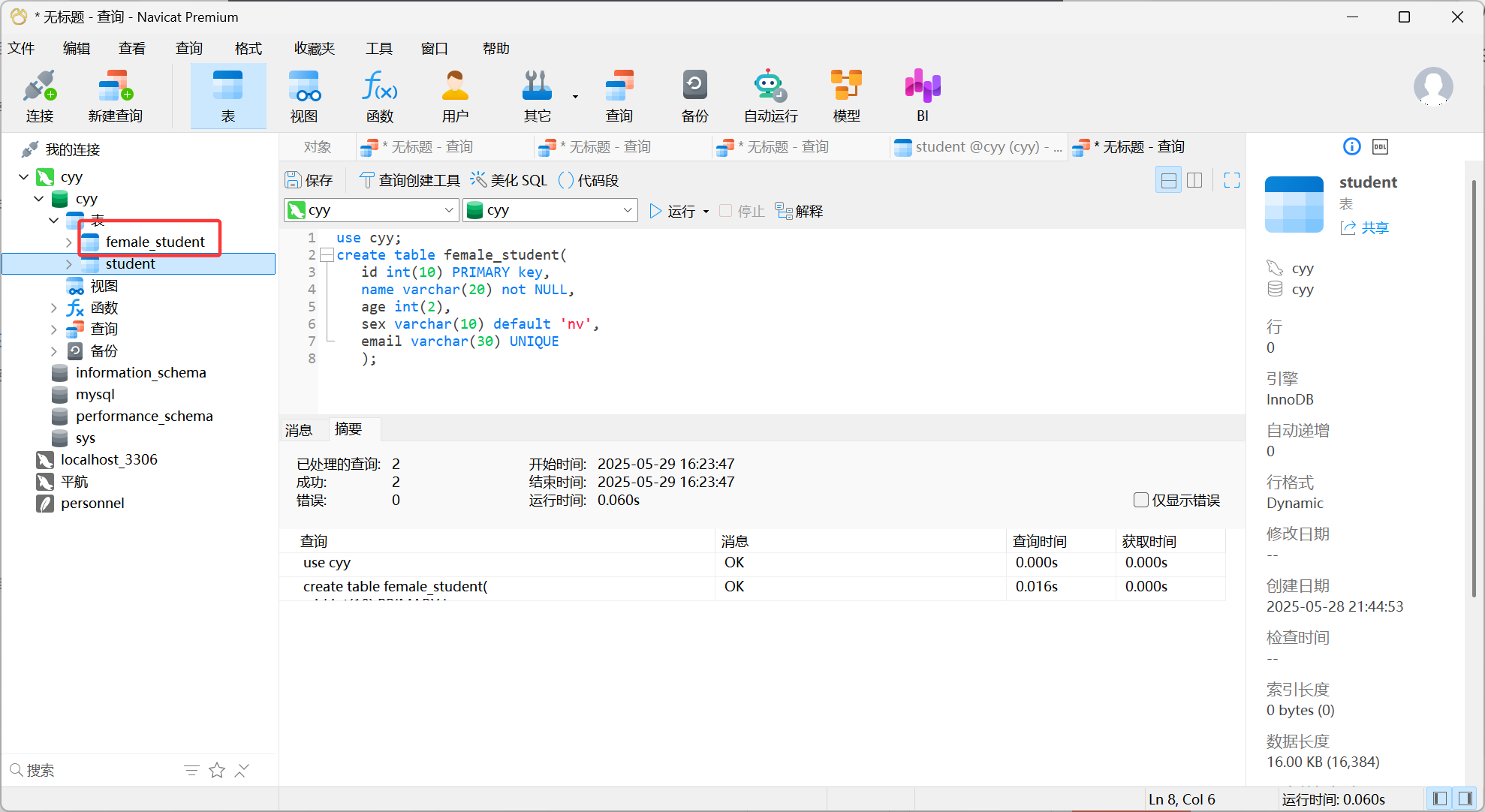
create table female_student(
stu_id int(10) primary key,
stu_name varchar(20) not null,
stu_age int(2),
stu_sex varchar(10) default 'nv',
stu_email varchar(30) unique
);由于表中的stu_sex字段设置的默认值为“nv”,因此只需要查询其他4个字段并将查询到的结果插入到表中即可
为指定字段同时插入多条数据
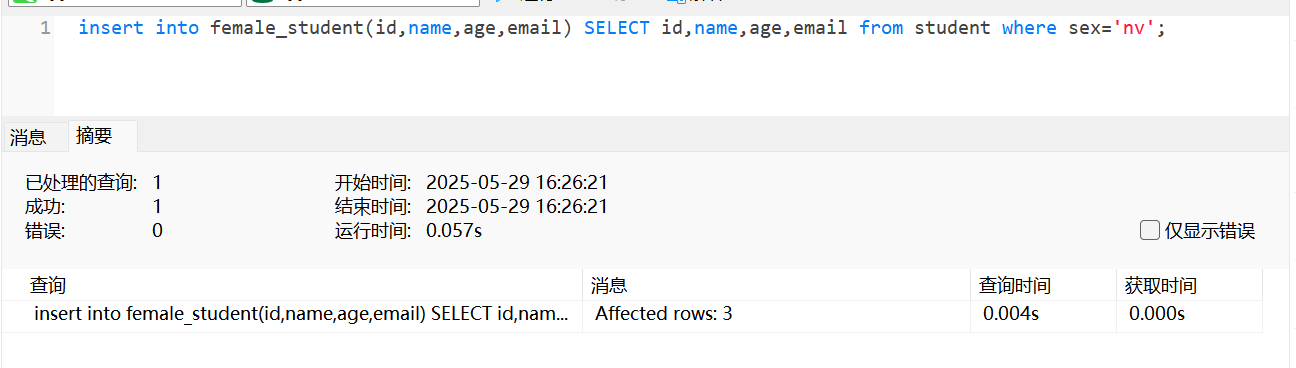
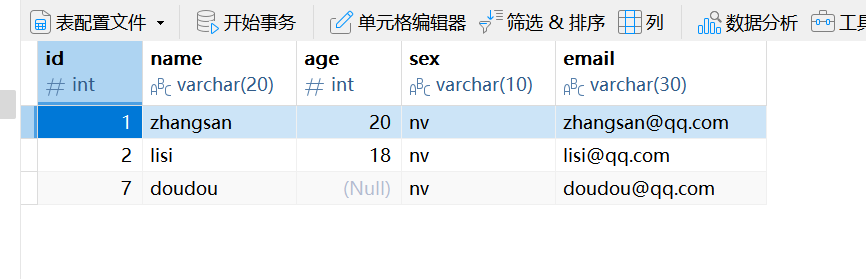
insert into female_student(stu_id, stu_name, stu_age, stu_email)
select stu_id, stu_name, stu_age, stu_email from student where stu_sex = 'nv';简单查询
查询数据是指用户根据不同的需求、使用不同的查询方式在数据表中获取自己所需要的数据。它是数据库操作中最重要,也是使用最频繁的一种操作。查询数据需要使用数据查询语言(DQL)。其基本结构是使用select子句、from子句和where子句的组合来查询一条或多条数据
如何对MySQL数据库中的一张数据表中的数据进行查询操作,即单表查询操作。在这之前,先创建一个新的数据库test,在该数据库中创建一张名为emp的员工表,表中字段包括empno(员工编号)、ename(员工姓名)、job(员工职位)、mgr(员工领导)、hiredate(员工入职日期)、sql(员工月薪)、comm(员工津贴)、deptno(员工部门编号)
知识点
所有字段查询
指定所有字段
在查询所有字段时,需要在select语句中指定所有的字段名
select column_name1, column_name2, ··· , column_namen from table_name;select为查询数据时必须使用的关键字
column_name1,column_name2, ...,column_name表示表中所有字段的名称,两个字段名之间使用”,“隔开
table_name表示要查询的表的名称
使用"*"通配符代替所有字段
如果要查询所有字段的数据并且不需要调整查询结果中字段的显示顺序,那么使用上述的SQL语法来实现比较麻烦,因此MySQL提供了一种简单的方式来实现,即使用”*“通配符代替所有的字段
select * from table_name;指定字段查询
查询指定字段时,只需要在select关键字后面指定要查询的字段即可,字段指定的顺序就是查询结果中字段的显示顺序
select column_name1, column_name2, ··· from table_name;去重查询
由于表中某些字段的值可能是重复的,因此会导致查询结果中出现重复的数据。那么就需要去除查询结果中重复的记录,这需要用到一个新的关键字distinct。
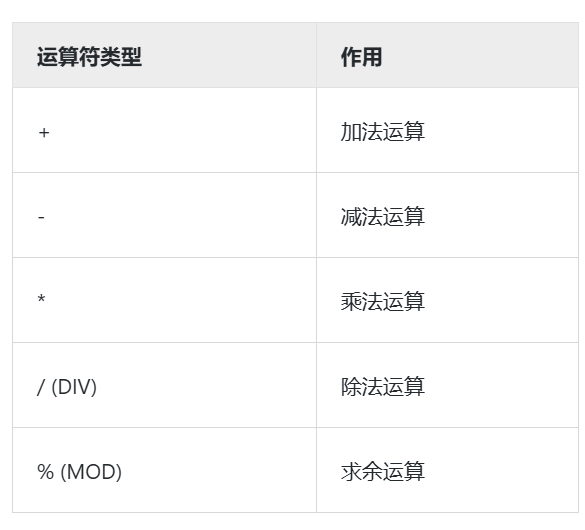
select distinct column_name1, column_name2, ··· from table_name;使用运算符查询
使用字段别名查询
select column_name1 [as] othername1, column_name2 [as] othername2, ··· from table_name;column_name1和column_name2表示要查询的字段名
as为可选项,可有可无
othername1和othername2分别为字段column_name1和column_name2的别名
实训
先创建一个新的数据库test,并在数据库中创建一张名为emp的员工表并插入员工数据
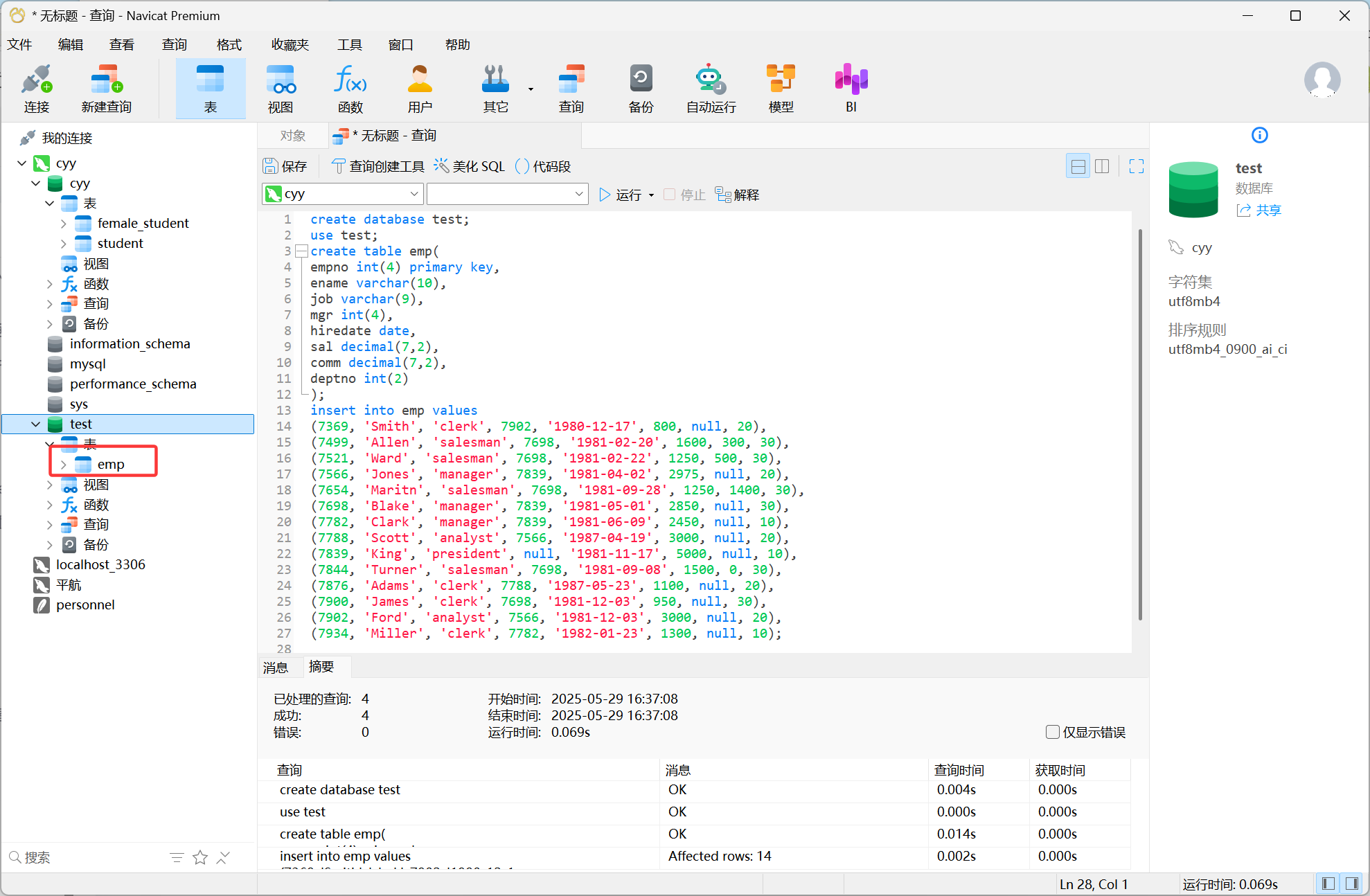
create database test;
use test;
create table emp(
empno int(4) primary key,
ename varchar(10),
job varchar(9),
mgr int(4),
hiredate date,
sal decimal(7,2),
comm decimal(7,2),
deptno int(2)
);
insert into emp values
(7369, 'Smith', 'clerk', 7902, '1980-12-17', 800, null, 20),
(7499, 'Allen', 'salesman', 7698, '1981-02-20', 1600, 300, 30),
(7521, 'Ward', 'salesman', 7698, '1981-02-22', 1250, 500, 30),
(7566, 'Jones', 'manager', 7839, '1981-04-02', 2975, null, 20),
(7654, 'Maritn', 'salesman', 7698, '1981-09-28', 1250, 1400, 30),
(7698, 'Blake', 'manager', 7839, '1981-05-01', 2850, null, 30),
(7782, 'Clark', 'manager', 7839, '1981-06-09', 2450, null, 10),
(7788, 'Scott', 'analyst', 7566, '1987-04-19', 3000, null, 20),
(7839, 'King', 'president', null, '1981-11-17', 5000, null, 10),
(7844, 'Turner', 'salesman', 7698, '1981-09-08', 1500, 0, 30),
(7876, 'Adams', 'clerk', 7788, '1987-05-23', 1100, null, 20),
(7900, 'James', 'clerk', 7698, '1981-12-03', 950, null, 30),
(7902, 'Ford', 'analyst', 7566, '1981-12-03', 3000, null, 20),
(7934, 'Miller', 'clerk', 7782, '1982-01-23', 1300, null, 10);
查询所有字段
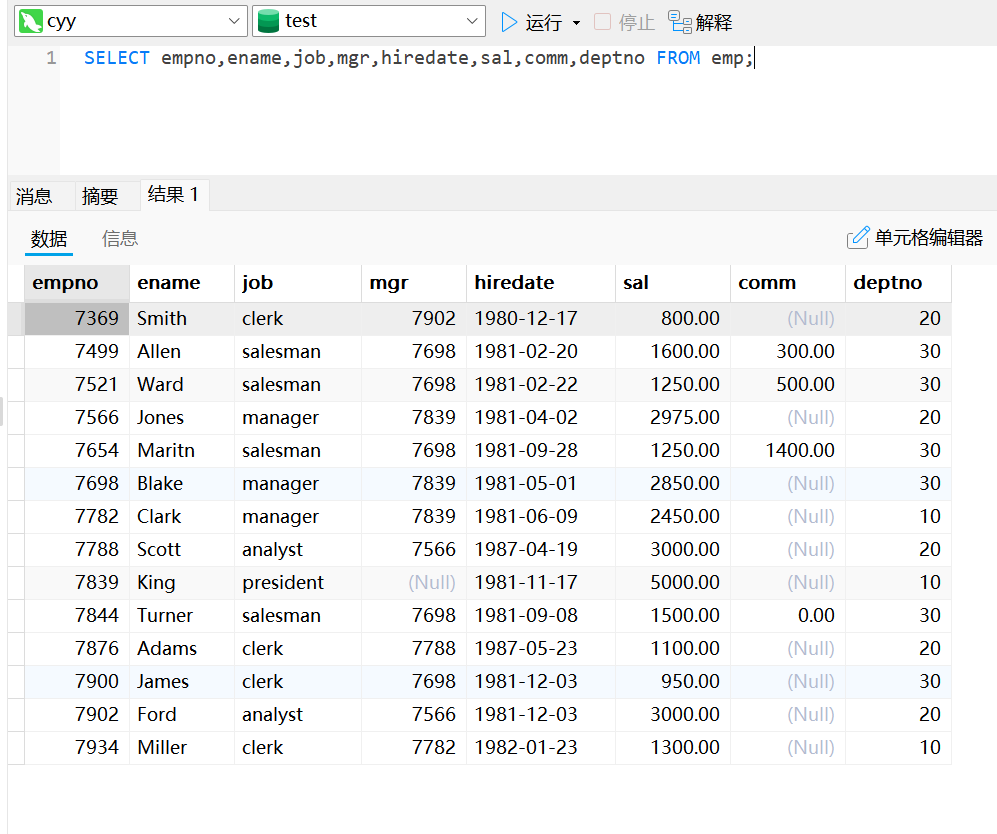
select empno, ename, job, mgr, hiredate, sal, comm, deptno from emp;使用通配符
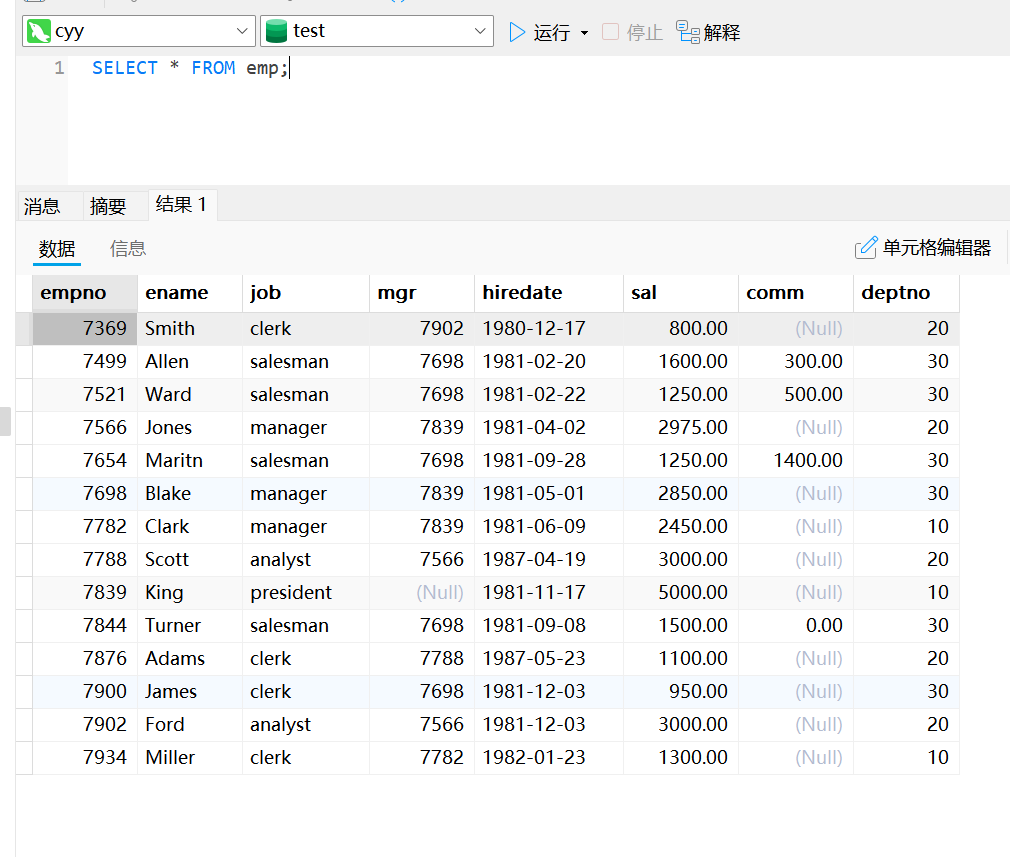
SELECT * FROM emp;指定字段查询
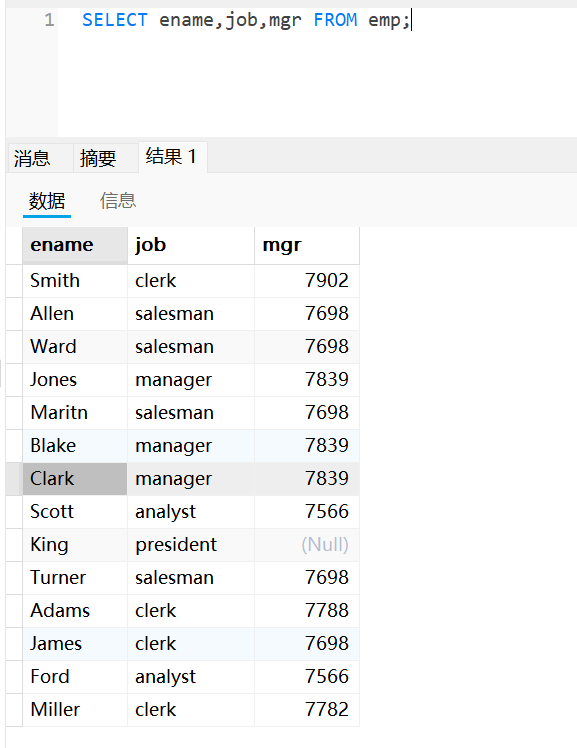
SELECT ename,job,mgr FROM emp;distinct关键字去重
作用于单个字段
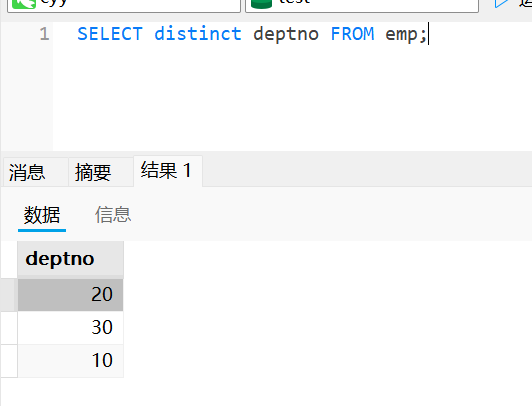
select distinct deptno from emp;作用于多个字段
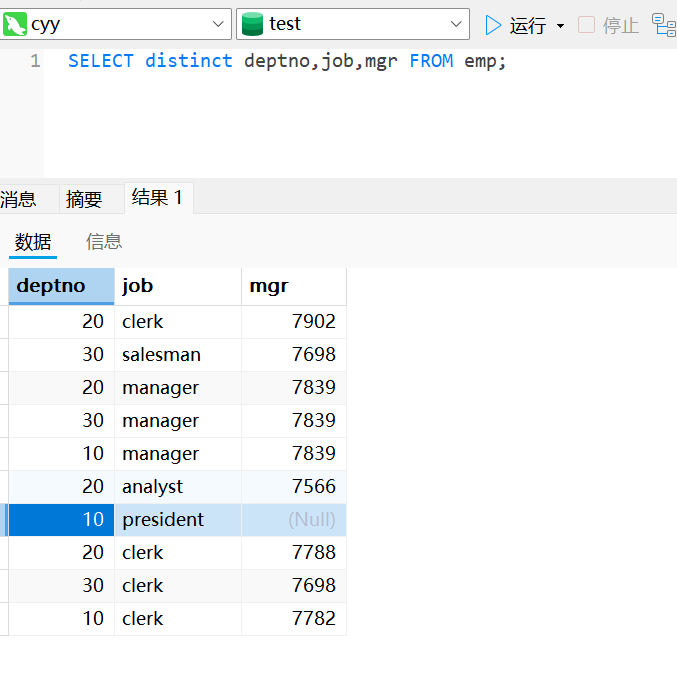
SELECT distinct deptno,job,mgr FROM emp;使用运算符的查询
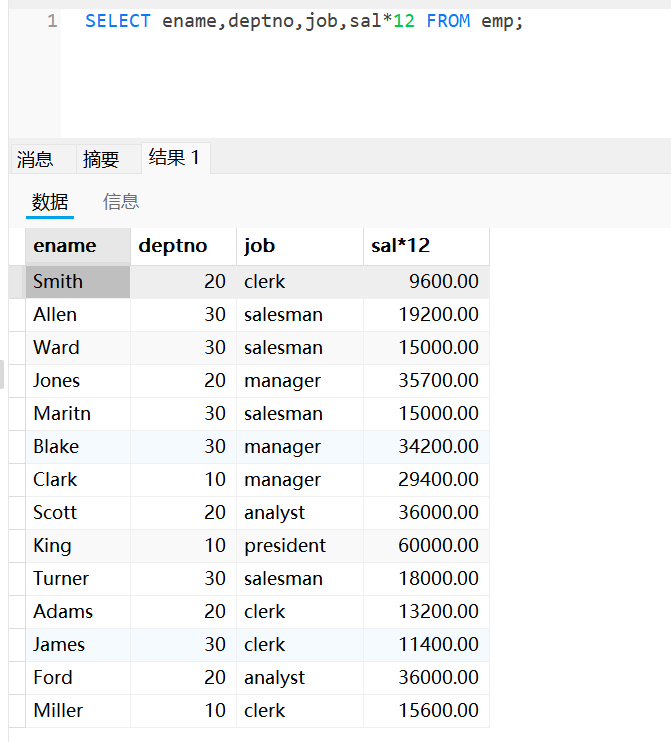
select ename, deptno, job, sal*12 from emp;使用字段别名查询
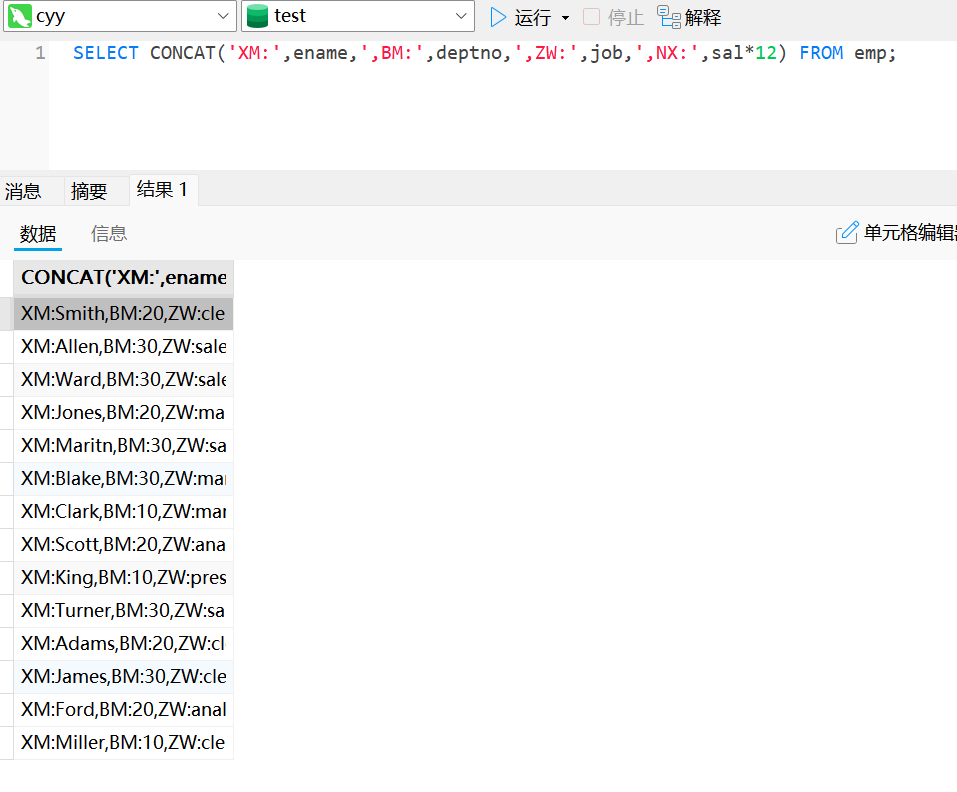
select concat('XM:',ename, ',BM:', deptno, ',ZW:', job, ',NX:', sal*12) info from emp;查询
在前面讲解的简单查询中,只能查询表中所有记录的指定字段,但是在实际开发中,表中记录的数量可能非常庞大,用户根本不需要查询所有的记录,而是只需要查询满足一定条件的部分记录即可。此时就需要使用where子句在select语句中指定查询条件,从而对查询结果进行过滤。条件查询的实现形式多种多样,可以在where子句中使用比较运算符、between and、in、is null、like、and、or等来指定查询条件
知识点
使用比较运算符的查询
MySQL可以在where子句中使用比较运算符来达到指定查询条件的目的,下表为MySQL中支持的比较运算符
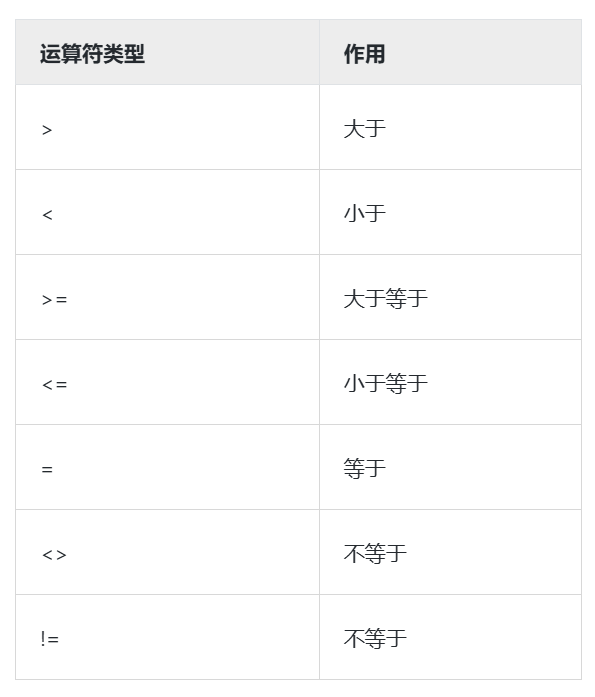
select column_name1, column_name2, ··· from table_name where where_condition;使用[not] between ... and ... 的范围查询
MySQL可以在where子句中使用between ... and ... 来实现判断某个字段的值是否在指定范围内的条件查询,如果某条记录指定字段的值在指定范围内,则说明该记录满足条件,将会在查询结果中显示出来
select column_name1, column_name2, ··· from table_name where column_name [not] between value1 and value2;column_name为指定要进行判断的字段名
between value1 and value2表示字段的值在value1和value2之间(包括value1和value2)
not为可选项,如果使用了not,则查询的是指定范围之外的所有记录
使用[not] in的指定集合查询
在MySQL中,不仅可以在where子句中使用between ... and ...来判断某个字段的值是否在指定范围内,还可以使用in关键字来判断某个字段的值是否在某个指定的集合内,如果某条记录指定字段的值在指定的集合内,则说明该纪录满足条件,将会在查询结果中显示出来
select column_name1, column_name2, ··· from table_name where column_name [not] in (value1, value2, ···);column_name为指定要进行判断的字段名
in (value1,value2,···)用来判断字段的值是否在(value1,value2,···)这个集合中
not为可选项,如果使用了not,则查询的是指定集合之外的所有记录
使用is [not] null的空值查询
在MySQL中,可以在where子句中使用is null来判断某个字段的值是否为空(空值为Null,并不是0或者空字符串),如果某条记录指定字段的值为空,则说明该记录满足条件,将会在查询结果中显示出来
select column_name1, column_name2, ··· from table_name where column_name is [not] null;column_name为指定要进行判断的字段名
is null用来判断字段的值是否为空
not为可选项,如果使用了not,则查询的是字段的值不为空的所有记录
使用[not] like的模糊查询
select column_name1, column_name2, ··· from table_name where column_name [not] like value;column_name为指定要进行比较的字段名
value表示要进行匹配的字符串值,value的值可以是一个完整的字符串,也可以是包含有一个或者多个通配符的字符串
not为可选项,如果使用了not,则查询的是字段的值与value不匹配的所有记录
使用and的多条件查询
select column_name1, column_name2, ··· from table_name where where_condition1 and where_condition2 [and where_condition3 ···];where_condition1、where_condition2和where_condition3为指定的多个查询条件,不同的查询条件之间使用and连接
使用or的多条件查询
select column_name1, column_name2, ··· from table_name where where_condition1 or where_condition2 [or where_condition3 ···];实训
建表并插入数据
create database test;
use test;
create table emp(
empno int(4) primary key,
ename varchar(10),
job varchar(9),
mgr int(4),
hiredate date,
sal decimal(7,2),
comm decimal(7,2),
deptno int(2)
);
insert into emp values
(7369, 'Smith', 'clerk', 7902, '1980-12-17', 800, null, 20),
(7499, 'Allen', 'salesman', 7698, '1981-02-20', 1600, 300, 30),
(7521, 'Ward', 'salesman', 7698, '1981-02-22', 1250, 500, 30),
(7566, 'Jones', 'manager', 7839, '1981-04-02', 2975, null, 20),
(7654, 'Maritn', 'salesman', 7698, '1981-09-28', 1250, 1400, 30),
(7698, 'Blake', 'manager', 7839, '1981-05-01', 2850, null, 30),
(7782, 'Clark', 'manager', 7839, '1981-06-09', 2450, null, 10),
(7788, 'Scott', 'analyst', 7566, '1987-04-19', 3000, null, 20),
(7839, 'King', 'president', null, '1981-11-17', 5000, null, 10),
(7844, 'Turner', 'salesman', 7698, '1981-09-08', 1500, 0, 30),
(7876, 'Adams', 'clerk', 7788, '1987-05-23', 1100, null, 20),
(7900, 'James', 'clerk', 7698, '1981-12-03', 950, null, 30),
(7902, 'Ford', 'analyst', 7566, '1981-12-03', 3000, null, 20),
(7934, 'Miller', 'clerk', 7782, '1982-01-23', 1300, null, 10);使用比较运算符的查询
使用“=” 查询
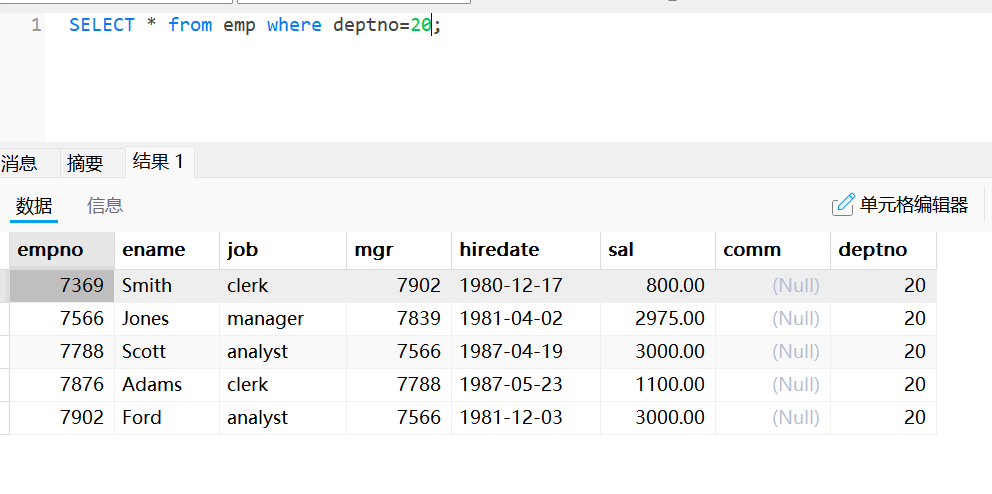
SELECT * from emp where deptno=20;使用“>=”查询
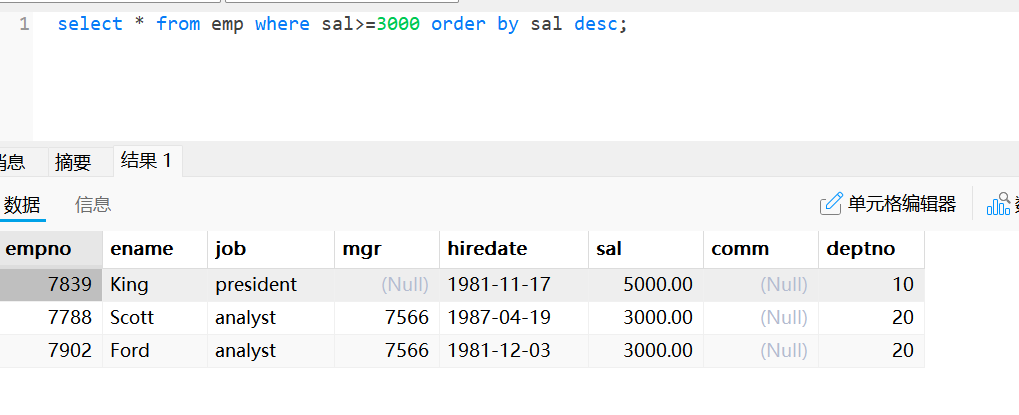
select * from emp where sal>=3000 order by sal desc;order by表示对查询结果进行排序,后面的sal是指定要根据哪个列进行排序,desc是降序,asc是升序
使用“=”查询字符串
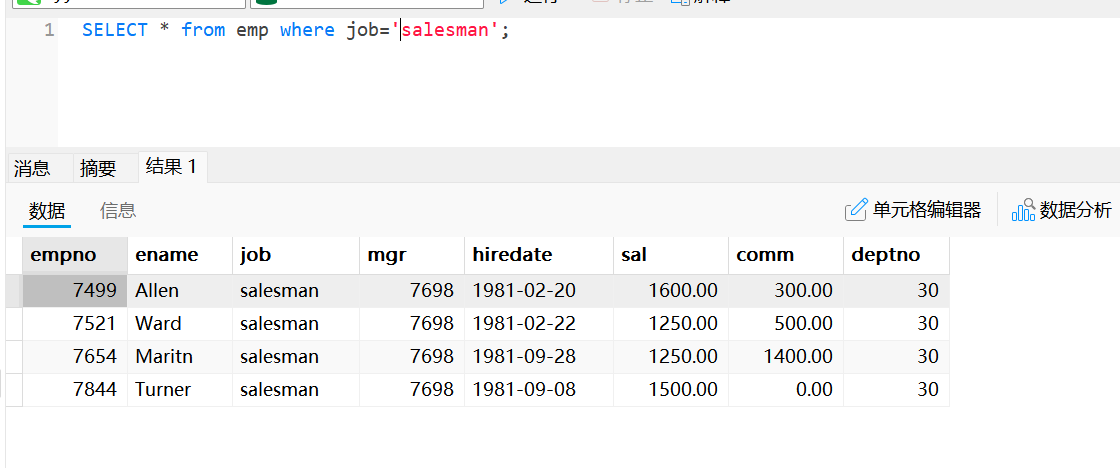
SELECT * from emp where job='salesman';使用“=”区分字符串大小写
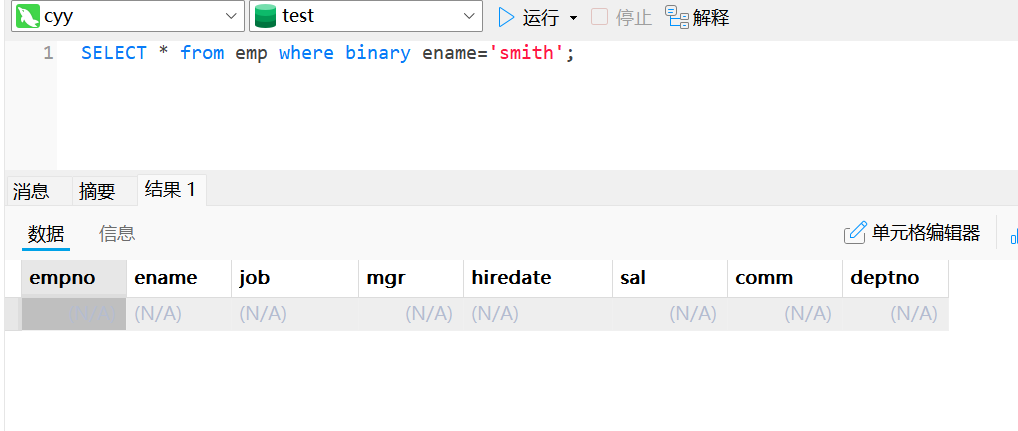
select * from emp where binary ename='smith';表中的数据是Smith所以没有
binary ename = 'smith'意味着即使ename列的默认排序规则是不区分大小写的,添加binary关键字也会临时改变这个比较行为,使其变成区分大小写
使用[not] between ... and ... 的范围查询
使用between and的条件查询
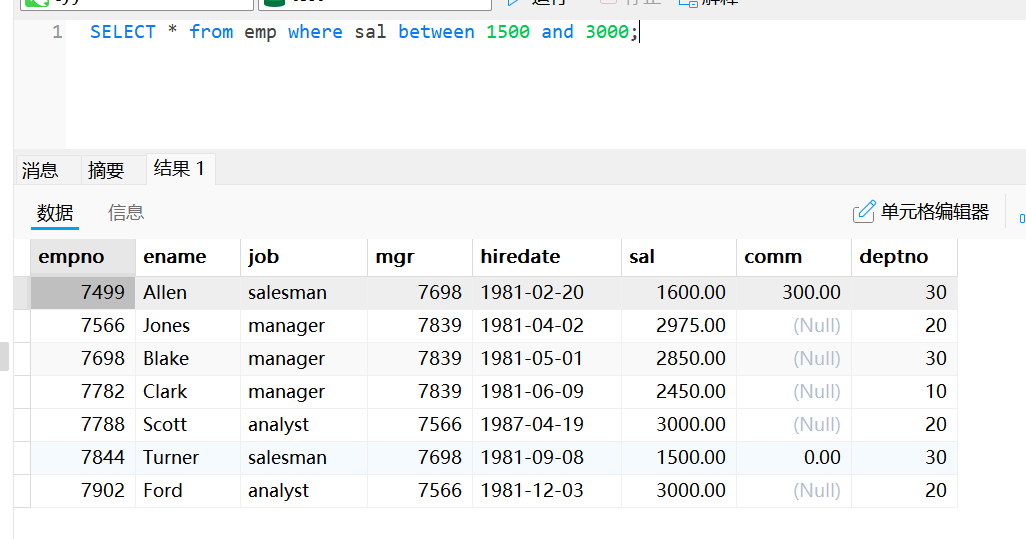
selact * from emp where sal between 1500 and 3000;使用not between and的条件查询
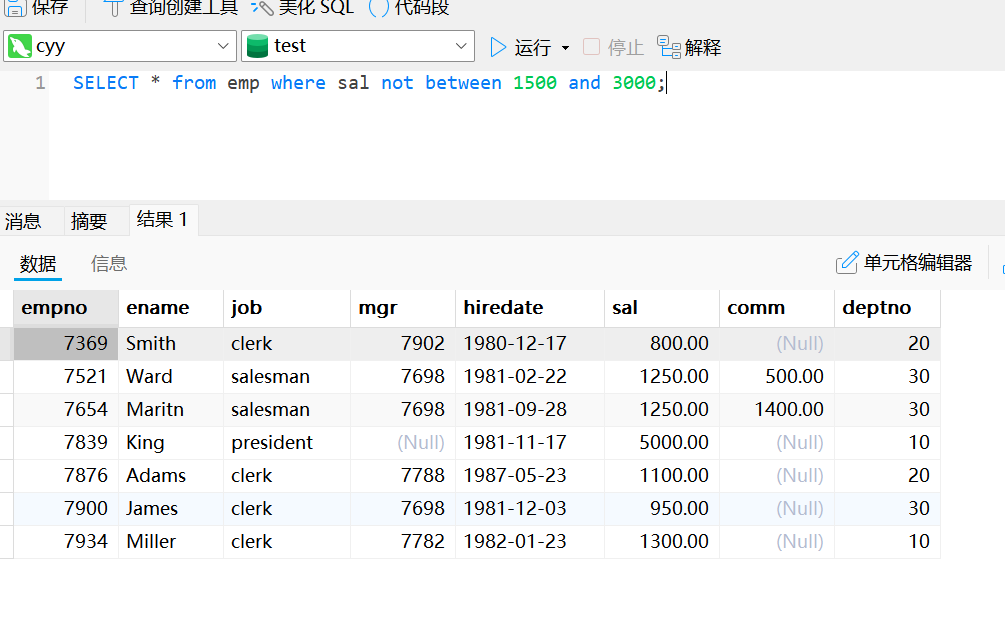
select * from emp where sal not between 1500 and 3000;使用[not] in的指定集合查询
使用in的条件查询
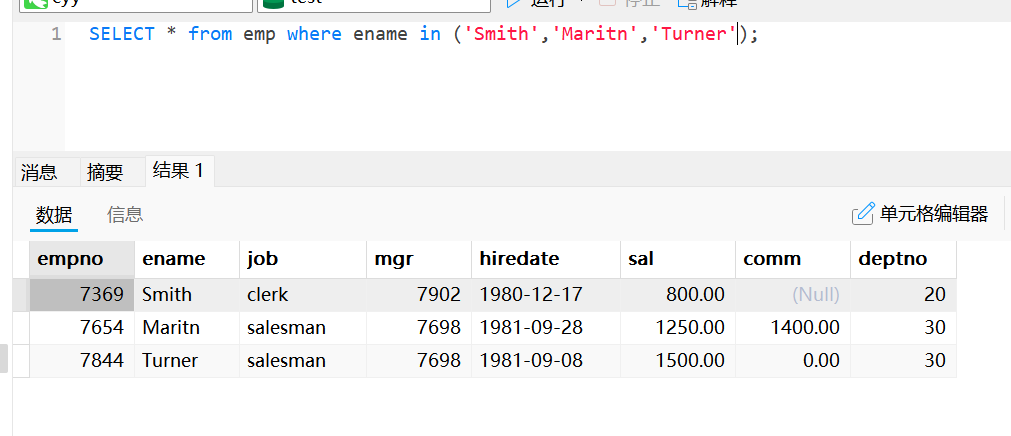
select * from emp where ename in ('Smith','Maritn','Turner');使用not in的条件查询
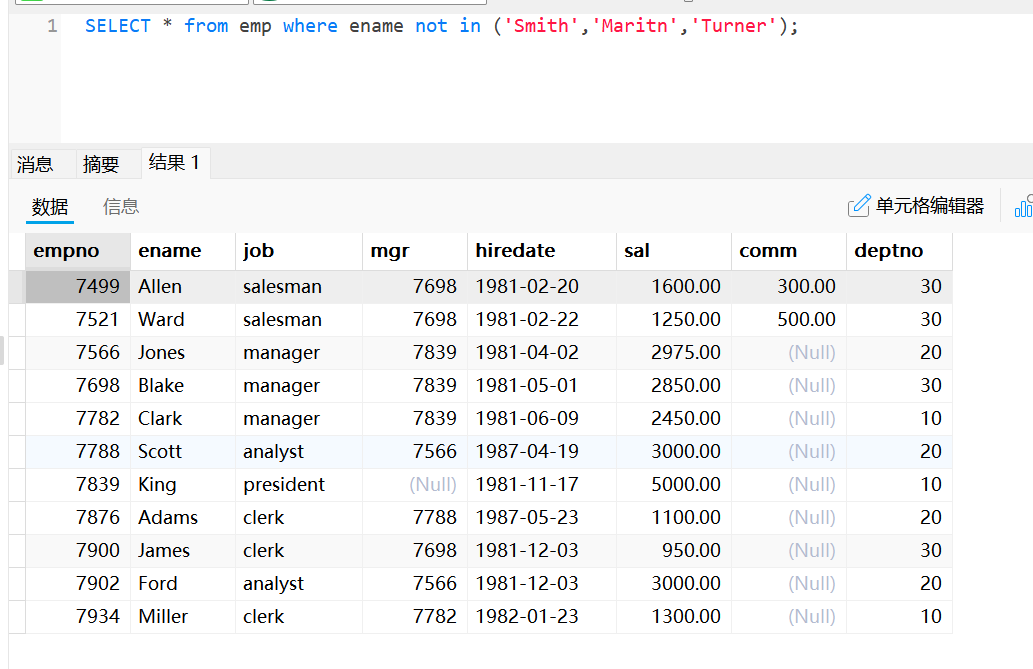
select * from emp where ename not in ('Smith','Maritn','Turner');使用is [not] null的空值查询
使用is null的条件查询
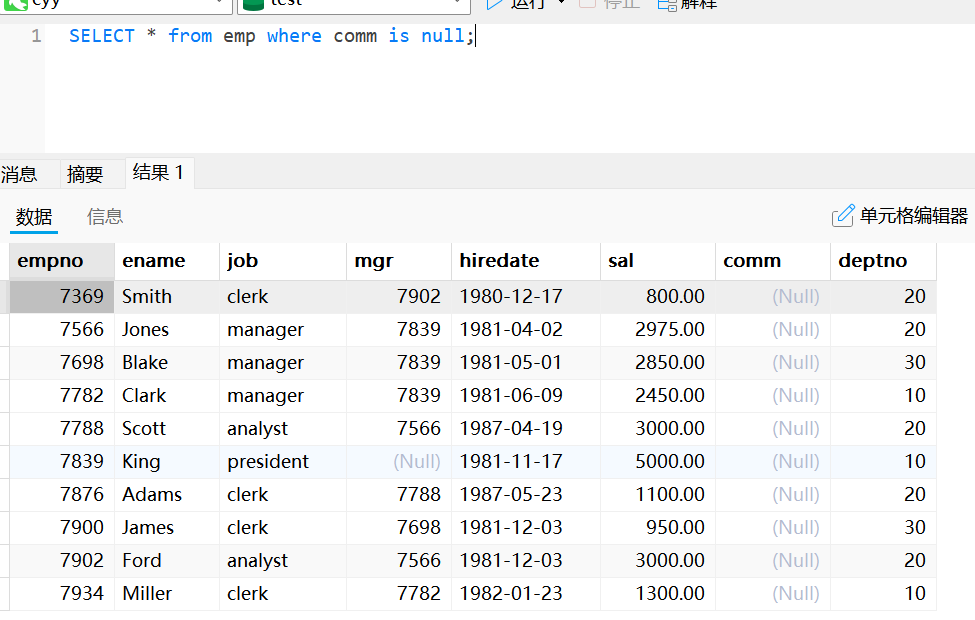
select * from emp where comm is null;使用is not null的条件查询
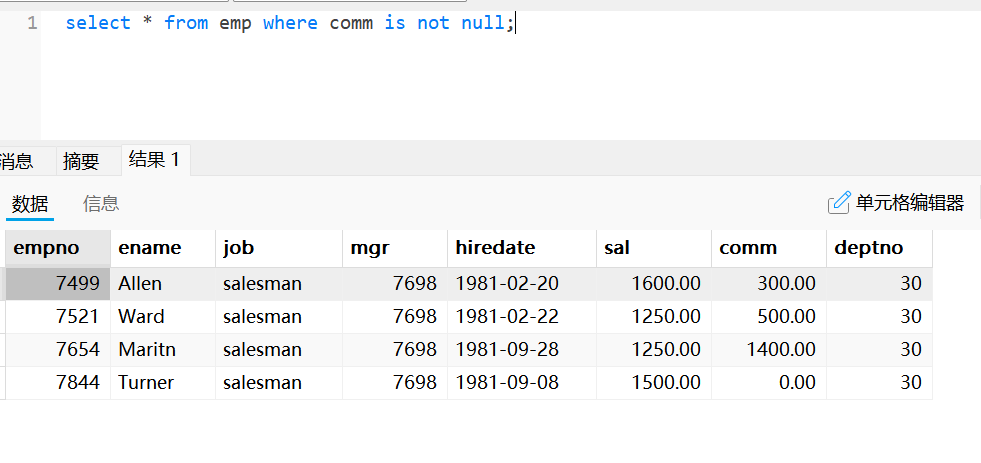
select * from emp where comm is not null;使用[not] like的模糊查询
使用like的模糊查询:ename列以“S”开头
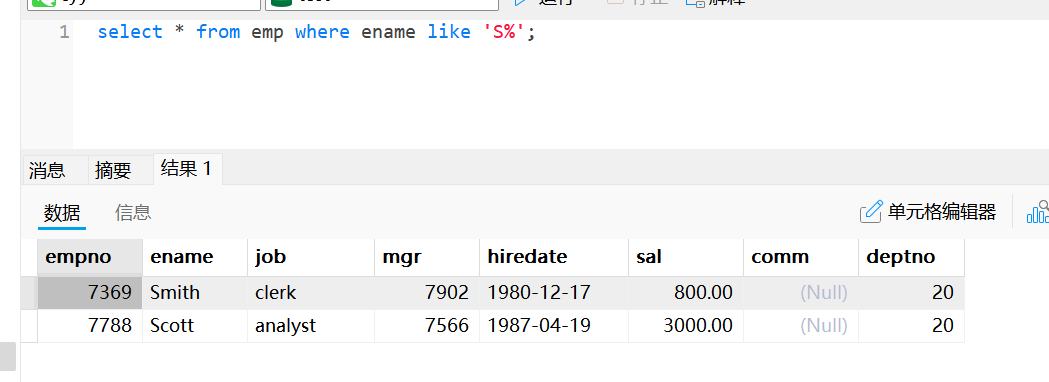
select * from emp where ename like 'S%';使用like的模糊查询:ename列以“S”结尾
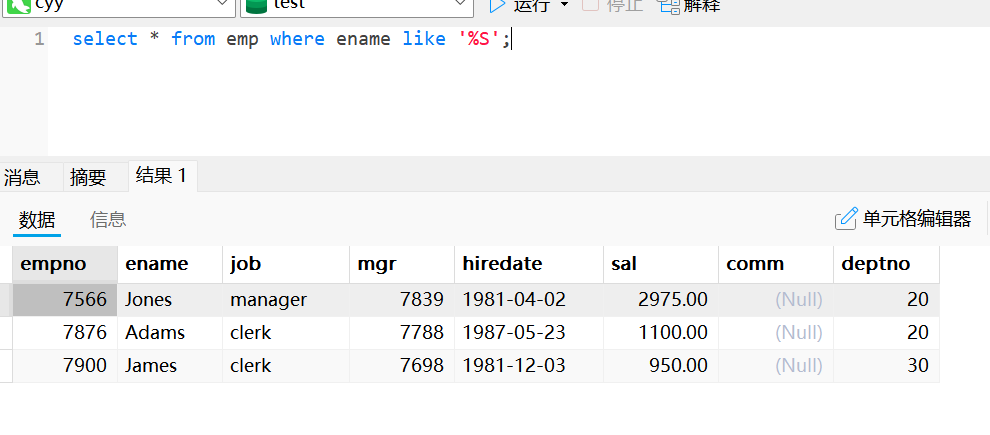
select * from emp where ename like '%S';使用like的模糊查询:ename列中包含“S”
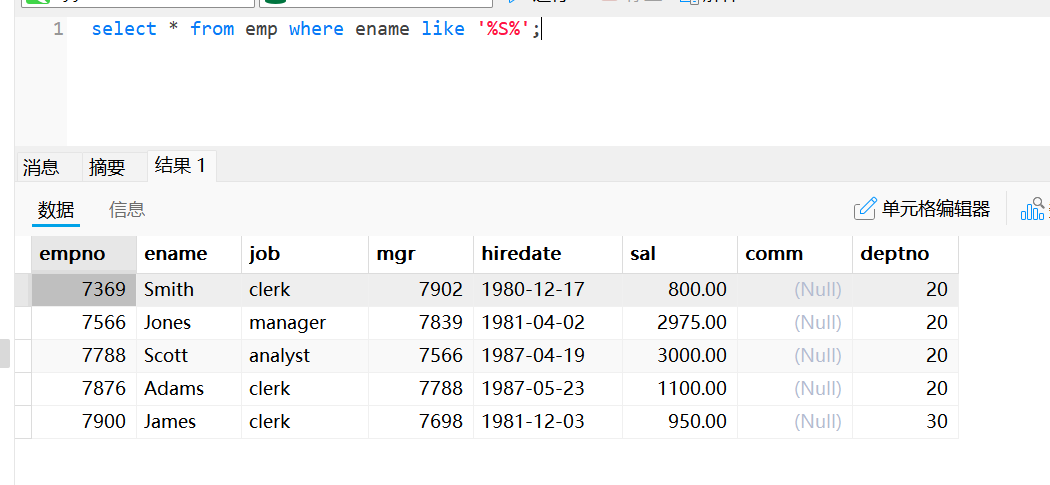
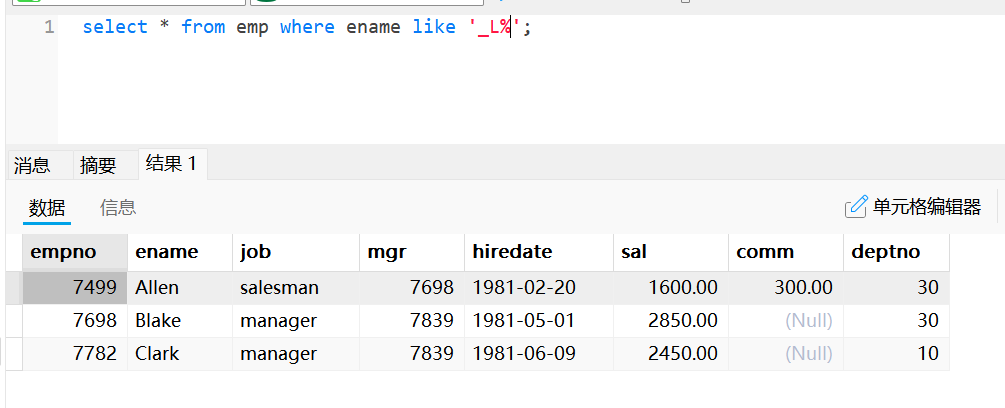
select * from emp where ename like '%S%';使用“_”通配符和like的模糊查询:ename的第二个字符是“L”
select * from emp where ename like '_L%';使用not like的模糊查询:ename中不包含字符“S”

select * from emp where ename not like '%S%';使用and的多条件查询
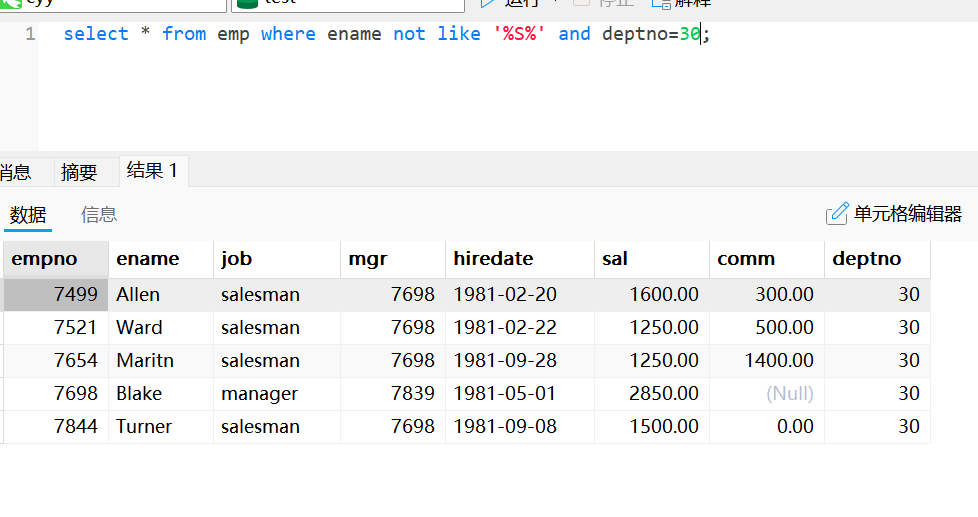
select * from emp where ename not like '%S%' and deptno=30;使用or的多条件查询
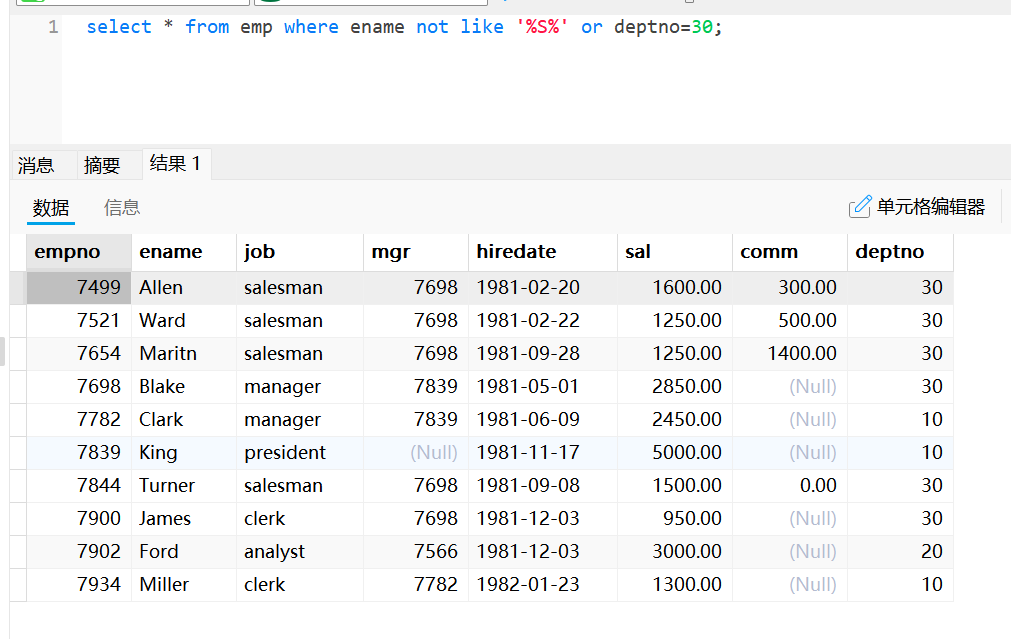
select * from emp where ename not like '%S%' or deptno=30;连接查询
在实际开发中往往需要针对两张甚至更多张数据表进行操作,而这多张表之间需要使用主键和外键关联在一起,然后使用连接查询来查询多张表中满足要求的数据记录。当相互关联的多张表中存在意义相同的字段时,便可以利用这些相同字段对多张表进行连接查询。连接查询主要分为交叉连接查询、自然连接查询、内连接查询和外连接查询四种,
知识点
交叉连接查询
交叉连接是对两个或者多个表进行笛卡尔积操作,笛卡尔积是关系代数中的一个概念,表示两个表中的每一行数据任意组合的结果。例如,有两个表,左表有m条数据记录,x个字段,右表有n条数据记录,y个字段,则执行交叉连接后将返回m*n条数据记录,x+y个字段
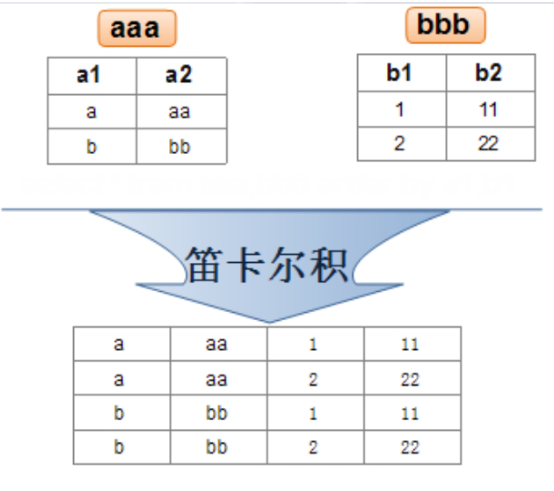
select * from table1 cross join table2;cross join用于连接要查询的两张表
table1和table2为要连接查询的两张表的名称
自然连接查询
自然连接查询是一种特殊的连接查询,该操作会在关系表生成的笛卡尔积记录中根据关系表中相同名称的字段进行记录的自动匹配(如果关系表中该字段的值相同则保留该纪录,否则舍弃该记录),然后去除重复字段
select column_name1, column_name2, ···from table1 natural join table2;natural join为自然连接所用到的关键字
column_name1和column_name2分别为要查询字段的名称
注:
- 在使用自然连接时,根据两张表中的相同字段(字段名和字段类型必须相同)自动进行匹配,因此用户无权指定进行匹配的字段。
- 自然连接查询的结果中只会保留一个进行匹配的字段。
- 在使用自然连接时,可以配合
where字句进行条件查询。
实训
建表并插入数据
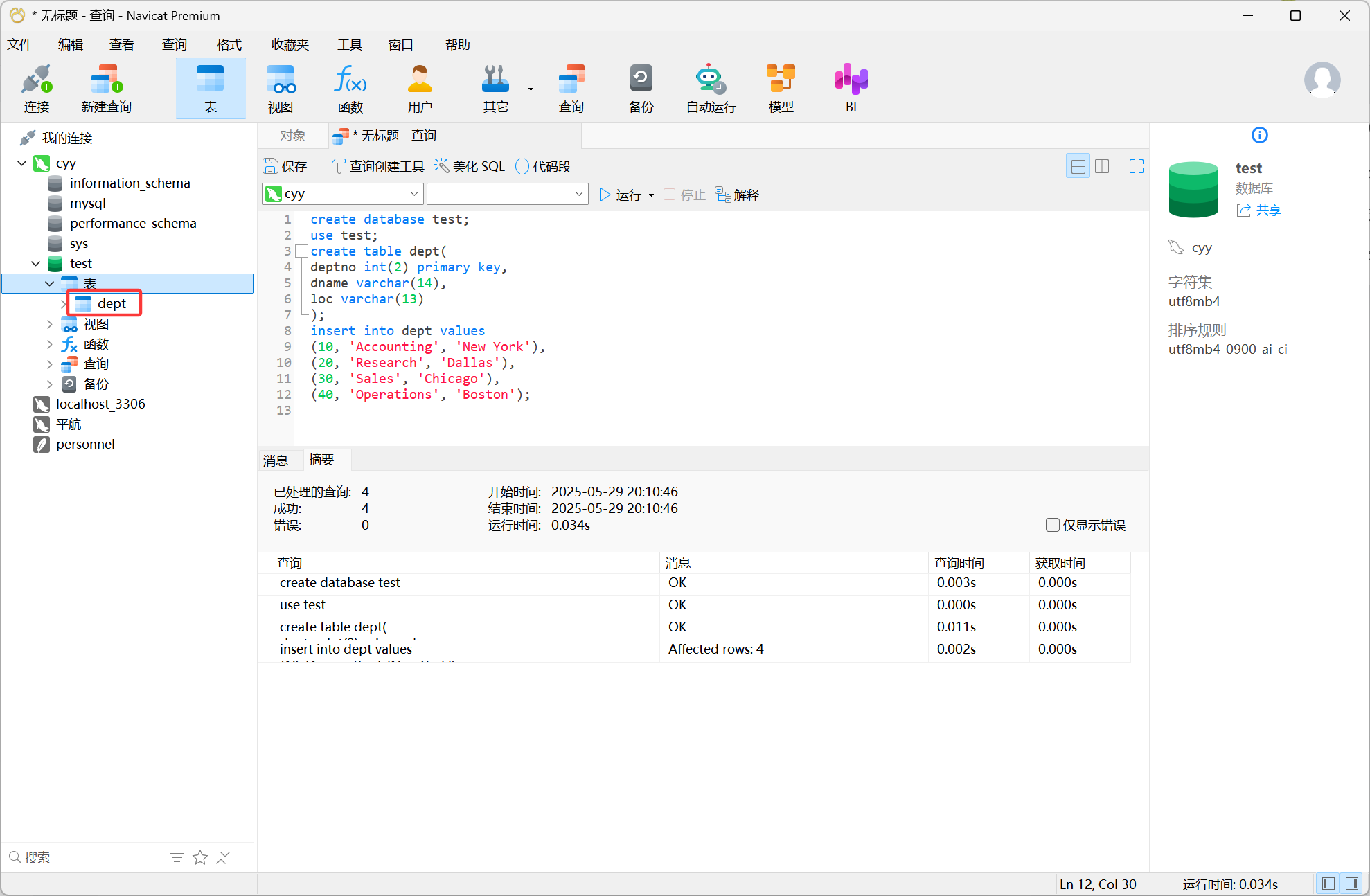
create database test;
use test;
create table dept(
deptno int(2) primary key,
dname varchar(14),
loc varchar(13)
);
insert into dept values
(10, 'Accounting', 'New York'),
(20, 'Research', 'Dallas'),
(30, 'Sales', 'Chicago'),
(40, 'Operations', 'Boston');创建data表并插入数据
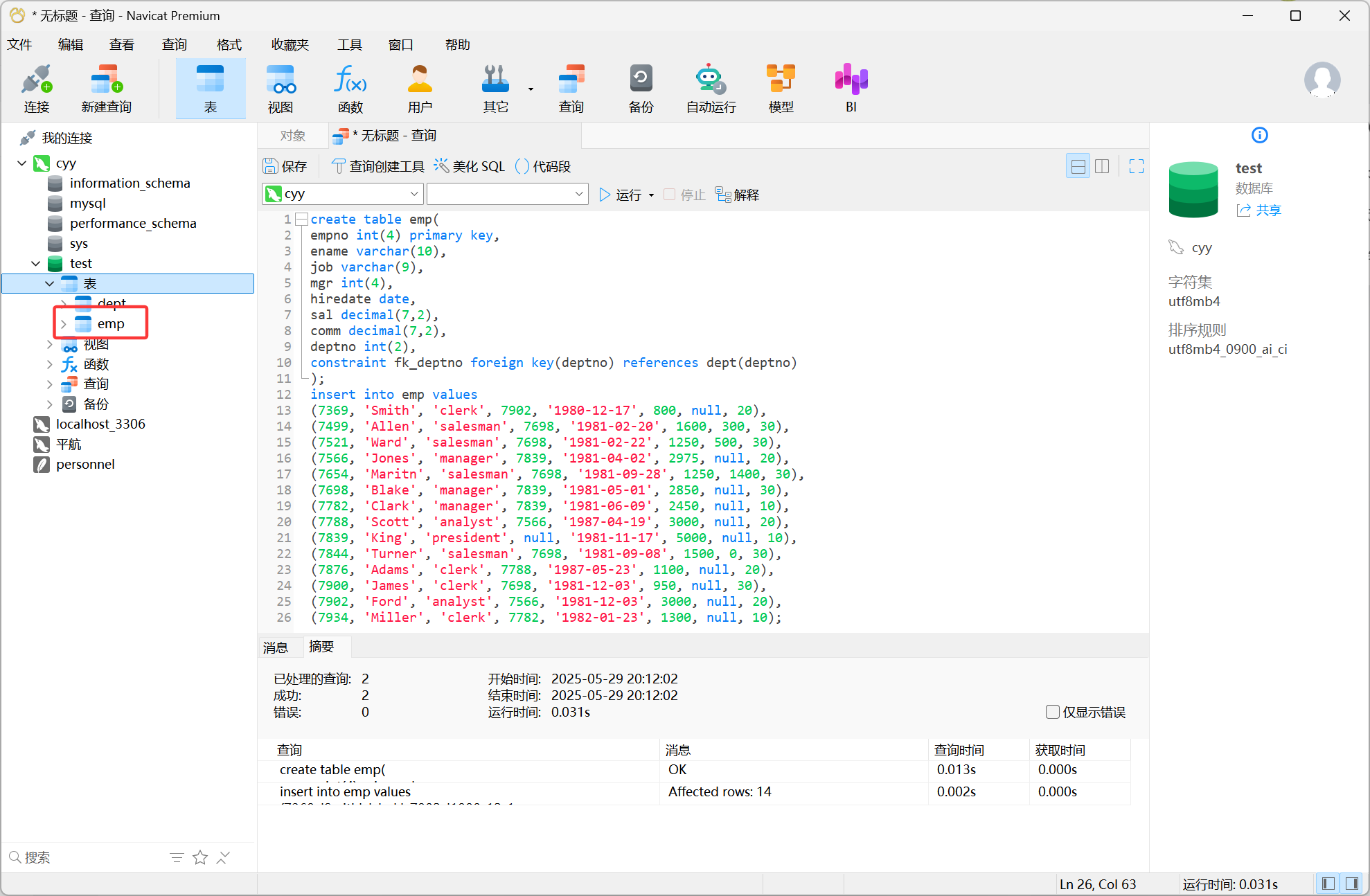
create table emp(
empno int(4) primary key,
ename varchar(10),
job varchar(9),
mgr int(4),
hiredate date,
sal decimal(7,2),
comm decimal(7,2),
deptno int(2),
constraint fk_deptno foreign key(deptno) references dept(deptno)
);
insert into emp values
(7369, 'Smith', 'clerk', 7902, '1980-12-17', 800, null, 20),
(7499, 'Allen', 'salesman', 7698, '1981-02-20', 1600, 300, 30),
(7521, 'Ward', 'salesman', 7698, '1981-02-22', 1250, 500, 30),
(7566, 'Jones', 'manager', 7839, '1981-04-02', 2975, null, 20),
(7654, 'Maritn', 'salesman', 7698, '1981-09-28', 1250, 1400, 30),
(7698, 'Blake', 'manager', 7839, '1981-05-01', 2850, null, 30),
(7782, 'Clark', 'manager', 7839, '1981-06-09', 2450, null, 10),
(7788, 'Scott', 'analyst', 7566, '1987-04-19', 3000, null, 20),
(7839, 'King', 'president', null, '1981-11-17', 5000, null, 10),
(7844, 'Turner', 'salesman', 7698, '1981-09-08', 1500, 0, 30),
(7876, 'Adams', 'clerk', 7788, '1987-05-23', 1100, null, 20),
(7900, 'James', 'clerk', 7698, '1981-12-03', 950, null, 30),
(7902, 'Ford', 'analyst', 7566, '1981-12-03', 3000, null, 20),
(7934, 'Miller', 'clerk', 7782, '1982-01-23', 1300, null, 10);创建emp表并插入数据
交叉连接查询
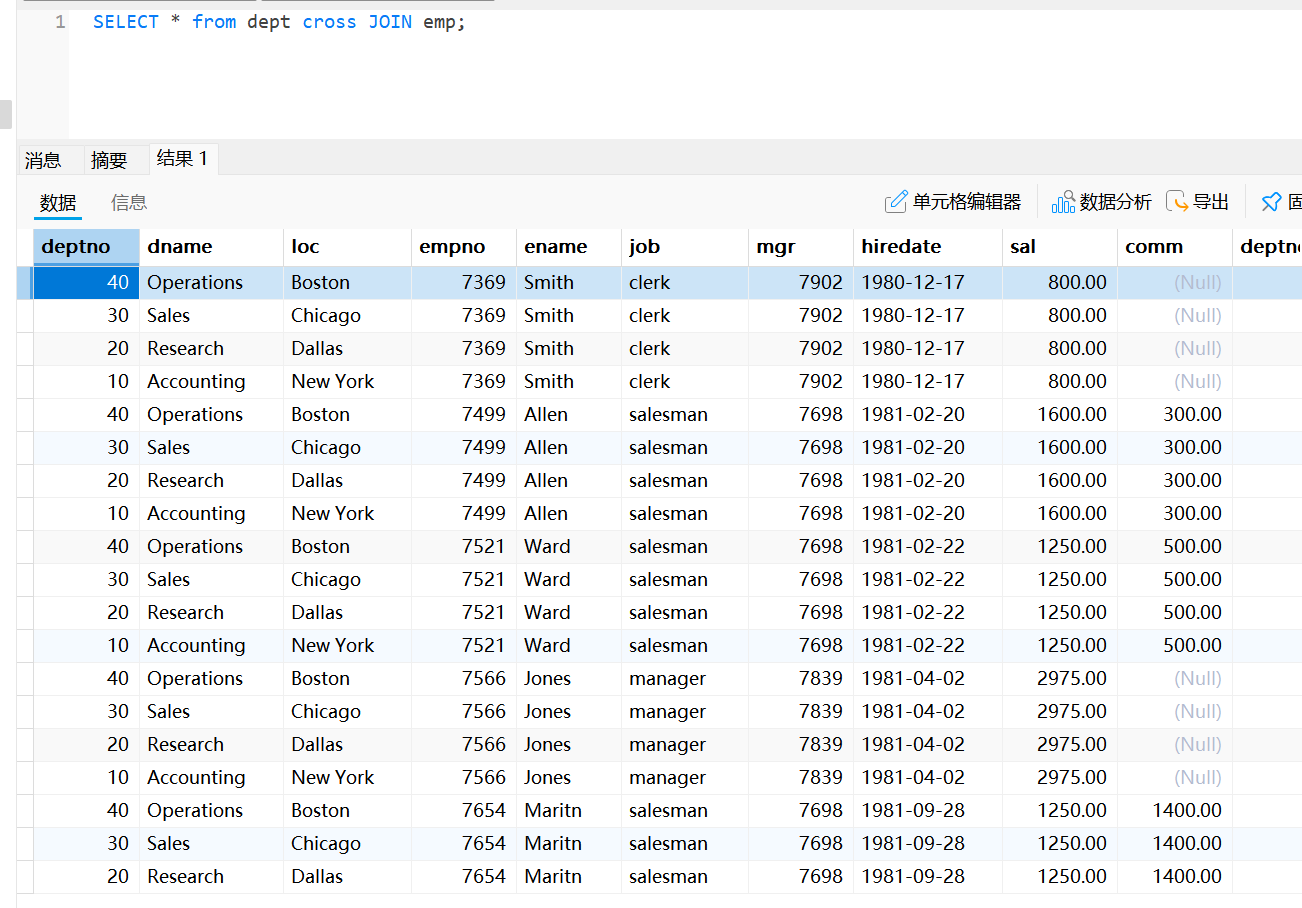
select * from dept cross join emp;将两个表所有的列进行整合并显示
自然连接查询
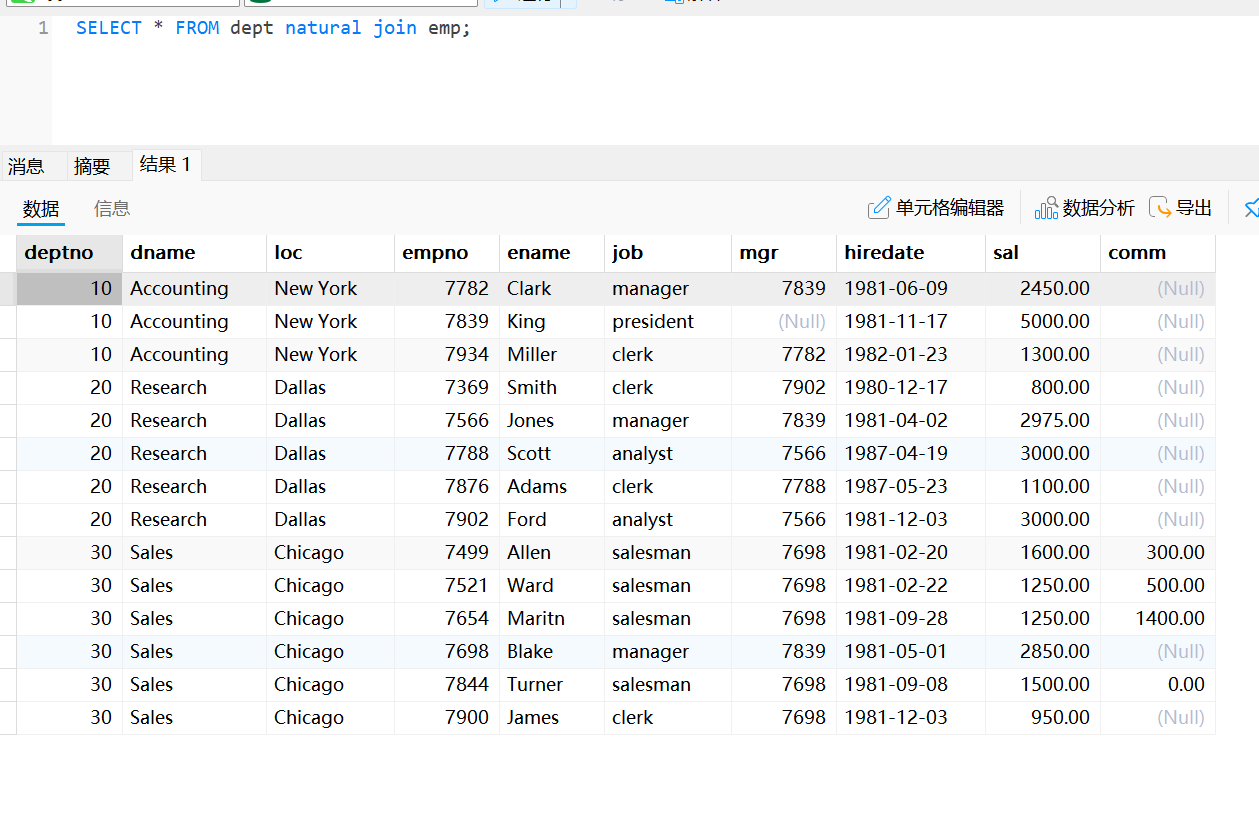
select * from dept natural join emp;自动匹配同名列进行连接
数据库对象创建与管理
视图
视图是一个从单张或多张基础数据表或其他视图中构建出来的虚拟表。同基础表一样,视图中也包含了一系列带有名称的列和行数据,但是数据库中只是存放视图的定义,也就是动态检索数据的查询语句,而并不存放视图中的数据,这些数据依旧存放于构建视图的基础表中,只有当用户使用视图时才去数据库请求相对应的数据,即视图中的数据是在引用视图时动态生成的。因此视图中的数据依赖于构建视图的基础表,如果基本表中的数据发生了变化,视图中相应的数据也会跟着改变
特点:
- 视图能简化用户操作。
- 视图能够对机密数据提供安全保护。
- 视图提供了一定程度上的数据逻辑独立性。
知识点
因为视图是一个从单张或多张基础数据表或其他视图中构建出来的虚拟表,所以视图的作用类似于对数据表进行筛选。因此,除了使用创建视图的关键字create view外,还必须使用SQL语句中的select语句来实现视图的创建
create [or replace] [algorithm = {undefined | merge | temptable}]
view view_name [(column_list)]
as select_statement
[with [cascaded | local] check option];create view为创建视图所使用的关键字
or replace为可选项,若给定了or replace,则表示新视图将会覆盖掉数据库中同名的原有视图
algorithm为可选项,表示视图选择的执行算法
merge和temptable为视图的执行算法
view_name表示将要创建的视图名称
实训
建表并插入数据
这里和上面的连接查询用到的表一致,就不写了
在单表上创建图
查看root权限
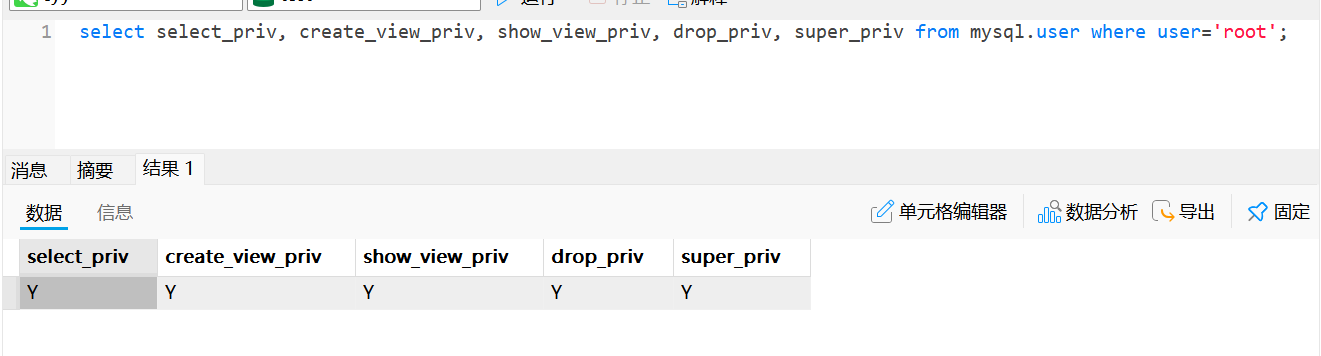
select select_priv, create_view_priv, show_view_priv, drop_priv, super_priv from mysql.user where user='root';select_priv: 查询(SELECT)数据的权限
create_view_priv: 创建视图(CREATE VIEW)的权限
show_view_priv: 查看视图(SHOW CREATE VIEW 等)定义的权限
drop_priv: 删除表、数据库、视图等(DROP)的权限
super_priv: SUPER 权限
创建视图
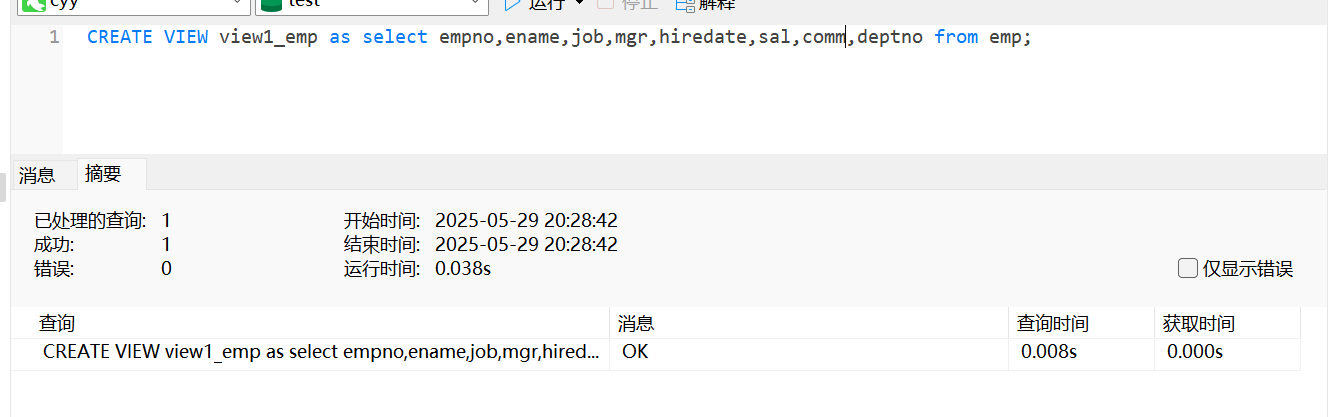
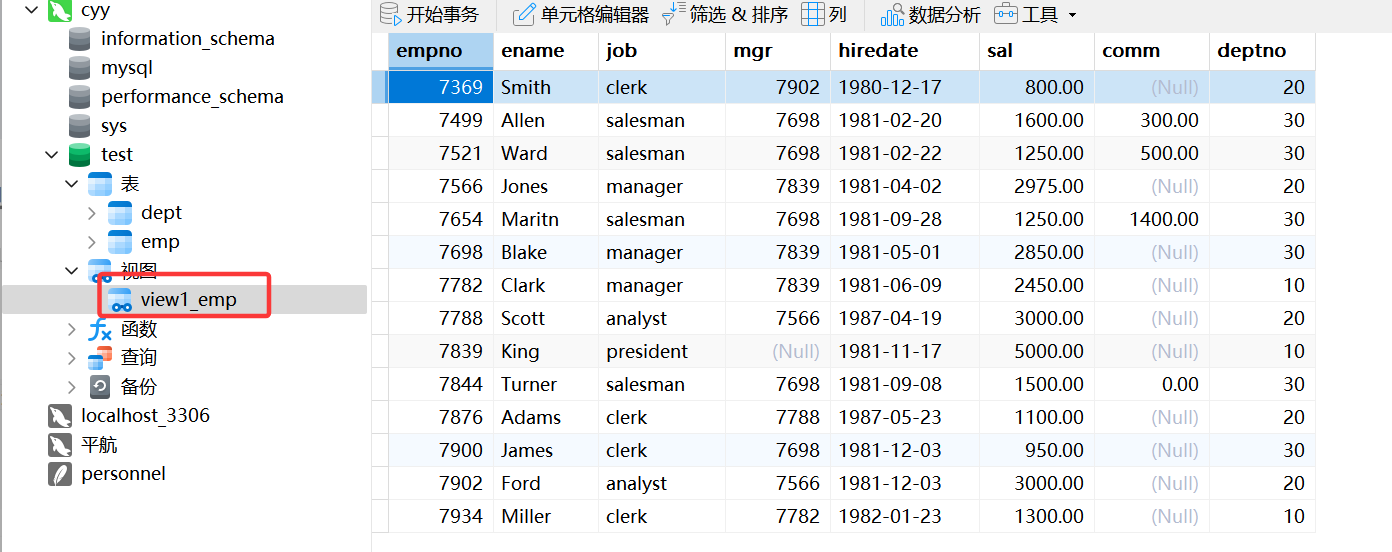
create view view1_emp as select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp;在表单上创建view1_emp视图,在mysql中查询视图可以用下面这个语句
select * from view1_emp;在多表上创建视图
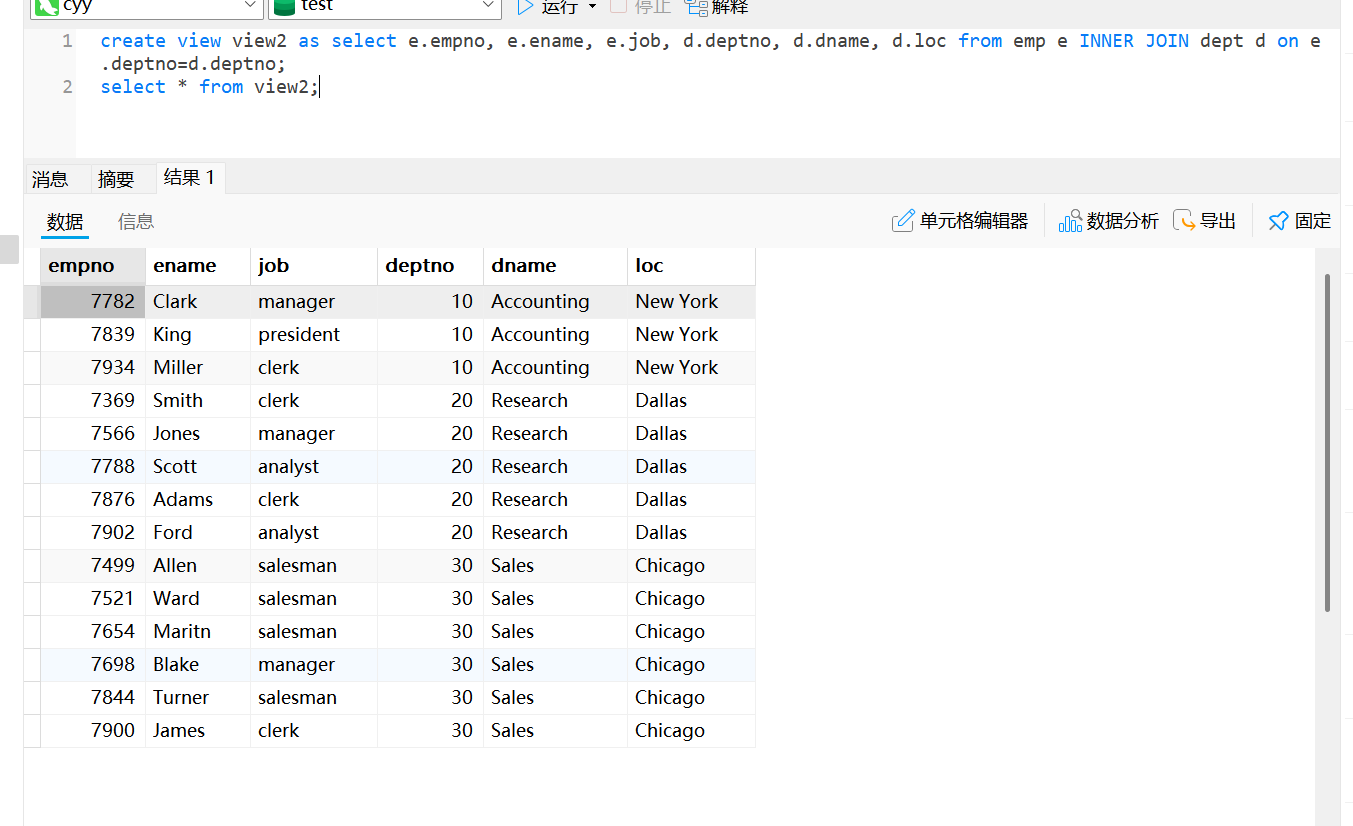
create view view2 as select e.empno, e.ename, e.job, d.deptno, d.dname, d.loc from emp e inner dept d on e.deptno=d.deptno;emp e: 指定从emp表中选择数据,并给它一个别名e
INNER JOIN dept d: 使用INNER JOIN连接emp表和dept表,并给dept表一个别名 d
ON e.deptno = d.deptno: 连接条件,表示只有当emp表的deptno列的值与dept表的deptno列的值相等时,才将两表的行组合起来,意味着只会显示那些有匹配部门的员工信息
在其他视图上创建视图
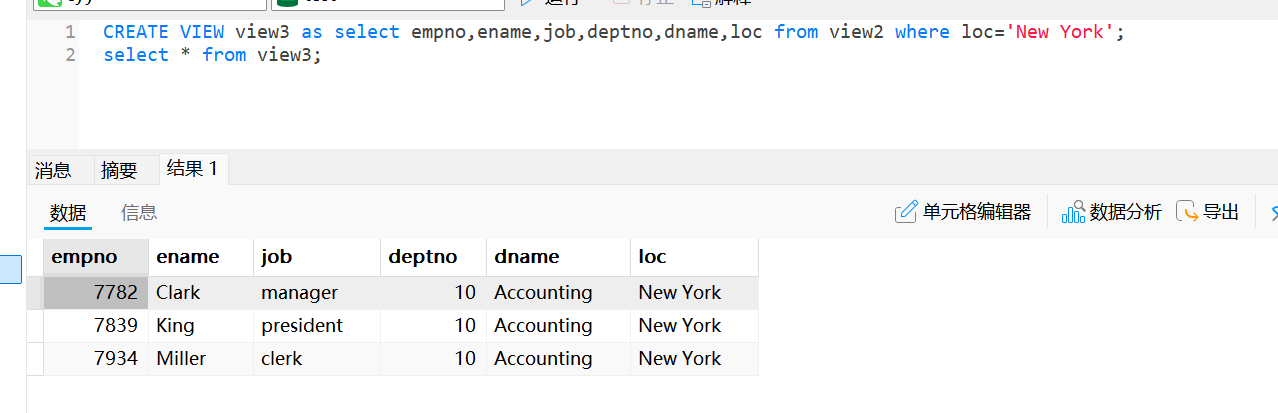
create view view3 as select empno,ename,job,deptno,dname,loc from view2 where loc='New York';只从view2_emp视图中选择那些loc (部门位置) 列的值等于'New York'的行
相关文章:
智警杯备赛--数据库管理与优化及数据库对象创建与管理
sql操作 插入数据 如果要操作数据表中的数据,首先应该确保表中存在数据。没有插入数据之前的表只是一张空表,需要使用insert语句向表中插入数据。插入数据有4种不同的方式:为所有字段插入数据、为指定字段插入数据、同时插入多条数据以及插…...

MySQL 在 CentOS 7 环境下的安装教程
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习Mysql的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...
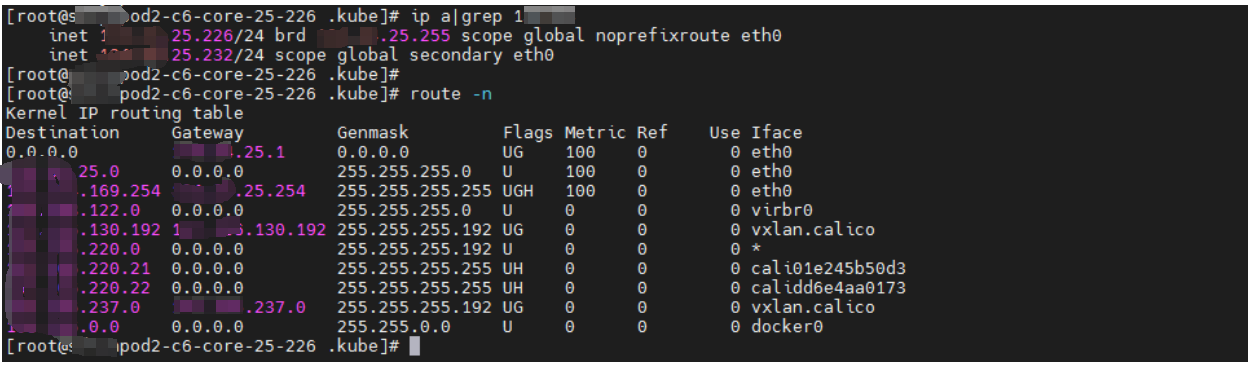
K8S集群主机网络端口不通问题排查
一、环境: k8s: v1.23.6 docker: 20.10.14 问题和故障现象:devops主机集群主机节点到端口8082不通(网络策略已经申请,并且网络策略已经实施完毕),而且网络实施人员再次确认,网络策…...

【Elasticsearch】retry_on_conflict
在 Elasticsearch 中,retry_on_conflict 是 _update 和 _update_by_query API 的一个参数,用于处理并发冲突。当多个客户端同时尝试更新同一个文档时,可能会发生版本冲突(version conflict)。retry_on_conflict 参数允…...

Android Cameara2 + MediaRecorder 完成录像功能
一、打开相机、预览 打开相机预览流程是Camera2的默认流程 可参考:https://blog.csdn.net/kk3087961/article/details/135616576 二、开启录像功能 开启录像主要包括以下3步: private void startRecording() {// 1. 停止预览并关闭会话if (mCameraSes…...

python打卡day39
知识点回顾 图像数据的格式:灰度和彩色数据模型的定义显存占用的4种地方 模型参数梯度参数优化器参数数据批量所占显存神经元输出中间状态 batchisize和训练的关系 课程代码: # 先继续之前的代码 import torch import torch.nn as nn import torch.opti…...

3.8.5 利用RDD统计网站每月访问量
本项目旨在利用Spark RDD统计网站每月访问量。首先,创建名为“SparkRDDWebsiteTraffic”的Maven项目,并添加Spark和Scala的依赖。接着,编写Scala代码,通过SparkContext读取存储在HDFS上的原始数据文件,使用map和reduce…...
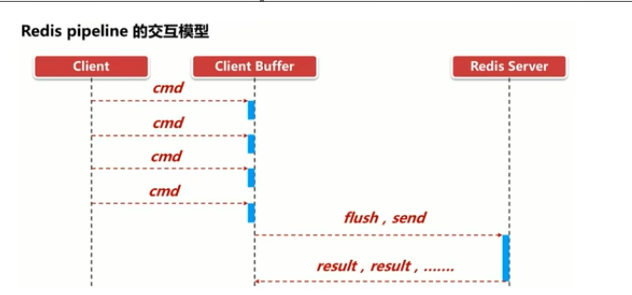
尚硅谷redis7 49-51 redis管道之理论简介
前提redis事务和redis管道有点像,但本质上截然不同 49 redis管道之理论简介 面试题 如何优化频繁命令往返造成的性能瓶颈? redis每秒可以承受8万的写操作和接近10万次以上的读操作。每条命令都发送、处理、返回,能不能批处理一次性搞定呢…...

Spring Boot + MyBatis-Plus实现操作日志记录
创建数据库表 CREATE TABLE sys_operation_log (log_id bigint NOT NULL AUTO_INCREMENT COMMENT 日志ID,operation_type varchar(20) NOT NULL COMMENT 操作类型,operation_module varchar(50) NOT NULL COMMENT 操作模块,operation_desc varchar(200) DEFAULT NULL COMMENT …...

JavaScript入门基础篇-day03
一、为什么需要数组? 在我们正式学习数组之前,先思考一个场景:假设我们要记录一个班级50位同学的期末成绩。如果不用数组,代码会是这样的: let score1 85; let score2 92; let score3 78; // ... 要写50个变量&am…...

Leetcode-5 好数对的数目
Leetcode-5 好数对的数目(简单) 题目描述思路分析通过代码(python) 题目描述 给你一个整数数组 nums 。 如果一组数字 (i,j) 满足 nums[i] nums[j] 且 i < j ,就可以认为这是一组 好数对 。 返回好数对的数目。 示…...
openEuler安装MySql8(tar包模式)
操作系统版本: openEuler release 22.03 (LTS-SP4) MySql版本: 下载地址: https://dev.mysql.com/downloads/mysql/ 准备安装: 关闭防火墙: 停止防火墙 #systemctl stop firewalld.service 关闭防火墙 #systemc…...

Opencv实用操作6 开运算 闭运算 梯度运算 礼帽 黑帽
1.相关函数 开运算 img_open cv2.morphologyEx(img,cv2.MORPH_OPEN,kernel)#(图片,算法,核) 闭运算 img_close cv2.morphologyEx(img,cv2.MORPH_CLOSE,kernel)#(图片,算法,核) 梯度…...
基于python,html,flask,echart,ids/ips,VMware,mysql,在线sdn防御ddos系统
详细视频:【基于python,html,flask,echart,ids/ips,VMware,mysql,在线sdn防御ddos系统-哔哩哔哩】 https://b23.tv/azUqQXe...

Git:现代软件开发的基石——原理、实践与行业智慧·优雅草卓伊凡
Git:现代软件开发的基石——原理、实践与行业智慧优雅草卓伊凡 一、Git的本质与核心原理 1. 技术定义 Git是一个分布式版本控制系统(DVCS),由Linus Torvalds在2005年为管理Linux内核开发而创建。其核心是通过快照(Sna…...
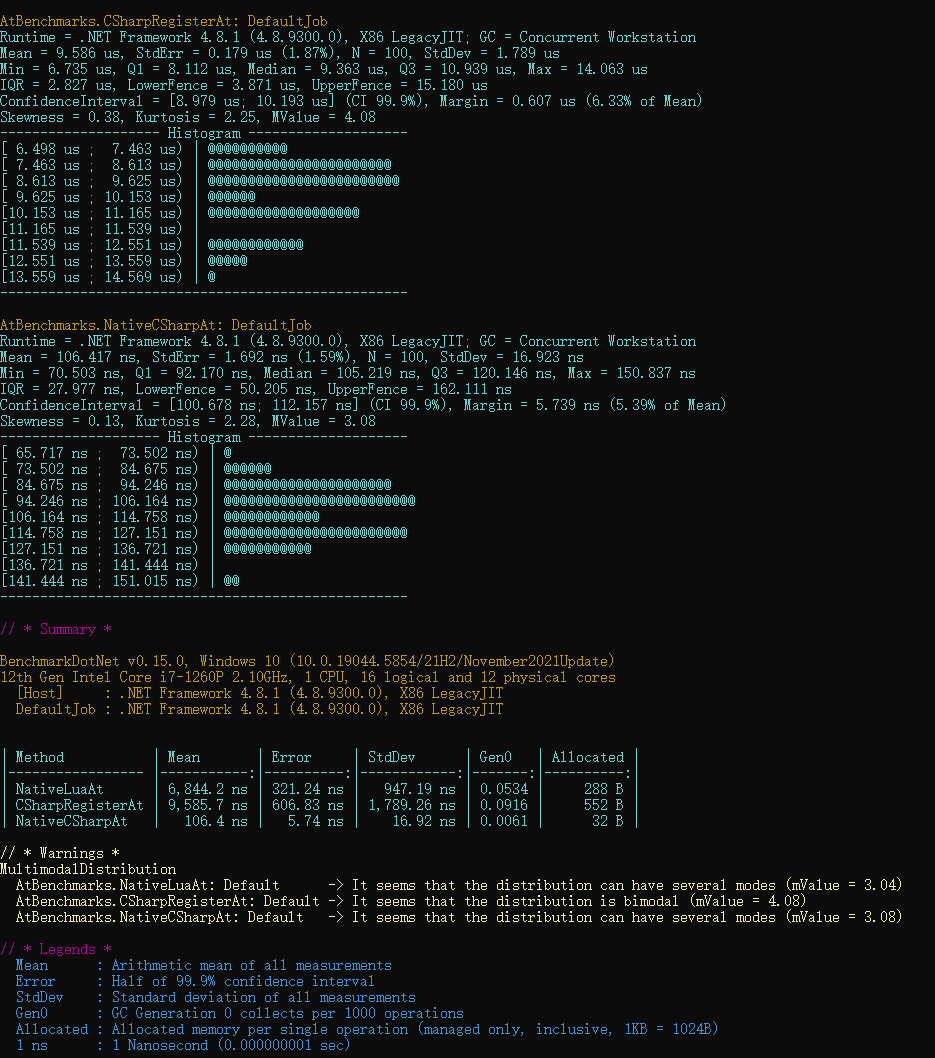
NLua性能对比:C#注册函数 vs 纯Lua实现
引言 在NLua开发中,我们常面临一个重要选择:将C#函数注册到Lua环境调用,还是直接在Lua中实现逻辑? 直觉告诉我们,C#作为编译型语言性能更高,但跨语言调用的开销是否会影响整体性能?本文通过基准…...

【计算机网络】第2章:应用层—Web and HTTP
目录 一、Web 与 HTTP 二、总结 (一)Web 的定义与功能 (二)HTTP 协议的定义与功能 (三)HTTP 协议的核心机制 1. HTTP 请求与响应流程 2. HTTP 的连接类型 3. HTTP 的状态码 (四…...

HarmonyOS 5 应用开发导读:从入门到实践
一、HarmonyOS 5 概述 HarmonyOS 5 是华为推出的新一代分布式操作系统,其核心设计理念是"一次开发,多端部署"。与传统的移动操作系统不同,HarmonyOS 5 提供了更强大的跨设备协同能力,支持手机、平板、智能穿戴、智慧屏…...

大数据治理:分析中的数据安全
引言 随着大数据技术在各行业的深度应用,海量数据蕴含的价值被不断挖掘。然而,数据规模的爆发式增长与分析场景的复杂化,使数据安全问题日益凸显。从数据泄露、隐私侵犯到非法访问,每一个安全漏洞都可能带来难以估量的损失。本文将…...

数字孪生技术赋能西门子安贝格工厂:全球智能制造标杆的数字化重构实践
在工业4.0浪潮席卷全球制造业的当下,西门子安贝格电子制造工厂(Electronic Works Amberg, EWA)凭借数字孪生技术的深度应用,构建起全球制造业数字化转型的典范。这座位于德国巴伐利亚州的“未来工厂”,通过虚实融合的数…...

国内高频混压PCB厂家有哪些?
一、技术领先型厂商(聚焦材料与工艺突破) 猎板PCB 技术亮点:真空层压工艺实现FR-4与罗杰斯高频材料(RO4350B/RO3003)混压,阻抗公差3%,支持64单元/板的5G天线模块,插损降低15%。 应用…...

【图像处理基石】立体匹配的经典算法有哪些?
1. 立体匹配的经典算法有哪些? 立体匹配是计算机视觉中从双目图像中获取深度信息的关键技术,其经典算法按技术路线可分为以下几类,每类包含若干代表性方法: 1.1 基于区域的匹配算法(Local Methods) 通过…...

day12 leetcode-hot100-19(矩阵2)
54. 螺旋矩阵 - 力扣(LeetCode) 1.模拟路径 思路:模拟旋转的路径 (1)设计上下左右方向控制器以及边界。比如zy1向右,zy-1向左;sx1向上,sx-1向下。上边界0,下边界hang-1&a…...

将Java应用集成到CI/CD管道:从理论到生产实践
在2025年的软件开发领域,持续集成与持续部署(CI/CD)已成为敏捷开发和DevOps的核心实践。根据2024年DevOps报告,85%的企业通过CI/CD管道实现了交付周期缩短50%以上,特别是在金融、电商和SaaS行业。Java,作为…...

密钥管理系统在存储加密场景中的深度实践:以TDE透明加密守护文件服务器安全
引言:数据泄露阴影下的存储加密革命 在数字化转型的深水区,企业数据资产正面临前所未有的安全挑战。据IBM《2025年数据泄露成本报告》显示,全球单次数据泄露事件平均成本已达465万美元,其中存储介质丢失或被盗导致的损失占比高达…...
webpack打包基本配置
需要的文件 具体代码 webpack.config.js const path require(path);const HTMLWebpackPlugin require(html-webpack-plugin);const {CleanWebpackPlugin} require(clean-webpack-plugin); module.exports {mode: production,entry: "./src/index.ts",output: {…...

酷派Cool20/20S/30/40手机安装Play商店-谷歌三件套-GMS方法
酷派Cool系列主打低端市场,系统无任何GMS程序,也不支持直接开启或者安装谷歌服务等功能,对于国内部分经常使用谷歌服务商店的小伙伴非常不友好。涉及机型有酷派Cool20/Cool20S /30/40/50/60等旗下多个设备。好在这些机型运行的系统都是安卓11…...
LabVIEW旋转机械智能监测诊断系统
采用 LabVIEW 开发旋转机械智能监测与故障诊断系统,通过集品牌硬件与先进信号处理技术,实现旋转机械振动信号的实时采集、分析及故障预警。系统突破传统监测手段的局限性,解决了复杂工业环境下信号干扰强、故障特征提取难等问题,为…...

数据结构 -- 判断正误
1、栈只能顺序存储。 答案: 错误 原因 栈是一种 逻辑结构,表示“后进先出”(LIFO)的操作规则。栈的实现方式不限于顺序存储,还可以使用链式存储。 顺序存储:使用数组实现栈,称为顺序栈。链式…...

vue3前端实现一键复制,wangeditor富文本复制
首先需要拿到要复制的内容,然后调用https的navigator.clipboard方法进行复制,但是这个因为浏览器策略只能在本地localhost和https环境下才能生效,http环境访问不到这个方法,在http环境在可以使用传统方式创建 textarea 进行复制 …...