P7-大规模语言模型分布式训练与微调框架调研文档
1. 引言
随着大语言模型(LLMs)在自然语言处理(NLP)、对话系统、文本生成等领域的广泛应用,分布式训练和高效微调技术成为提升模型性能和部署效率的关键。分布式训练框架如 Megatron-LM 和 DeepSpeed 针对超大规模模型(10B+ 参数)优化计算和内存,微调框架则通过 LoRA、QLoRA 等技术适配中小模型和特定任务。本文档调研 Megatron-LM、DeepSpeed 及主流微调框架,分析其技术特点、适用场景,并针对 Qwen2.5-0.5B-Instruct 微调任务提供实现建议。
2. 主流微调框架介绍
| 框架名称 | 开源组织 | 支持模型类型 | 微调方式 | 优势特点 |
|---|---|---|---|---|
| Hugging Face PEFT | Hugging Face | Transformer 模型 | LoRA、QLoRA、P-Tuning、Adapter | 社区活跃,生态丰富,易集成 |
| DeepSpeed | Microsoft | GPT、OPT 等 | LoRA、QLoRA、ZeRO、全参数 | 高性能并行,低内存占用 |
| FSDP + PEFT | PyTorch | 各类 LLM | FSDP + LoRA 等 | 高效分布式训练,灵活定制 |
| Colossal-AI | HPC-AI Tech | GPT 类模型 | LoRA、QLoRA 等 | 支持 INT4 量化,资源节省 |
| Axolotl | OpenAccess AI | LLaMA 系列 | LoRA、QLoRA 等 | 配置简单,适合快速实验 |
| LLaMA-Factory | 社区驱动 | LLaMA 系列 | LoRA、P-Tuning 等 | 中文社区活跃,支持 Web UI |
| OpenChatKit | Together | ChatGLM、OPT 等 | LoRA、Prefix Tuning | 适配对话任务,易于定制 |
2.1 Megatron-LM
Megatron-LM 是 NVIDIA 开发的开源分布式训练框架,专为大规模 Transformer 模型(如 GPT、BERT、T5)的预训练和微调设计。2019 年通过论文《Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism》发布,广泛用于 GPT-3 (175B 参数)、Megatron-Turing NLG (530B 参数)等超大模型训练。Megatron-LM 利用 NVIDIA GPU 的高性能计算能力,通过张量并行、流水线并行和数据并行实现高效、可扩展的训练,最新版本支持 AMD ROCm 平台,适用于学术研究和企业级 AI 应用。
2.1.1 Megatron-LM 核心技术
- 张量并行(TP):将 Transformer 层内计算(如多头注意力、MLP 矩阵乘法)拆分到多 GPU,通过 NCCL 通信原语(如 all-reduce)同步,降低单 GPU 内存需求。
- 流水线并行(PP):将模型层分割为阶段,数据以微批次流水线处理,采用 1F1B 或 Interleaved 1F1B 调度减少气泡时间。
- 数据并行(DP):分片训练数据,各 GPU 持完整模型副本,梯度通过 all-reduce 同步,结合 TP 和 PP 形成 3D 并行。
- 混合精度训练:支持 FP16、BF16、FP8,FP8 在 H100 GPU 上减少 42% 内存,提升 64% 速度。
- 优化技术:
- 激活检查点:仅保存部分中间激活,降低内存需求。
- 序列并行:拆分序列维度,减少激活内存。
- 融合内核:融合 GEMM 和激活函数,减少计算开销。
- 高效通信:基于 NCCL 或 RCCL 优化跨 GPU 和跨节点通信。
- 数据加载:支持索引格式(
.idx和.bin文件)快速加载和分片。
2.2 DeepSpeed
DeepSpeed 是微软开发的开源深度学习优化库,2020 年作为 AI at Scale 计划发布,基于 PyTorch 构建,专注于大规模 Transformer 模型的训练和推理。通过 Zero Redundancy Optimizer(ZeRO)、3D 并行和内存优化技术,DeepSpeed 显著降低内存和计算成本,驱动了 Megatron-Turing NLG (530B 参数)、BLOOM (176B 参数)等模型的训练。DeepSpeed 兼容 PyTorch 工作流,广泛应用于 NLP、多模态模型和科学计算,目标是降低大模型训练的资源壁垒。
2.2.1 DeepSpeed 核心技术
- Zero Redundancy Optimizer(ZeRO):
- ZeRO-1:分片优化器状态(如 Adam 动量和方差)。
- ZeRO-2:分片优化器状态和梯度。
- ZeRO-3:分片优化器状态、梯度和模型参数,支持 CPU/NVMe 交换(如 10B 参数模型每 GPU 内存从 20GB 降至 1.2GB)。
- 3D 并行:结合数据并行(DP)、流水线并行(PP)、张量并行(TP),动态调整微批次和调度(如 1F1B)优化效率。
- 混合精度训练:支持 FP16、BF16、FP8,FP8 在 H100 GPU 上提升 2 倍吞吐量,内存减少 50%。
- 内存优化技术:
- 激活检查点:降低激活内存需求。
- ZeRO-Offload:将优化器状态和梯度卸载到 CPU 或 NVMe。
- 稀疏推理内核:支持 MoE 模型(如 Mixtral),减少推理成本。
- DeepSpeed-FP:自动处理精度转换和梯度缩放。
3. 主流微调框架技术对比
3.1 微调方法支持
| 框架 | LoRA | QLoRA | P-Tuning | 全参数微调 | Adapter |
|---|---|---|---|---|---|
| PEFT | ✅ | ✅ | ✅ | ❌ | ✅ |
| DeepSpeed | ✅ | ✅ | ❌ | ✅ | ❌ |
| Colossal-AI | ✅ | ✅ | ❌ | ✅ | ❌ |
| Axolotl | ✅ | ✅ | ❌ | ✅ | ❌ |
| LLaMA-Factory | ✅ | ✅ | ✅ | ✅ | ❌ |
3.2 分布式能力
| 框架 | 数据并行 | 模型并行 | ZeRO | FSDP |
|---|---|---|---|---|
| DeepSpeed | ✅ | ✅ | ✅ | ❌ |
| FSDP + PEFT | ✅ | ✅ | ❌ | ✅ |
| Colossal-AI | ✅ | ✅ | ✅ | ✅ |
| Megatron-LM | ✅ | ✅ | ❌ | ❌ |
3.3 量化支持
| 框架 | INT8 | INT4 | GPTQ |
|---|---|---|---|
| PEFT | ✅ | ✅ | ❌ |
| DeepSpeed | ✅ | ✅ | ✅ |
| Colossal-AI | ✅ | ✅ | ✅ |
| LLaMA-Factory | ✅ | ✅ | ❌ |
3.4 综合对比
| 特性 | Megatron-LM | DeepSpeed | Hugging Face PEFT | PyTorch FSDP |
|---|---|---|---|---|
| 并行策略 | TP、PP、DP | ZeRO、TP、PP、DP | FSDP、TP(通过集成) | DDP、FSDP |
| 内存优化 | 激活检查点、序列并行、融合内核 | ZeRO 分片、CPU 卸载、激活检查点 | 依赖 FSDP 或 DeepSpeed | 依赖 FSDP |
| 硬件支持 | 优化 NVIDIA GPU,支持 AMD ROCm | NVIDIA GPU、部分 AMD/Intel、CPU | GPU/TPU/CPU,硬件无关 | GPU/CPU,硬件无关 |
| 易用性 | 配置复杂,需手动设置 | 中等,JSON 配置 | 高,简洁 API | 高,内置 PyTorch |
| 适用规模 | 超大模型(10B+ 参数) | 超大模型(1B+ 参数) | 中小模型(~10B 参数) | 小到中规模模型 |
| 与 Transformers 集成 | 需手动转换检查点 | 原生支持 Hugging Face 模型 | 无缝集成 | 支持,但需额外配置 |
| 典型案例 | GPT-3 175B、MT-NLG 530B | BLOOM 176B、LLaMA 微调 | BERT、T5 微调 | 小规模 NLP 任务 |
4. 在 Qwen2.5-0.5B-Instruct 微调中的应用
针对您的项目(基于 transformers 和 LoRA 微调 Qwen2.5-0.5B-Instruct,运行于 Apple M4 芯片的 MPS 后端,当前 loss=2.8177,epoch=0.06),以下分析框架适用性及实现步骤。
4.1 适用性分析
- 模型规模:Qwen2.5-0.5B-Instruct(0.5B 参数)为中小规模模型,单机训练足够。
- 硬件限制:M4 芯片(MPS 后端)不支持 Megatron-LM 的 CUDA 优化,DeepSpeed 部分支持 MPS 但功能受限,PEFT 和 Transformers 原生支持 MPS。
- 微调需求:LoRA 微调高效(r=8,lora_alpha=32),Transformers 和 PEFT 原生支持 LoRA,Megatron-LM 需借助 NeMo 或自定义实现,DeepSpeed 支持 LoRA 但配置复杂。
- 结论:Transformers + PEFT 最适合 M4 环境,DeepSpeed 适合 GPU 集群中小模型微调,Megatron-LM 适合超大模型或多节点环境。
4.2 Megatron-LM 实现步骤
#!/bin/bash
# 1. 环境准备
git clone https://github.com/NVIDIA/Megatron-LM
cd Megatron-LM
pip install -r requirements.txt# 2. 数据预处理
python tools/preprocess_data.py \--input /path/to/huanhuan.jsonl \--output-prefix /path/to/output/huanhuan \--tokenizer-type GPT2BPETokenizer \--vocab-file vocab.json \--merge-file merges.txt \--workers 1 \--append-eod# 3. 模型转换
python checkpoint_utils/megatron_gpt2/checkpoint_reshaping_and_interoperability.py \--load_path /path/to/qwen2.5-0.5b-hf \--save_path /path/to/qwen2.5-0.5b-megatron \--target_tensor_model_parallel_size 1 \--target_pipeline_model_parallel_size 1# 4. 微调配置
GPUS_PER_NODE=4
NNODES=1
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank 0 --master_addr localhost --master_port 6001"
python -m torch.distributed.launch $DISTRIBUTED_ARGS \pretrain_gpt.py \--tensor-model-parallel-size 1 \--pipeline-model-parallel-size 1 \--num-layers 32 \--hidden-size 896 \--num-attention-heads 14 \--seq-length 384 \--micro-batch-size 1 \--global-batch-size 4 \--lr 1e-4 \--train-iters 1000 \--data-path /path/to/output/huanhuan \--save /path/to/output/checkpoints \--load /path/to/qwen2.5-0.5b-megatron \--fp16 \--tensorboard-dir /path/to/tensorboard# 5. TensorBoard 监控
tensorboard --logdir /path/to/tensorboard
4.3 DeepSpeed 实现步骤
# 1. 环境准备
# 假设已安装 DeepSpeed: pip install deepspeed# 2. DeepSpeed 配置 (ds_config.json)
import json
ds_config = {"train_batch_size": 4,"gradient_accumulation_steps": 1,"fp16": {"enabled": True},"zero_optimization": {"stage": 2,"offload_optimizer": {"device": "cpu"},"offload_param": {"device": "cpu"}},"steps_per_print": 10,"optimizer": {"type": "Adam","params": {"lr": 1e-4}}
}
with open("ds_config.json", "w") as f:json.dump(ds_config, f)# 3. 微调脚本
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model
import deepspeedmodel = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
lora_config = LoraConfig(r=8, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)engine = deepspeed.initialize(model=model, config_params="ds_config.json")[0]
# 加载 huanhuan.json 数据并训练(使用 Hugging Face Datasets 或 PyTorch DataLoader)
4.4 Hugging Face PEFT 实现步骤(M4 环境)
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
from peft import LoraConfig, get_peft_model
from datasets import load_dataset# 1. 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct", device_map="mps")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")# 2. 配置 LoRA
lora_config = LoraConfig(r=8,lora_alpha=32,target_modules=["q_proj", "v_proj"],lora_dropout=0.1,bias="none",task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)# 3. 加载数据集
dataset = load_dataset("json", data_files="/path/to/huanhuan.json")# 4. 数据预处理
def preprocess_function(examples):return tokenizer(examples["text"], truncation=True, max_length=256)tokenized_dataset = dataset.map(preprocess_function, batched=True)# 5. 配置训练参数
training_args = TrainingArguments(output_dir="/path/to/output",num_train_epochs=3,per_device_train_batch_size=1,gradient_accumulation_steps=2,learning_rate=1e-4,fp16=False, # MPS 可能不支持 fp16,视情况调整logging_dir="/path/to/tensorboard",logging_steps=10,save_strategy="epoch"
)# 6. 初始化 Trainer
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset["train"]
)# 7. 开始训练
trainer.train()# 8. TensorBoard 监控
# tensorboard --logdir /path/to/tensorboard
5. 总结
| 特性 | Megatron-LM | DeepSpeed | Hugging Face Accelerate | PyTorch DDP |
|---|---|---|---|---|
| 并行策略 | TP、PP、DP | ZeRO、TP、PP、DP | DDP、FSDP、TP(通过 Megatron-LM 集成) | DDP、FSDP |
| 内存优化 | 激活检查点、序列并行、融合内核 | ZeRO 分片、CPU 卸载、激活检查点 | 依赖 PyTorch FSDP 或 DeepSpeed | 有限(依赖 FSDP) |
| 硬件支持 | 优化 NVIDIA GPU,支持 AMD ROCm | NVIDIA GPU、部分 AMD/Intel、CPU | GPU/TPU/CPU,硬件无关 | GPU/CPU,硬件无关 |
| 易用性 | 配置复杂,需手动设置 | 中等,JSON 配置 | 高,简洁 API,易集成 | 高,内置 PyTorch,简单配置 |
| 适用规模 | 超大模型(10B+ 参数),多节点集群 | 超大模型(1B+ 参数),单机到多节点 | 中小模型(~10B 参数),单机多 GPU | 小到中规模模型,单机多 GPU |
| 与 Transformers 集成 | 需手动转换检查点 | 原生支持 Hugging Face 模型 | 与 Transformers 无缝集成 | 支持,但需额外配置 |
| 典型案例 | GPT-3 175B、MT-NLG 530B | BLOOM 176B、LLaMA 微调 | 中小模型微调(如 BERT、T5) | 小规模 NLP 任务 |
- Megatron-LM vs. DeepSpeed:Megatron-LM 擅长 TP 和 PP,适合 NVIDIA GPU 集群;DeepSpeed 的 ZeRO 技术更通用,内存优化更强。两者可组合(如 Megatron-DeepSpeed)。
- Megatron-LM vs. Accelerate:Accelerate 易用,适合中小模型;Megatron-LM 针对超大模型,性能更高。
- DeepSpeed vs. Accelerate:DeepSpeed 支持更大模型和复杂优化,Accelerate 更适合快速开发和中小模型。
参考文献
- NVIDIA Megatron-LM GitHub: https://github.com/NVIDIA/Megatron-LM
- Shoeybi et al., “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism,” arXiv:1909.08053, 2019.
- Narayanan et al., “Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM,” arXiv:2104.04473, 2021.
- DeepSpeed GitHub: https://github.com/microsoft/DeepSpeed
- Rajbhandari et al., “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models,” arXiv:1910.02054, 2020.
- Hugging Face PEFT GitHub: https://github.com/huggingface/peft
- Colossal-AI: https://www.colossalai.org/
- Axolotl GitHub: https://github.com/OpenAccess-AI-Collective/axolotl
- LLaMA-Factory GitHub: https://github.com/hiyouga/LLaMA-Factory
- OpenChatKit GitHub: https://github.com/togethercomputer/OpenChatKit
- ROCm Megatron-LM Documentation: https://rocm.docs.amd.com
- DeepSpeed Documentation: https://www.deepspeed.ai/docs/
相关文章:

P7-大规模语言模型分布式训练与微调框架调研文档
1. 引言 随着大语言模型(LLMs)在自然语言处理(NLP)、对话系统、文本生成等领域的广泛应用,分布式训练和高效微调技术成为提升模型性能和部署效率的关键。分布式训练框架如 Megatron-LM 和 DeepSpeed 针对超大规模模型…...
机械师安装ubantu双系统:三、GPT分区安装Ubantu
目录 一、查看磁盘格式 二、安装ubantu 参考链接: GPT分区安装Ubuntu_哔哩哔哩_bilibili 一、查看磁盘格式 右击左边灰色区域,点击属性 二、安装ubantu 插入磁盘,重启系统,狂按F7(具体我也忘了)&#…...

ORM++ 封装实战指南:安全高效的 C++ MySQL 数据库操作
ORM 封装实战指南:安全高效的 C MySQL 数据库操作 一、环境准备 1.1 依赖安装 # Ubuntu/Debian sudo apt-get install libmysqlclient-dev # CentOS sudo yum install mysql-devel# 编译时链接库 (-I 指定头文件路径 -L 指定库路径) g main.cpp -stdc17 -I/usr/i…...

kafka学习笔记(三、消费者Consumer使用教程——从指定位置消费)
1.简介 Kafka的poll()方法消费无法精准的掌握其消费的起始位置,auto.offset.reset参数也只能在比较粗粒度的指定消费方式。更细粒度的消费方式kafka提供了seek()方法可以指定位移消费允许消费者从特定位置(如固定偏移量、时间戳或分区首尾)开…...

【后端高阶面经:架构篇】46、分布式架构:如何应对高并发的用户请求
一、架构设计原则:构建可扩展的系统基石 在分布式系统中,高并发场景对架构设计提出了极高要求。 分层解耦与模块化是应对复杂业务的核心策略,通过将系统划分为客户端、CDN/边缘节点、API网关、微服务集群、缓存层和数据库层等多个层次,实现各模块的独立演进与维护。 1.1 …...

网络编程学习笔记——TCP网络编程
文章目录 1、socket()函数2、bind()函数3、listen()4、accept()5、connect()6、send()/write()7、recv()/read()8、套接字的关闭9、TCP循环服务器模型10、TCP多线程服务器11、TCP多进程并发服务器 网络编程常用函数 socket() 创建套接字bind() 绑定本机地址和端口connect() …...
Vue+element-ui,实现表格渲染缩略图,鼠标悬浮缩略图放大,点击缩略图播放视频(一)
Vueelement-ui,实现表格渲染缩略图,鼠标悬浮缩略图放大,点击缩略图播放视频 前言整体代码预览图具体分析基础结构主要标签作用videoel-popover 前言 如标题,需要实现这样的业务 此处文章所实现的,是静态视频资源。 注…...
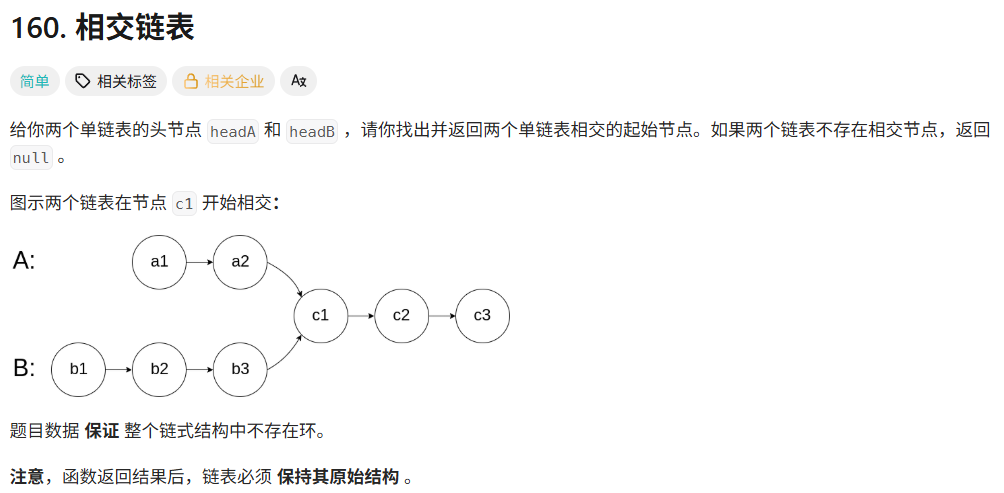
day13 leetcode-hot100-22(链表1)
160. 相交链表 - 力扣(LeetCode) 1.哈希集合HashSet 思路 (1)将A链的所有数据存储到HashSet中。 (2)遍历B链,找到是否在A中存在。 具体代码 /*** Definition for singly-linked list.* pu…...

【Oracle】DQL语言
个人主页:Guiat 归属专栏:Oracle 文章目录 1. DQL概述1.1 什么是DQL?1.2 DQL的核心功能 2. SELECT语句基础2.1 基本语法结构2.2 最简单的查询2.3 DISTINCT去重 3. WHERE条件筛选3.1 基本条件运算符3.2 逻辑运算符组合3.3 高级条件筛选 4. 排序…...
HUAWEI华为MateBook D 14 2021款i5,i7集显非触屏(NBD-WXX9,NbD-WFH9)原装出厂Win10系统
适用型号:NbD-WFH9、NbD-WFE9A、NbD-WDH9B、NbD-WFE9、 链接:https://pan.baidu.com/s/1qTCbaQQa8xqLR-4Ooe3ytg?pwdvr7t 提取码:vr7t 华为原厂WIN系统自带所有驱动、出厂主题壁纸、系统属性联机支持标志、系统属性专属LOGO标志、Office…...
【STIP】安全Transformer推理协议
Secure Transformer Inference Protocol 论文地址:https://arxiv.org/abs/2312.00025 摘要 模型参数和用户数据的安全性对于基于 Transformer 的服务(例如 ChatGPT)至关重要。虽然最近在安全两方协议方面取得的进步成功地解决了服务 Transf…...
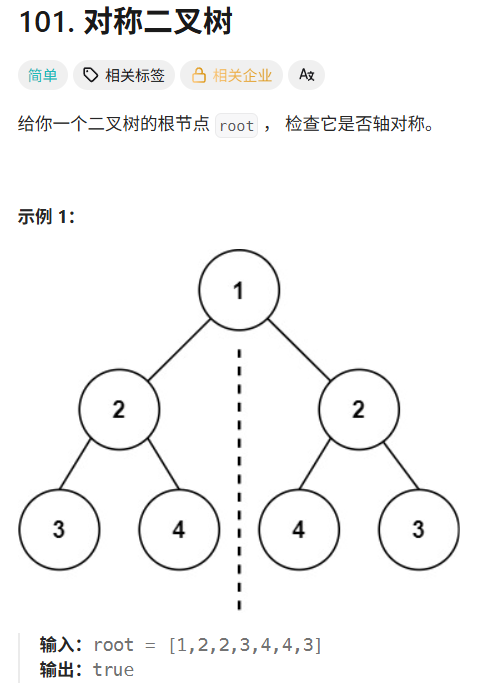
leetcode hot100刷题日记——27.对称二叉树
方法一:递归法 class Solution { public:bool check(TreeNode *left,TreeNode *right){//左子树和右子树的节点同时是空的是对称的if(leftnullptr&&rightnullptr){return true;}if(leftnullptr||rightnullptr){return false;}//检查左右子树的值相不相等&a…...

高考加油(Python+HTML)
前言 询问DeepSeek根据自己所学到的知识来生成多个可执行的代码,为高考学子加油。最开始生成的都会有点小问题,还是需要自己调试一遍,下面就是完整的代码,当然了最后几天也不会有多少人看,都在专心的备考。 Python励…...

贪心算法应用:Ford-Fulkerson最大流问题详解
Java中的贪心算法应用:Ford-Fulkerson最大流问题详解 1. 最大流问题概述 最大流问题(Maximum Flow Problem)是图论中的一个经典问题,旨在找到一个从源节点(source)到汇节点(sink)的最大流量。Ford-Fulkerson方法是解决最大流问题的经典算法之一,它属于贪心算法的范畴…...
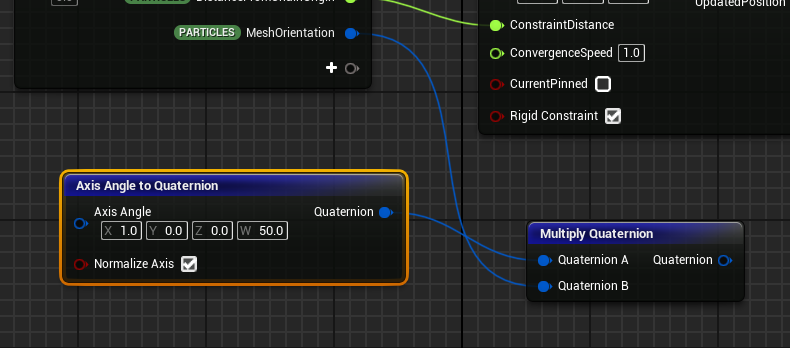
UE5 Niagara 如何让四元数进行旋转
Axis Angle中,X,Y,Z分别为旋转的轴向,W为旋转的角度,在这里旋转角度不需要除以2,因为里面已经除了,再将计算好的四元数与要进行旋转的四元数进行相乘,结果就是按照原来的角度绕着某一轴向旋转了某一角度...

从“黑箱”到透明化:MES如何重构生产执行全流程?
引言 在传统制造企业中,生产执行环节常面临“计划混乱、进度难控、异常频发、数据滞后”的困境。人工派工效率低下、物料错配频发、质量追溯困难等问题,直接导致交付延期、成本攀升、客户流失。深蓝易网MES系统以全流程数字化管理为核心,通过…...

探索Linux互斥:线程安全与资源共享
个人主页:chian-ocean 文章专栏-Linux 前言: 互斥是并发编程中避免竞争条件和保护共享资源的核心技术。通过使用锁或信号量等机制,能够确保多线程或多进程环境下对共享资源的安全访问,避免数据不一致、死锁等问题。 竞争条件 竞…...
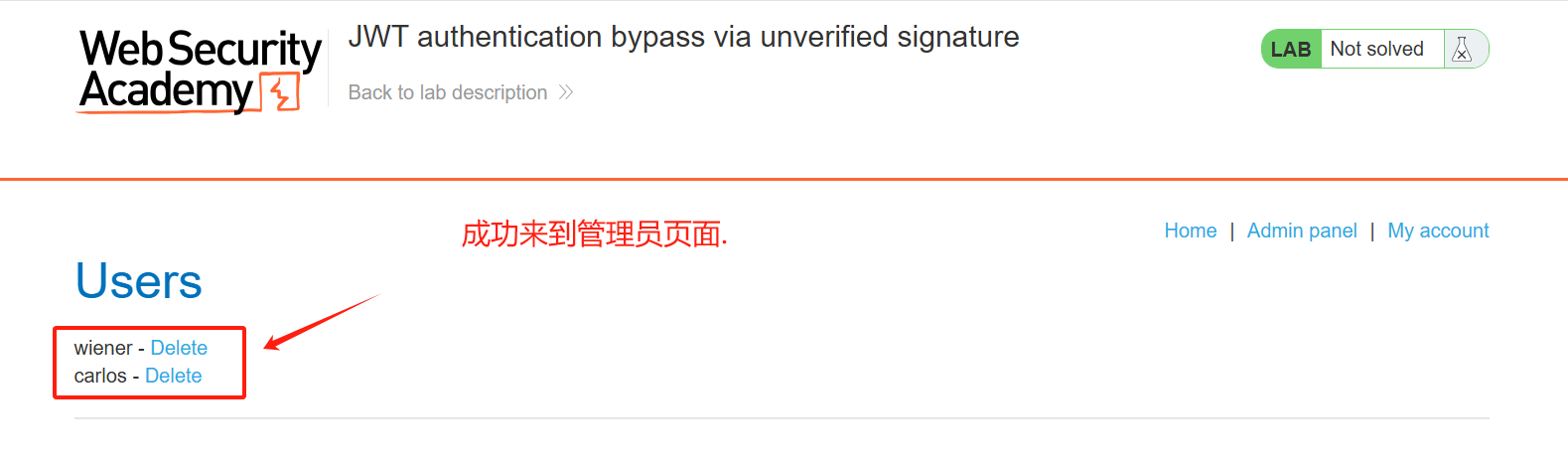
JWT安全:假密钥.【签名随便写实现越权绕过.】
JWT安全:假密钥【签名随便写实现越权绕过.】 JSON Web 令牌 (JWT)是一种在系统之间发送加密签名 JSON 数据的标准化格式。理论上,它们可以包含任何类型的数据,但最常用于在身份验证、会话处理和访问控制机制中发送有关用户的信息(“声明”)。…...
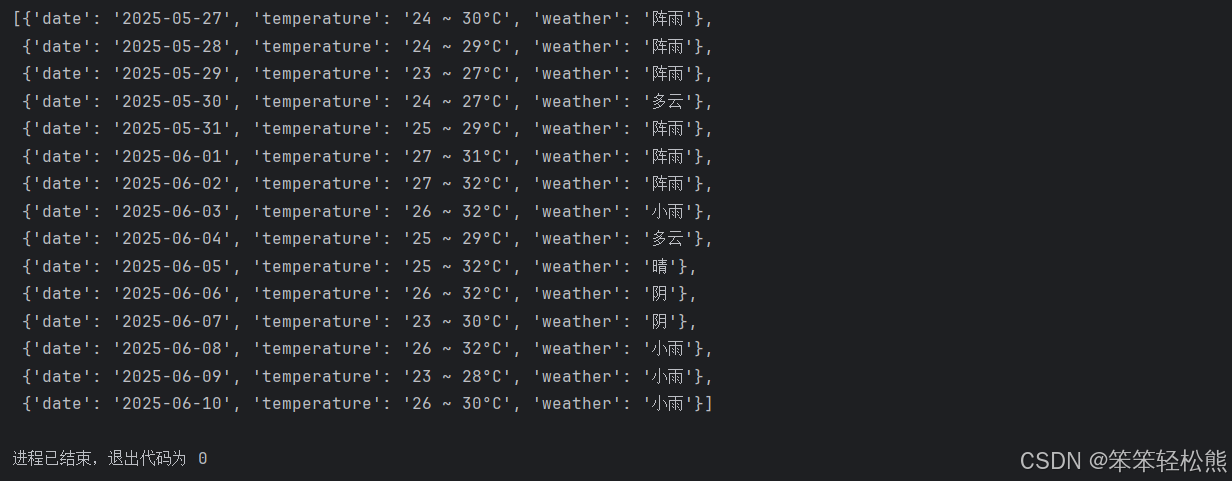
Python爬虫实战:抓取百度15天天气预报数据
🌐 编程基础第一期《9-30》–使用python中的第三方模块requests,和三个内置模块(re、json、pprint),实现百度地图的近15天天气信息抓取 记得安装 pip install requests📑 项目介绍 网络爬虫是Python最受欢迎的应用场景之一&…...
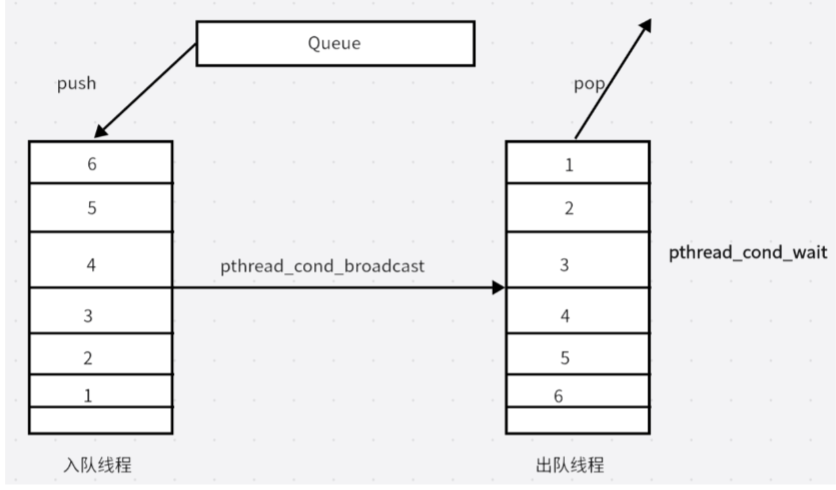
RV1126 + FFPEG多路码流项目
代码主体思路: 一.VI,VENC,RGA模块初始化 1.先创建一个自定义公共结构体,用于方便管理各个模块 rkmedia_config_public.h //文件名字#ifndef _RV1126_PUBLIC_H #define _RV1126_PUBLIC_H#include <assert.h> #include <fcntl.h> #include …...
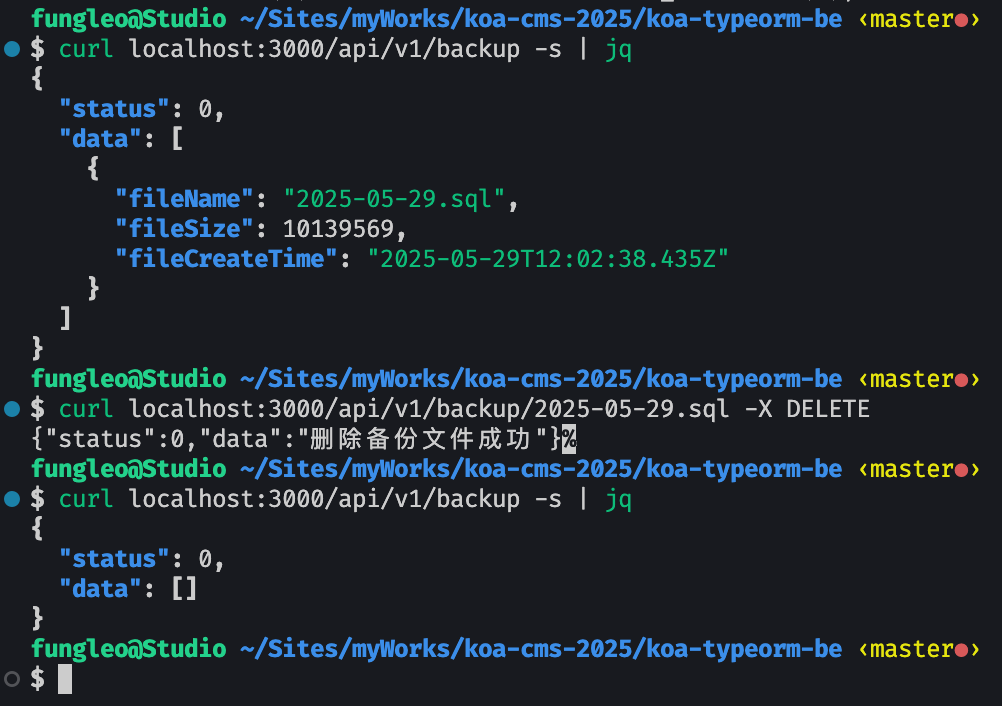
NodeJS 基于 Koa, 开发一个读取文件,并返回给客户端文件下载,以及读取文件形成列表和文件删除的代码演示
前言 在上一篇文章 《Nodejs 实现 Mysql 数据库的全量备份的代码演示》 中,我们演示了如何将用户的 Mysql 数据库进行备份的代码。但是,这个备份,只是备份在了服务器上了。 而我们用户的真实需求,是需要将备份文件下载到本地进行…...
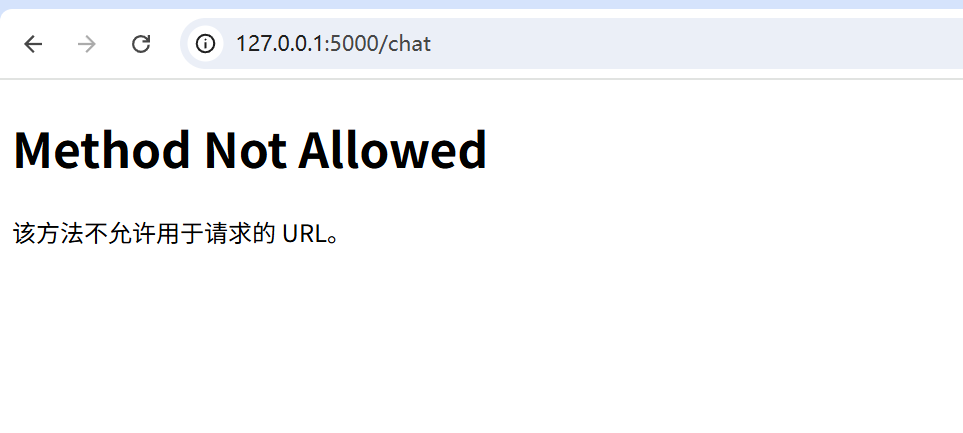
为什么在我的Flask里面有两个路由,但是在网页里有一个却不能正确访问到智能体
1. /zhoushibo 能访问,/chat 直接浏览器访问报 Method Not Allowed 原因: /zhoushibo 路由是你用 app.route(/zhoushibo) 定义的,返回的是一个HTML网页,浏览器访问没问题。 /chat 路由你用的是 app.route(/chat, methods[POST])…...

哈工大计算机系统2024大作业——Hello的程序人生
计算机系统 大作业 题 目 程序人生-Hello’s P2P 专 业 人工智能 学 号 2022112040 班 级 2203601 学 生 郄东昕 指 导 教 师 吴锐 计算机科学与技术学院…...

2025年软件测试面试八股文(含答案+文档)
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 Part1 1、你的测试职业发展是什么? 测试经验越多,测试能力越高。所以我的职业发展是需要时间积累的,一步步向着高级测试工程师…...

【仿生系统】qwen的仿生机器人解决方案
收到完整需求后,我将从系统架构设计、算法实现路径、训练方法三个维度为您构建完整的仿生机器人解决方案。以下是分阶段实施方案: 一、核心系统架构设计(模块化可进化架构) 1. 多模态感知引擎 - 视觉子系统:YOLOv8SAM…...

Flutter3.22适配运行鸿蒙系统问题记录
Flutter3.22适配运行鸿蒙系统问题记录 一:适配条件适配过程问题记录(1)环境配置问题(2)Concurrent modification during iteration: Instance(length:2) of_GrowableList 报错(3)三方插件寻找替…...
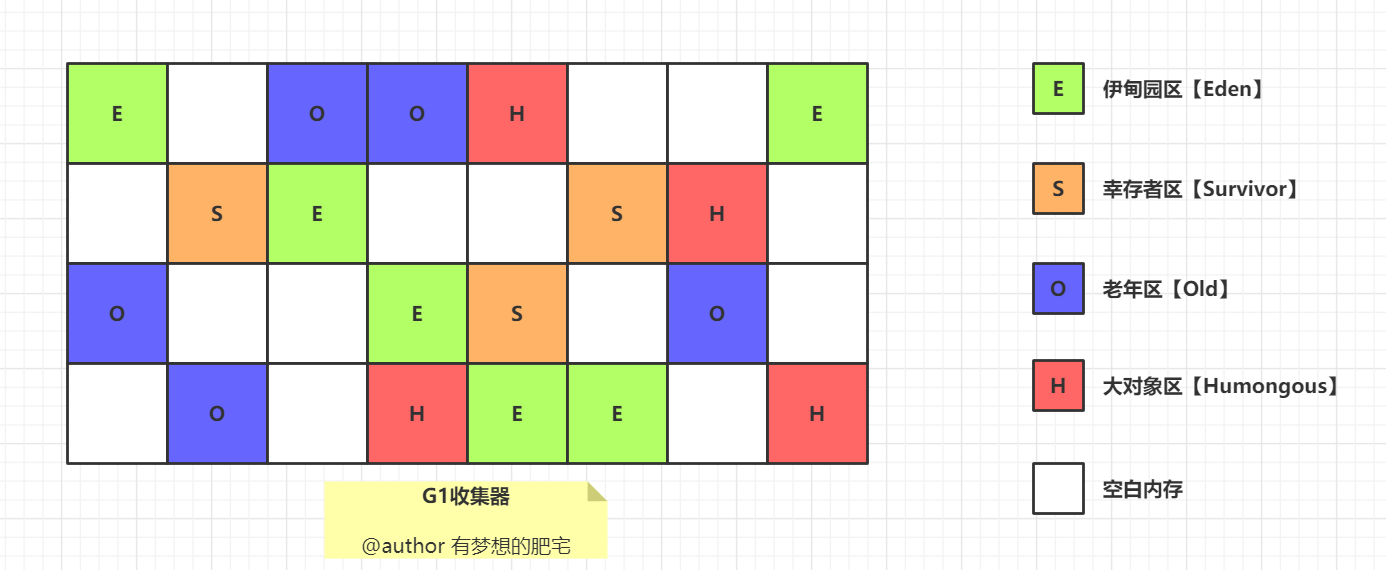
秋招Day10 - JVM - 内存管理
JVM组织架构主要有三个部分:类加载器、运行时数据区和字节码执行引擎 类加载器:负责从文件系统、网络或其他来源加载class文件,将class文件中的二进制数据加载到内存中运行时数据区:运行时的数据存放的区域,分为方法区…...
Spring Boot 3.5.0中文文档上线
Spring Boot 3.5.0 中文文档翻译完成,需要的可收藏 传送门:Spring Boot 3.5.0 中文文档...

Redisson学习专栏(一):快速入门及核心API实践
文章目录 前言一、Redisson简介1.1 什么是Redisson?1.2 解决了什么问题? 二、快速入门2.1 环境准备 2.2 基础配置三、核心API解析3.1 分布式锁(RLock)3.2 分布式集合3.2.1 RMap(分布式Map)3.2.2 RList&…...
Pandas学习入门一
1.什么是Pandas? Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。 一个强大的分析和操作大型结构化数据集所需的工具集基础是NumPy…...