【Oracle】DQL语言

个人主页:Guiat
归属专栏:Oracle

文章目录
- 1. DQL概述
- 1.1 什么是DQL?
- 1.2 DQL的核心功能
- 2. SELECT语句基础
- 2.1 基本语法结构
- 2.2 最简单的查询
- 2.3 DISTINCT去重
- 3. WHERE条件筛选
- 3.1 基本条件运算符
- 3.2 逻辑运算符组合
- 3.3 高级条件筛选
- 4. 排序和分页
- 4.1 ORDER BY排序
- 4.2 分页查询
- 5. 聚合函数和分组
- 5.1 常用聚合函数
- 5.2 GROUP BY分组
- 5.3 HAVING子句
- 6. 多表连接查询
- 6.1 连接类型概览
- 6.2 内连接(INNER JOIN)
- 6.3 外连接(OUTER JOIN)
- 6.4 自连接
- 7. 子查询
- 7.1 子查询类型
- 7.2 标量子查询
- 7.3 表子查询
- 7.4 相关子查询
- 8. 高级查询技巧
- 8.1 窗口函数
- 8.2 分析函数
- 8.3 集合运算
- 9. 实际应用案例
- 9.1 销售数据分析系统
- 9.2 员工绩效评估系统
- 9.3 库存管理分析
- 10. 性能优化技巧
- 10.1 查询优化策略
- 10.2 实用优化技巧
正文
DQL(Data Query Language)是SQL语言的核心组成部分,专门用于从数据库中查询和检索数据。在Oracle数据库中,DQL主要就是SELECT语句,但别小看这一个语句,它的功能强大到可以让你眼花缭乱!
1. DQL概述
1.1 什么是DQL?
DQL就像是数据库的"搜索引擎",你告诉它你想要什么数据,它就帮你从茫茫数据海洋中找出来。不管你的数据库有多大,DQL都能精准定位你需要的信息。
1.2 DQL的核心功能
Oracle DQL的功能可以分为以下几个层次:
2. SELECT语句基础
2.1 基本语法结构
SELECT语句就像是一个万能工具箱,每个关键字都有自己的作用:
-- Oracle SELECT语句的完整语法结构
SELECT [DISTINCT] column1, column2, ...
FROM table_name
[WHERE condition]
[GROUP BY column1, column2, ...]
[HAVING condition]
[ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...]
[OFFSET offset_value ROWS]
[FETCH NEXT number_of_rows ROWS ONLY];
2.2 最简单的查询
让我们从最基础的开始,就像学走路一样:
-- 查询所有员工信息
SELECT * FROM employees;-- 查询特定字段
SELECT employee_id, first_name, last_name, salary
FROM employees;-- 使用别名让结果更友好
SELECT employee_id AS "员工编号",first_name AS "名字",last_name AS "姓氏",salary AS "薪资"
FROM employees;-- 计算字段
SELECT first_name || ' ' || last_name AS "全名",salary * 12 AS "年薪",ROUND(salary * 1.1, 2) AS "涨薪后月薪"
FROM employees;
2.3 DISTINCT去重
有时候数据会有重复,DISTINCT就像是一个"去重神器":
-- 查询所有不重复的部门ID
SELECT DISTINCT department_id
FROM employees;-- 多字段组合去重
SELECT DISTINCT department_id, job_id
FROM employees;-- 统计不重复记录数
SELECT COUNT(DISTINCT department_id) AS "部门总数"
FROM employees;
3. WHERE条件筛选
3.1 基本条件运算符
WHERE子句就像是数据的"筛子",帮你过滤出想要的数据:
-- 数值比较
SELECT * FROM employees WHERE salary > 5000;
SELECT * FROM employees WHERE salary BETWEEN 3000 AND 8000;
SELECT * FROM employees WHERE department_id IN (10, 20, 30);-- 字符串匹配
SELECT * FROM employees WHERE first_name = 'John';
SELECT * FROM employees WHERE first_name LIKE 'J%'; -- 以J开头
SELECT * FROM employees WHERE first_name LIKE '%son'; -- 以son结尾
SELECT * FROM employees WHERE first_name LIKE '_ohn'; -- 第一个字符任意,后面是ohn-- 空值处理
SELECT * FROM employees WHERE commission_pct IS NULL;
SELECT * FROM employees WHERE commission_pct IS NOT NULL;
3.2 逻辑运算符组合
多个条件可以像搭积木一样组合起来:
-- AND:所有条件都必须满足
SELECT * FROM employees
WHERE salary > 5000 AND department_id = 20;-- OR:满足任一条件即可
SELECT * FROM employees
WHERE department_id = 10 OR department_id = 20;-- NOT:取反
SELECT * FROM employees
WHERE NOT (salary < 3000);-- 复杂条件组合
SELECT * FROM employees
WHERE (salary > 5000 OR commission_pct IS NOT NULL)AND department_id IN (10, 20, 30)AND hire_date > DATE '2005-01-01';
3.3 高级条件筛选
Oracle提供了一些特殊的条件运算符:
-- EXISTS:检查子查询是否返回结果
SELECT * FROM departments d
WHERE EXISTS (SELECT 1 FROM employees e WHERE e.department_id = d.department_id
);-- ANY/SOME:与子查询结果中的任一值比较
SELECT * FROM employees
WHERE salary > ANY (SELECT salary FROM employees WHERE department_id = 20
);-- ALL:与子查询结果中的所有值比较
SELECT * FROM employees
WHERE salary > ALL (SELECT salary FROM employees WHERE department_id = 20
);-- REGEXP_LIKE:正则表达式匹配
SELECT * FROM employees
WHERE REGEXP_LIKE(first_name, '^[A-D].*'); -- 名字以A-D开头
4. 排序和分页
4.1 ORDER BY排序
排序就像给数据排队,让它们按你想要的顺序站好:
-- 单字段排序
SELECT * FROM employees ORDER BY salary DESC; -- 按薪资降序
SELECT * FROM employees ORDER BY hire_date; -- 按入职日期升序(默认)-- 多字段排序
SELECT * FROM employees
ORDER BY department_id, salary DESC;-- 使用表达式排序
SELECT first_name, last_name, salary
FROM employees
ORDER BY LENGTH(first_name), salary DESC;-- 空值排序控制
SELECT * FROM employees
ORDER BY commission_pct NULLS LAST; -- 空值排在最后-- 使用CASE进行自定义排序
SELECT * FROM employees
ORDER BY CASE department_id WHEN 10 THEN 1WHEN 20 THEN 2WHEN 30 THEN 3ELSE 4END,salary DESC;
4.2 分页查询
Oracle 12c之后引入了标准的分页语法,比以前的ROWNUM方式更直观:
-- Oracle 12c+ 标准分页语法
SELECT employee_id, first_name, last_name, salary
FROM employees
ORDER BY salary DESC
OFFSET 10 ROWS FETCH NEXT 5 ROWS ONLY; -- 跳过前10行,取接下来的5行-- 传统的ROWNUM分页(适用于所有Oracle版本)
SELECT * FROM (SELECT ROWNUM rn, e.* FROM (SELECT * FROM employees ORDER BY salary DESC) e WHERE ROWNUM <= 15
) WHERE rn > 10;-- 使用ROW_NUMBER()窗口函数分页
SELECT * FROM (SELECT employee_id, first_name, last_name, salary,ROW_NUMBER() OVER (ORDER BY salary DESC) as rnFROM employees
) WHERE rn BETWEEN 11 AND 15;
5. 聚合函数和分组
5.1 常用聚合函数
聚合函数就像是数据的"计算器",帮你做各种统计:
-- 基本聚合函数
SELECT COUNT(*) AS "总员工数",COUNT(commission_pct) AS "有提成的员工数",AVG(salary) AS "平均薪资",SUM(salary) AS "薪资总和",MAX(salary) AS "最高薪资",MIN(salary) AS "最低薪资",STDDEV(salary) AS "薪资标准差",VARIANCE(salary) AS "薪资方差"
FROM employees;-- 字符串聚合函数
SELECT LISTAGG(first_name, ', ') WITHIN GROUP (ORDER BY first_name) AS "所有员工名字"
FROM employees;-- 日期聚合
SELECT MIN(hire_date) AS "最早入职日期",MAX(hire_date) AS "最晚入职日期"
FROM employees;
5.2 GROUP BY分组
分组就像是把数据按类别整理到不同的盒子里:
-- 按部门分组统计
SELECT department_id,COUNT(*) AS "员工数量",AVG(salary) AS "平均薪资",SUM(salary) AS "部门薪资总和"
FROM employees
GROUP BY department_id
ORDER BY department_id;-- 多字段分组
SELECT department_id,job_id,COUNT(*) AS "员工数量",AVG(salary) AS "平均薪资"
FROM employees
GROUP BY department_id, job_id
ORDER BY department_id, job_id;-- 使用表达式分组
SELECT EXTRACT(YEAR FROM hire_date) AS "入职年份",COUNT(*) AS "该年入职人数"
FROM employees
GROUP BY EXTRACT(YEAR FROM hire_date)
ORDER BY "入职年份";
5.3 HAVING子句
HAVING就像是对分组结果的"二次筛选":
-- 筛选员工数量大于5的部门
SELECT department_id,COUNT(*) AS "员工数量",AVG(salary) AS "平均薪资"
FROM employees
GROUP BY department_id
HAVING COUNT(*) > 5
ORDER BY "员工数量" DESC;-- 复杂的HAVING条件
SELECT department_id,COUNT(*) AS "员工数量",AVG(salary) AS "平均薪资"
FROM employees
WHERE hire_date > DATE '2005-01-01' -- WHERE先筛选原始数据
GROUP BY department_id
HAVING AVG(salary) > 5000 -- HAVING再筛选分组结果AND COUNT(*) >= 3
ORDER BY "平均薪资" DESC;
6. 多表连接查询
6.1 连接类型概览
多表连接就像是把不同的拼图片拼在一起,形成完整的画面:
6.2 内连接(INNER JOIN)
内连接是最常用的连接方式,只返回两表都有匹配的记录:
-- 标准内连接语法
SELECT e.employee_id,e.first_name,e.last_name,d.department_name,j.job_title
FROM employees e
INNER JOIN departments d ON e.department_id = d.department_id
INNER JOIN jobs j ON e.job_id = j.job_id;-- Oracle传统连接语法(等价于上面)
SELECT e.employee_id,e.first_name,e.last_name,d.department_name,j.job_title
FROM employees e, departments d, jobs j
WHERE e.department_id = d.department_idAND e.job_id = j.job_id;-- 多条件连接
SELECT e.first_name,e.last_name,m.first_name AS "经理名字"
FROM employees e
INNER JOIN employees m ON e.manager_id = m.employee_id
WHERE e.salary > 5000;
6.3 外连接(OUTER JOIN)
外连接能保留一侧表的所有记录,即使另一侧没有匹配:
-- 左外连接:显示所有部门,包括没有员工的部门
SELECT d.department_name,COUNT(e.employee_id) AS "员工数量"
FROM departments d
LEFT JOIN employees e ON d.department_id = e.department_id
GROUP BY d.department_id, d.department_name
ORDER BY d.department_name;-- 右外连接:显示所有员工,包括没有部门的员工
SELECT e.first_name,e.last_name,d.department_name
FROM departments d
RIGHT JOIN employees e ON d.department_id = e.department_id;-- 全外连接:显示所有部门和所有员工
SELECT e.first_name,e.last_name,d.department_name
FROM employees e
FULL OUTER JOIN departments d ON e.department_id = d.department_id;-- Oracle传统外连接语法(使用(+))
SELECT d.department_name,e.first_name
FROM departments d, employees e
WHERE d.department_id = e.department_id(+); -- 左外连接
6.4 自连接
自连接就像是表在照镜子,与自己进行连接:
-- 查询员工及其经理信息
SELECT emp.first_name || ' ' || emp.last_name AS "员工",mgr.first_name || ' ' || mgr.last_name AS "经理",emp.salary AS "员工薪资",mgr.salary AS "经理薪资"
FROM employees emp
LEFT JOIN employees mgr ON emp.manager_id = mgr.employee_id
ORDER BY emp.employee_id;-- 查找薪资比同部门平均薪资高的员工
SELECT e1.first_name,e1.last_name,e1.salary,e1.department_id
FROM employees e1
WHERE e1.salary > (SELECT AVG(e2.salary)FROM employees e2WHERE e2.department_id = e1.department_id
);
7. 子查询
7.1 子查询类型
子查询就像是"查询中的查询",可以嵌套使用:
7.2 标量子查询
标量子查询返回单个值,可以用在任何需要单个值的地方:
-- 查询薪资高于平均薪资的员工
SELECT first_name,last_name,salary,(SELECT AVG(salary) FROM employees) AS "平均薪资"
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);-- 在SELECT子句中使用子查询
SELECT first_name,last_name,salary,(SELECT department_name FROM departments d WHERE d.department_id = e.department_id) AS "部门名称"
FROM employees e;-- 在ORDER BY中使用子查询
SELECT first_name, last_name, department_id
FROM employees
ORDER BY (SELECT department_name FROM departments d WHERE d.department_id = employees.department_id
);
7.3 表子查询
表子查询返回多行多列,可以当作临时表使用:
-- 查询每个部门薪资最高的员工
SELECT e.first_name,e.last_name,e.salary,e.department_id
FROM employees e
WHERE (e.department_id, e.salary) IN (SELECT department_id, MAX(salary)FROM employeesGROUP BY department_id
);-- 使用子查询作为临时表
SELECT dept_stats.department_id,dept_stats.avg_salary,d.department_name
FROM (SELECT department_id,AVG(salary) as avg_salary,COUNT(*) as emp_countFROM employeesGROUP BY department_idHAVING COUNT(*) > 5
) dept_stats
JOIN departments d ON dept_stats.department_id = d.department_id;
7.4 相关子查询
相关子查询的执行依赖于外层查询的每一行:
-- 查询薪资高于本部门平均薪资的员工
SELECT e1.first_name,e1.last_name,e1.salary,e1.department_id
FROM employees e1
WHERE e1.salary > (SELECT AVG(e2.salary)FROM employees e2WHERE e2.department_id = e1.department_id
);-- 使用EXISTS的相关子查询
SELECT d.department_name
FROM departments d
WHERE EXISTS (SELECT 1FROM employees eWHERE e.department_id = d.department_idAND e.salary > 10000
);-- 查询每个部门中入职最早的员工
SELECT e1.first_name,e1.last_name,e1.hire_date,e1.department_id
FROM employees e1
WHERE e1.hire_date = (SELECT MIN(e2.hire_date)FROM employees e2WHERE e2.department_id = e1.department_id
);
8. 高级查询技巧
8.1 窗口函数
窗口函数是Oracle的强大功能,可以在不改变结果集行数的情况下进行分析:
-- ROW_NUMBER():为每行分配唯一序号
SELECT first_name,last_name,salary,department_id,ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary DESC) as dept_rank
FROM employees;-- RANK()和DENSE_RANK():处理并列排名
SELECT first_name,last_name,salary,RANK() OVER (ORDER BY salary DESC) as salary_rank,DENSE_RANK() OVER (ORDER BY salary DESC) as dense_rank
FROM employees;-- LAG()和LEAD():访问前后行数据
SELECT first_name,last_name,salary,LAG(salary, 1) OVER (ORDER BY hire_date) as prev_salary,LEAD(salary, 1) OVER (ORDER BY hire_date) as next_salary
FROM employees;-- 累计统计
SELECT first_name,last_name,salary,SUM(salary) OVER (ORDER BY hire_date ROWS UNBOUNDED PRECEDING) as running_total,AVG(salary) OVER (ORDER BY hire_date ROWS 2 PRECEDING) as moving_avg
FROM employees;
8.2 分析函数
分析函数提供了更多的统计分析能力:
-- NTILE():将数据分成N个桶
SELECT first_name,last_name,salary,NTILE(4) OVER (ORDER BY salary) as salary_quartile
FROM employees;-- PERCENT_RANK():百分位排名
SELECT first_name,last_name,salary,PERCENT_RANK() OVER (ORDER BY salary) as pct_rank,CUME_DIST() OVER (ORDER BY salary) as cumulative_dist
FROM employees;-- FIRST_VALUE()和LAST_VALUE()
SELECT first_name,last_name,salary,department_id,FIRST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary DESC ROWS UNBOUNDED PRECEDING) as highest_salary_in_dept,LAST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as lowest_salary_in_dept
FROM employees;
8.3 集合运算
集合运算可以组合多个查询的结果:
-- UNION:合并结果集(去重)
SELECT first_name, last_name FROM employees WHERE department_id = 10
UNION
SELECT first_name, last_name FROM employees WHERE salary > 10000;-- UNION ALL:合并结果集(不去重)
SELECT 'Employee' as type, first_name, last_name FROM employees
UNION ALL
SELECT 'Manager' as type, first_name, last_name FROM employees WHERE manager_id IS NULL;-- INTERSECT:交集
SELECT employee_id FROM employees WHERE department_id = 20
INTERSECT
SELECT employee_id FROM employees WHERE salary > 5000;-- MINUS:差集
SELECT employee_id FROM employees WHERE department_id = 20
MINUS
SELECT employee_id FROM employees WHERE salary > 8000;
9. 实际应用案例
9.1 销售数据分析系统
让我们看一个完整的销售数据分析案例:
-- 创建示例表结构
CREATE TABLE sales_data (sale_id NUMBER PRIMARY KEY,product_id NUMBER,customer_id NUMBER,sale_date DATE,quantity NUMBER,unit_price NUMBER(10,2),total_amount NUMBER(12,2),sales_rep_id NUMBER,region VARCHAR2(50)
);-- 复杂的销售分析查询
WITH monthly_sales AS (-- 月度销售统计SELECT EXTRACT(YEAR FROM sale_date) as sale_year,EXTRACT(MONTH FROM sale_date) as sale_month,region,SUM(total_amount) as monthly_total,COUNT(*) as transaction_count,AVG(total_amount) as avg_transactionFROM sales_dataWHERE sale_date >= ADD_MONTHS(SYSDATE, -12)GROUP BY EXTRACT(YEAR FROM sale_date), EXTRACT(MONTH FROM sale_date), region
),
regional_rankings AS (-- 区域排名SELECT *,RANK() OVER (PARTITION BY sale_year, sale_month ORDER BY monthly_total DESC) as region_rank,LAG(monthly_total) OVER (PARTITION BY region ORDER BY sale_year, sale_month) as prev_month_totalFROM monthly_sales
)
SELECT sale_year,sale_month,region,monthly_total,region_rank,CASE WHEN prev_month_total IS NULL THEN 'N/A'ELSE ROUND(((monthly_total - prev_month_total) / prev_month_total) * 100, 2) || '%'END as growth_rate,SUM(monthly_total) OVER (PARTITION BY region ORDER BY sale_year, sale_month) as running_total
FROM regional_rankings
ORDER BY sale_year, sale_month, region_rank;
9.2 员工绩效评估系统
-- 员工绩效综合评估
WITH employee_metrics AS (SELECT e.employee_id,e.first_name,e.last_name,e.department_id,e.salary,e.hire_date,-- 计算工作年限ROUND(MONTHS_BETWEEN(SYSDATE, e.hire_date) / 12, 1) as years_of_service,-- 部门内薪资排名RANK() OVER (PARTITION BY e.department_id ORDER BY e.salary DESC) as dept_salary_rank,-- 薪资百分位PERCENT_RANK() OVER (ORDER BY e.salary) as salary_percentileFROM employees e
),
performance_scores AS (SELECT em.*,d.department_name,-- 综合评分计算CASE WHEN salary_percentile >= 0.8 THEN 5WHEN salary_percentile >= 0.6 THEN 4WHEN salary_percentile >= 0.4 THEN 3WHEN salary_percentile >= 0.2 THEN 2ELSE 1END as salary_score,CASE WHEN years_of_service >= 10 THEN 5WHEN years_of_service >= 7 THEN 4WHEN years_of_service >= 5 THEN 3WHEN years_of_service >= 2 THEN 2ELSE 1END as experience_scoreFROM employee_metrics emJOIN departments d ON em.department_id = d.department_id
)
SELECT first_name,last_name,department_name,salary,years_of_service,dept_salary_rank,ROUND(salary_percentile * 100, 1) as salary_percentile_pct,(salary_score + experience_score) as total_score,CASE WHEN (salary_score + experience_score) >= 8 THEN 'Excellent'WHEN (salary_score + experience_score) >= 6 THEN 'Good'WHEN (salary_score + experience_score) >= 4 THEN 'Average'ELSE 'Below Average'END as performance_rating
FROM performance_scores
ORDER BY total_score DESC, salary DESC;
9.3 库存管理分析
-- 库存周转率分析
WITH inventory_analysis AS (SELECT p.product_id,p.product_name,p.category,i.current_stock,i.reorder_level,-- 计算过去30天的销售量NVL(s.sales_30days, 0) as sales_30days,-- 计算库存天数CASE WHEN NVL(s.sales_30days, 0) = 0 THEN 999ELSE ROUND(i.current_stock / (s.sales_30days / 30), 1)END as days_of_inventory,-- 库存状态CASE WHEN i.current_stock <= i.reorder_level THEN 'Low Stock'WHEN i.current_stock <= i.reorder_level * 1.5 THEN 'Medium Stock'ELSE 'High Stock'END as stock_statusFROM products pJOIN inventory i ON p.product_id = i.product_idLEFT JOIN (SELECT product_id,SUM(quantity) as sales_30daysFROM sales_dataWHERE sale_date >= SYSDATE - 30GROUP BY product_id) s ON p.product_id = s.product_id
)
SELECT product_name,category,current_stock,sales_30days,days_of_inventory,stock_status,-- 库存周转率分类CASE WHEN days_of_inventory <= 7 THEN 'Fast Moving'WHEN days_of_inventory <= 30 THEN 'Normal Moving'WHEN days_of_inventory <= 90 THEN 'Slow Moving'ELSE 'Dead Stock'END as turnover_category,-- 建议行动CASE WHEN stock_status = 'Low Stock' THEN 'Reorder Immediately'WHEN days_of_inventory > 90 THEN 'Consider Promotion'WHEN days_of_inventory <= 7 THEN 'Monitor Closely'ELSE 'Normal Operation'END as recommended_action
FROM inventory_analysis
ORDER BY CASE stock_status WHEN 'Low Stock' THEN 1WHEN 'Medium Stock' THEN 2ELSE 3END,days_of_inventory;
10. 性能优化技巧
10.1 查询优化策略
10.2 实用优化技巧
-- 1. 使用绑定变量避免硬解析
-- 不好的写法
SELECT * FROM employees WHERE employee_id = 100;
SELECT * FROM employees WHERE employee_id = 101;-- 好的写法(使用绑定变量)
SELECT * FROM employees WHERE employee_id = :emp_id;-- 2. 合理使用索引提示
SELECT /*+ INDEX(e, emp_department_ix) */ first_name, last_name
FROM employees e
WHERE department_id = 20;-- 3. 避免在WHERE子句中使用函数
-- 不好的写法
SELECT * FROM employees WHERE UPPER(first_name) = 'JOHN';-- 好的写法
SELECT * FROM employees WHERE first_name = 'John';-- 4. 使用EXISTS代替IN(当子查询返回大量数据时)
-- 可能较慢
SELECT * FROM departments
WHERE department_id IN (SELECT department_id FROM employees);-- 通常更快
SELECT * FROM departments d
WHERE EXISTS (SELECT 1 FROM employees e WHERE e.department_id = d.department_id);-- 5. 分页查询优化
-- 对于大数据量的分页,使用基于游标的分页
SELECT * FROM (SELECT employee_id, first_name, last_name, salary,ROW_NUMBER() OVER (ORDER BY employee_id) as rnFROM employeesWHERE salary > 5000
) WHERE rn BETWEEN 1001 AND 1020;
Oracle的DQL功能真的是博大精深,从简单的SELECT到复杂的分析函数,每一个功能都有其独特的应用场景。掌握这些技巧,你就能像数据库的"魔法师"一样,从海量数据中快速提取出有价值的信息。记住,实践是最好的老师,多写多练,你会发现DQL的魅力所在!
结语
感谢您的阅读!期待您的一键三连!欢迎指正!

相关文章:
【Oracle】DQL语言
个人主页:Guiat 归属专栏:Oracle 文章目录 1. DQL概述1.1 什么是DQL?1.2 DQL的核心功能 2. SELECT语句基础2.1 基本语法结构2.2 最简单的查询2.3 DISTINCT去重 3. WHERE条件筛选3.1 基本条件运算符3.2 逻辑运算符组合3.3 高级条件筛选 4. 排序…...
HUAWEI华为MateBook D 14 2021款i5,i7集显非触屏(NBD-WXX9,NbD-WFH9)原装出厂Win10系统
适用型号:NbD-WFH9、NbD-WFE9A、NbD-WDH9B、NbD-WFE9、 链接:https://pan.baidu.com/s/1qTCbaQQa8xqLR-4Ooe3ytg?pwdvr7t 提取码:vr7t 华为原厂WIN系统自带所有驱动、出厂主题壁纸、系统属性联机支持标志、系统属性专属LOGO标志、Office…...
【STIP】安全Transformer推理协议
Secure Transformer Inference Protocol 论文地址:https://arxiv.org/abs/2312.00025 摘要 模型参数和用户数据的安全性对于基于 Transformer 的服务(例如 ChatGPT)至关重要。虽然最近在安全两方协议方面取得的进步成功地解决了服务 Transf…...
leetcode hot100刷题日记——27.对称二叉树
方法一:递归法 class Solution { public:bool check(TreeNode *left,TreeNode *right){//左子树和右子树的节点同时是空的是对称的if(leftnullptr&&rightnullptr){return true;}if(leftnullptr||rightnullptr){return false;}//检查左右子树的值相不相等&a…...

高考加油(Python+HTML)
前言 询问DeepSeek根据自己所学到的知识来生成多个可执行的代码,为高考学子加油。最开始生成的都会有点小问题,还是需要自己调试一遍,下面就是完整的代码,当然了最后几天也不会有多少人看,都在专心的备考。 Python励…...

贪心算法应用:Ford-Fulkerson最大流问题详解
Java中的贪心算法应用:Ford-Fulkerson最大流问题详解 1. 最大流问题概述 最大流问题(Maximum Flow Problem)是图论中的一个经典问题,旨在找到一个从源节点(source)到汇节点(sink)的最大流量。Ford-Fulkerson方法是解决最大流问题的经典算法之一,它属于贪心算法的范畴…...
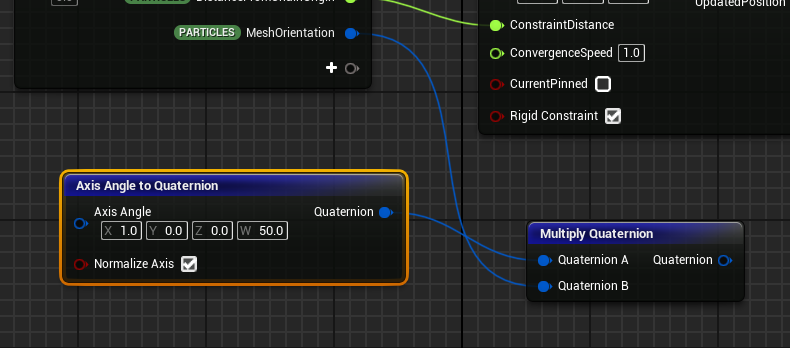
UE5 Niagara 如何让四元数进行旋转
Axis Angle中,X,Y,Z分别为旋转的轴向,W为旋转的角度,在这里旋转角度不需要除以2,因为里面已经除了,再将计算好的四元数与要进行旋转的四元数进行相乘,结果就是按照原来的角度绕着某一轴向旋转了某一角度...

从“黑箱”到透明化:MES如何重构生产执行全流程?
引言 在传统制造企业中,生产执行环节常面临“计划混乱、进度难控、异常频发、数据滞后”的困境。人工派工效率低下、物料错配频发、质量追溯困难等问题,直接导致交付延期、成本攀升、客户流失。深蓝易网MES系统以全流程数字化管理为核心,通过…...

探索Linux互斥:线程安全与资源共享
个人主页:chian-ocean 文章专栏-Linux 前言: 互斥是并发编程中避免竞争条件和保护共享资源的核心技术。通过使用锁或信号量等机制,能够确保多线程或多进程环境下对共享资源的安全访问,避免数据不一致、死锁等问题。 竞争条件 竞…...
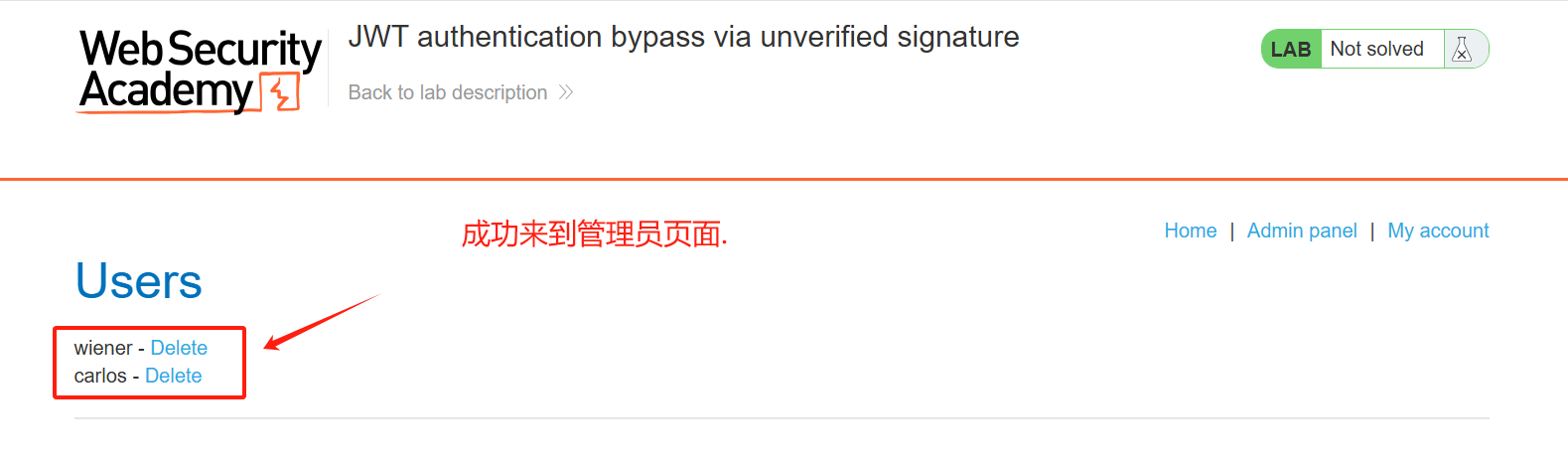
JWT安全:假密钥.【签名随便写实现越权绕过.】
JWT安全:假密钥【签名随便写实现越权绕过.】 JSON Web 令牌 (JWT)是一种在系统之间发送加密签名 JSON 数据的标准化格式。理论上,它们可以包含任何类型的数据,但最常用于在身份验证、会话处理和访问控制机制中发送有关用户的信息(“声明”)。…...
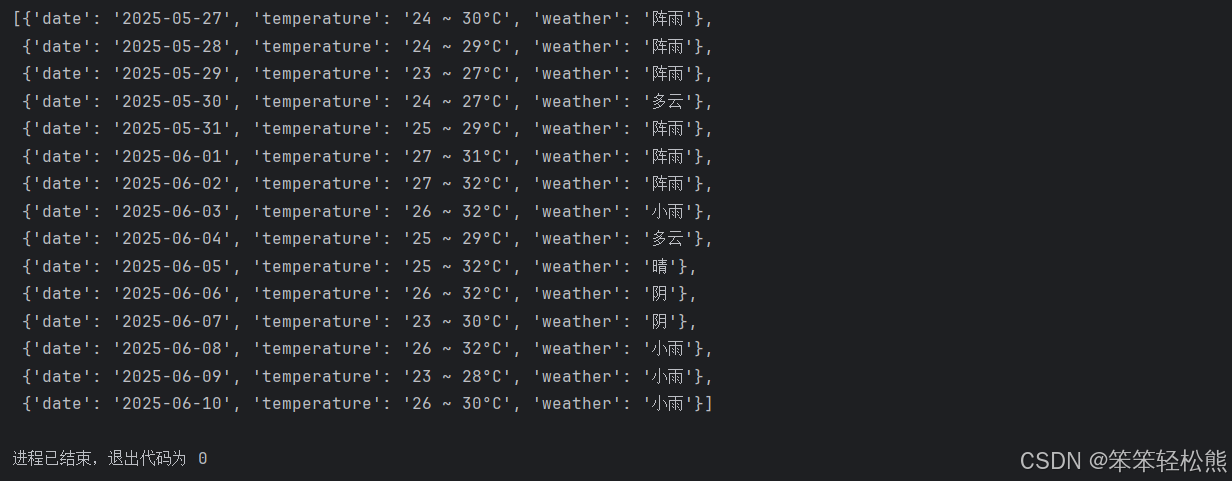
Python爬虫实战:抓取百度15天天气预报数据
🌐 编程基础第一期《9-30》–使用python中的第三方模块requests,和三个内置模块(re、json、pprint),实现百度地图的近15天天气信息抓取 记得安装 pip install requests📑 项目介绍 网络爬虫是Python最受欢迎的应用场景之一&…...
RV1126 + FFPEG多路码流项目
代码主体思路: 一.VI,VENC,RGA模块初始化 1.先创建一个自定义公共结构体,用于方便管理各个模块 rkmedia_config_public.h //文件名字#ifndef _RV1126_PUBLIC_H #define _RV1126_PUBLIC_H#include <assert.h> #include <fcntl.h> #include …...
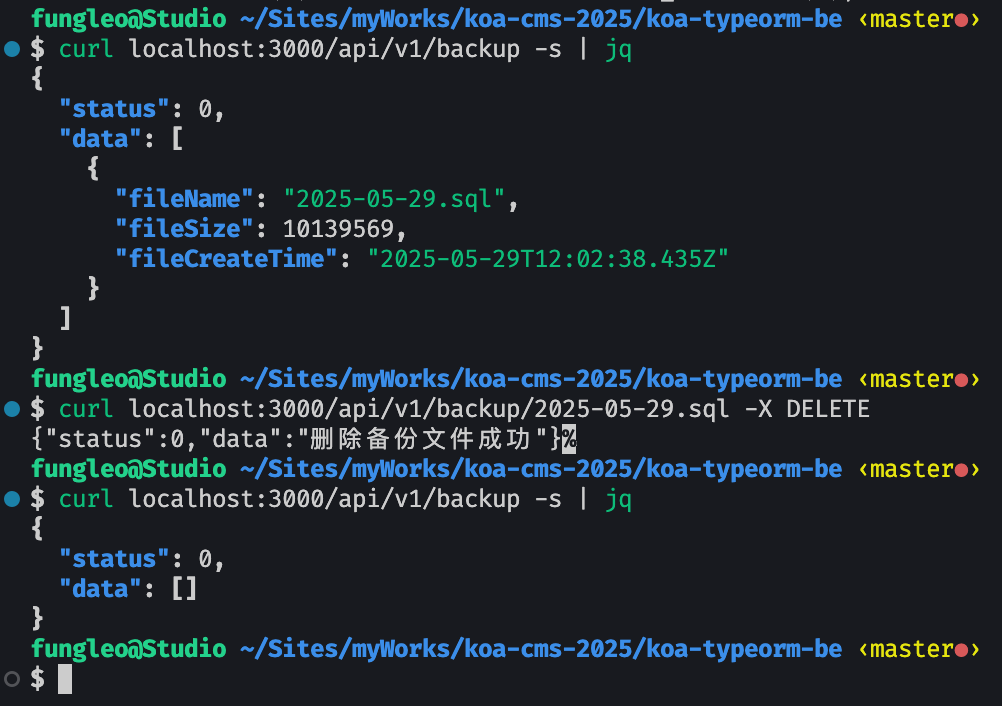
NodeJS 基于 Koa, 开发一个读取文件,并返回给客户端文件下载,以及读取文件形成列表和文件删除的代码演示
前言 在上一篇文章 《Nodejs 实现 Mysql 数据库的全量备份的代码演示》 中,我们演示了如何将用户的 Mysql 数据库进行备份的代码。但是,这个备份,只是备份在了服务器上了。 而我们用户的真实需求,是需要将备份文件下载到本地进行…...
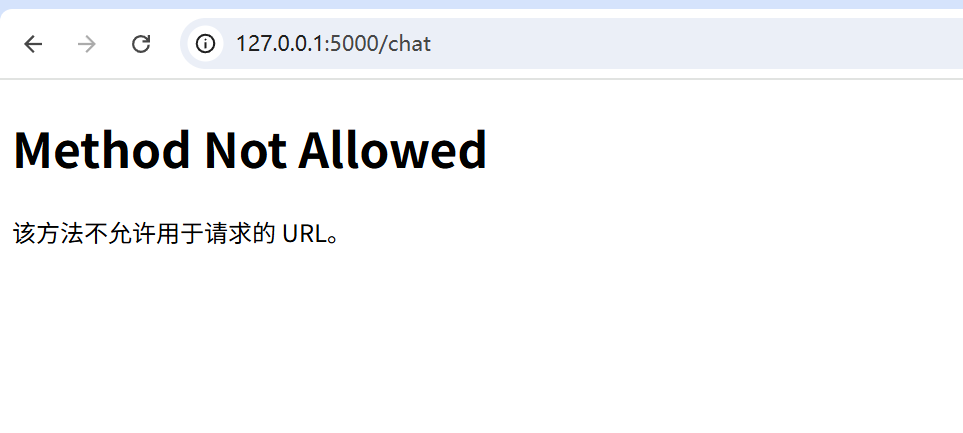
为什么在我的Flask里面有两个路由,但是在网页里有一个却不能正确访问到智能体
1. /zhoushibo 能访问,/chat 直接浏览器访问报 Method Not Allowed 原因: /zhoushibo 路由是你用 app.route(/zhoushibo) 定义的,返回的是一个HTML网页,浏览器访问没问题。 /chat 路由你用的是 app.route(/chat, methods[POST])…...

哈工大计算机系统2024大作业——Hello的程序人生
计算机系统 大作业 题 目 程序人生-Hello’s P2P 专 业 人工智能 学 号 2022112040 班 级 2203601 学 生 郄东昕 指 导 教 师 吴锐 计算机科学与技术学院…...

2025年软件测试面试八股文(含答案+文档)
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 Part1 1、你的测试职业发展是什么? 测试经验越多,测试能力越高。所以我的职业发展是需要时间积累的,一步步向着高级测试工程师…...

【仿生系统】qwen的仿生机器人解决方案
收到完整需求后,我将从系统架构设计、算法实现路径、训练方法三个维度为您构建完整的仿生机器人解决方案。以下是分阶段实施方案: 一、核心系统架构设计(模块化可进化架构) 1. 多模态感知引擎 - 视觉子系统:YOLOv8SAM…...

Flutter3.22适配运行鸿蒙系统问题记录
Flutter3.22适配运行鸿蒙系统问题记录 一:适配条件适配过程问题记录(1)环境配置问题(2)Concurrent modification during iteration: Instance(length:2) of_GrowableList 报错(3)三方插件寻找替…...
秋招Day10 - JVM - 内存管理
JVM组织架构主要有三个部分:类加载器、运行时数据区和字节码执行引擎 类加载器:负责从文件系统、网络或其他来源加载class文件,将class文件中的二进制数据加载到内存中运行时数据区:运行时的数据存放的区域,分为方法区…...
Spring Boot 3.5.0中文文档上线
Spring Boot 3.5.0 中文文档翻译完成,需要的可收藏 传送门:Spring Boot 3.5.0 中文文档...

Redisson学习专栏(一):快速入门及核心API实践
文章目录 前言一、Redisson简介1.1 什么是Redisson?1.2 解决了什么问题? 二、快速入门2.1 环境准备 2.2 基础配置三、核心API解析3.1 分布式锁(RLock)3.2 分布式集合3.2.1 RMap(分布式Map)3.2.2 RList&…...
Pandas学习入门一
1.什么是Pandas? Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。 一个强大的分析和操作大型结构化数据集所需的工具集基础是NumPy…...
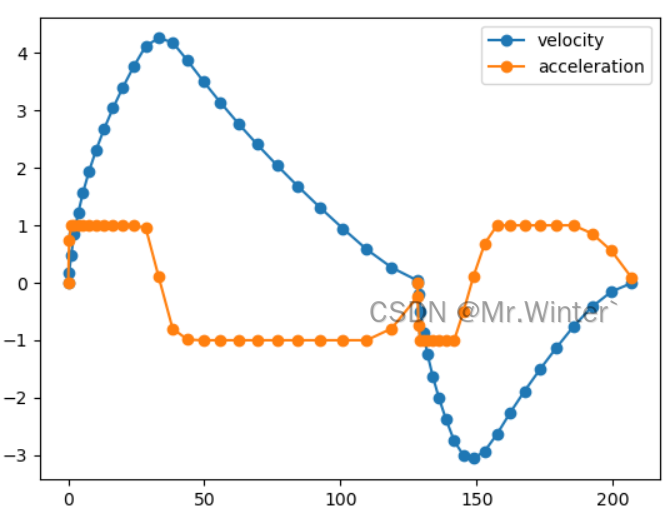
基于Piecewise Jerk Speed Optimizer的速度规划算法(附ROS C++/Python仿真)
目录 1 时空解耦运动规划2 PJSO速度规划原理2.1 优化变量2.2 代价函数2.3 约束条件2.4 二次规划形式 3 算法仿真3.1 ROS C仿真3.2 Python仿真 1 时空解耦运动规划 在自主移动系统的运动规划体系中,时空解耦的递进式架构因其高效性与工程可实现性被广泛采用。这一架…...

关于 JavaScript 版本、TypeScript、Vue 的区别说明, PHP 开发者入门 Vue 的具体方案
以下是关于 JavaScript 版本、TypeScript、Vue 的区别说明,以及 PHP 开发者入门 Vue 的具体方案: 一、JavaScript 版本演进 JavaScript 的核心版本以 ECMAScript 规范(ES) 命名: 版本发布时间关键特性ES52009严格模式…...

中断和信号详解
三种中断 中断分为三种:硬件中断、异常中断、软中断 硬件中断 设备向中断控制器发送中断请求,中断控制器生成对应中断号,然后通过中断引脚向cpu发送高电平,cpu收到请求后不会立即处理,cpu会处理完当前指令ÿ…...

STM32八股【10】-----stm32启动流程
启动流程 1.上电复位 2.系统初始化 3.跳转到 main 函数 启动入口: cpu被清空,程序从0x00000000开始运行0x00000000存放的是reset_handler的入口地址0x00000000的实际位置会变,根据不同的启动模式决定启动模式分为: flash启动&a…...

游戏引擎学习第312天:跨实体手动排序
运行游戏并评估当前状况 目前排序功能基本已经正常,能够实现特定的排序要求,针对单一区域、单个房间的场景,效果基本符合预期。 不过还有一些细节需要调试。现在有些对象的缩放比例不对,导致它们看起来有些怪异,需要…...
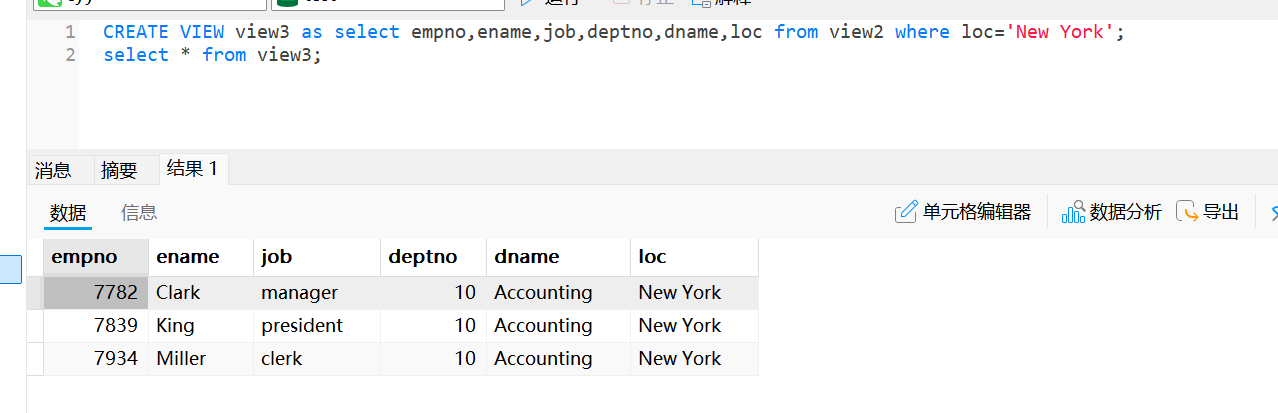
智警杯备赛--数据库管理与优化及数据库对象创建与管理
sql操作 插入数据 如果要操作数据表中的数据,首先应该确保表中存在数据。没有插入数据之前的表只是一张空表,需要使用insert语句向表中插入数据。插入数据有4种不同的方式:为所有字段插入数据、为指定字段插入数据、同时插入多条数据以及插…...

MySQL 在 CentOS 7 环境下的安装教程
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习Mysql的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...
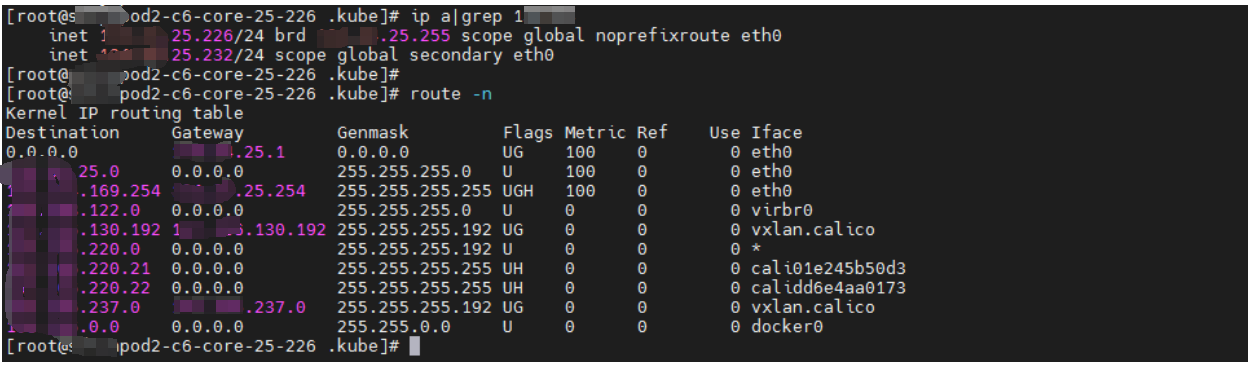
K8S集群主机网络端口不通问题排查
一、环境: k8s: v1.23.6 docker: 20.10.14 问题和故障现象:devops主机集群主机节点到端口8082不通(网络策略已经申请,并且网络策略已经实施完毕),而且网络实施人员再次确认,网络策…...