大数据量下的数据修复与回写Spark on Hive 的大数据量主键冲突排查:COUNT(DISTINCT) 的陷阱
背景与问题概述
这一周(2025-05-26-2026-05-30)我在搞数据拟合修复优化的任务,有大量的数据需要进行数据处理及回写,大概一个表一天一分区有五六千万数据,大约一百多列的字段。 具体是这样的我先取档案,关联对应表hive对应分区的数据,然后进行算法一系列逻辑处理后,将结果输出到hive,然后再从hive回写一份到oracle里面。
spark资源大概我给了不小,数据大概一天40左右吧,大概12个excutor,每一个12G内存,2core吧,拟合完数据,将数据入hive时候,进行了整体去重。 包括且不限于如下操作
1、.distinct(),
2、对应主键的去重.dropDuplicates(id),
3、row_number对id,type主键字段开窗取first
4、对id,type主键字段开窗,取后续字段的max()
经过以上操作,我的数据得以在没有主键冲突的情况下顺利的入库到hive中,并且我对入库数据进行group by id,type having count(1) >1时数据也没有出现重复的情况。
OK。鬼知道我对上述数据验证进行多少次跑批总结出来的上面的操作。以上是我写入hive的操作。 下面即将是从hive入到oracle艰辛的探索之路。 正常来讲经过上面的数据操作,我从hive入到oracle是不应该出现主键冲突的情况了,因为我有一部分表已经处理入库了,但有一个表就是死活入不进去,我impala都快查烂了,资源监控的同事都给我致电了。
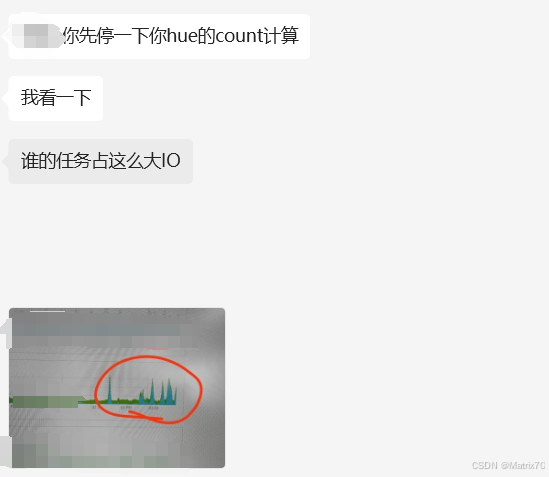
为什么调了一天呢,因为跑一个 程序就要个吧小时,代码都快被我调抑郁了。
Hive数据写入阶段的去重策略
经过多次实验和验证,我总结出一套有效的去重方法,确保数据在写入Hive时不出现主键冲突:
1. 整体去重 - distinct()
val distinctDF = originalDF.distinct()
这种方法简单直接,但性能开销较大,适合小数据集或初步去重。
2. 基于主键的去重 - dropDuplicates()
val dedupByKeyDF = originalDF.dropDuplicates("id")
比整体去重更高效,只针对指定列进行去重。
3. 开窗函数取第一条记录
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._val windowSpec = Window.partitionBy("id", "type").orderBy("timestamp")
val firstRecordDF = originalDF.withColumn("rn", row_number().over(windowSpec)).filter("rn = 1").drop("rn")
这种方法在有多条相同主键记录时,可以按指定排序条件保留一条。
4. 开窗函数取最大值记录
val maxValueDF = originalDF.groupBy("id", "type").agg(max("value1").as("value1"), max("value2").as("value2"),/* 其他字段的max操作 */)
对于需要保留最大值的场景,这种聚合方式非常有效。
Hive到Oracle的数据的迁移问题结局
尽管Hive中的数据已经严格去重,但在迁移到Oracle时仍遇到了两个主要问题:
问题1:NULL值导致的主键冲突
-- 问题发现查询
SELECT id, type, COUNT(1)
FROM hive_table
WHERE id IS NULL
GROUP BY id, type
HAVING COUNT(1) > 1;解决方案:
// 在写入Oracle前增加NULL值处理
val cleanDF = processedDF.na.fill("NULL", Seq("id")).filter("id IS NOT NULL") // 或者直接过滤问题2:资源不足导致的作业失败
最初配置:
-
12个Executor
-
每个Executor 12G内存,2个核心
-
一个表一天的分区大概处理约40GB数据
作业在运行10-20分钟后失败,经过多次调整,最终稳定运行的配置:
-
每个Executor 45G内存,这个我觉得得看集群资源,我们集群资源很紧张,大概10TB的内存,都不太够用
-
适当增加核心数(根据集群情况)我一般都设置2
性能优化经验总结
1. 内存配置黄金法则
对于大规模数据处理,Executor内存配置应遵循:
-
基础内存 = 数据分区大小 × 安全系数(2-3)
-
考虑序列化开销和中间数据结构
2. 高效去重策略选择
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| distinct() | 小数据集或全字段去重 | 简单 | 性能差 |
| dropDuplicates() | 已知主键字段 | 高效 | 仅针对指定列 |
| 开窗函数 | 需要按条件保留记录 | 灵活可控 | 计算开销大 |
| 聚合函数 | 需要保留极值 | 高效 | 只能处理数值字段 |
3. NULL值处理最佳实践
-
在数据处理的早期阶段识别和处理NULL值
-
对于主键字段,NULL值应被替换或过滤
-
考虑使用COALESCE或NVL函数提供默认值
4. 资源监控与调优技巧
-
观察GC时间和频率,内存不足时GC会频繁发生
-
监控Executor心跳丢失情况
-
适当增加
spark.memory.fraction(默认0.6) -
考虑启用
spark.memory.offHeap.enabled使用堆外内存
优化Demo示例代码
/*** @date 2025-05-30* @author hebei_xidaocun_laoli*/
// 1. 读取原始数据
val rawDF = spark.table("source_table").where("dt = '20250530'") // 按分区过滤// 2. 多阶段去重处理
val stage1DF = rawDF.dropDuplicates("id") // 初步去重val windowSpec = Window.partitionBy("id", "type").orderBy(col("update_time").desc)
val stage2DF = stage1DF.withColumn("rn", row_number().over(windowSpec)).filter("rn = 1").drop("rn")// 3. NULL值处理
val cleanDF = stage2DF.na.fill(Map("id" -> "NULL_ID","type" -> "DEFAULT"
)).filter("id != 'NULL_ID'") // 或者保留但确保不冲突// 4. 写入Hive
cleanDF.write.mode("overwrite").partitionBy("dt").saveAsTable("result_hive_table")// 5. 配置优化后写入Oracle
cleanDF.write.format("jdbc").option("url", "jdbc:oracle:thin:@//host:port/service").option("dbtable", "target_table").option("user", "username").option("password", "password").option("batchsize", 10000) // 调整批量大小.option("isolationLevel", "NONE") // 对于大数据量写入可提高性能.mode("append").save()通过这次项目,总结了以下经验:
-
数据质量优先:在数据处理早期阶段解决NULL值、重复数据等问题
-
渐进式调优:从较小资源开始,逐步增加直至作业稳定运行
-
监控驱动:密切监控作业执行情况,特别是GC和内存使用指标
-
文档记录:记录每次调整的参数和效果,形成知识库
大数据处理中的问题往往不是单一因素导致的,需要综合考虑数据特性、处理逻辑和集群资源。希望诸君避免类似的"坑",更高效地完成大数据处理任务。
这个资源调优是真的恶心,代码没问题,就是和资源有问题,跑着跑着就突然报错了,唉,还好这个端午节前解决了
相关文章:
大数据量下的数据修复与回写Spark on Hive 的大数据量主键冲突排查:COUNT(DISTINCT) 的陷阱
背景与问题概述 这一周(2025-05-26-2026-05-30)我在搞数据拟合修复优化的任务,有大量的数据需要进行数据处理及回写,大概一个表一天一分区有五六千万数据,大约一百多列的字段。 具体是这样的我先取档案&#x…...

Cursor 对话技巧 - 前端开发专版
引言 本文档旨在为前端开发团队提供与 Cursor AI 助手高效对话的技巧和方法,帮助团队成员更好地利用 AI 工具提升开发效率。文档中的技巧源自项目中的提示词相关文件,并经过整理和优化,专注于前端开发的各个场景。 目录 Cursor 对话技巧团队…...
历年南京理工大学计算机保研上机真题
2025南京理工大学计算机保研上机真题 2024南京理工大学计算机保研上机真题 2023南京理工大学计算机保研上机真题 在线测评链接:https://pgcode.cn/school 求阶乘 题目描述 给出一个数 n n n ( 1 ≤ n ≤ 13 ) (1 \leq n \leq 13) (1≤n≤13),求出它…...

Web前端常用面试题,九年程序人生 工作总结,Web开发必看
前端编程,JavaScript 从无知到觉醒 做 Web 开发,离不开 HTML,CSS,JavaScript,尽管日常工作以后台开发为主,但接触的多了,慢慢地理解深入,从只会使用 JS 写函数,发展到使用…...

HTML实战项目:高考加油和中考加油
设计思路 页面加载后会自动显示高考内容,点击顶部按钮可以切换到中考内容。倒计时会每秒更新,为考生提供实时的备考时间参考。 使用代表希望的蓝色和金色渐变作为主色调 顶部导航栏可切换高考/中考内容 添加动态倒计时功能 设计励志名言卡片和备考小贴…...

Rk3568驱动开发_设备树点亮LED_11
代码: #include <linux/module.h> #include <linux/kernel.h> #include <linux/init.h> #include <linux/fs.h> #include <linux/slab.h> #include <linux/uaccess.h> #include <linux/io.h> #include <linux/cdev.h…...
多功能文档处理工具推荐
软件介绍 今天为大家介绍一款功能强大的文档编辑工具坤Tools,这是一款在吾爱论坛广受好评的办公软件。 软件背景 坤Tools是由吾爱论坛用户分享的软件,在论坛软件榜单上长期位居前列,获得了用户的一致好评。 软件性质 这是一款完全离线、…...

如何科学测量系统的最高QPS?
要准确测量系统的最高QPS(Queries Per Second),既不能简单依赖固定请求数(如2万次),也不能盲目压到服务器崩溃。以下是专业的方法论和步骤: 1. 核心原则 目标:找到系统在稳定运行&a…...

ORM 框架的优缺点分析
ORM 框架的优缺点分析 一、ORM 框架概述 ORM(Object-Relational Mapping)是一种将关系型数据库与面向对象编程进行映射的技术框架。它通过将数据库表映射为编程语言中的类,将记录映射为对象,将字段映射为属性,实现了用面向对象的方式操作数据库。 核心价值:ORM 在数据库和…...
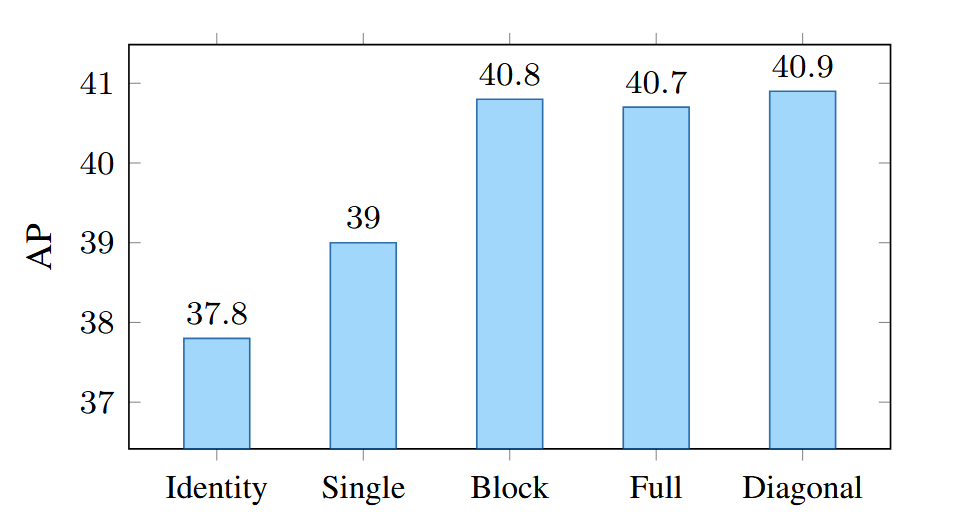
【目标检测】【ICCV 2021】条件式DETR实现快速训练收敛
Conditional DETR for Fast Training Convergence 条件式DETR实现快速训练收敛 代码链接 论文链接 摘要 最近提出的DETR方法将Transformer编码器-解码器架构应用于目标检测领域,并取得了显著性能。本文针对其训练收敛速度慢这一关键问题,提出了一种条…...
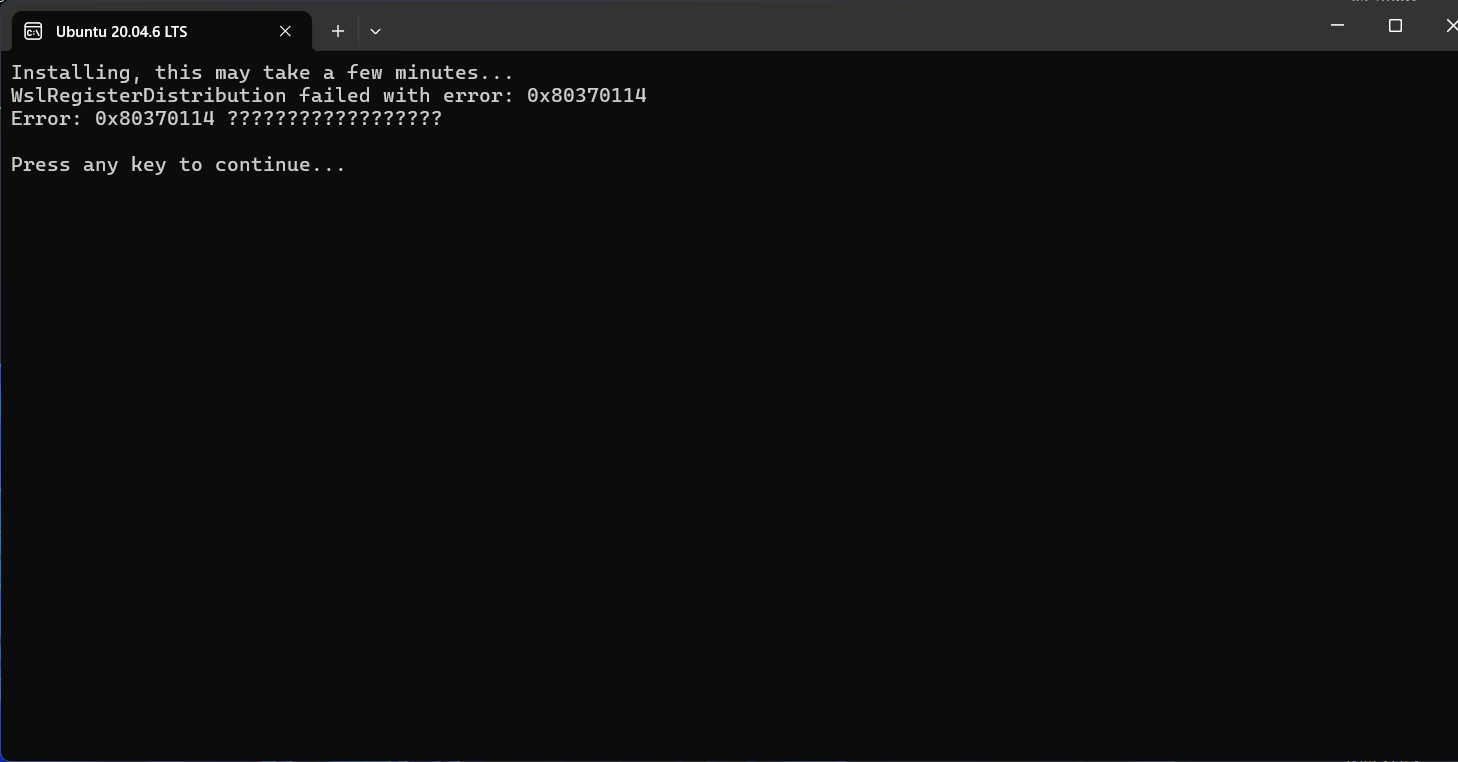
【工作笔记】 WSL开启报错
【工作笔记】 WSL开启报错 时间:2025年5月30日16:50:42 1.现象 Installing, this may take a few minutes... WslRegisterDistribution failed with error: 0x80370114 Error: 0x80370114 ??????????????????Press any key to continue......
VMware使用时出现的问题,此文章会不断更新分享使用过程中会出现的问题
VMware使用时出现的问题,此文章会不断更新分享使用过程中会出现的问题 一、VMware安装后没有虚拟网卡,VMnet1,VMnet8显示黄色三角警告 此文章会不断更新,分享VMware使用过程中出现的问题 如果没找到你的问题可以私信我 一、VMware…...

UniApp微信小程序自定义导航栏实现
UniApp微信小程序自定义导航栏 在UniApp开发微信小程序时,页面左上角默认有一个返回按钮(在导航栏左侧),但有时我们需要自定义这个按钮的样式和功能,同时保持与导航栏中间的标题和右侧胶囊按钮(药丸屏&…...

【Ubuntu】Ubuntu网络管理
Ubuntu 网络管理 ubuntu/debian 中的网络管理 NetworkManager,使用nmcli查询与操作网络配置 /run/NetworkManager/no-stub-resolv.conf 对应命令行例子: nmcli device showsystemd-networkd,使用netplan的yaml文件来配置网络 /usr/lib/systemd/systemd-networkdsystemd-resol…...
)
GitHub 趋势日报 (2025年05月27日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1Fosowl/agenticSeek完全本地的马努斯AI。没有API,没有200美元的每…...

VR视角下,浙西南革命的热血重生
VR 浙西南革命项目依托先进的 VR 技术,为浙西南革命历史的展示开辟了一条全新的道路 ,打破了时间与空间的限制,使革命历史变得触手可及。 (一)沉浸式体验革命场景 借助 VR 技术,在 VR 浙西南革命的展示…...

深入解析Kafka JVM堆内存:优化策略与监控实践
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...
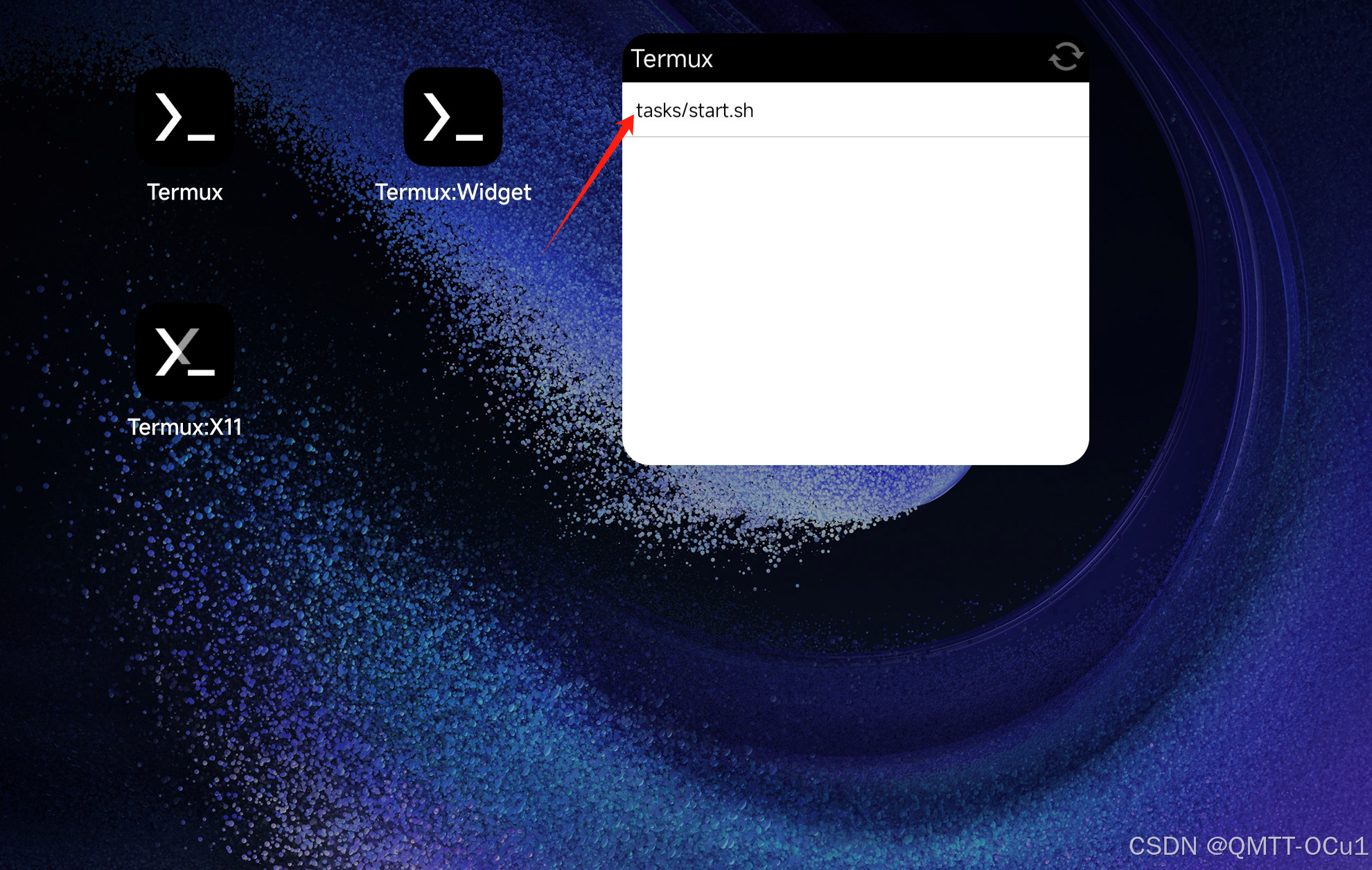
【高级终端Termux】在安卓手机/平板上使用Termux 搭建 Debian 环境并运行 PC 级 Linux 应用教程(含安装WPS,VS Code)
Termux 搭建 Debian 环境并运行 PC 级 Linux 应用教程 一、前言 1. 背景 众所周知,最新搭载澎湃OS和鸿蒙OS的平板都内置了PC级WPS,办公效率直接拉满(板子终于从“泡面盖”升级为“生产力”了)。但问题来了:如果不是这…...

基于BERT-Prompt的领域句子向量训练方法
基于BERT-Prompt的领域句子向量训练方法 一、核心原理:基于BERT-Prompt的领域句子向量训练方法 论文提出一种结合提示学习(Prompt Learning)和BERT的领域句子向量训练方法,旨在解决装备保障领域文本的语义表示问题。核心原理如下: 以下通过具体例子解释传统词向量方法和…...

高频面试--redis
Reids 1. 常见的数据结构(string, list, hash, set, zset) 答法模板: Redis 提供五种核心数据结构: String:最基本的类型,支持整数、自增、自减、位操作。 List:双端链表,支持消息…...
CRMEB 单商户Java版 v2.3公测版发布,欢迎体验!
当商城管理后台一成不变时,你是否也有过换换风格的想法? 当商城流量激增时,你是否也希望随时观察服务器负载状况,确保系统稳定运行? CRMEB单商户Java版v2.3公测版发布,更新200管理后台页面、弹窗…...
 本地YARN集群的部署)
(四) 本地YARN集群的部署
一、部署说明 Hadoop YARN分布式资源调度,会启动: ResourceManager进程作为管理节点NodeManager进程作为工作节点ProxyServer、JobHistoryServer这两个辅助节点 二、配置文件 在 $HADOOP_HOME/etc/hadoop 文件夹内,修改: 1.m…...

华为OD机试真题——求最多可以派出多少支队伍(2025A卷:100分)Java/python/JavaScript/C/C++/GO最佳实现
2025 A卷 100分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...
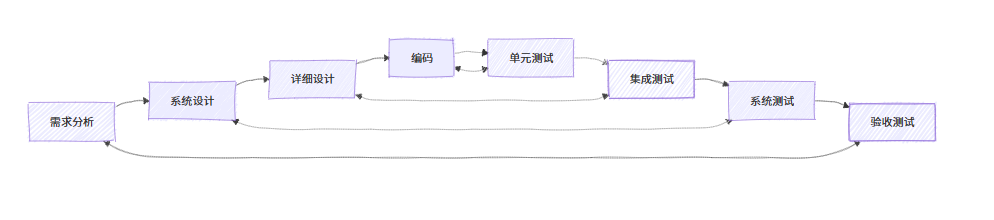
《软件工程》第 12 章 - 软件测试
软件测试是确保软件质量的关键环节,它通过执行程序来发现错误,验证软件是否满足需求。本章将依据目录,结合 Java 代码示例、可视化图表,深入讲解软件测试的概念、过程、方法及实践。 12.1 软件测试的概念 12.1.1 软件测试的任务 …...
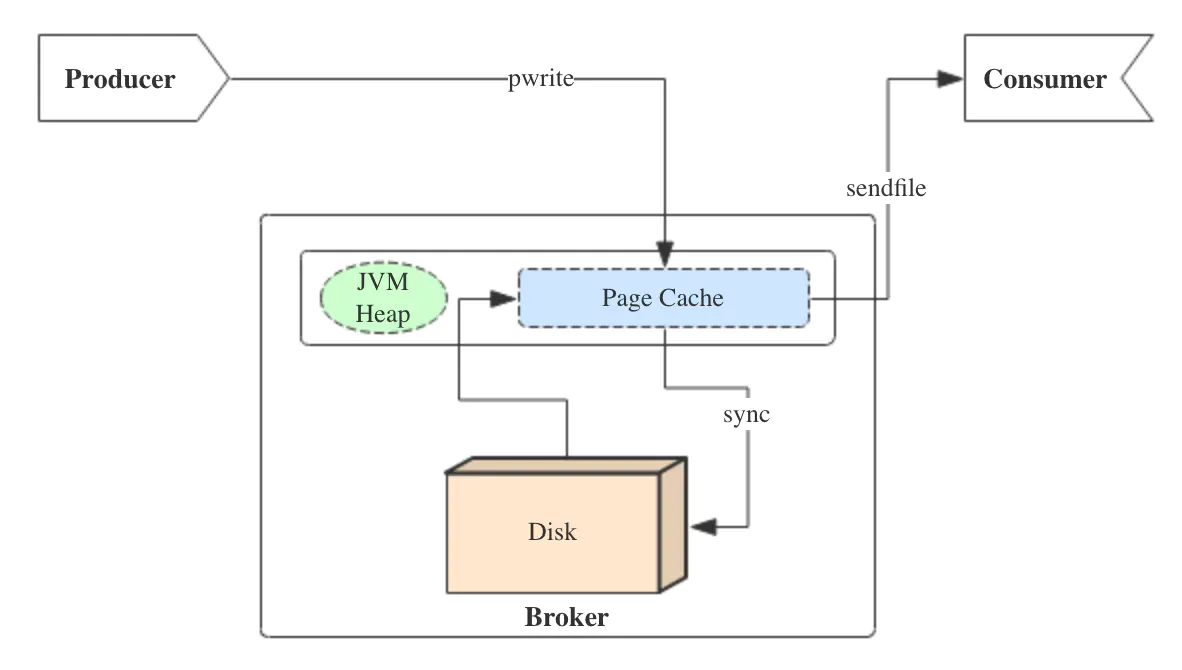
消息队列-kafka为例
目录 消息队列应用场景和基础知识MQ常见的应用场景MQ消息队列的两种消息模式如何保证消息队列的高可用?如何保证消息不丢失?如何保证消息不被重复消费?如何保证消息消费的幂等性?重复消费的原因解决方案 如何保证消息被消费的顺序…...

学习STC51单片机20(芯片为STC89C52RCRC)
每日一言 生活不会一帆风顺,但你的勇敢能让风浪变成风景。 串口助手的界面就等于是pc端的页面设置的是pc端的波特率等等参数 程序里面的是单片机的波特率等等参数 串口助手是 PC 端软件 串口助手(如 STC-ISP)是运行在 PC 上的工具&#x…...
链路追踪神器zipkin安装详细教程教程
今天分享下zipkin的详细安装教程,具体代码demo可以参考我上篇文章:Spring Cloud Sleuth与Zipkin深度整合指南:微服务链路追踪实战-CSDN博客 一、Zipkin是什么? Zipkin是由Twitter开源的一款分布式追踪系统(现由OpenZ…...

RabbitMQ备份与恢复技术详解:策略、工具与最佳实践
RabbitMQ作为广泛使用的消息中间件,其高可用性和数据持久化能力使其成为分布式系统的核心组件。然而,硬件故障、人为误操作或灾难性事件仍可能导致数据丢失或服务中断。因此,建立可靠的备份与恢复机制是运维工作的关键环节。本文基于RabbitMQ…...
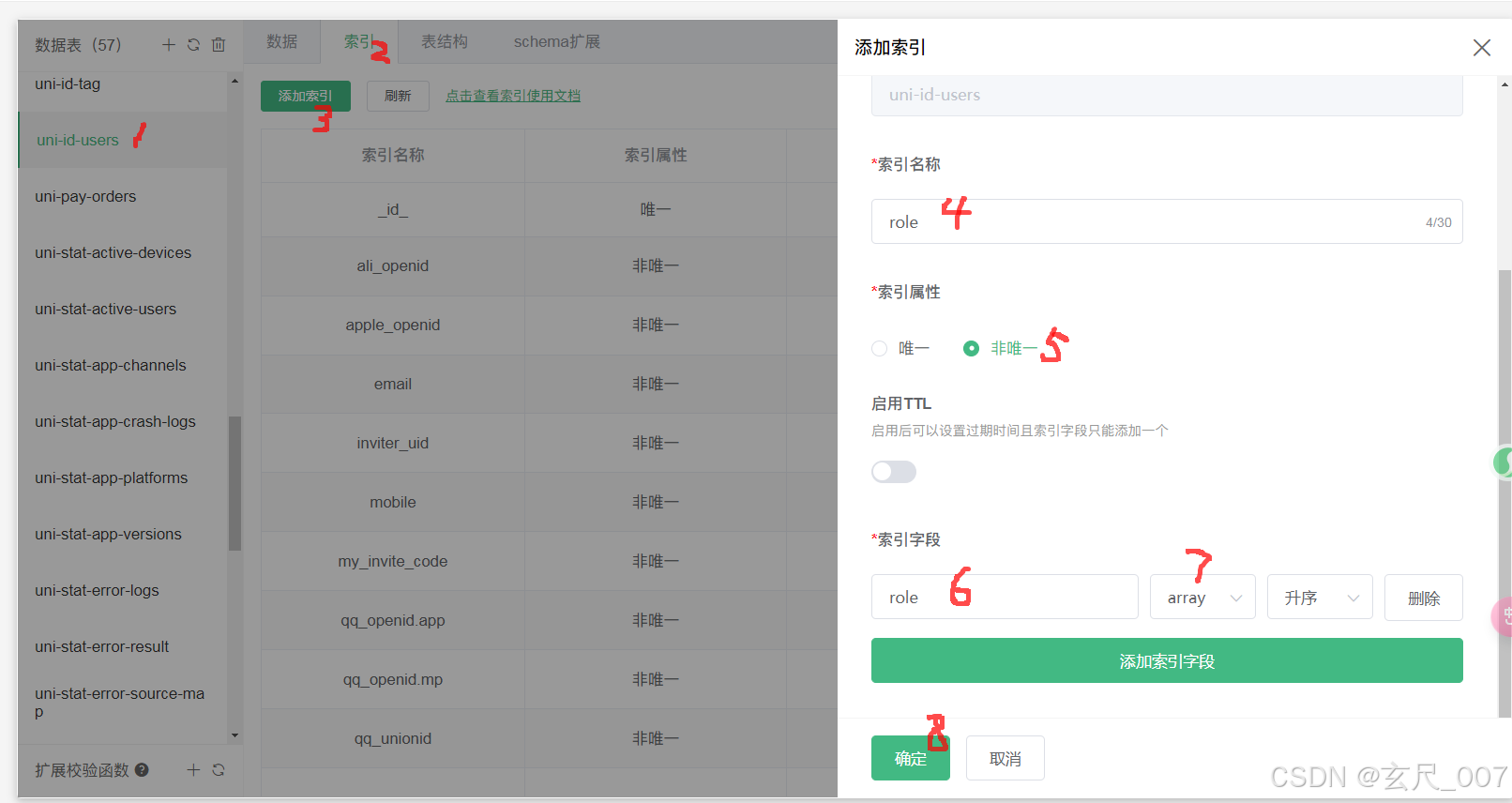
bug: uniCloud 查询数组字段失败
问题根源:使用了支付宝云 官方说:2024年11月之后创建的新的支付宝云空间,数组字段查询强制必须设置 array 类型的索引 布尔类型的查询,强制必须设置 bool 类型的索引。 方案一:找到云服务空间-》云数据库-》对应的表-…...

Php JIT 使用详解
简介 PHP 8 引入的 JIT(Just-In-Time 编译器) 是该版本的一个重要性能特性,首次让 PHP 有了运行时即时编译的能力,从解释型语言迈向了“编译执行”的方向。 什么是 JIT? JIT 是 即时编译(Just-In-Time c…...