针对Helsinki-NLP/opus-mt-zh-en模型进行双向互翻的微调
引言
题目听起来有点怪怪的,但是实际上就是对Helsinki-NLP/opus-mt-en-es模型进行微调。但是这个模型是单向的,只支持中到英的翻译,反之则不行。这样的话,如果要做中英双向互翻就需要两个模型,那模型体积直接大了两倍。尤其是部署到手机上,模型的体积是一个非常重要的考虑因素。于是自己就对这个模型的微调过程进行了一些改动,实现了单个模型进行双向互翻的能力。
原生模型
这里给出原生模型的使用方法:
from transformers import AutoModel , AutoTokenizer,MarianMTModeltext ="你好,你是谁?"
name ='Helsinki-NLP/opus-mt-zh-en'
tokenizer = AutoTokenizer.from_pretrained(name)
model = MarianMTModel.from_pretrained(name)
input_ids = tokenizer.encode(text, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded)
需要改动的地方
因为涉及到互翻,所以首先要告诉模型翻译的方向,具体就是在文本数据之前加一个目标语言的标识符,比如中翻英,原文“你好,你是谁?”,处理后就是“>>eng<< 你好,你是谁?”,英翻中则是“>>zho<< Hello,who are you?”
因此就引出了一个问题,词表vocab.json中并没有“>>eng<<”和“>>zho<<”,那么分词就会出现问题。我尝试过两种方法来解决:
- 首先是常规的解决办法,我最开始直接将这两个标识当做新的token加入词表中,最后也能跑通。这里只描述思想,具体的实现在下面的代码中会体现。
- 然后就是我自己想的非常规方法,为啥自己又想了非常规的方法呢,那是因为我在训练好模型之后,要将模型转换为CT2的格式,但是这个转换过程中因为添加了2个新token导致了报错,搞了一圈也没有解决,于是直接把词表中两个极其罕见的token给删除了,用两个语言标识替代,这样既不会对翻译产生大的影响,又能完成模型格式的转换。当然,这是需要先改词表后进行微调,顺序不能反了。
解决办法一
通过下面的代码微调之后,就能得到一个双向的翻译能力的模型了,使用的方法和原生模型一样,直接加载就能推理了。
import torch
import evaluate
import zhconv
from datasets import load_dataset, Dataset
import sacrebleu
import os
from transformers import (AutoTokenizer, MarianMTModel,Seq2SeqTrainer, Seq2SeqTrainingArguments,DataCollatorForSeq2Seq
)# 加载 tokenizer,并添加语言标签
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
special_tokens = [">>eng<<", ">>zho<<"]
tokenizer.add_special_tokens({"additional_special_tokens": special_tokens})# 加载模型,并扩展嵌入层大小
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
model.resize_token_embeddings(len(tokenizer))# 设置 token ID
model.config.eos_token_id = tokenizer.eos_token_id
model.config.pad_token_id = tokenizer.pad_token_id'''
加载 Tatoeba 数据集(中英句对)
这里我使用的是公开的数据集,可以通过下面的代码来加载到本地。加载到本地之后就可以把data_files换成你自己的地址
import kagglehub
alvations_tatoeba_path = kagglehub.dataset_download('alvations/tatoeba')
'''
tatoeba_dataset = load_dataset("csv",data_files="./data/tatoeba-sentpairs.tsv",delimiter="\t",encoding="utf-8",split="train"
)# 过滤中英句对(zh→en 和 en→zh)
zh2en_dataset = tatoeba_dataset.filter(lambda x: x['SRC LANG'] == "cmn" and x['TRG LANG'] == 'eng')
en2zh_dataset = tatoeba_dataset.filter(lambda x: x['SRC LANG'] == "eng" and x['TRG LANG'] == 'cmn')# 预处理函数:添加语言标签 + 分词
def preprocess_zh2en(batch):# 添加目标语言 tokeninputs = [">>eng<< " + x for x in batch['SRC']]# 可选:进行繁转简inputs = [zhconv.convert(x, 'zh-cn') for x in inputs]targets = batch['TRG']# 编码inputs_encoded = tokenizer(inputs, max_length=128, truncation=True, padding="max_length")outputs_encoded = tokenizer(targets, max_length=128, truncation=True, padding="max_length" )return {"input_ids": inputs_encoded["input_ids"],"attention_mask": inputs_encoded["attention_mask"],"decoder_input_ids": outputs_encoded["input_ids"],"decoder_attention_mask": outputs_encoded["attention_mask"],"labels": outputs_encoded["input_ids"].copy(), # labels 通常跟 decoder_input_ids 相同(训练时用于 loss)}def preprocess_en2zh(batch):# 添加目标语言 tokeninputs = [">>zho<< " + x for x in batch['SRC']]# 可选:进行繁转简targets = batch['TRG']targets = [zhconv.convert(x, 'zh-cn') for x in targets]# 编码inputs_encoded = tokenizer(inputs, max_length=128, truncation=True, padding="max_length")outputs_encoded = tokenizer(targets, max_length=128, truncation=True, padding="max_length" )return {"input_ids": inputs_encoded["input_ids"],"attention_mask": inputs_encoded["attention_mask"],"decoder_input_ids": outputs_encoded["input_ids"],"decoder_attention_mask": outputs_encoded["attention_mask"],"labels": outputs_encoded["input_ids"].copy(), # labels 通常跟 decoder_input_ids 相同(训练时用于 loss)}# 数据清洗 + 映射分词
zh2en_dataset = zh2en_dataset.map(preprocess_zh2en, batched=True)
en2zh_dataset = en2zh_dataset.map(preprocess_en2zh, batched=True)# 合并中→英和英→中双向数据
combined_dataset = Dataset.from_dict({key: zh2en_dataset[key] + en2zh_dataset[key] for key in zh2en_dataset.features
})# 拆分训练集和测试集
split_dataset = combined_dataset.train_test_split(test_size=0.1, seed=42)
train_dataset = split_dataset["train"]
eval_dataset = split_dataset["test"]def compute_metrics(pred):pred_ids = pred.predictionslabel_ids = pred.label_idspred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)label_ids[label_ids == -100] = tokenizer.pad_token_idlabel_str = tokenizer.batch_decode(label_ids, skip_special_tokens=True)bleu = sacrebleu.corpus_bleu(pred_str, [label_str])# 保存验证的结果到本地文件,这样可以实时查看微调的效果save_dir = "./eval_logs"os.makedirs(save_dir, exist_ok=True)eval_id = f"step_{trainer.state.global_step}" if hasattr(trainer, "state") else "eval"output_file = os.path.join(save_dir, f"pred_vs_ref_{eval_id}.txt")with open(output_file, "w", encoding="utf-8") as f:for i, (pred, ref) in enumerate(zip(pred_str, label_str)):f.write(f"Sample {i + 1}:\n")f.write(f"Prediction: {pred}\n")f.write(f"Reference : {ref}\n")f.write("=" * 50 + "\n")return {"bleu": bleu.score}# 训练参数
training_args = Seq2SeqTrainingArguments(output_dir='./model/marian-zh-en-bidirectional',num_train_epochs=30,per_device_train_batch_size=16,per_device_eval_batch_size=16,logging_steps=50,save_steps=100,eval_steps=100,eval_strategy="steps",predict_with_generate=True,save_total_limit=10,report_to="tensorboard", # 启用 TensorBoard 日志记录logging_dir='./logs', # 指定 TensorBoard 日志的保存路径
)# 构建 Trainer
trainer = Seq2SeqTrainer(model=model,args=training_args,train_dataset=train_dataset.with_format("torch"),eval_dataset=eval_dataset.with_format("torch"),tokenizer=tokenizer,data_collator=DataCollatorForSeq2Seq(tokenizer, model=model),compute_metrics=compute_metrics
)# 开始训练
trainer.train(resume_from_checkpoint=False)# 保存模型和 tokenizer
model.save_pretrained("./model/marian-zh-en-bidirectional")
tokenizer.save_pretrained("./model/marian-zh-en-bidirectional")解决办法二
上面是针对大众场景,具体的场景需要做具体的改动。本方法就是根据我的业务场景来修改的。
方法一训练得到的模型是使用tokenizer来编解码,因为目标语言标识符已经加入到词表里了,所以编解码没问题。但是我转为CT2格式之后,分词使用的是sentencepiece模型,具体就是用source.spm、target.spm分别对中文和英文进行分词,然后根据共享词表转换为token的id。 共享词表中是有语言标识符的,但是sentencepiece模型里却没有添加两个新token,所以就无法识别,导致分词错误。我的做法就是推理的时候先不加目标语言的标识符,先分词,然后手动加上去。这样分词就不会出问题了,然后进行编码就能根据共享词表来编码了。
还有一个问题就是,输入是中英混合的文本,这样sentencepiece分词器也无法正确识别,一个办法就是将中英文分开,分别进行分词,然后将分词的结果按顺序进行拼接。
最后,以上都是基于不重新训练分词模型的做法,如果可以重新训练分词模型,那么就不需要搞上面哪些操作了。
import torch
import evaluate
import zhconv
from datasets import load_dataset, Dataset
import sacrebleu
import os
from transformers import (AutoTokenizer, MarianMTModel,Seq2SeqTrainer, Seq2SeqTrainingArguments,DataCollatorForSeq2Seq
)# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-zh-en")# 加载模型
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-zh-en")# 设置 token ID
model.config.eos_token_id = tokenizer.eos_token_id
model.config.pad_token_id = tokenizer.pad_token_id'''
加载 Tatoeba 数据集(中英句对)
这里我使用的是公开的数据集,可以通过下面的代码来加载到本地。加载到本地之后就可以把data_files换成你自己的地址
import kagglehub
alvations_tatoeba_path = kagglehub.dataset_download('alvations/tatoeba')
'''
tatoeba_dataset = load_dataset("csv",data_files="./data/tatoeba-sentpairs.tsv",delimiter="\t",encoding="utf-8",split="train"
)# 过滤中英句对(zh→en 和 en→zh)
zh2en_dataset = tatoeba_dataset.filter(lambda x: x['SRC LANG'] == "cmn" and x['TRG LANG'] == 'eng')
en2zh_dataset = tatoeba_dataset.filter(lambda x: x['SRC LANG'] == "eng" and x['TRG LANG'] == 'cmn')# 预处理函数:添加语言标签 + 分词
def preprocess_zh2en(batch):# 添加目标语言 tokeninputs = [">>eng<< " + x for x in batch['SRC']]# 可选:进行繁转简inputs = [zhconv.convert(x, 'zh-cn') for x in inputs]targets = batch['TRG']# 编码inputs_encoded = tokenizer(inputs, max_length=128, truncation=True, padding="max_length")outputs_encoded = tokenizer(targets, max_length=128, truncation=True, padding="max_length" )return {"input_ids": inputs_encoded["input_ids"],"attention_mask": inputs_encoded["attention_mask"],"decoder_input_ids": outputs_encoded["input_ids"],"decoder_attention_mask": outputs_encoded["attention_mask"],"labels": outputs_encoded["input_ids"].copy(), # labels 通常跟 decoder_input_ids 相同(训练时用于 loss)}def preprocess_en2zh(batch):# 添加目标语言 tokeninputs = [">>zho<< " + x for x in batch['SRC']]# 可选:进行繁转简targets = batch['TRG']targets = [zhconv.convert(x, 'zh-cn') for x in targets]# 编码inputs_encoded = tokenizer(inputs, max_length=128, truncation=True, padding="max_length")outputs_encoded = tokenizer(targets, max_length=128, truncation=True, padding="max_length" )return {"input_ids": inputs_encoded["input_ids"],"attention_mask": inputs_encoded["attention_mask"],"decoder_input_ids": outputs_encoded["input_ids"],"decoder_attention_mask": outputs_encoded["attention_mask"],"labels": outputs_encoded["input_ids"].copy(), # labels 通常跟 decoder_input_ids 相同(训练时用于 loss)}# 数据清洗 + 映射分词
zh2en_dataset = zh2en_dataset.map(preprocess_zh2en, batched=True)
en2zh_dataset = en2zh_dataset.map(preprocess_en2zh, batched=True)# 合并中→英和英→中双向数据
combined_dataset = Dataset.from_dict({key: zh2en_dataset[key] + en2zh_dataset[key] for key in zh2en_dataset.features
})# 拆分训练集和测试集
split_dataset = combined_dataset.train_test_split(test_size=0.1, seed=42)
train_dataset = split_dataset["train"]
eval_dataset = split_dataset["test"]def compute_metrics(pred):pred_ids = pred.predictionslabel_ids = pred.label_idspred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)label_ids[label_ids == -100] = tokenizer.pad_token_idlabel_str = tokenizer.batch_decode(label_ids, skip_special_tokens=True)bleu = sacrebleu.corpus_bleu(pred_str, [label_str])# 保存验证的结果到本地文件,这样可以实时查看微调的效果save_dir = "./eval_logs"os.makedirs(save_dir, exist_ok=True)eval_id = f"step_{trainer.state.global_step}" if hasattr(trainer, "state") else "eval"output_file = os.path.join(save_dir, f"pred_vs_ref_{eval_id}.txt")with open(output_file, "w", encoding="utf-8") as f:for i, (pred, ref) in enumerate(zip(pred_str, label_str)):f.write(f"Sample {i + 1}:\n")f.write(f"Prediction: {pred}\n")f.write(f"Reference : {ref}\n")f.write("=" * 50 + "\n")return {"bleu": bleu.score}# 训练参数
training_args = Seq2SeqTrainingArguments(output_dir='./model/marian-zh-en-bidirectional',num_train_epochs=30,per_device_train_batch_size=16,per_device_eval_batch_size=16,logging_steps=50,save_steps=100,eval_steps=100,eval_strategy="steps",predict_with_generate=True,save_total_limit=10,report_to="tensorboard", # 启用 TensorBoard 日志记录logging_dir='./logs', # 指定 TensorBoard 日志的保存路径
)# 构建 Trainer
trainer = Seq2SeqTrainer(model=model,args=training_args,train_dataset=train_dataset.with_format("torch"),eval_dataset=eval_dataset.with_format("torch"),tokenizer=tokenizer,data_collator=DataCollatorForSeq2Seq(tokenizer, model=model),compute_metrics=compute_metrics
)# 开始训练
trainer.train(resume_from_checkpoint=False)# 保存模型和 tokenizer
model.save_pretrained("./model/marian-zh-en-bidirectional")
tokenizer.save_pretrained("./model/marian-zh-en-bidirectional")
基于训练好的模型我还搞了一套使用C++来推理的代码,方面在更多的平台使用,具体可以在github上搜"xinliu9451/Opus-Mt_Bidirectional_Translation"。
相关文章:

针对Helsinki-NLP/opus-mt-zh-en模型进行双向互翻的微调
引言 题目听起来有点怪怪的,但是实际上就是对Helsinki-NLP/opus-mt-en-es模型进行微调。但是这个模型是单向的,只支持中到英的翻译,反之则不行。这样的话,如果要做中英双向互翻就需要两个模型,那模型体积直接大了两倍…...
【笔记】Trae+Andrioid Studio+Kotlin开发安卓WebView应用
文章目录 简介依赖步骤AS(Andriod Studio)创建项目AS创建虚拟机TRAE CN 修改项目新增按键捕获功能 新增WebViewWebView加载本地资源在按键回调中向WebView注入JS代码 最终关键代码吐槽 简介 使用Trae配合Andriod Studio开发一个内嵌WebView的安卓应用, 在WebView中加载本地资源…...

Github 2025-05-30Java开源项目日报Top10
根据Github Trendings的统计,今日(2025-05-30统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Java项目10C++项目1TypeScript项目1Keycloak: 现代应用程序和服务的开源身份和访问管理解决方案 创建周期:3846 天开发语言:Java协议类型:Ap…...
Github上一些使用技巧(缩写、Issue的Highlight)自用
1. GIthub中的一些缩写 LGTM ! 最近经常看到一些迷之缩写,感觉挺有意思的,但是有时候看到一些没见过的缩写还是有点懵逼,不过缩写确实也是很方便去review,这里就记录汇总一下;顺便加了一些git的基操单词(加…...
TextIn OCR Frontend前端开源组件库发布!
为什么开源 TextIn OCR Frontend 前端组件库? 在 TextIn 社群中,我们时常接到用户反馈,调取 API 进行票据等文件批量识别后,需要另行完成前端工程,实现比对环节。为助力用户节省工程成本,TextIn 团队正式开…...
)
GitLens 教学(学习更新中)
GitLens 是什么? GitLens 是安装在 Visual Studio Code (VS Code) 中的一个功能极其强大的扩展程序,它直接内嵌在您的代码编辑器中,极大地增强了 VS Code 内置的 Git 功能。它的核心目标是: 深刻理解代码历史: 让您轻…...
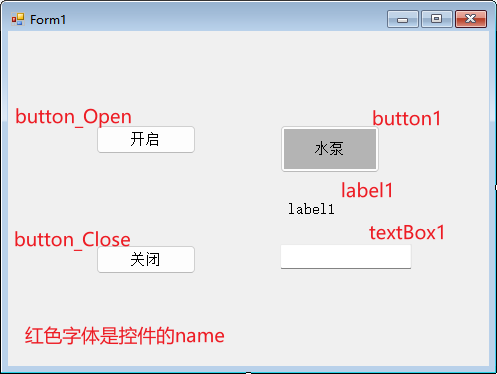
C#中数据绑定的简单例子
数据绑定允许将控件的属性和数据链接起来——控件属性值发生改变,会导致数据跟着自动改变。 数据绑定还可以是双向的——控件属性值发生改变,会导致数据跟着自动改变;数据发生改变,也会导致控件属性值跟着自动改变。 1、数据绑定…...
VR 技术在农业领域或许是一抹新曙光
在科技日新月异的今天,VR(虚拟现实)技术已不再局限于游戏、影视等娱乐范畴,正逐步渗透到各个传统行业,为其带来全新的发展契机,农业领域便是其中之一。VR 技术利用计算机生成三维虚拟世界,给予用户视觉、听觉、触觉等多…...
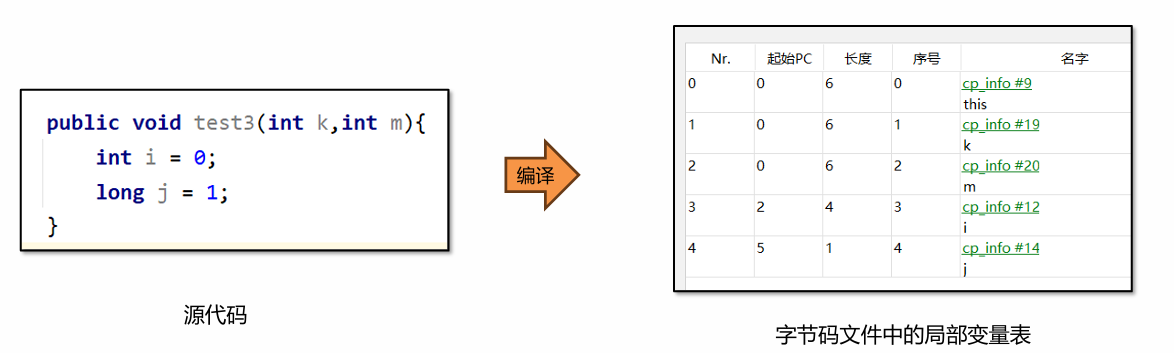
【JVM】Java程序运行时数据区
运行时数据区 运行时数据区是Java程序执行过程中管理的内存区域 Java 运行时数据区组成(JVM 内存结构) Java 虚拟机(JVM)的运行时数据区由以下核心部分组成: 线程私有:程序计数器、Java虚拟机栈、本地方…...

NVIDIA英伟达describe-anything软件本地电脑安装部署完整教程
describe-anything是英伟达联合其他大学开发的一款图片视频内容分析总结软件,可通过AI描述任意图片视频选中区域内容,非常强大,下面是describe-anything本地电脑安装部署教程。 首先电脑上安装git https://github.com/git-for-windows/git/…...

计算机视觉入门:OpenCV与YOLO目标检测
计算机视觉入门:OpenCV与YOLO目标检测 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 计算机视觉入门:OpenCV与YOLO目标检测摘要引言技术原理对比1. OpenCV:传统图像处理与机器学…...

Java 中的 ThreadLocal 详解:从基础到源码
Java 中的 ThreadLocal 详解:从基础到源码 引言 在 Java 多线程编程中,ThreadLocal是一个经常被提及的概念。它提供了一种线程局部变量的机制,使得每个线程都可以独立地存储和访问自己的变量副本,而不会与其他线程产生冲突。本文…...
开启深度学习动手之旅:先筑牢预备知识根基)
(二)开启深度学习动手之旅:先筑牢预备知识根基
1 数据操作 数据操作是深度学习的基础,包括数据的创建、索引、切片、运算等操作。这些操作是后续复杂模型构建和训练的前提。 入门 :理解如何使用NumPy创建数组,这是深度学习中数据存储的基本形式。掌握数组的属性(如数据类型dt…...

Spring Boot3.4.1 集成redis
Spring Boot3.4.1 集成redis 第一步 引入依赖 <!-- redis 缓存操作 --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <!-- pool 对象池 …...

【Prometheus+Grafana实战:搭建监控系统(含告警配置)】
什么是Prometheus和Grafana? Prometheus:一款开源的监控告警工具,擅长时序数据存储和多维度查询(通过PromQL),采用Pull模型主动抓取目标指标。Grafana:数据可视化平台,支持多种数据…...

操作系统原理第9章 磁盘存储器管理 重点内容
目录 (一)外存的组织方式种类 (二)FAT 系统(计算) (三)文件存储空间的管理方式 (一)外存的组织方式种类 连续组织方式 原理:在磁盘等外存上&…...
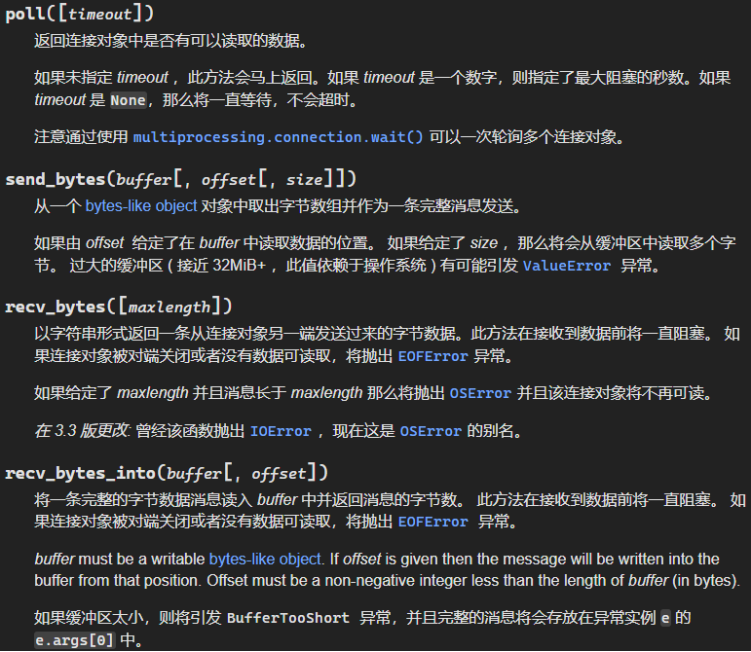
一文速通Python并行计算:11 Python多进程编程-进程之间的数据安全传输-基于队列和管道
一文速通 Python 并行计算:11 Python 多进程编程-进程之间的数据安全传输-基于队列和管道 摘要: Python 多进程中,Queue 和 Pipe 提供进程间安全通信。Queue 依赖锁和缓冲区,保障数据原子性和有序性;Pipe 实现点对点单…...
LangChain-Tool和Agent结合智谱AI大模型应用实例2
1.Tool(工具) 定义与功能 单一功能模块:Tool是完成特定任务的独立工具,每个工具专注于一项具体的操作,例如:搜索、计算、API调用等 无决策能力:工具本身不决定何时被调用,仅在被触发时执行预设操作 输入输出明确:每个工具需明确定义输入、输出参数及格式 2.Agent(…...

HTML、XML、JSON 是什么?有什么区别?又是做什么的?
在学习前端开发或者理解互联网工作原理的过程中,我们经常会遇到三个非常重要的概念:HTML、XML 和 JSON。它们看起来有点像,但其实干的事情完全不同。 🏁 一、他们是谁?什么时候诞生的? 名称全称诞生时间谁…...

C++中IO文件输入输出知识详解和注意事项
以下内容将从文件流类体系、打开模式、文本与二进制 I/O、随机访问、错误处理、性能优化等方面,详解 C 中文件输入输出的使用要点,并配以示例。 一、文件流类体系 C 标准库提供三种文件流类型,均定义在 <fstream> 中: std…...
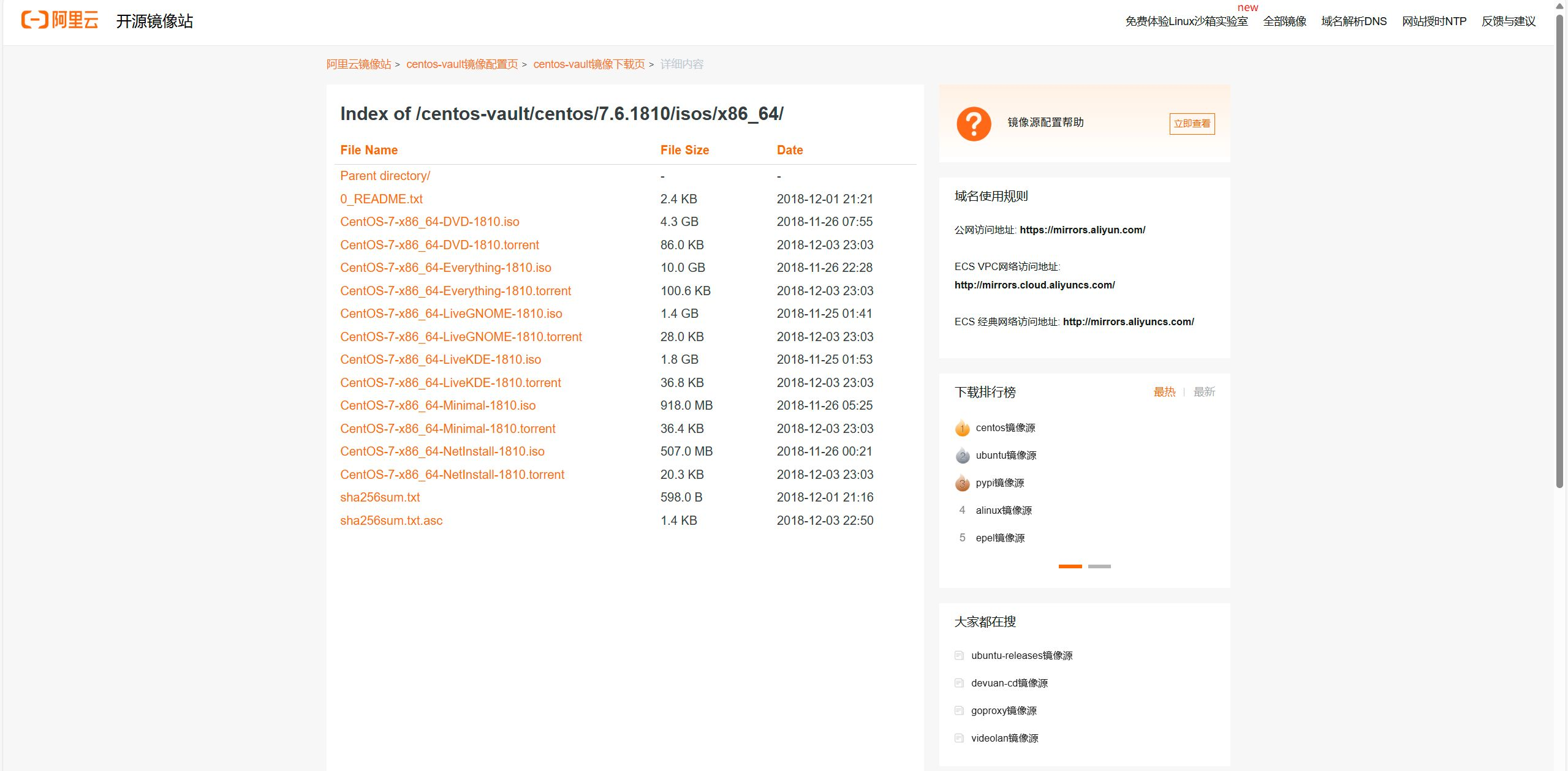
centos7.6阿里云镜像各个版本介绍
(水一期) Index of /centos-vault/centos/7.6.1810/isos/x86_64/ File NameFile SizeDateParent directory/--0_README.txt2.4 KB2018-12-01 21:21CentOS-7-x86_64-DVD-1810.iso4.3 GB2018-11-26 07:55CentOS-7-x86_64-DVD-1810.torrent86.0 KB2018-12-…...

InnoDB引擎逻辑存储结构及架构
简化理解版 想象 InnoDB 是一个高效运转的仓库: 核心内存区 (大脑 & 高速缓存 - 干活超快的地方) 缓冲池 Buffer Pool (最最核心!): 作用: 相当于仓库的“高频货架”。把最常用的数据(表数据、索引)从…...

KVM——CPU独占
文章目录 机器现况信息配置CPU独占(pin)启用 CPU 独占(隔离)验证 机器现况信息 [rootkvm-server ~]# virsh list --allId 名称 状态 --------------------------- CULinux-VM 关闭- ubuntu20.04 关闭- ubuntu24.04 关闭[roo…...
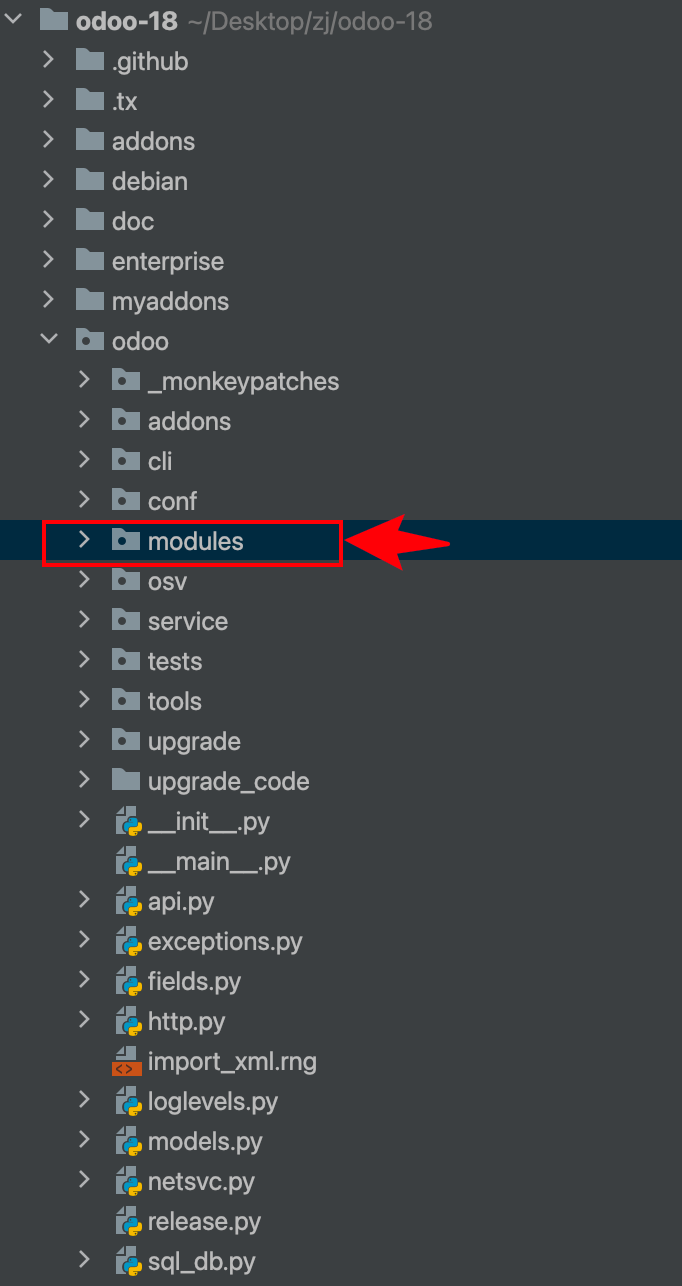
第4讲、Odoo 18 模块系统源码全解与架构深度剖析【modules】
引言 Odoo 是一款强大的开源企业资源规划(ERP)与客户关系管理(CRM)系统,其核心竞争力之一在于高度模块化的架构设计。模块系统不仅是 Odoo 框架的基石,更是实现功能灵活扩展与定制的关键。本文将结合 Odoo…...
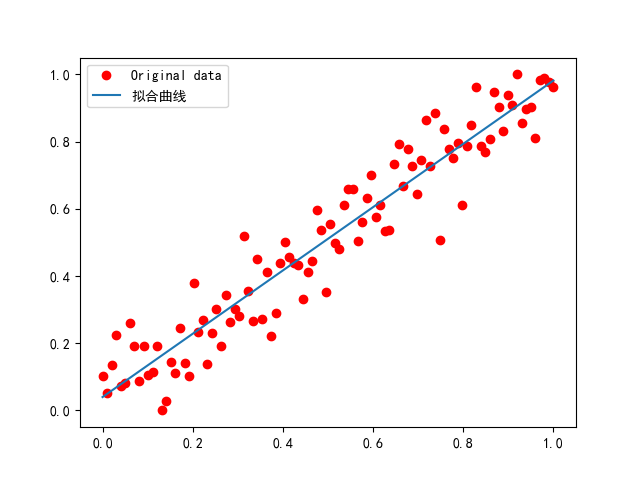
pytorch简单线性回归模型
模型五步走 1、获取数据 1. 数据预处理 2.归一化 3.转换为张量 2、定义模型 3、定义损失函数和优化器 4、模型训练 5、模型评估和调优 调优方法 6、可视化(可选) 示例代码 import torch import torch.nn as nn import numpy as np import matplot…...

在 HTML 文件中添加图片的常用方法
本文详解HTML图片插入方法:1)通过<img>标签实现,必须含src和alt属性;2)路径支持绝对/相对引用;3)建议设置width/height保持比例;4)响应式方案用srcset适配不同设备…...
四、web安全-行业术语
1. 肉鸡 所谓“肉鸡”是一种很形象的比喻,比喻那些可以随意被我们控制的电脑,对方可以是WINDOWS系统,也可以是UNIX/LINUX系统,可以是普通的个人电脑,也可以是大型的服务器,我们可以象操作自己的电脑那样来…...

Kafka核心技术解析与最佳实践指南
Apache Kafka作为分布式流处理平台的核心组件,以其高吞吐、低延迟和可扩展性成为现代数据架构的基石。本文基于Kafka官方文档,深度解析其核心技术原理,并结合实践经验总结关键技巧与最佳实践。 Kafka的高性能源于其精巧的架构设计࿰…...
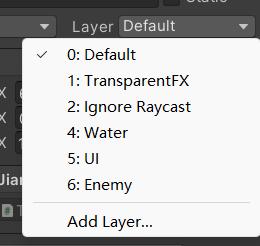
Unity基础学习(十二)Unity 物理系统之范围检测
目录 一、关于范围检测的主要API: 1. 盒状范围检测 Physics.OverlapBox 2. 球形范围检测 Physics.OverlapSphere 3. 胶囊范围检测 Physics.OverlapCapsule 4. 盒状检测 NonAlloc 版 5. 球形检测 NonAlloc 版 6. 胶囊检测 NonAlloc 版 二、关于API中的两个重…...
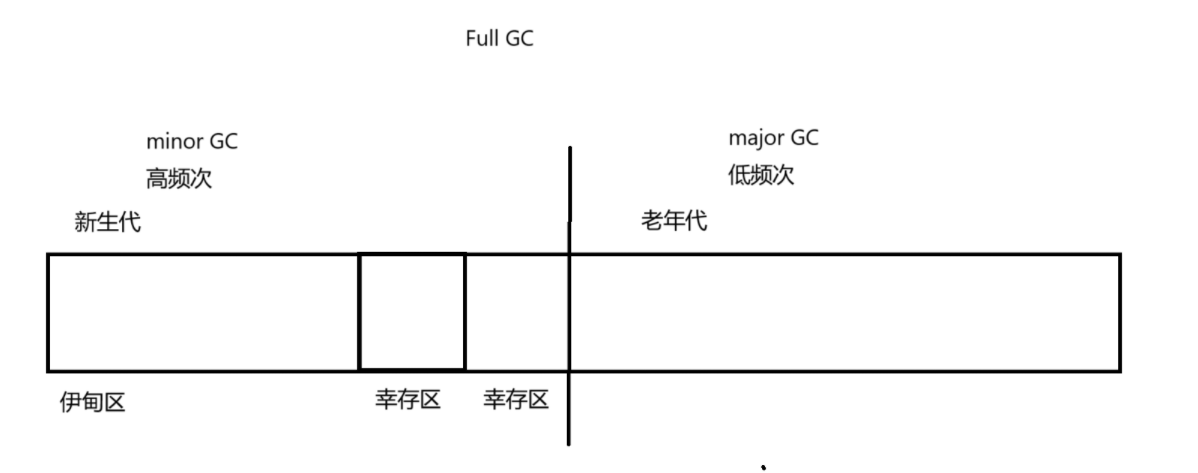
JVM 的垃圾回收机制 GC
C/C 这样的编程语言中,申请内存的时候,是需要用完了,进行手动释放的 C 申请内存 1)局部变量(不需要手动释放) 2)全局变量(不需要手动释放) 3)动态申请 malloc(通过 free 进行释放的) C 申请内存 1)局部变量 2)全局变量/静态变量 3)动态申请 new 通过 delete 进行释放 …...