(二)开启深度学习动手之旅:先筑牢预备知识根基
1 数据操作
数据操作是深度学习的基础,包括数据的创建、索引、切片、运算等操作。这些操作是后续复杂模型构建和训练的前提。
- 入门 :理解如何使用NumPy创建数组,这是深度学习中数据存储的基本形式。掌握数组的属性(如数据类型dtype和形状shape)对后续操作至关重要。
- 运算符 :学会对数组进行基本运算,这是数据变换和特征工程的基础。理解广播机制能让你更灵活地处理形状不同的数组运算。
- 索引和切片 :精准提取数据的能力在数据预处理和分析中非常关键,例如提取特定样本或特征。
- 节省内存 :理解内存共享机制能帮助你更高效地处理大数据集,避免不必要的内存占用。
- 转换为其他Python对象 :有时需要将数组转换为列表等其他形式以便于与其他Python库或函数配合使用。
1.1 入门
数据操作是深度学习的基础,通常使用NumPy库来创建和操作数组。使用NumPy创建和操作数组:
import numpy as np# 创建数组
data = np.array([[1, 2, 3], [4, 5, 6]])# 打印数据
print("数据类型:", data.dtype)
print("数据形状:", data.shape)
print("数据内容:\n", data)
1.2 运算符
对数组进行基本的数学运算,包括加法、减法、乘法、除法等。
# 基本运算
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])print("加法:", a + b)
print("减法:", a - b)
print("乘法:", a * b)
print("除法:", a / b)
1.3 广播机制
广播机制允许形状不同的数组进行运算,较小的数组会在较大的数组上广播。
# 广播机制
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([1, 2, 3])print("广播加法:\n", a + b)
1.4 索引和切片
索引和切片操作用于提取数组中的特定元素或子数组。对数组进行索引和切片操作:
# 索引和切片
data = np.array([[1, 2, 3], [4, 5, 6]])print("第一行:", data[0, :])
print("第一列:", data[:, 0])
1.5 节省内存
通过共享内存的方式节省内存,避免数据的复制:
# 节省内存
data = np.array([[1, 2, 3], [4, 5, 6]])
data_view = data[:2, :2]print("原数据:\n", data)
print("视图:\n", data_view)
1.6 转换为其他Python对象
将数组转换为其他Python对象,如列表:
# 转换为其他Python对象
data = np.array([1, 2, 3])
data_list = data.tolist()print("列表:", data_list)
2 数据预处理
数据预处理是深度学习中的重要步骤,包括读取数据集、处理缺失值、转换为张量等。数据预处理的目的是将原始数据转化为适合模型训练的形式,提高模型的性能和泛化能力。
- 读取数据集 :这是数据预处理的第一步,正确读取和加载数据是后续所有操作的基础。
- 处理缺失值 :缺失值会影响模型训练,学会合理处理(如删除或填充)是保证数据质量的关键。
- 转换为张量 :深度学习框架中的张量是模型训练的基本数据形式,掌握这一转换过程是使用深度学习框架的前提。
2.1 读取数据集
读取数据集是数据预处理的第一步,通常使用Pandas库来读取CSV文件:
import pandas as pd# 读取CSV文件
data = pd.read_csv('data.csv')# 查看数据
print(data.head())
2.2 处理缺失值
处理缺失值是数据预处理的重要步骤,可以删除缺失值或用特定值填充:
# 处理缺失值
data = data.dropna() # 删除缺失值
data = data.fillna(0) # 填充缺失值为0
2.3 转换为张量
将数据转换为深度学习框架中的张量,以便进行后续的训练和推理:
import torch# 转换为张量
data_array = data.values
data_tensor = torch.from_numpy(data_array)print("张量:\n", data_tensor)
3 线性代数
线性代数是深度学习的数学基础,包括标量、向量、矩阵、张量等概念。线性代数提供了深度学习中数据表示和操作的数学工具,是理解模型结构和算法的基础。
- 标量、向量、矩阵、张量 :这些是线性代数的基本元素,它们构成了深度学习中数据的各种表示形式,理解它们的维度和结构对于后续学习至关重要。
- 张量算法的基本性质 :掌握张量的基本操作(如加法、点积、矩阵乘法等)是理解模型内部计算逻辑的基础。
- 降维 :在处理高维数据时,降维操作有助于减少计算复杂度并去除冗余信息。
- 范数 :范数提供了衡量向量或矩阵大小的工具,常用于损失函数和正则化项中。
3.1 标量
标量是一个单独的数值,是0维张量:
# 标量
scalar = np.array(5)
print("标量:", scalar)
3.2 向量
向量是一维数组,是1维张量:
# 向量
vector = np.array([1, 2, 3])
print("向量:", vector)
3.3 矩阵
矩阵是二维数组,是2维张量:
# 矩阵
matrix = np.array([[1, 2, 3], [4, 5, 6]])
print("矩阵:\n", matrix)
3.4 张量
张量是多维数组,可以表示任意维度的数据:
# 张量
tensor = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
print("张量:\n", tensor)
3.5 张量算法的基本性质
张量算法包括加法、点积、矩阵乘法等基本操作:
# 张量操作
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])print("加法:", a + b)
print("点积:", np.dot(a, b))
3.6 降维
降维操作用于减少张量的维度,通常用于数据简化:
# 降维
data = np.array([[1, 2, 3], [4, 5, 6]])
print("降维后的数据:", np.sum(data, axis=1))
3.7 点积
点积是两个向量的内积,结果是一个标量:
# 点积
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])print("点积:", np.dot(a, b))
3.8 矩阵-向量积
矩阵-向量积是矩阵和向量的乘积,结果是一个向量:
# 矩阵-向量积
matrix = np.array([[1, 2, 3], [4, 5, 6]])
vector = np.array([1, 2, 3])print("矩阵-向量积:", np.dot(matrix, vector))
3.9 矩阵-矩阵乘法
矩阵-矩阵乘法是两个矩阵的乘积,结果是一个矩阵:
# 矩阵-矩阵乘法
matrix1 = np.array([[1, 2], [3, 4]])
matrix2 = np.array([[5, 6], [7, 8]])print("矩阵-矩阵乘法:\n", np.dot(matrix1, matrix2))
3.10 范数
范数是衡量张量大小的指标,常见的有L1范数和L2范数:
# 范数
data = np.array([1, 2, 3])print("L1范数:", np.linalg.norm(data, ord=1))
print("L2范数:", np.linalg.norm(data, ord=2))
4 微积分
微积分是深度学习中优化算法的数学基础。微积分是优化算法的理论基础,帮助我们理解模型训练过程中参数如何更新以最小化损失函数。
- 导数和微分 :导数描述了函数在某一点的变化率,是优化算法中计算梯度的基础。
- 偏导数和梯度 :在多变量函数中,偏导数和梯度指导我们如何调整多个参数以优化目标函数。
- 链式法则 :这是计算复合函数导数的关键法则,在神经网络的反向传播算法中发挥着核心作用。
4.1 导数和微分
导数是函数在某一点的瞬时变化率,微分是导数的另一种表达方式:
import sympy as sp# 定义变量和函数
x = sp.symbols('x')
f = x**2 + 3*x + 2# 计算导数
df = sp.diff(f, x)print("导数:", df)
4.2 偏导数
偏导数是多元函数对某一变量的导数,其他变量视为常数:
# 偏导数
x, y = sp.symbols('x y')
f = x**2 + y**2df_dx = sp.diff(f, x)
df_dy = sp.diff(f, y)print("偏导数对x:", df_dx)
print("偏导数对y:", df_dy)
4.3 梯度
梯度是多元函数在某一点的导数向量,指向函数增长最快的方向:
# 梯度
x, y = sp.symbols('x y')
f = x**2 + y**2gradient = [sp.diff(f, var) for var in (x, y)]print("梯度:", gradient)
4.4 链式法则
链式法则是计算复合函数导数的法则,常用于神经网络的反向传播:
# 链式法则
x = sp.symbols('x')
f = sp.sin(x**2)df = sp.diff(f, x)print("导数:", df)
5 自动微分
自动微分是深度学习框架中用于计算梯度的关键技术。也是深度学习框架自动计算梯度的技术,极大地简化了模型训练过程中的梯度计算。
- 自动微分机制 :理解自动微分如何通过记录操作并应用链式法则计算梯度,有助于更高效地训练复杂模型。
- 分离计算 :在训练过程中合理分离计算,避免梯度累积,是正确更新模型参数的重要步骤。
5.1 一个简单的例子
自动微分通过跟踪操作记录自动计算梯度,使用PyTorch计算梯度:
# 自动微分
import torchx = torch.tensor(2.0, requires_grad=True)
y = x**2 + 3*x + 2y.backward()
print("梯度:", x.grad)
5.2 非标量变量的反向传播
非标量变量的反向传播需要计算梯度的总和,计算非标量变量的梯度:
# 非标量变量的反向传播
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x**2y.sum().backward()
print("梯度:", x.grad)
5.3 分离计算
分离计算用于避免梯度累积,通常在训练循环中使用,分离计算以避免梯度累积:
# 分离计算
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x**2y.sum().backward()
print("梯度:", x.grad)x.grad.zero_() # 清空梯度y = x**2
y.sum().backward()
print("梯度:", x.grad)
5.4 Python控制流的梯度计算
在控制流中计算梯度需要考虑条件分支和循环的影响,在控制流中计算梯度:
# Python控制流的梯度计算
def function(x):if x.sum() > 0:return x**2else:return xx = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = function(x)
y.sum().backward()
print("梯度:", x.grad)
6 概率
概率是深度学习中处理不确定性的数学工具。在深度学习中用于建模数据分布和不确定性。
- 基本概率论 :理解概率分布、期望和方差等概念,有助于分析模型的输出和不确定性。
- 处理多个随机变量 :掌握联合概率和条件概率,对于理解数据中变量之间的关系至关重要。
6.1 基本概率论
概率论研究随机现象的统计规律,包括概率分布、期望、方差等。计算概率分布:
import numpy as np# 概率分布
probabilities = np.array([0.1, 0.2, 0.3, 0.4])
print("概率和:", np.sum(probabilities))
6.2 处理多个随机变量
多个随机变量的联合概率和条件概率用于描述变量之间的关系。计算联合概率和条件概率:
# 联合概率
joint_prob = np.array([[0.1, 0.2], [0.3, 0.4]])
print("联合概率和:", np.sum(joint_prob))# 条件概率
cond_prob = joint_prob[0, :] / np.sum(joint_prob[0, :])
print("条件概率:", cond_prob)
6.3 期望和方差
期望是随机变量的平均值,方差是随机变量的离散程度。计算期望和方差:
# 期望和方差
data = np.array([1, 2, 3, 4, 5])
mean = np.mean(data)
variance = np.var(data)print("期望:", mean)
print("方差:", variance)
7 查阅文档
查阅深度学习框架的文档以获取更多信息。能够高效地查阅深度学习框架的文档是自主学习和解决问题的关键技能。
7.1 查找模块中的所有函数和类
通过Python的 dir() 函数可以查看模块中的所有函数和类。查找模块中的所有函数和类:
import numpy as np# 查找模块中的所有函数和类
print(dir(np))
7.2 查找特定函数和类的用法
通过Python的 help() 函数可以查看特定函数和类的用法。查找特定函数和类的用法:
# 查找特定函数和类的用法
help(np.array)
通过对这些概念的深入理解,你可以更系统地掌握深度学习的预备知识,并为后续学习深度学习模型和算法打下坚实的基础。这些概念和技能将贯穿于深度学习的各个环节,帮助你更好地理解和应用相关技术。
相关文章:
开启深度学习动手之旅:先筑牢预备知识根基)
(二)开启深度学习动手之旅:先筑牢预备知识根基
1 数据操作 数据操作是深度学习的基础,包括数据的创建、索引、切片、运算等操作。这些操作是后续复杂模型构建和训练的前提。 入门 :理解如何使用NumPy创建数组,这是深度学习中数据存储的基本形式。掌握数组的属性(如数据类型dt…...

Spring Boot3.4.1 集成redis
Spring Boot3.4.1 集成redis 第一步 引入依赖 <!-- redis 缓存操作 --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <!-- pool 对象池 …...

【Prometheus+Grafana实战:搭建监控系统(含告警配置)】
什么是Prometheus和Grafana? Prometheus:一款开源的监控告警工具,擅长时序数据存储和多维度查询(通过PromQL),采用Pull模型主动抓取目标指标。Grafana:数据可视化平台,支持多种数据…...

操作系统原理第9章 磁盘存储器管理 重点内容
目录 (一)外存的组织方式种类 (二)FAT 系统(计算) (三)文件存储空间的管理方式 (一)外存的组织方式种类 连续组织方式 原理:在磁盘等外存上&…...
一文速通Python并行计算:11 Python多进程编程-进程之间的数据安全传输-基于队列和管道
一文速通 Python 并行计算:11 Python 多进程编程-进程之间的数据安全传输-基于队列和管道 摘要: Python 多进程中,Queue 和 Pipe 提供进程间安全通信。Queue 依赖锁和缓冲区,保障数据原子性和有序性;Pipe 实现点对点单…...
LangChain-Tool和Agent结合智谱AI大模型应用实例2
1.Tool(工具) 定义与功能 单一功能模块:Tool是完成特定任务的独立工具,每个工具专注于一项具体的操作,例如:搜索、计算、API调用等 无决策能力:工具本身不决定何时被调用,仅在被触发时执行预设操作 输入输出明确:每个工具需明确定义输入、输出参数及格式 2.Agent(…...

HTML、XML、JSON 是什么?有什么区别?又是做什么的?
在学习前端开发或者理解互联网工作原理的过程中,我们经常会遇到三个非常重要的概念:HTML、XML 和 JSON。它们看起来有点像,但其实干的事情完全不同。 🏁 一、他们是谁?什么时候诞生的? 名称全称诞生时间谁…...

C++中IO文件输入输出知识详解和注意事项
以下内容将从文件流类体系、打开模式、文本与二进制 I/O、随机访问、错误处理、性能优化等方面,详解 C 中文件输入输出的使用要点,并配以示例。 一、文件流类体系 C 标准库提供三种文件流类型,均定义在 <fstream> 中: std…...
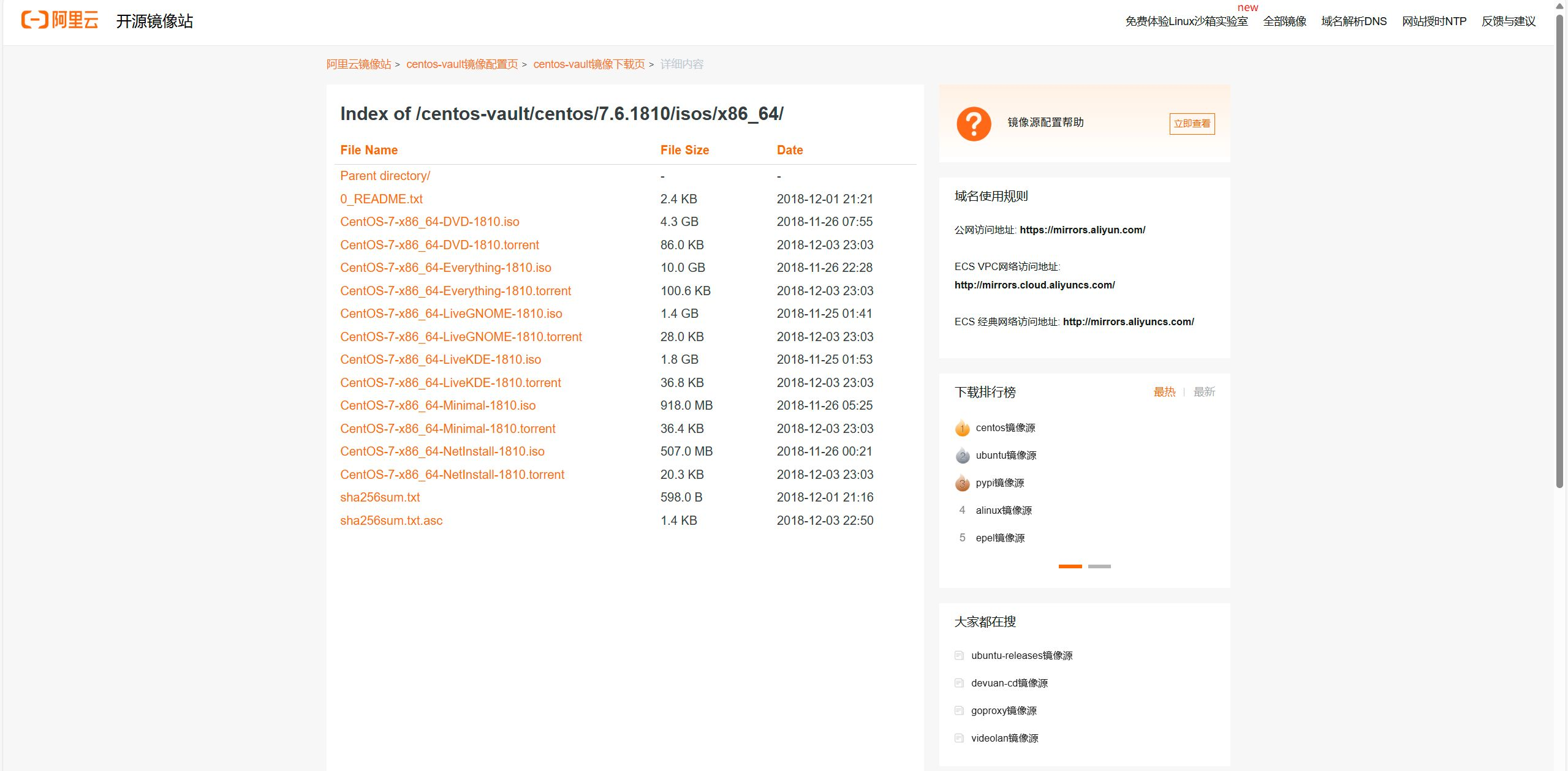
centos7.6阿里云镜像各个版本介绍
(水一期) Index of /centos-vault/centos/7.6.1810/isos/x86_64/ File NameFile SizeDateParent directory/--0_README.txt2.4 KB2018-12-01 21:21CentOS-7-x86_64-DVD-1810.iso4.3 GB2018-11-26 07:55CentOS-7-x86_64-DVD-1810.torrent86.0 KB2018-12-…...

InnoDB引擎逻辑存储结构及架构
简化理解版 想象 InnoDB 是一个高效运转的仓库: 核心内存区 (大脑 & 高速缓存 - 干活超快的地方) 缓冲池 Buffer Pool (最最核心!): 作用: 相当于仓库的“高频货架”。把最常用的数据(表数据、索引)从…...

KVM——CPU独占
文章目录 机器现况信息配置CPU独占(pin)启用 CPU 独占(隔离)验证 机器现况信息 [rootkvm-server ~]# virsh list --allId 名称 状态 --------------------------- CULinux-VM 关闭- ubuntu20.04 关闭- ubuntu24.04 关闭[roo…...
第4讲、Odoo 18 模块系统源码全解与架构深度剖析【modules】
引言 Odoo 是一款强大的开源企业资源规划(ERP)与客户关系管理(CRM)系统,其核心竞争力之一在于高度模块化的架构设计。模块系统不仅是 Odoo 框架的基石,更是实现功能灵活扩展与定制的关键。本文将结合 Odoo…...
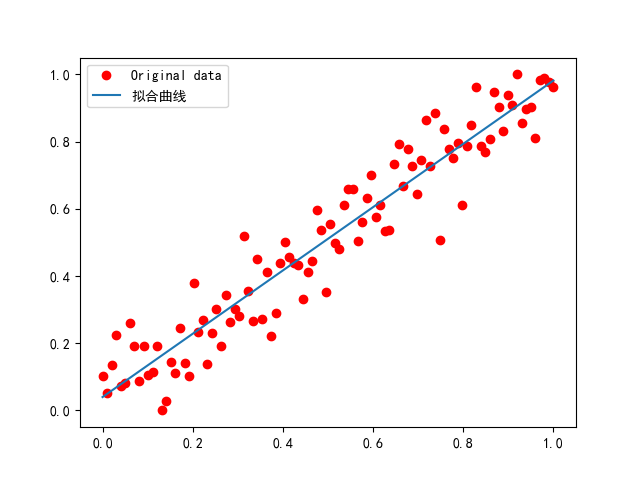
pytorch简单线性回归模型
模型五步走 1、获取数据 1. 数据预处理 2.归一化 3.转换为张量 2、定义模型 3、定义损失函数和优化器 4、模型训练 5、模型评估和调优 调优方法 6、可视化(可选) 示例代码 import torch import torch.nn as nn import numpy as np import matplot…...

在 HTML 文件中添加图片的常用方法
本文详解HTML图片插入方法:1)通过<img>标签实现,必须含src和alt属性;2)路径支持绝对/相对引用;3)建议设置width/height保持比例;4)响应式方案用srcset适配不同设备…...
四、web安全-行业术语
1. 肉鸡 所谓“肉鸡”是一种很形象的比喻,比喻那些可以随意被我们控制的电脑,对方可以是WINDOWS系统,也可以是UNIX/LINUX系统,可以是普通的个人电脑,也可以是大型的服务器,我们可以象操作自己的电脑那样来…...

Kafka核心技术解析与最佳实践指南
Apache Kafka作为分布式流处理平台的核心组件,以其高吞吐、低延迟和可扩展性成为现代数据架构的基石。本文基于Kafka官方文档,深度解析其核心技术原理,并结合实践经验总结关键技巧与最佳实践。 Kafka的高性能源于其精巧的架构设计࿰…...
Unity基础学习(十二)Unity 物理系统之范围检测
目录 一、关于范围检测的主要API: 1. 盒状范围检测 Physics.OverlapBox 2. 球形范围检测 Physics.OverlapSphere 3. 胶囊范围检测 Physics.OverlapCapsule 4. 盒状检测 NonAlloc 版 5. 球形检测 NonAlloc 版 6. 胶囊检测 NonAlloc 版 二、关于API中的两个重…...
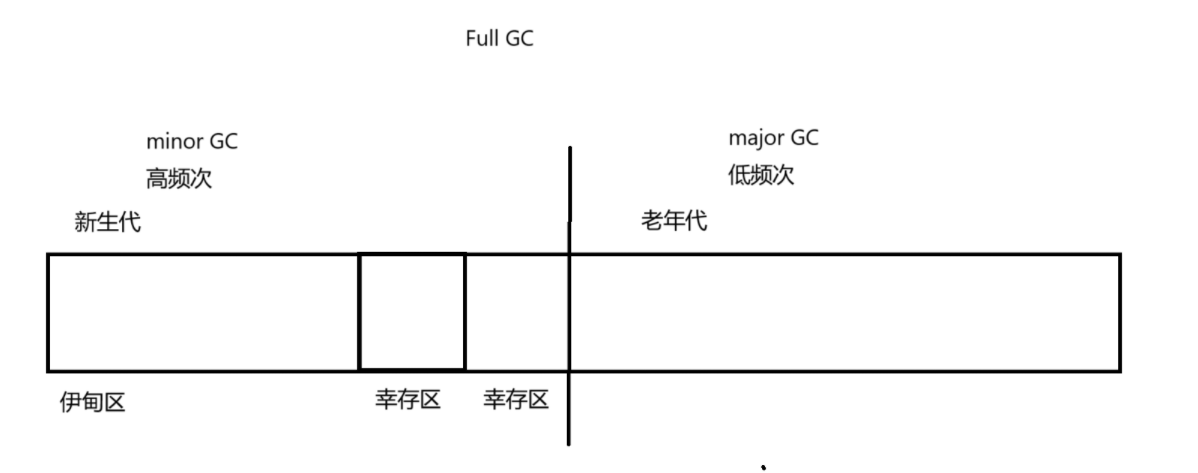
JVM 的垃圾回收机制 GC
C/C 这样的编程语言中,申请内存的时候,是需要用完了,进行手动释放的 C 申请内存 1)局部变量(不需要手动释放) 2)全局变量(不需要手动释放) 3)动态申请 malloc(通过 free 进行释放的) C 申请内存 1)局部变量 2)全局变量/静态变量 3)动态申请 new 通过 delete 进行释放 …...

TypeScript 针对 iOS 不支持 JIT 的优化策略总结
# **TypeScript 针对 iOS 不支持 JIT 的优化策略总结** 由于 iOS 的 **JavaScriptCore (JSC)** 引擎 **禁用 JIT(Just-In-Time 编译)**,JavaScript 在 iOS 上的执行性能较差,尤其是涉及动态代码时。 **TypeScript(T…...

00 QEMU源码中文注释与架构讲解
QEMU源码中文注释与架构讲解 先占坑:等后续完善后再更新此文章 注释作者将狼才鲸创建日期2025-05-30更新日期NULL CSDN阅读地址:00 QEMU源码中文注释与架构讲解Gitee源码仓库地址:才鲸嵌入式/qemu 一、前言 参考网址 QEMU 源码目录简介qe…...

ansible template 文件中如果包含{{}} 等非ansible 变量处理
在 Ansible 模板中,如果你的 Python 脚本里有大量 {}、f""、或者其他 Jinja 会误解析的语法,就需要用 {% raw %}…{% endraw %} 把它们包起来,只在需要替换变量的那一行单独“放行”。例如: {% raw %} #!/usr/bin/env …...
)
Screen 连接远程服务器(Ubuntu)
连接 1. 安装screen 默认预安装,可以通过命令查看: screen --version 若未安装: # Ubuntu/Debian sudo apt-get install screen 2. 本机连接远程服务器 ssh root192.168.x.x 在远程服务器中打开screen: screen -S <nam…...

路由器、网关和光猫三种设备有啥区别?
无论是家中Wi-Fi信号的覆盖,还是企业网络的高效运行,路由器、网关和光猫这些设备都扮演着不可或缺的角色。然而,对于大多数人来说,这三者的功能和区别却像一团迷雾,似懂非懂。你是否曾疑惑,为什么家里需要光…...

vscode实时预览编辑markdown
vscode实时预览编辑markdown 点击vsode界面,实现快捷键如下: 按下快捷键 CtrlShiftV(Windows/Linux)或 CommandShiftV(Mac)即可在侧边栏打开 Markdown 预览。 效果如下:...
2505软考高项第一、二批真题终极汇总
第一批2025.05综合题(75道选择题) 1、2025 年中央一号文件对进一步深化农村改革的各项任务作出全面部署。“推进农业科技力量协同攻关”的相关措施不包括()。 A.强化农业科研资源力量统筹,培育农业科技领军企业 B.发挥农业科研平台作用&…...
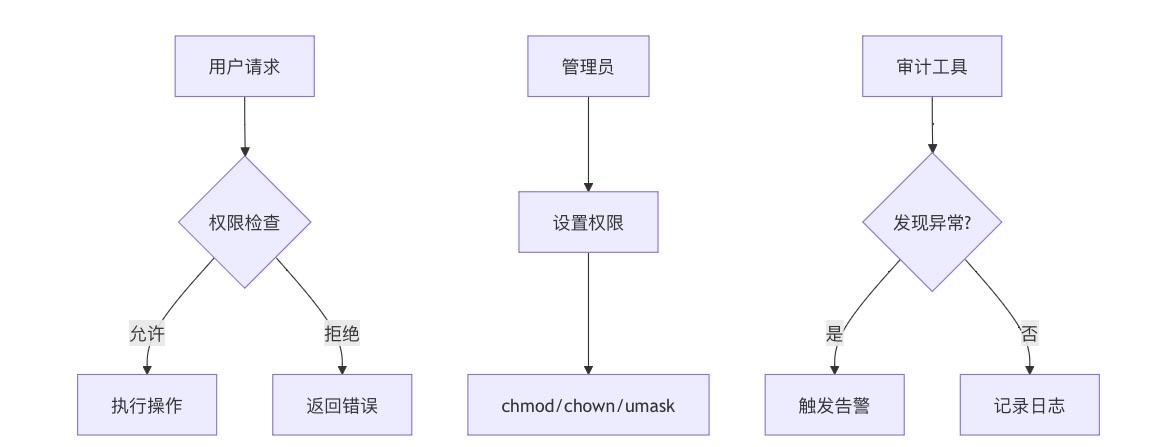
云原生安全基础:Linux 文件权限管理详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 在云原生环境中,Linux 文件权限管理是保障系统安全的核心技能之一。无论是容器化应用、微服务架构还是基础设施即代码(IaC…...
 默认路由 / 无效/未指定地址)
A类地址中最小网络号(0.x.x.x) 默认路由 / 无效/未指定地址
A类地址中最小网络号(0.x.x.x)为何不指派? 在IPv4的A类地址中,网络号范围为 0.0.0.0 ~ 127.0.0.0,但网络号0(即0.x.x.x) 通常不被指派给任何网络,原因如下: 1. 0.x.x.x …...

[嵌入式实验]实验二:LED控制
一、实验目的 1.熟悉开发环境 2.控制LED灯 二、实验环境 硬件:STM32开发板、CMSIS-DAP调试工具 软件:ARM的IDE:Keil C51 三、实验内容 1.实验原理 (1)LED灯原理与点亮 LED即发光二极管,有电流通过…...

6.4.2_3最短路径问题_Floyd算法
Floyd弗洛伊德 膜拜大佬,给大佬鞠躬鞠躬鞠躬。。。。。。。。。 Floyd算法 ----解决顶点间的最短路径: 过程: 如下: 初始化(没有中转点):2个邻接矩阵A和path,第一个是没有中转点的2个顶点之间的最短路径…...

<PLC><socket><西门子>基于西门子S7-1200PLC,实现手机与PLC通讯(通过websocket转接)
前言 本系列是关于PLC相关的博文,包括PLC编程、PLC与上位机通讯、PLC与下位驱动、仪器仪表等通讯、PLC指令解析等相关内容。 PLC品牌包括但不限于西门子、三菱等国外品牌,汇川、信捷等国内品牌。 除了PLC为主要内容外,PLC相关元器件如触摸屏(HMI)、交换机等工控产品,如…...