Kaggle-Predict Calorie Expenditure-(回归+xgb+cat+lgb+模型融合+预测结果)
Predict Calorie Expenditure
题意:
给出每个人的基本信息,预测运动后的卡路里消耗值。
数据处理:
1.构造出人体机能、运动相关的特征值。
2.所有特征值进行从新组合,注意唯独爆炸
3.对连续信息分箱变成离散
建立模型:
1.xgb模型,lgb模型,cat模型
2.使用stack堆叠融合,使用3折交叉验证
3.对xgb、lgb、cat进行K折交叉验证,最终和stack进行结果融合。
代码:
import os
import sys
import warnings
import numpy as np
import pandas as pd
import seaborn
from catboost import CatBoostRegressor
from lightgbm import LGBMRegressor
from matplotlib import pyplot as plt
import lightgbm
from mlxtend.regressor import StackingCVRegressor
from sklearn import clone
from sklearn.ensemble import VotingRegressor, StackingClassifier, StackingRegressor
from sklearn.linear_model import Lasso, LogisticRegression, RidgeCV
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score, make_scorer, mean_squared_log_error
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.preprocessing import StandardScaler
from xgboost import XGBRegressor
from sklearn.preprocessing import RobustScaler
from sklearn.model_selection import KFold
from sklearn.linear_model import Ridgedef init():os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 仅输出错误日志warnings.simplefilter('ignore') # 忽略警告日志pd.set_option('display.width', 1000)pd.set_option('display.max_colwidth', 1000)pd.set_option("display.max_rows", 1000)pd.set_option("display.max_columns", 1000)def show_dataframe(df):print("查看特征值和特征值类型\n" + str(df.dtypes) + "\n" + "-" * 100)print("查看前10行信息\n" + str(df.head()) + "\n" + "-" * 100)print("查看每个特征值的各种数据统计信息\n" + str(df.describe()) + "\n" + "-" * 100)print("输出重复行的个数\n" + str(df.duplicated().sum()) + "\n" + "-" * 100)print("查看每列的缺失值个数\n" + str(df.isnull().sum()) + "\n" + "-" * 100)print("查看缺失值的具体信息\n" + str(df.info()) + "\n" + "-" * 100)#print("输出X所有值出现的是什么,还有对应出现的次数\n" + str(df['X'].value_counts()) + "\n" + "-" * 100)def show_relation(data, colx, coly): # 输出某一特征值与目标值的关系if data[colx].dtype == 'object' or data[colx].dtype == 'category' or len(data[colx].unique()) < 20:seaborn.boxplot(x=colx, y=coly, data=data)else:plt.scatter(data[colx], data[coly])plt.xlabel(colx)plt.ylabel(coly)plt.show()# 自定义RMSLE评分函数(GridSearchCV需要最大化评分,因此返回负RMSLE)
def rmsle_scorer(y_true, y_pred):y_pred = np.clip(y_pred, 1e-15, None) # 防止对0取对数y_true = np.clip(y_true, 1e-15, None)log_error = np.log(y_pred + 1) - np.log(y_true + 1)rmsle = np.sqrt(np.mean(log_error ** 2))return -rmsle # 返回负值,因为GridSearchCV默认最大化评分if __name__ == '__main__':init()df_train = pd.read_csv('/kaggle/input/playground-series-s5e5/train.csv')df_test = pd.read_csv('/kaggle/input/playground-series-s5e5/test.csv')#for col in df_train.columns:# show_relation(df_train, col, 'Calories')#特征工程df_all = pd.concat([df_train.drop(['id', 'Calories'], axis=1), df_test.drop(['id'], axis=1)], axis=0)df_all['Sex'] = df_all['Sex'].map({'male': 0, 'female': 1})df_all = df_all.reset_index(drop=True)#构造BMIdf_all['BMI'] = df_all['Weight'] / (df_all['Height'] / 100) ** 2#Harris-Benedict公式df_all['BMR'] = 0df_all.loc[df_all['Sex'] == 0, 'BMR'] = 88.362 + (13.397 * df_all['Weight']) + (4.799 * df_all['Height']) - (5.677 * df_all['Age'])df_all.loc[df_all['Sex'] == 1, 'BMR'] = 447.593 + (9.247 * df_all['Weight']) + (3.098 * df_all['Height']) - (4.330 * df_all['Age'])# 数值特征标准化#numeric_features = ['Age', 'Height', 'Weight', 'Duration', 'Heart_Rate', 'Body_Temp']#scaler = StandardScaler()#df_all[numeric_features] = scaler.fit_transform(df_all[numeric_features])#运动强度特征df_all['Max_HR'] = 220 - df_all['Age'] # 最大心率df_all['HR_Reserve_Ratio'] = df_all['Heart_Rate'] / df_all['Max_HR']#交互特征df_all['Weight_Duration'] = df_all['Weight'] * df_all['Duration']df_all['Sex_Weight'] = df_all['Sex'] * df_all['Weight']# 构造运动功率特征df_all['workload'] = df_all['Weight'] * df_all['Duration'] * df_all['Heart_Rate'] / 1000# 构造生理特征交互项df_all['age_heart_ratio'] = df_all['Age'] / df_all['Heart_Rate']# 时间维度特征(如有时间戳)df_all['hour_of_day'] = df_all['Duration']/60/24# 组合特征numeric_cols = df_all.columnsfor i in range(len(numeric_cols)):feature_1 = numeric_cols[i]for j in range(i + 1, len(numeric_cols)):feature_2 = numeric_cols[j]df_all[f'{feature_1}_x_{feature_2}'] = df_all[feature_1] * df_all[feature_2]#数值归一化#scaler = RobustScaler()#df_all = scaler.fit_transform(df_all)now_col = ['Age', 'Height', 'Weight', 'Duration', 'Heart_Rate', 'Body_Temp', 'BMI']for i in now_col:df_all[i + "_box"] = pd.cut(df_all[i], bins=10, labels=False, right=False)X_train = df_all[:df_train.shape[0]]Y_train = np.log1p(df_train['Calories'])x_test = df_all[df_train.shape[0]:]#xgbmodel_xgb =estimator=XGBRegressor(random_state=42,n_estimators=8000,objective='reg:squarederror',eval_metric='rmse',device='cuda',learning_rate=0.05,max_depth=8,colsample_bytree=0.75,subsample=0.9,#reg_lambda = 1,#reg_alpha = 0.5,early_stopping_rounds=500,)#lgbmodel_lgb = lightgbm.LGBMRegressor(n_estimators=3000, # 增加迭代次数配合早停learning_rate=0.03, # 减小学习率num_leaves=15, # 限制模型复杂度min_child_samples=25, # 增加最小叶子样本数reg_alpha=0.1, # L1正则化reg_lambda=0.1, # L2正则化objective='regression_l1', # 改用MAE损失early_stopping_rounds=500,)#catmodel_cat = CatBoostRegressor(iterations=3500,learning_rate=0.02,depth=12,loss_function='RMSE',l2_leaf_reg=3,random_seed=42,eval_metric='RMSE',early_stopping_rounds=200,verbose=1000,task_type='GPU',)#融合#创建基模型列表(需禁用早停以生成完整预测)base_models = [('xgb', XGBRegressor(early_stopping_rounds=None, # 禁用早停**{k: v for k, v in model_xgb.get_params().items() if k != 'early_stopping_rounds'})),('lgb', LGBMRegressor(early_stopping_rounds=None, # 禁用早停**{k: v for k, v in model_lgb.get_params().items() if k != 'early_stopping_rounds'})),('cat', CatBoostRegressor(early_stopping_rounds=None, # 禁用早停**{k: v for k, v in model_cat.get_params().items() if k != 'early_stopping_rounds'}))]meta_model = RidgeCV()model_stack = StackingRegressor(estimators=base_models,final_estimator=meta_model,cv=3, # 使用3折交叉验证生成元特征passthrough=False, # 不使用原始特征verbose=1)FOLDS = 20KF = KFold(n_splits=FOLDS, shuffle=True, random_state=42)cat_features = ['Sex']oof_cat = np.zeros(len(df_train))pred_cat = np.zeros(len(df_test))oof_xgb = np.zeros(len(df_train))pred_xgb = np.zeros(len(df_test))oof_lgb = np.zeros(len(df_train))pred_lgb = np.zeros(len(df_test))for i, (train_idx, valid_idx) in enumerate(KF.split(X_train, Y_train)):print('#' * 15, i + 1, '#' * 15)## SPLIT DSx_train, y_train = X_train.iloc[train_idx], Y_train.iloc[train_idx]x_valid, y_valid = X_train.iloc[valid_idx], Y_train.iloc[valid_idx]## CATBOOST fitmodel_cat.fit(x_train, y_train, eval_set=[(x_valid, y_valid)], cat_features=cat_features,use_best_model=True, verbose=0)## XGB FIRmodel_xgb.fit(x_train, y_train, eval_set=[(x_valid, y_valid)], verbose=0)## LGB MODELmodel_lgb.fit(x_train, y_train, eval_set=[(x_valid, y_valid)])## PREDICTION CATBOOSToof_cat[valid_idx] = model_cat.predict(x_valid)pred_cat += model_cat.predict(x_test)## PREDICTION XGBoof_xgb[valid_idx] = model_xgb.predict(x_valid)pred_xgb += model_xgb.predict(x_test)## PREDICTION LGBoof_lgb[valid_idx] = model_lgb.predict(x_valid)pred_lgb += model_lgb.predict(x_test)cat_rmse = mean_squared_error(y_valid, oof_cat[valid_idx]) ** 0.5xgb_rmse = mean_squared_error(y_valid, oof_xgb[valid_idx]) ** 0.5lgb_rmse = mean_squared_error(y_valid, oof_lgb[valid_idx]) ** 0.5print(f'FOLD {i + 1} CATBOOST_RMSE = {cat_rmse:.4f} <=> XGB_RMSE = {xgb_rmse:.4f} <=> LGB_RMSE = {lgb_rmse:.4f}')#预测pred_cat /= FOLDSpred_xgb /= FOLDSpred_lgb /= FOLDSpred_stack = model_stack.predict(df_test)pred_all = np.expm1(pred_xgb) * 0.1 + np.expm1(pred_stack) * 0.80 + np.expm1(pred_cat) * 0.1submission = pd.DataFrame({'id': df_test['id'],'Calories': pred_all})submission['Calories'] = np.clip(submission['Calories'], a_min=1, a_max=20*df_test['Duration'])submission.to_csv('/kaggle/working/submission.csv', index=False)
代码
使用k折交叉验证,对预测结果再进行训练预测。
import os
import sys
import warnings
import numpy as np
import pandas as pd
import seaborn
from catboost import CatBoostRegressor
from lightgbm import LGBMRegressor
from matplotlib import pyplot as plt
import lightgbm
from mlxtend.regressor import StackingCVRegressor
from sklearn import clone
from sklearn.ensemble import VotingRegressor, StackingClassifier, StackingRegressor
from sklearn.linear_model import Lasso, LogisticRegression, RidgeCV
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score, make_scorer, mean_squared_log_error
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.preprocessing import StandardScaler
from xgboost import XGBRegressor
from sklearn.preprocessing import RobustScaler
from sklearn.model_selection import KFold
from sklearn.linear_model import Ridgedef init():os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 仅输出错误日志warnings.simplefilter('ignore') # 忽略警告日志pd.set_option('display.width', 1000)pd.set_option('display.max_colwidth', 1000)pd.set_option("display.max_rows", 1000)pd.set_option("display.max_columns", 1000)def show_dataframe(df):print("查看特征值和特征值类型\n" + str(df.dtypes) + "\n" + "-" * 100)print("查看前10行信息\n" + str(df.head()) + "\n" + "-" * 100)print("查看每个特征值的各种数据统计信息\n" + str(df.describe()) + "\n" + "-" * 100)print("输出重复行的个数\n" + str(df.duplicated().sum()) + "\n" + "-" * 100)print("查看每列的缺失值个数\n" + str(df.isnull().sum()) + "\n" + "-" * 100)print("查看缺失值的具体信息\n" + str(df.info()) + "\n" + "-" * 100)#print("输出X所有值出现的是什么,还有对应出现的次数\n" + str(df['X'].value_counts()) + "\n" + "-" * 100)def show_relation(data, colx, coly): # 输出某一特征值与目标值的关系if data[colx].dtype == 'object' or data[colx].dtype == 'category' or len(data[colx].unique()) < 20:seaborn.boxplot(x=colx, y=coly, data=data)else:plt.scatter(data[colx], data[coly])plt.xlabel(colx)plt.ylabel(coly)plt.show()def show_score(model_name, pred):mse = mean_squared_error(y_val, pred)mae = mean_absolute_error(y_val, pred)score = r2_score(y_val, pred)print(model_name)print(f"{'MSE':<10}{mse:<15.4f}")print(f"{'MAE':<10}{mae:<15.4f}")print(f"{'R²':<10}{score:<15.4f}")print("-" * 100)# Function to calculate RMSLE
def rmsle(y_true, y_pred):return np.sqrt(np.mean(np.power(np.log1p(y_true) - np.log1p(y_pred), 2)))if __name__ == '__main__':init()df_train = pd.read_csv('train.csv')df_test = pd.read_csv('test.csv')#for col in df_train.columns:# show_relation(df_train, col, 'Calories')#特征工程df_all = pd.concat([df_train.drop(['id', 'Calories'], axis=1), df_test.drop(['id'], axis=1)], axis=0)df_all['Sex_encoded'] = df_all['Sex'].map({'male': 0, 'female': 1})df_all.drop(['Sex'], axis=1, inplace=True)df_all = df_all.reset_index(drop=True)#构造BMIdf_all['BMI'] = df_all['Weight'] / (df_all['Height'] / 100) ** 2#Harris-Benedict公式df_all['BMR'] = 0df_all.loc[df_all['Sex_encoded'] == 0, 'BMR'] = 88.362 + (13.397 * df_all['Weight']) + (4.799 * df_all['Height']) - (5.677 * df_all['Age'])df_all.loc[df_all['Sex_encoded'] == 1, 'BMR'] = 447.593 + (9.247 * df_all['Weight']) + (3.098 * df_all['Height']) - (4.330 * df_all['Age'])# 数值特征标准化#numeric_features = ['Age', 'Height', 'Weight', 'Duration', 'Heart_Rate', 'Body_Temp']#scaler = StandardScaler()#df_all[numeric_features] = scaler.fit_transform(df_all[numeric_features])#运动强度特征df_all['Max_HR'] = 220 - df_all['Age'] # 最大心率df_all['HR_Reserve_Ratio'] = df_all['Heart_Rate'] / df_all['Max_HR']#交互特征df_all['Weight_Duration'] = df_all['Weight'] * df_all['Duration']df_all['Sex_Weight'] = df_all['Sex_encoded'] * df_all['Weight']# 构造运动功率特征df_all['workload'] = df_all['Weight'] * df_all['Duration'] * df_all['Heart_Rate'] / 1000# 构造生理特征交互项df_all['age_heart_ratio'] = df_all['Age'] / df_all['Heart_Rate']# 时间维度特征(如有时间戳)df_all['hour_of_day'] = df_all['Duration']/60/24# 组合特征numeric_cols = df_all.columnsfor i in range(len(numeric_cols)):feature_1 = numeric_cols[i]for j in range(i + 1, len(numeric_cols)):feature_2 = numeric_cols[j]df_all[f'{feature_1}_x_{feature_2}'] = df_all[feature_1] * df_all[feature_2]#数值归一化#scaler = RobustScaler()#df_all = scaler.fit_transform(df_all)# 分箱,把连续变成离散的,看你在哪一类now_col = ['Age', 'Height', 'Weight', 'Duration', 'Heart_Rate', 'Body_Temp', 'BMI']for i in now_col:df_all[i + "_box"] = pd.cut(df_all[i], bins=10, labels=False, right=False)baseline_temp = 37.0# Calculate 'Temp_Change' for the training datadf_all['Temp_Change'] = df_all['Body_Temp'] - baseline_temp# Calculate 'Intensity' for the training datadf_all['Intensity'] = df_all['Heart_Rate'] / df_all['Duration']# Calculate 'Heart_Rate_Ratio' for the training datadf_all['Heart_Rate_Ratio'] = df_all['Heart_Rate'] / df_all['Age']# Calculate 'Duration_x_HeartRate' for the training datadf_all['Duration_x_HeartRate'] = df_all['Duration'] * df_all['Heart_Rate']# Calculate 'Weight_x_Duration' for the training datadf_all['Weight_x_Duration'] = df_all['Weight'] * df_all['Duration']# Calculate 'Height_x_Duration' for the training datadf_all['Height_x_Duration'] = df_all['Height'] * df_all['Duration']# Calculate 'Weight_x_Height' for the training datadf_all['Weight_x_Height'] = df_all['Weight'] * df_all['Height']# Calculate 'Weight_x_Intensity' for the training datadf_all['Weight_x_Intensity'] = df_all['Weight'] * df_all['Intensity']# Calculate 'Height_x_Intensity' for the training datadf_all['Height_x_Intensity'] = df_all['Height'] * df_all['Intensity']X_train = df_all[:df_train.shape[0]]Y_train = np.log1p(df_train['Calories'])x_test = df_all[df_train.shape[0]:]#xgbmodel_xgb =estimator=XGBRegressor(random_state=42,n_estimators=8000,objective='reg:squarederror',eval_metric='rmse',device='cuda',learning_rate=0.05,max_depth=8,colsample_bytree=0.75,subsample=0.9,#reg_lambda = 1,#reg_alpha = 0.5,early_stopping_rounds=200,)#lgbmodel_lgb = lightgbm.LGBMRegressor(n_estimators=3000, # 增加迭代次数配合早停learning_rate=0.03, # 减小学习率num_leaves=15, # 限制模型复杂度min_child_samples=25, # 增加最小叶子样本数reg_alpha=0.1, # L1正则化reg_lambda=0.1, # L2正则化objective='regression_l1', # 改用MAE损失early_stopping_rounds=200,eval_metric='RMSE',)#catmodel_cat = CatBoostRegressor(iterations=3500,learning_rate=0.02,depth=12,loss_function='RMSE',l2_leaf_reg=3,random_seed=42,eval_metric='RMSE',verbose=1000,task_type='GPU',early_stopping_rounds=200,)#k折交叉print("🔄Generating Out-of-Fold (OOF) predictions and Test predictions for Base Models...\n" + "-"*70 + "\n")# --- Prediction Storage ---# Arrays to store out-of-fold (OOF)add_pred_val_cat = np.zeros(len(X_train))add_pred_val_xgb = np.zeros(len(X_train))add_pred_val_lgb = np.zeros(len(X_train))# Arrays to store test predictions (accumulated across folds for averaging)add_pred_test_cat = np.zeros(len(x_test))add_pred_test_xgb = np.zeros(len(x_test))add_pred_test_lgb = np.zeros(len(x_test))kf = KFold(n_splits=5, shuffle=True, random_state=42)for fold, (train_index, val_index) in enumerate(kf.split(X_train, Y_train)):print(f"\n---Fold {fold + 1}/{kf.n_splits} ---")x_train, x_val = X_train.iloc[train_index], X_train.iloc[val_index]y_train, y_val = Y_train.iloc[train_index], Y_train.iloc[val_index]#Apply log1p transformation to target for trainingy_train_log1p = np.log1p(y_train)y_val_log1p = np.log1p(y_val)# --- CatBoost Training and Prediction ---print(" ➡ Training CatBoost...")model_cat.fit(x_train, y_train_log1p,eval_set=[(x_val, y_val_log1p)],verbose=0 # Set to 100 if you want to see progress)pred_val_cat = model_cat.predict(x_val)pred_test_cat = model_cat.predict(x_test)# --- XGBoost Training and Prediction ---print(" ➡ Training XGBoost...")model_xgb.fit(x_train, y_train_log1p,eval_set=[(x_val, y_val_log1p)],verbose=0 # Set to 100 if you want to see progress)pred_val_xgb = model_xgb.predict(x_val)pred_test_xgb = model_xgb.predict(x_test)# --- LGBM Training and Prediction ---print(" ➡ Training LGBM...")model_lgb.fit(x_train, y_train_log1p,eval_set=[(x_val, y_val_log1p)],)pred_val_lgb = model_lgb.predict(x_val)pred_test_lgb = model_lgb.predict(x_test)# --- Store OOF and Test Predictions (transformed back to original scale) ---add_pred_val_cat[val_index] = np.expm1(pred_val_cat)add_pred_val_xgb[val_index] = np.expm1(pred_val_xgb)add_pred_val_lgb[val_index] = np.expm1(pred_val_lgb)add_pred_test_cat += np.expm1(pred_test_cat) / kf.n_splitsadd_pred_test_xgb += np.expm1(pred_test_xgb) / kf.n_splitsadd_pred_test_lgb += np.expm1(pred_test_lgb) / kf.n_splits# Ensure all predictions are non-negativeadd_pred_val_cat[add_pred_val_cat < 0] = 0add_pred_val_xgb[add_pred_val_xgb < 0] = 0add_pred_val_lgb[add_pred_val_lgb < 0] = 0# Note: test predictions will also be non-negative after final prediction step# Calculate and print RMSLE for individual models on this foldprint(f" CatBoost RMSLE (Fold {fold + 1}): {rmsle(y_val, add_pred_val_cat[val_index]):.4f}")print(f" XGBoost RMSLE (Fold {fold + 1}): {rmsle(y_val, add_pred_val_xgb[val_index]):.4f}")print(f" LGBM RMSLE (Fold {fold + 1}): {rmsle(y_val, add_pred_val_lgb[val_index]):.4f}")x_meta_train = pd.DataFrame({'cat_pred': add_pred_val_cat,'xgb_pred': add_pred_val_xgb,'lgbm_pred': add_pred_val_lgb,})y_meta_train = Y_trainx_meta_test = pd.DataFrame({'cat_pred': add_pred_test_cat,'xgb_pred': add_pred_test_xgb,'lgbm_pred': add_pred_test_lgb,})model_meta = Ridge(random_state=42)model_meta.fit(x_meta_train, y_meta_train)print(f" meta RMSLE :{rmsle(y_meta_train, model_meta.predict(x_meta_train)):.4f}")pred_all = np.expm1(model_meta.predict(x_meta_test))submission = pd.DataFrame({'id': df_test['id'],'Calories': pred_all})submission['Calories'] = np.clip(submission['Calories'], a_min=df_test['Duration'], a_max=20*df_test['Duration'])submission.to_csv('submission.csv', index=False)
相关文章:
)
Kaggle-Predict Calorie Expenditure-(回归+xgb+cat+lgb+模型融合+预测结果)
Predict Calorie Expenditure 题意: 给出每个人的基本信息,预测运动后的卡路里消耗值。 数据处理: 1.构造出人体机能、运动相关的特征值。 2.所有特征值进行从新组合,注意唯独爆炸 3.对连续信息分箱变成离散 建立模型&#x…...
【解决办法】Git报错error: src refspec main does not match any.
在命令行中使用 Git 进行 git push -u origin main 操作时遇到报错error: src refspec main does not match any。另一个错误信息是:error: failed to push some refs to https://github.com/xxx/xxx.git.这是在一个新设备操作时遇到的问题,之前没有注意…...

React与Vue的内置指令对比
React 与 Vue 在内置指令的设计理念和实现方式上有显著差异。Vue 提供了一套丰富的模板指令系统,而 React 更倾向于通过原生 JavaScript 语法和 JSX 实现类似功能。以下是两者的核心对比: 一、条件渲染 Vue 使用 “v-if”/ “v-else” 指令,…...

2025年5月24号高项综合知识真题以及答案解析(第1批次)
2025年5月24号高项综合知识真题以及答案解析...

【NATURE氮化镓】GaN超晶格多沟道场效应晶体管的“闩锁效应”
2025年X月X日,布里斯托大学的Akhil S. Kumar等人在《Nature Electronics》期刊发表了题为《Gallium nitride multichannel devices with latch-induced sub-60-mV-per-decade subthreshold slopes for radiofrequency applications》的文章,基于AlGaN/GaN超晶格多通道场效应晶…...

Ubuntu24.04换源方法(新版源更换方式,包含Arm64)
一、源文件位置 Ubuntu24.04的源地址配置文件发生改变,不再使用以前的sources.list文件,升级24.04之后,而是使用如下文件 /etc/apt/sources.list.d/ubuntu.sources二、开始换源 1. 备份源配置文件 sudo cp /etc/apt/sources.list.d/ubunt…...

26 C 语言函数深度解析:定义与调用、返回值要点、参数机制(值传递)、原型声明、文档注释
1 函数基础概念 1.1 引入函数的必要性 在《街霸》这类游戏中,实现出拳、出脚、跳跃等动作,每项通常需编写 50 - 80 行代码。若每次调用都重复编写这些代码,程序会变得臃肿不堪,代码可读性与维护性也会大打折扣。 为解决这一问题&…...

彻底理解一个知识点的具体步骤
文章目录 前言一、了解概念(是什么)二、理解原理(为什么)三、掌握方法(怎么用) 四、动手实践(会用)五、类比拓展(迁移能力)六、总结归纳(融会贯通…...

FFmpeg 时间戳回绕处理:保障流媒体时间连续性的核心机制
FFmpeg 时间戳回绕处理:保障流媒体时间连续性的核心机制 一、回绕处理函数 /** * Wrap a given time stamp, if there is an indication for an overflow * * param st stream // 传入一个指向AVStream结构体的指针,代表流信息 * pa…...

yolov8改进模型
YOLOv8 作为当前 YOLO 系列的最新版本,已经具备出色的性能。若要进一步改进,可以从网络架构优化、训练策略增强、多任务扩展和部署效率提升四个方向入手。以下是具体改进思路和实现示例: 1. 网络架构优化 (1) 骨干网络增强 引入 Transform…...

PostgreSQL日常运维
目录 一、PostgreSQL基础操作 1.1 登录数据库 1.2 数据库管理 1.3 数据表操作 二、数据备份与恢复 2.1 备份工具pg_dump 2.2 恢复工具pg_restore与psql 2.3 备份策略建议 三、模式(Schema) 3.1 模式的核心作用 3.2 模式操作全流程 四、远程连…...
<< C程序设计语言第2版 >> 练习 1-23 删除C语言程序中所有的注释语句
1. 前言 本篇文章介绍的是实现删除C语言源文件中所有注释的功能.希望可以给C语言初学者一点参考.代码测试并不充分, 所以肯定还有bug, 有兴趣的同学可以改进. 原题目是: 练习1-23 编写一个删除C语言程序中所有的注释语句. 要正确处理带引号的字符串与字符常量. 在C语言中, 注释…...

Fluence (FLT) 2026愿景:RWA代币化加速布局AI算力市场
2025年5月29日,苏黎世 - Fluence,企业级去中心化计算平台,荣幸地揭开其2026愿景的面纱,并宣布将于6月1日起启动四大新举措。 Fluence 成功建立、推出并商业化了其去中心化物理基础设施计算网络(DePIN)&…...

如何撰写一篇优质 Python 相关的技术文档 进阶指南
💝💝💝在 Python 项目开发与协作过程中,技术文档如同与团队沟通的桥梁,能极大提高工作效率。但想要打造一份真正实用且高质量的 Python 技术文档类教程,并非易事,需要在各个环节深入思考与精心打…...

选择if day5
5.scanf(“空白符”) 空白符作用表示匹配任意多个空白符 进入了内存缓冲区(本质就是一块内存空间) 6.scanf读取问题: a.遇到非法字符读取结束 2. %*d * 可以跳过一个字符 eg:%d%*d%d 读取第一和第三个字符…...

MiniMax V-Triune让强化学习(RL)既擅长推理也精通视觉感知
MiniMax 近日在github上分享了技术研究成果——V-Triune,这次MiniMax V-Triune的发布既是AI视觉技术也是应用工程上的一次“突围”,让强化学习(RL)既擅长推理也精通视觉感知,其实缓解了传统视觉RL“鱼和熊掌不可兼得”…...

Hash 的工程优势: port range 匹配
昨天和朋友聊到 “如何匹配一个 port range”,觉得挺有意思,简单写篇散文。 回想起十多年前,我移植并优化了 nf-HiPAC,当时还看不上 ipset hash,后来大约七八年前,我又舔 nftables,因为用它可直…...

同为.net/C#的跨平台运行时的mono和.net Core有什么区别?
Mono 和 .NET Core(现已统一为 .NET)都是 .NET 生态的跨平台实现,但它们在设计目标、技术特性和应用场景上有显著区别。以下是详细对比: 1. 历史背景 项目诞生时间开发者当前状态Mo…...

前端安全直传MinIO方案
目的:前端直接上传文件到Minio,不通过服务器中转文件。密钥不能在前端明文传输。 ## 一、架构设计 mermaid sequenceDiagram 前端->>后端: 1.请求上传凭证 后端->>MinIO: 2.生成预签名URL 后端-->>前端: 3.返回预签名URL 前端->…...
HackMyVM-Dejavu
信息搜集 主机发现 ┌──(root㉿kali)-[~] └─# arp-scan -l Interface: eth0, type: EN10MB, MAC: 00:0c:29:39:60:4c, IPv4: 192.168.43.126 Starting arp-scan 1.10.0 with 256 hosts (https://github.com/royhills/arp-scan) 192.168.43.1 c6:45:66:05:91:88 …...
)
LeetCode Hot100(动态规划)
70. 爬楼梯 题目: 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 题解: 不难发现,每一次都是从i-1或者i-2爬上来的,我们加起来求和即可 class So…...

Opencv实用操作5 图像腐蚀膨胀
相关函数 腐蚀函数 img1_erosion cv2.erode(img1,kernel,iterations1) (图片,卷积核,次数) 膨胀函数 img_dilate cv2.dilate(img2,kernel1,iterations1) (图片,卷积核,次数)…...

【赵渝强老师】OceanBase的部署架构
OceanBase数据库支持无共享(Shared-Nothing,SN)模式和共享存储(Shared-Storage,SS)模式两种部署架构。 一、 无共享(Shared-Nothing,SN)模式 在SN模式下,各…...
混合云架构部署)
(18)混合云架构部署
文章目录 🚀 混合云架构部署:Java应用的云原生之旅🌩️ 混合云架构简介⚡ Java应用云原生部署五大核心技术1️⃣ 容器化与编排技术2️⃣ 服务网格与API网关3️⃣ CI/CD自动化流水线4️⃣ 多云管理平台5️⃣ 云原生Java框架与运行时 …...

c/c++的opencv霍夫变换
OpenCV中的霍夫变换 (C/C) Hough Transform 霍夫变换 (Hough Transform) 是一种在图像分析中用于检测几何形状(如直线、圆形等)的特征提取技术。它通过一种投票机制在参数空间中寻找特定形状的实例。OpenCV 库为 C 开发者提供了强大且易用的霍夫变换函数…...
 --- AudioRecord录音逻辑分析(一))
AAOS系列之(七) --- AudioRecord录音逻辑分析(一)
一文讲透AAOS架构,点到为止不藏私 📌 这篇帖子给大家分析下 AudioRecord的初始化 1. 场景介绍: 在 AAOS 的 Framework 开发中,录音模块几乎是每个项目都会涉及的重要组成部分。无论是语音控制、车内对讲(同行者模式)…...

MySQL大表结构变更利器:pt-online-schema-change原理与实战指南
MySQL大表结构变更利器:pt-online-schema-change原理与实战指南 MySQL数据库运维中,最令人头疼的问题之一莫过于对大表进行结构变更(DDL操作)。传统的ALTER TABLE操作会锁表,导致业务长时间不可用,这在724小时运行的互联网业务中是不可接受的。本文将深入剖析Percona To…...
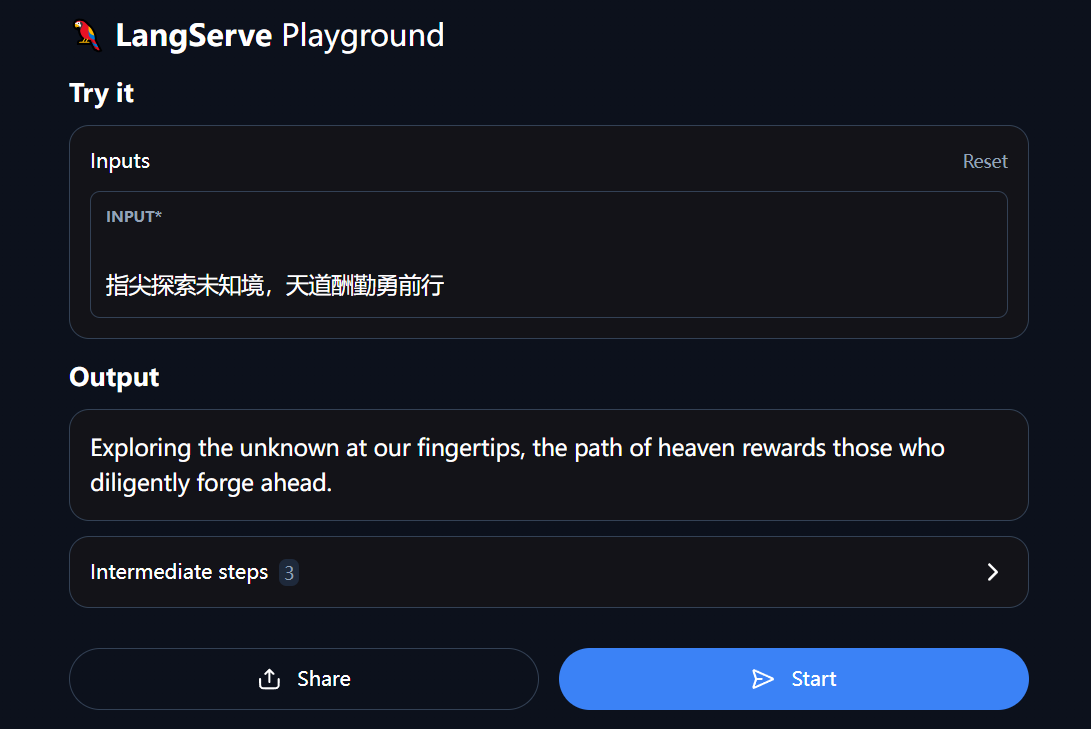
LangChain【3】之进阶内容
文章目录 说明一 LangChain Chat Model1.1 少量示例提示(Few-Shot Prompting)1.2 Few-Shot示例代码1.3 示例选择器(Eample selectors)1.4 ExampleSelector 类型1.5 ExampleSelector案例代码1.6 LangServe工具1.7 LangServe安装1.8 langchain项目结构1.9 …...

大规模JSON反序列化性能优化实战:Jackson vs FastJSON深度对比与定制化改造
背景:500KB JSON处理的性能挑战 在当今互联网复杂业务场景中,处理500KB以上的JSON数据已成为常态。 常规反序列化方案在CPU占用(超30%)和内存峰值(超原始数据3-5倍)方面表现堪忧。 本文通过Jackson与Fas…...

【OpenSearch】高性能 OpenSearch 数据导入
高性能 OpenSearch 数据导入 1.导入依赖库2.配置参数3.OpenSearch 客户端初始化4.创建索引函数5.数据生成器6.批量处理函数7.主导入函数7.1 函数定义和索引创建7.2 优化索引设置(导入前)7.3 初始化变量和打印开始信息7.4 线程池设置7.5 主数据生成和导入…...