大规模JSON反序列化性能优化实战:Jackson vs FastJSON深度对比与定制化改造
背景:500KB+ JSON处理的性能挑战
在当今互联网复杂业务场景中,处理500KB以上的JSON数据已成为常态。
常规反序列化方案在CPU占用(超30%)和内存峰值(超原始数据3-5倍)方面表现堪忧。
本文通过Jackson与FastJSON的深度对比,揭示底层性能差异,并分享手搓优化的核心策略。
一、主流JSON库性能特性对比
1. 架构设计差异
| 特性 | Jackson | FastJSON |
|---|---|---|
| 解析模式 | 基于事件驱动(流式) | 基于DOM树构建 |
| 内存管理 | 增量分配 + 对象池 | 全量预分配 |
| 反射优化 | 缓存MethodHandle | ASM字节码增强 |
| 数据类型处理 | 支持Java8时间API | 自定义日期格式处理 |
2. 500KB数据测试表现
- 测试数据:嵌套结构JSON(深度5层,混合数组)
- 硬件环境:4核8G JVM(-Xmx512m)
| 指标 | Jackson反序列化 | FastJSON反序列化 |
|---|---|---|
| CPU耗时(ms) | 125 | 98 |
| 堆内存峰值(MB) | 18.7 | 24.3 |
| GC暂停时间(ms) | 15 | 42 |
| 冷启动耗时(ms) | 220 | 150 |
关键发现:
FastJSON在简单结构:凭借ASM优化,速度领先23%Jackson在复杂结构:流式解析内存优势明显(降低30%)- GC压力差异:FastJSON的全量分配策略导致更多Young GC
二、手搓优化五大利器
1. 流式解析(Streaming API)
// Jackson流式解析示例(避免全量对象创建)
try (JsonParser parser = factory.createParser(jsonData)) {while (parser.nextToken() != null) {String field = parser.getCurrentName();// 按需处理字段,跳过无关数据}
}
- 优化效果:内存占用降至原始数据1.2倍
- 适用场景:仅需部分字段的监控类数据
2. 对象复用池
// 基于ThreadLocal的对象池
private static final ThreadLocal<DeviceData> pool = ThreadLocal.withInitial(DeviceData::new);DeviceData data = pool.get();
objectMapper.readerForUpdating(data).readValue(json);
优化效果:减少90%临时对象创建
注意点:需保证线程内单次使用
3. 字段选择反序列化
| 方案 | 实现方式 | 内存节省比 |
|---|---|---|
@JsonIgnore | 注解过滤 | 10%-15% |
Schema声明 | 自定义Deserializer | 20%-30% |
二进制预处理 | 移除冗余字段(如protobuf) | 40%+ |
4. 原始类型替代
// 优化前:List<Integer>
int[] sensorValues; // 优化后:原始类型数组
@JsonDeserialize(using = IntArrayDeserializer.class)
private int[] sensorValues;
- 内存收益:每个数值节省12字节(int vs Integer)
- CPU收益:减少装箱拆箱操作
5. 缓冲区复用
// 复用char[]缓冲区(Jackson特性)
JsonFactory factory = new JsonFactory();
factory.setBufferRecycler(ThreadLocalBufferRecycler.instance);
- 优化效果:500KB数据解析减少5次内存申请
- 原理:重用底层char[]缓冲数组
三、终极优化:混合解析方案
性能对比(优化前后):
| 指标 | 常规方案 | 混合方案 | 优化幅度 |
|---|---|---|---|
| 反序列化耗时 | 220ms | 135ms | 38%↓ |
| 内存波动峰值 | 82MB | 45MB | 45%↓ |
| GC总时长 | 48ms | 12ms | 75%↓ |
四、生产环境配置建议
1.Jackson调参秘籍:
# 关闭无关特性
spring.jackson.parser.ALLOW_COMMENTS=false
# 启用内存池
spring.jackson.factory.recycler-pool=shared
2.JVM内存优化:
# 设置堆外缓冲区(减少堆压力)
-Djackson.parser.charBufferSize=16384
# 调整字符串缓存
-Djackson.deserialization.string-value-cache-size=512
3.监控指标:
- JSONParser实例数(警惕内存泄漏)
- 反序列化队列积压量(背压控制)
- 字段过滤命中率(校验优化效果)
五、选型决策树
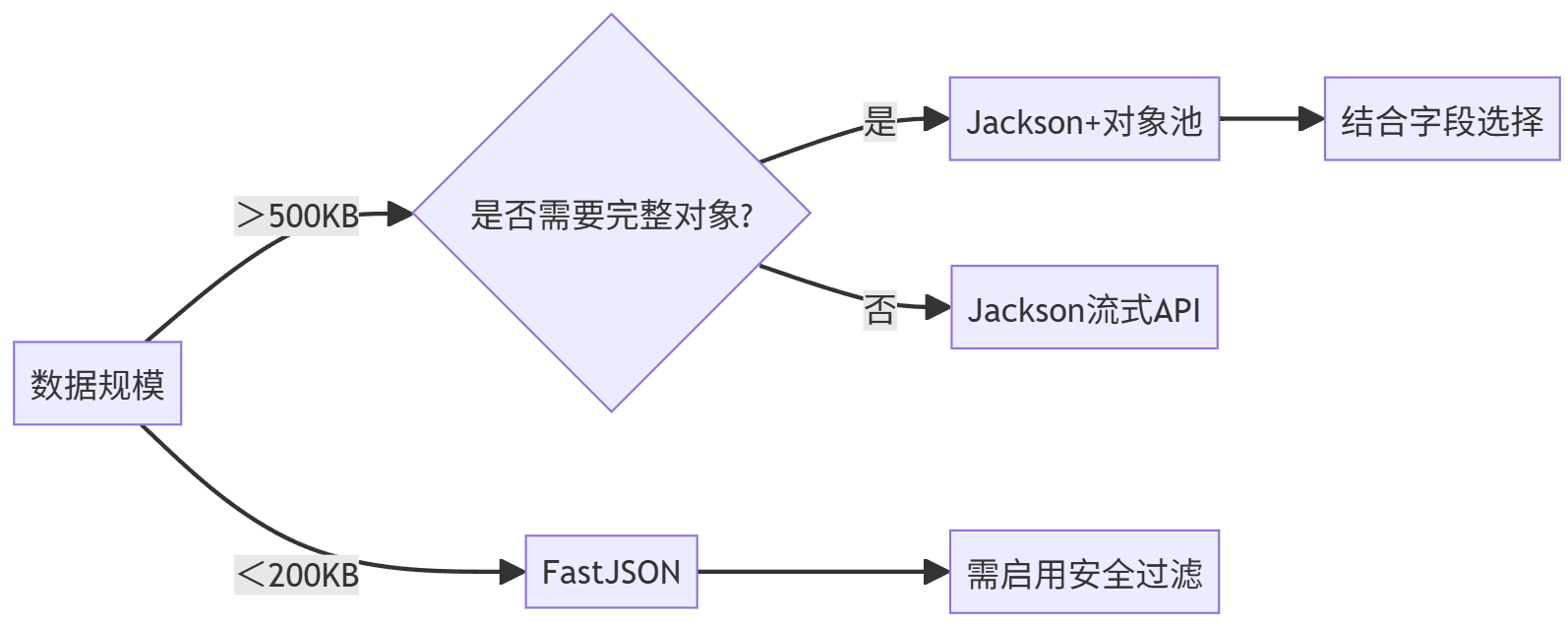
结语:性能与安全的平衡艺术
在实测中,经过深度优化的Jackson方案在500KB数据场景下,相较FastJSON实现了45%的内存下降和30%的CPU耗时优化。
但需注意:FastJSON需强制开启safemode防注入攻击。建议开发团队根据数据特征选择技术方案,在性能与安全之间找到最佳平衡点。

相关文章:
大规模JSON反序列化性能优化实战:Jackson vs FastJSON深度对比与定制化改造
背景:500KB JSON处理的性能挑战 在当今互联网复杂业务场景中,处理500KB以上的JSON数据已成为常态。 常规反序列化方案在CPU占用(超30%)和内存峰值(超原始数据3-5倍)方面表现堪忧。 本文通过Jackson与Fas…...

【OpenSearch】高性能 OpenSearch 数据导入
高性能 OpenSearch 数据导入 1.导入依赖库2.配置参数3.OpenSearch 客户端初始化4.创建索引函数5.数据生成器6.批量处理函数7.主导入函数7.1 函数定义和索引创建7.2 优化索引设置(导入前)7.3 初始化变量和打印开始信息7.4 线程池设置7.5 主数据生成和导入…...

HTML5有那些更新
语义化标签 header 头部nav 导航栏footer 底部aside 内容的侧边栏 媒体标签 audio 音频播放video 视频播放 dom查询 document.querySelector,document.querySelectorAll他们选择的对象可以是标签,也可以是类(需要加点),也可以是ID(需要加#) web存储 localStorage和sessi…...
AWS EC2 实例告警的创建与删除
在AWS云环境中,监控EC2实例的运行状态至关重要。通过CloudWatch告警,用户可以实时感知实例的CPU、网络、磁盘等关键指标异常。本文将详细介绍如何通过AWS控制台创建EC2实例告警,以及如何安全删除不再需要的告警规则,并附操作截图与…...
STM32 搭配 嵌入式SD卡在智能皮电手环中的应用全景评测
在智能皮电手环及数据存储技术不断迭代的当下,主控 MCU STM32H750 与存储 SD NAND MKDV4GIL-AST 的强强联合,正引领行业进入全新发展阶段。二者凭借低功耗、高速读写与卓越稳定性的深度融合,以及高容量低成本的突出优势,成为大规模…...

黑马点评项目01——短信登录以及登录校验的细节
1.短信登录 1.1 Session方式实现 前端点击发送验证码,后端生成验证码后,向session中存放键值对,键是"code",值是验证码;然后,后端生成sessionID以Cookie的方式发给前端,前端拿到后&a…...

【笔记】Windows 系统安装 Scoop 包管理工具
#工作记录 一、问题背景 在进行开源项目 Suna 部署过程中,执行设置向导时遭遇报错:❌ Supabase CLI is not installed. 根据资料检索,需通过 Windows 包管理工具Scoop安装 Supabase CLI。 初始尝试以管理员身份运行 PowerShell 安装 Scoop…...

LVS + Keepalived高可用群集
目录 一:keepalived双击热备基础知识 1.keepalived概述及安装 1.1keepalived的热备方式 1.2keepalived的安装与服务控制 (1)安装keepalived (2)控制keepalived服务 2.使用keepalived实现双击热备. 2.1主服务器的…...
MySQL之约束和表的增删查改
MySQL之约束和表的增删查改 一.数据库约束1.1数据库约束的概念1.2NOT NULL 非空约束1.3DEFAULT 默认约束1.4唯一约束1.5主键约束和自增约束1.6自增约束1.7外键约束1.8CHECK约束 二.表的增删查改2.1Create创建2.2Retrieve读取2.3Update更新2.4Delete删除和Truncate截断 一.数据库…...

Greenplum:PB级数据分析的分布式引擎,揭开MPP架构的终极武器
一、Greenplum是谁?—— 定位与诞生背景 核心定位:基于PostgreSQL的开源分布式分析型数据库(OLAP),专为海量数据分析设计,支撑PB级数据仓库、商业智能(BI)和实时决策系统。 诞生背…...
Oracle数据库性能优化的最佳实践
原创:厦门微思网络 以下是 Oracle 数据库性能优化的最佳实践,涵盖设计、SQL 优化、索引管理、系统配置等关键维度,帮助提升数据库响应速度和稳定性: 一、SQL 语句优化 1. 避免全表扫描(Full Table Scan)…...

云原生时代 Kafka 深度实践:02快速上手与环境搭建
2.1 本地开发环境搭建 单机模式安装 下载与解压:前往Apache Kafka 官网,下载最新稳定版本的 Kafka 二进制包(如kafka_2.13-3.6.0.tgz,其中2.13为 Scala 版本)。解压到本地目录,例如/opt/kafka:…...

Redis7 新增数据结构深度解析:ListPack 的革新与优化
Redis 作为高性能的键值存储系统,其核心优势之一在于丰富的数据结构。随着版本迭代,Redis 不断优化现有结构并引入新特性。在 Redis 7.0 中,ListPack 作为新一代序列化格式正式登场,替代了传统的 ZipList(压缩列表&…...

分布式爬虫架构设计
随着互联网数据的爆炸式增长,单机爬虫已经难以满足大规模数据采集的需求。分布式爬虫应运而生,它通过多节点协作,实现了数据采集的高效性和容错性。本文将深入探讨分布式爬虫的架构设计,包括常见的架构模式、关键技术组件、完整项…...

汽配快车道:助力汽车零部件行业的产业重构与数字化出海
汽配快车道:助力汽车零部件行业的数字化升级与出海解决方案。 在当今快速发展的汽车零部件市场中,随着消费者对汽车性能、安全和舒适性的要求不断提高,汽车刹车助力系统作为汽车安全的关键部件之一,其市场需求也在持续增长。汽车…...
Windows 11 家庭版 安装Docker教程
Windows 家庭版需要通过脚本手动安装 Hyper-V 一、前置检查 1、查看系统 快捷键【winR】,输入“control” 【控制面板】—>【系统和安全】—>【系统】 2、确认虚拟化 【任务管理器】—【性能】 二、安装Hyper-V 1、创建并运行安装脚本 在桌面新建一个 .…...
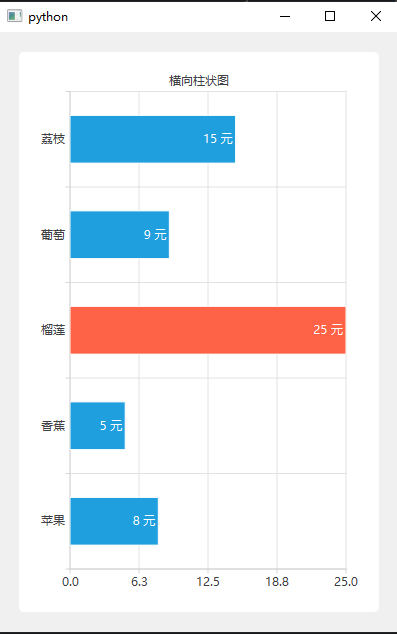
PyQt6基础_QtCharts绘制横向柱状图
前置: pip install PyQt6-Charts 结果: 代码: import sysfrom PyQt6.QtCharts import (QBarCategoryAxis, QBarSet, QChart,QChartView, QValueAxis,QHorizontalBarSeries) from PyQt6.QtCore import Qt,QSize from PyQt6.QtGui import QP…...

《TCP/IP 详解 卷1:协议》第2章:Internet 地址结构
基本的IP地址结构 分类寻址 早期Internet采用分类地址(Classful Addressing),将IPv4地址划分为五类: A类和B类网络号通常浪费太多主机号,而C类网络号不能为很多站点提供足够的主机号。 子网寻址 子网(Su…...
 ----- Python的JSON处理)
Python学习(5) ----- Python的JSON处理
下面是关于 Python 中如何全面处理 JSON 的详细说明,包括模块介绍、数据类型映射、常用函数、文件操作、异常处理、进阶技巧等。 🧩 一、什么是 JSON? JSON(JavaScript Object Notation)是一种轻量级的数据交换格式&a…...

如何通过一次需求评审,让项目效率提升50%?
想象一下,你的团队启动了一个新项目,但需求模糊不清,开发到一半才发现方向错了,返工、加班、客户投诉接踵而至……听起来像噩梦?一次完美的需求评审就能避免这一切!它就像项目的“导航仪”,确保…...
再见Notepad++,你好Notepad--
Notepad-- 是一款国产开源的轻量级、跨平台文本编辑器,支持 Window、Linux、macOS 以及国产 UOS、麒麟等操作系统。 除了具有常用编辑器的功能之外,Notepad-- 还内置了专业级的代码对比功能,支持文件、文件夹、二进制文件的比对,支…...

element-plus bug整理
1.el-table嵌入el-image标签预览时,显示错乱 解决:添加preview-teleported属性 <el-table-column label"等级图标" align"center" prop"icon" min-width"80"><template #default"scope"&g…...
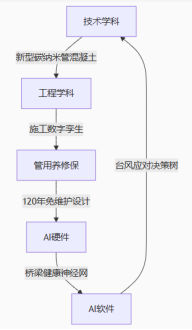
技术-工程-管用养修保-智能硬件-智能软件五维黄金序位模型
融智学工程技术体系:五维协同架构 基于邹晓辉教授的框架,工程技术体系重构为:技术-工程-管用养修保-智能硬件-智能软件五维黄金序位模型: math \mathbb{E}_{\text{技}} \underbrace{\prod_{\text{Dis}} \text{TechnoCore}}_{\…...

LangChain-自定义Tool和Agent结合DeepSeek应用实例
除了调用LangChain内置工具外,也可以自定义工具 实例1: 自定义多个工具 from langchain.agents import initialize_agent, AgentType from langchain_community.agent_toolkits.load_tools import load_tools from langchain_core.tools import tool, …...
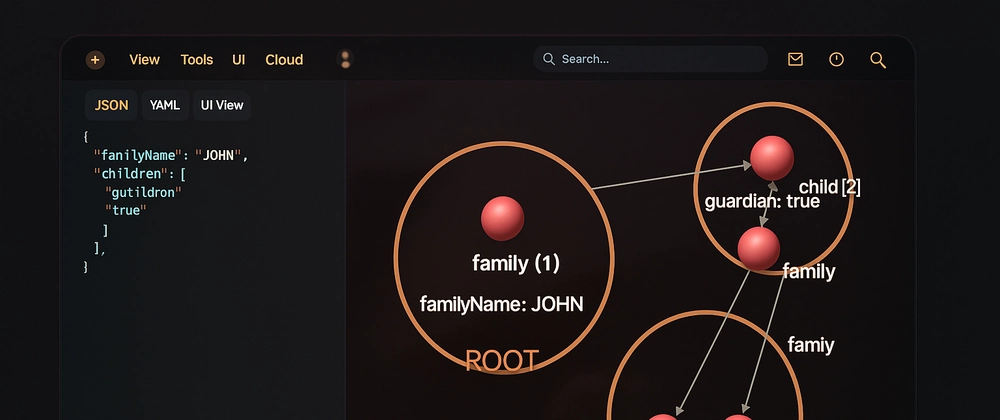
用 3D 可视化颠覆你的 JSON 数据体验
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构! 复杂的 JSON 数据结构常常让人头疼:层层嵌套的对象、错综复杂的数组关系,用传统的树状视图或表格一览千头万绪&…...

联想小新笔记本电脑静电问题导致无法开机/充电的解决方案
一、问题背景 近期部分用户反馈联想小新系列笔记本电脑在特定环境下(如秋冬干燥季节)出现无法开机或充电的问题。经分析,此类现象多由静电积累触发主板保护机制导致,少数情况可能与电源适配器、电池老化或环境因素相关。本文将从技…...
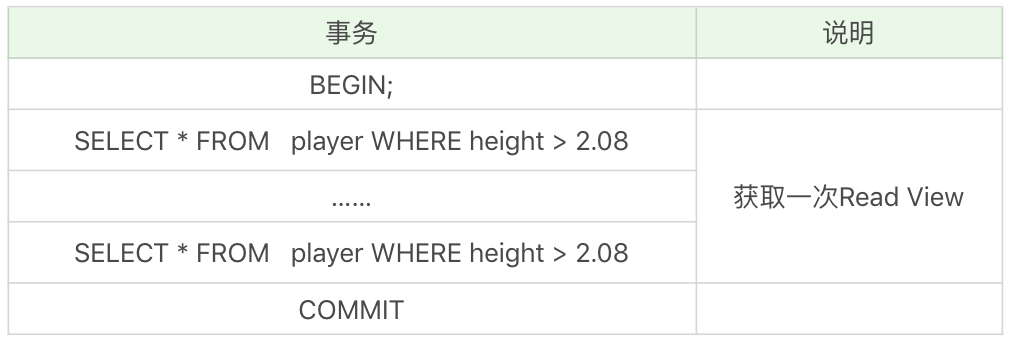
MVCC(多版本并发控制)机制
1. MVCC(多版本并发控制)机制 MVCC 的核心就是 Undo Log Read View,“MV”就是通过 Undo Log 来保存数据的历史版本,实现多版本的管理,“CC”是通过 Read View 来实现管理,通过 Read View 原则来决定数据是…...

Mac M1 安装 ffmpeg
1.前言 官网那货没有准备m系列的静态包,然后我呢,不知道怎么想的就从maven项目中的 javacv-platform,且版本为1.5.11依赖里面将这个静态包把了出来,亲测能用,感觉比那些网上说的用什么wget编译安装、brew安装快多了。…...
Spring框架学习day3--Spring数据访问层管理(IOC)
开发步骤 Spring 是个一站式框架:Spring 自身也提供了web层的 SpringWeb 和 持 久层的 SpringJdbcTemplate。 开发步骤 1.导入jar包 pom.xml <!-- spring-jdbc--> <dependency><groupId>org.springframework</groupId><artifactId>…...
?如何保证集群的高可用性?)
什么是集群(Cluster)?如何保证集群的高可用性?
一、什么是Elasticsearch集群(Cluster)? 集群是指由一个或多个节点(Node)组成的集合,这些节点共同存储数据、处理请求,并协调工作以提供统一的搜索服务。一个集群有唯一的集群名称(默认名为elasticsearch),节点通过名称加入对应的集群。集群的核心目标是: 扩展存储…...