分布式爬虫架构设计
随着互联网数据的爆炸式增长,单机爬虫已经难以满足大规模数据采集的需求。分布式爬虫应运而生,它通过多节点协作,实现了数据采集的高效性和容错性。本文将深入探讨分布式爬虫的架构设计,包括常见的架构模式、关键技术组件、完整项目示例以及面临的挑战与优化方向。
一、常见架构模式
1. 主从架构(Master - Slave)
架构组成
-
主节点(Master) :作为整个爬虫系统的控制中心,负责全局调度工作。
-
从节点(Slave) :接受主节点分配的任务,执行具体的网页爬取和数据解析操作。
工作原理
-
任务调度 :主节点维护一个待爬取 URL 队列,按照预设策略(如轮询、权重分配等)将任务分配给从节点。
-
负载均衡 :主节点实时监控从节点的负载情况(如 CPU 使用率、内存占用、网络带宽等),根据监控数据动态调整任务分配策略,确保各从节点的负载相对均衡。
-
容错管理 :主节点定期检测从节点的运行状态,一旦发现节点故障(如宕机、网络中断等),会将该节点未完成的任务重新分配给其他正常节点,保障任务的持续执行。
通信方式
-
HTTP/RPC 调用 :从节点通过调用主节点提供的 HTTP API 或 RPC 接口获取任务。
-
消息队列 :主节点利用 Redis、Kafka 等消息队列中间件推送任务,从节点订阅相应的队列接收任务。
代码示例(Python + Redis)
-
主节点:任务分发
# _*_ coding: utf - 8 _*_
import redis
import time
import threadingclass MasterNode:def __init__(self):self.r = redis.Redis(host='master', port=6379, decode_responses=True)self.task_timeout = 20 # 任务超时时间(秒)def task_distribute(self):# 清空之前的任务队列和任务状态记录self.r.delete('task_queue')self.r.delete('task_status')# 初始化待爬取的 URL 列表urls = ['https://example.com/page1', 'https://example.com/page2', 'https://example.com/page3']# 将任务推入 Redis 队列for url in urls:task_id = self.r.incr('task_id') # 生成任务 IDtask_info = {'task_id': task_id, 'url': url, 'status': 'waiting', 'assign_time': time.time()}self.r.hset('task_status', task_id, str(task_info))self.r.lpush('task_queue', task_id)print("任务分发完成,共有", len(urls), "个任务")def monitor_tasks(self):while True:# 获取所有任务状态task_statuses = self.r.hgetall('task_status')current_time = time.time()for task_id, task_info in task_statuses.items():task_info_dict = eval(task_info)if task_info_dict['status'] == 'processing':# 检查任务是否超时if current_time - task_info_dict['assign_time'] > self.task_timeout:print(f"任务 {task_id} 超时,重新分配")# 重新分配任务task_info_dict['status'] = 'waiting'self.r.hset('task_status', task_id, str(task_info_dict))self.r.rpush('task_queue', task_id)# 适当间隔检测time.sleep(5)if __name__ == "__main__":master = MasterNode()master.task_distribute()# 启动任务监控线程monitor_thread = threading.Thread(target=master.monitor_tasks)monitor_thread.daemon = Truemonitor_thread.start()# 阻止主线程退出monitor_thread.join()- 从节点:任务执行
# _*_ coding: utf - 8 _*_
import redis
import requests
from bs4 import BeautifulSoup
import time
import threadingclass SlaveNode:def __init__(self):self.r = redis.Redis(host='master', port=6379, decode_responses=True)def task_execute(self):while True:# 从 Redis 队列中获取任务 IDtask_id = self.r.brpop('task_queue', 10)if task_id:task_id = task_id[1]# 更新任务状态为处理中task_info = eval(self.r.hget('task_status', task_id))task_info['status'] = 'processing'self.r.hset('task_status', task_id, str(task_info))print(f"从节点获取到任务 {task_id}:", task_info['url'])try:response = requests.get(task_info['url'], timeout=5)if response.status_code == 200:# 解析网页数据soup = BeautifulSoup(response.text, 'html.parser')title = soup.find('title').get_text() if soup.find('title') else '无标题'links = [link.get('href') for link in soup.find_all('a') if link.get('href')]# 更新任务状态为完成task_info['status'] = 'completed'task_info['result'] = {'url': task_info['url'], 'title': title, 'links': links}self.r.hset('task_status', task_id, str(task_info))print(f"任务 {task_id} 处理完成,结果已存储")else:# 更新任务状态为失败task_info['status'] = 'failed'task_info['error'] = f"请求失败,状态码:{response.status_code}"self.r.hset('task_status', task_id, str(task_info))print(f"任务 {task_id} 请求失败,状态码:{response.status_code}")except Exception as e:# 更新任务状态为失败task_info['status'] = 'failed'task_info['error'] = f"请求或解析过程中出现错误:{str(e)}"self.r.hset('task_status', task_id, str(task_info))print(f"任务 {task_id} 处理过程中出现错误:", str(e))else:print("任务队列为空,等待新任务...")# 为避免频繁轮询,设置一个短暂的休眠时间time.sleep(1)if __name__ == "__main__":slave = SlaveNode()slave.task_execute()二、对等架构(Peer - to - Peer)
架构特点
-
节点平等 :所有节点地位平等,不存在中心化的控制节点,每个节点既是任务的执行者,也是任务的协调者。
-
自主协调 :节点通过分布式算法自主协调任务,实现任务的自分配和数据去重。
工作原理
-
任务自分配 :每个节点根据一定的规则(如 URL 哈希值)自主决定要爬取的任务。例如,采用一致性哈希算法将 URL 映射到特定的节点上。
-
数据去重 :利用布隆过滤器或分布式哈希表(DHT)等技术避免重复爬取,确保每个 URL 只被一个节点处理。
通信方式
-
哈希算法 :一致性哈希算法将 URL 映射到一个哈希环上,根据哈希值确定对应的节点。
-
P2P 协议 :节点之间通过 P2P 协议直接通信,传递任务信息、数据以及节点状态等。
代码示例(Node.js + RabbitMQ)
-
任务分配与发送
// _*_ coding: utf - 8 _*_
const amqplib = require('amqplib');
const crypto = require('crypto');async function sendTask(url) {try {// 连接 RabbitMQ 服务器const conn = await amqplib.connect('amqp://localhost');const ch = await conn.createChannel();// 定义任务队列const queueName = 'task_queue';await ch.assertQueue(queueName, { durable: true });// 计算 URL 哈希值并确定节点const hash = crypto.createHash('md5').update(url).digest('hex');const nodeId = hash % 3; // 假设有 3 个节点console.log(`URL ${url} 分配给节点 node_${nodeId}`);// 将任务发送到对应节点的队列const nodeQueue = `node_${nodeId}`;await ch.assertQueue(nodeQueue, { durable: true });ch.sendToQueue(nodeQueue, Buffer.from(url), { persistent: true });await ch.close();await conn.close();} catch (err) {console.error('发送任务出错:', err);}
}// 测试发送多个任务
const urls = ['https://example.com/page1', 'https://example.com/page2', 'https://example.com/page3', 'https://example.com/page4'];
urls.forEach(url => {sendTask(url);
});- 节点接收与处理任务
// _*_ coding: utf - 8 _*_
const amqplib = require('amqplib');
const axios = require('axios');async function receiveTask(nodeId) {try {// 连接 RabbitMQ 服务器const conn = await amqplib.connect('amqp://localhost');const ch = await conn.createChannel();// 定义节点对应的队列const queueName = `node_${nodeId}`;await ch.assertQueue(queueName, { durable: true });console.log(`节点 node_${nodeId} 开始接收任务...`);// 从队列中接收任务并处理ch.consume(queueName, async (msg) => {if (msg !== null) {const url = msg.content.toString();console.log(`节点 node_${nodeId} 获取到任务:${url}`);try {// 发送 HTTP 请求获取网页内容const response = await axios.get(url, { timeout: 5000 });if (response.status === 200) {// 解析网页数据(此处仅为简单示例,实际解析逻辑可根据需求定制)const data = {url: url,status: response.status,contentLength: response.headers['content-length']};console.log(`节点 node_${nodeId} 处理任务完成:`, data);// 这里可以将结果存储到分布式数据库等} else {console.log(`请求失败,状态码:${response.status}`);}} catch (error) {console.error(`请求或解析过程中出错:${error.message}`);} finally {// 确认任务已处理,可以从队列中移除ch.ack(msg);}}}, { noAck: false });} catch (err) {console.error('接收任务出错:', err);}
}// 启动多个节点接收任务(实际应用中每个节点运行独立的进程)
receiveTask(0);
receiveTask(1);
receiveTask(2);三、关键技术组件
(1)任务调度与队列
-
Redis 队列 :提供简单列表结构,实现任务缓冲与分发。主节点用 LPUSH 推任务,从节点用 BRPOP 获取任务,适用于小规模爬虫。
-
Kafka/RabbitMQ :适合大规模场景,支持高吞吐量任务流。Kafka 的分布式架构可将任务分配到多分区,实现并行消费,提升处理效率。
(2)数据存储
-
分布式数据库 :MongoDB 分片功能实现数据水平扩展,按业务需求设计分片策略,提升存储容量与读写速度。
-
分布式文件系统 :HDFS 存储大规模非结构化数据,采用冗余存储机制,保障数据安全可靠,便于后续解析处理。
(3)负载均衡策略
-
轮询调度 :主节点按固定顺序分配任务,实现简单但不适用节点性能差异大场景。
-
动态权重 :主节点依从节点性能动态调任务分配权重,充分利用资源,但需准确获取性能信息且算法复杂。
四、完整项目示例(Scrapy - Redis)
(1)settings.py
# _*_ coding: utf - 8 _*_
# Scrapy settings for scrapy_redis_example project
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = 'redis://master:6379/0'
SCHEDULER_PERSIST = True
DOWNLOAD_DELAY = 1
RANDOMIZE_DOWNLOAD_DELAY = True
CONCURRENT_REQUESTS = 16
CONCURRENT_REQUESTS_PER_DOMAIN = 8(2)items.py
# _*_ coding: utf - 8 _*_
import scrapyclass ScrapyRedisExampleItem(scrapy.Item):title = scrapy.Field()url = scrapy.Field()content = scrapy.Field()(3)spiders/distributed_spider.py
# _*_ coding: utf - 8 _*_
import scrapy
from scrapy_redis.spiders import RedisSpider
from scrapy_redis_example.items import ScrapyRedisExampleItemclass DistributedSpider(RedisSpider):name = 'distributed_spider'redis_key = 'distributed_spider:start_urls'def __init__(self, *args, **kwargs):super(DistributedSpider, self).__init__(*args, **kwargs)def parse(self, response):# 解析网页数据item = ScrapyRedisExampleItem()item['title'] = response.css('h1::text').get()item['url'] = response.urlitem['content'] = response.css('div.content::text').get()yield item# 提取新的 URL 并生成请求new_urls = response.css('a::attr(href)').getall()for url in new_urls:# 过滤掉非绝对 URLif url.startswith('http'):yield scrapy.Request(url, callback=self.parse)(4)启动爬虫 :
在主节点上启动 Redis 服务器,然后运行以下命令启动爬虫。在从节点上,只需安装相同的 Scrapy - Redis 项目,并连接到同一 Redis 服务器即可。
scrapy crawl distributed_spider五、挑战与优化方向
(1)反爬对抗
-
动态 IP 代理池 :构建动态 IP 代理池,从节点用不同代理 IP 发请求,防被目标网站封禁,可参考 proxy_pool 开源项目。
-
请求频率伪装 :随机延迟请求发送时间,轮换 User - Agent,打乱请求模式,降低被识别风险。
(2)容错机制
-
任务超时重试 :设任务超时时间,从节点未按时完成,主节点重试或转交其他节点,借鉴 Celery retry 机制。
-
节点心跳检测 :用 ZooKeeper 等服务监控节点存活,节点定期发心跳信号,主节点监听判断故障,及时重分配任务。
相关文章:

分布式爬虫架构设计
随着互联网数据的爆炸式增长,单机爬虫已经难以满足大规模数据采集的需求。分布式爬虫应运而生,它通过多节点协作,实现了数据采集的高效性和容错性。本文将深入探讨分布式爬虫的架构设计,包括常见的架构模式、关键技术组件、完整项…...

汽配快车道:助力汽车零部件行业的产业重构与数字化出海
汽配快车道:助力汽车零部件行业的数字化升级与出海解决方案。 在当今快速发展的汽车零部件市场中,随着消费者对汽车性能、安全和舒适性的要求不断提高,汽车刹车助力系统作为汽车安全的关键部件之一,其市场需求也在持续增长。汽车…...
Windows 11 家庭版 安装Docker教程
Windows 家庭版需要通过脚本手动安装 Hyper-V 一、前置检查 1、查看系统 快捷键【winR】,输入“control” 【控制面板】—>【系统和安全】—>【系统】 2、确认虚拟化 【任务管理器】—【性能】 二、安装Hyper-V 1、创建并运行安装脚本 在桌面新建一个 .…...
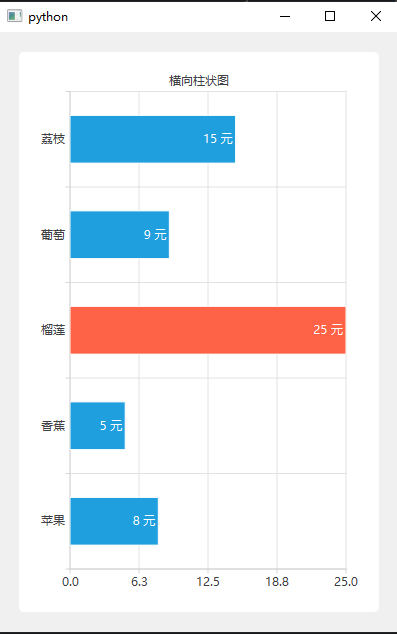
PyQt6基础_QtCharts绘制横向柱状图
前置: pip install PyQt6-Charts 结果: 代码: import sysfrom PyQt6.QtCharts import (QBarCategoryAxis, QBarSet, QChart,QChartView, QValueAxis,QHorizontalBarSeries) from PyQt6.QtCore import Qt,QSize from PyQt6.QtGui import QP…...

《TCP/IP 详解 卷1:协议》第2章:Internet 地址结构
基本的IP地址结构 分类寻址 早期Internet采用分类地址(Classful Addressing),将IPv4地址划分为五类: A类和B类网络号通常浪费太多主机号,而C类网络号不能为很多站点提供足够的主机号。 子网寻址 子网(Su…...
 ----- Python的JSON处理)
Python学习(5) ----- Python的JSON处理
下面是关于 Python 中如何全面处理 JSON 的详细说明,包括模块介绍、数据类型映射、常用函数、文件操作、异常处理、进阶技巧等。 🧩 一、什么是 JSON? JSON(JavaScript Object Notation)是一种轻量级的数据交换格式&a…...

如何通过一次需求评审,让项目效率提升50%?
想象一下,你的团队启动了一个新项目,但需求模糊不清,开发到一半才发现方向错了,返工、加班、客户投诉接踵而至……听起来像噩梦?一次完美的需求评审就能避免这一切!它就像项目的“导航仪”,确保…...
再见Notepad++,你好Notepad--
Notepad-- 是一款国产开源的轻量级、跨平台文本编辑器,支持 Window、Linux、macOS 以及国产 UOS、麒麟等操作系统。 除了具有常用编辑器的功能之外,Notepad-- 还内置了专业级的代码对比功能,支持文件、文件夹、二进制文件的比对,支…...

element-plus bug整理
1.el-table嵌入el-image标签预览时,显示错乱 解决:添加preview-teleported属性 <el-table-column label"等级图标" align"center" prop"icon" min-width"80"><template #default"scope"&g…...
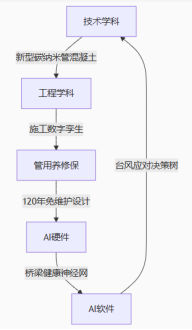
技术-工程-管用养修保-智能硬件-智能软件五维黄金序位模型
融智学工程技术体系:五维协同架构 基于邹晓辉教授的框架,工程技术体系重构为:技术-工程-管用养修保-智能硬件-智能软件五维黄金序位模型: math \mathbb{E}_{\text{技}} \underbrace{\prod_{\text{Dis}} \text{TechnoCore}}_{\…...

LangChain-自定义Tool和Agent结合DeepSeek应用实例
除了调用LangChain内置工具外,也可以自定义工具 实例1: 自定义多个工具 from langchain.agents import initialize_agent, AgentType from langchain_community.agent_toolkits.load_tools import load_tools from langchain_core.tools import tool, …...
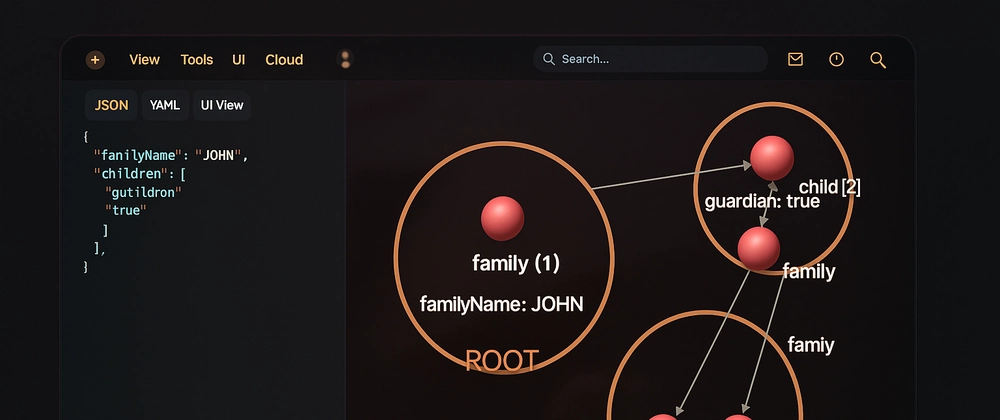
用 3D 可视化颠覆你的 JSON 数据体验
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构! 复杂的 JSON 数据结构常常让人头疼:层层嵌套的对象、错综复杂的数组关系,用传统的树状视图或表格一览千头万绪&…...

联想小新笔记本电脑静电问题导致无法开机/充电的解决方案
一、问题背景 近期部分用户反馈联想小新系列笔记本电脑在特定环境下(如秋冬干燥季节)出现无法开机或充电的问题。经分析,此类现象多由静电积累触发主板保护机制导致,少数情况可能与电源适配器、电池老化或环境因素相关。本文将从技…...
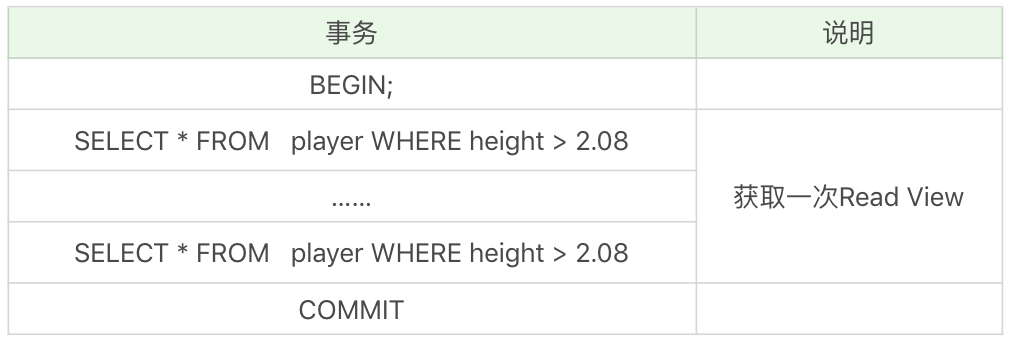
MVCC(多版本并发控制)机制
1. MVCC(多版本并发控制)机制 MVCC 的核心就是 Undo Log Read View,“MV”就是通过 Undo Log 来保存数据的历史版本,实现多版本的管理,“CC”是通过 Read View 来实现管理,通过 Read View 原则来决定数据是…...

Mac M1 安装 ffmpeg
1.前言 官网那货没有准备m系列的静态包,然后我呢,不知道怎么想的就从maven项目中的 javacv-platform,且版本为1.5.11依赖里面将这个静态包把了出来,亲测能用,感觉比那些网上说的用什么wget编译安装、brew安装快多了。…...
Spring框架学习day3--Spring数据访问层管理(IOC)
开发步骤 Spring 是个一站式框架:Spring 自身也提供了web层的 SpringWeb 和 持 久层的 SpringJdbcTemplate。 开发步骤 1.导入jar包 pom.xml <!-- spring-jdbc--> <dependency><groupId>org.springframework</groupId><artifactId>…...
?如何保证集群的高可用性?)
什么是集群(Cluster)?如何保证集群的高可用性?
一、什么是Elasticsearch集群(Cluster)? 集群是指由一个或多个节点(Node)组成的集合,这些节点共同存储数据、处理请求,并协调工作以提供统一的搜索服务。一个集群有唯一的集群名称(默认名为elasticsearch),节点通过名称加入对应的集群。集群的核心目标是: 扩展存储…...

React从基础入门到高级实战:React 核心技术 - 动画与过渡效果:提升 UI 交互体验
React 动画与过渡效果:提升 UI 交互体验 在现代 Web 开发中,动画和过渡效果不仅仅是视觉上的点缀,它们在提升用户体验、引导用户注意力以及增强交互性方面扮演着重要角色。作为一款广受欢迎的前端框架,React 提供了多种实现动画的…...

重读《人件》Peopleware -(13)Ⅱ 办公环境 Ⅵ 电话
当你开始收集有关工作时间质量的数据时,你的注意力自然会集中在主要的干扰源之一——打进来的电话。一天内接15个电话并不罕见。虽然这看似平常,但由于重新沉浸所需的时间,它可能会耗尽你几乎一整天的时间。当一天结束时,你会纳闷…...

Free2AI:企业智能化转型的加速器
随着数字化与智能化的深度交融,企业的竞争舞台已悄然转变为数据处理能力和智能服务水平的竞技场。Free2AI以其三大核心功能——智能数据采集、多格式文档解析、智能FAQ构建,为企业铺设了一条从数据洞察到智能服务的全链路升级之路,成为推动企…...
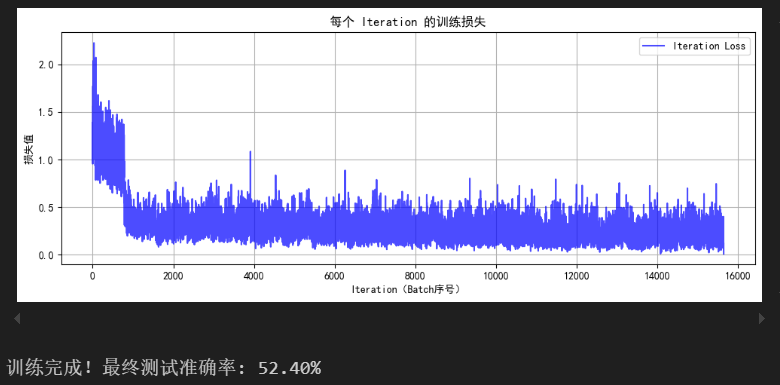
Python训练营打卡Day40
DAY 40 训练和测试的规范写法 知识点回顾: 1.彩色和灰度图片测试和训练的规范写法:封装在函数中 2.展平操作:除第一个维度batchsize外全部展平 3.dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作…...
制作一款打飞机游戏63:自动保存
1.编辑器的自动保存实现 目标:将自动保存功能扩展到所有编辑器,包括脑编辑器、模式编辑器、敌人编辑器和动画/精灵编辑器。实现方式: 代码复制:将关卡编辑器中的自动保存代码复制到其他编辑器中。标记数据变更&a…...

使用animation.css库快速实现CSS3旋转动画效果
CSS3旋转动画效果实现(使用Animate.css) 下面我将展示如何使用Animate.css库快速实现各种CSS3旋转动画效果,同时提供一个直观的演示界面。 思路分析 引入Animate.css库创建不同旋转动画的展示区域添加控制面板自定义动画效果实现实时预览功…...

基于NetWork的类FNAF游戏DEMO框架
脑洞大开 想做个fnaf1并加入自己的设计.. 开干!!!! #include <stdio.h> #include <iostream> #include <random> #include <ctime>bool leftdoor true, rightdoor true, camddoor true; float power 900,fanusepower 0;typedef struct movement…...

湖北理元理律师事务所:债务优化中的生活保障实践
在债务压力与生活质量失衡的普遍困境中,法律服务的价值不仅在于解决债务问题,更在于帮助债务人重建生活秩序。湖北理元理律师事务所通过其债务优化服务,探索出一条“法律生活”的双轨路径。 债务规划的核心矛盾:还款能力与生存需…...

golang连接sm3认证加密(app)
文章目录 环境文档用途详细信息 环境 系统平台:Linux x86-64 Red Hat Enterprise Linux 7 版本:4.5 文档用途 golang连接安全版sm3认证加密数据库,驱动程序详见附件。 详细信息 1.下载Linux golang安装包 go1.17.3.linux-amd64.tar.gz 1.1. 解压安…...
【Zephyr 系列 2】用 Zephyr 玩转 Arduino UNO / MEGA,实现串口通信与 CLI 命令交互
🎯 本篇目标 在 Ubuntu 下将 Zephyr 运行在 Arduino UNO / MEGA 上 打通串口通信,实现通过串口发送命令与反馈 使用 Zephyr Shell 模块,实现 CLI 命令处理 🪧 为什么 Arduino + Zephyr? 虽然 Arduino 开发板通常用于简单的 C/C++ 开发,但 Zephyr 的支持范围远超 STM32…...
)
AIS常见问题解答(AIS知识补充)
AIS常见问题解答 什么是 AIS? AIS 是“自动识别系统”的缩写。AIS 是一种基于甚高频 (VHF) 的导航和防撞工具,可以实现船舶之间的信息交换。这些信息(AIS 数据)还会被丹麦海事局运营的岸基 AIS 系统收集。因此,在提及 …...

基于Matlab实现指纹识别系统
【指纹识别系统基础概念】 指纹识别技术是一种生物特征识别技术,它利用人的指纹独一无二的特性进行个人身份的验证。指纹的细节特征,如脊、谷、分岔等,构成了指纹的唯一性,使得指纹识别在安全性、可靠性和便捷性上具有显著优势。…...
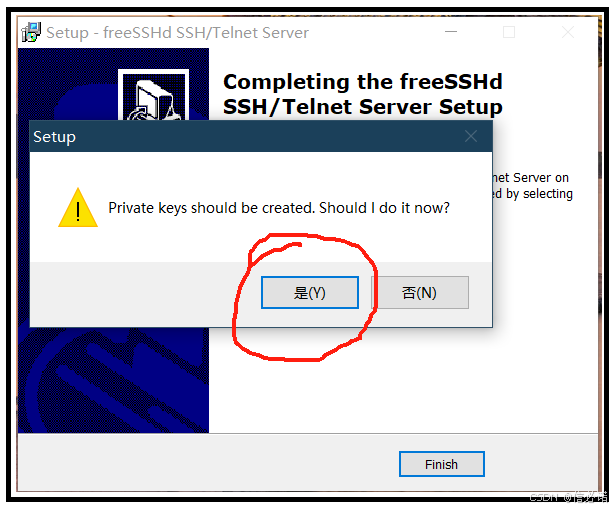
Windows10下搭建sftp服务器(附:详细搭建过程、CMD连接测试、连接失败问题分析解决等)
最终连接sftp效果 搭建sftp服务器 1、这里附上作者已找好的 freeSSHd安装包 ,使用它进行搭建sftp服务器。 2、打开freeSSHd安装包,进行安装 (1)、选择完全安装 (2)、安装完成后,对提示窗口选择关闭 (3)、安装完成后,提示是否安装私有密钥。我们选择"是" (4)、安…...