Python训练营打卡Day40
DAY 40 训练和测试的规范写法
知识点回顾:
1.彩色和灰度图片测试和训练的规范写法:封装在函数中
2.展平操作:除第一个维度batchsize外全部展平
3.dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
作业:仔细学习下测试和训练代码的逻辑,这是基础,这个代码框架后续会一直沿用,后续的重点慢慢就是转向模型定义阶段了。
@浙大疏锦行
DAY 40
昨天介绍了图像数据的格式以及模型定义的过程,发现和之前结构化数据的略有不同,主要差异体现在2处
- 模型定义的时候需要展平图像
- 由于数据过大,需要将数据集进行分批次处理,这往往涉及到了dataset和dataloader来规范代码的组织
现在我们把注意力放在训练和测试代码的规范写法上
单通道图片的规范写法
# 先继续之前的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt
import warnings
# 忽略警告信息
warnings.filterwarnings("ignore")
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64 # 每批处理64个样本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义模型、损失函数和优化器
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)# from torchsummary import summary # 导入torchsummary库
# print("\n模型结构信息:")
# summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 新增:记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号(从1开始)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):# enumerate() 是 Python 内置函数,用于遍历可迭代对象(如列表、元组)并同时获取索引和值。# batch_idx:当前批次的索引(从 0 开始)# (data, target):当前批次的样本数据和对应的标签,是一个元组,这是因为dataloader内置的getitem方法返回的是一个元组,包含数据和标签。# 只需要记住这种固定写法即可data, target = data.to(device), target.to(device) # 移至GPU(如果可用)optimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始# 统计准确率和损失running_loss += loss.item() #将loss转化为标量值并且累加到running_loss中,计算总损失_, predicted = output.max(1) # output:是模型的输出(logits),形状为 [batch_size, 10](MNIST 有 10 个类别)# 获取预测结果,max(1) 返回每行(即每个样本)的最大值和对应的索引,这里我们只需要索引total += target.size(0) # target.size(0) 返回当前批次的样本数量,即 batch_size,累加所有批次的样本数,最终等于训练集的总样本数correct += predicted.eq(target).sum().item() # 返回一个布尔张量,表示预测是否正确,sum() 计算正确预测的数量,item() 将结果转换为 Python 数字# 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 测试、打印 epoch 结果epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 保留原 epoch 级曲线(可选)# plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)return epoch_test_acc # 返回最终测试准确率
之前我们用mlp训练鸢尾花数据集的时候并没有用函数的形式来封装训练和测试过程,这样写会让代码更加具有逻辑-----隔离参数和内容。
- 后续直接修改参数就行,不需要去找到对应操作的代码
- 方便复用,未来有多模型对比时,就可以复用这个函数
这里我们先不写早停策略,因为规范的早停策略需要用到验证集,一般还需要划分测试集
- 划分数据集:训练集(用于训练)、验证集(用于早停和调参)、测试集(用于最终报告性能)。
- 在训练过程中,使用验证集触发早停。
- 训练结束后,仅用测试集运行一次测试函数,得到最终准确率。
测试函数和绘图函数均被封装在了train函数中,但是test和绘图函数在定义train函数之后,这是因为在 Python 中,函数定义的顺序不影响调用,只要在调用前已经完成定义即可。
# 6. 测试模型(不变)
def test(model, test_loader, criterion, device):model.eval() # 设置为评估模式test_loss = 0correct = 0total = 0with torch.no_grad(): # 不计算梯度,节省内存和计算资源for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()avg_loss = test_loss / len(test_loader)accuracy = 100. * correct / totalreturn avg_loss, accuracy # 返回损失和准确率
如果打印每一个bitchsize的损失和准确率,会看的更加清晰,更加直观
# 7. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()
# 8. 执行训练和测试(设置 epochs=2 验证效果)
epochs = 2
print("开始训练模型...")
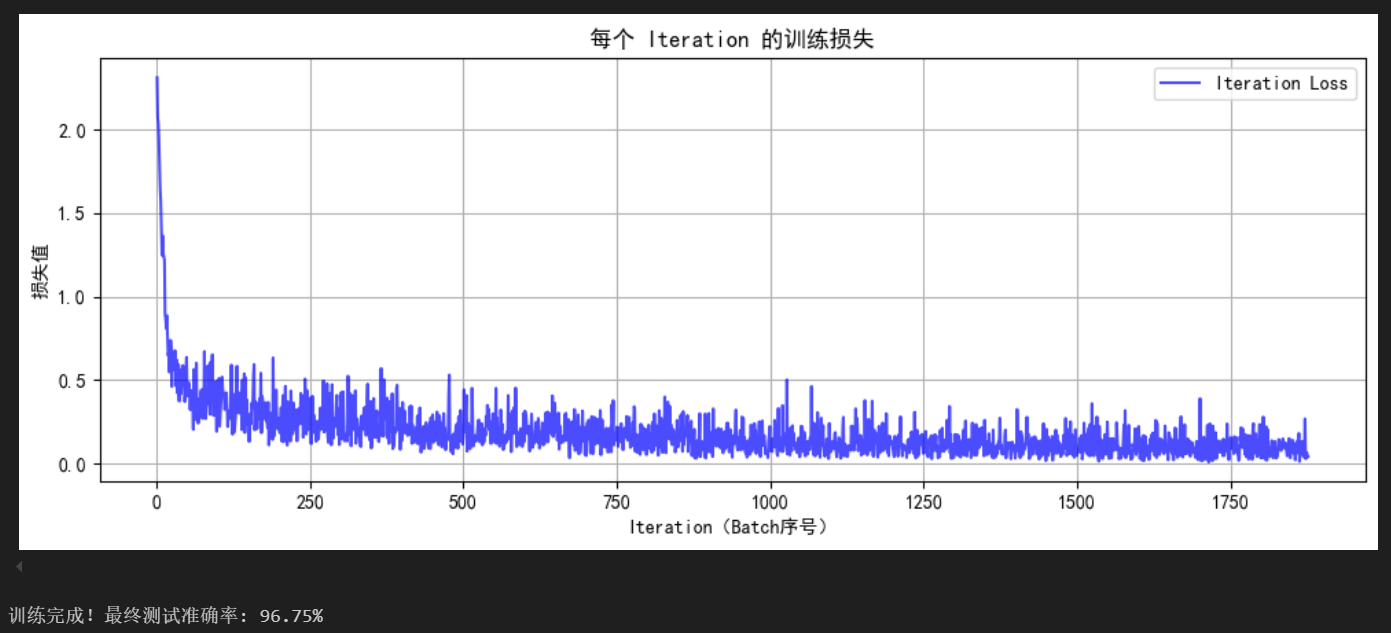
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
在PyTorch中处理张量(Tensor)时,以下是关于展平(Flatten)、维度调整(如view/reshape)等操作的关键点,这些操作通常不会影响第一个维度(即批量维度batch_size):
图像任务中的张量形状
输入张量的形状通常为:
(batch_size, channels, height, width)
例如:(batch_size, 3, 28, 28)
其中,batch_size 代表一次输入的样本数量。
NLP任务中的张量形状
输入张量的形状可能为:
(batch_size, sequence_length)
此时,batch_size 同样是第一个维度。
1. Flatten操作
- 功能:将张量展平为一维数组,但保留批量维度。
- 示例:
- 输入形状:
(batch_size, 3, 28, 28)(图像数据) - Flatten后形状:
(batch_size, 3×28×28)=(batch_size, 2352) - 说明:第一个维度
batch_size不变,后面的所有维度被展平为一个维度。
- 输入形状:
2. view/reshape操作
- 功能:调整张量维度,但必须显式保留或指定批量维度。
- 示例:
- 输入形状:
(batch_size, 3, 28, 28) - 调整为:
(batch_size, -1) - 结果:展平为两个维度,保留
batch_size,第二个维度自动计算为3×28×28=2352。
- 输入形状:
总结
- 批量维度不变性:无论进行flatten、view还是reshape操作,第一个维度
batch_size通常保持不变。 - 动态维度指定:使用
-1让PyTorch自动计算该维度的大小,但需确保其他维度的指定合理,避免形状不匹配错误。
下面是所有代码的整合版本
# import torch
# import torch.nn as nn
# import torch.optim as optim
# from torchvision import datasets, transforms
# from torch.utils.data import DataLoader
# import matplotlib.pyplot as plt
# import numpy as np# # 设置中文字体支持
# plt.rcParams["font.family"] = ["SimHei"]
# plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# # 1. 数据预处理
# transform = transforms.Compose([
# transforms.ToTensor(), # 转换为张量并归一化到[0,1]
# transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
# ])# # 2. 加载MNIST数据集
# train_dataset = datasets.MNIST(
# root='./data',
# train=True,
# download=True,
# transform=transform
# )# test_dataset = datasets.MNIST(
# root='./data',
# train=False,
# transform=transform
# )# # 3. 创建数据加载器
# batch_size = 64 # 每批处理64个样本
# train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# # 4. 定义模型、损失函数和优化器
# class MLP(nn.Module):
# def __init__(self):
# super(MLP, self).__init__()
# self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量
# self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元
# self.relu = nn.ReLU() # 激活函数
# self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)# def forward(self, x):
# x = self.flatten(x) # 展平图像
# x = self.layer1(x) # 第一层线性变换
# x = self.relu(x) # 应用ReLU激活函数
# x = self.layer2(x) # 第二层线性变换,输出logits
# return x# # 检查GPU是否可用
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# # 初始化模型
# model = MLP()
# model = model.to(device) # 将模型移至GPU(如果可用)# criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
# optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# # 5. 训练模型(记录每个 iteration 的损失)
# def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):
# model.train() # 设置为训练模式# # 新增:记录每个 iteration 的损失
# all_iter_losses = [] # 存储所有 batch 的损失
# iter_indices = [] # 存储 iteration 序号(从1开始)# for epoch in range(epochs):
# running_loss = 0.0
# correct = 0
# total = 0# for batch_idx, (data, target) in enumerate(train_loader):
# data, target = data.to(device), target.to(device) # 移至GPU(如果可用)# optimizer.zero_grad() # 梯度清零
# output = model(data) # 前向传播
# loss = criterion(output, target) # 计算损失
# loss.backward() # 反向传播
# optimizer.step() # 更新参数# # 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)
# iter_loss = loss.item()
# all_iter_losses.append(iter_loss)
# iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始# # 统计准确率和损失(原逻辑保留,用于 epoch 级统计)
# running_loss += iter_loss
# _, predicted = output.max(1)
# total += target.size(0)
# correct += predicted.eq(target).sum().item()# # 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)
# if (batch_idx + 1) % 100 == 0:
# print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '
# f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# # 原 epoch 级逻辑(测试、打印 epoch 结果)不变
# epoch_train_loss = running_loss / len(train_loader)
# epoch_train_acc = 100. * correct / total
# epoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)# print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# # 绘制所有 iteration 的损失曲线
# plot_iter_losses(all_iter_losses, iter_indices)
# # 保留原 epoch 级曲线(可选)
# # plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)# return epoch_test_acc # 返回最终测试准确率# # 6. 测试模型
# def test(model, test_loader, criterion, device):
# model.eval() # 设置为评估模式
# test_loss = 0
# correct = 0
# total = 0# with torch.no_grad(): # 不计算梯度,节省内存和计算资源
# for data, target in test_loader:
# data, target = data.to(device), target.to(device)
# output = model(data)
# test_loss += criterion(output, target).item()# _, predicted = output.max(1)
# total += target.size(0)
# correct += predicted.eq(target).sum().item()# avg_loss = test_loss / len(test_loader)
# accuracy = 100. * correct / total
# return avg_loss, accuracy # 返回损失和准确率# # 7.绘制每个 iteration 的损失曲线
# def plot_iter_losses(losses, indices):
# plt.figure(figsize=(10, 4))
# plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')
# plt.xlabel('Iteration(Batch序号)')
# plt.ylabel('损失值')
# plt.title('每个 Iteration 的训练损失')
# plt.legend()
# plt.grid(True)
# plt.tight_layout()
# plt.show()# # 8. 执行训练和测试(设置 epochs=2 验证效果)
# epochs = 2
# print("开始训练模型...")
# final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
# print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
彩色图片的规范写法
彩色的通道也是在第一步被直接展平,其他代码一致
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
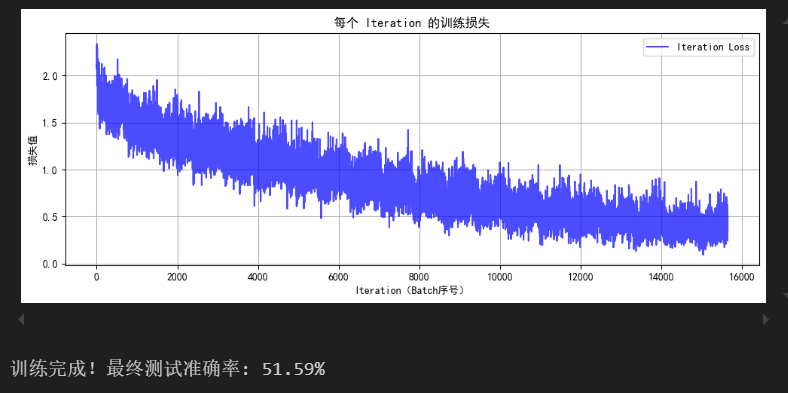
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_mlp_model.pth')
# # print("模型已保存为: cifar10_mlp_model.pth")
由于深度mlp的参数过多,为了避免过拟合在这里引入了dropout这个操作,他可以在训练阶段随机丢弃一些神经元,避免过拟合情况。dropout的取值也是超参数。
在测试阶段,由于开启了eval模式,会自动关闭dropout。
可以继续调用这个函数来复用
# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
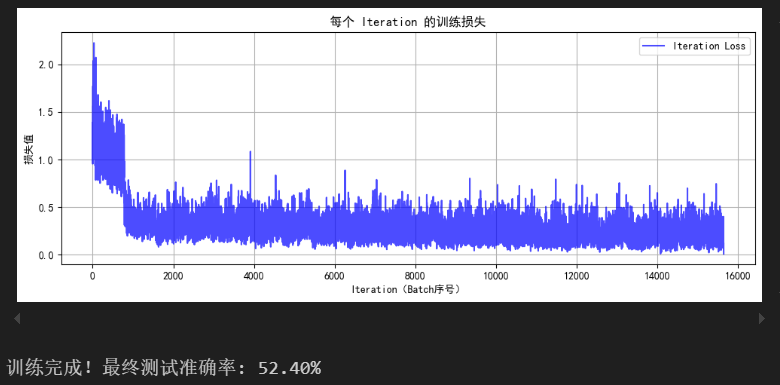
此时你会发现MLP(多层感知机)在图像任务上表现较差(即使增加深度和轮次也只能达到 50-55% 准确率),主要原因与图像数据的空间特性和MLP 的结构缺陷密切相关。
- MLP 的每一层都是全连接层,输入图像会被展平为一维向量(如 CIFAR-10 的 32x32x3 图像展平为 3072 维向量)。图像中相邻像素通常具有强相关性(如边缘、纹理),但 MLP 将所有像素视为独立特征,无法利用局部空间结构。例如,识别 “汽车轮胎” 需要邻近像素的组合信息,而 MLP 需通过大量参数单独学习每个像素的关联,效率极低。
- 深层 MLP 的参数规模呈指数级增长,容易过拟合
所以我们接下来将会学习CNN架构,CNN架构的参数规模相对较小,且训练速度更快,而且CNN架构可以解决图像识别问题,而MLP不能。
相关文章:
Python训练营打卡Day40
DAY 40 训练和测试的规范写法 知识点回顾: 1.彩色和灰度图片测试和训练的规范写法:封装在函数中 2.展平操作:除第一个维度batchsize外全部展平 3.dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作…...
制作一款打飞机游戏63:自动保存
1.编辑器的自动保存实现 目标:将自动保存功能扩展到所有编辑器,包括脑编辑器、模式编辑器、敌人编辑器和动画/精灵编辑器。实现方式: 代码复制:将关卡编辑器中的自动保存代码复制到其他编辑器中。标记数据变更&a…...

使用animation.css库快速实现CSS3旋转动画效果
CSS3旋转动画效果实现(使用Animate.css) 下面我将展示如何使用Animate.css库快速实现各种CSS3旋转动画效果,同时提供一个直观的演示界面。 思路分析 引入Animate.css库创建不同旋转动画的展示区域添加控制面板自定义动画效果实现实时预览功…...

基于NetWork的类FNAF游戏DEMO框架
脑洞大开 想做个fnaf1并加入自己的设计.. 开干!!!! #include <stdio.h> #include <iostream> #include <random> #include <ctime>bool leftdoor true, rightdoor true, camddoor true; float power 900,fanusepower 0;typedef struct movement…...

湖北理元理律师事务所:债务优化中的生活保障实践
在债务压力与生活质量失衡的普遍困境中,法律服务的价值不仅在于解决债务问题,更在于帮助债务人重建生活秩序。湖北理元理律师事务所通过其债务优化服务,探索出一条“法律生活”的双轨路径。 债务规划的核心矛盾:还款能力与生存需…...

golang连接sm3认证加密(app)
文章目录 环境文档用途详细信息 环境 系统平台:Linux x86-64 Red Hat Enterprise Linux 7 版本:4.5 文档用途 golang连接安全版sm3认证加密数据库,驱动程序详见附件。 详细信息 1.下载Linux golang安装包 go1.17.3.linux-amd64.tar.gz 1.1. 解压安…...
【Zephyr 系列 2】用 Zephyr 玩转 Arduino UNO / MEGA,实现串口通信与 CLI 命令交互
🎯 本篇目标 在 Ubuntu 下将 Zephyr 运行在 Arduino UNO / MEGA 上 打通串口通信,实现通过串口发送命令与反馈 使用 Zephyr Shell 模块,实现 CLI 命令处理 🪧 为什么 Arduino + Zephyr? 虽然 Arduino 开发板通常用于简单的 C/C++ 开发,但 Zephyr 的支持范围远超 STM32…...
)
AIS常见问题解答(AIS知识补充)
AIS常见问题解答 什么是 AIS? AIS 是“自动识别系统”的缩写。AIS 是一种基于甚高频 (VHF) 的导航和防撞工具,可以实现船舶之间的信息交换。这些信息(AIS 数据)还会被丹麦海事局运营的岸基 AIS 系统收集。因此,在提及 …...

基于Matlab实现指纹识别系统
【指纹识别系统基础概念】 指纹识别技术是一种生物特征识别技术,它利用人的指纹独一无二的特性进行个人身份的验证。指纹的细节特征,如脊、谷、分岔等,构成了指纹的唯一性,使得指纹识别在安全性、可靠性和便捷性上具有显著优势。…...
Windows10下搭建sftp服务器(附:详细搭建过程、CMD连接测试、连接失败问题分析解决等)
最终连接sftp效果 搭建sftp服务器 1、这里附上作者已找好的 freeSSHd安装包 ,使用它进行搭建sftp服务器。 2、打开freeSSHd安装包,进行安装 (1)、选择完全安装 (2)、安装完成后,对提示窗口选择关闭 (3)、安装完成后,提示是否安装私有密钥。我们选择"是" (4)、安…...

Vue3中Element-Plus中el-input及el-select 边框样式
如果不需要显示下边框,纯无边框直接将 【border-bottom: 1px solid #C0C4CC; 】注掉或去掉即可。 正常引用组件使用即可,无须自定义样式,最终效果CSS样式。 <style scoped> /* 输入框的样式 */ :deep(.el-input__wrapper) { box-sha…...

vue + ant-design + xlsx 实现Excel自定义模板导入功能
Vue Ant Design 扩展:实现Excel自定义模板导入功能 引言 在企业级应用场景中,除了数据导出,模板化导入是另一个核心需求。本文将深入讲解如何基于Vue3 Ant Design Vue xlsx技术栈,实现以下高级导入功能: 自定义模…...

SAP saml2 元数据 HTTP 错误
使⽤事务 SAML2 或 SAML2_IDP 在 ABAP 系统中配置 SAML 2.0 时, Web 页⾯返回 403 已禁⽌、 404 未找到 或 500 服务器内部错误。 在事务 SAML2 中下载元数据时, ⽹页返回 403 已禁⽌、 404 未找到或 500 服务器内部错误。 在事务 SAML2_IDP 中下载…...
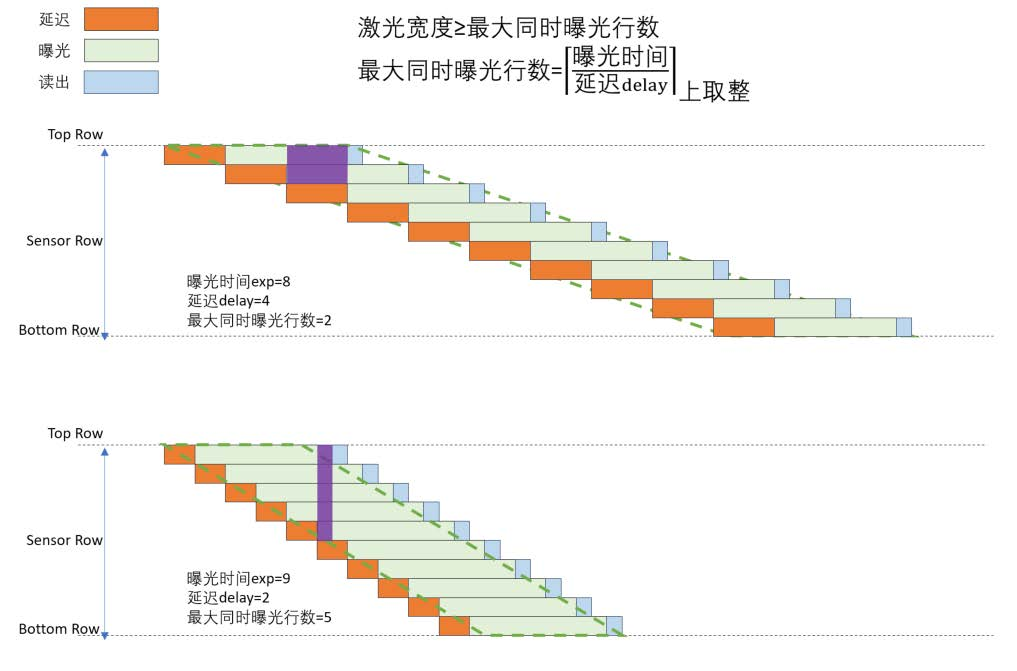
知识课堂|sCMOS相机可编程快门模式解析
sCMOS相机凭借高灵敏度、高动态、低读出噪声特性,成为生命科学成像领域的核心设备。在光片荧光显微镜LSFM成像应用中,传统卷帘快门的时序限制可能引发运动伪影或光片照明不均匀问题。可编程快门模式通过精确控制传感器曝光时序,实现与激光扫描…...

数据结构之栈:原理与常用方法
1. 栈的定义 Stack是Vector的一个子类,它实现标准的后进先出堆栈。Stack只定义了创建空堆栈的默认构造方法。(实际上是实现了List接口,因为Vector是List的子类)。 Stack() // 创建一个空栈 2. 栈的基本操作 // 压栈操作 publi…...
在React框架中使用Braft Editor集成Table表格的详细教程
简介:Braft Editor是一款基于draft-js开发的React富文本编辑器,支持多媒体、自定义样式和扩展功能。其表格扩展模块允许用户插入、调整表格结构,适合需要数据展示的场景(如CMS系统、报表工具)。 1.安装依赖 yarn add…...

跳动的爱心
跳动的心形图案,通过字符打印和延时效果模拟跳动,心形在两种大小间交替跳动。 通过数学公式生成心形曲线 #include <stdio.h> #include <windows.h> // Windows 系统头文件(用于延时和清屏) void printHeart(int …...

gbase8s数据库+mybatis问题记录
在实际使用中一般都是mybatis数据库连接池组合使用,单独使用mybatis 连接数据库时,在循环使用PreparedStatement 时 会发生内存泄漏,PreparedStatement资源得不到释放 测试代码片段如下 drawMapper sqlsession.getMapper(DrawMapper.class…...

实现安卓端与苹果端互通的方案多种多样,以下是一些主要的方案
一、使用跨平台开发框架 1.React Native:通过React Native,开发者可以利用React.js的强大生态系统来构建原生移动应用。该框架允许使用相同的代码库在Android和iOS上开发应用,从而节省时间和成本。它支持热重载功能,使得开发者在…...

SpringBoot开发——Spring Boot异常处理全攻略:五大方案实战对比
文章目录 一、血泪教训:异常处理的代价二、五大异常处理方案详解2.1 全局异常处理(推荐方案)2.2 控制器级处理2.3 HTTP状态码注解2.4 ResponseEntity精细控制2.5 自定义异常体系(企业级方案)三、五大方案对比决策表四、四大避坑指南4.1 异常吞噬陷阱4.2 循环依赖问题4.3 异…...

React-props
文章目录 前言✅ 一、什么是 props?✅ 二、props 的特点✅ 三、props 的核心细节 & 常见问题1. **props 是新对象还是引用?**2. **函数作为 props:闭包陷阱**3. **默认值 & 解构默认值**4. **props.children 是什么?**5. …...

【C++篇】list模拟实现
实现接口: list的无参构造、n个val构造、拷贝构造 operator重载 实现迭代器 push_back() push_front() erase() insert() 头尾删 #pragma once #include<iostream> #include<assert.h> using namespace std;namespace liu {//定义list节点temp…...

Oracle exist
Oracle中的EXISTS是用于检查子查询结果是否为空的逻辑运算符,其核心特点和用法如下: 基础语法 SELECT columns FROM table1 WHERE EXISTS (SELECT 1 FROM table2 WHERE condition); 当子查询返回至少一行时返回TRUE,否则返回FALSE。 执…...
带sdf 的post sim 小结
1.SDF文件主要内容 Delays(module,device,interconnect,port) Timing checks(setup,hold,setuphold,recovery,removal,recrem) Timing…...

【面试】喜茶Java面试题目
1、自我介绍、项目介绍; 2、equals 和 的区别?如何重写equals方法? 3、Java中的异常体系?运行时异常和非运行时异常的区别? 4、HashMap的底层数据结构?JDK1.7和1.8的区别? 5、线程池的核心…...

深入浅出:Spring IOCDI
什么是IOC IOC IOC(Inversion of Control),是一种设计思想,在之前的SpringMVC里就在类上添加RestController和Controller注解就是使用了IOC,这两个注解就是在Spring中创建一个对象,并将注解下的类交给Spring管理,Spr…...

PlankAssembly 笔记 DeepWiki 正交视图三维重建
manycore-research/PlankAssembly | DeepWiki PlankAssembly项目原理 这个项目是一个基于深度学习的3D重建系统,其核心原理是从三个正交视图的工程图纸中重建出3D形状的结构化程序表示。 核心技术原理 1. 问题定义 PlankAssembly旨在从三个正交视图的工程图纸中…...

某验4无感探针-js逆向
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、总体概述二、请求分析1.分析请求流程三、逆向分析四、执行验证总结一、总体概述 本文主要实现用协议过某验4无感探针,相关的链接:aHR0cHM6Ly9ndDQuZ2VldGVzdC5jb20vZGVtb3Y0L2ludmlzaWJsZS1…...

js中common.js和ECMAScript.js区别
以下是关于 CommonJS 和 ECMAScript Modules(ESM)的详细对比分析,包含底层原理和示例说明: 🧩 核心差异对比表 特性CommonJSES Modules来源Node.js 社区规范ECMAScript 语言标准加载方式动态加载(运行时解…...

C语言操作Kafka
Kafka服务 Kafka的快速入门 文档很详细,基本上几步就可以搭建一个Kafka测试环境。 下载Kafka的二进制包,然后解压。 wget https://www.apache.org/dyn/closer.cgi?path/kafka/4.0.0/kafka_2.13-4.0.0.tgz tar -xzf kafka_2.13-4.0.0.tgz cd kafka_2.…...