PlankAssembly 笔记 DeepWiki 正交视图三维重建
manycore-research/PlankAssembly | DeepWiki
PlankAssembly项目原理
这个项目是一个基于深度学习的3D重建系统,其核心原理是从三个正交视图的工程图纸中重建出3D形状的结构化程序表示。
核心技术原理
1. 问题定义
PlankAssembly旨在从三个正交视图的工程图纸中进行鲁棒的3D重建,使用学习到的形状程序来表示3D结构 README.md:3 。项目支持三种类型的输入:可见和隐藏线条、仅可见边缘、以及侧面视图 README.md:38 。
2. 模型架构
项目采用了基于Transformer的序列到序列(Sequence-to-Sequence)架构:
- 编码器-解码器结构:使用标准的Transformer编码器和解码器来处理输入线条序列并生成输出形状程序 models.py:59-69

TransformerEncoderLayer 在 PlankModel 中的使用
在 PlankAssembly 系统中,TransformerEncoderLayer 是从 PyTorch 导入的标准 Transformer 编码器层,用于构建 PlankModel 的编码器部分。 models.py:7-8
具体实现中,TransformerEncoderLayer 在 PlankModel 的初始化过程中被配置: models.py:60-63
这里创建了一个编码器层,配置了以下参数:
num_model: 隐藏维度 (默认 512)num_head: 多头注意力头数 (默认 8)num_feedforward: 前馈网络维度 (默认 1024)dropout: Dropout 率activation: 激活函数normalize_before: 是否在注意力前进行层归一化batch_first=True: 批次维度在第一位
在训练系统中的作用
这个 TransformerEncoderLayer 是整个训练系统的核心组件,通过 build_model(cfg) 函数在训练器中被实例化。 trainer_complete.py:29
训练过程中,编码器处理输入的 2D 线条数据序列,为后续的解码器生成 3D 边界框预测提供编码表示。
Notes
TransformerEncoderLayer 是 PyTorch 标准库的组件,在这个项目中被用作 PlankModel 架构的编码器部分。该模型支持多种输入模态(完整线条、可见线条、侧面数据),都使用相同的 Transformer 编码器架构进行处理。
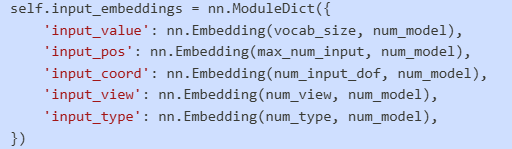
- 多模态嵌入:输入序列包含多种信息维度的嵌入,包括数值、位置、坐标、视图和类型信息 models.py:47-53
3. 输入表示
输入的工程图纸被转换为结构化的线条序列:
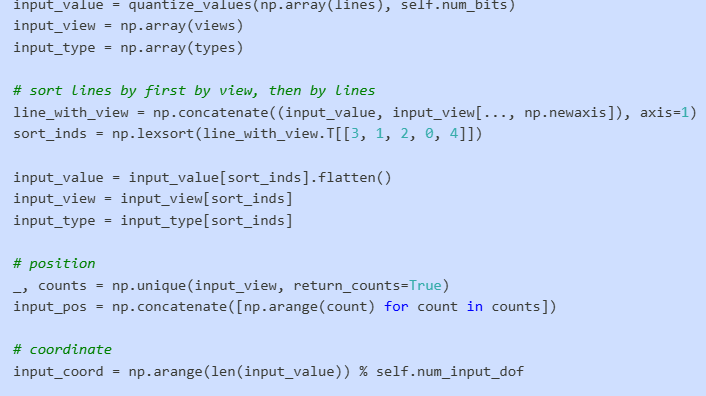
- 每条线段用4个自由度表示(x1, y1, x2, y2坐标) line_data.py:36-46
- 线条按视图和坐标进行排序,并添加位置、视图和类型等元信息 line_data.py:41-58
4. 输出表示
输出是量化的3D形状程序,每个"板块"(plank)用6个自由度的边界框表示 models.py:25 。输出序列经过量化处理并添加特殊标记 line_data.py:87-94 。
5. 指针网络机制
项目的一个关键创新是使用了指针网络(Pointer Network)机制:
- 词汇表分布:用于生成新的token
- 指针分布:用于指向之前生成的序列元素
- 切换机制:动态决定是从词汇表采样还是使用指针 models.py:72-74
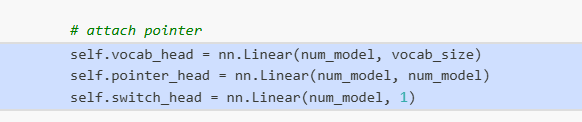
这种机制使模型能够处理结构化输出中的依赖关系和引用关系 models.py:140-188 。
6. 训练和推理
- 训练阶段:使用teacher forcing,同时计算词汇表损失和指针损失 models.py:190-233
def train_step(self, batch):"""Pass batch through plank model and get log probabilities under model."""inputs = {key:value for key, value in batch.items() if key[:5]=='input'}input_mask = batch['input_mask']output_value = batch['output_value']output_label = batch['output_label']output_mask = batch['output_mask']# embed inputinput_embeds = self._embed_input(inputs)# embed outputoutput_embeds = self._embed_output(output_value[:, :-1])memory = self.encoder(input_embeds, src_key_padding_mask=input_mask)# tgt masktgt_mask = self._generate_square_subsequent_mask(output_embeds.size(1)).to(input_embeds.device)# pass through decoderhiddens = self.decoder(output_embeds, memory, tgt_mask=tgt_mask,tgt_key_padding_mask=output_mask,memory_key_padding_mask=input_mask)# create categorical distributiondists = self._create_dist(hiddens)logits = dists.transpose(1, 2)loss = F.nll_loss(logits, output_label, ignore_index=self.token.PAD)predict = torch.argmax(logits, dim=1)valid = output_label != self.token.PADcorrect = (valid * (predict == output_label)).sum()accuracy = float(correct) / (valid.sum() + 1e-10)rets = {}rets['loss'] = lossrets['accuracy'] = accuracyreturn rets- 推理阶段:采用自回归生成,逐步构建输出序列直到遇到结束标记 models.py:267-323
def eval_step(self, batch):"""Autoregressive sampling."""inputs = {key:value for key, value in batch.items() if key[:5]=='input'}input_mask = inputs['input_mask']# embed inputsinput_embeds = self._embed_input(inputs)batch_size = len(input_embeds)device = input_embeds.devicememory = self.encoder(input_embeds, src_key_padding_mask=input_mask)output = torch.empty((batch_size, 0), dtype=torch.long, device=device)attach = torch.empty((batch_size, 0), dtype=torch.long, device=device)for _ in range(self.max_output_length):# embed decoder inputsoutput_embeds = self._embed_output(output)# tgt masktgt_mask = self._generate_square_subsequent_mask(output.size(1)+1).to(device)# pass through decoderhiddens = self.decoder(output_embeds, memory, tgt_mask=tgt_mask,memory_key_padding_mask=input_mask)# create categorical distributiondists = self._create_dist(hiddens)# sample from the distributionnext_output, next_attach = self._sample(dists, output)# update samplesoutput = torch.concat((output, next_output), dim=1)attach = torch.concat((attach, next_attach), dim=1)if torch.all(torch.any(output == self.token.END, dim=1)):breakpredicts, groundtruths = [], []for i in range(batch_size):predict = self.parse_sequence(output[i])groundtruth = self.parse_sequence(batch['output_value'][i])predicts.append(predict)groundtruths.append(groundtruth)rets = {}rets['samples'] = outputrets['attach'] = attachrets['predicts'] = predictsrets['groundtruths'] = groundtruthsreturn rets技术特点
- 鲁棒性:支持噪声输入和不完整的线条信息
- 结构化输出:直接生成可执行的3D形状程序而非点云或网格
- 多视图融合:有效整合来自三个正交视图的信息
- 端到端学习:从原始线条到3D形状程序的直接映射
Notes
PlankAssembly项目代表了将传统工程制图与现代深度学习技术结合的创新尝试。通过将3D重建问题转化为序列生成问题,并引入指针网络机制处理结构化约束,该方法在工程图纸理解方面取得了显著进展。项目还有后续工作CAD2Program,进一步探索了视觉Transformer在工程图纸理解中的应用
您询问的是PlankAssembly系统的输入数据和输出数据格式。基于代码分析,我来详细说明这个3D重建系统的数据流。
输入数据
PlankAssembly系统支持三种输入数据类型,都是从三视图工程图转换而来:
1. 完整线条数据 (Complete Lines)
包含可见线和隐藏线的完整工程图 README.md:85-86
2. 可见线条数据 (Visible Lines)
仅包含可见边缘的工程图 README.md:89-90
3. 侧面多边形数据 (Sideface Data)
提取的面多边形数据
输入数据的具体格式在LineDataset中处理,包含:
- 线条坐标 (
lines): 线段的边界框坐标 - 视图信息 (
views): 标识线条属于哪个视图(正视图、俯视图、侧视图) - 类型信息 (
types): 线条的类型标识 line_data.py:121-123
输出数据
系统输出3D形状程序,包含两个主要组件:
1. 3D几何坐标 (Planks)
表示3D模型中每个木板的几何参数,包含6个值(位置和尺寸信息) line_data.py:125
2. 连接信息 (Attach)
描述木板之间的连接关系和约束 line_data.py:126
输出序列经过量化处理并添加特殊标记:
- 添加停止标记 (
END token) - 添加填充标记 (
PAD token) - 生成对应的标签和掩码 line_data.py:87-107
数据处理流程
整个数据流程如下:
- 3D形状程序 (JSON格式) → SVG渲染 → 三视图SVG文件
- SVG文件 + 形状程序 → JSON信息文件 (通过
prepare_info.py) - 训练时: JSON信息文件 → 序列化输入/输出 → 模型训练 README.md:93-97
Notes
系统使用PythonOCC进行三视图正交工程图渲染 README.md:82 ,支持噪声注入进行数据增强 README.md:87-88 。输出的3D形状程序可以进一步转换为STL网格文件用于可视化。
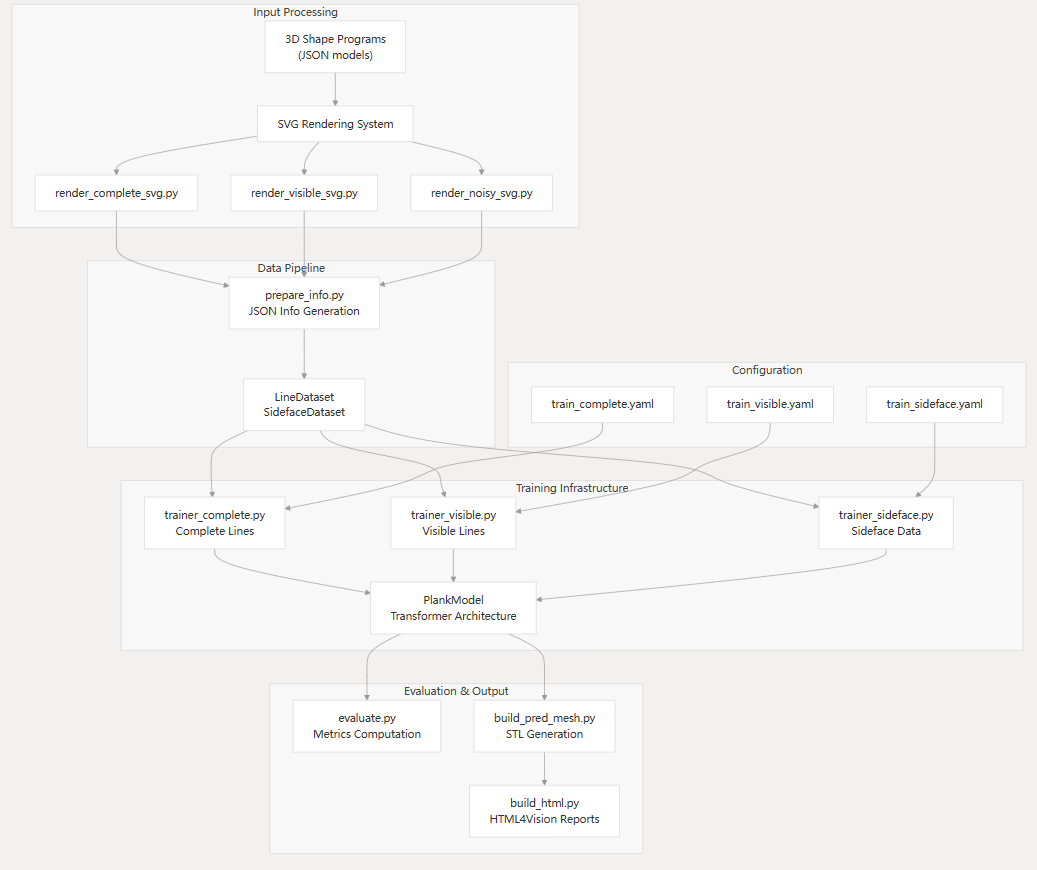
您询问的是关于PlankAssembly系统中SVG渲染系统的数据处理流程。SVG不是像素数据,而是矢量图形格式,用于表示3D模型的正交工程图。
SVG渲染系统概述
PlankAssembly使用SVG(可缩放矢量图形)格式来表示从3D模型生成的三视图工程图。这些SVG文件包含线条几何信息,而不是像素数据。 README.md:82
数据处理流程
1. SVG渲染脚本
系统提供三种不同的SVG渲染脚本来处理原始3D模型:
render_complete_svg.py- 渲染完整输入(可见线和隐藏线) README.md:85-86render_visible_svg.py- 仅渲染可见线 README.md:89-90render_noisy_svg.py- 渲染带噪声的输入 README.md:87-88
2. SVG数据结构
生成的SVG文件以GeoJSON格式存储线条几何信息,包含:
- 线条坐标边界框 [x_min, y_min, x_max, y_max]
- 视图索引(0=正视图,1=俯视图,2=侧视图)
- 线条类型分类 line_data.py:119-123
3. 数据打包
使用prepare_info.py将SVG文件和形状程序打包成JSON格式: README.md:96
SVG vs 像素数据
SVG是矢量格式,存储的是几何线条信息,具有以下特点:
- 可无限缩放而不失真
- 存储线条的数学描述而非像素点
- 适合工程图的精确表示
这与像素/栅格图像完全不同,后者存储固定分辨率的像素阵列。
Notes 注释
PlankAssembly系统专门设计用于处理矢量化的工程图,因为这种格式能够精确表示3D模型的几何特征。系统还支持栅格图像输入,但需要切换到不同的分支(raster branch)。
{"name": "MH2AYXIKTEMTEAABAAAAAAA8_2","id": "bcfce7f1-61c7-11ed-8fb6-5a377d2e67eb","planks": [[-1050.0000732051035,-290.0,-1000.0000006588434,1050.0000732051035,290.0,1000.0000006588434],[-1050.0000732051035,-290.0,-999.9999993411515,-1031.9999267948967,290.0,999.9999993411516],[1011.9999267948965,-270.0,-999.9999993411515,1030.0000732051035,290.0,999.9999993411516],[-1031.99995613098,-270.0,982.0,1012.0000438690199,290.0,1000.0],[1031.9999267948965,-290.0,-999.9999993411515,1050.0000732051035,-230.0,999.9999993411516]],"normal": [[0.0,0.0,1.0],[-1.0,0.0,-0.0],[-1.0,0.0,-0.0],[0.0,0.0,1.0],[-1.0,0.0,-0.0]],"attach": [[-1,-1,-1,-1,-1,-1],[0,1,2,-1,4,5],[-1,-1,2,-1,4,5],[9,-1,-1,12,4,5],[-1,1,2,3,-1,5]]
}这是PlankAssembly系统中的3D形状程序(shape program)数据格式,用于表示由多个木板(planks)组成的3D模型。
数据结构解析
这个JSON文件包含了一个3D模型的完整描述:
基本信息
name: 模型的唯一标识符 "MH2AYXIKTEMTEAABAAAAAAA8_2"id: 数据库ID "bcfce7f1-61c7-11ed-8fb6-5a377d2e67eb"
planks 数组
每个木板用6个浮点数表示边界框坐标 [x_min, y_min, z_min, x_max, y_max, z_max]:
- 第1个木板: 大型底板,从(-1050, -290, -1000)到(1050, 290, 1000)
- 第2-5个木板: 较小的连接板和支撑板 line_data.py:125-126
normal 数组 标准数组
每个木板的法向量,表示木板的朝向:
[0, 0, 1]: Z轴正方向(水平放置)[-1, 0, 0]: X轴负方向(垂直放置)
attach 数组 附加数组
这是关键的连接信息,用于transformer模型的指针机制。每个木板有6个连接点,值表示:
-1: 无连接- 数字: 连接到其他木板的特定坐标索引 line_data.py:98-101
在训练流程中的作用
这种数据格式在PlankAssembly系统中的处理流程:
-
输入准备:
planks数组被展平并量化为离散token line_data.py:87 -
指针机制:
attach数组用于创建标签,指针索引会加上词汇表大小的偏移 line_data.py:100 -
模型训练: transformer模型学习从2D工程图重建这种3D形状程序
数据特点
- 精确性: 使用浮点坐标确保几何精度
- 结构化: 标准化的6D边界框表示
- 连接性: attach数组编码了木板间的装配关系
- 可扩展: 支持任意数量的木板组合
Notes 注释
这是PlankAssembly系统的核心数据表示,与SVG渲染的2D线条数据形成输入-输出对。系统的目标是从2D工程图学习重建这种结构化的3D表示。每个数值的精度反映了工程制造的要求。
您询问的是PlankAssembly系统中attach数组里的数字12的含义。
attach数组中的指针索引
在您提供的例子中,[9, -1, -1, 12, 4, 5]是第4个木板的attach数组。这个数组表示该木板6个连接点的连接状态:
- 位置0: 指向索引9的坐标
- 位置1-2: 无连接(-1)
- 位置3: 指向索引12的坐标
- 位置4-5: 指向索引4和5的坐标
指针机制的工作原理
数字12是一个指针索引,指向展平后的坐标序列中的第12个位置。在训练过程中,这些指针会被转换为模型的标签: line_data.py:100
当attach数组中的值不等于-1时,系统会给这些指针索引加上词汇表大小(vocab_size)的偏移,将其转换为特殊的指针token。
坐标索引的计算
由于每个木板用6个坐标值表示[x_min, y_min, z_min, x_max, y_max, z_max],索引12对应:
- 木板索引: 12 ÷ 6 = 2 (第3个木板)
- 坐标分量: 12 % 6 = 0 (该木板的x_min坐标)
所以数字12指向第3个木板的x_min坐标值,表示当前木板的第4个连接点与第3个木板的左边界相连。
在模型训练中的作用
这种指针机制让transformer模型能够学习木板之间的装配关系: line_data.py:98-101
模型通过这些指针标签学会在生成3D形状程序时正确建立木板间的连接关系。
Notes 注释
这是PlankAssembly系统核心的指针机制,使模型能够处理结构化的3D装配任务。每个非-1的数值都代表一个具体的几何连接点,12只是其中一个指向特定坐标的索引。
您询问的是PlankAssembly系统中连接指针(attach指针)机制的作用和必要性。
连接指针的核心作用
连接指针机制是PlankAssembly系统解决结构化3D重建问题的关键创新。它让transformer模型能够学习和生成具有正确装配关系的3D形状程序。
为什么需要指针机制
1. 解决装配约束问题
在3D木板装配中,木板之间必须有精确的连接关系。传统的序列生成无法表达这种几何约束,而指针机制通过直接引用坐标索引来建立连接: line_data.py:100-101
当attach数组中的值不等于-1时,系统给指针索引加上vocab_size偏移,将其转换为特殊的指针token,使模型能够区分普通坐标token和连接指针。
2. 实现精确的几何连接
指针机制让模型能够精确指定木板间的连接点。例如,索引12指向第3个木板的x_min坐标,表示当前木板与该坐标位置相连。这种精确性对于生成可制造的3D模型至关重要。
3. 支持复杂装配结构
通过指针机制,模型可以处理任意复杂的装配关系:
- 一个木板可以连接到多个其他木板
- 连接可以指向任意坐标分量(x_min, y_min, z_min, x_max, y_max, z_max)
- 支持层次化的装配结构
在训练和推理中的作用
训练阶段line_data.py:98-101
模型学习预测正确的指针索引,建立输入2D线条与输出3D装配关系的映射。
推理阶段trainer_complete.py:97-106
模型生成的指针信息被用于构建最终的3D形状程序,确保木板间的连接关系正确。
与传统方法的对比
如果没有指针机制,模型只能生成独立的木板坐标,无法表达装配约束。指针机制使PlankAssembly能够:
- 保证几何一致性 - 连接的木板在指定位置必须对齐
- 支持结构化输出 - 生成的不是简单的坐标列表,而是带有装配关系的结构化程序
- 实现端到端学习 - 从2D工程图直接学习到3D装配关系
Notes 注释
这种指针机制是PlankAssembly系统的核心创新,使其能够处理结构化的3D重建任务。它将传统的序列到序列问题转化为带有结构约束的生成问题,这对于工程应用中的精确装配至关重要。
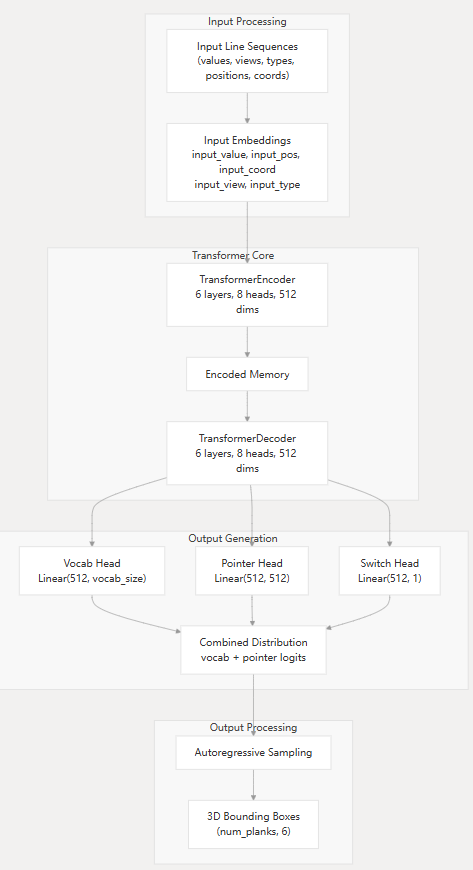
在PlankAssembly的PlankModel中,输入数据经过embedding后会被转换为多维特征表示。
Embedding组件结构
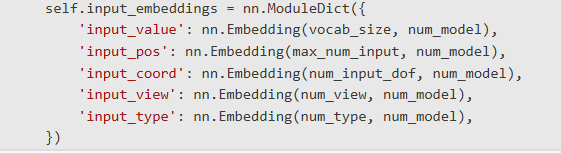
模型使用多模态embedding系统,包含5个不同的embedding层: models.py:47-53
每个embedding层的作用: 每个 embed
input_value: 量化后的坐标值embeddinginput_pos: 序列位置embeddinginput_coord: 坐标类型embedding (x/y坐标标识)input_view: 视图embedding (正视图/俯视图/侧视图)input_type: 线条类型embedding (可见线/隐藏线)
输入数据预处理
在LineDataset中,原始线条数据被处理成embedding所需的格式: line_data.py:34-83
处理步骤包括:
- 坐标量化为离散token
- 按视图和坐标排序
- 添加位置、坐标类型、视图、线条类型标识
- 添加END和PAD token进行填充
Embedding后的格式
经过embedding处理后,每个输入token被转换为num_model维度(默认512维)的向量表示。最终的输入格式是一个字典:
inputs = { 'input_value': [batch_size, max_input_length], # 量化坐标值 'input_pos': [batch_size, max_input_length], # 位置索引 'input_coord': [batch_size, max_input_length], # 坐标类型 'input_view': [batch_size, max_input_length], # 视图索引 'input_type': [batch_size, max_input_length], # 线条类型 'input_mask': [batch_size, max_input_length] # 填充掩码 }每个embedding层将对应的索引转换为512维向量,然后这些向量会被相加形成最终的输入表示,送入transformer encoder。
Notes 注释
这种多模态embedding设计让模型能够同时理解坐标值、空间位置、几何类型和视图信息,为从2D线条重建3D结构提供了丰富的特征表示。所有embedding维度都统一为num_model(512),便于后续的transformer处理。
您询问的是PlankAssembly系统中将输入数据转换为512维embedding向量的具体代码实现。
Embedding定义代码
在PlankModel的初始化中,定义了5个embedding层,每个都将离散索引映射到512维向量: models.py:47-53
这里num_model=512是配置参数,定义了embedding的输出维度。

去学embedding了
PlankAssembly系统的输入和输出数据格式不一致,它们代表完全不同的数据类型:
输入数据格式
输入是2D线条数据,经过预处理后包含:
input_value: 量化后的坐标值序列input_pos: 位置索引input_coord: 坐标类型标识input_view: 视图索引(0=正视图,1=俯视图,2=侧视图)input_type: 线条类型(可见线/隐藏线)
输出数据格式
输出是3D形状程序,包含:
output_value: 量化后的3D边界框坐标序列output_label: 带指针机制的标签序列output_mask: 填充掩码 sideface_data.py:207-213
关键差异
- 数据维度不同: 输入是2D线条(4维坐标),输出是3D边界框(6维坐标)
- 语义不同: 输入表示工程图线条,输出表示3D木板装配
- 结构不同: 输出包含指针机制用于表达装配关系,输入没有
您询问的是PlankAssembly系统中2D线条输入数据的具体格式。让我通过代码示例来说明这种格式。
2D线条数据的原始格式
在PlankAssembly中,输入的2D线条数据来自SVG渲染的工程图。每条线由4个坐标值表示:[x_min, y_min, x_max, y_max],加上视图信息和线条类型。
数据预处理示例
在 中,可以看到输入序列的准备过程:
原始线条数据经过以下处理:
- 坐标量化: 浮点坐标被转换为离散token
- 视图分类: 每条线标记属于哪个视图(0=正视图,1=俯视图,2=侧视图)
- 类型标识: 标记线条类型(可见线/隐藏线)
具体的数据格式示例
处理后的输入数据格式如下:

数据加载和使用
在训练器中,这些数据通过 trainer_complete.py:37-38 的LineDataset加载,然后送入模型进行处理。
每个token代表一个坐标分量,4个连续的token组成一条完整的2D线条。通过多模态embedding,这些离散的索引被转换为512维向量表示,供transformer模型处理。
Notes 注释
这种格式设计使得模型能够同时理解几何坐标、空间位置、视图信息和线条属性,为从2D工程图重建3D结构提供了丰富的输入表示。
您询问的是PlankAssembly系统中什么时候需要添加填充掩码(padding mask)。
填充掩码的添加时机
在PlankAssembly系统中,填充掩码在以下几个关键时刻被添加:
1. 数据预处理阶段
在LineDataset和SidefaceDataset的数据预处理过程中,当序列长度不足最大长度时需要添加填充: line_data.py:67-72 sideface_data.py:173-177
这里在添加PAD token后立即生成对应的掩码。
2. 输出序列准备时
在准备输出序列时也需要添加填充掩码: line_data.py:94-95 sideface_data.py:198-199
3. Transformer模型推理时
在模型的前向传播过程中,填充掩码被传递给transformer的encoder和decoder: models.py:206 models.py:212-214
4. 特殊情况检测
在SidefaceTrainer中,填充掩码用于检测是否有有效数据: trainer_sideface.py:61-65
添加填充掩码的原因
- 批处理需求: 不同样本的序列长度不同,需要填充到统一长度
- Attention机制: 防止模型关注无意义的填充位置
- 计算效率: 避免在填充位置进行不必要的计算
- 数据验证: 检测输入序列的有效性
Notes
填充掩码是在序列被填充到固定长度时自动生成的,这是transformer模型处理变长序列的标准做法。在PlankAssembly中,每当有PAD token被添加时,就需要相应的掩码来标识这些位置。
您询问的是PlankAssembly系统中序列的最大长度限制。
序列长度配置
PlankAssembly系统中的序列长度通过配置文件中的MAX_INPUT_LENGTH和MAX_OUTPUT_LENGTH参数控制,不同的训练模式有不同的最大长度设置:
输入序列最大长度
- Complete模式: 1200 train_complete.yaml:41
- Visible模式: 1000 train_visible.yaml:41
- Sideface模式: 300 train_sideface.yaml:41
输出序列最大长度
所有模式的输出序列最大长度都是128 train_complete.yaml:42
在模型中的使用
这些长度参数在PlankModel初始化时被使用: models.py:26-27
模型会根据这些参数计算最大输入和输出数量: models.py:32-33
长度差异的原因
不同模式的输入长度限制反映了数据复杂度的差异:
- Complete模式(1200): 包含可见线和隐藏线,数据最复杂
- Visible模式(1000): 只包含可见线,数据量中等
- Sideface模式(300): 处理侧面多边形,数据最简单
输出长度统一为128,因为3D形状程序的复杂度相对固定,每个木板用6个坐标表示,128长度足以容纳大多数装配结构。
Notes
这些长度限制是在配置文件中硬编码的,可以根据具体需求调整。较长的序列会消耗更多GPU内存,特别是在transformer的attention计算中,内存使用与序列长度的平方成正比。
您询问的是PlankAssembly系统中输出序列长度128能容纳多少个3D结构(木板)。
输出序列长度与结构数量的关系
在PlankAssembly系统中,输出序列的最大长度设置为128 train_complete.yaml:42 。
由于每个木板(plank)用6个坐标值表示边界框 [x_min, y_min, z_min, x_max, y_max, z_max] models.py:24-25 ,我们可以计算最大木板数量:
128 ÷ 6 = 21.33,即最多可以容纳21个完整的木板结构
模型中的计算逻辑
在PlankModel的初始化中,系统会根据输出长度和坐标维度计算最大输出数量: models.py:32-33
这里max_num_output = math.ceil(max_output_length / num_output_dof),即 math.ceil(128 / 6) = 22个木板位置。
实际使用中的考虑
在训练过程中,系统会验证预测输出的有效性,过滤掉无效的边界框:
然后将结果重塑为6维边界框格式:
结论
128长度的输出序列最多可以表示21-22个木板结构,这个设计足以容纳大多数实际的3D装配场景,因为典型的木制家具或结构通常不会超过20个主要组件。
Notes
这个限制是在配置文件中设定的,可以根据具体需求调整。更长的序列会消耗更多GPU内存,特别是在transformer的attention计算中。

您询问的是PlankAssembly系统中embedding处理后输出的数据格式。
Answer
在PlankAssembly系统中,embedding处理后输出的是高维向量表示,具体维度为num_model(默认512维)。
Input Embedding输出
_embed_input方法将多种输入特征组合成统一的embedding表示: models.py:103-112
该方法将所有输入特征(value、position、coordinate、view、type)的embedding相加,输出形状为(batch_size, sequence_length, num_model)的张量。
Output Embedding输出
_embed_output方法处理输出序列的embedding: models.py:114-138
输出embedding同样是512维向量,包含:
- 值embedding:量化后的坐标值
- 坐标embedding:表示当前处理的是x/y/z坐标还是长宽高
- 位置embedding:表示当前处理的是第几个3D边界框
Transformer处理后的数据
经过encoder处理后,embedding数据被转换为memory表示: models.py:206
经过decoder处理后,得到hidden states: models.py:212-214
这些hidden states随后被用于生成最终的预测分布。
最终输出数据
在训练阶段,embedding最终转换为概率分布用于损失计算: models.py:217-221
在推理阶段,通过自回归采样生成3D边界框序列: models.py:309-315
Notes
embedding的核心作用是将离散的输入token转换为连续的向量表示,使transformer能够处理和学习2D线条图到3D边界框的映射关系。所有embedding都是512维向量,这是模型的隐藏维度大小。
您询问的是如果PlankAssembly系统中没有embedding会发生什么。
Answer
如果PlankAssembly系统中没有embedding层,模型将无法正常工作,因为transformer架构完全依赖于embedding来处理输入数据。
Embedding的必要性
在PlankModel中,embedding是数据处理的第一步。 models.py:47-53
没有embedding层,系统将面临以下问题:
1. 无法处理离散输入
原始输入是离散的token ID(量化后的坐标值、位置索引等),transformer需要连续的向量表示才能进行计算。 models.py:103-112
2. 失去位置和语义信息
embedding不仅转换数据格式,还编码了重要的语义信息:
- 坐标维度信息(x/y/z坐标vs长宽高)
- 视图类型信息(前视图/顶视图/侧视图)
- 序列位置信息
3. Transformer无法运行
Encoder和decoder都期望接收embedding后的向量作为输入。 models.py:279
没有embedding,这些组件将无法处理原始的整数token。
4. 训练过程中断
训练步骤依赖于模型的正常前向传播。 trainer_complete.py:63-71
没有embedding,模型无法产生有效的loss和accuracy指标。
Notes
Embedding在PlankAssembly中不是可选组件,而是核心架构的基础部分。它将离散的2D线条图特征转换为transformer可以处理的连续向量空间,使得从2D到3D的映射学习成为可能。移除embedding等同于破坏了整个模型架构。
相关文章:
PlankAssembly 笔记 DeepWiki 正交视图三维重建
manycore-research/PlankAssembly | DeepWiki PlankAssembly项目原理 这个项目是一个基于深度学习的3D重建系统,其核心原理是从三个正交视图的工程图纸中重建出3D形状的结构化程序表示。 核心技术原理 1. 问题定义 PlankAssembly旨在从三个正交视图的工程图纸中…...

某验4无感探针-js逆向
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、总体概述二、请求分析1.分析请求流程三、逆向分析四、执行验证总结一、总体概述 本文主要实现用协议过某验4无感探针,相关的链接:aHR0cHM6Ly9ndDQuZ2VldGVzdC5jb20vZGVtb3Y0L2ludmlzaWJsZS1…...

js中common.js和ECMAScript.js区别
以下是关于 CommonJS 和 ECMAScript Modules(ESM)的详细对比分析,包含底层原理和示例说明: 🧩 核心差异对比表 特性CommonJSES Modules来源Node.js 社区规范ECMAScript 语言标准加载方式动态加载(运行时解…...

C语言操作Kafka
Kafka服务 Kafka的快速入门 文档很详细,基本上几步就可以搭建一个Kafka测试环境。 下载Kafka的二进制包,然后解压。 wget https://www.apache.org/dyn/closer.cgi?path/kafka/4.0.0/kafka_2.13-4.0.0.tgz tar -xzf kafka_2.13-4.0.0.tgz cd kafka_2.…...

STM32架构解析
在嵌入式开发领域,STM32作为广泛应用的Cortex-M系列微控制器,常常被问及一个基础而深刻的问题:STM32是哈佛结构,还是冯诺依曼结构?这个问题看似简单,却涉及到计算机架构发展的历史、理论与现实的融合。 一、计算体系结构基础:冯诺依曼 vs 哈佛 1.1 冯诺依曼结构的特性…...

在线政治采购系统架构构建指南
一、系统架构设计原则 合规性优先 系统需严格遵循《中华人民共和国政府采购法》及最新修订要求,例如采购流程需满足公开招标不少于 20 日的法定时限,合同需在中标通知书发出后 30 日内签订并备案。同时,需预留接口以适应未来法律修订带来的流…...

UHF RFID无源标签的芯片供电原理
作为无源物联网技术中最基础的一环,UHF RFID无源标签已经被广泛用于商超零售、物流仓储、图书档案、防伪溯源等量非常大的应用领域,仅2021年度,全球出货量就超过200亿。在实际应用中UHF RFID无源标签的芯片是究竟依靠什么来供电的呢? UHF RFID无源标签供电特点 1.借助无线…...

【NLP入门系列一】NLP概述和独热编码
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 博主简介:努力学习的22级本科生一枚 🌟;探索AI算法,C,go语言的世界;在迷茫中寻找光芒…...

洛谷习题V^V
1.帮贡排序 解题思路:按照题意,排序模拟即可 #include <iostream> #include <vector> #include <algorithm> #include <string> using namespace std;struct Member {string name;string position;int contribution;int level;…...
Wireshark 在 macOS 上使用及问题解决
wireshark概述 Wireshark 是被广泛使用的免费开源网络协议分析软件(network protocol analyzer)或网络数据包分析工具,它可以让你在微观层面上查看网络上发生的事情。它的主要功能是截取网络数据包,并尽可能详细地展示网络数据包…...
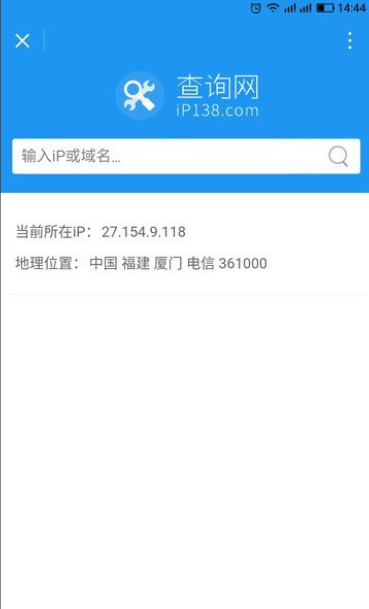
不同电脑同一个网络ip地址一样吗?如何更改
想象一下,你住在同一栋公寓楼里,所有住户对外共享一个统一的小区地址(类似公网IP),但每家每户又有独立的门牌号(类似内网IP)。网络世界中的IP地址也遵循这一逻辑:同一局域网内的设备…...

Qt使用智能指针
第一步:导入头文件 #include <QScopedPointer> 第二步:创建对象 .h文件 QSharedPointer<Student> m_pClass; .cpp文件 m_pClass.reset(new Student(param1,param2,...,param_n)); 第三步:绑定信号槽 connect(m_pClass.data(), &Class::sign…...
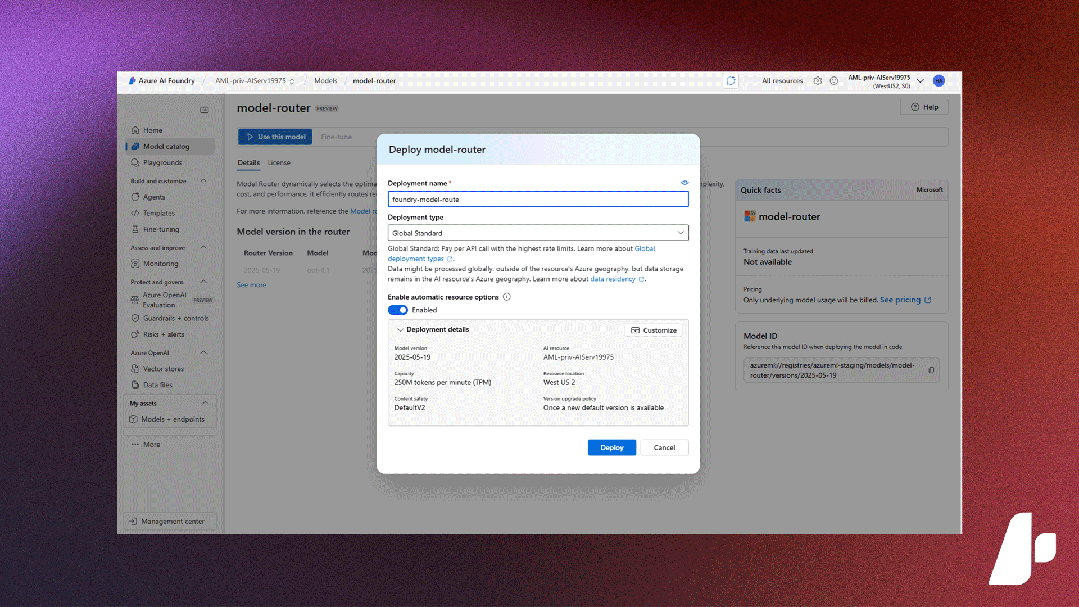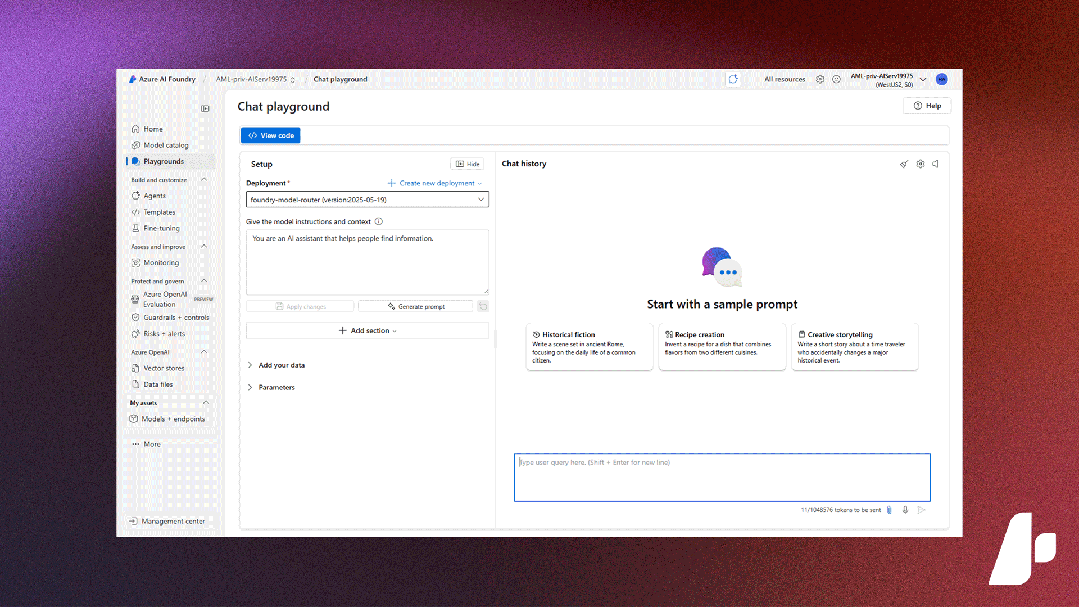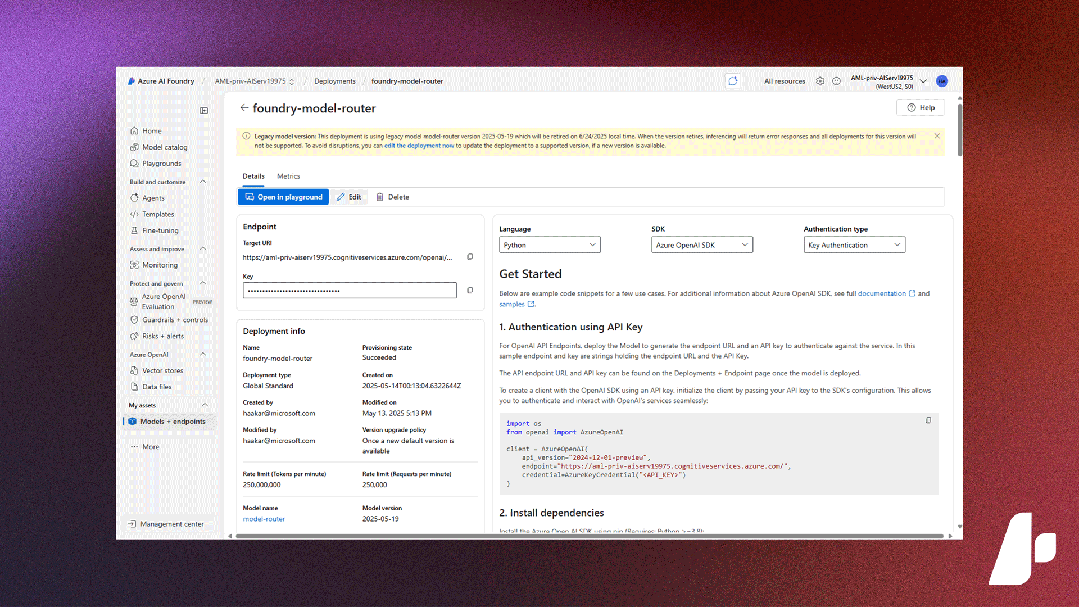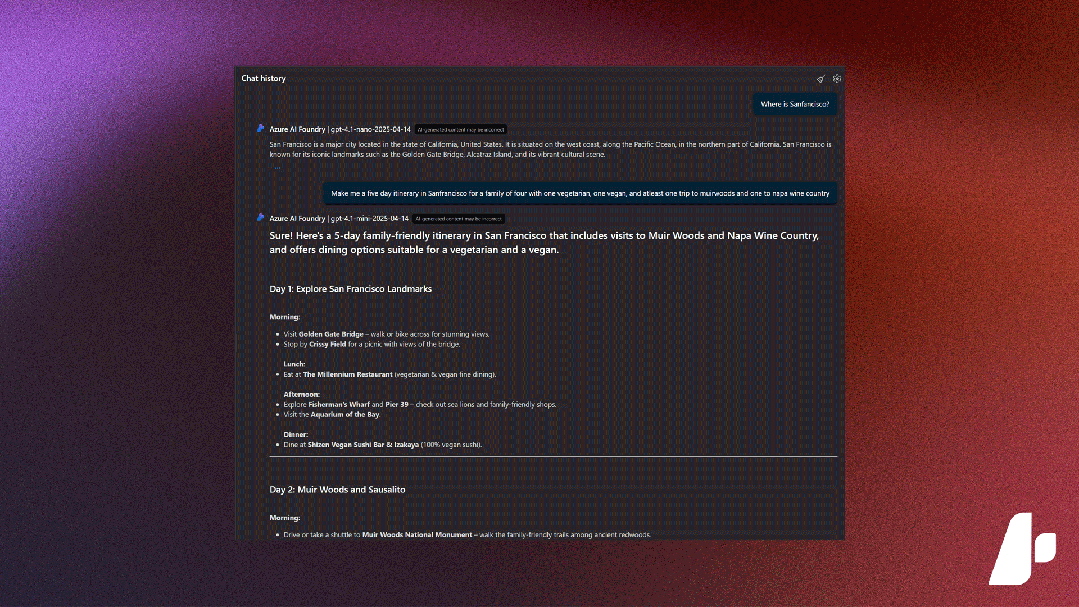
微软 Azure AI Foundry(国际版)十大重要更新
2025 年被广泛视为 “AI 智能体元年”。在过去半年,微软密集发布众多创新技术,构建起从基础设施层、开发工具层到场景应用层的完整技术矩阵,加速推动诸多具备自主决策能力的 “超级助理” 智能体落地,形成完整的 AI 赋能生态&…...

Realsense D435i 使用说明
D435i 驱动安装 及 ROS使用 Ubuntu16.04适配https://blog.csdn.net/lemonxiaoxiao/article/details/107834936 过程中遇到fatal error ; 需要添加标签。 使用下面网址的博客解决了。https://blog.csdn.net/xuzhengzhe/article/details/135407342 最终如下: target…...
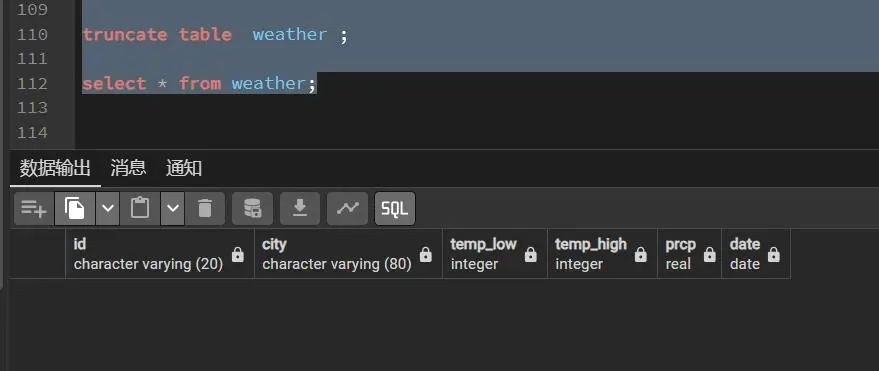
PostgreSQL如何更新和删除表数据
这节说下怎样更新和删除表数据,当然认识命令了,可以问AI帮忙写。 接上节先看下天气表weather的数据,增加了杭州和西安的数据: 一.UPDATE更新命令 用UPDATE命令更新现有的行。 假设所有 杭州 5月12日的温度低了两度,用…...

【leetcode】704. 二分查找
二分查找 题目代码 题目 704. 二分查找 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。 示例 1: 输入: nums [-1,0,3,…...

Golang | 运用分布式搜索引擎实现视频搜索业务
把前面所设计好的搜索引擎引用进来开发一个简单的具体的视频搜索业务。代码结构: handler目录:后端接口,负责接收请求并返回结果,不存在具体的搜索逻辑。video_search目录:具体的搜索逻辑存放在这,包括reca…...

针对Helsinki-NLP/opus-mt-zh-en模型进行双向互翻的微调
引言 题目听起来有点怪怪的,但是实际上就是对Helsinki-NLP/opus-mt-en-es模型进行微调。但是这个模型是单向的,只支持中到英的翻译,反之则不行。这样的话,如果要做中英双向互翻就需要两个模型,那模型体积直接大了两倍…...
【笔记】Trae+Andrioid Studio+Kotlin开发安卓WebView应用
文章目录 简介依赖步骤AS(Andriod Studio)创建项目AS创建虚拟机TRAE CN 修改项目新增按键捕获功能 新增WebViewWebView加载本地资源在按键回调中向WebView注入JS代码 最终关键代码吐槽 简介 使用Trae配合Andriod Studio开发一个内嵌WebView的安卓应用, 在WebView中加载本地资源…...

Github 2025-05-30Java开源项目日报Top10
根据Github Trendings的统计,今日(2025-05-30统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Java项目10C++项目1TypeScript项目1Keycloak: 现代应用程序和服务的开源身份和访问管理解决方案 创建周期:3846 天开发语言:Java协议类型:Ap…...
Github上一些使用技巧(缩写、Issue的Highlight)自用
1. GIthub中的一些缩写 LGTM ! 最近经常看到一些迷之缩写,感觉挺有意思的,但是有时候看到一些没见过的缩写还是有点懵逼,不过缩写确实也是很方便去review,这里就记录汇总一下;顺便加了一些git的基操单词(加…...
TextIn OCR Frontend前端开源组件库发布!
为什么开源 TextIn OCR Frontend 前端组件库? 在 TextIn 社群中,我们时常接到用户反馈,调取 API 进行票据等文件批量识别后,需要另行完成前端工程,实现比对环节。为助力用户节省工程成本,TextIn 团队正式开…...
)
GitLens 教学(学习更新中)
GitLens 是什么? GitLens 是安装在 Visual Studio Code (VS Code) 中的一个功能极其强大的扩展程序,它直接内嵌在您的代码编辑器中,极大地增强了 VS Code 内置的 Git 功能。它的核心目标是: 深刻理解代码历史: 让您轻…...
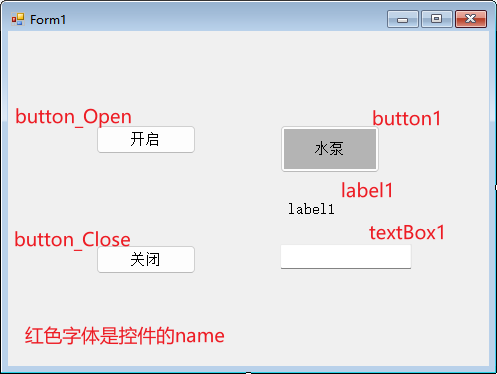
C#中数据绑定的简单例子
数据绑定允许将控件的属性和数据链接起来——控件属性值发生改变,会导致数据跟着自动改变。 数据绑定还可以是双向的——控件属性值发生改变,会导致数据跟着自动改变;数据发生改变,也会导致控件属性值跟着自动改变。 1、数据绑定…...
VR 技术在农业领域或许是一抹新曙光
在科技日新月异的今天,VR(虚拟现实)技术已不再局限于游戏、影视等娱乐范畴,正逐步渗透到各个传统行业,为其带来全新的发展契机,农业领域便是其中之一。VR 技术利用计算机生成三维虚拟世界,给予用户视觉、听觉、触觉等多…...
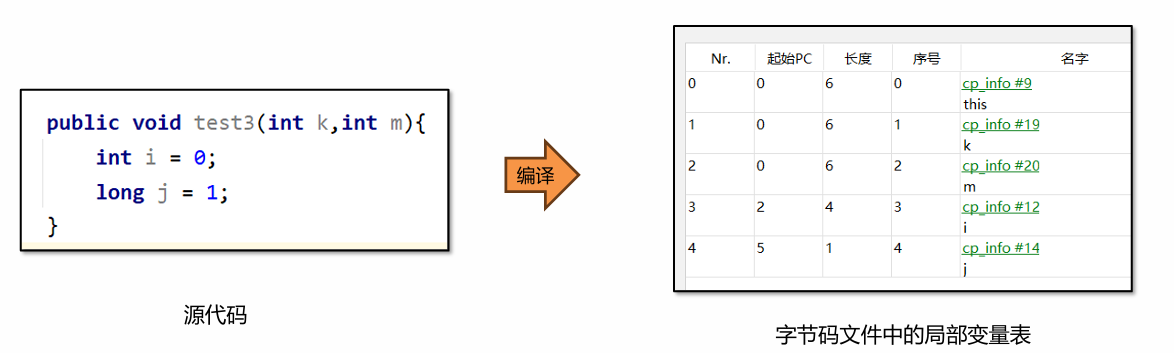
【JVM】Java程序运行时数据区
运行时数据区 运行时数据区是Java程序执行过程中管理的内存区域 Java 运行时数据区组成(JVM 内存结构) Java 虚拟机(JVM)的运行时数据区由以下核心部分组成: 线程私有:程序计数器、Java虚拟机栈、本地方…...

NVIDIA英伟达describe-anything软件本地电脑安装部署完整教程
describe-anything是英伟达联合其他大学开发的一款图片视频内容分析总结软件,可通过AI描述任意图片视频选中区域内容,非常强大,下面是describe-anything本地电脑安装部署教程。 首先电脑上安装git https://github.com/git-for-windows/git/…...

计算机视觉入门:OpenCV与YOLO目标检测
计算机视觉入门:OpenCV与YOLO目标检测 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 计算机视觉入门:OpenCV与YOLO目标检测摘要引言技术原理对比1. OpenCV:传统图像处理与机器学…...

Java 中的 ThreadLocal 详解:从基础到源码
Java 中的 ThreadLocal 详解:从基础到源码 引言 在 Java 多线程编程中,ThreadLocal是一个经常被提及的概念。它提供了一种线程局部变量的机制,使得每个线程都可以独立地存储和访问自己的变量副本,而不会与其他线程产生冲突。本文…...
开启深度学习动手之旅:先筑牢预备知识根基)
(二)开启深度学习动手之旅:先筑牢预备知识根基
1 数据操作 数据操作是深度学习的基础,包括数据的创建、索引、切片、运算等操作。这些操作是后续复杂模型构建和训练的前提。 入门 :理解如何使用NumPy创建数组,这是深度学习中数据存储的基本形式。掌握数组的属性(如数据类型dt…...