【NLP入门系列一】NLP概述和独热编码

- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
博主简介:努力学习的22级本科生一枚 🌟;探索AI算法,C++,go语言的世界;在迷茫中寻找光芒🌸
博客主页:羊小猪~~-CSDN博客
内容简介:NLP入门一。
🌸箴言🌸:去寻找理想的“天空“”之城
文章目录
- 1、NLP概论
- 什么是NLP?
- NLP存在的歧义问题
- NLP处理内容
- NLP评测
- 从汉字信息处理到汉语
- 2、独热编码
- 概念
- 英文本文案例
- 中文文本案例
👀 参考资料
- 哈工大nlp课件
1、NLP概论
什么是NLP?
📑自然语言处理可以定义为研究在人与人交际中以及在人与计算机交际中的语言问题的一门学科。自然语言处理要研制表示语言能力(linguistic competence)和语言应用(linguistic performance)的模型,建立计算框架来实现这样的语言模型,提出相应的方法来不断地完善这样的语言模型,根据这样的语言模型设计各种实用系统,并探讨这些实用系统的评测技术。
👓 有两个关键词:人与人交际、人与计算机交际,说白了就是机器理解人说话。
NLP存在的歧义问题
在自然语言处理的各个阶段广泛大量地存在着形形色色的歧义问题,这是自然语言与人工语言的根本差别之一,也是自然语言处理的难点所在。
⚜️ 如下案例:
-
分词
- 严守一把手机关了
- 严守/ 一把手/ 机关/ 了
- 严守一/ 把/ 手机/ 关/ 了
- 严守一把手机关了
-
词性标注
- 我/pro 计划/v 考/v 研/n
- 我/pro 完成/v 了/aux 计划/n
可以看出,不同分词意思是不一样的。
NLP处理内容





NLP评测


从汉字信息处理到汉语
📘 词处理
**词:**词是自然语言中最小的有意义的构成单位
分词规范:《信息处理用现代汉语分词规范》(中华人民共和国国家标准GB13715)
研究内容: 分词、词性标注、词义消歧等
📖 语句处理
- 语法分析
- 语句的语义分析
2、独热编码
概念
👀 词向量:
文字对于计算机来说就仅仅只是一个个符号,计算机无法理解其中含义,更无法处理。因此,NLP第一步就是:将文本数字化。
NLP中最早期的文本数字化方法,就是将文本转换为字典序列。如:“阿”是新华字典中第1个单词所以它的字典序列就是 1。

但是,这种数字化方法存在一个问题,就是模型可能会错误地认为不同类别之间存在一些顺序或距离关系,而实际上这些关系可能是不存在的或者不具有实际意义的。
📘 独热编码
one-hot编码的基本思想是将每个类别映射到一个向量,其中只有一个元素的值为1,其余元素的值为0。这样,每个类别之间就是相互独立的,不存在顺序或距离关系。
例如,对于三个类别的情况,可以使用如下的one-hot编码:
- 类别1:[1,0, 0]
- 类别2:[0,1,0]
- 类别3:[0,0, 1]
💛 优点
解决了分类器不好处理离散数据的问题,食能够处理非连续型数值。
特征。
😢 缺点
- one-hot 编码是一个词袋模型,是不考虑词和词之间的顺序问题,它是假设词和词之间是相互独立的,但是在大部分情况下词和词之间是相互影响的。
- one-hot编码得到的特征是离散稀疏的,每个单词的one-hot编码维度是整个词汇表的大小,维度非常巨大,编码稀疏,会使得计算代价变大。
英文本文案例
import torch
import torch.nn.functional as F # 案例文本
texts = ['Hello, how are you?', 'I am doing well, thank you!', 'Goodbye.']# 构造词汇表
word_index = {}
index_word = {}
for i, word in enumerate(set(" ".join(texts).split())): # " ".join(texts)字符串拼接,用' '; split默认空格分割; set去重重复项(哈希表)word_index[word] = i # word: iindex_word[i] = word # i: word# 将文本转化为整数序列
sequences = [[word_index[word] for word in text.split()] for text in texts] # 每句话分割,每句话就是一个特征向量# 获取词汇表大小
vocab_size = len(word_index)# 整数序列转化为独立编码
one_hot_results = torch.zeros(len(texts), vocab_size) # 创建矩阵
for i, seq in enumerate(sequences): # 遍历每个特征向量的元素one_hot_results[i, seq] = 1 # 打印结果
print("词汇表:")
print(word_index)
print("文本: ")
print(texts)
print("文本序列: ")
print(sequences)
print("one-hot:")
print(one_hot_results)
词汇表:
{'you!': 0, 'doing': 1, 'well,': 2, 'are': 3, 'how': 4, 'you?': 5, 'am': 6, 'Hello,': 7, 'thank': 8, 'Goodbye.': 9, 'I': 10}
文本:
['Hello, how are you?', 'I am doing well, thank you!', 'Goodbye.']
文本序列:
[[7, 4, 3, 5], [10, 6, 1, 2, 8, 0], [9]]
one-hot:
tensor([[0., 0., 0., 1., 1., 1., 0., 1., 0., 0., 0.],[1., 1., 1., 0., 0., 0., 1., 0., 1., 0., 1.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.]])
独热编码很想构造线性无关的特征向量,结合本案例,行表示每句话,列表示这句话有啥单词
中文文本案例
import torch
import torch.nn.functional as F # 文本
texts = ['你好,最近怎么样?', '我过得很好,谢谢!', '羊小猪']# 词汇表
word_index = {}
index_word = {}
for i, word in enumerate(set(" ".join(texts))): # 中文和英文不同注意,英文每个词都是空格分开word_index[word] = i index_word[i] = word # 将文本转化为整数序列
sequences = [[word_index[word] for word in text] for text in texts]# 获取词汇表大小
vocab_size = len(word_index)# 将整数转化为one-hot
one_hot_results = torch.zeros(len(texts), vocab_size) # 创建矩阵
for i, seq in enumerate(sequences):one_hot_results[i, seq] = i # 打印结果
print("词汇表:")
print(word_index)
print("文本: ")
print(texts)
print("文本序列: ")
print(sequences)
print("one-hot:")
print(one_hot_results)
词汇表:
{' ': 0, '样': 1, '你': 2, '?': 3, '猪': 4, '小': 5, '怎': 6, '过': 7, '很': 8, '么': 9, '最': 10, '得': 11, '好': 12, '羊': 13, '谢': 14, '我': 15, '近': 16, ',': 17, '!': 18}
文本:
['你好,最近怎么样?', '我过得很好,谢谢!', '羊小猪']
文本序列:
[[2, 12, 17, 10, 16, 6, 9, 1, 3], [15, 7, 11, 8, 12, 17, 14, 14, 18], [13, 5, 4]]
one-hot:
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0.],[0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 1., 1., 0., 1., 1., 0., 1.,1.],[0., 0., 0., 0., 2., 2., 0., 0., 0., 0., 0., 0., 0., 2., 0., 0., 0., 0.,0.]])
注意:上面案例都是以“字”为单位的,但是中文词拆开后会有歧义,不需要进行分词操作。
常用的分词有:结巴分词(jieba)
- 定义:
jieba是一个开源的中文分词 Python 库,广泛用于自然语言处理(NLP)任务,如文本分析、词频统计、情感分析等。 - 特点:
- 支持多种分词模式(精确模式、全模式、搜索引擎模式)。
- 支持自定义词典和词频调整。
- 支持繁体中文分词。
- 高效快速,基于前缀词典和动态规划算法。
- 提供关键词提取、词性标注等高级功能。
import torch
import torch.nn.functional as F
import jieba # 文本
texts = ['你好,最近怎么样?', '我过得很好,谢谢!', '羊小猪']# 分词
tokenized_texts = [list(jieba.cut(text)) for text in texts]print("tokenized_texts: ", tokenized_texts)# 词汇表
word_index = {}
index_word = {}
for i, word in enumerate(set([word for text in tokenized_texts for word in text])): # 将分词后的文本列表(tokenized_texts)合并为一个包含所有唯一词汇的集合word_index[word] = i index_word[i] = word # 将文本转化为整数序列
sequences = [[word_index[word] for word in text] for text in tokenized_texts]# 获取词汇表大小
vocab_size = len(word_index)# 将整数转化为one-hot
one_hot_results = torch.zeros(len(texts), vocab_size) # 创建矩阵
for i, seq in enumerate(sequences):one_hot_results[i, seq] = i # 打印结果
print("词汇表:")
print(word_index)
print("文本: ")
print(texts)
print("文本序列: ")
print(sequences)
print("one-hot:")
print(one_hot_results)
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\WY118C~1\AppData\Local\Temp\jieba.cache
Loading model cost 1.109 seconds.
Prefix dict has been built successfully.
tokenized_texts: [['你好', ',', '最近', '怎么样', '?'], ['我过', '得', '很', '好', ',', '谢谢', '!'], ['羊', '小猪']]
词汇表:
{'得': 0, '好': 1, '羊': 2, '怎么样': 3, '很': 4, '最近': 5, '?': 6, '!': 7, '我过': 8, ',': 9, '你好': 10, '小猪': 11, '谢谢': 12}
文本:
['你好,最近怎么样?', '我过得很好,谢谢!', '羊小猪']
文本序列:
[[10, 9, 5, 3, 6], [8, 0, 4, 1, 9, 12, 7], [2, 11]]
one-hot:
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[1., 1., 0., 0., 1., 0., 0., 1., 1., 1., 0., 0., 1.],[0., 0., 2., 0., 0., 0., 0., 0., 0., 0., 0., 2., 0.]])
相关文章:
【NLP入门系列一】NLP概述和独热编码
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 博主简介:努力学习的22级本科生一枚 🌟;探索AI算法,C,go语言的世界;在迷茫中寻找光芒…...

洛谷习题V^V
1.帮贡排序 解题思路:按照题意,排序模拟即可 #include <iostream> #include <vector> #include <algorithm> #include <string> using namespace std;struct Member {string name;string position;int contribution;int level;…...
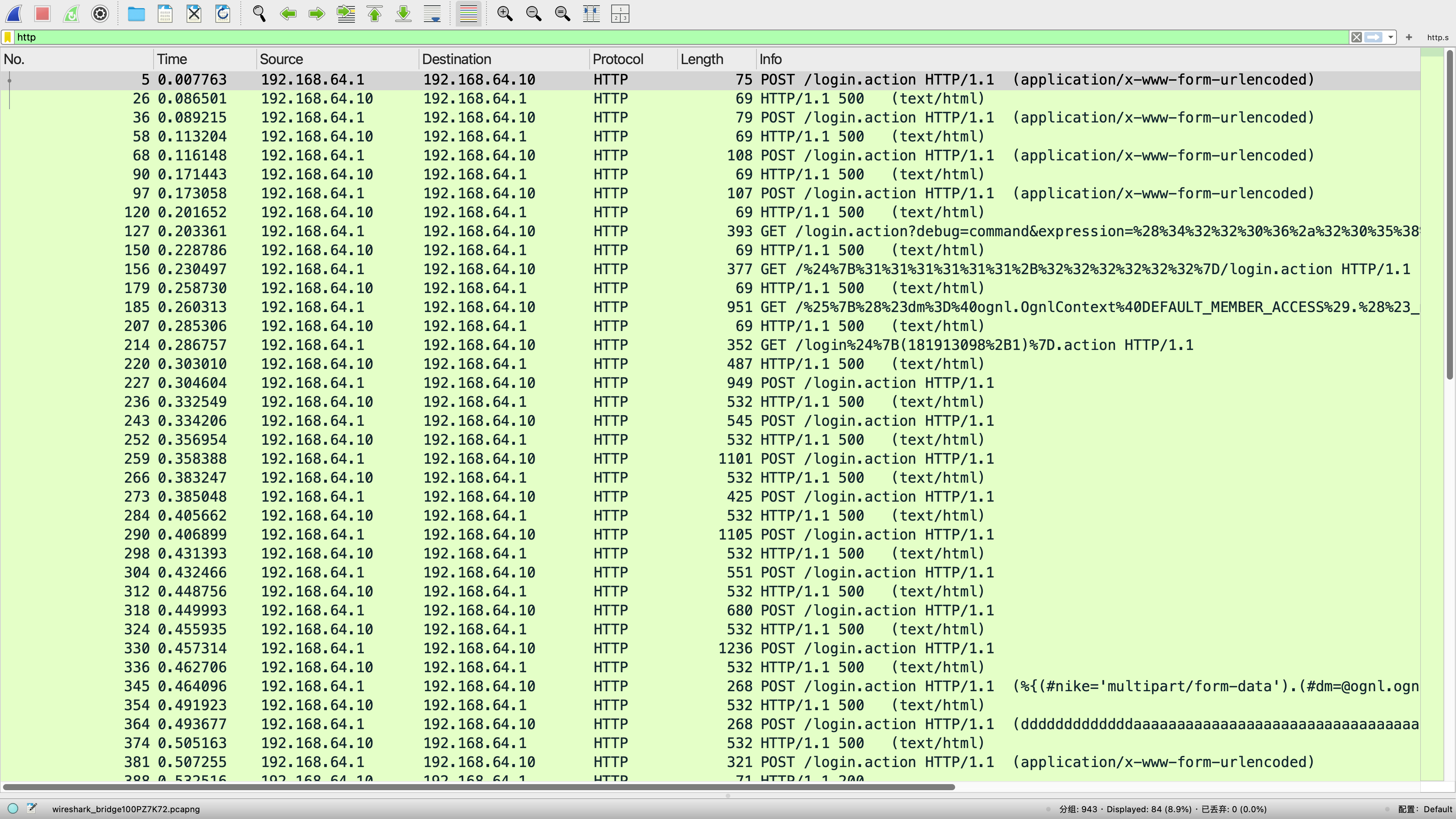
Wireshark 在 macOS 上使用及问题解决
wireshark概述 Wireshark 是被广泛使用的免费开源网络协议分析软件(network protocol analyzer)或网络数据包分析工具,它可以让你在微观层面上查看网络上发生的事情。它的主要功能是截取网络数据包,并尽可能详细地展示网络数据包…...
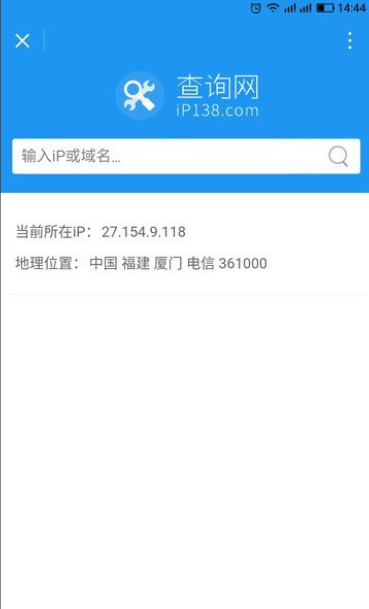
不同电脑同一个网络ip地址一样吗?如何更改
想象一下,你住在同一栋公寓楼里,所有住户对外共享一个统一的小区地址(类似公网IP),但每家每户又有独立的门牌号(类似内网IP)。网络世界中的IP地址也遵循这一逻辑:同一局域网内的设备…...

Qt使用智能指针
第一步:导入头文件 #include <QScopedPointer> 第二步:创建对象 .h文件 QSharedPointer<Student> m_pClass; .cpp文件 m_pClass.reset(new Student(param1,param2,...,param_n)); 第三步:绑定信号槽 connect(m_pClass.data(), &Class::sign…...
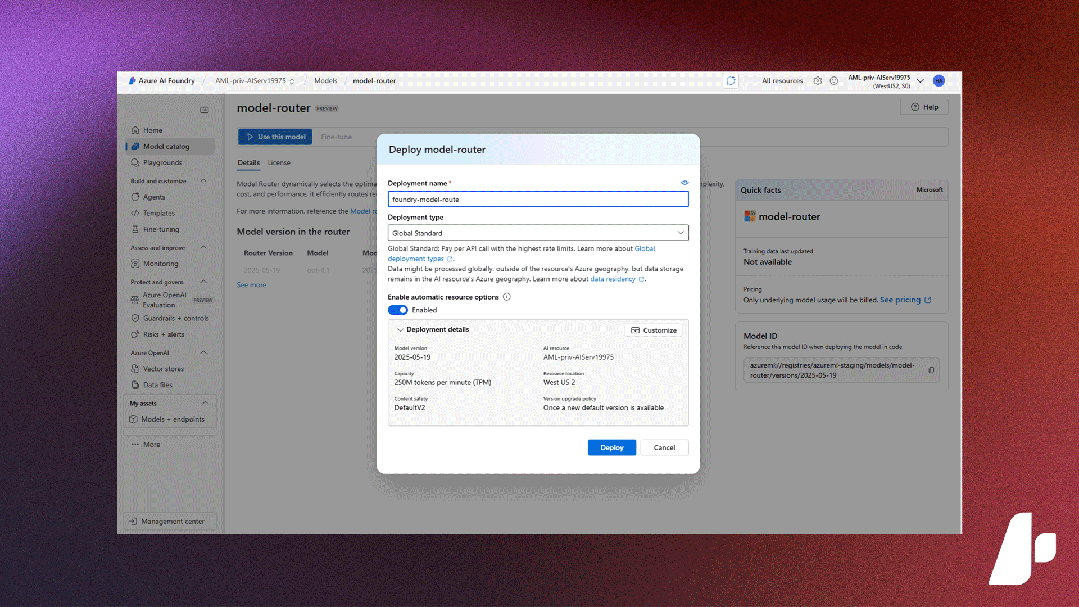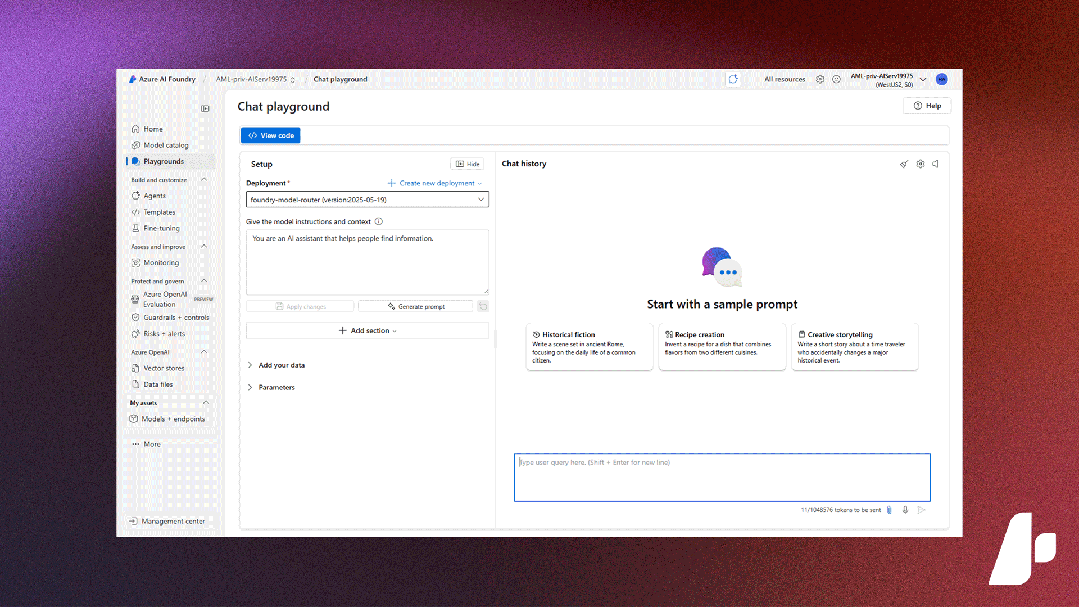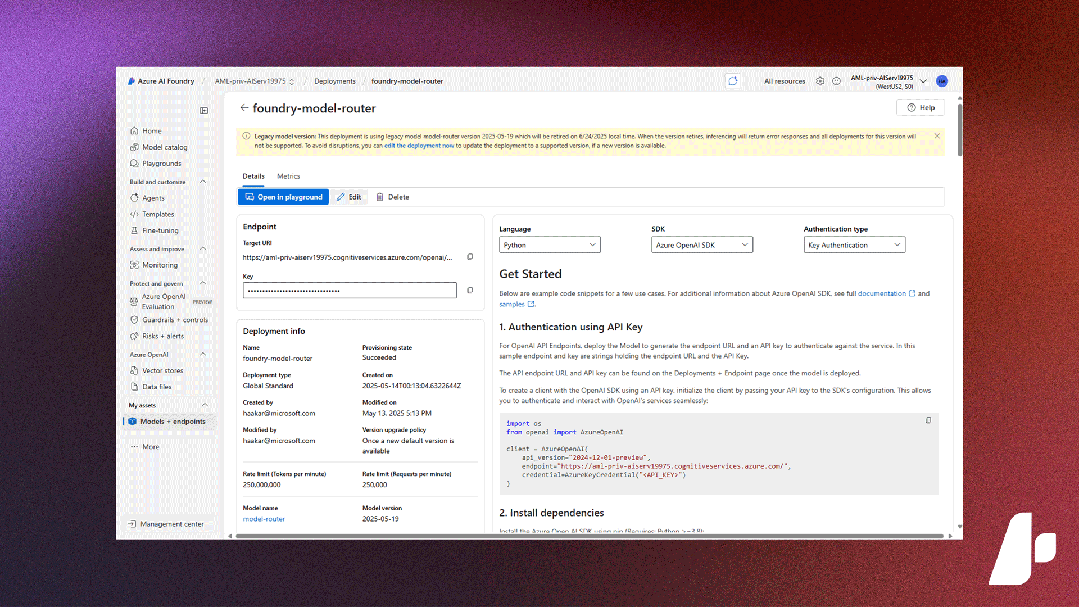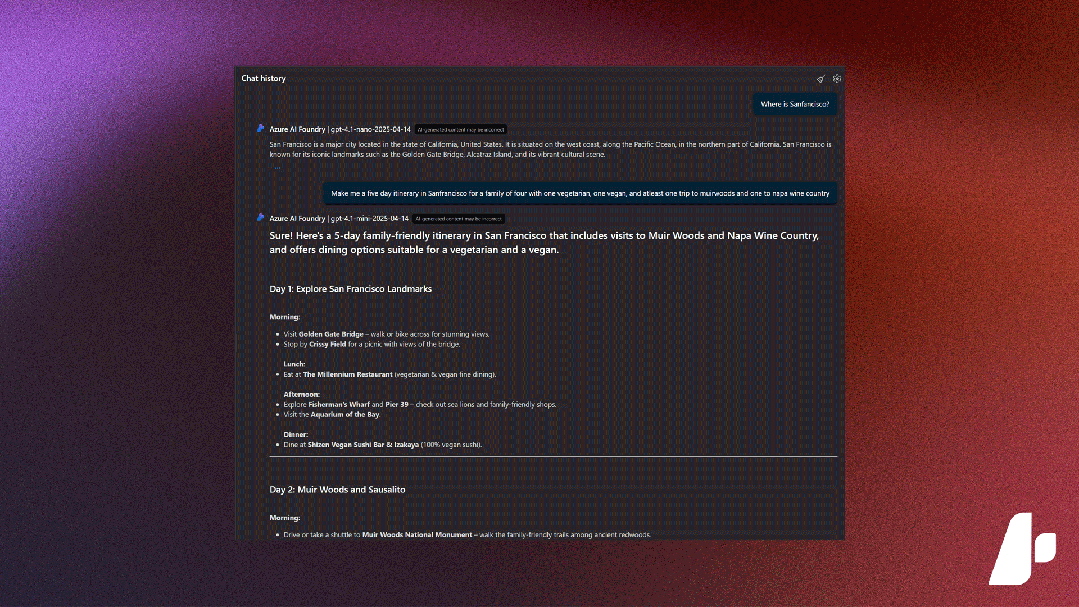
微软 Azure AI Foundry(国际版)十大重要更新
2025 年被广泛视为 “AI 智能体元年”。在过去半年,微软密集发布众多创新技术,构建起从基础设施层、开发工具层到场景应用层的完整技术矩阵,加速推动诸多具备自主决策能力的 “超级助理” 智能体落地,形成完整的 AI 赋能生态&…...

Realsense D435i 使用说明
D435i 驱动安装 及 ROS使用 Ubuntu16.04适配https://blog.csdn.net/lemonxiaoxiao/article/details/107834936 过程中遇到fatal error ; 需要添加标签。 使用下面网址的博客解决了。https://blog.csdn.net/xuzhengzhe/article/details/135407342 最终如下: target…...
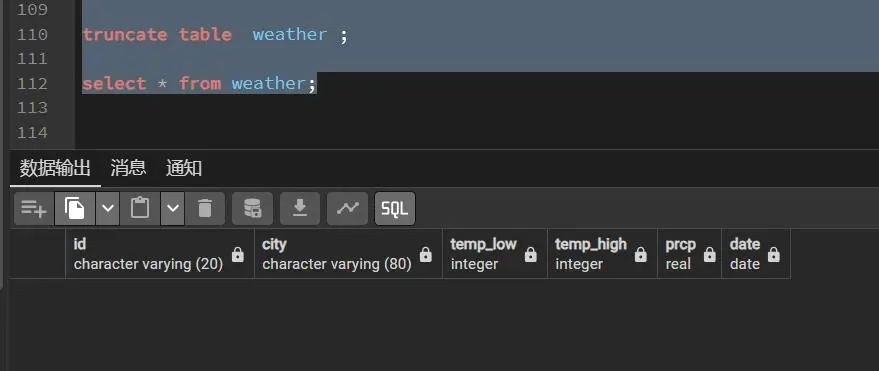
PostgreSQL如何更新和删除表数据
这节说下怎样更新和删除表数据,当然认识命令了,可以问AI帮忙写。 接上节先看下天气表weather的数据,增加了杭州和西安的数据: 一.UPDATE更新命令 用UPDATE命令更新现有的行。 假设所有 杭州 5月12日的温度低了两度,用…...

【leetcode】704. 二分查找
二分查找 题目代码 题目 704. 二分查找 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。 示例 1: 输入: nums [-1,0,3,…...

Golang | 运用分布式搜索引擎实现视频搜索业务
把前面所设计好的搜索引擎引用进来开发一个简单的具体的视频搜索业务。代码结构: handler目录:后端接口,负责接收请求并返回结果,不存在具体的搜索逻辑。video_search目录:具体的搜索逻辑存放在这,包括reca…...

针对Helsinki-NLP/opus-mt-zh-en模型进行双向互翻的微调
引言 题目听起来有点怪怪的,但是实际上就是对Helsinki-NLP/opus-mt-en-es模型进行微调。但是这个模型是单向的,只支持中到英的翻译,反之则不行。这样的话,如果要做中英双向互翻就需要两个模型,那模型体积直接大了两倍…...
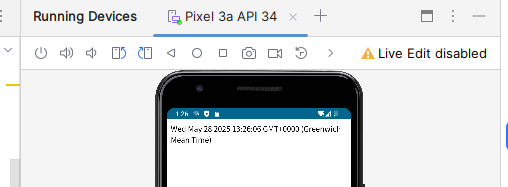
【笔记】Trae+Andrioid Studio+Kotlin开发安卓WebView应用
文章目录 简介依赖步骤AS(Andriod Studio)创建项目AS创建虚拟机TRAE CN 修改项目新增按键捕获功能 新增WebViewWebView加载本地资源在按键回调中向WebView注入JS代码 最终关键代码吐槽 简介 使用Trae配合Andriod Studio开发一个内嵌WebView的安卓应用, 在WebView中加载本地资源…...

Github 2025-05-30Java开源项目日报Top10
根据Github Trendings的统计,今日(2025-05-30统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Java项目10C++项目1TypeScript项目1Keycloak: 现代应用程序和服务的开源身份和访问管理解决方案 创建周期:3846 天开发语言:Java协议类型:Ap…...
Github上一些使用技巧(缩写、Issue的Highlight)自用
1. GIthub中的一些缩写 LGTM ! 最近经常看到一些迷之缩写,感觉挺有意思的,但是有时候看到一些没见过的缩写还是有点懵逼,不过缩写确实也是很方便去review,这里就记录汇总一下;顺便加了一些git的基操单词(加…...
TextIn OCR Frontend前端开源组件库发布!
为什么开源 TextIn OCR Frontend 前端组件库? 在 TextIn 社群中,我们时常接到用户反馈,调取 API 进行票据等文件批量识别后,需要另行完成前端工程,实现比对环节。为助力用户节省工程成本,TextIn 团队正式开…...
)
GitLens 教学(学习更新中)
GitLens 是什么? GitLens 是安装在 Visual Studio Code (VS Code) 中的一个功能极其强大的扩展程序,它直接内嵌在您的代码编辑器中,极大地增强了 VS Code 内置的 Git 功能。它的核心目标是: 深刻理解代码历史: 让您轻…...
C#中数据绑定的简单例子
数据绑定允许将控件的属性和数据链接起来——控件属性值发生改变,会导致数据跟着自动改变。 数据绑定还可以是双向的——控件属性值发生改变,会导致数据跟着自动改变;数据发生改变,也会导致控件属性值跟着自动改变。 1、数据绑定…...
VR 技术在农业领域或许是一抹新曙光
在科技日新月异的今天,VR(虚拟现实)技术已不再局限于游戏、影视等娱乐范畴,正逐步渗透到各个传统行业,为其带来全新的发展契机,农业领域便是其中之一。VR 技术利用计算机生成三维虚拟世界,给予用户视觉、听觉、触觉等多…...
【JVM】Java程序运行时数据区
运行时数据区 运行时数据区是Java程序执行过程中管理的内存区域 Java 运行时数据区组成(JVM 内存结构) Java 虚拟机(JVM)的运行时数据区由以下核心部分组成: 线程私有:程序计数器、Java虚拟机栈、本地方…...

NVIDIA英伟达describe-anything软件本地电脑安装部署完整教程
describe-anything是英伟达联合其他大学开发的一款图片视频内容分析总结软件,可通过AI描述任意图片视频选中区域内容,非常强大,下面是describe-anything本地电脑安装部署教程。 首先电脑上安装git https://github.com/git-for-windows/git/…...

计算机视觉入门:OpenCV与YOLO目标检测
计算机视觉入门:OpenCV与YOLO目标检测 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 计算机视觉入门:OpenCV与YOLO目标检测摘要引言技术原理对比1. OpenCV:传统图像处理与机器学…...

Java 中的 ThreadLocal 详解:从基础到源码
Java 中的 ThreadLocal 详解:从基础到源码 引言 在 Java 多线程编程中,ThreadLocal是一个经常被提及的概念。它提供了一种线程局部变量的机制,使得每个线程都可以独立地存储和访问自己的变量副本,而不会与其他线程产生冲突。本文…...
开启深度学习动手之旅:先筑牢预备知识根基)
(二)开启深度学习动手之旅:先筑牢预备知识根基
1 数据操作 数据操作是深度学习的基础,包括数据的创建、索引、切片、运算等操作。这些操作是后续复杂模型构建和训练的前提。 入门 :理解如何使用NumPy创建数组,这是深度学习中数据存储的基本形式。掌握数组的属性(如数据类型dt…...

Spring Boot3.4.1 集成redis
Spring Boot3.4.1 集成redis 第一步 引入依赖 <!-- redis 缓存操作 --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <!-- pool 对象池 …...

【Prometheus+Grafana实战:搭建监控系统(含告警配置)】
什么是Prometheus和Grafana? Prometheus:一款开源的监控告警工具,擅长时序数据存储和多维度查询(通过PromQL),采用Pull模型主动抓取目标指标。Grafana:数据可视化平台,支持多种数据…...

操作系统原理第9章 磁盘存储器管理 重点内容
目录 (一)外存的组织方式种类 (二)FAT 系统(计算) (三)文件存储空间的管理方式 (一)外存的组织方式种类 连续组织方式 原理:在磁盘等外存上&…...
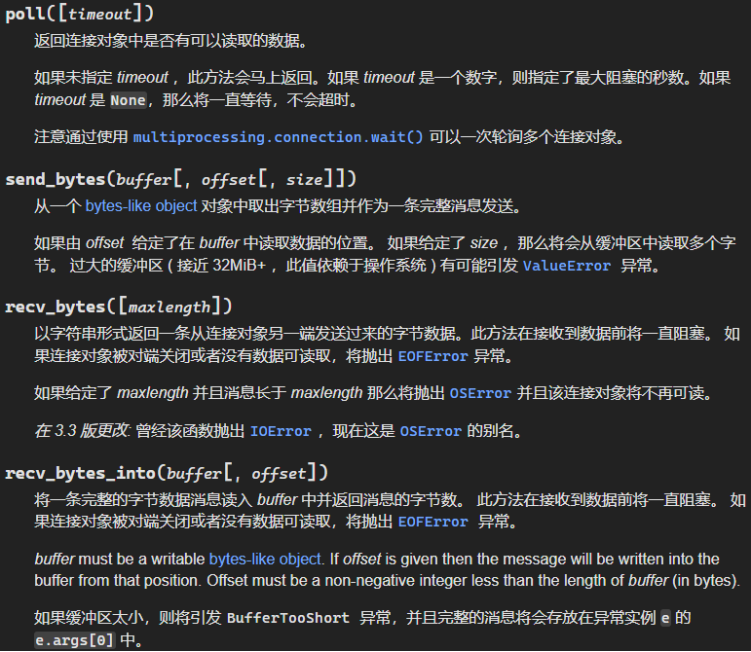
一文速通Python并行计算:11 Python多进程编程-进程之间的数据安全传输-基于队列和管道
一文速通 Python 并行计算:11 Python 多进程编程-进程之间的数据安全传输-基于队列和管道 摘要: Python 多进程中,Queue 和 Pipe 提供进程间安全通信。Queue 依赖锁和缓冲区,保障数据原子性和有序性;Pipe 实现点对点单…...
LangChain-Tool和Agent结合智谱AI大模型应用实例2
1.Tool(工具) 定义与功能 单一功能模块:Tool是完成特定任务的独立工具,每个工具专注于一项具体的操作,例如:搜索、计算、API调用等 无决策能力:工具本身不决定何时被调用,仅在被触发时执行预设操作 输入输出明确:每个工具需明确定义输入、输出参数及格式 2.Agent(…...

HTML、XML、JSON 是什么?有什么区别?又是做什么的?
在学习前端开发或者理解互联网工作原理的过程中,我们经常会遇到三个非常重要的概念:HTML、XML 和 JSON。它们看起来有点像,但其实干的事情完全不同。 🏁 一、他们是谁?什么时候诞生的? 名称全称诞生时间谁…...

C++中IO文件输入输出知识详解和注意事项
以下内容将从文件流类体系、打开模式、文本与二进制 I/O、随机访问、错误处理、性能优化等方面,详解 C 中文件输入输出的使用要点,并配以示例。 一、文件流类体系 C 标准库提供三种文件流类型,均定义在 <fstream> 中: std…...