MySQL之约束和表的增删查改
MySQL之约束和表的增删查改
- 一.数据库约束
- 1.1数据库约束的概念
- 1.2NOT NULL 非空约束
- 1.3DEFAULT 默认约束
- 1.4唯一约束
- 1.5主键约束和自增约束
- 1.6自增约束
- 1.7外键约束
- 1.8CHECK约束
- 二.表的增删查改
- 2.1Create创建
- 2.2Retrieve读取
- 2.3Update更新
- 2.4Delete删除和Truncate截断
一.数据库约束
1.1数据库约束的概念
C++中对于我们定义的数据有着一套检查的逻辑,当数据不符合你数据类型的范围时就会产生报错那么MySQL中是否也有这种设计呢?C++中对于数据的检查一般是编译器自己进行产生报错而MySQL则会通过约束来让强制程序员自己合法插入数据。
数据库约束是指对数据库表中的数据所施加的规则或条件,⽤于确保数据的准确性和可靠性。这
些约束可以是基于数据类型、值范围、唯⼀性、⾮空等规则,以确保数据的正确性和相容性。简单来说约束类似于我们的法律法规来让我们程序员自己遵守,只要不违反这个规定MySQL就不会发出警告。
例如我们之前介绍MySQL中数据类型时提到过不同类型的取值范围这就算是一种约束,只要我们插入的数据不符合这个范围MySQL也会发出警告。
1.2NOT NULL 非空约束
对于某些数据将其设为空是没有意义所以我们可以使用非空约束来让其不可能为空。
例如对于学生来说他的名字学号身份证这些都不可能为空,也不会将其设为空因为这样就没有意义了。
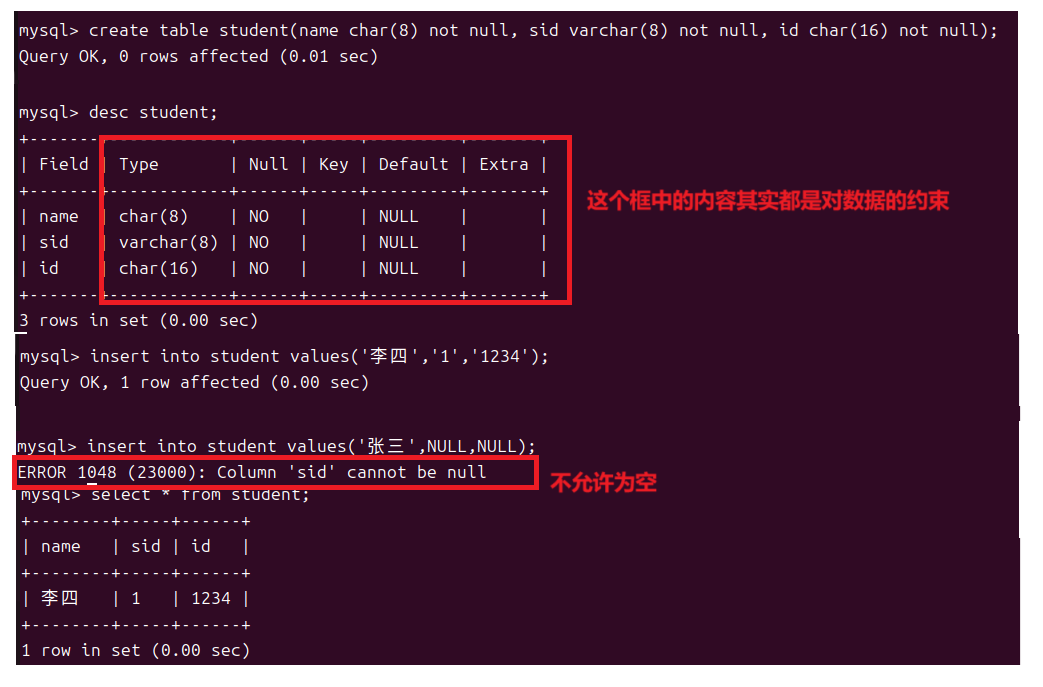
从图片中我们也可以发现想要对某列加约束的话我们只需要在创建表时在列后增加关键字即可,非空约束就是not null。
想要判断表中某列是否可以为空我们只需要使用desc来查看表结构其中的NULL为yes则说明可以为空no就是不可以。
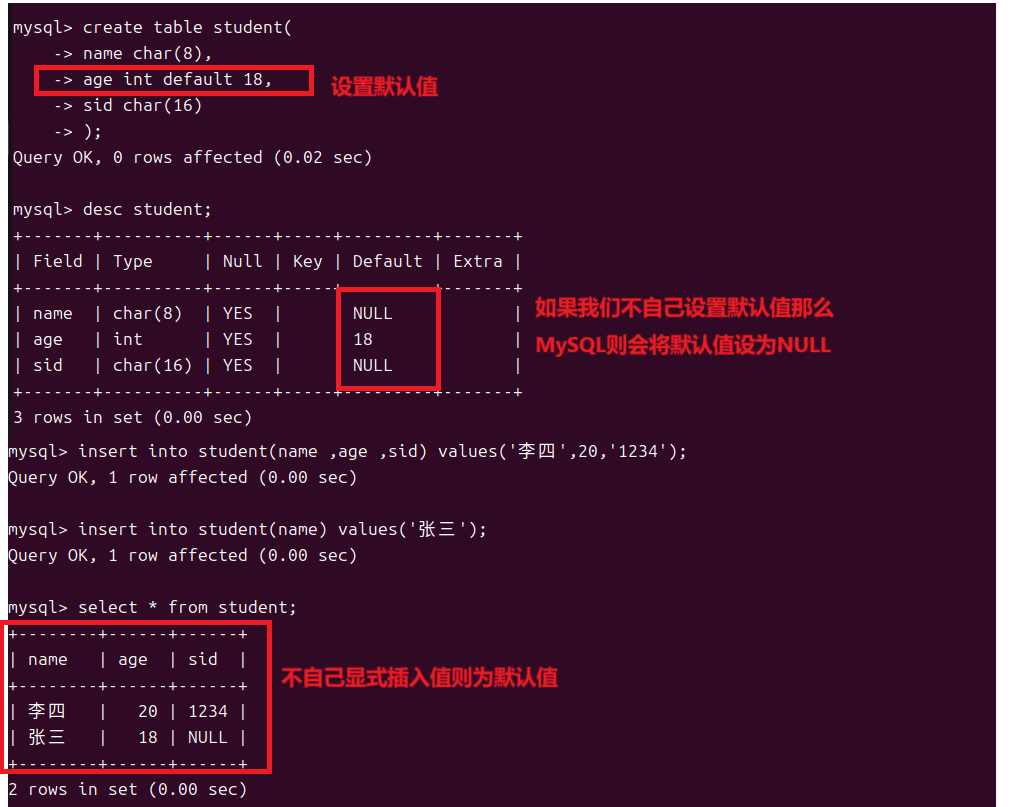
1.3DEFAULT 默认约束
我们同样可以为一列增加一个默认值类似于我们C++中的缺省参数,只要我们不显式设置列的值那么它就是默认值。
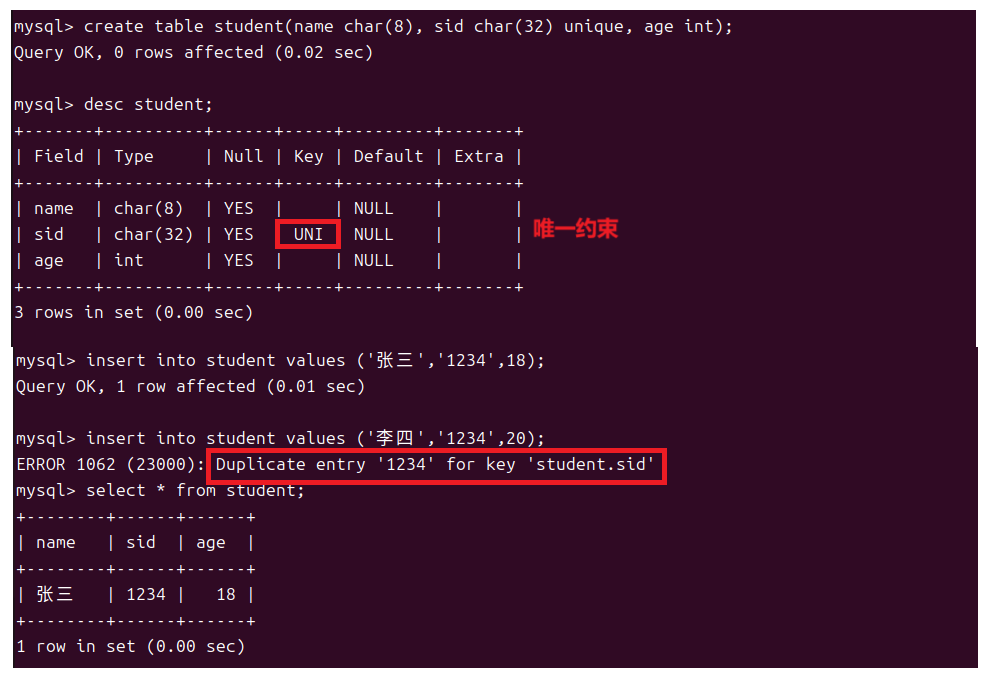
1.4唯一约束
对于数据来说我们有时候需要它是不重复的所以我们也可以将一个列增加唯一约束。这时候这列就被叫做唯一键。
1.5主键约束和自增约束
对于一个表来说我们有时候对于存储的数据我们是有轻重之分的,有些数据是这个表中最重要的数据例如学生表中的学号,即使其他的数据都为空工作人员也可以通过学号来找到一个学生。有些数据的存在又是比较无所谓的就像学生表中学生的爱好,这些数据就算不存在也不会影响什么。所以这些重要的数据我们需要来特别关注不能让它重复也不能为空,这就是主键。
主键约束用来标明一张表中的每条记录,主键既不能为空也不能重复并且一个表中只能有一个主键而主键可以由一列或者多列组成。
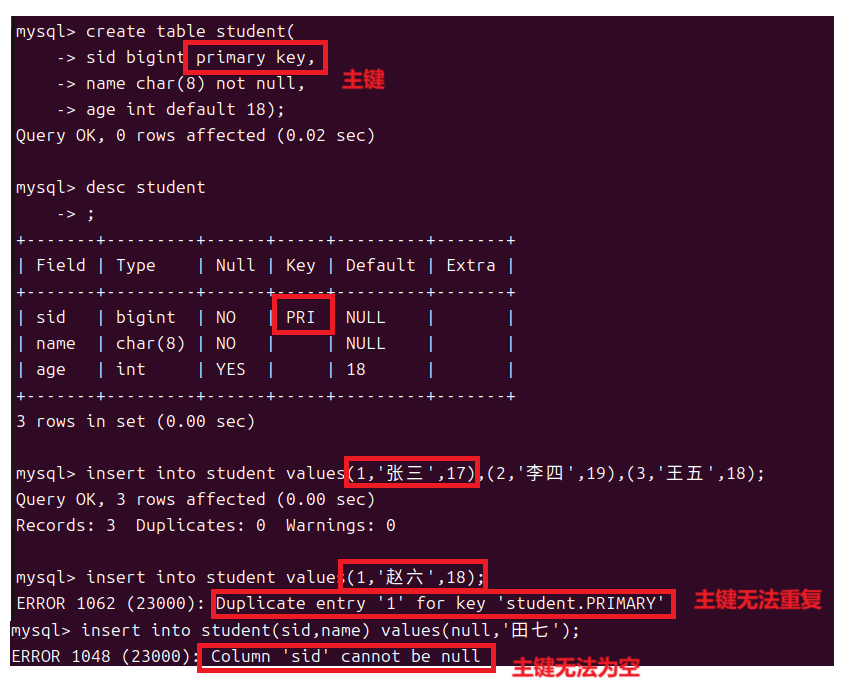
主键同样可以设为多列此时只要多列的内容不是完全相同则不算是重复,但是多列中每一个的内容都不可以为空。
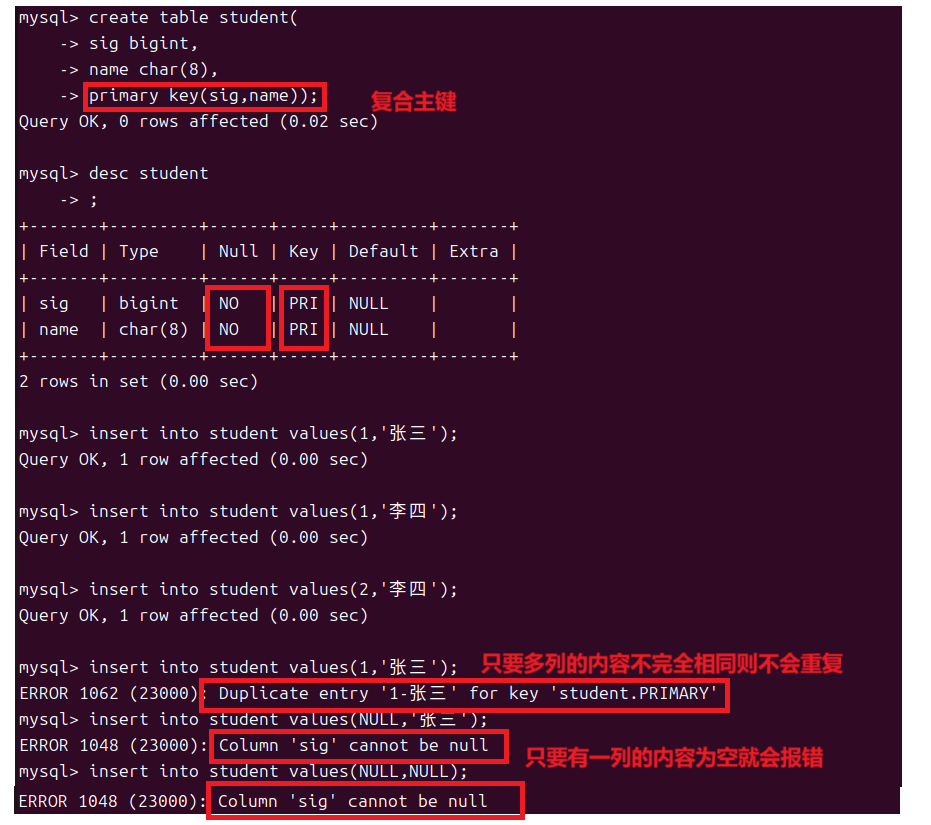
一个表中只能有一个主键

1.6自增约束
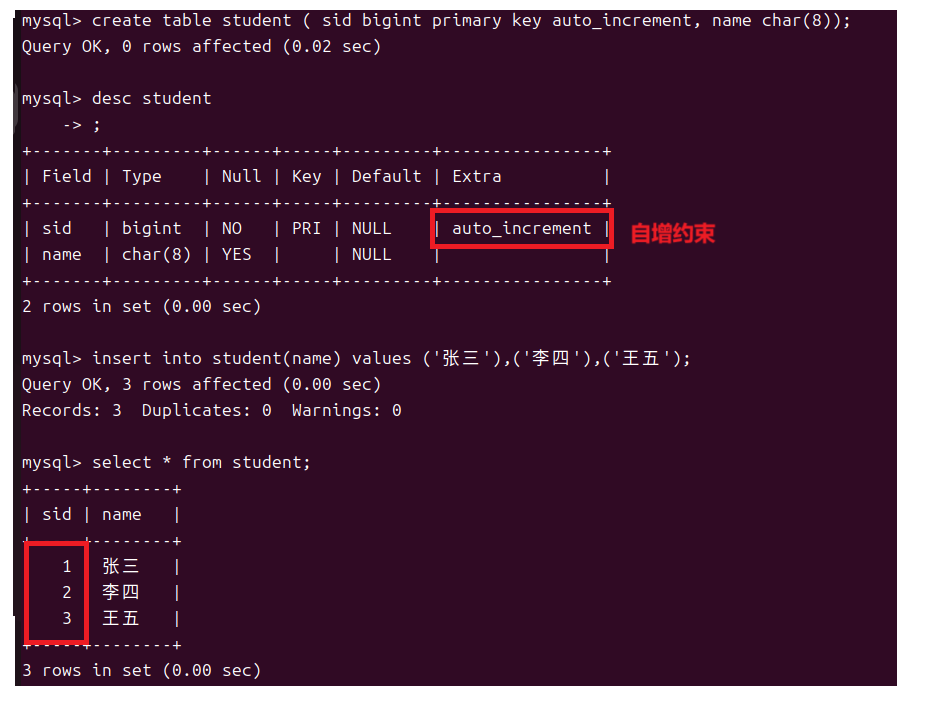
因为主键是用来标识表中的每个记录所以它一般搭配则自增约束来使用,它允许数据库自动为新插入行的特定列生成一个唯一的数字。这通常用于主键列,以确保每条记录都有一个唯一的标识符。
因为只有数字可以自增所以自增列必须是整数类型并且只能用于键列即唯一键,主键或者外键同时一个表中只能设置一个自增列。
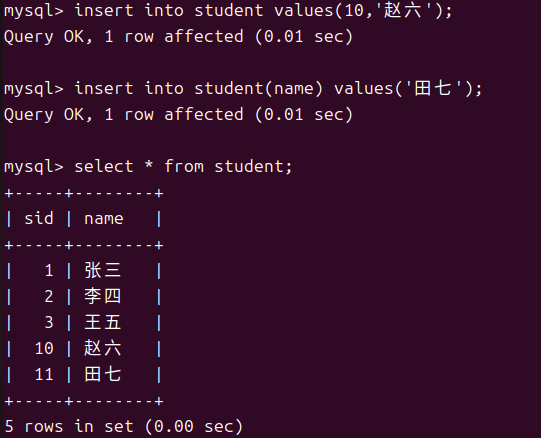
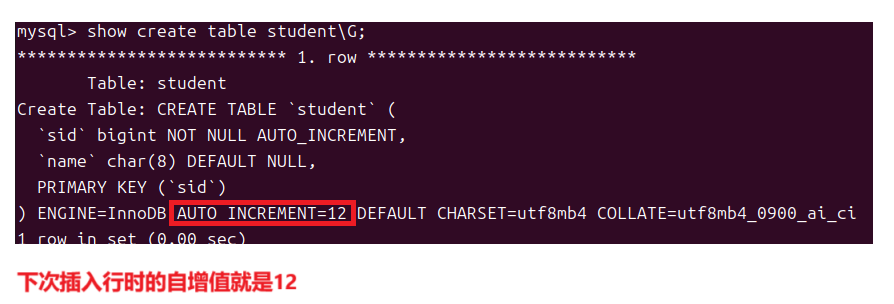
在一个键列被设为自增后我们仍然可以主动去设置它的值不过之后会在你设置的值的基础上进行自增。我们可以使用show create table table_name 来查看这个表的创建语句以及此时它的自增值是多少
1.7外键约束
人与人之间是有联系的同理表与表之间也是有联系的例如我是二班的学生那么这里就会有两个表一个为班级表一个是二班的成员表。那么这两个表不就形成了一种主从关系,主表是班级表而从表就是各班的成员表也可以说从表是对主表中对应内容的扩展。所以主表和从表中可以通过两表中各自的一列建立联系就像班级表中的班级编号和成员表中的班级编号。
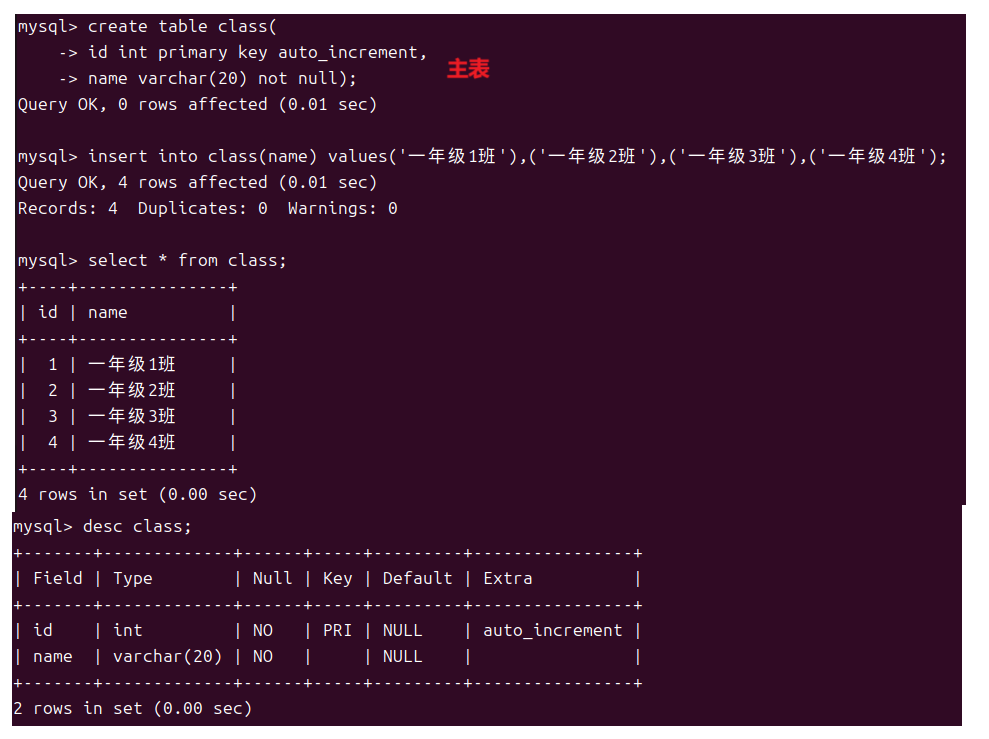
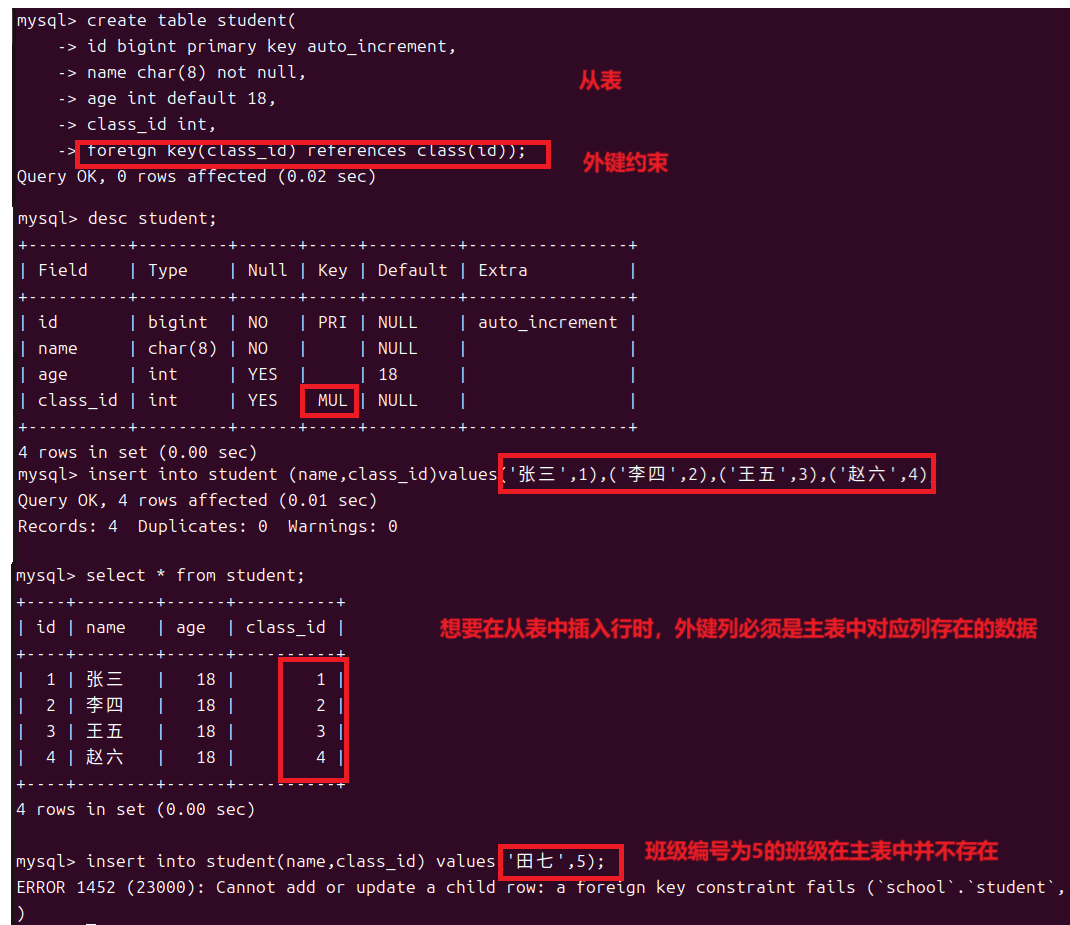
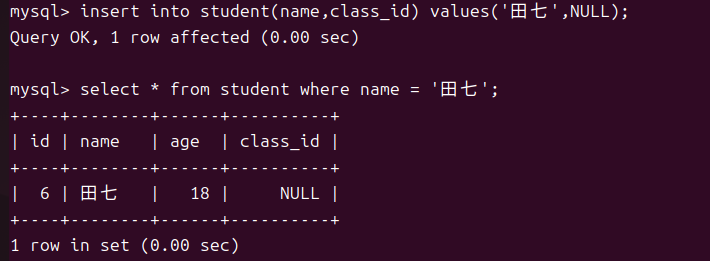
但是我们可以将从表中班级编号设为空来插入行
所以在使用外键约束时我们需要注意:
- 主表和从表对应的列数据类型必须相同
- 在从表插入行时外键列的值必须在主表中存在或者为空
- 在删除主表中某行时从表不能存在对这行的引用
- 删除主表前必须删除从表
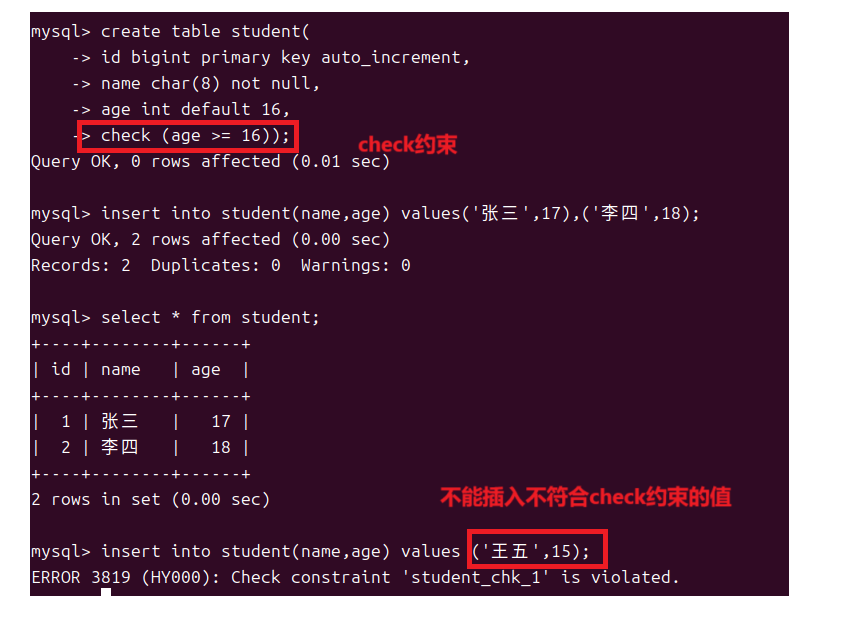
1.8CHECK约束
可以应⽤于⼀个或多个列,⽤于限制列中可接受的数据值,从⽽确保数据的完整性和准确性。
二.表的增删查改
对数据库中表的内容做操作一般被分为四类:Create,Retrieve,Update,Delete,简称CRUD。
2.1Create创建
insert
[into]
table_name #表名
[(column [,column],...)] #是否指定列
values (vast_list) [,(vast_list)],...#插入的数据以行为单位vast_list: value[,value] ...
对于使用insert插入行我们可以完成单行数据全列插入,单行数据指定列插入以及多行数据指定列插入。
-
单行数据全列插入
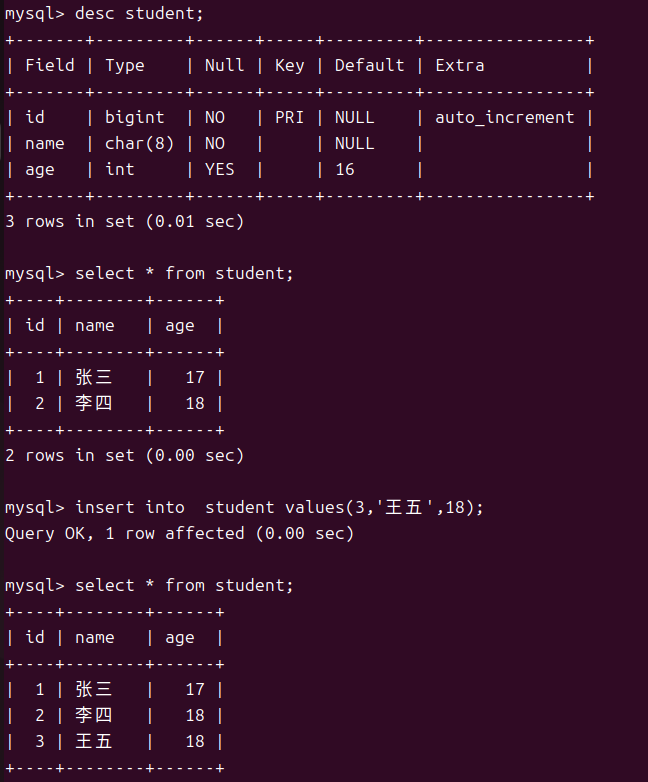
-
单行数据指定列插入
使用单行指定列插入时要注意没有被插入的列是否有非空约束或者主键约束以免出现报错
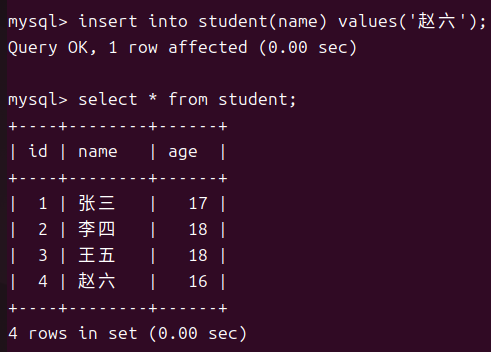
-
多行数据指定列插入
使用多行数据指定列插入时要注意每行的数据要用()各自包裹起来。
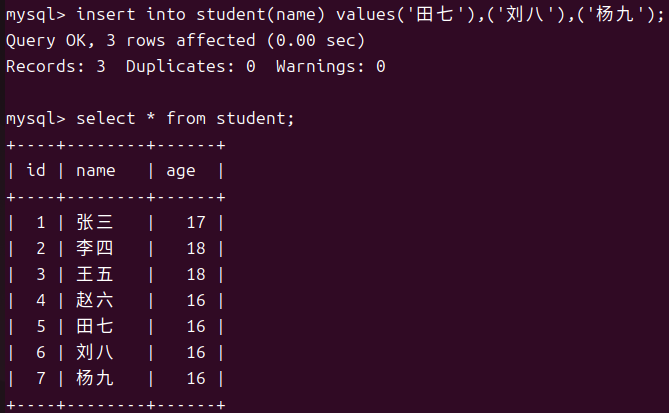
2.2Retrieve读取
SELECT[DISTINCT] #是否去重select_expr [, select_expr] ... #读取的列[FROM table_references] #是否从某个表中读取[WHERE where_condition] #是否有判断条件[GROUP BY {col_name | expr}, ...] #是否进行分表[HAVING where_condition] #在完成读取后是否再进行条件判断[ORDER BY {col_name | expr } [ASC | DESC], ... ] #是否进行排序[LIMIT {[offset,] row_count | row_count OFFSET offset}] #限制返回记录数量
在了解了语法后我们从简单的开始慢慢入手,用例子来为大家讲解语法中各个字段的作用
首先是最简单的查询,我们可以完成全列查询或者指定列查询亦或者我们可以查询一个表达式的结果。
- 全列查询
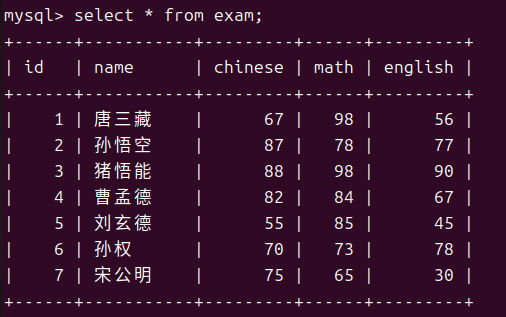
- 指定列查询
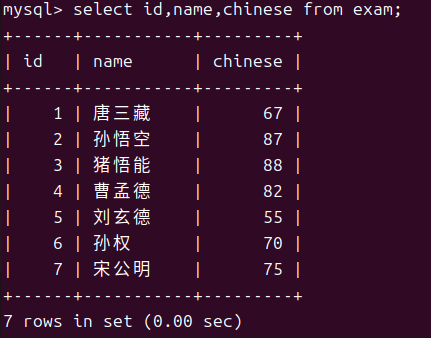
- 查询表达式结果
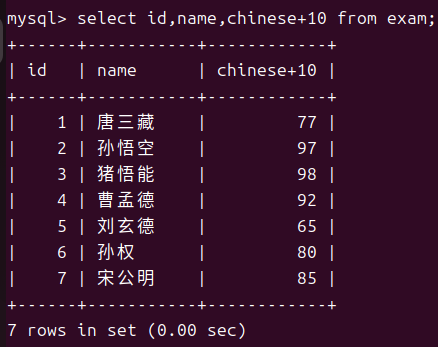
这其中chinese+10就算是一个表达式,有了这项特性我们就可以利用这些零碎的数据来完成需求例如我们想要知道总分。
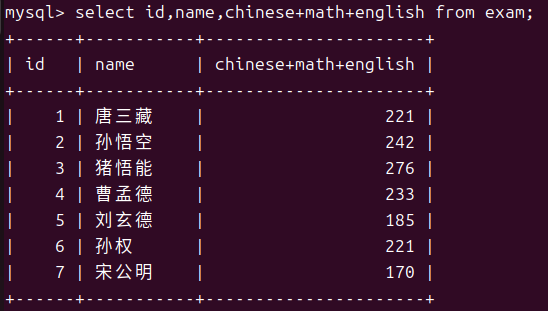
但是我们发现chinese+math+english的可读性也太差了所以我们还可以将这个表达式修改名称。
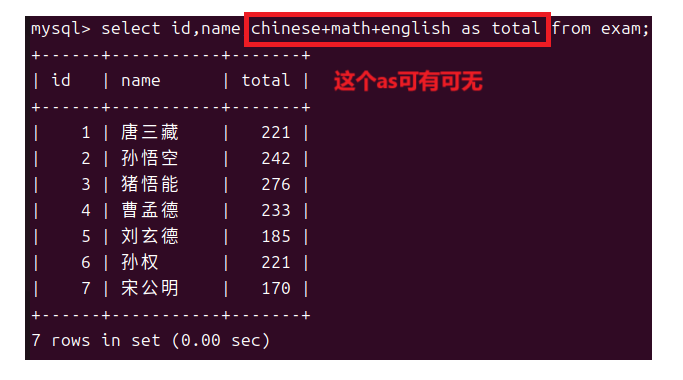
这就是最基础的查询工作接下来我们融合哪些可选性的字段来对查询进行升级
-
[DISTINCT] #是否去重
我们可以使用distinct来在查询的时候完成对表的去重
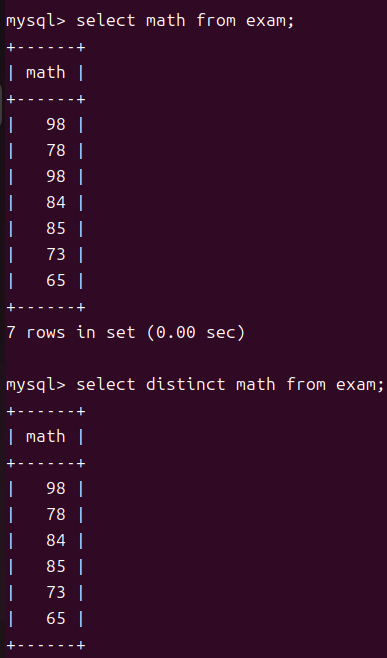
在使用math的时候要注意只要表中有任何一列的内容是不重复的那就不会被去重,同时我也希望大家可以理解表这个概念,表不但指存储在磁盘中数据库文件中的表文件,在MySQL中一切都是表都可以当做表比如我们完成查询后输出的内容也是一个表只不过我们可以将其分为逻辑表以及存储表。对表的理解会影响到后续我们对复合查询以及内外连接的理解。 -
[WHERE where_condition] #是否有判断条件
MySQL中我们一样可以在查询时进行条件判断来完成对数据的筛选工作,既然有判断功能那么我们就需要使用运算符,其中被分为两种:比较运算符和逻辑运算符。同时我们搭配例子来给大家说明
比较运算符:
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,对于NULL的比较不安全,比如NULL=NULL的结果一样为NULL |
| <=> | 等于,对于NULL的比较是安全的,比如NULL <=>NULL的结果是TRUE |
| !=,<> | 不等于 |
| value BETWEEN a0AND a1 | 范围匹配,[a0, a1],如果a0 <= value <= a1,返回TRUE或1,NOT BETWEEN则取反 |
| value IN (option, … | 如果value 在optoin列表中,则返回TRUE(1),NOT IN则取反 |
| IS NULL | 是NULL |
| IS NOT NULL | 不是NULL |
| LIKE | 模糊匹配,%表示任意多个字符包括零个,_表示任意一个字符,NOT LIKE则取反 |
#英语成绩大于60分
mysql> select * from exam where english > 60;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 6 | 孙权 | 70 | 73 | 78 |
+------+-----------+---------+------+---------+
4 rows in set (0.00 sec)#语文成绩大于英语成绩
mysql> select * from exam where chinese > english;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘⽞德 | 55 | 85 | 45 |
| 7 | 宋公明 | 75 | 65 | 30 |
+------+-----------+---------+------+---------+
5 rows in set (0.00 sec)#总分大于200分
mysql> select id,name,chinese+math+english total from exam where chinese+math+english > 200;
+------+-----------+-------+
| id | name | total |
+------+-----------+-------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 6 | 孙权 | 221 |
+------+-----------+-------+
5 rows in set (0.00 sec)
#注意:虽然我们给chinese+math+english重命名为total了但是这是在我们查询完成后输出表结构时完成的
#而where判断是在查询过程中进行的此时重命名并没有完成,所以我们仍然只能使用chinese+math+english来代表总分#语文成绩在60到80分之间
mysql> select id,name,chinese from exam where chinese between 60 and 80;
+------+-----------+---------+
| id | name | chinese |
+------+-----------+---------+
| 1 | 唐三藏 | 67 |
| 6 | 孙权 | 70 |
| 7 | 宋公明 | 75 |
+------+-----------+---------+
3 rows in set (0.00 sec)#语文成绩在67,70,71,72,73中任意一个
mysql> select id,name,chinese from exam where chinese in (67,70,71,72,73);
+------+-----------+---------+
| id | name | chinese |
+------+-----------+---------+
| 1 | 唐三藏 | 67 |
| 6 | 孙权 | 70 |
+------+-----------+---------+
2 rows in set (0.00 sec)#名字是孙某某,某某可以是零个字也可以是一个两个多个
mysql> select id,name from exam where name like '孙%';
+------+-----------+
| id | name |
+------+-----------+
| 2 | 孙悟空 |
| 6 | 孙权 |
+------+-----------+
2 rows in set (0.00 sec)#名字是孙某,某只能是一个字
mysql> select id,name from exam where name like '孙_';
+------+--------+
| id | name |
+------+--------+
| 6 | 孙权 |
+------+--------+
1 row in set (0.00 sec)逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为TRUE,结果都是TRUE |
| NOT | 条件为TRUE,结果为FALSE |
#语文和英语成绩都大于80
mysql> select id,name,chinese,english from exam where chinese >80 and english > 80;
+------+-----------+---------+---------+
| id | name | chinese | english |
+------+-----------+---------+---------+
| 3 | 猪悟能 | 88 | 90 |
+------+-----------+---------+---------+
1 row in set (0.00 sec)#语文或者英语成绩大于80
mysql> select id,name,chinese,english from exam where chinese >80 or english > 80;
+------+-----------+---------+---------+
| id | name | chinese | english |
+------+-----------+---------+---------+
| 2 | 孙悟空 | 87 | 77 |
| 3 | 猪悟能 | 88 | 90 |
| 4 | 曹孟德 | 82 | 67 |
+------+-----------+---------+---------+
3 rows in set (0.00 sec)#语文成绩不大于80
mysql> select id,name,chinese,english from exam where not chinese >80 ;
+------+-----------+---------+---------+
| id | name | chinese | english |
+------+-----------+---------+---------+
| 1 | 唐三藏 | 67 | 56 |
| 5 | 刘⽞德 | 55 | 45 |
| 6 | 孙权 | 70 | 78 |
| 7 | 宋公明 | 75 | 30 |
+------+-----------+---------+---------+
4 rows in set (0.00 sec)- [HAVING where_condition] #在完成读取后是否再进行条件判断
在where中我们提到过where是在查询过程中进行条件判断而having则是在查询完成后再进行条件判断,除了这方面不同例如运算符什么的都是相同的使用方式。
#总分超过200
#由于是在查询完成后进行判断所以having就可以使用列的别名来进行条件判断
mysql> select id,name,chinese+math+english total from exam having total > 200;
+------+-----------+-------+
| id | name | total |
+------+-----------+-------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 6 | 孙权 | 221 |
+------+-----------+-------+
5 rows in set (0.00 sec)- [ORDER BY {col_name | expr } [ASC | DESC], … ] #是否进行排序
想要进行排序时我们需要指出你想要进行排序的列并且也可以选择是升序还是降序,其中ASC是升序,DESC是降序。MySQL默认是进行升序排序
#默认是升序
mysql> select * from exam order by chinese;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 5 | 刘⽞德 | 55 | 85 | 45 |
| 1 | 唐三藏 | 67 | 98 | 56 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)#显式升序
mysql> select * from exam order by chinese asc;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 5 | 刘⽞德 | 55 | 85 | 45 |
| 1 | 唐三藏 | 67 | 98 | 56 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)#降序
mysql> select * from exam order by chinese desc;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 3 | 猪悟能 | 88 | 98 | 90 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 7 | 宋公明 | 75 | 65 | 30 |
| 6 | 孙权 | 70 | 73 | 78 |
| 1 | 唐三藏 | 67 | 98 | 56 |
| 5 | 刘⽞德 | 55 | 85 | 45 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)#总成绩降序
mysql> select id,name,chinese+math+english total from exam order by total desc;
+------+-----------+-------+
| id | name | total |
+------+-----------+-------+
| 3 | 猪悟能 | 276 |
| 2 | 孙悟空 | 242 |
| 4 | 曹孟德 | 233 |
| 1 | 唐三藏 | 221 |
| 6 | 孙权 | 221 |
| 5 | 刘⽞德 | 185 |
| 7 | 宋公明 | 170 |
+------+-----------+-------+
7 rows in set (0.00 sec)
#为什么这里我们又可以使用别名(给列重命名就是取别名)来进行排序了呢?
#这是因为排序是在查询之后完成的这时候别名也已经取好了自然可以使用了
- [LIMIT {[offset,] row_count | row_count OFFSET offset}] #限制返回记录数量
我们可以在查询完成后限制输出表的行数以及从哪行开始输出,直接上例子
#从0开始显式五行
mysql> select * from exam limit 5;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘⽞德 | 55 | 85 | 45 |
+------+-----------+---------+------+---------+
5 rows in set (0.00 sec)#从2开始显示5行
#注意:表结构的行数是从0开始算的
mysql> select * from exam limit 2,5;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘⽞德 | 55 | 85 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+------+-----------+---------+------+---------+
5 rows in set (0.00 sec)#从5开始显示两行
mysql> select * from exam limit 2 offset 5;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+------+-----------+---------+------+---------+
2 rows in set (0.00 sec)- [GROUP BY {col_name | expr}, …] #是否进行分表
在日常中我们可能面临一些数据是可以根据某列划分成不同的组的,例如我们在工作中不同的部门学校中不同的班级都是这种情况。所以group by通常是被叫做分组但是大家还记得我之前说的MySQL中一切都是表所以我觉得分表更加好理解,大家可以将其理解成根据某列将一个大表划分成几个小表但是它还是个表。
mysql> select * from emp;
+----+-----------+--------+------------+
| id | name | role | salary |
+----+-----------+--------+------------+
| 1 | 马云 | 老板 | 1500000.00 |
| 2 | 马化腾 | 老板 | 1300000.00 |
| 3 | 张三 | 经理 | 13000.00 |
| 4 | 赵四 | 经理 | 11000.00 |
| 5 | 王五 | 员工 | 5000.00 |
| 6 | 田七 | 员工 | 6000.00 |
| 7 | 路人甲 | 保安 | 2000.00 |
| 8 | 路人乙 | 保安 | 2000.00 |
+----+-----------+--------+------------+
8 rows in set (0.00 sec)#根据role来进行分表
mysql> select role from emp group by role;
+--------+
| role |
+--------+
| 老板 |
| 经理 |
| 员工 |
| 保安 |
+--------+
4 rows in set (0.00 sec)#根据role分表后我们还可以通过聚合函数来对分表进行处理
mysql> select role,count(*) from emp group by role;
+--------+----------+
| role | count(*) |
+--------+----------+
| 老板 | 2 |
| 经理 | 2 |
| 员工 | 2 |
| 保安 | 2 |
+--------+----------+
4 rows in set (0.00 sec)mysql> select role,max(salary),min(salary),avg(salary) from emp group by role;
+--------+-------------+-------------+----------------+
| role | max(salary) | min(salary) | avg(salary) |
+--------+-------------+-------------+----------------+
| 老板 | 1500000.00 | 1300000.00 | 1400000.000000 |
| 经理 | 13000.00 | 11000.00 | 12000.000000 |
| 员工 | 6000.00 | 5000.00 | 5500.000000 |
| 保安 | 2000.00 | 2000.00 | 2000.000000 |
+--------+-------------+-------------+----------------+
4 rows in set (0.00 sec)2.3Update更新
UPDATE
[LOW_PRIORITY] #是否将updata设为低优先级操作
[IGNORE] #是否忽略遇到不可重复键时的错误
table_reference #表的名称SET assignment [, assignment] ... #更新的内容[WHERE where_condition] #是否进行条件判断[ORDER BY ...] #是否进行排序[LIMIT row_count] #是否控制输出的内容
我们先举一些简单的例子来让大家知道怎么使用updata再讲解其中的比较重要的可选项。
mysql> select * from exam;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘⽞德 | 55 | 85 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)//给孙悟空的语文更新为30分
mysql> update exam set chinese = 30 where name = '孙悟空';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from exam where name = '孙悟空';
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 2 | 孙悟空 | 30 | 78 | 77 |
+------+-----------+---------+------+---------+
1 row in set (0.00 sec)//给曹孟德的英语更新为60数学更新为70
mysql> update exam set english = 60,math = 70 where name = '曹孟德';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from exam where name = '曹孟德';
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 4 | 曹孟德 | 82 | 70 | 60 |
+------+-----------+---------+------+---------+
1 row in set (0.00 sec)mysql> select id,name,math,chinese+math+english total from exam order by chinese+math+english asc;
+------+-----------+------+-------+
| id | name | math | total |
+------+-----------+------+-------+
| 5 | 刘⽞德 | 115 | 215 |
| 1 | 唐三藏 | 98 | 221 |
| 6 | 孙权 | 73 | 221 |
| 7 | 宋公明 | 125 | 230 |
| 4 | 曹孟德 | 100 | 242 |
| 2 | 孙悟空 | 138 | 245 |
| 3 | 猪悟能 | 98 | 276 |
+------+-----------+------+-------+
7 rows in set (0.00 sec)//给总分最低的三名数学各加30分
mysql> update exam set math =math + 30 where chinese+math+english is not null order by chinese+math+english asc limit 3;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0mysql> select id,name,math,chinese+math+english total from exam order by chinese+math+english asc;
+------+-----------+------+-------+
| id | name | math | total |
+------+-----------+------+-------+
| 7 | 宋公明 | 125 | 230 |
| 4 | 曹孟德 | 100 | 242 |
| 2 | 孙悟空 | 138 | 245 |
| 5 | 刘⽞德 | 145 | 245 |
| 1 | 唐三藏 | 128 | 251 |
| 6 | 孙权 | 103 | 251 |
| 3 | 猪悟能 | 98 | 276 |
+------+-----------+------+-------+
7 rows in set (0.00 sec)要注意在使用update时更新数据不能使用math += 30这种语法只能使用math = math + 30。并且我们使用update的时候一般都是需要搭配where来进行条件判断的不然更新就会造成全列数据的改变所以要更新数据要慎重。
update的使用比较简单但是它的两个可选项是需要我们说一下的。
- [LOW_PRIORITY]
这个可选项是是否将update以低优先度的方式进行,想要理解这个概念我们就需要先知道MySQL中优先度是如何进行设计的。从我们C++的经验中有优先级一般我们都会涉及到锁的概念所以在MySQL中也不例外,当我们进行CURD时需要SQL先申请锁申请成功之后才能进行操作否则就需要等待。如果我们不设置锁让CURD随意进行那么在高并发的情况下MySQL写入和读取数据就会变得很混乱可能此时我读取的数据是这个但是实际并不是这样的因为被其他人修改了,所以我们需要锁来完成MySQL中语句的调度。
那么我们可以使用读写者模型来对表的增删查改进行分类,我们将select也就是读取作为读取者,而insert,update和delete都是写入者。MySQL中默认的调度是这样的:写入操作优先级大于读取操作,写入操作在同一时刻只能发生一次并且写入请求需要按时间来进行排队,读取操作在可以多个同时进行的。而low_priority则是MySQL提供的更改调度策略的字段,在update后添加low_priority后就会将其的优先度调整的比读取操作低这就会导致如果一直有读取操作在进行因为update的优先度低所以它必须等所有的读取操作完成后才能进行也就是将update阻塞住了。 - [IGNORE]
这个可选项的作用是防止遇到不可重复键时的错误,我们知道表中有些列是不可重复键例如主键,唯一键,正常当我们使用update更新表中的数据时我们更新的数据如果原来的数据是重复的就会发生报错此时我们在update后添加IGNORE就会避免这个报错的产生。
2.4Delete删除和Truncate截断
DELETE
FROM
tbl_name #表名
[WHERE where_condition] #是否进行条件判断
[ORDER BY ...] #是否进行排序
[LIMIT row_count] #是否进行输出内容的控制
删除我就不进行演示了只是大家要注意如果我们不加条件判断就会将整个表的数据删除了所以无论是更新还是删除大家都最好加上where以防出现无法挽回的情况。
TRUNCATE [TABLE] tbl_name
截断和删除不同截断只能对整个表进行它无法进行条件判断从而对某行来进行。不仅如此截断还有和删除不同的地方,我直接给大家上例子
mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 张三 | 17 |
| 2 | 李四 | 18 |
| 3 | 王五 | 18 |
| 4 | 赵六 | 16 |
| 5 | 田七 | 16 |
| 6 | 刘八 | 16 |
| 7 | 杨九 | 16 |
+----+--------+------+
7 rows in set (0.00 sec)mysql> show create table student\G;
*************************** 1. row ***************************Table: student
Create Table: CREATE TABLE `student` (`id` bigint NOT NULL AUTO_INCREMENT,`name` char(8) NOT NULL,`age` int DEFAULT '16',PRIMARY KEY (`id`),CONSTRAINT `student_chk_1` CHECK ((`age` >= 16))
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)mysql> delete from student;
Query OK, 7 rows affected (0.01 sec)mysql> show create table student\G;
*************************** 1. row ***************************Table: student
Create Table: CREATE TABLE `student` (`id` bigint NOT NULL AUTO_INCREMENT,`name` char(8) NOT NULL,`age` int DEFAULT '16',PRIMARY KEY (`id`),CONSTRAINT `student_chk_1` CHECK ((`age` >= 16))
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)mysql> insert into student (name) values('张三'),('李四');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 8 | 张三 | 16 |
| 9 | 李四 | 16 |
+----+--------+------+
2 rows in set (0.00 sec)大家现在把关注点转移到表的创建语句中我们可以发现在使用delete删除表的数据后表的auto_increment也就是自增值是没有被清零的这点我们在上面讲自增约束的时候也提到过。现在我们去看看truncate的情况。
mysql> show create table student\G;
*************************** 1. row ***************************Table: student
Create Table: CREATE TABLE `student` (`id` bigint NOT NULL AUTO_INCREMENT,`name` char(8) NOT NULL,`age` int DEFAULT '16',PRIMARY KEY (`id`),CONSTRAINT `student_chk_1` CHECK ((`age` >= 16))
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)ERROR:
No query specifiedmysql> select * from student;
Empty set (0.01 sec)mysql> insert into student (name) values('张三'),('李四');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 8 | 张三 | 16 |
| 9 | 李四 | 16 |
+----+--------+------+
2 rows in set (0.00 sec)mysql> truncate table student;
Query OK, 0 rows affected (0.02 sec)mysql> select * from student;
Empty set (0.00 sec)mysql> show create table student\G;
*************************** 1. row ***************************Table: student
Create Table: CREATE TABLE `student` (`id` bigint NOT NULL AUTO_INCREMENT,`name` char(8) NOT NULL,`age` int DEFAULT '16',PRIMARY KEY (`id`),CONSTRAINT `student_chk_1` CHECK ((`age` >= 16))
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)mysql> insert into student (name) values('张三'),('李四');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 张三 | 16 |
| 2 | 李四 | 16 |
+----+--------+------+
2 rows in set (0.00 sec)大家可以发现在我们截断了表后不光表的数据被清空了表的自增值一样被清空了变成从零开始了。并且TRUNCATE命令通常比DELETE命令更快,因为它不记录单个行的删除操作。DELETE命令会为表中的每一行生成一个删除操作,而TRUNCATE命令则一次性删除表中的所有数据,因此执行速度更快。
相关文章:
MySQL之约束和表的增删查改
MySQL之约束和表的增删查改 一.数据库约束1.1数据库约束的概念1.2NOT NULL 非空约束1.3DEFAULT 默认约束1.4唯一约束1.5主键约束和自增约束1.6自增约束1.7外键约束1.8CHECK约束 二.表的增删查改2.1Create创建2.2Retrieve读取2.3Update更新2.4Delete删除和Truncate截断 一.数据库…...

Greenplum:PB级数据分析的分布式引擎,揭开MPP架构的终极武器
一、Greenplum是谁?—— 定位与诞生背景 核心定位:基于PostgreSQL的开源分布式分析型数据库(OLAP),专为海量数据分析设计,支撑PB级数据仓库、商业智能(BI)和实时决策系统。 诞生背…...
Oracle数据库性能优化的最佳实践
原创:厦门微思网络 以下是 Oracle 数据库性能优化的最佳实践,涵盖设计、SQL 优化、索引管理、系统配置等关键维度,帮助提升数据库响应速度和稳定性: 一、SQL 语句优化 1. 避免全表扫描(Full Table Scan)…...

云原生时代 Kafka 深度实践:02快速上手与环境搭建
2.1 本地开发环境搭建 单机模式安装 下载与解压:前往Apache Kafka 官网,下载最新稳定版本的 Kafka 二进制包(如kafka_2.13-3.6.0.tgz,其中2.13为 Scala 版本)。解压到本地目录,例如/opt/kafka:…...

Redis7 新增数据结构深度解析:ListPack 的革新与优化
Redis 作为高性能的键值存储系统,其核心优势之一在于丰富的数据结构。随着版本迭代,Redis 不断优化现有结构并引入新特性。在 Redis 7.0 中,ListPack 作为新一代序列化格式正式登场,替代了传统的 ZipList(压缩列表&…...

分布式爬虫架构设计
随着互联网数据的爆炸式增长,单机爬虫已经难以满足大规模数据采集的需求。分布式爬虫应运而生,它通过多节点协作,实现了数据采集的高效性和容错性。本文将深入探讨分布式爬虫的架构设计,包括常见的架构模式、关键技术组件、完整项…...

汽配快车道:助力汽车零部件行业的产业重构与数字化出海
汽配快车道:助力汽车零部件行业的数字化升级与出海解决方案。 在当今快速发展的汽车零部件市场中,随着消费者对汽车性能、安全和舒适性的要求不断提高,汽车刹车助力系统作为汽车安全的关键部件之一,其市场需求也在持续增长。汽车…...
Windows 11 家庭版 安装Docker教程
Windows 家庭版需要通过脚本手动安装 Hyper-V 一、前置检查 1、查看系统 快捷键【winR】,输入“control” 【控制面板】—>【系统和安全】—>【系统】 2、确认虚拟化 【任务管理器】—【性能】 二、安装Hyper-V 1、创建并运行安装脚本 在桌面新建一个 .…...
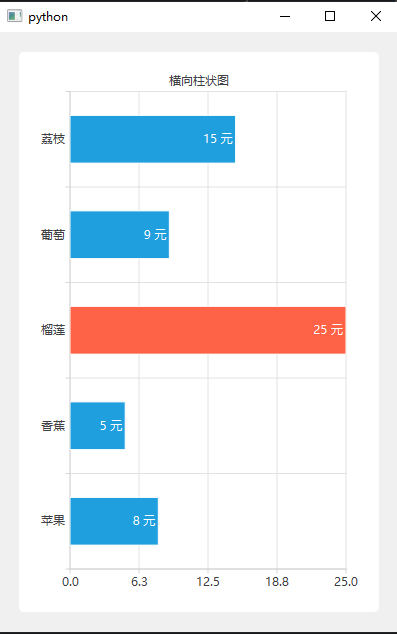
PyQt6基础_QtCharts绘制横向柱状图
前置: pip install PyQt6-Charts 结果: 代码: import sysfrom PyQt6.QtCharts import (QBarCategoryAxis, QBarSet, QChart,QChartView, QValueAxis,QHorizontalBarSeries) from PyQt6.QtCore import Qt,QSize from PyQt6.QtGui import QP…...

《TCP/IP 详解 卷1:协议》第2章:Internet 地址结构
基本的IP地址结构 分类寻址 早期Internet采用分类地址(Classful Addressing),将IPv4地址划分为五类: A类和B类网络号通常浪费太多主机号,而C类网络号不能为很多站点提供足够的主机号。 子网寻址 子网(Su…...
 ----- Python的JSON处理)
Python学习(5) ----- Python的JSON处理
下面是关于 Python 中如何全面处理 JSON 的详细说明,包括模块介绍、数据类型映射、常用函数、文件操作、异常处理、进阶技巧等。 🧩 一、什么是 JSON? JSON(JavaScript Object Notation)是一种轻量级的数据交换格式&a…...

如何通过一次需求评审,让项目效率提升50%?
想象一下,你的团队启动了一个新项目,但需求模糊不清,开发到一半才发现方向错了,返工、加班、客户投诉接踵而至……听起来像噩梦?一次完美的需求评审就能避免这一切!它就像项目的“导航仪”,确保…...
再见Notepad++,你好Notepad--
Notepad-- 是一款国产开源的轻量级、跨平台文本编辑器,支持 Window、Linux、macOS 以及国产 UOS、麒麟等操作系统。 除了具有常用编辑器的功能之外,Notepad-- 还内置了专业级的代码对比功能,支持文件、文件夹、二进制文件的比对,支…...

element-plus bug整理
1.el-table嵌入el-image标签预览时,显示错乱 解决:添加preview-teleported属性 <el-table-column label"等级图标" align"center" prop"icon" min-width"80"><template #default"scope"&g…...
技术-工程-管用养修保-智能硬件-智能软件五维黄金序位模型
融智学工程技术体系:五维协同架构 基于邹晓辉教授的框架,工程技术体系重构为:技术-工程-管用养修保-智能硬件-智能软件五维黄金序位模型: math \mathbb{E}_{\text{技}} \underbrace{\prod_{\text{Dis}} \text{TechnoCore}}_{\…...

LangChain-自定义Tool和Agent结合DeepSeek应用实例
除了调用LangChain内置工具外,也可以自定义工具 实例1: 自定义多个工具 from langchain.agents import initialize_agent, AgentType from langchain_community.agent_toolkits.load_tools import load_tools from langchain_core.tools import tool, …...
用 3D 可视化颠覆你的 JSON 数据体验
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构! 复杂的 JSON 数据结构常常让人头疼:层层嵌套的对象、错综复杂的数组关系,用传统的树状视图或表格一览千头万绪&…...

联想小新笔记本电脑静电问题导致无法开机/充电的解决方案
一、问题背景 近期部分用户反馈联想小新系列笔记本电脑在特定环境下(如秋冬干燥季节)出现无法开机或充电的问题。经分析,此类现象多由静电积累触发主板保护机制导致,少数情况可能与电源适配器、电池老化或环境因素相关。本文将从技…...
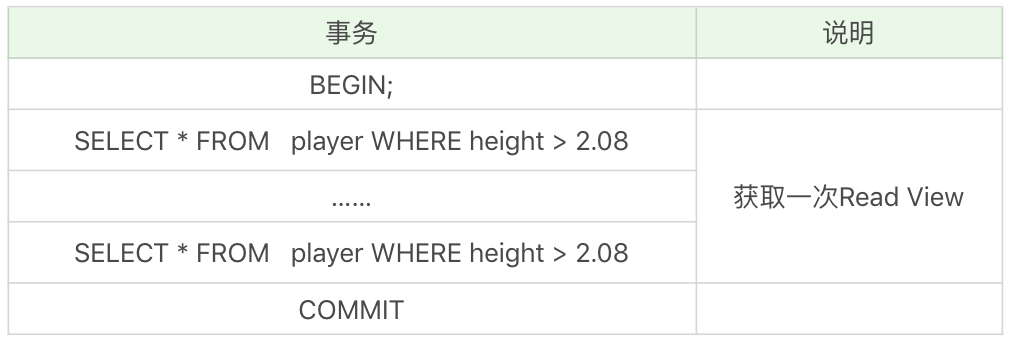
MVCC(多版本并发控制)机制
1. MVCC(多版本并发控制)机制 MVCC 的核心就是 Undo Log Read View,“MV”就是通过 Undo Log 来保存数据的历史版本,实现多版本的管理,“CC”是通过 Read View 来实现管理,通过 Read View 原则来决定数据是…...

Mac M1 安装 ffmpeg
1.前言 官网那货没有准备m系列的静态包,然后我呢,不知道怎么想的就从maven项目中的 javacv-platform,且版本为1.5.11依赖里面将这个静态包把了出来,亲测能用,感觉比那些网上说的用什么wget编译安装、brew安装快多了。…...
Spring框架学习day3--Spring数据访问层管理(IOC)
开发步骤 Spring 是个一站式框架:Spring 自身也提供了web层的 SpringWeb 和 持 久层的 SpringJdbcTemplate。 开发步骤 1.导入jar包 pom.xml <!-- spring-jdbc--> <dependency><groupId>org.springframework</groupId><artifactId>…...
?如何保证集群的高可用性?)
什么是集群(Cluster)?如何保证集群的高可用性?
一、什么是Elasticsearch集群(Cluster)? 集群是指由一个或多个节点(Node)组成的集合,这些节点共同存储数据、处理请求,并协调工作以提供统一的搜索服务。一个集群有唯一的集群名称(默认名为elasticsearch),节点通过名称加入对应的集群。集群的核心目标是: 扩展存储…...

React从基础入门到高级实战:React 核心技术 - 动画与过渡效果:提升 UI 交互体验
React 动画与过渡效果:提升 UI 交互体验 在现代 Web 开发中,动画和过渡效果不仅仅是视觉上的点缀,它们在提升用户体验、引导用户注意力以及增强交互性方面扮演着重要角色。作为一款广受欢迎的前端框架,React 提供了多种实现动画的…...

重读《人件》Peopleware -(13)Ⅱ 办公环境 Ⅵ 电话
当你开始收集有关工作时间质量的数据时,你的注意力自然会集中在主要的干扰源之一——打进来的电话。一天内接15个电话并不罕见。虽然这看似平常,但由于重新沉浸所需的时间,它可能会耗尽你几乎一整天的时间。当一天结束时,你会纳闷…...

Free2AI:企业智能化转型的加速器
随着数字化与智能化的深度交融,企业的竞争舞台已悄然转变为数据处理能力和智能服务水平的竞技场。Free2AI以其三大核心功能——智能数据采集、多格式文档解析、智能FAQ构建,为企业铺设了一条从数据洞察到智能服务的全链路升级之路,成为推动企…...
Python训练营打卡Day40
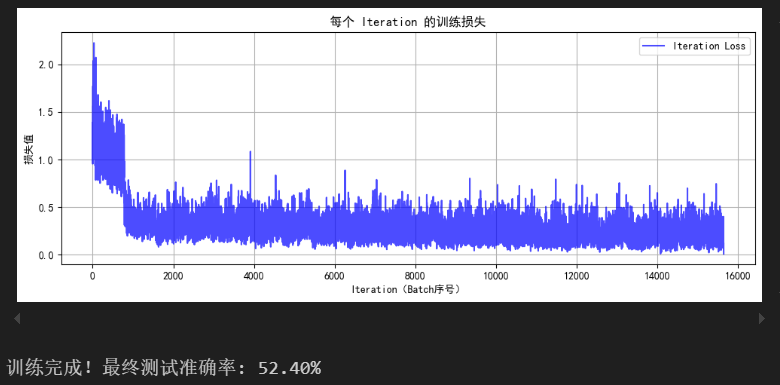
DAY 40 训练和测试的规范写法 知识点回顾: 1.彩色和灰度图片测试和训练的规范写法:封装在函数中 2.展平操作:除第一个维度batchsize外全部展平 3.dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作…...
制作一款打飞机游戏63:自动保存
1.编辑器的自动保存实现 目标:将自动保存功能扩展到所有编辑器,包括脑编辑器、模式编辑器、敌人编辑器和动画/精灵编辑器。实现方式: 代码复制:将关卡编辑器中的自动保存代码复制到其他编辑器中。标记数据变更&a…...

使用animation.css库快速实现CSS3旋转动画效果
CSS3旋转动画效果实现(使用Animate.css) 下面我将展示如何使用Animate.css库快速实现各种CSS3旋转动画效果,同时提供一个直观的演示界面。 思路分析 引入Animate.css库创建不同旋转动画的展示区域添加控制面板自定义动画效果实现实时预览功…...

基于NetWork的类FNAF游戏DEMO框架
脑洞大开 想做个fnaf1并加入自己的设计.. 开干!!!! #include <stdio.h> #include <iostream> #include <random> #include <ctime>bool leftdoor true, rightdoor true, camddoor true; float power 900,fanusepower 0;typedef struct movement…...

湖北理元理律师事务所:债务优化中的生活保障实践
在债务压力与生活质量失衡的普遍困境中,法律服务的价值不仅在于解决债务问题,更在于帮助债务人重建生活秩序。湖北理元理律师事务所通过其债务优化服务,探索出一条“法律生活”的双轨路径。 债务规划的核心矛盾:还款能力与生存需…...