【DAY34】GPU训练及类的call方法
内容来自@浙大疏锦行python打卡训练营
@浙大疏锦行
- CPU性能的查看:看架构代际、核心数、线程数
- GPU性能的查看:看显存、看级别、看架构代际
- GPU训练的方法:数据和模型移动到GPU device上
- 类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)
ps:在训练过程中可以在命令行输入nvida-smi查看显存占用情况
作业
复习今天的内容,再巩固下代码。思考下为什么会出现这个问题。
首先回顾下昨天的内容,我在训练开始和结束增加了time来查看运行时长
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np# 仍然用4特征,3分类的鸢尾花数据集作为我们今天的数据集
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# # 打印下尺寸
# print(X_train.shape)
# print(y_train.shape)
# print(X_test.shape)
# print(y_test.shape)# 归一化数据,神经网络对于输入数据的尺寸敏感,归一化是最常见的处理方式
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练
# y_train和y_test是整数,所以需要转化为long类型,如果是float32,会输出1.0 0.0
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型
model = MLP()# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# # 使用自适应学习率的化器
# optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每个 epoch 的损失值
losses = []import time
start_time = time.time() # 记录开始时间for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始# 前向传播outputs = model.forward(X_train) # 显式调用forward函数# outputs = model(X_train) # 常见写法隐式调用forward函数,其实是用了model类的__call__方法loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')
import matplotlib.pyplot as plt
# 可视化损失曲线
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()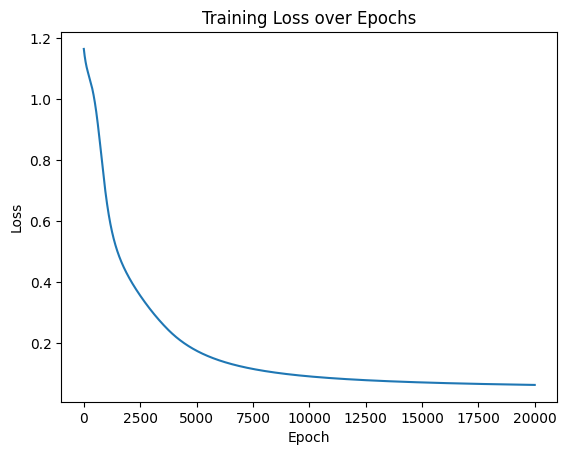
CPU性能的查看
上述是在cpu的情况下训练,(即使安装了cuda,但是没有使用cuda),我们借这个机会简单介绍下cpu的性能差异。
# pip install wmi -i https://pypi.tuna.tsinghua.edu.cn/simple
# 这是Windows专用的库,Linux和MacOS不支持,其他系统自行询问大模型
# 我想查看一下CPU的型号和核心数
import wmic = wmi.WMI()
processors = c.Win32_Processor()for processor in processors:print(f"CPU 型号: {processor.Name}")print(f"核心数: {processor.NumberOfCores}")print(f"线程数: {processor.NumberOfLogicalProcessors}")
解读下我的cpu配置:
- Intel 第 12 代酷睿(Alder Lake 架构,2021 年发布)
- K:支持超频(解锁倍频)
- F:无内置核显(需搭配独立显卡使用)
- 核心架构:
- 性能核(P-Core):8 核(支持超线程,共 16 线程),擅长单线程高性能任务(如游戏、视频剪辑)
- 能效核(E-Core):8 核(不支持超线程,共 8 线程),优化多线程能效比(如后台任务、虚拟机)。
判断 CPU 的好坏需要综合考虑硬件参数、性能表现、适用场景。
1. 看架构代际,新一代架构通常优化指令集、缓存设计和能效比。如Intel 第 13 代 i5-13600K 比第 12 代 i5-12600K 多核性能提升约 15%
2. 看制程工艺,制程越小,晶体管密度越高,能效比越好,如AMD Ryzen 7000 系列(5nm)比 Ryzen 5000 系列(7nm)能效比提升约 30%。
3. 看核心数:性能核负责高负载任务(如游戏、视频剪辑),单核性能强。能效核负责多任务后台处理(如下载、杀毒),功耗低。如游戏 / 办公:4-8 核足够,内容创作 / 编程:12 核以上更优。
4. 看线程数目
5. 看频率,高频适合单线程任务(如游戏、Office),低频多核适合多线程任务(如 3D 渲染)
6. 支持的指令集和扩展能力。
可以看到在我的电脑的配置下,cpu运行时长,是2.90s
昨天的训练是cpu的训练,今天介绍下gpu的训练。
GPU训练
要让模型在 GPU 上训练,主要是将模型和数据迁移到 GPU 设备上。
在 PyTorch 里,.to(device) 方法的作用是把张量或者模型转移到指定的计算设备(像 CPU 或者 GPU)上。
- 对于张量(Tensor):调用 .to(device) 之后,会返回一个在新设备上的新张量。
- 对于模型(nn.Module):调用 .to(device) 会直接对模型进行修改,让其所有参数和缓冲区都移到新设备上。
在进行计算时,所有输入张量和模型必须处于同一个设备。要是它们不在同一设备上,就会引发运行时错误。并非所有 PyTorch 对象都有 .to(device) 方法,只有继承自 torch.nn.Module 的模型以及 torch.Tensor 对象才有此方法。
RuntimeError: Tensor for argument #1 'input' is on CPU, but expected it to be on GPU
这个常见错误就是输入张量和模型处于不同的设备。
如何衡量GPU的性能好坏呢?
以RTX 3090 Ti, RTX 3080, RTX 3070 Ti, RTX 3070, RTX 4070等为例
- 通过“代”
前两位数字代表“代”: 40xx (第40代), 30xx (第30代), 20xx (第20代)。“代”通常指的是其底层的架构 (Architecture)。每一代新架构的发布,通常会带来工艺制程的进步和其他改进。也就是新一代架构的目标是在能效比和绝对性能上超越前一代同型号的产品。
- 通过级别
后面的数字代表“级别”,
- xx90: 通常是该代的消费级旗舰或次旗舰,性能最强,显存最大 (如 RTX 4090, RTX 3090)。
- xx80: 高端型号,性能强劲,显存较多 (如 RTX 4080, RTX 3080)。
- xx70: 中高端,甜点级,性能和价格平衡较好 (如 RTX 4070, RTX 3070)。
- xx60: 主流中端,性价比较高,适合入门或预算有限 (如 RTX 4060, RTX 3060)。
- xx50: 入门级,深度学习能力有限。
- 通过后缀
Ti 通常是同型号的增强版,性能介于原型号和更高一级型号之间 (如 RTX 4070 Ti 强于 RTX 4070,小于4080)。
- 通过显存容量 VRAM (最重要!!)
他是GPU 自身的独立高速内存,用于存储模型参数、激活值、输入数据批次等。单位通常是 GB(例如 8GB, 12GB, 24GB, 48GB)。如果显存不足,可能无法加载模型,或者被迫使用很小的批量大小,从而影响训练速度和效果
1. 训练阶段:小批量梯度是对真实梯度的一个有噪声的估计。批量越小,梯度的方差越大(噪声越大)。显存小只能够使用小批量梯度。
2. 推理阶段:有些模型本身就非常庞大(例如大型语言模型、高分辨率图像的复杂 CNN 网络)。即使你将批量大小减到 1,模型参数本身占用的显存可能就已经超出了你的 GPU 显存上限。
import torch# 检查CUDA是否可用
if torch.cuda.is_available():print("CUDA可用!")# 获取可用的CUDA设备数量device_count = torch.cuda.device_count()print(f"可用的CUDA设备数量: {device_count}")# 获取当前使用的CUDA设备索引current_device = torch.cuda.current_device()print(f"当前使用的CUDA设备索引: {current_device}")# 获取当前CUDA设备的名称device_name = torch.cuda.get_device_name(current_device)print(f"当前CUDA设备的名称: {device_name}")# 获取CUDA版本cuda_version = torch.version.cudaprint(f"CUDA版本: {cuda_version}")# 查看cuDNN版本(如果可用)print("cuDNN版本:", torch.backends.cudnn.version())else:print("CUDA不可用。")
# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
# 分类问题交叉熵损失要求标签为long类型
# 张量具有to(device)方法,可以将张量移动到指定的设备上
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10)self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
# MLP继承nn.Module类,所以也具有to(device)方法
model = MLP().to(device)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000
losses = []start_time = time.time()for epoch in range(num_epochs):# 前向传播outputs = model(X_train)loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time
print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()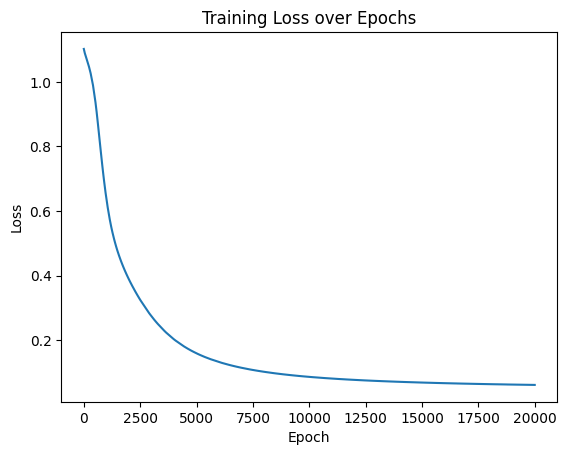
你这时可能会好奇,不是说gpu比cpu快很多吗?怎么cpu跑了3s,gpu跑了11s。
你问AI,他会告诉你,对于非常小的数据集和简单的模型,CPU 通常会比 GPU 更快。实际上,这并非本质的原因。
这需要你进一步理解二者的区别,深度学习项目的运行时长往往很长,如果只停留在跑通的层面,那是不够的。
本质是因为GPU在计算的时候,相较于cpu多了3个时间上的开销
1. 数据传输开销 (CPU 内存 <-> GPU 显存)
2. 核心启动开销 (GPU 核心启动时间)
3. 性能浪费:计算量和数据批次
下面详细介绍下:
数据传输开销 (CPU 内存 <-> GPU 显存)
- 在 GPU 进行任何计算之前,数据(输入张量 X_train、y_train,模型参数)需要从计算机的主内存 (RAM) 复制到 GPU 专用的显存 (VRAM) 中。
- 当结果传回 CPU 时(例如,使用 loss.item() 获取损失值用于打印或记录,或者获取最终预测结果),数据也需要从 GPU 显存复制回 CPU 内存。
- 对于少量数据和非常快速的计算任务,这个传输时间可能比 GPU 通过并行计算节省下来的时间还要长。
在上述代码中,循环里的 loss.item() 操作会在每个 epoch 都进行一次从 GPU 到 CPU 的数据同步和传输,以便获取标量损失值。对于20000个epoch来说,这会累积不少的传输开销。
核心启动开销 (GPU 核心启动时间)
- GPU 执行的每个操作(例如,一个线性层的前向传播、一个激活函数)都涉及到在 GPU 上启动一个“核心”(kernel)——一个在 GPU 众多计算单元上运行的小程序。
- 启动每个核心都有一个小的、固定的开销。
- 如果核心内的实际计算量非常小(本项目的小型网络和鸢尾花数据),这个启动开销在总时间中的占比就会比较大。相比之下,CPU 执行这些小操作的“调度”开销通常更低。
性能浪费:计算量和数据批次
- 这个数据量太少,gpu的很多计算单元都没有被用到,即使用了全批次也没有用到的全部计算单元。
综上,数据传输和各种固定开销的总和,超过了 GPU 在这点计算量上通过并行处理所能节省的时间,导致了 GPU 比 CPU 慢的现象。
- CPU (12th Gen Intel Core i9-12900KF): 对于这种小任务,CPU 的单核性能强劲,且没有显著的数据传输到“另一块芯片”的开销。它可以非常迅速地完成计算。
- GPU (NVIDIA GeForce RTX 3080 Ti):需要花费时间将数据和模型从 CPU 内存移动到 GPU 显存。
- 每次在 GPU 上执行运算(如 model(X_train)、loss.backward()) 都有核心启动的固定开销。
- loss.item() 在每个 epoch 都需要将结果从 GPU 传回 CPU,这在总共 20000 个 epoch 中会累积。
- GPU 强大的并行计算能力在这种小任务上完全没有用武之地。
这些特性导致GPU在处理鸢尾花分类这种“玩具级别”的问题时,它的优势无法体现,反而会因为上述开销显得“笨重”。
那么什么时候 GPU 会发挥巨大优势?
- 大型数据集: 例如,图像数据集成千上万张图片,每张图片维度很高。
- 大型模型: 例如,深度卷积网络 (CNNs like ResNet, VGG) 或 Transformer 模型,它们有数百万甚至数十亿的参数,计算量巨大。
- 合适的批处理大小: 能够充分利用 GPU 并行性的 batch size,不至于还有剩余的计算量没有被 GPU 处理。
- 复杂的、可并行的运算: 大量的矩阵乘法、卷积等。
针对上面反应的3个问题,能够优化的只有数据传输时间,针对性解决即可,很容易想到2个思路:
1. 直接不打印训练过程的loss了,但是这样会没办法记录最后的可视化图片,只能肉眼观察loss数值变化。
2. 每隔200个epoch保存一下loss,不需要20000个epoch每次都打印,
下面先尝试第一个思路:
# 知道了哪里耗时,针对性优化一下
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np# 仍然用4特征,3分类的鸢尾花数据集作为我们今天的数据集
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# # 打印下尺寸
# print(X_train.shape)
# print(y_train.shape)
# print(X_test.shape)
# print(y_test.shape)# 归一化数据,神经网络对于输入数据的尺寸敏感,归一化是最常见的处理方式
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练
# y_train和y_test是整数,所以需要转化为long类型,如果是float32,会输出1.0 0.0
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型
model = MLP()# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# # 使用自适应学习率的化器
# optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每个 epoch 的损失值
losses = []import time
start_time = time.time() # 记录开始时间for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始# 前向传播outputs = model.forward(X_train) # 显式调用forward函数# outputs = model(X_train) # 常见写法隐式调用forward函数,其实是用了model类的__call__方法loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值# losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')优化后发现确实效果好,近乎和用cpu训练的时长差不多。所以可以理解为数据从gpu到cpu的传输占用了大量时间。
下面尝试下第二个思路:
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每100个epoch的损失值和对应的epoch数
losses = []start_time = time.time() # 记录开始时间for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值if (epoch + 1) % 200 == 0:losses.append(loss.item()) # item()方法返回一个Python数值,loss是一个标量张量print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线
plt.plot(range(len(losses)), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()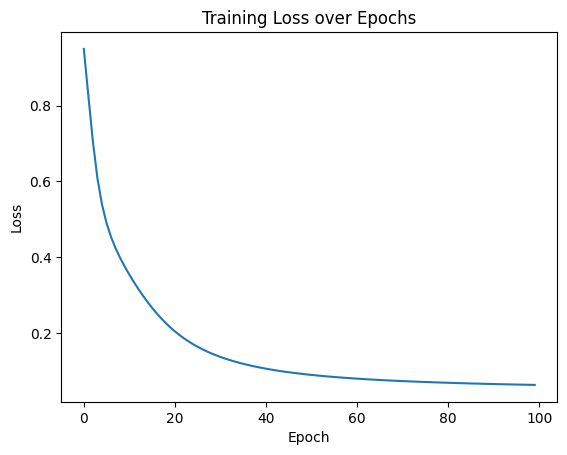
__call__方法
在 Python 中,__call__ 方法是一个特殊的魔术方法(双下划线方法),它允许类的实例像函数一样被调用。这种特性使得对象可以表现得像函数,同时保留对象的内部状态。
# 我们来看下昨天代码中你的定义函数的部分
class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数
# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out可以注意到,self.fc1 = nn.Linear(4, 10) 此时,是实例化了一个nn.Linear(4, 10)对象,并把这个对象赋值给了MLP的初始化函数中的self.fc1变量。
那为什么下面的前向传播中却可以out = self.fc1(x) 呢?,self.fc1是一个实例化的对象,为什么具备了函数一样的用法,这是因为nn.Linear继承了nn.Module类,nn.Module类中定义了__call__方法。(可以ctrl不断进入来查看)
在 Python 中,任何定义了 __call__ 方法的类,其实例都可以像函数一样被调用。
当调用 self.fc1(x) 时,实际上执行的是:
- self.fc1.__call__(x)(Python 的隐式调用)
- 而 nn.Module 的 __call__ 方法会调用子类的 forward 方法(即 self.fc1.forward(x))。这个方法就是个前向计算方法。
relu是torch.relu()这个函数为了保持写法一致,又封装成了nn.ReLU()这个类。来保证接口的一致性
PyTorch 官方强烈建议使用 self.fc1(x),因为它会触发完整的前向传播流程(包括钩子函数)这是 PyTorch 的核心设计模式,几乎所有组件(如 nn.Conv2d、nn.ReLU、甚至整个模型)都可以这样调用。
我们来介绍一下call方法是什么:
# 不带参数的call方法
class Counter:def __init__(self):self.count = 0def __call__(self):self.count += 1return self.count# 使用示例
counter = Counter()
print(counter()) # 输出: 1
print(counter()) # 输出: 2
print(counter.count) # 输出: 2类名后跟(),表示创建类的实例(对象),仅在第一次创建对象时发生。
call方法无参数的情况下,在实例化之后,每次调用实例时触发 __call__ 方法
# 带参数的call方法
class Adder:def __call__(self, a, b):print("唱跳篮球rap")return a + badder = Adder()
print(adder(3, 5)) # 输出: 8相关文章:
【DAY34】GPU训练及类的call方法
内容来自浙大疏锦行python打卡训练营 浙大疏锦行 知识点: CPU性能的查看:看架构代际、核心数、线程数GPU性能的查看:看显存、看级别、看架构代际GPU训练的方法:数据和模型移动到GPU device上类的call方法:为什么定义前…...
Flutte ListView 列表组件
目录 1、垂直列表 1.1 实现用户中心的垂直列表 2、垂直图文列表 2.1 动态配置列表 2.2 for循环生成一个动态列表 2.3 ListView.builder配置列表 列表布局是我们项目开发中最常用的一种布局方式。Flutter中我们可以通过ListView来定义列表项,支持垂直和水平方向展示…...
muduo库的初步认识和基本使用,创建一个简单查询单词服务系统
小编在学习完muduo库之后,觉得对于初学者,muduo库还是有点不好理解,所以在此,小编来告诉大家muduo库的初步认识和基本使用,让初学者也可以更快的上手和使用muduo库。 Muduo由陈硕大佬开发,是⼀个基于 非阻塞…...

电脑如何保养才能用得更久
在这个数字化的时代,电脑已经成为了我们生活和工作中不可或缺的伙伴。无论是处理工作文档、追剧娱乐,还是进行创意设计,电脑都发挥着至关重要的作用。那么,如何让我们的电脑“健康长寿”,陪伴我们更久呢?今…...

Oracle的NVL函数
Oracle的NVL函数是一个常用的空值处理函数,主要用于在查询结果中将NULL值替换为指定的默认值。以下是关于NVL函数的详细说明: 基本语法 NVL(expr1, expr2) 如果expr1为NULL,则返回expr2如果expr1不为NULL,则返回expr1本身 …...
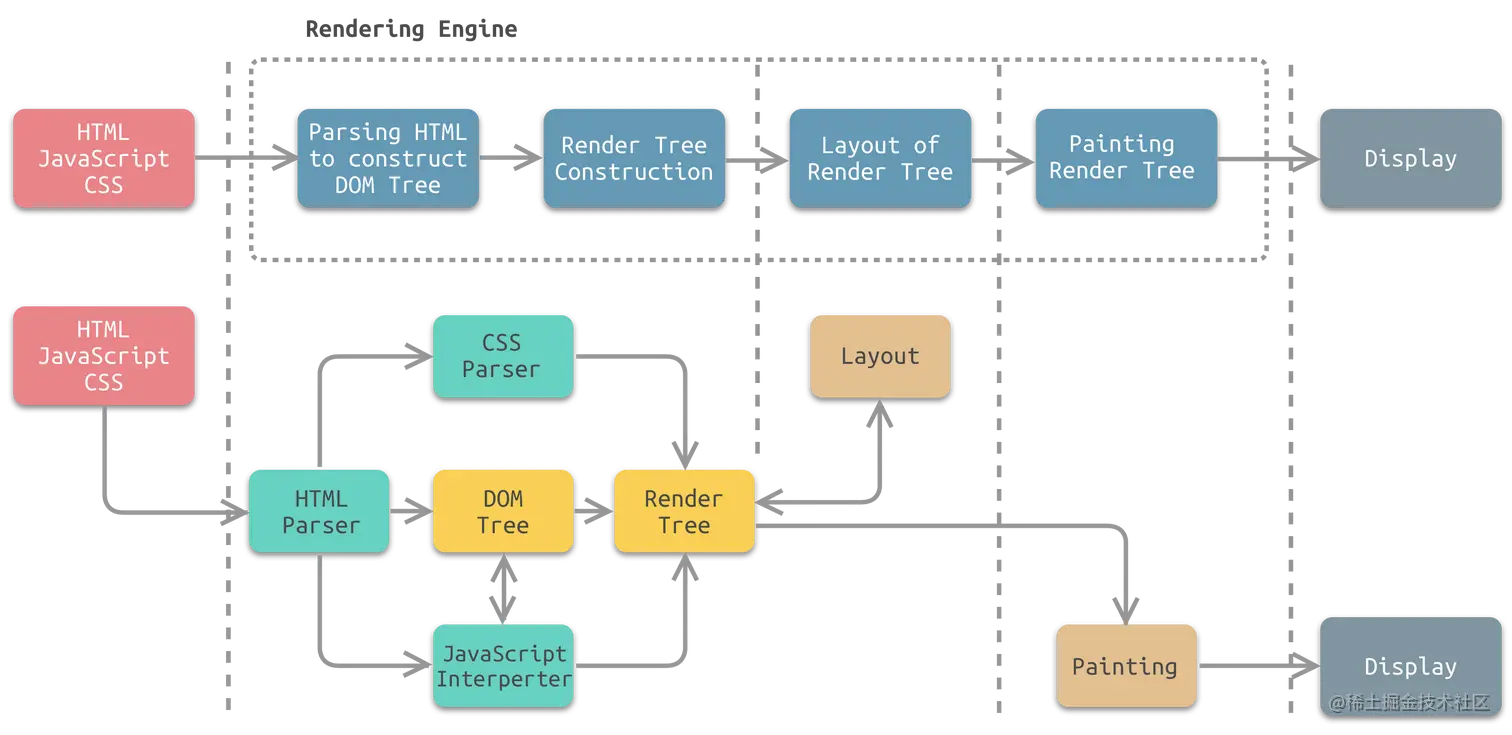
【HTML/CSS面经】
HTML/CSS面经 HTML1. script标签中的async和defer的区别2. H5新特性(1 标签语义化(2 表单功能增强(3 音频和视频标签(4 canvas和svg绘画(5 地理位置获取(6 元素拖动API(7 Web Worker(…...
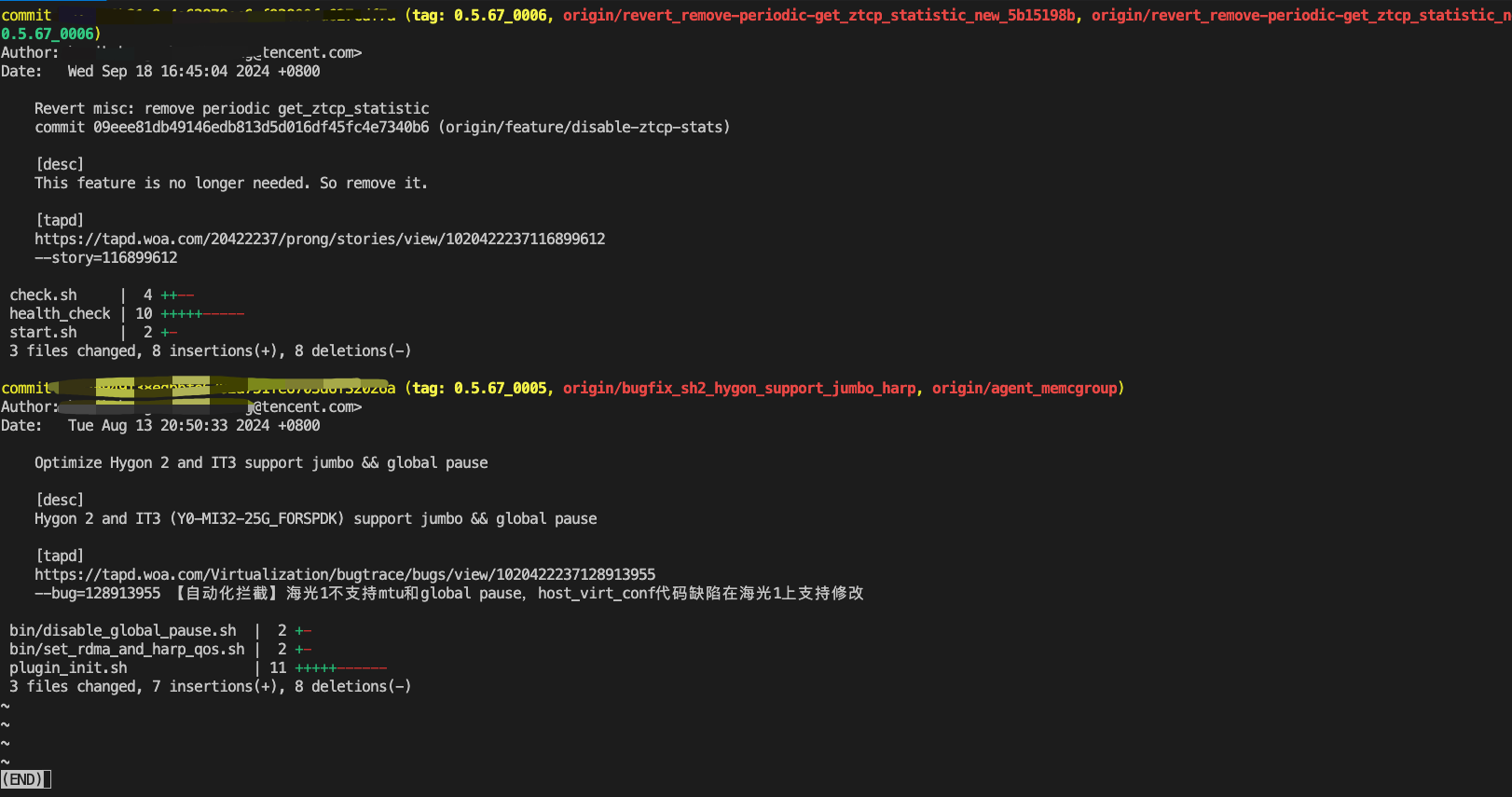
git查看commit属于那个tag
1. 快速确认commit原始分支及合入tag # git describe 213b4b3bbef2771f7a1b8166f6e6989442ca67c8 查看commit合入tag # git describe 213b4b3bbef2771f7a1b8166f6e6989442ca67c8 --all 查看commit原始分支 2.查看分支与master关系 # git show --all 0.5.67_0006 --stat 以缩…...

如何从ISO镜像直接制作Docker容器基础镜像
引言 这段最值得总结的经验知识,就是如何在ISO镜像的基础上,直接做出docker base image,无需联网! 特别地,对于一些老旧OS系统,都能依此做出docker base image! 例如,某些老旧系统,CentOS 6,…...
)
网站缓存入门与实战:浏览器与Nginx/Apache服务器端缓存,让网站速度起飞!(2025)
更多服务器知识,尽在hostol.com 嘿,各位站长和网站管理员朋友们!咱们精心打造的网站,内容再好,设计再炫,如果用户打开它的时候,加载速度慢得像“老牛拉破车”,那体验可就大打折扣了…...
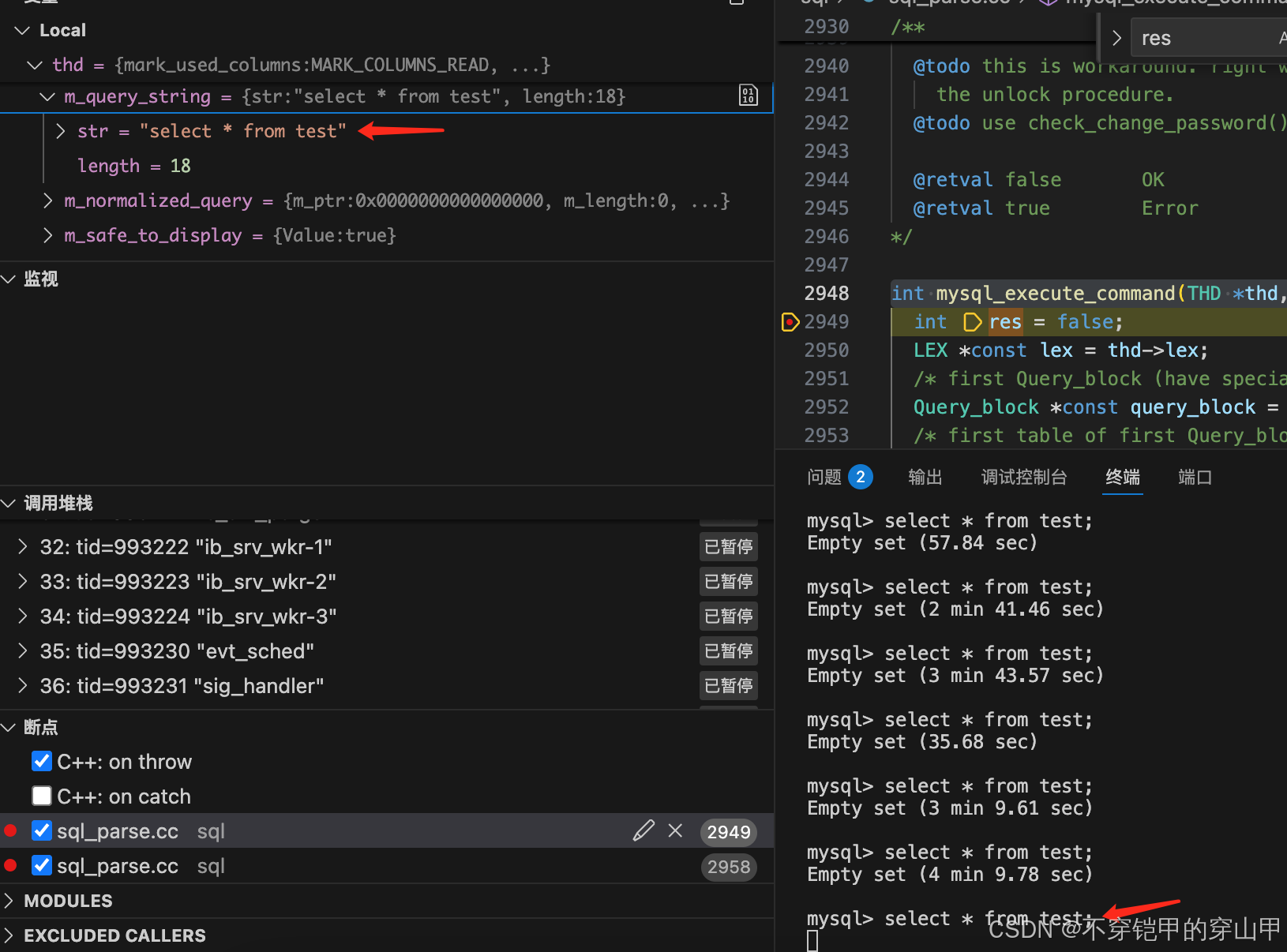
mysql-mysql源码本地调试
前言 先进行mysql源码本地编译:mysql源码本地编译 1.本地调试 这里以macbook为例 1.使用vscode打开mysql源码 2.创建basedir目录、数据目录、配置文件目录、配置文件 cd /Users/test/ mkdir mysqldir //创建数据目录和配置目录 cd mysqldir mkdir conf data …...
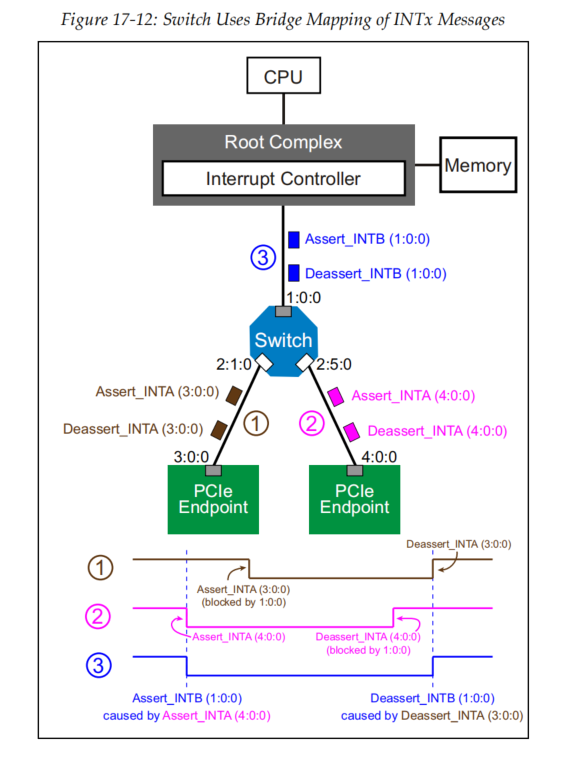
PCIe— Legacy PCI
Legacy Model 该器件通过将其引脚置位到控制器来生成中断。 在较旧的系统中,这个控制 器通常是Intel 8259 PIC,有15个IRQ输入和一个INTR输出。 然后,PIC将断 言INTR以通知CPU一个或多个中断正在挂起。 一旦CPU检测到INTR的断言…...
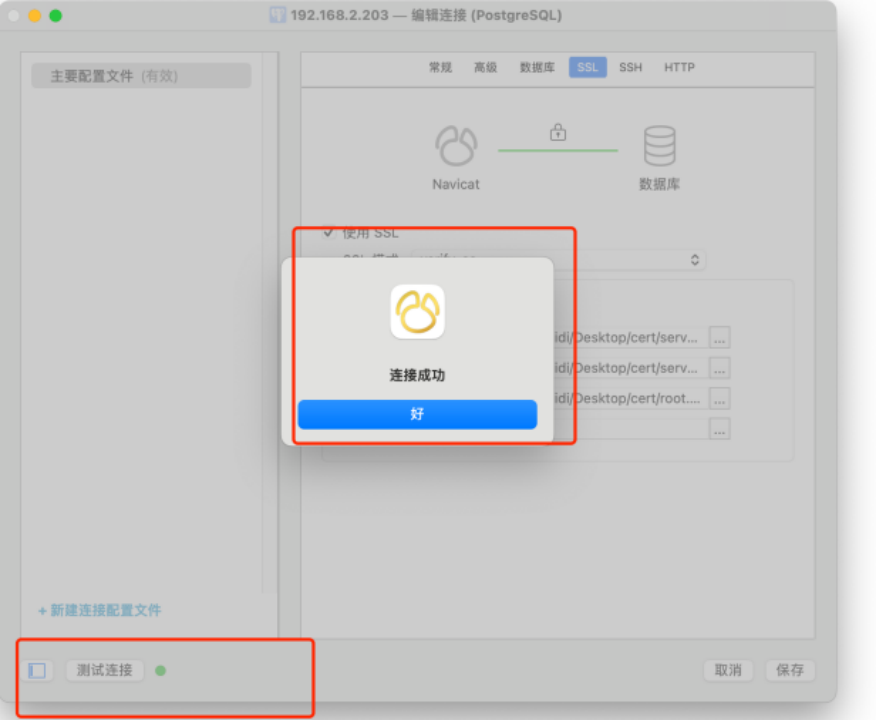
PostgreSQL数据库配置SSL操作说明书
背景: 因为postgresql或者mysql目前通过docker安装,只需要输入主机IP、用户名、密码即可访问成功,这样其实是不安全的,可能会通过一些手段获取到用户名密码导致数据被窃取。而ES、kafka等也是通过用户名/密码方式连接,…...

MySQL 的 super_read_only 和 read_only 参数
MySQL 的 super_read_only 和 read_only 参数 一、参数基本概念 1. read_only 参数 作用:控制普通用户是否只能读取数据影响范围:所有非SUPER权限的用户默认值:OFF(可读写) 2. super_read_only 参数 作用…...

低碳理念在道路工程中的应用-预制路面
一、引子 在上一篇文章里,给大家介绍了预制基层的应用,有人提出,既然基层能够预制,那么,道路面层能不能预制呢,有没有相关的研究成果和应用实例呢?答案是肯定的,在本篇文章中&#x…...
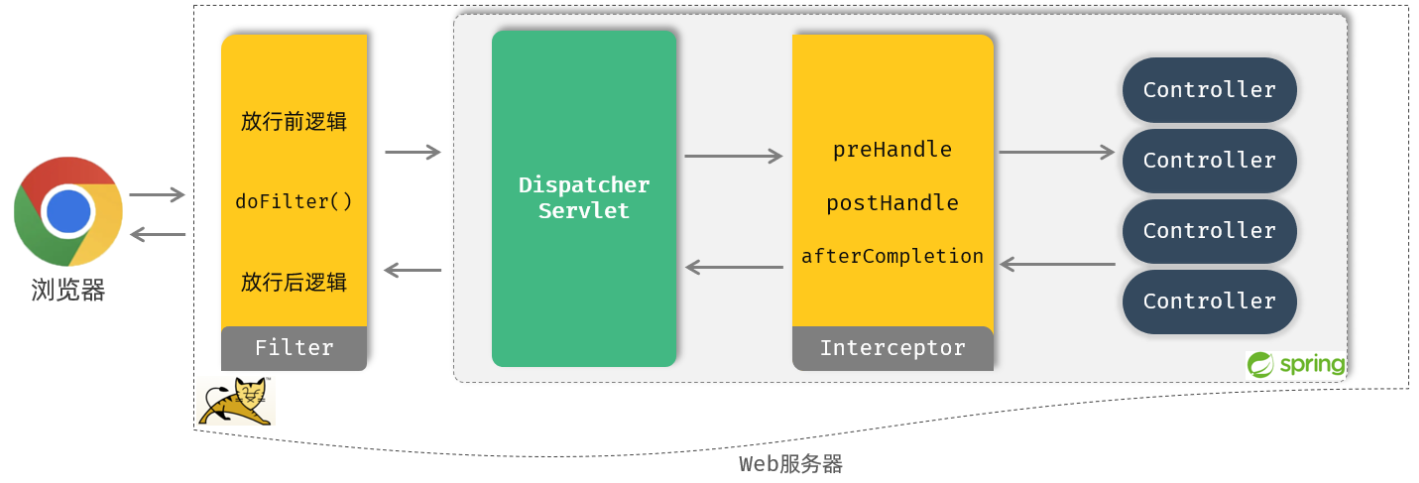
12-后端Web实战(登录认证)
在前面的课程中,我们已经实现了部门管理、员工管理的基本功能,但是大家会发现,我们并没有登录,就直接访问到了Tlias智能学习辅助系统的后台。 这是不安全的,所以我们今天的主题就是登录认证。最终要实现的效果是&#…...

TIDB创建索引失败 mkdir /tmp/tidb/tmp_ddl-4000/1370: no such file or directory.
TIDB创建索引失败:解决“mkdir /tmp/tidb/tmp_ddl-4000/1370: no such file or directory”问题 在使用 TIDB 数据库时,我们有时会遇到创建索引失败的问题。常见的错误信息为: mkdir /tmp/tidb/tmp_ddl-4000/1370: no such file or directo…...

Redis 插入中文乱码键
Java 代码: Bean// 静态代理模式: Redis 客户端代理类增强public StringRedisTemplateProxy stringRedisTemplateProxy(RedisKeySerializer redisKeySerializer,StringRedisTemplate stringRedisTemplate,RedissonClient redissonClient) {stringRedisTemplate.setK…...

Mac OS 使用说明
Mac 的启动组合键 了解可通过在启动时按住一个或多个按键来访问的 Mac 功能和工具。 若要使用这些组合键中的任何一个,请在按下电源按钮以开启 Mac 后或在 Mac 开始重新启动后,立即按住相应按键。请一直按住,直至电脑出现对应的行为。 !!!上…...

4.2.2 Spark SQL 默认数据源
在本实战概述中,我们探讨了如何在 Spark SQL 中使用 Parquet 格式作为默认数据源。首先,我们了解了 Parquet 文件的存储特性,包括其二进制存储方式和内嵌的 Schema 信息。接着,通过一系列命令,我们演示了如何在 HDFS 上…...

234. Palindrome Linked List
目录 一、题目描述 方法一、使用栈 方法二、将链表全部结点值复制到数组,再用双指针法 方法三、递归法逆序遍历链表 方法四、快慢指针反转链表 一、题目描述 234. Palindrome Linked List 方法一、使用栈 需要遍历两次。时间复杂度O(n),空间复杂度…...

广州邮科高频开关电源:以创新科技赋能通信能源绿色未来
在数字化浪潮席卷全球的当下,通信网络作为信息社会的基石,其稳定运行对电源系统的可靠性、效率及智能化水平提出了更高要求。作为国内通信电源领域的领军企业,广州邮科凭借其自主研发的高频开关电源技术,以高效节能、智能管控、绿…...

day41 python图像识别任务
目录 一、数据预处理:为模型打下坚实基础 二、模型构建:多层感知机的实现 三、训练过程:迭代优化与性能评估 四、测试结果:模型性能的最终检验 五、总结与展望 在深度学习的旅程中,多层感知机(MLP&…...

无人机报警器探测模块技术解析!
一、运行方式 1. 频谱监测与信号识别 全频段扫描:模块实时扫描900MHz、1.5GHz、2.4GHz、5.8GHz等无人机常用频段,覆盖遥控、图传及GPS导航信号。 多路分集技术:采用多传感器阵列,通过信号加权合并提升信噪比,…...

Docker 替换宿主与容器的映射端口和文件路径
在使用 Docker 容器化应用程序时,经常需要将宿主机的端口和文件路径映射到容器中,以便在本地访问容器中的服务和数据。本文将详细介绍如何替换和配置 Docker 容器的端口和文件路径映射。 1. 端口映射 端口映射用于将宿主机的端口转发到容器中的端口&am…...

我的3种AI写作节奏搭配模型,适合不同类型写作者
—不用内耗地高效写完一篇内容,原来可以这样搭配AI ✍️ 开场:为什么要“搭配节奏”写作? 很多人以为用AI写作,就是丢一句提示词,然后“等它写完”。 但你有没有遇到这些情况: AI写得很快,学境…...

Bonjour
Bonjour 是苹果的一套零配置网络协议,用于发现局域网内的其他设备并进行通信,比如发现打印机、手机、电视等。 一句话:发现局域网其他设备和让其他设备发现。 Bonjour 可以完成的工作 IP 获取名称解析搜索服务 实际应用场景示例࿰…...
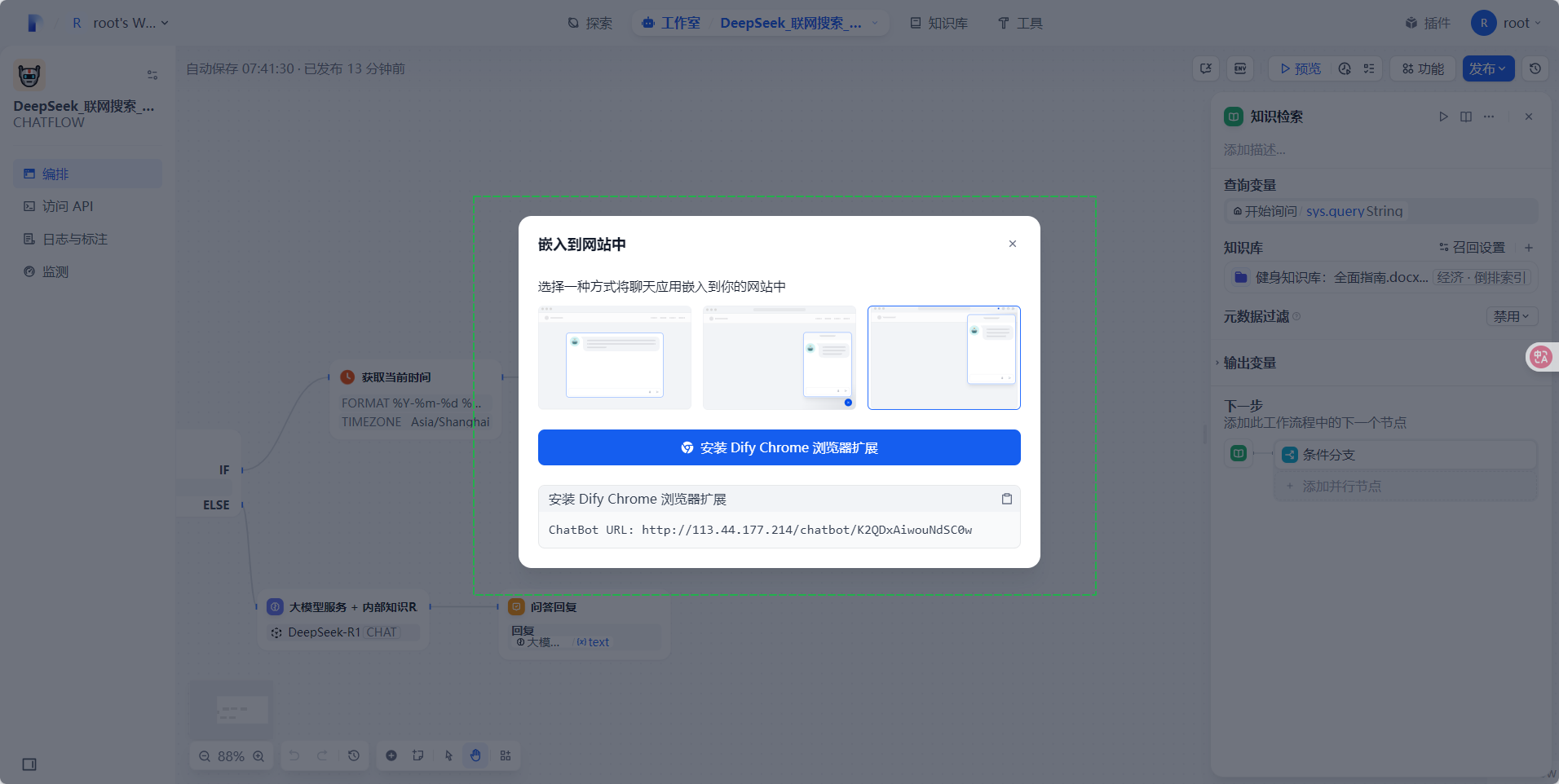
华为云Flexus+DeepSeek征文 | 基于Dify和DeepSeek-R1开发企业级AI Agent全流程指南
作者简介 我是摘星,一名专注于云计算和AI技术的开发者。本次通过华为云MaaS平台体验DeepSeek系列模型,将实际使用经验分享给大家,希望能帮助开发者快速掌握华为云AI服务的核心能力。 目录 1. 前言 2. 环境准备 2.1 华为云资源准备 2.1 实…...
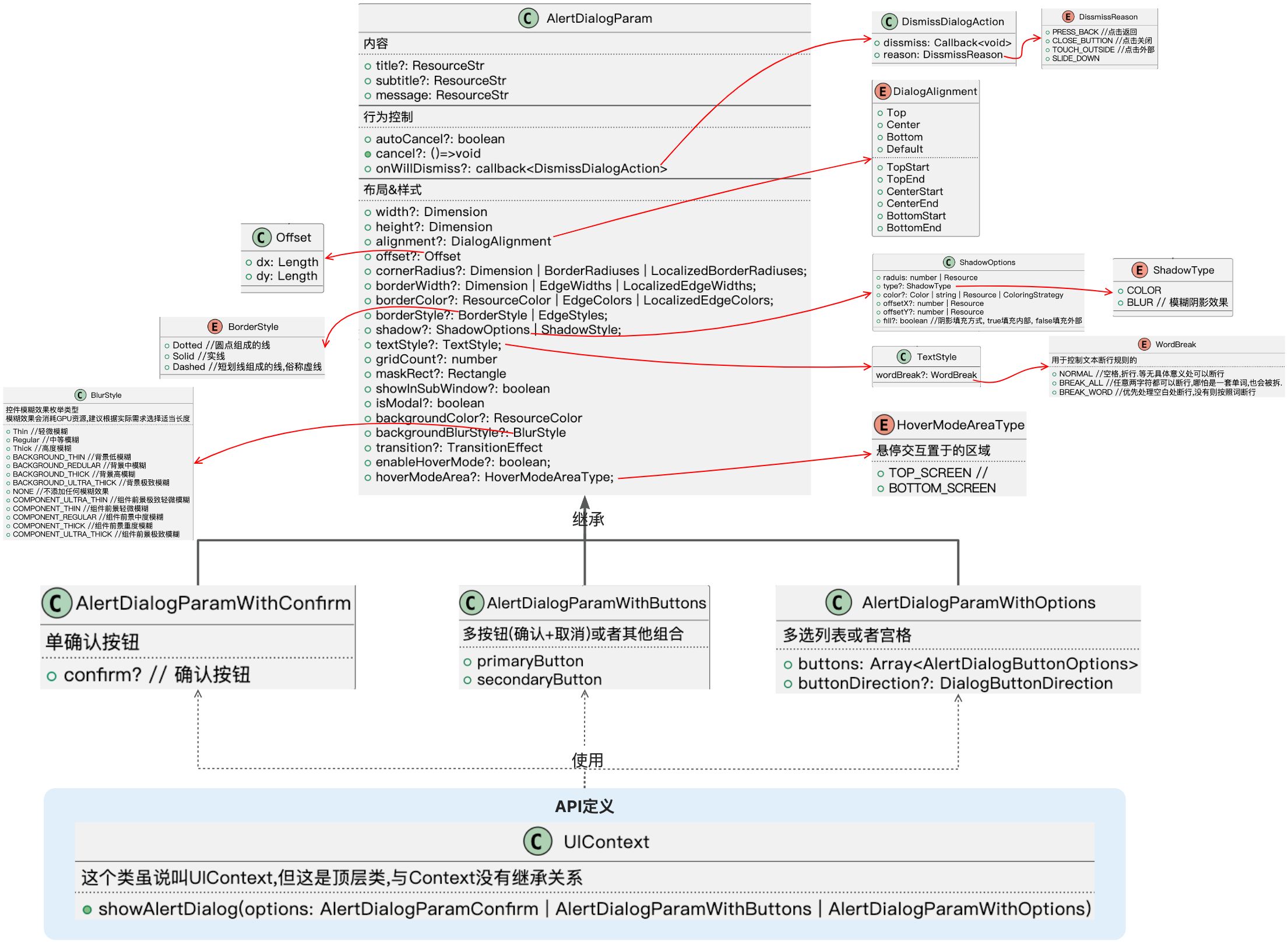
HarmonyOS-ArkUI固定样式弹窗(1)
固定样式弹窗指的就是ArkUI中为我们提供的一些具备界面模板性质的弹窗。样式是固定的,我们可以决定在这些模板里输入什么样的内容。常见的有,警告弹窗, 列表选择弹窗, 选择器弹窗,对话框,操作菜单。 下图是本文中要讲到的基类固定样式弹窗,其中选择器弹窗没有包含在内,…...

痉挛性斜颈相关内容说明
一、颈部姿态的异常偏移 痉挛性斜颈会打破颈部原本自然笔直的状态,让颈部像被无形的力量牵引,出现不自主的歪斜、扭转。它就像打乱了颈部原本和谐的 “平衡游戏”,使得颈部姿态偏离正常,影响日常的体态与活动。 二、容易察觉…...

C语言| 函数参数传递指针
C语言| 拷贝传递(指针控制内存单元)-CSDN博客 【函数参数传指针和传数据的区别】 如果希望在另外一个函数中修改本函数中变量的值,那么在调用函数时只能传递该变量的地址。 1 普通变量,传递它的地址,可以直接操作该变量的内存空间。 举例…...