day41 python图像识别任务
目录
一、数据预处理:为模型打下坚实基础
二、模型构建:多层感知机的实现
三、训练过程:迭代优化与性能评估
四、测试结果:模型性能的最终检验
五、总结与展望
在深度学习的旅程中,多层感知机(MLP)作为最基础的神经网络结构,是每位初学者的必经之路。最近,我通过实现和训练MLP模型,对图像识别任务有了更深入的理解。本文将从数据预处理、模型构建、训练过程到最终的测试结果,详细记录我的学习过程,并总结MLP在图像识别任务中的优势与局限。
一、数据预处理:为模型打下坚实基础
在任何机器学习任务中,数据预处理都是至关重要的第一步。对于图像数据,我们需要将其转换为适合模型处理的格式。以MNIST手写数字数据集为例,我使用了torchvision.transforms库对图像进行了标准化处理:
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])通过ToTensor()操作,图像被转换为张量格式,并且像素值被归一化到[0,1]区间。Normalize()操作则进一步对图像进行标准化,使其均值为0,标准差为1。这有助于加速模型的收敛。
对于彩色图像数据集(如CIFAR-10),处理方式类似,只是需要对每个通道分别进行标准化:
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])数据加载器DataLoader的使用也非常关键,它能够高效地批量加载数据,并支持多线程加速数据读取:
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)通过设置shuffle=True,训练数据会在每个epoch开始时被打乱,这有助于模型更好地泛化。
二、模型构建:多层感知机的实现
多层感知机(MLP)是一种经典的神经网络结构,由多个全连接层组成。在MNIST数据集上,我构建了一个简单的MLP模型:
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x在CIFAR-10数据集上,我将模型进行了扩展,增加了层数和神经元数量,并引入了Dropout来防止过拟合:
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]x = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出x = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logitsDropout是一种有效的正则化技术,它在训练阶段随机丢弃部分神经元的输出,从而防止模型对训练数据过度拟合。
三、训练过程:迭代优化与性能评估
训练过程是模型学习数据特征的关键阶段。我使用了Adam优化器和交叉熵损失函数,这是分类任务中常用的组合:
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器在训练过程中,我记录了每个iteration的损失,并绘制了损失曲线,以便直观地观察模型的收敛情况:
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc通过每100个批次打印一次训练信息,我可以实时监控模型的训练进度。同时,每个epoch结束后,我会对模型进行测试,评估其在测试集上的性能。
四、测试结果:模型性能的最终检验
经过多次实验,我发现在MNIST数据集上,MLP模型能够达到较高的准确率(约96.75%)。然而,在更具挑战性的CIFAR-10数据集上,即使增加了模型的深度和训练轮次,最终测试准确率也仅能达到约52.40%。这表明MLP在处理复杂图像数据时存在明显的局限性。
五、总结与展望
通过这次学习,我深刻认识到MLP在图像识别任务中的优势与不足。MLP结构简单,易于理解和实现,但在处理图像数据时,它无法有效利用图像的空间结构信息,导致在复杂任务上性能受限。此外,深层MLP的参数规模呈指数级增长,容易过拟合,训练成本也较高。未来,我将深入学习卷积神经网络(CNN),它专门针对图像数据设计,能够自动提取图像的空间特征,具有更少的参数和更快的训练速度,是解决图像识别问题的更优选择。
@浙大疏锦行
相关文章:

day41 python图像识别任务
目录 一、数据预处理:为模型打下坚实基础 二、模型构建:多层感知机的实现 三、训练过程:迭代优化与性能评估 四、测试结果:模型性能的最终检验 五、总结与展望 在深度学习的旅程中,多层感知机(MLP&…...

无人机报警器探测模块技术解析!
一、运行方式 1. 频谱监测与信号识别 全频段扫描:模块实时扫描900MHz、1.5GHz、2.4GHz、5.8GHz等无人机常用频段,覆盖遥控、图传及GPS导航信号。 多路分集技术:采用多传感器阵列,通过信号加权合并提升信噪比,…...

Docker 替换宿主与容器的映射端口和文件路径
在使用 Docker 容器化应用程序时,经常需要将宿主机的端口和文件路径映射到容器中,以便在本地访问容器中的服务和数据。本文将详细介绍如何替换和配置 Docker 容器的端口和文件路径映射。 1. 端口映射 端口映射用于将宿主机的端口转发到容器中的端口&am…...

我的3种AI写作节奏搭配模型,适合不同类型写作者
—不用内耗地高效写完一篇内容,原来可以这样搭配AI ✍️ 开场:为什么要“搭配节奏”写作? 很多人以为用AI写作,就是丢一句提示词,然后“等它写完”。 但你有没有遇到这些情况: AI写得很快,学境…...

Bonjour
Bonjour 是苹果的一套零配置网络协议,用于发现局域网内的其他设备并进行通信,比如发现打印机、手机、电视等。 一句话:发现局域网其他设备和让其他设备发现。 Bonjour 可以完成的工作 IP 获取名称解析搜索服务 实际应用场景示例࿰…...
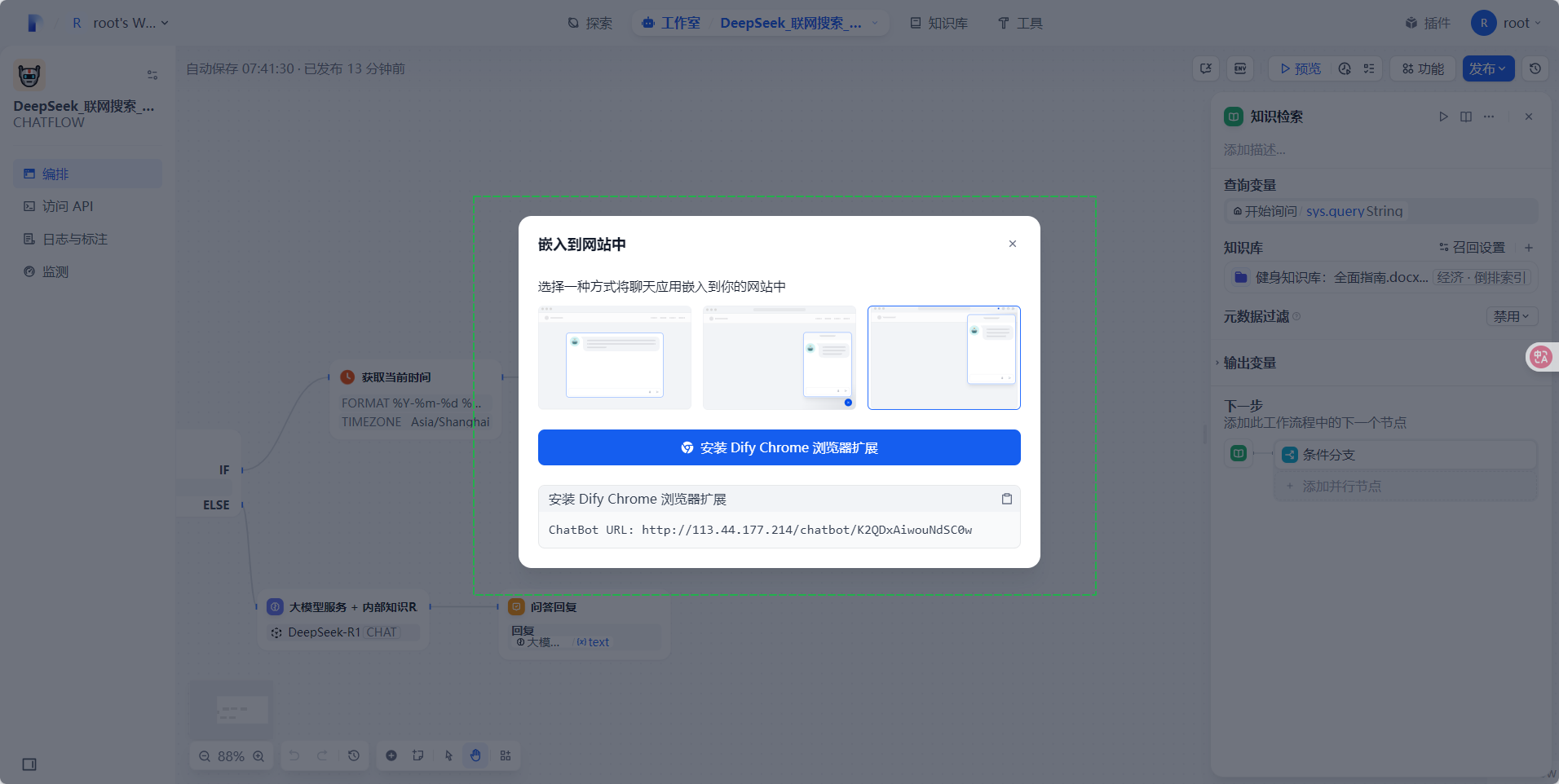
华为云Flexus+DeepSeek征文 | 基于Dify和DeepSeek-R1开发企业级AI Agent全流程指南
作者简介 我是摘星,一名专注于云计算和AI技术的开发者。本次通过华为云MaaS平台体验DeepSeek系列模型,将实际使用经验分享给大家,希望能帮助开发者快速掌握华为云AI服务的核心能力。 目录 1. 前言 2. 环境准备 2.1 华为云资源准备 2.1 实…...
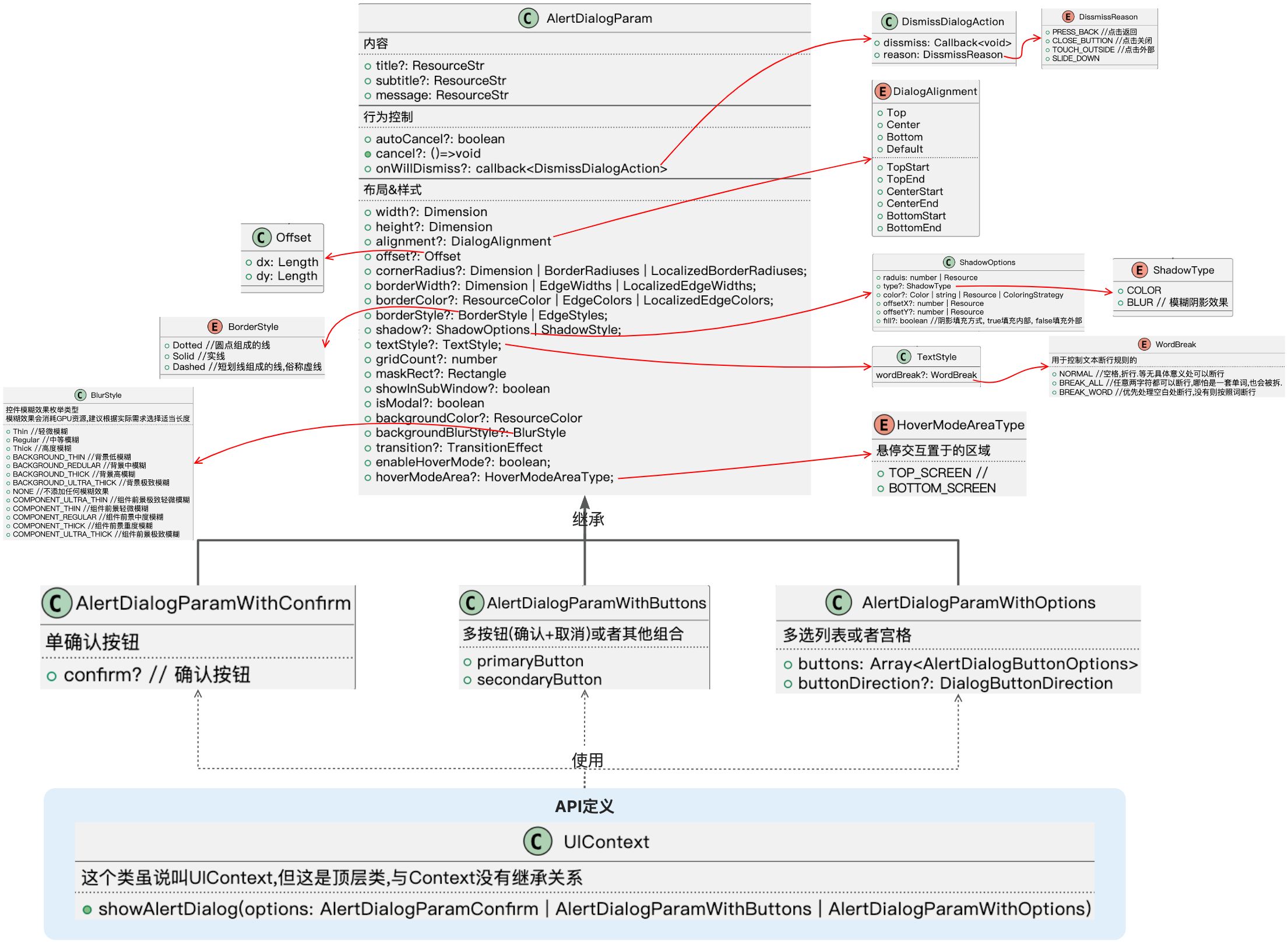
HarmonyOS-ArkUI固定样式弹窗(1)
固定样式弹窗指的就是ArkUI中为我们提供的一些具备界面模板性质的弹窗。样式是固定的,我们可以决定在这些模板里输入什么样的内容。常见的有,警告弹窗, 列表选择弹窗, 选择器弹窗,对话框,操作菜单。 下图是本文中要讲到的基类固定样式弹窗,其中选择器弹窗没有包含在内,…...

痉挛性斜颈相关内容说明
一、颈部姿态的异常偏移 痉挛性斜颈会打破颈部原本自然笔直的状态,让颈部像被无形的力量牵引,出现不自主的歪斜、扭转。它就像打乱了颈部原本和谐的 “平衡游戏”,使得颈部姿态偏离正常,影响日常的体态与活动。 二、容易察觉…...

C语言| 函数参数传递指针
C语言| 拷贝传递(指针控制内存单元)-CSDN博客 【函数参数传指针和传数据的区别】 如果希望在另外一个函数中修改本函数中变量的值,那么在调用函数时只能传递该变量的地址。 1 普通变量,传递它的地址,可以直接操作该变量的内存空间。 举例…...

【25-cv-05917】HSP律所代理Le Petit Prince 小王子商标维权案
Le Petit Prince 小王子 案件号:25-cv-05917 立案时间:2025年5月28日 原告:SOCIETE POUR LOEUVRE ET LA MEMOIRE DANTOINE DE SAINT EXUPERY - SUCCESSION DE SAINT EXUPERY-DAGAY 代理律所:HSP 原告介绍 《小王子》&#x…...

MyBatis 动态 SQL 详解:灵活构建强大查询
MyBatis 的动态 SQL 功能是其最强大的特性之一,它允许开发者根据不同条件动态生成 SQL 语句,极大地提高了 SQL 的灵活性和复用性。本文将深入探讨 MyBatis 的动态 SQL 功能,包括 OGNL 表达式的使用以及各种动态 SQL 元素(如 if、c…...
)
从 “金屋藏娇” 到 自然语言处理(NLP)
文章目录 从两个问题理解自然语言处理(NLP)1、汉武帝喜欢阿娇吗1. 政治联姻的背景2. 早期情感与后期疏远3. 历史评价的复杂性4. 现代视角结论 2、刘彻和淮南王关系一、背景:诸侯王与中央的矛盾二、刘彻与刘安的互动三、深层原因与历史评价结论…...
vue3 ElMessage提示语换行渲染
在 ElMessage.error 中使用换行符 \n 并不会实现换行,因为 ElMessage 默认会将字符串中的换行符忽略。要实现换行显示,可以使用 HTML 标签 <br> 并结合 ElMessage 的 dangerouslyUseHTMLString 选项。以下是实现换行提示的代码示例: i…...

Java 微服务架构设计:服务拆分与服务发现的策略
Java 微服务架构设计:服务拆分与服务发现的策略 微服务架构作为一种热门的软件架构风格,在 Java 领域有着广泛的应用。它通过将系统拆分为一组小型服务来实现更灵活、可扩展的系统设计。在微服务架构中,服务拆分和服务发现是两个关键环节。本…...

华为OD机试真题——二叉树中序遍历(2025A卷:200分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 200分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C++、C语言、GO六种语言的最佳实现方式! 2025华为OD真题目录+全流程解析/备考攻略/经验分享 华为OD机试真题《二叉树中序遍历》: 目录 …...

解决 Go 中 `loadinternal: cannot find runtime/cgo` 错误
在 Go 开发中,loadinternal: cannot find runtime/cgo 是一个相对不常见但可能令人困惑的错误。这个错误通常与 CGO 的使用和配置有关。本文将探讨这个错误的成因,并提供解决方案,帮助你在未来的开发中避免类似问题。 错误背景 在 Go 项目中…...

VSCode + GD32F407 构建烧录
前言 最近调试一块 GD32F407VET6(168Mhz,8Mhz晶振) 板子时,踩了一些“启动失败”的坑。本以为是时钟配置有误,最后发现是链接脚本(.ld 文件)没有配置好,导致程序根本没能正常执行 ma…...
Linux研学-入门命令
一 目录介绍 1 介绍 Linux与Windows在目录结构组织上差异显著:Linux采用树型目录结构,以单一根目录/为起点,所有文件和子目录由此向下延伸形成层级体系,功能明确的目录各司其职,使文件系统层次清晰、逻辑连贯…...

Hive在实际应用中,如何选择合适的JOIN优化策略?
在实际应用中选择Hive JOIN优化策略时,需综合考虑数据规模、分布特征、表结构设计、集群资源及业务需求。以下是具体的决策流程和参考标准: 一、数据特征分析 1. 统计数据规模 通过DESCRIBE FORMATTED table_name查看表大小和分区信息。使用SELECT CO…...
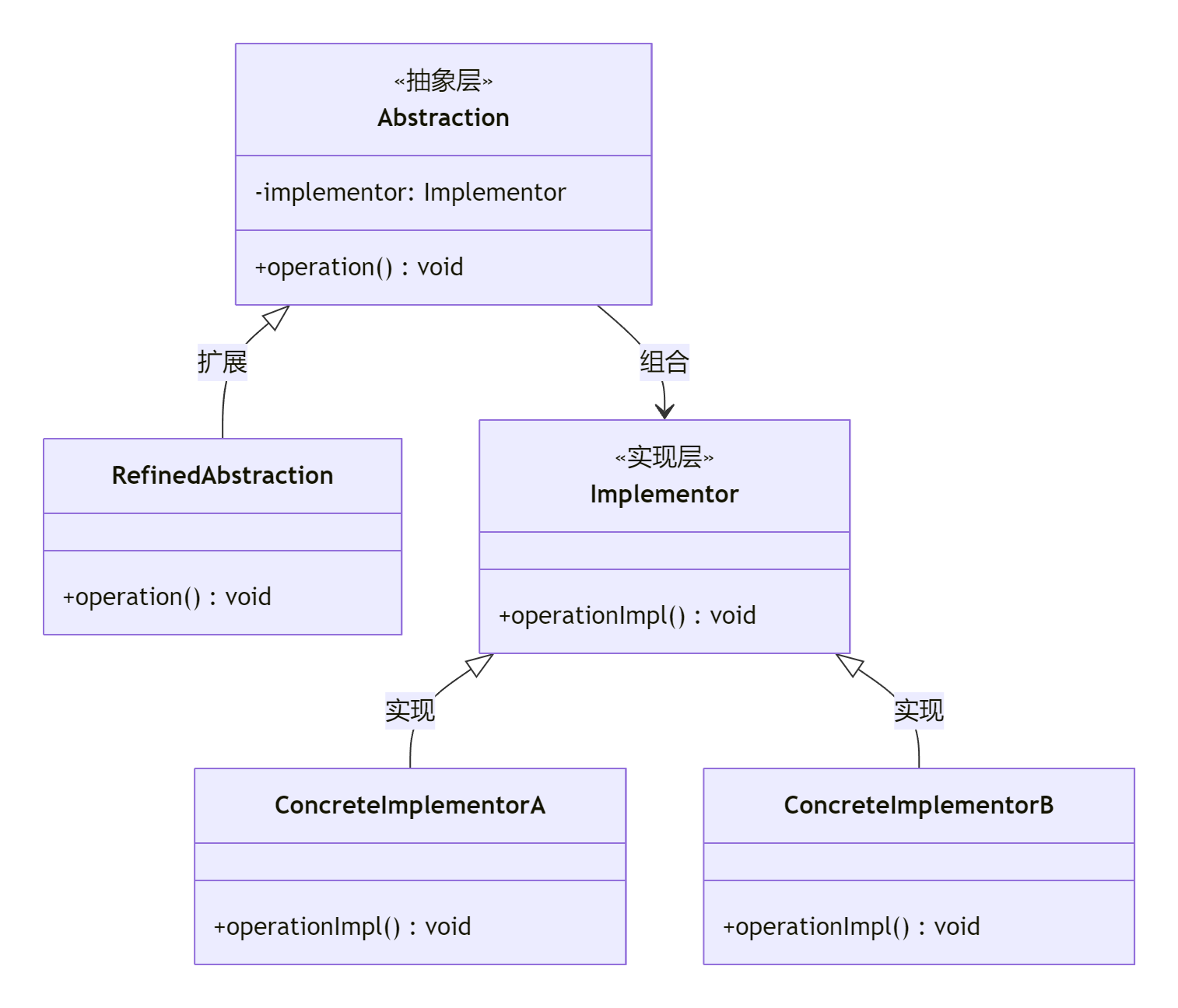
设计模式之结构型:桥接模式
桥接模式(Bridge Pattern) 定义 桥接模式是一种结构型设计模式,通过将抽象部分与实现部分分离,使它们可以独立变化。它通过组合代替继承,解决多层继承导致的类爆炸问题,适用于多维度变化的场景(如形状与颜…...

监控 Oracle Cloud 负载均衡器:使用 Applications Manager 释放最佳性能
设想你正在运营一个受欢迎的在线学习平台,在考试前的高峰期,平台流量激增。全球的学生同时登录,观看视频、提交作业和参加测试。如果 Oracle Cloud 负载均衡器不能高效地分配流量,或者后端服务器难以应对负载,学生可能…...
早发现=早安心!超导心磁图如何捕捉早期病变信号?
随着生活节奏的加快,心血管疾病已成为威胁人们健康的“隐形杀手”。据国家心血管病中心发布的《中国心血管健康与疾病报告2022》显示,我国心血管病现患者人数已高达3.3亿,每5例死亡中就有2例死于心血管病。这一数据触目惊心,提醒我…...

使用Vditor将Markdown文档渲染成网页(Vite+JS+Vditor)
1. 引言 编写Markdown文档现在可以说是程序员的必备技能了,因为Markdown很好地实现了内容与排版分离,可以让程序员更专注于内容的创作。现在很多技术文档,博客发布甚至AI文字输出的内容都是以Markdown格式的形式输出的。那么,Mar…...

Python打卡DAY40
知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业:仔细学习下测试和训练代码…...
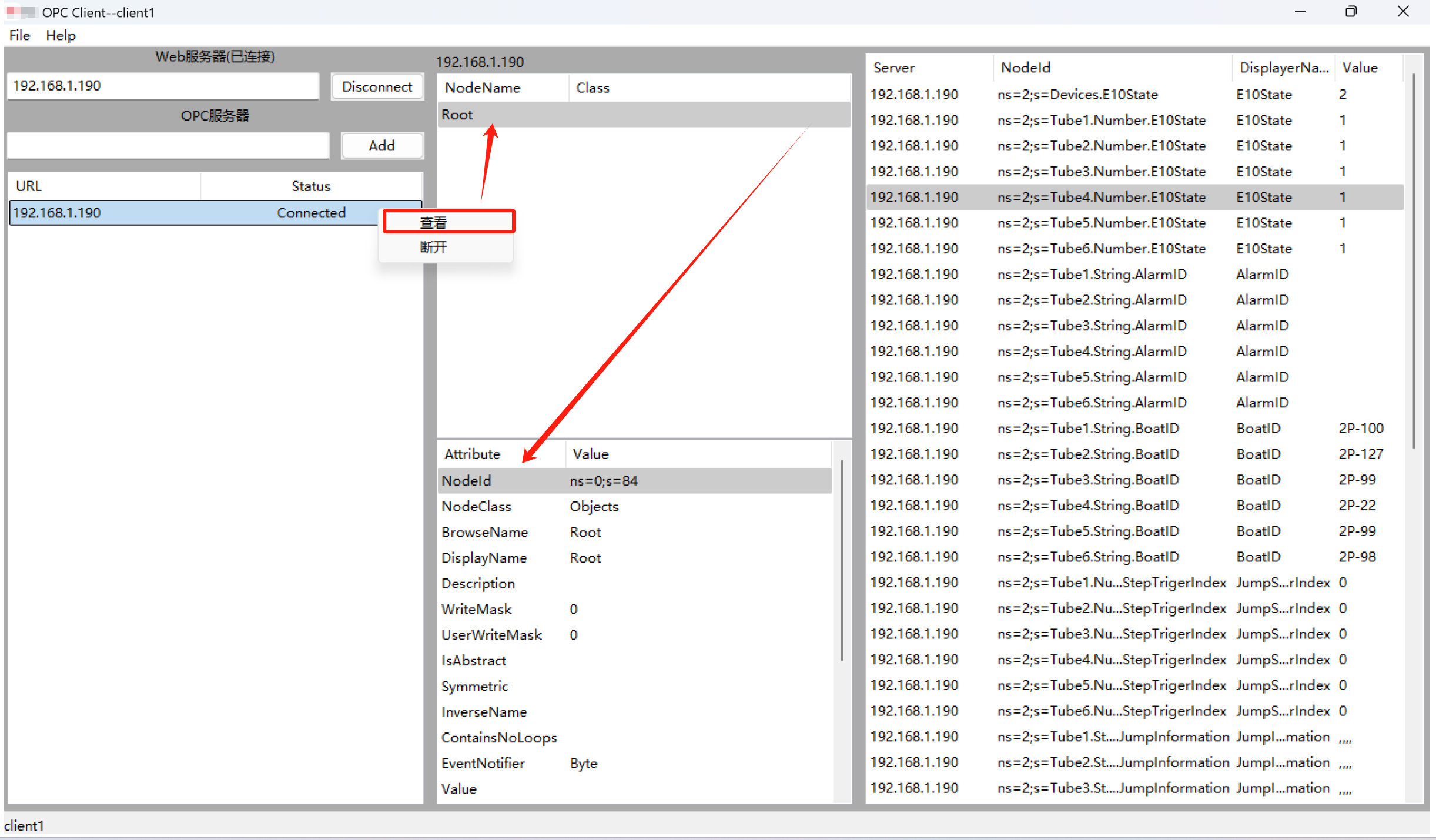
OPC Client第6讲(wxwidgets):Logger.h日志记录文件(单例模式);登录后的主界面
接上一讲三、2、2>4》,创建logger.h和helper_t.h里的gettime函数 即解决下图的报红 同时,接上一讲二、3、点击“确认”按钮后,进入MainFrame.h对应的下述界面,此讲下图进行实现 一、创建Logger.h:日志记录文件&…...

CesiumInstancedMesh 实例
CesiumInstancedMesh 实例 import * as Cesium from cesium;// Three.js 风格的 InstancedMesh 类, https://threejs.org/docs/#api/en/objects/InstancedMesh export class CesiumInstancedMesh {/*** Creates an instance of InstancedMesh.** param {Cesium.Geometry} geom…...

单细胞注释前沿:CASSIA——无参考、可解释、自动化细胞注释的大语言模型
细胞类型注释是单细胞RNA-seq分析的重要步骤,目前有许多注释方法。大多数注释方法都需要计算和特定领域专业知识的结合,而且经常产生不一致的结果,难以解释。大语言模型有可能在减少人工输入和提高准确性的同时扩大可访问性,但现有…...
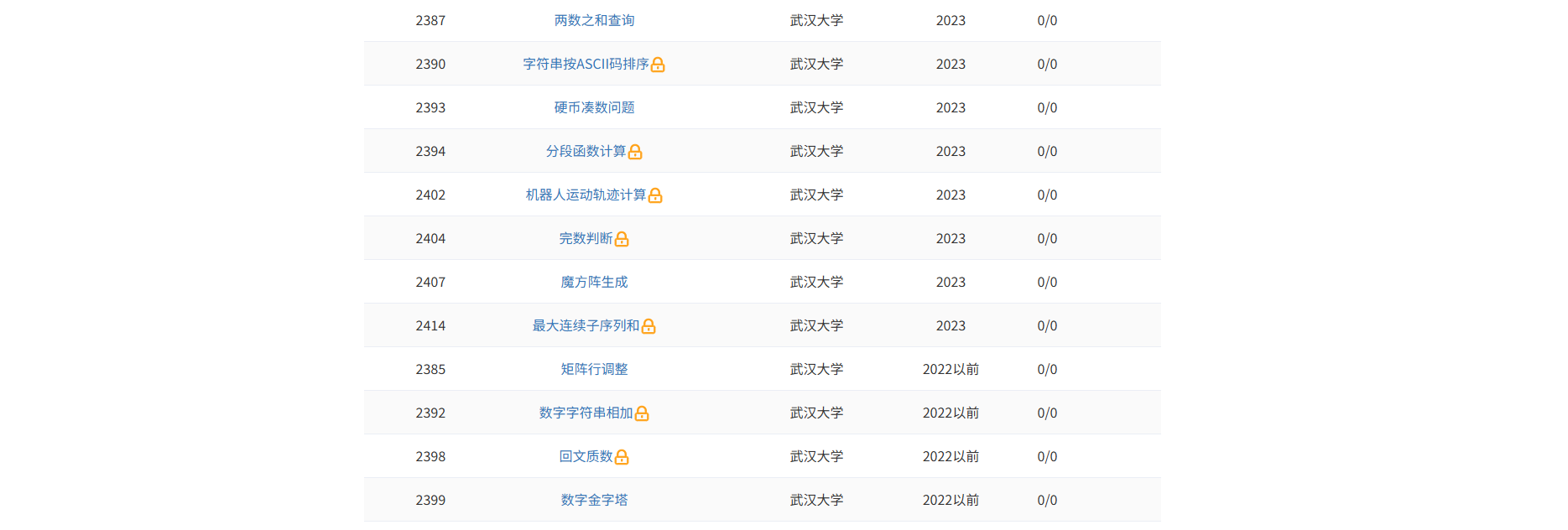
历年武汉大学计算机保研上机真题
2025武汉大学计算机保研上机真题 2024武汉大学计算机保研上机真题 2023武汉大学计算机保研上机真题 在线测评链接:https://pgcode.cn/school 分段函数计算 题目描述 写程序计算如下分段函数: 当 x > 0 x > 0 x>0 时, f ( x ) …...
:みます)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(30):みます
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(30):みます 1、前言(1)情况说明(2)工程师的信仰2、知识点(1)ように 復習:1、ように Change12、ように Ideal state(理想(りそう)の状態(じょうたい))3、V辞書・Vない ようにしています いつも気をつけて…...

AR-HUD 光波导方案优化难题待解?OAS 光学软件来破局
波导-HUD系统案例分析 简介 光波导技术凭借其平板超薄结构和强大的二维扩展能力,在解决AR-HUD问题方面展现出显著优势。一方面,其独特的结构特性能够大幅减小对光机体积的需求,成为 HUD 未来发展的重要技术方向;另一方面…...