Hive在实际应用中,如何选择合适的JOIN优化策略?
在实际应用中选择Hive JOIN优化策略时,需综合考虑数据规模、分布特征、表结构设计、集群资源及业务需求。以下是具体的决策流程和参考标准:
一、数据特征分析
1. 统计数据规模
- 通过
DESCRIBE FORMATTED table_name查看表大小和分区信息。 - 使用
SELECT COUNT(DISTINCT key)评估JOIN键的基数(唯一值数量)。
2. 检测数据倾斜
- 查询倾斜率:
SELECT key, COUNT(*) AS cnt, COUNT(*) * 1.0 / SUM(COUNT(*)) OVER () AS ratio FROM table GROUP BY key ORDER BY ratio DESC; - 判断标准:若某键的
ratio显著高于其他键(如>5%),则存在倾斜。
二、JOIN类型与优化策略匹配
1. 小表 JOIN 大表
- 策略:优先使用 MapJoin。
- 条件:小表大小 <
hive.mapjoin.smalltable.filesize(默认25MB)。 - 实现:
SET hive.auto.convert.join=true; -- 自动转换 SELECT /*+ MAPJOIN(small_table) */ * -- 手动指定 FROM big_table JOIN small_table ON ...;
2. 大表 JOIN 大表
- 策略1:若两表均为分桶表且满足以下条件,使用 SMB Join:
- 分桶键 = JOIN键;
- 分桶数相同或成倍数关系;
- 数据按JOIN键排序。
- 实现:
SET hive.optimize.bucketmapjoin=true; SET hive.optimize.sortmerge.join=true;
- 策略2:若不满足分桶条件,使用 普通Shuffle JOIN,并优化Reduce并行度:
SET mapreduce.job.reduces=100; -- 根据数据量调整
3. 存在数据倾斜的 JOIN
- 策略:
- 拆分倾斜键:对NULL值或热门键单独处理。
SELECT * FROM big_table b LEFT JOIN small_table s ON CASE WHEN b.key IS NULL THEN 'NULL_SPLIT' ELSE b.key END = s.key;- 两阶段聚合:对倾斜键添加随机前缀,分散负载。
-- 第一阶段:随机前缀聚合 SELECT key + FLOOR(RAND()*1000) AS tmp_key, COUNT(*) FROM table GROUP BY key + FLOOR(RAND()*1000);- 启用自动倾斜优化:
SET hive.optimize.skewjoin=true; SET hive.skewjoin.key=100000; -- 倾斜阈值
三、表结构优化建议
1. 分桶表设计
- 适用场景:频繁JOIN的大表(如每日上亿记录的日志表)。
- 设计原则:
- 分桶键 = JOIN键;
- 分桶数 = Reducer数(通常100~1000);
- 示例:
CREATE TABLE orders (order_id INT, user_id INT) CLUSTERED BY (user_id) INTO 100 BUCKETS;
2. 分区表设计
- 适用场景:按时间、地域等维度过滤的表。
- 设计原则:
- 分区键 = 高频过滤条件(如
dt日期); - 避免过深分区(如年/月/日三级分区可能导致目录爆炸)。
- 示例:
CREATE TABLE logs (event_type STRING) PARTITIONED BY (dt STRING); - 分区键 = 高频过滤条件(如
四、集群资源与配置
1. 内存参数调整
- 增大Map/Reduce任务内存:
SET mapreduce.map.java.opts=-Xmx4g; SET mapreduce.reduce.java.opts=-Xmx8g; - 调整MapJoin缓冲区大小:
SET hive.auto.convert.join.noconditionaltask.size=100000000; -- 100MB
2. 并行度控制
- 根据集群资源和数据量调整Reducer数:
SET mapreduce.job.reduces=200; -- 总数据量/每个Reducer处理量
3. 推测执行与重试
- 启用推测执行,加速慢任务:
SET mapreduce.map.speculative=true; SET mapreduce.reduce.speculative=true;
五、多表JOIN优化策略
1. 小表优先原则
- 将最小的表放在前面JOIN,减少中间结果集:
SELECT /*+ MAPJOIN(small1, small2) */ * FROM small1 JOIN small2 ON small1.key = small2.key JOIN big_table ON small1.key = big_table.key;
2. 合并JOIN操作
- 减少Shuffle次数:
-- 低效:两次Shuffle SELECT * FROM a JOIN b ON a.key = b.key; SELECT * FROM c JOIN d ON c.key = d.key;-- 高效:一次Shuffle SELECT * FROM a JOIN b ON a.key = b.key JOIN c ON b.key = c.key;
六、验证与监控
1. 执行计划分析
- 使用
EXPLAIN查看优化后的执行计划:EXPLAIN SELECT * FROM a JOIN b ON a.key = b.key; - 关键检查点:
- 是否存在
MapJoinOperator(表示已启用MapJoin)。 - 是否有
SkewJoin标记(表示检测到倾斜)。
- 是否存在
2. 性能监控
- 通过YARN界面监控:
- Task执行时间和数据量分布;
- 内存使用情况(是否有OOM错误);
- 慢Task所在节点。
七、决策流程图
八、常见场景与策略选择
| 场景 | 优化策略 |
|---|---|
| 实时数仓(高频小查询) | MapJoin + 预聚合表 |
| 离线批量ETL(大表JOIN) | SMB Join + 分区剪枝 |
| 电商热门商品分析(数据倾斜) | 倾斜键拆分 + 两阶段聚合 |
| 多维分析(多表JOIN) | 分桶表设计 + 小表优先原则 |
| 日志分析(含大量NULL值) | NULL值单独处理 + 分区过滤 |
通过以上步骤,可系统性选择最优的JOIN优化策略,平衡性能与资源消耗。实际应用中需结合业务场景灵活调整,并通过监控持续验证效果。
相关文章:

Hive在实际应用中,如何选择合适的JOIN优化策略?
在实际应用中选择Hive JOIN优化策略时,需综合考虑数据规模、分布特征、表结构设计、集群资源及业务需求。以下是具体的决策流程和参考标准: 一、数据特征分析 1. 统计数据规模 通过DESCRIBE FORMATTED table_name查看表大小和分区信息。使用SELECT CO…...
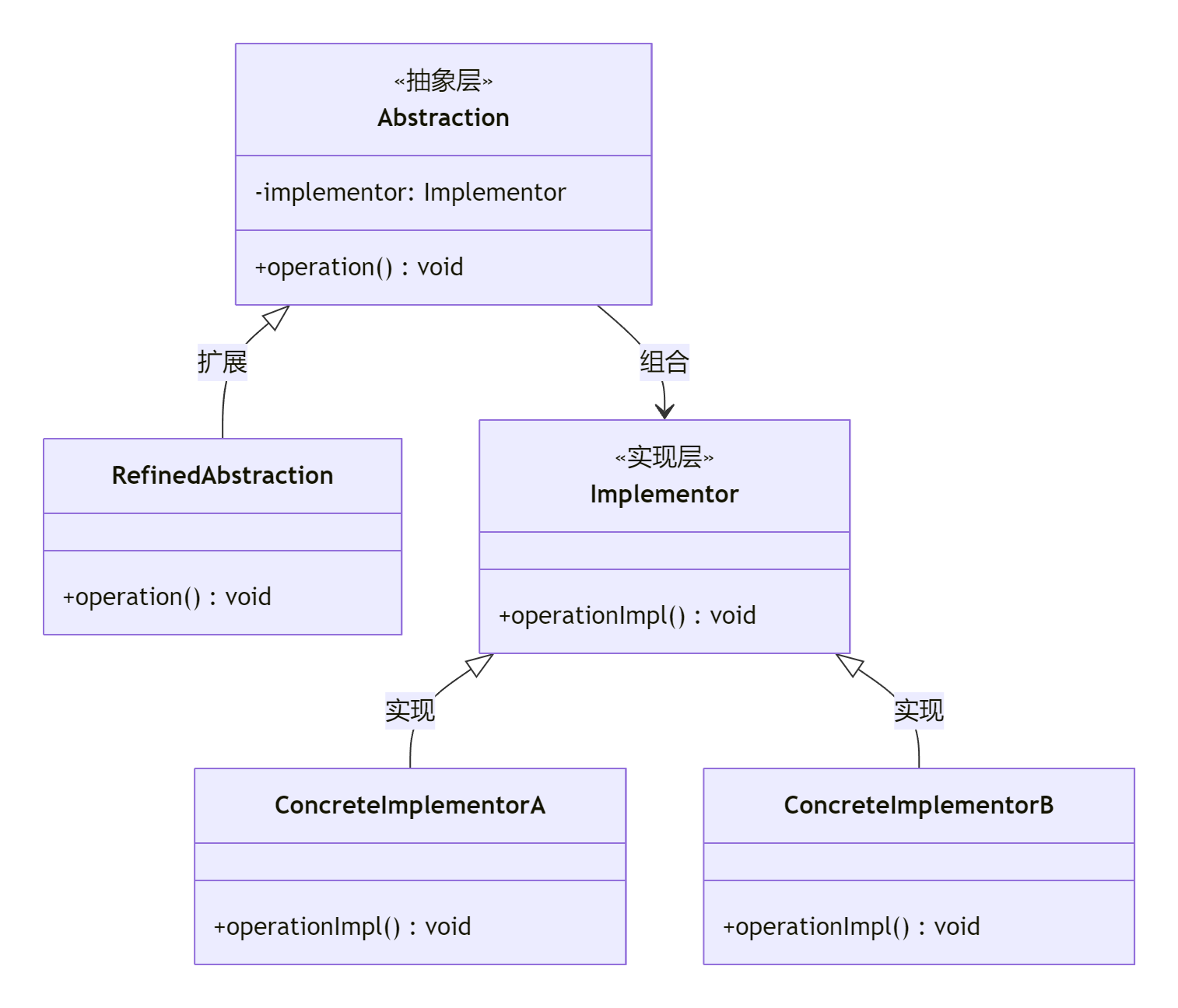
设计模式之结构型:桥接模式
桥接模式(Bridge Pattern) 定义 桥接模式是一种结构型设计模式,通过将抽象部分与实现部分分离,使它们可以独立变化。它通过组合代替继承,解决多层继承导致的类爆炸问题,适用于多维度变化的场景(如形状与颜…...

监控 Oracle Cloud 负载均衡器:使用 Applications Manager 释放最佳性能
设想你正在运营一个受欢迎的在线学习平台,在考试前的高峰期,平台流量激增。全球的学生同时登录,观看视频、提交作业和参加测试。如果 Oracle Cloud 负载均衡器不能高效地分配流量,或者后端服务器难以应对负载,学生可能…...
早发现=早安心!超导心磁图如何捕捉早期病变信号?
随着生活节奏的加快,心血管疾病已成为威胁人们健康的“隐形杀手”。据国家心血管病中心发布的《中国心血管健康与疾病报告2022》显示,我国心血管病现患者人数已高达3.3亿,每5例死亡中就有2例死于心血管病。这一数据触目惊心,提醒我…...

使用Vditor将Markdown文档渲染成网页(Vite+JS+Vditor)
1. 引言 编写Markdown文档现在可以说是程序员的必备技能了,因为Markdown很好地实现了内容与排版分离,可以让程序员更专注于内容的创作。现在很多技术文档,博客发布甚至AI文字输出的内容都是以Markdown格式的形式输出的。那么,Mar…...

Python打卡DAY40
知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业:仔细学习下测试和训练代码…...
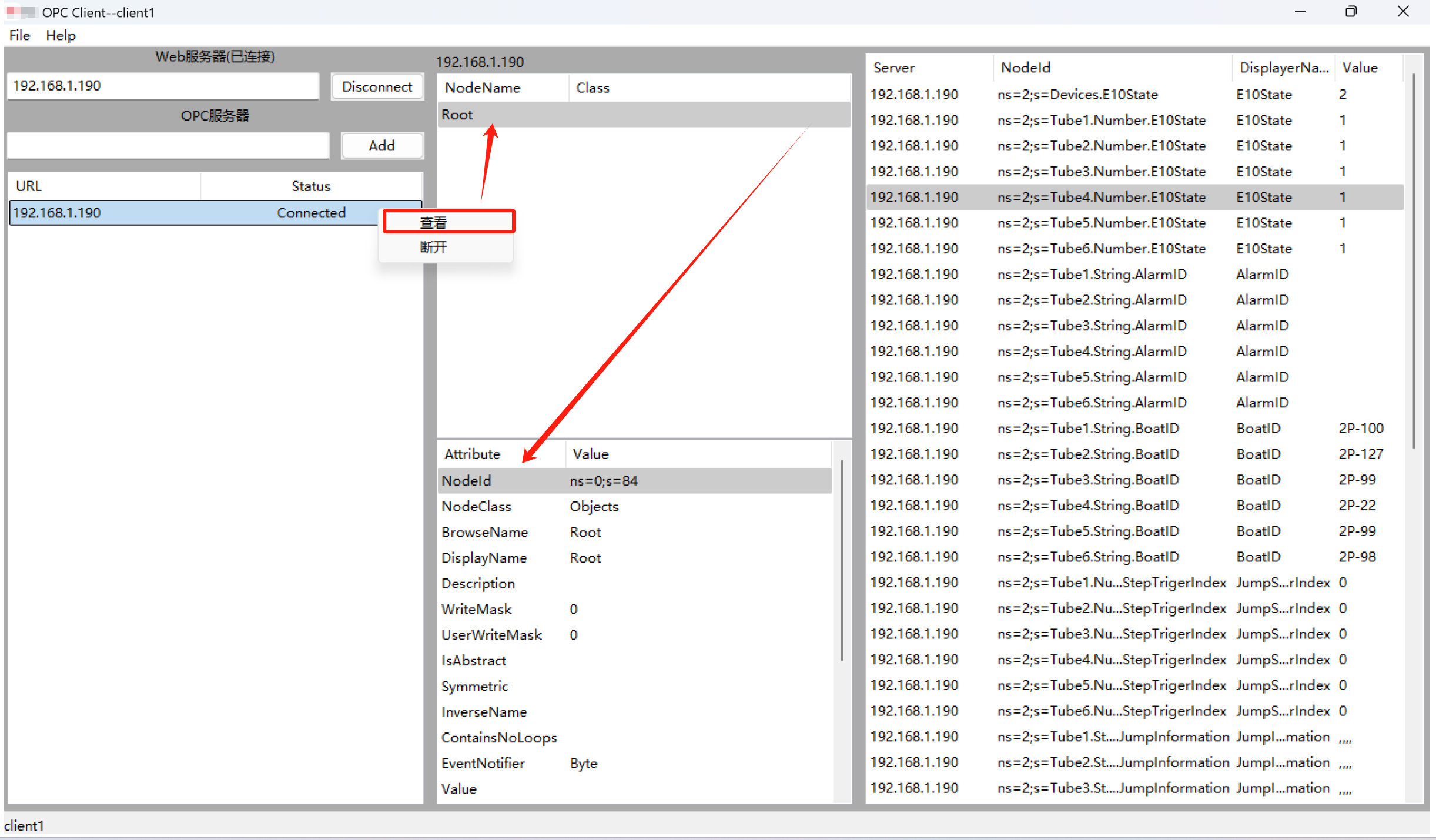
OPC Client第6讲(wxwidgets):Logger.h日志记录文件(单例模式);登录后的主界面
接上一讲三、2、2>4》,创建logger.h和helper_t.h里的gettime函数 即解决下图的报红 同时,接上一讲二、3、点击“确认”按钮后,进入MainFrame.h对应的下述界面,此讲下图进行实现 一、创建Logger.h:日志记录文件&…...

CesiumInstancedMesh 实例
CesiumInstancedMesh 实例 import * as Cesium from cesium;// Three.js 风格的 InstancedMesh 类, https://threejs.org/docs/#api/en/objects/InstancedMesh export class CesiumInstancedMesh {/*** Creates an instance of InstancedMesh.** param {Cesium.Geometry} geom…...

单细胞注释前沿:CASSIA——无参考、可解释、自动化细胞注释的大语言模型
细胞类型注释是单细胞RNA-seq分析的重要步骤,目前有许多注释方法。大多数注释方法都需要计算和特定领域专业知识的结合,而且经常产生不一致的结果,难以解释。大语言模型有可能在减少人工输入和提高准确性的同时扩大可访问性,但现有…...
历年武汉大学计算机保研上机真题
2025武汉大学计算机保研上机真题 2024武汉大学计算机保研上机真题 2023武汉大学计算机保研上机真题 在线测评链接:https://pgcode.cn/school 分段函数计算 题目描述 写程序计算如下分段函数: 当 x > 0 x > 0 x>0 时, f ( x ) …...
:みます)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(30):みます
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(30):みます 1、前言(1)情况说明(2)工程师的信仰2、知识点(1)ように 復習:1、ように Change12、ように Ideal state(理想(りそう)の状態(じょうたい))3、V辞書・Vない ようにしています いつも気をつけて…...

AR-HUD 光波导方案优化难题待解?OAS 光学软件来破局
波导-HUD系统案例分析 简介 光波导技术凭借其平板超薄结构和强大的二维扩展能力,在解决AR-HUD问题方面展现出显著优势。一方面,其独特的结构特性能够大幅减小对光机体积的需求,成为 HUD 未来发展的重要技术方向;另一方面…...
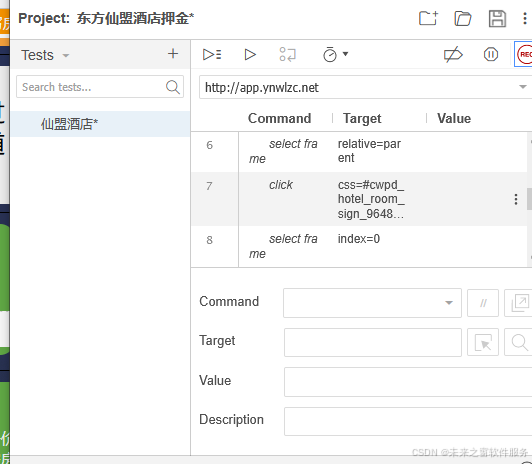
火狐安装自动录制表单教程——仙盟自动化运营大衍灵机——仙盟创梦IDE
打开火狐插件页面 安装完成 使用 功能 录制浏览器操作 录入地址 开始操作 录制完成 在当今快速发展的软件开发生态中,自动化测试已从一种新兴技术手段,转变为保障软件质量与开发效率不可或缺的关键环节。其重要性体现在多个维度,同时&#x…...

线程池的详细知识(含有工厂模式)
前言 下午学习了线程池的知识。重点探究了ThreadPoolExecutor里面的各种参数的含义。我详细了解了这部分的知识。其中有一个参数涉及工厂模式,我将这一部分知识分享给大家~ 线程池的详细介绍(含工厂模式) 结语 分享到此结束啦。byebye~...

木愚科技闪亮第63届高博会 全栈式智能教育解决方案助力教学升级
5月23日,第63届高等教育博览会在长春东北亚国际博览中心开幕,木愚科技积极筹备,奔赴展会现场。彼时,木愚科技企业领导及相关职能部门负责人亲临展位指导工作,通过特装展位、资料发放及现场交流等方式,全方位…...
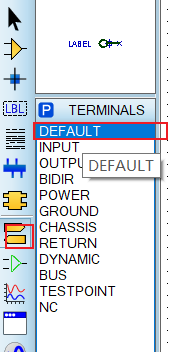
Proteus寻找元器件(常见)
一 元件库 二 找元件 1 主控 32 51 输入 stm32 AT89c51 2 找屏幕 oled 3 找按键button 4 电阻、电容 res cap 5 电机驱动 l298n 6 电机 motor 7 滑动变阻器 pot 8 找电源和 GND 9 找晶振 选择 D 开头的 CRYSTAL 10 网络标签...
RK3566 Android12 HG24C02MM/TR EEPROM适配
一、背景 近期项目中,有一个需求,要使用RK3566 Android12平台适配一款HG24C02MM/TR EEPROM芯片,通过i2c实现主板与EEPROM芯片的数据通讯。废话不多说,来看资料。 二、芯片资料 HG24C02 / HG24C04 / HG24C08 / HG24C16是提供2048…...

IoTDB 集成 DBeaver,简易操作实现时序数据清晰管理
数据结构一目了然,跨库分析轻松实现,方便 IoTDB “内部构造”管理! 随着物联网场景对时序数据处理需求激增,时序数据库与数据库管理工具的集成尤为关键。作为数据资产的 “智能管家”,借助数据库管理工具的可视化操作界…...

sqli-labs第二十八关——Trick with ‘union select‘
一:分析 这一关的提示和上一关一样,所以我们查看源码,屏蔽了注释符,空格,union,select等关键词 分析这一条源码的几个新增添符号 \s: 匹配任何的空白字符(普通空格,\t&…...

mapbox高阶,PMTiles介绍,MBTiles、PMTiles对比,加载PMTiles文件
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象1.2 ☘️mapboxgl.Map style属性1.3 ☘️Fill面图层样式1.4 ☘️PMTiles介绍1.5…...

Go语言通道如何实现通信
在Go语言中,通道(channel)是一种内置的数据结构,用于在不同的goroutine之间进行通信和同步。通道提供了一种安全且有效的方式来传递数据,避免了数据竞争和死锁等问题。 要在Go语言中使用通道进行通信,你需…...
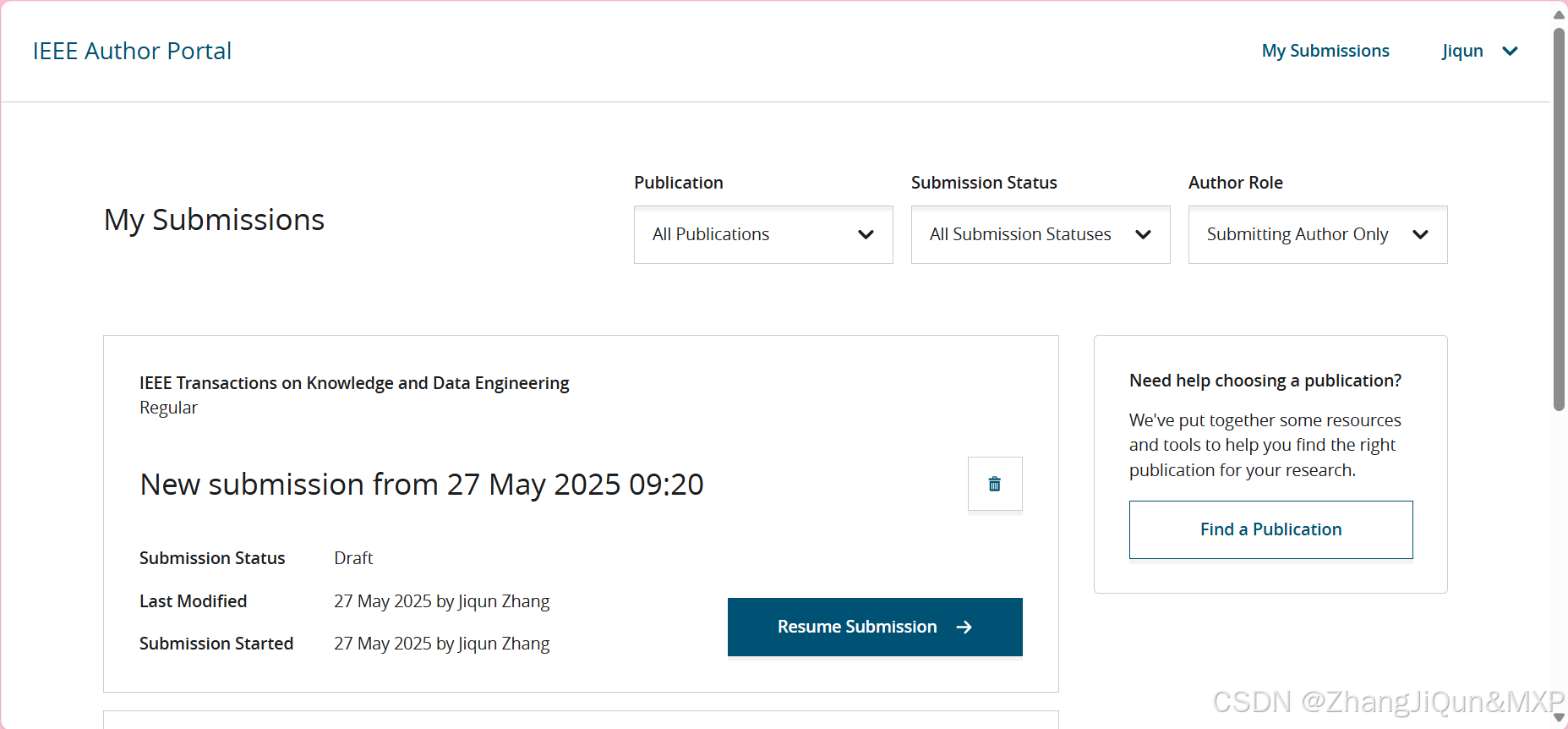
投稿 IEEE Transactions on Knowledge and Data Engineering 注意事项
投稿 IEEE Transactions on Knowledge and Data Engineering 注意事项 要IEEE overleaf 模板私信,我直接给我自己论文,便于编辑 已经投稿完成了,有一些小坑 准备工作 注册IEEE账户:若没有IEEE账户,需前往IEEE官网注册。注册成功后,可用于登录投稿系统。现在新的系统,…...

题目 3316: 蓝桥杯2025年第十六届省赛真题-数组翻转
题目 3316: 蓝桥杯2025年第十六届省赛真题-数组翻转 时间限制: 3s 内存限制: 512MB 提交: 101 解决: 24 题目描述 小明生成了一个长度为 n 的正整数数组 a1, a2, . . . , an,他可以选择连续的一 段数 al , al1, ..., ar,如果其中所有数都相等即 al al1 …...
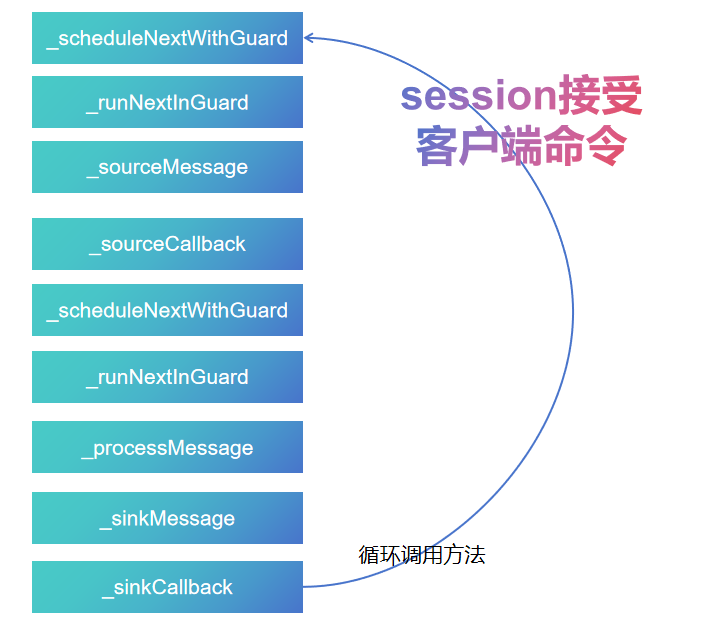
mongodb源码分析session接受客户端find命令过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制。 现在继续研究ASIOSession和connection是怎么接受客户端命令的? mongo/transport/service_state_machine.cpp核心方法有…...

Netty 实战篇:为自研 RPC 框架加入异步调用与 Future 支持
我们在上篇实现了一个轻量级 RPC 框架,现在要进一步优化 —— 加入异步响应支持,让 RPC 通信变得真正高效、非阻塞、支持并发。 一、为什么需要异步调用? 上篇的 RPC 框架是“同步阻塞”的: 每次发送请求后,必须等待服…...

python37天打卡
知识点回顾: 过拟合的判断:测试集和训练集同步打印指标 模型的保存和加载 仅保存权重 保存权重和模型 保存全部信息checkpoint,还包含训练状态 早停策略 作业:对信贷数据集训练后保存权重,加载权重后继续训练50轮&am…...
变焦位移计:机器视觉如何克服人工疲劳与主观影响?精准对结构安全实时监测
变焦视觉位移监测与人工监测的对比 人工监测是依靠目测检查或借助于全站仪,水准仪,RTK等便携式仪器测量得到的信息,但是随着整个行业的发展,传统的人工监测方法已经不能满足监测需求,从人工监测到自动化监测已是必然趋…...

嵌入式硬件篇---Ne555定时器
文章目录 前言1. 基本概述类型功能封装形式2. 引脚功能(DIP-8 封装)内部结构阈值电压两种工作模式4. 主要特性优点:缺点:5. 典型应用场景定时控制脉冲生成检测与触发信号处理6. 关键参数速查表前言 本文简单介绍了Ne555定时器(多谐振荡器/定时器)。DIP与SOP封装。 1. 基…...
【Axure结合Echarts绘制图表】
1.绘制一个矩形,用于之后存放图表,将其命名为test: 2.新建交互 -> 载入时 -> 打开链接: 3.链接到URL或文件路径: 4.点击fx: 5.输入: javascript: var script document.createEleme…...
使用web3工具结合fiscobcos网络部署调用智能合约
借助 web3 工具,在 FISCO BCOS 网络上高效部署与调用智能合约,解锁区块链开发新体验。 搭建的区块链网络需要是最新的fiscobcos3.0,最新的才支持web3调用 现在分享踩坑经验,希望大家点赞 目录 1.搭建fiscobcos节点(3.…...