python37天打卡
知识点回顾:
过拟合的判断:测试集和训练集同步打印指标
模型的保存和加载
仅保存权重
保存权重和模型
保存全部信息checkpoint,还包含训练状态
早停策略
作业:对信贷数据集训练后保存权重,加载权重后继续训练50轮,并采取早停策略
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, random_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import (accuracy_score, precision_score, recall_score, f1_score, roc_auc_score,confusion_matrix)
import matplotlib.pyplot as plt
import seaborn as sns
import os
from pathlib import Path
from typing import Tuple, Dict, List, Optional# --- 1. 配置常量 ---
# 使用Path对象处理路径,确保跨平台兼容性
BASE_DIR = Path(__file__).parent.resolve()
DATA_PATH = BASE_DIR / "data" / "credit_risk_data.csv"
MODEL_SAVE_DIR = BASE_DIR / "saved_models"
MODEL_SAVE_PATH = MODEL_SAVE_DIR / "credit_risk_model.pth"# 确保目录存在
MODEL_SAVE_DIR.mkdir(parents=True, exist_ok=True)# 训练超参数
RANDOM_SEED = 42
BATCH_SIZE = 64
LEARNING_RATE = 0.001
NUM_EPOCHS = 50
HIDDEN_LAYER_SIZES = [128, 64, 32] # 隐藏层配置
DROPOUT_RATE = 0.3 # 添加dropout防止过拟合# 设备配置
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {DEVICE}")# 设置随机种子确保可复现性
def set_seed(seed):torch.manual_seed(seed)np.random.seed(seed)if torch.cuda.is_available():torch.cuda.manual_seed_all(seed)torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falseset_seed(RANDOM_SEED)# --- 2. 数据加载与预处理 ---
class CreditRiskDataset(Dataset):"""信贷风险数据集类"""def __init__(self, features: np.ndarray, labels: np.ndarray):self.features = torch.tensor(features, dtype=torch.float32)self.labels = torch.tensor(labels, dtype=torch.float32).unsqueeze(1)def __len__(self) -> int:return len(self.labels)def __getitem__(self, idx: int) -> Tuple[torch.Tensor, torch.Tensor]:return self.features[idx], self.labels[idx]def load_and_preprocess_data(file_path: Path, target_col: str = 'default') -> Tuple[DataLoader, DataLoader, DataLoader, StandardScaler]:"""加载并预处理数据"""print(f"加载数据: {file_path}")# 检查文件是否存在if not file_path.exists():raise FileNotFoundError(f"数据文件不存在: {file_path}")# 读取数据df = pd.read_csv(file_path)print(f"数据形状: {df.shape}")# 处理缺失值if df.isnull().sum().sum() > 0:print("处理缺失值...")for col in df.select_dtypes(include=np.number).columns:df[col].fillna(df[col].median(), inplace=True)# 分离特征和目标X = df.drop(target_col, axis=1).valuesy = df[target_col].values# 标准化特征scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 创建数据集full_dataset = CreditRiskDataset(X_scaled, y)# 划分数据集 (70% 训练, 15% 验证, 15% 测试)train_size = int(0.7 * len(full_dataset))val_size = int(0.15 * len(full_dataset))test_size = len(full_dataset) - train_size - val_sizetrain_dataset, val_dataset, test_dataset = random_split(full_dataset, [train_size, val_size, test_size], generator=torch.Generator().manual_seed(RANDOM_SEED))# 创建数据加载器train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE)test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE)print(f"数据集划分: 训练集 {len(train_dataset)} | 验证集 {len(val_dataset)} | 测试集 {len(test_dataset)}")return train_loader, val_loader, test_loader, scaler# --- 3. 模型架构 ---
class CreditRiskPredictor(nn.Module):"""信贷风险预测神经网络"""def __init__(self, input_size: int, hidden_sizes: List[int], output_size: int = 1):super().__init__()layers = []prev_size = input_size# 构建隐藏层for i, h_size in enumerate(hidden_sizes):layers.append(nn.Linear(prev_size, h_size))layers.append(nn.BatchNorm1d(h_size)) # 添加批归一化layers.append(nn.ReLU())layers.append(nn.Dropout(DROPOUT_RATE)) # 添加dropoutprev_size = h_size# 输出层layers.append(nn.Linear(prev_size, output_size))self.model = nn.Sequential(*layers)def forward(self, x: torch.Tensor) -> torch.Tensor:return self.model(x)# --- 4. 训练函数 ---
def train_model(model, train_loader, val_loader, optimizer, criterion, epochs, device):"""训练模型并返回训练历史"""history = {'train_loss': [], 'val_loss': [], 'val_auc': []}best_val_loss = float('inf')model.to(device)for epoch in range(epochs):# 训练阶段model.train()train_loss = 0.0for inputs, targets in train_loader:inputs, targets = inputs.to(device), targets.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()train_loss += loss.item() * inputs.size(0)train_loss = train_loss / len(train_loader.dataset)history['train_loss'].append(train_loss)# 验证阶段model.eval()val_loss = 0.0all_targets = []all_probs = []with torch.no_grad():for inputs, targets in val_loader:inputs, targets = inputs.to(device), targets.to(device)outputs = model(inputs)loss = criterion(outputs, targets)val_loss += loss.item() * inputs.size(0)probs = torch.sigmoid(outputs)all_targets.extend(targets.cpu().numpy())all_probs.extend(probs.cpu().numpy())val_loss = val_loss / len(val_loader.dataset)val_auc = roc_auc_score(all_targets, all_probs)history['val_loss'].append(val_loss)history['val_auc'].append(val_auc)# 保存最佳模型if val_loss < best_val_loss:best_val_loss = val_losstorch.save(model.state_dict(), MODEL_SAVE_PATH)print(f"保存最佳模型 @ Epoch {epoch+1}, Val Loss: {val_loss:.4f}, AUC: {val_auc:.4f}")print(f"Epoch {epoch+1}/{epochs} | "f"Train Loss: {train_loss:.4f} | "f"Val Loss: {val_loss:.4f} | "f"AUC: {val_auc:.4f}")# 绘制训练历史plt.figure(figsize=(12, 5))plt.subplot(1, 2, 1)plt.plot(history['train_loss'], label='Train Loss')plt.plot(history['val_loss'], label='Validation Loss')plt.title('Training and Validation Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.grid(True)plt.subplot(1, 2, 2)plt.plot(history['val_auc'], 'g-', label='Validation AUC')plt.title('Validation AUC')plt.xlabel('Epoch')plt.ylabel('AUC')plt.legend()plt.grid(True)plt.tight_layout()plt.savefig('training_history.png')plt.show()return history# --- 5. 评估函数 ---
def evaluate_model(model, test_loader, device):"""评估模型性能"""model.eval()model.to(device)all_targets = []all_preds = []all_probs = []with torch.no_grad():for inputs, targets in test_loader:inputs, targets = inputs.to(device), targets.to(device)outputs = model(inputs)probs = torch.sigmoid(outputs)preds = (probs > 0.5).float()all_targets.extend(targets.cpu().numpy())all_preds.extend(preds.cpu().numpy())all_probs.extend(probs.cpu().numpy())# 计算指标metrics = {'accuracy': accuracy_score(all_targets, all_preds),'precision': precision_score(all_targets, all_preds),'recall': recall_score(all_targets, all_preds),'f1': f1_score(all_targets, all_preds),'roc_auc': roc_auc_score(all_targets, all_probs)}# 打印指标print("\n模型评估结果:")for metric, value in metrics.items():print(f"{metric.capitalize()}: {value:.4f}")# 绘制混淆矩阵cm = confusion_matrix(all_targets, all_preds)plt.figure(figsize=(8, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['No Default', 'Default'],yticklabels=['No Default', 'Default'])plt.title('Confusion Matrix')plt.xlabel('Predicted')plt.ylabel('Actual')plt.savefig('confusion_matrix.png')plt.show()return metrics# --- 6. 主函数 ---
def main():# 加载数据try:train_loader, val_loader, test_loader, scaler = load_and_preprocess_data(DATA_PATH)except Exception as e:print(f"数据加载失败: {e}")return# 初始化模型sample_features, _ = next(iter(train_loader))input_size = sample_features.shape[1]model = CreditRiskPredictor(input_size, HIDDEN_LAYER_SIZES)print(f"模型架构:\n{model}")# 损失函数和优化器criterion = nn.BCEWithLogitsLoss()optimizer = optim.AdamW(model.parameters(), lr=LEARNING_RATE, weight_decay=1e-5)# 训练模型history = train_model(model, train_loader, val_loader, optimizer, criterion, NUM_EPOCHS, DEVICE)# 加载最佳模型进行评估best_model = CreditRiskPredictor(input_size, HIDDEN_LAYER_SIZES)best_model.load_state_dict(torch.load(MODEL_SAVE_PATH))best_model.to(DEVICE)# 在测试集上评估test_metrics = evaluate_model(best_model, test_loader, DEVICE)# 示例预测sample_idx = np.random.randint(0, len(test_loader.dataset))sample_data, true_label = test_loader.dataset[sample_idx]best_model.eval()with torch.no_grad():sample_data = sample_data.unsqueeze(0).to(DEVICE)logit = best_model(sample_data)prob = torch.sigmoid(logit).item()pred = 1 if prob > 0.5 else 0print(f"\n示例预测:")print(f"原始特征: {sample_data.cpu().numpy().squeeze()}")print(f"真实标签: {true_label.item()}")print(f"预测概率: {prob:.4f}")print(f"预测结果: {pred}")if __name__ == "__main__":main()@浙大疏锦行
相关文章:

python37天打卡
知识点回顾: 过拟合的判断:测试集和训练集同步打印指标 模型的保存和加载 仅保存权重 保存权重和模型 保存全部信息checkpoint,还包含训练状态 早停策略 作业:对信贷数据集训练后保存权重,加载权重后继续训练50轮&am…...
变焦位移计:机器视觉如何克服人工疲劳与主观影响?精准对结构安全实时监测
变焦视觉位移监测与人工监测的对比 人工监测是依靠目测检查或借助于全站仪,水准仪,RTK等便携式仪器测量得到的信息,但是随着整个行业的发展,传统的人工监测方法已经不能满足监测需求,从人工监测到自动化监测已是必然趋…...

嵌入式硬件篇---Ne555定时器
文章目录 前言1. 基本概述类型功能封装形式2. 引脚功能(DIP-8 封装)内部结构阈值电压两种工作模式4. 主要特性优点:缺点:5. 典型应用场景定时控制脉冲生成检测与触发信号处理6. 关键参数速查表前言 本文简单介绍了Ne555定时器(多谐振荡器/定时器)。DIP与SOP封装。 1. 基…...
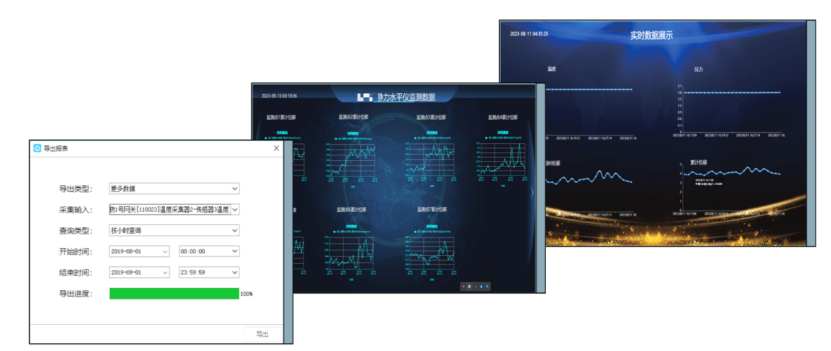
【Axure结合Echarts绘制图表】
1.绘制一个矩形,用于之后存放图表,将其命名为test: 2.新建交互 -> 载入时 -> 打开链接: 3.链接到URL或文件路径: 4.点击fx: 5.输入: javascript: var script document.createEleme…...
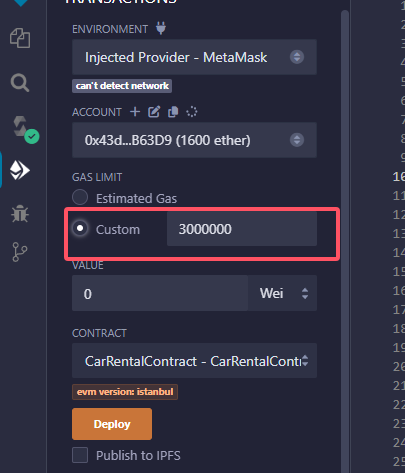
使用web3工具结合fiscobcos网络部署调用智能合约
借助 web3 工具,在 FISCO BCOS 网络上高效部署与调用智能合约,解锁区块链开发新体验。 搭建的区块链网络需要是最新的fiscobcos3.0,最新的才支持web3调用 现在分享踩坑经验,希望大家点赞 目录 1.搭建fiscobcos节点(3.…...
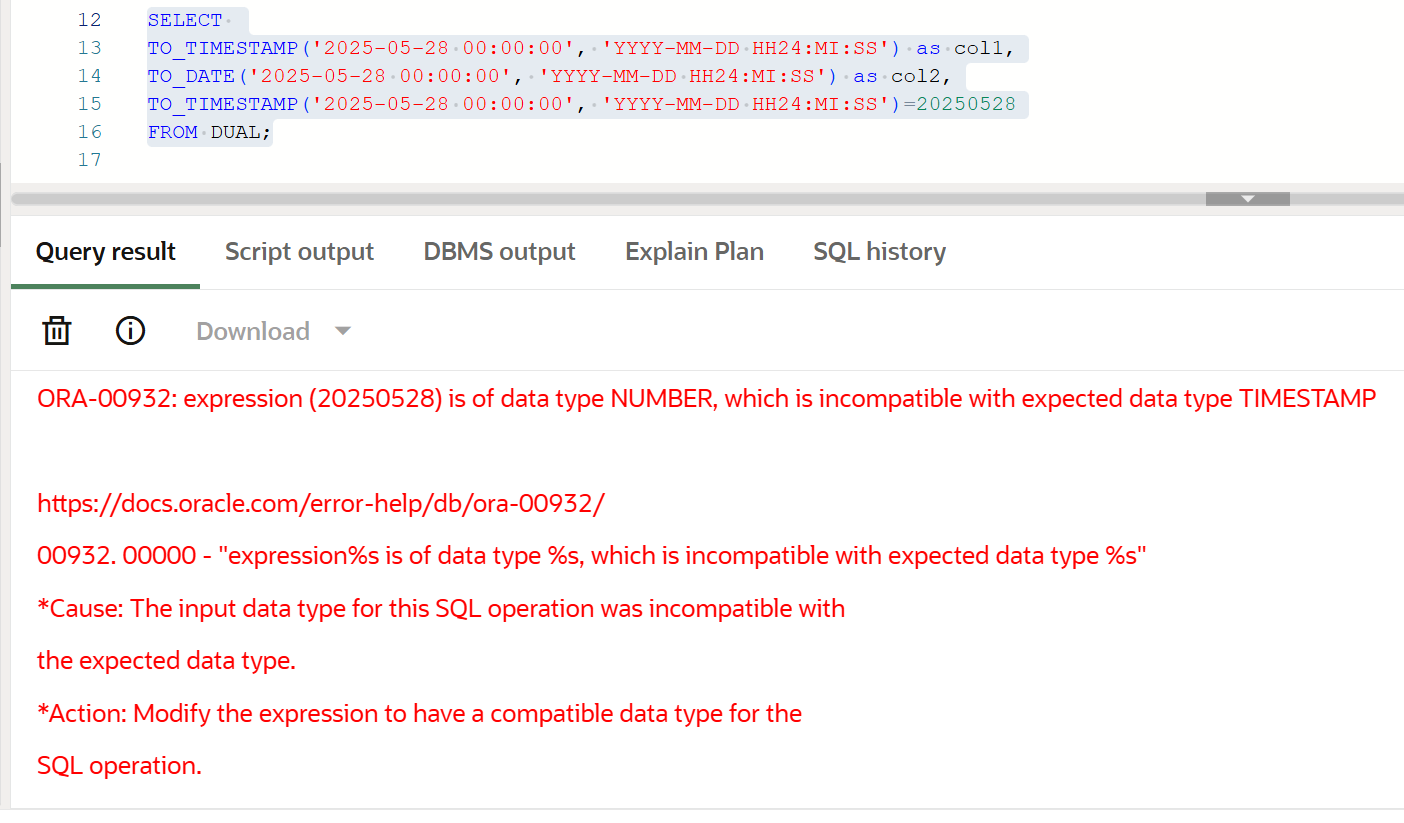
Oracle/openGauss中,DATE/TIMESTAMP与数字日期/字符日期比较
ORACLE 运行环境 openGauss 运行环境 0、前置知识 ORACLE:DUMP()函数用于返回指定表达式的数据类型、字节长度及内部存储表示的详细信息 SELECT DUMP(123) FROM DUAL; -- Typ2 Len3: 194,2,24 SELECT DUMP(123) FROM DUAL;-- Typ96 Len3: 49,50,51 -- ASCII值&am…...

Datatable和实体集合互转
1.使用已废弃的 JavaScriptSerializer,且反序列化为弱类型 ArrayList。可用但不推荐。 using System; using System.Collections; using System.Collections.Generic; using System.Data; using System.Linq; using System.Reflection; using System.Web; using Sy…...

Win11切换JDK版本批处理脚本
维护的老项目jdk1.8,新项目开发采用jdk21,所以寻找类似nvm的软件,都不太满意,最后还是决定采用写一个脚本算了,先不折腾了。 1、创建switch_jdk.bat文件 2、把如下内容复制进行 echo off chcp 65001 >nul setloc…...
爬虫学习-Scrape Center spa6 超简单 JS 逆向
关卡 spa6 电影数据网站,无反爬,数据通过 Ajax 加载,数据接口参数加密且有时间限制,适合动态页面渲染爬取或 JavaScript 逆向分析。 首先抓包发现get请求的参数token有加密。 offset表示翻页,limit表示每一页有多少…...

对数的运算困惑
难点总结 学生在对数运算中的难点分析: 一、不理解对数,不会用对数公式或错用对数公式 ①对数 l o g 2 3 log_23 log23和指数幂 2 3 2^3 23一样,也就是个实数而已,所以其也会有加减乘除乘方开方等运算; 比如 2 2 + l o g 2 3 = 2 2 ⋅ 2 l o g 2 3 = 4 ⋅ 3 = 12 2^{2…...
)
C++ 图像处理库 CxImage 简介 (迁移至OpenCV)
文章目录 核心功能特点局限性与替代方案常用方法构造函数从数组创建图像访问属性访问像素点Windows平台支持 常用方法迁移至OpenCV CxImage 是一款功能强大的图像处理类库,主要用于 Windows 平台的图像处理任务。它支持多种图像格式的加载、保存、编辑及特效处理&am…...

linux系统与shell 笔记
Linux 系统 Linux 是一种开源的操作系统内核,基于 Unix 设计,具有多用户、多任务、高稳定性和安全性的特点。它广泛应用于服务器、嵌入式设备和个人计算机领域。Linux 系统的核心组件包括内核、系统库、工具链和用户界面(如命令行或图形界面…...

尚硅谷redis7 86 redis集群分片之3主3从集群搭建
86 redis集群分片之3主集群搭建 3主3从redis集群配置 找3台真实虚拟机,各自新建 mķdir -p /myredis/cluster 新建6个独立的redis实例服务 IP:192.168.111.175端口6381/端口6382 vim /myredis/cluster/redisCluster6381.conf bind 0.0.0.0 daemonize yes protected-mode no …...
)
Kaggle-Predict Calorie Expenditure-(回归+xgb+cat+lgb+模型融合+预测结果)
Predict Calorie Expenditure 题意: 给出每个人的基本信息,预测运动后的卡路里消耗值。 数据处理: 1.构造出人体机能、运动相关的特征值。 2.所有特征值进行从新组合,注意唯独爆炸 3.对连续信息分箱变成离散 建立模型&#x…...
【解决办法】Git报错error: src refspec main does not match any.
在命令行中使用 Git 进行 git push -u origin main 操作时遇到报错error: src refspec main does not match any。另一个错误信息是:error: failed to push some refs to https://github.com/xxx/xxx.git.这是在一个新设备操作时遇到的问题,之前没有注意…...

React与Vue的内置指令对比
React 与 Vue 在内置指令的设计理念和实现方式上有显著差异。Vue 提供了一套丰富的模板指令系统,而 React 更倾向于通过原生 JavaScript 语法和 JSX 实现类似功能。以下是两者的核心对比: 一、条件渲染 Vue 使用 “v-if”/ “v-else” 指令,…...

2025年5月24号高项综合知识真题以及答案解析(第1批次)
2025年5月24号高项综合知识真题以及答案解析...

【NATURE氮化镓】GaN超晶格多沟道场效应晶体管的“闩锁效应”
2025年X月X日,布里斯托大学的Akhil S. Kumar等人在《Nature Electronics》期刊发表了题为《Gallium nitride multichannel devices with latch-induced sub-60-mV-per-decade subthreshold slopes for radiofrequency applications》的文章,基于AlGaN/GaN超晶格多通道场效应晶…...

Ubuntu24.04换源方法(新版源更换方式,包含Arm64)
一、源文件位置 Ubuntu24.04的源地址配置文件发生改变,不再使用以前的sources.list文件,升级24.04之后,而是使用如下文件 /etc/apt/sources.list.d/ubuntu.sources二、开始换源 1. 备份源配置文件 sudo cp /etc/apt/sources.list.d/ubunt…...

26 C 语言函数深度解析:定义与调用、返回值要点、参数机制(值传递)、原型声明、文档注释
1 函数基础概念 1.1 引入函数的必要性 在《街霸》这类游戏中,实现出拳、出脚、跳跃等动作,每项通常需编写 50 - 80 行代码。若每次调用都重复编写这些代码,程序会变得臃肿不堪,代码可读性与维护性也会大打折扣。 为解决这一问题&…...

彻底理解一个知识点的具体步骤
文章目录 前言一、了解概念(是什么)二、理解原理(为什么)三、掌握方法(怎么用) 四、动手实践(会用)五、类比拓展(迁移能力)六、总结归纳(融会贯通…...

FFmpeg 时间戳回绕处理:保障流媒体时间连续性的核心机制
FFmpeg 时间戳回绕处理:保障流媒体时间连续性的核心机制 一、回绕处理函数 /** * Wrap a given time stamp, if there is an indication for an overflow * * param st stream // 传入一个指向AVStream结构体的指针,代表流信息 * pa…...

yolov8改进模型
YOLOv8 作为当前 YOLO 系列的最新版本,已经具备出色的性能。若要进一步改进,可以从网络架构优化、训练策略增强、多任务扩展和部署效率提升四个方向入手。以下是具体改进思路和实现示例: 1. 网络架构优化 (1) 骨干网络增强 引入 Transform…...

PostgreSQL日常运维
目录 一、PostgreSQL基础操作 1.1 登录数据库 1.2 数据库管理 1.3 数据表操作 二、数据备份与恢复 2.1 备份工具pg_dump 2.2 恢复工具pg_restore与psql 2.3 备份策略建议 三、模式(Schema) 3.1 模式的核心作用 3.2 模式操作全流程 四、远程连…...
<< C程序设计语言第2版 >> 练习 1-23 删除C语言程序中所有的注释语句
1. 前言 本篇文章介绍的是实现删除C语言源文件中所有注释的功能.希望可以给C语言初学者一点参考.代码测试并不充分, 所以肯定还有bug, 有兴趣的同学可以改进. 原题目是: 练习1-23 编写一个删除C语言程序中所有的注释语句. 要正确处理带引号的字符串与字符常量. 在C语言中, 注释…...

Fluence (FLT) 2026愿景:RWA代币化加速布局AI算力市场
2025年5月29日,苏黎世 - Fluence,企业级去中心化计算平台,荣幸地揭开其2026愿景的面纱,并宣布将于6月1日起启动四大新举措。 Fluence 成功建立、推出并商业化了其去中心化物理基础设施计算网络(DePIN)&…...

如何撰写一篇优质 Python 相关的技术文档 进阶指南
💝💝💝在 Python 项目开发与协作过程中,技术文档如同与团队沟通的桥梁,能极大提高工作效率。但想要打造一份真正实用且高质量的 Python 技术文档类教程,并非易事,需要在各个环节深入思考与精心打…...

选择if day5
5.scanf(“空白符”) 空白符作用表示匹配任意多个空白符 进入了内存缓冲区(本质就是一块内存空间) 6.scanf读取问题: a.遇到非法字符读取结束 2. %*d * 可以跳过一个字符 eg:%d%*d%d 读取第一和第三个字符…...

MiniMax V-Triune让强化学习(RL)既擅长推理也精通视觉感知
MiniMax 近日在github上分享了技术研究成果——V-Triune,这次MiniMax V-Triune的发布既是AI视觉技术也是应用工程上的一次“突围”,让强化学习(RL)既擅长推理也精通视觉感知,其实缓解了传统视觉RL“鱼和熊掌不可兼得”…...

Hash 的工程优势: port range 匹配
昨天和朋友聊到 “如何匹配一个 port range”,觉得挺有意思,简单写篇散文。 回想起十多年前,我移植并优化了 nf-HiPAC,当时还看不上 ipset hash,后来大约七八年前,我又舔 nftables,因为用它可直…...