从零开始的数据结构教程(四) 图论基础与算法实战
🌐 标题一:图的表示——六度空间理论如何用代码实现?
核心需求
图(Graph)是用于表达实体间关系的强大数据结构,比如社交网络中的好友关系,或者城市路网的交叉路口连接。关键在于如何高效存储和遍历这些关系。
两种主流表示法
-
邻接矩阵(Adjacency Matrix):
- 适用场景:适合稠密图(边的数量接近节点数量的平方),可以快速判断两个节点之间是否存在边。
- 实现方式:使用二维数组
graph[i][j]表示节点i到j是否有边(0 表示无边,1 表示有边;带权图则存储权重)。
# 示例:一个包含3个节点的无向图 # 节点0连接节点1和2 # 节点1连接节点0 # 节点2连接节点0 graph = [[0, 1, 1],[1, 0, 0],[1, 0, 0] ] -
邻接表(Adjacency List):
- 适用场景:适合稀疏图(边的数量远小于节点数量的平方),更节省空间。
- 实现方式:使用哈希表(或数组)存储每个节点,每个节点的值是一个列表,包含其所有邻居节点。
import java.util.ArrayList; import java.util.Arrays; import java.util.HashMap; import java.util.List; import java.util.Map;// 示例:一个包含3个节点的无向图 Map<Integer, List<Integer>> graph = new HashMap<>(); graph.put(0, Arrays.asList(1, 2)); // 节点0的邻居是1和2 graph.put(1, Arrays.asList(0)); // 节点1的邻居是0 graph.put(2, Arrays.asList(0)); // 节点2的邻居是0
复杂度对比
| 操作 | 邻接矩阵 | 邻接表 |
|---|---|---|
| 检查两节点边 | O ( 1 ) O(1) O(1) | O ( k ) O(k) O(k) |
| 遍历所有邻居 | O ( n ) O(n) O(n) | O ( k ) O(k) O(k) |
- n n n 为节点数,
k为目标节点的邻居数。
🔍 标题二:图的遍历——社交网络的“共同好友”如何找?
图的遍历是探索节点和边关系的基础。主要有两种核心策略。
BFS vs DFS 核心区别
-
BFS (广度优先搜索):
- 策略:像水波一样,从起始点开始,按层级向外扩散,先访问所有直接邻居,再访问它们的邻居,以此类推。
- 适用场景:查找最短路径(因为它是按层级扩展的,最先找到的路径就是最短的),例如在社交网络中查找“最近的共同联系人”。
from collections import dequedef bfs(graph, start):visited = set() # 记录已访问的节点,避免重复访问queue = deque([start]) # 使用队列存储待访问的节点visited.add(start) # 标记起点已访问while queue:node = queue.popleft() # 取出队头节点# print(node) # 访问当前节点(根据需求打印或处理)for neighbor in graph.get(node, []): # 遍历当前节点的所有邻居if neighbor not in visited:visited.add(neighbor)queue.append(neighbor) -
DFS (深度优先搜索):
- 策略:像探险家一样,从起始点开始,沿着一条路径尽可能深地探索,直到无路可走或遇到已访问节点,然后回溯,尝试其他路径。
- 适用场景:拓扑排序、查找连通分量(如在社交网络中挖掘完整的“关系链”或社群)。
def dfs(graph, start):visited = set()stack = [start] # 使用栈模拟递归,存储待访问节点visited.add(start)while stack:node = stack.pop() # 取出栈顶节点# print(node) # 访问当前节点for neighbor in graph.get(node, []):if neighbor not in visited:visited.add(neighbor)stack.append(neighbor)
高频变形题
双向 BFS:
-
优化场景:当需要查找两个节点之间的最短路径时,可以从起点和终点同时进行 BFS。当两个搜索队列相遇时,就找到了最短路径,这通常比单向 BFS 效率更高,尤其是在图较大时。
import java.util.HashSet; import java.util.LinkedList; import java.util.Queue; import java.util.Set;// 假设 Node 类包含 ID 和邻居列表 class Node {int id;List<Node> neighbors;Node(int id) { this.id = id; this.neighbors = new ArrayList<>(); } }int bidirectionalBFS(Node start, Node end) {if (start == null || end == null) return -1;if (start == end) return 0; // 起点终点相同,路径长度为0Queue<Node> queue1 = new LinkedList<>();Queue<Node> queue2 = new LinkedList<>();Set<Node> visited1 = new HashSet<>();Set<Node> visited2 = new HashSet<>();queue1.offer(start);visited1.add(start);queue2.offer(end);visited2.add(end);int level = 0; // 记录路径长度while (!queue1.isEmpty() && !queue2.isEmpty()) {level++; // 每扩展一层,路径长度增加1// 优先扩展较小的队列,减少搜索空间if (queue1.size() > queue2.size()) {Queue<Node> tempQ = queue1;queue1 = queue2;queue2 = tempQ;Set<Node> tempV = visited1;visited1 = visited2;visited2 = tempV;}int size = queue1.size();for (int i = 0; i < size; i++) {Node current = queue1.poll();for (Node neighbor : current.neighbors) {if (visited2.contains(neighbor)) {return level; // 相遇,找到最短路径}if (!visited1.contains(neighbor)) {visited1.add(neighbor);queue1.offer(neighbor);}}}}return -1; // 无路径 }
🛣️ 标题三:最短路径算法——快递配送路线如何规划?
在带有权重的图中,我们常常需要找到连接两点的“最短”路径,这里的“短”可能指时间、距离或成本。
Dijkstra 算法
- 特点:适用于没有负权边的加权图,采用贪心思想。
- 核心步骤:
- 维护一个优先队列(通常是小顶堆),其中存储
(当前距离, 节点)对,按距离从小到大排序。 - 每次从堆中取出距离最小的未访问节点
u。 - 松弛其所有邻居
v:如果从u到v的路径比之前已知从起点到v的路径更短,则更新v的距离并将其加入优先队列。
- 维护一个优先队列(通常是小顶堆),其中存储
import heapq # 引入 heapq 模块实现最小堆def dijkstra(graph, start):# graph 示例: {node1: {neighbor1: weight1, neighbor2: weight2}, ...}# dist 字典用于存储从起点到各个节点的最短距离dist = {node: float('inf') for node in graph}dist[start] = 0# 优先队列 (min-heap), 存储 (距离, 节点) 对# 堆中存储的是元组,会根据元组的第一个元素(距离)进行排序heap = [(0, start)]while heap:current_dist, u = heapq.heappop(heap) # 取出距离最小的节点# 如果已经找到更短的路径,则跳过if current_dist > dist[u]:continue# 遍历当前节点 u 的所有邻居 vfor v, weight in graph.get(u, {}).items():if dist[v] > current_dist + weight: # 松弛操作dist[v] = current_dist + weightheapq.heappush(heap, (dist[v], v)) # 更新距离并加入堆return dist
- 时间复杂度: O ( E log V ) O(E \log V) O(ElogV)( E E E 边数, V V V 节点数),使用优先队列优化后。
Bellman-Ford 算法
- 特点:适用于包含负权边的加权图,并且能够检测负权环(如果图中有负权环,则某些节点的最短路径将无限小)。
- 核心步骤:对所有边进行
n-1轮松弛操作。如果在第n轮还能进行松弛,则说明存在负权环。
import java.util.Arrays;
import java.util.List;
import java.util.ArrayList;// 边类定义
class Edge {int from, to, weight;Edge(int from, int to, int weight) {this.from = from;this.to = to;this.weight = weight;}
}class BellmanFord {// n: 节点数量,edges: 边的列表public int[] bellmanFord(int n, List<Edge> edges, int startNode) {int[] dist = new int[n];Arrays.fill(dist, Integer.MAX_VALUE);dist[startNode] = 0;// 进行 n-1 轮松弛操作for (int i = 0; i < n - 1; i++) {boolean updated = false; // 标记本轮是否有更新for (Edge edge : edges) {if (dist[edge.from] != Integer.MAX_VALUE && // 确保起始点可达dist[edge.to] > dist[edge.from] + edge.weight) {dist[edge.to] = dist[edge.from] + edge.weight;updated = true;}}if (!updated) { // 如果一轮下来没有更新,说明已经达到最短路径,可以提前结束break;}}// 检测负权环:再进行一轮松弛for (Edge edge : edges) {if (dist[edge.from] != Integer.MAX_VALUE &&dist[edge.to] > dist[edge.from] + edge.weight) {// System.out.println("检测到负权环!");return null; // 或者返回特殊值表示存在负环}}return dist;}
}
🌉 标题四:高频面试题——岛屿数量问题(连通分量计数)
场景
在一个二维网格中,计算“岛屿”的数量,其中 ‘1’ 代表陆地,‘0’ 代表水。一个岛屿是由水平或垂直相连的陆地组成。这个问题本质上是图的连通分量计数。
def numIslands(grid):if not grid or not grid[0]:return 0rows, cols = len(grid), len(grid[0])count = 0def dfs(r, c):# 边界条件或已访问过的水域/陆地if r < 0 or c < 0 or r >= rows or c >= cols or grid[r][c] != '1':returngrid[r][c] = '#' # 标记为已访问,避免重复计数# 向四个方向探索dfs(r + 1, c)dfs(r - 1, c)dfs(r, c + 1)dfs(r, c - 1)for i in range(rows):for j in range(cols):if grid[i][j] == '1': # 发现新的岛屿count += 1dfs(i, j) # 从当前陆地开始,把整个岛屿都标记为已访问return count
- 时间复杂度: O ( m n ) O(mn) O(mn),其中 m m m 是行数, n n n 是列数,因为每个单元格最多被访问一次。
📊 总结表:图算法对比
| 算法 | 适用场景 | 时间复杂度 | 空间复杂度 |
|---|---|---|---|
| BFS | 无权图最短路径、层级遍历 | O ( V + E ) O(V+E) O(V+E) | O ( V ) O(V) O(V) |
| DFS | 拓扑排序、连通分量、路径查找 | O ( V + E ) O(V+E) O(V+E) | O ( V ) O(V) O(V) |
| Dijkstra | 无负权边的加权图最短路径 | O ( E log V ) O(E \log V) O(ElogV) | O ( V ) O(V) O(V) |
| Bellman-Ford | 含负权边的加权图最短路径、检测负环 | O ( V E ) O(VE) O(VE) | O ( V ) O(V) O(V) |
相关文章:
 图论基础与算法实战)
从零开始的数据结构教程(四) 图论基础与算法实战
🌐 标题一:图的表示——六度空间理论如何用代码实现? 核心需求 图(Graph)是用于表达实体间关系的强大数据结构,比如社交网络中的好友关系,或者城市路网的交叉路口连接。关键在于如何高效存储和…...
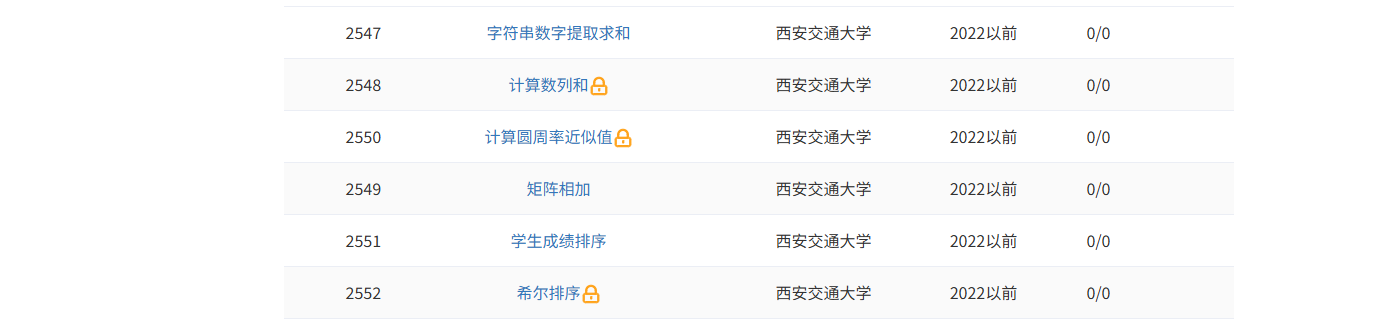
历年西安交通大学计算机保研上机真题
2025西安交通大学计算机保研上机真题 2024西安交通大学计算机保研上机真题 2023西安交通大学计算机保研上机真题 在线测评链接:https://pgcode.cn/school 计算圆周率近似值 题目描述 根据公式 π / 4 1 − 1 / 3 1 / 5 − 1 / 7 … \pi / 4 1 - 1/3 1/5 - …...

可视化与动画:构建沉浸式Vue应用的进阶实践
在现代Web应用中,高性能可视化和流畅动画已成为提升用户体验的核心要素。本节将深入探索Vue生态中的可视化与动画技术,分享专业级解决方案与最佳实践。 一、 Canvas高性能渲染体系 01、Konva.js流程图引擎深度优化 <template><div class"…...
:简单哈希压缩256色算法)
Python |GIF 解析与构建(3):简单哈希压缩256色算法
Python |GIF 解析与构建(3):简单哈希压缩256色算法 目录 Python |GIF 解析与构建(3):简单哈希压缩256色算法 一、算法性能表现 二、算法核心原理与实现 (一…...

蓝桥杯2114 李白打酒加强版
问题描述 话说大诗人李白, 一生好饮。幸好他从不开车。 一天, 他提着酒显, 从家里出来, 酒显中有酒 2 斗。他边走边唱: 无事街上走,提显去打酒。 逢店加一倍, 遇花喝一斗。 这一路上, 他一共遇到店 N 次, 遇到花 M 次。已知最后一次遇到的是花, 他正好把酒喝光了。…...
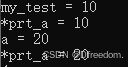
基本数据指针的解读-C++
1、引言 笔者认为对于学习指针要弄清楚如下问题基本可以应付大部分的场景: ① 指针是什么? ② 指针的类型是什么? ③ 指针指向的类型是什么? ④ 指针指向了哪里? 2、如何使用指针 使用时的步骤如下: ① …...

Android Studio里的BLE数据接收策略
#本人是初次接触Android蓝牙开发,若有不对地方,欢迎指出。 #由于是讲接收数据策略(其中还包含数据发送的部分策略),因此其他问题部分不会讲述,只描述数据接收。 简介(对于客户端---手机端) 博主在处理数据接收的时候࿰…...

【Office】Excel两列数据比较方法总结
在Excel中,比较两列数据是否相等有多种方法,以下是常用的几种方式: 方法1:使用公式(返回TRUE/FALSE) 在空白列(如C列)输入公式,向下填充即可逐行比较两列(如…...
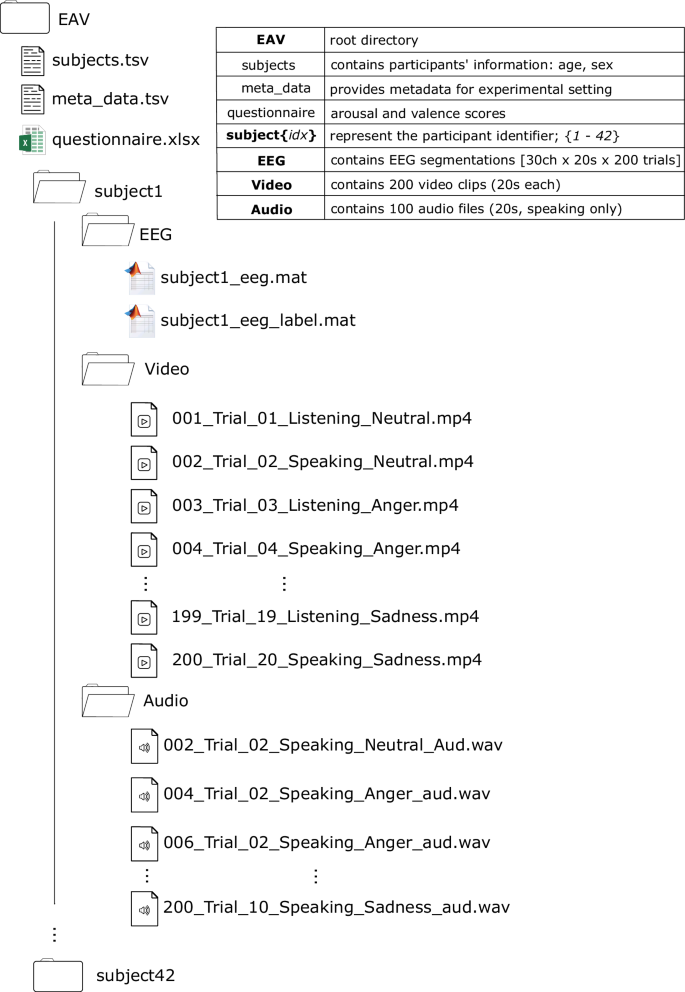
基于多模态脑电、音频与视觉信号的情感识别算法【Nature核心期刊,EAV:EEG-音频-视频数据集】
简述 理解情感状态对于开发下一代人机交互界面至关重要。社交互动中的人类行为会引发受感知输入影响的心理生理过程。因此,探索大脑功能与人类行为的努力或将推动具有类人特质人工智能模型的发展。这里原作者推出一个多模态情感数据集,包含42名参与者的3…...
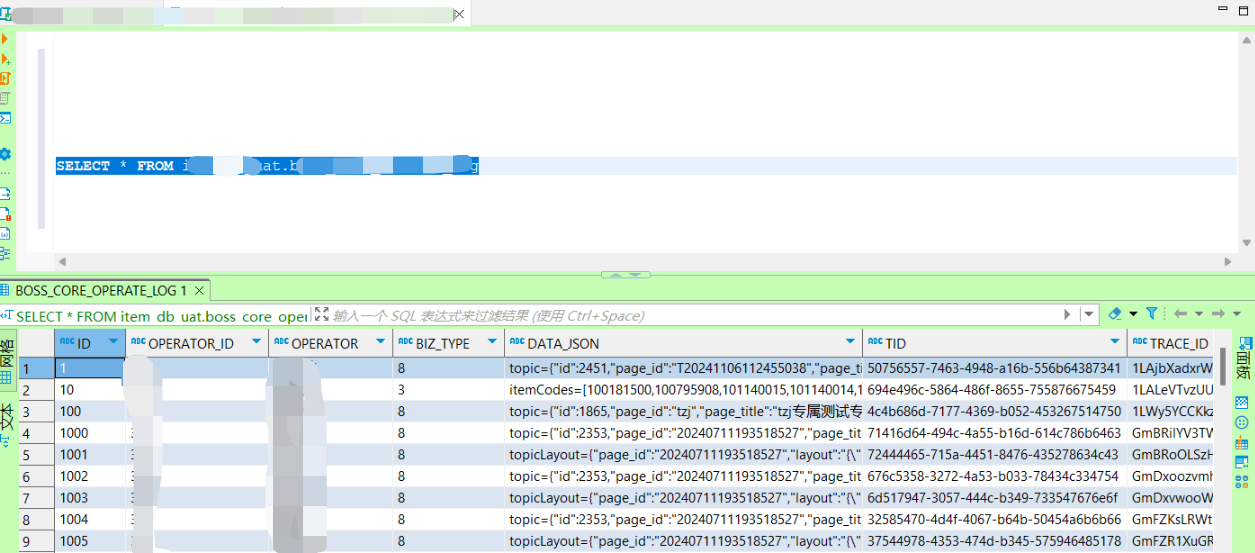
【QueryServer】dbeaver使用phoenix连接Hbase(轻客户端方式)
一、轻客户端连接方式 (推荐) 演示无认证配置方式, 有认证填入下方有认证参数即可 1, 新建连接 → Hadoop/大数据 → Apache Phoenix 2, 手动配置QueryServer驱动: 填入: “类名”, “URL模版”(注意区分有无认证), “端口号”, (勾选无认证) 类名: org.apache.phoenix…...
)
数据湖 (特点+与数据仓库和数据沼泽的对比讲解)
数据湖就像一个“数据水库”,把企业所有原始数据(结构化的表格、半结构化的日志、非结构化的图片/视频)原样存储,供后续按需分析。 对比传统数据仓库: 数据仓库数据湖数据清洗后的结构化数据(如Excel表格&…...

深入链表剖析:从原理到 C 语言实现,涵盖单向、双向及循环链表全解析
1 引言 在数据结构的学习中,链表是一种基础且极为重要的线性数据结构。与数组不同,链表通过指针将一系列节点连接起来,每个节点包含数据域和指向下一个节点的指针域。这种动态的存储方式使得链表在插入、删除等操作上具有独特的优势。本文将深…...

编码总结如下
VS2019一般的编码是UTF-8编码, win11操作系统的编码可能为GB2312,VS整个工程中使用的都是UTF-8编码,但是在系统内生成的其他文件夹的名字则是系统的编码 如何选择? Qt 项目:优先用 QString 和 QByteArray(…...

《算力觉醒!ONNX Runtime + DirectML如何点燃Windows ARM设备的AI引擎》
ONNX Runtime是一个跨平台的高性能推理引擎,它就像是一位精通多种语言的翻译官,能够无缝运行来自不同深度学习框架转化为ONNX格式的模型。这种兼容性打破了框架之间的隔阂,让开发者可以将更多的精力投入到模型的优化和应用中。 从内部机制来…...

[9-1] USART串口协议 江协科技学习笔记(13个知识点)
1 2 3 4全双工就是两个数据线,半双工就是一个数据线 5 6 7 8 9 10 TTL(Transistor-Transistor Logic)电平是一种数字电路中常用的电平标准,它使用晶体管来表示逻辑状态。TTL电平通常指的是5V逻辑电平,其中:…...

Oracle基础知识(五)——ROWID ROWNUM
目录 一、ROWID 伪列 二、ROWNUM——限制查询结果集行数 1.ROWNUM使用介绍 2.使用ROWNUM进行分页查询 3.使用ROWNUM查看薪资前五位的员工 4.查询指定条数直接的数据 三、ROWNUM与ROWID不同 一、ROWID 伪列 表中的每一行在数据文件中都有一个物理地址,ROWID…...

简述synchronized和java.util.concurrent.locks.Lock的异同 ?
主要相同点: Lock能完成synchronized所实现的所有功能。 主要不同点: Lock有比synchronized更精确的线程语义和更好的性能。synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且必须在finally从句中释放Lock还有更强大…...
)
OpenCV CUDA模块直方图计算------在 GPU 上计算图像直方图的函数calcHist()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 OpenCV 的 CUDA 模块 中用于在 GPU 上计算图像直方图的一个函数。 计算单通道 8-bit 图像的灰度直方图(Histogram)。 该函…...

EMS只是快递那个EMS吗?它跟能源有什么关系?
在刚刚落幕的深圳人工智能终端展上,不少企业展示了与数字能源相关的技术和服务,其中一项关键系统——EMS(Energy Management System,能量管理系统)频频亮相。这个看似低调的名字,实际上正悄然成为未来能源管…...
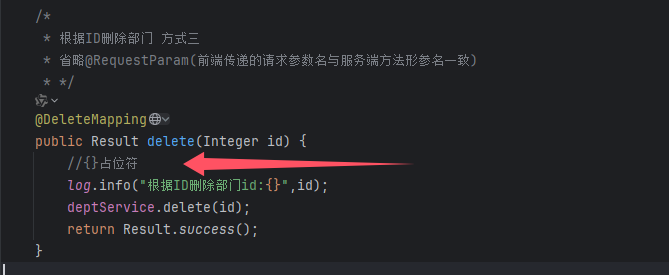
日志技术-LogBack、Logback快速入门、Logback配置文件、Logback日志级别
一. 日志技术 1. 程序中的日志,是用来记录应用程序的运行信息、状态信息、错误信息等。 2. JUL:(java.util.logging)这是JavaSE平台提供的官方日志框架,也被称为JUL。配置相对简单,但不够灵活,性能较差。 3.Logs4j&…...

修改Cinnamon主题
~/.themes/Brunnera-Dark/cinnamon/cinnamon.css 1.修改 Tooltip 圆角大小,边框颜色,背景透明度 #Tooltip { border-radius: 10px; color: rgba(255, 255, 255, 0.8); border: 1px solid rgba(255, 255, 255, 0.6); background-color: rgba(0,…...
91.评论日记
2025年5月30日20:27:06 AI画减速器图纸? 呜呜为什么读到机械博士毕业了才有啊 | 新迪数字2025新品发布会 | AI工业软件 | 三维CAD | 国产自主_哔哩哔哩_bilibili...

HTML5实现简洁的端午节节日网站源码
HTML5实现简洁的端午节节日网站源码 前言一、设计来源1.1 网站首页界面1.2 端午由来界面1.3 节日活动界面1.4 传统美食界面1.5 民俗文化界面1.6 登录界面1.7 注册界面 二、效果和源码2.1 动态效果2.2 源代码 结束语 HTML5实现简洁的端午节节日网站源码,酷炫的大气简…...

Window10+ 安装 go环境
一、 下载 golang 源码: 去官网下载: https://go.dev/dl/ ,当前时间(2025-05)最新版本如下: 二、 首先在指定的磁盘下创建几个文件夹 比如在 E盘创建 software 文件夹 E:\SoftWare,然后在创建如下几个文件夹 E:\S…...
: ICE Agent的作用)
AWS WebRTC:获取ICE服务地址(part 2): ICE Agent的作用
上一篇,已经获取到了ICE服务地址,从返回结果中看,是两组TURN服务地址。 拿到这些地址有什么用呢?接下来就要说到WebRTC中ICE Agent的作用了,返回的服务地址会传给WebRTC最终给到ICE Agent。 ICE Agent的作用…...

一、Sqoop历史发展及原理
作者:IvanCodes 日期:2025年5月30日 专栏:Sqoop教程 在大数据时代,数据往往分散存储在各种不同类型的系统中。其中,传统的关系型数据库 (RDBMS) 如 MySQL, Oracle, PostgreSQL 等,仍然承载着大量的关键业务…...

React 编译器 RC
🤖 作者简介:水煮白菜王,一位前端劝退师 👻 👀 文章专栏: 前端专栏 ,记录一下平时在博客写作中,总结出的一些开发技巧和知识归纳总结✍。 感谢支持💕💕&#…...

PyTorch 中mm和bmm函数的使用详解
torch.mm 是 PyTorch 中用于 二维矩阵乘法(matrix-matrix multiplication) 的函数,等价于数学中的 A B 矩阵乘积。 一、函数定义 torch.mm(input, mat2) → Tensor执行的是两个 2D Tensor(矩阵)的标准矩阵乘法。 in…...
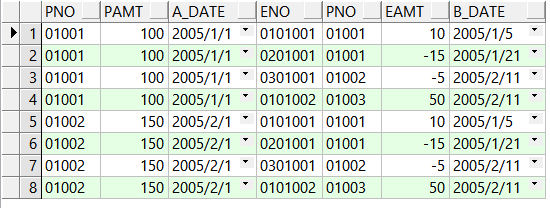
关于表连接
目录 1.左连接 2.右连接 3.内连接 4.全外连接 5.笛卡尔积 -- 创建表A CREATE TABLE A(PNO VARCHAR2(10) PRIMARY KEY, PAMT NUMBER, A_DATE DATE);-- 向表A插入数据 INSERT INTO A VALUES (01001, 100, TO_DATE(2005-01-01, YYYY-MM-DD)); INSERT INTO A VALUES (010…...
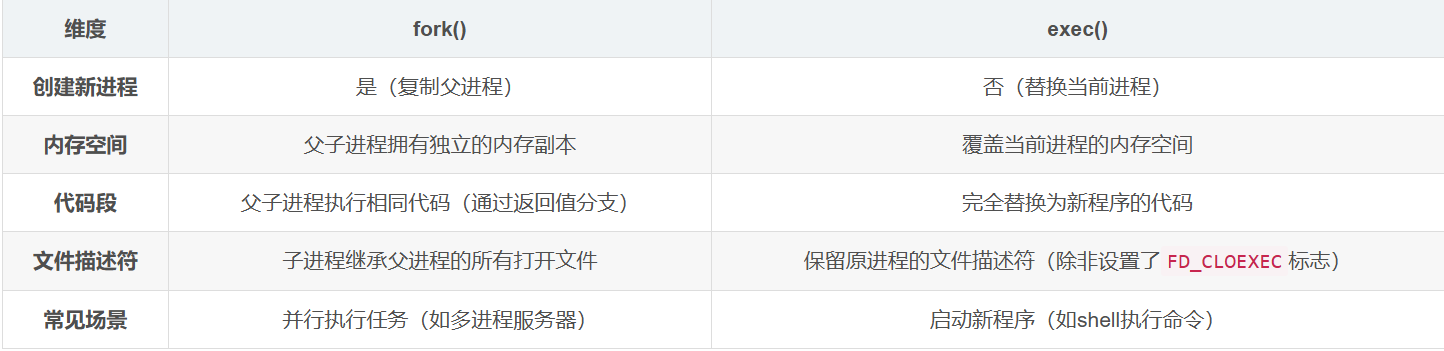
【计算机网络】fork()+exec()创建新进程(僵尸进程及孤儿进程)
文章目录 一、基本概念1. fork() 系统调用2. exec() 系列函数 二、典型使用场景1. 创建子进程执行新程序2. 父子进程执行不同代码 三、核心区别与注意事项四、组合使用技巧1. 重定向子进程的输入/输出2. 创建多级子进程 五、常见问题与解决方案僵尸进程(Zombie Proc…...