【SpringCache 提供的一套基于注解的缓存抽象机制】
Spring 缓存(Spring Cache)是 Spring 提供的一套基于注解的缓存抽象机制,常用于提升系统性能、减少重复查询数据库或接口调用。
✅ 一、基本原理
Spring Cache 通过对方法的返回结果进行缓存,后续相同参数的调用将直接从缓存中读取,而不是再次执行方法。
常用的注解:
| 注解 | 说明 |
|---|---|
@EnableCaching | 开启缓存功能 |
@Cacheable | 有缓存则用缓存,无缓存则调用方法并缓存结果 |
@CachePut | 每次执行方法,并将返回结果放入缓存(更新缓存) |
@CacheEvict | 清除缓存 |
@Caching | 组合多个缓存操作注解 |
✅ 二、使用示例
1. 添加依赖(使用 Caffeine 举例)
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency><dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId>
</dependency>
2. 启用缓存
@SpringBootApplication
@EnableCaching // 启用缓存功能注解
public class App {public static void main(String[] args) {SpringApplication.run(App.class, args);}
}3. 使用缓存注解
@Service
public class UserService {// 第一次调用查询数据库,结果会被缓存@Cacheable(cacheNames = "user", key = "#id")public User getUserById(Long id) {System.out.println("查询数据库中的用户信息");return userMapper.selectById(id);}// 更新用户后,缓存也要更新@CachePut(cacheNames = "user", key = "#user.id")public User updateUser(User user) {userMapper.updateById(user);return user;}// 删除用户时,清除缓存@CacheEvict(cacheNames = "user", key = "#id")public void deleteUser(Long id) {userMapper.deleteById(id);}
}
4. 配置缓存(application.yml)
spring:cache:cache-names: user # 作用:定义一个或多个缓存名称(缓存空间),在注解如 @Cacheable(cacheNames="user") 中引用。 示例含义:你这里定义了一个缓存名称叫 user,用于用户相关数据缓存。caffeine:# 作用:配置 Caffeine 缓存的参数,使用一种类似 Java 配置的 DSL 风格字符串,和 Caffeine.newBuilder().xxx() 一一对应。# maximumSize=1000 设置缓存最大条目数为 1000,超过后触发淘汰(基于 W-TinyLFU)# expireAfterWrite=60s 写入后 60 秒过期(不管有没有被访问)spec: maximumSize=1000,expireAfterWrite=60s
✅ 三、缓存存储方案
Spring Cache 是抽象接口,底层可接入多种缓存方案:
| 方案 | 特点 |
|---|---|
| Caffeine | 本地缓存,性能极高,适合单体应用 |
| EhCache | 本地缓存,功能丰富但不如 Caffeine 快 |
| Redis | 分布式缓存,适合集群部署、高并发环境 |
| Guava | 轻量但已不推荐,Caffeine 是它的替代者 |
✅ 四、进阶功能
-
条件缓存:@Cacheable(condition = “#id > 100”)
-
缓存为空不存:unless = “#result == null”
-
组合注解:@Caching(cacheable = {…}, evict = {…})
-
手动缓存:使用 CacheManager 操作缓存对象
✅ 五、总结
| 功能场景 | 建议使用 |
|---|---|
| 本地缓存 | Caffeine |
| 分布式缓存 | Redis |
| 单体轻量项目 | Spring Cache + Caffeine |
| 高并发分布式系统 | Redis + 自定义注解 |
✅ 六、实战
一个完整的 Spring Boot 项目示例,集成 Spring Cache + Caffeine,模拟一个 用户信息查询缓存的业务场景。
🧱 项目结构(简化单模块)
spring-cache-demo/
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ └── com/example/cache/
│ │ │ ├── CacheApplication.java
│ │ │ ├── controller/
│ │ │ │ └── UserController.java
│ │ │ ├── service/
│ │ │ │ └── UserService.java
│ │ │ └── model/
│ │ │ └── User.java
│ └── resources/
│ └── application.yml1️⃣ 引入依赖(pom.xml)
<project><modelVersion>4.0.0</modelVersion><groupId>com.example</groupId><artifactId>spring-cache-demo</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency><dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId></dependency></dependencies>
</project>2️⃣ 启动类 CacheApplication.java
package com.example.cache;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cache.annotation.EnableCaching;@SpringBootApplication
@EnableCaching // 开启缓存注解支持
public class CacheApplication {public static void main(String[] args) {SpringApplication.run(CacheApplication.class, args);}
}3️⃣ 用户模型 User.java
package com.example.cache.model;public class User {private Long id;private String name;private String email;public User() {}public User(Long id, String name, String email) {this.id = id;this.name = name;this.email = email;}// getter、setter省略
}4️⃣ 服务类 UserService.java
package com.example.cache.service;import com.example.cache.model.User;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.cache.annotation.CachePut;
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.stereotype.Service;@Service
public class UserService {// 模拟从数据库获取数据@Cacheable(cacheNames = "user", key = "#id")public User getUserById(Long id) {System.out.println("❗查询数据库获取用户信息");return new User(id, "User" + id, "user" + id + "@example.com");}// 更新用户信息并更新缓存@CachePut(cacheNames = "user", key = "#user.id")public User updateUser(User user) {System.out.println("🔄更新用户并刷新缓存");return user;}// 删除用户缓存@CacheEvict(cacheNames = "user", key = "#id")public void deleteUser(Long id) {System.out.println("❌删除缓存");}
}
5️⃣ 控制器 UserController.java
package com.example.cache.controller;import com.example.cache.model.User;
import com.example.cache.service.UserService;
import org.springframework.web.bind.annotation.*;@RestController
@RequestMapping("/users")
public class UserController {private final UserService userService;public UserController(UserService userService) {this.userService = userService;}@GetMapping("/{id}")public User getUser(@PathVariable Long id) {return userService.getUserById(id);}@PutMapping("/")public User updateUser(@RequestBody User user) {return userService.updateUser(user);}@DeleteMapping("/{id}")public String deleteUser(@PathVariable Long id) {userService.deleteUser(id);return "deleted";}
}6️⃣ 配置文件 application.yml
server:port: 8080spring:cache:type: caffeinecache-names: usercaffeine:spec: maximumSize=1000,expireAfterWrite=60s✅ 测试流程
1.第一次请求:GET /users/1
→ 控制台输出“查询数据库获取用户信息”
2.第二次请求:GET /users/1
→ 不再输出,直接使用缓存结果
3.更新用户:PUT /users,提交 JSON:
{ "id": 1, "name": "新名字", "email": "new@example.com" }
4.删除缓存:DELETE /users/1
→ 控制台输出“删除缓存”
✅ 七、Cache注解详解
✅ @Cacheable 参数详解(用于读取缓存)
@Cacheable(value = "user", // 指定缓存的名称(可以是多个),即 cacheNames 的别名key = "#id", // SpEL 表达式定义缓存 keycondition = "#id > 0", // 满足条件时才缓存unless = "#result == null", // 返回值不为 null 才缓存sync = false // 是否同步加载(避免缓存击穿)
)
public User getUserById(Long id) { ... }
| 参数 | 说明 |
|---|---|
value / cacheNames | 缓存名称,对应 @EnableCaching 配置的缓存管理器(CacheManager)中定义的缓存空间 |
key | 缓存 key,使用 Spring Expression Language(SpEL)表达式(如:#id, #user.name) |
keyGenerator | 指定 key 生成器(和 key 二选一) |
condition | 缓存条件:满足时才执行缓存,如 #id != null |
unless | 排除条件:结果满足时不缓存,如 #result == null |
sync | 是否启用同步缓存(防止缓存击穿,多线程同时查同一 key)【仅限某些缓存实现支持,如 Caffeine 支持】 |
✅ @CachePut 参数详解(用于更新缓存)
@CachePut(value = "user",key = "#user.id"
)
public User updateUser(User user) { ... }与 @Cacheable 基本相同,但始终执行方法体并更新缓存
适用于“更新数据库并同步更新缓存”的场景
✅ @CacheEvict 参数详解(用于删除缓存)
@CacheEvict(value = "user",key = "#id",condition = "#id != null",beforeInvocation = false
)
public void deleteUser(Long id) { ... }| 参数 | 说明 |
|---|---|
value | 缓存名 |
key | 指定要删除的 key |
allEntries | 是否清除所有缓存项,如:true 表示清空整个 cache |
beforeInvocation | 是否在方法执行前清除缓存,默认是 false(即执行后才清除) |
| 常见组合用法: |
@CacheEvict(value = "user", allEntries = true)
public void clearCache() { }🔄 多个注解组合:@Caching
如果你想组合多个缓存注解(如读一个,清除另一个),可以使用 @Caching:
@Caching(cacheable = {@Cacheable(value = "user", key = "#id")},evict = {@CacheEvict(value = "userList", allEntries = true)}
)
public User getUserById(Long id) { ... }📌 SpEL 表达式说明
| 表达式 | 说明 |
|---|---|
#p0 / #a0 | 第一个参数 |
#id | 名称为 id 的参数 |
#user.name | 参数 user 的 name 属性 |
#result | 方法返回值(only unless) |
✅ 示例回顾
@Cacheable(value = "user", key = "#id", unless = "#result == null")
public User getUser(Long id) { ... }@CachePut(value = "user", key = "#user.id")
public User updateUser(User user) { ... }@CacheEvict(value = "user", key = "#id")
public void deleteUser(Long id) { ... }✅ 八、使用细节详解
⚙️ 1. Cache 配置类
springboot 可以有properties配置方式,改成bean方式配置
✅ 使用 Java Config 自定义 Caffeine Cache
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.cache.Cache;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.caffeine.CaffeineCache;
import org.springframework.cache.concurrent.ConcurrentMapCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.concurrent.TimeUnit;@Configuration
@EnableCaching
public class CacheConfig {/*** 创建 Caffeine 缓存管理器* 自定义一个 Spring 的缓存管理器 CacheManager,* 当缓存名称为 "user" 时,使用手动创建的 CaffeineCache 实例;* 否则使用默认的内存 Map 缓存。**/@Beanpublic CacheManager cacheManager() {CaffeineCache userCache = new CaffeineCache("user", // 创建了一个名为 user 的缓存实例,使用了 Caffeine 提供的构建器Caffeine.newBuilder().initialCapacity(100) // 缓存容器的初始大小,优化扩容性能.maximumSize(1000) // 最多缓存 1000 条记录,超出会使用 Caffeine 的 W-TinyLFU 淘汰算法移除最不常用的条目。.expireAfterWrite(60, TimeUnit.SECONDS) // 写入后 60 秒自动过期(不管是否访问)。.recordStats() // 启用统计功能(命中率、缓存数量等,调试和监控可用)。.build()); // 最终构建出一个 Cache<Object, Object>。// Caffeine 缓存被包装成 Spring 的 CaffeineCache 实例(Spring 使用自己的缓存接口 org.springframework.cache.Cache 进行统一抽象)。return new ConcurrentMapCacheManager() { // 创建了一个匿名内部类 ConcurrentMapCacheManager(Spring 默认的基于内存的缓存管理器),并重写了其 createConcurrentMapCache 方法:@Overrideprotected Cache createConcurrentMapCache(final String name) {// 每当系统使用 @Cacheable(cacheNames = "user") 时 会触发 createConcurrentMapCache("user") 判断名称是否是 "user",是就返回我们手动构建的 CaffeineCache。if ("user".equals(name)) {return userCache;}// 如果是其他缓存名,则走父类默认实现(使用 ConcurrentHashMap 的简单内存缓存,不带过期等特性)。return super.createConcurrentMapCache(name);}};}
}
✅ 总结:使用 Bean 的优点
| 优点 | 说明 |
|---|---|
| ✅ 更灵活 | 可用 Java 代码动态定义缓存逻辑 |
| ✅ 无需写配置文件 | 统一管理更清晰 |
| ✅ 支持多个缓存策略 | 每个缓存可用不同的配置 |
🧠 提示:如何支持多个不同策略的 Caffeine 缓存?
要实现 Spring Cache + Caffeine 中不同缓存名使用不同策略的配置方式,咱们可以改写配置,使其更通用且可扩展 —— 比如:
✅ 多缓存名,不同策略的 Caffeine 缓存管理器
👇 示例:每个缓存名对应一个不同的策略
@Configuration
@EnableCaching
public class CacheConfig {@Beanpublic CacheManager cacheManager() {// 构建不同的缓存实例Map<String, CaffeineCache> cacheMap = new HashMap<>();// user 缓存:60秒后过期,最大1000条cacheMap.put("user", new CaffeineCache("user",Caffeine.newBuilder().maximumSize(1000).expireAfterWrite(60, TimeUnit.SECONDS).build()));// product 缓存:5分钟过期,最大500条cacheMap.put("product", new CaffeineCache("product",Caffeine.newBuilder().maximumSize(500).expireAfterWrite(5, TimeUnit.MINUTES).build()));// order 缓存:10分钟后失效,最大200条cacheMap.put("order", new CaffeineCache("order",Caffeine.newBuilder().maximumSize(200).expireAfterWrite(10, TimeUnit.MINUTES).build()));// 创建一个自定义 CacheManager,支持上面这些策略return new SimpleCacheManager() {{setCaches(new ArrayList<>(cacheMap.values()));}};}
}✅ 总结对比
| 配置方式 | 特点 |
|---|---|
application.yml 配置 | 简单、适合统一策略 |
自定义 CacheManager Bean | 更灵活、支持不同缓存名自定义策略,适合中大型项目需求 |
✅ recordStats 查看
一、如何启用
Caffeine.newBuilder().maximumSize(1000).expireAfterWrite(60, TimeUnit.SECONDS).recordStats() // ✅ 开启统计.build();二、如何获取统计数据
@Autowired
private CacheManager cacheManager;public void printUserCacheStats() {CaffeineCache caffeineCache = (CaffeineCache) cacheManager.getCache("user");com.github.benmanes.caffeine.cache.Cache<?, ?> nativeCache = caffeineCache.getNativeCache();CacheStats stats = nativeCache.stats();System.out.println("命中次数:" + stats.hitCount());System.out.println("未命中次数:" + stats.missCount());System.out.println("命中率:" + stats.hitRate());System.out.println("加载成功次数:" + stats.loadSuccessCount());System.out.println("加载失败次数:" + stats.loadFailureCount());System.out.println("平均加载时间:" + stats.averageLoadPenalty() + "ns");System.out.println("被驱逐次数:" + stats.evictionCount());
}三、如果你想实时查看:建议加个接口
@RestController
@RequestMapping("/cache")
public class CacheStatsController {@Autowiredprivate CacheManager cacheManager;@GetMapping("/stats/{name}")public Map<String, Object> getCacheStats(@PathVariable String name) {CaffeineCache cache = (CaffeineCache) cacheManager.getCache(name);com.github.benmanes.caffeine.cache.Cache<?, ?> nativeCache = cache.getNativeCache();CacheStats stats = nativeCache.stats();Map<String, Object> result = new HashMap<>();result.put("hitCount", stats.hitCount());result.put("missCount", stats.missCount());result.put("hitRate", stats.hitRate());result.put("evictionCount", stats.evictionCount());result.put("loadSuccessCount", stats.loadSuccessCount());result.put("loadFailureCount", stats.loadFailureCount());result.put("averageLoadPenalty(ns)", stats.averageLoadPenalty());return result;}
}相关文章:

【SpringCache 提供的一套基于注解的缓存抽象机制】
Spring 缓存(Spring Cache)是 Spring 提供的一套基于注解的缓存抽象机制,常用于提升系统性能、减少重复查询数据库或接口调用。 ✅ 一、基本原理 Spring Cache 通过对方法的返回结果进行缓存,后续相同参数的调用将直接从缓存中读…...

DALI DT6与DALI DT8介绍
“DT”全称Device Type,是DALI-2 标准协议中的IEC 62386-102(即为Part 102)部分对不同类型的控制设备进行一个区分。不同的Device Type代表不同特性的控制设备,也代表了这种控制设备拥有的扩展的特性。 在DALI(数字可寻址照明接口)…...

day13 leetcode-hot100-24(链表3)
234. 回文链表 - 力扣(LeetCode) 1.转化法 思路 将链表转化为列表进行比较 复习到的知识 arraylist的长度函数:list.size() 具体代码 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode ne…...

Python实战:打造高效通讯录管理系统
📋 编程基础第一期《8-30》–通讯录管理系统 📑 项目介绍 在信息化时代,高效管理个人或团队联系人信息变得尤为重要。本文将带您实现一个基于Python的通讯录管理系统,该系统采用字典数据结构和JSON文件存储,实现了联系…...
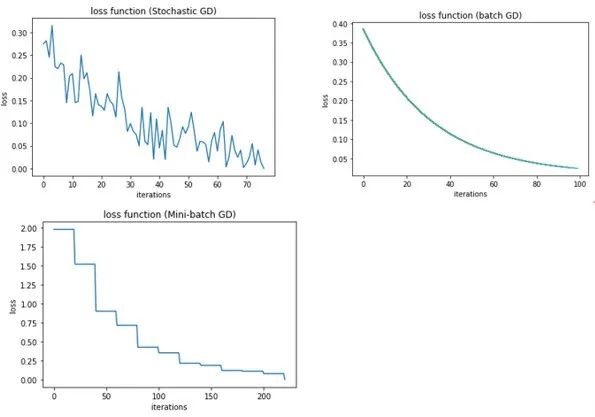
图解深度学习 - 基于梯度的优化(梯度下降)
在模型优化过程中,我们曾尝试通过手动调整单个标量系数来观察其对损失值的影响。具体来说,当初始系数为0.3时,损失值为0.5。随后,我们尝试增加系数至0.35,发现损失值上升至0.6;相反,当系数减小至…...
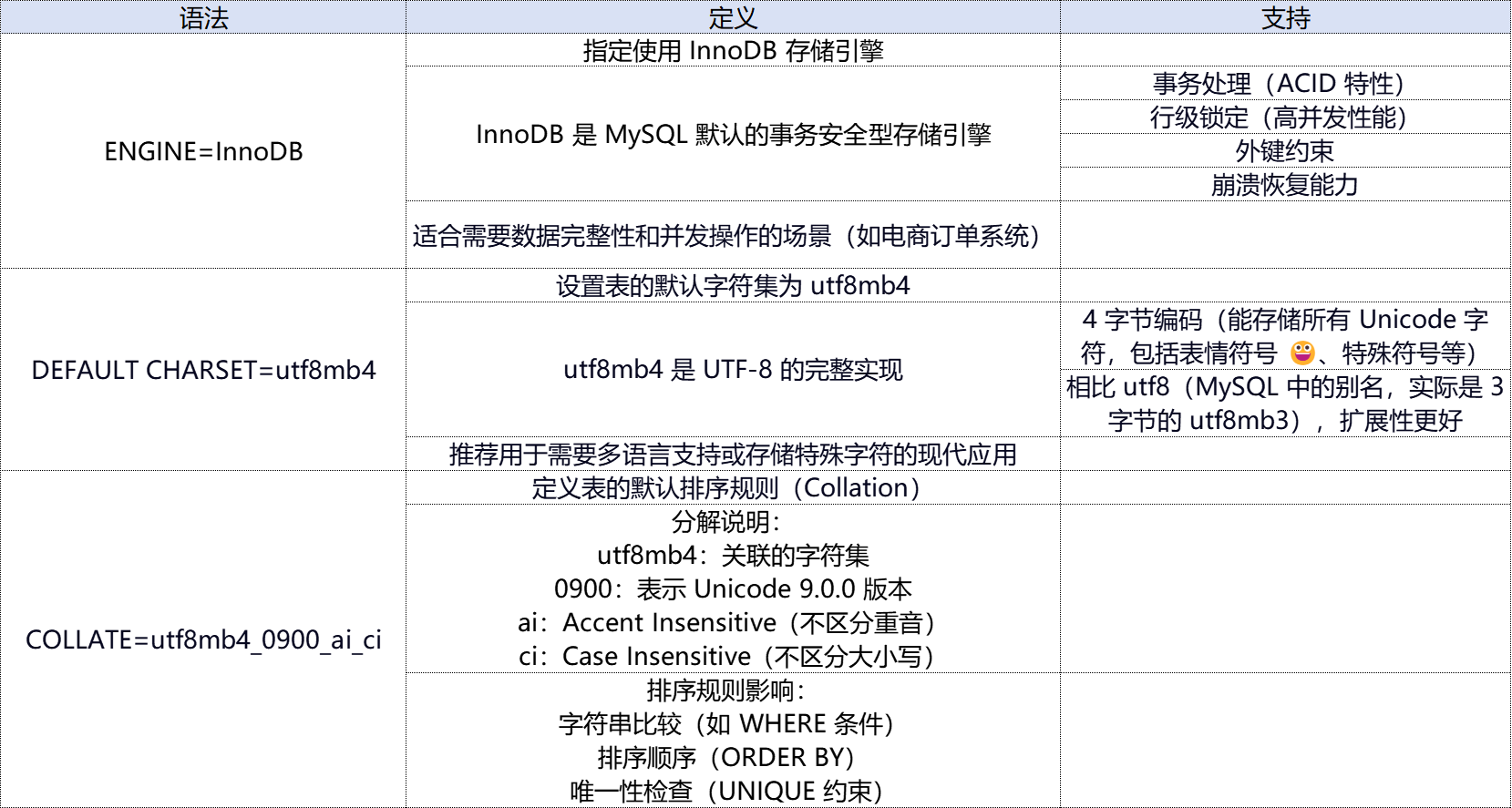
MySql--定义表存储引擎、字符集和排序规则
示例: CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci,email VARCHAR(100) ) ENGINEInnoDB DEFAULT CHARSETutf8mb4 COLLATEutf8mb4_0900_ai_ci;注意事项: 字符集和排序规则可以按列覆盖表…...

【部署】在离线服务器的docker容器下升级dify-import程序
回到目录 在离线服务器的docker容器下升级dify-import程序 dify 0.1.0-release 变化很大,重构整个项目代码并且增加制度类txt文件知识库父子分段支持,详见 读取制度类txt文件导入dify的父子分段知识库(20250526发布). 。下面是kylin Linux环境下&#…...
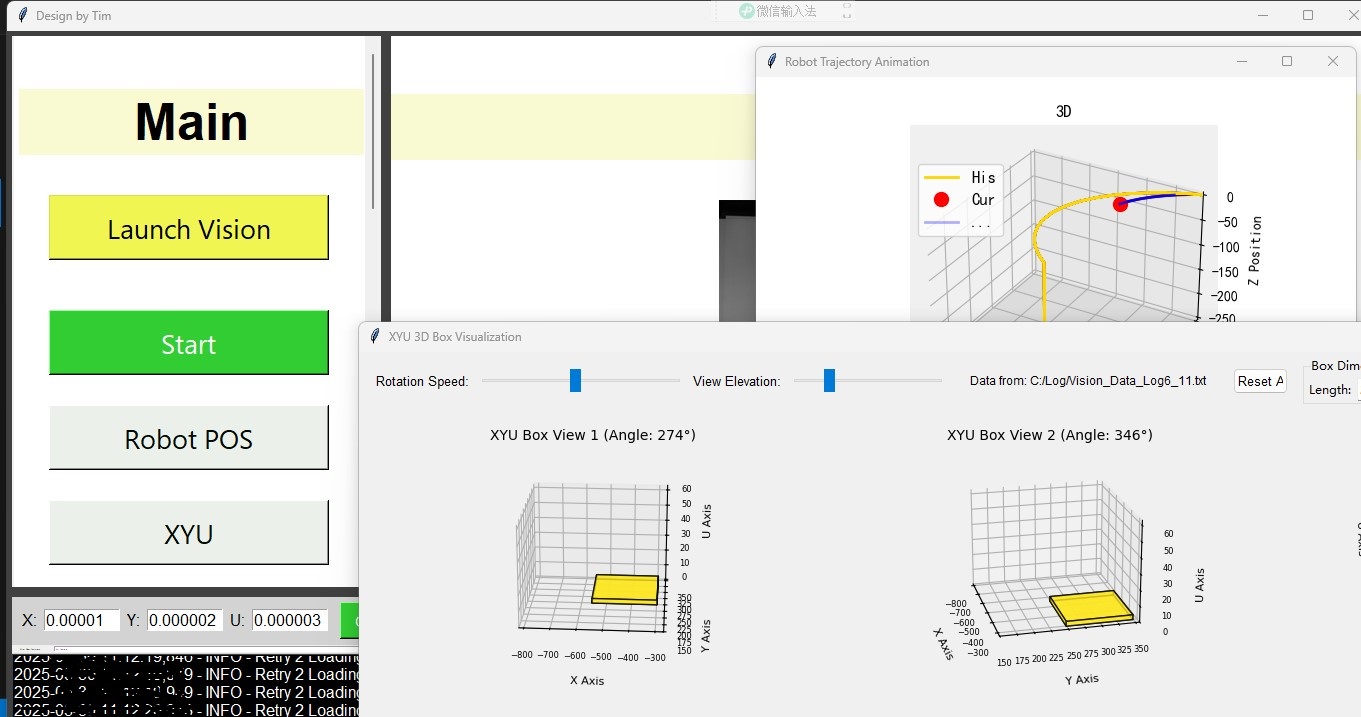
优化版本,增加3D 视觉 查看前面的记录
上图先 运来的超出发表上限,重新发。。。 #11:06:57Current_POS_is: X:77Y:471Z:0U:-2 C:\Log\V55.txt import time import tkinter as tk from tkinter import messagebox from PIL import Image, ImageTk import socket import threading from date…...

写作-- 复合句练习
文章目录 练习 11. 家庭的支持和老师的指导对学生的学术成功有积极影响。2. 缺乏准备和未能适应通常会导致在挑战性情境中的糟糕表现。3. 吃垃圾食品和忽视锻炼可能导致严重的健康问题,因此人们应注重保持均衡的生活方式。4. 昨天的大雨导致街道洪水泛滥,因此居民们迁往高地以…...
WWW22-可解释推荐|用于推荐的神经符号描述性规则学习
论文来源:WWW 2022 论文链接:https://web.archive.org/web/20220504023001id_/https://dl.acm.org/doi/pdf/10.1145/3485447.3512042 最近读到一篇神经符号集成的论文24年底TOIS的,神经符号集成是人工智能领域中,将符号推理与深…...
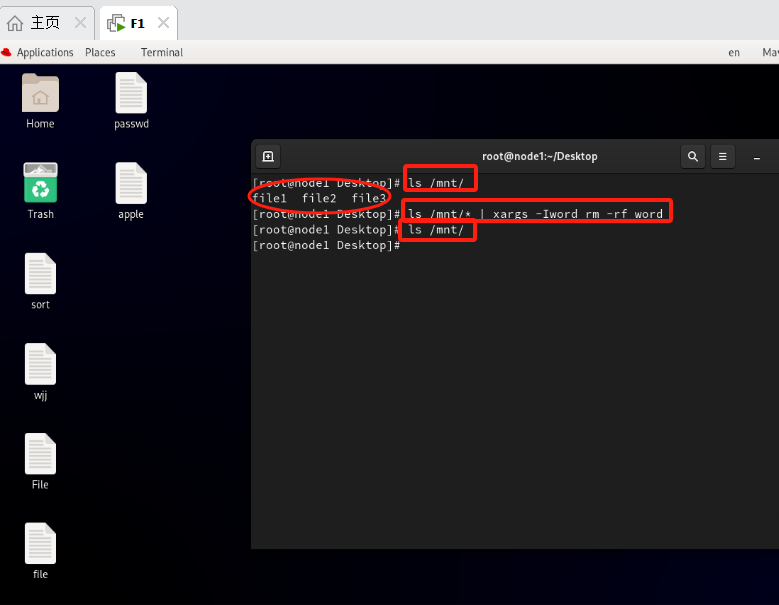
Linux:shell脚本常用命令
一、设置主机名称 1、查看主机名称 2、用文件的方式更改主机名称 重启后: 3、 通过命令修改主机名 重启后: 二、网络管理命令 1、查看网卡 2、设置网卡 (1)网卡未被设置过时 (2)当网卡被设定,…...

专业课复习笔记 11
从今天开始每天下午复习专业课。慢慢复习专业课。目标至少考一个一百分吧。毕竟专业课还是比较难的。要是考不到一百分,我感觉自己就废掉了呢。下面稍微复习一下计组。 复习指令格式和数据通路设计。完全看不懂,真是可恶啊。计组感觉就是死记硬背&#…...

OpenTelemetry × Elastic Observability 系列(一):整体架构介绍
本文是 OpenTelemetry Elastic Observability 系列的第一篇,将介绍 OpenTelemetry Demo 的整体架构,以及如何集成 Elastic 来采集和可视化可观测性数据。后续文章将分别针对不同编程语言,深入讲解 OpenTelemetry 的集成实践。 程序架构 Op…...
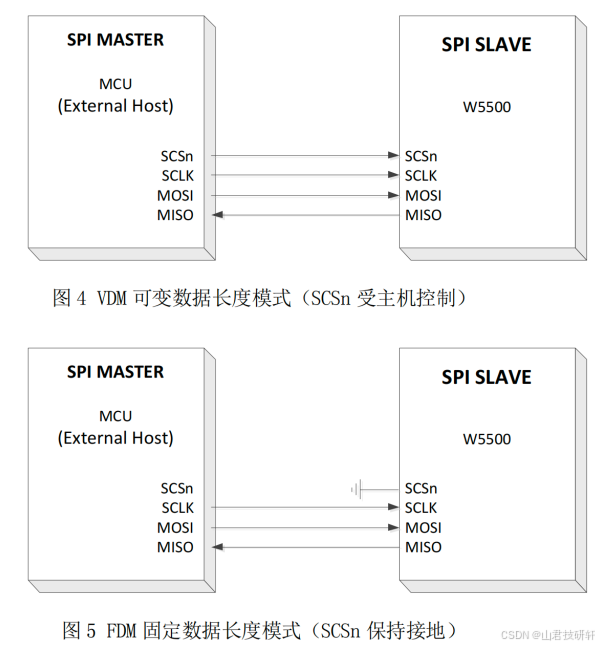
STM32高级物联网通信之以太网通讯
目录 以太网通讯基础知识 什么是以太网 互联网和以太网的区别 1)概念与范围 (1)互联网 (2)以太网 2)技术特点 (1)互联网 (2)以太网 3)应…...

从Java的Jvm的角度解释一下为什么String不可变?
从Java的Jvm的角度解释一下为什么String不可变? 从 JVM 的角度看,Java 中 String 的不可变性是由多层次的机制共同保障的,这些设计涉及内存管理、性能优化和安全保障: 1. JVM 内存模型与字符串常量池 字符串常量池(St…...
 图论基础与算法实战)
从零开始的数据结构教程(四) 图论基础与算法实战
🌐 标题一:图的表示——六度空间理论如何用代码实现? 核心需求 图(Graph)是用于表达实体间关系的强大数据结构,比如社交网络中的好友关系,或者城市路网的交叉路口连接。关键在于如何高效存储和…...
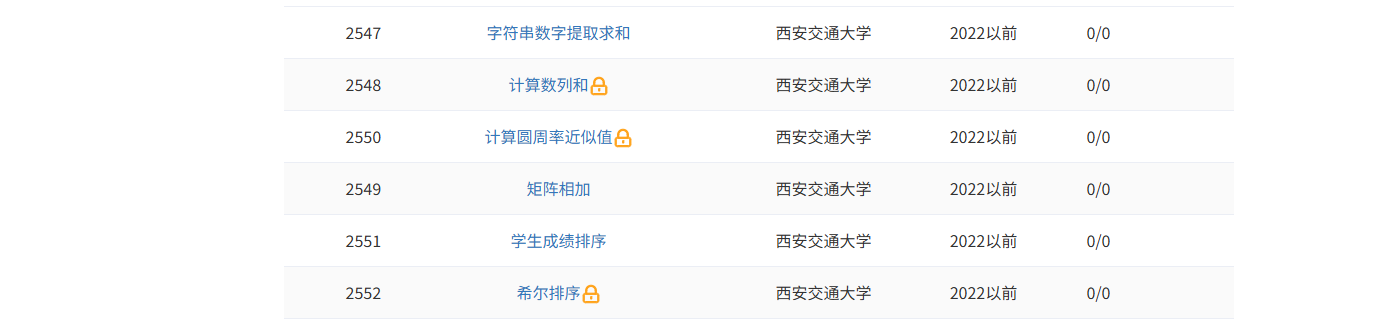
历年西安交通大学计算机保研上机真题
2025西安交通大学计算机保研上机真题 2024西安交通大学计算机保研上机真题 2023西安交通大学计算机保研上机真题 在线测评链接:https://pgcode.cn/school 计算圆周率近似值 题目描述 根据公式 π / 4 1 − 1 / 3 1 / 5 − 1 / 7 … \pi / 4 1 - 1/3 1/5 - …...

可视化与动画:构建沉浸式Vue应用的进阶实践
在现代Web应用中,高性能可视化和流畅动画已成为提升用户体验的核心要素。本节将深入探索Vue生态中的可视化与动画技术,分享专业级解决方案与最佳实践。 一、 Canvas高性能渲染体系 01、Konva.js流程图引擎深度优化 <template><div class"…...
:简单哈希压缩256色算法)
Python |GIF 解析与构建(3):简单哈希压缩256色算法
Python |GIF 解析与构建(3):简单哈希压缩256色算法 目录 Python |GIF 解析与构建(3):简单哈希压缩256色算法 一、算法性能表现 二、算法核心原理与实现 (一…...

蓝桥杯2114 李白打酒加强版
问题描述 话说大诗人李白, 一生好饮。幸好他从不开车。 一天, 他提着酒显, 从家里出来, 酒显中有酒 2 斗。他边走边唱: 无事街上走,提显去打酒。 逢店加一倍, 遇花喝一斗。 这一路上, 他一共遇到店 N 次, 遇到花 M 次。已知最后一次遇到的是花, 他正好把酒喝光了。…...
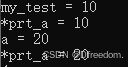
基本数据指针的解读-C++
1、引言 笔者认为对于学习指针要弄清楚如下问题基本可以应付大部分的场景: ① 指针是什么? ② 指针的类型是什么? ③ 指针指向的类型是什么? ④ 指针指向了哪里? 2、如何使用指针 使用时的步骤如下: ① …...

Android Studio里的BLE数据接收策略
#本人是初次接触Android蓝牙开发,若有不对地方,欢迎指出。 #由于是讲接收数据策略(其中还包含数据发送的部分策略),因此其他问题部分不会讲述,只描述数据接收。 简介(对于客户端---手机端) 博主在处理数据接收的时候࿰…...

【Office】Excel两列数据比较方法总结
在Excel中,比较两列数据是否相等有多种方法,以下是常用的几种方式: 方法1:使用公式(返回TRUE/FALSE) 在空白列(如C列)输入公式,向下填充即可逐行比较两列(如…...
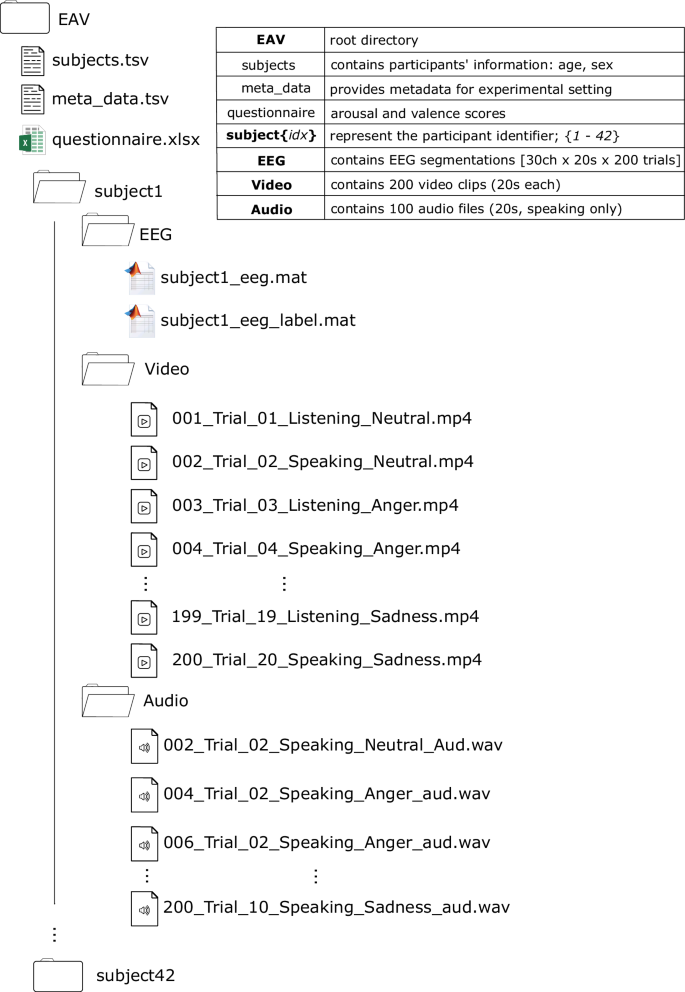
基于多模态脑电、音频与视觉信号的情感识别算法【Nature核心期刊,EAV:EEG-音频-视频数据集】
简述 理解情感状态对于开发下一代人机交互界面至关重要。社交互动中的人类行为会引发受感知输入影响的心理生理过程。因此,探索大脑功能与人类行为的努力或将推动具有类人特质人工智能模型的发展。这里原作者推出一个多模态情感数据集,包含42名参与者的3…...
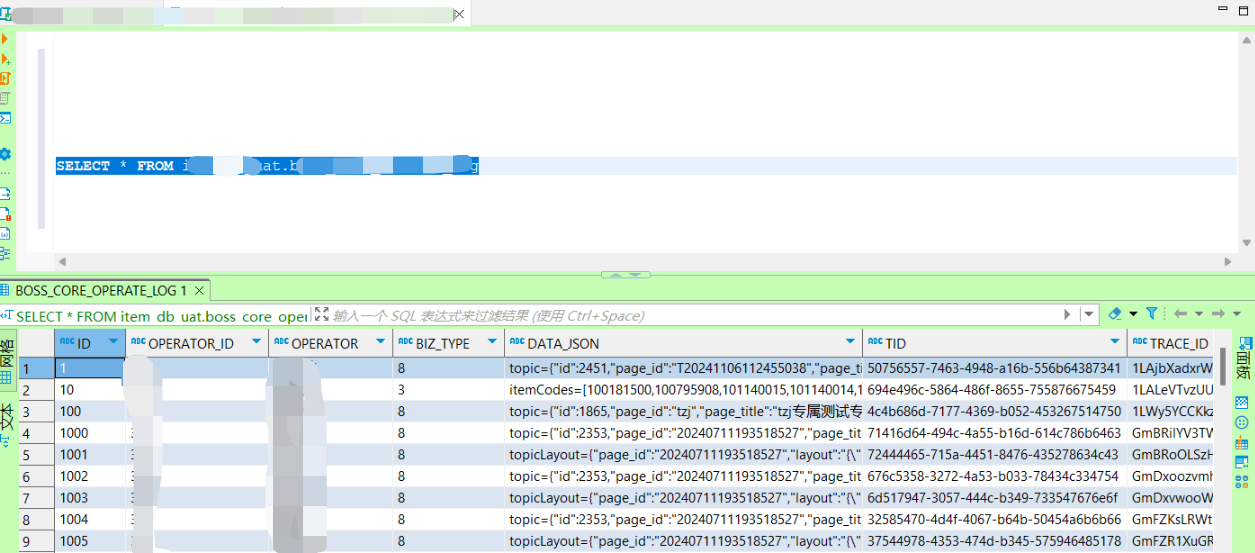
【QueryServer】dbeaver使用phoenix连接Hbase(轻客户端方式)
一、轻客户端连接方式 (推荐) 演示无认证配置方式, 有认证填入下方有认证参数即可 1, 新建连接 → Hadoop/大数据 → Apache Phoenix 2, 手动配置QueryServer驱动: 填入: “类名”, “URL模版”(注意区分有无认证), “端口号”, (勾选无认证) 类名: org.apache.phoenix…...
)
数据湖 (特点+与数据仓库和数据沼泽的对比讲解)
数据湖就像一个“数据水库”,把企业所有原始数据(结构化的表格、半结构化的日志、非结构化的图片/视频)原样存储,供后续按需分析。 对比传统数据仓库: 数据仓库数据湖数据清洗后的结构化数据(如Excel表格&…...

深入链表剖析:从原理到 C 语言实现,涵盖单向、双向及循环链表全解析
1 引言 在数据结构的学习中,链表是一种基础且极为重要的线性数据结构。与数组不同,链表通过指针将一系列节点连接起来,每个节点包含数据域和指向下一个节点的指针域。这种动态的存储方式使得链表在插入、删除等操作上具有独特的优势。本文将深…...

编码总结如下
VS2019一般的编码是UTF-8编码, win11操作系统的编码可能为GB2312,VS整个工程中使用的都是UTF-8编码,但是在系统内生成的其他文件夹的名字则是系统的编码 如何选择? Qt 项目:优先用 QString 和 QByteArray(…...

《算力觉醒!ONNX Runtime + DirectML如何点燃Windows ARM设备的AI引擎》
ONNX Runtime是一个跨平台的高性能推理引擎,它就像是一位精通多种语言的翻译官,能够无缝运行来自不同深度学习框架转化为ONNX格式的模型。这种兼容性打破了框架之间的隔阂,让开发者可以将更多的精力投入到模型的优化和应用中。 从内部机制来…...

[9-1] USART串口协议 江协科技学习笔记(13个知识点)
1 2 3 4全双工就是两个数据线,半双工就是一个数据线 5 6 7 8 9 10 TTL(Transistor-Transistor Logic)电平是一种数字电路中常用的电平标准,它使用晶体管来表示逻辑状态。TTL电平通常指的是5V逻辑电平,其中:…...