实测,大模型谁更懂数据可视化?

大家好,我是 Ai 学习的老章
看论文时,经常看到漂亮的图表,很多不知道是用什么工具绘制的,或者很想复刻类似图表。
实测,大模型 LaTeX 公式识别,出乎预料
前文,我用 Kimi、Qwen-3-235B-A22B、Claude-3.7-sonnet、GPT-4.1、Gemini 2.5 Pro 测试了其在 LaTeX 公式识别中的表现。
本文就测试一下他们在图表识别、复刻中的表现,看看谁更擅长干这件事
备注:Kimi 开启了长思考,Qwen3 未开启深度思考,因为开启之后巨慢且失败
省流:Gemini 2.5 Pro 是最强大的代码模型,毫无争议
排名:Gemini 2.5 Pro > Claude 3.7 Sonnet > Kimi = Qwen3 > GPT-4.1
第一题
Kimi
有点弱智,绘制了傻瓜箱线图,图像理解有问题
Qwen-3-235B-A22B
也很傻瓜,与 kimi 半斤八两
Claude-3.7-sonnet
好一点点,绘制了半小提琴图 (half-violin plot) 结合箱线图 (box plot)
后续我又试了一下
如果明确告诉它用 R 绘制,Claude-3.7 结果如下,还不错!
GPT-4.1
失败,生成的代码满满得 bug,无法生成图表
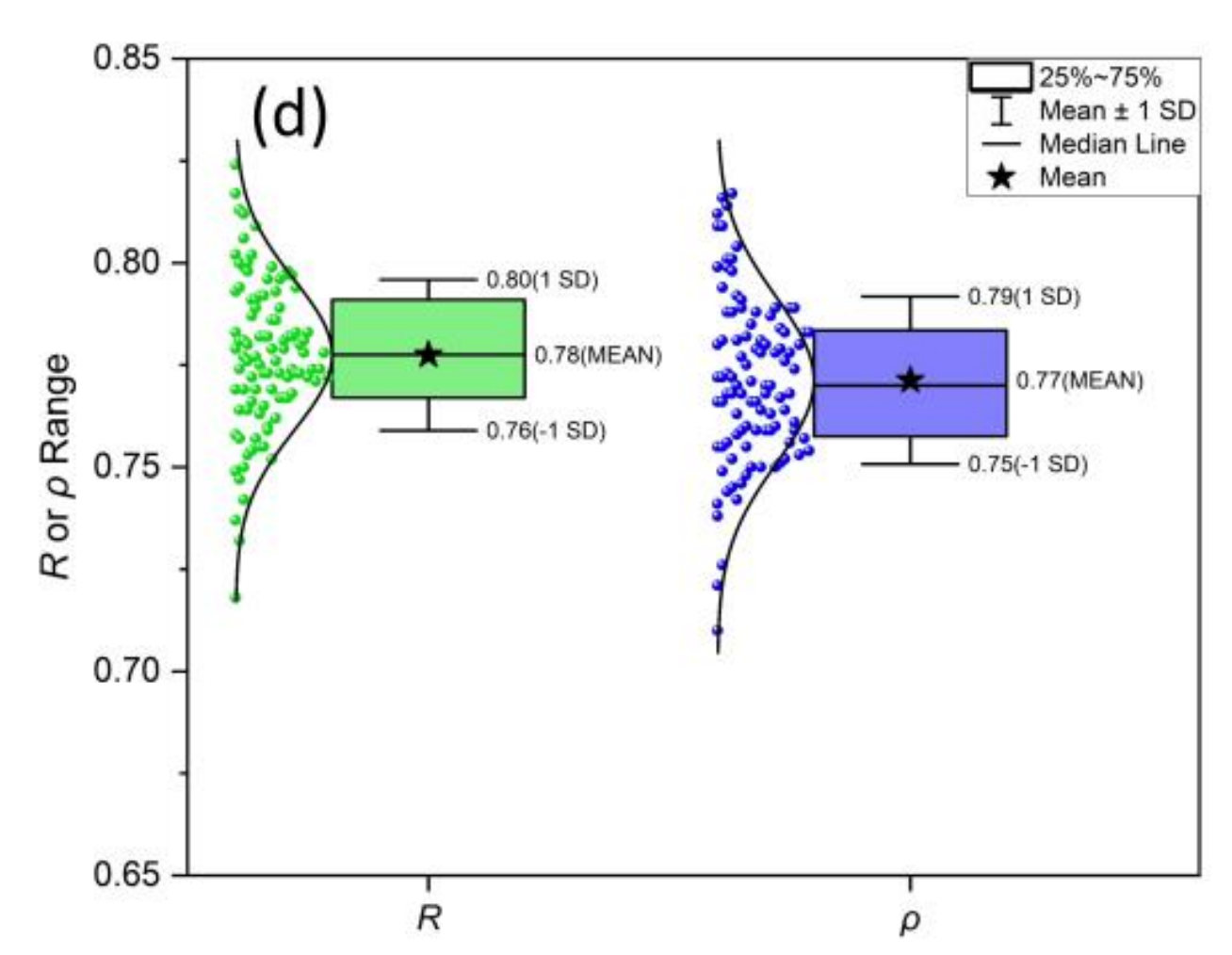
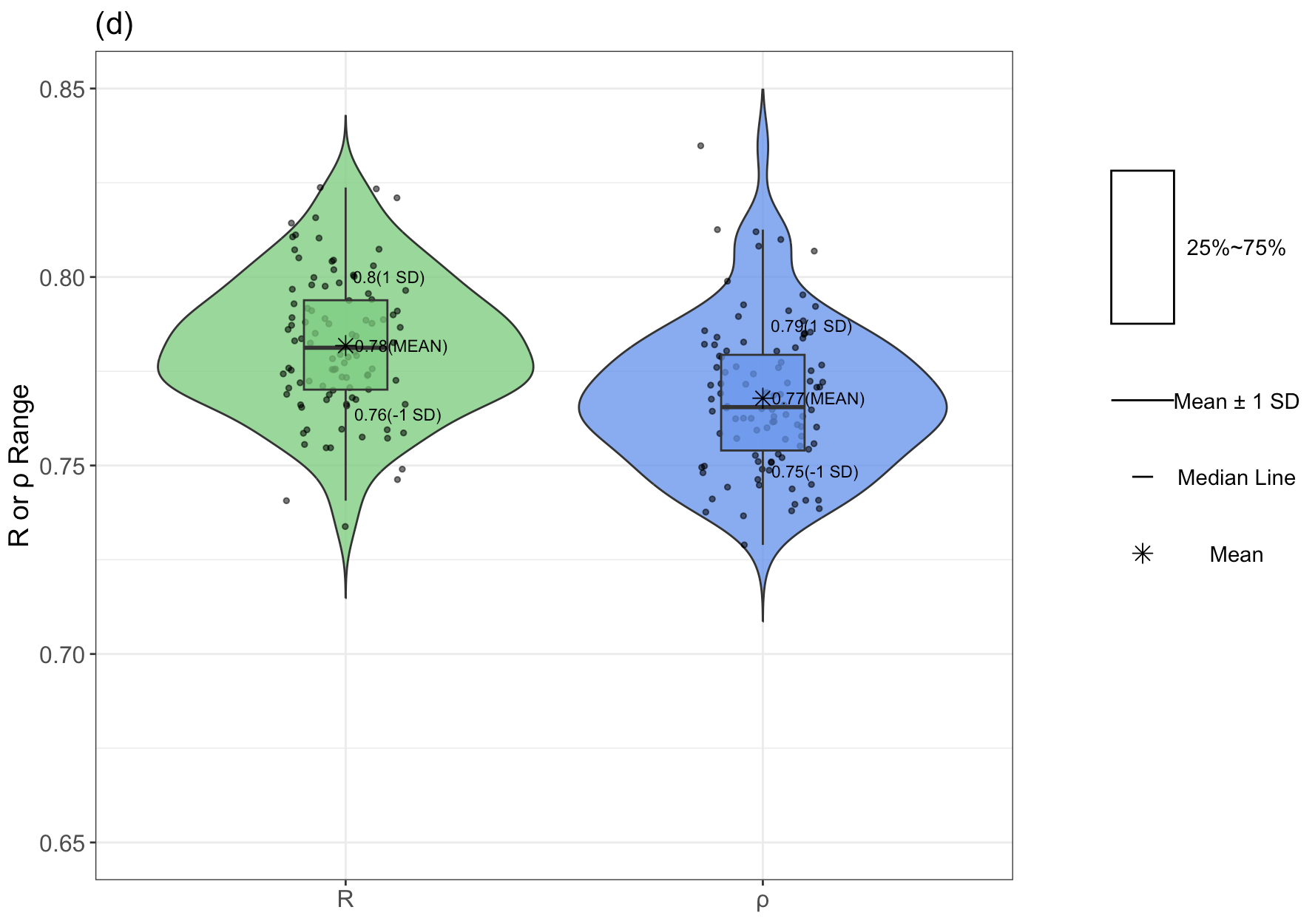
Gemini 2.5 Pro
震惊了
它识别出这是雨云图 (raincloudplot),结合了以下 3 图表的元素:
散点图 (Scatter/Strip plot):显示每 1.个单独的数据点 (图中的绿色和蓝色小点)
箱形图 (Box plot):显示数据的分布摘要 (中位数、四分位数、均值和标准差范围)
小提琴图 (Violin plot) 或 核密度估计图 (KDE plot):显示数据分布的平滑曲线 (图中数据点左侧的曲线)
代码放文末了,大家欣赏一下
第二题
上难度,一次性复刻、输出 4 张图表
Kimi
看了下,其样例数据很简单,第四幅图没有完美复刻
Qwen-3-235B-A22B
没理解意思,且只生成了一张,出现 bug
没想到它居然还不如 kimi。。。
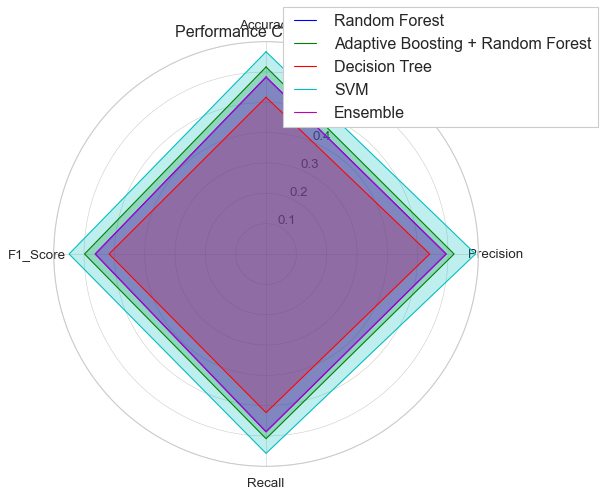
Claude-3.7-sonnet
第四幅图没有绘制成功,报错是颜色问题
让其修复颜色问题后,输出如下,第四幅图没有依然没有完美复刻
GPT-4.1
绘制失败,换了 GPT-4o 依然失败
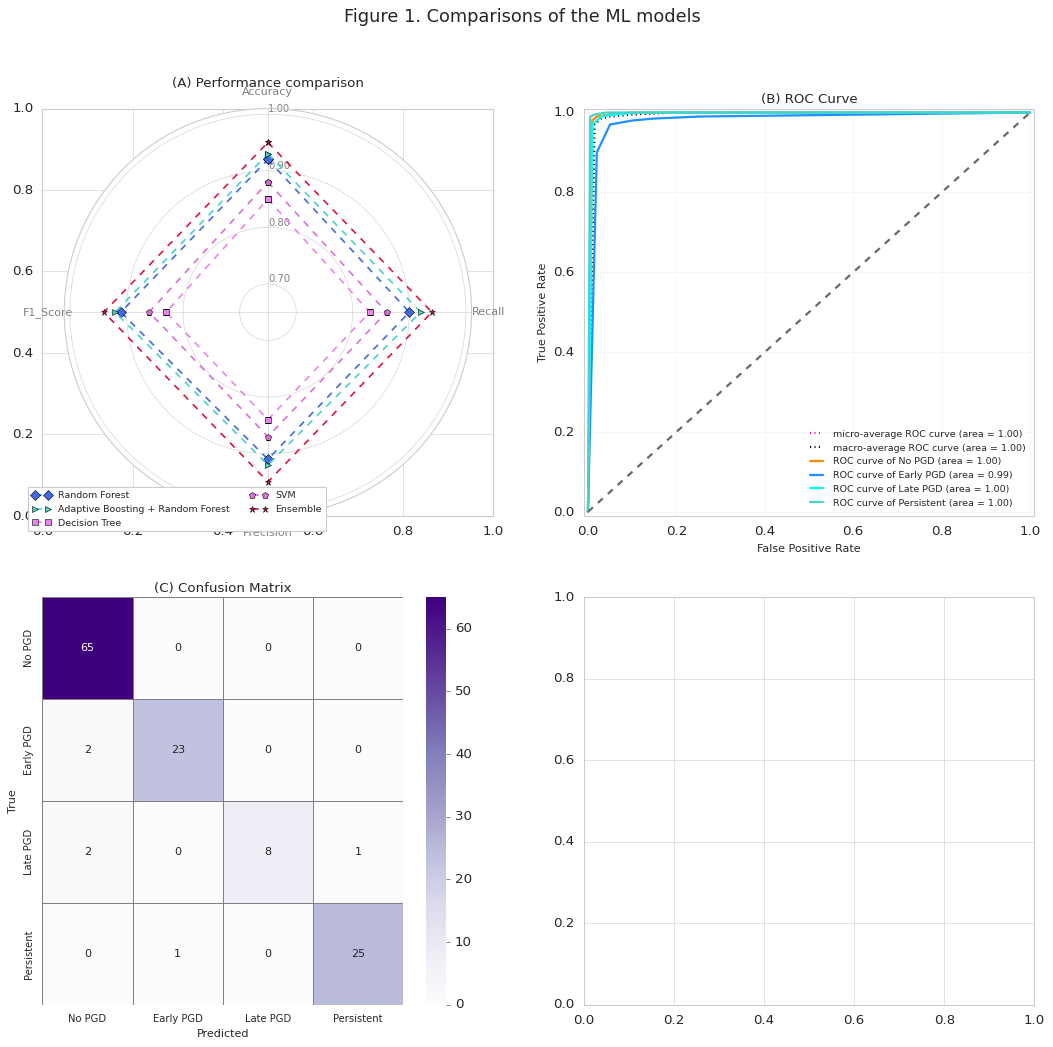
Gemini 2.5 Pro
第四张绘制失败
第三题
换个简单点的
省点事儿,直接让大模型用 R 复刻
用 R _复刻_了一张图,附代码
Kimi
复刻失败
Qwen-3-235B-A22B
还行,有点丑
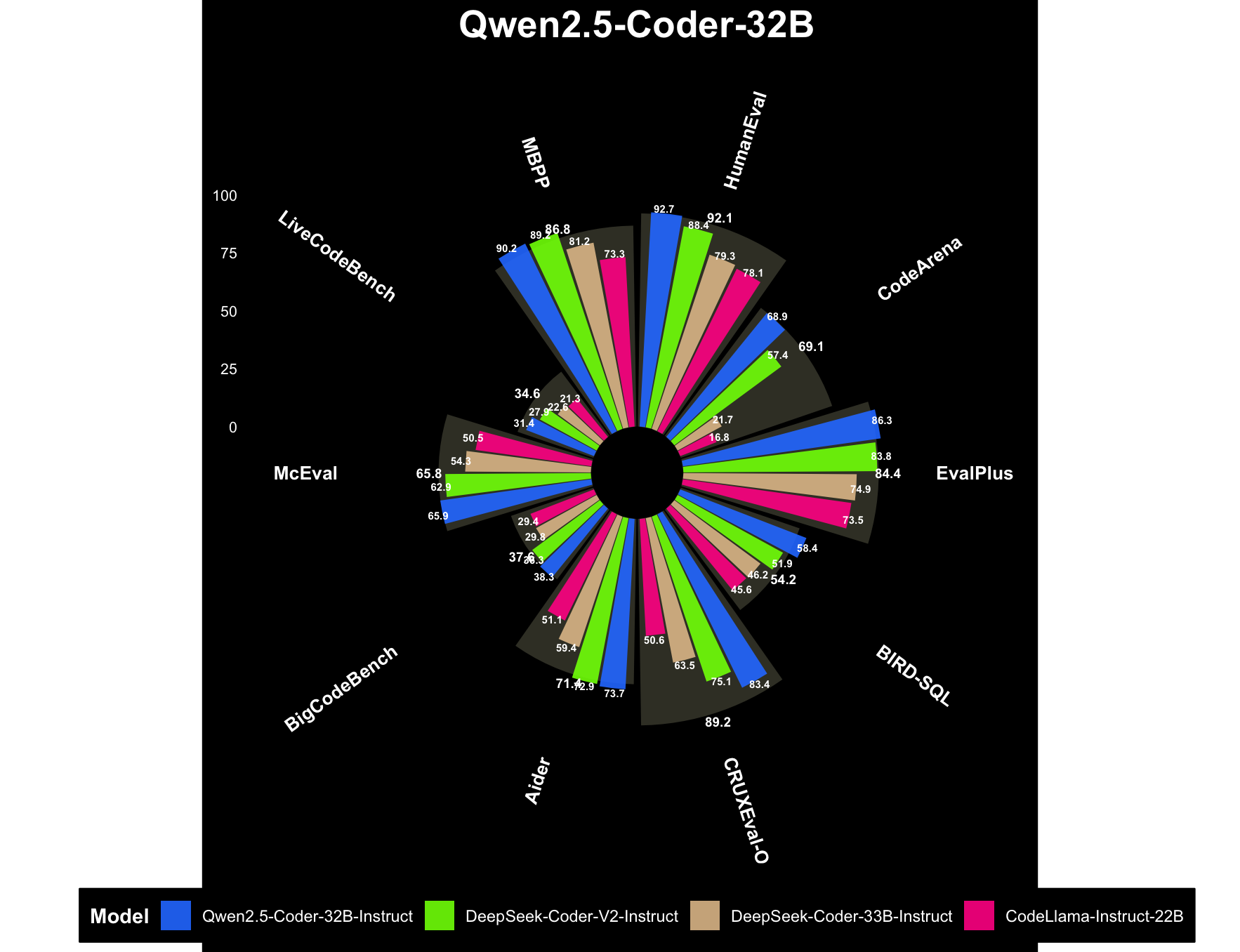
Claude-3.7-sonnet
“径向条形图”或“放射状条形图”(Radial Bar Chart)
GPT-4.1
复刻失败
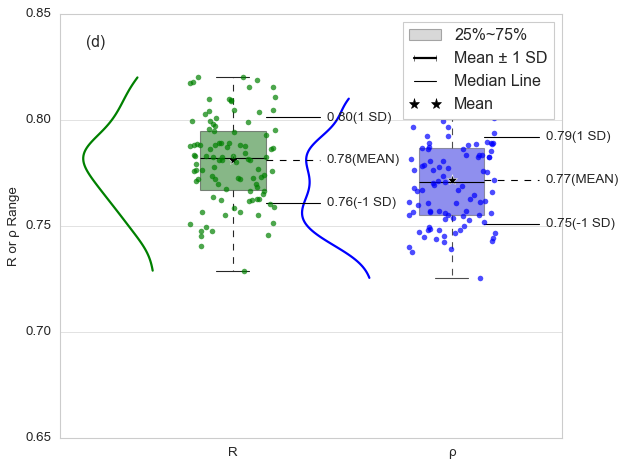
Gemini 2.5 Pro
接近完美复刻
Gemini-2.5-Pro 绘制的云雨图代码
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np# 1. 生成模拟数据
# 根据图片估算 R 和 rho 的数据特征
np.random.seed(0) # 为了结果可复现# R 的数据
r_mean = 0.78
r_std = 0.02 # 根据 1 SD 范围 (0.76-0.80) 估算
r_data = np.random.normal(loc=r_mean, scale=r_std, size=100)
# 限制数据在图中大致范围内
r_data = np.clip(r_data, 0.72, 0.82)# rho 的数据
rho_mean = 0.77
rho_std = 0.02 # 根据 1 SD 范围 (0.75-0.79) 估算
rho_data = np.random.normal(loc=rho_mean, scale=rho_std, size=100)
# 限制数据在图中大致范围内
rho_data = np.clip(rho_data, 0.70, 0.81)# 将数据整合到 Pandas DataFrame 中,方便 seaborn 处理
df_r = pd.DataFrame({'value': r_data, 'category': 'R'})
df_rho = pd.DataFrame({'value': rho_data, 'category': 'ρ'})
df_combined = pd.concat([df_r, df_rho])# 2. 绘制图表
fig, ax = plt.subplots(figsize=(8, 6))# 使用 seaborn 绘制
# 为了实现雨云图的效果,我们会组合 stripplot, boxplot, 和 violinplot (只显示一半)# 定义颜色
colors = {"R": "green", "ρ": "blue"}# 绘制 R
# 散点 (左移一点,给箱线图和 KDE 留空间)
sns.stripplot(x='category', y='value', data=df_r, order=['R'],color=colors['R'], alpha=0.7, jitter=0.2, size=5, ax=ax, dodge=True, label='_nolegend_')# 箱线图 (居中)
sns.boxplot(x='category', y='value', data=df_r, order=['R'],color=colors['R'], width=0.3, showfliers=False, ax=ax,boxprops=dict(alpha=0.5), medianprops=dict(color='black'))# 小提琴图/KDE (右移一点,只画一半)
# Seaborn 的 violinplot 可以通过 cut=0 和 inner=None 以及调整位置来实现类似效果
# 或者更精确地使用 KDE 图并手动定位
from scipy import stats
kde_r = stats.gaussian_kde(df_r['value'])
x_vals_r = np.linspace(df_r['value'].min(), df_r['value'].max(), 100)
y_vals_r = kde_r(x_vals_r)
# 将 KDE 曲线画在散点图的左边
# 需要计算合适的横坐标位置,这里简化处理,通常雨云图库会处理这个对齐
ax.plot(0 - 0.35 - y_vals_r / (y_vals_r.max()*3) , x_vals_r, color=colors['R'], lw=2) # 调整分母控制宽度# 绘制 ρ
# 散点
sns.stripplot(x='category', y='value', data=df_rho, order=['ρ'],color=colors['ρ'], alpha=0.7, jitter=0.2, size=5, ax=ax, dodge=True, label='_nolegend_')# 箱线图
sns.boxplot(x='category', y='value', data=df_rho, order=['ρ'],color=colors['ρ'], width=0.3, showfliers=False, ax=ax,boxprops=dict(alpha=0.5), medianprops=dict(color='black'))# 小提琴图/KDE for rho
kde_rho = stats.gaussian_kde(df_rho['value'])
x_vals_rho = np.linspace(df_rho['value'].min(), df_rho['value'].max(), 100)
y_vals_rho = kde_rho(x_vals_rho)
ax.plot(1 - 0.35 - y_vals_rho / (y_vals_rho.max()*3) , x_vals_rho, color=colors['ρ'], lw=2)# 3. 添加图例和标签 (类似原图)
# R 的均值和标准差标注
mean_r_val = df_r['value'].mean()
std_r_val = df_r['value'].std()
ax.plot([0 + 0.15, 0.25 + 0.15], [mean_r_val + std_r_val, mean_r_val + std_r_val], color='black', lw=1)
ax.text(0.28 + 0.15, mean_r_val + std_r_val, f'{mean_r_val + std_r_val:.2f}(1 SD)', va='center')
ax.plot([0 + 0.15, 0.25 + 0.15], [mean_r_val, mean_r_val], color='black', lw=1, linestyle='--') # 均值线 (用星号表示)
ax.plot(0, mean_r_val, marker='*', markersize=10, color='black', markeredgecolor='white') # 原图是星号
ax.text(0.28 + 0.15, mean_r_val, f'{mean_r_val:.2f}(MEAN)', va='center')
ax.plot([0 + 0.15, 0.25 + 0.15], [mean_r_val - std_r_val, mean_r_val - std_r_val], color='black', lw=1)
ax.text(0.28 + 0.15, mean_r_val - std_r_val, f'{mean_r_val - std_r_val:.2f}(-1 SD)', va='center')# ρ 的均值和标准差标注
mean_rho_val = df_rho['value'].mean()
std_rho_val = df_rho['value'].std()
ax.plot([1 + 0.15, 1.25 + 0.15], [mean_rho_val + std_rho_val, mean_rho_val + std_rho_val], color='black', lw=1)
ax.text(1.28 + 0.15, mean_rho_val + std_rho_val, f'{mean_rho_val + std_rho_val:.2f}(1 SD)', va='center')
ax.plot([1 + 0.15, 1.25 + 0.15], [mean_rho_val, mean_rho_val], color='black', lw=1, linestyle='--')
ax.plot(1, mean_rho_val, marker='*', markersize=10, color='black', markeredgecolor='white')
ax.text(1.28 + 0.15, mean_rho_val, f'{mean_rho_val:.2f}(MEAN)', va='center')
ax.plot([1 + 0.15, 1.25 + 0.15], [mean_rho_val - std_rho_val, mean_rho_val - std_rho_val], color='black', lw=1)
ax.text(1.28 + 0.15, mean_rho_val - std_rho_val, f'{mean_rho_val - std_rho_val:.2f}(-1 SD)', va='center')# 图表标题和轴标签
ax.set_ylabel('R or ρ Range')
ax.set_xlabel('') # X 轴通常不显示标签,直接用类别名
ax.set_xticks([0, 1])
ax.set_xticklabels(['R', 'ρ'])
ax.set_ylim(0.65, 0.85) # 根据原图设定
ax.text(0.05, 0.95, '(d)', transform=ax.transAxes, fontsize=14, va='top') # 子图标签# 添加图例 (模拟原图的图例)
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
legend_elements = [Patch(facecolor='grey', alpha=0.3, edgecolor='black', label='25%~75%'),Line2D([0], [0], color='black', lw=2, label='Mean ± 1 SD', marker='|', markersize=5, linestyle='-'),Line2D([0], [0], color='black', lw=1, label='Median Line'),Line2D([0], [0], marker='*', color='w', label='Mean',markerfacecolor='black', markersize=10)
]
ax.legend(handles=legend_elements, loc='upper right', bbox_to_anchor=(1.0, 1.0))plt.tight_layout()
plt.show()
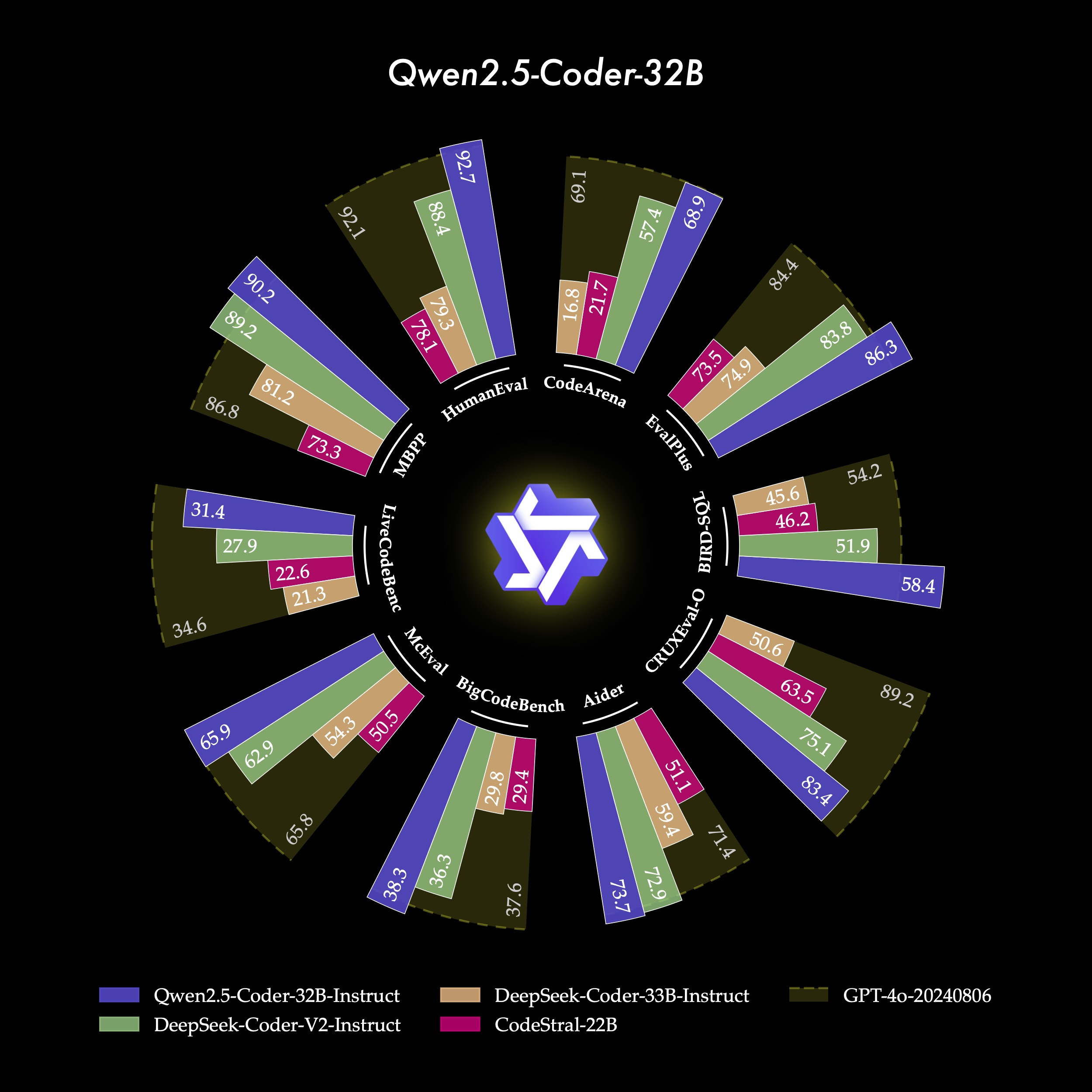
Gemini-2.5-Pro 绘制南丁格尔玫瑰图代码
# 安装和加载必要的包
# install.packages("ggplot2")
# install.packages("dplyr")
# install.packages("tidyr") # For pivot_longer if neededlibrary(ggplot2)
library(dplyr)# 1. 准备数据
# 主模型数据
model_data <- data.frame(benchmark = factor(rep(c("HumanEval", "CodeArena", "EvalPlus", "BIRD-SQL", "CRUXEval-O", "Aider", "BigCodeBench", "McEval", "LiveCodeBench", "MBPP"), each = 4),levels = c("HumanEval", "CodeArena", "EvalPlus", "BIRD-SQL", "CRUXEval-O", "Aider", "BigCodeBench", "McEval", "LiveCodeBench", "MBPP")),model = factor(rep(c("Qwen2.5-Coder-32B-Instruct", "DeepSeek-Coder-V2-Instruct", "DeepSeek-Coder-33B-Instruct", "CodeLlama-Instruct-22B"), times = 10),levels = c("Qwen2.5-Coder-32B-Instruct", "DeepSeek-Coder-V2-Instruct", "DeepSeek-Coder-33B-Instruct", "CodeLlama-Instruct-22B")),value = c(# HumanEval92.7, 88.4, 79.3, 78.1,# CodeArena68.9, 57.4, 21.7, 16.8,# EvalPlus86.3, 83.8, 74.9, 73.5,# BIRD-SQL58.4, 51.9, 46.2, 45.6,# CRUXEval-O83.4, 75.1, 63.5, 50.6,# Aider73.7, 72.9, 59.4, 51.1,# BigCodeBench38.3, 36.3, 29.8, 29.4,# McEval65.9, 62.9, 54.3, 50.5,# LiveCodeBench31.4, 27.9, 22.6, 21.3,# MBPP90.2, 89.2, 81.2, 73.3)
)# GPT-4o 背景数据 (定义每个 benchmark "轨道" 的最大值)
gpt4o_data <- data.frame(benchmark = factor(c("HumanEval", "CodeArena", "EvalPlus", "BIRD-SQL", "CRUXEval-O", "Aider", "BigCodeBench", "McEval", "LiveCodeBench", "MBPP"),levels = levels(model_data$benchmark)),value = c(92.1, 69.1, 84.4, 54.2, 89.2, 71.4, 37.6, 65.8, 34.6, 86.8)
)# 2. 定义颜色
# 顺序应与 model factor levels 对应: Blue, Green, Beige, Pink
color_palette <- c("Qwen2.5-Coder-32B-Instruct" = "#2A7FFF", # 鲜艳的蓝色"DeepSeek-Coder-V2-Instruct" = "#7CFC00", # 亮绿色/酸橙绿"DeepSeek-Coder-33B-Instruct" = "#E0C097", # 米色/浅棕"CodeLlama-Instruct-22B" = "#FF1493", # 深粉色/品红"GPT-4o-Track" = "#4A4A3B" # 暗橄榄色 (用于背景轨道)
)# 3. 创建图表
# 计算 benchmark 标签的位置
num_benchmarks <- length(levels(model_data$benchmark))
benchmark_labels_data <- data.frame(benchmark = levels(model_data$benchmark),angle = 90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2,hjust_val = ifelse( (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) < -90 | (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) > 90, 1, 0),angle_text = ifelse( (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) < -90 | (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) > 90, (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) + 180, (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) )
)
# 合并以获取 benchmark 的 x 值
benchmark_labels_data <- benchmark_labels_data %>%mutate(x_pos = as.numeric(factor(benchmark, levels = levels(model_data$benchmark))))# 调整y轴上限以容纳标签
y_axis_max <- 115 #max(c(model_data$value, gpt4o_data$value)) * 1.15p <- ggplot() +# A. 绘制 GPT-4o 背景 "轨道"# 使用 geom_col 为每个 benchmark 创建一个单独的背景条,宽度覆盖整个类别geom_col(data = gpt4o_data,aes(x = benchmark, y = value), # 使用 y = y_axis_max 来创建完整的扇区背景fill = color_palette["GPT-4o-Track"], # 使用预定义的颜色alpha = 0.8, # 透明度width = 0.95) + # 宽度,确保覆盖# B. 绘制模型数据条形geom_col(data = model_data, aes(x = benchmark, y = value, fill = model),position = position_dodge2(width = 0.9, preserve = "single"), # 分组条形width = 0.85, # 条形宽度alpha = 0.9) + # 条形透明度# C. 在 GPT-4o 轨道上添加数值标签geom_text(data = gpt4o_data,aes(x = benchmark, y = value + 4, label = sprintf("%.1f", value)), # 标签位置略高于轨道末端color = "white", size = 2.5, fontface = "bold", vjust = 0.5) +# D. 在模型数据条形上添加数值标签geom_text(data = model_data,aes(x = benchmark, y = value + 2, label = sprintf("%.1f", value), group = model),position = position_dodge2(width = 0.9, preserve = "single"),color = "white", size = 2, vjust = 0.5, hjust=0.5, fontface="bold") +# E. 应用极坐标转换coord_polar(theta = "x", start = 0, direction = 1) +# F. 设置 Y 轴范围和刻度 (半径)# 移除默认的Y轴网格线和标签,因为它们在极坐标图中通常不直观scale_y_continuous(limits = c(-20, y_axis_max), breaks = c(0, 25, 50, 75, 100), labels = c("0", "25", "50", "75", "100")) +# G. 自定义颜色scale_fill_manual(values = color_palette, name = "Model") +# H. 添加 Benchmark 标签 (X轴标签)# 使用 annotate 或 geom_text 来手动放置 benchmark 标签# 这里我们使用 scale_x_discrete 并尝试通过主题调整,但自定义 geom_text 通常效果更好geom_text(data = benchmark_labels_data,aes(x = x_pos, y = y_axis_max * 0.95, label = benchmark, angle = angle_text, hjust = hjust_val), # y值设在外部color = "white", size = 3.5, fontface = "bold") +# I. 设置主题和样式theme_minimal() +theme(plot.background = element_rect(fill = "black", color = "black"),panel.background = element_rect(fill = "black", color = "black"),panel.grid = element_blank(), # 移除主要网格线axis.title = element_blank(),axis.text.y = element_text(color = "white", size = 8), # Y轴刻度标签(半径)axis.text.x = element_blank(), # 移除默认的X轴标签,因为我们用geom_text自定义了legend.position = "bottom",legend.background = element_rect(fill = "black"),legend.title = element_text(color = "white", face = "bold"),legend.text = element_text(color = "white"),plot.title = element_text(color = "white", size = 20, hjust = 0.5, face = "bold", margin = margin(b = 20))) +# J. 添加标题ggtitle("Qwen2.5-Coder-32B")# 显示图表
print(p)制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
搭建完美的写作环境:工具篇(12 章)
图解机器学习 - 中文版(72 张 PNG)
ChatGPT、大模型系列研究报告(50 个 PDF)
108 页 PDF 小册子:搭建机器学习开发环境及 Python 基础
116 页 PDF 小册子:机器学习中的概率论、统计学、线性代数
史上最全!371 张速查表,涵盖 AI、ChatGPT、Python、R、深度学习、机器学习等
相关文章:
实测,大模型谁更懂数据可视化?
大家好,我是 Ai 学习的老章 看论文时,经常看到漂亮的图表,很多不知道是用什么工具绘制的,或者很想复刻类似图表。 实测,大模型 LaTeX 公式识别,出乎预料 前文,我用 Kimi、Qwen-3-235B-A22B、…...

小程序32-简易双向数据绑定
在WXML中,普通属性的绑定是单向的,例如:<input value"{{value}}" /> 如果希望用户输入数据的同时改变data中的数据,可以借助简易双向绑定机制。在对应属性之前添加model:前缀即可: 例如<input model:value"{{value}…...

jenkins报错java.lang.OutOfMemoryError: Java heap space
报错信息 2025-05-27 09:17:16.2340000 [id38] WARNING j.u.ErrorLoggingScheduledThreadPoolExecutor#afterExecute: failure in task not wrapped in SafeTimerTask java.lang.OutOfMemoryError: Java heap spaceat java.base/java.lang.StringUTF16.compress(StringUTF16.j…...

leetcode669.修剪二叉搜索树:递归法利用有序性精准剪枝
一、题目深度解析与BST特性应用 题目描述 给定一棵二叉搜索树(BST)和一个值区间[low, high],修剪BST使得所有节点的值都落在该区间内。修剪后的树必须保持BST的性质,且不能改变原有节点的相对位置关系。 BST的核心特性应用 二…...
)
Spring Boot 中 @RequestParam 和 @RequestPart 的区别详解(含实际项目案例)
Spring Boot 中 RequestParam 和 RequestPart 的区别详解(含实际项目案例) 在日常的 Spring Boot 开发中,我们经常会遇到表单提交、文件上传、JSON 参数绑定等需求。而在处理这类请求时,两个常见的注解——RequestParam 和 Reque…...

Linux入门(十一)进程管理
Linux 中每个执行的程序都称为一个进程,每个进程都分配一个ID号(PID) 每个进程都可能以两种方式存在,前台(屏幕上可以操作的)和后台(屏幕上无法看到的),一般系统的服务都…...

【课堂笔记】EM算法
文章目录 背景极大似然估计隐变量高斯混合模型EM算法合理性分析相关好文章背景 EM算法(期望最大化算法,Expectation-Maximization Algorithm)是一种迭代优化算法,用于在含有隐变量的概率模型中估计最大似然参数。 这是概括性的定义,下面我会解释其中的名词并用具体例子…...
)
怎样将win11+ubuntu双系统的ubuntu从机械硬盘迁移至固态硬盘(1)
将 Ubuntu 从机械硬盘迁移到固态硬盘是一个涉及多个步骤的过程。以下是一个基本的迁移指南: 1. 前期准备 1.1 备份数据: 确保你已备份数据,以防止在迁移过程中出现意外导致任何数据丢失。 1.2 固态硬盘安装: 确保固态硬盘正确…...

el-table设置自定义css
隔行变色、表头颜色 // 设置table字体颜色、背景色 .el-table {color: #ffffff;background-color: transparent !important; }设置隔行变色功能 .el-table__body {tr.el-table__row {&:nth-child(even) {td.el-table__cell {background-color: #08417f;}}&:nth-child(…...

Compose中导航跳转的实现NavHost
文章目录 1、添加依赖2、两个页面导航跳转的实现2.1 定义导航图2.2 创建导航控制器2.3 实现两个页面跳转 2、带参数的导航2.1 定义带参数的路径2.2 定义接收参数2.3 导航到带参数的屏幕 3、关键点 1、添加依赖 // build.gradle dependencies {implementation "androidx.n…...

VSCode/Cursor中Red Hat Dependency Analytics扩展的自动依赖注入files:分析
VSCode/Cursor中Red Hat Dependency Analytics扩展的自动依赖注入files:分析 问题描述 最近在使用VSCode开发时,发现一个令人困扰的问题:每次打开或保存package.json文件时,都会自动添加一个自引用的依赖项。具体表现为: {&quo…...
【技能篇】RabbitMQ消息中间件面试专题
1. RabbitMQ 中的 broker 是指什么?cluster 又是指什么? 2. 什么是元数据?元数据分为哪些类型?包括哪些内容?与 cluster 相关的元数据有哪些?元数据是如何保存的?元数据在 cluster 中是如何分布…...
Linux研学-环境搭建
一 概述 1 Linux 概述 Linux系统由内核、Shell、文件系统、应用程序及系统库等关键部分组成。内核作为核心,管理硬件资源与系统服务;Shell提供用户与系统交互的命令行界面,让用户能便捷执行操作;文件系统负责数据的存储、组织与管…...
Ubuntu系统下可执行文件在桌面单击运行教程
目录 编辑 操作环境:这个可执行文件在原目录下还有它的依赖文件 1,方法1:创建启动脚本 操作步骤: (1)在桌面创建脚本文件(如 run_main_improve.sh): …...
Linux之文件进程间通信信号
Linux之文件&进程间通信&信号 文件文件描述符文件操作重定向缓冲区一切皆文件的理解文件系统磁盘物理结构&块文件系统结构 软硬链接 进程间通信匿名管道命名管道system V共享内存 信号 文件 首先,Linux下一切皆文件。对于大量的文件,自然要…...

shell脚本打包成可以在麒麟桌面操作系统上使用的deb包
以下是将 .sh 的 shell 脚本打包成可以在麒麟桌面操作系统上使用的 .deb 包的详细步骤和分析过程: 准备工作 安装必要的工具:在麒麟桌面操作系统上,需要安装 dh-make 和 devscripts 等工具,这些工具用于生成和构建 Debian 包。打…...
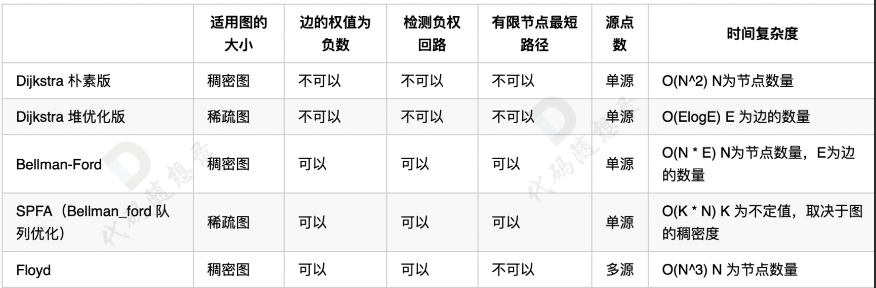
代码随想录算法训练营 Day61 图论ⅩⅠ Floyd A※ 最短路径算法
图论 题目 97. 小明逛公园 本题是经典的多源最短路问题。 在这之前我们讲解过,dijkstra朴素版、dijkstra堆优化、Bellman算法、Bellman队列优化(SPFA) 都是单源最短路,即只能有一个起点。 而本题是多源最短路,即求多…...

【Python】yield from 功能解析
yield from 功能解析 1.基本功能1.1 传统写法(手动迭代)1.2 使用 yield from 2.与普通 yield 的区别3.yield from 的底层行为4.关键应用场景场景 1:拼接多个生成器(如 gen_concatenate)场景 2:捕获子生成器…...
)
私有云大数据部署:从开发到生产(Docker、K8s、HDFS/Flink on K8s)
✅ 背景 在数据工程进入深水区后,很多企业选择将大数据平台迁移到私有云或混合云部署:一方面降低成本,另一方面增强数据安全掌控。本文将详细介绍如何在私有云中部署高可用的大数据平台,涵盖: 大数据组件的容器化 Flink on Kubernetes 部署方案 HDFS 本地/远程存储支持 运…...
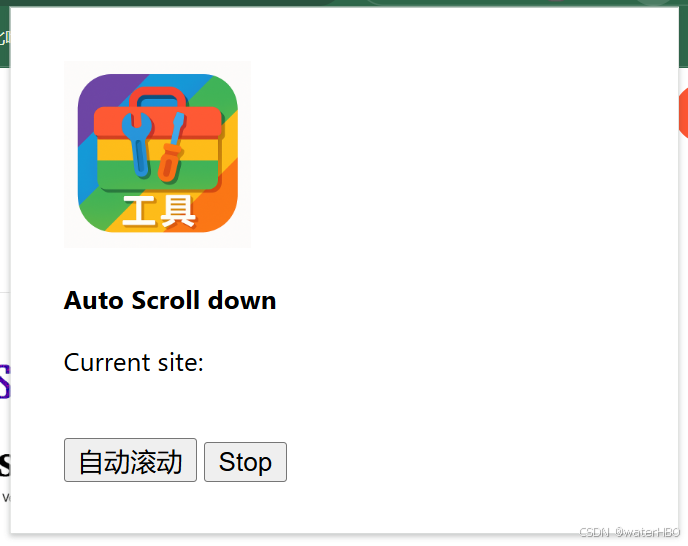
改写自己的浏览器插件工具 myChromeTools
1. 起因, 目的: 前面我写过, 自己的一个浏览器插件小工具 最近又增加一个小功能,可以自动滚动页面,尤其是对于那些瀑布流加载的网页。最新的代码都在这里 2. 先看效果 3. 过程: 代码 1, 模拟鼠标自然滚动 // 处理滚动控制逻辑…...
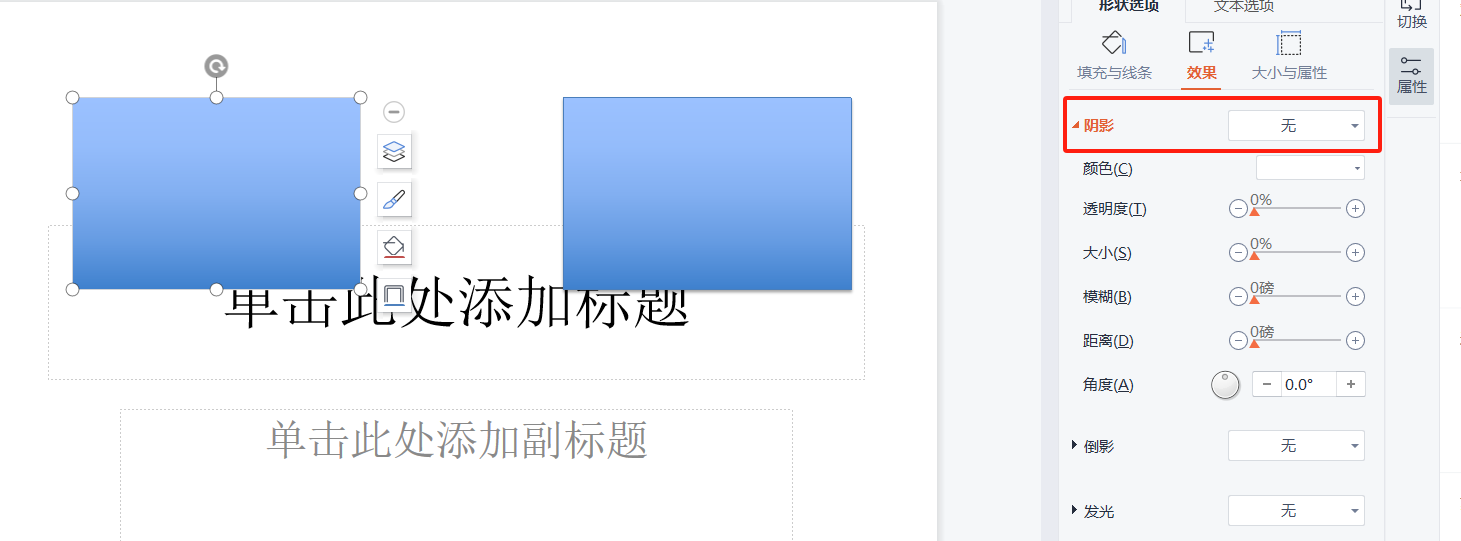
python-pptx去除形状默认的阴影
文章目录 效果原理1. 阴影继承机制解析2. XML层操作细节3. 注意事项 扩展应用1. 批量去除阴影2. 复合效果控制 效果 右边这个是直接添加一个形状。可以看到它会默认被赋予一个阴影。 然而,这个东西在特定的场合,其实是我们所不需要的。 那怎么把这个阴…...

kuboard自带ETCD存储满了处理方案
一、前言 当运行 ETCD 日志报 Erro: mvcc database space exceeded 时,说明 ETCD 存储不足了(默认 ETCD 存储是 2G),配额会触发告警,然后 Etcd 系统将进入操作受限的维护模式。 通过下面命令可以查看 ETCD 存储使用情…...

SpringBoot+tabula+pdfbox解析pdf中的段落和表格数据
一、前言 在日常业务需求中,往往会遇到解析pdf文件中的段落或者表格数据的需求。 常见的做法是使用 pdfbox 来做,但是它只能提取文本数据,没有我们在文件页面上面的那种结构化组织,文本通常是散乱的包含各种换行回车空格等格式&a…...

外包项目交付后还能怎么加固?我用 Ipa Guard 给 iOS IPA 增加了一层保障
在我们技术团队的日常工作中,接手外包开发者提交的 iOS 项目是一件常见的事。但你有没有遇到过这种情况:只交付了 IPA 文件,没有源码,也不方便追溯开发过程,但客户要求“上线前必须加一层安全防护”。 这是我们最近真…...
GitHub push失败解决办法-fatal: unable to access ‘https://github.com/xxx
问题描述: 问题解决: 1、首先查找自己电脑的代理地址和端口 windows教程如下: 1、搜索控制面板-打开Internet选项 2、点击局域网设置: 3、如图为地址和端口号 即可获得本机地址和端口号 2、根据上一步获得的本机地址和端口号为…...

USB MSC SCCI
🔍 数据包完整内容 0000 1b 00 10 09 22 8b 8b 9b ff ff 00 00 00 00 09 00 0010 00 02 00 02 00 02 03 1f 00 00 00 55 53 42 43 10 0020 09 22 8b 00 02 00 00 80 00 0a 28 00 00 00 00 00 0030 00 00 01 00 00 00 00 00 00 00 ⚙️ 一、…...

解决Acrobat印前检查功能提示无法为用户配置文件问题
转载:https://zhuanlan.zhihu.com/p/18845570057 Acrobat整理页面时往往需要用到印前检查功能中的将页面缩放为A4,可以一键统一PDF文件所有页面大小,十分快捷。 不过,最新版本的Acrobat在安装时尽管勾选了可选功能-印前检查往往…...
)
华为OD最新机试真题-反转每对括号间的子串-OD统一考试(B卷)
题目描述: 给出一个字符串s(仅含有小写英文字母和括号)。 请你按照从括号内到外的顺序,逐层反转每对匹配括号中的字符串,并返回最终的结果。注意,您的结果中不应包含任何括号。 示例1: 输入: s = “(abcd)” 输出: “dcba” 示例2:...
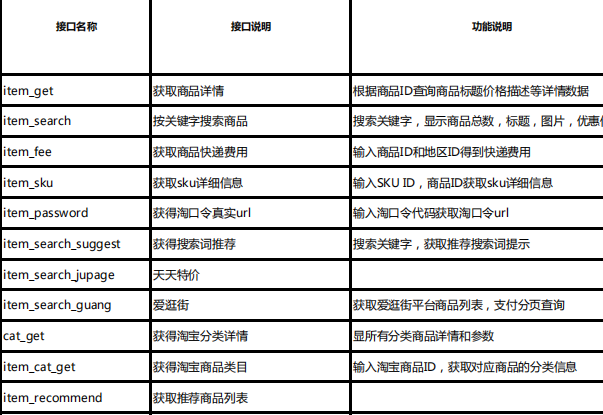
电商平台 API、数据抓取与爬虫技术的区别及优势分析
一、技术定义与核心原理 电商平台 API(应用程序编程接口) 作为平台官方提供的标准化数据交互通道,API 通过 HTTP 协议实现不同系统间的结构化数据传输。开发者需申请授权(如 API 密钥),按照文档规范调用接口…...
)
领域驱动设计 (Domain-Driven Design, DDD)
文章目录 1. 引言1.1 什么是领域驱动设计1.2 为什么需要DDD1.3 DDD适用场景 2. DDD基础概念2.1 领域(Domain)2.2 模型(Model)与领域模型(Domain Model)2.3 通用语言(Ubiquitous Language) 3. 战略设计3.1 限界上下文(Bounded Context)3.2 上下文映射(Context Mapping)3.3 大型核…...