c++流之sstream/堆or优先队列的应用[1]
目录
c++流之sstream
解释
注意事项
215.数据流的第k'大
问题分析
修正代码
主要修改点
优先队列的比较规则
代码中的比较逻辑
为什么这样能维护第 k 大元素?
举个例子
总结
Python 实现(使用heapq库)
Java 实现(使用PriorityQueue)
复杂度分析
347.前k大频率数字
复杂度分析:
代码解释:
复杂度分析:
具体规则
为什么代码中用小顶堆?
示例验证
输出结果
总结
c++流之sstream
要使用 std::istringstream,你需要包含 <sstream> 头文件。
#include <iostream>
#include <sstream> // 包含 sstream 头文件int main() {std::string input = "push 15";int number;// 使用 std::istringstream 从字符串中提取数字std::istringstream iss(input);std::string command;iss >> command >> number; // 读取命令和数字// 输出提取的数字std::cout << "Command: " << command << std::endl;std::cout << "Extracted number: " << number << std::endl;return 0;
}
![]()
引用
解释
- 包含头文件:确保包含了
<sstream>头文件,以便使用std::istringstream。 - 使用
std::istringstream:创建一个std::istringstream对象,并将输入字符串传递给它。 - 提取数据:使用
>>运算符从std::istringstream中提取数据。
注意事项
std::istringstream是一个字符串输入流,可以用于从字符串中读取数据。>>运算符用于从流中提取数据,类似于从标准输入中读取数据。
通过这种方式,你可以从字符串中提取命令和数字。
事实上 这样用到qingwen还是不行.为什么了?自己造字符串能读,他给的就不行.
我的代码
int k;cin>>n;cin>>k;string a;string command;int m;for(int i=0;i<n;i++){ cin >> a;istringstream iss(a);iss >> command >> m;cout<<command<<m;hp[i+1]=m;}// for(int i=n/2;i>=1;i--)// downAdjust(i,n);for(int i=0;i<n;i++)cout<<hp[i+1]<<(i==n-1?"":" ");输入数据
7 2 Push 1 Print Push 3 Print Push 7 Push 6 Print
你的输出
Push010Print0Push030Print0Push00 0 0 0 0 0 0
真不知道为什么,自己写了push 15 是可以识别的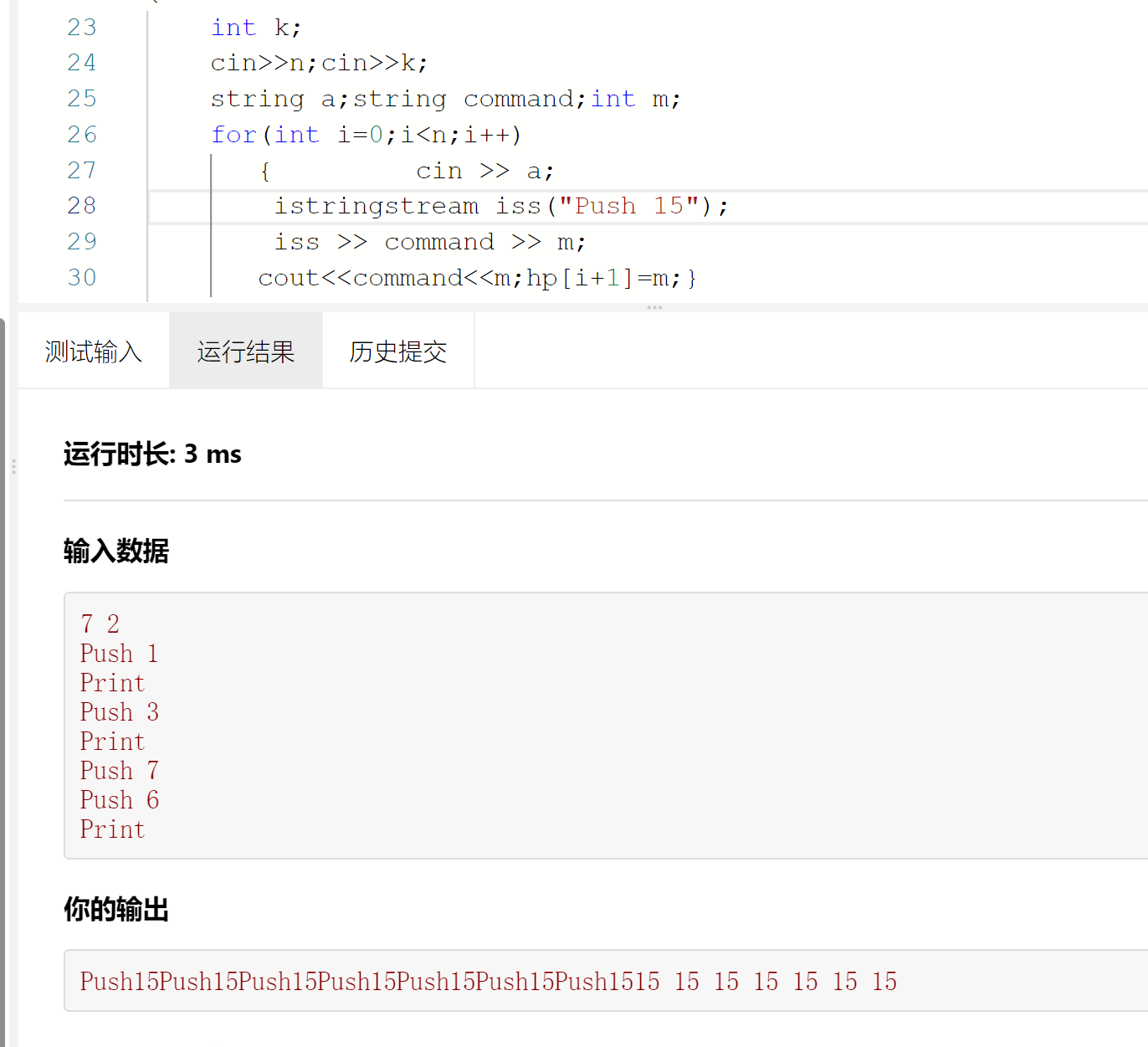
换成他的输入a瞬间就不行了 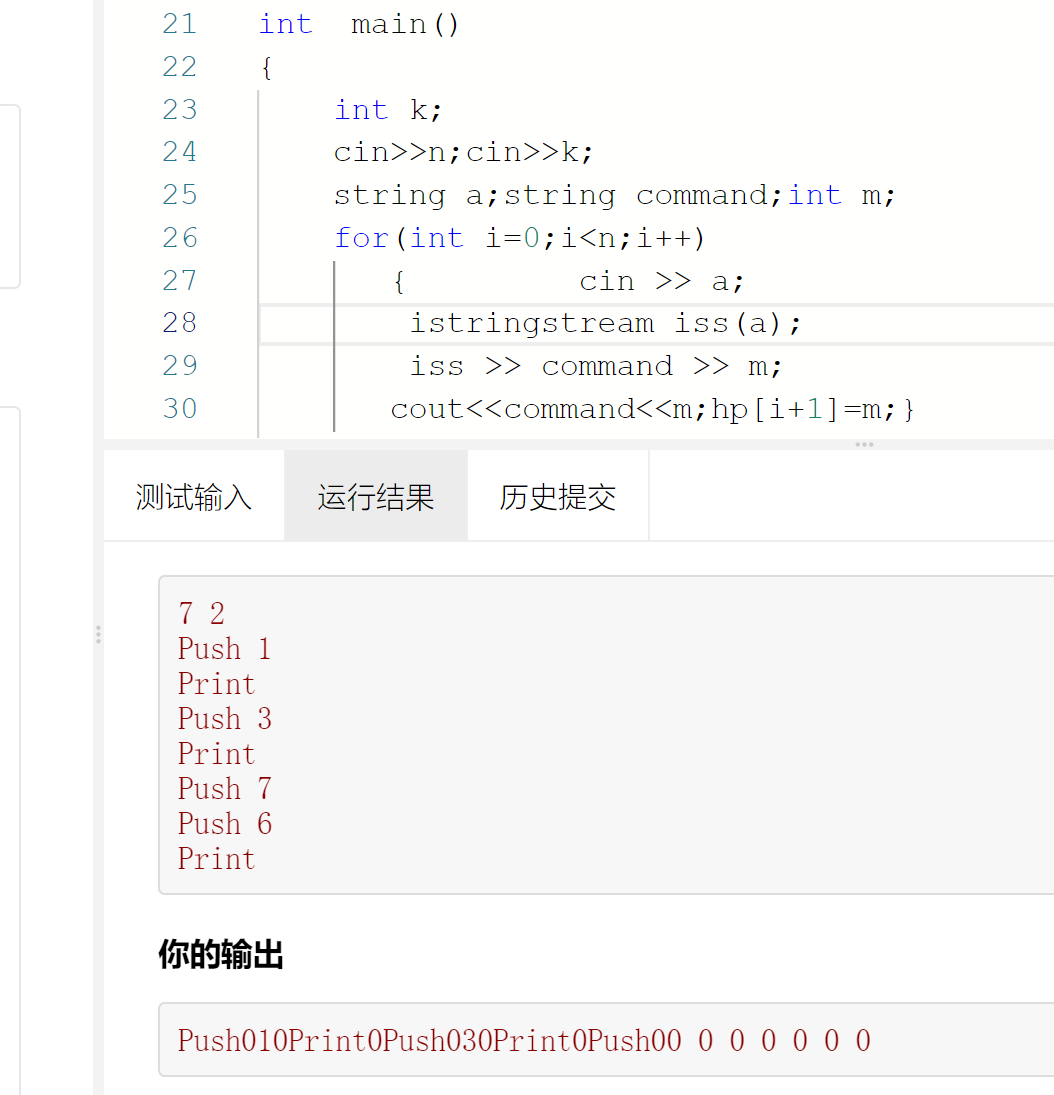
老老实实scanf吧....
215.数据流的第k'大
#include <iostream> #include <vector> #include <string> #include <queue> using namespace std; int main() { priority_queue<int, vector<int>, greater<int> > q; int n, k, x; cin >> n >> k; string action; for (int i = 0; i < n; i++) { cin >> action; if (action == "Print") { if (q.size() >= k) { cout << q.top() << endl; } else { cout << -1 << endl; } } else if (action == "Push") { cin >> x; q.push(x); if (q.size() > k) { q.pop(); } } } return 0; }这对吗
你的代码基本逻辑是正确的,但有一个小问题需要修正。
问题分析
-
功能逻辑:代码使用最小堆(优先队列)维护当前最大的 k 个元素。每次 Push 操作时,如果队列大小超过 k,则弹出最小元素;每次 Print 操作时,如果队列中有至少 k 个元素,则输出堆顶元素(即第 k 大元素),否则输出 - 1。
-
潜在问题:当 k=0 时,Push 操作会导致队列大小超过 k(变为 1),触发 pop (),但此时队列实际容量应为 0,因此不应该执行 push 操作。
修正代码
以下是修正后的完整代码:
cpp
运行
#include <iostream>
#include <vector>
#include <string>
#include <queue>
using namespace std;int main() {priority_queue<int, vector<int>, greater<int>> q;int n, k, x;cin >> n >> k;string action;for (int i = 0; i < n; i++) {cin >> action;if (action == "Print") {if (q.size() >= k) {cout << q.top() << endl;} else {cout << -1 << endl;}} else if (action == "Push") {cin >> x;// 关键修改:只有当队列当前元素不足k时才pushif (q.size() < k) {q.push(x);} else if (k > 0 && x > q.top()) {// 如果队列已满且新元素比堆顶大,则替换堆顶q.pop();q.push(x);}}}return 0;
}
主要修改点
-
Push 操作优化:
- 增加判断
if (q.size() < k)确保队列不会超过 k 个元素 - 增加
k > 0检查防止 k=0 时的非法操作 - 当队列已满时,仅当新元素大于堆顶元素才替换堆顶
- 增加判断
-
边界处理:
- 正确处理 k=0 的情况(此时 Print 始终输出 - 1,Push 不执行任何操作)
- 当 k=1 时,队列始终维护最大值
这个修正后的代码能够正确处理所有边界情况,包括 k=0 和 k=1 的特殊情况,以及元素替换逻辑。
为什么他能用队列维护最小堆?没看到他在哪大小比较了
在这段代码中,priority_queue 的比较逻辑是通过模板参数 greater<int> 指定的,这决定了队列的排序规则。让我解释一下:
优先队列的比较规则
在 C++ 中,priority_queue 的默认比较规则是 less<T>(大顶堆),但这段代码使用了:
cpp
运行
priority_queue<int, vector<int>, greater<int>> q;
这里的 greater<int> 是一个比较函数对象,它定义了元素间的顺序关系:
greater<int>会让较小的元素排在队列前面(升序)- 因此堆顶元素始终是当前队列中的最小值
- 这就实现了一个最小堆的功能
代码中的比较逻辑
虽然代码里没有显式的比较语句,但比较逻辑隐藏在 greater<int> 中:
- 每次
push(x)时,队列会自动调整,确保堆顶是最小值 - 当队列大小超过 k 时,
pop()操作会移除当前最小值(堆顶) - 因此队列始终维护着最大的 k 个元素,堆顶是这 k 个中的最小值
为什么这样能维护第 k 大元素?
- 假设我们有一个动态的数据流,每次插入元素后:
- 如果队列未满(size < k),直接插入
- 如果队列已满(size == k),且新元素比堆顶大:
- 弹出堆顶(当前最小值)
- 插入新元素
- 这样队列始终保存着最大的 k 个元素,而堆顶就是第 k 大元素
举个例子
假设 k=3,数据流是 5, 3, 7, 2, 8:
- 插入 5:队列 [5]
- 插入 3:队列 [3, 5]
- 插入 7:队列 [3, 5, 7](堆顶 3 是当前第 3 大)
- 插入 2:2 比堆顶 3 小,丢弃,队列仍为 [3, 5, 7]
- 插入 8:8 比堆顶 3 大,弹出 3,插入 8,队列变为 [5, 7, 8]
- 最终队列保存最大的 3 个元素,堆顶 5 就是第 3 大元素
总结
比较逻辑由 greater<int> 隐式实现,它确保:
- 堆顶始终是队列中的最小值
- 通过限制队列大小为 k,堆顶就是第 k 大元素
这种方法巧妙地利用了最小堆的特性,避免了显式排序,时间复杂度为 O (log k),非常高效。
要解决 “数据流中的第 K 大元素” 问题,通常可以使用 ** 最小堆(小顶堆)** 来高效实现。这种方法在维护一个大小为 K 的堆时,能保证堆顶元素始终是第 K 大的元素。以下是具体的实现思路:
- 初始化堆:创建一个最小堆,并在添加元素时保持堆的大小不超过 K。
- 添加元素:对于每个新元素,如果堆的大小小于 K,则直接加入堆;否则,比较新元素与堆顶元素的大小,若新元素更大,则替换堆顶元素并调整堆。
以下是使用 Python 和 Java 实现的代码示例:
Python 实现(使用heapq库)
python
运行
import heapqclass KthLargest:def __init__(self, k: int, nums: list[int]):self.k = kself.heap = numsheapq.heapify(self.heap) # 将列表转换为最小堆# 保持堆的大小为kwhile len(self.heap) > k:heapq.heappop(self.heap)def add(self, val: int) -> int:if len(self.heap) < self.k:heapq.heappush(self.heap, val)elif val > self.heap[0]: # 堆顶元素是当前第k大的元素heapq.heapreplace(self.heap, val)return self.heap[0] # 返回堆顶元素,即第k大的元素# 示例用法
kth_largest = KthLargest(3, [4, 5, 8, 2])
print(kth_largest.add(3)) # 输出: 4
print(kth_largest.add(5)) # 输出: 5
Java 实现(使用PriorityQueue)
java
import java.util.PriorityQueue;class KthLargest {private PriorityQueue<Integer> minHeap;private int k;public KthLargest(int k, int[] nums) {this.k = k;minHeap = new PriorityQueue<>(k);for (int num : nums) {add(num);}}public int add(int val) {if (minHeap.size() < k) {minHeap.offer(val);} else if (val > minHeap.peek()) {minHeap.poll();minHeap.offer(val);}return minHeap.peek();}public static void main(String[] args) {KthLargest kthLargest = new KthLargest(3, new int[]{4, 5, 8, 2});System.out.println(kthLargest.add(3)); // 输出: 4System.out.println(kthLargest.add(5)); // 输出: 5}
}
复杂度分析
- 时间复杂度:初始化时为 O (n log k),每次添加操作为 O (log k)。
- 空间复杂度:O (k),主要用于维护堆的大小。
这种方法通过最小堆动态维护数据流中的前 K 大元素,确保在处理海量数据时依然高效。
347.前k大频率数字
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
为了解决这个问题,我们可以使用哈希表统计元素频率,然后结合最小堆来维护前 k 高的元素。以下是具体的实现步骤:
- 统计元素频率:使用哈希表记录每个元素的出现次数。
- 维护最小堆:遍历哈希表,使用最小堆维护当前频率最高的 k 个元素。如果堆的大小超过 k,则移除频率最小的元素。
- 提取结果:最终堆中的元素即为频率前 k 高的元素。
下面是实现代码:
python
运行
from collections import Counter
import heapqdef topKFrequent(nums, k):# 统计每个元素的频率count = Counter(nums)# 使用最小堆维护前k个高频元素heap = []for num, freq in count.items():# 若堆的大小小于k,直接添加if len(heap) < k:heapq.heappush(heap, (freq, num))# 否则比较当前频率与堆顶元素频率else:if freq > heap[0][0]:heapq.heappop(heap)heapq.heappush(heap, (freq, num))# 提取堆中的元素return [num for freq, num in heap]# 示例测试
nums = [1,1,1,2,2,3]
k = 2
print(topKFrequent(nums, k)) # 输出: [1, 2]
复杂度分析:
- 时间复杂度:O (n log k),其中 n 是数组的长度。遍历数组统计频率需要 O (n) 时间,每次堆操作需要 O (log k) 时间。
- 空间复杂度:O (n),主要用于哈希表存储频率。
c++
cpp
运行
#include <vector>
#include <unordered_map>
#include <queue>
using namespace std;vector<int> topKFrequent(vector<int>& nums, int k) {// 统计每个元素的频率unordered_map<int, int> freq;for (int num : nums) {freq[num]++;}// 使用最小堆维护前k个高频元素priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> heap;for (auto& pair : freq) {heap.push({pair.second, pair.first});if (heap.size() > k) {heap.pop();}}// 提取堆中的元素vector<int> result(k);for (int i = k - 1; i >= 0; i--) {result[i] = heap.top().second;heap.pop();}return result;
}
代码解释:
- 统计频率:使用
unordered_map统计每个元素的出现次数。 - 维护最小堆:遍历频率表,将元素按频率插入最小堆(优先队列)。当堆大小超过 k 时,弹出堆顶(最小频率元素)。
- 提取结果:堆中剩余的 k 个元素即为频率前 k 高的元素,按频率从低到高提取并反转。
复杂度分析:
- 时间复杂度:O (n log k),其中 n 是数组长度。统计频率 O (n),堆操作 O (log k)。
- 空间复杂度:O (n),主要用于哈希表存储频率。
优先队列元素是pair<int,int>我怎么知道它是按哪一个优先?
在 C++ 中,当优先队列(priority_queue)的元素类型是pair<int, int>时,默认的比较规则是按第一个元素降序排列。如果第一个元素相同,则按第二个元素降序排列。这是因为pair的比较运算符默认先比较第一个元素(first),再比较第二个元素(second)。
具体规则
-
默认比较规则(大顶堆):
cpp
运行
priority_queue<pair<int, int>> heap; // 默认使用 less<pair<int, int>>- 堆顶元素是第一个元素(
first)最大的 pair - 如果多个 pair 的第一个元素相同,则取第二个元素(
second)最大的
- 堆顶元素是第一个元素(
-
自定义比较规则(小顶堆):
cpp
运行
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> heap;- 堆顶元素是第一个元素(
first)最小的 pair - 如果多个 pair 的第一个元素相同,则取第二个元素(
second)最小的
- 堆顶元素是第一个元素(
为什么代码中用小顶堆?
在之前的 Top K 高频元素代码中,我们使用了小顶堆:
cpp
运行
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> heap;
- 元素类型:
pair<int, int>中first是频率,second是元素值 - 比较规则:
greater使堆按频率升序排列(频率小的在堆顶) - 作用:每次弹出频率最小的元素,最终堆中保留频率最大的 k 个元素
示例验证
以下代码验证优先队列对pair的排序规则:
cpp
运行
#include <iostream>
#include <queue>
using namespace std;int main() {// 大顶堆(默认)priority_queue<pair<int, int>> maxHeap;maxHeap.push({3, 100}); // 频率3,元素100maxHeap.push({1, 200}); // 频率1,元素200maxHeap.push({3, 50}); // 频率3,元素50cout << "大顶堆顺序:" << endl;while (!maxHeap.empty()) {auto p = maxHeap.top();cout << "频率: " << p.first << ", 元素: " << p.second << endl;maxHeap.pop();}// 小顶堆priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> minHeap;minHeap.push({3, 100});minHeap.push({1, 200});minHeap.push({3, 50});cout << "\n小顶堆顺序:" << endl;while (!minHeap.empty()) {auto p = minHeap.top();cout << "频率: " << p.first << ", 元素: " << p.second << endl;minHeap.pop();}return 0;
}
输出结果
plaintext
大顶堆顺序:
频率: 3, 元素: 100
频率: 3, 元素: 50
频率: 1, 元素: 200小顶堆顺序:
频率: 1, 元素: 200
频率: 3, 元素: 50
频率: 3, 元素: 100
总结
在 Top K 高频元素问题中:
- 小顶堆按频率升序排列,堆顶是频率最小的元素
- 通过限制堆的大小为 k,每次弹出最小频率元素,最终堆中保留的就是前 k 大频率元素
相关文章:
c++流之sstream/堆or优先队列的应用[1]
目录 c流之sstream 解释 注意事项 215.数据流的第k大 问题分析 修正代码 主要修改点 优先队列的比较规则 代码中的比较逻辑 为什么这样能维护第 k 大元素? 举个例子 总结 Python 实现(使用heapq库) Java 实现(使用P…...
SAR ADC 比较器噪声分析(二)
SAR ADC的比较器是非常重要的模块,需要仔细设计。主要考虑比较器的以下指标: 1)失调电压 2)输入共模范围 3)比较器精度 4)传输延时 5)噪声 6)功耗 这里主要讲一下动态比较器的noise。 动态比较器一般用于高速SAR ADC中,且精度不会超过12bit…...

c#与java的相同点和不同点
C# 和 Java 是两大主流的、面向对象的、托管型编程语言,它们共享许多相似的设计理念和语法,但也在细节、生态系统和运行平台上存在显著差异。以下是它们的相同点和不同点的详细对比: 一、相同点 (核心相似之处) 语法高度相似: 都源…...

phpmyadmin
安装PHPMyAdmin PHPMyAdmin通常可通过包管理器安装或手动部署。对于Linux系统(如Ubuntu),使用以下命令安装: sudo apt update sudo apt install phpmyadmin安装过程中会提示选择Web服务器(如Apache或Nginx࿰…...
机器学习Day5-模型诊断
实现机器学习算法的技巧。当我们训练模型或使用模型时,发现预测误差很 大,可以考虑进行以下优化: (1)获取更多的训练样本 (2)使用更少的特征 (3)获取其他特征 ÿ…...

如何将 WSL 的 Ubuntu-24.04 迁移到其他电脑
在使用 Windows Subsystem for Linux (WSL) 时,我们可能会遇到需要将现有的 WSL 环境迁移到其他电脑的情况。无论是为了备份、更换设备,还是在不同电脑之间共享开发环境,掌握迁移 WSL 子系统的方法都是非常有用的。本文将以 Ubuntu-24.04 为例…...

金融欺诈有哪些检测手段
金融欺诈检测是一个多层次的动态防御过程,需要结合技术手段、数据分析、人工智能和人工审核。以下是当前主流的检测手段和技术分类。 ### **一、核心技术手段** 1. **规则引擎(Rule-Based Systems)** - **原理**:预设基于历史…...

HTML5 全面知识点总结
一、HTML 基础概念 HTML:超文本标记语言,用于创建网页和 Web 应用的结构。 超文本:可以包含文字、图片、音频、视频、链接等多种媒体。 标记语言:通过标签标记网页的各个部分。 二、HTML5 的新特性(区别于 HTML4&am…...
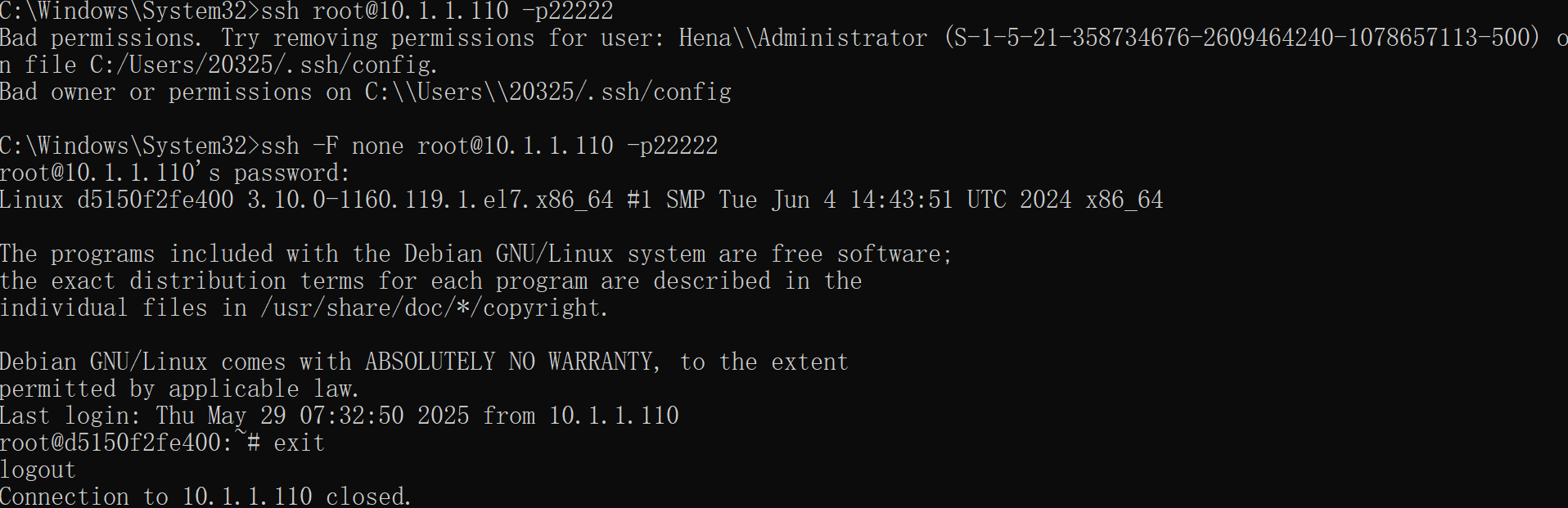
vscode一直连接不上虚拟机或者虚拟机容器怎么办?
1. 检查并修复文件权限 右键点击 C:\Users\20325\.ssh\config 文件,选择 属性 → 安全 选项卡。 确保只有你的用户账户有完全控制权限,移除其他用户(如 Hena\Administrator)的权限。 如果 .ssh 文件夹权限也有问题,同…...

初学c语言21(文件操作)
一.为什么使用文件 之前我们写的程序的数据都是存储到内存里面的,当程序结束时,内存回收,数据丢失, 再次运行程序时,就看不到上次程序的数据,如果要程序的数据一直保存得使用文件 二.文件 文件一般可以…...

数学复习笔记 21
4.15 稍微有点难啊。克拉默法则忘掉了,然后第二类数学归纳法是第一次见。行列式和矩阵,向量和方程组。这是前面四章。现在考研只剩下一个大题。所以就是考最后两章,特征值和二次型。感觉看网课的作用就是辅助理解,自己看书的话&am…...

华为OD机试真题——数据分类(2025B卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 B卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C++、C语言、GO六种语言的最佳实现方式! 本文收录于专栏:《2025华为OD真题目录+全流程解析/备考攻略/经验分享》 华为OD机试真题《数据…...
JavaWeb开发基础Servlet生命周期与工作原理
Servlet生命周期 Servlet的生命周期由Servlet容器(如Tomcat、Jetty等)管理,主要包括以下5个阶段: 加载Servlet类 创建Servlet实例 调用init方法 调用service方法 调用destroy方法 加载(Loading): 当Servlet容器启动或第一次接收到对某个…...

三防平板科普:有什么特殊功能?应用在什么场景?
在数字化浪潮席卷全球的今天,智能设备已成为现代工业、应急救援、户外作业等领域的核心工具。然而,常规平板电脑在极端环境下的脆弱性,如高温、粉尘、水浸或撞击,往往成为制约效率与安全的短板。三防平板(防水、防尘、…...

百度外链生态的优劣解构与优化策略深度研究
本文基于搜索引擎算法演进与外链建设实践,系统剖析百度外链的作用机制与价值模型。通过数据统计、案例分析及算法逆向工程,揭示不同类型外链在权重传递、流量获取、信任背书等维度的差异化表现,提出符合搜索引擎规则的外链建设技术方案&#…...

笔记: 在WPF中ContentElement 和 UIElement 的主要区别
一、目的:简要姐扫在WPF中ContentElement 和 UIElement 的主要区别 ContentElement 和 UIElement 是 WPF 中的两个基类,它们在功能和用途上有显著的区别。 二、主要区别 ContentElement 主要特点: • 没有视觉表示: ContentElement 本身不直接渲染任…...

项目中使用到了多个UI组件库,也使用了Tailwindcss,如何确保新开发的组件样式隔离?
在项目中使用多个组件库,同时使用 TailwindCSS,确保新开发的组件样式隔离是非常重要的。样式隔离可以避免样式冲突、全局污染以及意外的样式覆盖问题。以下是一些常见的策略和最佳实践: 1. 使用 TailwindCSS 的 layer 机制 TailwindCSS 提供…...
高级技巧详解)
AI提示工程(Prompt Engineering)高级技巧详解
AI提示工程(Prompt Engineering)高级技巧详解 文章目录 一、基础设计原则二、高级提示策略三、输出控制技术四、工程化实践五、专业框架应用提示工程是与大型语言模型(LLM)高效交互的关键技术,精心设计的提示可以显著提升模型输出的质量和相关性。以下是经过验证的详细提示工…...
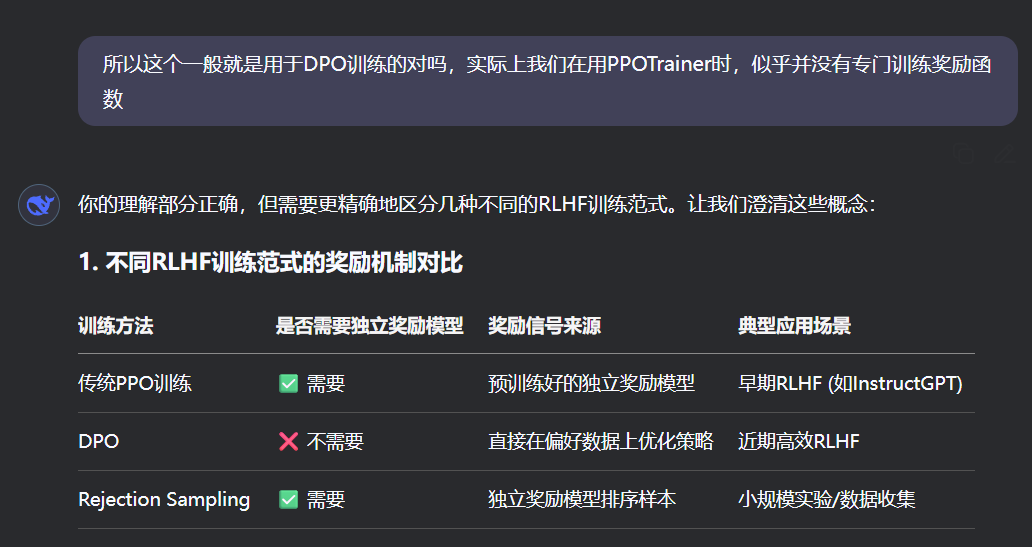
【速写】PPOTrainer样例与错误思考(少量DAPO)
文章目录 序言1 TRL的PPO官方样例分析2 确实可行的PPOTrainer版本3 附录:DeepSeek关于PPOTrainer示例代码的对话记录Round 1(给定模型数据集,让它开始写PPO示例)Round 2 (指出PPOTrainer的参数问题)关键问题…...
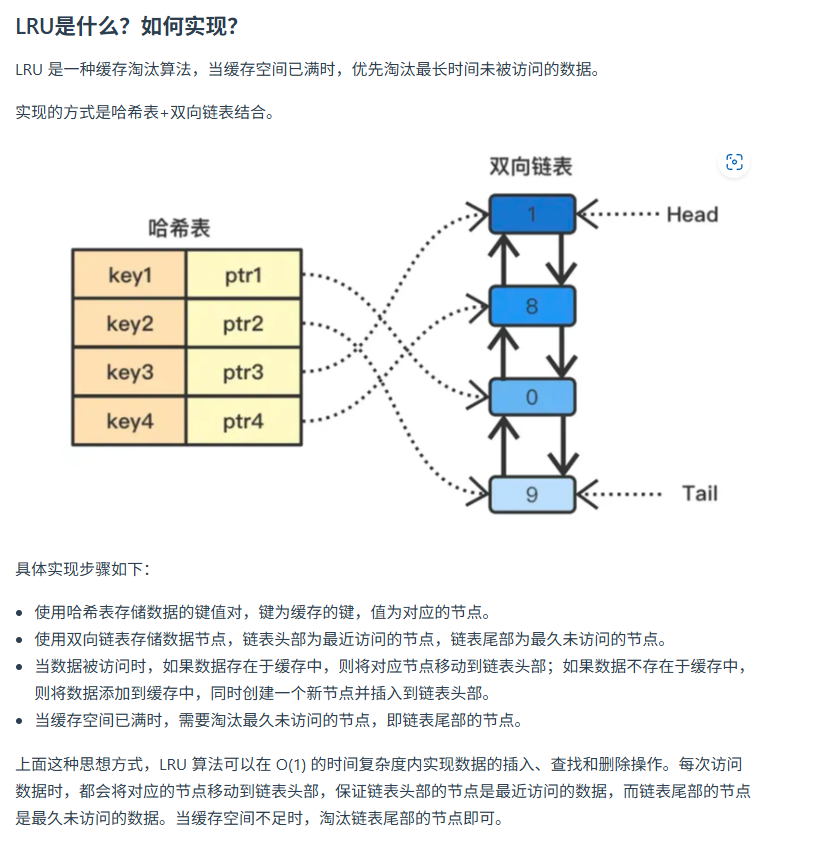
5.26 面经整理 360共有云 golang
select … for update 参考:https://www.cnblogs.com/goloving/p/13590955.html select for update是一种常用的加锁机制,它可以在查询数据的同时对所选的数据行进行锁定,避免其他事务对这些数据行进行修改。 比如涉及到金钱、库存等。一般这…...

中国移动咪咕助力第五届全国人工智能大赛“AI+数智创新”专项赛道开展
第五届全国人工智能大赛由鹏城实验室主办,新一代人工智能产业技术创新战略联盟承办,华为、中国移动、鹏城实验室科教基金会等单位协办,广东省人工智能与机器人学会支持。 大赛发布“AI图像编码”、“AI增强视频质量评价”、“AI数智创新”三大…...

模具制造业数字化转型:精密模塑,以数字之力铸就制造基石
模具被誉为 “工业之母”,是制造业的重要基石,其精度直接决定了工业产品的质量与性能。在工业制造向高精度、智能化发展的当下,《模具制造业数字化转型:精密模塑,以数字之力铸就制造基石》这一主题,精准点明…...

PECVD 生成 SiO₂ 的反应方程式
在PECVD工艺中,沉积氧化硅薄膜以SiH₄基与TEOS基两种工艺路线为主。 IMD Oxide(USG) 这部分主要沉积未掺杂的SiO₂,也叫USG(Undoped Silicate Glass),常用于IMD(Inter-Metal Diele…...

React与Vue核心区别对比
React 和 Vue 都是当今最流行、功能强大的前端 JavaScript 框架,用于构建用户界面。它们有很多相似之处(比如组件化、虚拟 DOM、响应式数据绑定),但也存在一些核心差异。以下是它们的主要区别: 1. 核心设计与哲学 Rea…...
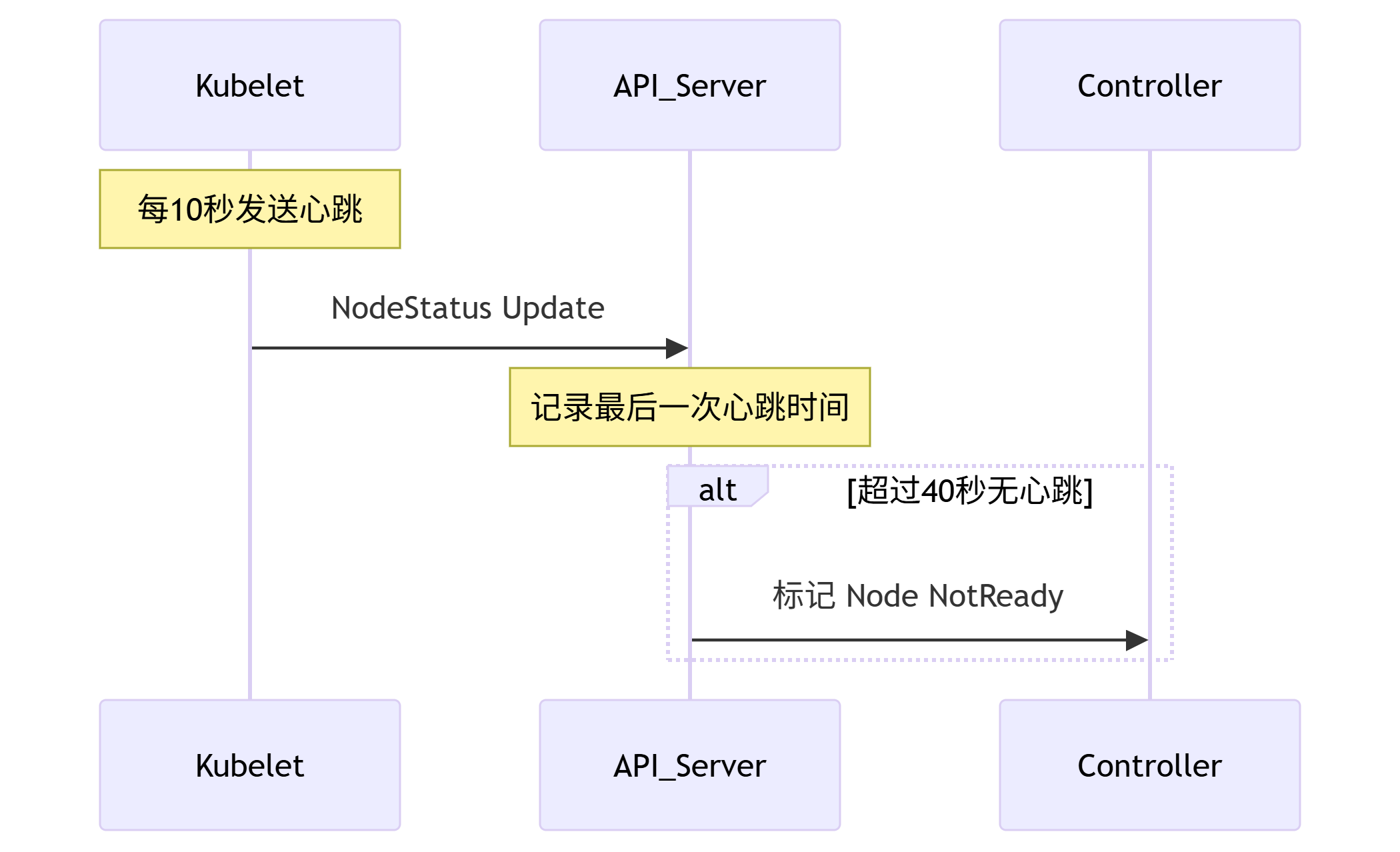
2024 CKA模拟系统制作 | Step-By-Step | 17、题目搭建-排查故障节点
目录 免费获取题库配套 CKA_v1.31_模拟系统 一、题目 二、考点分析 1. Kubernetes 节点状态诊断 2. 节点故障修复技能 3. 持久化修复方案 4. SSH 特权操作 三、考点详细讲解 1. 节点状态机制详解 2. 常见故障原因深度分析 3. 永久修复技术方案 四、实验环境搭建步骤…...

如何将图像插入 PDF:最佳工具比较
无论您是编辑营销材料、写报告还是改写原来的PDF文件,将图像插入 PDF 都至关重要。幸运的是,有多种在线和离线工具可以简化此任务。在本文中,我们将比较一些常用的 PDF 添加图像工具,并根据您的使用场景推荐最佳解决方案ÿ…...

Linux 文件 IO 性能监控与分析指南
Linux 文件 I/O 性能监控与分析指南 继 CPU 和网络之后,文件系统 I/O 是影响系统性能的第三大关键领域。无论是数据库响应缓慢、应用加载时间过长,还是日志写入延迟,其根源都可能指向磁盘 I/O 瓶颈。本章将深入探讨文件 I/O 的核心概念、监控…...

ABP VNext + Apache Flink 实时流计算:打造高可用“交易风控”系统
ABP VNext Apache Flink 实时流计算:打造高可用“交易风控”系统 🌐 📚 目录 ABP VNext Apache Flink 实时流计算:打造高可用“交易风控”系统 🌐一、背景🚀二、系统整体架构 🏗️三、实战展示…...

前端面试题-HTML篇
1. 请谈谈你对 Web 标准以及 W3C 的理解和认识。 我对 Web 标准 的理解是,它就像是互联网世界的“交通规则”,由 W3C(World Wide Web Consortium,万维网联盟) 这样一个国际性组织制定。这些规则规范了我们在编写 HTML…...
 与扩展运算符的深度解析与最佳实践)
JS数组 concat() 与扩展运算符的深度解析与最佳实践
文章目录 前言一、语法对比1. Array.prototype.concat()2. 扩展运算符(解构赋值) 二、性能差异(大规模数组)关键差异原因 三、适用场景建议总结 前言 最近工作中遇到了一个大规模数组合并相关的问题,在数据合并时有些…...