【EdgeYOLO】《EdgeYOLO: An Edge-Real-Time Object Detector》

Liu S, Zha J, Sun J, et al. EdgeYOLO: An edge-real-time object detector[C]//2023 42nd Chinese Control Conference (CCC). IEEE, 2023: 7507-7512.
CCC-2023
源码:https://github.com/LSH9832/edgeyolo
论文:https://arxiv.org/pdf/2302.07483
文章目录
- 1、Background and Motivation
- 2、Related Work
- 3、Advantages / Contributions
- 4、Method
- 4.1、Enhanced-Mosaic & Mixup
- 4.2、Lite-Decoupled Head
- 4.3、Staged Loss Function
- 5、Experiments
- 5.1、Datasets and Metrics
- 5.2、Results & Comparison
- 5.3、Ablation Study
- 5.4、Tricks for Edge Computing Devices
- 6、Conclusion(own) / Future work
1、Background and Motivation
- 边缘计算设备的需求增长
- 现有物体检测器的局限性(传统的两阶段物体检测器(如R-CNN系列)虽然在精度上表现较好,但由于其复杂的结构和较高的计算需求,难以在边缘设备上实现实时运行。而一些轻量级的一阶段检测器(如MobileNet和ShuffleNet)虽然能在边缘设备上运行,但往往以牺牲精度为代价。)
- YOLO系列算法的发展(随着YOLO系列版本的更新,虽然精度不断提高,但在边缘设备上的实时性能却难以保证)
- 小物体检测的挑战
- 在设计和评估物体检测器时,考虑整个检测任务的完整性,包括预处理、模型推理和后处理时间,以确保在边缘设备上实现真正的实时性能。
This paper proposes an efficient, low-complexity and anchor-free object detector based on the state-of-the-art YOLO framework, which can be implemented in real time on edge computing platforms
2、Related Work
- Anchor-free Object Detector
- anchor-point-based(本文)
- keypoint-based
- Data Augmentation
- geometric augmentation
- photometric augmentation(eg HSV & brightness adjustment)
- Model Reduction
- lossy reduction(有损压缩,builds smaller networks)
- lossless reduction(无损压缩,eg re-parameterizing techniques)
- Decoupled Regression
- different tasks use the same convolution kernel if they are closely related. However, relations between the object’s location, confidence and category are not close enough in numerical logic
- 优点,accelerate the loss convergence
- 缺点, brings extra inference costs.
- Small Object Detecting Optimization
- 小目标信息有限
- small objects always account for a less proportion of loss in total loss while training
- 解决方式:(1)replication augmentation, (2)zoomed(指的是大目标缩小成小目标,提高了小目标的占比) and spliced, (3)Loss function
- 解决方式(1)的缺点:scale mismatch and background mismatch,本文作者探索的是(2)(3)
3、Advantages / Contributions
- anchor-free object detector is designed——EdgeYOLO
- a more powerful data augmentation method is proposed(ensures the quantity and validity of training data)
- 设计了轻量级的解耦头结构,Structures that can be re-parameterized are used(减少推理时间)
- A loss function is designed to improve the precision on small objects.
- 在公开数据集上取得了优异性能
- 开源了代码和模型权重
- 多进程/多线程计算架构等优化技巧,进一步提高了EdgeYOLO在边缘设备上的实时性能。
4、Method
4.1、Enhanced-Mosaic & Mixup

还是 mosaic 和 mixup 的混搭,作者 mosaic 的时候做了个分组,然后 mixup,group = 2(the group number can be set according to the richness of the average number of labels in a single picture in the dataset.)
看论文的描述没有 get 到作者的意思,举得例子也仅仅是图片中数量上的差异导致的区别

是提高了 mosaic 的图片数量吗?比如原来 4 张,现在 8 张?
4.2、Lite-Decoupled Head

基于 FCOS 的decouple head 进行了轻量化改进,引入了 re-parameterization 技术(推理的时候部分结构合并到一起)和 implicit konwledge 技术
With the method of re-parameterizing, implicit representation layers are integrated into convolutional layers for lower inference costs.
implicit konwledge 出自
Wang C Y, Yeh I H, Liao H Y M. You only learn one representation: Unified network for multiple tasks[J]. arXiv preprint arXiv:2105.04206, 2021.


yolov7 中也采用了这个技术
【YOLOv7】《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》
4.3、Staged Loss Function
整体 loss 结构, L Δ L_{\Delta} LΔ 是 regulation loss

loss 分为三个阶段,每个阶段不一致
第一阶段
gIOU loss for IOU loss, Balanced Cross Entropy loss for classification loss and object loss, regulation loss 被设置为 0
第二阶段
at the last few data-augmentation-enabled epochs
分类和目标损失采用的是 Hybrid-Random Loss,应该是作者原创,没有看到列出的参考文献

基于交叉熵损失的改进
第三阶段
close data augmentation
set L1 loss as our regulation loss, and replace gIOU loss by cIOU loss
5、Experiments
训练时网络配置参数
默认参数
# models & weights------------------------------------------------------------------------------------------------------
model_cfg: "params/model/edgeyolo.yaml" # model structure config file
weights: "output/train/edgeyolo_coco/last.pth" # contains model_cfg, set null or a no-exist filename if not use it
use_cfg: false # force using model_cfg instead of cfg in weights to build model# output----------------------------------------------------------------------------------------------------------------
output_dir: "output/train/edgeyolo_coco" # all train output file will save in this dir
save_checkpoint_for_each_epoch: true # save models for each epoch (epoch_xxx.pth, not only best/last.pth)
log_file: "log.txt" # log file (in output_dir)# dataset & dataloader--------------------------------------------------------------------------------------------------
dataset_cfg: "params/dataset/coco.yaml" # dataset config
batch_size_per_gpu: 8 # batch size for each GPU
loader_num_workers: 4 # number data loader workers for each GPU
num_threads: 1 # pytorch threads number for each GPU# device & data type----------------------------------------------------------------------------------------------------
device: [0, 1, 2, 3] # training device list
fp16: false # train with fp16 precision
cudnn_benchmark: false # it's useful when multiscale_range is set zero# train hyper-params----------------------------------------------------------------------------------------------------
optimizer: "SGD" # or Adam
max_epoch: 300 # or 400
close_mosaic_epochs: 15 # close data augmentation at last several epochs# learning rate---------------------------------------------------------------------------------------------------------
lr_per_img: 0.00015625 # total_lr = lr_per_img * batch_size_per_gpu * len(devices)
warmup_epochs: 5 # warm-up epochs at the beginning of training
warmup_lr_ratio: 0.0 # warm-up learning rate start from value warmup_lr_ratio * total_lr
final_lr_ratio: 0.05 # final_lr_per_img = final_lr_ratio * lr_per_img# training & dataset augmentation---------------------------------------------------------------------------------------
# [cls_loss, conf_loss, iou_loss]
loss_use: ["bce", "bce", "giou"] # bce: BCE loss. bcf: Balanced Focal loss. hyb: HR loss, iou, c/g/s iou is available
input_size: [640, 640] # image input size for model
multiscale_range: 5 # real_input_size = input_size + randint(-multiscale_range, multiscale_range) * 32
weight_decay: 0.0005 # optimizer weight decay
momentum: 0.9 # optimizer momentum
enhance_mosaic: true # use enhanced mosaic method
use_ema: true # use EMA method
enable_mixup: true # use mixup
mixup_scale: [0.5, 1.5] # mixup image scale
mosaic_scale: [0.1, 2.0] # mosaic image scale
flip_prob: 0.5 # flip image probability
mosaic_prob: 1 # mosaic probability
mixup_prob: 1 # mixup probability
degrees: 10 # maximum rotate degrees
hsv_gain: [0.0138, 0.664, 0.464] # hsv gain ratio# evaluate--------------------------------------------------------------------------------------------------------------
eval_at_start: false # evaluate loaded model before training
val_conf_thres: 0.001 # confidence threshold when doing evaluation
val_nms_thres: 0.65 # NMS IOU threshold when doing evaluation
eval_only: false # do not train, run evaluation program only for all weights in output_dir
obj_conf_enabled: true # use object confidence when doing inference
eval_interval: 1 # evaluate interval epochs# show------------------------------------------------------------------------------------------------------------------
print_interval: 100 # print result after every $print_interval iterations# others----------------------------------------------------------------------------------------------------------------
load_optimizer_params: true # load optimizer params when resume train, set false if there is an error.
train_backbone: true # set false if you only want to train yolo head
train_start_layers: 51 # if not train_backbone, train from this layer, see params/models/edgeyolo.yaml
force_start_epoch: -1 # set -1 to disable this option
5.1、Datasets and Metrics
- VisDrone2019-DET dataset:https://github.com/VisDrone/VisDrone-Dataset
- MS COCO2017
metric 是 COCO 数据集的 mAP
5.2、Results & Comparison
baseline 是 yolov7 的 ELAN-Darknet

作者的方法在小目标上的提升尤为明显
VisDrone 数据上的模型 pre-trained on MS COCO2017-train.
FPS 在 device Jetson AGX Xavier 测试得到的
5.3、Ablation Study
(1)Decoupled head

改进后又快又好
(2)Segmentation labels (poor effect)
旋转增广后 bbox 可能框的没有那么准(由于bbox没有角度平行于边界导致),作者用分割的标签辅助生成旋转后的 bbox,不会产生 contain more invalid background information 的现象了
When the data augmentation is enabled and the loss enters a stable decline phase, using segmentation labels can bring a significant increase by 2% - 3% AP.
训练末期的时候,关掉了数据增强, all labels become more accurate,even if the segmentation labels are not used, the final accuracy decreases only by about 0.04% AP(这说明 bbox 没有 segmentation 的标签准???)
(3)Loss function

To sum up, a better precision can be obtained by using HR loss and cIOU loss in later training stages
5.4、Tricks for Edge Computing Devices
(1)Input size adaptation.
训练的时候 640x640,部署的时候适配 device 的尺寸,4:3 or 16:9,可以显著提速

(2)Multi-process & multi-thread computing architecture
用多线程或者多进程来提速网络运行时的三个阶段
pre-process, model input and post-process
achieve about 8%-14% FPS increase.
可视化的结果展示


6、Conclusion(own) / Future work
- pre-process, model inference and post-process
- edge computing device
- time latency in post-processing is almost proportional to the number of anchors of each grid cell
- Decouple,However, relations between the object’s location, confidence and category are not close enough in numerical logic
- Multi-process & multi-thread computing architecture
- we believe that the framework can be extended to other pixel level recognition tasks such as instance segmentation
- Jetson AGX Xavier


更多论文解读,请参考 【Paper Reading】
相关文章:
【EdgeYOLO】《EdgeYOLO: An Edge-Real-Time Object Detector》
Liu S, Zha J, Sun J, et al. EdgeYOLO: An edge-real-time object detector[C]//2023 42nd Chinese Control Conference (CCC). IEEE, 2023: 7507-7512. CCC-2023 源码:https://github.com/LSH9832/edgeyolo 论文:https://arxiv.org/pdf/2302.07483 …...

Python打卡 DAY 38
知识点回顾: Dataset类的__getitem__和__len__方法(本质是python的特殊方法)Dataloader类minist手写数据集的了解 作业:了解下cifar数据集,尝试获取其中一张图片 import torch import torch.nn as nn import torch.opt…...
调试技巧总结
目录 一.调试1.什么是调试2.调试语义的分类2.1 静态语义2.2 动态语义 二.实用的调试技巧1.屏蔽代码2.借助打印3.查看汇编代码4.调试技巧总结 一.调试 1.什么是调试 调试,通俗易懂地说就是不断排查代码的错误,进行修正的过程,在写代码的时候…...

ubuntu安装blender并配置应用程序图标
ubuntu安装blender并配置应用程序图标 下载blender安装包解压缩并安装启动blender添加应用程序启动图标 下载blender安装包 blender中文服务站的下载网址 这里选择Linux 64位的Blender 4.2.4 LTS。下载速度很快。下载得到 解压缩并安装 将下载的压缩包放在/opt目录下&#…...
基于LBS的上门代厨APP开发全流程解析
上门做饭将会取代外卖行业成为新一轮的创业风口吗?杭州一位女士的3菜一汤88元套餐引爆社交网络,这个包含做饭、洗碗、收拾厨房的全套服务,正在重新定义"到家经济"的边界。当25岁的研究生系着围裙出现在客户厨房,当年轻姑…...

Redisson学习专栏(三):高级特性与实战(Spring/Spring Boot 集成,响应式编程,分布式服务,性能优化)
文章目录 前言一、Spring Boot深度整合实战1.1 分布式缓存管理1.2 声明式缓存1.3 响应式编程 二、分布式服务治理2.1 服务端实现2.2 客户端调用2.3 高级特性2.4 服务治理功能 三、分布式任务调度引擎四、连接池配置与网络参数调优4.1 连接池配置4.2 网络参数调优4.3 集群模式特…...
华为欧拉系统中部署FTP服务与Filestash应用:实现高效文件管理和共享
华为欧拉系统中部署FTP服务与Filestash应用:实现高效文件管理和共享 前言一、相关服务介绍1.1 Huawei Cloud EulerOS介绍1.2 Filestash介绍1.3 华为云Flexus应用服务器L实例介绍二、本次实践介绍2.1 本次实践介绍2.2 本次环境规划三、检查云服务器环境3.1 登录华为云3.2 SSH远…...

基于Docker和YARN的大数据环境部署实践最新版
基于Docker和YARN的大数据环境部署实践 目的 本操作手册旨在指导用户通过Docker容器技术,快速搭建一个完整的大数据环境。该环境包含以下核心组件: Hadoop HDFS/YARN(分布式存储与资源调度)Spark on YARN(分布式计算…...

【大模型】Bert
一、背景与起源 上下文建模的局限:在 BERT 之前,诸如 Word2Vec、GloVe 等词向量方法只能给出静态的词表示;而基于单向或浅层双向 LSTM/Transformer 的语言模型(如 OpenAI GPT)只能捕捉文本从左到右(或右到…...

《Go小技巧易错点100例》第三十四篇
本期分享: 1.sync.Mutex锁复制导致的异常 2.Go堆栈机制下容易导致的并发问题 sync.Mutex锁复制导致的异常 以下代码片段存在一个隐蔽的并发安全问题: type Counter struct {sync.MutexCount int }func foo(c Counter) {c.Lock()defer c.Unlock()…...

vue3+element-plus el-date-picker日期、年份筛选设置本周、本月、近3年等快捷筛选
一、页面代码: <template> <!-- 日期范围筛选框 --> <el-date-picker v-model"dateRange" value-format"YYYY-MM-DD" type"daterange" range-separator"至" start-placeholder"开始日期" end-…...

Vue 技术文档
一、引言 Vue 是一款用于构建用户界面的渐进式 JavaScript 框架,具有易上手、高性能、灵活等特点,能够帮助开发者快速开发出响应式的单页面应用。本技术文档旨在全面介绍 Vue 的相关技术知识,为开发人员提供参考和指导。 二、环境搭建 2.1…...
3 分钟学会使用 Puppeteer 将 HTML 转 PDF
需求背景 1、网页存档与文档管理 需要将网页内容长期保存或归档为PDF,确保内容不被篡改或丢失,适用于法律文档、合同、技术文档等场景。PDF格式便于存储和检索。 2、电子报告生成 动态生成的HTML内容(如数据分析报告、仪表盘)需导出为PDF供下载或打印。PDF保留排版和样…...

速通《Sklearn 与 TensorFlow 机器学习实用指南》
1.机器学习概览 1.1 什么是机器学习 机器学习是通过编程让计算机从数据中进行学习的科学。 1.2 为什么使用机器学习? 使用机器学习,是为了让计算机通过数据自动学习规律并进行预测或决策,无需显式编程规则。 1.3 机器学习系统的类型 1.…...
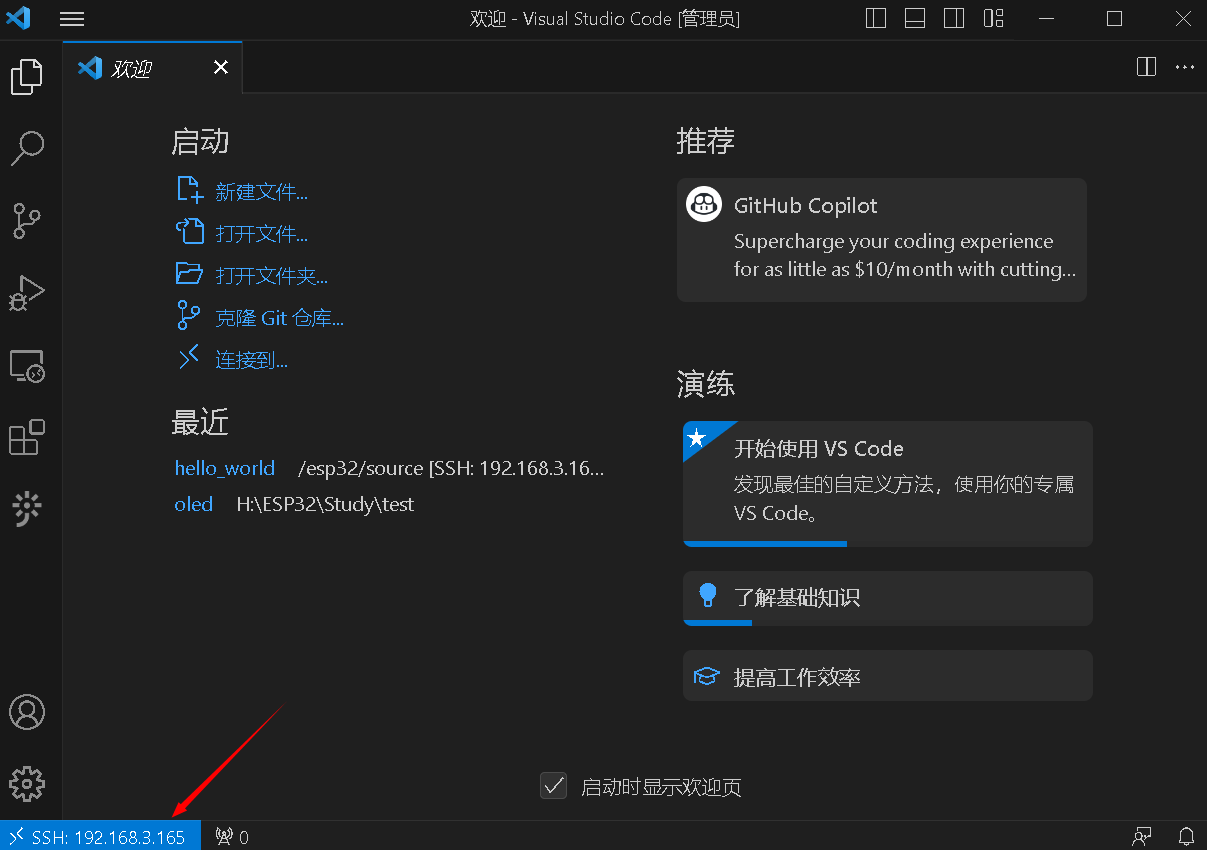
Ubuntu 下搭建ESP32 ESP-IDF开发环境,并在windows下用VSCode通过SSH登录Ubuntu开发ESP32应用
Ubuntu 下搭建ESP32 ESP-IDF开发环境,网上操作指南很多,本来一直也没有想过要写这么一篇文章。因为我其实不太习惯在linux下开发应用,平时更习惯windows的软件操作,只是因为windows下开发ESP32的应用编译时太慢,让人受…...

[FreeRTOS- 野火] - - - 临界段
一、介绍 临界段最常出现在对一些全局变量进行操作的场景。 1.1 临界段的定义 临界段是指在多任务系统中,一段需要独占访问共享资源的代码。在这段代码执行期间,必须确保没有任何其他任务或中断可以访问或修改相同的共享资源。 临界段的主要目的是防…...

【洛谷P9303题解】AC代码- [CCC 2023 J5] CCC Word Hunt
在CCC单词搜索游戏中,单词可以隐藏在字母网格中,以直线或直角的方式排列。以下是对代码的详细注释和解题思路的总结: 传送门: https://www.luogu.com.cn/problem/P9303 代码注释 #include <iostream> #include <vecto…...
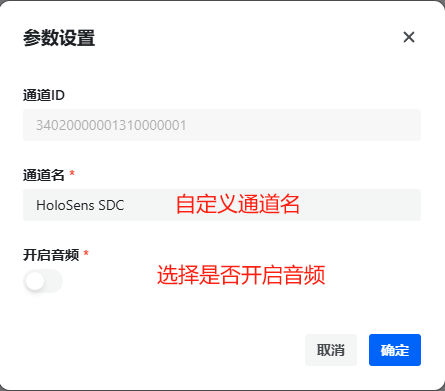
NodeMediaEdge接入NodeMediaServer
如何使用NME接入NMS 简介 NodeMediaEdge是一款部署在监控摄像机网络前端中,拉取Onvif或者rtsp/rtmp/http视频流并使用rtmp/kmp推送到公网流媒体服务器的工具。 通过云平台协议注册到NodeMediaServer后,可以同NodeMediaServer结合使用。使用图形化的管理…...

【Java基础-环境搭建-创建项目】IntelliJ IDEA创建Java项目的详细步骤
在Java开发的世界里,选择一个强大的集成开发环境(IDE)是迈向高效编程的第一步。而IntelliJ IDEA无疑是Java开发者中最受欢迎的选择之一。它以其强大的功能、智能的代码辅助和简洁的用户界面,帮助无数开发者快速构建和部署Java项目…...

WebSocket指数避让与重连机制
1. 引言 在现代Web应用中,WebSocket技术已成为实现实时通信的重要手段。与传统的HTTP请求-响应模式不同,WebSocket建立持久连接,使服务器能够主动向客户端推送数据,极大地提升了Web应用的实时性和交互体验。然而,在实…...

DrissionPage WebPage模式:动态交互与高效爬取的完美平衡术
在Python自动化领域,开发者常面临两难选择:Selenium虽能处理动态页面但效率低下,Requests库轻量高效却难以应对JavaScript渲染。DrissionPage的WebPage模式创新性地将浏览器控制与数据包收发融为一体,为复杂网页采集场景提供了全新…...

adb查看、设置cpu相关信息
查内存 adb shell dumpsys meminfo查CPU top -m 10打开 system_monitor adb shell am start -n eu.chainfire.perfmon/.LaunchActivity设置CPU的核心数 在/sys/devices/system/cpu目录下可以看到你的CPU有几个核心,如果是双核,就是cpu0和cpu1,…...
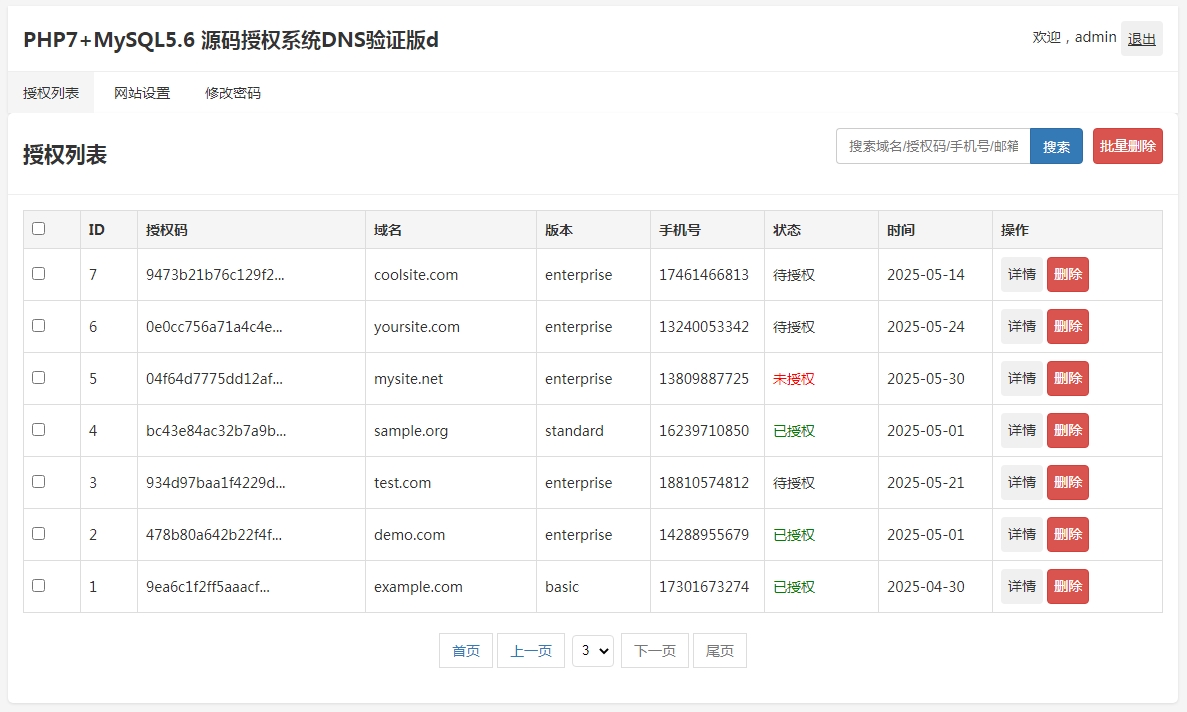
PHP7+MySQL5.6 查立得源码授权系统DNS验证版
# PHP7MySQL5.6 查立得源码授权系统DNS验证版 ## 一、系统概述 本系统是一个基于PHP7和MySQL5.6的源码授权系统,使用DNS TXT记录验证域名所有权,实现对软件源码的授权保护。 系统支持多版本管理,可以灵活配置不同版本的价格和下载路径&#…...

68元开发板,开启智能硬件新篇章——明远智睿SSD2351深度解析
在智能硬件开发领域,开发板的选择至关重要。它不仅关系到项目的开发效率,还直接影响到最终产品的性能与稳定性。而今天,我要为大家介绍的这款明远智睿SSD2351开发板,仅需68元,却拥有远超同价位产品的性能与功能&#x…...

【QQ音乐】sign签名| data参数加密 | AES-GCM加密 | webpack (下)
1.目标 网址:https://y.qq.com/n/ryqq/toplist/26 我们知道了 sign P(n.data),其中n.data是明文的请求参数 2.webpack生成data加密参数 那么 L(n.data)就是密文的请求参数。返回一个Promise {<pending>},所以L(n.data) 是一个异步函数…...

基于netmiko模块实现支持SSH or Telnet的多线程多厂商网络设备自动化巡检脚本
自动化巡检的需求 巡检工作通常包含大量的重复性操作,而这些重复性特征意味着其背后存在明确的规则和逻辑。这种规律性为实现自动化提供了理想的前提条件。 自动化工具 我们这里采用python作为自动化的执行工具。 过程 安装 netmiko pip install netmiko 模块的使…...
)
不用 apt 的解决方案(从源码手动安装 PortAudio)
第一步:下载并编译 PortAudio 源码 cd /tmp wget http://www.portaudio.com/archives/pa_stable_v190600_20161030.tgz tar -xvzf pa_stable_v190600_20161030.tgz cd portaudio# 使用 cmake 构建(推荐): mkdir build &&…...

【前端】JS引擎 v.s. 正则表达式引擎
JS引擎 v.s. 正则表达式引擎 它们的转义符都是\ 经过JS引擎会进行一次转义 经过正则表达式会进行一次转义在一次转义中\\\\\的转义过程: 第一个 \ (转义符) 会“吃掉”第二个 \,结果是得到一个字面量的 \。 第三个 \ (转义符) 会“吃掉”第四个 \&#x…...

开发体育平台,怎么接入最合适的数据接口
一、核心需求匹配:明确平台功能定位 1.实时数据驱动型平台 需重点关注毫秒级延迟与多端同步能力。选择支持 WebSocket 协议的接口,可实现比分推送延迟 < 0.5秒。例如某电竞直播平台通过接入支持边缘计算的接口,将团战数据同步速度提升至…...

3D虚拟工厂
1、在线体验 3D虚拟工厂在线体验 vue3three.jsblender 2、功能介绍 1. 全屏显示功能2. 镜头重置功能3. 企业概况信息模块4. 标签隐藏/显示功能5. 模型自动旋转功能6. 办公楼分层分解展示7. 白天/夜晚 切换8. 场景资源预加载功能9. 晴天/雨天/雾天10. 无人机视角模式11. 行人…...