Spring AI系列之Spring AI 集成 ChromaDB 向量数据库
1. 概述
在传统数据库中,我们通常依赖精确的关键词或基本的模式匹配来实现搜索功能。虽然这种方法对于简单的应用程序已经足够,但它无法真正理解自然语言查询背后的含义和上下文。
向量存储解决了这一限制,它通过将数据以数值向量的形式存储,从而捕捉数据的语义。相似的词会在向量空间中靠得很近,这使得语义搜索成为可能——即使查询中没有包含确切的关键词,也能返回相关结果。
在本教程中,我们将探讨如何将 ChromaDB(一款开源的向量存储库)与 Spring AI 集成使用。
为了将文本数据转换成 ChromaDB 能够存储和搜索的向量,我们需要使用一个嵌入模型。我们将使用 Ollama 在本地运行嵌入模型。
2. 依赖项
首先,我们需要在项目的 pom.xml 文件中添加必要的依赖项:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-chroma-store-spring-boot-starter</artifactId><version>1.0.0-M6</version>
</dependency>
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-ollama-spring-boot-starter</artifactId><version>1.0.0-M6</version>
</dependency>ChromaDB starter依赖项使我们能够建立与 ChromaDB 向量存储的连接并与之交互。
此外,我们还引入了 Ollama 启动器依赖项,用于运行我们的嵌入模型。
由于当前版本(1.0.0-M6)是一个里程碑版本,我们还需要在 pom.xml 文件中添加 Spring Milestones 仓库:
<repositories><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository>
</repositories>这个仓库用于发布里程碑版本,不同于标准的 Maven Central 仓库。
由于我们在项目中使用了多个SpringAI启动器(starter),我们还需要在pom.xml中引入SpringAI的BOM(依赖管理清单,Bill of Materials):
<dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>1.0.0-M6</version><type>pom</type><scope>import</scope></dependency></dependencies>
</dependencyManagement>通过引入 BOM,我们现在可以从两个启动器依赖中移除版本号标签。
BOM 的作用是消除版本冲突的风险,并确保我们使用的 Spring AI 相关依赖彼此兼容。
3. 使用 Testcontainers 搭建本地测试环境
为了便于本地开发和测试,我们将使用Testcontainers来搭建 ChromaDB 向量存储和 Ollama 服务。
通过Testcontainers运行这些服务的前提是本机已安装并正在运行 Docker。
3.1 测试依赖项
首先,我们需要在 pom.xml 中添加必要的测试依赖项:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-spring-boot-testcontainers</artifactId><scope>test</scope>
</dependency>
<dependency><groupId>org.testcontainers</groupId><artifactId>chromadb</artifactId><scope>test</scope>
</dependency>
<dependency><groupId>org.testcontainers</groupId><artifactId>ollama</artifactId><scope>test</scope>
</dependency>这些依赖项为我们提供了必要的类,可以快速创建用于两个外部服务的临时 Docker 实例。
3.2 定义 Testcontainers Bean
接下来,我们创建一个带有
@TestConfiguration 注解的类,用于定义我们的 Testcontainers Bean:
@TestConfiguration(proxyBeanMethods = false)
class TestcontainersConfiguration {@Bean@ServiceConnectionpublic ChromaDBContainer chromaDB() {return new ChromaDBContainer("chromadb/chroma:0.5.20");}@Bean@ServiceConnectionpublic OllamaContainer ollama() {return new OllamaContainer("ollama/ollama:0.4.5");}
}我们为容器指定了最新的稳定版本。
同时,我们使用 @ServiceConnection 注解标注了 Bean 方法。该注解会自动注册所有连接外部服务所需的属性,从而建立连接。
即使不使用 Testcontainers 支持,Spring AI 在本地运行时也会自动连接到ChromaDB和Ollama,前提是它们分别运行在默认端口 8000 和 11434 上。
然而,在生产环境中,我们可以通过相应的 Spring AI 配置属性来覆盖这些连接信息:
spring:ai:vectorstore:chroma:client:host: ${CHROMADB_HOST}port: ${CHROMADB_PORT}ollama:base-url: ${OLLAMA_BASE_URL}一旦连接信息配置正确,SpringAI会自动为我们创建 VectorStore
和 EmbeddingModel 类型的 Bean,
使我们可以分别与向量存储和嵌入模型进行交互。我们将在本教程后续部分了解如何使用这些 Bean。
尽管@ServiceConnection会自动定义所需的连接信息,但我们仍然需要在 application.yml 文件中配置一些额外的属性:
spring:ai:vectorstore:chroma:initialize-schema: trueollama:embedding:options:model: nomic-embed-textinit:chat:include: falsepull-model-strategy: WHEN_MISSING在这里,我们启用了ChromaDB的schema初始化。接着,我们将nomic-embed-text配置为嵌入模型,并指示Ollama在本地未安装该模型时自动拉取。
当然,我们也可以根据需求使用Ollama中的其他嵌入模型,或是 Hugging Face 的模型。
3.3 开发过程中使用 Testcontainers
虽然 Testcontainers 主要用于集成测试,但我们也可以在本地开发时使用它。
为此,我们将在src/test/java目录中创建一个单独的主类(main class):
class TestApplication {public static void main(String[] args) {SpringApplication.from(Application::main).with(TestcontainersConfiguration.class).run(args);}
}我们创建了一个TestApplication类,
并在其main方法中,通过
TestcontainersConfiguration 启动我们的主应用类 Application。
这个配置有助于我们在本地搭建和管理外部服务。我们可以运行Spring Boot 应用程序,并让它连接通过 Testcontainers 启动的外部服务。
4. 在应用启动时填充 ChromaDB
现在我们已经搭建好了本地环境,接下来在应用启动时向 ChromaDB 向量存储中填充一些示例数据。
4.1 从 PoetryDB 获取诗歌数据
为了演示,我们将使用 PoetryDB API 获取一些诗歌。
我们先创建一个名为 PoetryFetcher 的工具类来实现这个功能:
class PoetryFetcher {private static final String BASE_URL = "https://poetrydb.org/author/";private static final String DEFAULT_AUTHOR_NAME = "Shakespeare";public static List<Poem> fetch() {return fetch(DEFAULT_AUTHOR_NAME);}public static List<Poem> fetch(String authorName) {return RestClient.create().get().uri(URI.create(BASE_URL + authorName)).retrieve().body(new ParameterizedTypeReference<>() {});}}record Poem(String title, List<String> lines) {}我们使用 RestClient 调用 PoetryDB API,并传入指定的 authorName。为了将API响应反序列化为Poem记录的列表,我们使用了 ParameterizedTypeReference,无需显式指定泛型类型,Java 会为我们自动推断类型。我们还重载了fetch()方法(不带任何参数),以便默认获取莎士比亚(Shakespeare)的诗歌。
4.2 将文档存入 ChromaDB 向量存储
现在,为了在应用启动时将诗歌填充到 ChromaDB 向量存储中,我们将创建一个 VectorStoreInitializer 类,并实现 ApplicationRunner 接口:
@Component
class VectorStoreInitializer implements ApplicationRunner {private final VectorStore vectorStore;// standard constructor@Overridepublic void run(ApplicationArguments args) {List<Document> documents = PoetryFetcher.fetch().stream().map(poem -> {Map<String, Object> metadata = Map.of("title", poem.title());String content = String.join("\n", poem.lines());return new Document(content, metadata);}).toList();vectorStore.add(documents);}}在我们的VectorStoreInitializer中,我们通过自动注入(@Autowired)获取了一个 VectorStore 实例。
在run()方法中,我们使用
PoetryFetcher 工具类获取诗歌列表。
然后,将每首诗映射成一Document,将诗的内容(lines)作为文本内容,标题(title)作为元数据。
最后,我们将所有文档存入向量存储。当调用 add() 方法时,Spring AI 会自动将纯文本内容转换成向量表示,然后存入向量存储中,无需我们显式调用 EmbeddingModel Bean 进行转换。
默认情况下,Spring AI使用
SpringAiCollection作为向量存储中
的集合名称,但我们可以通过spring.ai.vectorstore.chroma.collection-name
属性来覆盖该名称。
5. 测试语义搜索
在 ChromaDB 向量存储被填充数据后,让我们来验证语义搜索功能:
private static final int MAX_RESULTS = 3;@ParameterizedTest
@ValueSource(strings = {"Love and Romance", "Time and Mortality", "Jealousy and Betrayal"})
void whenSearchingShakespeareTheme_thenRelevantPoemsReturned(String theme) {SearchRequest searchRequest = SearchRequest.builder().query(theme).topK(MAX_RESULTS).build();List<Document> documents = vectorStore.similaritySearch(searchRequest);assertThat(documents).hasSizeLessThanOrEqualTo(MAX_RESULTS).allSatisfy(document -> {String title = String.valueOf(document.getMetadata().get("title"));assertThat(title).isNotBlank();});
}这里,我们使用 @ValueSource 向测试方法传入一些常见的莎士比亚主题。然后,创建一个SearchRequest对象,将主题作为查询内容,将 MAX_RESULTS 设为期望的返回结果数量。
接着,我们调用 vectorStore Bean 的 similaritySearch() 方法,传入我们的 searchRequest。与 add() 方法类似,Spring AI 会先将查询内容转换为向量表示,再去向量存储中执行搜索。
返回的文档中包含的诗歌都是与给定主题语义相关的,即使它们没有包含确切的关键词。
6. 总结
本文介绍了如何将 ChromaDB 向量存储与 Spring AI 集成。
我们通过Testcontainers启动了ChromaDB 和 Ollama 的 Docker 容器,搭建了本地测试环境。演示了如何在应用启动时通过 PoetryDB API 向向量存储中填充诗歌数据。最后,我们用常见的诗歌主题验证了语义搜索功能。
私信1v1直连大厂总监·「免。米」
相关文章:

Spring AI系列之Spring AI 集成 ChromaDB 向量数据库
1. 概述 在传统数据库中,我们通常依赖精确的关键词或基本的模式匹配来实现搜索功能。虽然这种方法对于简单的应用程序已经足够,但它无法真正理解自然语言查询背后的含义和上下文。 向量存储解决了这一限制,它通过将数据以数值向量的形式存储…...

lua的注意事项2
总之,下面的返回值不是10,a,b 而且...

主流电商平台的反爬机制解析
随着数据成为商业决策的重要资源,越来越多企业和开发者希望通过技术手段获取电商平台的公开信息,用于竞品分析、价格监控、市场调研等。然而,主流电商平台如京东、淘宝(含天猫)等为了保护数据安全和用户体验࿰…...

前端八股之HTML
前端秘籍-HTML篇 1. src和href的区别 src 用于替换当前元素,href 用于在当前文档和引用资源之间确立联系。 (1)src src 是 source 的缩写,指向外部资源的位置,指向的内容将会嵌入到文档中当前标签所在位置࿱…...

tiktoken学习
1.tiktoken是OpenAI编写的进行高效分词操作的库文件。 2.操作过程: enc tiktoken.get_encoding("gpt2") train_ids enc.encode_ordinary(train_data) val_ids enc.encode_ordinary(val_data) 以这段代码为例,get_encoding是创建了一个En…...
鲲鹏Arm+麒麟V10,国产化信创 K8s 离线部署保姆级教程
Rainbond V6 国产化部署教程,针对鲲鹏 CPU 麒麟 V10 的离线环境,手把手教你从环境准备到应用上线,所有依赖包提前打包好,步骤写成傻瓜式操作指南。别说技术团队了,照着文档一步步来,让你领导来都能独立完成…...

历年厦门大学计算机保研上机真题
2025厦门大学计算机保研上机真题 2024厦门大学计算机保研上机真题 2023厦门大学计算机保研上机真题 在线测评链接:https://pgcode.cn/school 数字变换过程的最大值与步数 题目描述 输入一个数字 n n n,如果 n n n 是偶数就将该偶数除以 2 2 2&…...
【C++ Qt】认识Qt、Qt 项目搭建流程(图文并茂、通俗易懂)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本章将开启Qt的学习,Qt是一个较为古老但仍然在GUI图形化界面设计中有着举足轻重的地位,因为它适合嵌入式和多种平台而被广泛使用…...
IoT/HCIP实验-1/物联网开发平台实验Part2(HCIP-IoT实验手册版)
文章目录 概述产品和设备实例的产品和设备产品和设备的关联单个产品有多个设备为产品创建多个设备产品模型和物模型设备影子(远程代理) 新建产品模型定义编解码插件开发编解码插件工作原理消息类型与二进制码流添加消息(数据上报消息…...
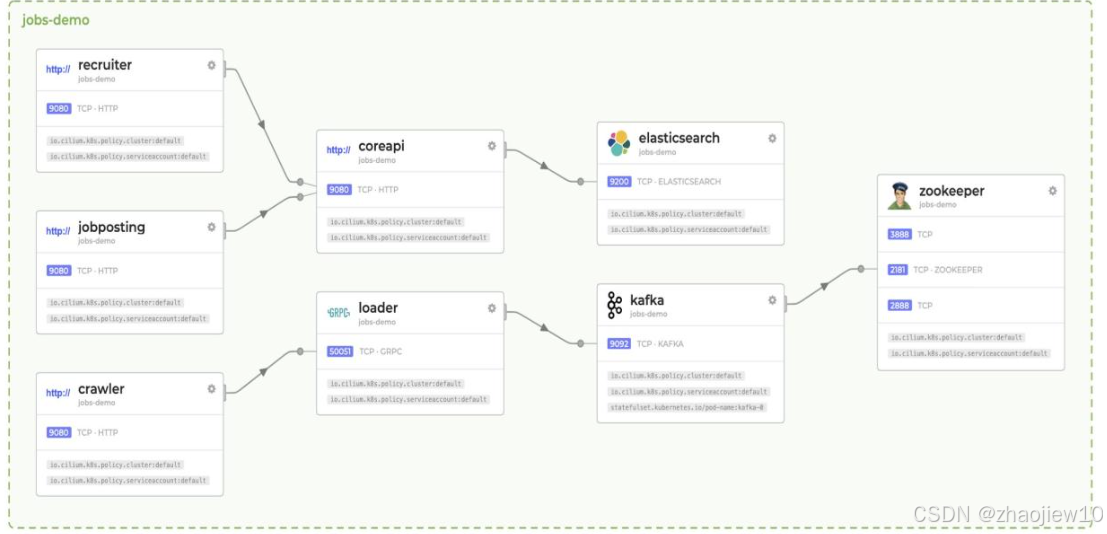
Replacing iptables with eBPF in Kubernetes with Cilium
source: https://archive.fosdem.org/2020/schedule/event/replacing_iptables_with_ebpf/attachments/slides/3622/export/events/attachments/replacing_iptables_with_ebpf/slides/3622/Cilium_FOSDEM_2020.pdf 使用Cilium,结合eBPF、Envoy、Istio和Hubble等技术…...

推荐系统排序指标:MRR、MAP和NDCG
文章目录 MRR: Mean Reciprocal RankMAP: Mean Average PrecisionNDCG: Normalized Discounted Cumulative Gain3个度量标准来自于两个度量家族。第一种度量包括基于二进制相关性的度量。这些度量标准关心的是一个物品在二进制意义上是否是好的。第二个系列包含基于应用的度量。…...
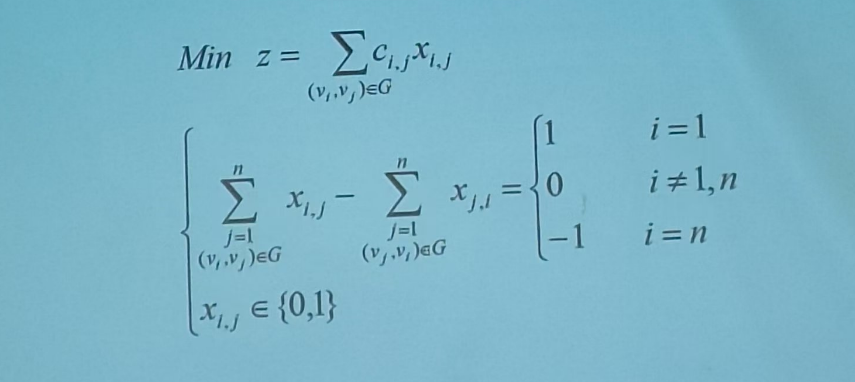
数学建模之最短路径问题
1 问题的提出 这个是我们的所要写的题目,我们要用LINGO编程进行编写这个题目,那么就是需要进行思考这个怎么进行构建这个问题的模型 首先起点,中间点,终点我们要对这个进行设计 2 三个点的设计 起点的设计 起点就是我们进去&am…...
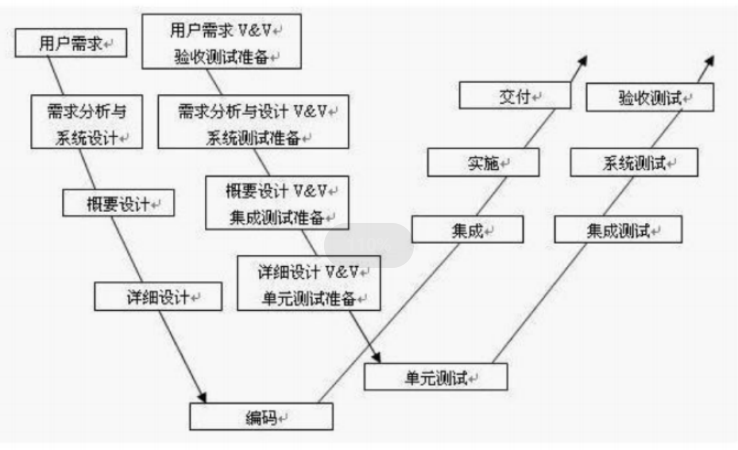
测试概念 和 bug
一 敏捷模型 在面对在开发项目时会遇到客户变更需求以及合并新的需求带来的高成本和时间 出现的敏捷模型 敏捷宣言 个人与交互重于过程与工具 强调有效的沟通 可用的软件重于完备的文档 强调轻文档重产出 客户协作重于合同谈判 主动及时了解当下的要求 相应变化…...
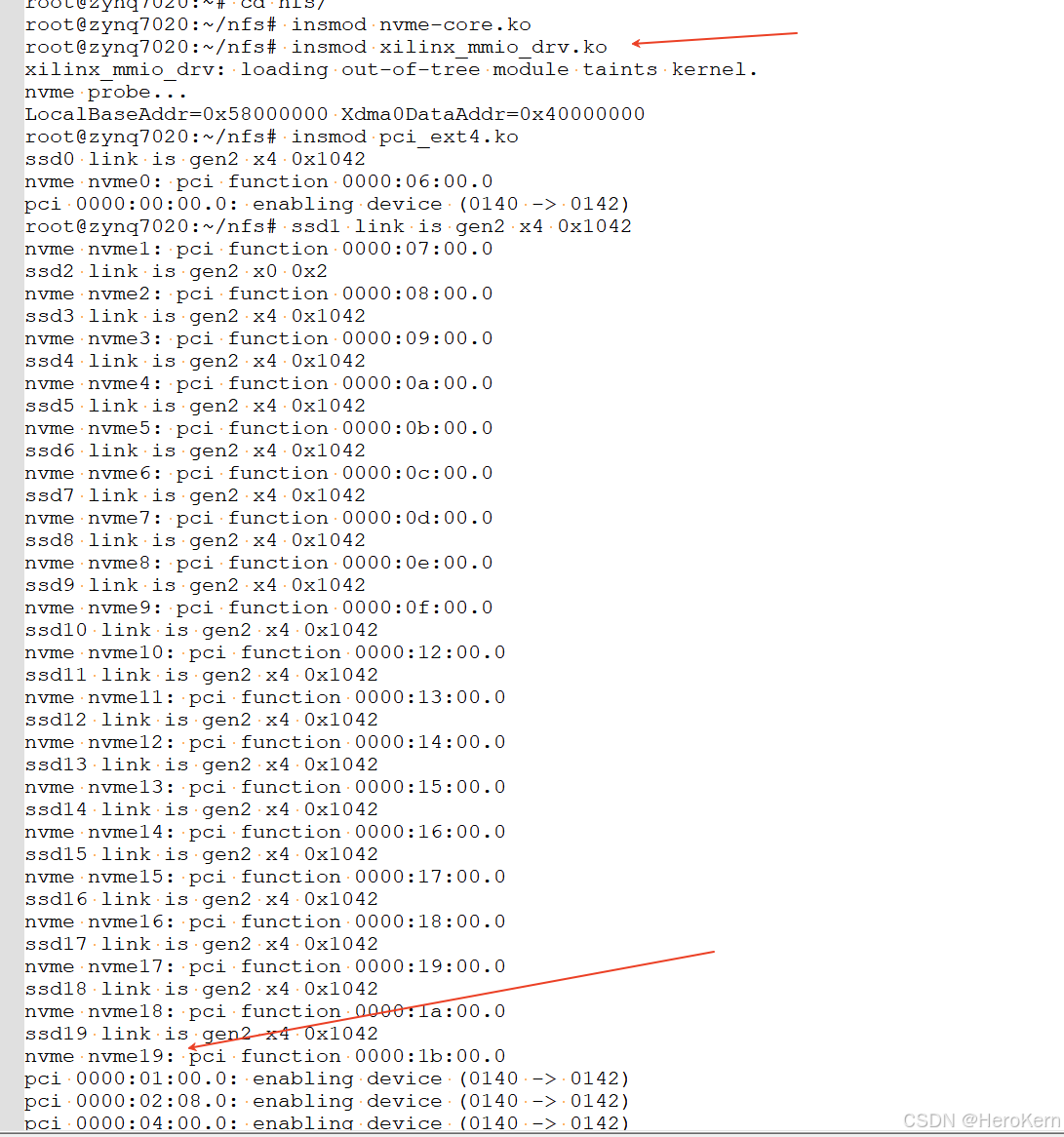
zynq 级联多个ssd方案设计(ECAM BUG修改)
本文讲解采用zynq7045芯片如何实现200T容量高速存储方案设计,对于大容量高速存储卡,首先会想到采用pcie switch级联方式,因为单张ssd的容量是有限制的(目前常见的m.2接口容量为4TB,U.2接口容量为16TB)&…...

brep2seq 论文笔记
Brep2Seq: a dataset and hierarchical deep learning network for reconstruction and generation of computer-aided design models | Journal of Computational Design and Engineering | Oxford Academic 这段文本描述了一个多头自注意力机制(MultiHead Attenti…...

【运维实战】Linux 中设置 sudo ,8个有用的 sudoers 配置!
在Linux及其他类Unix操作系统中,只有 root 用户能够执行所有命令并进行关键系统操作,例如安装更新软件包、删除程序、创建用户与用户组、修改重要系统配置文件等。 但担任 root 角色的系统管理员可通过配置sudo命令,允许普通系统用户执行特定…...

Ad Hoc
什么是 Ad Hoc? Ad hoc 一词源于拉丁语,意为“为此目的”或“为此特定原因”。一般来讲,它指的是为解决某一特定问题或任务(而非为了广泛重复应用)而设计的行动、解决方案或组合。在加密货币和区块链领域,…...
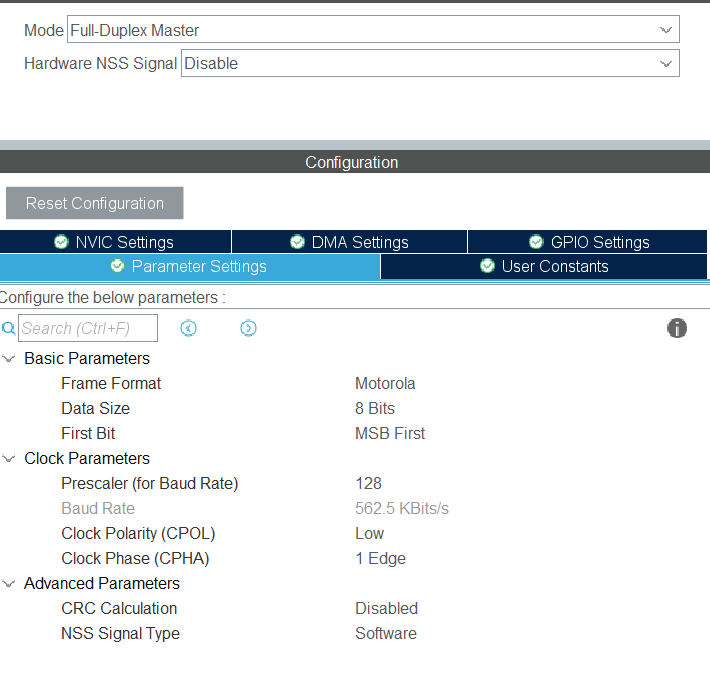
江科大SPI串行外设接口hal库实现
hal库相关函数 初始化结构体 typedef struct {uint32_t Mode; /*SPI模式*/uint32_t Direction; /*SPI方向*/uint32_t DataSize; /*数据大小*/uint32_t CLKPolarity; /*时钟默认极性控制CPOL*/uint32_t CLKPhase; /*…...

[网页五子棋][对战模块]前后端交互接口(建立连接、连接响应、落子请求/响应),客户端开发(实现棋盘/棋子绘制)
文章目录 约定前后端交互接口建立连接建立连接响应针对"落子"的请求和响应 客户端开发实现棋盘/棋子绘制部分逻辑解释 约定前后端交互接口 对战模块和匹配模块使用的是两套逻辑,使用不同的 websocket 的路径进行处理,做到更好的耦合 建立连接 …...

【ArcGIS Pro微课1000例】0071:将无人机照片生成航线、轨迹点、坐标高程、方位角
文章目录 一、照片预览二、生成轨迹点三、照片信息四、查看方位角五、轨迹点连成线一、照片预览 数据位于配套实验数据包中的0071.rar,解压之后如下: 二、生成轨迹点 地理标记照片转点 (数据管理),用于根据存储在地理标记照片文件(.jpg 或 .tif)元数据中的 x、y 和 z 坐…...
Ubuntu Zabbix 钉钉报警
文章目录 概要Zabbix警监控脚本技术细节配置zabbix告警 概要 提示:本教程用于Ubuntu ,zabbix7.0 Zabbix警监控脚本 提示:需要创建一个脚本 #检查是否有 python3 和版本 rootzabbix:~# python3 --version Python 3.12.3在/usr/lib/zabbix/…...
threejs顶点UV坐标、纹理贴图
1. 创建纹理贴图 通过纹理贴图加载器TextureLoader的load()方法加载一张图片可以返回一个纹理对象Texture,纹理对象Texture可以作为模型材质颜色贴图.map属性的值。 const geometry new THREE.PlaneGeometry(200, 100); //纹理贴图加载器TextureLoader const te…...

STM32 RTC实时时钟\BKP备份寄存器\时间戳
一、Unix时间戳 想要计算当地北京时间,需要根据经度和闰年之类的运算得到(c语言里面可以调用time.h的函数) 二、UTC/GMT(科普) 三、时间戳转化 C语言的time.h模块提供了时间获取和时间戳转换的相关函数,可以方便的进行秒计数器、…...

springcloud---gateway
目录标题 理解gateway代码示例filter与aop的联系ServerWebExchangeReactor 的 Context那是隐式传递Map吗Context和ThreadLocalSpring 的 AOP 是用的什么为什么过滤器要用异步非阻塞,而 AOP 用同步阻塞?理解gateway 代码示例 import io.netty.channel.Channel; import lombo…...

Axure设计案例——科技感立体柱状图
想让你的数据展示告别平淡无奇,成为吸引全场目光的焦点吗?快来瞧瞧这个Axure设计的科技感立体柱状图案例!科技感设计风格借助逼真的立体效果打破传统柱状图的平面感,营造出一种令人眼前一亮的视觉震撼。每一个柱状体都仿佛是真实存…...

app获取相册权限是否意味着所有相片都可随时读取?
针对安卓手机相册的隐私安全问题,我也比较好奇,App授予了相册权限,真的能自动读取用户的照片吗?最近做了一个小实验,我开发了2个小App,这2个App安装的时候只授予了相册权限,没有授予其他任何权限…...

2025年05月29日Github流行趋势
项目名称:agenticSeek 项目地址url:https://github.com/Fosowl/agenticSeek项目语言:Python历史star数:11898今日star数:2379项目维护者:Fosowl, steveh8758, klimentij, ganeshnikhil, apps/copilot-pull-…...

第十一节:第一部分:正则表达式:应用案例、爬取信息、搜索替换
正则表达式介绍 String提供的正则表达式的方法的书写规则 正则表达式总结 正则表达式作用: 作用三:搜索替换 案例分析及代码(图片解析) 代码: 代码一:校验手机号和邮箱格式是否正确 package com.itheima.…...

跟我学c++中级篇——动态库的资源处理
一、动态库的资源管理 动态库在编程中几乎是一个无法绕过的问题,不管是在哪个平台上都一样。在前面的文章中分析知道,编程的一个核心目标就是对计算机的资源进行管理和控制。动态库编程做为一个重要的技术,同样要面对资源的管理这个重要问题…...
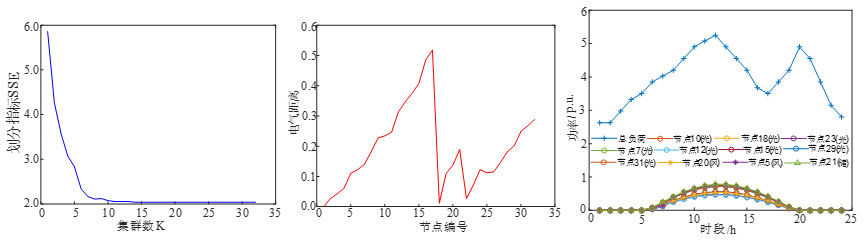
新能源集群划分+电压调节!基于分布式能源集群划分的电压调节策略!
适用平台:MatlabYalmip Cplex (具体操作已在程序文件中说明) 参考文献:基于分布式能源集群化分的电压调节策略[D]. 一、文献解读 1. 主要内容/创新点 提出了一种基于分布式能源集群化的电压调节策略,计及分布式能源的有功、无功调节能力&a…...