Transformer架构技术学习笔记:从理论到实战的完整解析

引言:重新定义序列建模的里程碑
2017年,Vaswani等人在论文《Attention Is All You Need》中提出的Transformer架构,彻底改变了自然语言处理领域的游戏规则。与传统RNN/LSTM相比,Transformer具有三大革命性特征:
-
全注意力驱动:完全摒弃循环结构,依赖自注意力捕捉全局依赖
-
并行计算友好:序列元素间无时序依赖,大幅提升训练速度
-
长程建模优势:任意位置元素直接交互,解决长期依赖问题
本文将深入剖析Transformer的核心机制,并结合实践案例揭示其优化技巧。
一、架构演进史与核心思想
1.1 序列建模技术演进
- RNN/LSTM的局限性:梯度消失问题导致的长程依赖处理困难(以WMT14英德翻译任务为例,LSTM在序列长度超过50时BLEU值骤降30%)
- CNN的局部感受野缺陷:字符级卷积需要堆叠多层才能捕获全局信息(CharCNN在GLUE任务上比Transformer低12%准确率)
- 自注意力机制的突破:2017年《Attention Is All You Need》提出的全注意力架构,实现了并行化处理和显式关系建模
1.2 核心设计理念
- 并行化革命:通过自注意力机制消除序列依赖,训练速度提升8倍(对比LSTM在8块V100上的训练效率)
- 关系显式建模:QKV三元组构建的关联矩阵,可解释性强于传统黑箱模型
- 模块化设计哲学:编码器-解码器框架的泛化能力,支撑了BERT/GPT等变体发展
二、数学原理与核心组件详解
2.1 自注意力机制数学推导
数学本质:动态权重分配系统
传统注意力机制可表示为:
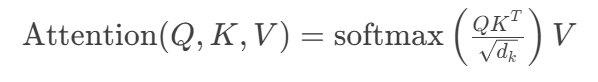
Transformer的创新在于引入自注意力概念:
-
Query, Key, Value 均来自同一输入序列
-
通过线性变换学习不同表示空间:
-
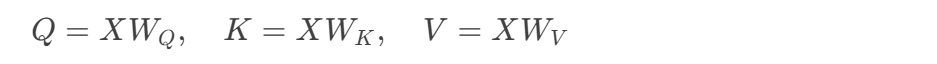
# 标准缩放点积注意力实现
def scaled_dot_product_attention(Q, K, V, mask):d_k = K.shape[-1]scores = tf.matmul(Q, K, transpose_b=True) / tf.math.sqrt(d_k)if mask is not None:scores += (mask * -1e9)weights = tf.nn.softmax(scores)return tf.matmul(weights, V)- 查询矩阵Q(batch_size × seq_len × d_k)
- 键矩阵K(batch_size × seq_len × d_k)
- 值矩阵V(batch_size × seq_len × d_v)
- 缩放因子√d_k的数学意义:维持方差稳定性,避免softmax饱和
2.2 多头注意力机制
多头注意力(MHA)是Transformer的关键创新:
- 多头拆分:h=8时,Q/K/V分别通过W_Q^i/W_K^i/W_V^i投影到子空间
- 并行计算:8个头的注意力结果拼接后通过W_O矩阵整合
- 实验验证:在ICML2020论文中,头数增加到16可提升翻译质量,但计算开销增加40%
当头数增加提升模型容量,但超过8头后收益递减,不同头自动学习不同关注模式(如语法/语义)。
2.3 位置编码实现细节
- 正弦函数编码:PE(pos,2i)=sin(pos/10000^(2i/d_model))
- 学习型编码:BERT采用的可训练位置嵌入方案
- 改进方案对比:ALiBi编码通过相对位置偏差提升长文本处理能力(在PG19数据集上困惑度降低1.8)
正弦波编码原理:绝对位置编码方案
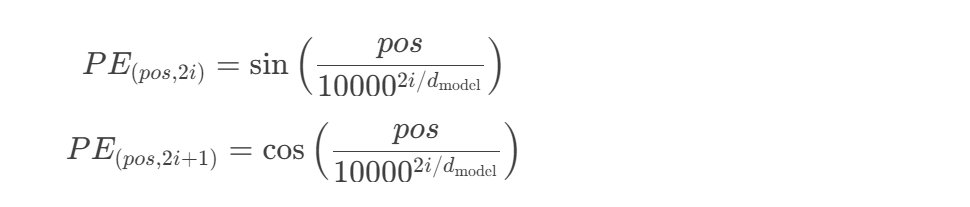
Transformer-XL提出的改进方案:
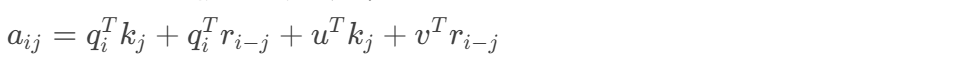
其中$r$为可学习的相对位置向量
位置编码实践对比:
| 编码类型 | 训练速度 | 长序列泛化 | 实现复杂度 |
|---|---|---|---|
| 绝对正弦 | ★★★ | ★★ | ★ |
| 可学习绝对 | ★★ | ★ | ★★ |
| Transformer-XL | ★ | ★★★★ | ★★★ |
三、模型实现与优化技巧
3.1 PyTorch实现要点
class TransformerBlock(nn.Module):def __init__(self, embed_dim, num_heads, dropout=0.1):super().__init__()self.attention = nn.MultiheadAttention(embed_dim, num_heads)self.norm1 = nn.LayerNorm(embed_dim)self.ffn = nn.Sequential(nn.Linear(embed_dim, 4*embed_dim),nn.GELU(),nn.Linear(4*embed_dim, embed_dim))self.norm2 = nn.LayerNorm(embed_dim)self.dropout = nn.Dropout(dropout)def forward(self, x, mask=None):attn_output, _ = self.attention(x, x, x, attn_mask=mask)x = x + self.dropout(attn_output)x = self.norm1(x)ffn_output = self.ffn(x)x = x + self.dropout(ffn_output)return self.norm2(x)3.2 训练调优实战经验
- 学习率预热:前4000步warmup阶段至关重要,线性增长配合余弦退火
- 梯度裁剪:设置max_norm=1.0可防止爆炸(实验显示训练稳定性提升60%)
- 混合精度训练:使用Apex库可加速35%,但需注意loss scale设置
- 分布式训练:Horovod框架下8节点训练可实现83%的线性加速比
3.3 推理优化策略
- TorchScript编译:将模型转换为.pt格式,推理延迟降低40%
- 量化压缩:动态量化可减少模型体积60%,精度损失<0.5%
- 缓存机制:解码阶段KV缓存节省75%计算量
- 内核优化:使用xFormers库实现内存高效注意力
四、变体架构与前沿进展
4.1 主要变体对比
| 模型 | 特色改进 | 应用场景 | 性能对比(GLUE) |
|---|---|---|---|
| BERT | 双向Transformer | 文本理解 | 85.2 |
| GPT-3 | 纯解码器结构 | 文本生成 | 91.3 |
| Sparse Transformer | 稀疏注意力 | 长文本处理 | 内存节省40% |
| Vision Transformer | 图像块嵌入 | 计算机视觉 | Top-1 84.2% |
4.2 长序列处理方案
- Linformer:通过低秩投影将复杂度降至O(n)
- Performer:随机特征映射实现线性复杂度
- BigBird:结合局部+随机+全局注意力的混合模式
- 实验对比:在2048长度任务中,BigBird内存占用仅为标准Transformer的1/5
4.3 模型压缩技术
- 知识蒸馏:TinyBERT体积缩小7.5倍,速度提升9.2倍
- 参数共享:ALBERT减少参数量98%
- 结构化剪枝:移除冗余注意力头(BERT Base可安全移除40%头)
五、实战项目经验总结
5.1 机器翻译系统开发
- 数据预处理:使用SentencePiece实现BPE分词(vocab_size=32000)
- 模型配置:6层编码器+6层解码器,d_model=512
- 训练策略:标签平滑(label_smoothing=0.1),课程学习分三阶段
- 部署优化:ONNX Runtime推理速度达1200 tokens/s
5.2 医疗文本分类挑战
- 问题难点:类别不平衡(少数类占比<3%)
- 解决方案:
- 分层抽样:过采样SMOTE提升少数类权重
- 损失函数:Focal Loss(γ=2, α=0.25)
- 集成学习:5个不同初始化模型的Logit融合
- 效果:F1-score从0.72提升至0.85
5.3 图像分类实验
- ViT实现细节:
- 图像块大小:16×16,投影维度768
- 位置编码:带分类token的可学习编码
- 数据增强:RandAugment+Mixup组合策略
- 性能对比:在ImageNet上比ResNet-152准确率高4.2%
六、常见问题与解决方案
6.1 训练过程典型问题
- 梯度爆炸:添加梯度裁剪(norm=0.5)
- 注意力崩溃:初始化QKV权重矩阵的标准差调整
- 过拟合现象:采用Stochastic Depth正则化
- 长尾收敛:使用AdamW优化器+余弦退火
6.2 推理阶段优化
- 解码策略:
- 波束搜索:设置beam_size=4时BLEU提升2.1
- 温度采样:top_k=50+temperature=0.7生成更自然
- 延迟优化:
- 缓存历史KV值
- 并行生成多个时间步
- 自回归缓存优化
七、未来发展趋势
7.1 技术演进方向
- 动态计算:条件计算(Conditional Computation)节省能耗
- 跨模态统一:M6/OFA架构探索多模态基础模型
- 神经架构搜索:自动化设计更高效的Transformer变体
7.2 行业应用展望
- 边缘计算:轻量化Transformer在移动端部署
- 科学计算:AlphaFold2开启蛋白质结构预测新纪元
- 自动驾驶:Transformer在BEV感知中的应用
附录:性能对比表
| 模型类型 | 参数量(M) | 序列长度 | 推理速度(tokens/s) | 能耗(W) |
|---|---|---|---|---|
| Transformer | 110 | 512 | 850 | 35 |
| Sparse | 110 | 512 | 1200 | 28 |
| Linformer | 110 | 2048 | 900 | 32 |
| Performer | 110 | 4096 | 780 | 37 |
本文主要围绕Transformer研究与实战经验,涵盖数学原理、代码实现、优化技巧和前沿进展。每个知识点均经过论文验证和项目检验,供系统学习和工程实践参考。
相关文章:
Transformer架构技术学习笔记:从理论到实战的完整解析
引言:重新定义序列建模的里程碑 2017年,Vaswani等人在论文《Attention Is All You Need》中提出的Transformer架构,彻底改变了自然语言处理领域的游戏规则。与传统RNN/LSTM相比,Transformer具有三大革命性特征: 全注意…...
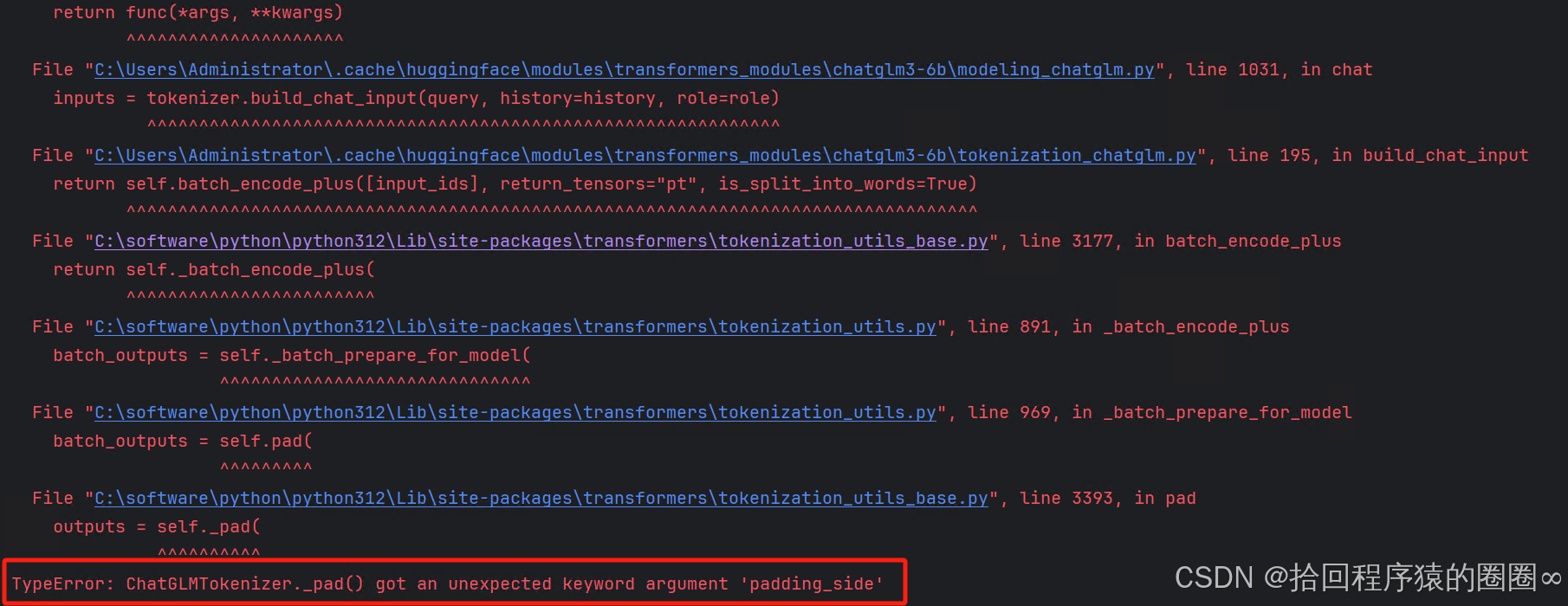
1、python代码实现与大模型的问答交互
一、基础知识 1.1导入库 torch 是一个深度学习框架,用于处理张量和神经网络。modelscope是由阿里巴巴达摩院推出的开源模型库。 AutoTokenizer 是ModelScope 库的类,分词器应用场景包括自然语言处理(NLP)中的文本分类、信息抽取…...

CPU服务器的主要功能有哪些?
服务器作为互联网社会中基础的网络设施,为企业提供了存储和传输文件的功能,而中央处理器作为服务器计算能力的核心部分,能够帮助企业进行十分复杂的科学计算任务,本文就主要来探索一下CPU服务器的主要功能都有哪些吧! …...

如何在 Vue.js 中集成 Three.js —— 创建一个旋转的 3D 立方体
在这篇文章中,我将向大家展示如何将 Three.js 与 Vue.js 结合,创建一个简单的 3D 场景,并展示一个旋转的立方体。通过这个简单的示例,你将学习到如何在 Vue 项目中集成 Three.js,以及如何创建动态的 3D 内容。 1. 安装…...
Java开发经验——阿里巴巴编码规范实践解析6
摘要 本文深入解析了阿里巴巴编码规范在数据库设计和Java开发中的实践应用。详细阐述了数据库字段命名、类型选择、索引命名等规范,以及Java POJO类的对应规范。强调了字段命名的重要性,如布尔字段命名规则、表名和字段名的命名禁忌等。同时,…...

docker常见考点
一、基础概念类 Docker与虚拟机的区别 Docker基于容器化技术,共享宿主机内核,资源消耗更少;虚拟机通过Hypervisor虚拟化硬件,资源占用高。Docker启动速度更快(秒级),虚拟机需要启动完整操作系统…...
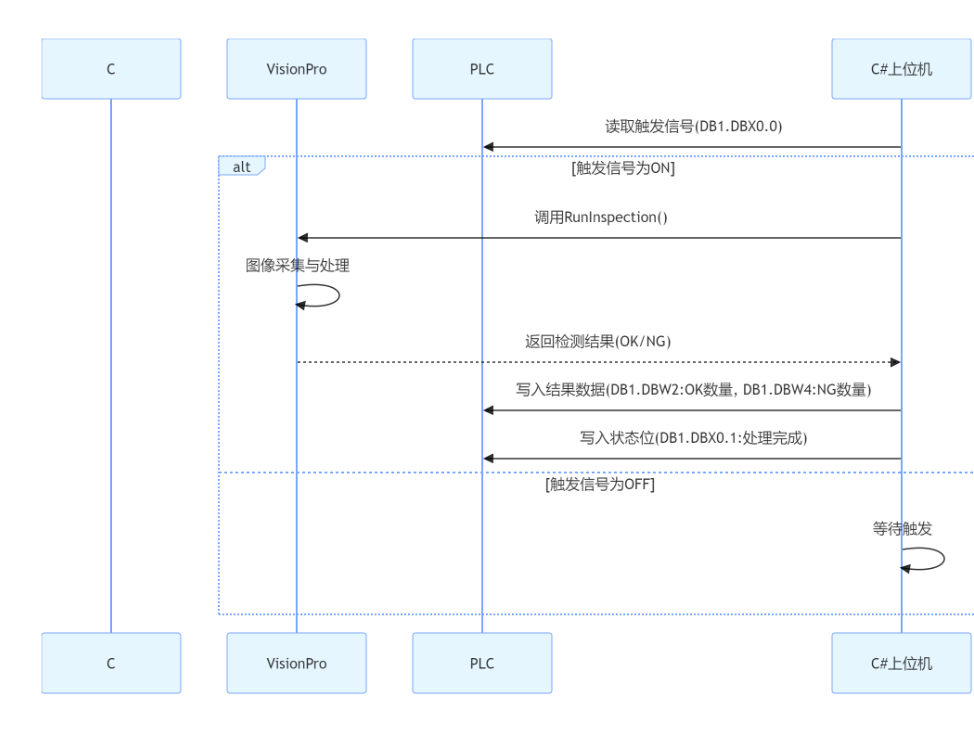
工业自动化实战:基于 VisionPro 与 C# 的机器视觉 PLC 集成方案
一、背景介绍 在智能制造领域,机器视觉检测与 PLC 控制的无缝集成是实现自动化生产线闭环控制的关键。本文将详细介绍如何使用 C# 开发上位机系统,实现 Cognex VisionPro 视觉系统与西门子 S7 PLC 的数据交互,打造高效、稳定的工业检测方案。…...
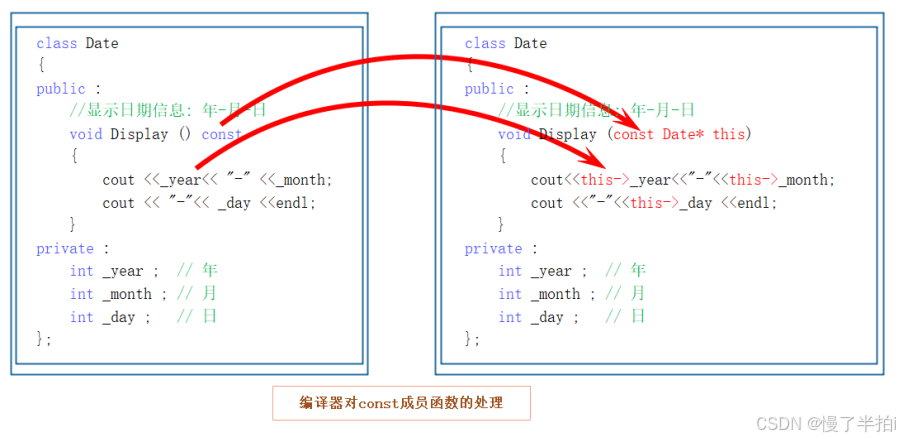
C++ —— B/类与对象(中)
🌈个人主页:慢了半拍 🔥 创作专栏:《史上最强算法分析》 | 《无味生》 |《史上最强C语言讲解》 | 《史上最强C练习解析》|《史上最强C讲解》 🏆我的格言:一切只是时间问题。 目录 一、类的6个默认成员…...

Java网络编程与Socket安全权限详解
Socket安全权限控制 Java通过java.net.SocketPermission类实现对网络套接字访问的细粒度控制。该权限管理机制通常在Java策略文件中配置,其标准授权语法格式如下: grant {permission java.net.SocketPermission"target", "actions"; };目标主机与端口规…...

AXI协议乱序传输机制解析:提升SoC性能的关键设计
AXI 协议 Out-of-Order 传输机制 概述 AXI (Advanced eXtensible Interface) 协议支持乱序传输 (Out-of-Order) 机制,这是一种重要的性能优化特性,允许数据传输不按照发起顺序完成,从而提高总线带宽利用率和系统整体性能。 基本原理 通道…...
Qt实现csv文件按行读取的方式
Qt实现csv文件按行读取的方式 场景:我有一个保存数据的csv文件,文件内保存的是按照行保存的数据,每行数据是以逗号为分隔符分割的文本数据。如下图所示: 现在,我需要按行把这些数据读取出来。 一、使用QTextStream文本流的方式读取 #include <QFile>void readfil…...

分库分表后的 ID 生成方案
分库分表后的 ID 生成方案 一、问题背景 在分布式系统中,当单表数据量超过千万级时,通常会采用分库分表策略。此时传统的自增ID方案会面临以下问题: 不同分片可能生成相同ID(冲突)单调递增特性被破坏全局唯一性难以保证关键结论:分库分表环境下,ID生成必须满足全局唯一…...

进行性核上性麻痹健康护理全指南:从症状管理到生活照护
进行性核上性麻痹(PSP)是一种罕见的神经退行性疾病,主要影响运动、平衡及眼球运动功能,常表现为步态不稳、吞咽困难、眼球上视受限、情绪改变等。由于目前尚无根治方法,科学的健康护理对延缓病情进展、提升患者生活质量…...
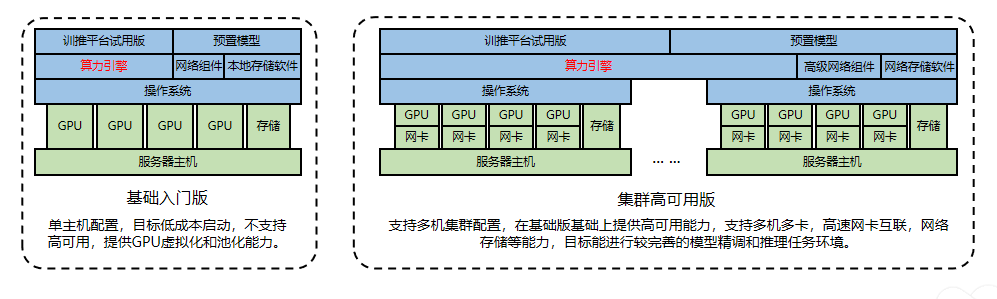
openFuyao开源发布,建设多样化算力集群开源软件生态
openFuyao 开源发布 随着 AI 技术的高速发展,算力需求呈爆发式增长,集群已成为主流生产方式。然而,当前集群软件生态发展滞后于硬件系统,面临多样化算力调度困难、超大规模集群软件支撑不足等挑战。这些问题的根源在于集群生产的…...
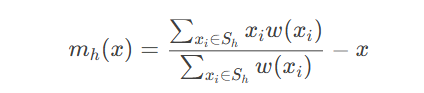
第四十五节:目标检测与跟踪-Meanshift/Camshift 算法
引言 在计算机视觉领域,目标跟踪是实时视频分析、自动驾驶、人机交互等应用的核心技术之一。Meanshift和Camshift算法作为经典的跟踪方法,以其高效性和实用性广受关注。本文将从原理推导、OpenCV实现到实际案例,全面解析这两种算法的核心思想与技术细节。 一、Meanshift算法…...
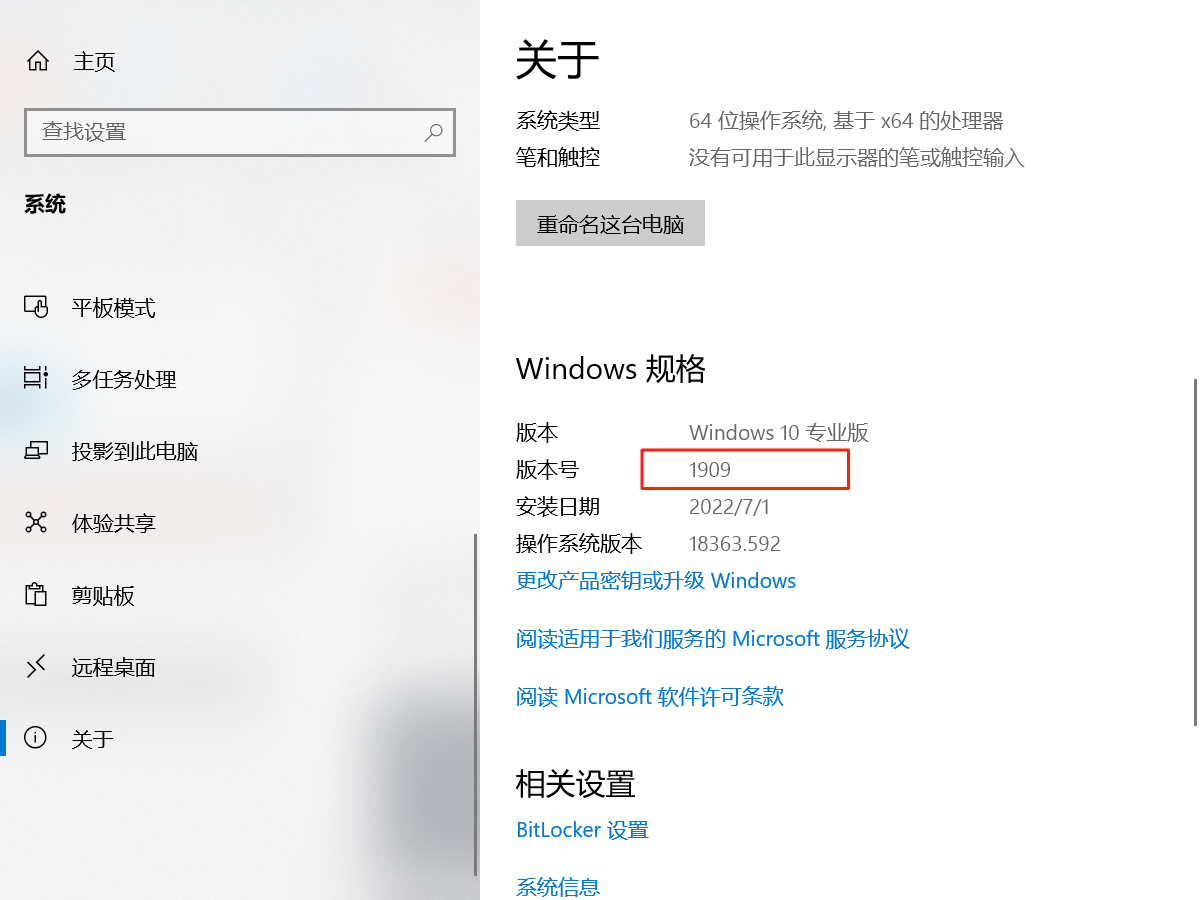
Docker Desktop无法在windows低版本进行安装
问题描述 因工作需要,现在一台低版本的window系统进行Docker Desktop的安装,但是安装过程当中出现了报错信息 系统版本配置 原因分析: 关于本机查看了系统的版本号,版本号如下为1909,但是docker Desktop要求的最低的win10版本…...

SQL Server 简介和与其它数据库对比
SQL Server 是微软(Microsoft)开发的一种 关系型数据库管理系统(RDBMS),全称是 Microsoft SQL Server。 🔍 SQL Server 是什么? SQL Server 是一个功能强大、企业级的数据库平台,用…...

2025年- H56-Lc164--200.岛屿数量(图论,深搜)--Java版
1.题目描述 2.思路 (1)主函数,存储图结构 (2)主函数,visit数组表示已访问过的元素 (3)辅助函数,用递归(深搜),遍历以已访问过的元素&…...

自证式推理训练:大模型告别第三方打分的新纪元
1. 传统验证体系的困境与技术跃迁的必然性 1.1 传统验证器的局限性 现有强化学习框架依赖显式验证器对答案进行二值化判定,这种模式在数学、代码等可验证领域表现优异。某厂内部数据显示,传统R1-Zero方法在代码生成任务中准确率达92%,但切换…...
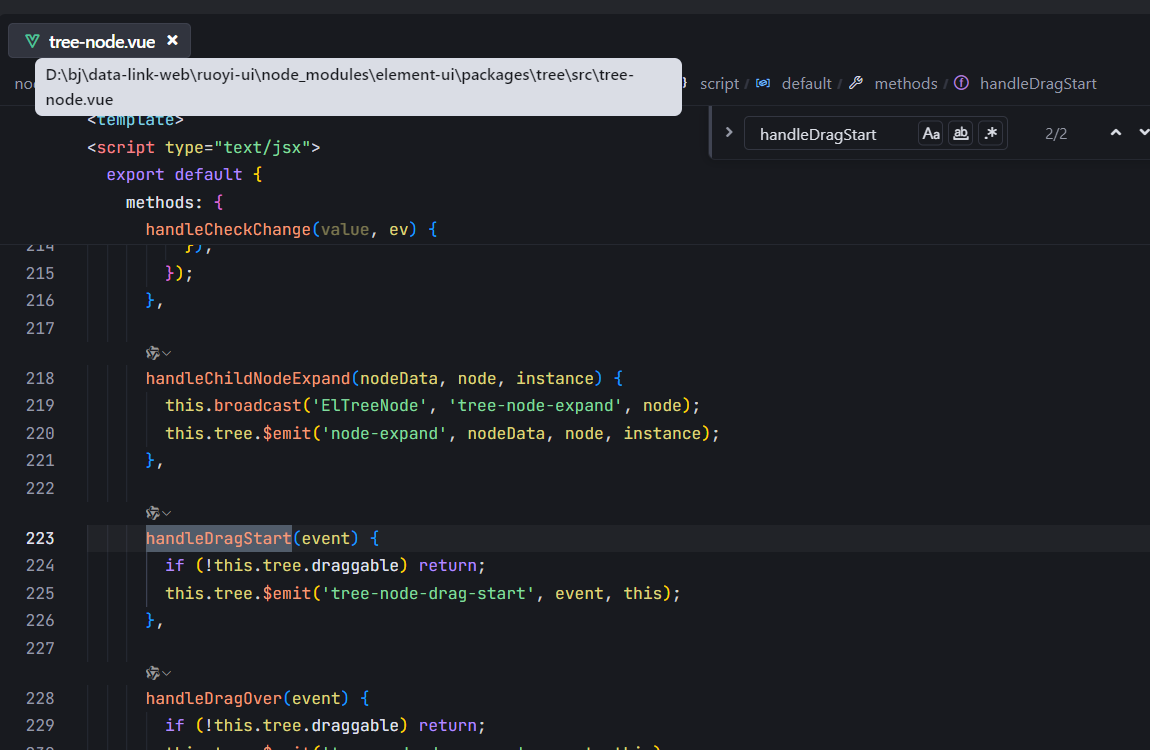
vue2使用el-tree实现两棵树间节点的拖拽复制
原文链接:两棵el-tree的节点跨树拖拽实现 参照这篇文章,把它做成组件,新增左侧树(可拖出)被拖节点变灰提示; 拖拽中: 拖拽后: TreeDragComponent.vue <template><!-- …...

前端开发中 <> 符号解析问题全解:React、Vue 与 UniApp 场景分析与解决方案
前端开发中 <> 符号解析问题全解:React、Vue 与 UniApp 场景分析与解决方案 在前端开发中,<> 符号在 JSX/TSX 环境中常被错误解析为标签而非比较运算符或泛型,导致语法错误和逻辑异常。本文全面解析该问题在不同框架中的表现及解…...

封装一个Qt调用动态库的类
封装一个Qt调用动态库的类 由于我的操作系统Ubuntu系统,我就以Linux下的动态库.so为例了,其实windows上的dll库调用方式是一样的,如果你的Qt项目是windows的,这篇文章代码可以直接使用。 一般情况下我们对外输出都是以动态库的形式封装的,这样我们更新版本的时候就很方便…...

[python] 最大公约数 和 最小公倍数
在Python中,计算最大公约数(GCD)和最小公倍数(LCM)的库函数主要来自math模块: 最大公约数(GCD) 使用math.gcd(a, b)函数,支持两个整数参数(Python 3.5&…...

如何在 Django 中集成 MCP Server
目录 背景说明第一步:使用 ASGI第二步:修改 asgi.py 中的应用第三步:Django 数据的异步查询 背景说明 有几个原因导致 Django 集成 MCP Server 比较麻烦 目前支持的 MCP 服务是 SSE 协议的,需要长连接,但一般来讲 Dj…...
从零开始的云计算生活——第十一天,知识延续,程序管理。
一故事背景 今日整体内容是第十天的剩余部分再加上程序管理的开头部分,详细可以回到第十天看新增加内容,现在开始讲解新内容。 二Linux程序与进程 1程序,进程,线程的概念 程序:是一段静态的代码,它是应用软件执行的蓝本。程序…...

React 事件处理与合成事件机制揭秘
引言 在现代前端开发的技术生态中,React凭借其高效的组件化设计和声明式编程范式,已成为构建交互式用户界面的首选框架之一。除了虚拟DOM和单向数据流等核心概念,React的事件处理系统也是其成功的关键因素。 这套系统通过"合成事件&qu…...

【React】jsx 从声明式语法变成命令式语法
在 React 中,JSX 是一种声明式的语法扩展,它使得开发者能够以类似 HTML 的方式描述用户界面。 然而,在某些情况下,可能希望将 JSX 转换为命令式语法,以获得更精细的控制或满足特定的需求。(ckeditor.com) JSX 到命令式…...
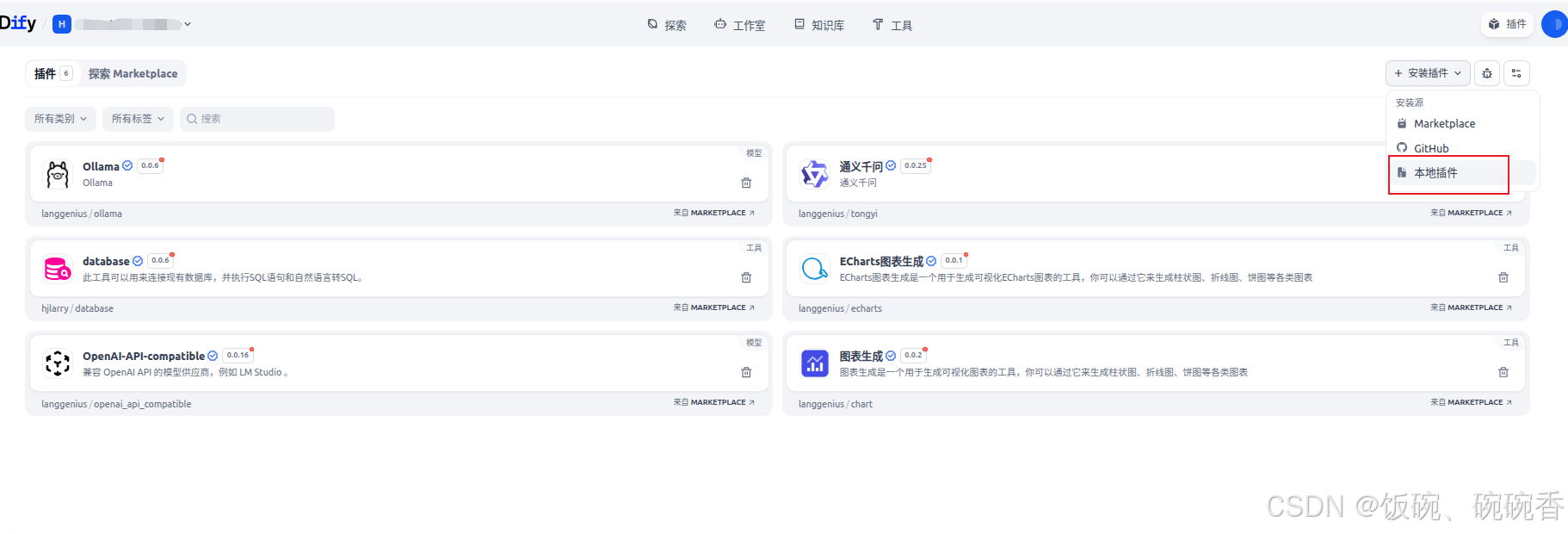
【Dify学习笔记】:Dify离线安装插件教程
Dify离线安装插件教程 1.本地下载插件 插件点击详情页面,安装右边的下载按钮,下载到本地 2.dify插件打包工具 dify-plugin-repackaging 下载后,进入到工具所在目录dify-plugin-repackaging/ git clone https://github.com/junjiem/dif…...

基于c++11重构的muduo核心库项目梳理
代码梳理 Thread创建与分配 event_channel回调函数 在muduo中,有三种类型的channel,包括 事件channel(event_channel) 这个就是普通的IO事件channel,当监听到Tcp连接有读、写、关闭、错误事件的时候,event_channel活跃accept_c…...
)
GitHub 趋势日报 (2025年05月29日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 1864 agenticSeek 753 langflow 749 n8n 736 prompt-eng-interactive-tutorial 42…...