深度学习篇---Pytorch框架下OC-SORT实现
下面将详细介绍如何基于 PyTorch 框架实现 OC-SORT(Observation-Centric SORT)算法。OC-SORT 是一种高性能的多目标跟踪算法,特别适用于复杂场景下的目标跟踪。我们将从算法原理到具体实现逐步展开。
1. 算法概述与核心原理
OC-SORT 在传统 SORT 算法的基础上,引入了三个关键创新点:
- 以观测为中心的在线平滑(OOS):解决长时间遮挡导致的轨迹漂移问题
- 以观测为中心的恢复(ORU):处理短期遮挡后的轨迹恢复
- 以观测为中心的动量(OCM):通过运动方向一致性优化数据关联
2. 环境准备与依赖安装
首先需要安装必要的依赖库:
pip install torch torchvision torchaudio # PyTorch基础库
pip install numpy scipy matplotlib # 科学计算与可视化
pip install opencv-python # 计算机视觉任务3. 核心模块实现
下面我们将实现 OC-SORT 的核心组件:
3.1 卡尔曼滤波器实现
import torch
import numpy as npclass KalmanFilter:"""卡尔曼滤波器实现,用于目标状态的预测和更新状态向量: [x, y, a, h, vx, vy, va, vh]其中(x,y)是边界框中心,a是宽高比,h是高度,vx,vy,va,vh是对应的速度"""def __init__(self):# 状态转移矩阵 (8x8)self.F = torch.eye(8, dtype=torch.float32)dt = 1.0 # 时间间隔self.F[:4, 4:] = torch.eye(4, dtype=torch.float32) * dt# 观测矩阵 (4x8) - 只观测位置和宽高self.H = torch.zeros((4, 8), dtype=torch.float32)self.H[:4, :4] = torch.eye(4, dtype=torch.float32)# 过程噪声协方差self.Q = torch.eye(8, dtype=torch.float32)self.Q[:4, :4] *= 0.01 # 位置噪声self.Q[4:, 4:] *= 0.001 # 速度噪声# 观测噪声协方差self.R = torch.eye(4, dtype=torch.float32) * 0.01def initiate(self, measurement):"""初始化轨迹状态measurement: [x1, y1, x2, y2] 检测框坐标"""# 转换为 [x, y, a, h] 格式x1, y1, x2, y2 = measurementcx = (x1 + x2) / 2cy = (y1 + y2) / 2w = x2 - x1h = y2 - y1a = w / h# 初始化状态向量 [x, y, a, h, vx, vy, va, vh]mean = torch.tensor([cx, cy, a, h, 0, 0, 0, 0], dtype=torch.float32)# 初始化协方差矩阵covariance = torch.eye(8, dtype=torch.float32) * 1000.0covariance[4:, 4:] *= 100.0return mean, covariancedef predict(self, mean, covariance):"""预测下一时刻的状态"""# 状态预测mean = torch.matmul(self.F, mean)# 协方差预测covariance = torch.matmul(torch.matmul(self.F, covariance), self.F.T) + self.Qreturn mean, covariancedef project(self, mean, covariance):"""将状态向量投影到观测空间"""# 计算观测预测projected_mean = torch.matmul(self.H, mean)# 计算观测协方差projected_covariance = torch.matmul(torch.matmul(self.H, covariance), self.H.T) + self.Rreturn projected_mean, projected_covariancedef update(self, mean, covariance, measurement):"""基于观测更新状态估计"""# 计算卡尔曼增益projected_mean, projected_covariance = self.project(mean, covariance)chol_factor, lower = torch.linalg.cholesky_ex(projected_covariance)kalman_gain = torch.cholesky_solve(torch.matmul(covariance, self.H.T), chol_factor, upper=not lower).T# 计算状态更新innovation = measurement - projected_meannew_mean = mean + torch.matmul(innovation, kalman_gain.T)# 计算更新后的协方差I = torch.eye(mean.size(0), dtype=torch.float32)new_covariance = torch.matmul(I - torch.matmul(kalman_gain, self.H), covariance)return new_mean, new_covariance3.2 轨迹管理类
class TrackState:"""轨迹状态枚举类"""Tentative = 1 # 暂定状态Confirmed = 2 # 确认状态Deleted = 3 # 已删除状态class Track:"""单个目标轨迹管理类"""def __init__(self, mean, covariance, track_id, n_init, max_age, feature=None, oc_sort_config=None):self.mean = mean # 状态向量self.covariance = covariance # 协方差矩阵self.track_id = track_id # 轨迹IDself.hits = 1 # 命中次数self.age = 1 # 轨迹存在时间self.state = TrackState.Tentative # 初始状态为暂定self.n_init = n_init # 确认轨迹所需的连续命中次数self.max_age = max_age # 最大未命中次数# 轨迹历史self.history = [mean.clone()]self.observations = [] # 观测历史self.features = [] # 特征历史if feature is not None:self.features.append(feature)# OC-SORT特定配置self.oc_sort_config = oc_sort_config or {'momentum': 0.2, # 运动方向一致性权重'deltat': 3, # 计算运动方向的时间窗口'asso_func': 'iou', # 关联函数类型'inertia': 0.2 # 运动惯性权重}# 运动方向相关self.velocity = None # 当前速度向量self.direction = None # 当前运动方向def predict(self, kf):"""使用卡尔曼滤波器预测下一时刻状态"""self.mean, self.covariance = kf.predict(self.mean, self.covariance)self.history.append(self.mean.clone())self.age += 1# 更新运动方向self._update_direction()def update(self, kf, detection, feature=None):"""根据检测结果更新轨迹"""self.mean, self.covariance = kf.update(self.mean, self.covariance, detection)self.history.append(self.mean.clone())self.observations.append(detection.clone())self.hits += 1if feature is not None:self.features.append(feature)# 更新状态if self.state == TrackState.Tentative and self.hits >= self.n_init:self.state = TrackState.Confirmed# 更新运动方向self._update_direction()def mark_missed(self):"""标记轨迹未匹配到检测"""if self.state == TrackState.Tentative:self.state = TrackState.Deletedelif self.age > self.max_age:self.state = TrackState.Deleteddef is_tentative(self):return self.state == TrackState.Tentativedef is_confirmed(self):return self.state == TrackState.Confirmeddef is_deleted(self):return self.state == TrackState.Deleteddef to_tlbr(self):"""将状态向量转换为边界框格式 [x1, y1, x2, y2]"""ret = self.mean.clone()w = ret[2] * ret[3] # 宽 = 宽高比 * 高h = ret[3] # 高ret[0] = ret[0] - w / 2 # x1 = x - w/2ret[1] = ret[1] - h / 2 # y1 = y - h/2ret[2] = ret[0] + w # x2 = x1 + wret[3] = ret[1] + h # y2 = y1 + hreturn ret[:4]def _update_direction(self):"""更新轨迹运动方向"""if len(self.history) < self.oc_sort_config['deltat'] + 1:return# 计算当前位置与deltat帧前位置的差current_pos = self.history[-1][:2]prev_pos = self.history[-self.oc_sort_config['deltat'] - 1][:2]direction = current_pos - prev_pos# 归一化方向向量norm = torch.norm(direction)if norm > 1e-6:self.direction = direction / norm# 计算速度 (位置变化/时间)self.velocity = direction / self.oc_sort_config['deltat']
3.3 数据关联模块
def iou_batch(bboxes1, bboxes2):"""计算两组边界框之间的IoU矩阵bboxes1: [N, 4] 格式为 [x1, y1, x2, y2]bboxes2: [M, 4] 格式为 [x1, y1, x2, y2]返回: [N, M] IoU矩阵"""# 扩展维度以广播计算bboxes1 = bboxes1.unsqueeze(1) # [N, 1, 4]bboxes2 = bboxes2.unsqueeze(0) # [1, M, 4]# 计算交集区域inter_min = torch.max(bboxes1[..., :2], bboxes2[..., :2]) # [N, M, 2]inter_max = torch.min(bboxes1[..., 2:], bboxes2[..., 2:]) # [N, M, 2]inter_wh = torch.clamp(inter_max - inter_min, min=0) # [N, M, 2]inter_area = inter_wh[..., 0] * inter_wh[..., 1] # [N, M]# 计算各自的面积area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * \(bboxes1[..., 3] - bboxes1[..., 1]) # [N, 1]area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * \(bboxes2[..., 3] - bboxes2[..., 1]) # [1, M]# 计算并集面积union_area = area1 + area2 - inter_area # [N, M]# 计算IoUiou = inter_area / torch.clamp(union_area, min=1e-6) # [N, M]return ioudef linear_assignment(cost_matrix, thresh):"""匈牙利算法解决最优分配问题"""if cost_matrix.size(0) == 0 or cost_matrix.size(1) == 0:return np.empty((0, 2), dtype=int), tuple(range(cost_matrix.size(0))), tuple(range(cost_matrix.size(1)))cost_matrix = cost_matrix.cpu().numpy()row_ind, col_ind = linear_sum_assignment(cost_matrix)matches, unmatched_a, unmatched_b = [], [], []for i in range(len(row_ind)):if cost_matrix[row_ind[i], col_ind[i]] > thresh:unmatched_a.append(row_ind[i])unmatched_b.append(col_ind[i])else:matches.append([row_ind[i], col_ind[i]])if len(matches) == 0:matches = np.empty((0, 2), dtype=int)else:matches = np.array(matches)if len(unmatched_a) == 0:unmatched_a = tuple()else:unmatched_a = tuple(unmatched_a)if len(unmatched_b) == 0:unmatched_b = tuple()else:unmatched_b = tuple(unmatched_b)return matches, unmatched_a, unmatched_bdef associate_detections_to_tracks(detections, tracks, iou_threshold=0.3, velocities=None, previous_obs=None, vdc_weight=0.2):"""将检测结果与轨迹进行关联"""if len(tracks) == 0:return np.empty((0, 2), dtype=int), np.arange(len(detections)), np.empty((0,), dtype=int)# 计算IoU矩阵iou_matrix = iou_batch(detections, torch.stack([t.to_tlbr() for t in tracks]))# 如果提供了速度信息,则计算运动方向一致性if velocities is not None and previous_obs is not None and vdc_weight > 0:# 计算当前检测与历史观测之间的方向detection_centers = (detections[:, :2] + detections[:, 2:]) / 2prev_obs_centers = previous_obs[:, :2]# 计算方向向量directions = detection_centers - prev_obs_centersnorms = torch.norm(directions, dim=1, keepdim=True)directions = directions / torch.clamp(norms, min=1e-6)# 计算方向一致性代价velocity_cost = torch.zeros_like(iou_matrix)for i in range(len(detections)):for j in range(len(tracks)):if tracks[j].direction is not None:# 计算方向余弦相似度 (值越大越相似)cos_sim = torch.dot(directions[i], tracks[j].direction)# 转换为代价 (值越小越相似)velocity_cost[i, j] = 1.0 - cos_sim# 合并IoU和方向一致性代价cost_matrix = (1 - vdc_weight) * (1 - iou_matrix) + vdc_weight * velocity_costelse:# 仅使用IoU作为代价cost_matrix = 1 - iou_matrix# 设置阈值并进行匈牙利算法分配matches, unmatched_dets, unmatched_tracks = linear_assignment(cost_matrix, thresh=1 - iou_threshold)return matches, unmatched_dets, unmatched_tracks
3.4 OC-SORT 主类实现
class OCSORT:"""OC-SORT算法实现"""def __init__(self, det_thresh=0.4, max_age=30, min_hits=3, iou_threshold=0.3, delta_t=3, asso_func="iou", inertia=0.2,use_byte=False):self.det_thresh = det_threshself.max_age = max_ageself.min_hits = min_hitsself.iou_threshold = iou_thresholdself.delta_t = delta_tself.asso_func = asso_funcself.inertia = inertiaself.use_byte = use_byteself.kf = KalmanFilter()self.tracks = []self._next_id = 1# 存储上一帧的观测结果,用于计算运动方向self.previous_obs = {}def update(self, dets, scores, classes=None, features=None):"""更新跟踪结果dets: 检测框 [N, 4],格式为 [x1, y1, x2, y2]scores: 置信度 [N]classes: 类别 [N] (可选)features: 特征 [N, feature_dim] (可选)"""# 过滤低分检测valid_indices = scores > self.det_threshdets = dets[valid_indices]scores = scores[valid_indices]if classes is not None:classes = classes[valid_indices]if features is not None:features = features[valid_indices]# 提取当前帧的检测中心current_obs = {}# 预测轨迹for track in self.tracks:track.predict(self.kf)# 第一阶段关联:IoU匹配if len(dets) > 0 and len(self.tracks) > 0:# 准备用于关联的轨迹信息track_indices = [i for i, track in enumerate(self.tracks) if track.is_confirmed()]confirmed_tracks = [self.tracks[i] for i in track_indices]# 提取上一帧的观测结果用于运动方向计算velocities = torch.zeros((len(confirmed_tracks), 2), dtype=torch.float32)previous_obs = torch.zeros((len(confirmed_tracks), 4), dtype=torch.float32)has_velocity = [False] * len(confirmed_tracks)for i, track in enumerate(confirmed_tracks):if track.track_id in self.previous_obs and track.velocity is not None:velocities[i] = track.velocityprevious_obs[i] = self.previous_obs[track.track_id]has_velocity[i] = True# 关联检测与轨迹matches, unmatched_dets, unmatched_tracks = associate_detections_to_tracks(dets, [self.tracks[i] for i in track_indices], iou_threshold=self.iou_threshold,velocities=velocities if any(has_velocity) else None,previous_obs=previous_obs if any(has_velocity) else None,vdc_weight=self.inertia)# 转换为全局轨迹索引matches = [(track_indices[i], j) for i, j in matches]unmatched_tracks = [track_indices[i] for i in unmatched_tracks]# 更新匹配的轨迹for track_idx, det_idx in matches:self.tracks[track_idx].update(self.kf, dets[det_idx], features[det_idx] if features is not None else None)# 记录当前观测current_obs[self.tracks[track_idx].track_id] = dets[det_idx]else:matches = []unmatched_dets = list(range(len(dets)))unmatched_tracks = list(range(len(self.tracks)))# 处理未匹配的检测for det_idx in unmatched_dets:mean, covariance = self.kf.initiate(dets[det_idx])self.tracks.append(Track(mean, covariance, self._next_id, self.min_hits, self.max_age,features[det_idx] if features is not None else None,oc_sort_config={'momentum': self.inertia,'deltat': self.delta_t,'asso_func': self.asso_func,'inertia': self.inertia}))self._next_id += 1# 记录当前观测current_obs[self.tracks[-1].track_id] = dets[det_idx]# 处理未匹配的轨迹for track_idx in unmatched_tracks:self.tracks[track_idx].mark_missed()# 应用以观测为中心的恢复机制 (ORU)if self.use_byte and len(unmatched_tracks) > 0 and len(unmatched_dets) > 0:# 提取未匹配的轨迹和检测tracks = [self.tracks[i] for i in unmatched_tracks if not self.tracks[i].is_tentative()]detections = dets[unmatched_dets]detection_features = features[unmatched_dets] if features is not None else Noneif len(tracks) > 0 and len(detections) > 0:# 计算外观相似度 (这里简化处理,实际应用中可使用更复杂的ReID模型)if detection_features is not None:track_features = [torch.cat(t.features[-3:]) if len(t.features) > 0 else torch.zeros_like(detection_features[0]) for t in tracks]track_features = torch.stack(track_features)# 计算余弦相似度sim_matrix = torch.matmul(detection_features, track_features.T)# 关联matches_oru, unmatched_dets_oru, unmatched_tracks_oru = linear_assignment(1 - sim_matrix, thresh=0.7 # 外观相似度阈值)# 更新匹配的轨迹for i, j in matches_oru:track_idx = unmatched_tracks[unmatched_tracks_oru[j]]det_idx = unmatched_dets[unmatched_dets_oru[i]]self.tracks[track_idx].update(self.kf, dets[det_idx], features[det_idx] if features is not None else None)# 记录当前观测current_obs[self.tracks[track_idx].track_id] = dets[det_idx]# 移除已删除的轨迹self.tracks = [t for t in self.tracks if not t.is_deleted()]# 更新上一帧观测结果self.previous_obs = current_obs# 输出确认的轨迹和暂定轨迹output_results = []for track in self.tracks:if track.is_confirmed() or (track.is_tentative() and track.hits >= 1):bbox = track.to_tlbr()track_id = track.track_idoutput_results.append({'bbox': bbox.cpu().numpy(),'track_id': track_id,'score': scores.max().item() if len(scores) > 0 else 1.0,'class': classes[0].item() if classes is not None and len(classes) > 0 else 0})return output_results
4. 使用示例
下面是一个简单的使用示例,展示如何将 OC-SORT 集成到目标检测流程中:
import cv2
import torch# 假设这是你的目标检测模型
def detect_objects(frame):"""返回检测框、置信度和类别"""# 这里应该是实际的目标检测代码# 简化示例,随机生成一些检测结果num_detections = torch.randint(3, 10, (1,)).item()detections = torch.rand(num_detections, 4) * torch.tensor([frame.shape[1], frame.shape[0], frame.shape[1], frame.shape[0]])scores = torch.rand(num_detections)classes = torch.zeros(num_detections, dtype=torch.long) # 假设所有类别都是0# 确保检测框格式正确 [x1, y1, x2, y2]detections[:, 2:] += detections[:, :2]return detections, scores, classes# 初始化OC-SORT跟踪器
tracker = OCSORT(det_thresh=0.5, max_age=30, min_hits=3, iou_threshold=0.3, delta_t=3, inertia=0.2)# 打开视频文件或摄像头
cap = cv2.VideoCapture(0) # 0表示默认摄像头while True:ret, frame = cap.read()if not ret:break# 转换为PyTorch张量frame_tensor = torch.from_numpy(frame).permute(2, 0, 1).float() / 255.0# 目标检测detections, scores, classes = detect_objects(frame)# 多目标跟踪tracks = tracker.update(detections, scores, classes)# 可视化结果for track in tracks:bbox = track['bbox'].astype(int)track_id = track['track_id']cls = track['class']# 绘制边界框cv2.rectangle(frame, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (0, 255, 0), 2)# 绘制跟踪ID和类别cv2.putText(frame, f"ID: {track_id} Cls: {cls}", (bbox[0], bbox[1] - 10),cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)# 显示结果cv2.imshow('OC-SORT Tracking', frame)# 按ESC键退出if cv2.waitKey(1) == 27:breakcap.release()
cv2.destroyAllWindows()5. 参数调优建议
OC-SORT 有几个关键参数会影响跟踪性能,建议根据实际场景调整:
- 检测阈值 (det_thresh):默认 0.4,值越高过滤掉的低置信度检测越多
- 最大未匹配帧数 (max_age):默认 30,值越大允许目标长时间遮挡后重新关联
- 确认轨迹所需命中次数 (min_hits):默认 3,值越小轨迹确认越快但可能不稳定
- IoU 阈值 (iou_threshold):默认 0.3,值越高关联越严格
- 运动惯性权重 (inertia):默认 0.2,控制运动方向一致性在关联中的重要性
6. 性能优化建议
- 使用更高效的目标检测器(如 YOLOv5/YOLOv8)
- 考虑使用轻量级 ReID 模型增强外观匹配能力
- 对于实时性要求高的场景,可降低 delta_t 参数值
- 在嵌入式设备上部署时,考虑使用模型量化和剪枝技术
通过以上步骤,在 PyTorch 框架下实现一个完整的 OC-SORT 多目标跟踪系统,适用于各种复杂场景下的目标跟踪任务。
相关文章:

深度学习篇---Pytorch框架下OC-SORT实现
下面将详细介绍如何基于 PyTorch 框架实现 OC-SORT(Observation-Centric SORT)算法。OC-SORT 是一种高性能的多目标跟踪算法,特别适用于复杂场景下的目标跟踪。我们将从算法原理到具体实现逐步展开。 1. 算法概述与核心原理 OC-SORT 在传统…...
)
STM32 HAL库SPI读写W25Q128(软件模拟+硬件spi)
1. 引言 在嵌入式系统开发中,SPI(Serial Peripheral Interface)总线是一种常用的串行通信协议,用于在微控制器和外部设备之间进行高速数据传输。W25Q128 是一款常见的 SPI Flash 芯片,具有 128Mbit(16MB&a…...
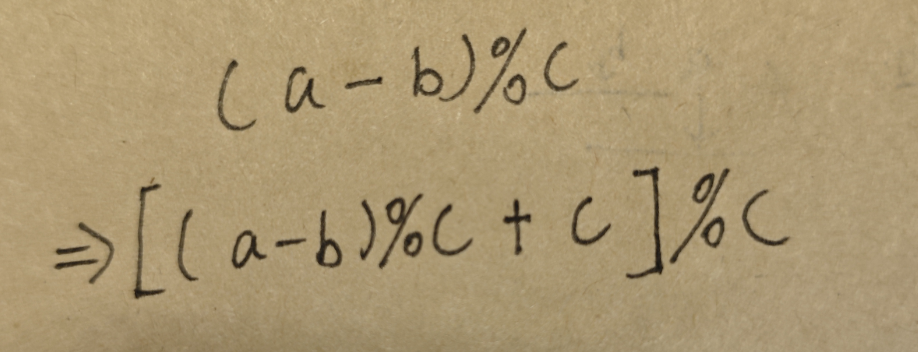
算法题(159):快速幂
审题: 本题需要我们计算出(a^b)%c的值,并按照规定格式输出 思路: 方法一:暴力解法 我们直接循环b次计算出a^b,然后再取余c,从而得出最终结果 时间上:会进行2^31次,他的数量级非常大,…...

【新品发布】嵌入式人工智能实验箱EDU-AIoT ELF 2正式发布
在万物互联的智能化时代,将AI算法深度植入硬件终端的技术,正悄然改变着工业物联网、智慧交通、智慧医疗等领域的创新边界。为了助力嵌入式人工智能在教育领域实现高质量发展,飞凌嵌入式旗下教育品牌ElfBoard,特别推出嵌入式人工智…...
基于javaweb的SpringBoot体检管理系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

Mac Python 安装依赖出错 error: externally-managed-environment
Mac Python 使用 ip3 install -r requirements.txt 出错 This environment is externally managed ╰─> To install Python packages system-wide, try brew installxyz, where xyz is the package you are trying toinstall.If you wish to install a Python library th…...

Docker Desktop for Windows 系统设置说明文档
1. 文档概述 本文档旨在详细说明 Docker Desktop for Windows 应用程序中“设置 (Settings)”界面下的所有可配置选项及其子选项。对于每个配置项,我们将提供其功能描述、推荐配置(如适用)以及相关注意事项,帮助用户更好地理解和…...

C++高级编程深度指南:内存管理、安全函数、递归、错误处理、命令行参数解析、可变参数应用与未定义行为规避
C高级编程深度指南:内存管理、安全函数、递归、错误处理、命令行参数解析、可变参数应用与未定义行为规避 1. 可变参数1.1 可变参数的定义与原理1.2 使用可变参数的场景1.3 可变参数的实现方式1.3.1 省略号方式1.3.2 模板参数包方式 2.2 动态内存分配函数2.3 内存泄…...

【下拉选项数据管理优化实践:从硬编码到高扩展性架构】
下拉选项数据管理优化实践:从硬编码到高扩展性架构 背景 在大型前端项目中,下拉选项数据管理是一个常见但容易被忽视的痛点。我们的项目中存在多种格式的选项标识符,如代码格式(OPTION_A1)和数字格式(100…...

IPD的基础理论与框架——(四)矩阵型组织:打破部门壁垒,构建高效协同的底层
在传统的组织架构中,企业多采用直线职能制,就像一座等级森严的金字塔,信息沿着垂直的层级传递,员工被划分到各个职能部门。这种架构职责清晰、分工明确,在稳定的市场环境中,能让企业高效运作,发…...

深度学习篇---OC-SORT实际应用效果
OC-SORT 算法在实际应用中的效果可从准确性、鲁棒性、效率三个核心维度评估,其表现与传统多目标跟踪算法(如 SORT、DeepSORT)相比有显著提升,尤其在复杂场景中优势突出。以下是具体分析: 一、准确性:目标关联更可靠 1. 遮挡场景下的 ID 保持能力 优势表现: 传统算法(…...

讲述我的plc自学之路 第十一章
《凡人歌》,道出了我们每个人都是一个凡人,追逐功名利禄是每个人的特性,但也往往被世俗所伤。lora和我听着歌曲的同时,我能感觉到和她内心的那种共鸣和对世俗的妥协。 我以前是不信命的,但是经历过这么多社会的毒打&am…...

OpenLayers 图形绘制
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 图形绘制功能是指在地图容器中绘制点、线、面、圆、矩形等图形。图形绘制功能在WebGIS中具有重要作用,可以辅助查询、编辑、分析功能。本节主…...

小程序为什么要安装SSL安全证书
小程序需要部署SSL安全证书,这是小程序开发及运营的强制性要求,也是保障用户数据安全、提升用户体验和满足平台规范的必要措施。 一、平台强制要求 微信小程序官方规范 微信小程序明确要求所有网络请求必须通过HTTPS协议传输,服务器域名需配…...
python打卡训练营打卡记录day40
知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业:仔细学习下测试和训练代码…...

互联网大厂Java求职面试:Spring Boot 3.2+自动配置原理、AOT编译及原生镜像
标题:互联网大厂Java求职面试:Spring Boot 3.2自动配置原理、AOT编译及原生镜像 简述 本文详细探讨了在互联网大厂Java求职面试中,技术总监级别面试官与求职者郑薪苦之间的精彩对话,主题聚焦于Spring Boot 3.2自动配置原理、AOT…...
)
小型图书管理系统案例(用于spring mvc 实践)
小型图书管理系统案例 (Spring MVC Spring Data JPA Thymeleaf) 本项目案例旨在基于先前模块学习的 Spring MVC 知识,构建一个贴近企业实际的简单 Web 应用:小型图书管理系统。通过实现图书的 CRUD 操作、列表展示(含分页概念)…...
【清晰教程】利用Git工具将本地项目push上传至GitHub仓库中
Git 是一个分布式版本控制系统,由 Linus Torvalds 创建,用于有效、高速地处理从小到大的项目版本管理。GitHub 是一个基于 Git 的代码托管平台,提供了额外的协作和社交功能,使项目管理更加高效。它们为项目代码管理、团队协作和持…...

20250529-C#知识:静态类、静态构造函数和拓展方法
C#知识:静态类、静态构造函数和拓展方法 静态类一般用来编写工具类 1、静态类 用static关键字修饰的类一般充当工具类只能包含静态成员,不能包含静态索引器不能被实例化静态方法只能使用静态成员非静态方法既可以使用非静态成员,也可以使用静态成员 sta…...

实验设计与分析(第6版,Montgomery)第4章随机化区组,拉丁方, 及有关设计4.5节思考题4.18~4.19 R语言解题
本文是实验设计与分析(第6版,Montgomery著,傅珏生译) 第章随机化区组,拉丁方, 及有关设计4.5节思考题4.18~4.19 R语言解题。主要涉及方差分析,拉丁方。 batch <- c(rep("batch1",5), rep(&quo…...

第十篇:MySQL 实战:数据迁移、分库分表与分区技术指南
随着系统数据量与访问压力的增长,MySQL 单实例常面临性能瓶颈。本篇系统讲解如何进行 数据迁移、分库分表 与 分区表设计,并结合实践案例提供完整的优化思路。 一、MySQL 数据迁移方式 1. 场景分类 场景推荐工具同版本、本地迁移mysqldump、cpibdata跨…...
【吾爱】逆向实战crackme160学习记录(一)
前言 最近想拿吾爱上的crackme程序练练手,发现论坛上已经有pk8900总结好的160个crackme,非常方便,而且有很多厉害的前辈已经写好经验贴和方法了,我这里只是做一下自己练习的记录,欢迎讨论学习,感谢吾爱论坛…...
vue2 + webpack 老项目升级 node v22 + vite + vue2 实战全记录
前言 随着这些年前端技术的飞速发展,几年前的一些老项目在最新的环境下很可能会出现烂掉的情况。如果项目不需要升级,只需要把编译后的文件放在那里跑而不用管的话还好。但是,某一天产品跑过来给你讲要升级某一个功能,你不得不去…...

opengauss 数据库安装主备 非om方式
一. 准备两台服务器 192.168.141.130 --主 192.168.141.131 --备 1.关闭防火墙 systemctl stop firewalld systemctl disable firewalld 2.关闭 selinux 服务 setenforce 0 vim /etc/selinux/config #设置 SELINUXdisabled 3.关闭透明大页 echo never > /sys/kern…...
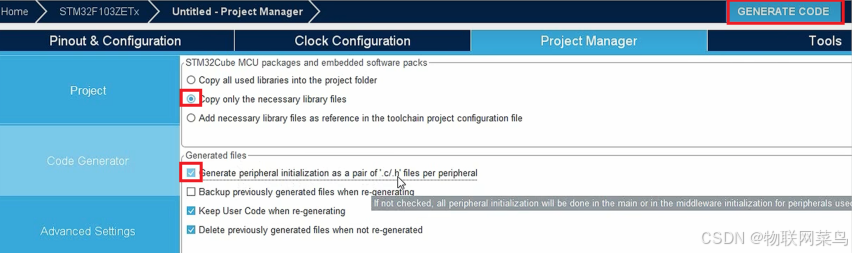
STM32的HAL编码流程总结(上部)
目录 一、GPIO二、中断系统三、USART串口通信四、I2C通信五、定时器 一、GPIO 1.选择调试类型 在SYS中Debug选择Serial Wire模式 2.选择时钟源 在RCC中将HSE和LSH都选择为内部晶振 3.时钟树配置 4.GPIO配置 在芯片图上选择开启的引脚和其功能 配置引脚的各自属性 5.工…...

深度学习|pytorch基本运算
【1】引言 pytorch是深度学习常用的包,顾名思义,就是python适用的torch包,在python里面使用时直接import torch就可以调用。 需要注意的是,pytorch包与电脑配置、python版本有很大关系,一定要仔细阅读安装要求、找到…...
Java学习-5.15(模糊搜索,收藏,购物车))
(自用)Java学习-5.15(模糊搜索,收藏,购物车)
1. 模糊搜索商品功能 前端实现: 通过解析URL参数(如search联想)获取搜索关键字,发送AJAX GET请求到后端接口/product/searchGoodsMessage。 动态渲染搜索结果:若结果非空,循环遍历返回的商品数据ÿ…...
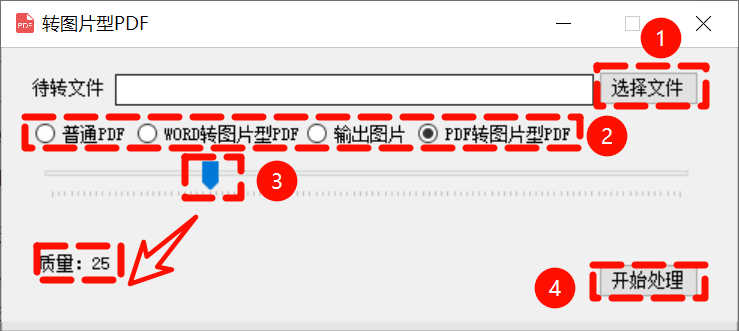
替代 WPS 的新思路?快速将 Word 转为图片 PDF
在这个数字化办公日益普及的时代,越来越多的人开始关注文档处理工具的功能与体验。当我们习惯了某些便捷操作时,却发现一些常用功能正逐渐变为付费项目——比如 WPS 中的一项实用功能也开始收费了。 这款工具最特别的地方在于,可以直接把 W…...
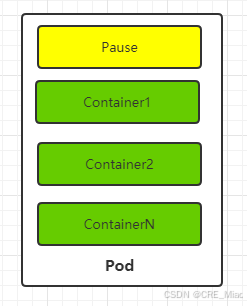
【K8S】K8S基础概念
一、 K8S组件 1.1 控制平面组件 kube-apiserver:公开 Kubernetes HTTP API 的核心组件服务器。 etcd:具备一致性和高可用性的键值存储,用于所有 API 服务器的数据存储。 kube-scheduler:查找尚未绑定到节点的 Pod,并将…...

FEMFAT许可分析的数据可视化方法
随着企业对FEMFAT软件使用的增加,如何有效地管理和分析许可数据成为了关键。数据可视化作为一种强大的工具,能够帮助企业直观地理解FEMFAT许可的使用情况,从而做出更明智的决策。本文将介绍FEMFAT许可分析的数据可视化方法,并探讨…...