MySQL + CloudCanal + Iceberg + StarRocks 构建全栈数据服务
简述
在业务数据快速膨胀的今天,企业对 低成本存储 与 实时查询分析能力 的需求愈发迫切。
本文将带你实战构建一条 MySQL 到 Iceberg 的数据链路,借助 CloudCanal 快速完成数据迁移与同步,并使用 StarRocks 完成数据查询等操作,构建涵盖 关系型数据库服务、实时数据分析、大数据存取 的全栈数据架构。
Iceberg 简介
Iceberg 是什么?
Iceberg 是一种开放的数据表格式,包含 Catalog 和 数据存储 两种子概念。
Catalog 可简单理解为对数据的结构描述,如表列表、对应的表属性、包含的列、列类型、列长度等信息,这也是之所以为表格的原因。
数据存储 即以上 Catalog 数据 以及 实际业务数据 所组成的文件存放位置。
Iceberg 有什么特点?
Iceberg 架构开放,定义了 Catalog 、文件格式、数据存储、数据访问 等标准,从而被众多第三方组件实现和支持。
- Catalog: AWS Glue、Hive、Nessie、Jdbc,或者专用的 Catalog 服务通过 Rest 方式读写。
- 数据文件格式: Parquet、ORC、Avro 等。
- 数据存储: AWS S3、Azure Blob Storage、MinIO、HDFS、Posix FS 等各类云存储或本地存储。
- 数据访问: 可通过类似 StarRocks、Doris、ClickHouse 等实时数仓,Spark、Flink、Hive 等流/批计算引擎检索、分析、操作数据和结构。
除了 开放 这一大特点,Iceberg 同时在 超大数据量存储 和 准实时增、删、改 之间实现了平衡。
下表从数据容量、增量实时性、事务支持、存储成本、架构开放度 5 个纬度,对各类数据库进行对比(仅作参考,欢迎讨论):
| 数据库种类 | 关系型数据库 | 实时数据仓库 | 传统大数据 | 数据湖 |
|---|---|---|---|---|
| 数据容量 | 几 TB 级别 | 百 TB 级别 | PB 级别 | PB 级别 |
| 增量实时性 | 业务级别增量写入,延迟毫秒级别,万级别 QPS | 业务级别增量写入,延迟秒到分钟级别,千级别 QPS | 运维级别增量写入,延迟小时到天级别,个位数 QPS | 业务级别增量写入,延迟分钟级别,个位数 QPS(攒批) |
| 事务支持 | ACID 强一致 | ACID 强一致或最终一致 | 否 | 否 |
| 存储成本 | 高 | 高或很高 | 很低 | 低 |
| 架构开放度 | 低 | 中(存算分离) | 否 | 高 |
从上表来看,使用 Iceberg,即可得到一个 低成本、超大数据存储容量、丰富数据检索分析工具的数据库,从某种意义上来说,可以作为传统大数据系统的换代升级产品。
当然得益于其架构的开放性,还可以不断探索更多的数据使用场景。
CloudCanal 技术亮点
典型 Catalog 和存储支持
CloudCanal 支持 Iceberg 3 种 Catalog 和 2 种存储方式,搭配关系为
- AWS Glue + AWS S3
- Nessie + MinIO / AWS S3
- Rest + MinIO / AWS S3
对于全栈数据上云,AWS RDS + EC2 部署 CloudCanal + AWS Glue + AWS S3 即可构建。
对于全私有数据,自建关系型数据库 + 虚拟机部署 CloudCanal + Nessis/Rest Catalog + MinIO 则可快速达成。
数据迁移同步一体化
对于数据同步开始之前的繁重工作,CloudCanal 一直尝试利用自身的数据库知识,实现结构准备、历史数据迁移全自动化。
对于 Iceberg 这类非传统意义数据库交互的产品,CloudCanal 也实现了数据迁移同步的自动化流程,包括结构定义转换、类型映射、约束清理、类型长度适配等工作,都可在 CloudCanal 一站式完成。
全栈数据服务架构总览
本次构建的数据服务链路包含 4 大组件:
MySQL → CloudCanal → Iceberg (Glue + S3) → StarRocks
- MySQL: 关系型数据库,源数据产生地。
- CloudCanal: 数据迁移同步平台,支持结构转换、类型映射、全量+增量同步。
- Iceberg (AWS Glue + S3): 数据湖存储 + 元数据管理。
- StarRocks: 支持实时查询的分析型数据库,用于数据服务出口。
操作示例
前置准备
- 下载安装 CloudCanal 私有部署版本。
- 准备数据源:
- 源端:自建 MySQL
- 目标端:Iceberg (AWS Glue + S3)
添加数据源
- 登录 CloudCanal 平台,点击 数据源管理 > 添加数据源,添加 2 个数据源。
- 添加 Iceberg 所要填写的信息如下(
<>内按实际情况替换)。
- 网络地址:本例填写 AWS Glue 服务地址。
glue.<aws_glue_region_code>.amazonaws.com - 版本:保持默认值即可。
- 描述:用于辨别实例用途。
- 额外参数:
- httpsEnabled:打开开关,即设置为 true。
- catalogName:设置一个意义明确的名字,如 glue_<biz_name>_catalog。
- catalogType:设置为 GLUE。
- catalogWarehouse:元数据和数据文件最终存放位置,如 s3://<biz_name>_iceberg。
- catalogProps:参考如下
{"io-impl": "org.apache.iceberg.aws.s3.S3FileIO","s3.endpoint": "https://s3.<aws_s3_region_code>.amazonaws.com","s3.access-key-id": "<aws_s3_iam_user_access_key>","s3.secret-access-key": "<aws_s3_iam_user_secret_key>","s3.path-style-access": "true","client.region": "<aws_s3_region>","client.credentials-provider.glue.access-key-id": "<aws_glue_iam_user_access_key>","client.credentials-provider.glue.secret-access-key": "<aws_glue_iam_user_secret_key>","client.credentials-provider": "com.amazonaws.glue.catalog.credentials.GlueAwsCredentialsProvider" }
创建任务
-
点击 同步任务 > 创建任务。
-
选择源和目标实例,并分别点击 测试连接。其中 Iceberg 数据源 结构迁移属性配置 推荐如下:
{"format-version": "2","parquet.compression": "snappy","iceberg.write.format": "parquet","write.metadata.delete-after-commit.enabled": "true","write.metadata.previous-versions-max": "3","write.update.mode": "merge-on-read","write.delete.mode": "merge-on-read","write.merge.mode": "merge-on-read","write.distribution-mode": "hash","write.object-storage.enabled": "true","write.spark.accept-any-schema": "true" } -
在 功能配置 页面,选择 增量同步,并勾选 全量初始化。
-
在 表&action过滤 页面,选择需要迁移同步的表,可同时选择多张。
-
在 数据处理 页面,保持默认配置。
-
在 创建确认 页面,点击 创建任务,开始运行。

验证数据(接入 StarRocks)
-
造增删改数据。
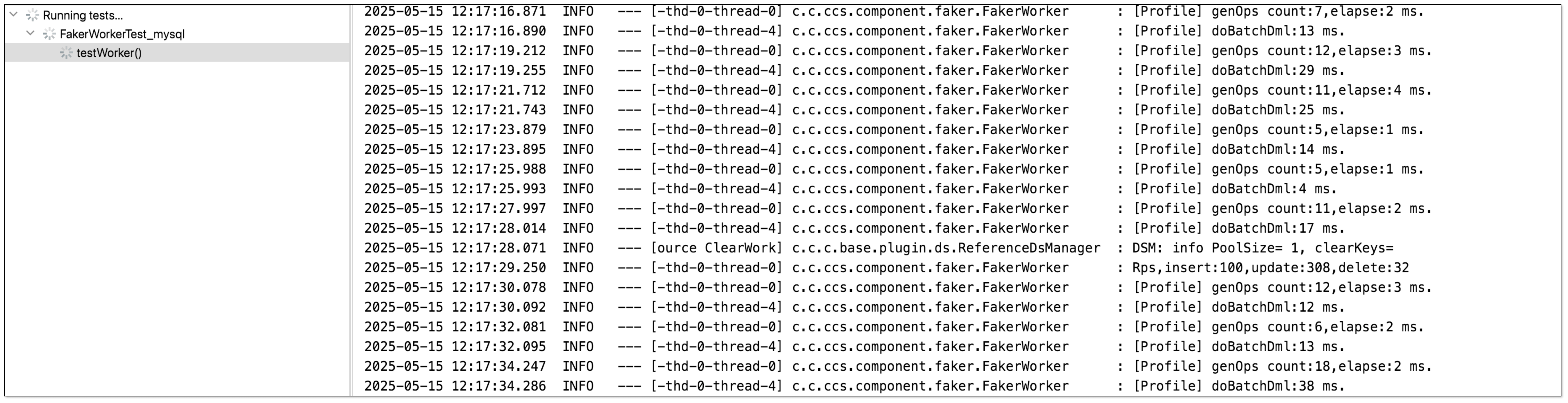
-
停止造数据。
-
创建一个按量 Aliyun EMR for StarRocks,添加 AWS Glue 的 Iceberg Catalog 并查询。
-
StarRocks 中添加 External Catalog 并设置查询环境。
CREATE EXTERNAL CATALOG glue_test PROPERTIES ("type" = "iceberg","iceberg.catalog.type" = "glue","aws.glue.use_instance_profile" = "false","aws.glue.access_key" = "<aws_glue_iam_user_access_key>","aws.glue.secret_key" = "<aws_glue_iam_user_secret_key>","aws.glue.region" = "ap-southeast-1","aws.s3.use_instance_profile" = "false","aws.s3.access_key" = "<aws_s3_iam_user_access_key>","aws.s3.secret_key" = "<aws_s3_iam_user_secret_key>","aws.s3.region" = "ap-southeast-1" )set CATALOG glue_test;set global new_planner_optimize_timeout=30000; -
MySQL 数据量
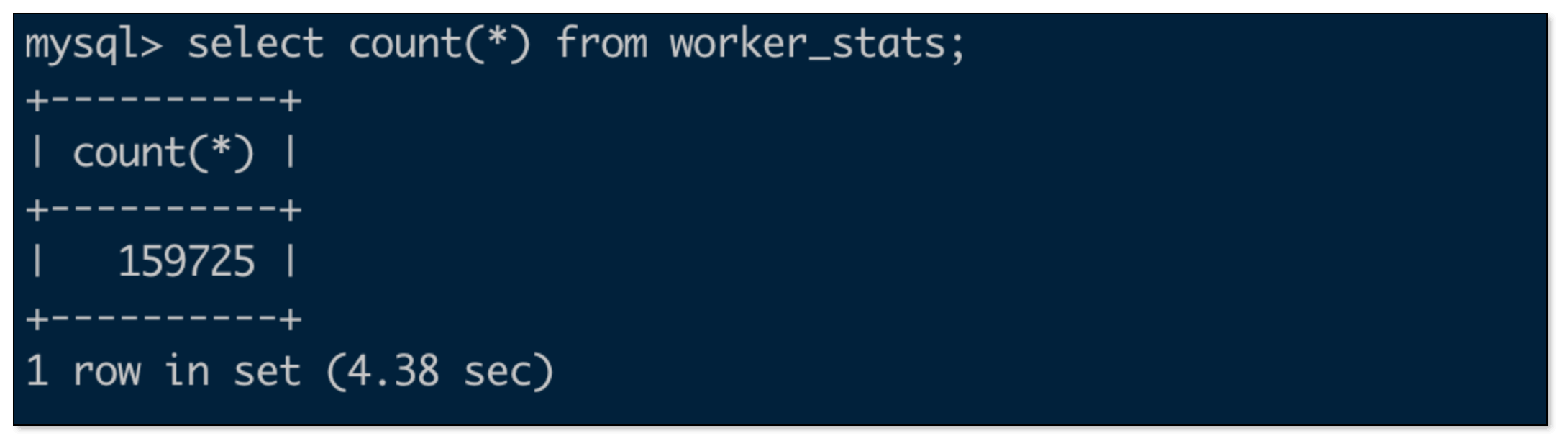
-
Iceberg 数据量
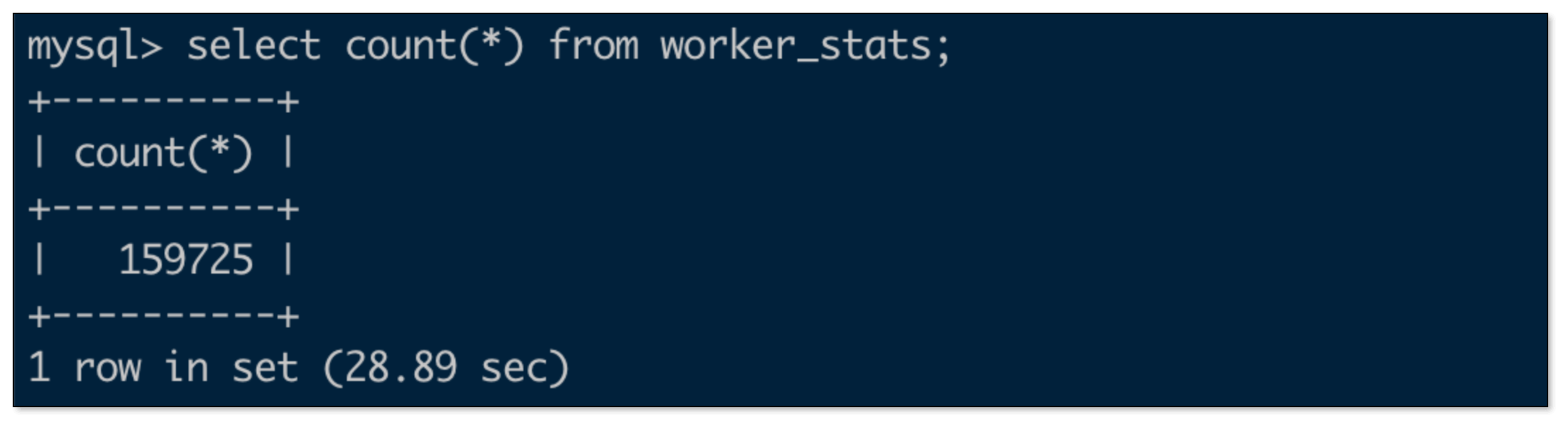
总结
通过 CloudCanal,你可以轻松打通 MySQL 与 Iceberg 之间的实时同步通道,并结合 StarRocks 实现高效查询,实现实时数据服务闭环,打造真正的全栈数据结构解决方案。
相关文章:
MySQL + CloudCanal + Iceberg + StarRocks 构建全栈数据服务
简述 在业务数据快速膨胀的今天,企业对 低成本存储 与 实时查询分析能力 的需求愈发迫切。 本文将带你实战构建一条 MySQL 到 Iceberg 的数据链路,借助 CloudCanal 快速完成数据迁移与同步,并使用 StarRocks 完成数据查询等操作,…...

MSVC支持但是Clang会报错的C++行为
MSVC的非标 目的友元别名模板类显式特例化的命名空间限制 目的 因为在使用clang进行ast分析msvc项目的时候,出现了爆红现象,了解到msvc会有一些不严格按照c标准但是允许的语法,在这点上clang就很严格,所以本文以clang为基准&…...

截屏精灵:轻松截屏,高效编辑
在移动互联网时代,截图已经成为我们日常使用手机时的一项基本操作。无论是记录重要信息、分享有趣内容,还是进行学习和工作,一款好用的截图工具都能极大地提升我们的效率。截屏精灵就是这样一款功能强大、操作简单的截图工具,它不…...
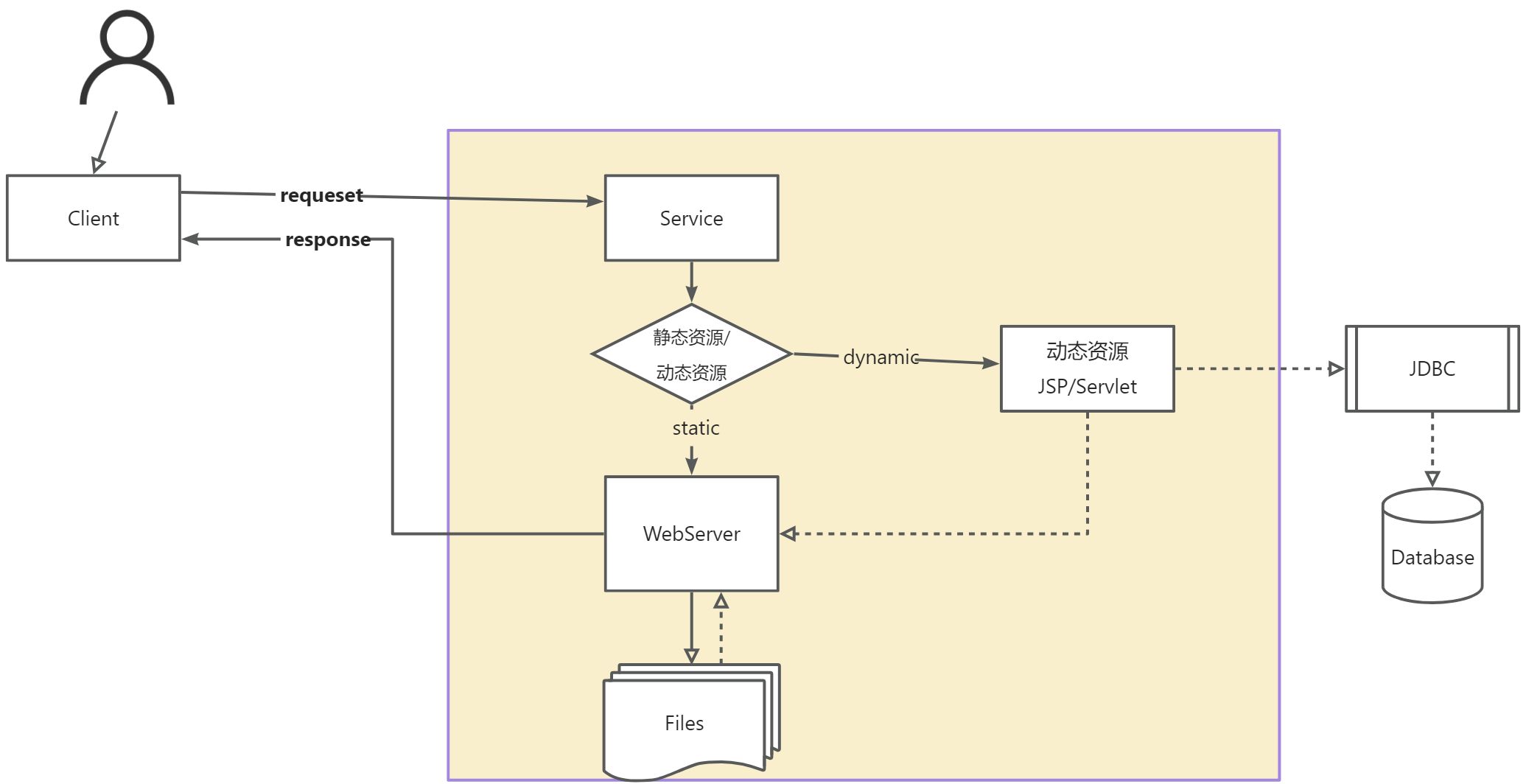
【JavaWeb】基本概念、web服务器、Tomcat、HTTP协议
目录 1. 基本概念1.1 基本概念1.2 web应用程序1.3 静态web1.4 动态web 2. web服务器3. tomcat详解3.1 安装3.2 启动3.3 配置3.3.1 配置启动的端口号3.3.2 配置主机的名称3.3.3 其他常用配置项日志配置数据源配置安全配置 3.4 发布一个网站 4. Http协议4.1 什么是http4.2 http的…...

黑马程序员C++核心编程笔记--4 类和对象--封装
C面向对象三大特征:封装、继承、多态 C认为万事万物皆对象,对象有其属性和行为,具有相同性质的对象可以抽象称为类 4.1 封装 4.1.1 封装的意义 将属性和行为作为一个整体,表现生活中的事物将属性和行为加以权限控制 在设计类…...

Debian:自由操作系统的精神图腾与技术基石
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 ——解码Linux世界最纯粹的开源哲学 一、Debian的诞生:从个人实验到全球协作 1993年,一位名为Ian Murdock的程序员在开源社区的启…...
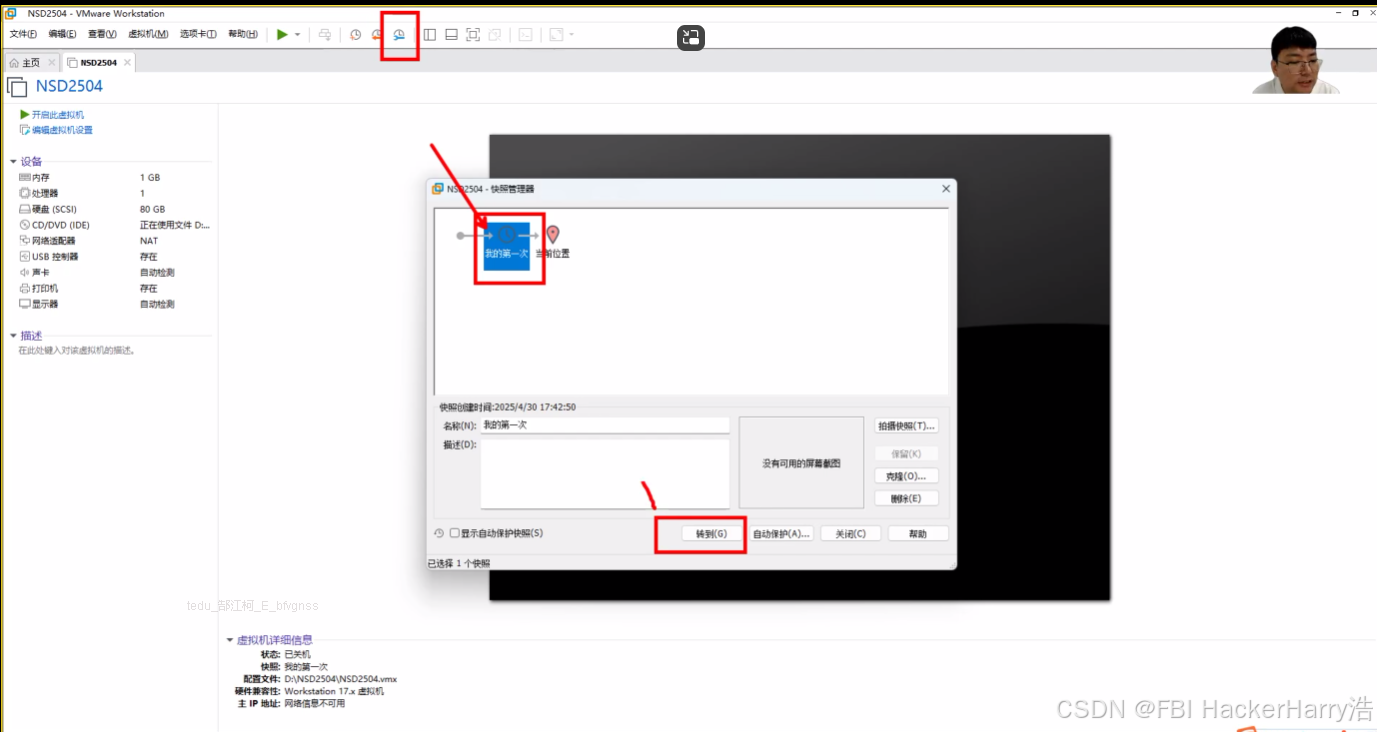
云计算Linux Rocky day02(安装Linux系统、设备表示方式、Linux基本操作)
云计算Linux Rocky day02(安装Linux系统、设备表示方式、Linux基本操作) 目录 云计算Linux Rocky day02(安装Linux系统、设备表示方式、Linux基本操作)1、虚拟机VMware安装Rocky2、Linux命令行3、Linux Rocky修改字体大小和背景颜…...

在 ODROID-H3+ 上安装 Win11 系统
在 ODROID-H3 上安装 Windows 11 系统。 以下是完整的步骤,包括 BIOS 设置、U 盘制作、安装和驱动处理,全程不保留之前的系统数据。 ✅ 准备工作 1. 准备一个 ≥8GB 的 USB 启动盘 用另一台电脑制作 Windows 11 安装盘。 👉 推荐工具&…...
)
Docker常用命令操作指南(一)
Docker常用命令操作指南-1 一、Docker镜像相关命令1.1 搜索镜像(docker search)1.2 拉取镜像(docker pull)1.3 查看本地镜像(docker images)1.4 删除镜像(docker rmi) 二、Docker容器…...

什么是 SQL 注入?如何防范?
什么是 SQL 注入?如何防范? 1. SQL 注入概述 1.1 基本定义 SQL 注入(SQL Injection)是一种通过将恶意SQL 语句插入到应用程序的输入参数中,从而欺骗服务器执行非预期SQL命令的攻击技术。攻击者可以利用此漏洞绕过认证、窃取数据甚至破坏数据库。 关键结论:SQL 注入是O…...
使用el-input数字校验,输入汉字之后校验取消不掉
先说说复现方式 本来input是只能输入数字的,然后你不小心输入了汉字,触发校验了,然后这时候,你发现校验取消不掉了 就这样了 咋办啊,你一看校验没错啊,各种number啥的也写了,发现没问题啊 <el-inputv…...

Docker容器启动失败的常见原因分析
我们在开发部署的时候,用 Docker 打包环境,理论上是“我装好了你就能跑”。但理想很丰满,现实往往一 docker run 下去就翻车了。 今天来盘点一下我实际工作中经常遇到的 Docker 容器启动失败的常见原因,顺便给点 debug 的小技巧&a…...

Java提取markdown中的表格
Java提取markdown中的表格 说明 这篇博文是一个舍近求远的操作,如果只需要要对markdown中的表格数据进行提取,完全可以通过正在表达式或者字符串切分来完成。但是鉴于学习的目的,这次采用了commonmark包中的工具来完成。具体实现过程如下 实…...
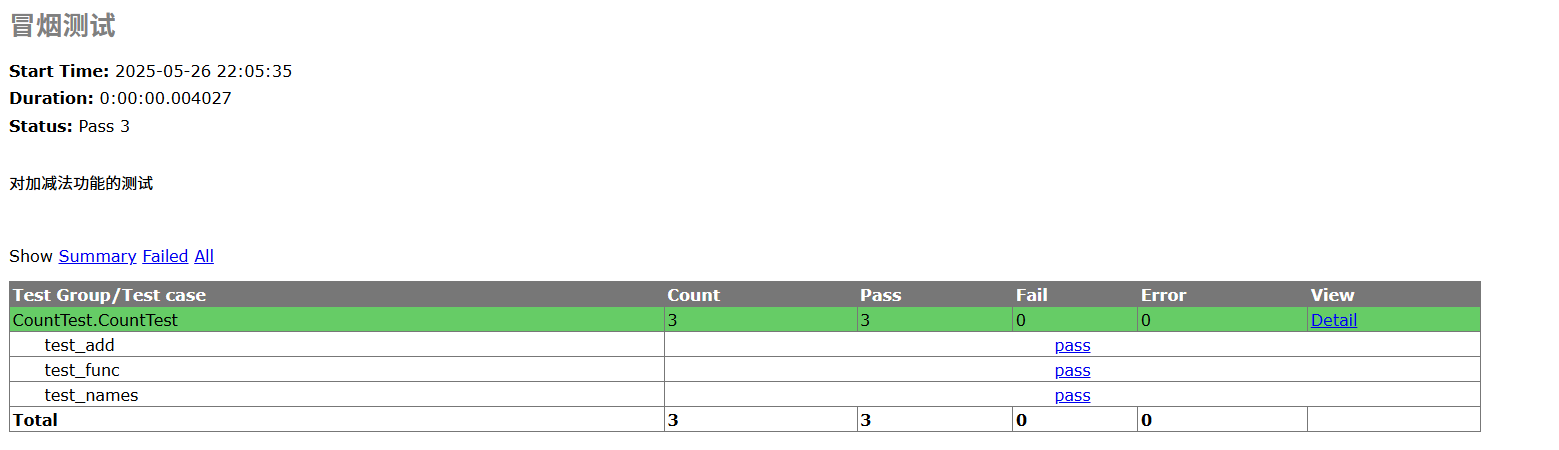
立志成为一名优秀测试开发工程师(第七天)——unittest框架的学习
目录 unittest框架的学习 一、测试类的编写 创建相关测试类cal.py、CountTest.py 二、常见断言方法 使用unittest单元测试框架编写测试用例CountTest.py 注意:执行的时候光标一定要放在括号后面,鼠标右键运行 三、对测试环境的初始化和清除模块…...
:营收阶段的核心指标与盈利模型优化——从数据到商业决策的落地)
精益数据分析(85/126):营收阶段的核心指标与盈利模型优化——从数据到商业决策的落地
精益数据分析(85/126):营收阶段的核心指标与盈利模型优化——从数据到商业决策的落地 c。 一、营收健康度的核心指标:投资回报率模型 (一)季度再发性营收增长率(QRR) 该指标衡量…...
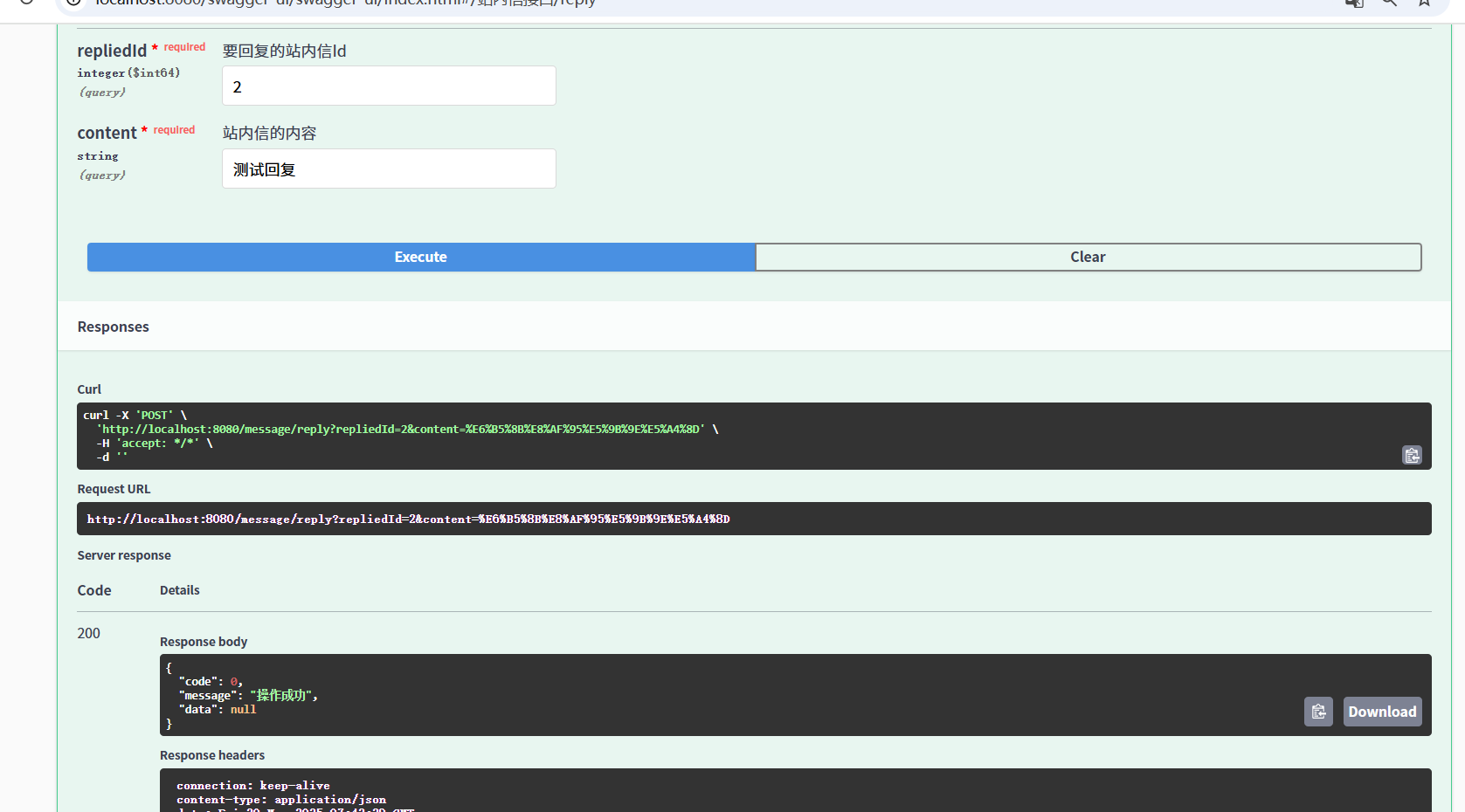
论坛系统(4)
用户详情 获取用户信息 实现逻辑 ⽤⼾提交请求,服务器根据是否传⼊Id参数决定返回哪个⽤⼾的详情 1. 不传⽤⼾Id,返回当前登录⽤⼾的详情(从session获取) 2. 传⼊⽤⼾Id,返回指定Id的⽤⼾详情(根据用户id去查) 俩种方式获得用户信息 参…...

本地Markdown开源知识库选型指南
本地Markdown开源知识库选型指南 以下是几款优秀的本地Markdown开源知识库解决方案,适合不同需求场景: 1. Obsidian (非完全开源但免费) 特点:基于Markdown的本地优先知识管理,丰富的插件生态优势:双向链接、图形视…...

【.net core】SkiaSharp 如何在Linux上实现
1. 安装依赖库 首先需要安装 SkiaSharp 运行时依赖: # Ubuntu/Debian sudo apt-get update sudo apt-get install -y libfontconfig1 libfreetype6 libx11-6 libx11-xcb1 libxcb1 \libxcomposite1 libxcursor1 libxdamage1 libxi6 libxtst6 \libnss3 libcups2 lib…...

后端项目中静态文案国际化语言包构建选型
这是一个很关键的问题。在做国际化(i18n)时,不同语言包格式如 .resx、.properties 和 .json 都可用,但各自有适用场景、特性与限制,你在选择时可以根据你的开发语言、生态和维护成本权衡。 ✅ 一张对比表:.…...

前端面经 React常见的生命周期
初始化阶段 constructor state的初始化,防抖节流的绑定getDerivedStateFromProps 静态函数 当作纯函数使用 传入props和state,合并成一个新的statecomponentWillMount 组件如果有getDrivedStatefromprops不会执行 针对一些接口的预请求时使用rendercomp…...
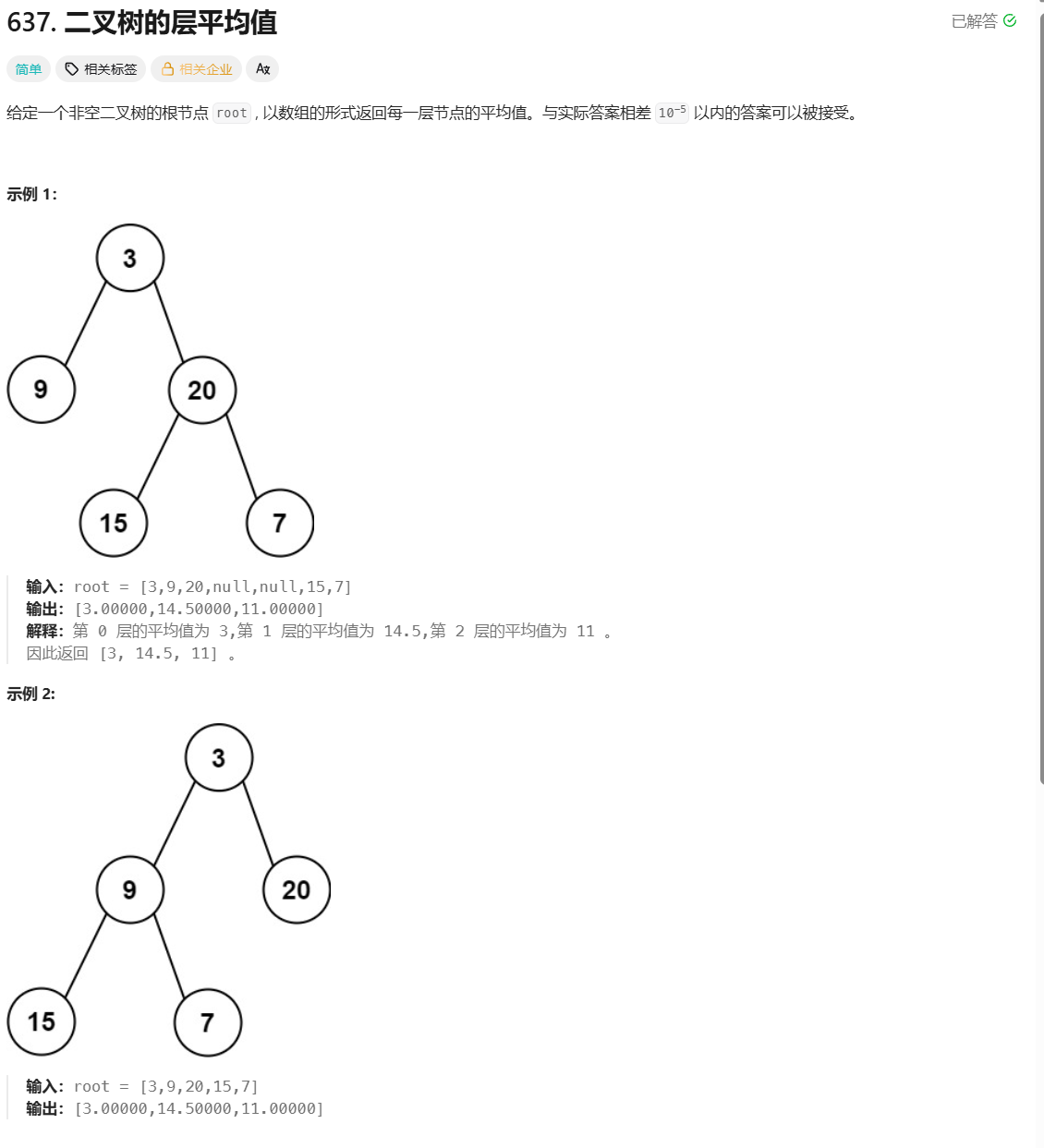
力扣面试150题--二叉树的层平均值
Day 54 题目描述 思路 初次做法(笨):使用两个队列,一个队列存放树的节点,一个队列存放对应节点的高度,使用x存放上一个节点,highb存放上一个节点的高度,sum存放当前层的节点值之和…...
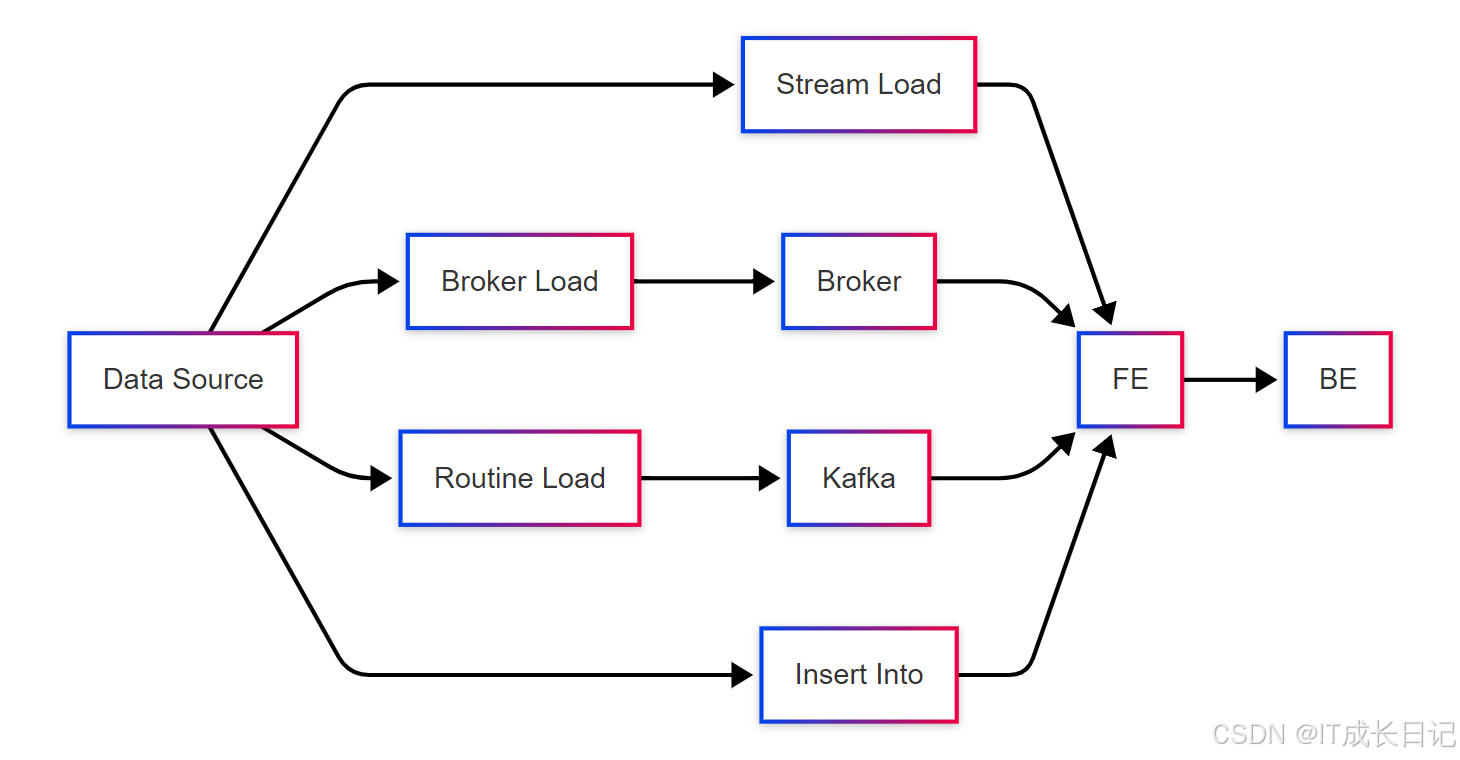
【Doris入门】Doris初识:分布式分析型数据库的核心价值与架构解析
目录 1 Doris简介与核心价值 2 Doris架构深度解析 2.1 Frontend(FE)架构 2.2 Backend(BE)架构 3 Doris核心概念详解 3.1 数据分布模型 3.2 Tablet与Replica 3.3 数据模型 4 Doris关键技术解析 4.1 存储引擎 4.2 查询执…...

C#面试问题41-60
41. What is the Singleton design pattern? Singleton is a class that only allows creating a single instance of itselt. 单例设计模式是一个类,它只允许创建自己的单个实例。 构造函数防止他在单例类以外的地方被调用。 使用情景:need a sing…...

数据结构与算法学习笔记(Acwing 提高课)----动态规划·区间DP
数据结构与算法学习笔记----动态规划区间DP author: 明月清了个风 first publish time: 2025.5.26 ps⭐️区间DP的特征在于子结构一般是一个子区间上的问题,涉及到的问题也非常多,如环形区间,记录方案数,高精度,二维…...

【合集】Linux——31个普通信号
Linux普通信号总表(1-31) 编号信号名触发原因默认动作1SIGHUP终端连接断开(如SSH会话终止)或守护进程重载配置(如nginx -s reload)终止进程2SIGINT用户输入CtrlC中断前台进程终止进程…...

从0到1搭建AI绘画模型:Stable Diffusion微调全流程避坑指南
从0到1搭建AI绘画模型:Stable Diffusion微调全流程避坑指南 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 从0到1搭建AI绘画模型:Stable Diffusion微调全流程避坑指南摘要引言一、数据集构…...

ASP.NET Core 中JWT的基本使用
文章目录 前言一、JWT与RBAC二、JWT 的作用三、RBAC 的核心思想四、使用1、配置文件 (appsettings.json)2、JWT配置模型 (Entity/JwtSettings.cs)3、服务扩展类,JWT配置 (Extensions/ServiceExtensions.cs)4、用户仓库接口服务5、认证服务 (Interface/IAuthService.…...

未来技术展望
应用场景:海量数据并行处理 技术融合: # 概念代码:量子加速的数据清洗 from quantum_processor import PhotonicProcessordef quantum_data_cleaning(data):# 使用光量子处理器并行处理千万级数据processor = PhotonicProcessor(model="Xanadu Borealis")return …...
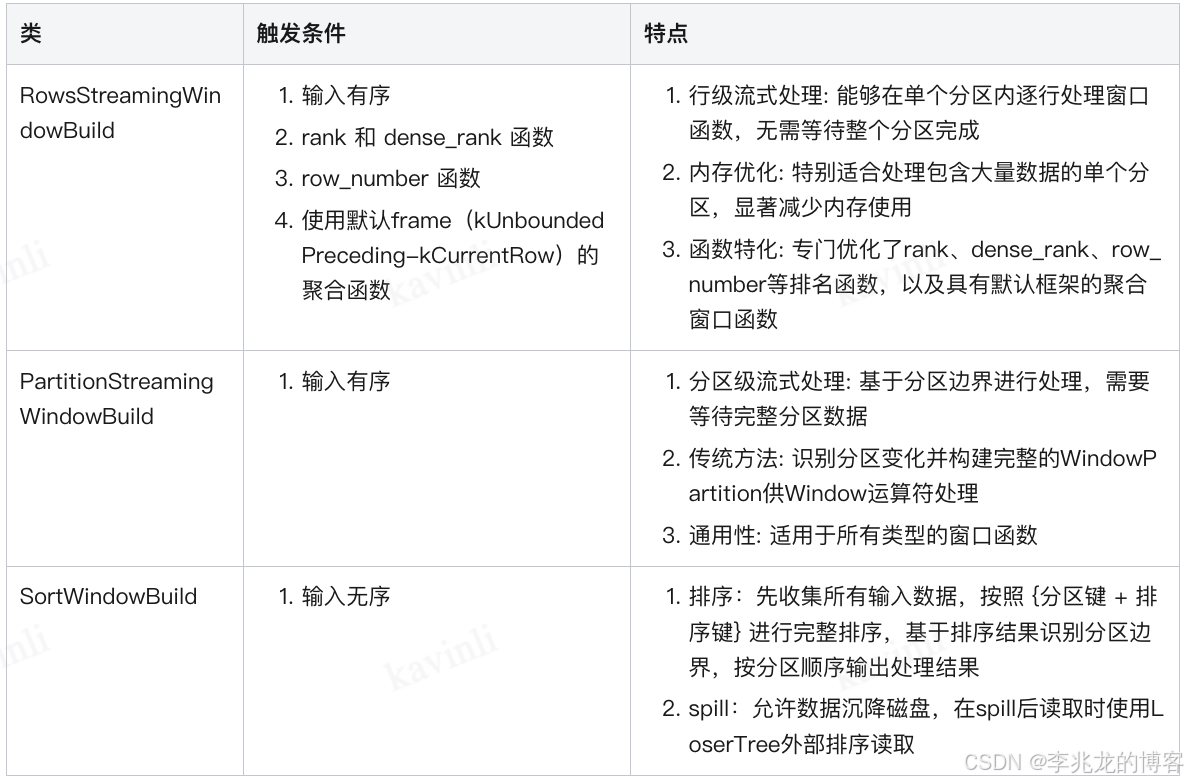
从一到无穷大 #46:探讨时序数据库Deduplicate与Compaction的设计权衡
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 引言Compaction AlgorithmsCompact Execution Flow Based On VeloxLocalMergeSource的…...
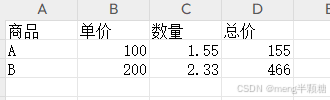
vue3 导出excel
需求:导出自带格式的excel表格 1.自定义二维数组格式 导出 全部代码: <el-button click"exportExcel">导出</el-button> const exportExcel () > {const data [[商品, 单价, 数量, 总价],[A, 100, 1.55, { t: n, f: B2*C2…...