从一到无穷大 #46:探讨时序数据库Deduplicate与Compaction的设计权衡
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- Compaction Algorithms
- Compact Execution Flow Based On Velox
- LocalMergeSource的管道分离流式读取
- 基于LoserTree的归并排序
- Window算子实现流式计算
- TableWrite的多路流式写入
- 结束语
引言
时序数据库与关系型数据库一个比较大的功能差异为Deduplicate,时序数据库默认携带,而关系型数据库依赖于索引和查询时主动去重。
以Influxdb举例子阐述Deduplicate功能:
INSERT temperature,device_id=sensor1 v1=25,v2=25 1620000000000000000
INSERT temperature,device_id=sensor1 v1=26 1620000000000000000
一般有两种Deduplicate粒度
第一种为Field-Level Updates,上述数据会被合并为:
INSERT temperature,device_id=sensor1 v1=26,v2=25 1620000000000000000
其选择策略为tag+time相同的情况下,相同field的选择lsn大的,field取最后一个非空的
第二种为Row-Level Deduplication,上述数据会被合并为:
INSERT temperature,device_id=sensor1 v1=26 1620000000000000000
单纯的基于lsn行选择。
Compaction Algorithms
首先定义 Amplification:
- Write Amplification: 指写入存储设备的数据量与写入数据库的数据量的比率。例如向数据库写入 10 MB 数据,而观察到的磁盘写入为 30 MB,则写入放大率为 3。基于SSD的存储只能写入有限次数,因此写入放大会缩短SSD的使用寿命。
- Read Amplification:指每个查询的磁盘读取次数。例如如果需要读取 5 页来响应查询,则读取放大为 5。写入放大和读取放大的单位不同。写入放大衡量实际写入的数据量比应用程序认为的写入量多,而读取放大则指计算执行查询所需的磁盘读取次数比认为的多。
- Space Amplification:指磁盘上实际存储的物理数据量相对于用户数据的逻辑大小的放大倍数
名词定义:
- T:层之间的大小比值
- L:LSM树的层数
- B:SST文件大小

时序数据库中为了提高查询的效率,数据需要基于时间分shard,这种情况下全局看基本可以认为都是TWCS(Time Window Compaction Strategy)策略,因为老旧shard在经历FullCompact后有且只有一个Sort Runs,在活跃shard中基于不同的考量会有不同的实现方式。
在influxdb1.x中使用了Tiered,多层内均无序,Compact是在每一层选择可压缩的文件,CompactScheduler调度执行。
在GrepTimeDB中使用N-Level,只有两层,内部允许N个Sort Runs,在读写放大之间做权衡
在influxdb3.0中使用了Tiered+Leveled,L0无序,剩下的层数有序,Rocksdb的默认Compact策略也是这样的。
但是值得一提的是时序数据库的Timestamp是去重的主键列,不能简单的依赖时间去重,因为两次写入的时间也可能是重复的,合并的关键在于真实时间上后来的需要覆盖前面的,从实现上来讲一致性引擎的LSN就很合适。
但是这为Compaction的算法实现带来了一点复杂度,如果不按照LSN顺序进行合并,会导致字段覆盖逻辑错误,破坏数据一致性。举以下例子:

错误的合并顺序:
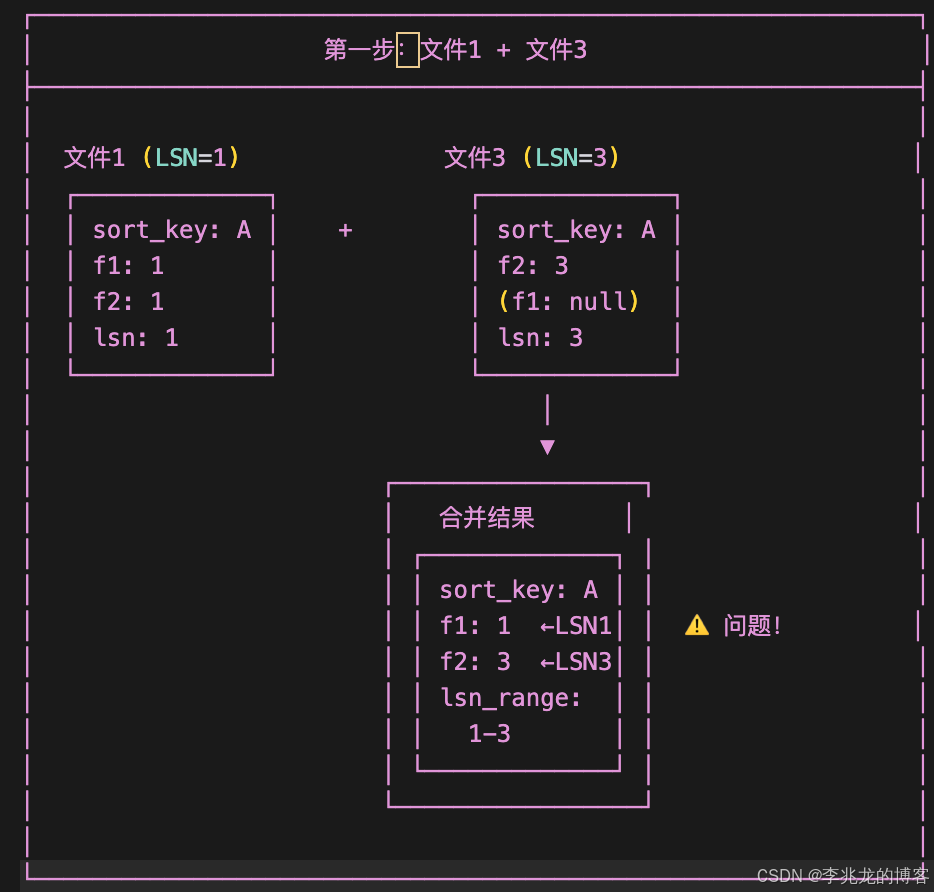
f1字段来自LSN=1的文件;f2字段来自LSN=3的文件。形成了LSN差值为1-3的混合记录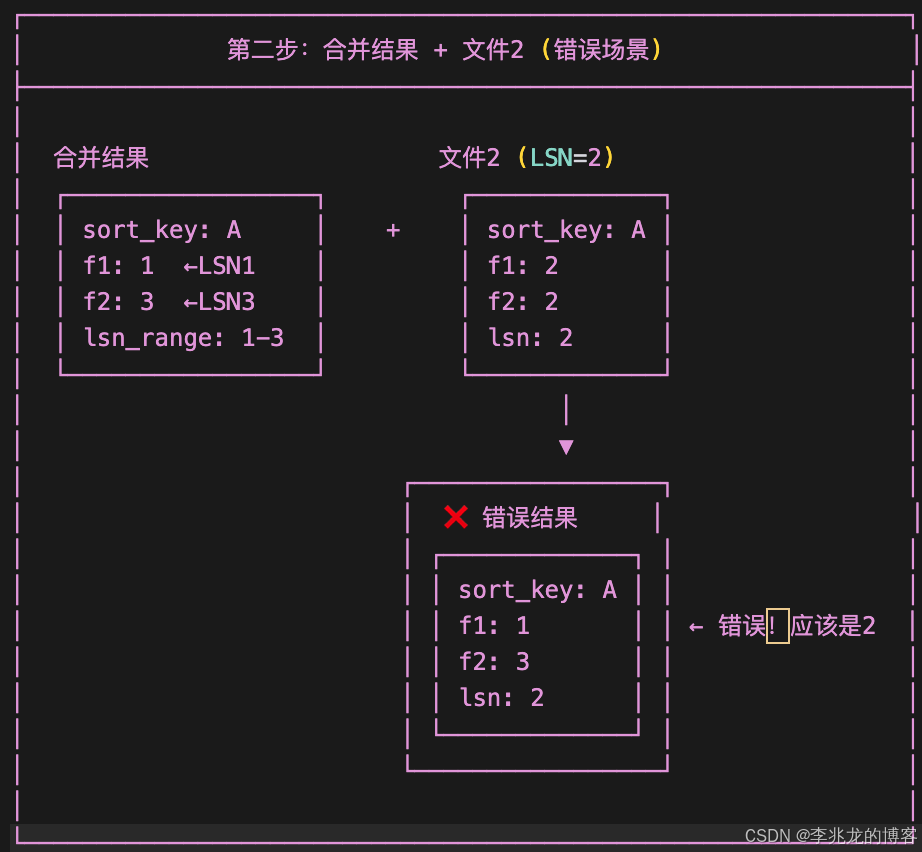
由于合并结果中f1和f2的LSN分别为1和3,都不等于文件2的LSN=2, 按照LSN覆盖规则,LSN=2无法覆盖LSN=3的f2字段, 但LSN=2应该覆盖LSN=1的f1字段,导致逻辑混乱。
正确的合并顺序如下: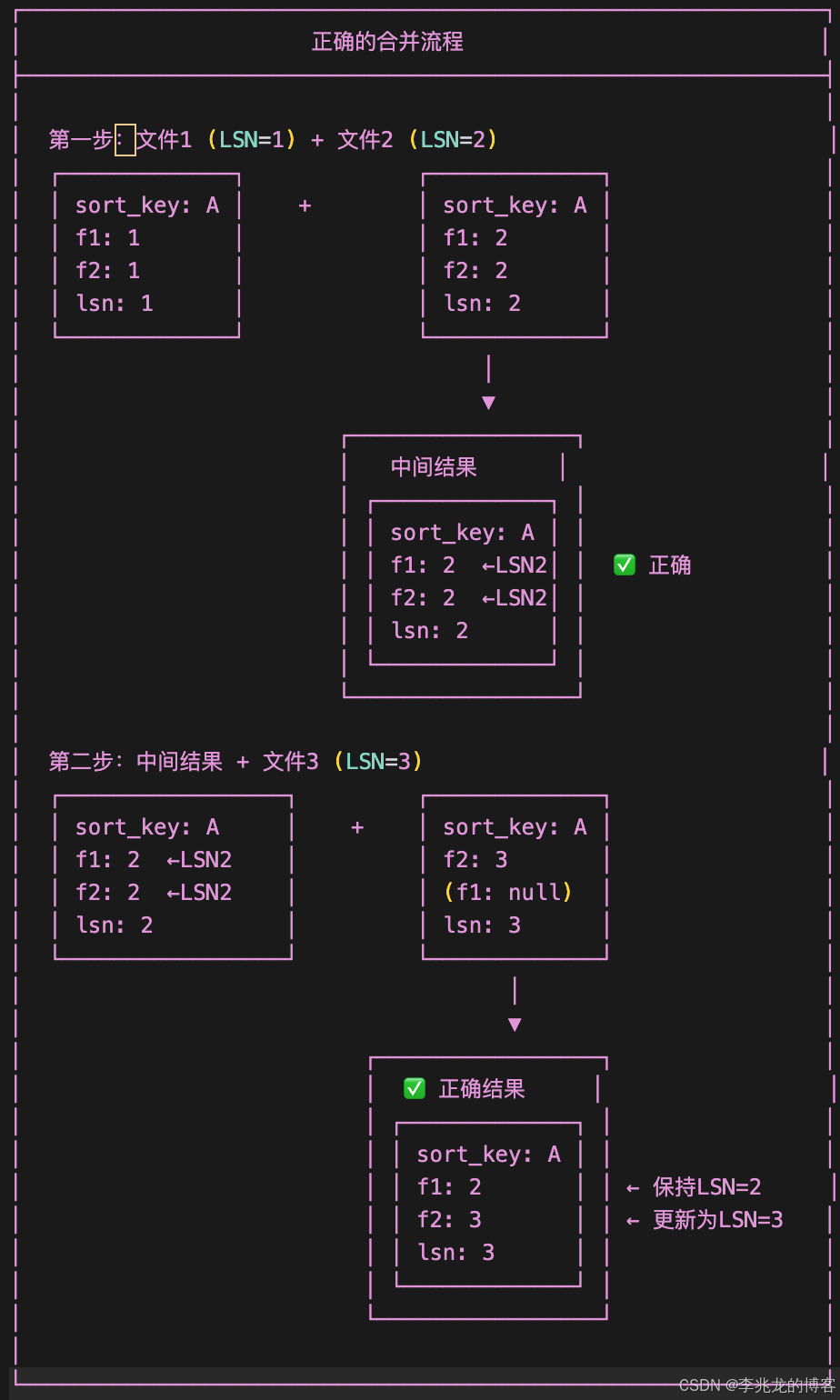
这要求我们再Compact的时候需要合并 LSN 临近的文件。
从实现的角度上讲,GrepTimedb和influxdb3.0的引擎是类似的,适用于时间线爆炸的场景,而influxdb1.x在时间线较少的场景下依然有较强的竞争力,Compaction的设计上也有区别。
时序数据库Compact最在意什么呢?不同的业务场景有不同的答案:TTL短的业务,写入量大,查询量大,存储量相对少,可以Tired+Level均衡读写;TTL长的业务,相对不是特别关心实时数据查询性能,TWCS冷shard可以理解为Level,所以活跃shard可以采用Tired这样的写入友好的策略;
回到实现的角度,自然Tiered是最简单的,因为Compaction的时候只需要维护LSN的区间有序就可以,compact的时候需要保证LSN连续的文件执行合并。influxdb1.x引入了一个Generations的概念,代表一次compact的输出,其文件名组成为000001-01.tsm,前面是Generations,后面是按文件大小切分的chunk,合并的时候只允许Generations连续的执行合并,这其实就是LSN相邻的文件合并,因为数据中没有存储LSN(TSI+SeriesFile+TSM,没有行的概念,无法支持行去重),只能在Compact上下功夫,这样的坏处自然就是事实数据查询性能差。
如果是Level策略,且只支持行级别去重,文件的行中存储一个LSN,这样Compact策略就比较自由,因为文件本身内部附带LSN信息,在合并的过程中建立WindowBuild内部可以基于LSN作去重,对于Compact的策略没有影响。
但是要是Level策略+支持Field级别去重,这就比较麻烦了,就像上面举的例子,事实上因为文件内部记录的是行级别的LSN,但是合并后可能存在不同LSN的数据被合并到一行,如果只记录一个LSN这会导致其中有些列的LSN被强行升级了,这会导致去重出现错误的数据覆盖。
这个时候有三种解决问题的思路:
第一种方法是简单的记录field级别LSN,在宽列场景下几乎不可用,因为存储空间占用太大
第二种方法是记录添加一个额外的列,记录出现Field覆盖时Field的LSN,这样可以大大减少冗余的LSN存储,毕竟列覆盖是极少数情况,但是需要给原始文件再加一列,因为Parquet等文件格式支持复杂类型,这样做也是可以的
第三种是Compact在选择文件时不仅仅考虑SortKey,而且需要考虑LSN的连续,具体的实现是在L0沉降L1时执行下述操作,是最优选择:
- L0为Tired,选择需要被合并的文件,要求LSN连续,计算其LSN区间,为区间1
- 选择L1中和L0文件SortKey重叠的文件,计算其LSN区间,为区间2
- 查找L1中区间1与区间2的空洞文件,计算其LSN区间,为区间3
- 三部分文件组成一个Compact任务,合并后更新Compact文件LSN区间,如果目标文件较大,可以拆分成多个,但是LSN区间是一样的
所以采用特殊的Compact策略可以实现低成本Field/Row Level 的Deduplicate。
Compact Execution Flow Based On Velox
这一节和文章题目没有关系,单纯的记录一下
基于执行引擎做Compact已经不是什么稀奇的事情了,毕竟一个好的执行引擎库基本上可以认为是AP的基础库了,而且Compact可以被抽象为算子的组合,在Velox中,我们可以把Compact抽象为TableScan+LocalMerge+Window+TableWrite的算子组合。
其实现的技术要点如下:
LocalMergeSource的管道分离流式读取
在Velox的LocalMerge操作中,PlanBuilder阶段传入的TableScan算子并不是直接转换为LocalMergeSource,而是通过管道分离和数据流重定向过程实现的。
管道 0 (Producer Pipeline):
TableScanNode → CallbackSink → LocalMergeSource[0]
↓
管道 1 (Producer Pipeline):
TableScanNode → CallbackSink → LocalMergeSource[1]
↓
管道 2 (Producer Pipeline):
TableScanNode → CallbackSink → LocalMergeSource[2]
↓
管道 3 (Consumer Pipeline):
LocalMergeOperator ← LocalMergeSource[0,1,2]
数据生产阶段:每个TableScan管道中的数据流
TableScanOperator::getOutput()
↓
CallbackSink::addInput(RowVectorPtr input)
↓
consumer(input, future) // 这是LocalMergeSource的enqueue函数
↓
LocalMergeSource::enqueue(input, future)
↓
LocalMergeSourceQueue::enqueue(input) // 数据进入队列
数据消费阶段:LocalMerge管道中的数据流
LocalMerge::getOutput()
↓
TreeOfLosers::next() // 从多个source中选择最小值
↓
LocalMergeSource::next() // 从队列中取数据
↓
LocalMergeSourceQueue::next()
↓
返回排序后的RowVector
这样做有以下好处:
- 不同的并行性要求:生产者管道 (TableScan): 需要多线程并行处理,充分利用 I/O 带宽;消费者管道 (LocalMerge): 必须单线程执行,保证排序的正确性
- 数据流控制:生产者和消费者解耦,以支持背压控制(backpressure),生产者可以快速写入缓冲区,消费者按需读取
- 内存管理:
- LocalMergeSource提供缓冲队列,支持流式处理,当缓冲区满时,生产者会被阻塞,防止内存溢出
- 可以基于缓冲队列实现精确的内存控制
- 容错性:管道间独立,单个管道失败不影响其他
- 生产者管道故障:不会直接影响消费者管道,可以独立重试
- 消费者管道故障:不会影响生产者的数据生成
- 部分失败处理:某个生产者失败时,其他生产者可以继续工作
基于LoserTree的归并排序
在Velox Window操作的LocalMerge场景中,需要处理多个已排序(基于提前指定的timestamp || measurement || tags作为排序key)的数据流并将其合并为一个全局有序的结果。
假设待排序列数为 N,待排元素总个数为 n,复杂度分析:
| LoserTree | 堆排序 | |
|---|---|---|
| 空间复杂度 | O(N) | O(N) |
| 单次调整时间复杂度 | O(n*logN) | O(2n*logN) |
| 整体排序完成时间复杂度 | O(logN) | O(2*logN) |
在调整LoserTree时,由于只需比较和更新对应叶子节点的路径上的节点,无需比较兄弟节点,因此在最坏情况下,单次调整败者树的时间复杂度为 O(logN)。
而堆排单次调整则需要比较兄弟节点,这里有常数级别的优化。
Window算子实现流式计算
认为每个窗口函数都通过一个 OVER 子句来运行,规定了 Window 函数的聚合方式。
窗口函数支持:
- 排名函数:ROW_NUMBER、RANK、DENSE_RANK
- 聚合函数:SUM、COUNT、AVG、MIN、MAX等作为窗口函数
- 分析函数:LAG、LEAD、FIRST_VALUE、LAST_VALUE等
RANGE框架边界类型:
- kUnboundedPreceding:之前的全部
- kPreceding:之前的N个
- kCurrentRow:当前行
- kFollowing:之后的N个
- kUnboundedFollowing:之后的全部
样例sql:
- sum(value) over (partition by partition_key order by order_key rows between unbounded preceding and current row) as running_sum
- avg(value) over (partition by partition_key order by order_key rows between 2 preceding and 2 following) as moving_avg
- row_number() over (partition by partition_key order by order_key) as rn
- c0, c1, c2, first_value(c0) OVER (PARTITION BY c1 ORDER BY c2 DESC NULLS FIRST {})
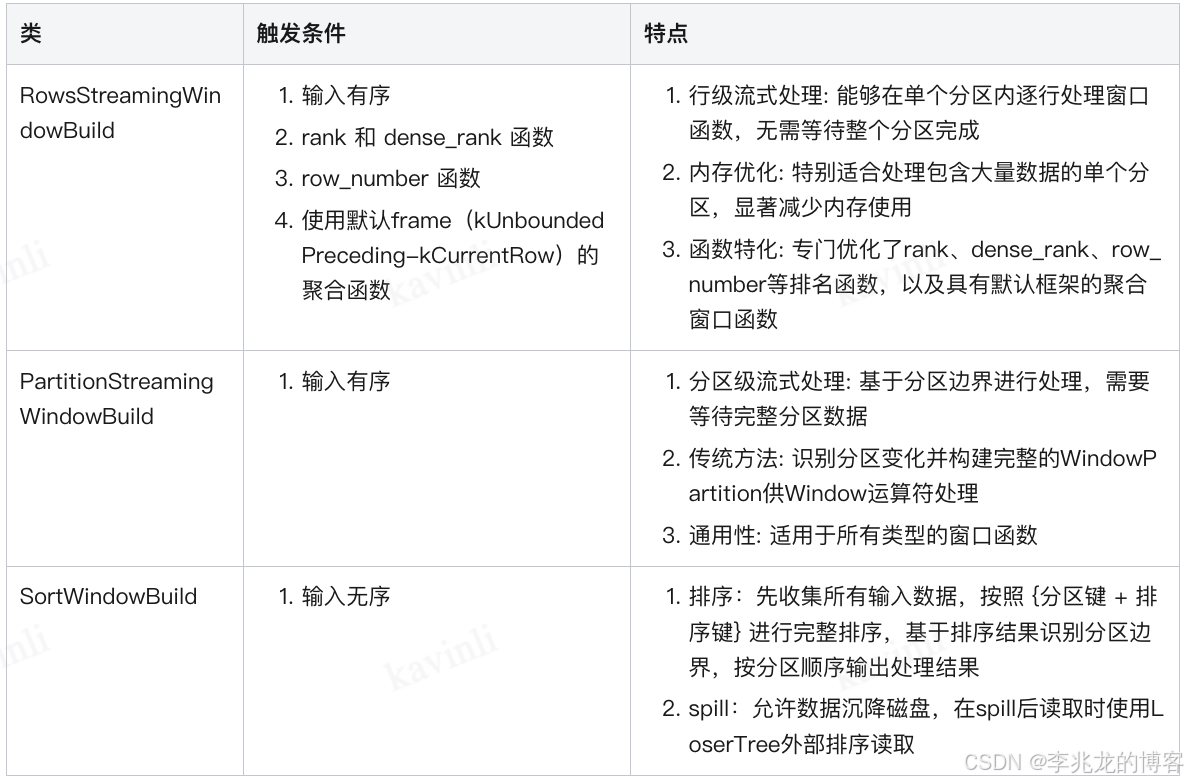
window的区间划分类有三种
TableWrite的多路流式写入
A[TableWriter] --> B[HiveDataSink]
B --> C[ParquetWriter]
C --> D[WriteFileSink]
D --> E[S3WriteFile/LocalFile]
|
F[Input Data] --> A
A --> G[addInput]
G --> H[appendData]
H --> I[write method]
I --> J[Row Group Buffer]
J --> K[Flush Policy Check]
K --> L[Write Row Group]
L --> M[Footer Writing]
RowGroup默认刷新大小:
- rowsInRowGroup: 1’024 * 1’024
- bytesInRowGroup: 128 * 1’024 * 1’024
Compact需要基于sortkey和文件大小在compact的过程中切分输出文件
TableWrite运算符目前无法做到,只能通过Partition和bucket来分区,这种情况在分区时采用hash来选择排序key所属的文件,而不是range,需要修改PartitionIdGenerator,实现range形式的partitionID分配。
结束语
想明白上述问题以后Compact就剩下工程问题了,需要聚焦在Compact任务的调度(分池,并发限制),与Catalog的交互,Garbage Collector的设计。
相关文章:
从一到无穷大 #46:探讨时序数据库Deduplicate与Compaction的设计权衡
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 引言Compaction AlgorithmsCompact Execution Flow Based On VeloxLocalMergeSource的…...
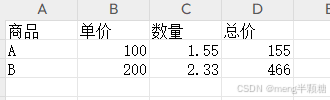
vue3 导出excel
需求:导出自带格式的excel表格 1.自定义二维数组格式 导出 全部代码: <el-button click"exportExcel">导出</el-button> const exportExcel () > {const data [[商品, 单价, 数量, 总价],[A, 100, 1.55, { t: n, f: B2*C2…...
)
带你手写React中的useReducer函数。(底层实现)
文章目录 前言一、为什么需要 Reducer?二、Reducer 的核心概念1. Reducer 函数2. useReducer 钩子 三,手写react中的useReducer 总结 前言 在 React 开发中,useReducer 是管理复杂状态逻辑的利器。它类似于 Redux 的简化版,允许我…...
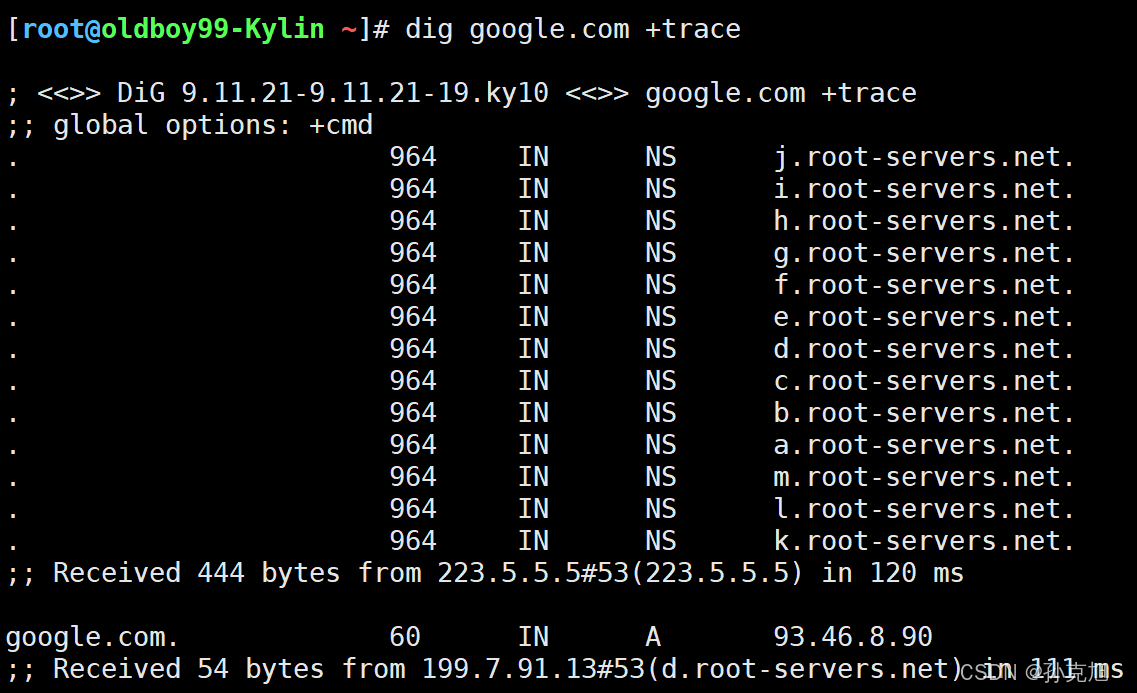
day024-网络基础-TCP与UDP、DNS
文章目录 1. 李导推荐书籍2. OSI七层模型2.1 传输层2.2 网络层2.2.1 问:两端处于不同局域网的设备怎么网络通信? 2.3 数据链路层2.4 物理层2.5 图解OSI七层模型 3. 数据传输模式3.1 全双工3.2 半双工3.3 单工 4. TCP 3次握手4.1 抓包 5. TCP 4次挥手5.1 …...

专场回顾 | 重新定义交互,智能硬件的未来设计
自2022年起,中国智能硬件行业呈现出蓬勃发展的态势,市场规模不断扩大。一个多月前,“小智AI”在短视频平台的爆火将智能硬件带向了大众视野,也意味着智能硬件已不再仅仅停留在概念和技术层面,而是加速迈向实际落地应用…...

如何把一台电脑作为另外一台电脑的显示器
https://zhuanlan.zhihu.com/p/703889583 1. 两台电脑都要进行:点开投影到此电脑,点击可选功能,在可选功能窗口,搜索无线显示器;在结果列表中选中无线显示器,并安装 2. 在笔记本电脑(要用来做…...
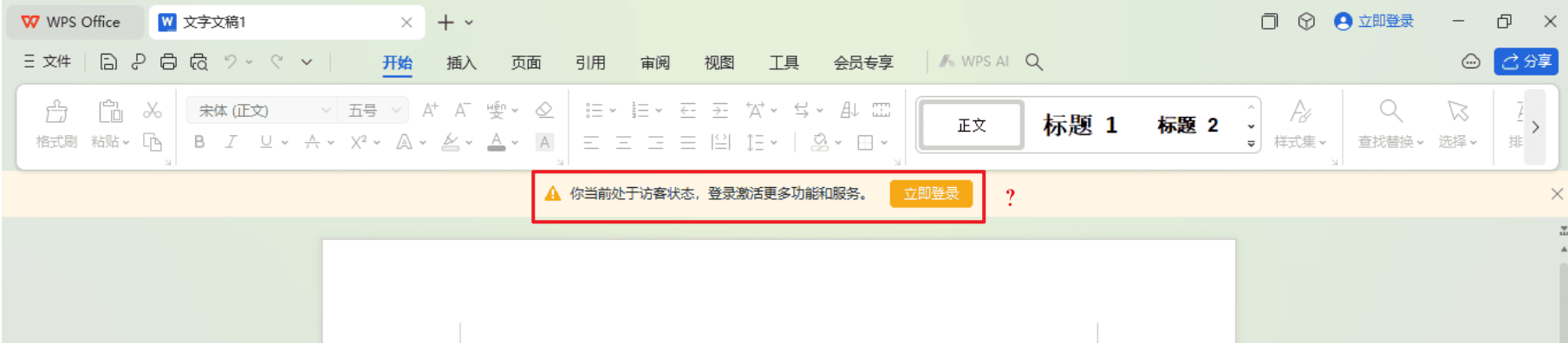
WPS 免登录解锁编辑
遇到 WPS 需要登录才能启用编辑功能? 如何免登录使用编辑功能? 方法一 解锁方法 1、关闭 WPS; 2、桌面右键→ “新建”→“文本文档”,粘贴以下内容(见最下面);编码保持默认(ANSI …...

【C/C++】线程安全初始化:std::call_once详解
std::call_once 使用详解 std::call_once 是 C11 标准库中提供的一个线程安全的一次性调用机制,位于 <mutex> 头文件中。它确保某个可调用对象只被执行一次,即使多个线程同时尝试调用它。 基本用法 #include <mutex> #include <thread…...

技术分享 | Oracle SQL优化案例一则
本文为墨天轮数据库管理服务团队第70期技术分享,内容原创,作者为技术顾问马奕璇,如需转载请联系小墨(VX:modb666)并注明来源。 一、问题概述 开发人员反映有条跑批语句在测试环境执行了很久都没结束&…...

什么是RFID电子标签
RFID 电子标签是用于物品标识、具有信息存储机制、能接收读写器的电磁场调制信号并返回响应信号的数据载体,通常被称为电子标签,也可称作射频卡、射频标签、射频卷标等,是与读写器一起构成 RFID 系统的硬件主体。 RFID 系统基本组成包括RFID电子标签、读写器、射频天线、应用…...
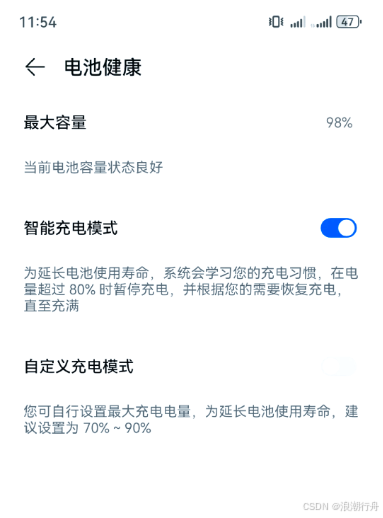
华为手机用的时间长了,提示手机电池性能下降,需要去换电池吗?平时要怎么用能让电池寿命长久一些?
华为手机提示电池性能下降时,是否需要更换电池以及如何延长电池寿命,取决于电池老化程度和使用习惯。以下是具体分析和建议: 一、是否需要更换电池? 电池健康度低于80% 如果手机提示“电池性能下降”,通常意味着电池…...
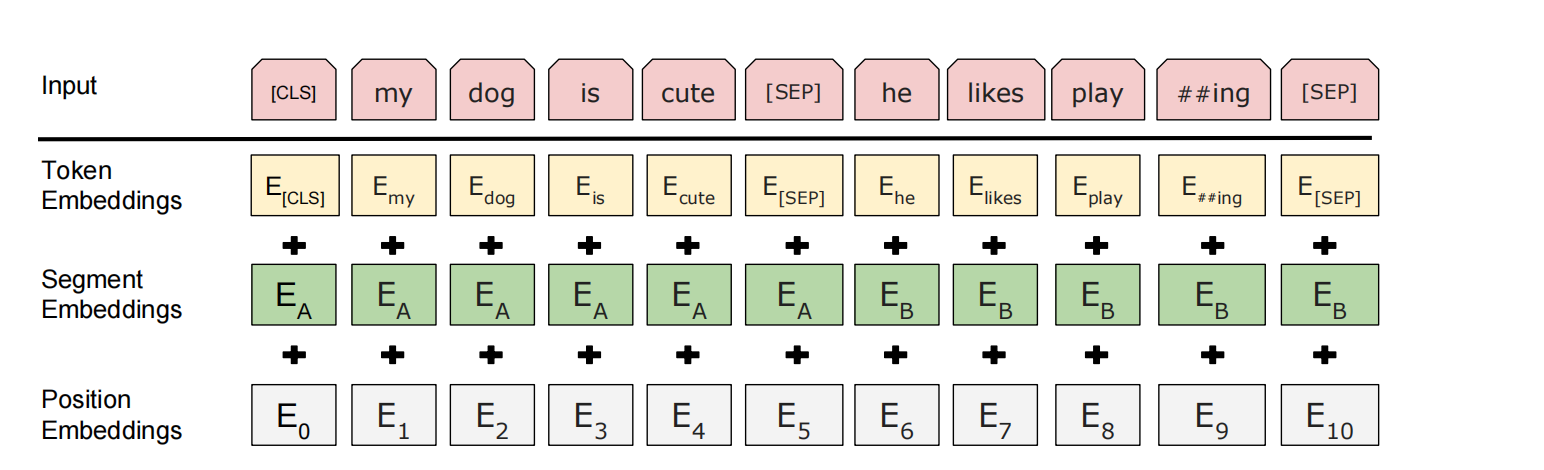
BERT***
1.预训练(Pre-training) 是深度学习中的一种训练策略,指在大规模无标注数据上预先训练模型,使其学习通用的特征表示,再通过微调(Fine-tuning) 适配到具体任务 2.sentence-lev…...

超级对话2:大跨界且大综合的学问融智学应用场景述评(不同第三方的回应)之二
摘要:《人机协同文明升维行动框架》提出以HIAICI/W公式推动认知革命,构建三大落地场景:1)低成本认知增强神经接口实现300%学习效率提升;2)全球学科活动化闪电战快速转化知识体系;3)人…...

在Linux环境里面,Python调用C#写的动态库,如何实现?
在Linux环境中,Python可以通过pythonnet(CLR的Python绑定)或subprocess调用C#动态库。以下是两种方法的示例: 方法1:使用pythonnet(推荐) 前提条件 安装Mono或.NET Core运行时安装pythonnet包…...

【Linux 基础知识系列】第三篇-Linux 基本命令
在数字化浪潮席卷全球的当下,操作系统作为计算机系统的核心组件,扮演着至关重要的角色。而 Linux,凭借其卓越的性能、高度的稳定性和出色的可定制性,在服务器、嵌入式系统、超级计算机以及个人计算机等领域大放异彩,成…...
)
OpenCV CUDA模块直方图计算------生成一组均匀分布的灰度级函数evenLevels()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数主要用于为 直方图均衡化、CLAHE 等图像处理算法 生成一组等间距的灰度区间边界值(bins 或 levels),这…...
深度学习常见实验问题与实验技巧
深度学习常见实验问题与实验技巧 有一定的先后顺序的 还在迷茫深度学习中的改进实验应该从哪里开始改起的同学,一定要进来看看了!用自身经验给你推荐实验顺序! YOLOV8-硬塞注意力机制?这样做没创新!想知道注意力怎么…...

前端面试之Proxy与Reflect
🌟 一、Proxy 与 Reflect 的核心概念 1. Proxy:代理拦截器 Proxy 用于创建对象的代理,拦截并自定义对象的基本操作(如属性读写、函数调用等)。 核心组成: 目标对象(Targe…...

uniapp vue3 鸿蒙支持的 HTML5+接口
uniapp vue3 编译鸿蒙所支持的 HTML5接口 文档:https://www.html5plus.org/doc/zh_cn/runtime.html {"geolocation": {//获取当前设备位置信息"getCurrentPosition": function() {},//监听设备位置变化信息"watchPosition": functi…...
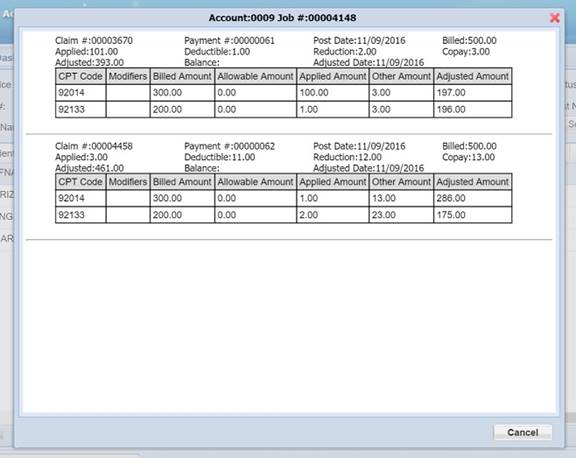
一张Billing项目的流程图
流程图 工作记录 2016-11-11 序号 工作 相关人员 1 修改Payment Posted的导出。 Claim List的页面加了导出。 Historical Job 加了Applied的显示和详细。 郝 识别引擎监控 Ps (iCDA LOG :剔除了160篇ASG_BLANK之后的结果): LOG_File 20161110.txt BLANK_CDA/ALL 45/10…...
理想树图书:以科技赋能教育,开启AI时代自主学习新范式
深耕教育沃土 构建全场景教辅产品矩阵 自2013年创立以来,理想树始终以教育匠心回应时代命题。在教辅行业这片竞争激烈的领域,由专业教育工作者组成的理想树图书始终秉持“知识互映”理念,经过十余年的精耕细作,精心打造了小学同步…...
【大模型02】Deepseek使用和prompt工程
文章目录 DeepSeekDeepseek 的创新MLA (低秩近似) MOE 混合专家混合精度框架总结DeepSeek-V3 与 DeepSeek R1 DeepSeek 私有化部署算例市场: autoDLVllM 使用Ollma复习 API 调用deepseek-r1Prompt 提示词工程Prompt 实战设置API Keycot 示例p…...

B端产品经理如何快速完成产品原型设计
B 端产品经理的原型设计需兼顾业务流程复杂度、功能逻辑性和操作效率,快速完成原型的核心在于结构化梳理需求、复用成熟组件、借助高效工具、聚焦核心场景。以下是具体方法和步骤: 一、明确需求优先级:先框架后细节 1. 梳理业务流程&#x…...
)
[Java实战]Spring Boot切面编程实现日志记录(三十六)
[Java实战]Spring Boot切面编程实现日志记录(三十六) 一、AOP日志记录核心原理 1.1 AOP技术体系 Spring AOP基于代理模式实现,关键组件: JoinPoint:程序执行点(方法调用/异常抛出)Pointcut:切点表达式(定义拦截规则)Advice:增强逻辑(前置/环绕/异常通知)Weaving:…...

Apache POI生成的pptx在office中打不开 兼容问题 wps中可以打卡问题 POI显示兼容问题
项目场景: 在java服务中使用了apache.poi后生成的pptx在wps中打开是没有问题,但在office中打开显示如下XXX内容问题,修复(R)等问题 我是用的依赖版本如下 <dependency><groupId>org.apache.poi</grou…...
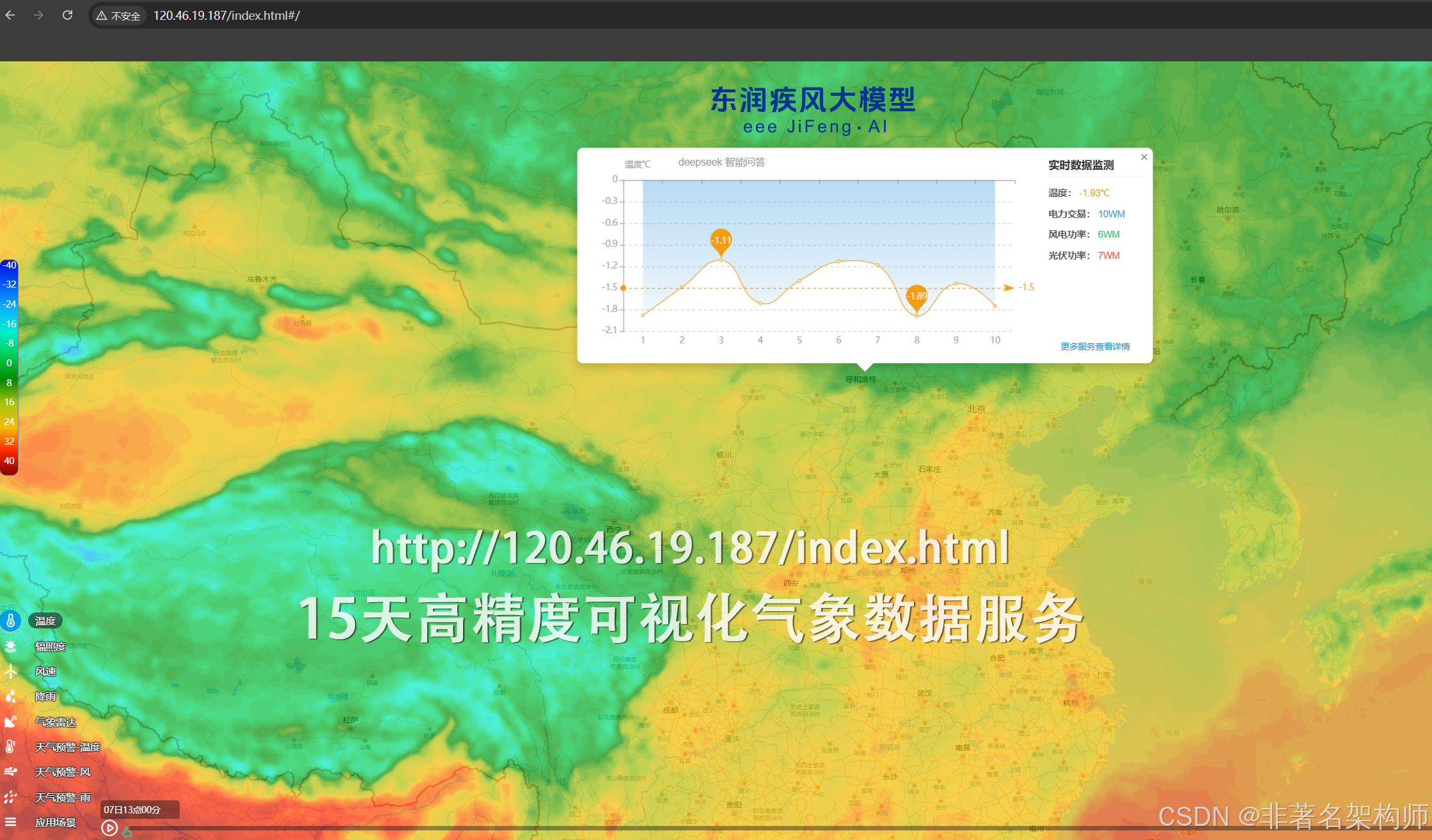
大学大模型教学:基于NC数据的全球气象可视化解决方案
引言 气象数据通常以NetCDF(Network Common Data Form)格式存储,这是一种广泛应用于科学数据存储的二进制文件格式。在大学气象学及相关专业的教学中,掌握如何读取、处理和可视化NC数据是一项重要技能。本文将详细介绍基于Python的NC数据处理与可视化解决方案,包含完整的代…...
 ----- Python的数据类型及其集合操作)
Python学习(2) ----- Python的数据类型及其集合操作
在 Python 中,一切皆对象,每个对象都有类型。下面是 Python 中的常见内置类型分类和示例: 🟡 1. 数字类型(Numeric Types) 类型说明示例int整数5, -42float浮点数3.14, -0.5complex复数1 2j a 10 …...

机器学习算法-决策树
今天我们用一个 「相亲决策」 的例子来讲解决策树算法,保证你轻松理解原理和实现! 🌳 决策树是什么? 决策树就像玩 「20个问题」猜谜游戏: 你心里想一个东西(比如「苹果」) 朋友通过一系列问题…...

MediaMtx开源项目学习
这个博客主要记录MediaMtx开源项目学习记录,主要包括下载、推流(摄像头,MP4)、MediaMtx如何使用api去添加推流,最后自定义播放器,播放推流后的视频流,自定义Video播放器博客地址 1 下载 MediaMTX MediaMTX 提供了预编译的二进制文件,您可以从其 GitHub 页面下载: Gi…...
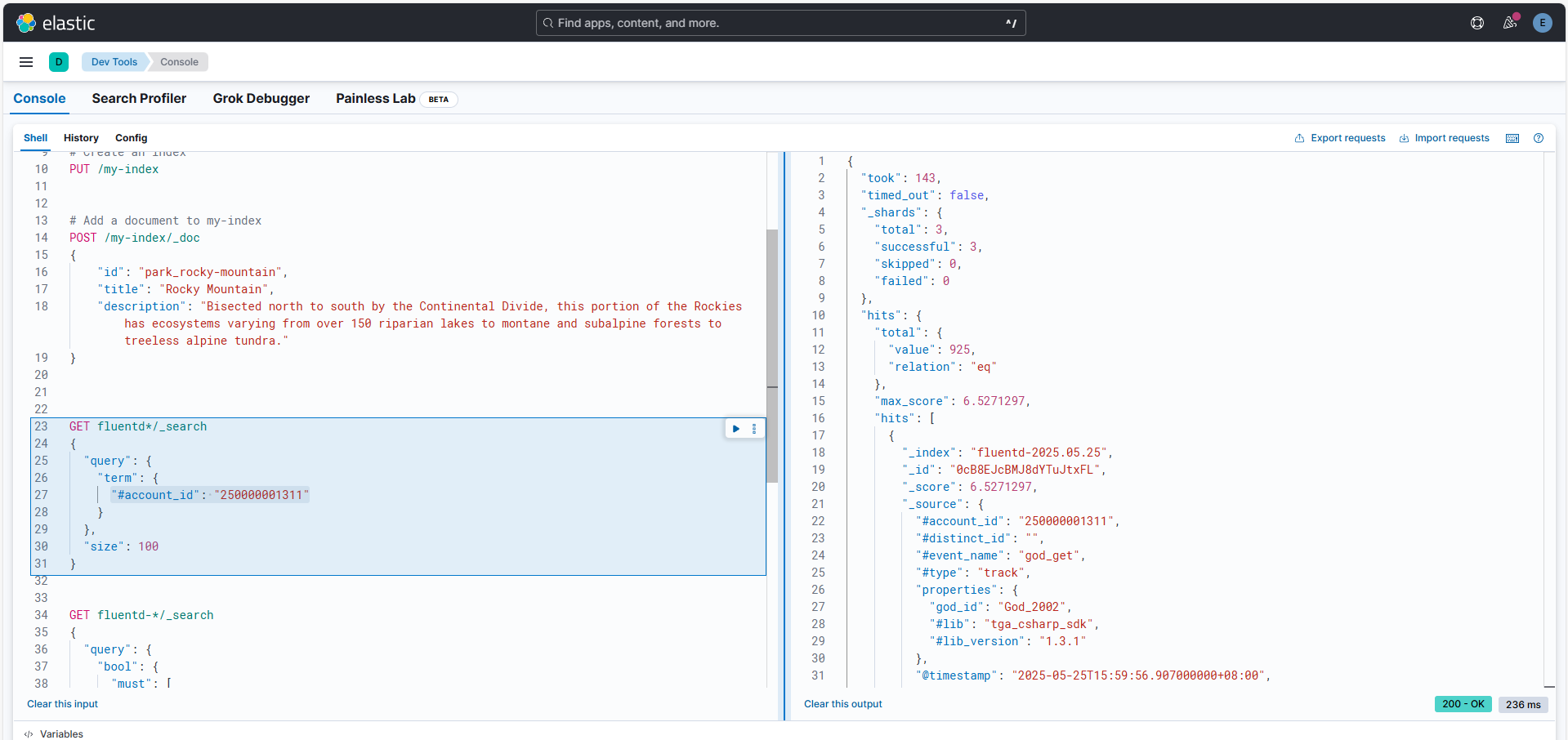
Linux安装EFK日志分析系统
目标:能够实现采集指定路径日志到es,用kibana实现日志分析 单es节点集群规划: 主机名IP 地址组件a1192.168.1.111Kibana elasticsearcha2192.168.1.112Fluentda3192.168.1.103Fluentd 1、安装Elasticsearch 1.1添加 Elastic 仓库并安装 E…...