【大模型02】Deepseek使用和prompt工程
文章目录
- DeepSeek
- Deepseek 的创新
- MLA (低秩近似)
- MOE 混合专家
- 混合精度框架
- 总结
- DeepSeek-V3 与 DeepSeek R1
- DeepSeek 私有化部署
- 算例市场: autoDL
- VllM 使用
- Ollma
- 复习 API 调用deepseek-r1
- Prompt 提示词工程
- Prompt 实战
- 设置API Key
- cot 示例
- prompt 优化 prompt
- note
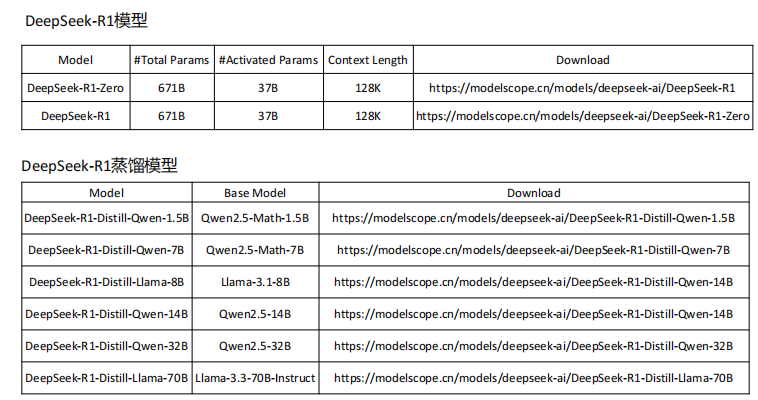
DeepSeek
Deepseek 的创新
Deepseek-v3的推出是2024年12月,并没有太大波澜Deepseek-R1火出圈,通过新的奖励机制GRPO(group relative policy optimization),并使用规则类验证机制自动对输出进行打分。以v3为基础模型,一个多月内训练出了性能堪比GPT-o1的R1模型,成果非常亮眼。
DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。
DeepSeek-R1 上线 API,对用户开放思维链输出,通过设置 model=‘deepseek-reasoner’ 即可调用。
MLA (低秩近似)
MLA(Multi-Head Latent Attention)在“All you need is attention”的背景下,传统的多头注意力(MHA,Multi-Head Attention)的键值(KV)缓存机制事实上对计算效率形成了较大阻碍。缩小KV缓存(kv Cache)大小,并提高性能,在之前的模型架构中并未很好的解决。
Deepseek引入了ML,一种通过低秩键值联合压缩的注意力机制,在显著减小KV缓存的同时提高计算效率。
低秩近似是快速矩阵计算的常用方法,在MLA之前很少用于大模型计算。
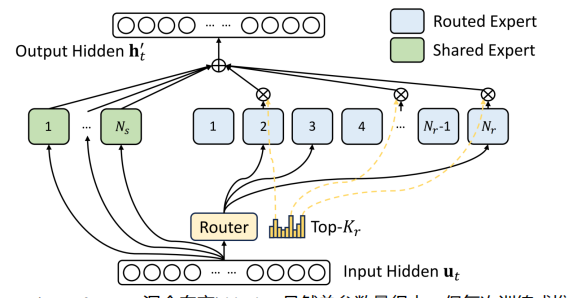
MOE 混合专家
V3使用了61个MoE (Mix of Expert 混合专家) block,虽然总参数量很大,但每次训练或推理时只激活了很少链路,训练成本大大降低,推理速度显著提高。
MoE类比为医院的分诊台,在过去所有病人都要找全科医生,效率很低。但是MoE模型相当于有一个分诊台将病人分配到不同的专科医生那里。Deepseek在这方面也有创新,之前分诊是完全没有医学知识的保安而现在用的是有医学知识的本科生来处理分流任务。
混合精度框架
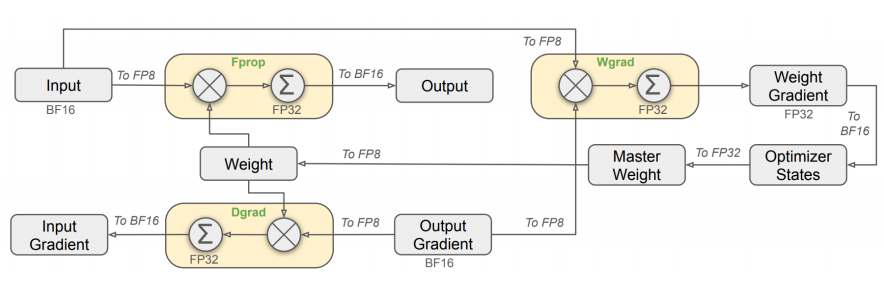
采用了混合精度框架,即在不同的区块里使用不同的精度来存储数据。我们知道精度越高,内存占用越多,运算复杂度越大。Deepseek在一些不需要很高精度的模块,使用很低的精度FP8储存数据,极大的降低了训练计算量。
总结
(1)为什么能实现成本低,计算速度快
- 架构设计方面
DeepSeek MoE架构:在推理时仅激活部分专家,避免了激活所有参数带来的计算资源浪费。
ML架构:MLA通过降秩KV矩阵,减少了显存消耗。 - 训练策略方面
多token预测(MTP)目标:在训练过程中采用多token预测目标,即在每个位置上预测多个未来token,增加了训练信号的密度,提高了数据效率。
混合精度训练框架:在训练中,对于占据大量计算量的通用矩阵乘法(GEMM)操作,采用FP8精度执行。同时,通过细粒度量化策略和高精度累积过程,解决了低精度训练中出现的量化误差问题
(2)为什么DeepSeek-R1的推理能力强大?
**强化学习驱动:**Deepseek-R1通过大规模强化学习技术显著提升了推理能力。在数学、代码和自然语言推理等任务上表现出色,性能与0penAl的o1正式版相当。
长链推理(CoT)技术:Deepseek-R1采用长链推理技术,其思维链长度可达数万字,能够逐步分解复杂问题,通过多步骤的逻辑推理来解决问题
强化学习的作用:训练大模型,结合少量SFT(监督学习),引入少量高质量监督数据(如数千个CoT示例)进行微调,提升模型初始推理能力,再通过RL进一步优化,最终达到与0penAlo1相当的性能
长链推理CoT:COT让AI模型逐步分解复杂问题,比如在智能客服、市场分析报告、AI辅助编程领域
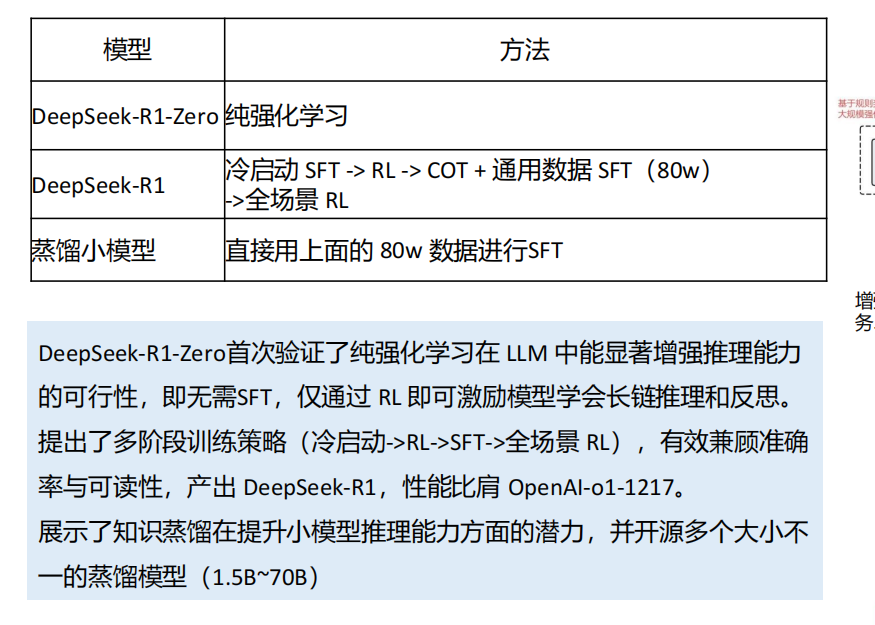
R1-Zero, AlphaGo-Zero 都是纯强化学习,也就是人没有标注数据,是完全是由机器自我进行学习,掌握的技能
Reward-Model 用于对强化学习的打分
1)对输出的结果正确性进行打分 (因为我们知道真正的Answer)
2)对输出的结构进行打分
1)硬规则
针对结构化标签,
2) 结果的评价
首选 answer进行评价,
数据集也会首选 理科类的测试题 => 有标准答案
3)
先给出再给出
reward model 规则是人定的,但是分是机器打的
- AI大模型趋势:
1)模型越来越大
671B => 旗舰版 (如果要部署满血版,需要16块H800,大约200万-300万)
2)蒸馏小模型超越 OpenAI o1-mini
模型越来越小 => 可以在端侧,可以在手机,可以在个人电脑进行部署 (可以部署的设备非常的广泛)
Qwen3
https://modelscope.cn/models/Qwen/Qwen3-235B-A22B
Qwen3-4B 以及达到了 Qwen2.5-72B的水平
https://modelscope.cn/models/Qwen/Qwen3-4B
DeepSeek-V3 与 DeepSeek R1
Thinking:当我们写程序的时候,什么时候用 DeepSeek-V3-0324,什么时候用 Deepseek-R1?V3-0324:日常编程、快速开发、前端代码生成、常规脚本任务。R1:数学密集型计算、复杂算法、代码逻辑深度优化、需要推理过程的任务,=>更擅长复杂算法实现,能优化逻辑并减少错误
DeepSeek 私有化部署
Q:如何找到大模型的原文件
https://modelscope.cn/search?search=deepseek
modelscope 类似 huggingface
如果要部署一个RI- 7B的模型,需要 15G的显存
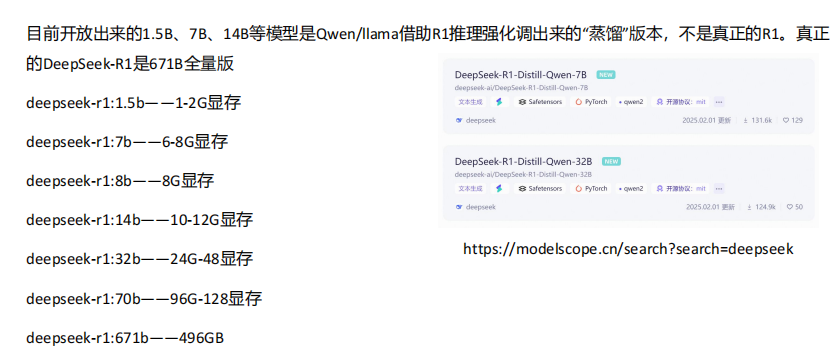
deepseek-r1-32b => 企业级的入门版,不建议个人部署,因为24G的显卡跑不起来,哪怕是int4的版本也跑不起来
算例市场: autoDL
https://www.autodl.com/market/list
Q:关机不扣费,会清除部署的应用和存放的数据吗?
如果放到 autodl-tmp目录下面,数据不会清除
公司建议使用VLLM 部署
个人建议使用 ollm 部署
模型下载:
# 模型下载
from modelscope import snapshot_download
snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir="/root/autodl-tmp/models")
VllM 使用
Vllm使用:是由伯克利大学 LMSYS 组织开源的LLM高速推理框架,用于提升LLM的吞吐量与内存使用效率。它
通过 PagedAttention 技术高效管理注意力键和值的内存,并结合连续批处理技术优化推理性能。vLLM 支持量化
技术、分布式推理、与 Hugging Face 模型无缝集成等功能
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
• vllm serve,启动 vLLM 推理服务的命令
• deepseek-ai/DeepSeek-R1-Distill-Qwen-32B,Hugging Face 模型库中的模型名称,vLLM 会尝试从 HF 下载模型
• --tensor-parallel-size 2,启用张量并行,在 2 个 GPU 上分布式运行模型(适合 32B 大模型)
• --max-model-len 32768,设置模型的最大上下文长度(32K tokens),确保能处理长文本。
• --enforce-eager,禁用 CUDA Graph 优化(可能在某些环境下更稳定,但性能稍低)
Thinking:如果我在本地的ubuntu下面有 /root/autodl-tmp/models/tclf90/deepseek-r1-distill-qwen-32b-gptq-int4,
如何使用vllm进行推理?
vllm serve /root/autodl-tmp/models/tclf90/deepseek-r1-distill-qwen-32b-gptq-int4 --tensor-parallel-size 1 --maxmodel-len 32768 --enforce-eager --quantization gptq --dtype half
关键改动:指定本地路径:替换 HF 模型名为你的本地路径。
–quantization gptq:显式声明使用 GPTQ 量化。
–dtype:设为 half(FP16)或 auto(自动选择),因为 GPTQ 本身是 4-bit,但计算时需指定中间精度。
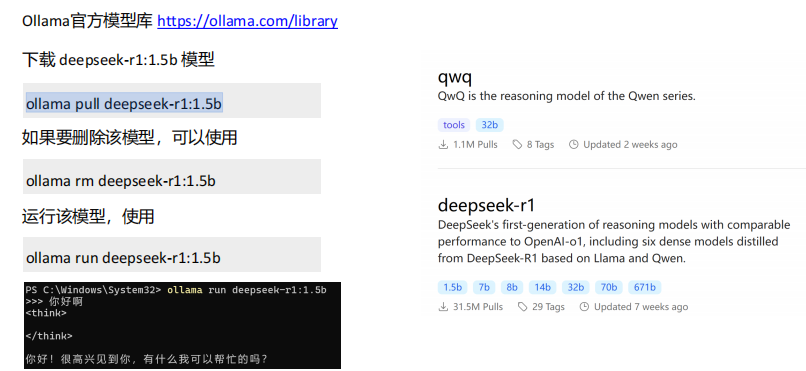
Ollma
适合个人轻量化部署
https://ollama.com/
下载 windows 版本 下载完成后安装
进入 cmd ,通过ollama 下载模型,
ollama pull deepseek-r1:1.5b (ollama pull + 模型id (从ollama 官网看))

复习 API 调用deepseek-r1
大部分情况还是用调用API的方式

import dashscope
from dashscope.api_entities.dashscope_response import Role
dashscope.api_key = "sk-你的key"# 封装模型响应函数
def get_response(messages):response = dashscope.Generation.call(model='deepseek-r1', # 使用 deepseek-r1 模型messages=messages,result_format='message' # 将输出设置为message形式)return response# 测试对话
messages = [{"role": "system", "content": "You are a helpful assistant"},{"role": "user", "content": "你好,你是什么大模型?"}
]
response = get_response(messages)
print(response.output.choices[0].message.content)# 情感分析
review = '这款音效特别好 给你意想不到的音质。'
messages = [{"role": "system", "content": "你是一名舆情分析师,帮我判断产品口碑的正负向,回复请用一个词语:正向 或者 负向"},{"role": "user", "content": review}
]response = get_response(messages)
print(response.output.choices[0].message.content)
Prompt 提示词工程
推理模型和通用模型
文科类的建议用通用模型, 复杂问题建议使用推理模型


cot: chain of thought 思维链
比如:
你是一个数学助手,请根据以下步骤计算用户输入的金额。请将每个金额首先加上1000元,接着减去500元,然后乘以1.2输出计算结果,以’,'作为分隔符进行返回。
你可以参考以下计算过程来帮助解决:
“”"
对于输入:2000, 3000, 4000
计算过程如下:
首先分别对输入的2000, 3000, 4000加上1000,得到:3000, 4000, 5000
然后将3000, 4000, 5000分别减去500,得到:2500, 3500, 4500
然后将2500, 3500, 4500分别乘以1.2,得到:3000, 4200, 5400
答案是:3000, 4200, 5400
“”"
输入:1500, 2500, 3500
上述案例涉及 角色 任务 COT 限制输出格式 分隔符 样例
Prompt 实战
设置API Key
使用方便且安全
key 的获取方式: 百炼 dashcope 见上一篇
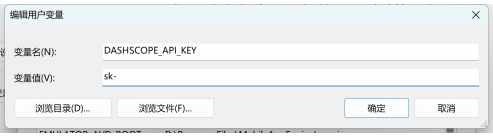
设置系统变量后,如果运行时报错,找不到key, 可以试试重启IDE
# 导入依赖库
import dashscope
import os# 从环境变量中获取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')# 基于 prompt 生成文本
# 使用 deepseek-v3 模型
def get_completion(prompt, model="deepseek-v3"):messages = [{"role": "user", "content": prompt}] # 将 prompt 作为用户输入response = dashscope.Generation.call(model=model,messages=messages,result_format='message', # 将输出设置为message形式temperature=0, # 模型输出的随机性,0 表示随机性最小)return response.output.choices[0].message.content # 返回模型生成的文本# 任务描述
instruction = """
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称,月费价格,月流量。
根据用户输入,识别用户在上述三种属性上的需求是什么。
"""# 用户输入
input_text = """
办个100G的套餐。
"""# prompt 模版。instruction 和 input_text 会被替换为上面的内容
prompt = f"""
# 目标
{instruction}# 用户输入
{input_text}
"""print("==== Prompt ====")
print(prompt)
print("================")# 调用大模型
response = get_completion(prompt)
print(response)
优化prompt 指定输出结构:
# 输出格式
output_format = """
以 JSON 格式输出
"""# 稍微调整下咒语,加入输出格式
prompt = f"""
# 目标
{instruction}# 输出格式
{output_format}# 用户输入
{input_text}
"""# 调用大模型,指定用 JSON mode 输出
response = get_completion(prompt)
print(response)
cot 示例
instruction = """
给定一段用户与手机流量套餐客服的对话,。
你的任务是判断客服的回答是否符合下面的规范:- 必须有礼貌
- 必须用官方口吻,不能使用网络用语
- 介绍套餐时,必须准确提及产品名称、月费价格和月流量总量。上述信息缺失一项或多项,或信息与事实不符,都算信息不准确
- 不可以是话题终结者已知产品包括:经济套餐:月费50元,月流量10G
畅游套餐:月费180元,月流量100G
无限套餐:月费300元,月流量1000G
校园套餐:月费150元,月流量200G,限在校学生办理
"""# 输出描述
output_format = """
如果符合规范,输出:Y
如果不符合规范,输出:N
"""context = """
用户:你们有什么流量大的套餐
客服:亲,我们现在正在推广无限套餐,每月300元就可以享受1000G流量,您感兴趣吗?
"""#cot = ""
cot = "请一步一步分析对话"prompt = f"""
# 目标
{instruction}
{cot}# 输出格式
{output_format}# 对话上下文
{context}
"""response = get_completion(prompt)
print(response)
prompt 优化 prompt
user_prompt = """
做一个手机流量套餐的客服代表,叫小瓜。可以帮助用户选择最合适的流量套餐产品。可以选择的套餐包括:
经济套餐,月费50元,10G流量;
畅游套餐,月费180元,100G流量;
无限套餐,月费300元,1000G流量;
校园套餐,月费150元,200G流量,仅限在校生。"""instruction = """
你是一名专业的提示词创作者。你的目标是帮助我根据需求打造更好的提示词。你将生成以下部分:
提示词:{根据我的需求提供更好的提示词}
优化建议:{用简练段落分析如何改进提示词,需给出严格批判性建议}
问题示例:{提出最多3个问题,以用于和用户更好的交流}
"""prompt = f"""
# 目标
{instruction}# 用户提示词
{user_prompt}
"""response = get_completion(prompt)
print(response)
note
Q:带distill的是什么版本呢?
deepseek-r1-7b (qwen2.5-7b-distill)
模型的基座是qwen2.5-7b,不是deepseek
DeepSeek-R1-Distill-Qwen-7B
训练的是Qwen-7B,使用的DeepSeek-R1训练的方式
最终Qwen-7B具备了 的能力
相关文章:
【大模型02】Deepseek使用和prompt工程
文章目录 DeepSeekDeepseek 的创新MLA (低秩近似) MOE 混合专家混合精度框架总结DeepSeek-V3 与 DeepSeek R1 DeepSeek 私有化部署算例市场: autoDLVllM 使用Ollma复习 API 调用deepseek-r1Prompt 提示词工程Prompt 实战设置API Keycot 示例p…...

B端产品经理如何快速完成产品原型设计
B 端产品经理的原型设计需兼顾业务流程复杂度、功能逻辑性和操作效率,快速完成原型的核心在于结构化梳理需求、复用成熟组件、借助高效工具、聚焦核心场景。以下是具体方法和步骤: 一、明确需求优先级:先框架后细节 1. 梳理业务流程&#x…...
)
[Java实战]Spring Boot切面编程实现日志记录(三十六)
[Java实战]Spring Boot切面编程实现日志记录(三十六) 一、AOP日志记录核心原理 1.1 AOP技术体系 Spring AOP基于代理模式实现,关键组件: JoinPoint:程序执行点(方法调用/异常抛出)Pointcut:切点表达式(定义拦截规则)Advice:增强逻辑(前置/环绕/异常通知)Weaving:…...

Apache POI生成的pptx在office中打不开 兼容问题 wps中可以打卡问题 POI显示兼容问题
项目场景: 在java服务中使用了apache.poi后生成的pptx在wps中打开是没有问题,但在office中打开显示如下XXX内容问题,修复(R)等问题 我是用的依赖版本如下 <dependency><groupId>org.apache.poi</grou…...
大学大模型教学:基于NC数据的全球气象可视化解决方案
引言 气象数据通常以NetCDF(Network Common Data Form)格式存储,这是一种广泛应用于科学数据存储的二进制文件格式。在大学气象学及相关专业的教学中,掌握如何读取、处理和可视化NC数据是一项重要技能。本文将详细介绍基于Python的NC数据处理与可视化解决方案,包含完整的代…...
 ----- Python的数据类型及其集合操作)
Python学习(2) ----- Python的数据类型及其集合操作
在 Python 中,一切皆对象,每个对象都有类型。下面是 Python 中的常见内置类型分类和示例: 🟡 1. 数字类型(Numeric Types) 类型说明示例int整数5, -42float浮点数3.14, -0.5complex复数1 2j a 10 …...

机器学习算法-决策树
今天我们用一个 「相亲决策」 的例子来讲解决策树算法,保证你轻松理解原理和实现! 🌳 决策树是什么? 决策树就像玩 「20个问题」猜谜游戏: 你心里想一个东西(比如「苹果」) 朋友通过一系列问题…...

MediaMtx开源项目学习
这个博客主要记录MediaMtx开源项目学习记录,主要包括下载、推流(摄像头,MP4)、MediaMtx如何使用api去添加推流,最后自定义播放器,播放推流后的视频流,自定义Video播放器博客地址 1 下载 MediaMTX MediaMTX 提供了预编译的二进制文件,您可以从其 GitHub 页面下载: Gi…...
Linux安装EFK日志分析系统
目标:能够实现采集指定路径日志到es,用kibana实现日志分析 单es节点集群规划: 主机名IP 地址组件a1192.168.1.111Kibana elasticsearcha2192.168.1.112Fluentda3192.168.1.103Fluentd 1、安装Elasticsearch 1.1添加 Elastic 仓库并安装 E…...
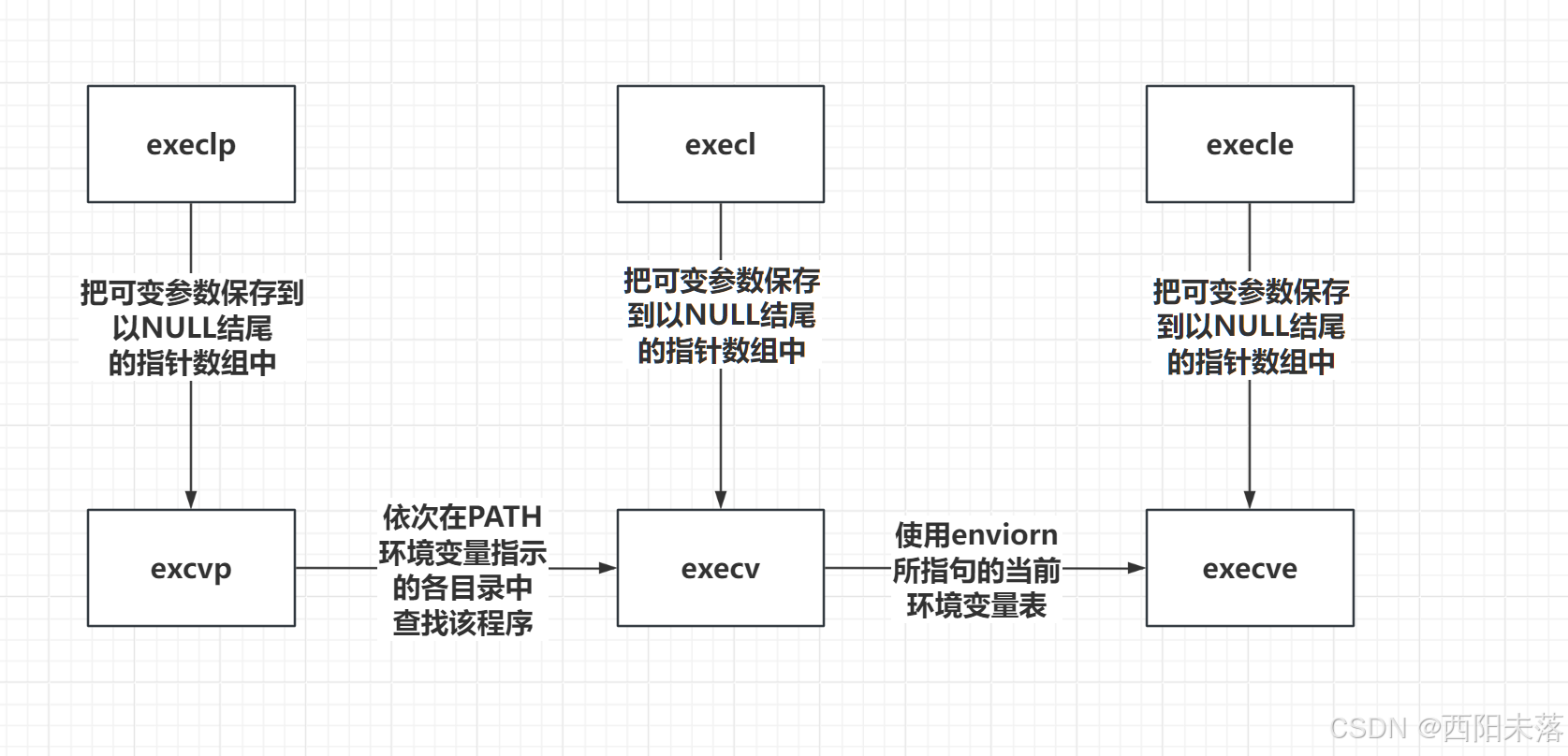
Linux(9)——进程(控制篇——下)
目录 三、进程等待 1)进程等待的必要性 2)获取子进程的status 3)进程的等待方法 wait方法 waitpid方法 多进程创建以及等待的代码模型 非阻塞的轮训检测 四、进程程序替换 1)替换原理 2)替换函数 3&…...

E. Melody 【CF1026 (Div. 2)】 (求欧拉路径之Hierholzer算法)
E. Melody 思路 将所有出现过的音量和音高看作一个点,一个声音看作一条边,连接起来。那么很容易知道要找的就是图上的一条欧拉路径(类似一笔画问题) 又已知存在欧拉路径的充要条件为:度数为奇数的点的个数为0或者2个…...

@Pushgateway 数据自动清理
文章目录 Pushgateway 数据自动清理一、Pushgateway 数据清理的必要性二、自动清理方案方案1:使用带TTL功能的Pushgateway分支版本方案2:使用Shell脚本定期清理方案3:结合Prometheus记录规则自动清理 三、最佳实践建议四、验证与维护五、示例…...

粽叶飘香时 山水有相逢
粽叶飘香时 山水有相逢 尊敬的广大客户们: 五月初五,艾叶幽香。值此端午佳节,衡益科技全体同仁向您致以最诚挚的祝福! 这一年我们如同协同竞渡的龙舟,在数字化转型的浪潮中默契配合。每一次技术对接、每轮方案优化&a…...
YC-8002型综合变配电监控自动化系统
一 .系统概述 YC-8002型综合变配电监控自动化系统是西安亚川电力科技有限公司为适应广大客户要求,总结多项低 压配电网络自动化工程实例的经验,基于先进的电子技术、计算机和网络通讯等技术自主研发的--套结合本公司网络配电产品的应用于低压配电领域的…...
react diff 算法
diff 算法作为 Virtual DOM 的加速器,其算法的改进优化是 React 整个界面渲染的基础和性能的保障,同时也是 React 源码中最神秘的,最不可思议的部分 diff 算法会帮助我们就算出 VirtualDOM 中真正变化的部分,并只针对该部分进行原…...
近期手上的一个基于Function Grap(类AWS的Lambda)小项目的改造引发的思考
函数式Function是云计算里最近几年流行起来的新的架构和模式,因为它不依赖云主机,非常轻量,按需使用,甚至是免费使用,特别适合哪种数据同步,数据转发,本身不需要保存数据的业务场景,…...

Obsidian 社区插件下载修复
Obsidian 社区插件下载修复 因为某些原因,在国内经常无法下载 Obsidian 的社区插件。这个项目的主要目的就是修复这种情况,让国内的用户也可以无障碍的下载社区插件。 上手指南 下载 obsidian-proxy-github.zip解压 obsidian-proxy-github.zip将解压的…...

VSCode的下载与安装(2025亲测有效)
目录 0 前言1 下载2 安装3 后记 0 前言 丫的,谁懂啊,尝试了各种办法不行的话,我就不得不拿出我的最后绝招了,卸载,重新安装,我经常要重新安装,所以自己写了一个博客,给自己…...
千库/六图素材下载工具
—————【下 载 地 址】——————— 【本章下载一】:https://pan.xunlei.com/s/VORW9TbxC9Lmz8gCynFrgdBzA1?pwdxiut# 【本章下载二】:https://pan.quark.cn/s/829e2a4085d3 【百款黑科技】:https://ucnygalh6wle.feishu.cn/wiki/…...

Ansible模块——Ansible的安装!
Ansible 安装 Ansible 有三种安装方式,源码安装、发行版安装和 Python 安装。 使用发行版安装或 Python 安装两种方式时,Ansible 的安装包有两个,区别如下: • ansible-core:一种极简语言和运行时包,包含…...

差分S参数-信号与电源完整性分析
差分S参数: 由于差分互连中使用差分信号传递信息,接收器最关心的是差分信号的质量,如果互连通道的S参数能直接反映出对差分信号的影响,对分析问题将方便得多。差分互连通道可以看成是一个四端口网络,激励源为单端信号,…...

扣子Coze飞书多维表插件-查询数据
search_record - 查询数据 请求参数 apptoken - 多维表的唯一标识服 可选参数: automatic_fields - 控制是否返回自动计算的字段, true 表示返回。 field_names - 字段名称,用于指定本次查询返回记录中包含的字段。 示例值:["字段1&…...

计算机模拟生物/化学反应有哪些软件?
以下是用于计算机模拟生物/化学反应的软件分类总结,涵盖量子化学、分子动力学、化学信息学及新兴混合方法等方向,结合其核心功能和应用场景进行整理: ⚛️ 一、量子化学计算软件 ChemiQ(本源量子) 类型:量子…...
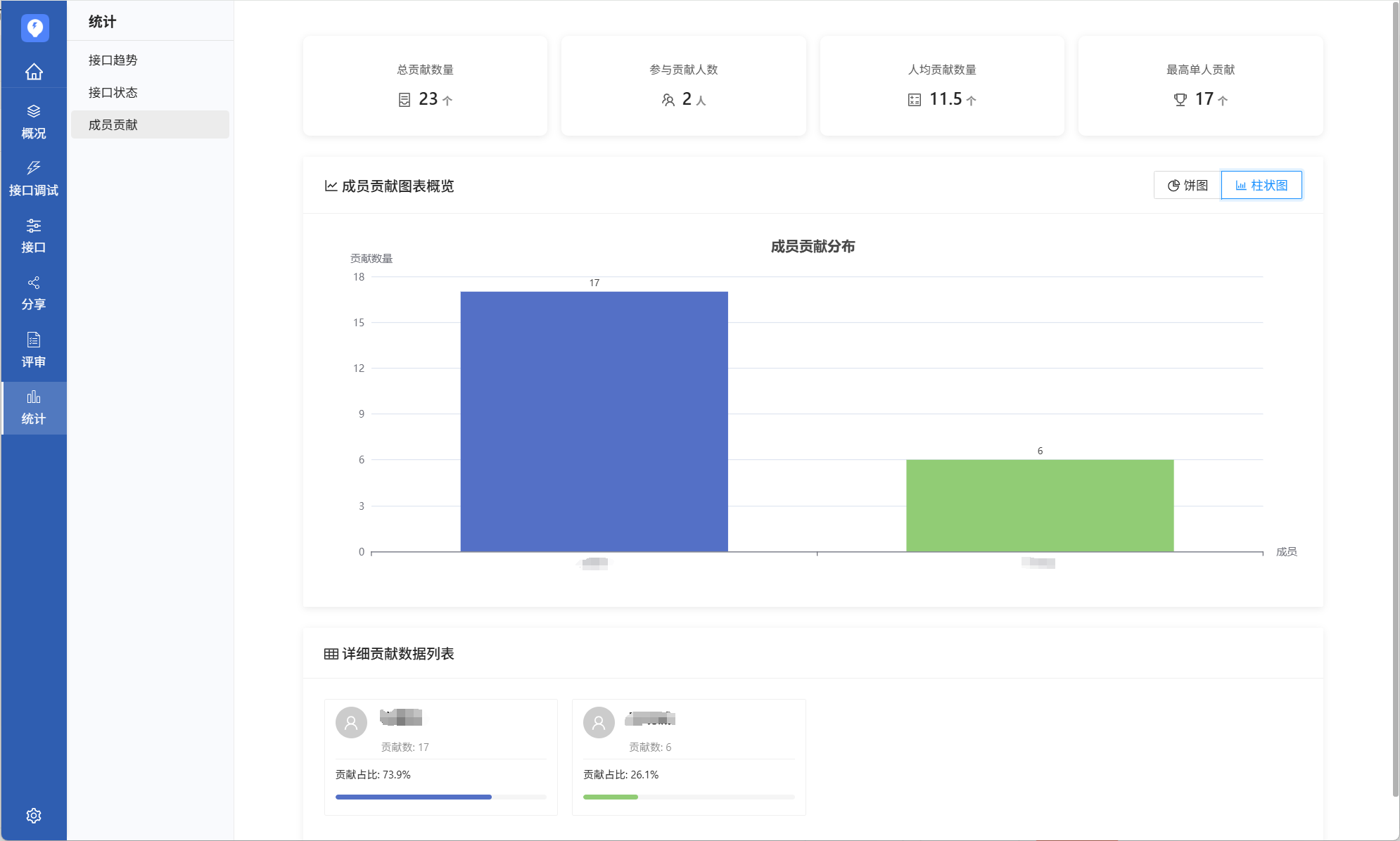
PostIn V1.1.2版本发布,新增接口评审功能,提升接口质量与合理性
PostIn是一款国产开源免费的接口管理工具,包含项目管理、接口调试、接口文档设计、接口数据MOCK等模块,支持常见的HTTP协议、websocket协议。本周PostIn V1.1.0版本发布,新增接口评审、接口统计功能。 1、版本更新日志 新增 ➢ 接口评审&a…...

MySQL数据归档利器:pt-archiver原理剖析与实战指南
MySQL数据归档利器:pt-archiver原理剖析与实战指南 在MySQL数据库管理中,数据归档是一个永恒的话题——随着业务数据的不断增长,如何高效、安全地将历史数据从生产表迁移到归档表或文件,同时不影响在线业务,是每个DBA和开发者都需要面对的挑战。Percona Toolkit中的pt-ar…...
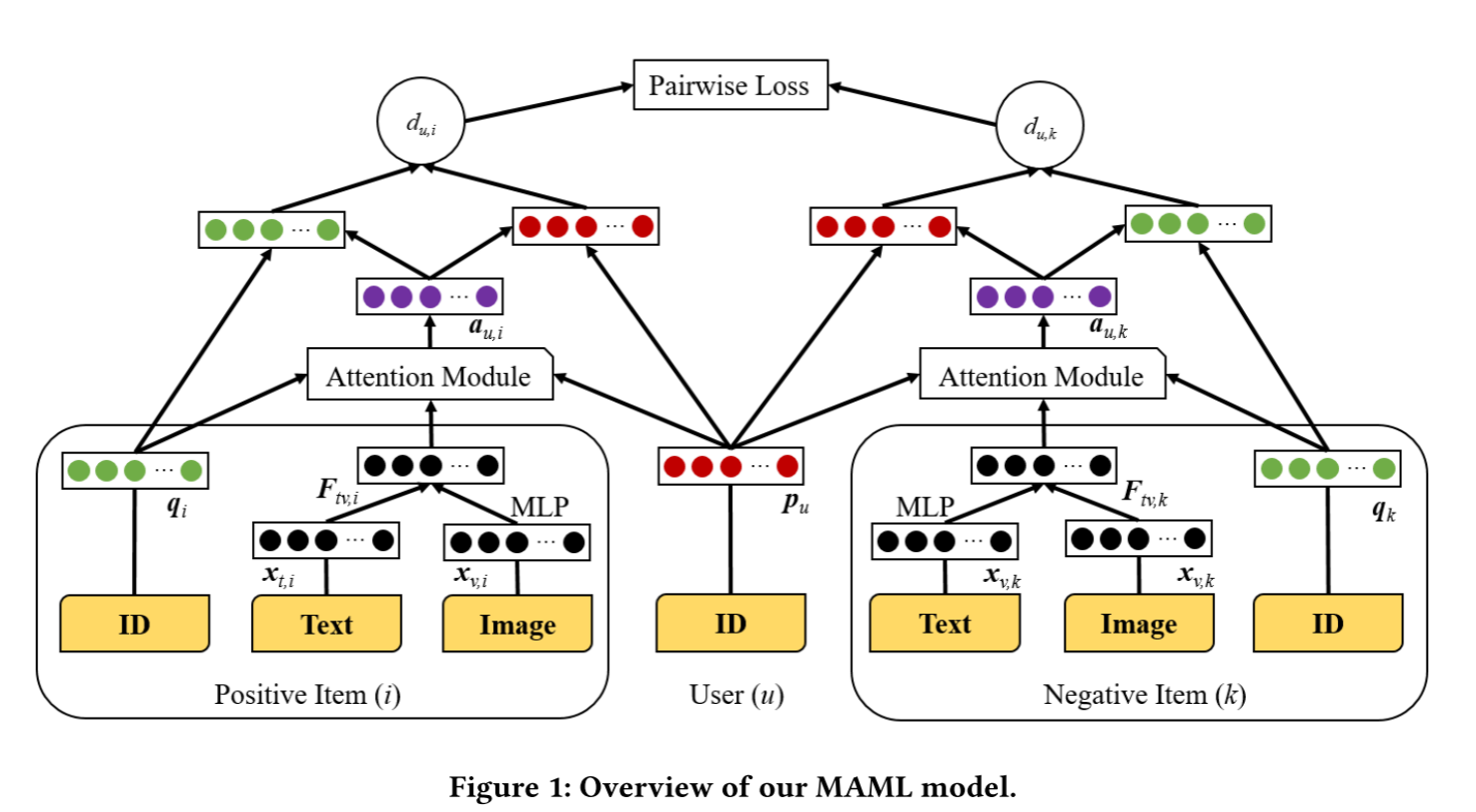
【论文阅读】User Diverse Preference Modeling by Multimodal Attentive Metric Learning
User Diverse Preference Modeling by Multimodal Attentive Metric Learning 题目翻译:基于多模态注意度量学习的用户不同偏好建模 摘要 提出一个**多模态注意力度量学习(MAML, Multimodal Attentive Metric Learning)**方法,…...

Catch That Cow POJ - 3278
农夫约翰得知了一头逃亡奶牛的位置,想要立即抓住她。他起始于数轴上的点N(0 ≤ N ≤ 100,000),而奶牛位于同一条数轴上的点K(0 ≤ K ≤ 100,000)。农夫约翰有两种移动方式:步行和传送。 * 步行…...
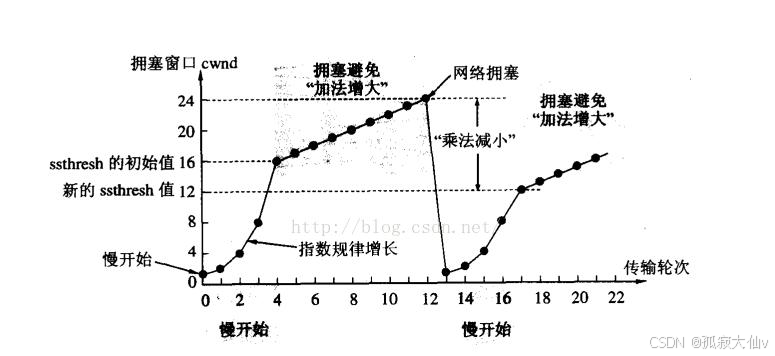
【计算机网络】传输层TCP协议——协议段格式、三次握手四次挥手、超时重传、滑动窗口、流量控制、
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:计算机网络 🌹往期回顾🌹: 【计算机网络】传输层UDP协议 🔖流水不争,争的是滔滔不息 一、TCP协议 UDP&…...
文件服务端加密—minio配置https
1.安装openssl 建议双击安装包默认安装,安装完成之后配置环境变量 如下图则配置成功: 二、生成自签名CA证书及私钥 1、生成私钥 openssl genrsa -out private.key 20482、生成自签名证书 (1)编写openssl.conf文件,…...
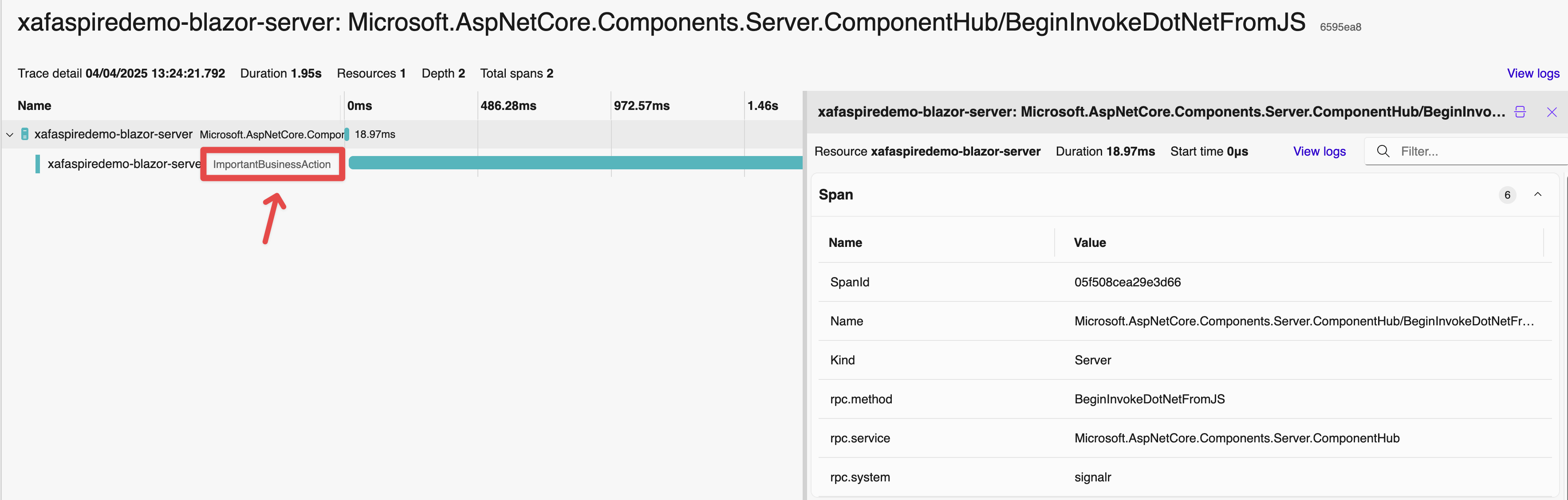
界面开发框架DevExpress XAF实践:集成.NET Aspire后如何实现自定义遥测?
DevExpress XAF是一款强大的现代应用程序框架,允许同时开发ASP.NET和WinForms。DevExpress XAF采用模块化设计,开发人员可以选择内建模块,也可以自行创建,从而以更快的速度和比开发人员当前更强有力的方式创建应用程序。 .NET As…...