【论文阅读】User Diverse Preference Modeling by Multimodal Attentive Metric Learning
User Diverse Preference Modeling by Multimodal Attentive Metric Learning
题目翻译:基于多模态注意度量学习的用户不同偏好建模
摘要
提出一个**多模态注意力度量学习(MAML, Multimodal Attentive Metric Learning)**方法,
核心思路:针对每一个用户-物品对,设计了一个注意力神经网络,利用物品的多模态信息来估计用户对物品不同方面的特别关注。
引言
在当时虽然有新的研究通过评论、神经网络等方式建模用户对不同方面的关注如(ALFM、A3NCF、DIN),但是这些方法基于MF的点积,点积不是度量(不满足三角不等式),表达能力有限。
Hsieh等人[20]提出了一种度量协同过滤(CML)方法,该方法通过最小化用户和项目向量(即||pu - qi ||)之间的距离来学习偏好。
纯度量学习(如CML)虽然克服了点积问题,但又面临“所有正交互的用户-物品需映射到同一点,几何表达受限”等新问题。
我们提出了一种新的多模态注意度量学习(MAML)方法,该方法利用物品的多模态信息来模拟用户对不同物品的不同偏好。
我们的MAML模型通过向每个用户-项目对引入权重向量来增强CML方法,通过设计一个注意力神经网络来实现的,该网络通过利用目标物品的文本和视觉特征来分析用户对目标物品的注意力。
MAML的优点:
- 1)由于采用了基于度量的学习方法,满足了不等式性质,从而避免了点积相似度预测方法的问题;
- 2)解决了CML中的几何限制问题。
MAML model
符号说明
| 符号 | 含义说明 |
|---|---|
| U U U | 用户集合(所有用户的集合) |
| I I I | 物品集合(所有物品的集合) |
| R R R | 用户-物品交互矩阵 |
| r u , i r_{u,i} ru,i | 用户 u u u 与物品 i i i 之间的交互值,属于矩阵 R R R |
| 隐式反馈 | 若用户 u u u 与物品 i i i 有交互, r u , i = 1 r_{u,i}=1 ru,i=1;否则为0 |
| 显式反馈 | r u , i r_{u,i} ru,i 通常为用户 u u u 对物品 i i i 的评分 |
| R R R(集合) | 所有值不为零的用户-物品对 ( u , i ) (u, i) (u,i) 的集合 |
| R u R_u Ru | 用户 u u u 已交互过的物品集合 |
| p u p_u pu | 用户 u u u 的潜在特征向量,维度为 f f f |
| q i q_i qi | 物品 i i i 的潜在特征向量,维度为 f f f |
| r ^ u , j \hat{r}_{u,j} r^u,j | 用户 u u u 对物品 j j j 的推荐得分(由特征向量计算得到) |
背景
矩阵分解(Matrix Factorization,MF)方法将用户和物品映射到一个共享的潜在特征空间中,并通过用户和物品特征向量之间的点积来估计未观测到的交互,即
r ^ u , i = p u T q i \hat{r}_{u,i} = p_u^T q_i r^u,i=puTqi
对于所有的用户 u ∈ U u \in U u∈U 和物品 i ∈ I i \in I i∈I, p u p_u pu 和 q i q_i qi 的学习目标是最小化预测得分 r ^ u , i \hat{r}_{u,i} r^u,i 与实际交互值 r u , i r_{u,i} ru,i 之间的误差,即:
∑ ( u , i ) ∈ R ∥ r ^ u , i − r u , i ∥ \sum_{(u,i) \in R} \| \hat{r}_{u,i} - r_{u,i} \| (u,i)∈R∑∥r^u,i−ru,i∥
(注:这里省略了正则项,仅保留了预测误差部分。)
最初的矩阵分解(MF)模型是为了评分预测而设计的【19, 27】,后来被扩展为带权正则化矩阵分解(WRMF),以用于隐式反馈的预测【21】。由于推荐系统的目标是为目标用户提供一份最有可能被其喜欢的物品的排名列表,因此,推荐本质上是一个排序问题,而非简单的评分预测问题。基于这一点,MF方法逐渐发展为建模不同物品之间的相对偏好,并广泛采用了*成对学习(pairwise learning)*的方法来实现这一目标【35, 54】。
在成对学习中,用户和物品的特征向量通过设定如下约束来学习:
对于任意满足 ( u , i ) ∈ R (u, i) \in R (u,i)∈R 且 ( u , k ) ∉ R (u, k) \notin R (u,k)∈/R 的两个物品对,应有
r ^ u , i > r ^ u , k \hat{r}_{u,i} > \hat{r}_{u,k} r^u,i>r^u,k
其中,典型的例子是**贝叶斯个性化排序(BPR)**方法【35】。BPR 是一种基于MF的方法,其中
r ^ u , i = p u T q i , r ^ u , k = p u T q k \hat{r}_{u,i} = p_u^T q_i, \quad \hat{r}_{u,k} = p_u^T q_k r^u,i=puTqi,r^u,k=puTqk
因此,优化目标就是保证 p u T q i > p u T q k p_u^T q_i > p_u^T q_k puTqi>puTqk(其中 ( u , i ) ∈ R (u, i) \in R (u,i)∈R, ( u , k ) ∉ R (u, k) \notin R (u,k)∈/R)。
尽管矩阵分解(MF)方法取得了成功,但它并不是一种基于度量的学习方法,因为其采用的点积相似度并不满足三角不等式这一性质,而这一性质对于刻画用户的细粒度偏好非常关键,这一点在相关研究【20, 53】中已经有所证明。从度量学习的角度来看,既然用户和物品都被表示为共享空间中的潜在向量,那么用户与物品之间的相似度可以通过它们向量之间的欧氏距离来衡量,如下所示:
d ( u , i ) = ∥ p u − q i ∥ d(u, i) = \|p_u - q_i\| d(u,i)=∥pu−qi∥
数学定义
对于两个 f f f 维空间中的点(向量) a = ( a 1 , a 2 , . . . , a f ) \mathbf{a} = (a_1, a_2, ..., a_f) a=(a1,a2,...,af) 和 b = ( b 1 , b 2 , . . . , b f ) \mathbf{b} = (b_1, b_2, ..., b_f) b=(b1,b2,...,bf),它们之间的欧氏距离定义为:
∥ a − b ∥ = ( a 1 − b 1 ) 2 + ( a 2 − b 2 ) 2 + ⋯ + ( a f − b f ) 2 \|\mathbf{a} - \mathbf{b}\| = \sqrt{(a_1 - b_1)^2 + (a_2 - b_2)^2 + \cdots + (a_f - b_f)^2} ∥a−b∥=(a1−b1)2+(a2−b2)2+⋯+(af−bf)2
考虑到成对学习(pairwise learning),很自然地可以得到这样的推论:对于满足 ( u , i ) ∈ R (u, i) \in R (u,i)∈R 且 ( u , k ) ∉ R (u, k) \notin R (u,k)∈/R 的情况,有
d ( u , i ) < d ( u , k ) d(u, i) < d(u, k) d(u,i)<d(u,k)
其中, i i i 表示用户 u u u 喜欢的物品, k k k 表示用户 u u u 不喜欢的物品。**协同度量学习(CML)**方法【20】正是基于这个简单的思想设计的。由于这种方法是一种基于度量的学习方式,它天然地避免了点积的局限性,并且在性能上优于传统的MF模型【20】。因此,在本研究中,我们也基于这种思想来推导用户多样化偏好建模方法,而不是采用传统的MF方法。
MAML
用户对物品的各个部分的专注度是不一样的,比如他在意的某个部分,就往往决定了他会不会选择这个物品。
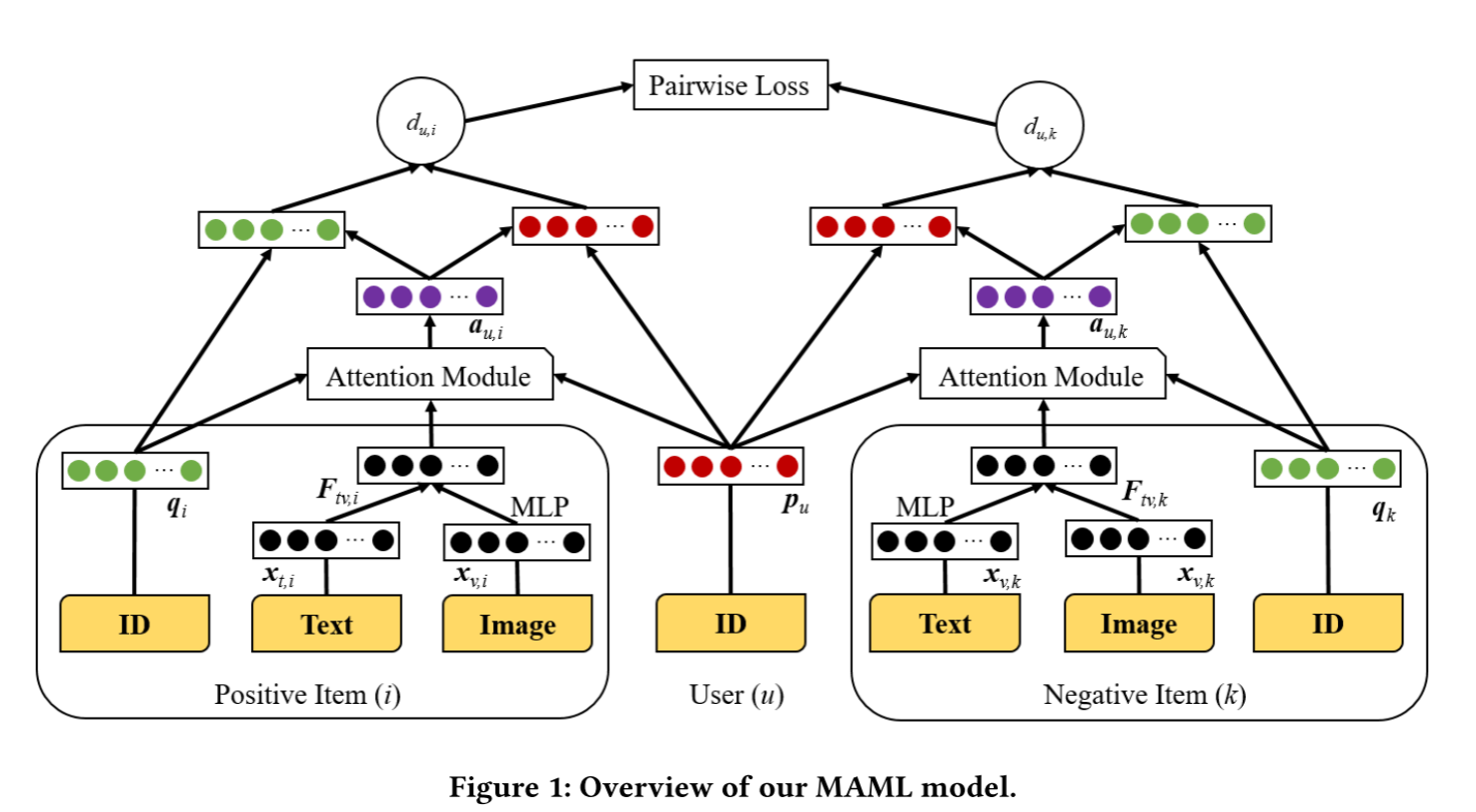
基于上述考虑,我们提出了一种多模态注意力度量学习(MAML)模型。对于每一个用户-物品 ( u , i ) (u, i) (u,i) 对,我们的模型都会计算一个权重向量 a u , i ∈ R f a_{u,i} \in \mathbb{R}^f au,i∈Rf,用以表示物品 i i i 的各个方面对用户 u u u 的重要性。
此外,模型还利用物品的侧信息来估计这个权重向量,因为侧信息(如文本评论和商品图片)能够反映物品在不同方面的丰富特征,这些特征往往是显著且互补的【9, 54】。我们采用了最新的注意力机制【6, 10】来估算注意力(权重)向量。
在引入注意力(权重)向量后,我们模型中用户 u u u 与物品 i i i 之间的欧氏距离定义为:
d ( u , i ) = ∥ a u , i ⊙ p u − a u , i ⊙ q i ∥ d(u, i) = \|a_{u,i} \odot p_u - a_{u,i} \odot q_i\| d(u,i)=∥au,i⊙pu−au,i⊙qi∥
其中, ⊙ \odot ⊙ 表示向量的按元素乘积。
读到这里,我很想知道他是怎么把注意力干进去的,好难猜啊
直观比喻
你可以理解成:
普通的MF或者CML,用户和物品就是静静地摆在空间里的点;
而MAML,每遇到一个用户和物品,都会用“注意力放大镜”针对这对组合“重新定制”一套权重,让你关注的地方和我关注的不一样,然后在加权后的空间里比距离。具体来说,他是这样“把注意力机制加进去的”:
1. 为每个用户-物品对单独计算一个“注意力向量”
- 不是只为用户算一组注意力,也不是只为物品算一组注意力,而是每对用户-物品都重新算一次注意力向量 a u , i a_{u,i} au,i。
- 这个向量的每一维,其实就代表了“用户对这个物品在第 l l l 个特征/方面上的关注度”。
- 关注度不一样,后续距离计算时的权重就不一样。
2. 注意力怎么计算出来?
作者用一个两层神经网络,输入信息包括:
- 用户特征向量 p u p_u pu
- 物品特征向量 q i q_i qi
- 物品的多模态侧信息(文本+图片特征,合并后记作 F t v , i F_{tv,i} Ftv,i)
把它们拼接起来后,先用Tanh激活,后用ReLU激活,再线性变换,得到注意力“初值”。
然后对每一维做“归一化”,让它像一个权重分布(这一步细节作者有改进,见下说明)。
3. 注意力机制怎么和距离结合?
普通欧氏距离是 ∥ p u − q i ∥ \|p_u - q_i\| ∥pu−qi∥。
MAML变成:
d ( u , i ) = ∥ a u , i ⊙ p u − a u , i ⊙ q i ∥ d(u, i) = \| a_{u,i} \odot p_u - a_{u,i} \odot q_i \| d(u,i)=∥au,i⊙pu−au,i⊙qi∥
也就是:对每一维都乘上这个注意力权重,然后再做距离计算。
这样一来,“用户对不同物品、不同方面的关注度不同”就体现在距离计算里了。
4. 注意力的归一化方法
- 论文特别提到:如果用标准softmax归一化,权重太小,会导致距离区分能力减弱。所以作者把归一化后的权重整体放大了(乘以特征维数f),这样每一维的贡献更显著,模型区分力更强。
5. 用神经网络动态学习注意力
- 这个权重 a u , i a_{u,i} au,i不是靠人工规则算的,而是用训练数据,通过反向传播、自动微调神经网络参数学出来的。
值得一提的是,通过引入注意力向量,我们的模型不仅能够准确捕捉用户对不同物品的多样化偏好,还能够解决CML方法中存在的几何限制问题【41】。从公式1可以看出,CML方法试图将一个用户和其所有交互过的物品都拟合到潜在空间中的同一个点上,然而,每个物品又同时有许多交互过的用户。因此,从几何上来看,实现这个目标是不可能的。
而在我们的方法中,由于 a u , i a_{u,i} au,i 是针对每个用户-物品对唯一生成的,它就像一个变换向量,将目标用户和物品“投影”到一个新的空间中进行距离计算。因此,我们的方法能够自然而然地避免CML中的几何限制问题。我们所提出的MAML模型的整体框架如图1所示。
我们采用成对学习(pairwise learning)的方法进行优化,其损失函数定义如下:
L m ( d ) = ∑ ( u , i ) ∈ R ∑ ( u , k ) ∉ R ω u i [ m + d ( u , i ) 2 − d ( u , k ) 2 ] + L_m(d) = \sum_{(u,i)\in R} \sum_{(u,k)\notin R} \omega_{ui} \left[ m + d(u, i)^2 - d(u, k)^2 \right]_+ Lm(d)=(u,i)∈R∑(u,k)∈/R∑ωui[m+d(u,i)2−d(u,k)2]+
其中, i i i 表示用户 u u u 喜欢的物品, k k k 表示用户 u u u 不喜欢的物品; [ z ] + = max ( z , 0 ) [z]_+ = \max(z, 0) [z]+=max(z,0) 表示标准的合页损失函数(hinge loss)。
ω u i \omega_{ui} ωui 是排名损失权重(详见3.2.3节), m > 0 m > 0 m>0 是安全间隔(margin)大小。
d ( u , i ) d(u, i) d(u,i) 和 d ( u , k ) d(u, k) d(u,k) 按照公式2计算。
接下来,我们将介绍如何为每个用户-物品对计算注意力向量 a u , i a_{u,i} au,i。
好难坚持啊,真不想继续阅读了,但是这是注意力机制啊!
3.2.2 注意力机制
在本节中,我们介绍MAML模型中用于捕捉用户 u u u 对物品 i i i 的特定注意力 a u , i a_{u,i} au,i 的注意力机制。由于文本评论和图片包含了丰富的用户偏好和物品特征信息,因此我们利用这些多模态信息来刻画用户对物品不同方面的关注。
我们采用了一个两层神经网络来计算注意力向量,具体如下:
e u , i = tanh ( W 1 [ p u ; q i ; F t v , i ] + b 1 ) , e_{u,i} = \tanh\left(W_1 \left[ p_u; q_i; F_{tv,i} \right] + b_1\right), eu,i=tanh(W1[pu;qi;Ftv,i]+b1),
a ^ u , i = v T R e L U ( W 2 e u , i + b 2 ) , \hat{a}_{u,i} = v^T \mathrm{ReLU}\left(W_2 e_{u,i} + b_2\right), a^u,i=vTReLU(W2eu,i+b2),
其中, W 1 , W 2 W_1, W_2 W1,W2 分别为两层的权重矩阵, b 1 , b 2 b_1, b_2 b1,b2 为偏置向量, v v v 是将隐藏层投影到输出注意力权重向量的参数向量。 F t v , i F_{tv,i} Ftv,i 表示物品 i i i 的特征向量,是该物品文本特征和图像特征融合后的结果(后文会详细描述)。 [ p u ; q i ; F t v , i ] [p_u; q_i; F_{tv,i}] [pu;qi;Ftv,i] 表示将用户向量、物品向量和物品多模态特征进行拼接。第一层激活函数使用Tanh,第二层使用ReLU【29, 30, 36】。
这篇论文多模态融合的实现思路
1. 多模态特征指哪些?
- 文本特征:商品描述、评论、标题等
- 图像特征:商品图片(通常用CNN提特征)
2. 具体怎么融合?
根据论文原文的表达(后文会详细介绍),通常流程是这样的:
(1) 提取文本特征
- 把商品的文本描述或评论经过文本编码器(如Word2Vec、LSTM、BERT、甚至MLP),得到一个定长向量,记为 F t e x t , i F_{text, i} Ftext,i。
(2) 提取图片特征
- 把商品图片输入到预训练的卷积神经网络(CNN)(如ResNet、VGG、Inception等),提取图片的深层向量特征,记为 F v i s , i F_{vis, i} Fvis,i。
(3) 拼接融合
最直接的方法:把文本向量和图片向量直接拼接(concatenate)起来,得到多模态融合特征
F t v , i = [ F t e x t , i ; F v i s , i ] F_{tv, i} = [F_{text, i}; F_{vis, i}] Ftv,i=[Ftext,i;Fvis,i]
这样融合后的 F t v , i F_{tv, i} Ftv,i 既包含了文本的信息,也包含了图片的信息,作为物品i的多模态特征输入到后续的注意力网络中。
3. 融合方式的常见变体(扩展理解)
- 有些工作会用加权融合、MLP进一步融合、或用注意力机制动态融合,但在这篇论文的原文里,最核心的是直接拼接。
- 这种方式简单直接,信息保留完整,也便于神经网络后续学习每种模态的权重。
4. 总结一句话
- 这篇论文的多模态融合方法是:把文本特征和图像特征提出来后直接拼接,形成一个更大的融合向量,然后作为物品的特征输入到注意力机制中。
3. 融合方式的常见变体(扩展理解)
- 有些工作会用加权融合、MLP进一步融合、或用注意力机制动态融合,但在这篇论文的原文里,最核心的是直接拼接。
- 这种方式简单直接,信息保留完整,也便于神经网络后续学习每种模态的权重。
4. 总结一句话
- 这篇论文的多模态融合方法是:把文本特征和图像特征提出来后直接拼接,形成一个更大的融合向量,然后作为物品的特征输入到注意力机制中。
相关文章:
【论文阅读】User Diverse Preference Modeling by Multimodal Attentive Metric Learning
User Diverse Preference Modeling by Multimodal Attentive Metric Learning 题目翻译:基于多模态注意度量学习的用户不同偏好建模 摘要 提出一个**多模态注意力度量学习(MAML, Multimodal Attentive Metric Learning)**方法,…...

Catch That Cow POJ - 3278
农夫约翰得知了一头逃亡奶牛的位置,想要立即抓住她。他起始于数轴上的点N(0 ≤ N ≤ 100,000),而奶牛位于同一条数轴上的点K(0 ≤ K ≤ 100,000)。农夫约翰有两种移动方式:步行和传送。 * 步行…...
【计算机网络】传输层TCP协议——协议段格式、三次握手四次挥手、超时重传、滑动窗口、流量控制、
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:计算机网络 🌹往期回顾🌹: 【计算机网络】传输层UDP协议 🔖流水不争,争的是滔滔不息 一、TCP协议 UDP&…...
文件服务端加密—minio配置https
1.安装openssl 建议双击安装包默认安装,安装完成之后配置环境变量 如下图则配置成功: 二、生成自签名CA证书及私钥 1、生成私钥 openssl genrsa -out private.key 20482、生成自签名证书 (1)编写openssl.conf文件,…...
界面开发框架DevExpress XAF实践:集成.NET Aspire后如何实现自定义遥测?
DevExpress XAF是一款强大的现代应用程序框架,允许同时开发ASP.NET和WinForms。DevExpress XAF采用模块化设计,开发人员可以选择内建模块,也可以自行创建,从而以更快的速度和比开发人员当前更强有力的方式创建应用程序。 .NET As…...
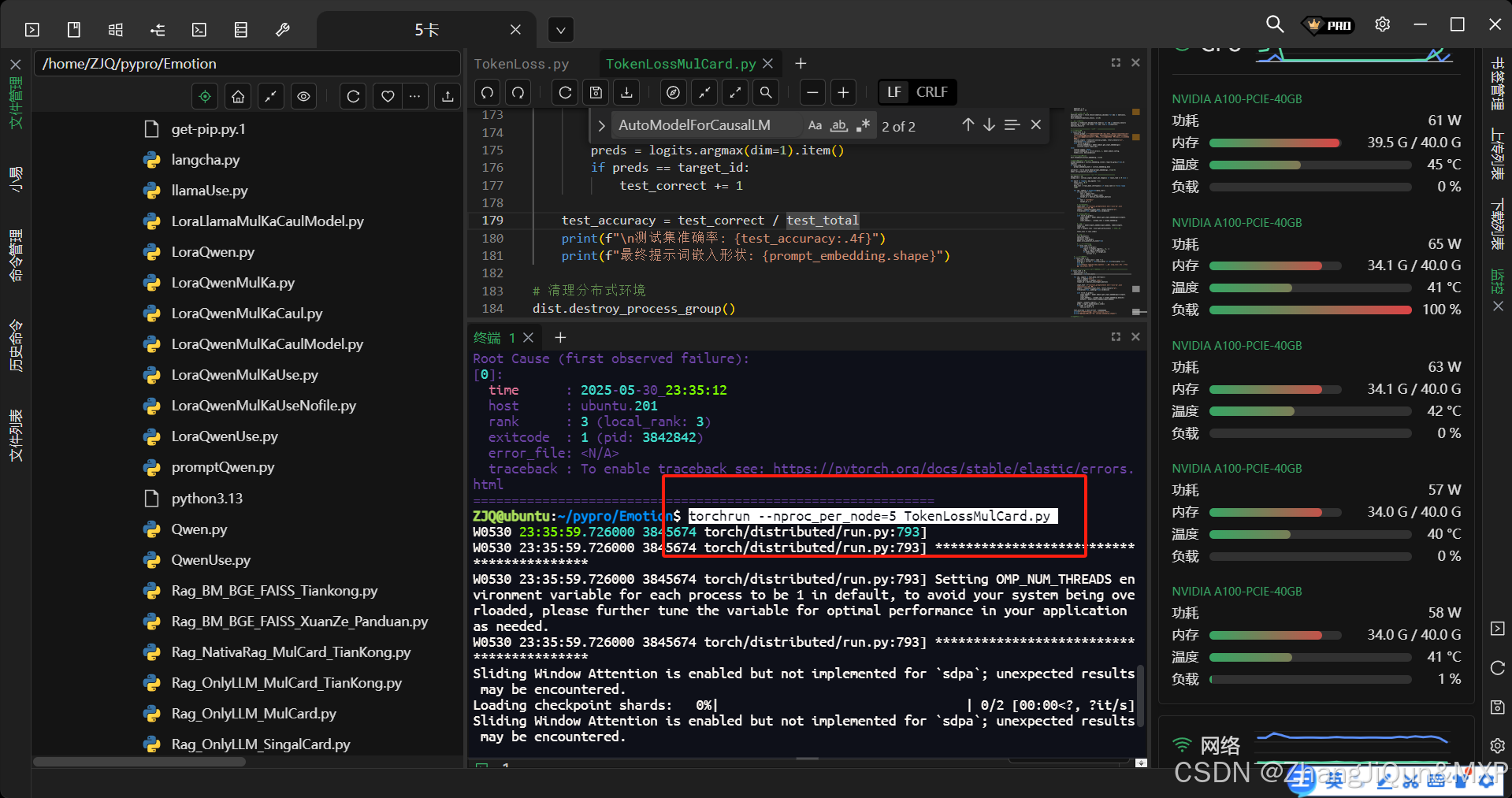
多卡训练核心技术详解
多卡训练核心技术详解 多卡训练 主要围绕分布式环境初始化、模型并行化、数据分片和梯度同步展开。下面结合您的代码,详细解释这些核心部分: 并行执行命令 torchrun --nproc_per_node=5 TokenLossMulCard.py 1. 分布式环境初始化 def init_distributed():init_process_…...

深度学习全面掌握指南
一、引言 深度学习是机器学习的一个分支,它通过构建多层神经网络来模拟人类大脑的信息处理方式,从而实现对复杂数据的自动特征提取和模式识别。近年来,深度学习在计算机视觉、自然语言处理、语音识别等领域取得了巨大的突破,引发…...

magic-api配置Git插件教程
一、配置gitee.com 1,生成rsa密钥,在你的电脑右键使用管理员身份运行(命令提示符),执行下面命令 ssh-keygen -t rsa -b 2048 -m PEM一直按回车键,不需要输入内容 找到 你电脑中的~/.ssh/id_rsa.pub 文件…...

算法打卡第11天
36.有效的括号 (力扣20题) 示例 1: **输入:**s “()” **输出:**true 示例 2: **输入:**s “()[]{}” **输出:**true 示例 3: **输入:**s “(]”…...

【决策分析】基于Excel的多变量敏感性分析解决方案
在Excel中实现多变量敏感性分析(3个及以上变量)需要结合更灵活的工具和方法,因为Excel内置的数据表功能仅支持最多双变量分析。以下是针对多变量场景的解决方案,按复杂度和实用性排序: 方法1:场景管理器 摘…...

php:5.6-apache Docker镜像中安装 gd mysqli 库 【亲测可用】
Dockerfile 代码如下: FROM php:5.6-apache# 使用Debian归档源 RUN echo "deb http://archive.debian.org/debian stretch main contrib non-free" > /etc/apt/sources.list && \echo "deb http://archive.debian.org/debian-security s…...

小程序跳转H5或者其他小程序
1. h5跳转小程序有两种情况 (1)从普通浏览器打开的h5页面跳转小程序使用wx-open-launch-weapp可以实现h5跳转小程序 <wx-open-launch-weappstyle"display:block;"v-elseid"launch-btn":username"wechatYsAppid":path…...

【AI赋能,视界升级】智微智能S134 AI OPS,重构智慧大屏未来
智慧教室中,教师通过电子白板,4K高清课件、3D教学模型同步呈现,后排学生也能看清画面细节,课堂变得趣味十足;智能会议室里,会议内容、多人云会议多屏投放依旧畅通清晰,会议纪要自动生成Word/PPT…...
外网访问可视化工具 Grafana (Linux版本)
Grafana 是一款强大的可视化监控指标的展示工具,可以将不同的数据源数据以图形化的方式展示,不仅通用而且非常美观。它支持多种数据源,如 prometheus 等,也可以通过插件和 API 进行扩展以满足各种需求。 本文将详细介绍如何在本地…...

ass字幕嵌入mp4带偏移
# 格式转化文件,包含多种文件的互相转化,主要与视频相关 from pathlib import Path import subprocess import random import os import reclass Utils(object):staticmethoddef get_decimal_part(x: float) -> float:s format(x, .15f) # 格式化为…...

WPF响应式UI的基础:INotifyPropertyChanged
INotifyPropertyChanged 1 实现基础接口2 CallerMemberName优化3 数据更新触发策略4 高级应用技巧4.1 表达式树优化4.2 性能优化模式4.3 跨平台兼容实现 5 常见错误排查 在WPF的MVVM架构中, INotifyPropertyChanged是实现数据驱动界面的核心机制。本章将深入解析属…...

JavaScript字符串方法全面指南:从基础到高级应用
在JavaScript开发中,字符串(String)是最常用的数据类型之一,用于存储和操作文本数据。JavaScript提供了丰富的内置方法来处理字符串,掌握这些方法能极大提高开发效率。本文将全面介绍JavaScript中的字符串方法,按照"先总后分…...

浅谈 JavaScript 性能优化
文章目录 概要一、代码执行优化1. 减少全局变量访问2. 避免不必要的计算3. 优化循环操作 二、内存管理优化1. 减少内存泄漏2. 对象池与内存复用 三、渲染性能优化1. 避免强制同步布局2. 减少 DOM 操作3. 优化动画与合成 四、网络加载优化1. 代码压缩与 Tree Shaking2. 按需加载…...

React从基础入门到高级实战:React 生态与工具 - 构建与部署
React 构建与部署 引言 在现代Web开发中,构建与部署是项目从开发到上线的关键环节。对于React开发者而言,掌握构建优化和部署策略不仅能提升应用的性能,还能确保项目的稳定性和安全性。随着React应用的复杂性不断增加,合理的构建…...

Kafka性能调优三剑客:深度解析buffer_memory、linger_ms和batch_size
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 持续学习,不断…...
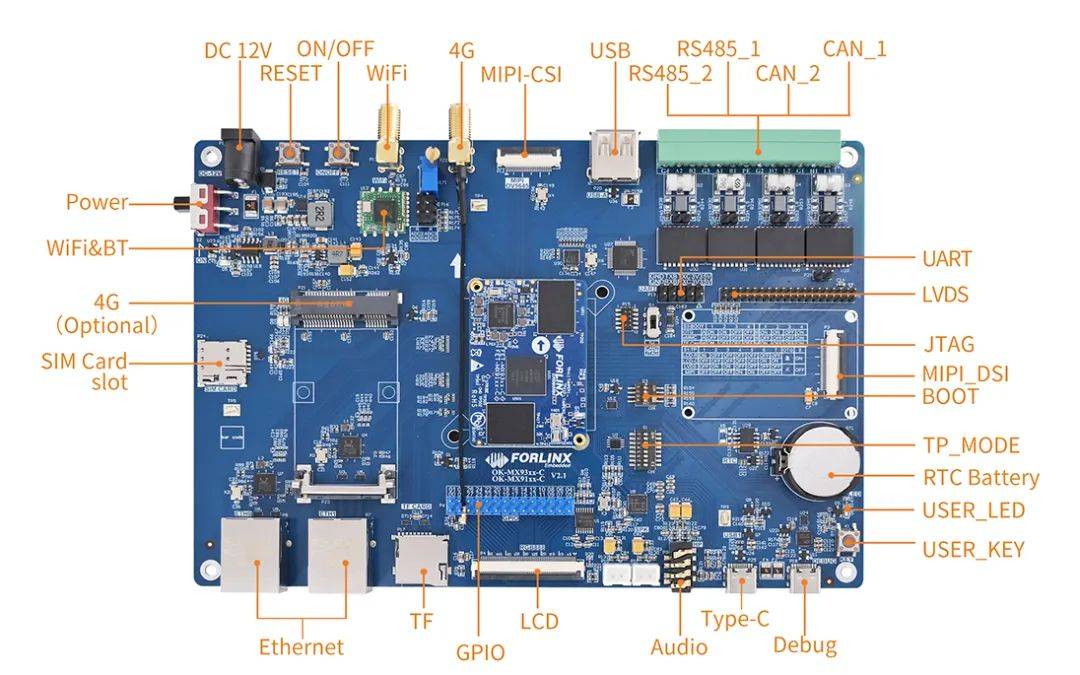
5分钟学会网络服务搭建,飞凌i.MX9352 + Linux 6.1实战示例
在“万物互联”的技术浪潮下,网络服务已成为连接物理世界与数字世界的核心纽带,它不仅赋予了终端设备“开口说话”的能力,更构建了智能设备的开发范式。 本文就将以飞凌嵌入式OK-MX9352-C开发板(搭载了在工业物联网领域广泛应用的…...
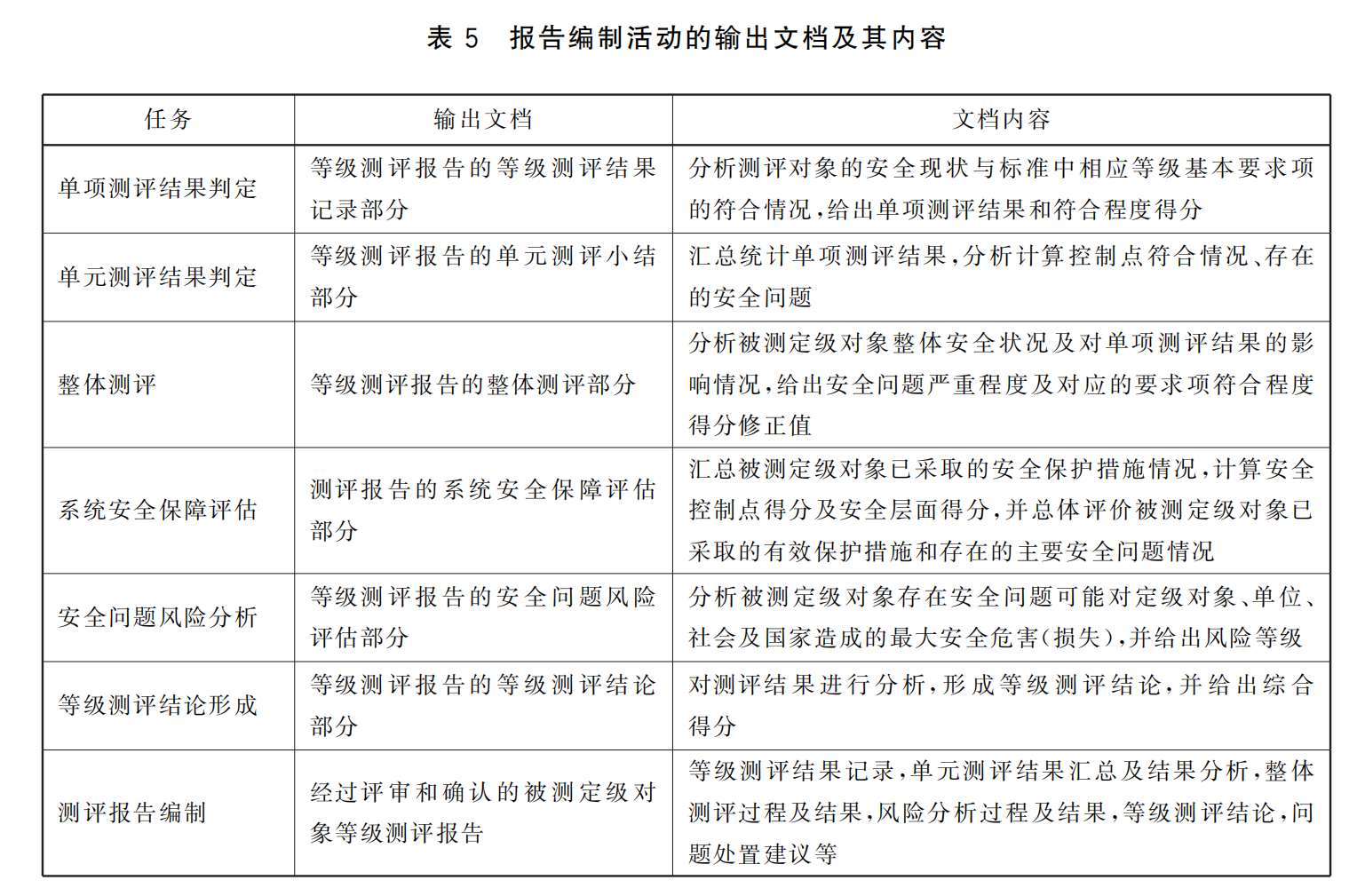
网络安全-等级保护(等保) 3-2-2 GB/T 28449-2019 第7章 现场测评活动/第8章 报告编制活动
################################################################################ GB/T 28449-2019《信息安全技术 网络安全等级保护测评过程指南》是规定了等级测评过程,是纵向的流程,包括:四个基本测评活动:测评准备活动、方案编制活…...
)
74道TypeScript高频题整理(附答案背诵版)
1.简述什么是TypeScript ? TypeScript是一种由Microsoft开发和维护的开源编程语言。它是JavaScript的一个超集,意味着它扩展了JavaScript的功能,包括添加了类型系统和对ES6的新特性的支持。TypeScript的设计目标是帮助开发者捕捉代码中的错误…...

PostgreSQL 临时表空间
PostgreSQL 临时表空间 PostgreSQL 使用临时表空间来存储查询执行过程中产生的临时数据,与 Oracle 类似但实现方式有所不同。 一、临时表空间基本概念 PostgreSQL 的临时表空间主要用于存储: 排序操作(ORDER BY、GROUP BY、DISTINCT&…...

N2语法 状態
1,~てならない 接続:て型 意味:…得不得了(强调自然产生的情感,可接自发动词) 例文: お腹が痛くてならない。 心配でならない。 両親に会いたくてならない。(非常…...
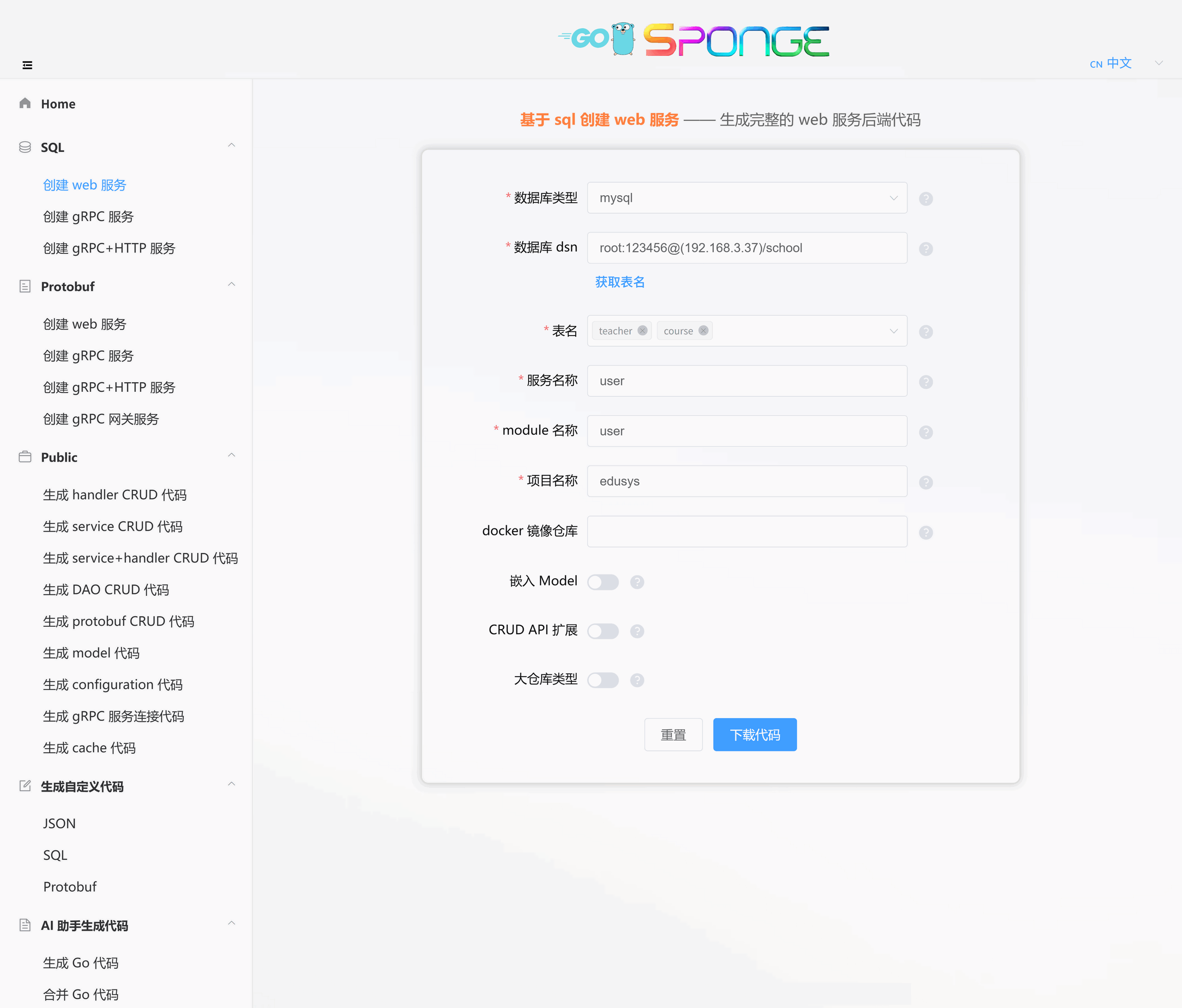
从Node.js到Go:如何从NestJS丝滑切换并爱上Sponge框架
引言 各位 NestJS 老司机们, 不得不说,用装饰器开发 API 简直像在键盘上跳华尔兹——Controller 转个圈,Get 踮个脚,Injectable 优雅谢幕,三下五除二就能搭出个像模像样的后端服务。TypeScript 的类型检查就像个贴心管…...
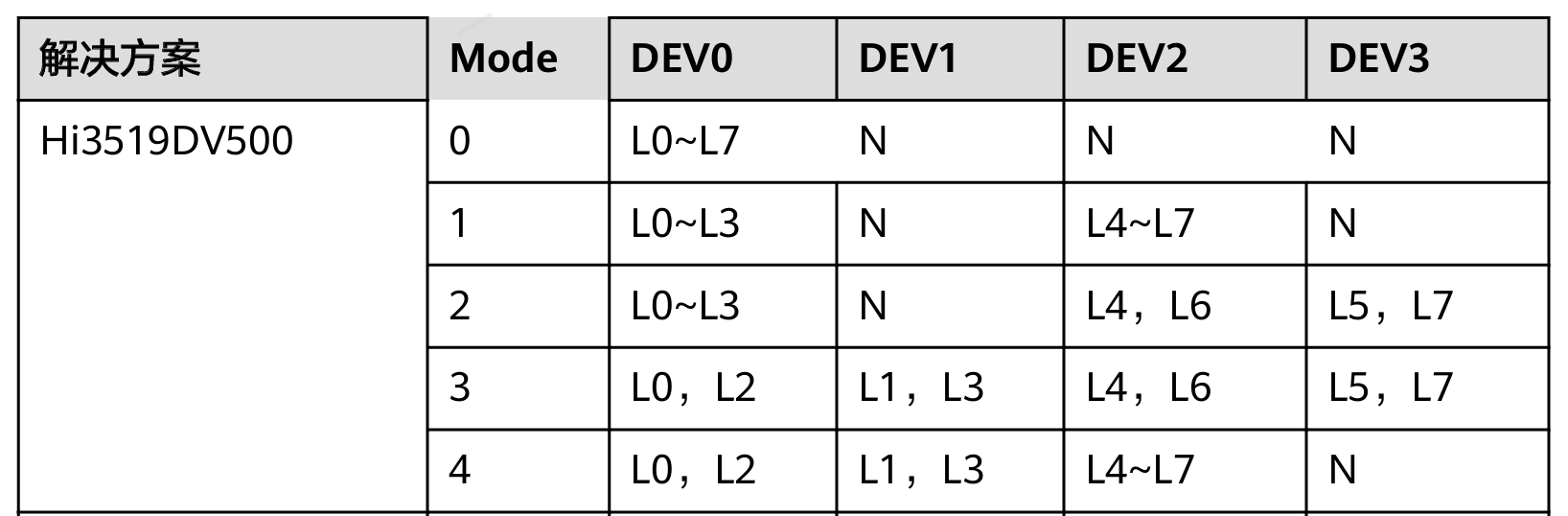
海思 35XX MIPI读取YUV422
1.项目背景: 使用海思芯片,接收FPGA发送的MIPI数据,不需要ISP处理,YUV图像格式为YUV422。 2.移植MIPI驱动 修改IMX347的驱动远吗,将I2C读写的部分注释,其他的不用再做修改。 int imx347_slave_i2c_init(ot…...

sass三大循环语法
for for 指令可以在限制的范围内重复输出格式,每次按要求(变量的值)对输出结果做出变动。这个指令包含两种格式:for $var from through ,或者 for v a r f r o m < s t a r t > t o < e n d > ÿ…...
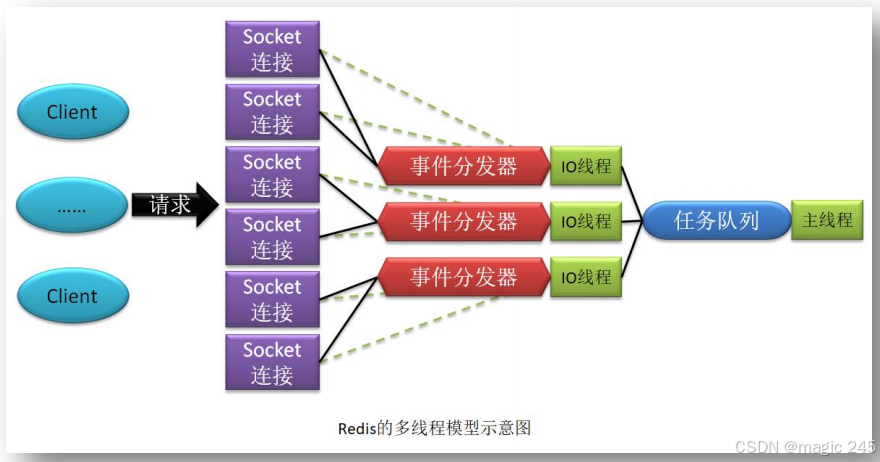
第1章 Redis 概述
一、Redis 简介 Redis,Remote Dictionary Server,远程字典服务,由意大利人Salvatore Sanfilippo(又名Antirez)开发,是一个使用ANSI C 语言编写、支持网络、 可基于内存亦可持久化的日志型、NoSQL 开源内存数据库,其提供多种语言的API。…...
硬件工程师笔记——二极管Multisim电路仿真实验汇总
目录 1 二极管基础知识 1.1 工作原理 1.2 二极管的结构 1.3 PN结的形成 1.4 二极管的工作原理详解 正向偏置 反向偏置 multisim使用说明链接 2 二极管特性实验 2.1 二极管加正向电压 2.2 二极管加反向电压 2.3 二极管两端的电阻 2.4 交流电下二级管工作 2.5 二极…...