BERT***
1.预训练(Pre-training)
是深度学习中的一种训练策略,指在大规模无标注数据上预先训练模型,使其学习通用的特征表示,再通过微调(Fine-tuning) 适配到具体任务
2.sentence-level(句子级任务)和token-level(词元级任务)
自然语言处理(NLP)中,sentence-level(句子级任务)和token-level(词元级任务)是根据任务处理的文本粒度划分的两类任务。
在自然语言处理(NLP)中,Feature-based (Elmo) 与 Fine-tuning (GPT) 是两种使用预训练语言模型的策略。它们的主要区别在于 如何将预训练模型应用到下游任务 中。
在自然语言处理(NLP)中,sentence-level(句子级任务)和token-level(词元级任务)是根据任务处理的文本粒度划分的两类任务。它们的区别主要体现在输入输出的形式和应用场景上:
1. Sentence-Level(句子级任务)
定义:以整个句子或句子对作为输入,输出是对句子整体属性的预测或分类。
特点:
- 输入是一个完整的句子(或两个句子的组合)。
- 输出是句子级别的标签或分数。
- 通常用于理解句子的语义、情感或关系。
典型任务:
- 文本分类(如情感分析、主题分类)
- 输入:
"这部电影太精彩了!" - 输出:
正面情感
- 输入:
- 自然语言推理(NLI)
- 输入:
"句子A:猫在沙发上。句子B:沙发上有一只动物。" - 输出:
蕴含(Entailment)
- 输入:
- 句子相似度
- 输入:
"句子A:天气真好。句子B:今天阳光明媚。" - 输出:
相似度0.9(0-1范围)
- 输入:
BERT中的应用:
- 使用
[CLS]标签的最终隐藏状态作为整个句子的表示,接分类器输出结果。
2. Token-Level(词元级任务)
定义:以句子中的每个词或子词(Token)为处理单元,输出对每个Token的预测或标注。
特点:
- 输入是一个句子,但需要对每个Token单独处理。
- 输出是Token级别的标签序列。
- 通常用于细粒度的语言分析。
典型任务:
- 命名实体识别(NER)
- 输入:
"马云在杭州创立了阿里巴巴。" - 输出:
[B-PER, I-PER, O, B-LOC, O, O, B-ORG]
- 输入:
- 词性标注(POS Tagging)
- 输入:
"我爱自然语言处理" - 输出:
[代词, 动词, 名词, 名词, 名词]
- 输入:
- 问答任务(QA)
- 输入:
"问题:谁写了《哈利波特》? 上下文:J.K.罗琳是《哈利波特》的作者。" - 输出:答案跨度
"J.K.罗琳"(定位起始和结束Token的位置)。
- 输入:
3.Feature-based (Elmo) 与 Fine-tuning (GPT)
Feature-based(基于特征的方法,如 ELMo)
-
核心思想:
使用预训练模型(如 ELMo)提取每个词的上下文表示作为“静态特征”,然后将这些特征作为输入提供给一个单独训练的下游模型(如 BiLSTM+CRF)。 -
过程如下:
-
用预训练好的语言模型(如 ELMo)生成文本的上下文嵌入(embeddings)。
-
将这些嵌入作为特征输入到任务特定的模型中(如文本分类器、NER模型等)。
-
只训练下游模型的参数,ELMo参数保持不变(有时可以微调,但本质上是特征提取)。
-
Fine-tuning(微调方法,如 GPT/BERT)
代表模型:GPT、BERT、T5、LLAMA 等
-
核心思想:
将整个预训练模型和下游任务模型作为一个整体进行端到端训练。 -
过程如下:
-
将下游任务的数据输入预训练模型(如 GPT/BERT)。
-
在其顶层添加一个或多个任务特定的层(如分类器)。
-
使用任务数据对整个模型进行微调,包括预训练模型本身。
-
4.BERT
1.BERT结构
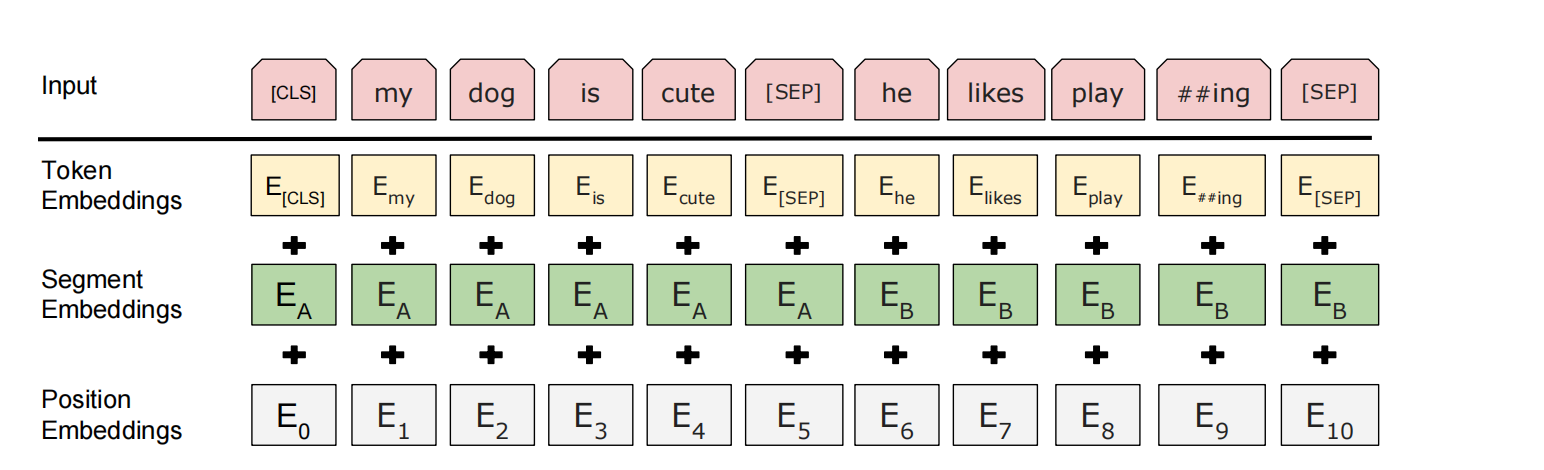
1.输入
BERT的输入由三部分嵌入(Embedding)相加组成:
-
Token Embeddings(词嵌入)
- 使用WordPiece分词(30,000词表),解决未登录词(OOV)问题。
- 特殊标记:
[CLS]:分类任务的聚合表示(位于序列开头)。[SEP]:分隔句子对(如问答中的问题和答案)。[MASK]:预训练时用于掩码语言模型(MLM)。
-
Segment Embeddings(句子嵌入)
- 区分句子A和句子B(如问答对、句对任务),用
E_A和E_B表示。
- 区分句子A和句子B(如问答对、句对任务),用
-
Position Embeddings(位置嵌入)
- 使用可学习的位置编码(而非Transformer的固定正弦/余弦函数),支持最长512个Token的序列。
2.BERT通过两个无监督任务预训练:
(1) 掩码语言模型(Masked Language Model, MLM)
- 方法:随机掩盖15%的输入Token,其中:
- 80%替换为
[MASK]。 - 10%替换为随机Token。
- 10%保持不变(缓解预训练-微调不一致)。
- 80%替换为
- 目标:基于上下文预测被掩盖的原始Token。
(2) 下一句预测(Next Sentence Prediction, NSP)
- 方法:给定句子A和B,预测B是否是A的下一句(50%正例,50%随机负例)。
- 目标:学习句子间关系,提升问答(QA)、自然语言推理(NLI)等任务性能。
2.Bert用途
语言模型(Language Model, LM) 的目标是:给定前面的词序列,预测下一个词的概率。
Transformer 本身只是一个神经网络架构,包含以下两种主要模块:
-
Encoder:用于建模整段输入(如 BERT)
-
Decoder:用于按序生成词(如 GPT)
| Transformer 结构 | 能不能用来做语言模型? |
|---|---|
| Encoder-only(如 BERT) | ❌ 不能做自回归语言模型(会信息泄露) |
| Decoder-only(如 GPT) | ✅ 可以做语言模型(逐词生成) |
| Encoder-Decoder(如 T5) | ✅ 可用于生成任务,也能做语言建模(但更常用于翻译、摘要) |
-
BERT 不是用来生成句子的(不像 GPT);
-
它做的是填空、理解,不会从左到右一步步生成;
-
BERT 的核心用途是做“理解”类任务,是为各种 NLP 下游任务提供语义理解的预训练模型。
| 应用 | 举例 | 用 BERT 怎么做 |
|---|---|---|
| 1️⃣ 文本分类 | 情感分析、垃圾邮件检测 | 将整段文本喂给 BERT,取 [CLS] 向量接全连接层做分类 |
| 2️⃣ 序列标注 | 命名实体识别(NER)、分词 | 每个词有一个表示,接一个分类器预测标签(如人名、地名) |
| 3️⃣ 句子对判断 | 语义相似度、句子关系判断 | 把两个句子拼在一起,让 BERT 判断是否相关 |
| 4️⃣ 问答系统(QA) | 给你一段文章,问“谁是美国总统” | BERT 提取答案的起止位置 |
| 5️⃣ 多轮对话理解 | 对话状态跟踪、意图识别 | 同样是对语言的“理解” |
相关文章:
BERT***
1.预训练(Pre-training) 是深度学习中的一种训练策略,指在大规模无标注数据上预先训练模型,使其学习通用的特征表示,再通过微调(Fine-tuning) 适配到具体任务 2.sentence-lev…...

超级对话2:大跨界且大综合的学问融智学应用场景述评(不同第三方的回应)之二
摘要:《人机协同文明升维行动框架》提出以HIAICI/W公式推动认知革命,构建三大落地场景:1)低成本认知增强神经接口实现300%学习效率提升;2)全球学科活动化闪电战快速转化知识体系;3)人…...

在Linux环境里面,Python调用C#写的动态库,如何实现?
在Linux环境中,Python可以通过pythonnet(CLR的Python绑定)或subprocess调用C#动态库。以下是两种方法的示例: 方法1:使用pythonnet(推荐) 前提条件 安装Mono或.NET Core运行时安装pythonnet包…...

【Linux 基础知识系列】第三篇-Linux 基本命令
在数字化浪潮席卷全球的当下,操作系统作为计算机系统的核心组件,扮演着至关重要的角色。而 Linux,凭借其卓越的性能、高度的稳定性和出色的可定制性,在服务器、嵌入式系统、超级计算机以及个人计算机等领域大放异彩,成…...
)
OpenCV CUDA模块直方图计算------生成一组均匀分布的灰度级函数evenLevels()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数主要用于为 直方图均衡化、CLAHE 等图像处理算法 生成一组等间距的灰度区间边界值(bins 或 levels),这…...
深度学习常见实验问题与实验技巧
深度学习常见实验问题与实验技巧 有一定的先后顺序的 还在迷茫深度学习中的改进实验应该从哪里开始改起的同学,一定要进来看看了!用自身经验给你推荐实验顺序! YOLOV8-硬塞注意力机制?这样做没创新!想知道注意力怎么…...

前端面试之Proxy与Reflect
🌟 一、Proxy 与 Reflect 的核心概念 1. Proxy:代理拦截器 Proxy 用于创建对象的代理,拦截并自定义对象的基本操作(如属性读写、函数调用等)。 核心组成: 目标对象(Targe…...

uniapp vue3 鸿蒙支持的 HTML5+接口
uniapp vue3 编译鸿蒙所支持的 HTML5接口 文档:https://www.html5plus.org/doc/zh_cn/runtime.html {"geolocation": {//获取当前设备位置信息"getCurrentPosition": function() {},//监听设备位置变化信息"watchPosition": functi…...
一张Billing项目的流程图
流程图 工作记录 2016-11-11 序号 工作 相关人员 1 修改Payment Posted的导出。 Claim List的页面加了导出。 Historical Job 加了Applied的显示和详细。 郝 识别引擎监控 Ps (iCDA LOG :剔除了160篇ASG_BLANK之后的结果): LOG_File 20161110.txt BLANK_CDA/ALL 45/10…...
理想树图书:以科技赋能教育,开启AI时代自主学习新范式
深耕教育沃土 构建全场景教辅产品矩阵 自2013年创立以来,理想树始终以教育匠心回应时代命题。在教辅行业这片竞争激烈的领域,由专业教育工作者组成的理想树图书始终秉持“知识互映”理念,经过十余年的精耕细作,精心打造了小学同步…...
【大模型02】Deepseek使用和prompt工程
文章目录 DeepSeekDeepseek 的创新MLA (低秩近似) MOE 混合专家混合精度框架总结DeepSeek-V3 与 DeepSeek R1 DeepSeek 私有化部署算例市场: autoDLVllM 使用Ollma复习 API 调用deepseek-r1Prompt 提示词工程Prompt 实战设置API Keycot 示例p…...

B端产品经理如何快速完成产品原型设计
B 端产品经理的原型设计需兼顾业务流程复杂度、功能逻辑性和操作效率,快速完成原型的核心在于结构化梳理需求、复用成熟组件、借助高效工具、聚焦核心场景。以下是具体方法和步骤: 一、明确需求优先级:先框架后细节 1. 梳理业务流程&#x…...
)
[Java实战]Spring Boot切面编程实现日志记录(三十六)
[Java实战]Spring Boot切面编程实现日志记录(三十六) 一、AOP日志记录核心原理 1.1 AOP技术体系 Spring AOP基于代理模式实现,关键组件: JoinPoint:程序执行点(方法调用/异常抛出)Pointcut:切点表达式(定义拦截规则)Advice:增强逻辑(前置/环绕/异常通知)Weaving:…...

Apache POI生成的pptx在office中打不开 兼容问题 wps中可以打卡问题 POI显示兼容问题
项目场景: 在java服务中使用了apache.poi后生成的pptx在wps中打开是没有问题,但在office中打开显示如下XXX内容问题,修复(R)等问题 我是用的依赖版本如下 <dependency><groupId>org.apache.poi</grou…...
大学大模型教学:基于NC数据的全球气象可视化解决方案
引言 气象数据通常以NetCDF(Network Common Data Form)格式存储,这是一种广泛应用于科学数据存储的二进制文件格式。在大学气象学及相关专业的教学中,掌握如何读取、处理和可视化NC数据是一项重要技能。本文将详细介绍基于Python的NC数据处理与可视化解决方案,包含完整的代…...
 ----- Python的数据类型及其集合操作)
Python学习(2) ----- Python的数据类型及其集合操作
在 Python 中,一切皆对象,每个对象都有类型。下面是 Python 中的常见内置类型分类和示例: 🟡 1. 数字类型(Numeric Types) 类型说明示例int整数5, -42float浮点数3.14, -0.5complex复数1 2j a 10 …...

机器学习算法-决策树
今天我们用一个 「相亲决策」 的例子来讲解决策树算法,保证你轻松理解原理和实现! 🌳 决策树是什么? 决策树就像玩 「20个问题」猜谜游戏: 你心里想一个东西(比如「苹果」) 朋友通过一系列问题…...

MediaMtx开源项目学习
这个博客主要记录MediaMtx开源项目学习记录,主要包括下载、推流(摄像头,MP4)、MediaMtx如何使用api去添加推流,最后自定义播放器,播放推流后的视频流,自定义Video播放器博客地址 1 下载 MediaMTX MediaMTX 提供了预编译的二进制文件,您可以从其 GitHub 页面下载: Gi…...
Linux安装EFK日志分析系统
目标:能够实现采集指定路径日志到es,用kibana实现日志分析 单es节点集群规划: 主机名IP 地址组件a1192.168.1.111Kibana elasticsearcha2192.168.1.112Fluentda3192.168.1.103Fluentd 1、安装Elasticsearch 1.1添加 Elastic 仓库并安装 E…...
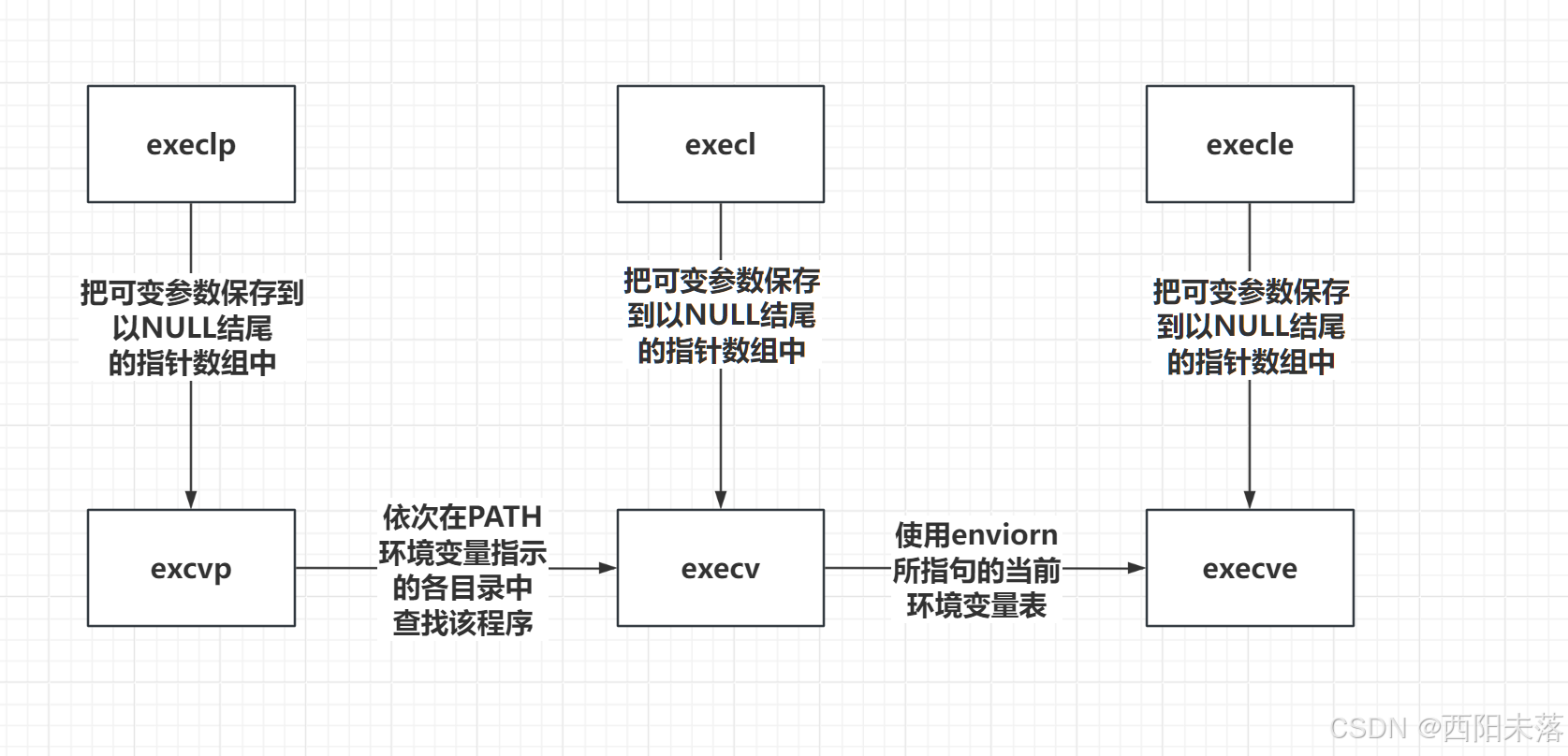
Linux(9)——进程(控制篇——下)
目录 三、进程等待 1)进程等待的必要性 2)获取子进程的status 3)进程的等待方法 wait方法 waitpid方法 多进程创建以及等待的代码模型 非阻塞的轮训检测 四、进程程序替换 1)替换原理 2)替换函数 3&…...

E. Melody 【CF1026 (Div. 2)】 (求欧拉路径之Hierholzer算法)
E. Melody 思路 将所有出现过的音量和音高看作一个点,一个声音看作一条边,连接起来。那么很容易知道要找的就是图上的一条欧拉路径(类似一笔画问题) 又已知存在欧拉路径的充要条件为:度数为奇数的点的个数为0或者2个…...

@Pushgateway 数据自动清理
文章目录 Pushgateway 数据自动清理一、Pushgateway 数据清理的必要性二、自动清理方案方案1:使用带TTL功能的Pushgateway分支版本方案2:使用Shell脚本定期清理方案3:结合Prometheus记录规则自动清理 三、最佳实践建议四、验证与维护五、示例…...

粽叶飘香时 山水有相逢
粽叶飘香时 山水有相逢 尊敬的广大客户们: 五月初五,艾叶幽香。值此端午佳节,衡益科技全体同仁向您致以最诚挚的祝福! 这一年我们如同协同竞渡的龙舟,在数字化转型的浪潮中默契配合。每一次技术对接、每轮方案优化&a…...
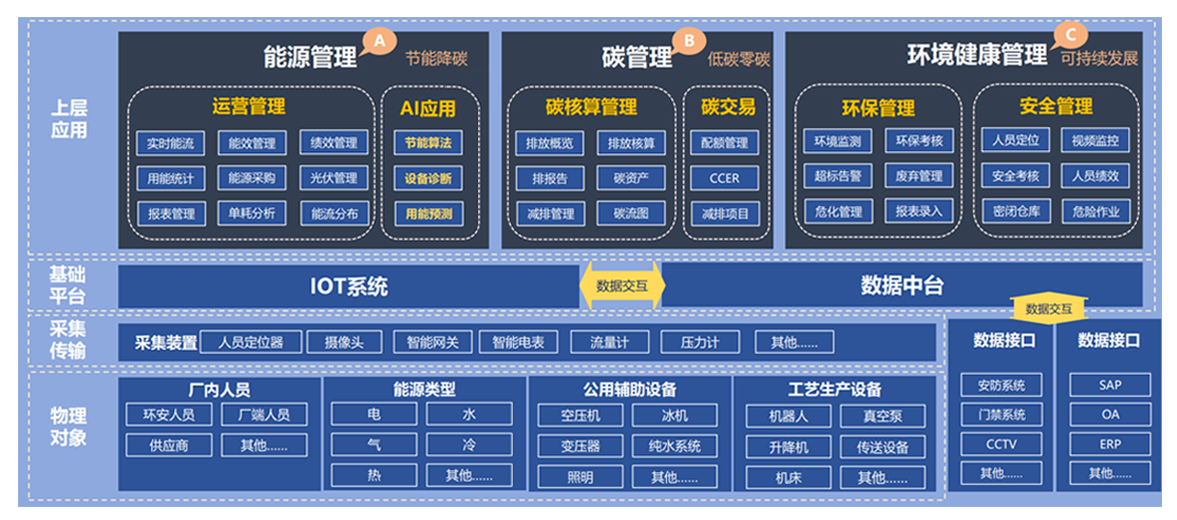
YC-8002型综合变配电监控自动化系统
一 .系统概述 YC-8002型综合变配电监控自动化系统是西安亚川电力科技有限公司为适应广大客户要求,总结多项低 压配电网络自动化工程实例的经验,基于先进的电子技术、计算机和网络通讯等技术自主研发的--套结合本公司网络配电产品的应用于低压配电领域的…...
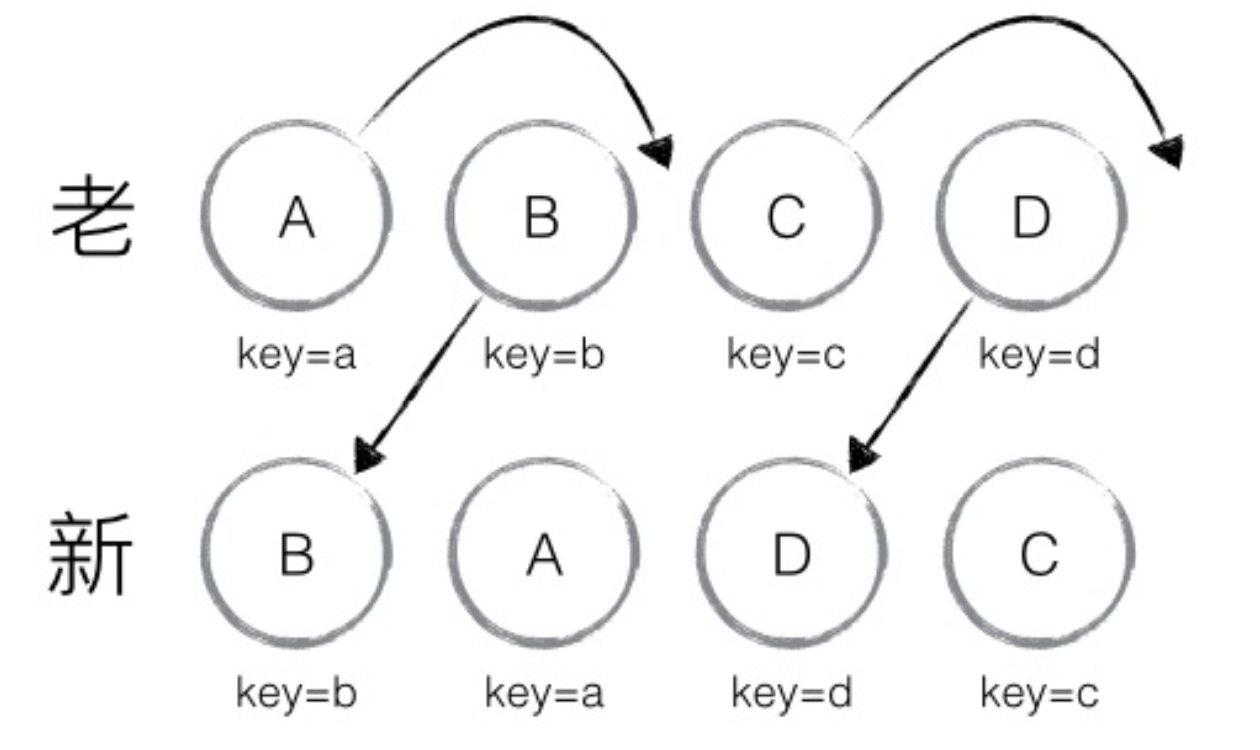
react diff 算法
diff 算法作为 Virtual DOM 的加速器,其算法的改进优化是 React 整个界面渲染的基础和性能的保障,同时也是 React 源码中最神秘的,最不可思议的部分 diff 算法会帮助我们就算出 VirtualDOM 中真正变化的部分,并只针对该部分进行原…...
近期手上的一个基于Function Grap(类AWS的Lambda)小项目的改造引发的思考
函数式Function是云计算里最近几年流行起来的新的架构和模式,因为它不依赖云主机,非常轻量,按需使用,甚至是免费使用,特别适合哪种数据同步,数据转发,本身不需要保存数据的业务场景,…...

Obsidian 社区插件下载修复
Obsidian 社区插件下载修复 因为某些原因,在国内经常无法下载 Obsidian 的社区插件。这个项目的主要目的就是修复这种情况,让国内的用户也可以无障碍的下载社区插件。 上手指南 下载 obsidian-proxy-github.zip解压 obsidian-proxy-github.zip将解压的…...

VSCode的下载与安装(2025亲测有效)
目录 0 前言1 下载2 安装3 后记 0 前言 丫的,谁懂啊,尝试了各种办法不行的话,我就不得不拿出我的最后绝招了,卸载,重新安装,我经常要重新安装,所以自己写了一个博客,给自己…...
千库/六图素材下载工具
—————【下 载 地 址】——————— 【本章下载一】:https://pan.xunlei.com/s/VORW9TbxC9Lmz8gCynFrgdBzA1?pwdxiut# 【本章下载二】:https://pan.quark.cn/s/829e2a4085d3 【百款黑科技】:https://ucnygalh6wle.feishu.cn/wiki/…...

Ansible模块——Ansible的安装!
Ansible 安装 Ansible 有三种安装方式,源码安装、发行版安装和 Python 安装。 使用发行版安装或 Python 安装两种方式时,Ansible 的安装包有两个,区别如下: • ansible-core:一种极简语言和运行时包,包含…...