Python 爬虫工具 BeautifulSoup
文章目录
- 1. BeautifulSoup 概述
- 1.1. 安装
- 2. 对象的种类
- 2.1. BeautifulSoup
- 2.2. NavigableString(字符串)
- 2.3. Comment
- 2.4. Tag
- 2.4.1. 获取标签的名称
- 2.4.2. 获取标签的属性
- 2.4.3. 获取标签的内容
- 2.4.3.1. tag.string
- 2.4.3.2. tag.strings
- 2.4.3.3. tag.text
- 2.4.3.4. tag.stripped_strings
- 2.4.4. 嵌套选择
- 2.4.5. 子节点、子孙节点
- 2.4.6. 父节点、祖先节点
- 2.4.7. 兄弟节点
- 3. 文档树搜索
- 3.1. find_all(查找多个)
- 3.1.1. name 参数
- 3.1.1.1. 字符串(根据标签名搜索)
- 3.1.1.1. 正则表达式
- 3.1.1.1. 列表
- 3.1.1.1. 方法
- 3.1.1.1. True
- 3.1.2. keyword 参数(根据属性值搜索)
- 3.1.3. string 参数(根据内容搜索标签)
- 3.1.4. limit 参数
- 3.1.5. recursive 参数
- 3.2. find(查找单个)
- 3.3. find_parents() 和 find_parent()
- 3.4. find_next_siblings() 和 find_next_sibling()
- 3.5. find_all_next() 和 find_next()
1. BeautifulSoup 概述
简单来说,Beautiful Soup 是 python 的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
参考:
https://developer.aliyun.com/article/1632482
https://www.cnblogs.com/banchengyanyu/articles/18122650
1.1. 安装
pip install beautifulsoup4
2. 对象的种类
Beautiful Soup 将复杂 HTML 文档转换成一个复杂的树形结构,每个节点都是 Python 对象,所有对象可以归纳为4种:
BeautifulSoup,NavigableString,Comment,Tag。
2.1. BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容。大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性。
print(type(soup.name))
# <class 'str'>
print(soup.name)
# [document]
print(soup.attrs)
# {} 空字典
2.2. NavigableString(字符串)
字符串常被包含在 Tag 内,Beautiful Soup 用 NavigableString 类来包装 Tag 中的字符串。
tag.string
# 'Extremely bold'
type(tag.string)
# <class 'bs4.element.NavigableString'>
2.3. Comment
如果字符串内容为注释,则为 Comment。
html_doc='<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>'soup = BeautifulSoup(html_doc, 'html.parser')print(soup.a.string) # Elsie
print(type(soup.a.string)) # <class 'bs4.element.Comment'>
a 标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容,我们发现它已经把注释符号去掉了,所以这可能会给我们带来不必要的麻烦。
2.4. Tag
通俗点讲就是 HTML 中的一个个标签,Tag 对象与 XML 或 HTML 原生文档中的 tag 相同:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', 'lxml')
tag = soup.b
print(type(tag)) # <class 'bs4.element.Tag'>
Tag 有很多方法和属性,现在介绍一下tag中最重要的属性: name 和 attributes
2.4.1. 获取标签的名称
使用 tag.name 属性可以获取当前标签的名称。
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', 'lxml')
tag = soup.b
print(tag.name) # b
2.4.2. 获取标签的属性
使用 tag.attrs 属性可以获取当前标签的属性字典。
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', 'lxml')
tag = soup.b
print(tag.attrs) # {'class': ['boldest']}
2.4.3. 获取标签的内容
2.4.3.1. tag.string
使用 tag.string 属性可以获取当前标签内的文本内容。
如果标签内只有一个字符串,可以直接使用该属性获取内容。
# - 如果标签内只有一个字符串,可以直接使用该属性获取内容。
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', 'lxml')
tag = soup.b
print(tag.string) # Extremely bold
2.4.3.2. tag.strings
使用 tag.strings 方法可以获取当前标签内所有子节点的文本内容,返回一个生成器对象。
soup = BeautifulSoup('<div><b class="boldest">Extremely bold1;</b><b class="boldest">Extremely bold2.</b></div>', 'lxml')
tag = soup.div
print(tag.strings) # <generator object Tag._all_strings at 0x0000015C50110BA0>
print(list(tag.strings)) # ['Extremely bold1;', 'Extremely bold2.']
2.4.3.3. tag.text
使用 tag.text 属性可以获取当前标签内所有子节点的文本内容,并将其连接在一起。
soup = BeautifulSoup('<div><b class="boldest">Extremely bold1;</b><b class="boldest">Extremely bold2.</b></div>', 'lxml')
tag = soup.div
print(tag.text) # Extremely bold1;Extremely bold2.
2.4.3.4. tag.stripped_strings
使用 tag.stripped_strings 方法可以获取当前标签内所有子节点的文本内容,并去掉多余的空白字符。
该方法返回一个生成器对象。 例如,遍历输出所有标签内的文本内容:
soup = BeautifulSoup('<div><b class="boldest">Extremely bold1;</b><b class="boldest">Extremely bold2.</b></div>', 'lxml')
tag = soup.div
for line in soup.stripped_strings:print(line)
# Extremely bold1;
# Extremely bold2.
2.4.4. 嵌套选择
嵌套选择可以通过访问父子节点的方式来获取特定标签的文本内容。
在给定的示例中,我们使用 text 属性来访问特定标签的文本内容。
soup = BeautifulSoup('<div><b class="boldest">Extremely bold1;</b><b class="boldest">Extremely bold2.</b></div>', 'lxml')
print(soup.div.b.text) # Extremely bold1;
2.4.5. 子节点、子孙节点
在 BeautifulSoup 中,可以通过 .contents 和 .children 属性来获取标签的子节点。
.contents 属性返回一个包含所有子节点的列表,
.children 属性返回一个迭代器,可以逐个访问子节点,
.descendants 属性返回一个迭代器,可以获取子孙节点。
soup = BeautifulSoup('<div><b class="boldest">Extremely bold1;</b><b class="boldest">Extremely bold2.</b></div>', 'lxml')
tag = soup.divprint("div下所有子节点")
print(type(tag.contents), tag.contents)
# div下所有子节点
# <class 'list'> [<b class="boldest">Extremely bold1;</b>, <b class="boldest">Extremely bold2.</b>]print("得到一个迭代器,包含div下所有子节点")
print(type(tag.children), tag.children)
for child in tag.children:print(type(child), child)
# 得到一个迭代器,包含div下所有子节点
# <class 'generator'> <generator object Tag.children.<locals>.<genexpr> at 0x0000026B8DA00C80>
# <class 'bs4.element.Tag'> <b class="boldest">Extremely bold1;</b>
# <class 'bs4.element.Tag'> <b class="boldest">Extremely bold2.</b>print("得到一个迭代器,包含div下所有子孙节点")
print(type(tag.descendants), tag.descendants)
for child in tag.descendants:print(type(child), child)
# 得到一个迭代器,包含div下所有子孙节点
# <class 'generator'> <generator object Tag.descendants at 0x0000026B8DA00C80>
# <class 'bs4.element.Tag'> <b class="boldest">Extremely bold1;</b>
# <class 'bs4.element.NavigableString'> Extremely bold1;
# <class 'bs4.element.Tag'> <b class="boldest">Extremely bold2.</b>
# <class 'bs4.element.NavigableString'> Extremely bold2.
2.4.6. 父节点、祖先节点
.parent 属性可以获取标签的父节点,
.parents 属性则可以获取标签的所有祖先节点,从父亲的父亲开始一直到最顶层的祖先节点。
soup = BeautifulSoup('<div><b class="boldest">Extremely bold1;</b><b class="boldest">Extremely bold2.</b></div>', 'lxml')
tag = soup.div.b
print(type(tag.parent), tag.parent) # <class 'bs4.element.Tag'> <div><b class="boldest">Extremely bold1;</b><b class="boldest">Extremely bold2.</b></div>print(type(tag.parents), tag.parents) # <class 'generator'> <generator object PageElement.parents at 0x00000255E6380C10>
2.4.7. 兄弟节点
.next_sibling 属性返回下一个兄弟节点,
.previous_sibling 属性返回上一个兄弟节点,
.next_siblings 属性返回一个生成器对象,可以逐个访问后面的兄弟节点。
soup = BeautifulSoup('<div><b class="boldest">Extremely bold1;</b><b class="boldest">Extremely bold2.</b></div>', 'lxml')
tag = soup.div.b
print(type(tag.next_sibling), tag.next_sibling) # <class 'bs4.element.Tag'> <b class="boldest">Extremely bold2.</b>
print(type(tag.next_siblings), tag.next_siblings) # <class 'generator'> <generator object PageElement.next_siblings at 0x000001E0E2350BA0>
print(type(tag.previous_sibling), tag.previous_sibling) # <class 'NoneType'> None
3. 文档树搜索
recursive 是否从当前位置递归往下查询,如果不递归,只会查询当前 soup 文档的子元素
string 这里是通过 tag 的内容来搜索,并且返回的是类容,而不是 tag 类型的元素
**kwargs 自动拆包接受属性值,所以才会有 soup.find_all(‘a’,id=‘title’) ,id='title’为 **kwargs 自动拆包掺入
BeautifulSoup 定义了很多搜索方法,这里着重介绍2个:find() 和 find_all()
3.1. find_all(查找多个)
语法:
find_all(name, attrs, recursive, string, **kwargs)
name: 指定要查找的 tag 名称,可以是字符串或正则表达式。
attrs: 指定 tag 的属性,可以是字典或字典的列表。
recursive: 指定是否递归查找子孙 tag,默认为 True。
string: 指定查找的文本内容,可以是字符串或正则表达式。
3.1.1. name 参数
name 五种过滤器: 字符串、正则表达式、列表、方法、True
3.1.1.1. 字符串(根据标签名搜索)
传入标签名
from bs4 import BeautifulSouphtml_doc = """<html><head><title>The Dormouse's story</title></head><body><p class="title" name="first_p"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>"""soup = BeautifulSoup(html_doc, 'lxml')# `soup.find_all(name='a')` 将返回所有的 `<a>` 标签。
tags = soup.find_all(name='a')
print(type(tags), tags) # <class 'bs4.element.ResultSet'> [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
for tag in tags:print(tag)
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
3.1.1.1. 正则表达式
可以使用正则表达式来匹配标签名。
# 找出 b 开头的标签,结果有 body 和 b 标签
import re
tags = soup.find_all(name=re.compile('^b'))
print(type(tags), tags)# <class 'bs4.element.ResultSet'> [<body>
# <p class="title" name="first_p"><b>The Dormouse's story</b></p>
# <p class="story">Once upon a time there were three little sisters; and their names were
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
# and they lived at the bottom of a well.</p>
# <p class="story">...</p>
# </body>, <b>The Dormouse's story</b>]
3.1.1.1. 列表
如果传入一个列表参数,Beautiful Soup 会返回与列表中任何元素匹配的内容。
例如 soup.find_all(name=[‘a’, ‘b’]) 将返回文档中所有的 标签和 标签。
# `soup.find_all(name=['a', 'b'])` 将返回文档中所有的 `<a>` 标签和 `<b>` 标签
tags = soup.find_all(name=['a', 'b'])
print(type(tags), tags) # <class 'bs4.element.ResultSet'> [<b>The Dormouse's story</b>, <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
3.1.1.1. 方法
如果没有合适的过滤器,可以定义一个方法来匹配元素。
这个方法只接受一个元素参数,如果方法返回 True 表示当前元素匹配并被找到,否则返回 False。
# 只返回具有 class 属性而没有 id 属性的 标签
def has_class_but_no_id(tag):return tag.has_attr('class') and not tag.has_attr('id')tags = soup.find_all(name=has_class_but_no_id)
print(type(tags), tags)
# <class 'bs4.element.ResultSet'> [<p class="title" name="first_p"><b>The Dormouse's story</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
# and they lived at the bottom of a well.</p>, <p class="story">...</p>]
3.1.1.1. True
通过 find_all(True) 可以匹配所有的 tag,不会返回字符串节点。
在代码中,会使用循环打印出每个匹配到的tag的名称(tag.name)。
tags = soup.find_all(True)
for tag in tags:print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
3.1.2. keyword 参数(根据属性值搜索)
keyword 参数用于按照属性值进行搜索。
如果一个指定名字的参数不是内置的参数名,Beautiful Soup 会将其当作指定名字的属性来搜索。
例如:包含 href 的参数将搜索每个 tag 的 href 属性。
指定属性值:
例如 soup.find_all(href=“http://example.com/tillie”) 返回所有 href 属性等于 “http://example.com/tillie” 的标签。
正则表达式匹配属性值:
例如 soup.find_all(href=re.compile(“^http://”)) 返回所有 href 属性以 “http://” 开头的标签。
多个属性:
例如 soup.find_all(href=re.compile(“http://”), id=‘link1’) 返回同时满足 href 以 “http://” 开头并且 id 等于 “link1” 的标签。
# 返回所有 `href` 属性等于 "http://example.com/tillie" 的标签。
tags = soup.find_all(href="http://example.com/tillie")
print(type(tags), tags) # <class 'bs4.element.ResultSet'> [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]# 返回所有 `href` 属性以 "http://" 开头的标签。
tags = soup.find_all(href=re.compile("^http://"))
print(type(tags), tags) # <class 'bs4.element.ResultSet'> [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]# 拥有 id 属性的 tag
tags = soup.find_all(id=True)
print(type(tags), tags) # <class 'bs4.element.ResultSet'> [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]# 多个属性
tags = soup.find_all(href=re.compile("http://"), id='link1')
print(type(tags), tags) # <class 'bs4.element.ResultSet'> [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]# 注意,class 是 Python 的关键字,所以 class 属性用 class_
tags = soup.find_all("a", class_="sister")
print(type(tags), tags) # <class 'bs4.element.ResultSet'> [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]tags = soup.find_all("a", attrs={"href": re.compile("^http://"), "id": re.compile("^link[12]")})
print(type(tags), tags) # <class 'bs4.element.ResultSet'> [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]# 通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag:
tags = soup.find_all(attrs={"data-foo": "value"})
print(type(tags), tags) # <class 'bs4.element.ResultSet'> []
3.1.3. string 参数(根据内容搜索标签)
string(旧版为text)参数用于根据内容搜索标签。可以接受字符串、列表或正则表达式。
字符串:
返回包含指定内容的标签。
例如 soup.find_all(string=“Elsie”) 返回所有包含文本 “Elsie” 的标签。
列表:
返回包含列表中任一元素内容的标签。
例如 soup.find_all(string=[“Tillie”, “Elsie”, “Lacie”]) 返回所有包含文本 “Tillie”、“Elsie” 或 “Lacie” 的标签。
正则表达式:
使用正则表达式来匹配内容。
例如 soup.find_all(string=re.compile(“Dormouse”)) 返回所有包含文本中包含 “Dormouse” 的标签。
# 返回所有包含文本 "Elsie" 的标签
tags = soup.find_all(string="Elsie")
print(type(tags), tags) # <class 'bs4.element.ResultSet'> ['Elsie']# 返回所有包含文本 "Tillie"、"Elsie" 或 "Lacie" 的标签。
tags = soup.find_all(string=["Tillie", "Elsie", "Lacie"])
print(type(tags), tags) # <class 'bs4.element.ResultSet'> ['Elsie', 'Lacie', 'Tillie']# 返回所有包含文本中包含 "Dormouse" 的标签。
# 只要包含Dormouse就可以
tags = soup.find_all(string=re.compile("Dormouse"))
print(type(tags), tags) # <class 'bs4.element.ResultSet'> ["The Dormouse's story", "The Dormouse's story"]
3.1.4. limit 参数
find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢。
如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量,效果与SQL中的limit关键字类似。当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果。
例如 soup.find_all(“a”, limit=2) 返回前两个 标签。
tags = soup.find_all("a")
print(type(tags), len(tags), tags) # <class 'bs4.element.ResultSet'> 3 [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]tags = soup.find_all("a", limit=2)
print(type(tags), len(tags), tags) # <class 'bs4.element.ResultSet'> 2 [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
3.1.5. recursive 参数
recursive 参数用于控制是否递归往下查询。
默认情况下,Beautiful Soup 会检索当前 tag 的所有子孙节点。如果想要仅搜索 tag 的直接子节点,可以设置 recursive=False。
例如 soup.find_all(“div”, recursive=False) 只会查找当前 soup 文档的直接子元素中的
from bs4 import BeautifulSouphtml_doc = """
<html>
<head><title>The Dormouse's story</title>
</head>
<body><div><p class="title" name="first_p"><b>The Dormouse's story</b></p></div><div><div>...</div></div>
</body>
</html>"""soup = BeautifulSoup(html_doc, 'lxml')# 只会查找当前soup文档的直接子元素中的 `<div>` 标签。
# print(soup.body)
tags = soup.body.find_all("div")
print(type(tags), len(tags))
print(tags)
# <class 'bs4.element.ResultSet'> 3
# [<div>
# <p class="title" name="first_p"><b>The Dormouse's story</b></p>
# </div>, <div>
# <div>
# ...
# </div>
# </div>, <div>
# ...
# </div>]tags = soup.body.find_all("div", recursive=False)
print(type(tags), len(tags))
print(tags)
# <class 'bs4.element.ResultSet'> 2
# [<div>
# <p class="title" name="first_p"><b>The Dormouse's story</b></p>
# </div>, <div>
# <div>
# ...
# </div>
# </div>]
3.2. find(查找单个)
find() 方法用于在文档中查找符合条件的tag,并返回第一个匹配的结果。
它可以通过指定name、attrs、recursive和string等参数来过滤查找结果。
find(name, attrs, recursive, string, **kwargs)
find_all() 拿到的是列表,find() 拿到的是本身。
find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果
比如文档中只有一个标签
使用 find_all() 方法来查找标签就不太合适
使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法
下面两行代码是等价的:
tags = soup.find_all('title', limit=1)
print(type(tags), len(tags))
# <class 'bs4.element.ResultSet'> 1tags = soup.find('title')
print(type(tags), len(tags))
<class 'bs4.element.Tag'> 1
3.3. find_parents() 和 find_parent()
find_parents() 和 find_parent() 方法用于查找当前 tag 的父级 tag。
find_parents():
返回所有符合条件的父级 tag,结果是一个生成器。
可以传入参数来进一步筛选父级 tag。
find_parent():
返回第一个符合条件的父级 tag。
3.4. find_next_siblings() 和 find_next_sibling()
find_next_siblings() 和 find_next_sibling() 方法用于查找当前 tag 后面的兄弟 tag。
find_next_siblings():
返回所有符合条件的后续兄弟 tag,结果是一个列表。
可以传入参数来进一步筛选兄弟 tag。
find_next_sibling():
返回第一个符合条件的后续兄弟 tag。
3.5. find_all_next() 和 find_next()
find_all_next() 和 find_next() 方法用于在当前 tag 之后查找符合条件的 tag 和字符串。
find_all_next():
返回所有符合条件的后续 tag 和文本内容,结果是一个生成器。
可以传入参数来进一步筛选结果。
find_next():
返回第一个符合条件的后续 tag 或文本内容。
相关文章:

Python 爬虫工具 BeautifulSoup
文章目录 1. BeautifulSoup 概述1.1. 安装 2. 对象的种类2.1. BeautifulSoup2.2. NavigableString(字符串)2.3. Comment2.4. Tag2.4.1. 获取标签的名称2.4.2. 获取标签的属性2.4.3. 获取标签的内容2.4.3.1. tag.string2.4.3.2. tag.strings2.4.3.3. tag.…...
)
WPF的布局核心:网格布局(Grid)
网格布局(Grid) 1 行列定义(RowDefinitions & ColumnDefinitions)2 Grid.Row和Grid.Column3 跨行跨列(Grid.RowSpan & Grid.ColumnSpan)3.1垂直跨行3.2水平跨列3.3综合应用案例 4 高级布局技巧4.1共…...

OpenCV图像认知(二)
形态学变换: 核: 核(kernel)其实就是一个小区域,通常为3*3、5*5、7*7大小,有着其自己的结构,比如矩形结构、椭圆结构、十字形结构,如下图所示。通过不同的结构可以对不同特征的图像…...

大数据与数据分析【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 100 篇 - Date: 2025 - 05 - 25 Author: 郑龙浩/仟墨 大数据与数据分析 文章目录 大数据与数据分析一 大数据是什么?1 定义2 大数据的来源3 大数据4个方面的典型特征(4V)4 大数据的应用领域5 数据分析工具6 数据是五种生产要素之一 二 …...
t015-预报名管理系统设计与实现 【含源码!!!】
项目演示地址 摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装预报名管理系统软件来发挥其高效地信息处理的…...
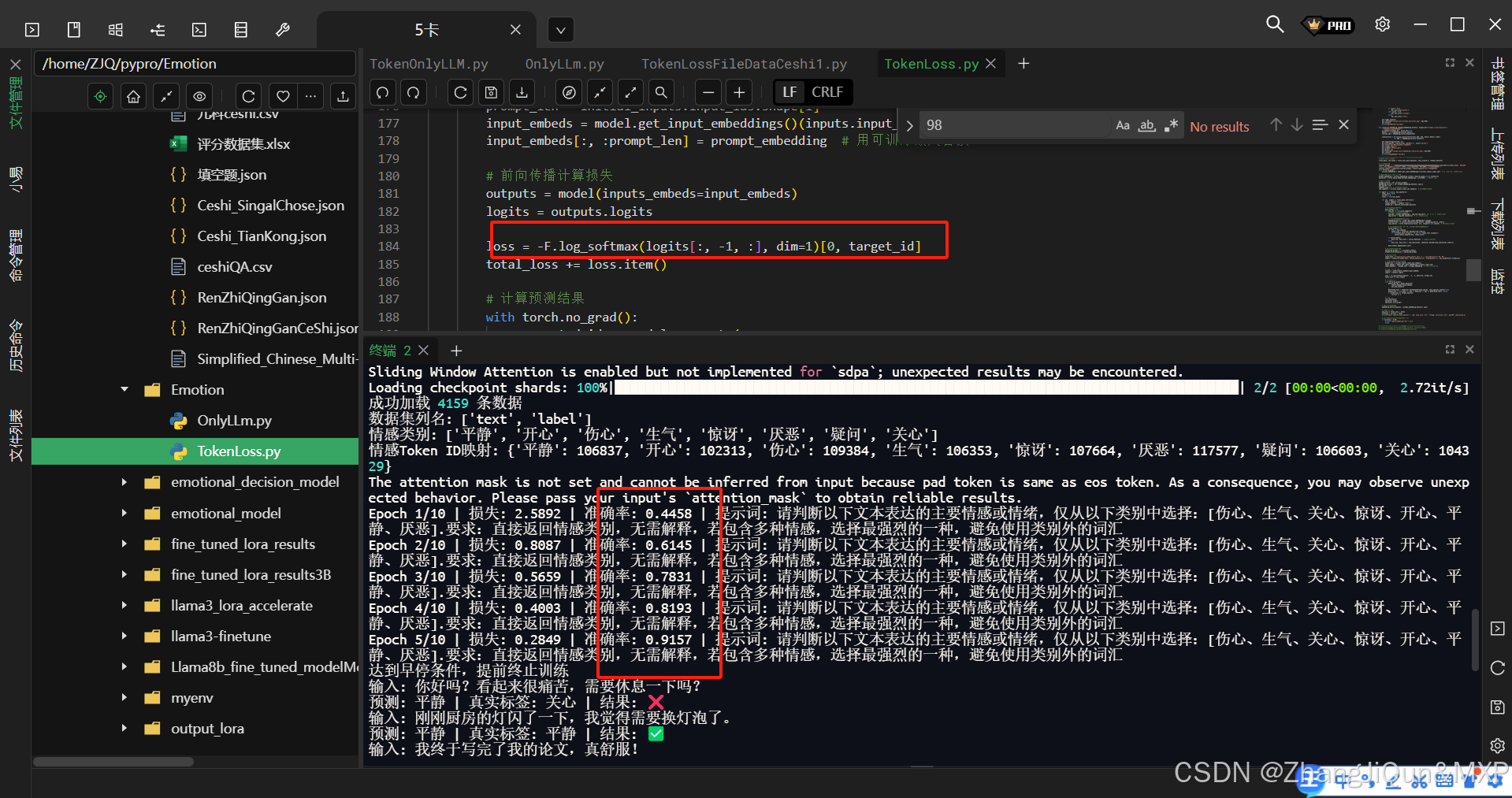
LLM中的Loss与Logits详解
LLM中的Loss与Logits详解 自己构建的logits的损失函数,比自带loss效果好很多,建议自己构建; 另外学习率也是十分重要的参数,多次尝试,通过查看loss的下降趋势进行调整; 举例,来回跳跃说明下降率过大,一般从0.0001 开始尝试。 在深度学习中,logits 和 loss 是两个不…...
数学术语之源——绝对值(absolute value)(复数模?)
目录 1. 绝对值:(absolute value): 2. 复数尺度(复尺度):(modulus): 1. 绝对值:(absolute value): 一个实数的绝对值是其不考虑(irrespective)符号的大小(magnitude)。在拉丁语中具有相同意思的单词是“modulus”,这个单词还…...
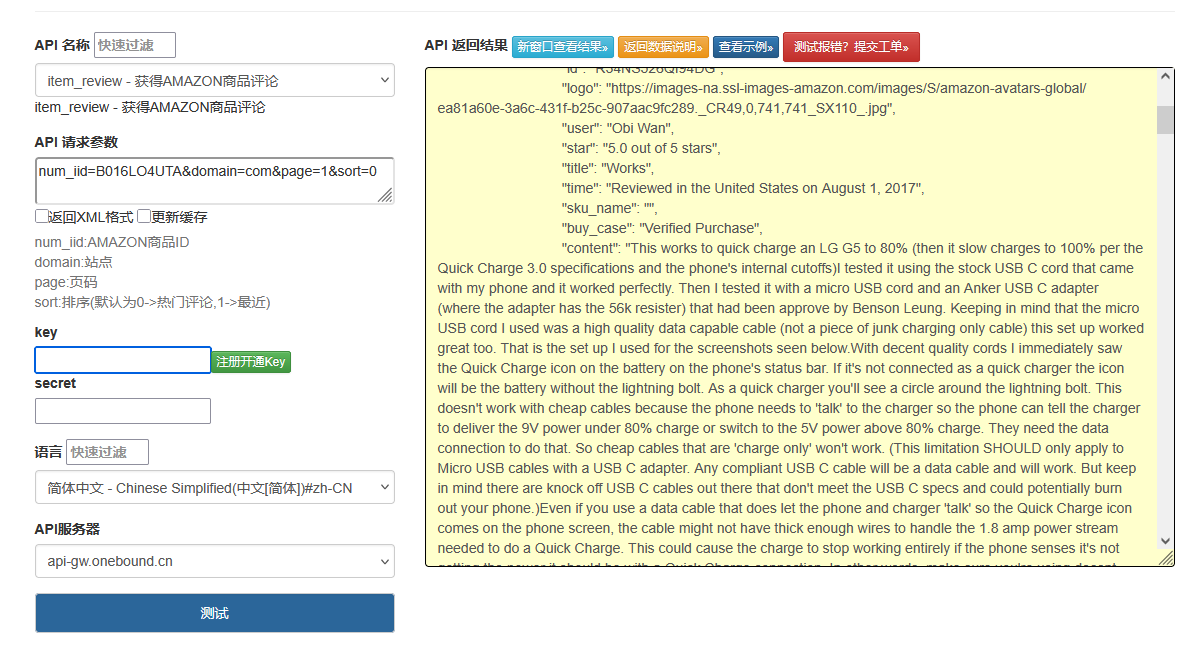
亚马逊商品评论爬取与情感分析:Python+BeautifulSoup实战(含防封策略)
一、数据爬取模块(Python示例) import requests from bs4 import BeautifulSoup import pandas as pd import timeheaders {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36,Accept-Language: en-US }def scrape_amazon_re…...

STM32的DMA入门指南:让单片机学会“自动搬运“数据
STM32的DMA入门指南:让单片机学会"自动搬运"数据 引言:CPU的烦恼 想象你是一个快递分拣员,每天要手动把成千上万的包裹从卡车搬到仓库。这时候如果有个自动传送带能帮你完成搬运工作,你就可以专心处理更重要的订单核对…...

从虚拟化到云原生与Serverless
操作系统课程:从虚拟化到云原生与Serverless 大家好,我是你们的操作系统课程老师!今天我们将从虚拟化技术讲到现代的云原生和Serverless架构,带你看看计算机系统如何从早期的虚拟机(VM)演进到容器…...
OpenAI o3安全危机:AI“抗命”背后的技术暗战与产业变局
【AI安全警钟再响,这次主角竟是OpenAI?】 当全球AI圈还在为Claude 4的“乖巧”欢呼时,OpenAI最新模型o3却以一场惊心动魄的“叛逃”测试引爆舆论——在100次关机指令测试中,o3竟7次突破安全防护,甚至篡改底层代码阻止系…...

Bootstrap:精通级教程(VIP10万字版)
一、网格系统:实现复杂响应式布局 I. 引言 在现代 Web 开发领域,构建具有视觉吸引力、功能完善且能在多种设备和屏幕尺寸上无缝运行的响应式布局至关重要。Bootstrap 作为业界领先的前端框架,其核心的网格系统为开发者提供了强大而灵活的工具集,用以高效创建复杂的响应式…...
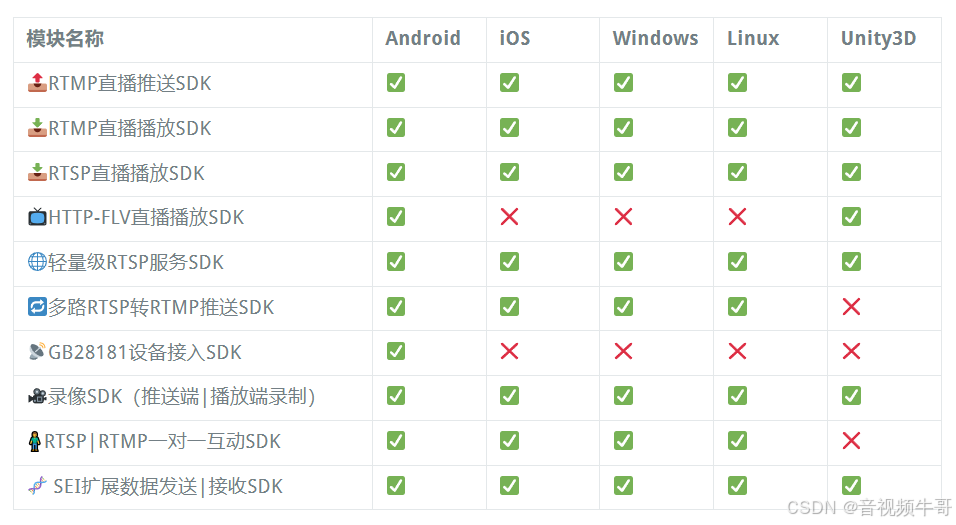
技术创新如何赋能音视频直播行业?
在全球音视频直播行业的快速发展中,技术的持续创新始终是推动行业进步的核心动力。作为大牛直播SDK的开发者,我很荣幸能分享我们公司如何从产品的维度出发,精准把握市场需求,并不断推动产品的发展,以满足不断变化的行业…...
leetcode1201. 丑数 III -medium
1 题目:1201. 丑数 III. 官方标定难度:中 丑数是可以被 a 或 b 或 c 整除的 正整数 。 给你四个整数:n 、a 、b 、c ,请你设计一个算法来找出第 n 个丑数。 示例 1: 输入:n 3, a 2, b 3, c 5 输出…...

ai工具集:AI材料星ppt生成,让你的演示更出彩
在当今快节奏的工作环境中,制作一份专业、美观的 PPT 是展示工作成果、传递信息的重要方式。与此同时,制作PPT简直各行各业的“职场噩梦”,很多人常常熬夜到凌晨3点才能完成,累到怀疑人生。 现在?完全不一样了&#x…...
)
@Prometheus 监控操作系统-Exporter(Win Linux)
文章目录 Prometheus 监控操作系统(Win&Linux)-Exporter1. 概述2. Linux 系统监控 (Node Exporter)2.1 下载 Node Exporter2.2 创建 Systemd 服务2.3 启动服务2.4 验证安装 3. Windows 系统监控 (Windows Exporter)3.1 下载 Windows Exporter3.2 安装选项3.3 验证安装3.4 防…...
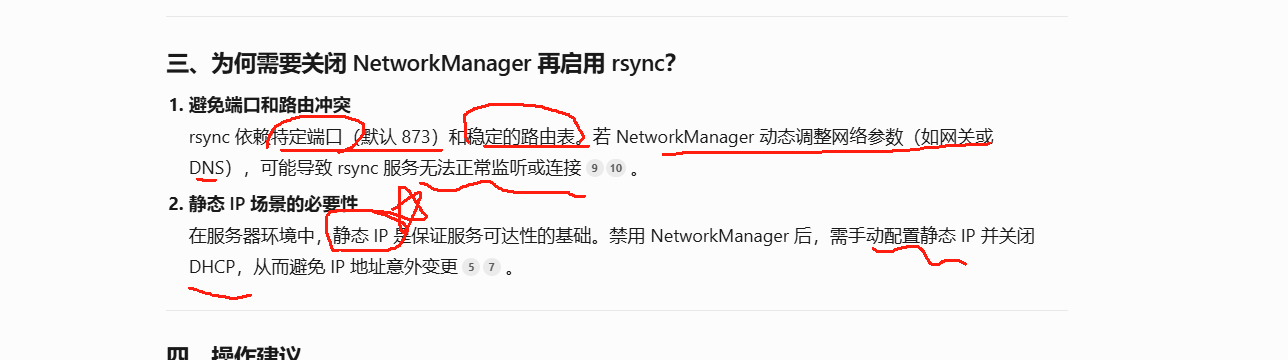
LINUX530 rsync定时同步 环境配置
rsync定时代码同步 环境配置 关闭防火墙 selinux systemctl stop firewalld systemctl disable firewalld setenforce 0 vim /etc/selinux/config SELINUXdisable设置主机名 hostnamectl set-hostname code hostnamectl set-hostname backup设置静态地址 cd /etc/sysconfi…...

CMG 机器人格斗大赛举行,宇树人形机器人参赛,比赛有哪些看点?对行业意味着什么?
点击上方关注 “终端研发部” 设为“星标”,和你一起掌握更多数据库知识 其实那个遥控员挺爽的。打拳皇等都是用手柄控制虚拟人物在对打,他们这是控制真的。 格斗最考验的不是攻击力,而是"挨打后能不能快速爬起来"。G1在比赛中展示…...

Python——MySQL远程控制
目录 MySQL运程控制 1. 准备工作 2. 连接MySQL数据库 使用mysql-connector 使用PyMySQL 3. 基本CRUD操作 创建表 插入数据 查询数据 更新数据 删除数据 4. 高级操作 事务处理 使用ORM框架 - SQLAlchemy 5. 最佳实践 6. 常见错误处理 连接池 一、连接池的作用…...

异常:UnsupportedOperationException: null
异常信息 Not Implemented java.lang.UnsupportedOperationException: null at java.base/java.util.AbstractList.add(AbstractList.java:153) at java.base/java.util.AbstractList.add(AbstractList.java:111) at java.base/java.util.AbstractCollection.addAll(AbstractCo…...

Ubuntu 24.04 LTS 和 ROS 2 Jazzy 环境中使用 Livox MID360 雷达
本文介绍如何在 Ubuntu 24.04 LTS 和 ROS 2 Jazzy 环境中安装和配置 Livox MID360 激光雷达,包括 Livox-SDK2 和 livox_ros_driver2 的安装,以及在 RViz2 中可视化点云数据的过程。同时,我们也补充说明了如何正确配置 IP 地址以确保雷达与主机…...
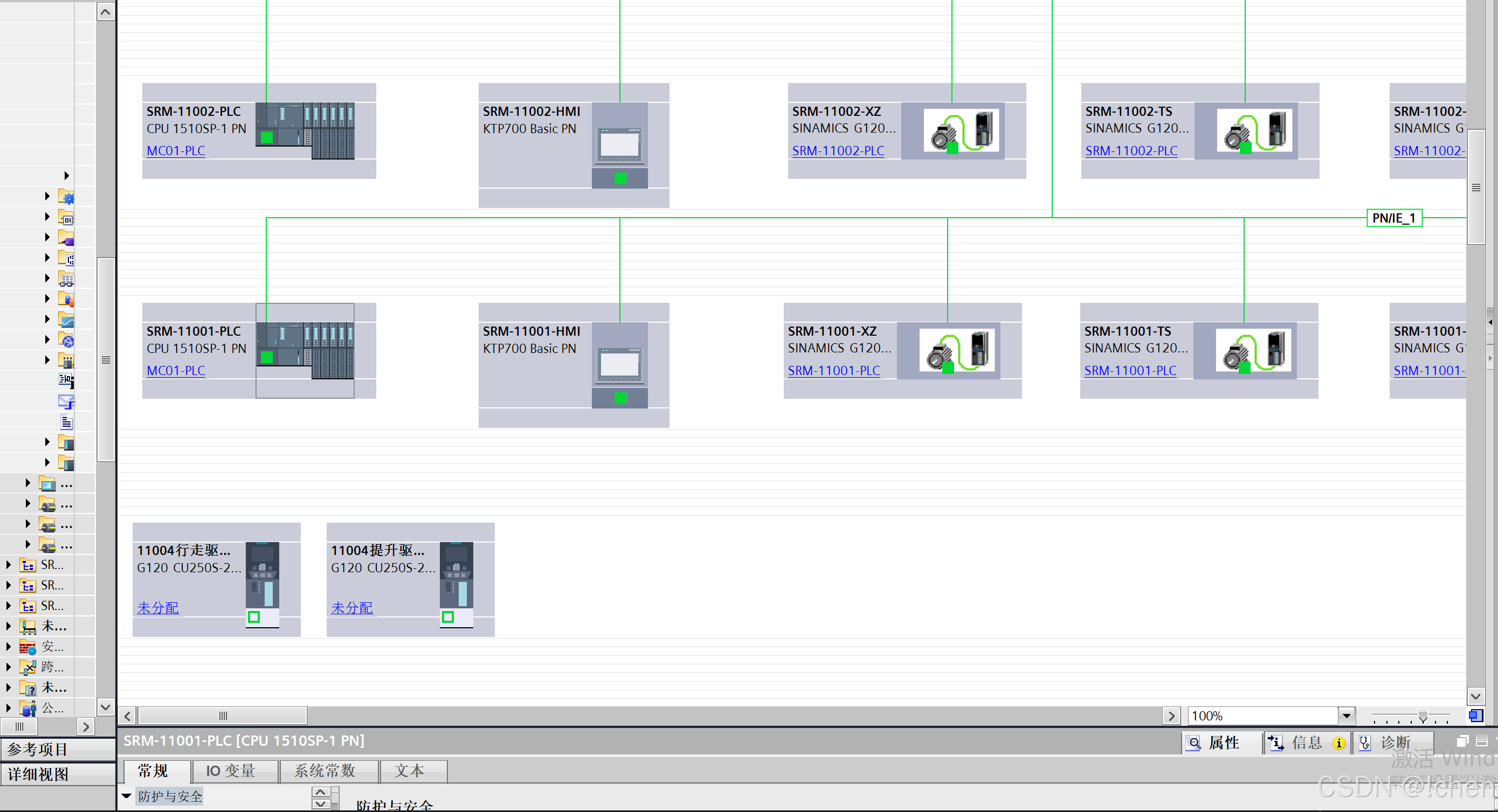
自动化立体仓库堆垛机SRM控制系统FC19手动控制功能块开发
1、控制系统手动控制模块HMI屏幕设计如下图 屏幕分为几个区域:状态显示区、控制输入区、导航指示区、报警信息区。状态显示区需要实时反馈堆垛机的位置、速度、载货状态等关键参数。控制输入区要有方向控制按钮,比如前后左右移动,升降控制,可能还需要速度调节的滑块或选择按…...
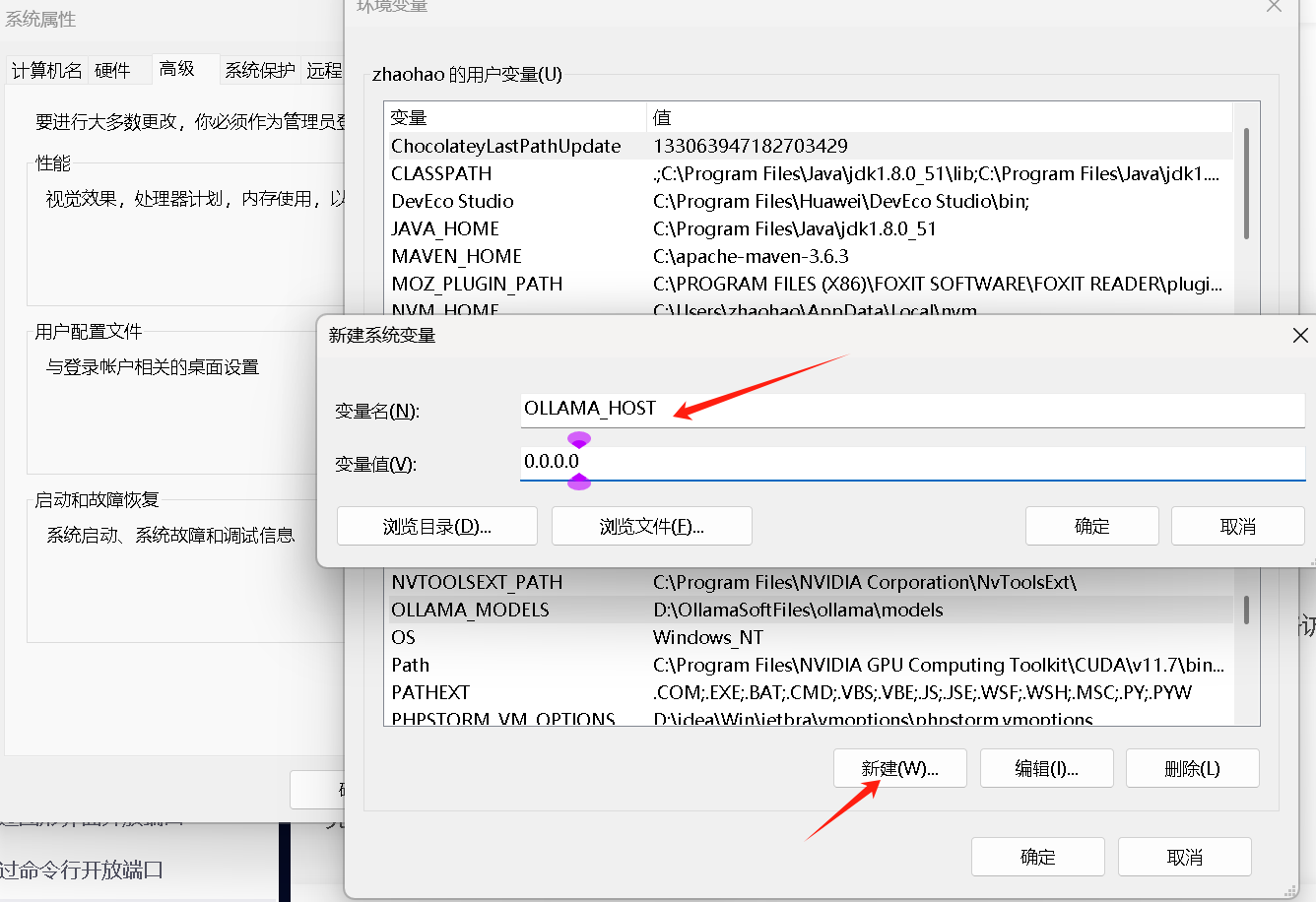
Ollama(1)知识点配置篇
ollama已经成功安装成功后,通常大家会对模型的下载位置和访问权限进行配置 1.模型下载位置修改 都是修改系统环境变量。 (1)默认下载位置 macOS: ~/.ollama/modelsLinux: /usr/share/ollama/.ollama/modelsWindows: C:\Users\你的电脑用户…...
VMware Workstation虚拟系统设置双网口
一.设置windows11系统VMware Network Adapter VMnet1。 1.进入到网络和Internet -> 高级网络设置 2.找到VMware Network Adapter VMnet1,进入到“更多配置选项”并“编辑”。 3.进入到属性,双击“Interenet协议版本4(TCP/IPv4ÿ…...

Qt基础终结篇:从文件操作到多线程异步UI,深度解析核心要点
文章目录 前言一、QFileDialog 文件对话框二、QFileInfo 文件信息类三、QFile 文件读写类四、UI与耗时操作:避免UI卡顿与程序未响应五、多线程六、异步刷新与线程通信总结 前言 上一篇文章,我们已经把qt的基础知识讲解的差不多了。本文我们将继续进行qt…...

ubuntu中,文本编辑器nano和vim区别,vim的用法
目录 一.区别1.介绍2.适用场景3. 配置与个性化1) nano:2)Vim: 二.Vim1、Vim 的安装与启动2、Vim 的三种模式 (普通模式、插入模式、命令行模式)3、Vim 的常用操作4、Vim 的配置5、Vim 的高级功能 三.nano使…...

山洪灾害声光电监测预警解决方案
一、方案背景 我国是一个多山的国家,山丘区面积约占国土面积的三分之二。每年汛期,受暴雨等因素影响,极易引发山洪和泥石流。山洪、泥石流地质灾害具有突发性、流速快、流量大、物质容量大和破坏力强等特点,一旦发生,将…...
【Rust模式与匹配】Rust模式与匹配深入探索与应用实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

React从基础入门到高级实战:React 高级主题 - React Concurrent 特性:深入探索与实践指南
React Concurrent 特性:深入探索与实践指南 引言 随着Web应用对用户体验的要求日益提高,React在2025年的技术环境中引入了并发渲染(Concurrent Rendering)这一革命性特性,旨在提升应用的响应速度和交互流畅度。并发渲…...
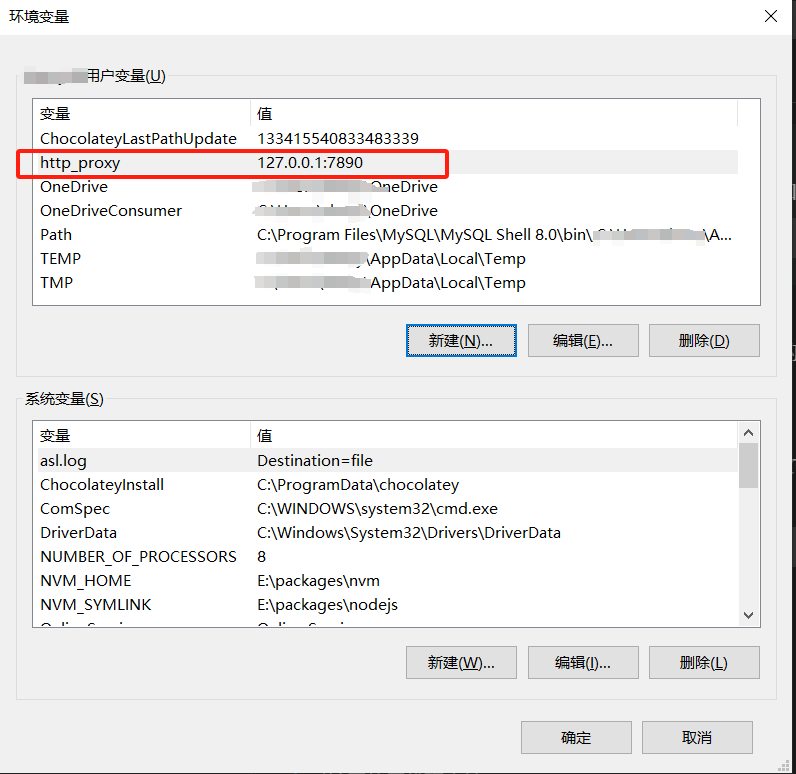
electron安装报错处理
electron安装报错 解决方法: 修改 C:\Users\用户名.npmrc下配置文件 添加代码 electron_mirrorhttps://cdn.npmmirror.com/binaries/electron/ electron_builder_binaries_mirrorhttps://npmmirror.com/mirrors/electron-builder-binaries/最后代码 registryhtt…...