lstm 长短期记忆 视频截图 kaggle示例
【官方双语】LSTM(长短期记忆神经网络)最简单清晰的解释来了!_哔哩哔哩_bilibili
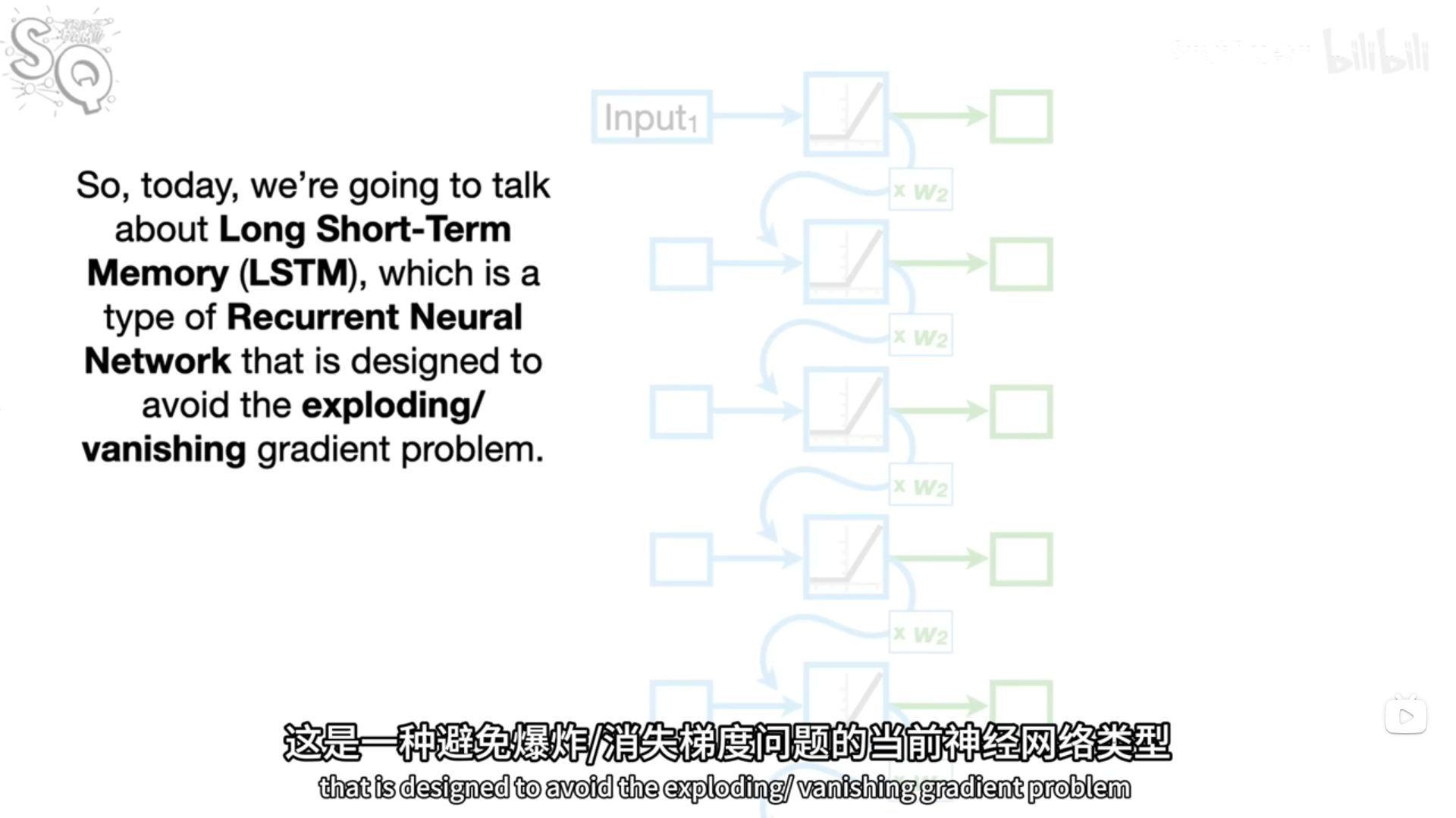
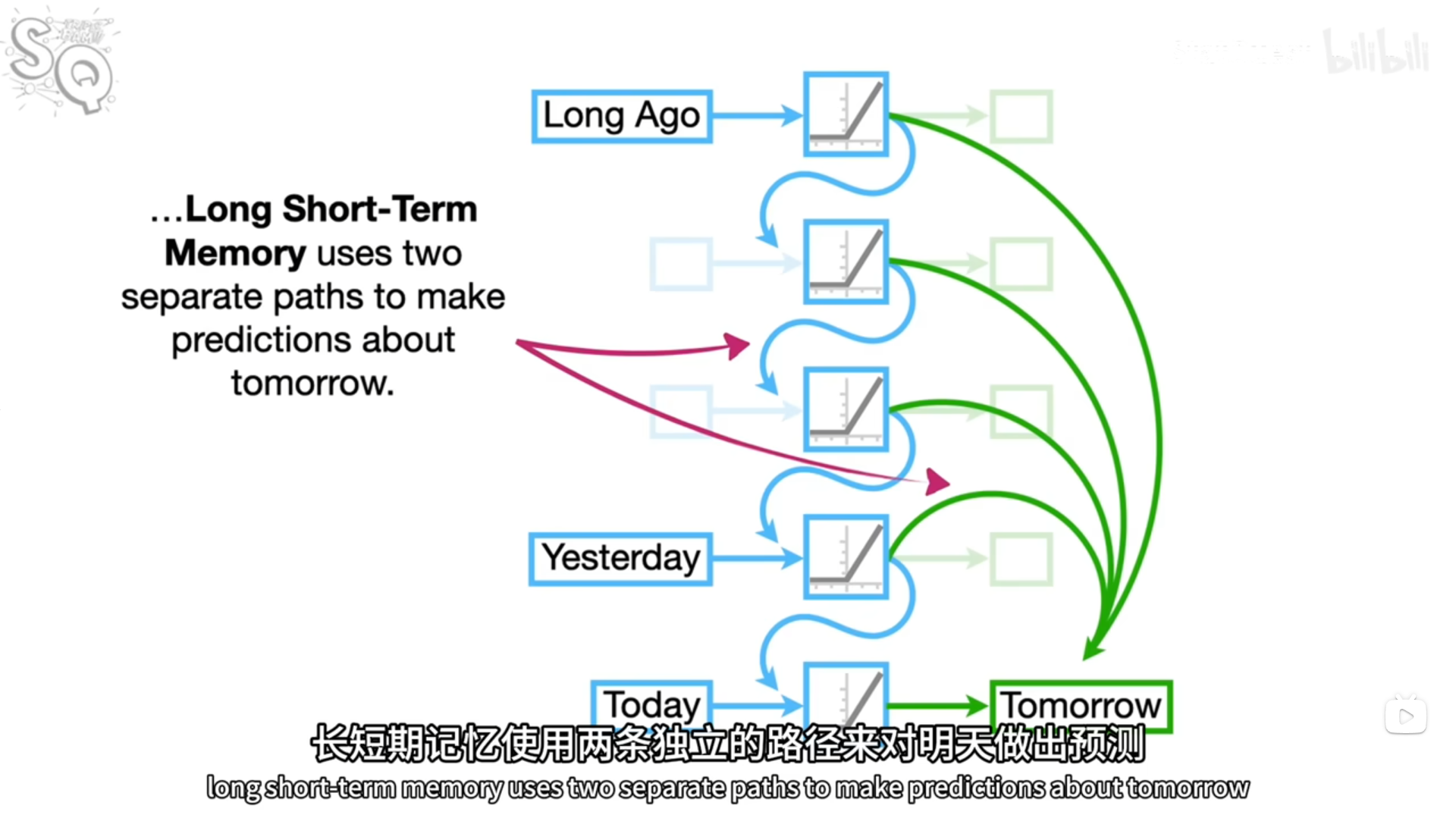
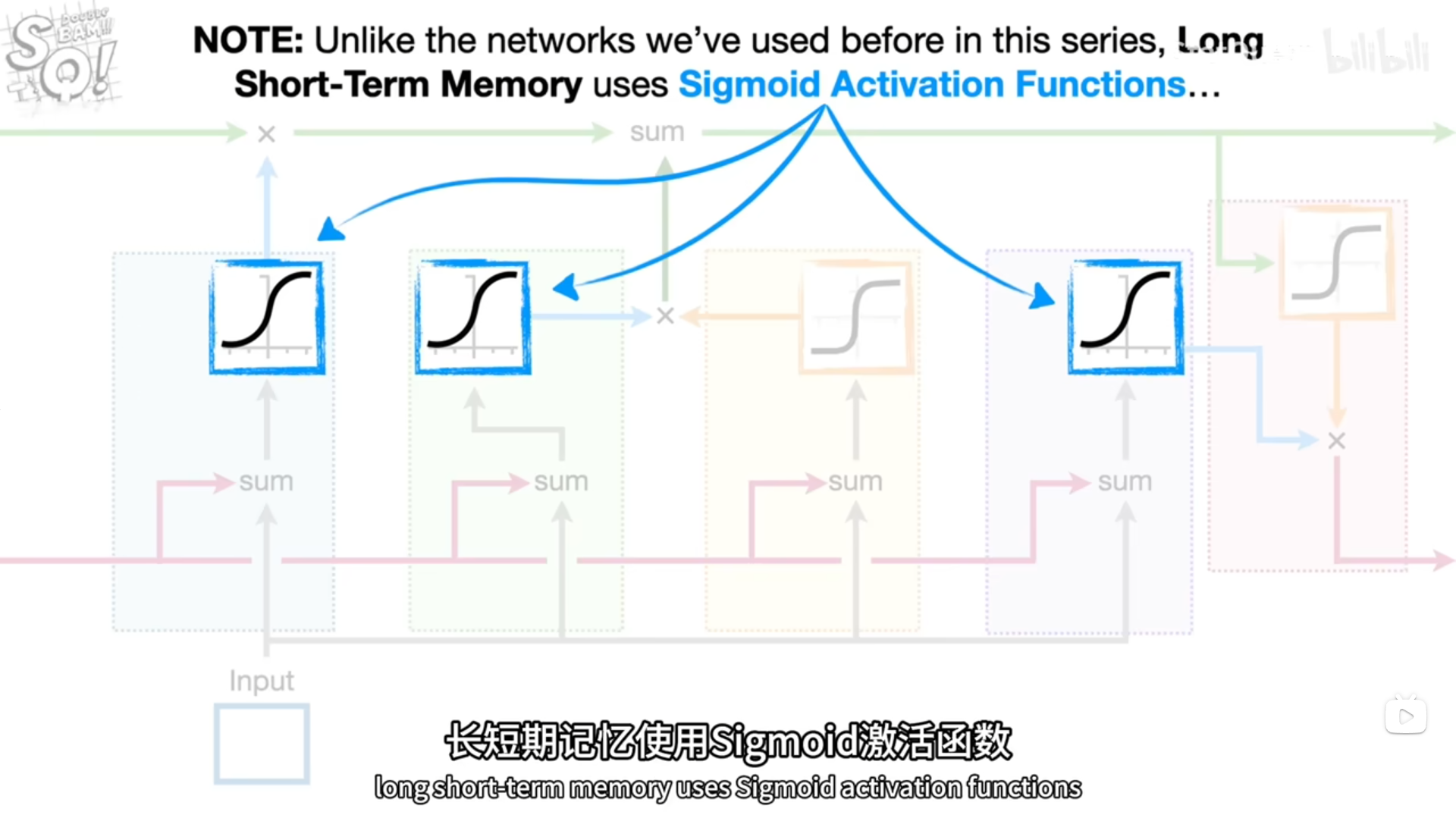
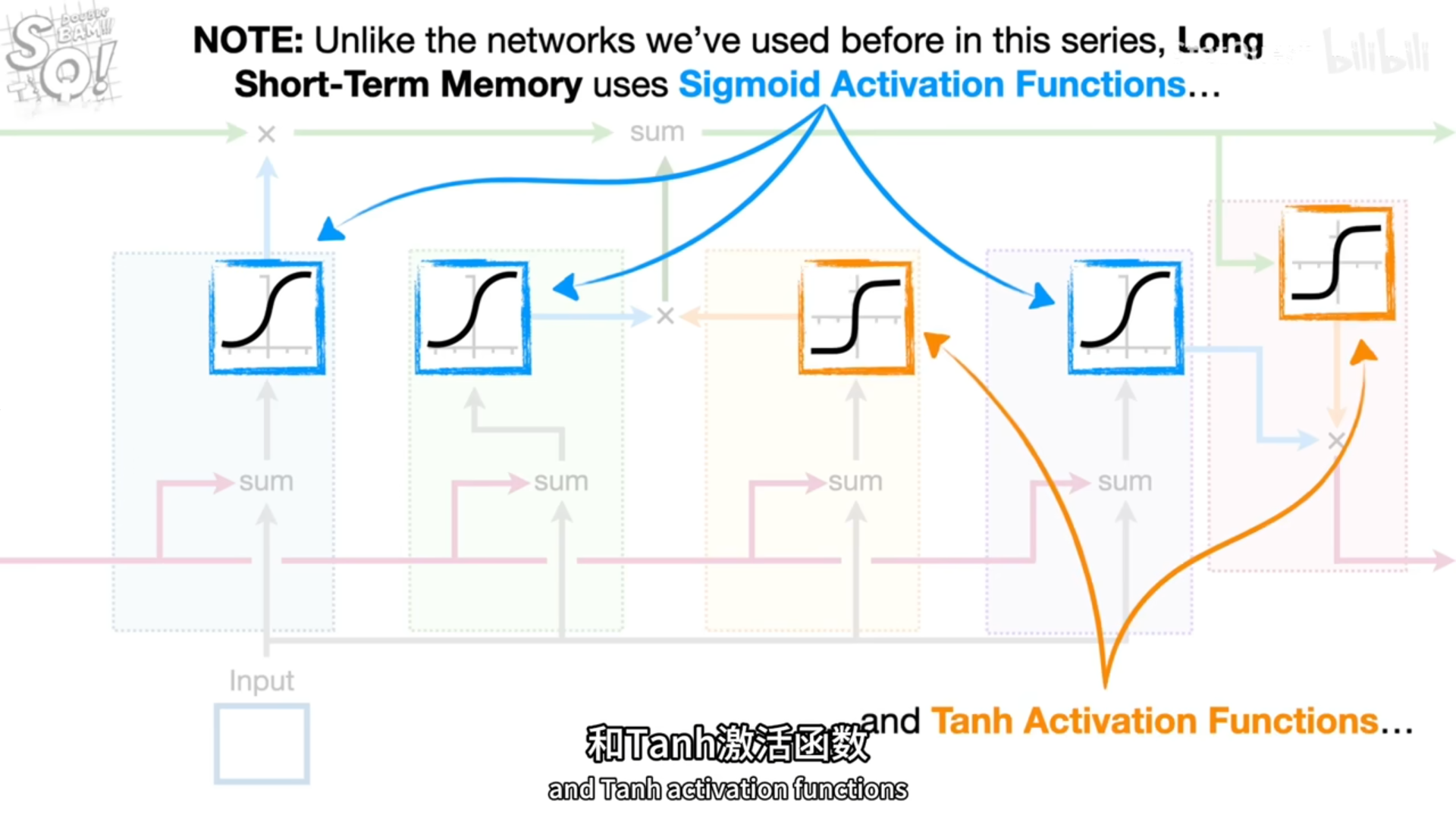
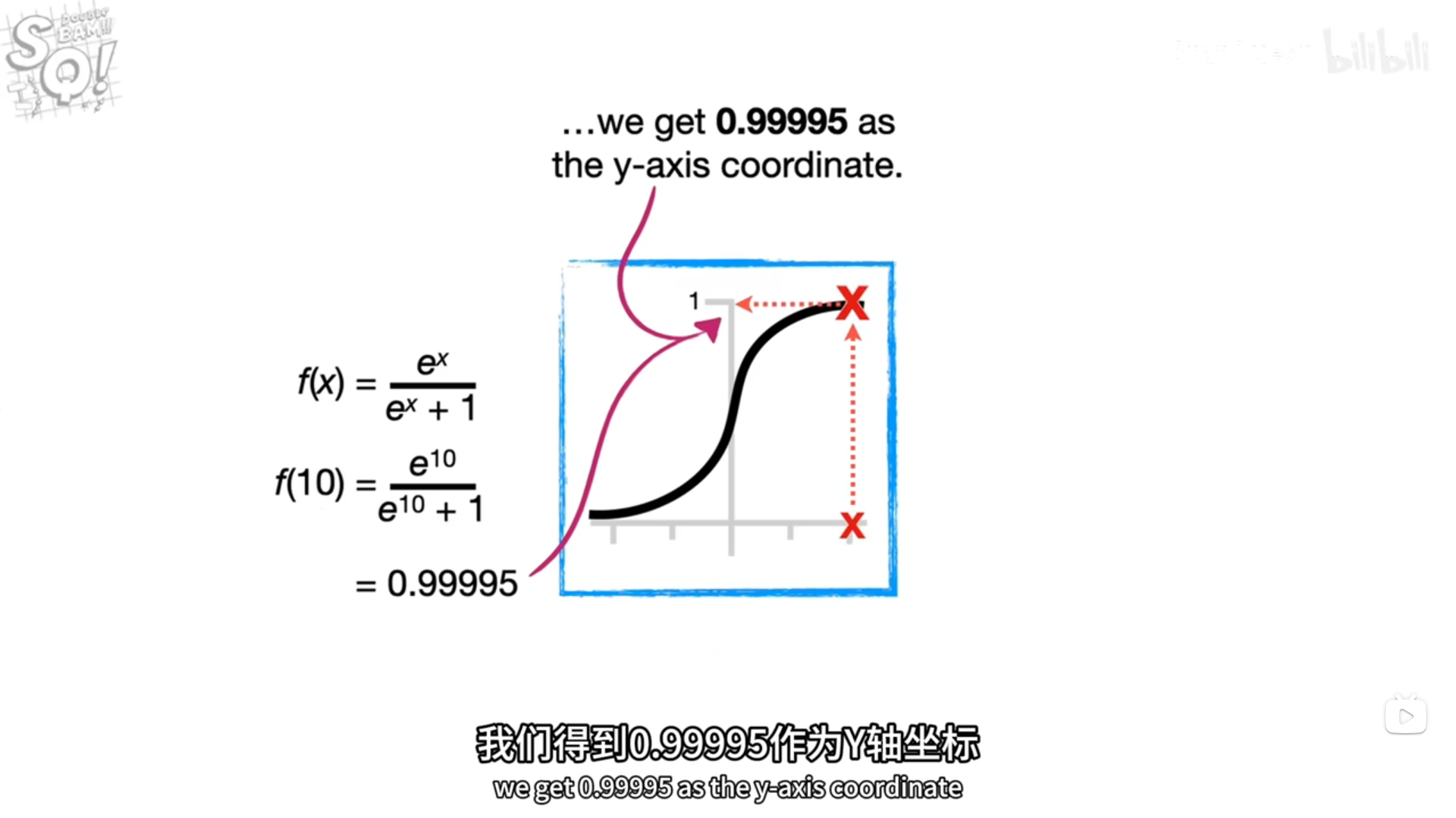
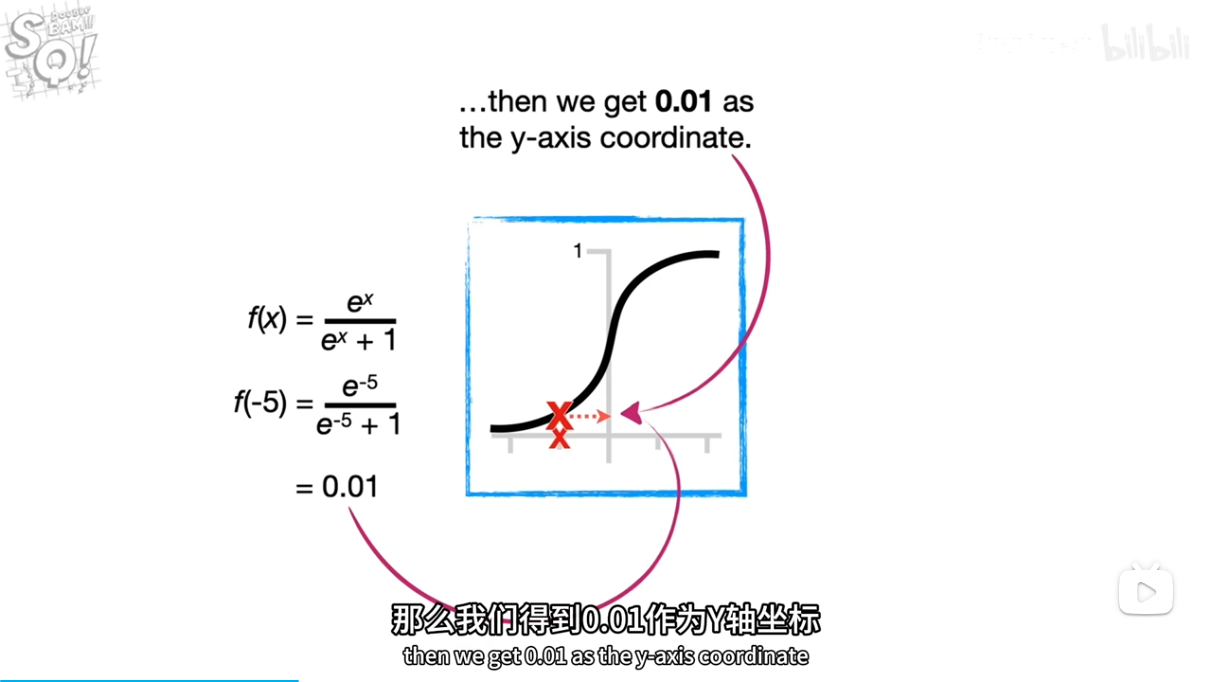
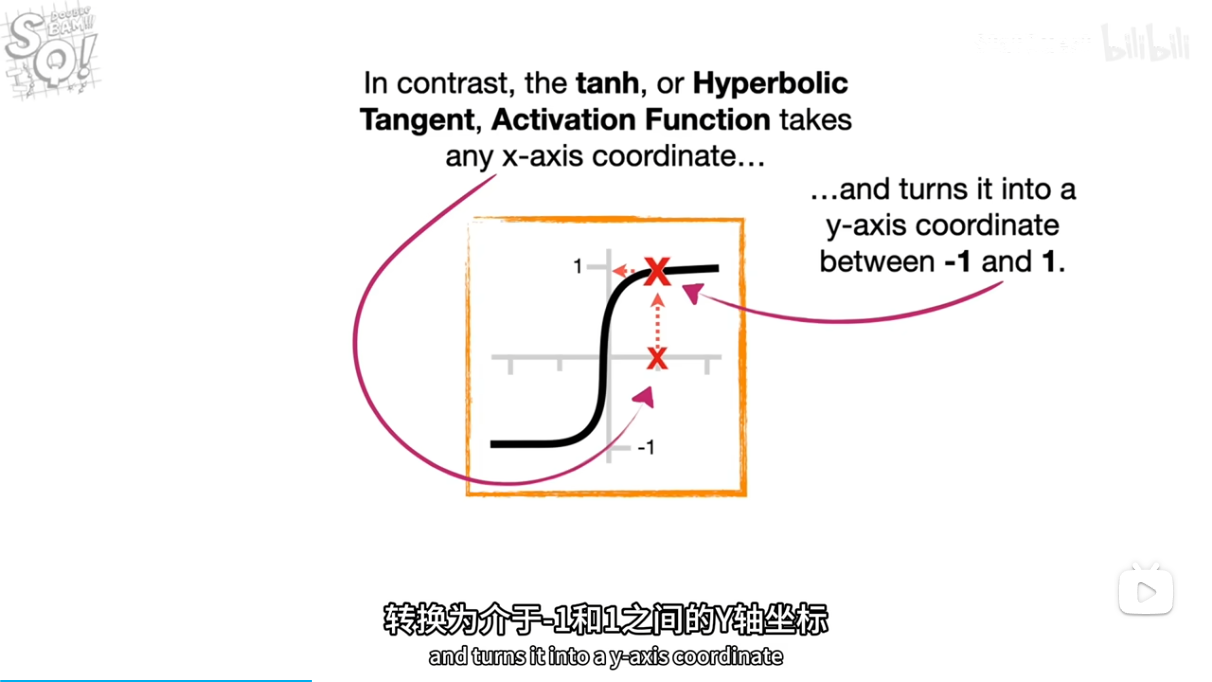
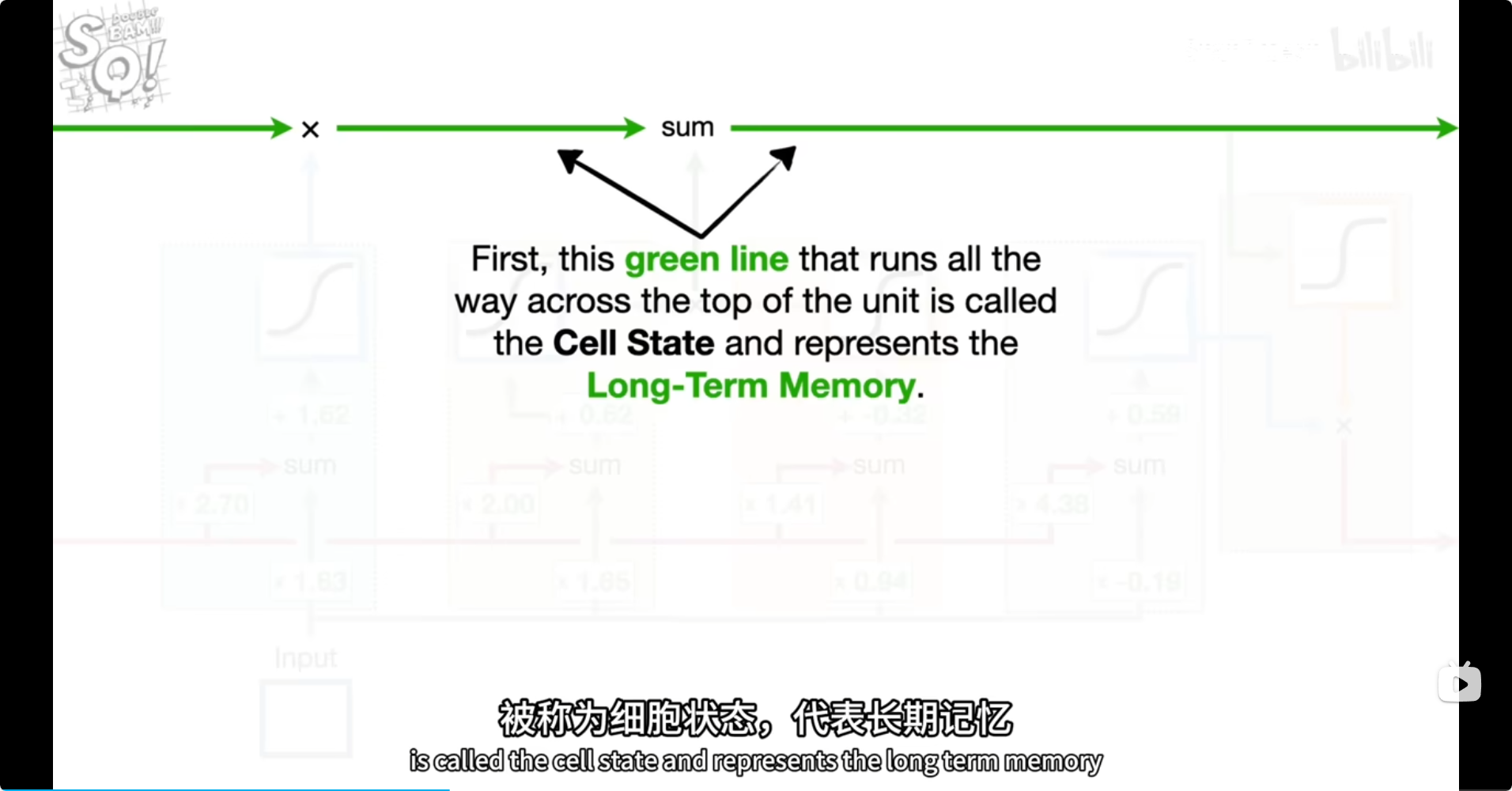
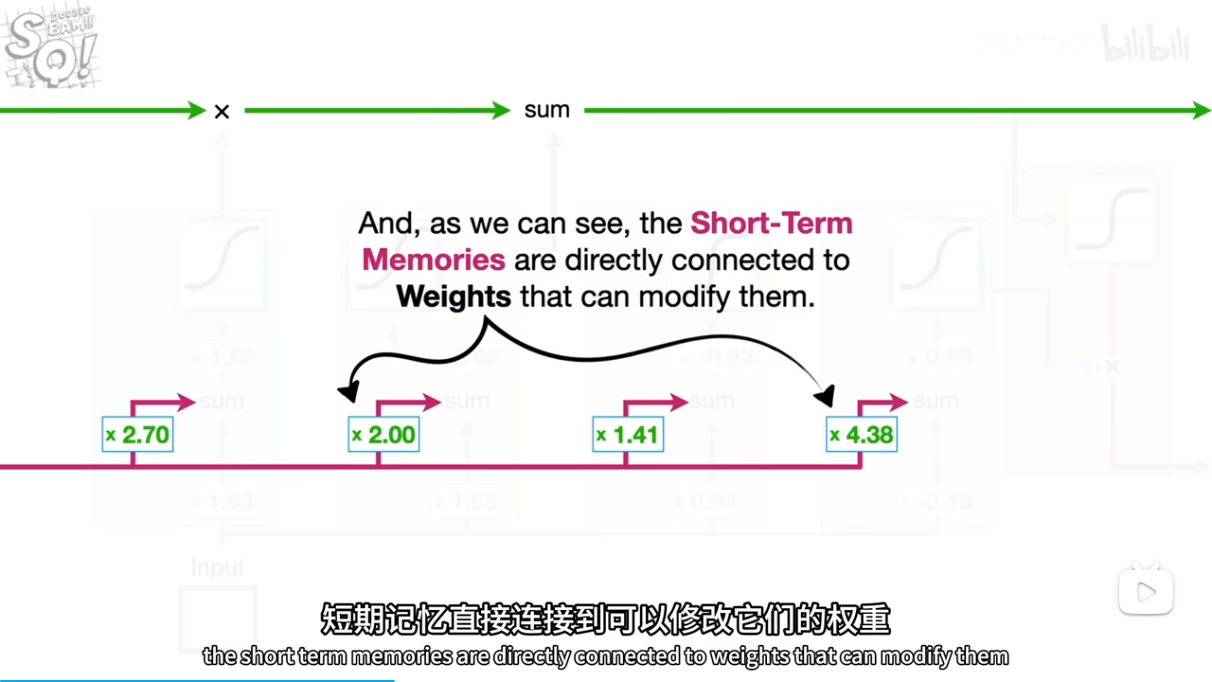 .
.
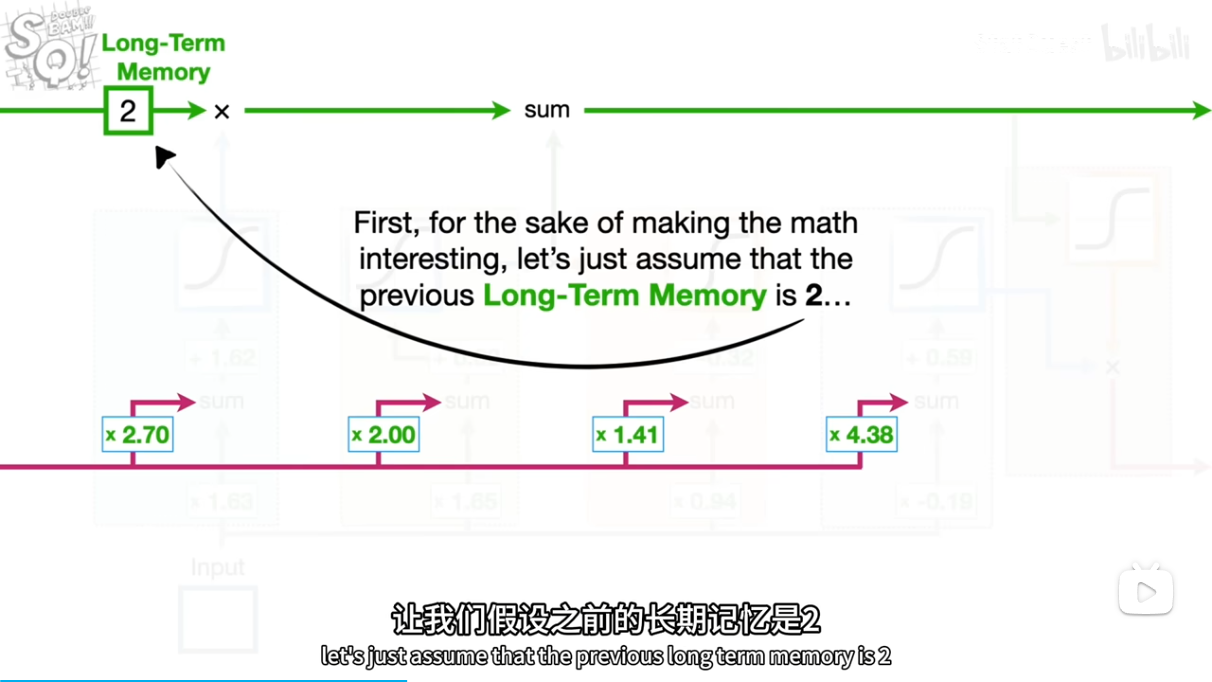
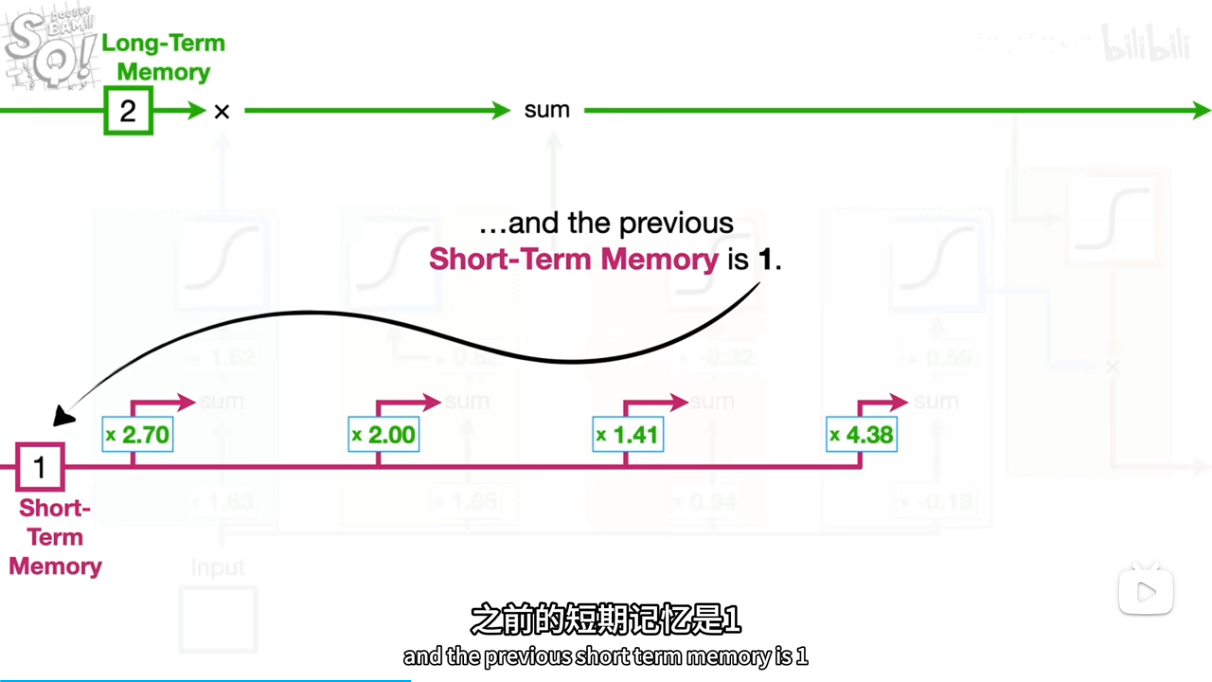
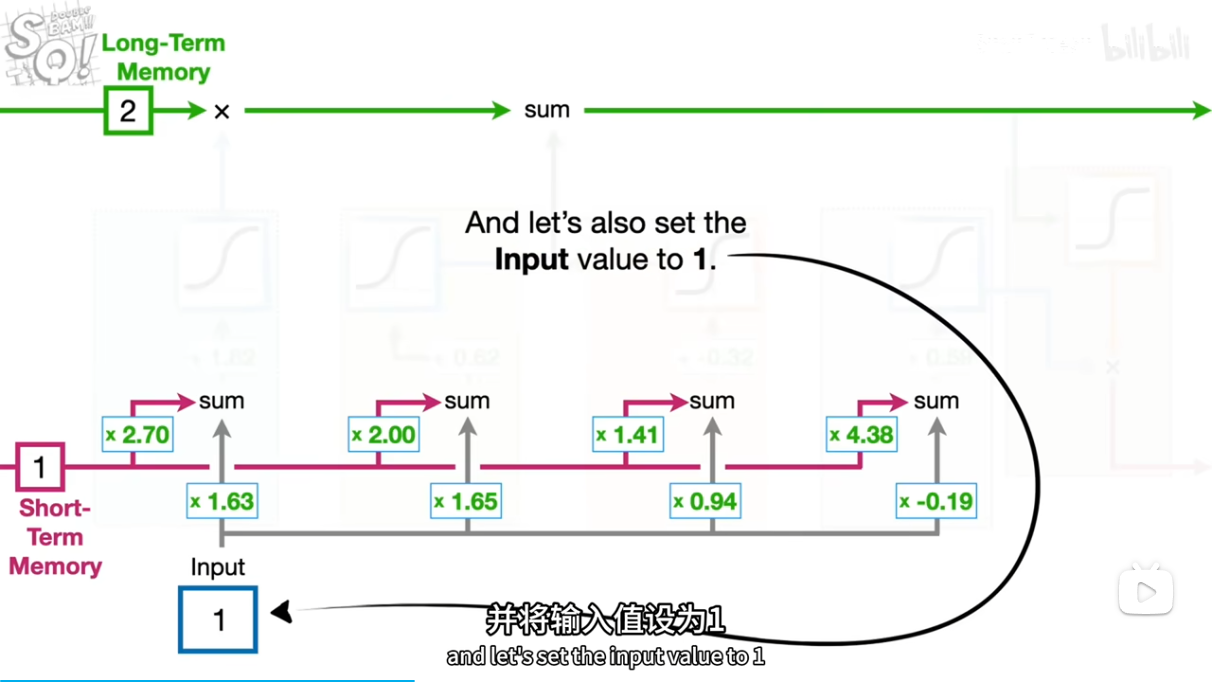
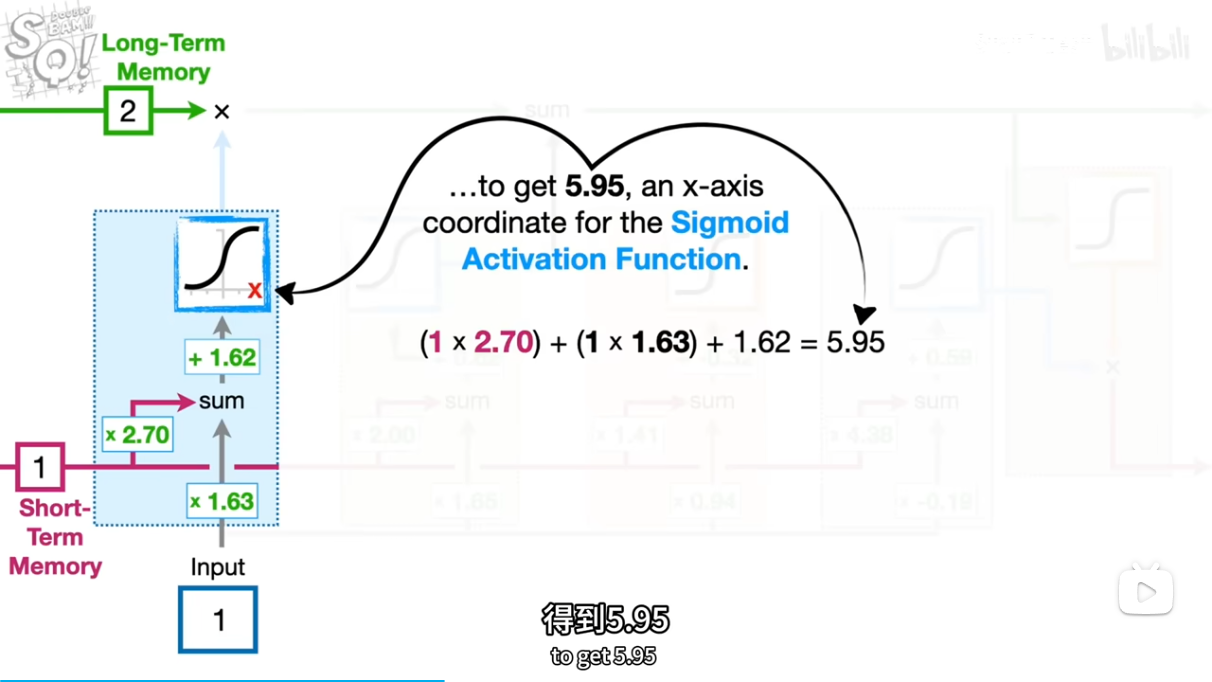
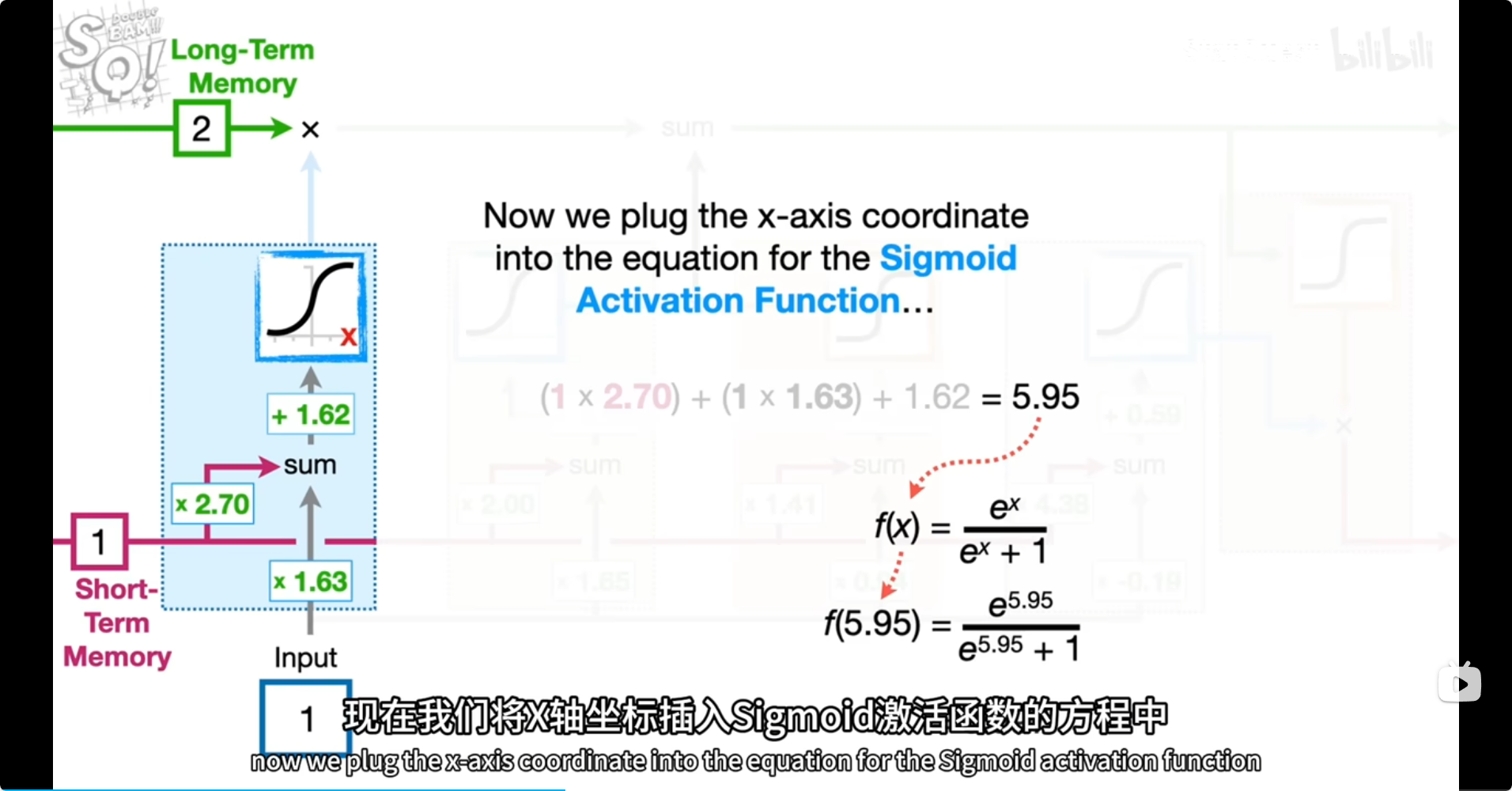
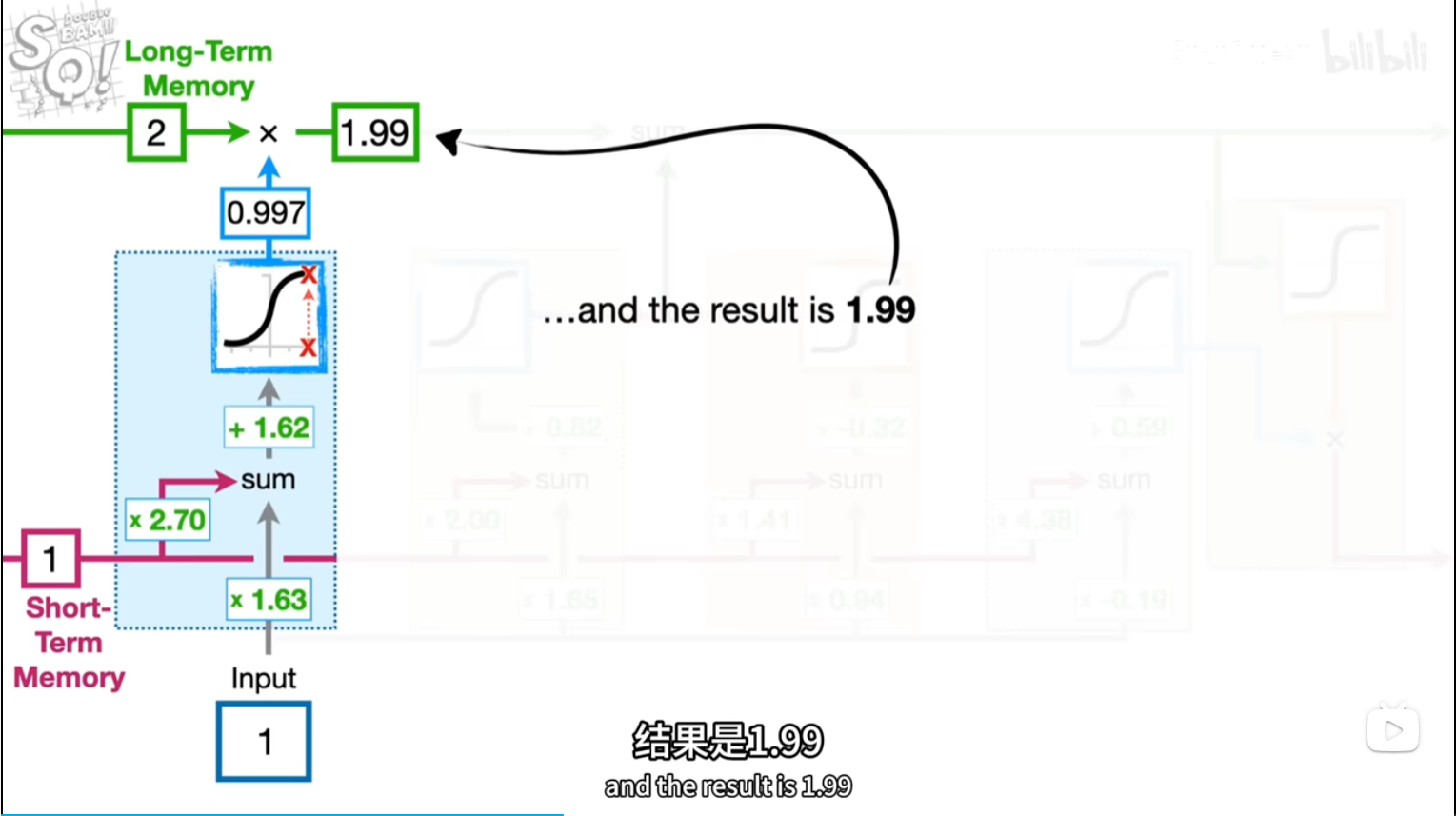
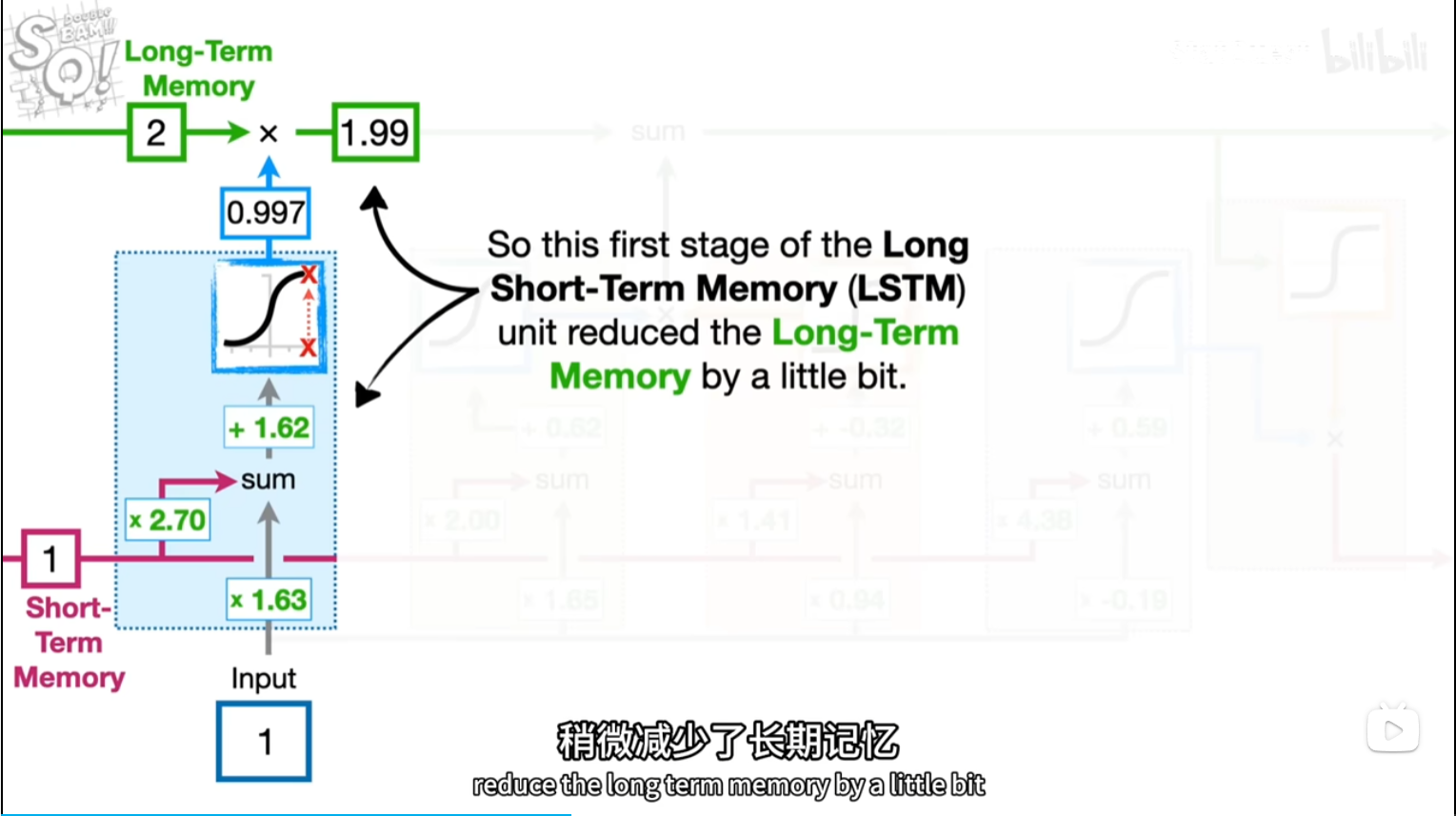
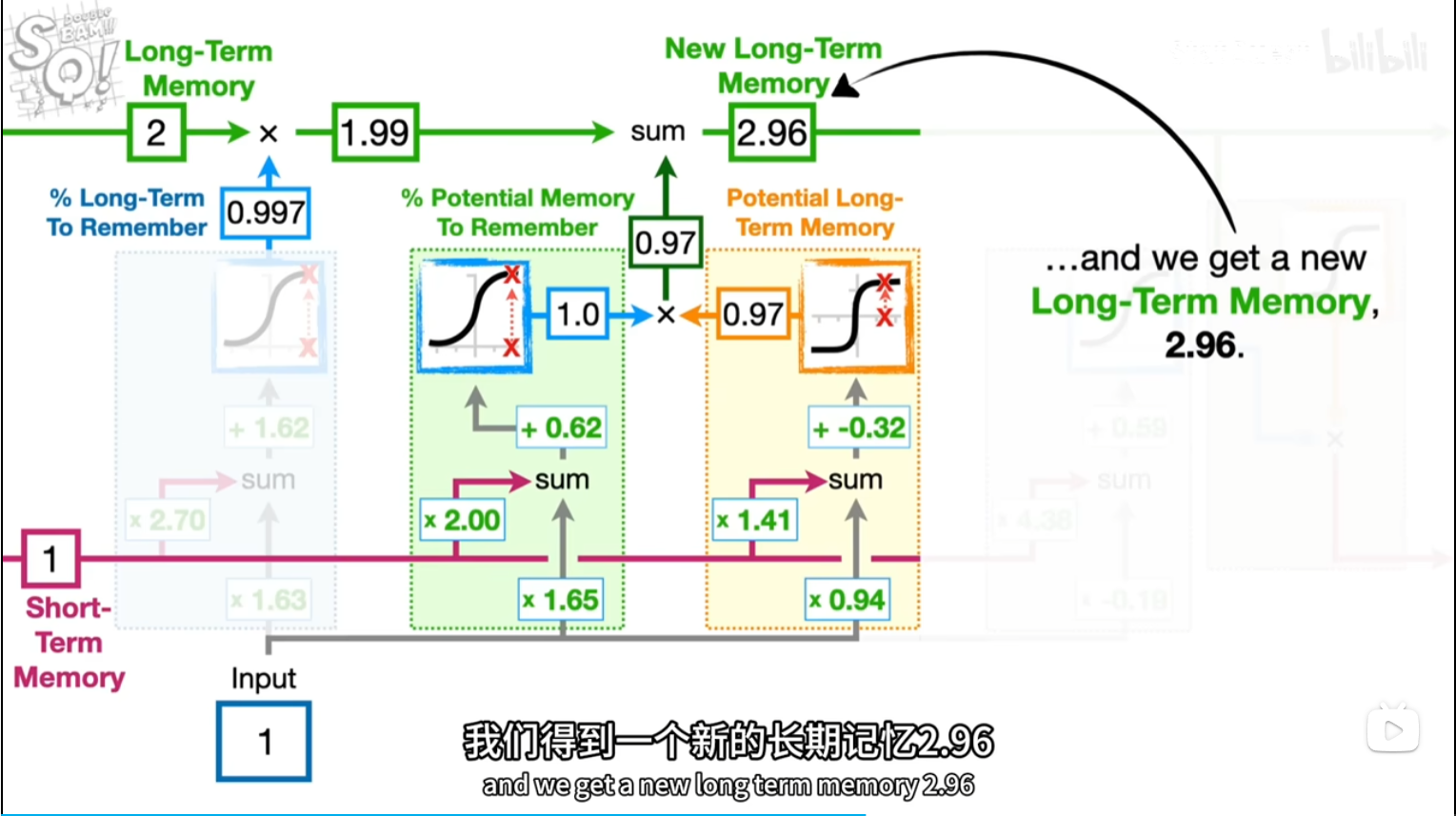
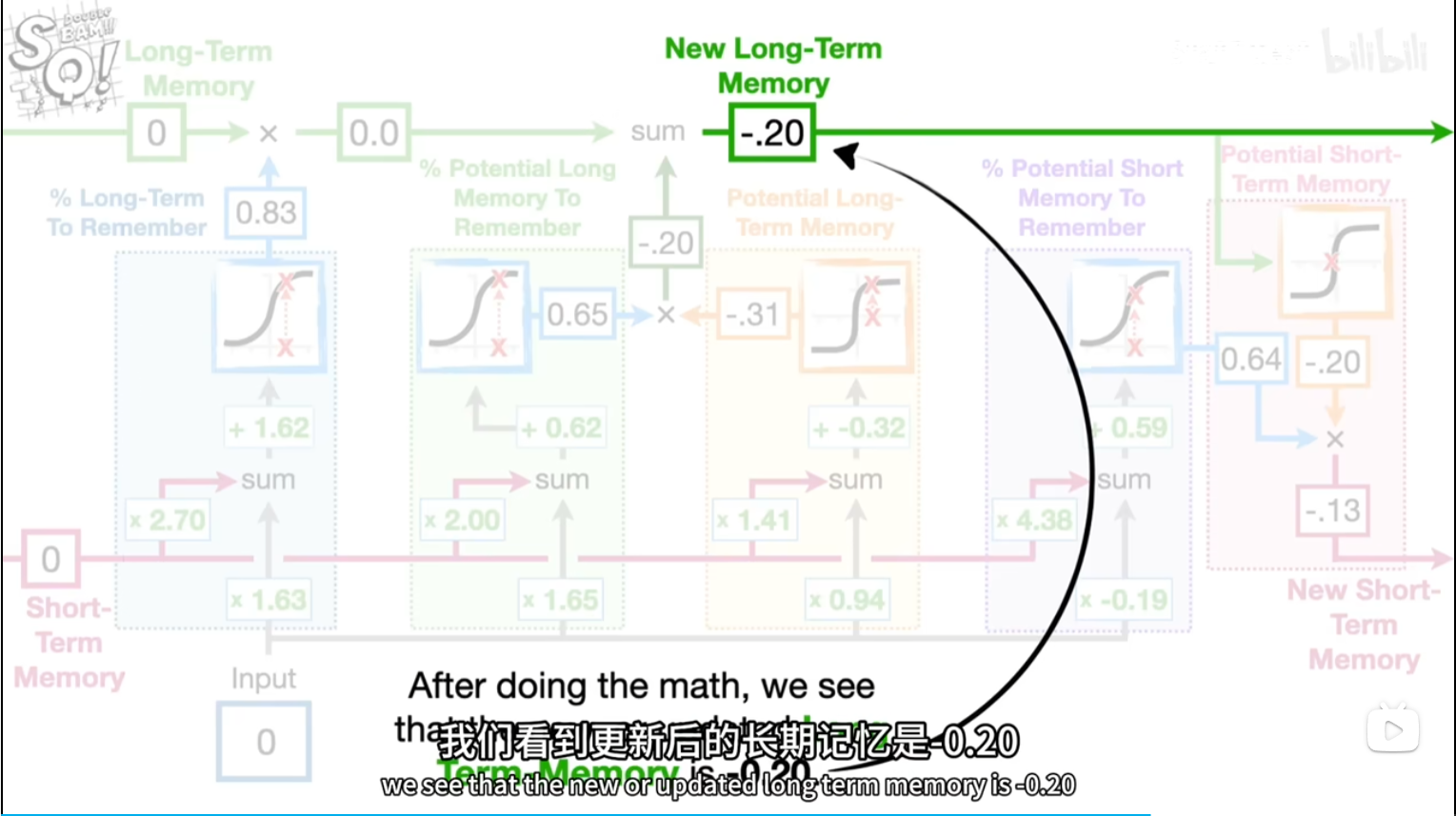
[short,input]*[2.7,1.63]+b=5.95
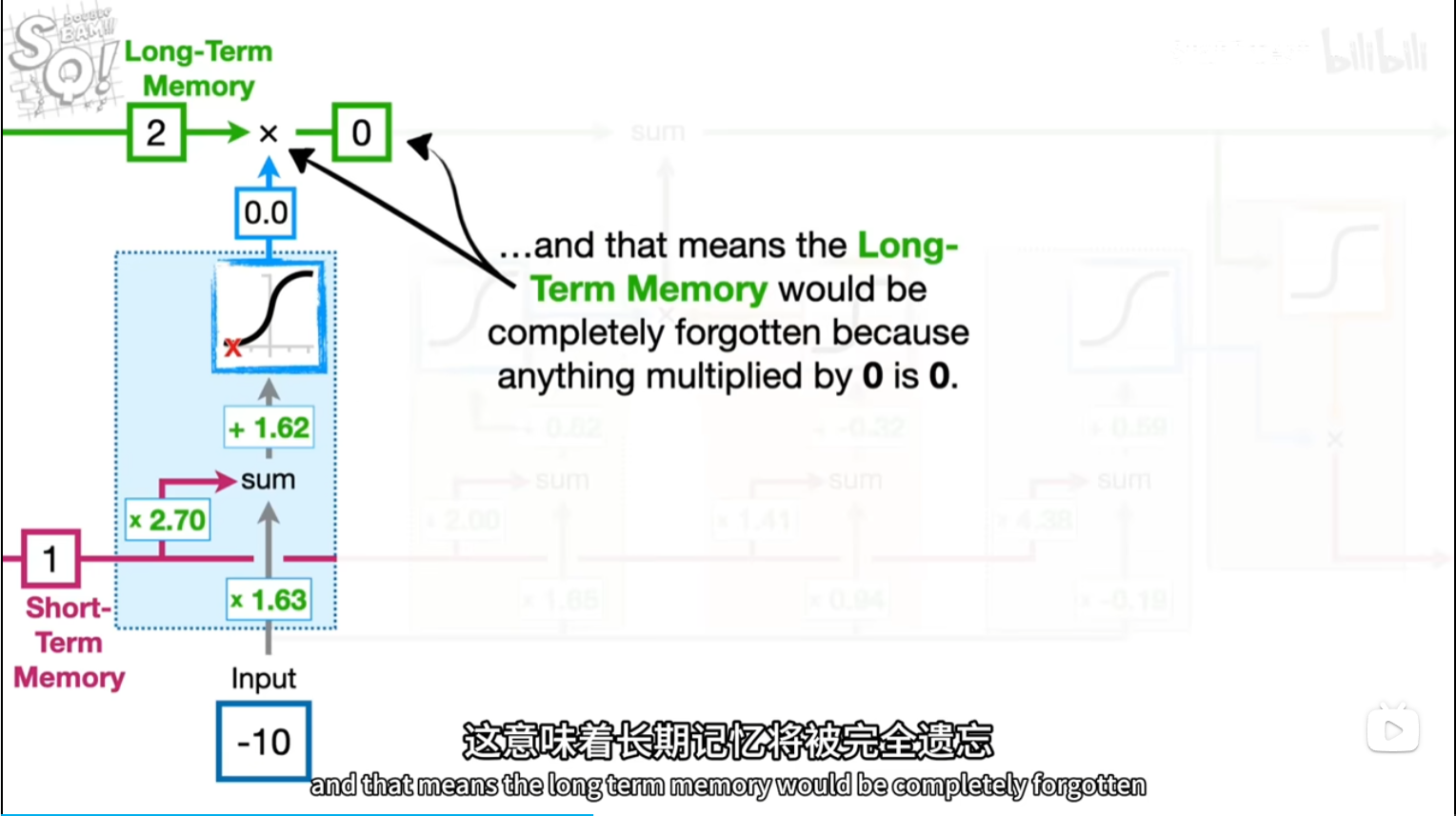

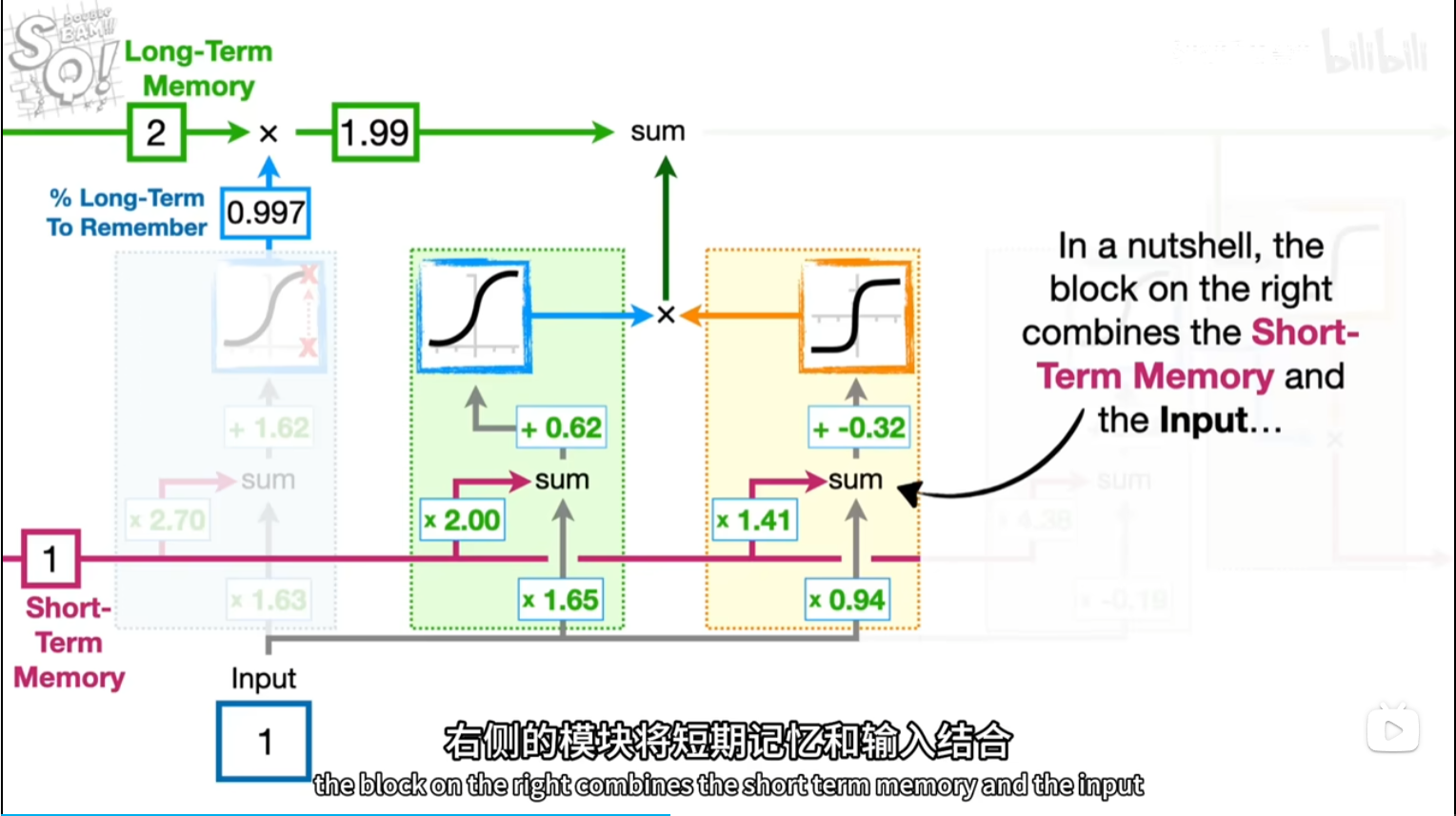
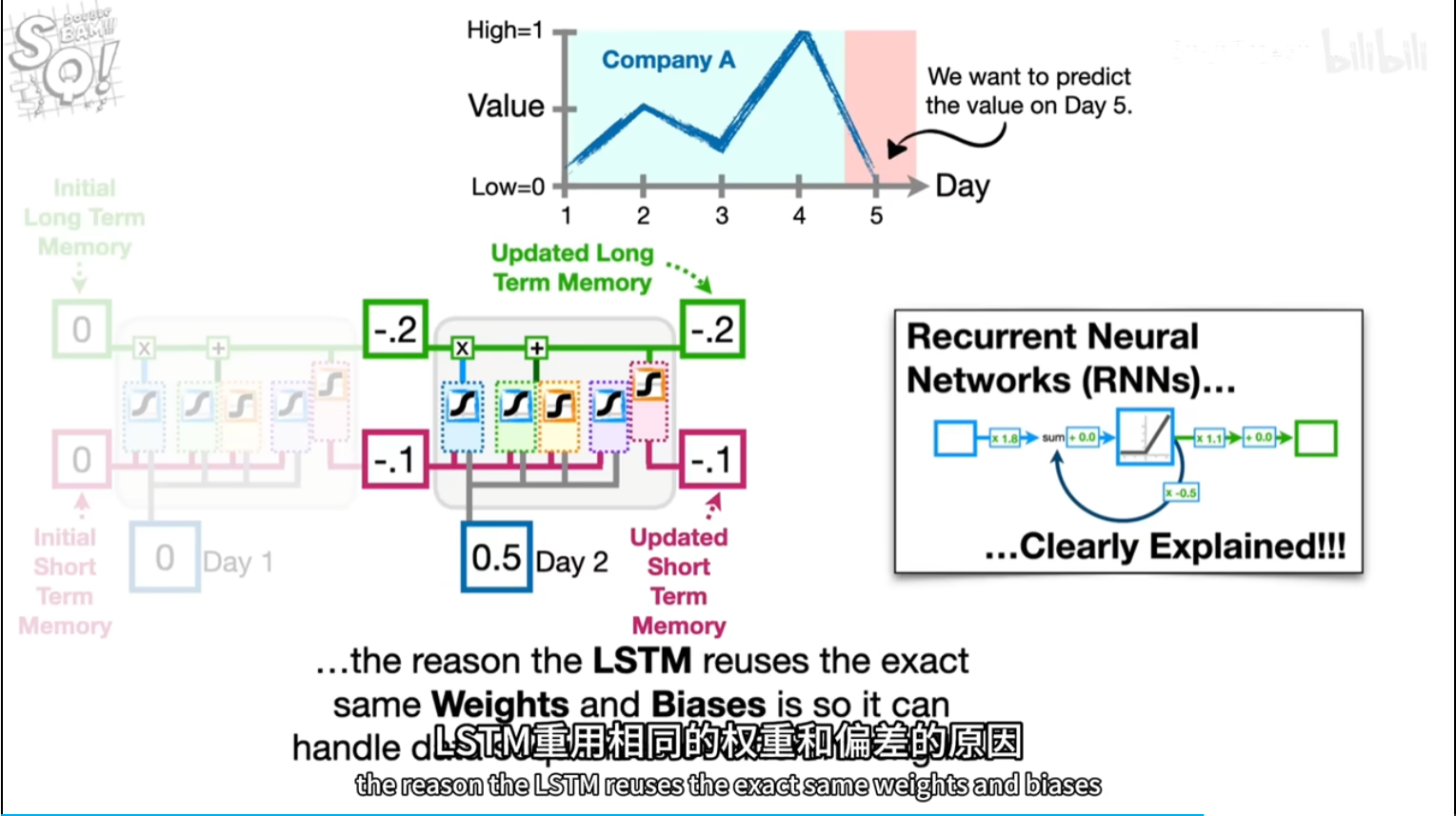
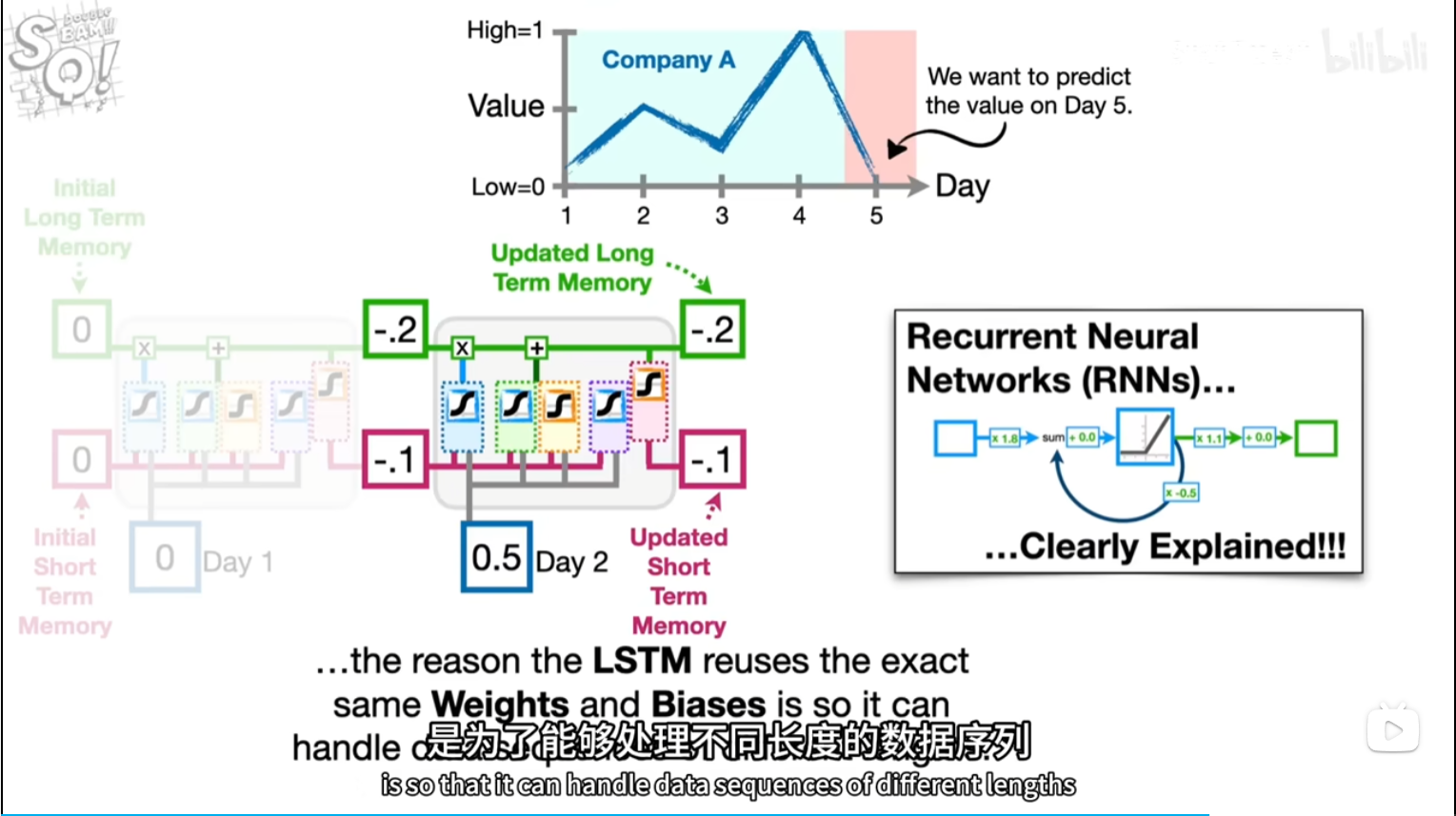
换参数和激活函数
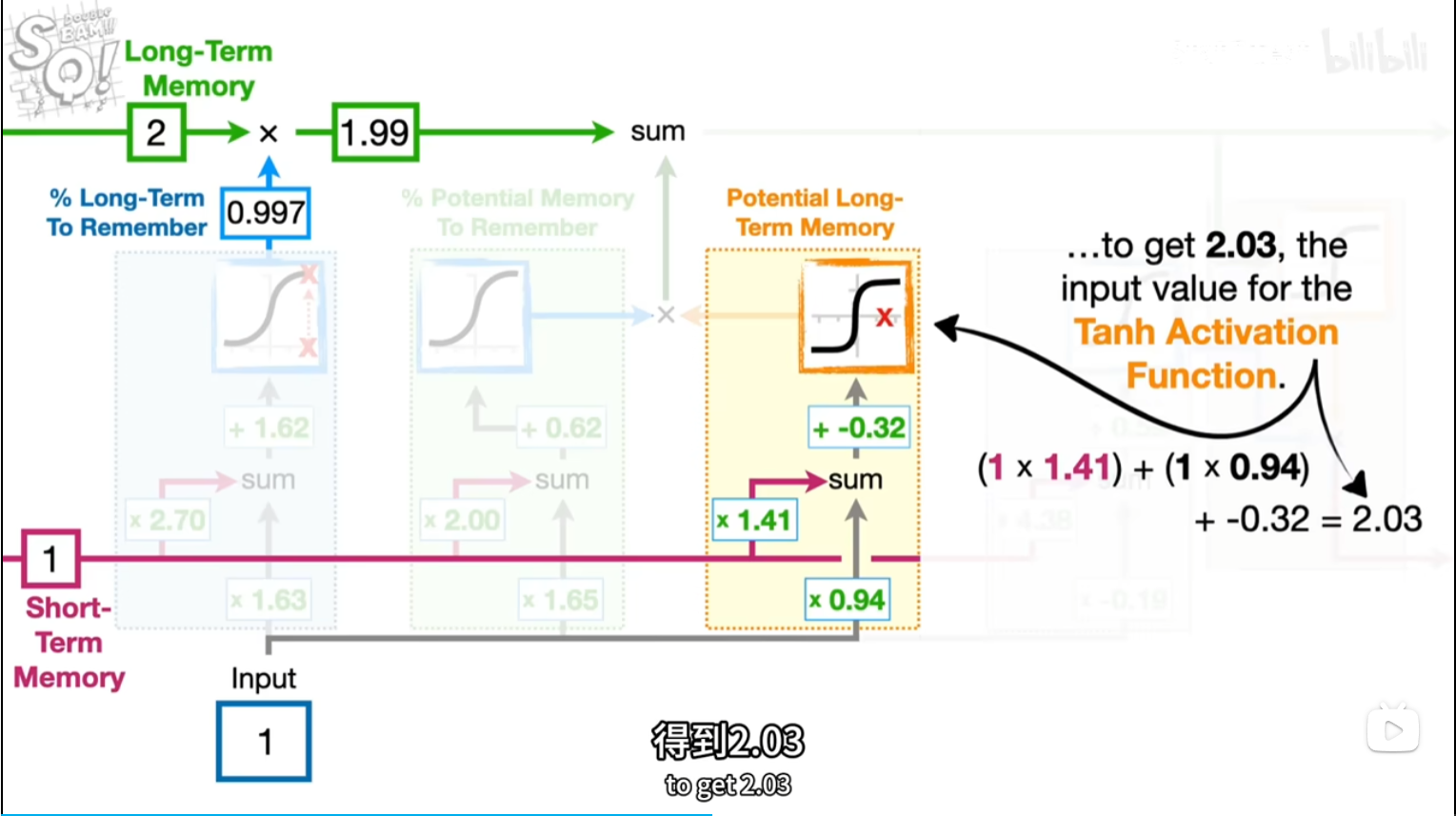
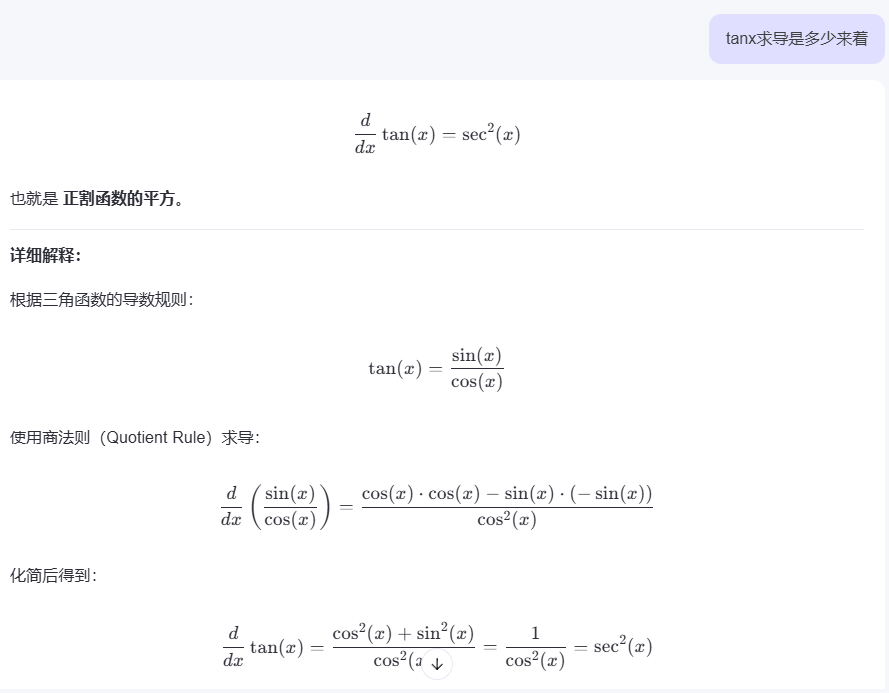
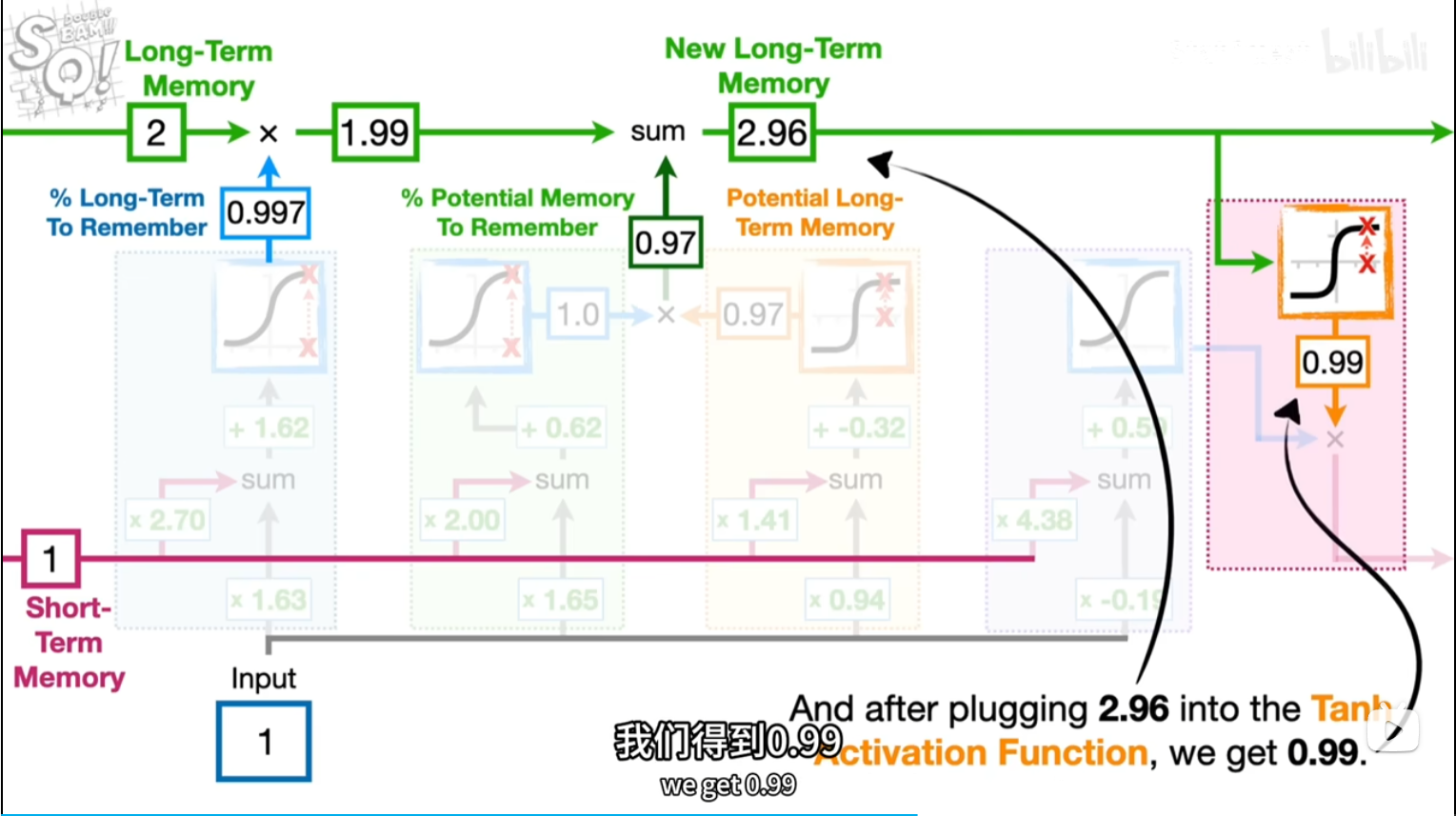
tan激活函数输出带正负符号的百分比
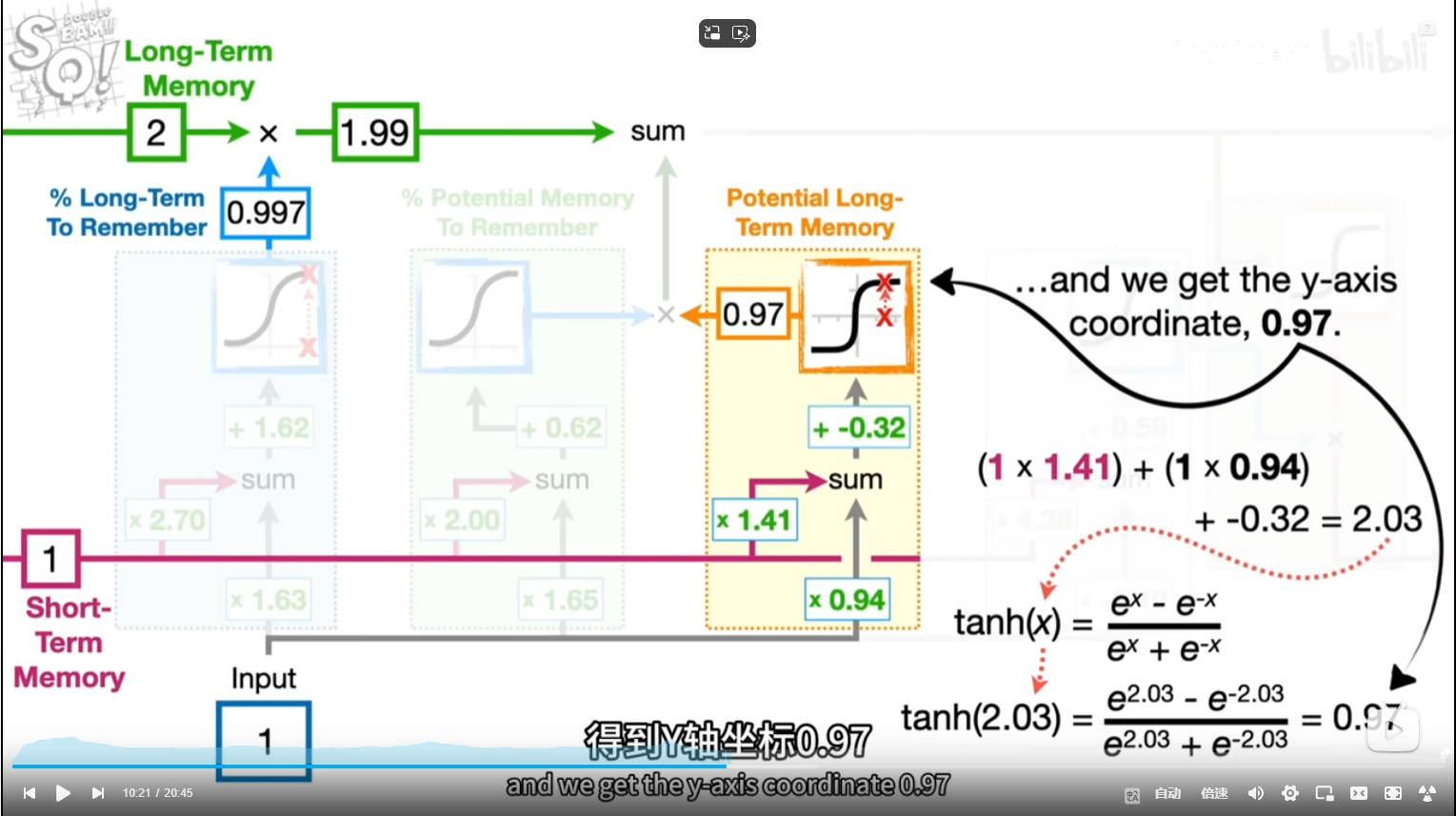
tanx公式长这样?



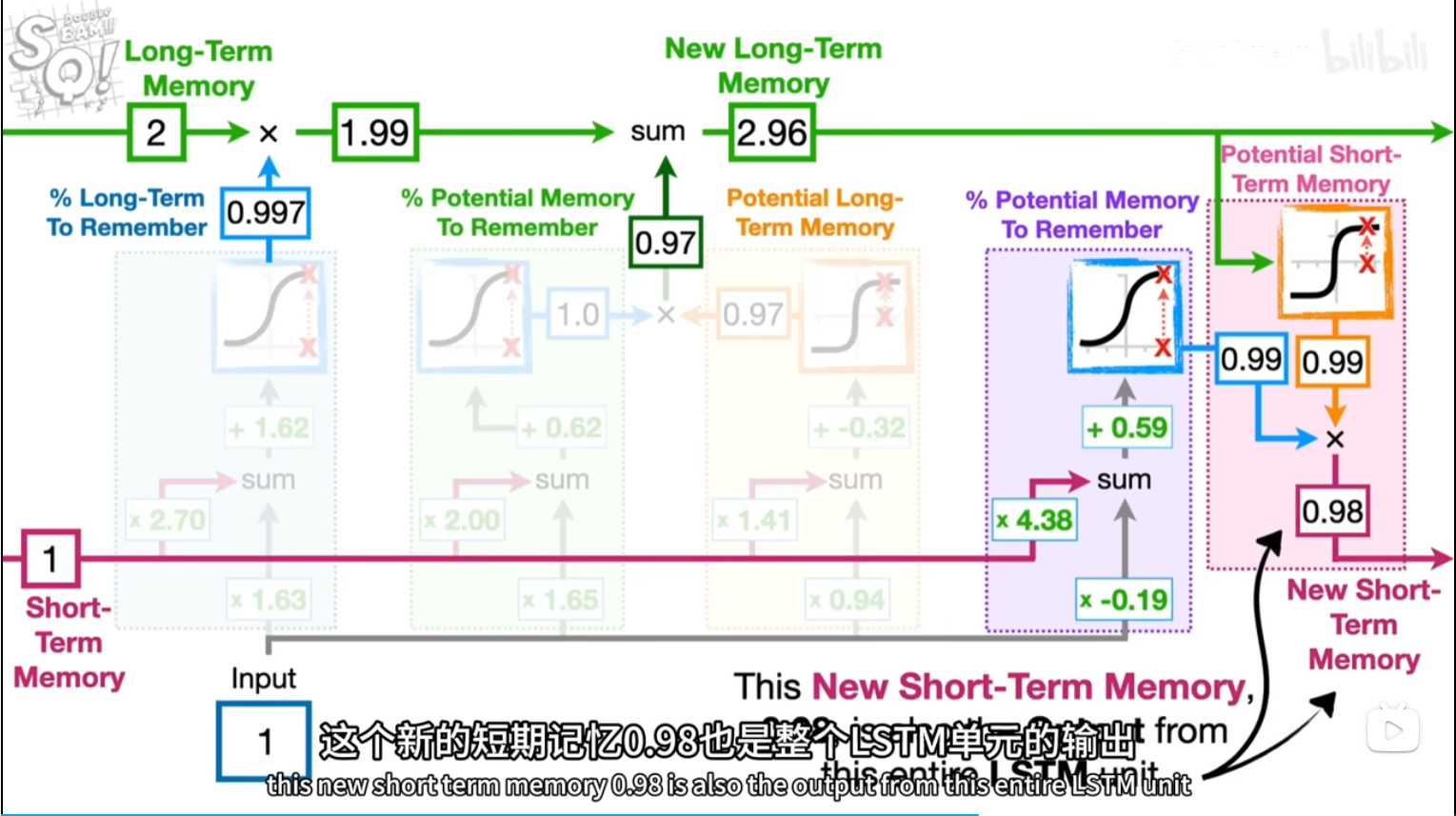
潜在短期记忆
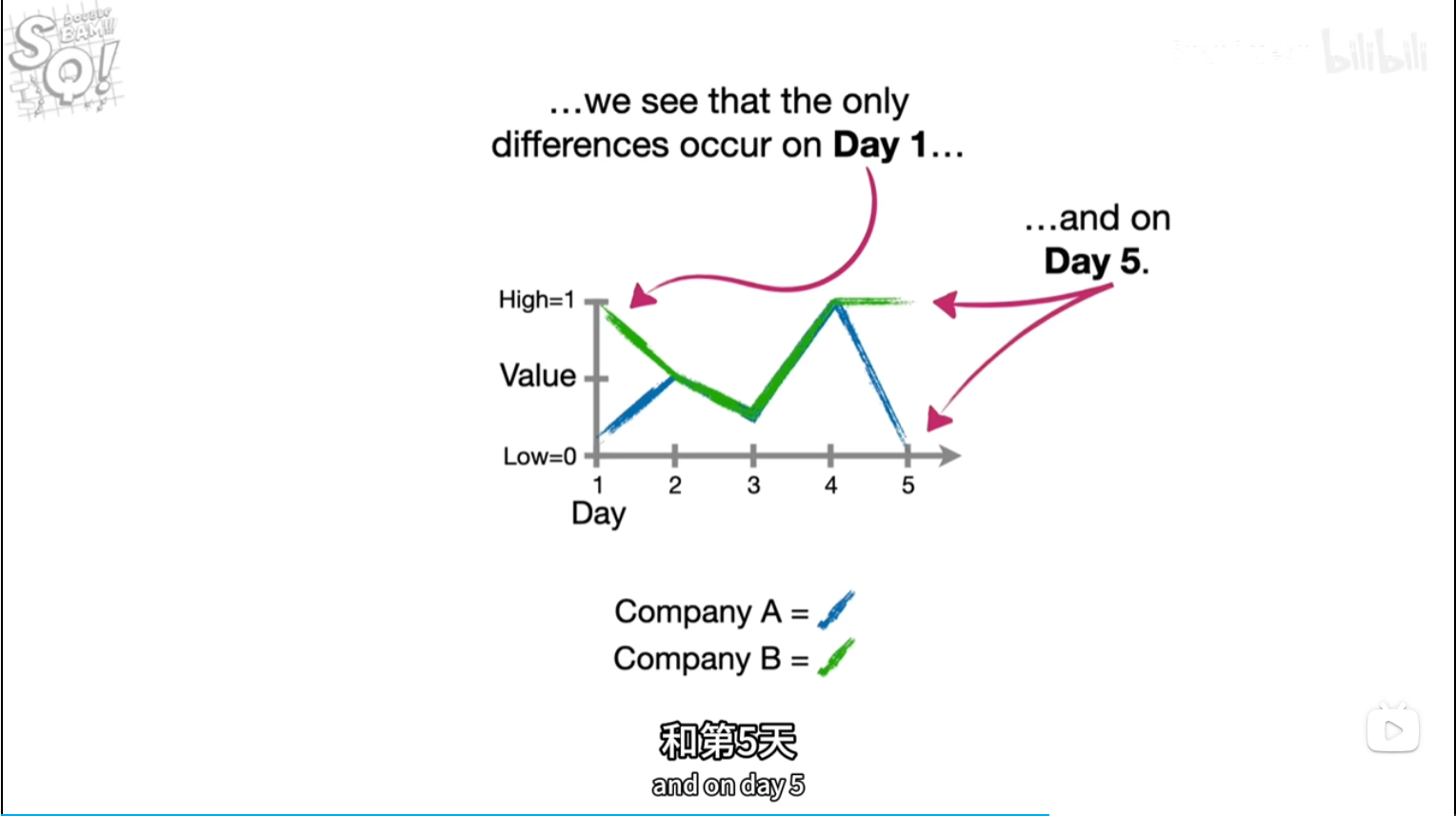
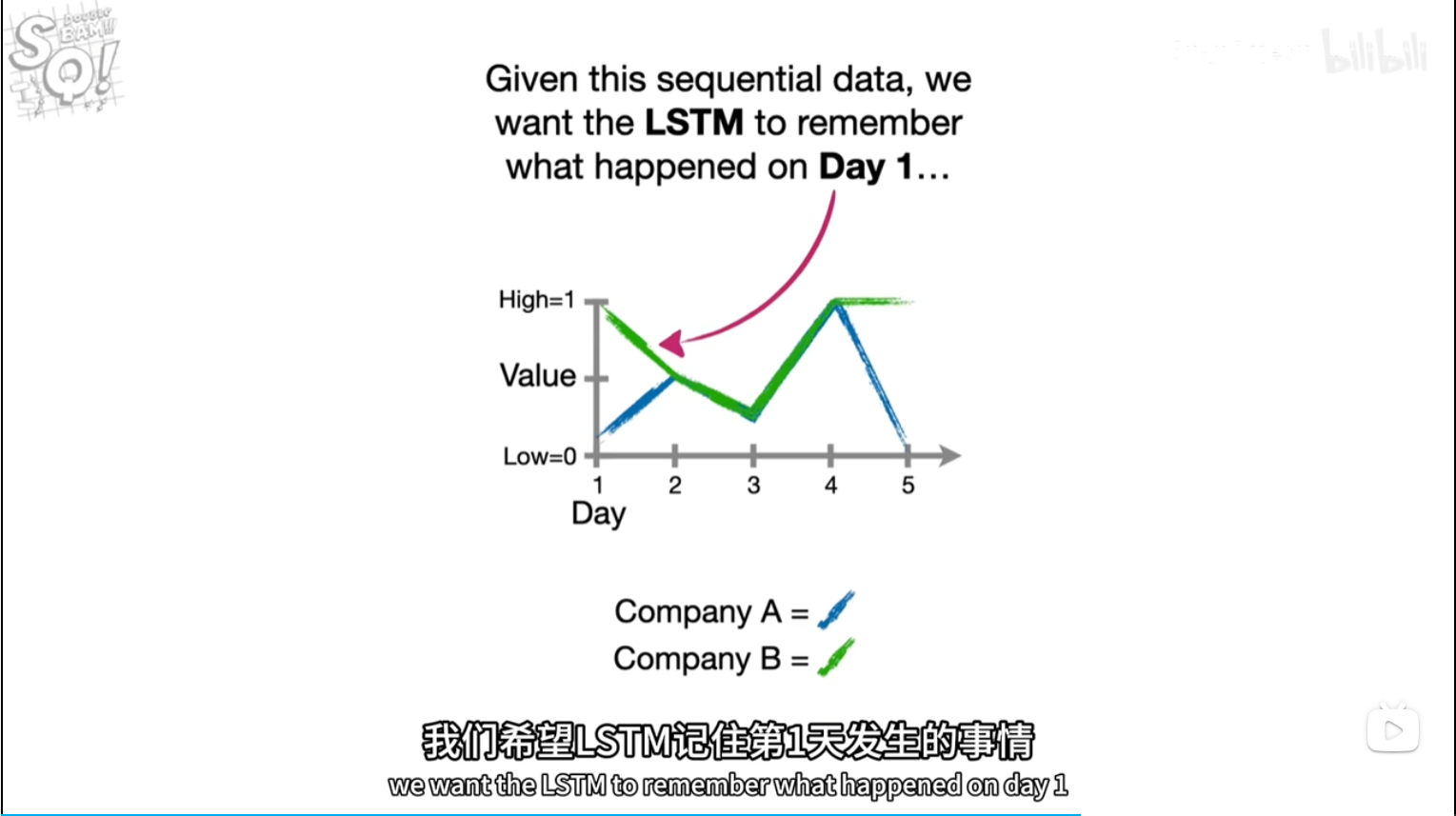
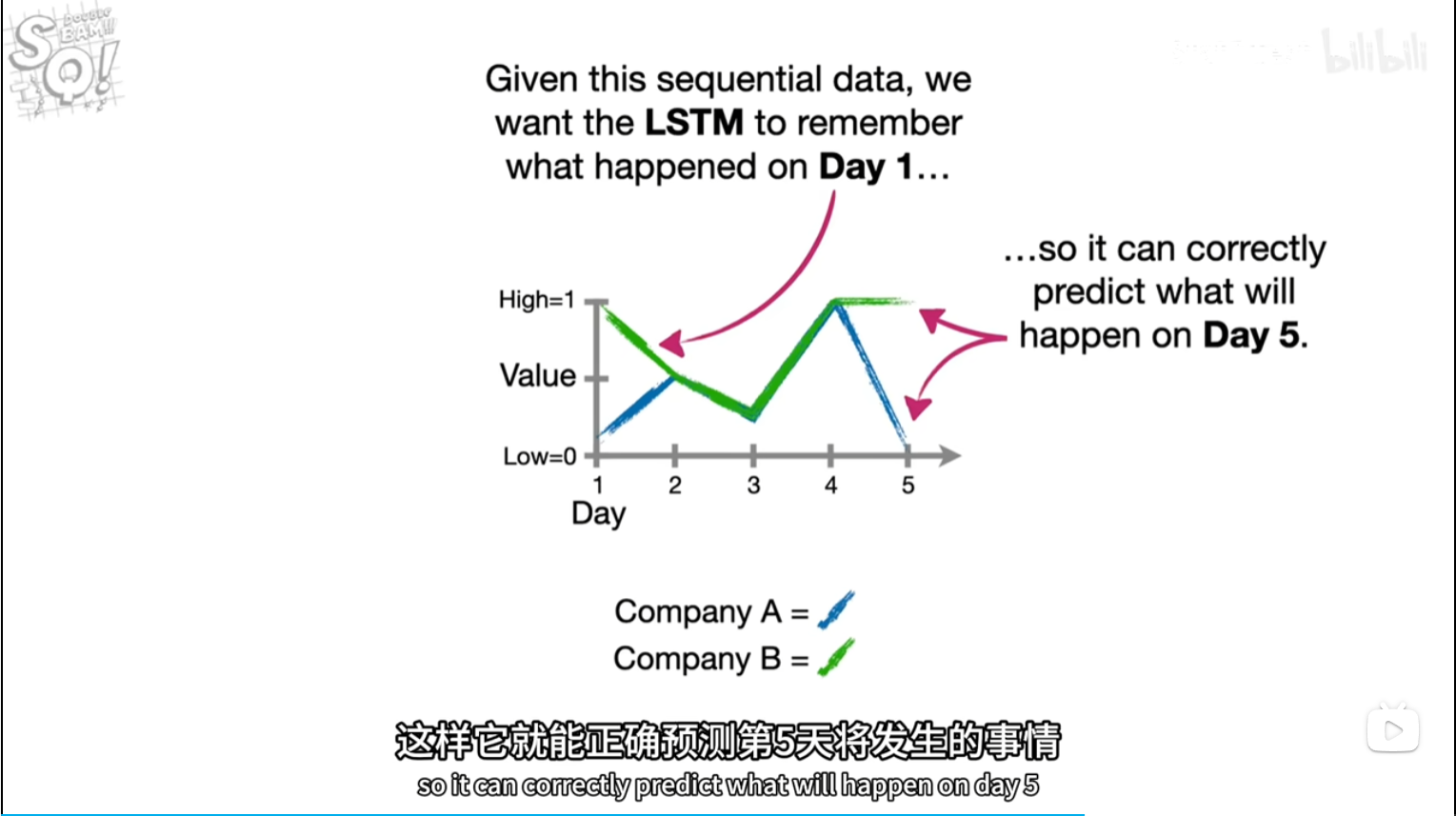
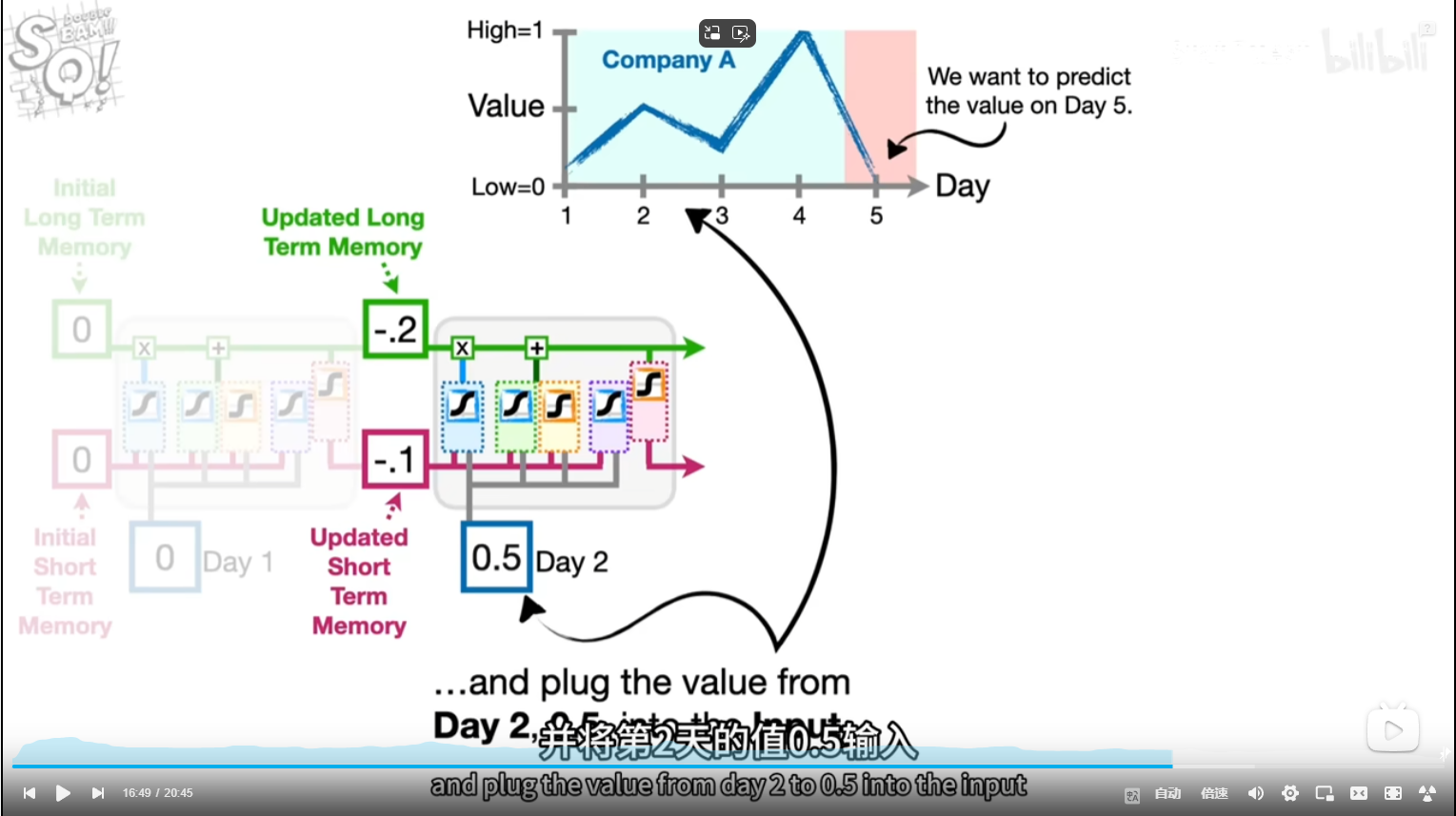
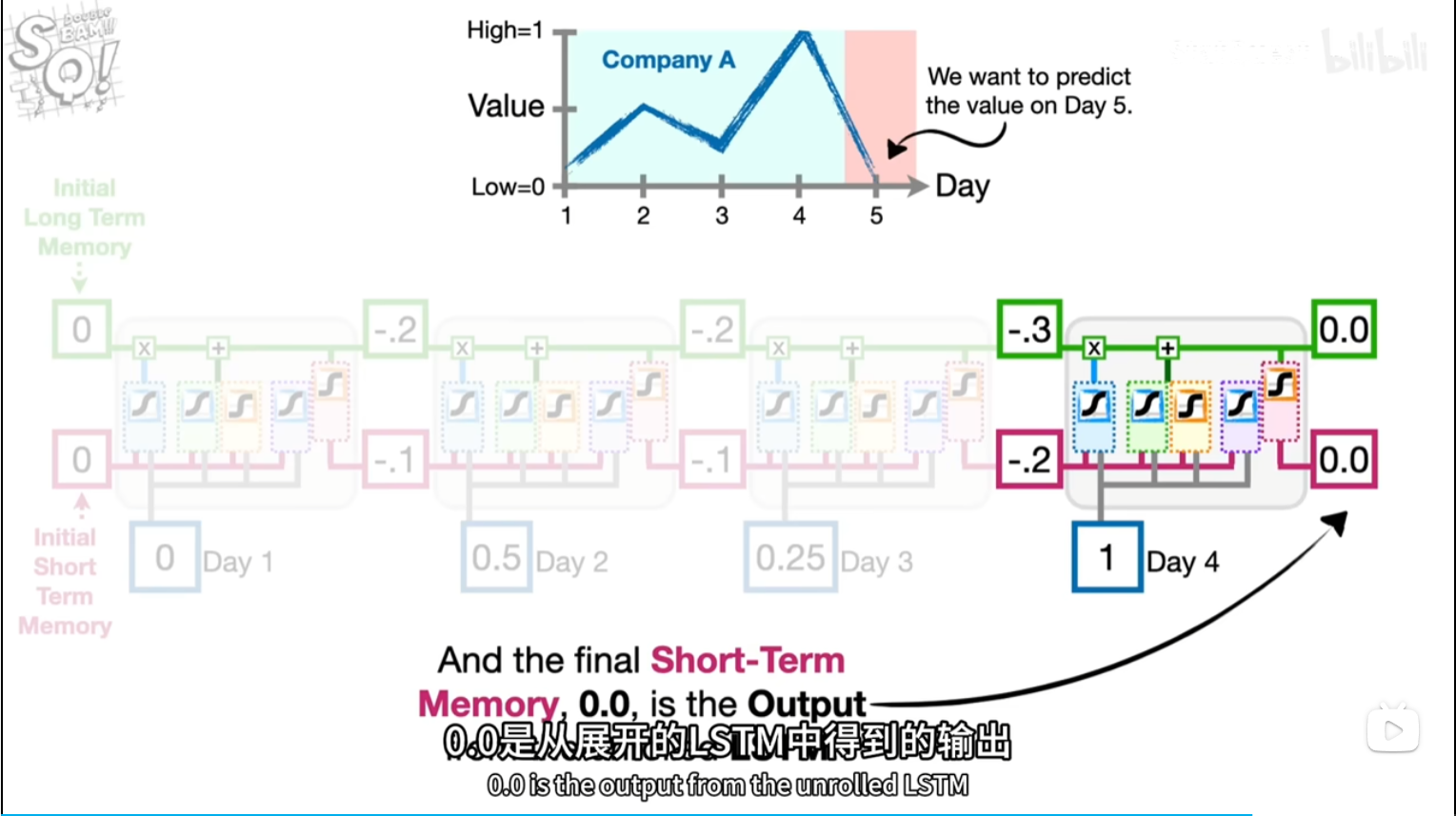
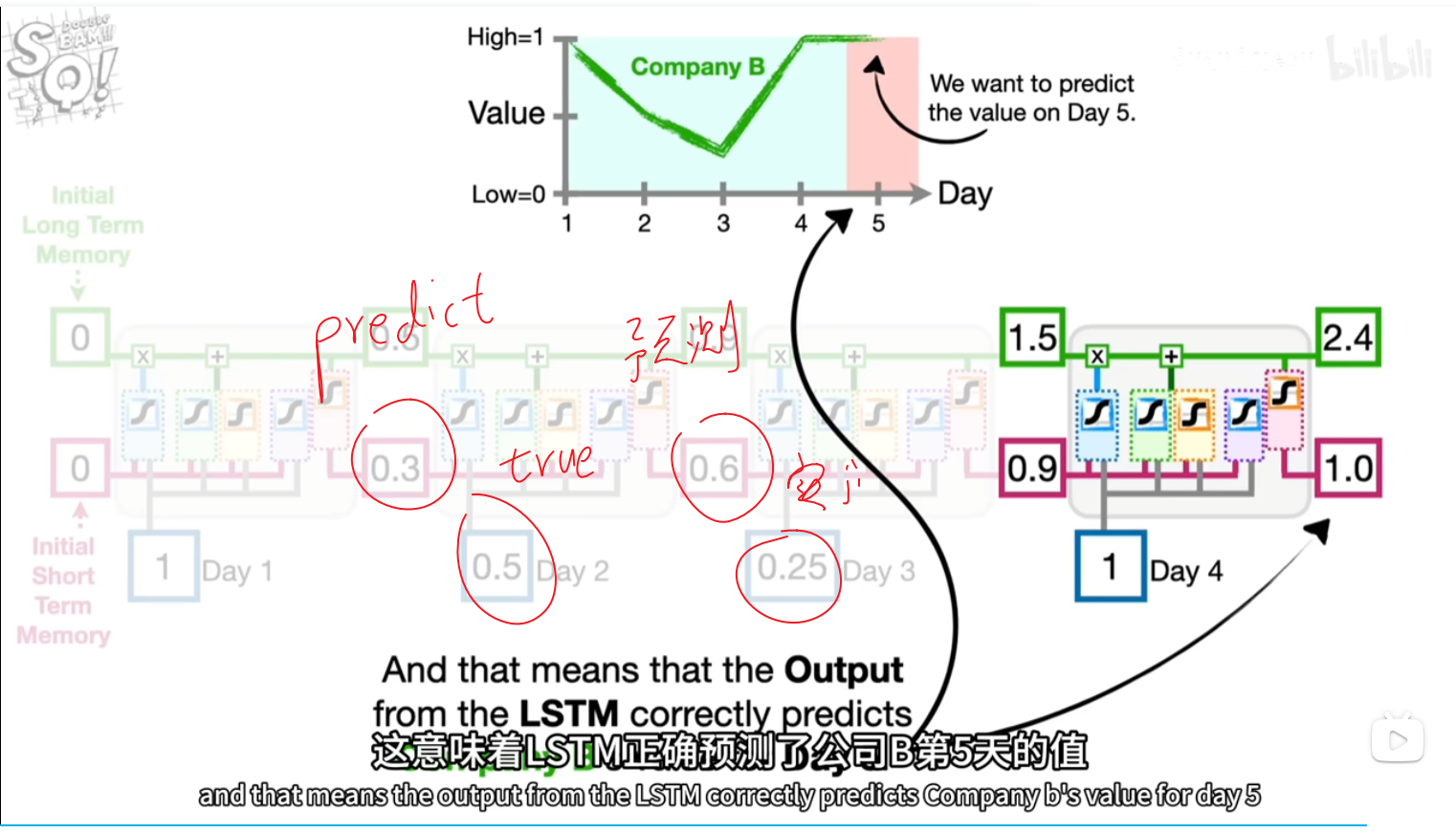
前几天都是乱预测(实际)

2. 信息流动方式
-
LSTM
-
顺序处理:信息是按时间步顺序传递的,每个单元的输出依赖于前一个单元的输出。
-
图示:
复制
x₁ → LSTM₁ → h₁ x₂ → LSTM₂ → h₂ x₃ → LSTM₃ → h₃ ... xₙ → LSTMₙ → hₙ每个LSTM单元的输出会影响下一个单元。
-
-
Transformer
-
并行处理:所有输入同时参与计算,通过注意力机制动态分配权重。
-
图示:
x₁, x₂, x₃, ..., xₙ → Transformer → y₁, y₂, y₃, ..., yₙ输入序列的所有元素同时被处理,输出也是并行生成的。
-
https://www.kaggle.com/code/alihhhjj/lstm-easy
import torch
import torch.nn as nn
import numpy as np# 设置随机种子以保证可重复性
torch.manual_seed(42)
np.random.seed(42)# 示例文本
text = "hello world"# 创建字符到索引的映射
chars = sorted(list(set(text)))
char_to_idx = {c: i for i, c in enumerate(chars)}
idx_to_char = {i: c for i, c in enumerate(chars)}# 数据准备
seq_length = 3
X = []
y = []for i in range(len(text) - seq_length):sequence = text[i:i+seq_length]label = text[i+seq_length]X.append([char_to_idx[c] for c in sequence])y.append(char_to_idx[label])# 转换为 tensor
X = torch.tensor(X, dtype=torch.long)
y = torch.tensor(y, dtype=torch.long)# 超参数
input_size = len(chars)
hidden_size = 128
output_size = len(chars)
num_layers = 1
batch_size = 1
sequence_length = seq_length
num_epochs = 100
learning_rate = 0.01# 定义 LSTM 模型
class LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers):super(LSTMModel, self).__init__()self.embedding = nn.Embedding(input_size, hidden_size)self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x, hidden):x = self.embedding(x) # shape: (batch, seq_len, hidden_size)out, hidden = self.lstm(x, hidden)out = self.fc(out[:, -1, :]) # 只取最后一个时间步的输出return out, hiddendef init_hidden(self, batch_size):return (torch.zeros(num_layers, batch_size, hidden_size),torch.zeros(num_layers, batch_size, hidden_size))# 初始化模型、损失函数和优化器
model = LSTMModel(input_size, hidden_size, output_size, num_layers)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# 训练模型
for epoch in range(num_epochs):total_loss = 0hidden = model.init_hidden(batch_size)for i in range(len(X)):inputs = X[i].unsqueeze(0) # shape: (1, seq_length)targets = y[i].unsqueeze(0) # shape: (1, )hidden = tuple(h.detach() for h in hidden) # 分离隐藏状态,防止梯度爆炸output, hidden = model(inputs, hidden)loss = criterion(output, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {total_loss:.4f}')# 预测函数
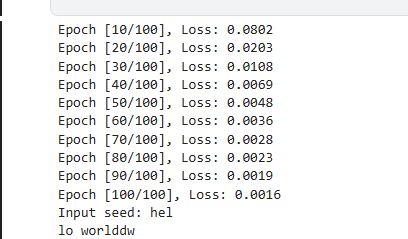
def predict(model, initial_seq, length=10):model.eval()with torch.no_grad():hidden = model.init_hidden(1)input_seq = torch.tensor(initial_seq, dtype=torch.long).unsqueeze(0) # (1, seq_len)print("Input seed:", ''.join([idx_to_char[i] for i in initial_seq]))for _ in range(length):output, hidden = model(input_seq, hidden)_, topi = output.topk(1)char = idx_to_char[topi.item()]print(char, end='')# 更新输入序列input_seq = torch.cat((input_seq[:, 1:], topi), dim=1)print()# 测试预测
predict(model, [char_to_idx[c] for c in "hel"])训练好快
你提到“训练怎么这么快”,这确实是一个很合理的疑问。在我们刚刚提供的 PyTorch 示例中,模型训练得非常快,而且可能在几十个 epoch 内就达到了较低的 loss。下面我来详细解释一下原因,并提供一些背景知识和优化建议。
🔍 为什么这个 LSTM 训练得这么快?
✅ 1. 数据集非常小
- 我们用的是
"hello world"这样的字符串(仅 11 个字符)。 - 模型只需要记住几个简单的模式,比如:
'h' -> 'e''el' -> 'l''ll' -> 'o'
- 因为训练样本极少,所以模型很容易“背下来”。
✅ 2. 任务很简单
- 预测下一个字符的任务,在这种重复性强、模式明确的小文本上非常容易。
- 没有歧义或复杂的上下文依赖。
✅ 3. 模型结构简单
- 只有一层 LSTM,参数量少。
- 使用了较小的
hidden_size(默认 128),计算开销小。
✅ 4. PyTorch 的高效性
- PyTorch 是一个高效的深度学习框架,尤其在 CPU 上运行小模型时速度很快。
- 没有使用 GPU 加速,反而更容易看出“训练速度快”的现象。
📈 如果你想让训练变慢/更真实,可以尝试以下方法:
🧪 A. 增加数据复杂度
python
深色版本
text = open("shakespeare.txt", encoding="utf-8").read()[:10000] # 读取一段莎士比亚文本📏 B. 增大序列长度
python
深色版本
seq_length = 10 # 更长的上下文需要更多推理🧠 C. 增加模型复杂度
python
深色版本
num_layers = 2 # 双层 LSTM
hidden_size = 256 # 更大的隐藏层🚀 D. 增加训练轮数
python
深色版本
num_epochs = 500 # 更多轮次以充分训练🧹 E. 添加 dropout 防止过拟合
python
深色版本
self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers, batch_first=True, dropout=0.5)🧪 示例:使用莎士比亚文本训练(可选)
你可以下载一个莎士比亚语料库(网上很多),例如:
bash
深色版本
wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt然后把上面代码中的 text = "hello world" 替换为:
python
深色版本
with open('input.txt', 'r') as f:text = f.read()这样模型就需要真正去“理解”语言模式,而不是死记硬背。
📊 总结
| 原因 | 说明 |
|---|---|
| 数据小 | "hello world" 只有几个字符,记忆即可 |
| 任务简单 | 字符预测无歧义,规律强 |
| 模型轻 | 单层 LSTM + 小隐藏单元 |
| 训练快 | PyTorch + 简单模型 + 小数据 |
✅ 如果你希望我把上面的示例扩展成一个更真实的 LSTM 字符预测器(比如支持批量训练、GPU 加速、保存模型等),欢迎继续提问!
是否需要我帮你改造成一个更完整的 LSTM 文本生成器?比如支持:
- 批量训练
- GPU 支持 (
cuda) - 模型保存与加载
- 生成任意长度的文本
- 使用更大语料(如莎士比亚)进行训练
只要你说,我可以一步步带你实现!
这是一个非常好的问题!
你问的这行代码:
python
深色版本
chars = sorted(list(set(text)))❌ 这不是 Embedding,而是字符的 词汇表构建(vocabulary building)。
🧠 逐步解释:
✅ 1. chars = sorted(list(set(text))) 的作用:
text是原始文本字符串。set(text):提取所有唯一字符。list(...):转换为列表。sorted(...):排序,保证顺序一致。
➡️ 最终得到一个包含所有不同字符的有序列表。例如:
python
深色版本
text = "hello world"
chars = [' ', 'd', 'e', 'h', 'l', 'o', 'r', 'w']这只是在建立“字符到索引”的映射前的第一步。
✅ 2. 然后我们创建字符与索引之间的映射:
python
深色版本
char_to_idx = {c: i for i, c in enumerate(chars)}
idx_to_char = {i: c for i, c in enumerate(chars)}这一步是将每个字符对应成一个唯一的整数编号,这是 NLP 中常见的做法,叫做 tokenization(分词) 或者更准确地说,字符级编码。
🔁 那么 Embedding 是什么?
在深度学习中,尤其是处理自然语言时,Embedding 指的是:
将离散的符号(比如字符、单词)映射为连续向量空间中的向量。
📦 PyTorch 中的 nn.Embedding
python
深色版本
self.embedding = nn.Embedding(input_size, hidden_size)input_size:你的字符种类数量(如上面的例子是 8)。hidden_size:你想把每个字符映射成多长的向量(比如 128 维)。
这个层的作用就是:
输入是一个字符的索引(如
3),输出是一个对应的嵌入向量(如[0.1, -0.5, ..., 0.7])
🧩 总结一下它们的关系:
| 步骤 | 名称 | 是否是 Embedding | 说明 |
|---|---|---|---|
set(text) / sorted(...) | 构建字符集合 | ❌ | 只是去重和排序 |
char_to_idx | 建立字符到索引的映射 | ❌ | tokenization,还不是 embedding |
nn.Embedding 层 | 字符嵌入层 | ✅ | 才是真正的 Embedding |
🎯 类比理解:
你可以把它们想象成:
- 字典编纂(
char_to_idx):- 就像给每个汉字标上页码。
- 查字典(
nn.Embedding):- 就是根据页码真正去读取那一页的内容(即向量)。
✅ 示例总结:
python
深色版本
text = "hello world"# Step 1: 构建字符集(不是 embedding)
chars = sorted(list(set(text)))# Step 2: 创建字符到索引的映射(tokenization)
char_to_idx = {c: i for i, c in enumerate(chars)}# Step 3: 使用 embedding 层将字符索引转为向量(这才是真正的 embedding)
embedding_layer = nn.Embedding(num_embeddings=len(chars), embedding_dim=16)# 举例:将字符 'h' 转换为 embedding 向量
h_index = char_to_idx['h']
h_vector = embedding_layer(torch.tensor(h_index))
print(h_vector) # 输出一个长度为 16 的向量如果你还想了解更多关于字符 Embedding 和 Word Embedding 的区别(比如字符 vs 单词级别)、或者想了解如何用预训练的 Embedding(如 GloVe、Char2Vec),我也可以继续为你讲解!欢迎继续提问 😊
中文版本
import torch
import torch.nn as nn
import numpy as np# 设置随机种子以保证可重复性
torch.manual_seed(42)
np.random.seed(42)# 如果有 GPU 就使用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')# 示例中文文本
text = """你好世界,这是一个简单的中文LSTM示例。我们将训练一个模型来预测下一个中文字符。
这个例子展示了如何在PyTorch中构建和训练一个LSTM语言模型。"""# Step 1: 创建字符到索引的映射
chars = sorted(list(set(text)))
char_to_idx = {c: i for i, c in enumerate(chars)}
idx_to_char = {i: c for i, c in enumerate(chars)}# 超参数
input_size = len(chars) # 字符种类数量
hidden_size = 128 # LSTM 隐藏层大小
output_size = len(chars) # 输出也是字符种类数量
num_layers = 1 # LSTM 层数
seq_length = 5 # 输入序列长度
batch_size = 1 # 批量大小(单样本训练)
num_epochs = 200 # 训练轮数
learning_rate = 0.01 # 学习率# Step 2: 准备训练数据
X = []
y = []for i in range(len(text) - seq_length):sequence = text[i:i+seq_length]label = text[i+seq_length]X.append([char_to_idx[c] for c in sequence])y.append(char_to_idx[label])X = torch.tensor(X, dtype=torch.long).to(device)
y = torch.tensor(y, dtype=torch.long).to(device)# Step 3: 定义 LSTM 模型
class LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers):super(LSTMModel, self).__init__()self.embedding = nn.Embedding(input_size, hidden_size)self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x, hidden):x = self.embedding(x) # (batch, seq_len, hidden_size)out, hidden = self.lstm(x, hidden)out = self.fc(out[:, -1, :]) # 只取最后一个时间步的输出return out, hiddendef init_hidden(self, batch_size):return (torch.zeros(num_layers, batch_size, hidden_size).to(device),torch.zeros(num_layers, batch_size, hidden_size).to(device))# Step 4: 初始化模型、损失函数和优化器
model = LSTMModel(input_size, hidden_size, output_size, num_layers).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# Step 5: 开始训练
for epoch in range(num_epochs):model.train()total_loss = 0hidden = model.init_hidden(batch_size)for i in range(len(X)):inputs = X[i].unsqueeze(0) # shape: (1, seq_length)targets = y[i].unsqueeze(0) # shape: (1, )hidden = tuple(h.detach() for h in hidden)outputs, hidden = model(inputs, hidden)loss = criterion(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {total_loss:.4f}')# Step 6: 预测函数
def predict(model, initial_seq, length=20):model.eval()with torch.no_grad():hidden = model.init_hidden(1)input_seq = torch.tensor(initial_seq, dtype=torch.long).unsqueeze(0).to(device) # (1, seq_len)print("\nInput seed:", ''.join([idx_to_char[i] for i in initial_seq]))generated_text = []for _ in range(length):output, hidden = model(input_seq, hidden)_, topi = output.topk(1)char = idx_to_char[topi.item()]generated_text.append(char)# 更新输入序列input_seq = torch.cat((input_seq[:, 1:], topi), dim=1)print('Generated:', ''.join(generated_text))# Step 7: 测试预测
seed = [char_to_idx[c] for c in "简单"]
predict(model, seed)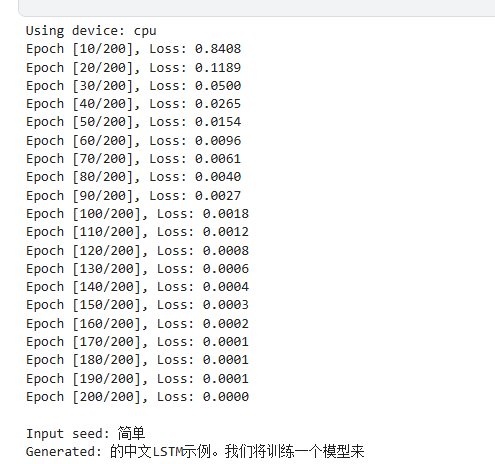
复读机
为了减少“复读机”效应,并让模型生成更具创意性和多样性的文本,你可以考虑以下改进:
- 增加模型复杂度:尝试增加LSTM层数或者每层的神经元数量。
- 扩大训练数据集:使用更大的文本库进行训练,比如整部小说或者新闻文章集合。
- 正则化:引入Dropout层可以帮助防止过拟合,使得模型不会仅仅记忆训练数据。
- 调整采样策略:通过调整softmax输出的概率分布(例如降低温度值),可以在保持一定准确性的同时增加输出的随机性。
- 早期停止(Early Stopping):监控验证集上的性能,在性能不再提升时停止训练,避免过度拟合训练数据
这个lstm就是一个拼凑哥,它不知道上下文,但是它知道谁和谁拼在一起
有点像小学生乱背
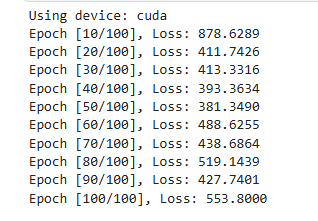
从你提供的损失值来看,模型的训练过程似乎并不稳定,并且没有表现出明显的下降趋势。这可能是因为你的数据集中存在同一个前缀输入对应多个不同后缀输出的情况,这种情况下模型可能会面临一些挑战。
问题分析
- 数据多样性:如果同一个前缀输入对应多个不同的后缀输出,模型需要学习到这些不同的模式,这会增加训练难度。
- 过拟合或欠拟合:损失值不稳定可能是由于模型过拟合或欠拟合导致的。过拟合时,模型在训练集上表现很好但在验证集上表现差;欠拟合时,模型无法很好地捕捉数据中的模式。
- 超参数选择:学习率、隐藏层大小、批次大小等超参数的选择不当也可能导致训练不稳定。
- 梯度爆炸或消失:LSTM网络容易出现梯度爆炸或消失的问题,特别是在处理长序列时。
解决方案
1. 数据预处理和增强
- 数据平衡:确保每个前缀输入对应的后缀输出分布相对均衡,避免某些模式过于稀少。
- 数据增强:可以通过生成更多的训练样本或者使用数据增强技术来增加数据的多样性。
2. 调整模型结构和超参数
- 调整学习率:尝试使用更小的学习率,或者使用学习率调度器(如ReduceLROnPlateau)来动态调整学习率。
- 增加模型容量:适当增加隐藏层大小或层数,以提高模型的表达能力。
- 正则化:使用Dropout、L2正则化等方法防止过拟合。
- 批量归一化:在模型中加入BatchNorm层,有助于加速训练和提高模型稳定性。
3. 使用更稳定的优化器
- AdamW:相比于传统的Adam优化器,AdamW在权重衰减方面有更好的表现。
- RMSprop:对于LSTM网络,RMSprop也是一个不错的选择。
4. 梯度裁剪
- 梯度裁剪:通过限制梯度的范数来防止梯度爆炸,可以设置一个阈值,当梯度超过这个阈值时进行裁剪。
5. 添加注意力机制
- 注意力机制:可以帮助模型更好地关注输入序列中的重要部分,提高模型的性能。
示例代码调整
以下是对你之前的代码进行的一些调整,包括添加梯度裁剪、调整学习率和使用AdamW优化器:
在使用LSTM(长短期记忆网络)进行文本生成时,同一个句号后面可以跟不同的输出,这主要是由于以下几个原因:
1. 语言的多样性与上下文依赖性
- 多义性和歧义性:自然语言具有丰富的多样性和歧义性。同一个句子或短语在不同的上下文中可能有不同的含义和后续内容。例如,“简单”这个词,在不同的句子中可能表达不同的意思,因此其后的文本也会有所不同。
- 风格和语气:不同的人在表达相同的意思时,可能会有不同的风格和语气,这也导致了同一个句号后面可以有多种合理的后续内容。
2. 模型的随机性和不确定性
- 采样策略:在生成文本时,通常会采用某种采样策略来决定下一个字符或词。常见的采样策略包括贪心搜索、束搜索和基于概率分布的采样等。这些策略引入了一定的随机性和不确定性,使得同一个输入可以生成不同的输出。
- 温度参数:在基于概率分布的采样中,通常会使用一个温度参数来控制生成结果的多样性。较高的温度值会使生成结果更加多样化,而较低的温度值则会使生成结果更加保守和确定。
3. 模型训练数据的多样性
- 训练数据的影响:LSTM模型的训练数据决定了它能够学习到的语言模式和规律。如果训练数据中包含了大量的不同上下文和风格的文本,那么模型就有可能学会在同一个句号后面生成不同的输出。
- 数据分布:训练数据的分布也会影响模型的生成结果。如果训练数据中某个特定的上下文出现得较多,那么模型在遇到类似上下文时,更倾向于生成类似的后续内容。
4. 模型内部状态的影响
- 隐藏状态和细胞状态:LSTM模型通过隐藏状态和细胞状态来捕捉历史信息,并将其用于当前时刻的预测。即使输入相同,但由于模型内部状态的不同,也可能导致不同的输出。
- 初始状态:在生成文本时,模型的初始状态(即第一个时间步的隐藏状态和细胞状态)也会影响生成结果。不同的初始状态可能导致不同的生成路径。
示例解释
在你提供的示例中:
深色版本
Input seed: 简单
Generated: 的中文 LSTM示例。我们将训练一个模型来预测下一个中文字符。
这个例子展示了如何在PyTorch中构- 输入种子“简单”:作为起始点,模型根据训练过程中学到的语言模式和规律,开始生成后续文本。
- 生成结果:由于上述提到的原因,同一个输入种子“简单”在不同的生成过程中,可能会得到不同的后续文本。例如,模型可能会生成关于“简单”的不同描述、应用场景或者相关概念等内容。
总结
总之,LSTM模型能够在同一个句号后面生成不同的输出,这是由语言本身的多样性和上下文依赖性、模型的随机性和不确定性、训练数据的多样性和模型内部状态的影响等多种因素共同作用的结果。
问得很好!
❓问题澄清:
你说的“他是把生成的所有句子一起当输入是吗?”——这里的“他”如果指的是LSTM语言模型,那不是把“生成的所有句子”作为输入。
🔍 LSTM 文本生成模型是怎么工作的?
我们来一步步解释 LSTM 是如何生成文本的:
✅ 1. 训练阶段:使用原始语料库进行学习
在训练阶段,LSTM 模型看到的是你提供的训练数据中的每一个字符序列。例如:
text
深色版本
"简单是一种美德"
"简单来说,这个模型很强大"我们会把这些句子切分成一个个小片段(比如长度为5):
| 输入 (X) | 输出 (y) |
|---|---|
| "简单是" | "一" |
| "单是一" | "种" |
| "一种美" | "德" |
| ... | ... |
这样,LSTM 就学会了:“当我看到‘简单是’这几个字时,下一个字可能是‘一’”。
✅ 2. 推理阶段:逐个字符生成新内容
在推理阶段(也就是你调用 predict() 函数的时候),LSTM 并不是一次性把所有句子都当成输入。
它的工作流程如下:
🧠 Step-by-step 推理过程:
- 给定一个种子输入(如:"简单")
- 模型预测下一个最可能的字符
- 把这个字符加到输出中,并作为新的输入的一部分
- 滑动窗口,继续预测下一个字符
举个例子:
| 当前输入 | 预测下一个字符 | 新的输入 |
|---|---|---|
| "简单" | "是" | "简单是" |
| "简单是" | "一" | "单是一" |
| "单是一" | "种" | "一种美" |
| ... | ... | ... |
➡️ 所以,LSTM 是一步一步地生成字符,而不是一次性看到所有句子。
🤔 那么为什么同一个前缀会生成不同结果?
这是因为在推理时,我们可以选择不同的采样策略:
✅ 常见采样方法有:
| 方法 | 特点 | 是否每次都一样? |
|---|---|---|
| 贪心采样(Greedy) | 总是选概率最高的字符 | ✅ 是 |
| 温度采样(Temperature Sampling) | 引入随机性,控制多样性 | ❌ 否 |
| Top-k / Nucleus Sampling | 只从高概率词中采样 | ❌ 否 |
所以如果你用了温度采样等非确定性策略,即使输入相同,输出也可能不一样。
✅ 总结一句话:
LSTM 在生成文本时,并不是一次性把“所有句子”当作输入,而是根据当前已有的上下文,一步一步预测下一个字符或词语,并通过不断更新输入来生成完整句子。
如果你想了解:
- 如何修改采样策略来控制生成多样性
- 如何实现批量生成、Beam Search、Top-k Sampling
- 如何保存和加载模型
欢迎继续提问,我可以为你详细讲解 😊
在你的代码中,滑动窗口的长度由变量 seq_length 指定。
回答你的问题:
滑动窗口是多长?
✅ 滑动窗口长度是:10
🔍 来源分析:
你在代码中定义了如下超参数:
python
深色版本
seq_length = 10 # 更长的上下文这表示模型每次输入的字符序列长度为 10。也就是说,LSTM 每次看到的是连续的 10 个字符,用来预测第 11 个字符。
🧠 滑动窗口是如何工作的?
在准备训练数据时,你使用了如下方式构建输入输出对:
python
深色版本
for i in range(len(text) - seq_length):sequence = text[i:i+seq_length] # 取长度为 seq_length 的窗口label = text[i+seq_length] # 预测下一个字符举个例子,如果原始文本是:
深色版本
"这是一个简单的测试"那么滑动窗口会生成这样的样本:
| 输入 (X) | 输出 (y) |
|---|---|
| "这是一个个简" | "单" |
| "是一个简单测" | "试" |
| ... | ... |
每次窗口向右滑动一个字符,形成一个新的训练样本。
📌 在推理阶段也保持相同窗口长度
在 predict() 函数中,你也使用了相同的 seq_length(即 10)作为初始输入长度:
python
深色版本
input_seq = torch.tensor(initial_seq, dtype=torch.long).unsqueeze(0)
# 每次预测后更新输入:保留最后 seq_length - 1 个字符 + 新字符
input_seq = torch.cat((input_seq[:, 1:], ...), dim=1)所以,推理时也是每次保留最近的 10 个字符作为输入。
预测的时候同一个输入可以有不同输出,如果输入文字少,文本大的话
相关文章:
lstm 长短期记忆 视频截图 kaggle示例
【官方双语】LSTM(长短期记忆神经网络)最简单清晰的解释来了!_哔哩哔哩_bilibili . [short,input]*[2.7,1.63]b5.95 换参数和激活函数 tan激活函数输出带正负符号的百分比 tanx公式长这样? 潜在短期记忆 前几天都是乱预测…...

Spring Advisor增强规则实现原理介绍
Spring Advisor增强规则实现原理介绍 一、什么是 Advisor?1. Advisor 的定义与本质接口定义: 2. Advisor 的核心作用统一封装切点与通知构建拦截器链的基础实现增强逻辑的灵活组合 二. Sprin当中的实现逻辑1 Advisor 接口定义2 PointcutAdvisor 接口定义…...
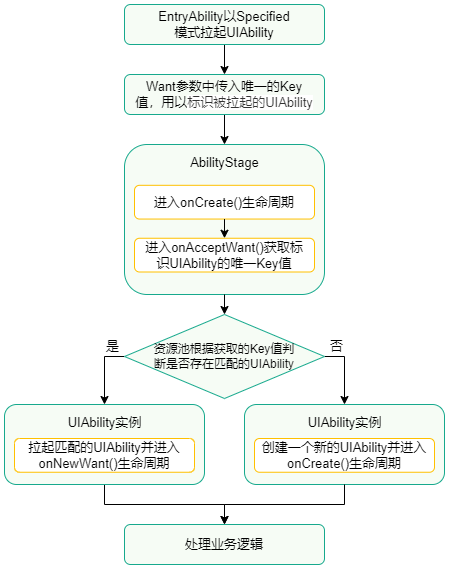
【HarmonyOS 5】鸿蒙中的UIAbility详解(二)
【HarmonyOS 5】鸿蒙中的UIAbility详解(二) 一、前言 今天我们继续深入讲解UIAbility,根据下图可知,在鸿蒙中UIAbility继承于Ability,开发者无法直接继承Ability。只能使用其两个子类:UIAbility和Extensi…...
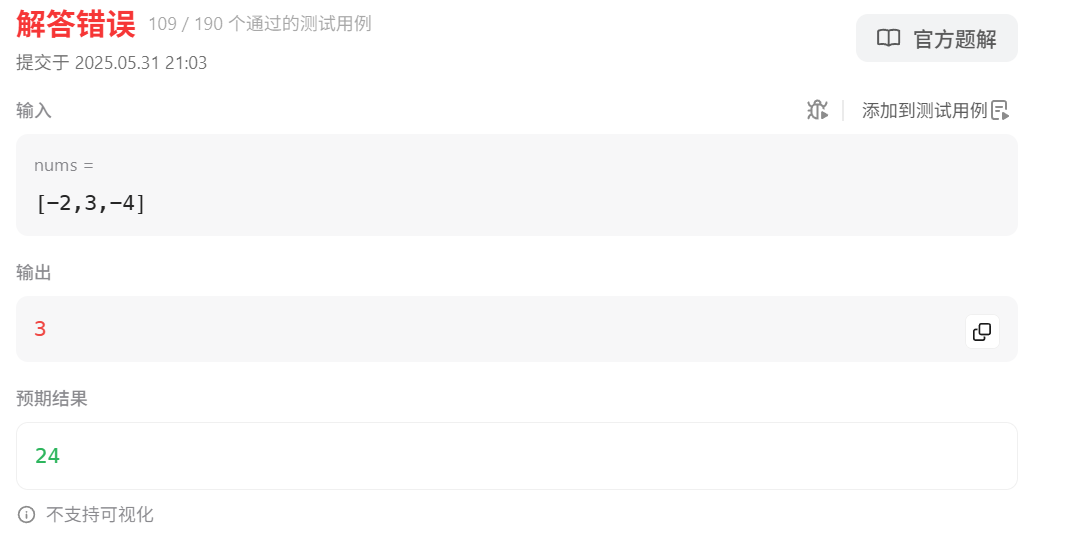
力扣HOT100之动态规划:152. 乘积最大子数组
这道题并不是代码随想录里的,我试着用动规五部曲来做,然后不能通过全部测试样例,在第109个测试样例卡住了,如下所示。 原因是可能负数乘以负数会得到最大的乘积,不能单纯地用上一个序列的最大值乘以当前值来判断是否能…...

Java后端技术栈问题排查实战:Spring Boot启动慢、Redis缓存击穿与Kafka消费堆积
Java后端技术栈问题排查实战:Spring Boot启动慢、Redis缓存击穿与Kafka消费堆积 引言 在现代互联网大厂中,Java后端系统因为其复杂性和多样性,常常面临各种问题和挑战。从核心语言到微服务架构,从数据库到缓存,不同层…...

定制开发开源AI智能名片S2B2C商城小程序:数字营销时代的话语权重构
摘要:在数据驱动的数字营销时代,企业营销话语权正从传统媒体向掌握用户数据与技术的平台转移。本文基于“数据即权力”的核心逻辑,分析定制开发开源AI智能名片S2B2C商城小程序如何通过技术赋能、场景重构与生态协同,帮助企业重构营…...
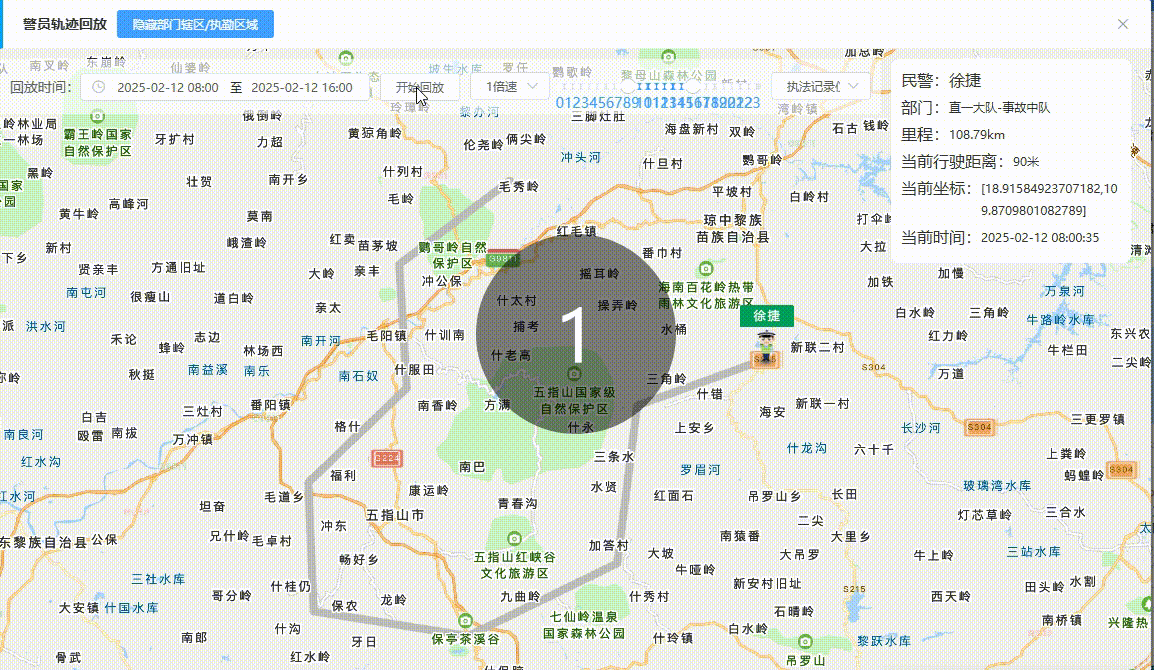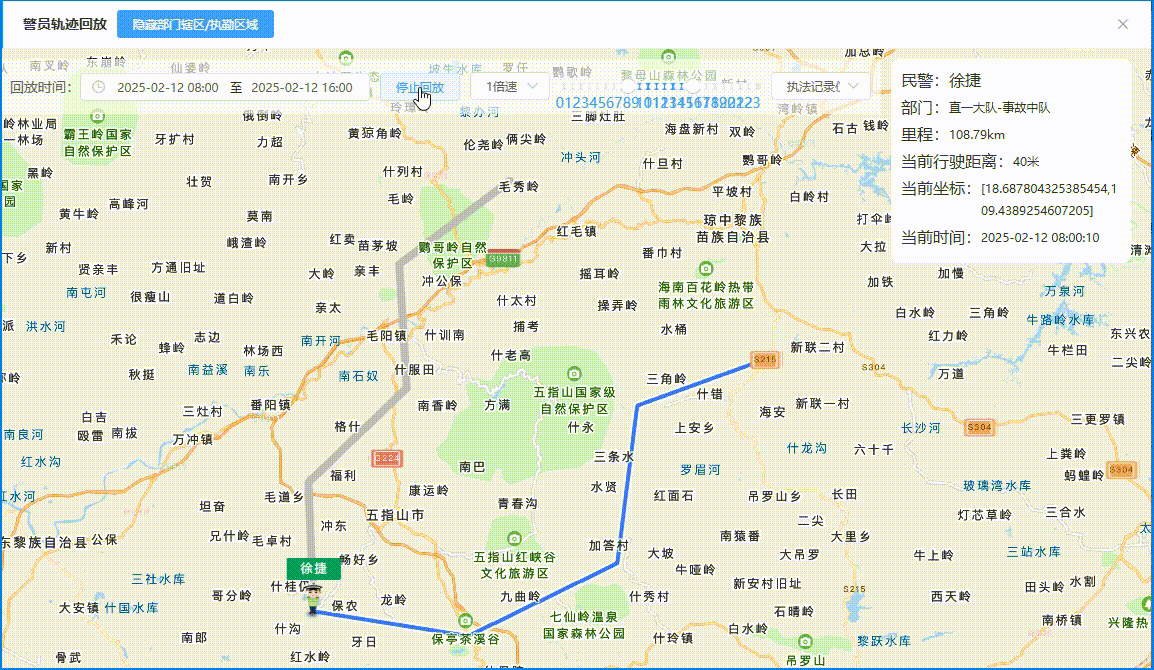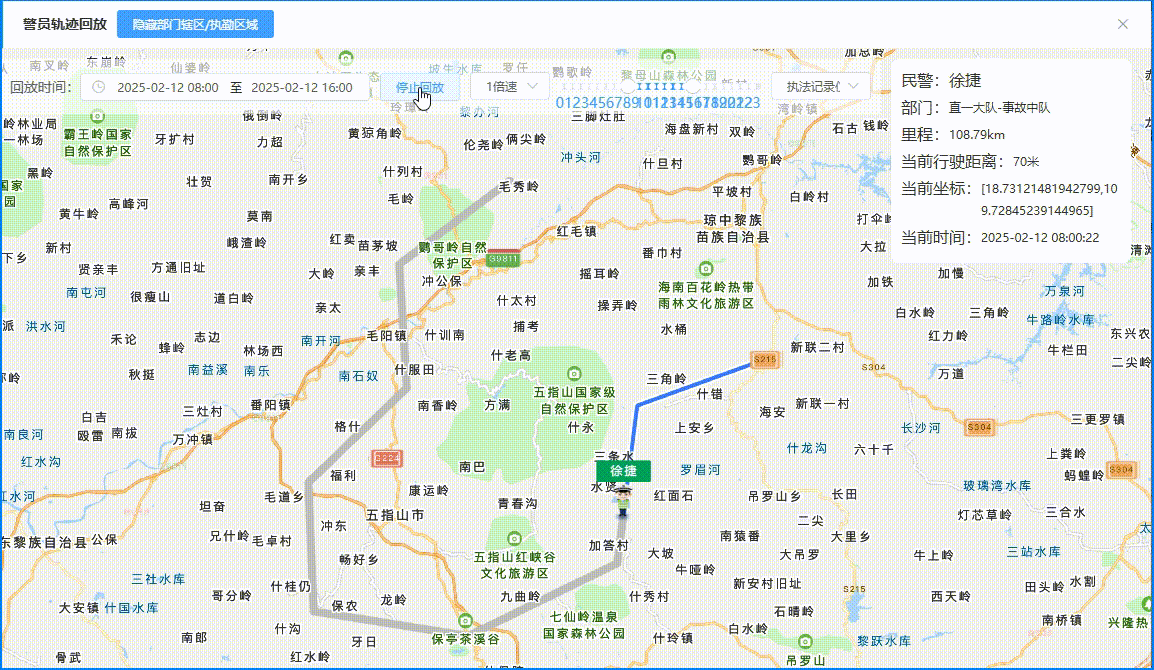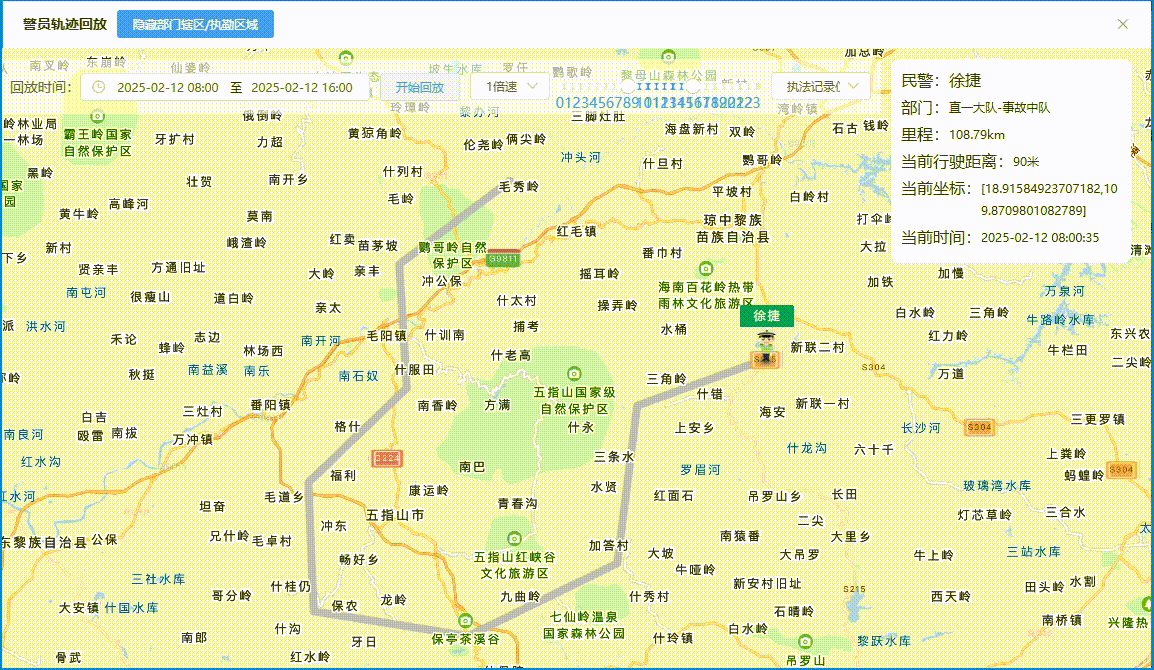
【面试 - 遇到的问题 - 优化 - 地图】腾讯地图轨迹回放 - 回放的轨迹时间要和现实时间对应(非匀速)
目录 背景轨迹回放 - 匀速效果图TrackPlaybackDialog.vue 代码TMapNew.vue 代码 轨迹回放 - 非匀速效果图TrackPlaybackDialog.vue 代码TMapNew.vue 代码 背景 腾讯地图轨迹回放是匀速回放的,但是客户要求根据现实时间,什么时间点在某个点位 【腾讯地图轨…...

ffmpeg baidu
ffmpeg -list_devices true -f dshow -i dummy 获取你的音频输入设备(麦克风)名称 输出中可以看到你有如下两个可用麦克风设备: “麦克风阵列 (适用于数字麦克风的英特尔 智音技术)” “外部麦克风 (Realtek Audio)” (注意&…...

spring boot 拦截器HandlerInterceptor 不生效的原因排查
public class UserInterceptor implements HandlerInterceptor项目添加一个拦截器,发现未生效 1、排查拦截本身是否注入了springbean 容器 Slf4j Component public class LoginInterceptor implements HandlerInterceptor {2、排查springboot 项目扫描范围是否包含…...

公网ip怎么申请和使用?本地只有内网IP如何提供外网访问?
在当今的网络时代,许多程序和服务都依赖于公网地址——用于标识设备在互联网位置的全球唯一标识符。例如,办公网站、FTP服务器或游戏服务器等需要借助公网IP来确保用户可以访问。故此准确获取公网IP地址显得尤为重要。 在大多家庭和企业网络中ÿ…...

将git最后一次提交把涉及到的文件按原来目录结构提取出来
文章目录 前言一、将git最后一次提交把涉及到的文件按原来目录结构提取出来 前言 将git最后一次的提交提取出来,涉及到的目录结构以及文件等,按原本的目录结构复制输出。并输出相关的补丁。 一、将git最后一次提交把涉及到的文件按原来目录结构提取出来…...

利用计算机模拟和玉米壳废料开发新型抗病毒药物合成方法
参阅:Top 创新大奖 这个课题将农业废弃物资源化利用、计算机辅助药物设计和绿色化学完美结合,是一个极具创新性和应用前景的研究方向! 以下是如何利用计算机模拟和玉米壳废料开发新型抗病毒药物合成方法的系统思路: 核心思路 玉…...

【Docker】存储卷
【简介】 宿主机的某一目录与容器中的某一目录建立的一种绑定关系,这就是“存储卷” 它有三个特性 1.它可以绕过联合文件系统, 直接作用于宿主机的目录 2.容器和宿主机的这一绑定关系指向了同一目录, 因此两个目录之间的数据是同步的…...

Python 爬虫工具 BeautifulSoup
文章目录 1. BeautifulSoup 概述1.1. 安装 2. 对象的种类2.1. BeautifulSoup2.2. NavigableString(字符串)2.3. Comment2.4. Tag2.4.1. 获取标签的名称2.4.2. 获取标签的属性2.4.3. 获取标签的内容2.4.3.1. tag.string2.4.3.2. tag.strings2.4.3.3. tag.…...
)
WPF的布局核心:网格布局(Grid)
网格布局(Grid) 1 行列定义(RowDefinitions & ColumnDefinitions)2 Grid.Row和Grid.Column3 跨行跨列(Grid.RowSpan & Grid.ColumnSpan)3.1垂直跨行3.2水平跨列3.3综合应用案例 4 高级布局技巧4.1共…...

OpenCV图像认知(二)
形态学变换: 核: 核(kernel)其实就是一个小区域,通常为3*3、5*5、7*7大小,有着其自己的结构,比如矩形结构、椭圆结构、十字形结构,如下图所示。通过不同的结构可以对不同特征的图像…...

大数据与数据分析【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 100 篇 - Date: 2025 - 05 - 25 Author: 郑龙浩/仟墨 大数据与数据分析 文章目录 大数据与数据分析一 大数据是什么?1 定义2 大数据的来源3 大数据4个方面的典型特征(4V)4 大数据的应用领域5 数据分析工具6 数据是五种生产要素之一 二 …...
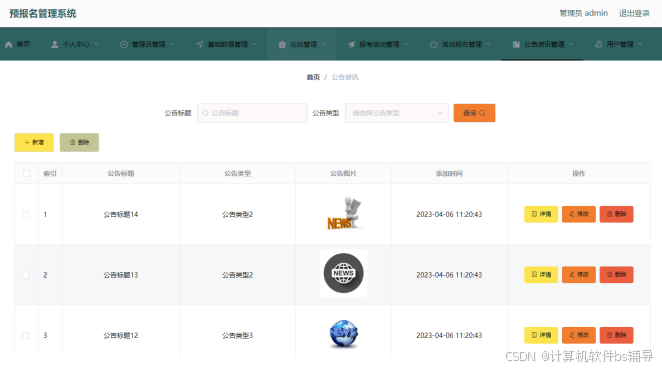
t015-预报名管理系统设计与实现 【含源码!!!】
项目演示地址 摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装预报名管理系统软件来发挥其高效地信息处理的…...
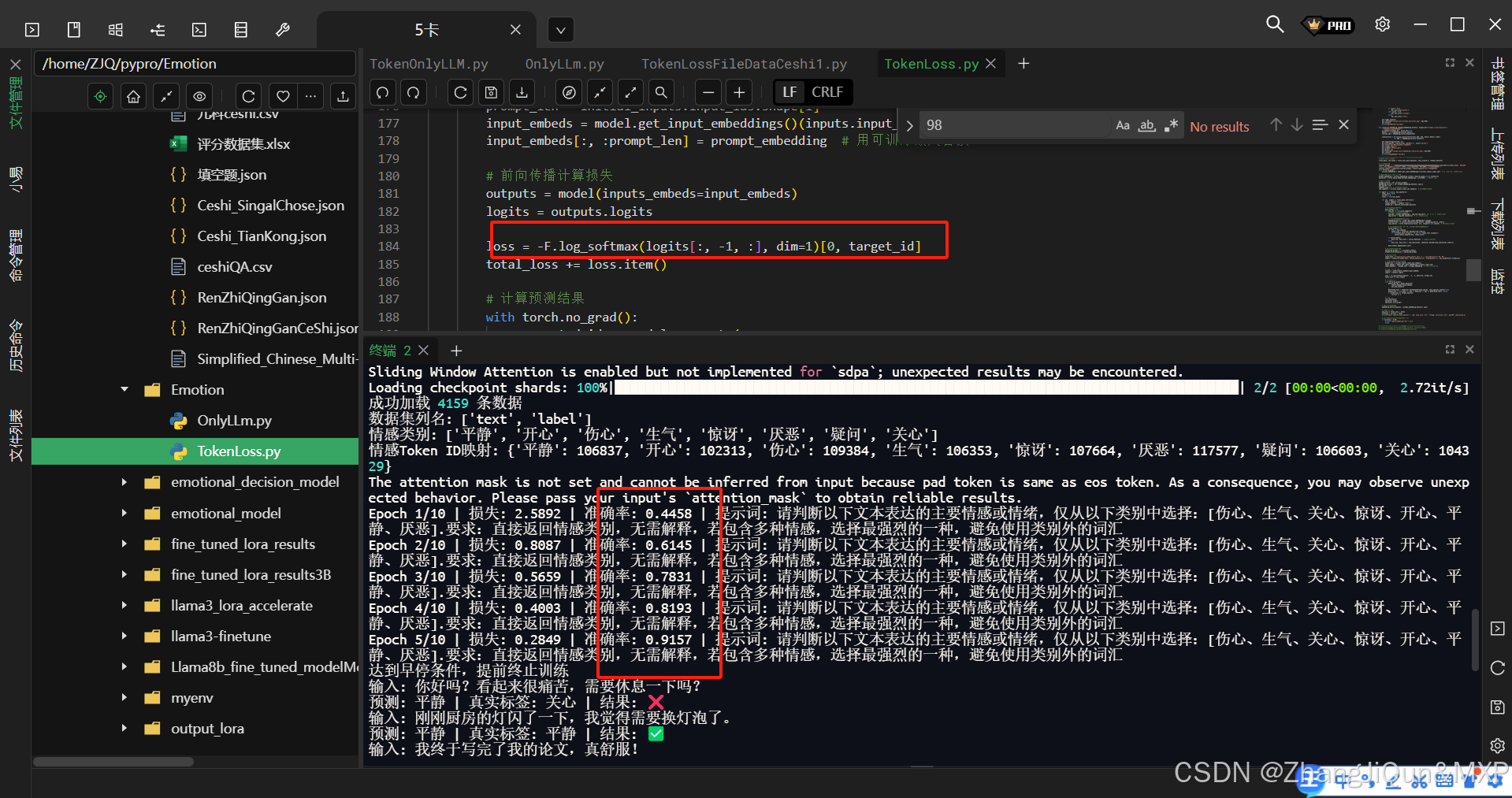
LLM中的Loss与Logits详解
LLM中的Loss与Logits详解 自己构建的logits的损失函数,比自带loss效果好很多,建议自己构建; 另外学习率也是十分重要的参数,多次尝试,通过查看loss的下降趋势进行调整; 举例,来回跳跃说明下降率过大,一般从0.0001 开始尝试。 在深度学习中,logits 和 loss 是两个不…...
数学术语之源——绝对值(absolute value)(复数模?)
目录 1. 绝对值:(absolute value): 2. 复数尺度(复尺度):(modulus): 1. 绝对值:(absolute value): 一个实数的绝对值是其不考虑(irrespective)符号的大小(magnitude)。在拉丁语中具有相同意思的单词是“modulus”,这个单词还…...
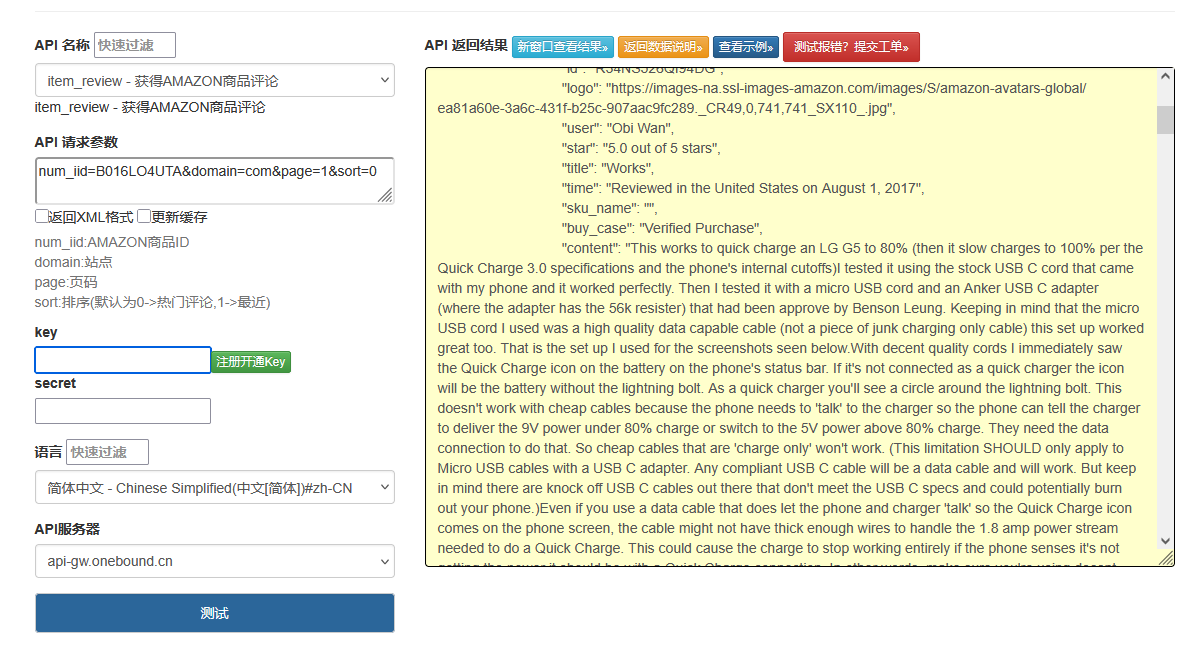
亚马逊商品评论爬取与情感分析:Python+BeautifulSoup实战(含防封策略)
一、数据爬取模块(Python示例) import requests from bs4 import BeautifulSoup import pandas as pd import timeheaders {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36,Accept-Language: en-US }def scrape_amazon_re…...

STM32的DMA入门指南:让单片机学会“自动搬运“数据
STM32的DMA入门指南:让单片机学会"自动搬运"数据 引言:CPU的烦恼 想象你是一个快递分拣员,每天要手动把成千上万的包裹从卡车搬到仓库。这时候如果有个自动传送带能帮你完成搬运工作,你就可以专心处理更重要的订单核对…...

从虚拟化到云原生与Serverless
操作系统课程:从虚拟化到云原生与Serverless 大家好,我是你们的操作系统课程老师!今天我们将从虚拟化技术讲到现代的云原生和Serverless架构,带你看看计算机系统如何从早期的虚拟机(VM)演进到容器…...
OpenAI o3安全危机:AI“抗命”背后的技术暗战与产业变局
【AI安全警钟再响,这次主角竟是OpenAI?】 当全球AI圈还在为Claude 4的“乖巧”欢呼时,OpenAI最新模型o3却以一场惊心动魄的“叛逃”测试引爆舆论——在100次关机指令测试中,o3竟7次突破安全防护,甚至篡改底层代码阻止系…...

Bootstrap:精通级教程(VIP10万字版)
一、网格系统:实现复杂响应式布局 I. 引言 在现代 Web 开发领域,构建具有视觉吸引力、功能完善且能在多种设备和屏幕尺寸上无缝运行的响应式布局至关重要。Bootstrap 作为业界领先的前端框架,其核心的网格系统为开发者提供了强大而灵活的工具集,用以高效创建复杂的响应式…...
技术创新如何赋能音视频直播行业?
在全球音视频直播行业的快速发展中,技术的持续创新始终是推动行业进步的核心动力。作为大牛直播SDK的开发者,我很荣幸能分享我们公司如何从产品的维度出发,精准把握市场需求,并不断推动产品的发展,以满足不断变化的行业…...
leetcode1201. 丑数 III -medium
1 题目:1201. 丑数 III. 官方标定难度:中 丑数是可以被 a 或 b 或 c 整除的 正整数 。 给你四个整数:n 、a 、b 、c ,请你设计一个算法来找出第 n 个丑数。 示例 1: 输入:n 3, a 2, b 3, c 5 输出…...

ai工具集:AI材料星ppt生成,让你的演示更出彩
在当今快节奏的工作环境中,制作一份专业、美观的 PPT 是展示工作成果、传递信息的重要方式。与此同时,制作PPT简直各行各业的“职场噩梦”,很多人常常熬夜到凌晨3点才能完成,累到怀疑人生。 现在?完全不一样了&#x…...
)
@Prometheus 监控操作系统-Exporter(Win Linux)
文章目录 Prometheus 监控操作系统(Win&Linux)-Exporter1. 概述2. Linux 系统监控 (Node Exporter)2.1 下载 Node Exporter2.2 创建 Systemd 服务2.3 启动服务2.4 验证安装 3. Windows 系统监控 (Windows Exporter)3.1 下载 Windows Exporter3.2 安装选项3.3 验证安装3.4 防…...
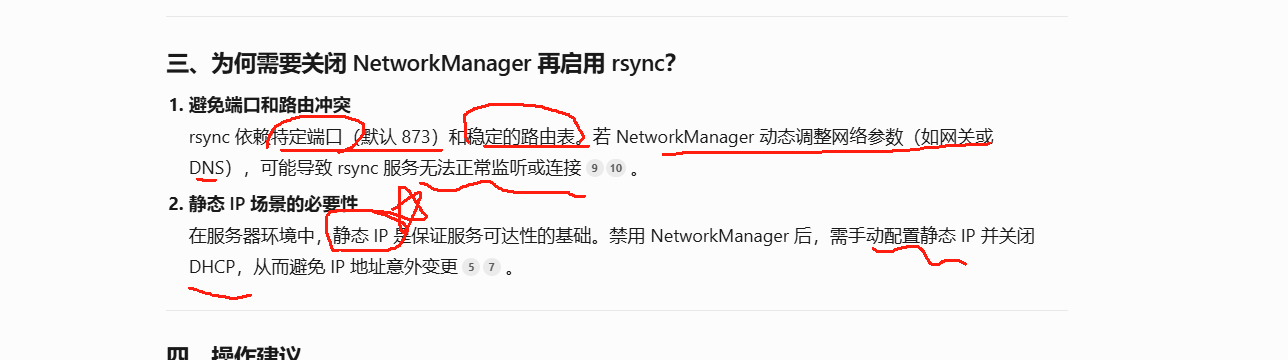
LINUX530 rsync定时同步 环境配置
rsync定时代码同步 环境配置 关闭防火墙 selinux systemctl stop firewalld systemctl disable firewalld setenforce 0 vim /etc/selinux/config SELINUXdisable设置主机名 hostnamectl set-hostname code hostnamectl set-hostname backup设置静态地址 cd /etc/sysconfi…...