深入探讨redis:主从复制
前言
如果某个服务器程序,只部署在一个物理服务器上就可能会面临一下问题(单点问题)
- 可用性问题,如果这个机器挂了,那么对应的客户端服务也相继断开
- 性能/支持的并发量有限
所以为了解决这些问题,就要引入分布式系统,在分布式系统中,会在多台服务器上部署redis服务,从而形成一个redis集群,此时就可以让这个集群给整个分布式系统提供更稳定有效的服务。
redis存在多种部署方式
- 主从模式
- 主从+哨兵模式
- 集群模式
主从模式
介绍
在若干个redis节点(物理服务器)中,有的节点被作为主节点,有的则作为从节点分别部署在redis-server进程中,从节点上的数据跟随主节点上的数据变化并保持一致。也就是说如果主节点上保存了一些数据,那么就要将这些数据复制一份出来给从节点,当主节点对这些数据有修改时,从节点也要进行对应的修改,并且从节点上的数据是不能主动或直接修改的,只能读取数据。
//从节点也可以看作是主节点的副本。
通过引入从节点,让我们的服务器有了更多的硬件资源,后续如果有客户端来进行读取数据,就可以在所有节点中随机挑选一个进行读取,因为从节点的数据和主节点的数据是保持一致的,也就可以互相分担更多的请求量,从而提高了服务器的性能。
而且引入多台服务器,也能大大提高服务器的稳定性,当有一台机器挂了的时候,还可以访问其他服务器,如果是主节点挂了,那么影响的也只是写操作,读操作依然可以通过从节点进行(主节点只有一个)。但是这种方式只能提高读操作的效率和稳定性,对于写操作因为只能在主节点上完成所以并没有什么提高。
通过单机实现主从模式
虽然主从模式需要多台服务器才能部署,但是我们可以通过在一台机器上,开启多个redis进程服务来模拟一个主从模式,但是这些进程的端口号必须不同。
这里我们来模拟部署一个主节点两个从节点
首先先复制两个配置文件,在配置文件中配置不同的redis端口
mkdir redis-conf
cp /etc/redis/redis.conf ./slave1.conf
cp /etc/redis/redis.conf ./slave2.conf
接着配置端口号
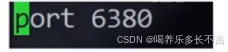
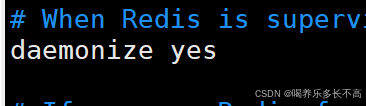

这个daemonize表示让redis按照后台进程的方式来运行
最后运行redis服务器
vim slave1.conf
vim slave2.conf
redis-server ./slave1.conf
redis-server ./slave2.conf
可以看到三个端口都成功运行,但是这只是三个redis服务器,互相独立并没有构成主从结构,想要实现主从结构还需要进一步配置
想要配置成主从结构,需要使用slaveof
- 在配置文件中加入slaveof (masterHost) (masterPort)随redis启动时生效
- 在redis-server启动命令时加入 --slaveof (masterHost) (masterPort)随redis关闭
- 直接使用redis命令:slaveof (masterHost) (masterPort)
这里我们使用配置文件的方式
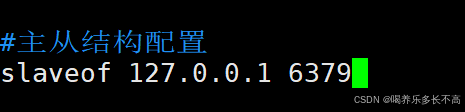
将两个文件都加上该配置,配置完之后需要重新启动redis,这里世界使用kill -9
netstat -anp | grep redis
kill -9 3748325 3748331不过这种停止redis-server的方式是和之前直接运行redis-server命令的方式搭配,如果使用的是service redis-server start 的方式启动,就必须使用service redis-server stop停止,因为使用service redis-server start的方式启动的进程,如果使用kill -9杀掉之后,这个redis-server进程会立刻自动重启

当重新启动后会看到多了几个tcp连接,这些连接就代表着主从节点直接的连接,每两个是一对。主节点就相当于服务器,从节点就相当于客户端。
//另外一个连接则是单独启动redis-cli来和redis主节点建立的连接
我们来看看到底有没有连上
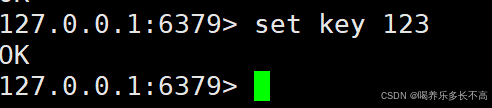


可以看到我们在6379端口插入的key,在6380依然可以查看到 并且在6380端口不能进行写操作,说明我们已经构建了一个主从模式。
查看redis节点信息
info replication主节点信息
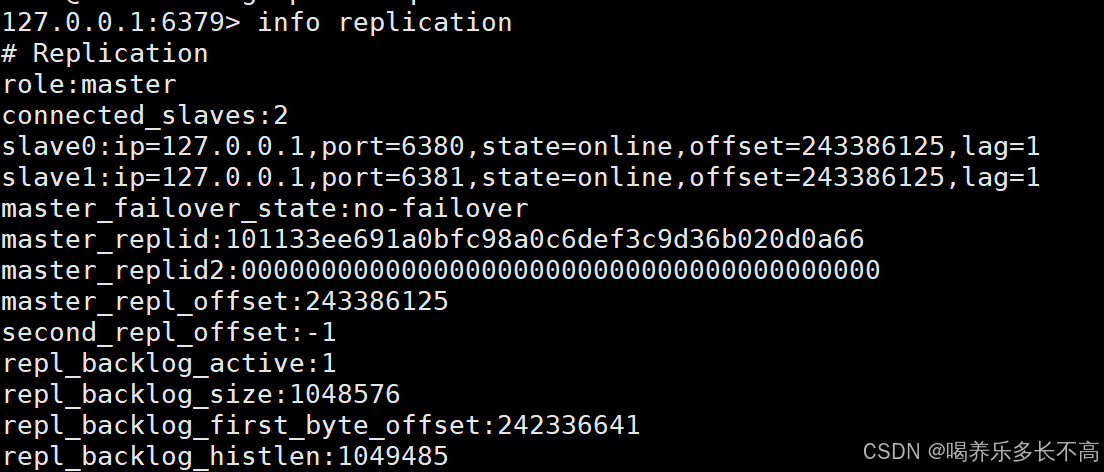
- role:表示是主节点还是从节点
- connected_slaves:表示该主节点有几个从节点
- slave:ip:表示从节点地址
- port:表示从节点端口号
- state:表示从节点在线状态
- offset: 表示主节点和从节点之间同步数据的进度
- lag:表示延迟
从节点信息
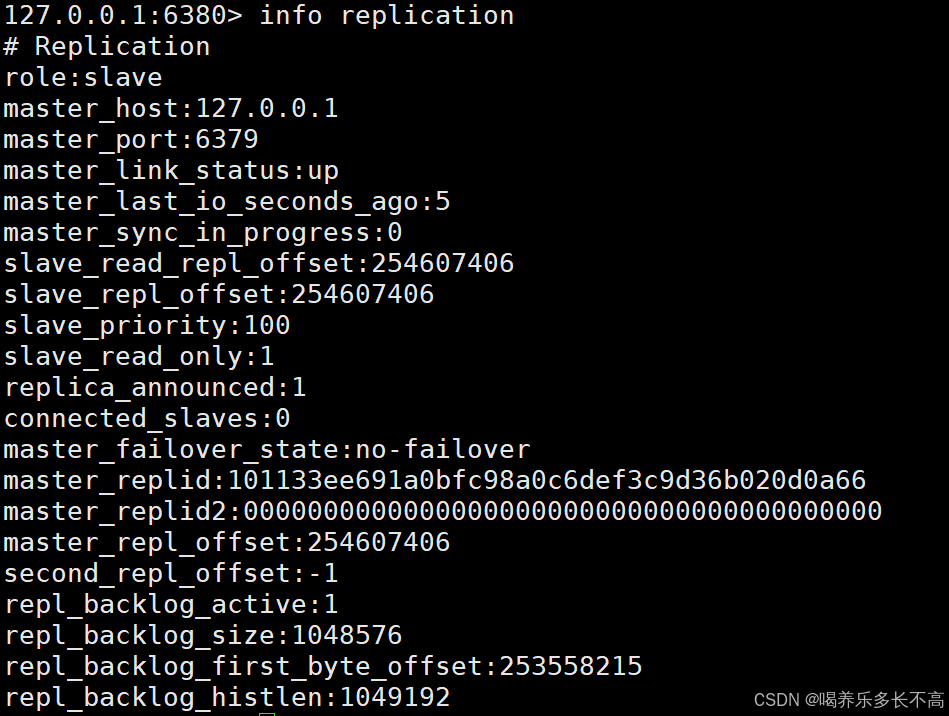
可以看到从节点也有 connected_slaves表示从节点也可以有自己的从节点,主从结构不一定就是一个主机连多台从节点,每个从节点也可以再连其他从节点。
断开主从连接
slaveof no one直接使用这个命令,就会断开当前的主从关系,当从节点断开主节点时,虽然已经不属于这个从节点了,但是里面的数据是不会被删除的,只是后面主节点的数据再发生更改,这个从节点就不会再同步数据了。
主节点

从节点
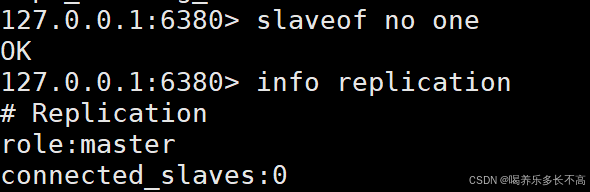
从信息中可以看到主从节点的关系已经断开,接下来我们实现是否还能同步数据

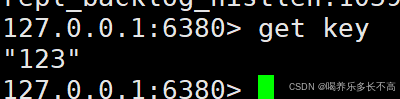
数据已经无法同步
因为6379和6380已经不是主从节点,所以我们就可以更换6380的主节点
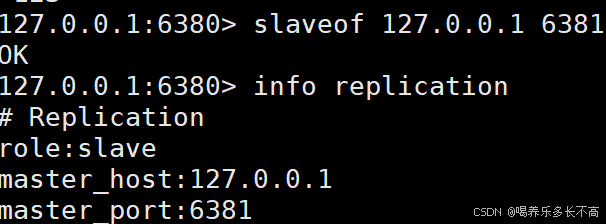
看以看到已经成功把6380的主节点更换成6381,主从模式的结构也发生了改变
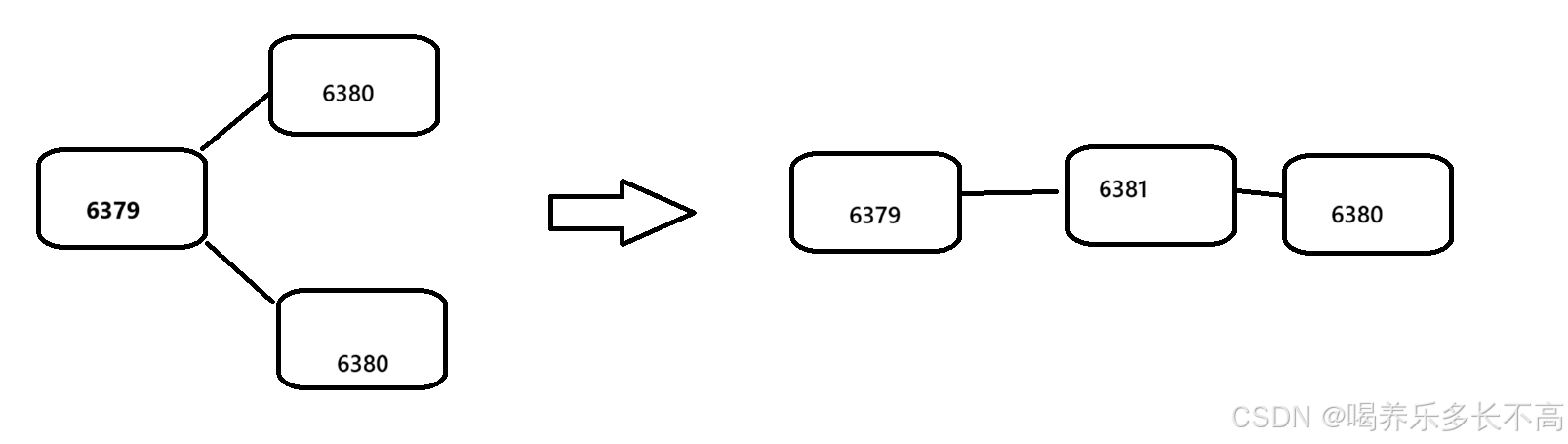

此时6380端口的redis服务的数据又和6379一致了,不过虽然此时的6381看起来像是6380的主节点,但是实际上并不是,他仍然是一个从节点不能进行写操作,只是作为6380同步数据的来源。
//刚才通过slaveof修改了主从结构,但是此处的主从结构修改是临时的,如果重启了redis服务器,仍然会变成刚开始的结构,因为我们的配置文件里所配置的结构就是和刚开始的结构一样。
拓扑结构
一主一从
一主一从结构是最简单的复制拓扑结构,用于主节点出现故障时向从节点提供故障转移支持。
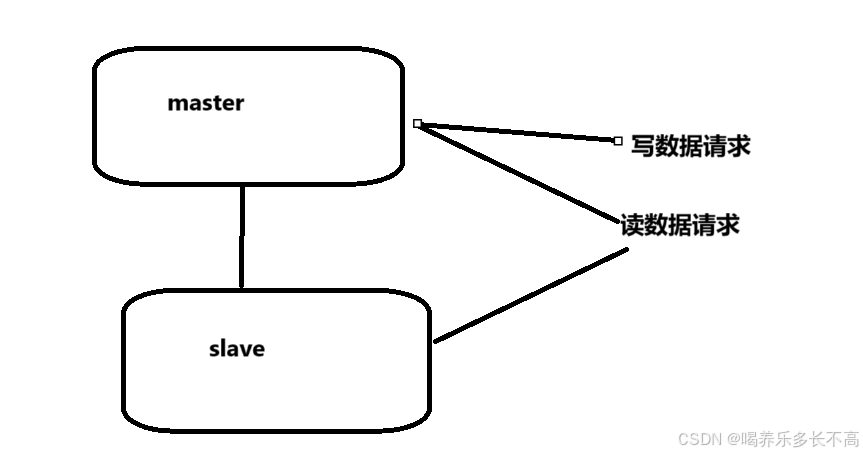
这种结构可以帮主节点分担读数据请求,但是如果写数据请求太多,此时也是会给主节点造成不小的压力,可以通过关闭主节点的AOF,只在从节点上开启。也就是只让主节点进行写内存操作,这样就可以减小主节点的压力。
但是这样的设定有一个问题,如果主节点挂了,不能让他自动重启,因为如果自动重启了,此时因为没有AOF文件,就会导致主节点数据丢失,并且因为主从复制,就会把从节点的数据也给删了。所以当主节点挂了之后,应该让主节点先在从节点那里获取AOF文件后,在启动。
一主多从(星形结构)
一种多从的结构方式,可以使节点读写分离,当有大量读请求时可以将请求分摊给各个从节点,还可以让一个从节点专门处理一些比较复杂的读操作以此来提高整体稳定性。
但是主节点上的数据改变时,需要把数据同时同步给所以从节点,也就意味着,随着从节点个数的增加,每次同步数据都会带来更大的开销。而且主从节点之间需要通过网络通信,这就要求主节点有更大的带宽,进而提高整体设备的成本。
树形主从结构
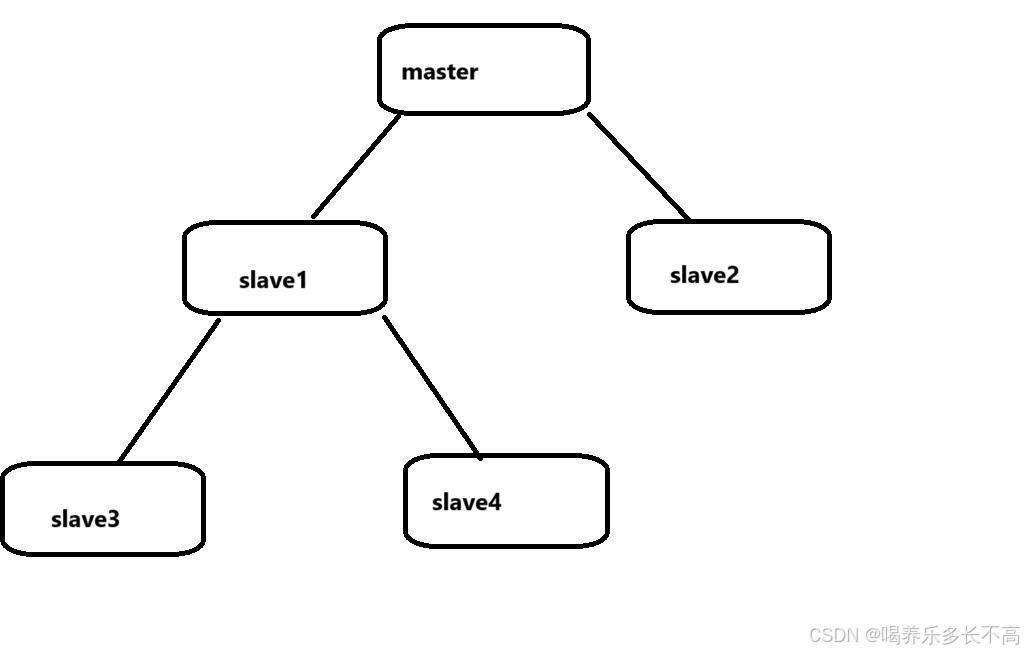
通过这样的结果就可以让主节点有固定的从节点,可以通过从节点来对其他从节点的数据进行同步,但是相应的同步的效率也会变低
主从复制原理
主从复制流程
- 保存主节点信息,开始配置主从同步关系后,从节点只保存主节点的地址信息
- 主从节点建立tcp连接(三次握手),从节点内部通过每秒运行的定时任务,维护复制相关逻辑,当定时任务发现存在存在新的主节点后,会尝试与主节点建立基于tcp的网络连接,如果连接失败,定时任务会无限重试直到连接成功或者用户停止主从复制。
- 发送ping命令,验证主节点是否正常工作
- 如果redis主节点设置了密码(requirepass参数),就要验证权限,从节点通过配置masterauth参数来设置密码。
- 同步数据集,主节点会把当前的所有数据全部发送给从节点,这步也是耗时最大的,分为全量同步和部分同步
- 命令持续复制,从节点复制主节点数据后,主节点会持续把命令发给从节点,从节点执行修改命令,确保主从数据一致
redis提供了psync replicationid offset命令来完成数据同步,不过一般这个命令是由服务器建立tcp连接后自动执行。
replicationid
这个id是由主节点生成的,每次服务器重启主节点的replicationid都会不同,并且每个主节点有两个id,id1和id2,但是一般只是用id1,从节点和主节点建立关系就会获取主节点的replicationid。另外当从节点通过一些心跳包确定主节点已经挂了的话,就会自己成为主节点,并且给自己生成一个replicationid,但是此时这个节点会通过id2任然记住之前的主节点的id,等到主节点上线后这个节点就可以通过id2再找到原来的主节点。
offset 偏移量
主节点和从节点上都会维护offset偏移量,主节点的偏移量就是,主节点会有很多修改操作,每个命令都会占用几个字节,主节点就会把这些字节累加。从节点的偏移量就描述了同步数据的进度,如果从节点和主节点的replicationid和offset偏移量都一样,就可以认为主从节点数据一致。
psync流程
从节点发送psync命令给主节点,主节点会根据psync的参数(id和offset)以及自身数据情况决定响应情况。
- FULLRESYNC:全量数据同步
- CONTINFU:增量数据同步
- -ERR:比较老版本的redis不支持psync
psync可以从主节点获取全部数据也可以获得部分数据主要看参数offset,如果是-1(默认)的话就是获取全量数据,如果是一个具体的值就是部分复制而且从当前偏移量开始复制,不过也不是从节点想从哪个地方复制就从那个地方复制,主节点也会根据实际判断。
什么时候全量复制
- 首次和主节点进行数据同步
- 主节点不方便进行部分复制
什么时候部分复制
- 从节点已经从主节点上复制过数据了,因为一些原因断开连接了,从节点需要重新从主节点这边同步数据,此时因为从节点上已经有数据了所以只需要复制一部分就行
全量复制流程
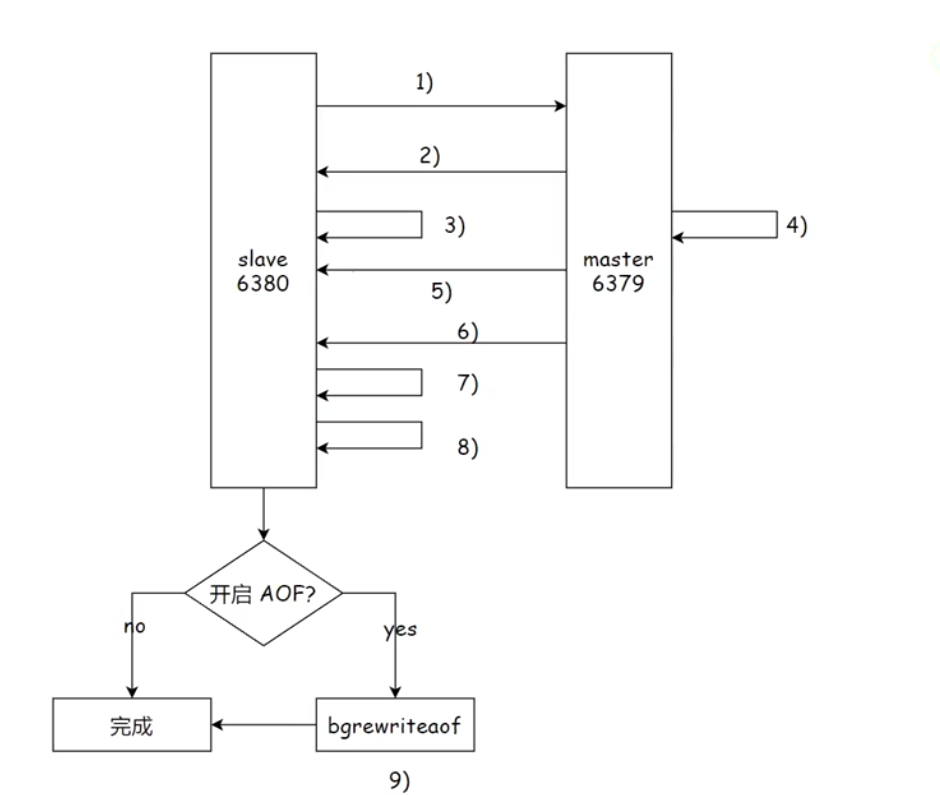
1)从节点发送psync命令向主节点要数据,因为是第一次进行复制则psync参数就是(?,-1)表示进行全量复制。
2)主节点收到命令解析后回复FULLRESYNC响应
3)从节点收到响应后会保存主节点的运行信息
4)之后主节点会自动执行bgsave命令,进行快照操作完成持久化,并复制出一个新的rdb文件。(因为从节点的数据和主节点的数据要求完全同步,所以必须使用新的rdb文件以保证数据的实时性)
5)主节点将新复制的rdb文件传输给从节点(因为复制rdb文件是一个较高消耗的操作,而且这次是全量复制所以要传输的数据也比较多,所以整体过程较为耗时。就会导致在这个过程中会有新的修改命令,那么我们从节点接收到的rdb文件就不是最新的了)
6)因为无法保证传输的rdb文件是最新的,所以主节点会将复制和传输rdb文件期间接收到的写命令放入一个缓冲区,当从节点保存完rdb文件后,主节点就会将缓冲区中的数据传输给从节点,这些数据任然是按照rdb的二进制格式追加到从节点的rdb文件中,以保证主从节点数据的完全一致。
7)从节点清除自身的旧数据
8)从节点加载rdb文件
9)如果从节点开启了AOF,那么在加载的时候就会产生大量的aof日志,因为全量复制的数据量很大就会出现很多冗余的日志,因此这里就会执行bgrewriteaof,将aof文件里该删的删,该合并的合并,对文件进行一个整理。
无硬盘模式全量复制
在刚刚的流程中主节点复制一份新的rdb文件目的就是为了,将数据传输给从节点,那么为了节省开销,就可以省去这个读写硬盘的操作(复制rdb),直接将数据通过网络传输给从节点,这样就节省了一次复制rdb的时间,从节点接收到数据后也是写入到rdb文件然后加载数据,那么将这个过程也省略掉,直接把收到的数据进行加载,这样就又省了一系列读写硬盘的操作。
部分复制流程
当主从节点都正常工作一段时间后,此时从节点已经有了主节点的复制,如果在某一时刻因为网络抖动,或者其他原因主从节之间的连接断开了的话,后续再连接上就只需要进行部分复制(具体连接过程上文有提到)。
1)如果主从节点断开的时间超过repi-timeout设定的时间,那么主节点就认为从节点断开了
2)从节点在断开连接时依然会响应命令,但是由于这些复制命令发不出去都会放在一个积压缓冲区里(一个用数组实现的环形队列)
3)重新连接后,从节点会根据之前保存的主节点的replicationid和offset通过psync的参数发送给主节点
4)主节点接收到psync命令后会对replicationid和offset(描绘的就是主从节点的复制进度)进行判断,如果replicationid不是自己的replicationid主节点就会认为这个从节点是新连接上的就会进行全量复制,如果replicationid正确则进行部分复制。判断offset的值,主要是判断从节点当前的复制进度是多少,如果从节点当前缺失的部分刚好是积压缓冲区里的数据,就可以直接将这部分数据复制过去,如果不是则需要将之前缺失的数据也复制过去,最后主节点还要响应CONTINUE表示这是一次部分复制。
实时复制
从节点已经和主节点同步好了数据,但是主节点依然会又源源不断的新的请求,主节点的数据改变,从节点的数据也就要改变。
主从节点之间会通过TCP建立长连接,然后主节点会把自己收到的修改数据的请求通过连接发送给从节点,从节点在根据这些请求修改自己的数据。(如果主从结构是树型的那么发送的过程就会较为耗时)
因为在实时复制时,主从节点需要保证连接的稳定,就会通过心跳机制来确定对方是否正常在线。
- 主节点:默认是每10s给从节点发送一个ping命令,从节点收到后就会返回pong
- 从节点:默认每个1s就给主节点发送一个特殊的请求,就会通知主节点自己当前的复制进度offset
总结
全量复制的部分复制都是在从节点第一次连接主节点时进行的,如果以前没连过就进行全量复制,如果连接过又断开的就进行部分复制,也就是说全量复制和部分复制都是给从节点进行一个初始化的。而后续的主从节点间数据的同步则是通过实时复制。
相关文章:
深入探讨redis:主从复制
前言 如果某个服务器程序,只部署在一个物理服务器上就可能会面临一下问题(单点问题) 可用性问题,如果这个机器挂了,那么对应的客户端服务也相继断开性能/支持的并发量有限 所以为了解决这些问题,就要引入分布式系统,…...

帕金森常见情况解读
一、身体出现的异常节奏 帕金森会让身体原本协调的 “舞步” 出现错乱。它是一种影响身体行动能力的状况,随着时间推进,就像老旧的时钟,齿轮转动不再顺畅,使得身体各个部位的配合逐渐失衡,打乱日常行动的节奏。 …...
清华大学发Nature!光学工程+神经网络创新结合
2025深度学习发论文&模型涨点之——光学工程神经网络 清华大学的一项开创性研究成果在《Nature》上发表,为光学神经网络的发展注入了强劲动力。该研究团队巧妙地提出了一种全前向模式(Fully Forward Mode,FFM)的训练方法&…...
【android bluetooth 案例分析 04】【Carplay 详解 3】【Carplay 连接之车机主动连手机】
1. 背景 在前面的文章中,我们已经介绍了 carplay 在车机中的角色划分, 并实际分析了 手机主动连接车机的案例。 感兴趣可以 查看如下文章介绍。 【android bluetooth 案例分析 04】【Carplay 详解 1】【CarPlay 在车机侧的蓝牙通信原理与角色划分详解】…...
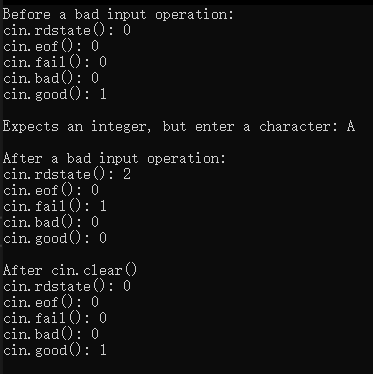
C++学习-入门到精通【11】输入/输出流的深入剖析
C学习-入门到精通【11】输入/输出流的深入剖析 目录 C学习-入门到精通【11】输入/输出流的深入剖析一、流1.传统流和标准流2.iostream库的头文件3.输入/输出流的类的对象 二、输出流1.char* 变量的输出2.使用成员函数put进行字符输出 三、输入流1.get和getline成员函数2.istrea…...

NW969NW978美光闪存颗粒NW980NW984
NW969NW978美光闪存颗粒NW980NW984 技术解析:NW969、NW978、NW980与NW984的架构创新 美光(Micron)的闪存颗粒系列,尤其是NW969、NW978、NW980和NW984,代表了存储技术的前沿突破。这些产品均采用第九代3D TLC…...
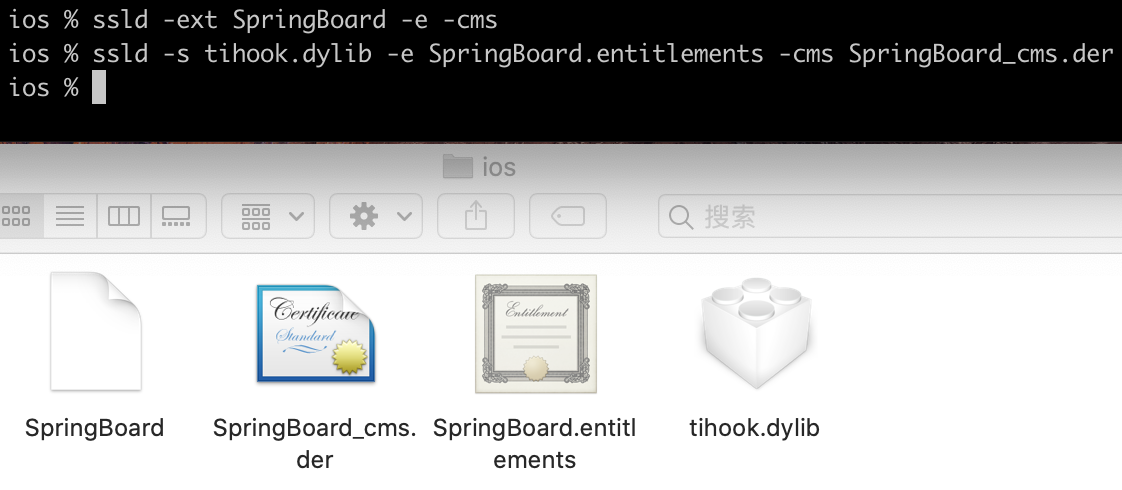
使用 ssld 提取CMS 签名并重签名
拿SpringBoard的cms签名和entitlements.xml,对tihook.dylib进行重签名 工具来源:https://github.com/eksenior/ssld...
—路由集成》)
前端基础之《Vue(17)—路由集成》
一、页面应用程序分类 1、单页面应用程序(SPA) 通过路由系统把组件串联起来的并且只有一个根index.html页面的程序,叫做单页面应用程序。 2、多页面应用程序(MPA) 整个应用程序中,有多个.html页面。每次用…...

大厂前端研发岗位PWA面试题及解析
文章目录 一、基础概念二、Service Worker 深度三、缓存策略实战四、高级能力五、性能与优化六、调试与部署七、安全与更新八、跨平台兼容九、架构设计十、综合场景十一、前沿扩展一、基础概念 什么是PWA?列举3个核心特性 解析:渐进式网页应用。核心特性:离线可用、类原生体…...

第十四章 MQTT订阅
系列文章目录 系列文章目录 第一章 总体概述 第二章 在实体机上安装ubuntu 第三章 Windows远程连接ubuntu 第四章 使用Docker安装和运行EMQX 第五章 Docker卸载EMQX 第六章 EMQX客户端MQTTX Desktop的安装与使用 第七章 EMQX客户端MQTTX CLI的安装与使用 第八章 Wireshark工具…...

element ui 表格 勾选复选框后点击分页不保存之前的数据问题
element ui 表格 勾选复选框后点击分页不保存之前的数据问题 给 el-table上加 :row-key"getRowKey"给type“selection” 上加 :reserve-selection"true"...
)
DataAgent产品经理(数据智能方向)
DataAgent产品经理(数据智能方向) 一、核心岗位职责 AI智能体解决方案设计 面向工业/政务场景构建「数据-模型-交互」闭环,需整合多源异构数据(如传感器数据、业务系统日志)与AI能力(如大模型微调、知识图…...
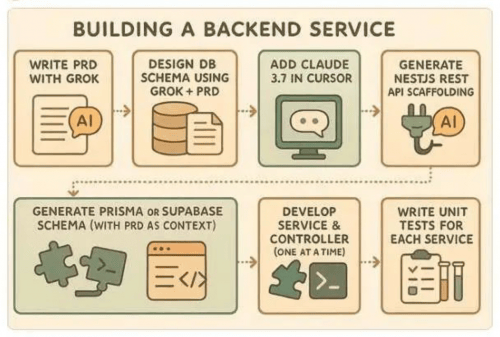
腾讯云推出云开发AI Toolkit,国内首个面向智能编程的后端服务
5月28日,腾讯云开发 CloudBase 宣布推出 AI Toolkit(CloudBase AI Toolkit),这是国内首个面向智能编程的后端服务,适配 Cursor 等主流 AI 编程工具。 云开发 AI Toolkit旨在解决 AI 辅助编程的“最后一公里”问题&…...

华为计试——刷题
判断两个IP是否属于同一子网 题目:给定一个子网掩码和两个 IP 地址,判断这两个 IP 地址是否在同一个子网中。 思路:首先,判断这个 IP 地址和子网掩码格式是否正确,不正确输出 ‘1’,进而结束;…...

【AI-安装指南】Redis Stack 的安装与使用
目录 一、Redis Stack 的介绍 二、安装方式 2.1 安装 2.2 添加依赖 2.3 设置配置信息 2.4 Redis 添加向量数据 2.5 查询向量数据 一、Redis Stack 的介绍 传统的 Redis 服务是不能存储向量的,因此我们需要首先安装 Redis Stack,而 Windows 电脑安 装 Redis Stack,官方…...
)
LeetCode Hot100(矩阵)
73. 矩阵置零 这边提供nm的做法以及更少的思路,对于nm的做法,我们只需要开辟标记当前行是否存在0以及当前列是否存在0即可,做法如下 class Solution {public void setZeroes(int[][] matrix) {int arr[]new int[matrix.length];int brr[]ne…...

spark在执行中如何选择shuffle策略
目录 1. SortShuffleManager与HashShuffleManager的选择2. Shuffle策略的自动选择机制3. 关键配置参数4. 版本差异(3.0+新特性)5. 异常处理与调优6. 高级Shuffle服务(CSS)1. SortShuffleManager与HashShuffleManager的选择 SortShuffleManager:默认使用,适用于大规模数据…...
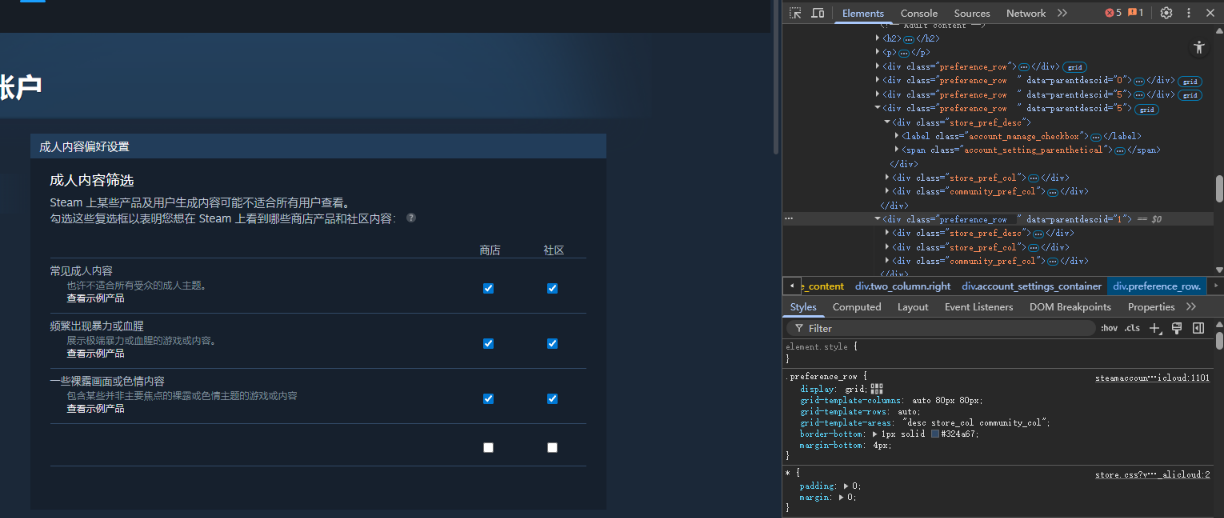
前端-不对用户显示
这是steam的商店偏好设置界面,在没有被锁在国区的steam账号会有5个选项,而被锁在国区的账号只有3个选项,这里使用的技术手段仅仅在前端隐藏了这个其他两个按钮。 单击F12打开开发者模式 单击1处,找到这一行代码,可以看…...
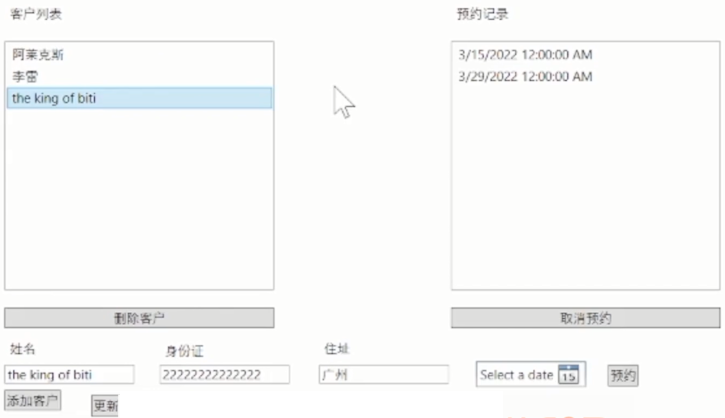
WPF【10_2】数据库与WPF实战-示例
客户预约关联示例图 MainWindow.xaml 代码 <Window x:Class"WPF_CMS.MainWindow" xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml" xmlns:d"ht…...

Hive的数据倾斜是什么?
一、Hive数据倾斜的定义 数据倾斜指在Hive分布式计算过程中,某一个或几个Task(如Map/Reduce任务)处理的数据量远大于其他Task,导致这些Task成为整个作业的性能瓶颈,甚至因内存不足而失败。数据倾斜通常发生在Shuffle阶…...
Cursor奇技淫巧篇(经常更新ing)
Dot files protection :Cursor当开启了Agent模式之后可以自动帮我们写文件,但是一般项目中的一些配置文件(通常以.开头的)都是非常重要性,为了防止Cursor在运行的过程中自己修改这些文件,导致风险ÿ…...
Unity3D仿星露谷物语开发58之保存时钟信息到文件
1、目标 保存当前的时钟信息到文件中。 2、修改TimeManager对象 TimeManager对象添加组件:Generate GUID 3、修改SceneSave.cs脚本 添加1行代码: 4、修改TimeManager.cs脚本 添加: using System; 修改TimeManager类: 添加属…...
lstm 长短期记忆 视频截图 kaggle示例
【官方双语】LSTM(长短期记忆神经网络)最简单清晰的解释来了!_哔哩哔哩_bilibili . [short,input]*[2.7,1.63]b5.95 换参数和激活函数 tan激活函数输出带正负符号的百分比 tanx公式长这样? 潜在短期记忆 前几天都是乱预测…...

Spring Advisor增强规则实现原理介绍
Spring Advisor增强规则实现原理介绍 一、什么是 Advisor?1. Advisor 的定义与本质接口定义: 2. Advisor 的核心作用统一封装切点与通知构建拦截器链的基础实现增强逻辑的灵活组合 二. Sprin当中的实现逻辑1 Advisor 接口定义2 PointcutAdvisor 接口定义…...
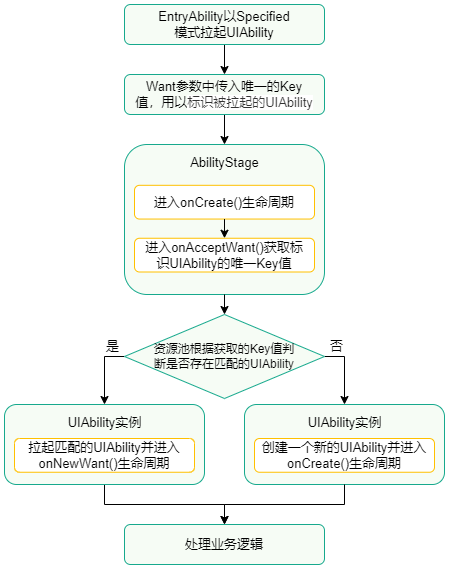
【HarmonyOS 5】鸿蒙中的UIAbility详解(二)
【HarmonyOS 5】鸿蒙中的UIAbility详解(二) 一、前言 今天我们继续深入讲解UIAbility,根据下图可知,在鸿蒙中UIAbility继承于Ability,开发者无法直接继承Ability。只能使用其两个子类:UIAbility和Extensi…...
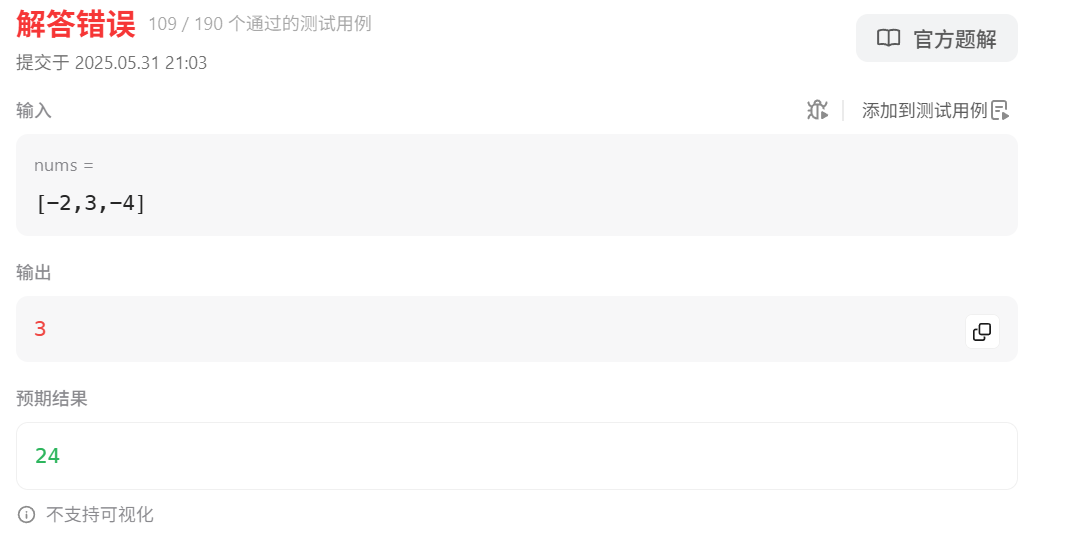
力扣HOT100之动态规划:152. 乘积最大子数组
这道题并不是代码随想录里的,我试着用动规五部曲来做,然后不能通过全部测试样例,在第109个测试样例卡住了,如下所示。 原因是可能负数乘以负数会得到最大的乘积,不能单纯地用上一个序列的最大值乘以当前值来判断是否能…...

Java后端技术栈问题排查实战:Spring Boot启动慢、Redis缓存击穿与Kafka消费堆积
Java后端技术栈问题排查实战:Spring Boot启动慢、Redis缓存击穿与Kafka消费堆积 引言 在现代互联网大厂中,Java后端系统因为其复杂性和多样性,常常面临各种问题和挑战。从核心语言到微服务架构,从数据库到缓存,不同层…...

定制开发开源AI智能名片S2B2C商城小程序:数字营销时代的话语权重构
摘要:在数据驱动的数字营销时代,企业营销话语权正从传统媒体向掌握用户数据与技术的平台转移。本文基于“数据即权力”的核心逻辑,分析定制开发开源AI智能名片S2B2C商城小程序如何通过技术赋能、场景重构与生态协同,帮助企业重构营…...
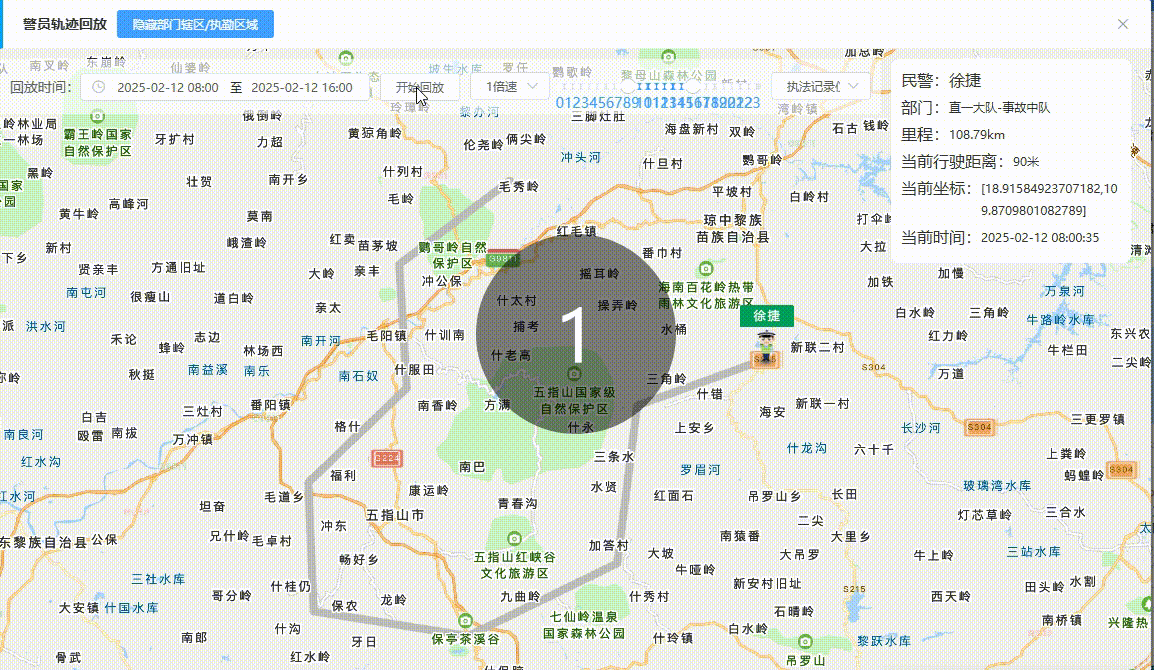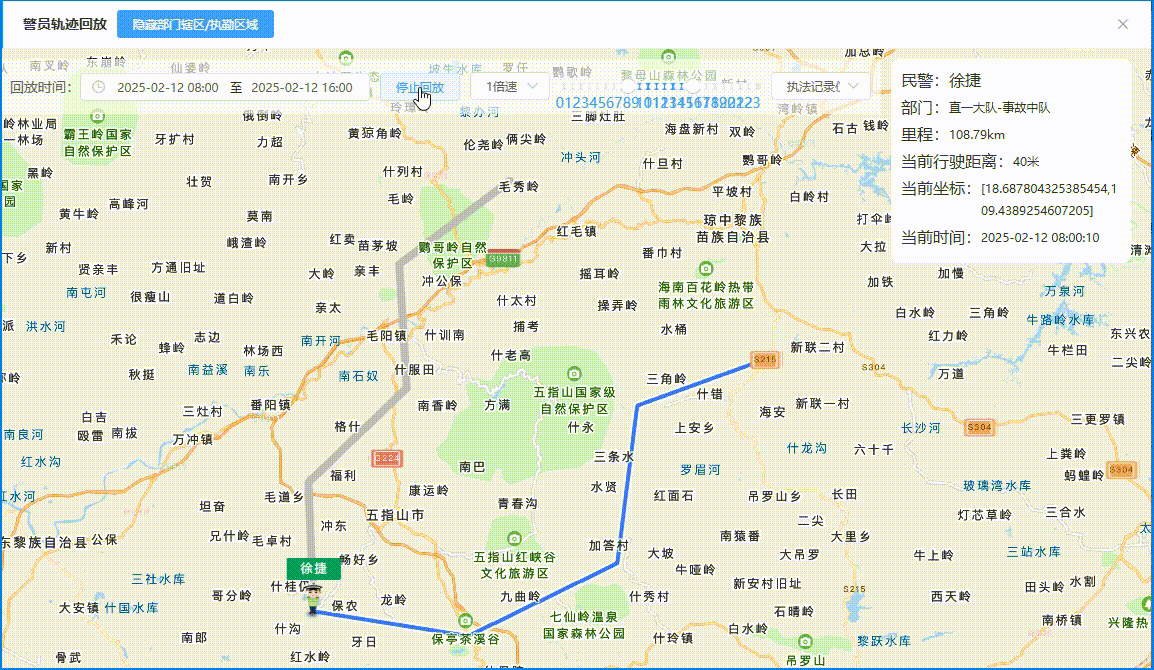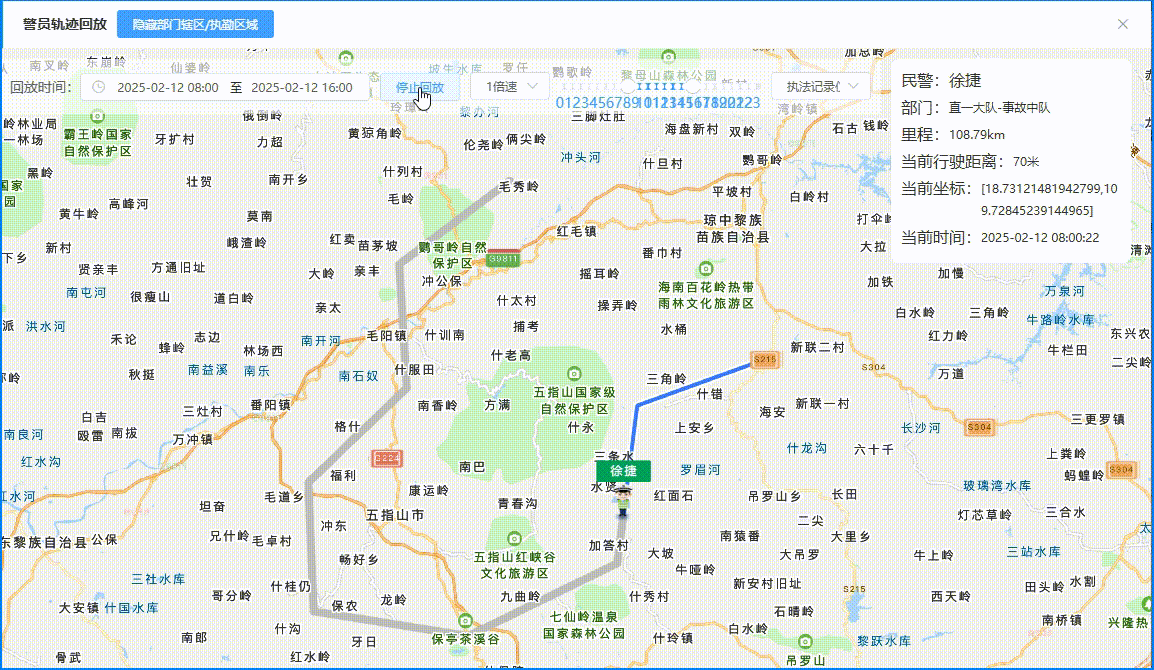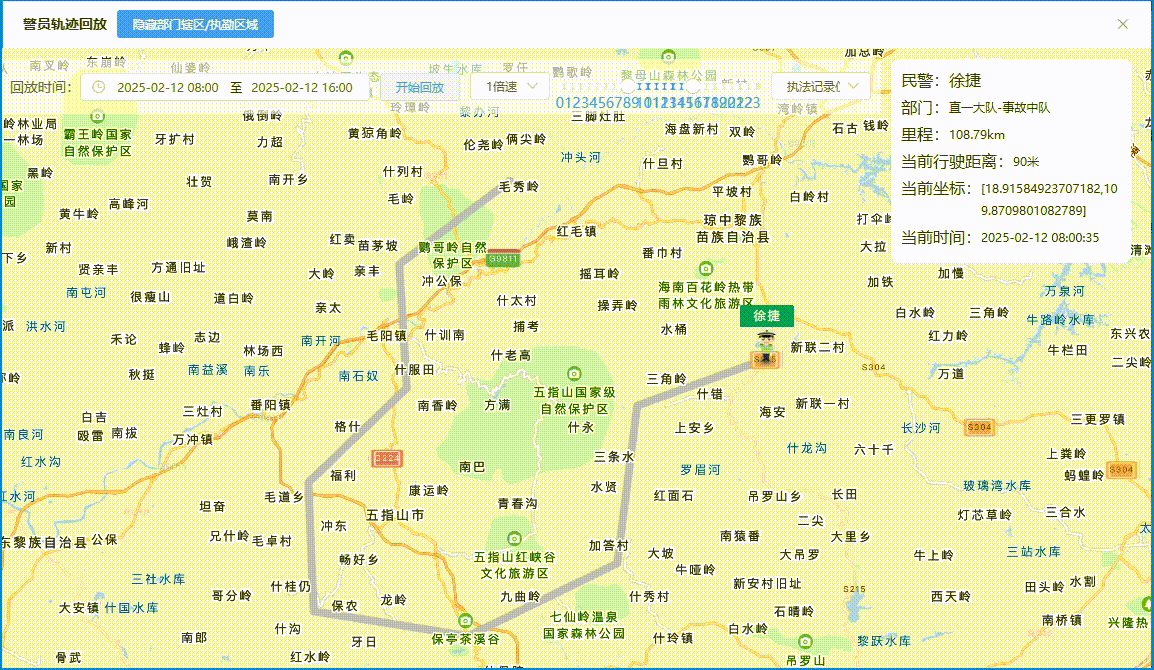
【面试 - 遇到的问题 - 优化 - 地图】腾讯地图轨迹回放 - 回放的轨迹时间要和现实时间对应(非匀速)
目录 背景轨迹回放 - 匀速效果图TrackPlaybackDialog.vue 代码TMapNew.vue 代码 轨迹回放 - 非匀速效果图TrackPlaybackDialog.vue 代码TMapNew.vue 代码 背景 腾讯地图轨迹回放是匀速回放的,但是客户要求根据现实时间,什么时间点在某个点位 【腾讯地图轨…...

ffmpeg baidu
ffmpeg -list_devices true -f dshow -i dummy 获取你的音频输入设备(麦克风)名称 输出中可以看到你有如下两个可用麦克风设备: “麦克风阵列 (适用于数字麦克风的英特尔 智音技术)” “外部麦克风 (Realtek Audio)” (注意&…...