【Python训练营打卡】day40 @浙大疏锦行
DAY 40 训练和测试的规范写法
知识点回顾:
1. 彩色和灰度图片测试和训练的规范写法:封装在函数中
2. 展平操作:除第一个维度batchsize外全部展平
3. dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
作业:仔细学习下测试和训练代码的逻辑,这是基础,这个代码框架后续会一直沿用,后续的重点慢慢就是转向模型定义阶段了。
单通道图片的规范写法
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64 # 每批处理64个样本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义模型、损失函数和优化器
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 新增:记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号(从1开始)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPU(如果可用)optimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始# 统计准确率和损失(原逻辑保留,用于 epoch 级统计)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 原 epoch 级逻辑(测试、打印 epoch 结果)不变epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 保留原 epoch 级曲线(可选)# plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)return epoch_test_acc # 返回最终测试准确率# 6. 测试模型
def test(model, test_loader, criterion, device):model.eval() # 设置为评估模式test_loss = 0correct = 0total = 0with torch.no_grad(): # 不计算梯度,节省内存和计算资源for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()avg_loss = test_loss / len(test_loader)accuracy = 100. * correct / totalreturn avg_loss, accuracy # 返回损失和准确率# 7.绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试(设置 epochs=2 验证效果)
epochs = 2
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")彩色图片的规范写法
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
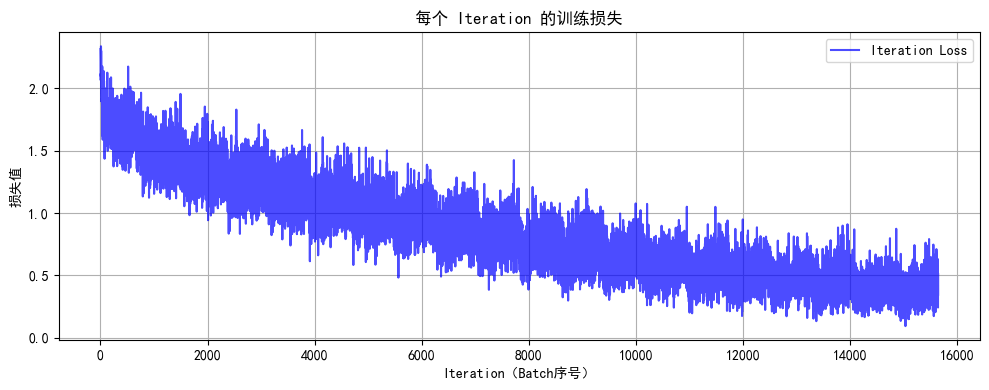
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_mlp_model.pth')
# # print("模型已保存为: cifar10_mlp_model.pth")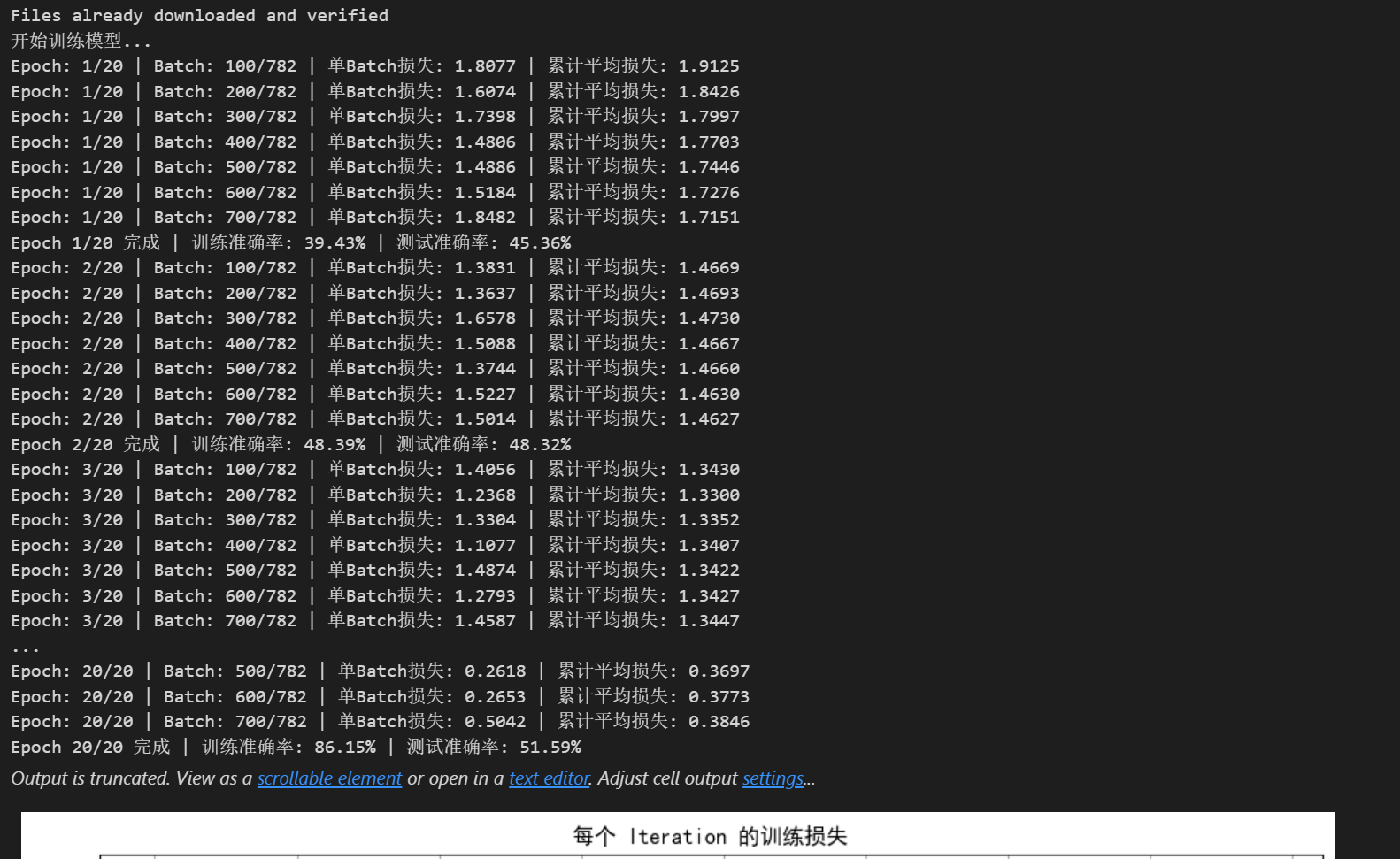
由于深度mlp的参数过多,为了避免过拟合在这里引入了dropout这个操作,他可以在训练阶段随机丢弃一些神经元,避免过拟合情况。dropout的取值也是超参数。
在测试阶段,由于开启了eval模式,会自动关闭dropout。
可以继续调用这个函数来复用
# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")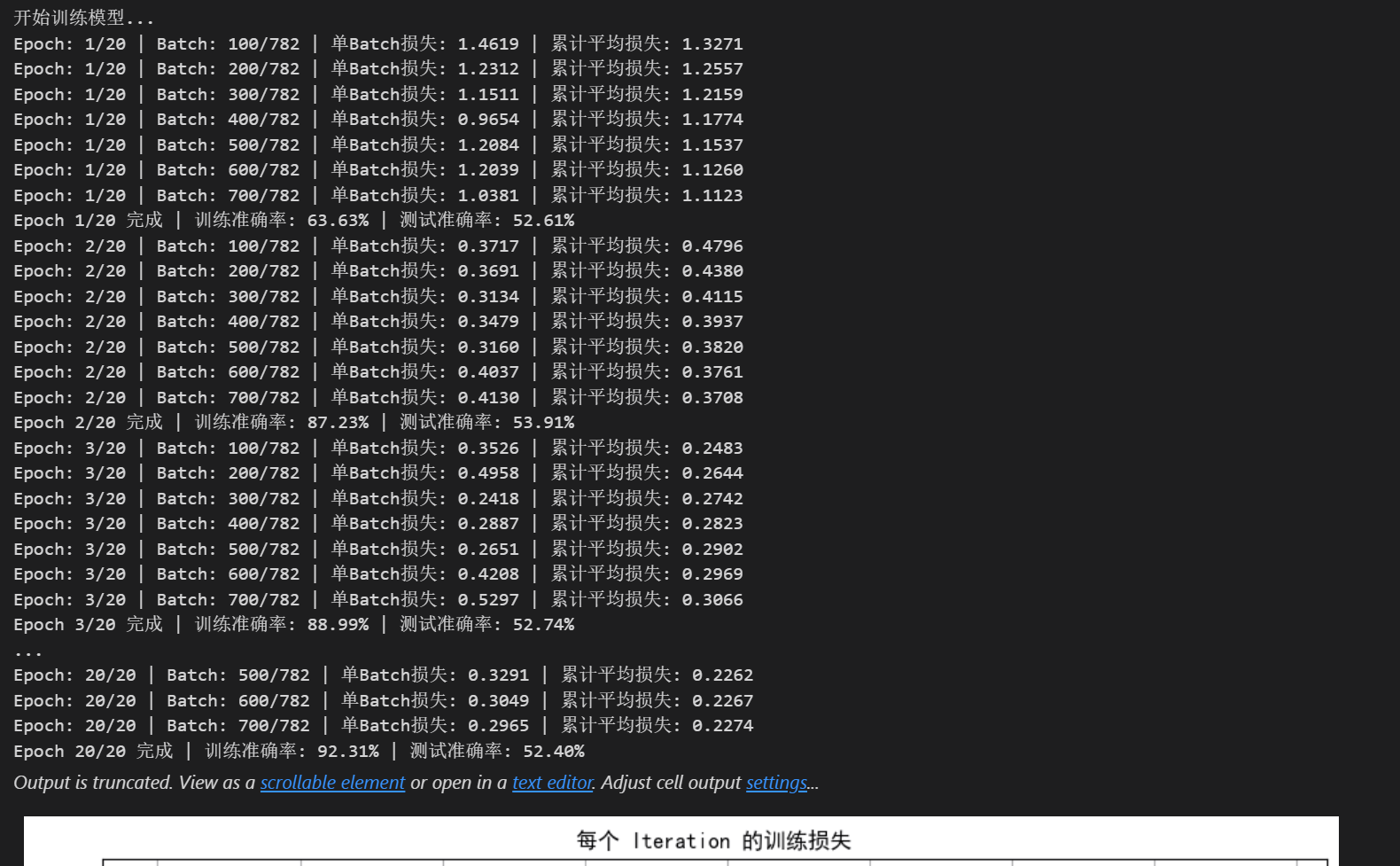
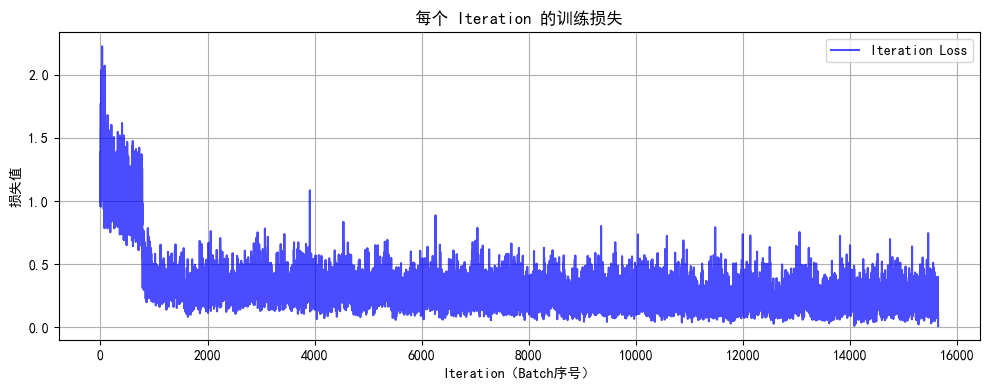
此时你会发现MLP(多层感知机)在图像任务上表现较差(即使增加深度和轮次也只能达到 50-55% 准确率),主要原因与图像数据的空间特性和MLP 的结构缺陷密切相关。
1. MLP 的每一层都是全连接层,输入图像会被展平为一维向量(如 CIFAR-10 的 32x32x3 图像展平为 3072 维向量)。图像中相邻像素通常具有强相关性(如边缘、纹理),但 MLP 将所有像素视为独立特征,无法利用局部空间结构。例如,识别 “汽车轮胎” 需要邻近像素的组合信息,而 MLP 需通过大量参数单独学习每个像素的关联,效率极低。
2. 深层 MLP 的参数规模呈指数级增长,容易过拟合
所以我们接下来将会学习CNN架构,CNN架构的参数规模相对较小,且训练速度更快,而且CNN架构可以解决图像识别问题,而MLP不能。
笔记
在 PyTorch 中处理张量(Tensor)时,以下是关于展平(Flatten)、维度调整(如 view/reshape)等操作的关键点,这些操作通常不会影响第一个维度(即批量维度batch_size):
图像任务中的张量形状
输入张量的形状通常为:
(batch_size, channels, height, width)
例如:(batch_size, 3, 28, 28)
其中,batch_size 代表一次输入的样本数量。
NLP 任务中的张量形状
输入张量的形状可能为:
(batch_size, sequence_length)
此时,batch_size 同样是第一个维度。
1. Flatten 操作
- 功能:将张量展平为一维数组,但保留批量维度。
- 示例:
- 输入形状:
(batch_size, 3, 28, 28)(图像数据) - Flatten 后形状:
(batch_size, 3×28×28)=(batch_size, 2352) - 说明:第一个维度
batch_size不变,后面的所有维度被展平为一个维度。
- 输入形状:
2. view/reshape 操作
- 功能:调整张量维度,但必须显式保留或指定批量维度。
- 示例:
- 输入形状:
(batch_size, 3, 28, 28) - 调整为:
(batch_size, -1) - 结果:展平为两个维度,保留
batch_size,第二个维度自动计算为3×28×28=2352。
- 输入形状:
总结
- 批量维度不变性:无论进行 flatten、view 还是 reshape 操作,第一个维度
batch_size通常保持不变。 - 动态维度指定:使用
-1让 PyTorch 自动计算该维度的大小,但需确保其他维度的指定合理,避免形状不匹配错误。
@浙大疏锦行
相关文章:
【Python训练营打卡】day40 @浙大疏锦行
DAY 40 训练和测试的规范写法 知识点回顾: 1. 彩色和灰度图片测试和训练的规范写法:封装在函数中 2. 展平操作:除第一个维度batchsize外全部展平 3. dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropo…...
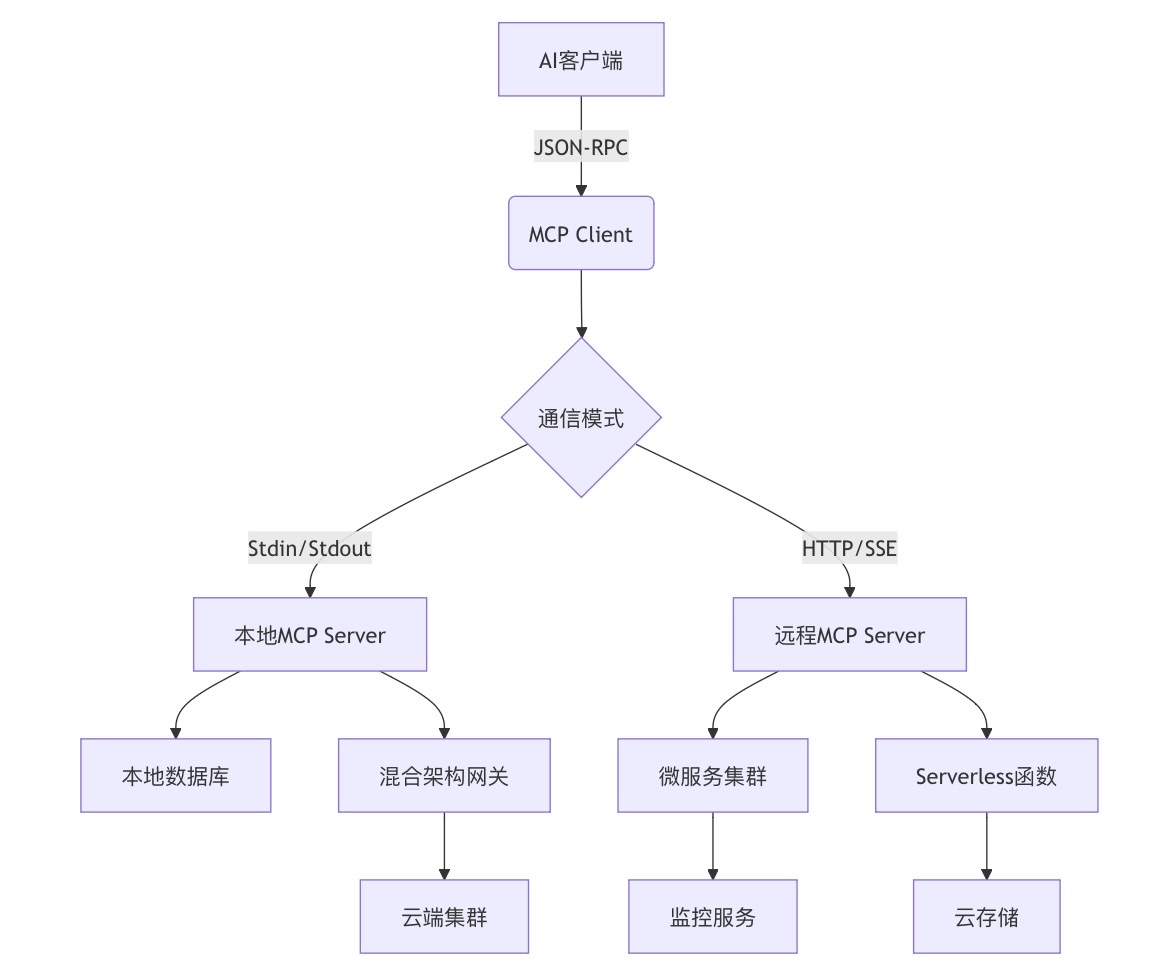
MCP Server的五种主流架构:从原理到实践的深度解析
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 在AI大模型与外部数据交互的浪潮中,MCP Server(Model Context Protocol Server)已成为连接模型与现实世界的桥梁。本文…...

跨协议协同智造新实践:DeviceNet-EtherCAT网关驱动汽车焊接装配效能跃迁
在汽车制造领域,机器人协作对于提升生产效率与产品质量至关重要。焊接、装配等关键环节,需要机器人与各类设备紧密配合。JH-DVN-ECT疆鸿智能的devicenet从站转ethercat主站协议网关,成为实现这一高效协作的得力助手,尤其是在连接欧…...

在Linux上安装Docker并配置镜像加速器:从入门到实战
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 Docker作为容器化技术的标杆工具,已经成为现代软件开发和运维的必备技能。对于程序员和技术爱好者来说,在Linux系统上搭建D…...
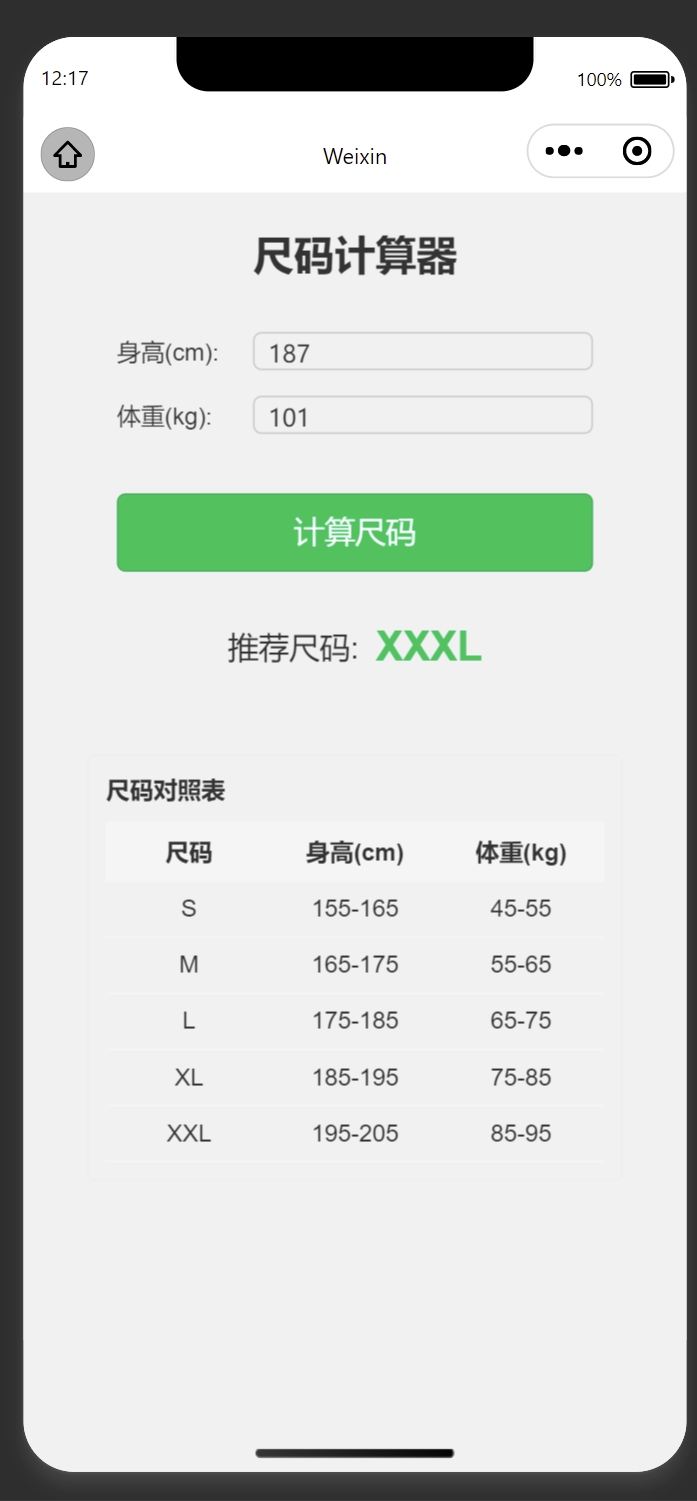
让 Deepseek 写一个尺码计算器
下面是一个简单的尺码计算器微信小程序的代码实现,包含页面布局、逻辑处理和样式。 1. 项目结构 size-calculator/ ├── pages/ │ ├── index/ │ │ ├── index.js │ │ ├── index.json │ │ ├── index.wxml │ │ └── inde…...

代码随想录算法训练营第60期第五十三天打卡
大家好,我们今天来到了最后一章图论,其实图论比较难,涉及的算法也比较多,今天比较重要的就是深度优先搜索与广度优先搜索,后面的迪杰斯特拉算法等算法在我们求最短路都会涉及到,还有最近公共祖先࿰…...
Nacos实战——动态 IP 黑名单过滤
1、需求分析 一些恶意用户(可能是黑客、爬虫、DDoS 攻击者)可能频繁请求服务器资源,导致资源占用过高。针对这种问题,可以通过IP 封禁,可以有效拉黑攻击者,防止资源被滥用,保障合法…...
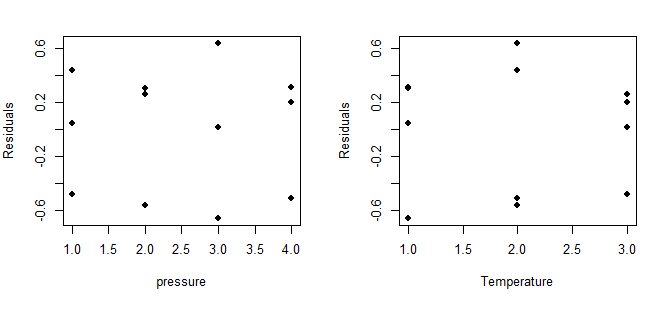
实验设计与分析(第6版,Montgomery)第5章析因设计引导5.7节思考题5.14 R语言解题
本文是实验设计与分析(第6版,Montgomery著,傅珏生译) 第5章析因设计引导5.7节思考题5.14 R语言解题。主要涉及方差分析,正态假设检验,残差分析,交互作用图。 dataframe<-data.frame( strengthc(9.60,9.…...
在Ubuntu20.04上安装ROS Noetic
本章教程,主要记录在Ubuntu20.04上安装ROS Noetic。 一、添加软件源 sudo sh -c . /etc/lsb-release && echo "deb http://mirrors.tuna.tsinghua.edu.cn/ros/ubuntu/ `lsb_release -cs` main" > /etc/apt/sources.list.d/ros-latest.list二、设置秘钥 …...
python里面导入yfinance的时候报错
我的代码: import yfinance as yf import os proxy http://127.0.0.1:7890 # 代理设置,此处修改 os.environ[HTTP_PROXY] proxy os.environ[HTTPS_PROXY] proxydata yf.download("AAPL",start"2010-1-1",end"2021-8-1&quo…...
winform LiveCharts2的使用--图表的使用
介绍 对于图标,需要使用到livechart2中的CartesianChart 控件,是一个“即用型”控件,用于使用笛卡尔坐标系创建绘图。需要将Series属性分配一组ICartesianSeries。 例如下面代码,创建一个最简单的图表: cartesianCha…...
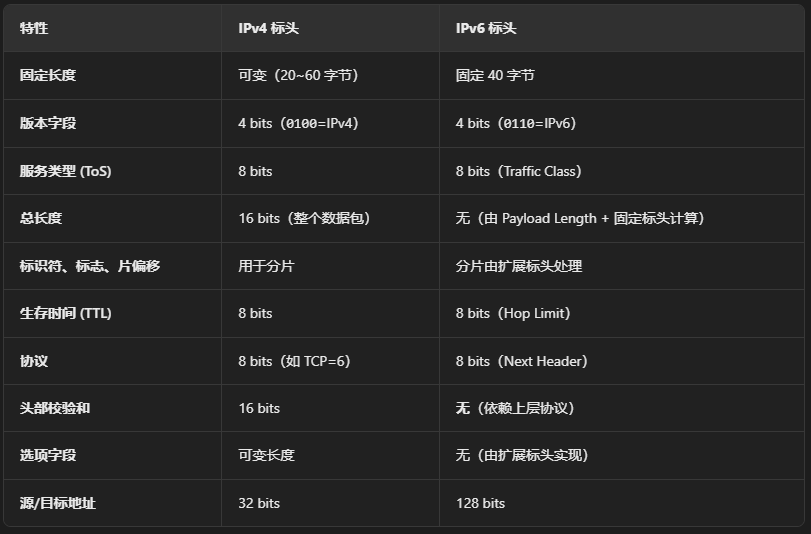
【计算机网络】IPv6和NAT网络地址转换
IPv6 IPv6协议使用由单/双冒号分隔一组数字和字母,例如2001:0db8:85a3:0000:0000:8a2e:0370:7334,分成8段。IPv6 使用 128 位互联网地址,有 2 128 2^{128} 2128个IP地址无状态地址自动配置,主机可以通过接口标识和网络前缀生成全…...
flutter简单自定义跟随手指滑动的横向指示器
ScrollController _scrollController ScrollController();double _scrollIndicatorWidth 60.w;//指示器的长度double _maxScrollPaddingValue 30.w;//指示器中蓝条可移动的最大距离double _scrollPaddingValue 0.0;//指示器中蓝条左边距(蓝条移动距离)overridevoid initSta…...

项目日记 -Qt音乐播放器 -搜索模块
最近期末,时间较少,详细内容之后再补充。 搜索 用得最多的一个 格式:https://music.163.com/api/search/get/web?s搜索词&type1&limit66&offset0 s 后跟搜索词 type 后跟类型,1表歌手 limit 限制每次最多返回多少…...

JavaScript 性能优化实战研讨
核心优化方向 执行效率:减少主线程阻塞内存管理:避免泄漏和过度消耗加载性能:加快解析与执行速度渲染优化:减少布局重排与重绘 🔥 关键优化策略与代码示例 1️⃣ 减少重排(Reflow)与重绘(Repaint) // 避免逐行修改样…...

有机黑鸡蛋与普通鸡蛋:差异剖析与选购指南
在我们的日常饮食结构里,鸡蛋始终占据着不可或缺的位置,是人们获取营养的重要来源。如今,市场上鸡蛋种类丰富,除了常见的普通鸡蛋,有机黑鸡蛋也逐渐崭露头角,其价格通常略高于普通鸡蛋。这两者究竟存在哪些…...
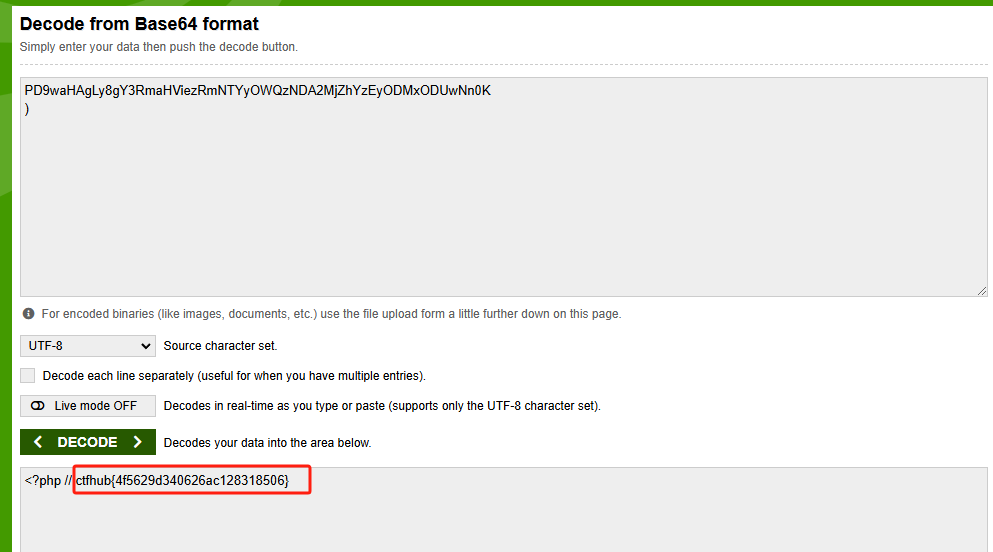
CTFHub-RCE 命令注入-无过滤
观察源代码 判断是Windows还是Linux 源代码中有 ping -c 4 说明是Linux 查看有哪些文件 127.0.0.1|ls 发现除了index.php文件外,还存在一个可疑的文件 打开flag文件 我们尝试打开这个文件 127.0.0.1|cat 19492844826916.php 可是发现 文本内容显示不出来&…...

spring IOC控制反转
控制反转,将对象的创建进行反转,常规情况下,对象都是开发者手动创建的,使用 loC 开发者不再需要创建对象,而是由IOC容器根据需求自动创建项目所需要的对象 不用IOC,所有对象IOC开发者自己创建使用IOC&…...

hot100 -- 1.哈希系列
1.两数之和 题目: 给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。 题解: 方法1:暴力求解 def get_two_sum(nums, target):for i in range(len(nums)):for j in range(i1, len(nums)):if nums[i] nums[j…...
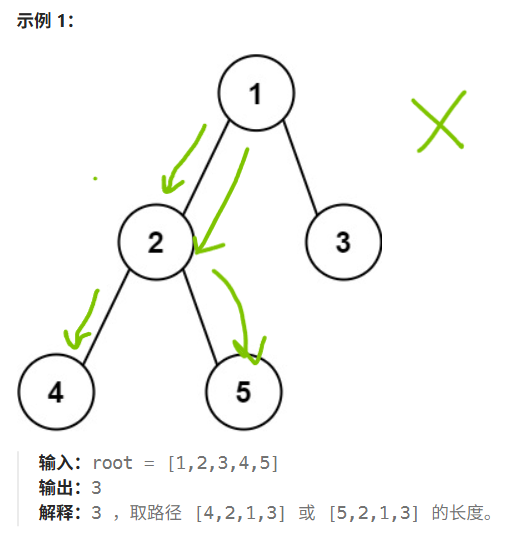
leetcode hot100刷题日记——31.二叉树的直径
二叉树直径详解 题目描述对直径的理解解答:dfs小TIPS 题目描述 对直径的理解 实际上,二叉树的任意一条路径均可以被看作由某个节点为起点,从其左儿子和右儿子向下遍历的路径拼接得到。 那我们找二叉树的直径(最大路径)…...
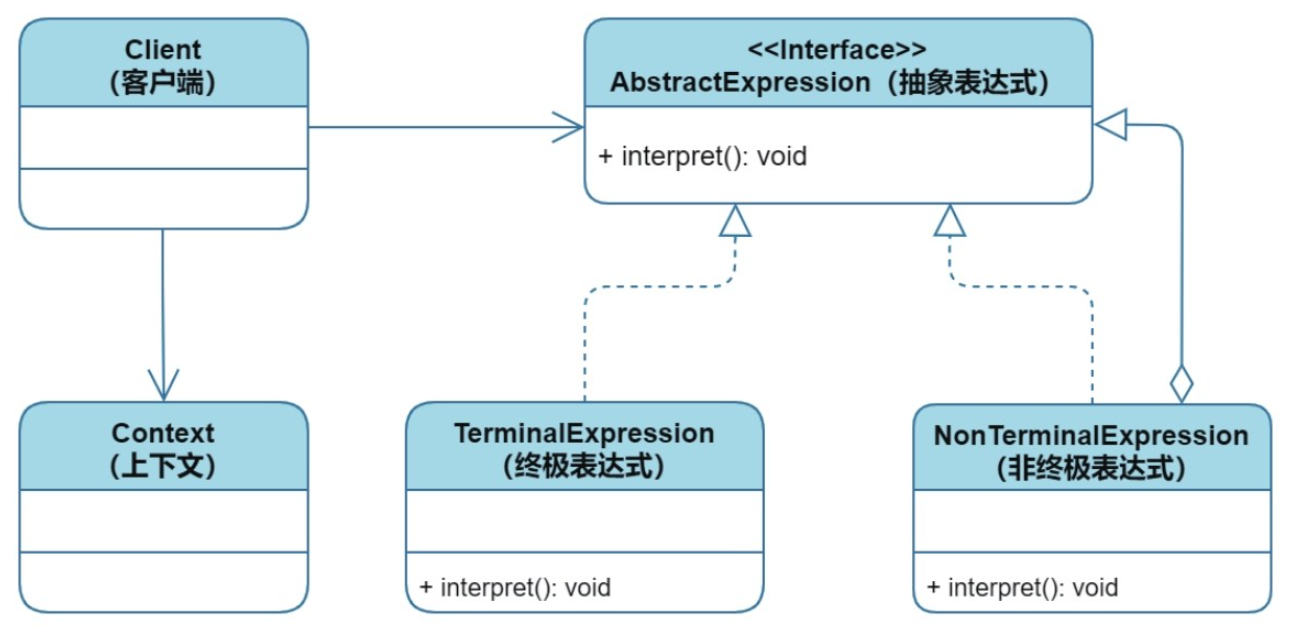
行为型:解释器模式
目录 1、核心思想 2、实现方式 2.1 模式结构 2.2 实现案例 3、优缺点分析 4、适用场景 5、注意事项 1、核心思想 目的:针对某种语言并基于其语法特征创建一系列的表达式类(包括终极表达式与非终极表达式),利用树结构模式…...

逻辑回归详解:从原理到实践
在机器学习的广阔领域中,逻辑回归(Logistic Regression)虽名为 “回归”,实则是一种用于解决二分类(0 或 1)问题的有监督学习算法。它凭借简单易懂的原理、高效的计算性能以及出色的解释性,在数…...
)
FastAPI集成APsecheduler的BackgroundScheduler+mongodb(精简)
项目架构: FastAPI(folder) >app(folder) >core(folder) >models(folder) >routers(folder) >utils(folder) main.py(file) 1 utils文件夹下新建schedulers.py from apscheduler.schedulers.background import BackgroundScheduler from apschedu…...

本地部署FreeGPT+内网穿透公网远程访问,搞定ChatGPT外网访问难题
FreeGPT是一个基于GPT 3.5/4的ChatGPT聊天网页用户界面,提供了一个开放的聊天界面,开箱即用。ChatGPT是非常热门的,但访问体验一直不太理想。为了解决这一问题,出现了各类方法和工具,其中FreeGPT是一款非常实用的…...

linux 1.0.3
挂载 这个虚拟机啥时候都能挂起 会有一个这个东东 选择连接虚拟机,然后就连到linux了 这有两个键,一个是和主机连接一个是和虚拟机连接 先把U盘拔掉 原本是没有这个盘的,但是插上去之后,电脑创建了一个虚拟的盘 也就是图中的F…...

基于RK3588的智慧农场系统开发|RS485总线|华为云IOT|node-red|MQTT
一、硬件连接流程 本次采用的是 总线型拓扑:所有设备并联到两根 RS485 总线上(A 和 B-) 二、通信协议配置 1. 主从通信模式 RS485 是半双工:同一时间只能有一个设备发送数据主从架构:通常一个主设备(…...

解锁程序人生学习成长密码,从目标设定开始
解锁程序人生学习成长密码,从目标设定开始 关键词:程序员成长、目标设定、学习路径、技能提升、职业规划、刻意练习、反馈机制 摘要:本文深入探讨程序员如何通过科学的目标设定方法实现职业成长。文章从目标设定的重要性出发,详细介绍了SMART原则、OKR方法等技术,并结合程…...

简单cnn
数据增强 在图像数据预处理环节,为提升数据多样性,可采用数据增强(数据增广)策略。该策略通常不改变单次训练的样本总数,而是通过对现有图像进行多样化变换,使每次训练输入的样本呈现更丰富的形态差异&…...
C#集合循环删除某些行
你想要在遍历集合(例如List)的同时删除某些元素时,直接在循环中删除元素可能会导致问题,因为这可能会改变集合的大小和导致索引问题; 可以用for循环的倒序来删除; 如果要删除满足特定条件的所有元素&…...

相机定屏问题分析四:【cameraserver 最大request buffer超标】后置视频模式预览定屏闪退至桌面
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:相机定屏问题分析三:【配流ConfigStream失败】外屏打开相机视频照片人像来回切换后,相机页面卡死,点击没反应9055522 这一篇我们开始讲: 相机定屏问题分析四:【cameraserver 最大request buffer超…...