简单cnn
数据增强
在图像数据预处理环节,为提升数据多样性,可采用数据增强(数据增广)策略。该策略通常不改变单次训练的样本总数,而是通过对现有图像进行多样化变换,使每次训练输入的样本呈现更丰富的形态差异,从而有效扩展模型训练的样本空间多样性。
常见的修改策略包括以下几类
1. 几何变换:如旋转、缩放、平移、剪裁、裁剪、翻转
2. 像素变换:如修改颜色、亮度、对比度、饱和度、色相、高斯模糊(模拟对焦失败)、增加噪声、马赛克
3. 语义增强(暂时不用):mixup,对图像进行结构性改造、cutout随机遮挡等
此外,在数据极少的场景长,常常用生成模型来扩充数据集,如GAN、VAE等。
# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])CNN模型
卷积的本质:通过卷积核在输入通道上的滑动乘积,提取跨通道的空间特征。所以只需要定义几个参数即可
1. 卷积核大小:卷积核的大小,如3x3、5x5、7x7等。
2. 输入通道数:输入图片的通道数,如1(单通道图片)、3(RGB图片)、4(RGBA图片)等。
3. 输出通道数:卷积核的个数,即输出的通道数。如本模型中通过 32→64→128 逐步增加特征复杂度
4. 步长(stride):卷积核的滑动步长,默认为1。
#定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)batch归一化
Batch 归一化是深度学习中常用的一种归一化技术,加速模型收敛并提升泛化能力。通常位于卷积层后。
卷积操作常见流程如下:
1. 输入 → 卷积层 → Batch归一化层(可选) → 池化层 → 激活函数 → 下一层
2. Flatten -> Dense (with Dropout,可选) -> Dense (Output)
其中,BatchNorm 应在池化前对空间维度的特征完成归一化,以确保归一化统计量基于足够多的样本(空间位置),避免池化导致的统计量偏差
旨在解决深度神经网络训练中的内部协变量偏移问题:深层网络中,随着前层参数更新,后层输入分布会发生变化,导致模型需要不断适应新分布,训练难度增加。就好比你在学新知识,知识体系的基础一直在变,你就得不断重新适应,模型训练也是如此,这就导致训练变得困难,这就是内部协变量偏移问题。
通过对每个批次的输入数据进行标准化(均值为 0、方差为 1),想象把一堆杂乱无章、分布不同的数据规整到一个标准的样子。
1. 使各层输入分布稳定,让数据处于激活函数比较合适的区域,缓解梯度消失 / 爆炸问题;
2. 因为数据分布稳定了,所以允许使用更大的学习率,提升训练效率。
特征图
卷积层输出的叫做特征图,通过输入尺寸和卷积核的尺寸、步长可以计算出输出尺寸。可以通过可视化中间层的特征图,理解 CNN 如何从底层特征(如边缘)逐步提取高层语义特征(如物体部件、整体结构)。MLP是不输出特征图的,因为他输出的一维向量,无法保留空间维度
特征图就代表着在之前特征提取器上提取到的特征,可以通过 Grad-CAM方法来查看模型在识别图像时,特征图所对应的权重是多少。
调度器
ReduceLROnPlateau调度器适用于当监测的指标(如验证损失)停滞时降低学习率。是大多数任务的首选调度器,尤其适合验证集波动较大的情况
这种学习率调度器的方法相较于之前只有单纯的优化器,是一种超参数的优化方法,它通过调整学习率来优化模型。
常见的优化器有 adam、SGD、RMSprop 等,而除此之外学习率调度器有 lr_scheduler.StepLR、lr_scheduler.ExponentialLR、lr_scheduler.CosineAnnealingLR 等。
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)@浙大疏锦行
相关文章:

简单cnn
数据增强 在图像数据预处理环节,为提升数据多样性,可采用数据增强(数据增广)策略。该策略通常不改变单次训练的样本总数,而是通过对现有图像进行多样化变换,使每次训练输入的样本呈现更丰富的形态差异&…...
C#集合循环删除某些行
你想要在遍历集合(例如List)的同时删除某些元素时,直接在循环中删除元素可能会导致问题,因为这可能会改变集合的大小和导致索引问题; 可以用for循环的倒序来删除; 如果要删除满足特定条件的所有元素&…...

相机定屏问题分析四:【cameraserver 最大request buffer超标】后置视频模式预览定屏闪退至桌面
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:相机定屏问题分析三:【配流ConfigStream失败】外屏打开相机视频照片人像来回切换后,相机页面卡死,点击没反应9055522 这一篇我们开始讲: 相机定屏问题分析四:【cameraserver 最大request buffer超…...
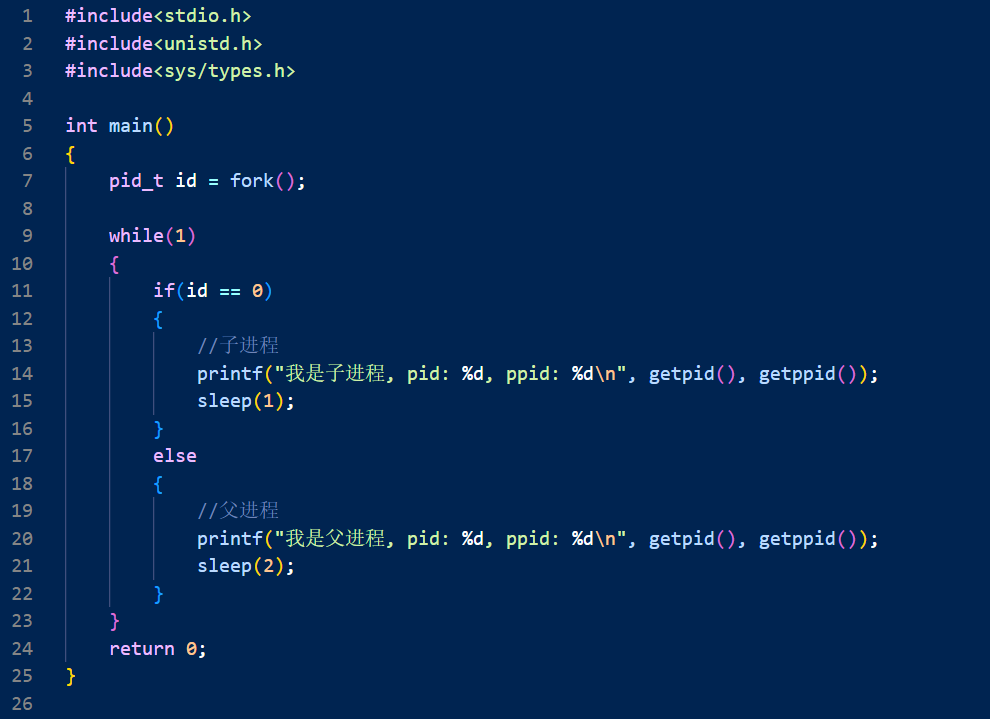
【Linux 学习计划】-- 进程地址空间
目录 进程地址的引入 进程地址空间基础原理 区域划分的本质 如何理解进程地址空间 越界访问的本质 进一步理解写时拷贝 重谈 fork 返回值 结语 进程地址的引入 我们先来看一段代码: 首先我们可以看到,父进程和子进程是可以同时可以看到一个变量…...

告别重复 - Ansible 配置管理入门与核心价值
告别重复 - Ansible 配置管理入门与核心价值 还记得我们在 SRE 基础系列中反复强调的“减少琐事 (Toil)”和“拥抱自动化”吗?想象一下这些场景: 你需要部署一个新的 Web 服务集群,每台服务器都需要安装 Nginx、配置防火墙规则、同步 Web 内容、启动服务……手动操作不仅耗时…...

3D Gaussian splatting 04: 代码阅读-提取相机位姿和稀疏点云
目录 3D Gaussian splatting 01: 环境搭建3D Gaussian splatting 02: 快速评估3D Gaussian splatting 03: 用户数据训练和结果查看3D Gaussian splatting 04: 代码阅读-提取相机位姿和稀疏点云3D Gaussian splatting 05: 代码阅读-训练整体流程3D Gaussian splatting 06: 代码…...
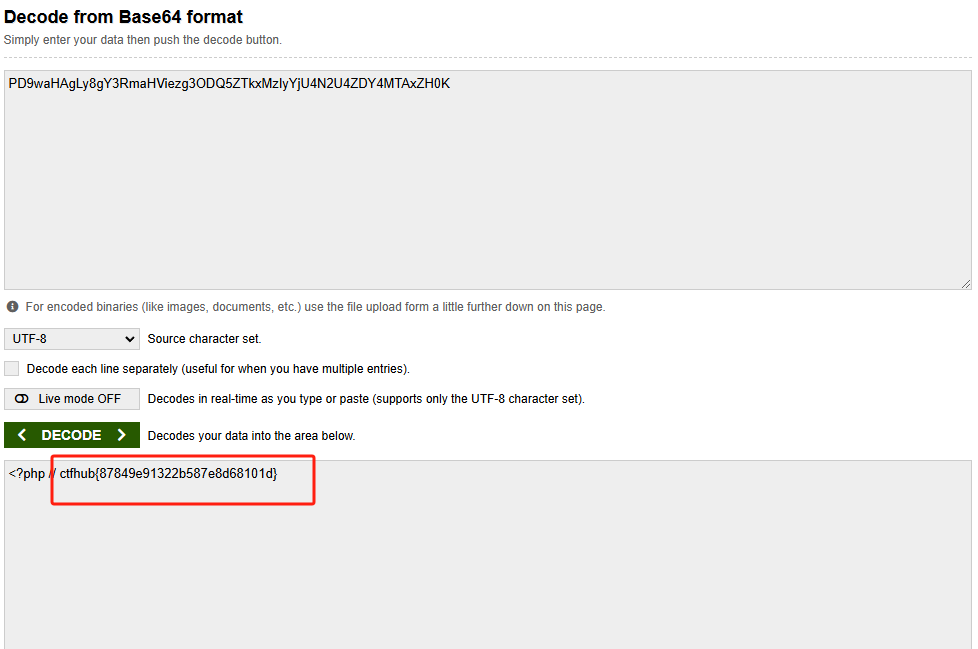
CTFHub-RCE 命令注入-过滤空格
观察源代码 代码里面可以发现过滤了空格 判断是Windows还是Linux 源代码中有 ping -c 4 说明是Linux 查看有哪些文件 127.0.0.1|ls 打开flag文件 我们尝试将空格转义打开这个文件 利用 ${IFS} 127.0.0.1|cat${IFS}flag_195671031713417.php 可是发现 文本内容显示不出来&…...

卫生间改造翻新怎么选产品?我在瑞尔特找到了解决方案
在一场打掉重来的卫生间翻新改造中,最令人头疼的,从来都不是瓷砖、吊顶这类“看得见”的工序,而是那些每天都在用、但选错一次就要懊悔好多年的卫浴产品。从功能到体验,从老人适配到美学搭配,这事真不是买个贵的就够了…...

C++ list数据删除、list数据访问、list反转链表、list数据排序
list数据删除,代码见下 #include<iostream> #include<list>using namespace std;void printList(const list<int>& l) {for (list<int>::const_iterator it l.begin(); it ! l.end(); it) {cout << *it << " "…...
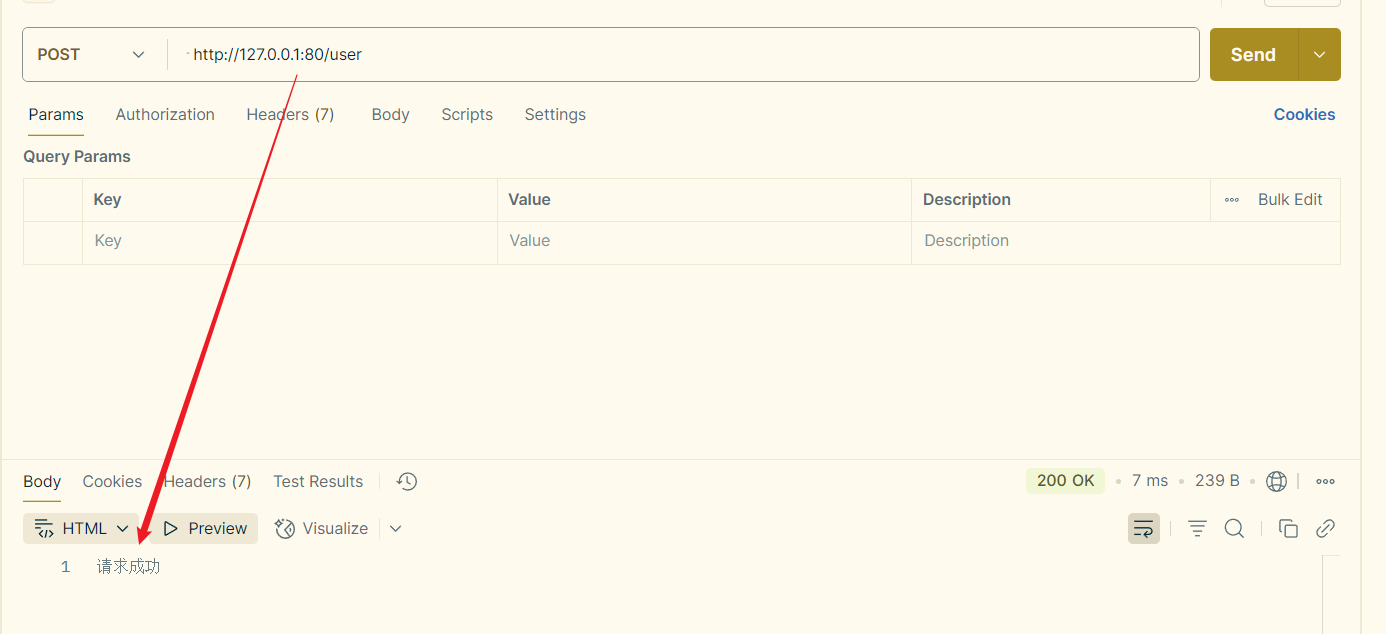
Express教程【002】:Express监听GET和POST请求
文章目录 2、监听post和get请求2.1 监听GET请求2.2 监听POST请求 2、监听post和get请求 创建02-app.js文件。 2.1 监听GET请求 1️⃣通过app.get()方法,可以监听客户端的GET请求,具体的语法格式如下: // 1、导入express const express req…...

mysql安装教程--笔记
一、Windows 系统安装 方法1:使用 MySQL Installer(推荐) 1. 下载安装包 访问 MySQL 官网下载页面,选择 MySQL Installer for Windows。 2. 运行安装程序 双击下载的 .msi 文件,选择安装类型: ◦ Developer…...

C++ 观察者模式:设计与实现详解
一、引言 在现代软件开发中,组件间的交互与通信是系统设计的核心挑战之一。观察者模式(Observer Pattern)作为一种行为设计模式,提供了一种优雅的解决方案,用于实现对象间的一对多依赖关系。本文将深入探讨 C++ 中观察者模式的设计理念、实现方式及其应用场景。 二、观察…...
【PostgreSQL 03】PostGIS空间数据深度实战:从地图服务到智慧城市
PostGIS空间数据深度实战:从地图服务到智慧城市 关键词 PostGIS, 空间数据库, 地理信息系统, GIS, 空间查询, 地理分析, 位置服务, 智慧城市, 空间索引, 坐标系统 摘要 PostGIS是PostgreSQL的空间数据扩展,它将普通的关系数据库转变为强大的地理信息系统…...
HIT-csapp大作业:程序人生-HELLO‘s P2P
计算机系统 大作业 题 目 程序人生-Hello’s P2P 专 业 计算学部 学 号 2023111813 班 级 23L0518 学 生 鲁永哲 指 导 教 师 史先俊 计…...
深入探讨redis:主从复制
前言 如果某个服务器程序,只部署在一个物理服务器上就可能会面临一下问题(单点问题) 可用性问题,如果这个机器挂了,那么对应的客户端服务也相继断开性能/支持的并发量有限 所以为了解决这些问题,就要引入分布式系统,…...

帕金森常见情况解读
一、身体出现的异常节奏 帕金森会让身体原本协调的 “舞步” 出现错乱。它是一种影响身体行动能力的状况,随着时间推进,就像老旧的时钟,齿轮转动不再顺畅,使得身体各个部位的配合逐渐失衡,打乱日常行动的节奏。 …...
清华大学发Nature!光学工程+神经网络创新结合
2025深度学习发论文&模型涨点之——光学工程神经网络 清华大学的一项开创性研究成果在《Nature》上发表,为光学神经网络的发展注入了强劲动力。该研究团队巧妙地提出了一种全前向模式(Fully Forward Mode,FFM)的训练方法&…...
【android bluetooth 案例分析 04】【Carplay 详解 3】【Carplay 连接之车机主动连手机】
1. 背景 在前面的文章中,我们已经介绍了 carplay 在车机中的角色划分, 并实际分析了 手机主动连接车机的案例。 感兴趣可以 查看如下文章介绍。 【android bluetooth 案例分析 04】【Carplay 详解 1】【CarPlay 在车机侧的蓝牙通信原理与角色划分详解】…...
C++学习-入门到精通【11】输入/输出流的深入剖析
C学习-入门到精通【11】输入/输出流的深入剖析 目录 C学习-入门到精通【11】输入/输出流的深入剖析一、流1.传统流和标准流2.iostream库的头文件3.输入/输出流的类的对象 二、输出流1.char* 变量的输出2.使用成员函数put进行字符输出 三、输入流1.get和getline成员函数2.istrea…...

NW969NW978美光闪存颗粒NW980NW984
NW969NW978美光闪存颗粒NW980NW984 技术解析:NW969、NW978、NW980与NW984的架构创新 美光(Micron)的闪存颗粒系列,尤其是NW969、NW978、NW980和NW984,代表了存储技术的前沿突破。这些产品均采用第九代3D TLC…...
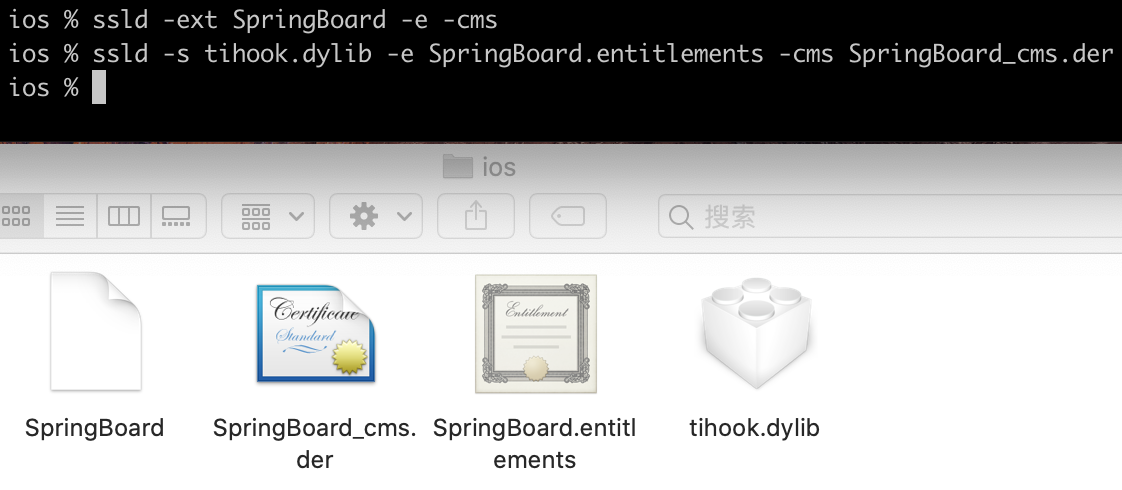
使用 ssld 提取CMS 签名并重签名
拿SpringBoard的cms签名和entitlements.xml,对tihook.dylib进行重签名 工具来源:https://github.com/eksenior/ssld...
—路由集成》)
前端基础之《Vue(17)—路由集成》
一、页面应用程序分类 1、单页面应用程序(SPA) 通过路由系统把组件串联起来的并且只有一个根index.html页面的程序,叫做单页面应用程序。 2、多页面应用程序(MPA) 整个应用程序中,有多个.html页面。每次用…...

大厂前端研发岗位PWA面试题及解析
文章目录 一、基础概念二、Service Worker 深度三、缓存策略实战四、高级能力五、性能与优化六、调试与部署七、安全与更新八、跨平台兼容九、架构设计十、综合场景十一、前沿扩展一、基础概念 什么是PWA?列举3个核心特性 解析:渐进式网页应用。核心特性:离线可用、类原生体…...

第十四章 MQTT订阅
系列文章目录 系列文章目录 第一章 总体概述 第二章 在实体机上安装ubuntu 第三章 Windows远程连接ubuntu 第四章 使用Docker安装和运行EMQX 第五章 Docker卸载EMQX 第六章 EMQX客户端MQTTX Desktop的安装与使用 第七章 EMQX客户端MQTTX CLI的安装与使用 第八章 Wireshark工具…...

element ui 表格 勾选复选框后点击分页不保存之前的数据问题
element ui 表格 勾选复选框后点击分页不保存之前的数据问题 给 el-table上加 :row-key"getRowKey"给type“selection” 上加 :reserve-selection"true"...
)
DataAgent产品经理(数据智能方向)
DataAgent产品经理(数据智能方向) 一、核心岗位职责 AI智能体解决方案设计 面向工业/政务场景构建「数据-模型-交互」闭环,需整合多源异构数据(如传感器数据、业务系统日志)与AI能力(如大模型微调、知识图…...
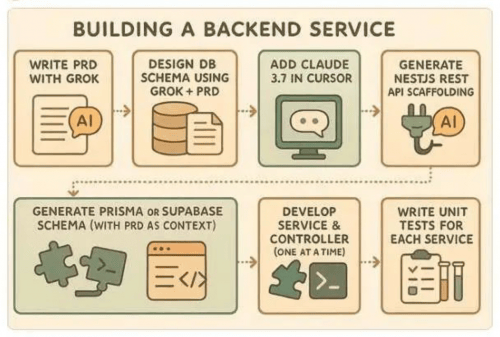
腾讯云推出云开发AI Toolkit,国内首个面向智能编程的后端服务
5月28日,腾讯云开发 CloudBase 宣布推出 AI Toolkit(CloudBase AI Toolkit),这是国内首个面向智能编程的后端服务,适配 Cursor 等主流 AI 编程工具。 云开发 AI Toolkit旨在解决 AI 辅助编程的“最后一公里”问题&…...

华为计试——刷题
判断两个IP是否属于同一子网 题目:给定一个子网掩码和两个 IP 地址,判断这两个 IP 地址是否在同一个子网中。 思路:首先,判断这个 IP 地址和子网掩码格式是否正确,不正确输出 ‘1’,进而结束;…...

【AI-安装指南】Redis Stack 的安装与使用
目录 一、Redis Stack 的介绍 二、安装方式 2.1 安装 2.2 添加依赖 2.3 设置配置信息 2.4 Redis 添加向量数据 2.5 查询向量数据 一、Redis Stack 的介绍 传统的 Redis 服务是不能存储向量的,因此我们需要首先安装 Redis Stack,而 Windows 电脑安 装 Redis Stack,官方…...
)
LeetCode Hot100(矩阵)
73. 矩阵置零 这边提供nm的做法以及更少的思路,对于nm的做法,我们只需要开辟标记当前行是否存在0以及当前列是否存在0即可,做法如下 class Solution {public void setZeroes(int[][] matrix) {int arr[]new int[matrix.length];int brr[]ne…...