【PostgreSQL 03】PostGIS空间数据深度实战:从地图服务到智慧城市
PostGIS空间数据深度实战:从地图服务到智慧城市
关键词
PostGIS, 空间数据库, 地理信息系统, GIS, 空间查询, 地理分析, 位置服务, 智慧城市, 空间索引, 坐标系统
摘要
PostGIS是PostgreSQL的空间数据扩展,它将普通的关系数据库转变为强大的地理信息系统。本文将从零开始,通过生动的实例和通俗易懂的语言,带你掌握PostGIS的核心概念和实战技能。从简单的地图服务到复杂的智慧城市应用,从基础的空间查询到高级的地理分析,我们将一步步构建完整的空间数据解决方案。无论你是想要开发LBS应用,还是要构建城市管理系统,这篇文章都将为你提供扎实的技术基础。
引言:当数据库遇上地图
想象一下这样的场景:
你正在开发一个外卖平台,产品经理提出了这些需求:
- “用户下单时,自动推荐附近2公里内的餐厅”
- “配送员接单后,计算最优配送路线”
- “分析哪些区域订单密度最高,方便商家选址”
- “实时监控配送员位置,预估送达时间”
如果用传统的关系数据库,你可能会这样处理:
-- 传统方案:用三角函数计算距离
SELECT restaurant_name,SQRT(POW(lat - 39.9042, 2) + POW(lng - 116.4074, 2)) as distance
FROM restaurants
WHERE SQRT(POW(lat - 39.9042, 2) + POW(lng - 116.4074, 2)) < 0.02
ORDER BY distance;
但这种方案有什么问题呢?
- 计算不准确(地球是球体,不是平面)
- 性能很差(无法使用索引)
- 功能有限(无法处理复杂的地理关系)
- 扩展困难(新增地理功能需要大量代码)
PostGIS就是为了解决这些问题而生的。它让数据库原生支持地理数据,就像支持数字和文本一样自然。
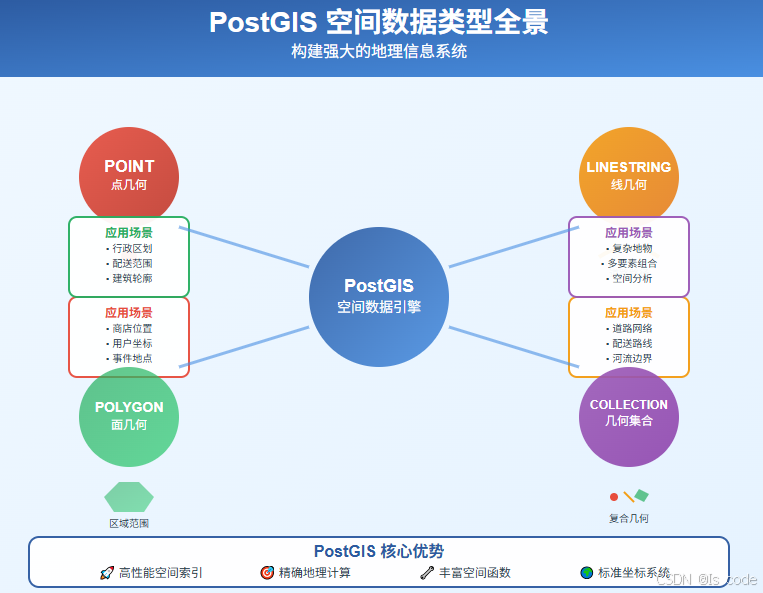
第一部分:PostGIS基础 - 让数据库理解地理世界
什么是PostGIS?
PostGIS可以理解为PostgreSQL的"地理大脑"。它为数据库添加了:
- 空间数据类型:点、线、面等几何对象
- 空间函数:距离计算、相交判断等地理运算
- 空间索引:高效的地理查询性能
- 坐标系统:支持全球各种地图投影
安装和启用PostGIS
-- 安装PostGIS扩展
CREATE EXTENSION postgis;-- 查看PostGIS版本
SELECT PostGIS_Version();-- 查看支持的空间参考系统
SELECT srid, proj4text FROM spatial_ref_sys LIMIT 5;
核心空间数据类型
PostGIS提供了丰富的空间数据类型,就像几何学中的基本图形:
1. POINT(点)
-- 创建点几何
SELECT ST_GeomFromText('POINT(116.4074 39.9042)', 4326) as beijing_center;-- 从经纬度创建点
SELECT ST_Point(116.4074, 39.9042) as point_geom;
2. LINESTRING(线)
-- 创建线几何(道路、路径)
SELECT ST_GeomFromText('LINESTRING(116.40 39.90, 116.41 39.91, 116.42 39.92)', 4326) as road;
3. POLYGON(面)
-- 创建多边形(区域、边界)
SELECT ST_GeomFromText('POLYGON((116.40 39.90, 116.41 39.90, 116.41 39.91, 116.40 39.91, 116.40 39.90))', 4326) as area;
坐标系统:地球不是平的
这是PostGIS中最重要但也最容易被忽视的概念。想象一下:
- 地理坐标系(如WGS84,SRID 4326):就像地球仪上的经纬度
- 投影坐标系(如UTM):就像把地球仪摊平成地图
-- WGS84地理坐标系(经纬度)
SELECT ST_GeomFromText('POINT(116.4074 39.9042)', 4326) as wgs84_point;-- 转换为投影坐标系(米为单位)
SELECT ST_Transform(ST_GeomFromText('POINT(116.4074 39.9042)', 4326), 3857) as web_mercator;
第二部分:空间查询实战 - 掌握地理关系分析

实战案例:构建外卖配送系统
让我们构建一个完整的外卖配送系统,学习各种空间查询:
-- 创建餐厅表
CREATE TABLE restaurants (id SERIAL PRIMARY KEY,name VARCHAR(100),location GEOMETRY(POINT, 4326),delivery_radius INTEGER DEFAULT 3000, -- 配送半径(米)cuisine_type VARCHAR(50),rating DECIMAL(3,2)
);-- 创建用户表
CREATE TABLE users (id SERIAL PRIMARY KEY,name VARCHAR(100),current_location GEOMETRY(POINT, 4326),address TEXT
);-- 创建配送员表
CREATE TABLE drivers (id SERIAL PRIMARY KEY,name VARCHAR(100),current_location GEOMETRY(POINT, 4326),is_available BOOLEAN DEFAULT true,vehicle_type VARCHAR(20)
);-- 插入测试数据
INSERT INTO restaurants (name, location, delivery_radius, cuisine_type, rating) VALUES
('老北京炸酱面', ST_Point(116.4551, 39.9380, 4326), 2000, '中餐', 4.5),
('麦当劳', ST_Point(116.4579, 39.9081, 4326), 3000, '快餐', 4.2),
('海底捞', ST_Point(116.3105, 39.9830, 4326), 5000, '火锅', 4.8);INSERT INTO users (name, current_location, address) VALUES
('张三', ST_Point(116.4520, 39.9350, 4326), '三里屯SOHO'),
('李四', ST_Point(116.3100, 39.9800, 4326), '中关村大街');INSERT INTO drivers (name, current_location, vehicle_type) VALUES
('王师傅', ST_Point(116.4500, 39.9300, 4326), '电动车'),
('赵师傅', ST_Point(116.3150, 39.9820, 4326), '摩托车');
核心空间查询操作
1. 距离查询 - ST_DWithin
-- 查找用户附近2公里内的餐厅
SELECT r.name,r.cuisine_type,r.rating,ST_Distance(r.location, u.current_location) as distance_meters
FROM restaurants r,users u
WHERE u.name = '张三'AND ST_DWithin(r.location, u.current_location, 2000)
ORDER BY distance_meters;
2. 包含查询 - ST_Contains
-- 创建配送区域
CREATE TABLE delivery_zones (id SERIAL PRIMARY KEY,zone_name VARCHAR(100),boundary GEOMETRY(POLYGON, 4326),delivery_fee DECIMAL(10,2)
);-- 插入配送区域
INSERT INTO delivery_zones (zone_name, boundary, delivery_fee) VALUES
('市中心区', ST_GeomFromText('POLYGON((116.35 39.85, 116.50 39.85, 116.50 39.95, 116.35 39.95, 116.35 39.85))', 4326), 5.00);-- 查找用户所在的配送区域
SELECT u.name,dz.zone_name,dz.delivery_fee
FROM users u
JOIN delivery_zones dz ON ST_Contains(dz.boundary, u.current_location);
3. 最近邻查询 - ST_Distance + ORDER BY
-- 为订单分配最近的配送员
WITH order_location AS (SELECT ST_Point(116.4550, 39.9370, 4326) as location
)
SELECT d.name,d.vehicle_type,ST_Distance(d.current_location, ol.location) as distance
FROM drivers d,order_location ol
WHERE d.is_available = true
ORDER BY distance
LIMIT 1;
4. 相交查询 - ST_Intersects
-- 查找与配送路线相交的区域
CREATE TABLE traffic_zones (id SERIAL PRIMARY KEY,zone_name VARCHAR(100),boundary GEOMETRY(POLYGON, 4326),traffic_level VARCHAR(20)
);-- 配送路线
WITH delivery_route AS (SELECT ST_MakeLine(ARRAY[ST_Point(116.4551, 39.9380, 4326), -- 餐厅ST_Point(116.4520, 39.9350, 4326) -- 用户]) as route
)
SELECT tz.zone_name,tz.traffic_level
FROM traffic_zones tz,delivery_route dr
WHERE ST_Intersects(tz.boundary, dr.route);
第三部分:高级空间分析 - 构建智能决策系统
缓冲区分析
缓冲区就像在地图上画圆圈,用于分析影响范围:
-- 分析餐厅配送覆盖范围
SELECT r.name,ST_Buffer(r.location, r.delivery_radius) as coverage_area
FROM restaurants r;-- 查找配送覆盖范围重叠的餐厅
SELECT r1.name as restaurant1,r2.name as restaurant2,ST_Area(ST_Intersection(ST_Buffer(r1.location, r1.delivery_radius),ST_Buffer(r2.location, r2.delivery_radius))) as overlap_area
FROM restaurants r1,restaurants r2
WHERE r1.id < r2.idAND ST_Intersects(ST_Buffer(r1.location, r1.delivery_radius),ST_Buffer(r2.location, r2.delivery_radius));
热力图分析
分析订单密度分布,帮助商家选址:
-- 创建订单表
CREATE TABLE orders (id SERIAL PRIMARY KEY,user_id INTEGER REFERENCES users(id),restaurant_id INTEGER REFERENCES restaurants(id),delivery_location GEOMETRY(POINT, 4326),order_time TIMESTAMP DEFAULT NOW(),total_amount DECIMAL(10,2)
);-- 网格化热力图分析
WITH order_grid AS (SELECT ST_SnapToGrid(delivery_location, 0.01) as grid_cell, -- 创建1km网格COUNT(*) as order_count,AVG(total_amount) as avg_amountFROM ordersWHERE order_time >= NOW() - INTERVAL '30 days'GROUP BY ST_SnapToGrid(delivery_location, 0.01)
)
SELECT ST_X(grid_cell) as longitude,ST_Y(grid_cell) as latitude,order_count,avg_amount,CASE WHEN order_count > 100 THEN '热点区域'WHEN order_count > 50 THEN '活跃区域'ELSE '一般区域'END as area_type
FROM order_grid
WHERE order_count > 10
ORDER BY order_count DESC;
路径分析
计算最优配送路线:
-- 简化的路径分析(实际应用中需要路网数据)
CREATE OR REPLACE FUNCTION calculate_delivery_route(restaurant_point GEOMETRY,user_point GEOMETRY
) RETURNS TABLE(route_geometry GEOMETRY,distance_km DECIMAL,estimated_time_minutes INTEGER
) AS $$
BEGINRETURN QUERYSELECT ST_MakeLine(restaurant_point, user_point) as route_geometry,ROUND(ST_Distance(restaurant_point, user_point)::DECIMAL / 1000, 2) as distance_km,ROUND(ST_Distance(restaurant_point, user_point) / 500)::INTEGER as estimated_time_minutes; -- 假设500米/分钟
END;
$$ LANGUAGE plpgsql;-- 使用路径分析函数
SELECT * FROM calculate_delivery_route(ST_Point(116.4551, 39.9380, 4326), -- 餐厅位置ST_Point(116.4520, 39.9350, 4326) -- 用户位置
);
第四部分:智慧城市应用 - 大规模空间数据处理
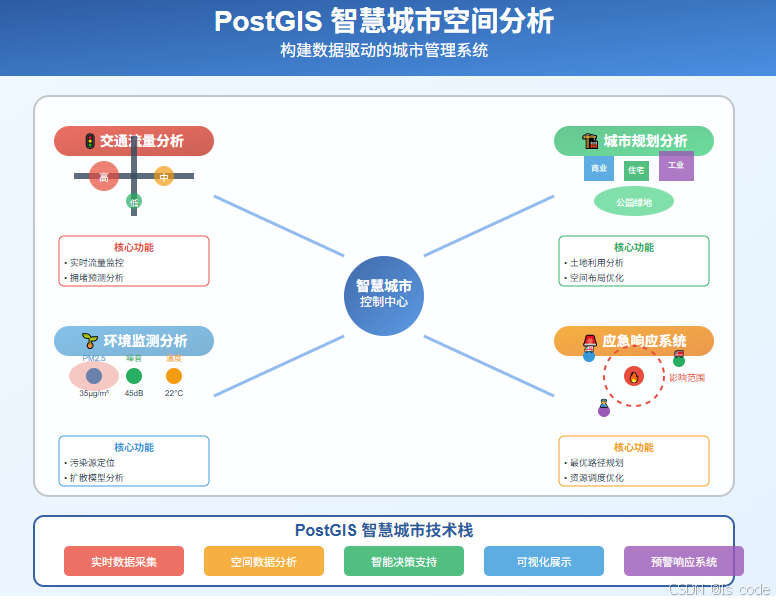
交通流量分析系统
-- 创建交通监测点表
CREATE TABLE traffic_sensors (id SERIAL PRIMARY KEY,sensor_name VARCHAR(100),location GEOMETRY(POINT, 4326),road_segment_id INTEGER,sensor_type VARCHAR(50)
);-- 创建交通流量数据表
CREATE TABLE traffic_data (id SERIAL PRIMARY KEY,sensor_id INTEGER REFERENCES traffic_sensors(id),timestamp TIMESTAMP,vehicle_count INTEGER,average_speed DECIMAL(5,2),congestion_level VARCHAR(20)
);-- 实时交通流量分析
WITH current_traffic AS (SELECT ts.sensor_name,ts.location,td.vehicle_count,td.average_speed,td.congestion_level,ST_Buffer(ts.location, 500) as influence_area -- 500米影响范围FROM traffic_sensors tsJOIN traffic_data td ON ts.id = td.sensor_idWHERE td.timestamp >= NOW() - INTERVAL '5 minutes'
),
congestion_areas AS (SELECT ST_Union(influence_area) as congested_areaFROM current_trafficWHERE congestion_level = '拥堵'
)
-- 查找受拥堵影响的配送路线
SELECT o.id as order_id,ST_Length(ST_Intersection(ST_MakeLine(r.location, o.delivery_location),ca.congested_area)) as affected_route_length
FROM orders o
JOIN restaurants r ON o.restaurant_id = r.id,congestion_areas ca
WHERE o.order_time >= NOW() - INTERVAL '1 hour'AND ST_Intersects(ST_MakeLine(r.location, o.delivery_location),ca.congested_area);
环境监测与分析
-- 创建环境监测站表
CREATE TABLE environmental_stations (id SERIAL PRIMARY KEY,station_name VARCHAR(100),location GEOMETRY(POINT, 4326),station_type VARCHAR(50)
);-- 创建环境数据表
CREATE TABLE environmental_data (id SERIAL PRIMARY KEY,station_id INTEGER REFERENCES environmental_stations(id),timestamp TIMESTAMP,pm25_value DECIMAL(6,2),temperature DECIMAL(4,1),humidity DECIMAL(4,1),noise_level DECIMAL(4,1)
);-- 空气质量影响分析
WITH pollution_sources AS (SELECT es.location,ed.pm25_value,-- 根据PM2.5值计算影响半径CASE WHEN ed.pm25_value > 75 THEN 2000WHEN ed.pm25_value > 35 THEN 1000ELSE 500END as influence_radiusFROM environmental_stations esJOIN environmental_data ed ON es.id = ed.station_idWHERE ed.timestamp >= NOW() - INTERVAL '1 hour'AND ed.pm25_value > 35 -- 轻度污染以上
)
-- 分析受空气污染影响的餐厅
SELECT r.name,r.location,ps.pm25_value,ST_Distance(r.location, ps.location) as distance_to_pollution
FROM restaurants r,pollution_sources ps
WHERE ST_DWithin(r.location, ps.location, ps.influence_radius)
ORDER BY ps.pm25_value DESC, distance_to_pollution;
应急响应系统
-- 创建应急事件表
CREATE TABLE emergency_events (id SERIAL PRIMARY KEY,event_type VARCHAR(50),location GEOMETRY(POINT, 4326),severity_level INTEGER, -- 1-5级event_time TIMESTAMP DEFAULT NOW(),description TEXT,status VARCHAR(20) DEFAULT 'active'
);-- 创建应急资源表
CREATE TABLE emergency_resources (id SERIAL PRIMARY KEY,resource_type VARCHAR(50), -- 消防车、救护车、警车current_location GEOMETRY(POINT, 4326),is_available BOOLEAN DEFAULT true,capacity INTEGER
);-- 应急响应资源调度
CREATE OR REPLACE FUNCTION emergency_response(event_location GEOMETRY,event_severity INTEGER
) RETURNS TABLE(resource_id INTEGER,resource_type VARCHAR,distance_km DECIMAL,estimated_arrival_minutes INTEGER,priority_score DECIMAL
) AS $$
DECLAREresponse_radius INTEGER;
BEGIN-- 根据事件严重程度确定响应半径response_radius := event_severity * 2000; -- 每级2公里RETURN QUERYSELECT er.id,er.resource_type,ROUND(ST_Distance(er.current_location, event_location)::DECIMAL / 1000, 2),ROUND(ST_Distance(er.current_location, event_location) / 800)::INTEGER, -- 假设800米/分钟-- 优先级评分:距离越近、容量越大分数越高ROUND((10000 - ST_Distance(er.current_location, event_location)) / 100 + er.capacity, 2)FROM emergency_resources erWHERE er.is_available = trueAND ST_DWithin(er.current_location, event_location, response_radius)ORDER BY priority_score DESC;
END;
$$ LANGUAGE plpgsql;-- 使用应急响应函数
SELECT * FROM emergency_response(ST_Point(116.4074, 39.9042, 4326), -- 天安门广场4 -- 4级严重事件
);
第五部分:性能优化与最佳实践
空间索引优化
-- 创建空间索引
CREATE INDEX idx_restaurants_location ON restaurants USING GIST (location);
CREATE INDEX idx_users_location ON users USING GIST (current_location);
CREATE INDEX idx_drivers_location ON drivers USING GIST (current_location);-- 查看索引使用情况
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM restaurants
WHERE ST_DWithin(location, ST_Point(116.4074, 39.9042, 4326), 2000);
数据分区策略
-- 按地理区域分区
CREATE TABLE orders_partitioned (id SERIAL,user_id INTEGER,restaurant_id INTEGER,delivery_location GEOMETRY(POINT, 4326),order_time TIMESTAMP,region_code INTEGER
) PARTITION BY RANGE (region_code);-- 创建分区表
CREATE TABLE orders_beijing PARTITION OF orders_partitionedFOR VALUES FROM (1100) TO (1200);CREATE TABLE orders_shanghai PARTITION OF orders_partitionedFOR VALUES FROM (3100) TO (3200);
查询优化技巧
-- 1. 使用边界框预过滤
SELECT * FROM restaurants
WHERE location && ST_MakeEnvelope(116.3, 39.8, 116.5, 40.0, 4326) -- 边界框过滤AND ST_DWithin(location, ST_Point(116.4074, 39.9042, 4326), 2000); -- 精确距离过滤-- 2. 避免不必要的坐标转换
-- 好的做法:在同一坐标系中计算
SELECT ST_Distance(location1, location2) FROM table_name;
-- 不好的做法:频繁转换坐标系
SELECT ST_Distance(ST_Transform(location1, 3857), ST_Transform(location2, 3857)) FROM table_name;-- 3. 使用合适的几何类型
-- 对于简单的圆形范围查询,使用ST_DWithin而不是ST_Buffer + ST_Contains
SELECT * FROM restaurants
WHERE ST_DWithin(location, user_location, 2000); -- 推荐-- 而不是
SELECT * FROM restaurants
WHERE ST_Contains(ST_Buffer(user_location, 2000), location); -- 不推荐
第六部分:实战项目:智能配送优化系统
让我们整合所有知识,构建一个完整的智能配送优化系统:
-- 创建综合配送优化函数
CREATE OR REPLACE FUNCTION optimize_delivery_assignment(user_location GEOMETRY,max_distance INTEGER DEFAULT 5000
) RETURNS TABLE(restaurant_id INTEGER,restaurant_name VARCHAR,driver_id INTEGER,driver_name VARCHAR,total_distance DECIMAL,estimated_time INTEGER,optimization_score DECIMAL
) AS $$
BEGINRETURN QUERYWITH available_restaurants AS (SELECT r.id,r.name,r.location,r.rating,ST_Distance(r.location, user_location) as distance_to_userFROM restaurants rWHERE ST_DWithin(r.location, user_location, max_distance)),available_drivers AS (SELECT d.id,d.name,d.current_location,d.vehicle_typeFROM drivers dWHERE d.is_available = true),delivery_combinations AS (SELECT ar.id as restaurant_id,ar.name as restaurant_name,ad.id as driver_id,ad.name as driver_name,ar.distance_to_user,ST_Distance(ad.current_location, ar.location) as driver_to_restaurant,ar.rating,CASE ad.vehicle_type WHEN '摩托车' THEN 1.5 WHEN '电动车' THEN 1.0 ELSE 0.8 END as speed_factorFROM available_restaurants arCROSS JOIN available_drivers ad)SELECT dc.restaurant_id,dc.restaurant_name,dc.driver_id,dc.driver_name,ROUND((dc.driver_to_restaurant + dc.distance_to_user)::DECIMAL / 1000, 2),ROUND((dc.driver_to_restaurant + dc.distance_to_user) / (500 * dc.speed_factor))::INTEGER,-- 综合评分:考虑距离、餐厅评分、配送效率ROUND((10 - (dc.driver_to_restaurant + dc.distance_to_user) / 1000) * 0.4 + -- 距离权重40%dc.rating * 0.3 + -- 餐厅评分权重30%dc.speed_factor * 2 * 0.3, -- 配送效率权重30%2)FROM delivery_combinations dcORDER BY optimization_score DESCLIMIT 10;
END;
$$ LANGUAGE plpgsql;-- 使用优化函数
SELECT * FROM optimize_delivery_assignment(ST_Point(116.4520, 39.9350, 4326), -- 用户位置3000 -- 最大搜索距离3公里
);
实时监控仪表板
-- 创建实时监控视图
CREATE OR REPLACE VIEW delivery_dashboard AS
WITH real_time_stats AS (SELECT COUNT(*) as total_orders,COUNT(*) FILTER (WHERE order_time >= NOW() - INTERVAL '1 hour') as orders_last_hour,AVG(ST_Distance(r.location, o.delivery_location)) as avg_delivery_distance,COUNT(DISTINCT d.id) FILTER (WHERE d.is_available = true) as available_driversFROM orders oJOIN restaurants r ON o.restaurant_id = r.idLEFT JOIN drivers d ON trueWHERE o.order_time >= NOW() - INTERVAL '24 hours'
),
busy_areas AS (SELECT ST_SnapToGrid(delivery_location, 0.01) as grid_cell,COUNT(*) as order_densityFROM ordersWHERE order_time >= NOW() - INTERVAL '2 hours'GROUP BY ST_SnapToGrid(delivery_location, 0.01)ORDER BY order_density DESCLIMIT 5
)
SELECT rts.*,json_agg(json_build_object('longitude', ST_X(ba.grid_cell),'latitude', ST_Y(ba.grid_cell),'order_count', ba.order_density)) as hot_spots
FROM real_time_stats rts,busy_areas ba
GROUP BY rts.total_orders, rts.orders_last_hour, rts.avg_delivery_distance, rts.available_drivers;-- 查看实时监控数据
SELECT * FROM delivery_dashboard;
总结:PostGIS的空间数据革命
通过这篇文章的学习,我们从零开始构建了一个完整的空间数据应用系统。让我们回顾一下PostGIS的核心价值:
技术优势总结
- 原生空间支持:数据库级别的地理数据处理
- 标准兼容:支持OGC标准,与各种GIS工具兼容
- 高性能:空间索引和优化算法保证查询效率
- 功能丰富:数百个空间函数覆盖各种应用场景
- 扩展性强:可以处理从简单LBS到复杂GIS的各种需求
应用场景回顾
| 应用领域 | 核心功能 | 关键技术 |
|---|---|---|
| 位置服务 | 附近搜索、路径规划 | ST_DWithin, ST_Distance |
| 智慧城市 | 交通分析、环境监测 | 空间聚合、热力图分析 |
| 物流配送 | 路线优化、区域管理 | 缓冲区分析、网络分析 |
| 应急响应 | 资源调度、影响评估 | 最近邻查询、空间关系 |
最佳实践指南
- 合理选择坐标系:地理坐标系用于存储,投影坐标系用于计算
- 创建空间索引:所有空间字段都应该有GIST索引
- 优化查询策略:使用边界框预过滤,避免不必要的坐标转换
- 数据分区管理:大规模数据按地理区域分区
- 监控性能指标:定期分析查询性能,优化慢查询
发展趋势展望
PostGIS正在向更智能、更高效的方向发展:
- 3D空间分析:支持三维地理数据处理
- 时空数据:集成时间维度的空间分析
- 机器学习集成:空间数据的AI分析能力
- 实时流处理:支持实时地理数据流分析
- 云原生优化:更好的云环境性能表现
PostGIS不仅仅是一个数据库扩展,它是连接现实世界与数字世界的桥梁。无论你是在开发下一个独角兽级别的LBS应用,还是在构建智慧城市的基础设施,PostGIS都将是你最可靠的技术伙伴。
下一篇预告:《PostgreSQL性能调优深度实战:从查询优化到服务器配置》
我们将深入探讨PostgreSQL的性能优化技巧,从SQL查询优化到服务器参数调优,从索引策略到连接池配置,帮你构建高性能的数据库系统。
如果这篇文章对你有帮助,欢迎点赞、收藏和分享。有任何问题或建议,欢迎在评论区讨论!
相关文章:
【PostgreSQL 03】PostGIS空间数据深度实战:从地图服务到智慧城市
PostGIS空间数据深度实战:从地图服务到智慧城市 关键词 PostGIS, 空间数据库, 地理信息系统, GIS, 空间查询, 地理分析, 位置服务, 智慧城市, 空间索引, 坐标系统 摘要 PostGIS是PostgreSQL的空间数据扩展,它将普通的关系数据库转变为强大的地理信息系统…...
HIT-csapp大作业:程序人生-HELLO‘s P2P
计算机系统 大作业 题 目 程序人生-Hello’s P2P 专 业 计算学部 学 号 2023111813 班 级 23L0518 学 生 鲁永哲 指 导 教 师 史先俊 计…...
深入探讨redis:主从复制
前言 如果某个服务器程序,只部署在一个物理服务器上就可能会面临一下问题(单点问题) 可用性问题,如果这个机器挂了,那么对应的客户端服务也相继断开性能/支持的并发量有限 所以为了解决这些问题,就要引入分布式系统,…...

帕金森常见情况解读
一、身体出现的异常节奏 帕金森会让身体原本协调的 “舞步” 出现错乱。它是一种影响身体行动能力的状况,随着时间推进,就像老旧的时钟,齿轮转动不再顺畅,使得身体各个部位的配合逐渐失衡,打乱日常行动的节奏。 …...
清华大学发Nature!光学工程+神经网络创新结合
2025深度学习发论文&模型涨点之——光学工程神经网络 清华大学的一项开创性研究成果在《Nature》上发表,为光学神经网络的发展注入了强劲动力。该研究团队巧妙地提出了一种全前向模式(Fully Forward Mode,FFM)的训练方法&…...
【android bluetooth 案例分析 04】【Carplay 详解 3】【Carplay 连接之车机主动连手机】
1. 背景 在前面的文章中,我们已经介绍了 carplay 在车机中的角色划分, 并实际分析了 手机主动连接车机的案例。 感兴趣可以 查看如下文章介绍。 【android bluetooth 案例分析 04】【Carplay 详解 1】【CarPlay 在车机侧的蓝牙通信原理与角色划分详解】…...
C++学习-入门到精通【11】输入/输出流的深入剖析
C学习-入门到精通【11】输入/输出流的深入剖析 目录 C学习-入门到精通【11】输入/输出流的深入剖析一、流1.传统流和标准流2.iostream库的头文件3.输入/输出流的类的对象 二、输出流1.char* 变量的输出2.使用成员函数put进行字符输出 三、输入流1.get和getline成员函数2.istrea…...

NW969NW978美光闪存颗粒NW980NW984
NW969NW978美光闪存颗粒NW980NW984 技术解析:NW969、NW978、NW980与NW984的架构创新 美光(Micron)的闪存颗粒系列,尤其是NW969、NW978、NW980和NW984,代表了存储技术的前沿突破。这些产品均采用第九代3D TLC…...
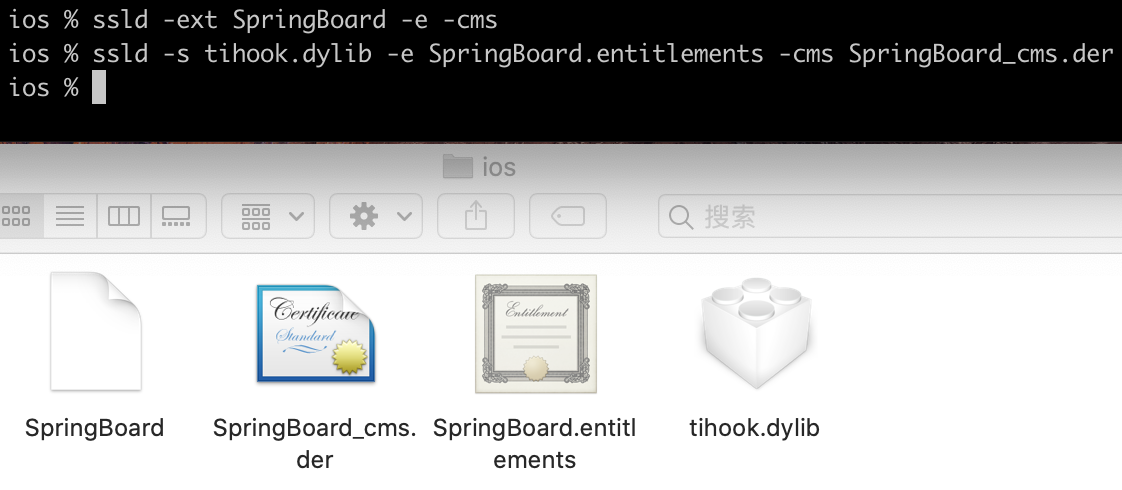
使用 ssld 提取CMS 签名并重签名
拿SpringBoard的cms签名和entitlements.xml,对tihook.dylib进行重签名 工具来源:https://github.com/eksenior/ssld...
—路由集成》)
前端基础之《Vue(17)—路由集成》
一、页面应用程序分类 1、单页面应用程序(SPA) 通过路由系统把组件串联起来的并且只有一个根index.html页面的程序,叫做单页面应用程序。 2、多页面应用程序(MPA) 整个应用程序中,有多个.html页面。每次用…...

大厂前端研发岗位PWA面试题及解析
文章目录 一、基础概念二、Service Worker 深度三、缓存策略实战四、高级能力五、性能与优化六、调试与部署七、安全与更新八、跨平台兼容九、架构设计十、综合场景十一、前沿扩展一、基础概念 什么是PWA?列举3个核心特性 解析:渐进式网页应用。核心特性:离线可用、类原生体…...

第十四章 MQTT订阅
系列文章目录 系列文章目录 第一章 总体概述 第二章 在实体机上安装ubuntu 第三章 Windows远程连接ubuntu 第四章 使用Docker安装和运行EMQX 第五章 Docker卸载EMQX 第六章 EMQX客户端MQTTX Desktop的安装与使用 第七章 EMQX客户端MQTTX CLI的安装与使用 第八章 Wireshark工具…...

element ui 表格 勾选复选框后点击分页不保存之前的数据问题
element ui 表格 勾选复选框后点击分页不保存之前的数据问题 给 el-table上加 :row-key"getRowKey"给type“selection” 上加 :reserve-selection"true"...
)
DataAgent产品经理(数据智能方向)
DataAgent产品经理(数据智能方向) 一、核心岗位职责 AI智能体解决方案设计 面向工业/政务场景构建「数据-模型-交互」闭环,需整合多源异构数据(如传感器数据、业务系统日志)与AI能力(如大模型微调、知识图…...
腾讯云推出云开发AI Toolkit,国内首个面向智能编程的后端服务
5月28日,腾讯云开发 CloudBase 宣布推出 AI Toolkit(CloudBase AI Toolkit),这是国内首个面向智能编程的后端服务,适配 Cursor 等主流 AI 编程工具。 云开发 AI Toolkit旨在解决 AI 辅助编程的“最后一公里”问题&…...

华为计试——刷题
判断两个IP是否属于同一子网 题目:给定一个子网掩码和两个 IP 地址,判断这两个 IP 地址是否在同一个子网中。 思路:首先,判断这个 IP 地址和子网掩码格式是否正确,不正确输出 ‘1’,进而结束;…...

【AI-安装指南】Redis Stack 的安装与使用
目录 一、Redis Stack 的介绍 二、安装方式 2.1 安装 2.2 添加依赖 2.3 设置配置信息 2.4 Redis 添加向量数据 2.5 查询向量数据 一、Redis Stack 的介绍 传统的 Redis 服务是不能存储向量的,因此我们需要首先安装 Redis Stack,而 Windows 电脑安 装 Redis Stack,官方…...
)
LeetCode Hot100(矩阵)
73. 矩阵置零 这边提供nm的做法以及更少的思路,对于nm的做法,我们只需要开辟标记当前行是否存在0以及当前列是否存在0即可,做法如下 class Solution {public void setZeroes(int[][] matrix) {int arr[]new int[matrix.length];int brr[]ne…...

spark在执行中如何选择shuffle策略
目录 1. SortShuffleManager与HashShuffleManager的选择2. Shuffle策略的自动选择机制3. 关键配置参数4. 版本差异(3.0+新特性)5. 异常处理与调优6. 高级Shuffle服务(CSS)1. SortShuffleManager与HashShuffleManager的选择 SortShuffleManager:默认使用,适用于大规模数据…...
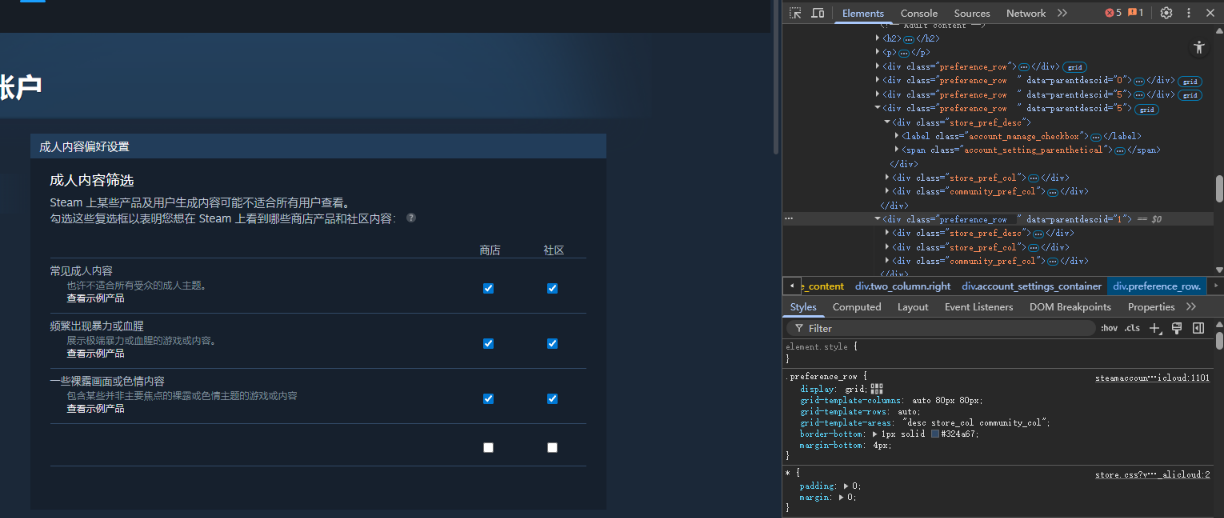
前端-不对用户显示
这是steam的商店偏好设置界面,在没有被锁在国区的steam账号会有5个选项,而被锁在国区的账号只有3个选项,这里使用的技术手段仅仅在前端隐藏了这个其他两个按钮。 单击F12打开开发者模式 单击1处,找到这一行代码,可以看…...
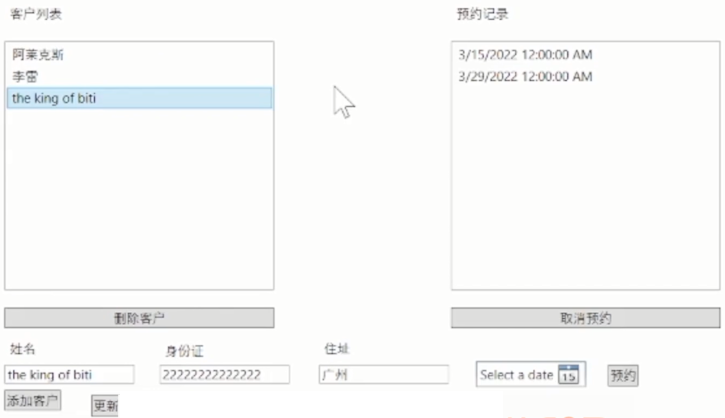
WPF【10_2】数据库与WPF实战-示例
客户预约关联示例图 MainWindow.xaml 代码 <Window x:Class"WPF_CMS.MainWindow" xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml" xmlns:d"ht…...

Hive的数据倾斜是什么?
一、Hive数据倾斜的定义 数据倾斜指在Hive分布式计算过程中,某一个或几个Task(如Map/Reduce任务)处理的数据量远大于其他Task,导致这些Task成为整个作业的性能瓶颈,甚至因内存不足而失败。数据倾斜通常发生在Shuffle阶…...
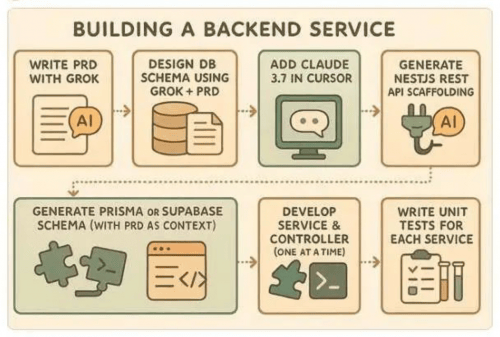
Cursor奇技淫巧篇(经常更新ing)
Dot files protection :Cursor当开启了Agent模式之后可以自动帮我们写文件,但是一般项目中的一些配置文件(通常以.开头的)都是非常重要性,为了防止Cursor在运行的过程中自己修改这些文件,导致风险ÿ…...
Unity3D仿星露谷物语开发58之保存时钟信息到文件
1、目标 保存当前的时钟信息到文件中。 2、修改TimeManager对象 TimeManager对象添加组件:Generate GUID 3、修改SceneSave.cs脚本 添加1行代码: 4、修改TimeManager.cs脚本 添加: using System; 修改TimeManager类: 添加属…...
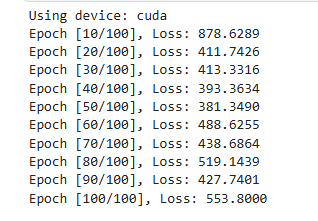
lstm 长短期记忆 视频截图 kaggle示例
【官方双语】LSTM(长短期记忆神经网络)最简单清晰的解释来了!_哔哩哔哩_bilibili . [short,input]*[2.7,1.63]b5.95 换参数和激活函数 tan激活函数输出带正负符号的百分比 tanx公式长这样? 潜在短期记忆 前几天都是乱预测…...

Spring Advisor增强规则实现原理介绍
Spring Advisor增强规则实现原理介绍 一、什么是 Advisor?1. Advisor 的定义与本质接口定义: 2. Advisor 的核心作用统一封装切点与通知构建拦截器链的基础实现增强逻辑的灵活组合 二. Sprin当中的实现逻辑1 Advisor 接口定义2 PointcutAdvisor 接口定义…...
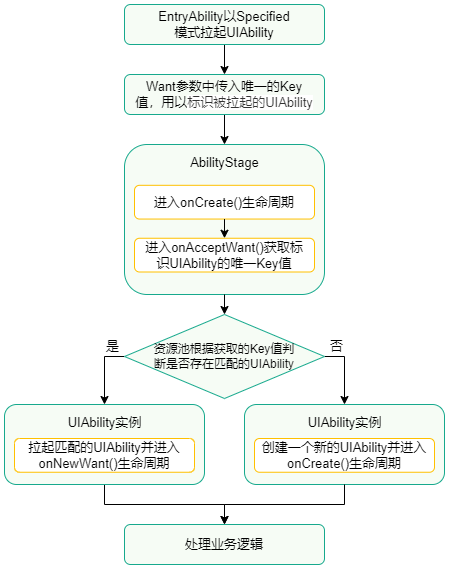
【HarmonyOS 5】鸿蒙中的UIAbility详解(二)
【HarmonyOS 5】鸿蒙中的UIAbility详解(二) 一、前言 今天我们继续深入讲解UIAbility,根据下图可知,在鸿蒙中UIAbility继承于Ability,开发者无法直接继承Ability。只能使用其两个子类:UIAbility和Extensi…...
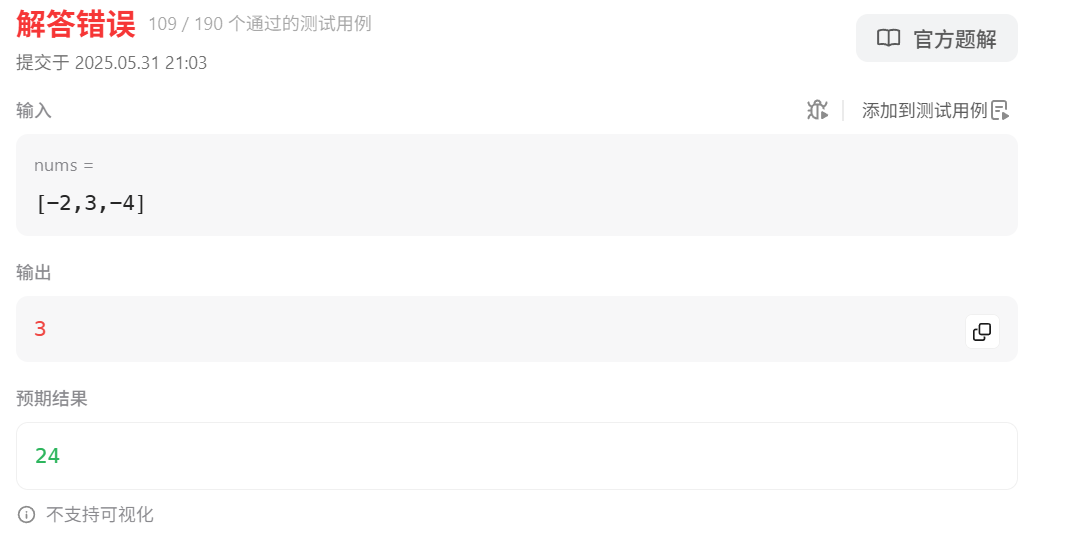
力扣HOT100之动态规划:152. 乘积最大子数组
这道题并不是代码随想录里的,我试着用动规五部曲来做,然后不能通过全部测试样例,在第109个测试样例卡住了,如下所示。 原因是可能负数乘以负数会得到最大的乘积,不能单纯地用上一个序列的最大值乘以当前值来判断是否能…...

Java后端技术栈问题排查实战:Spring Boot启动慢、Redis缓存击穿与Kafka消费堆积
Java后端技术栈问题排查实战:Spring Boot启动慢、Redis缓存击穿与Kafka消费堆积 引言 在现代互联网大厂中,Java后端系统因为其复杂性和多样性,常常面临各种问题和挑战。从核心语言到微服务架构,从数据库到缓存,不同层…...

定制开发开源AI智能名片S2B2C商城小程序:数字营销时代的话语权重构
摘要:在数据驱动的数字营销时代,企业营销话语权正从传统媒体向掌握用户数据与技术的平台转移。本文基于“数据即权力”的核心逻辑,分析定制开发开源AI智能名片S2B2C商城小程序如何通过技术赋能、场景重构与生态协同,帮助企业重构营…...