【PostgreSQL 02】PostgreSQL数据类型革命:JSON、数组与地理信息让你的应用飞起来
PostgreSQL数据类型革命:JSON、数组与地理信息让你的应用飞起来
关键词
PostgreSQL高级数据类型, JSONB, 数组类型, PostGIS, 地理信息系统, NoSQL, 文档数据库, 空间数据, 数据库设计, PostgreSQL扩展
摘要
PostgreSQL的高级数据类型是其区别于传统关系数据库的核心优势。本文将通过实际案例深入解析JSON/JSONB、数组、地理信息等高级数据类型的使用方法和最佳实践。从电商用户画像到外卖配送系统,从社交网络到智慧城市,我们将看到这些数据类型如何让复杂的业务需求变得简单优雅。无论你是想要存储灵活的文档数据,还是需要处理复杂的地理位置信息,这篇文章都将为你提供完整的解决方案。
引言:当传统数据库遇到现代需求
想象一下,你正在开发一个现代化的电商平台。产品经理走过来说:
“我们需要存储用户的个性化偏好,每个用户的偏好结构都不一样,有些用户关心价格,有些关心品牌,有些关心配送速度…”
“我们还要做基于位置的推荐,用户在哪里,就推荐附近的商家…”
“用户的标签系统要灵活,可能有几个标签,也可能有几十个…”
如果你用的是传统的关系数据库思维,你可能会这样设计:
-- 传统方案:需要多个表
CREATE TABLE users (id, name, email);
CREATE TABLE user_preferences (user_id, preference_key, preference_value);
CREATE TABLE user_tags (user_id, tag_name);
CREATE TABLE user_locations (user_id, latitude, longitude);
但这样的设计有什么问题呢?
- 查询复杂,需要多次JOIN
- 性能不佳,特别是当数据量大时
- 扩展困难,新增偏好类型需要修改表结构
- 地理位置计算复杂,需要复杂的数学公式
PostgreSQL的高级数据类型就是为了解决这些问题而生的。让我们看看用PostgreSQL如何优雅地解决这些需求。
第一部分:JSON/JSONB - 让数据库拥抱NoSQL的灵活性
JSON vs JSONB:选择的智慧
PostgreSQL提供了两种JSON数据类型:JSON和JSONB。这就像选择存储文档的方式:
JSON类型:就像把文档原样保存在文件柜里
- 保留原始格式(包括空格、键的顺序)
- 存储为文本格式
- 查询时需要重新解析
JSONB类型:就像把文档整理后放入高效的档案系统
- 以二进制格式存储
- 自动去除空格,重新排序键
- 支持索引,查询速度快

实战案例:电商用户画像系统
让我们用一个真实的例子来看看JSONB的威力:
-- 创建用户表,使用JSONB存储复杂的偏好数据
CREATE TABLE users (id SERIAL PRIMARY KEY,name VARCHAR(100),email VARCHAR(255),preferences JSONB,created_at TIMESTAMP DEFAULT NOW()
);-- 插入用户数据
INSERT INTO users (name, email, preferences) VALUES
('张三', 'zhangsan@example.com', '{"shopping": {"categories": ["电子产品", "图书", "服装"],"price_range": {"min": 100, "max": 5000},"brands": ["苹果", "华为", "小米"],"delivery": {"preferred_time": "晚上","accept_weekend": true}},"notifications": {"email": true,"sms": false,"push": true},"privacy": {"share_location": true,"show_online_status": false}
}'),
('李四', 'lisi@example.com', '{"shopping": {"categories": ["美食", "旅游"],"price_range": {"min": 50, "max": 2000},"delivery": {"preferred_time": "中午","accept_weekend": false}},"notifications": {"email": false,"sms": true,"push": true}
}');
现在看看JSONB的强大查询能力:
-- 1. 查找偏好电子产品的用户
SELECT name, email
FROM users
WHERE preferences->'shopping'->'categories' ? '电子产品';-- 2. 查找价格范围在1000-3000的用户
SELECT name, preferences->'shopping'->'price_range'->>'min' as min_price,preferences->'shopping'->'price_range'->>'max' as max_price
FROM users
WHERE (preferences->'shopping'->'price_range'->>'min')::int <= 1000AND (preferences->'shopping'->'price_range'->>'max')::int >= 3000;-- 3. 查找接受邮件通知的用户
SELECT name, email
FROM users
WHERE preferences->'notifications'->>'email' = 'true';-- 4. 更新用户偏好(只更新特定字段)
UPDATE users
SET preferences = preferences || '{"shopping": {"new_feature": true}}'
WHERE id = 1;-- 5. 添加新的偏好类别
UPDATE users
SET preferences = jsonb_set(preferences, '{shopping,categories}', preferences->'shopping'->'categories' || '["运动用品"]'
)
WHERE name = '张三';
JSONB的高级技巧
1. 创建索引提升查询性能
-- 为JSONB字段创建GIN索引
CREATE INDEX idx_user_preferences ON users USING GIN (preferences);-- 为特定路径创建索引
CREATE INDEX idx_user_shopping_categories
ON users USING GIN ((preferences->'shopping'->'categories'));-- 查询性能测试
EXPLAIN ANALYZE
SELECT * FROM users
WHERE preferences->'shopping'->'categories' ? '电子产品';
2. 复杂的聚合查询
-- 统计各个类别的用户数量
SELECT category,COUNT(*) as user_count
FROM users,jsonb_array_elements_text(preferences->'shopping'->'categories') as category
GROUP BY category
ORDER BY user_count DESC;-- 计算平均价格范围
SELECT AVG((preferences->'shopping'->'price_range'->>'min')::int) as avg_min_price,AVG((preferences->'shopping'->'price_range'->>'max')::int) as avg_max_price
FROM users
WHERE preferences->'shopping'->'price_range' IS NOT NULL;
3. 动态查询构建
-- 根据多个条件动态查询
WITH user_filters AS (SELECT id, name, preferences,CASE WHEN preferences->'shopping'->'categories' ? '电子产品' THEN 1 ELSE 0 END as likes_electronics,CASE WHEN (preferences->'shopping'->'price_range'->>'max')::int > 3000 THEN 1 ELSE 0 END as high_budget,CASE WHEN preferences->'notifications'->>'email' = 'true' THEN 1 ELSE 0 END as email_enabledFROM users
)
SELECT name, (likes_electronics + high_budget + email_enabled) as match_score
FROM user_filters
WHERE (likes_electronics + high_budget + email_enabled) >= 2
ORDER BY match_score DESC;
第二部分:数组类型 - 一对多关系的优雅解决方案
为什么需要数组类型?
传统的关系数据库处理一对多关系时,通常需要创建关联表:
-- 传统方案
CREATE TABLE users (id, name);
CREATE TABLE tags (id, name);
CREATE TABLE user_tags (user_id, tag_id);
但如果标签系统比较简单,这种设计就显得过于复杂。PostgreSQL的数组类型提供了更直接的解决方案:
-- PostgreSQL数组方案
CREATE TABLE users (id SERIAL PRIMARY KEY,name VARCHAR(100),tags TEXT[], -- 文本数组scores INTEGER[], -- 整数数组metadata JSONB[] -- 甚至可以是JSONB数组
);
实战案例:社交媒体标签系统
-- 创建用户表,使用数组存储标签和技能
CREATE TABLE social_users (id SERIAL PRIMARY KEY,username VARCHAR(50),tags TEXT[],skills TEXT[],skill_levels INTEGER[],interests JSONB[],created_at TIMESTAMP DEFAULT NOW()
);-- 插入数据
INSERT INTO social_users (username, tags, skills, skill_levels, interests) VALUES
('tech_guru', ARRAY['程序员', '技术博主', 'AI爱好者', '开源贡献者'],ARRAY['Python', 'PostgreSQL', 'Docker', 'Kubernetes'],ARRAY[9, 8, 7, 6],ARRAY['{"category": "技术", "topic": "机器学习", "level": "高级"}'::jsonb,'{"category": "生活", "topic": "摄影", "level": "中级"}'::jsonb]
),
('design_master',ARRAY['设计师', 'UI/UX', '创意工作者'],ARRAY['Photoshop', 'Figma', 'Sketch', 'After Effects'],ARRAY[9, 8, 7, 6],ARRAY['{"category": "设计", "topic": "平面设计", "level": "专家"}'::jsonb,'{"category": "艺术", "topic": "插画", "level": "高级"}'::jsonb]
);
数组的强大操作
1. 基础查询操作
-- 查找包含特定标签的用户
SELECT username, tags
FROM social_users
WHERE '程序员' = ANY(tags);-- 查找包含多个标签的用户
SELECT username, tags
FROM social_users
WHERE tags @> ARRAY['程序员', 'AI爱好者'];-- 查找标签数量超过3个的用户
SELECT username, array_length(tags, 1) as tag_count
FROM social_users
WHERE array_length(tags, 1) > 3;-- 查找Python技能等级高于7的用户
SELECT username, skills, skill_levels
FROM social_users
WHERE skills @> ARRAY['Python'] AND skill_levels[array_position(skills, 'Python')] > 7;
2. 数组操作和更新
-- 添加新标签
UPDATE social_users
SET tags = array_append(tags, '新标签')
WHERE username = 'tech_guru';-- 删除特定标签
UPDATE social_users
SET tags = array_remove(tags, 'AI爱好者')
WHERE username = 'tech_guru';-- 合并数组
UPDATE social_users
SET tags = tags || ARRAY['机器学习专家', '数据科学家']
WHERE username = 'tech_guru';-- 去重数组
UPDATE social_users
SET tags = (SELECT ARRAY(SELECT DISTINCT unnest(tags) ORDER BY 1)
);
3. 高级数组查询
-- 统计最受欢迎的标签
SELECT tag, COUNT(*) as user_count
FROM social_users,unnest(tags) as tag
GROUP BY tag
ORDER BY user_count DESC
LIMIT 10;-- 查找技能匹配度高的用户
WITH skill_matches AS (SELECT u1.username as user1,u2.username as user2,array_length(u1.skills & u2.skills, 1) as common_skillsFROM social_users u1CROSS JOIN social_users u2WHERE u1.id < u2.id
)
SELECT user1, user2, common_skills
FROM skill_matches
WHERE common_skills >= 2
ORDER BY common_skills DESC;-- 创建技能推荐系统
SELECT username,skills,ARRAY(SELECT DISTINCT skill FROM social_users s2,unnest(s2.skills) as skillWHERE s2.tags && s1.tags -- 有共同标签AND NOT skill = ANY(s1.skills) -- 但用户还没有这个技能GROUP BY skillORDER BY COUNT(*) DESCLIMIT 3) as recommended_skills
FROM social_users s1;
4. 数组索引优化
-- 为数组字段创建GIN索引
CREATE INDEX idx_social_users_tags ON social_users USING GIN (tags);
CREATE INDEX idx_social_users_skills ON social_users USING GIN (skills);-- 查询性能对比
EXPLAIN ANALYZE
SELECT * FROM social_users WHERE tags @> ARRAY['程序员'];
第三部分:地理信息类型 - 构建位置智能应用
PostGIS:让PostgreSQL拥有空间超能力
PostGIS是PostgreSQL的地理信息扩展,它让数据库能够存储和查询地理空间数据。这就像给数据库装上了GPS导航系统。
-- 启用PostGIS扩展
CREATE EXTENSION postgis;-- 查看PostGIS版本
SELECT PostGIS_Version();

实战案例:外卖配送系统
让我们构建一个完整的外卖配送系统,看看地理信息类型的威力:
-- 创建餐厅表
CREATE TABLE restaurants (id SERIAL PRIMARY KEY,name VARCHAR(100),address TEXT,location GEOMETRY(POINT, 4326), -- 使用WGS84坐标系delivery_radius INTEGER DEFAULT 3000, -- 配送半径(米)rating DECIMAL(3,2),cuisine_type TEXT[],created_at TIMESTAMP DEFAULT NOW()
);-- 创建用户表
CREATE TABLE delivery_users (id SERIAL PRIMARY KEY,name VARCHAR(100),phone VARCHAR(20),current_location GEOMETRY(POINT, 4326),home_address GEOMETRY(POINT, 4326),work_address GEOMETRY(POINT, 4326),created_at TIMESTAMP DEFAULT NOW()
);-- 创建配送员表
CREATE TABLE delivery_drivers (id SERIAL PRIMARY KEY,name VARCHAR(100),phone VARCHAR(20),current_location GEOMETRY(POINT, 4326),is_available BOOLEAN DEFAULT true,vehicle_type VARCHAR(20),created_at TIMESTAMP DEFAULT NOW()
);-- 创建订单表
CREATE TABLE orders (id SERIAL PRIMARY KEY,user_id INTEGER REFERENCES delivery_users(id),restaurant_id INTEGER REFERENCES restaurants(id),driver_id INTEGER REFERENCES delivery_drivers(id),delivery_address GEOMETRY(POINT, 4326),status VARCHAR(20) DEFAULT 'pending',created_at TIMESTAMP DEFAULT NOW()
);
插入地理数据
-- 插入餐厅数据(北京地区)
INSERT INTO restaurants (name, address, location, delivery_radius, rating, cuisine_type) VALUES
('老北京炸酱面', '北京市朝阳区三里屯', ST_GeomFromText('POINT(116.4551 39.9380)', 4326), 2000, 4.5, ARRAY['中餐', '面食']),
('麦当劳', '北京市朝阳区国贸', ST_GeomFromText('POINT(116.4579 39.9081)', 4326), 3000, 4.2, ARRAY['快餐', '西餐']),
('海底捞', '北京市海淀区中关村', ST_GeomFromText('POINT(116.3105 39.9830)', 4326), 5000, 4.8, ARRAY['火锅', '中餐']),
('星巴克', '北京市西城区西单', ST_GeomFromText('POINT(116.3770 39.9065)', 4326), 1500, 4.3, ARRAY['咖啡', '轻食']);-- 插入用户数据
INSERT INTO delivery_users (name, phone, current_location, home_address, work_address) VALUES
('张三', '13800138001', ST_GeomFromText('POINT(116.4520 39.9350)', 4326), -- 当前位置:三里屯附近ST_GeomFromText('POINT(116.4200 39.9100)', 4326), -- 家庭地址ST_GeomFromText('POINT(116.4600 39.9200)', 4326) -- 工作地址
),
('李四', '13800138002',ST_GeomFromText('POINT(116.3100 39.9800)', 4326), -- 当前位置:中关村附近ST_GeomFromText('POINT(116.3000 39.9750)', 4326),ST_GeomFromText('POINT(116.3200 39.9850)', 4326)
);-- 插入配送员数据
INSERT INTO delivery_drivers (name, phone, current_location, vehicle_type) VALUES
('王师傅', '13900139001', ST_GeomFromText('POINT(116.4500 39.9300)', 4326), '电动车'),
('赵师傅', '13900139002', ST_GeomFromText('POINT(116.3150 39.9820)', 4326), '摩托车'),
('刘师傅', '13900139003', ST_GeomFromText('POINT(116.4000 39.9150)', 4326), '电动车');
地理空间查询的魔法
1. 基础距离查询
-- 查找用户附近2公里内的餐厅
SELECT r.name,r.cuisine_type,r.rating,ST_Distance(r.location, u.current_location) as distance_meters
FROM restaurants r,delivery_users u
WHERE u.name = '张三'AND ST_DWithin(r.location, u.current_location, 2000)
ORDER BY distance_meters;-- 查找餐厅配送范围内的用户
SELECT u.name,u.phone,ST_Distance(r.location, u.current_location) as distance_meters
FROM restaurants r,delivery_users u
WHERE r.name = '海底捞'AND ST_DWithin(r.location, u.current_location, r.delivery_radius);
2. 智能配送员分配
-- 为订单分配最近的可用配送员
WITH order_location AS (SELECT ST_GeomFromText('POINT(116.4550 39.9370)', 4326) as location
),
available_drivers AS (SELECT d.*,ST_Distance(d.current_location, ol.location) as distanceFROM delivery_drivers d,order_location olWHERE d.is_available = true
)
SELECT name,phone,vehicle_type,distance
FROM available_drivers
ORDER BY distance
LIMIT 1;
3. 配送路径优化
-- 计算从餐厅到用户的配送路径
SELECT r.name as restaurant,u.name as customer,ST_Distance(r.location, u.current_location) as direct_distance,-- 如果有路网数据,可以计算实际路径距离ST_Length(ST_MakeLine(r.location, u.current_location)) as route_length
FROM restaurants r,delivery_users u
WHERE r.name = '老北京炸酱面'AND u.name = '张三';
4. 热力图分析
-- 分析订单密度热点
WITH order_grid AS (SELECT ST_SnapToGrid(delivery_address, 0.01) as grid_point, -- 创建网格COUNT(*) as order_countFROM ordersWHERE created_at >= NOW() - INTERVAL '30 days'GROUP BY ST_SnapToGrid(delivery_address, 0.01)
)
SELECT ST_X(grid_point) as longitude,ST_Y(grid_point) as latitude,order_count
FROM order_grid
WHERE order_count > 10
ORDER BY order_count DESC;
5. 地理围栏功能
-- 创建配送区域多边形
CREATE TABLE delivery_zones (id SERIAL PRIMARY KEY,name VARCHAR(100),zone_polygon GEOMETRY(POLYGON, 4326),delivery_fee DECIMAL(10,2)
);-- 插入配送区域
INSERT INTO delivery_zones (name, zone_polygon, delivery_fee) VALUES
('市中心区', ST_GeomFromText('POLYGON((116.35 39.85, 116.50 39.85, 116.50 39.95, 116.35 39.95, 116.35 39.85))', 4326), 5.00),
('郊区', ST_GeomFromText('POLYGON((116.25 39.80, 116.60 39.80, 116.60 40.00, 116.25 40.00, 116.25 39.80))', 4326), 8.00);-- 判断用户位置属于哪个配送区域
SELECT u.name,dz.name as zone_name,dz.delivery_fee
FROM delivery_users u
JOIN delivery_zones dz ON ST_Within(u.current_location, dz.zone_polygon);
地理空间索引优化
-- 为地理字段创建空间索引
CREATE INDEX idx_restaurants_location ON restaurants USING GIST (location);
CREATE INDEX idx_users_current_location ON delivery_users USING GIST (current_location);
CREATE INDEX idx_drivers_location ON delivery_drivers USING GIST (current_location);-- 查看索引使用情况
EXPLAIN ANALYZE
SELECT * FROM restaurants
WHERE ST_DWithin(location, ST_GeomFromText('POINT(116.4520 39.9350)', 4326), 2000);
第四部分:其他高级数据类型
UUID:全局唯一标识符
-- 启用UUID扩展
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";-- 使用UUID作为主键
CREATE TABLE products (id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),name VARCHAR(100),price DECIMAL(10,2),created_at TIMESTAMP DEFAULT NOW()
);-- 插入数据
INSERT INTO products (name, price) VALUES
('iPhone 15', 7999.00),
('MacBook Pro', 15999.00);-- 查询
SELECT * FROM products;
枚举类型:类型安全的选择
-- 创建枚举类型
CREATE TYPE order_status AS ENUM ('pending', 'confirmed', 'preparing', 'delivering', 'completed', 'cancelled');
CREATE TYPE priority_level AS ENUM ('low', 'medium', 'high', 'urgent');-- 使用枚举类型
CREATE TABLE tasks (id SERIAL PRIMARY KEY,title VARCHAR(200),status order_status DEFAULT 'pending',priority priority_level DEFAULT 'medium',created_at TIMESTAMP DEFAULT NOW()
);-- 插入数据
INSERT INTO tasks (title, status, priority) VALUES
('完成数据库设计', 'preparing', 'high'),
('编写API文档', 'pending', 'medium');-- 枚举类型的优势:类型安全
-- 这会报错:INSERT INTO tasks (status) VALUES ('invalid_status');
范围类型:处理区间数据
-- 使用范围类型处理时间段和数值区间
CREATE TABLE events (id SERIAL PRIMARY KEY,name VARCHAR(100),time_range TSRANGE, -- 时间范围price_range NUMRANGE, -- 价格范围age_range INT4RANGE -- 年龄范围
);-- 插入数据
INSERT INTO events (name, time_range, price_range, age_range) VALUES
('音乐节', '[2024-06-01 10:00, 2024-06-01 22:00)', '[100, 500)', '[18, 65)'),
('儿童剧', '[2024-06-02 14:00, 2024-06-02 16:00)', '[50, 200)', '[3, 12)');-- 范围查询
-- 查找特定时间有哪些活动
SELECT name FROM events
WHERE time_range @> '2024-06-01 15:00'::timestamp;-- 查找价格区间重叠的活动
SELECT name FROM events
WHERE price_range && '[150, 300)'::numrange;-- 查找适合25岁用户的活动
SELECT name FROM events
WHERE age_range @> 25;
复合类型:自定义数据结构
-- 创建复合类型
CREATE TYPE address_type AS (street VARCHAR(100),city VARCHAR(50),state VARCHAR(50),zip_code VARCHAR(10),country VARCHAR(50)
);CREATE TYPE contact_info AS (email VARCHAR(100),phone VARCHAR(20),address address_type
);-- 使用复合类型
CREATE TABLE companies (id SERIAL PRIMARY KEY,name VARCHAR(100),contact contact_info
);-- 插入数据
INSERT INTO companies (name, contact) VALUES
('科技公司', ROW('tech@company.com', '010-12345678', ROW('中关村大街1号', '北京', '北京市', '100000', '中国')));-- 查询复合类型
SELECT name,(contact).email,((contact).address).city
FROM companies;
第五部分:性能优化与最佳实践
索引策略
-- 1. JSONB索引策略
-- GIN索引:适合包含查询
CREATE INDEX idx_user_preferences_gin ON users USING GIN (preferences);-- 表达式索引:适合特定路径查询
CREATE INDEX idx_user_email_notifications
ON users ((preferences->'notifications'->>'email'));-- 2. 数组索引策略
-- GIN索引:适合数组包含查询
CREATE INDEX idx_user_tags_gin ON social_users USING GIN (tags);-- 3. 地理空间索引策略
-- GIST索引:适合空间查询
CREATE INDEX idx_restaurants_location_gist ON restaurants USING GIST (location);
查询优化技巧
-- 1. 使用EXPLAIN ANALYZE分析查询性能
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM users
WHERE preferences->'shopping'->'categories' ? '电子产品';-- 2. 避免不必要的数据转换
-- 好的做法
SELECT * FROM users WHERE preferences->>'email_verified' = 'true';
-- 不好的做法
SELECT * FROM users WHERE (preferences->>'email_verified')::boolean = true;-- 3. 使用合适的操作符
-- 包含查询使用 @>
SELECT * FROM social_users WHERE tags @> ARRAY['程序员'];
-- 相交查询使用 &&
SELECT * FROM social_users WHERE tags && ARRAY['程序员', '设计师'];
数据建模最佳实践
1. 何时使用JSONB
- ✅ 数据结构灵活,经常变化
- ✅ 嵌套层级不深(建议不超过3层)
- ✅ 查询模式相对固定
- ❌ 需要强类型约束
- ❌ 需要复杂的关联查询
2. 何时使用数组
- ✅ 一对多关系,且"多"的一方结构简单
- ✅ 不需要复杂的关联查询
- ✅ 数组元素数量相对固定(建议不超过100个)
- ❌ 需要频繁的增删改操作
- ❌ 需要复杂的统计分析
3. 何时使用地理类型
- ✅ 需要距离计算
- ✅ 需要空间关系判断
- ✅ 需要地理围栏功能
- ❌ 只是简单的经纬度存储
第六部分:实战项目:构建智能推荐系统
让我们把所有学到的知识整合起来,构建一个完整的智能推荐系统:
-- 创建综合用户表
CREATE TABLE smart_users (id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),username VARCHAR(50) UNIQUE,email VARCHAR(100),profile JSONB,interests TEXT[],location GEOMETRY(POINT, 4326),activity_zones GEOMETRY(POLYGON, 4326)[],created_at TIMESTAMP DEFAULT NOW(),updated_at TIMESTAMP DEFAULT NOW()
);-- 创建内容表
CREATE TABLE content_items (id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),title VARCHAR(200),content_type VARCHAR(50),tags TEXT[],metadata JSONB,location GEOMETRY(POINT, 4326),target_audience JSONB,created_at TIMESTAMP DEFAULT NOW()
);-- 创建用户行为表
CREATE TABLE user_behaviors (id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),user_id UUID REFERENCES smart_users(id),content_id UUID REFERENCES content_items(id),behavior_type VARCHAR(20), -- view, like, share, commentbehavior_data JSONB,location GEOMETRY(POINT, 4326),created_at TIMESTAMP DEFAULT NOW()
);-- 插入示例数据
INSERT INTO smart_users (username, email, profile, interests, location) VALUES
('tech_lover', 'tech@example.com', '{"age": 28, "occupation": "软件工程师", "experience_years": 5, "skills": ["Python", "PostgreSQL", "React"]}',ARRAY['编程', '人工智能', '开源项目', '技术博客'],ST_GeomFromText('POINT(116.4074 39.9042)', 4326)
);-- 智能推荐查询
WITH user_profile AS (SELECT * FROM smart_users WHERE username = 'tech_lover'
),
content_scores AS (SELECT c.*,-- 兴趣匹配分数(SELECT COUNT(*) FROM unnest(c.tags) tag WHERE tag = ANY(up.interests)) * 10 as interest_score,-- 位置分数(距离越近分数越高)CASE WHEN c.location IS NOT NULL AND up.location IS NOT NULL THENGREATEST(0, 100 - ST_Distance(c.location, up.location) / 100)ELSE 0END as location_score,-- 用户画像匹配分数CASE WHEN c.target_audience->'age_range' IS NOT NULL THENCASE WHEN (up.profile->>'age')::int BETWEEN (c.target_audience->'age_range'->>'min')::int AND (c.target_audience->'age_range'->>'max')::int THEN 20 ELSE 0ENDELSE 10END as demographic_scoreFROM content_items c, user_profile up
)
SELECT title,content_type,tags,interest_score + location_score + demographic_score as total_score
FROM content_scores
WHERE interest_score > 0 OR location_score > 50
ORDER BY total_score DESC
LIMIT 10;
总结:拥抱PostgreSQL的数据类型革命
PostgreSQL的高级数据类型不仅仅是技术特性,它们代表了一种新的数据建模思维:
核心优势回顾
-
JSONB:让关系数据库拥有NoSQL的灵活性
- 高性能的文档存储
- 强大的查询能力
- 完整的索引支持
-
数组类型:简化一对多关系的处理
- 减少表连接
- 提升查询性能
- 保持数据完整性
-
地理信息类型:构建位置智能应用
- 精确的距离计算
- 高效的空间查询
- 丰富的地理函数
-
其他高级类型:满足特殊业务需求
- UUID保证全局唯一性
- 枚举类型提供类型安全
- 范围类型处理区间数据
选择指南
| 数据特征 | 推荐类型 | 使用场景 |
|---|---|---|
| 结构灵活、层级嵌套 | JSONB | 用户偏好、配置信息、产品属性 |
| 一对多、结构简单 | 数组 | 标签系统、技能列表、分类 |
| 地理位置相关 | PostGIS | LBS应用、配送系统、地图服务 |
| 需要全局唯一 | UUID | 分布式系统、微服务架构 |
| 有限选择集合 | 枚举 | 状态字段、优先级、类别 |
最佳实践总结
- 合理建模:根据查询模式选择合适的数据类型
- 索引优化:为高级数据类型创建合适的索引
- 性能监控:使用EXPLAIN ANALYZE分析查询性能
- 渐进迁移:从简单场景开始,逐步应用高级特性
PostgreSQL的高级数据类型让我们能够用更自然的方式表达复杂的业务逻辑,减少不必要的表连接,提升应用性能。在数据驱动的时代,掌握这些特性将让你的应用更加强大和灵活。
下一篇预告:《PostGIS空间数据深度实战:从地图服务到智慧城市》
我们将深入探讨PostGIS的高级功能,学习如何构建复杂的地理信息系统,从简单的地图服务到智慧城市的空间分析应用。
如果这篇文章对你有帮助,欢迎点赞、收藏和分享。有任何问题或建议,欢迎在评论区讨论!
相关文章:
【PostgreSQL 02】PostgreSQL数据类型革命:JSON、数组与地理信息让你的应用飞起来
PostgreSQL数据类型革命:JSON、数组与地理信息让你的应用飞起来 关键词 PostgreSQL高级数据类型, JSONB, 数组类型, PostGIS, 地理信息系统, NoSQL, 文档数据库, 空间数据, 数据库设计, PostgreSQL扩展 摘要 PostgreSQL的高级数据类型是其区别于传统关系数据库的核心…...

Acrobat DC v25.001 最新专业版已破,像word一样编辑PDF!
在数字化时代,PDF文件以其稳定性和通用性成为了文档交流和存储的热门选择。无论是阅读、编辑、转换还是转曲,大家对PDF文件的操作需求日益增加。因此,一款出色的PDF处理软件不仅要满足多样化的需求,还要通过简洁的界面和强大的功能…...

tmux基本原理
目录 **一、核心架构:客户端-服务器模型****二、终端虚拟化:伪终端(PTY)****三、会话持久化原理****四、窗格分割的实现****五、关键系统调用****六、与传统终端对比****七、典型工作流示例****总结** tmux(Terminal M…...

RAGFlow从理论到实战的检索增强生成指南
目录 前言 一、RAGFlow是什么?为何需要它? 二、RAGFlow技术架构拆解 三、实战指南:从0到1搭建RAGFlow系统 步骤1:环境准备 步骤2:数据接入 步骤3:检索与生成 四、优化技巧:让RAGFlow更精…...

【Java】ForkJoin 框架
在Java中,ForkJoin框架是并行编程的一个重要工具,它主要用于处理可以分解为多个子任务的复杂任务。ForkJoin框架的核心是ForkJoinPool,它是一个线程池,专门用于执行ForkJoinTask任务。通过将大任务分解为多个小任务,并…...

PHP实战:安全实现文件上传功能教程
HTML部分: <form action"upload.php" method"post" enctype"multipart/form-data"> <input type"file" name"userfile"> <input type"submit" value"上传"> <…...

桥 接 模 式
在玩游戏的时候我们常常会遇到这样的机制:我们可以随意选择不同的角色,搭配不同的武器。这时只有一个抽象上下文的策略模式就不那么适用了,因为一旦我们使用继承的方式,武器和角色总有一方会变得难以扩展。这时,我们就…...

基于 Flink+Paimon+Hologres 搭建淘天集团湖仓一体数据链路
摘要:本文整理自淘天集团高级数据开发工程师朱奥老师在 Flink Forward Asia 2024 流式湖仓论坛的分享。内容主要为以下五部分: 1、项目背景 2、核心策略 3、解决方案 4、项目价值 5、未来计划 01、项目背景 1.1 当前实时数仓架构 当前的淘天实时架构是从…...
多杆合一驱动城市空间治理智慧化
引言:城市“杆林困境”与智慧化破局 走在现代城市的街道上,路灯、监控、交通信号灯、5G基站等杆体林立,不仅侵占公共空间,更暴露了城市治理的碎片化问题。如何让这些“沉默的钢铁”升级为城市的“智慧神经元”?答案在…...
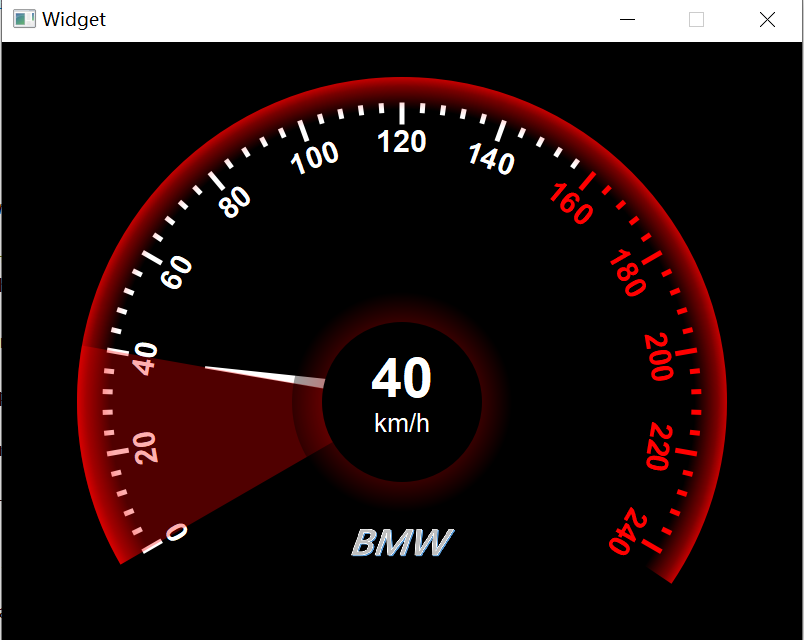
用QT写一个车速表
主要包含以下绘制步骤: 1、绘制画布: /** 绘制画布 */ void Widget::initCanvas(QPainter &painter) {//消除锯齿painter.setRenderHint(QPainter::Antialiasing,true);//设置底色painter.setBrush(QColor(0,0,0));painter.drawRect(rect());//平移…...
java在区块链中的应用)
(19)java在区块链中的应用
🔗 Java在区块链中的应用:智能合约开发全攻略 TL;DR: Java在区块链领域主要通过Hyperledger Fabric、Web3j和专用JVM实现智能合约开发,相比Solidity具有更强的企业级支持和开发效率,但在执行效率和Gas消耗方面存在差异,…...

数控技术应用理实一体化平台VR实训系统
::产品概述:: 目前我国本科类院校学生普遍存在的问题就是缺少对实际工作的了解,一直在学习相关专业的理论知识,对社会的相关企业的用人情况不了解。这也就直接导致了毕业的学生和社会上的用人单位需求有点脱节,这也是由于我国的现行本科教育侧…...

C# 将HTML文档、HTML字符串转换为图片
在.NET开发中,将HTML内容转换为图片的需求广泛存在于报告生成、邮件内容存档、网页快照等场景。Free Spire.Doc for .NET作为一款免费的专业文档处理库,无需Microsoft Word依赖,即可轻松实现这一功能。本文将深入解析HTML文档和字符串转图片两…...
界面控件DevExpress WinForms v24.2新版亮点:富文本编辑器功能全新升级
DevExpress WinForms拥有180组件和UI库,能为Windows Forms平台创建具有影响力的业务解决方案。DevExpress WinForms能完美构建流畅、美观且易于使用的应用程序,无论是Office风格的界面,还是分析处理大批量的业务数据,它都能轻松胜…...
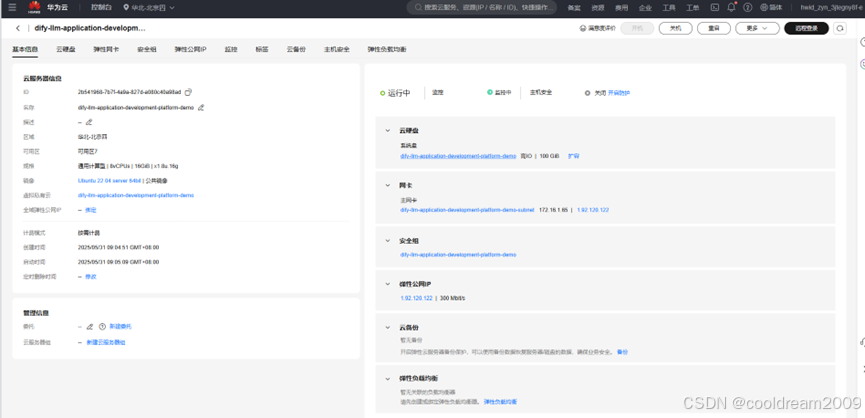
华为云Flexus+DeepSeek征文|华为云 Flexus X 加速 Dify 平台落地:高性能、低成本、强可靠性的云上选择
目录 前言 1 一键部署 Dify 平台的完整步骤 1.1 选择模板 1.2 参数配置 1.3 资源栈设置 1.4 配置确认与部署 2 Flexus X 服务器的技术优势 2.1 柔性算力随心配 2.2 一直加速一直快 2.3 越用越省降本多 2.4 安全可靠更放心 3 Flexus X 在 Dify 解决方案中的性能体验…...
Jenkins 2.479.1安装和邮箱配置教程
1.安装 在JDK安装并设置环境变量完成后,下载官网对应的war版本,在对应目录下打开命令行窗口并输入 java -jar jenkins.war其余参数感兴趣可以自行查阅,这里启动的 jenkins 服务默认占用8080端口,在浏览器输入 localhost:8080进入…...

MySQL 大战 PostgreSQL
一、底层架构对比 维度MySQLPostgreSQL存储引擎多引擎支持(InnoDB、MyISAM等)单一存储引擎(支持扩展如Zheap、Zedstore)事务实现基于UNDO日志的MVCC基于堆表(Heap)的MVCC锁机制…...

DFS入门刷题c++
目录 821. 跳台阶 - AcWing题库 92. 递归实现指数型枚举 - AcWing题库 P1706 全排列问题 - 洛谷 (luogu.com.cn) P1157 组合的输出 - 洛谷 (luogu.com.cn) P1036 [NOIP 2002 普及组] 选数 - 洛谷 (luogu.com.cn) P2089 烤鸡 - 洛谷 (luogu.com.cn) P1088 [NOIP 2…...
ToolsSet之:十六进制及二进制编辑运算工具
ToolsSet是微软商店中的一款包含数十种实用工具数百种细分功能的工具集合应用,应用基本功能介绍可以查看以下文章: Windows应用ToolsSet介绍https://blog.csdn.net/BinField/article/details/145898264 ToolsSet中Number菜单下的Hex Operate工具可以进…...

服务器液冷:突破散热瓶颈,驱动算力革命的“冷静”引擎
在人工智能大模型训练、高性能计算和超密集数据中心爆发的时代,CPU/GPU芯片的功耗已突破千瓦大关,传统风冷散热捉襟见肘。液冷技术正从实验室走向数据中心核心,成为解锁更高算力密度的关键钥匙。本文将深度解析液冷技术的原理、方案与应用。 …...

1.2 HarmonyOS NEXT分布式架构核心技术解析
HarmonyOS NEXT分布式架构核心技术解析 在数字化浪潮中,HarmonyOS NEXT以其卓越的分布式架构,重塑了设备间协同交互的格局,为开发者开拓出全新的应用设计思路。本章节将深入剖析HarmonyOS NEXT分布式架构的三大核心技术,助力开发…...
【Python训练营打卡】day40 @浙大疏锦行
DAY 40 训练和测试的规范写法 知识点回顾: 1. 彩色和灰度图片测试和训练的规范写法:封装在函数中 2. 展平操作:除第一个维度batchsize外全部展平 3. dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropo…...
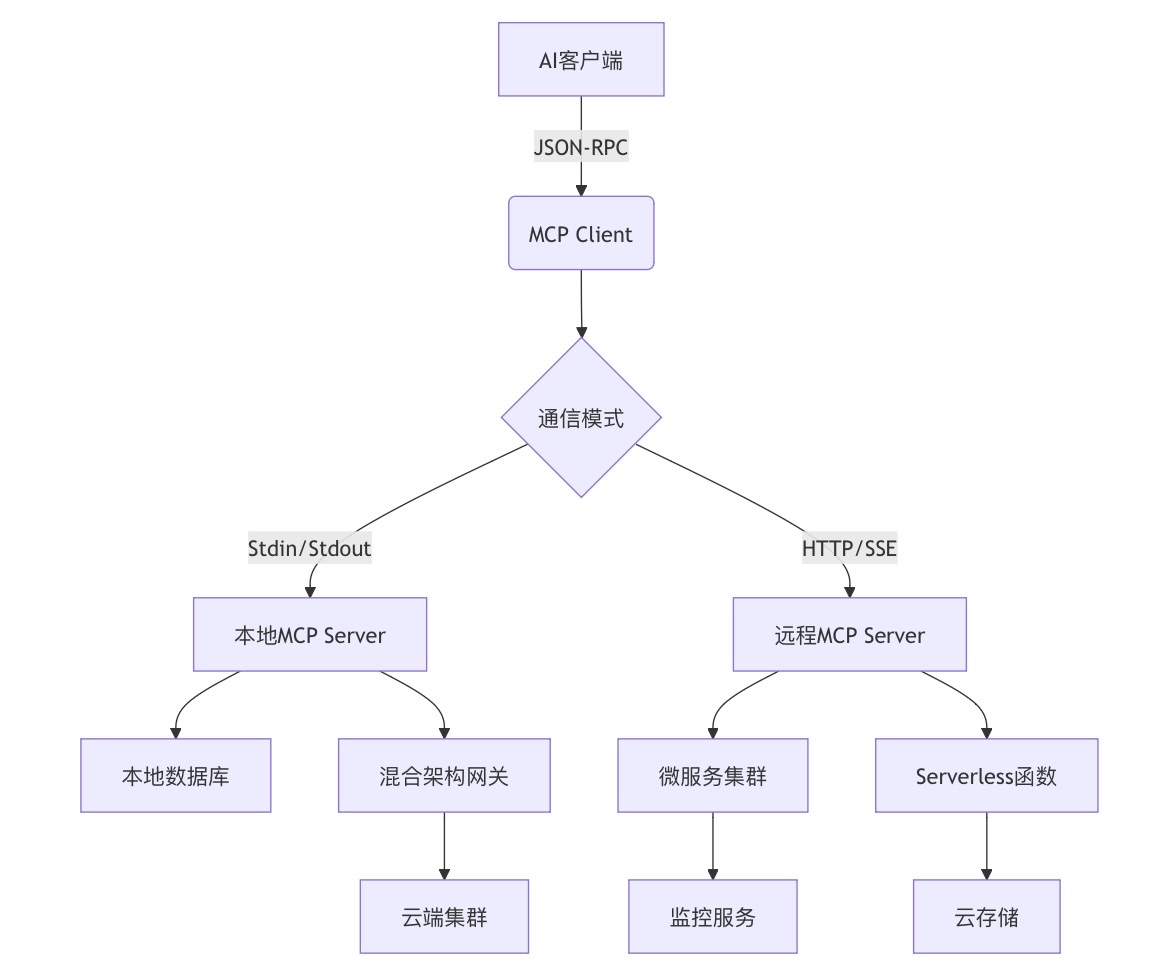
MCP Server的五种主流架构:从原理到实践的深度解析
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 在AI大模型与外部数据交互的浪潮中,MCP Server(Model Context Protocol Server)已成为连接模型与现实世界的桥梁。本文…...

跨协议协同智造新实践:DeviceNet-EtherCAT网关驱动汽车焊接装配效能跃迁
在汽车制造领域,机器人协作对于提升生产效率与产品质量至关重要。焊接、装配等关键环节,需要机器人与各类设备紧密配合。JH-DVN-ECT疆鸿智能的devicenet从站转ethercat主站协议网关,成为实现这一高效协作的得力助手,尤其是在连接欧…...

在Linux上安装Docker并配置镜像加速器:从入门到实战
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 Docker作为容器化技术的标杆工具,已经成为现代软件开发和运维的必备技能。对于程序员和技术爱好者来说,在Linux系统上搭建D…...
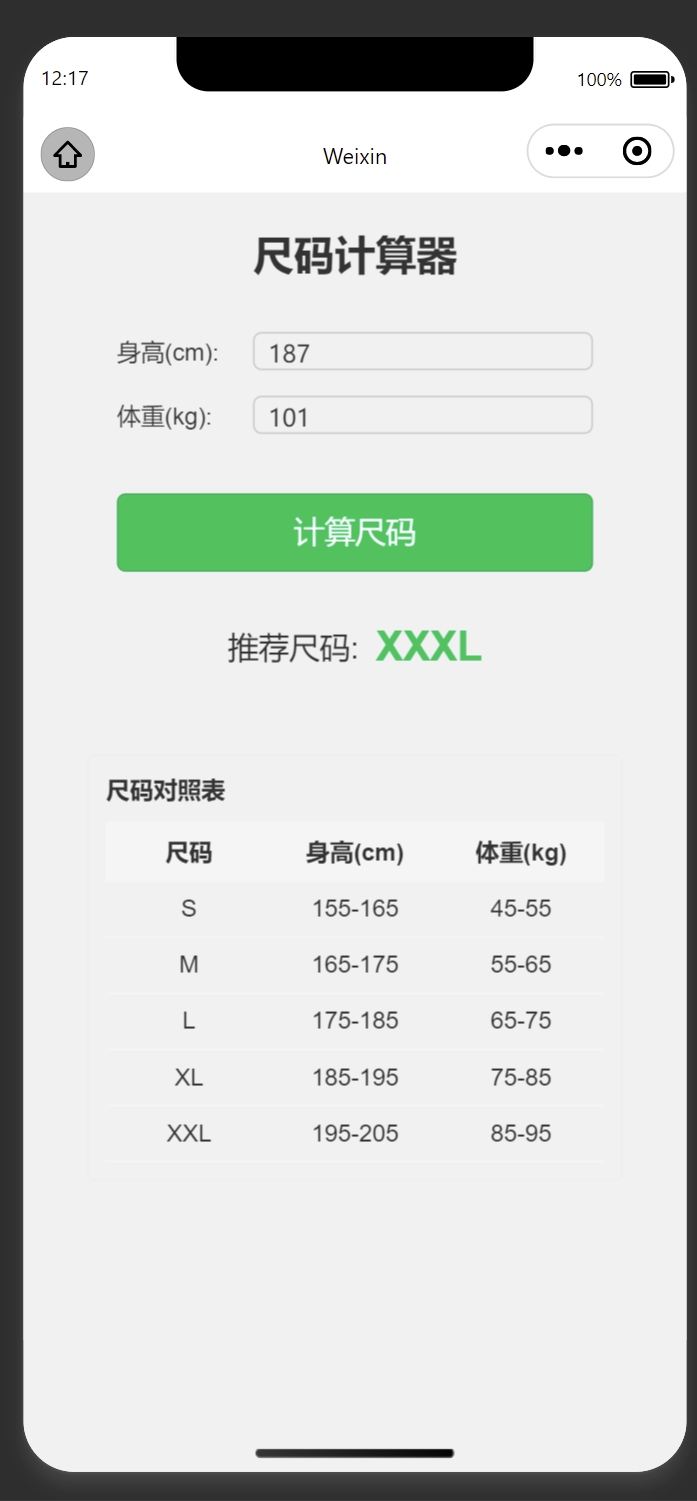
让 Deepseek 写一个尺码计算器
下面是一个简单的尺码计算器微信小程序的代码实现,包含页面布局、逻辑处理和样式。 1. 项目结构 size-calculator/ ├── pages/ │ ├── index/ │ │ ├── index.js │ │ ├── index.json │ │ ├── index.wxml │ │ └── inde…...

代码随想录算法训练营第60期第五十三天打卡
大家好,我们今天来到了最后一章图论,其实图论比较难,涉及的算法也比较多,今天比较重要的就是深度优先搜索与广度优先搜索,后面的迪杰斯特拉算法等算法在我们求最短路都会涉及到,还有最近公共祖先࿰…...
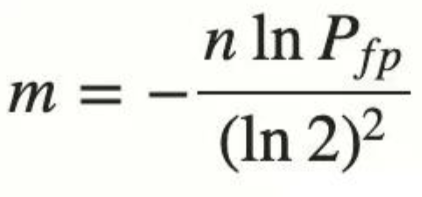
Nacos实战——动态 IP 黑名单过滤
1、需求分析 一些恶意用户(可能是黑客、爬虫、DDoS 攻击者)可能频繁请求服务器资源,导致资源占用过高。针对这种问题,可以通过IP 封禁,可以有效拉黑攻击者,防止资源被滥用,保障合法…...
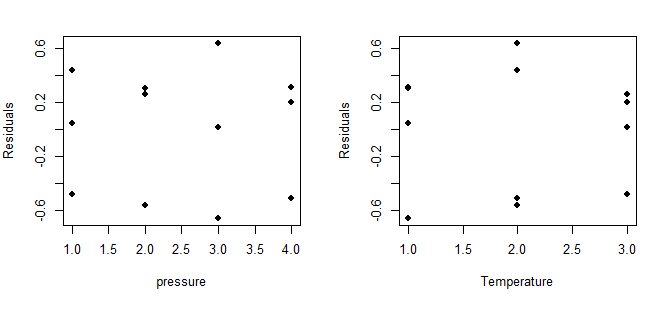
实验设计与分析(第6版,Montgomery)第5章析因设计引导5.7节思考题5.14 R语言解题
本文是实验设计与分析(第6版,Montgomery著,傅珏生译) 第5章析因设计引导5.7节思考题5.14 R语言解题。主要涉及方差分析,正态假设检验,残差分析,交互作用图。 dataframe<-data.frame( strengthc(9.60,9.…...
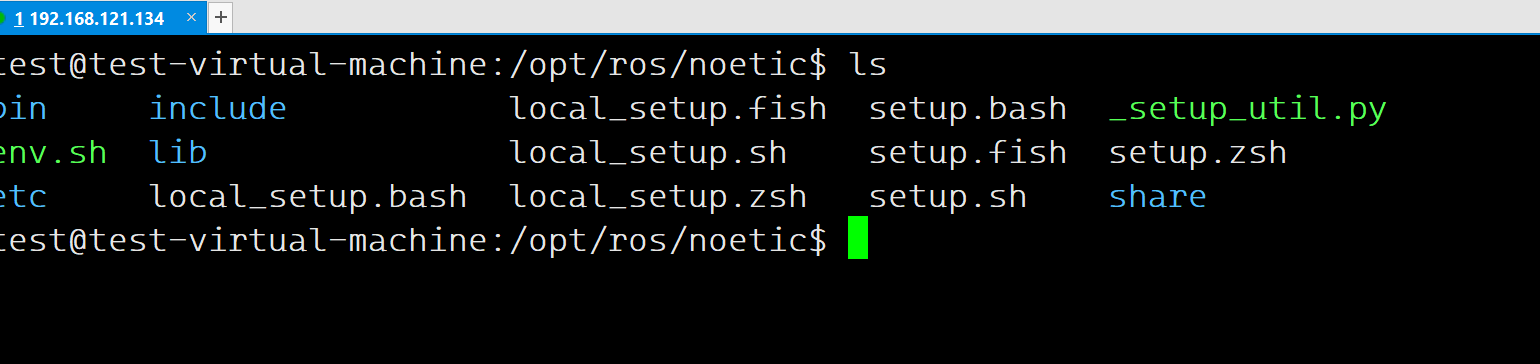
在Ubuntu20.04上安装ROS Noetic
本章教程,主要记录在Ubuntu20.04上安装ROS Noetic。 一、添加软件源 sudo sh -c . /etc/lsb-release && echo "deb http://mirrors.tuna.tsinghua.edu.cn/ros/ubuntu/ `lsb_release -cs` main" > /etc/apt/sources.list.d/ros-latest.list二、设置秘钥 …...