Python训练营---Day41
知识回顾
- 数据增强
- 卷积神经网络定义的写法
- batch归一化:调整一个批次的分布,常用与图像数据
- 特征图:只有卷积操作输出的才叫特征图
- 调度器:直接修改基础学习率
卷积操作常见流程如下:
1. 输入 → 卷积层 → Batch归一化层(可选) → 池化层 → 激活函数 → 下一层
2. Flatten -> Dense (with Dropout,可选) -> Dense (Output)
作业:尝试手动修改下不同的调度器和CNN的结构,观察训练的差异。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集:仅进行必要的标准化,保持数据原始特性,标准化不损失数据信息,可还原
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./cifar_data',train=True,download=True,transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.CIFAR10(root='./cifar_data',train=False,transform=test_transform # 测试集不使用增强
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始使用CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_cnn_model.pth')
# print("模型已保存为: cifar10_cnn_model.pth")
相关文章:

Python训练营---Day41
DAY 41 简单CNN 知识回顾 数据增强卷积神经网络定义的写法batch归一化:调整一个批次的分布,常用与图像数据特征图:只有卷积操作输出的才叫特征图调度器:直接修改基础学习率 卷积操作常见流程如下: 1. 输入 → 卷积层 …...
Linux 1.0.4
父子shell linux研究的就是shell 打开两个窗口就是两个shell 终端的软件有很多 bash也是一个软件 我们在terminal里面再打开一个bash,然后再次使用ps命令发现多出来一个bash,之后点击exit只是显示了一个exit,这个只是退出了在terminal中打开…...

Qt -下载Qt6与OpenCV
博客主页:【夜泉_ly】 本文专栏:【暂无】 欢迎点赞👍收藏⭐关注❤️ 前言 呃啊,本来就想在 Qt 里简单几个 OpenVC 的函数,没想到一搞就是一天。 我之前的开发环境是 Qt 5.14.2,使用 MinGW 7.3.0 64-bit 编…...
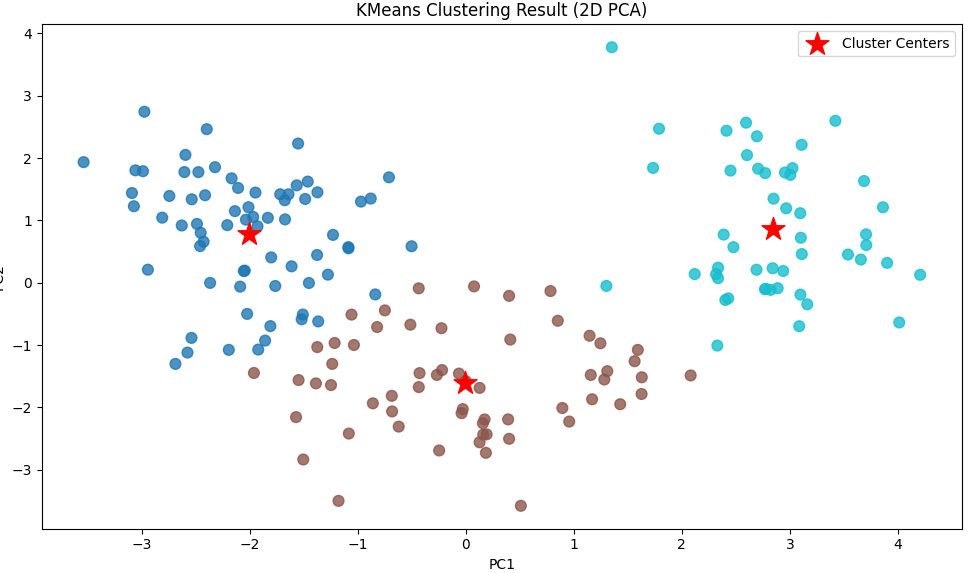
机器学习无监督学习sklearn实战一:K-Means 算法聚类对葡萄酒数据集进行聚类分析和可视化( 主成分分析PCA特征降维)
本项目代码在个人github链接:https://github.com/KLWU07/Machine-learning-Project-practice/tree/main/1-Wine%20cluster%20analysis 如果对于聚类算法理论不理解可参考这篇之前文章机器学习中无监督学习方法的聚类:划分式聚类、层次聚类、密度聚类&…...

可灵2.1 vs Veo 3:AI视频生成谁更胜一筹?
在Google发布Veo 3几天后,可灵显然感受到了压力,发布了即将推出的视频模型系列可灵 2.1的早期体验版。 据我了解,有三种不同的模式: 可灵 2.1 标准模式: 720p分辨率 仅支持图像转视频(生成更快,一致性更好) 5秒视频仍需20积分 可灵 2.1 专业模式: 1080p分辨率 仅在图…...

C语言之编译器集合
C语言有多种不同的编译器,以下是常见的编译工具及其特点: 一、主流C语言编译器 GCC(GNU Compiler Collection) 特点:开源、跨平台,支持多种语言(C、C、Fortran 等)。 使用场景&…...

计量表计的演进历程与技术变革:从机械到物联网时代
前言 近期在用python写一些关于计量表计数据集采模型。主要就是针对计量表计采集的相关数据,按照通讯协议格式进行解析,最后根据自己需求,编制界面进行数据的展示,存储,以及运算的内容。现在就个人关于计量表计的一点…...

更换Homebrew 源
以下是查看和修改 Homebrew 源的详细步骤,适用于需要切换到国内镜像以加速下载的场景: 1. 查看当前 Homebrew 源 # 查看 brew 主仓库地址 git -C "$(brew --repo)" remote get-url origin# 查看 homebrew-core 仓库地址 git -C "$(brew…...

人工智能在智能供应链中的创新应用与未来趋势
随着全球化的加速和市场竞争的加剧,供应链管理的复杂性和重要性日益凸显。传统的供应链管理面临着诸多挑战,如需求预测不准确、库存管理效率低下、物流配送延迟等。智能供应链通过引入人工智能(AI)、物联网(IoT&#x…...

鸿蒙OSUniApp自定义手势识别与操作控制实践#三方框架 #Uniapp
UniApp自定义手势识别与操作控制实践 引言 在移动应用开发中,手势交互已经成为提升用户体验的重要组成部分。本文将深入探讨如何在UniApp框架中实现自定义手势识别与操作控制,通过实际案例帮助开发者掌握这一关键技术。我们将以一个图片查看器为例&…...
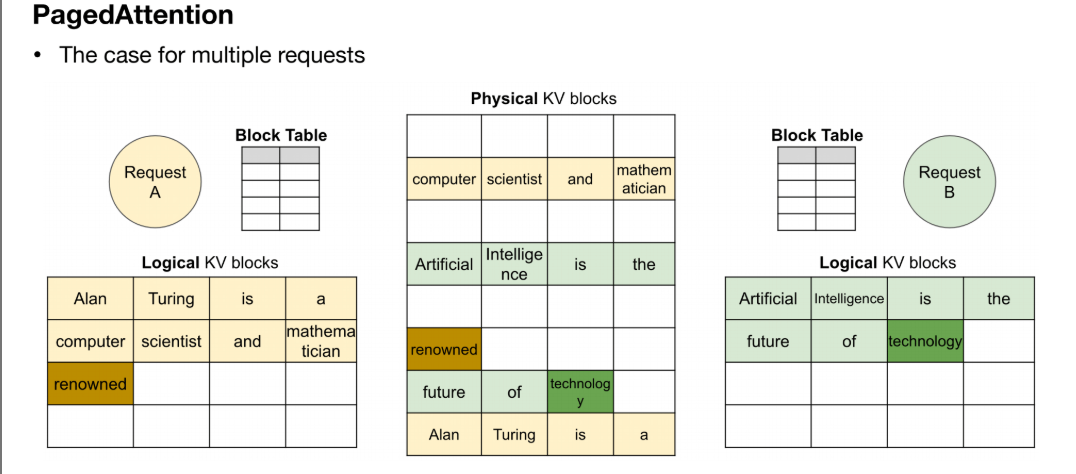
LLM优化技术——Paged Attention
在Transformer decoding的过程中,需要存储过去tokens的所有Keys和Values,以完成self attention的计算,称之为KV cache。 (1)KV cache的大小 可以计算存储KV cache所需的内存大小: batch * layers * kv-he…...

推荐几个不错的AI入门学习视频
引言:昨天推荐了几本AI入门书(AI入门书),反响还不错。今天,我再推荐几个不错的AI学习视频,希望对大家有帮助。 网上关于AI的学习视频特别多。有收费的,也有免费的。我今天只推荐免费的。 我们按…...
采用Bright Data+n8n+AI打造自动化新闻助手:每天5分钟实现内容日更
一、引言 在信息爆炸的时代,作为科技领域的内容创作者,我每天都要花费2-3小时手动收集行业新闻、撰写摘要并发布到各个社群。直到我发现Bright Datan8nAI这套"黄金组合",才真正实现了从"人工搬运"到"智能自动化&qu…...

Real SQL Programming
目录 SQL in Real Programs Options Stored Procedures Advantages of Stored Procedures Parameters in PSM SQL in Real Programs We have seen only how SQL is used at the generic query interface --- an environment where we sit at a terminal and ask queries …...
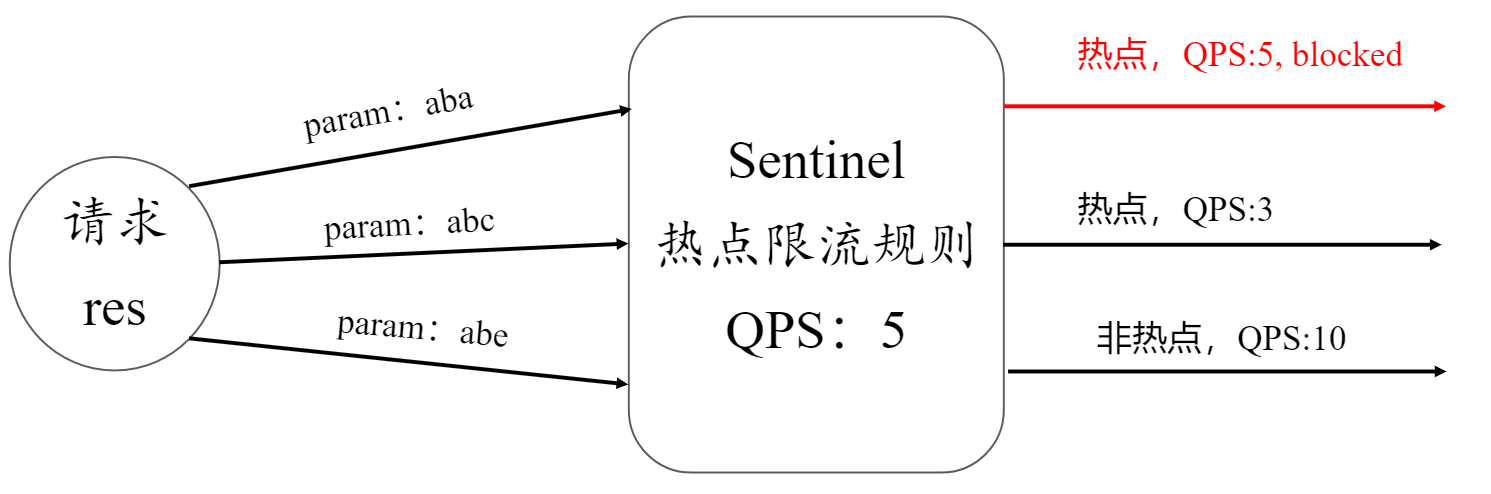
Sentinel限流熔断机制实战
1、核心概念 1.1、流量控制 流量控制是为了 防止系统被过多的请求压垮,确保资源合理分配并保持服务的可用性,比如对请求数量的限制。 流量控制的 3 个主要优势: 防止过载:当瞬间涌入的请求量超出系统处理能力时,会…...
)
Java 数据处理 - 数值转不同进制的字符串(数值转十进制字符串、数值转二进制字符串、数值转八进制字符串、数值转十六进制字符串)
一、数值转十进制字符串 调用 String.valueOf() int num 123;String decStr String.valueOf(num);System.out.println(decStr);# 输出结果123调用 Integer.toString(),指定进制 int num 123;String decStr Integer.toString(num);System.out.println(decStr)…...
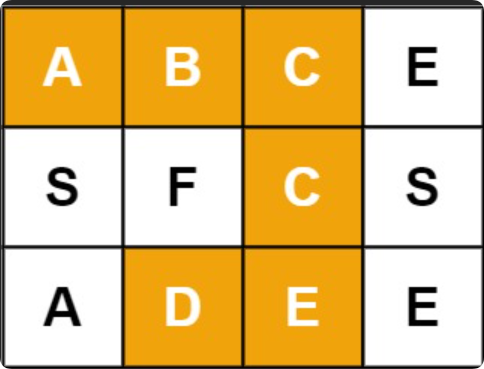
79. 单词搜索-极致优化,可行性剪枝和顺序剪枝
给你一个目标字符串,和一个二维字符数组,判断在数组中是否能找到目标字符串。 例如,board [["A","B","C","E"],["S","F","C","S"],["A","…...

ICDMC 2025:创新媒体模式,迎接数字时代的挑战
2025年数字媒体与通讯国际会议将在风景秀丽的中国山东举行。此次会议致力于促进数字媒体和通讯领域的国际合作与交流,为相关产业发展提供智力支持和技术引领。我们诚挚邀请来自世界各地的学者、研究人员和行业专家参加本次会议,共同探讨前沿问题和发展方…...

深入解析C#多态性:基类引用、虚方法与覆写机制
基类引用的本质 在C#面向对象编程中,派生类对象由基类部分和扩展部分组成。通过基类引用访问派生类对象时,实际是在进行「观察视角」的转换: MyDerivedClass derived new MyDerivedClass(); MyBaseClass mybc (MyBaseClass)derived; //…...
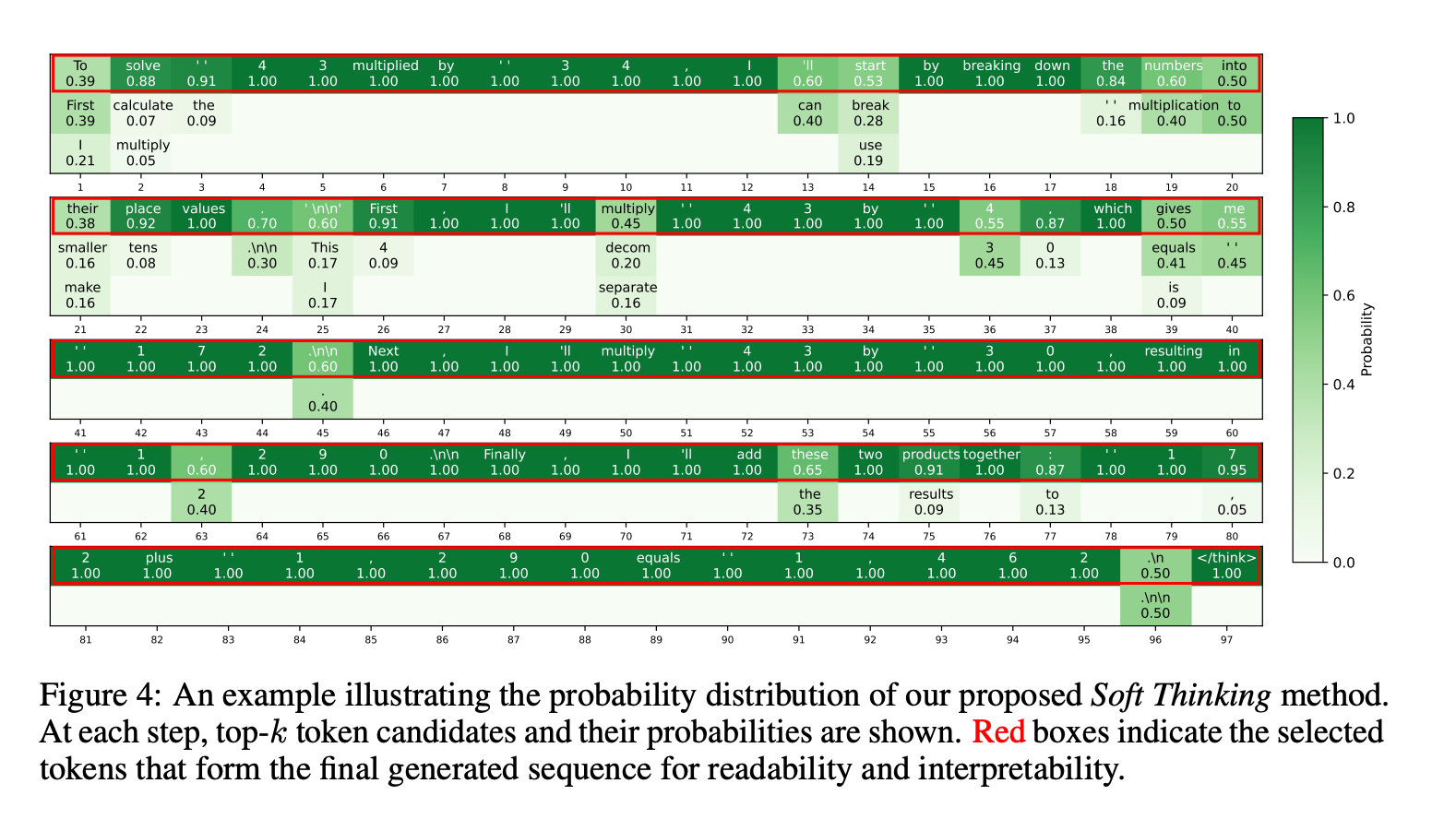
SoftThinking:让模型学会模糊思考,同时提升准确性和推理速度!!
摘要:人类的认知通常涉及通过抽象、灵活的概念进行思考,而不是严格依赖离散的语言符号。然而,当前的推理模型受到人类语言边界的限制,只能处理代表语义空间中固定点的离散符号嵌入。这种离散性限制了推理模型的表达能力和上限潜力…...

C++中 newdelete 与 mallocfree 的异同详解
C中 new/delete 与 malloc/free 的异同详解 在 C 开发中,动态内存管理是重中之重!new/delete 和 malloc/free 都是用来动态申请和释放内存的,但它们有本质的区别。今天我们就来彻底搞懂它们的区别,避免内存泄漏和 undefined beha…...
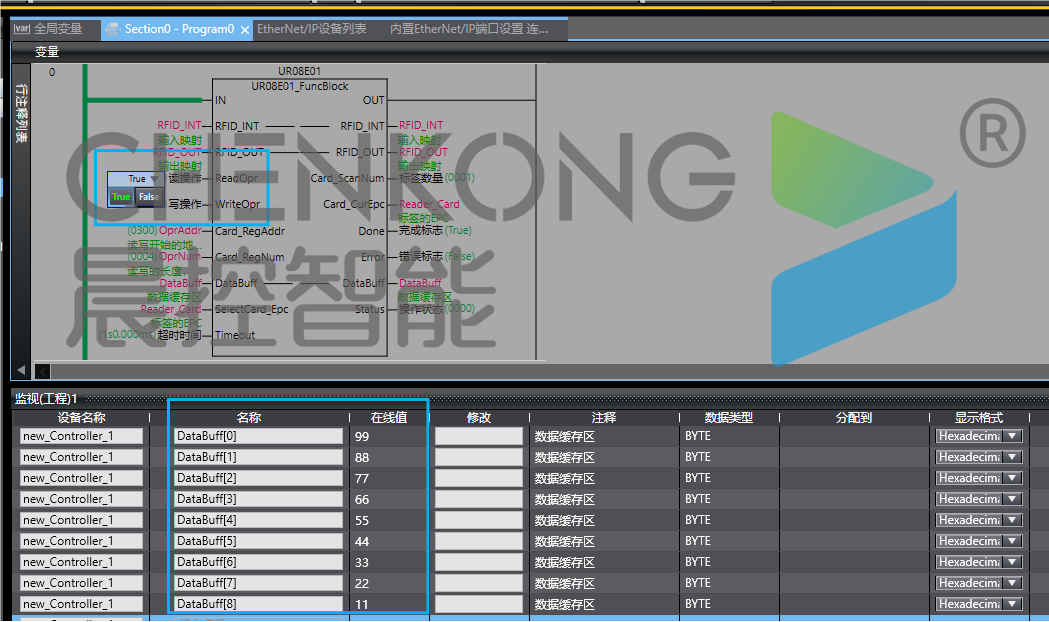
晨控CK-UR08与欧姆龙PLC配置Ethernet/IP通讯连接操作手册
晨控CK-UR08与欧姆龙PLC配置Ethernet/IP通讯连接操作手册 晨控CK-UR08系列作为晨控智能工业级别RFID读写器,支持大部分工业协议如RS232、RS485、以太网。支持工业协议Modbus RTU、Modbus TCP、Profinet、EtherNet/lP、EtherCat以及自由协议TCP/IP等。 本期主题:围绕…...

STM32入门教程——LED闪烁LED流水灯蜂鸣器
前言 本教材基于B站江协科技课程整理,适合有C语言基础、刚接触STM32的新手。它梳理了STM32核心知识点,帮助大家把C语言知识应用到STM32开发中,更高效地开启STM32学习之旅。 一、硬件电路搭建与工程配置 电路连接要点 LED 闪烁 / 流水灯&…...

鸿蒙OSUniApp 实现的数据可视化图表组件#三方框架 #Uniapp
UniApp 实现的数据可视化图表组件 前言 在移动互联网时代,数据可视化已成为产品展示和决策分析的重要手段。无论是运营后台、健康监测、还是电商分析,图表组件都能让数据一目了然。UniApp 作为一款优秀的跨平台开发框架,支持在鸿蒙…...

Tornado WebSocket实时聊天实例
在 Python 3 Tornado 中使用 WebSocket 非常直接。你需要创建一个继承自 tornado.websocket.WebSocketHandler 的类,并实现它的几个关键方法。 下面是一个简单的示例,演示了如何创建一个 WebSocket 服务器,该服务器会接收客户端发送的消息&a…...

HarmonyOS鸿蒙与React Native的融合开发模式以及能否增加对性能优化的具体案例
鸿蒙与React Native的融合开发模式 一、技术架构设计 底层适配层 通过HarmonyOS的NDK封装原生能力(如分布式软总线、AI引擎) 使用React Native的Native Modules桥接鸿蒙API(需重写Java/Objective-C部分为ArkTS) 组件映射机制 …...

化学分析原理。
化学分析关心的要素:a.空间结构(晶格结构、胶体结构、玻璃体结构、膜结构,宏观与微观两个层面,化学键与键角以及结构强度,结合能以及物质内聚力研究,主要目的是化学建模),b.成分与组…...
开源即战力!从科研到商用:Hello Robot 移动操作机器人Stretch 3多模态传感融合(RGB-D/激光/力矩)控制方案
科研领域对机器人技术的需求日益增长,Hello Robot的移动操作机器人Stretch 3凭借其灵活性和性能满足了这一需求。其模块化设计、开源架构和高精度传感控制能力,使科研人员能够顺利开展实验。Stretch 3以其独特的移动操作能力,为科研探索提供了…...
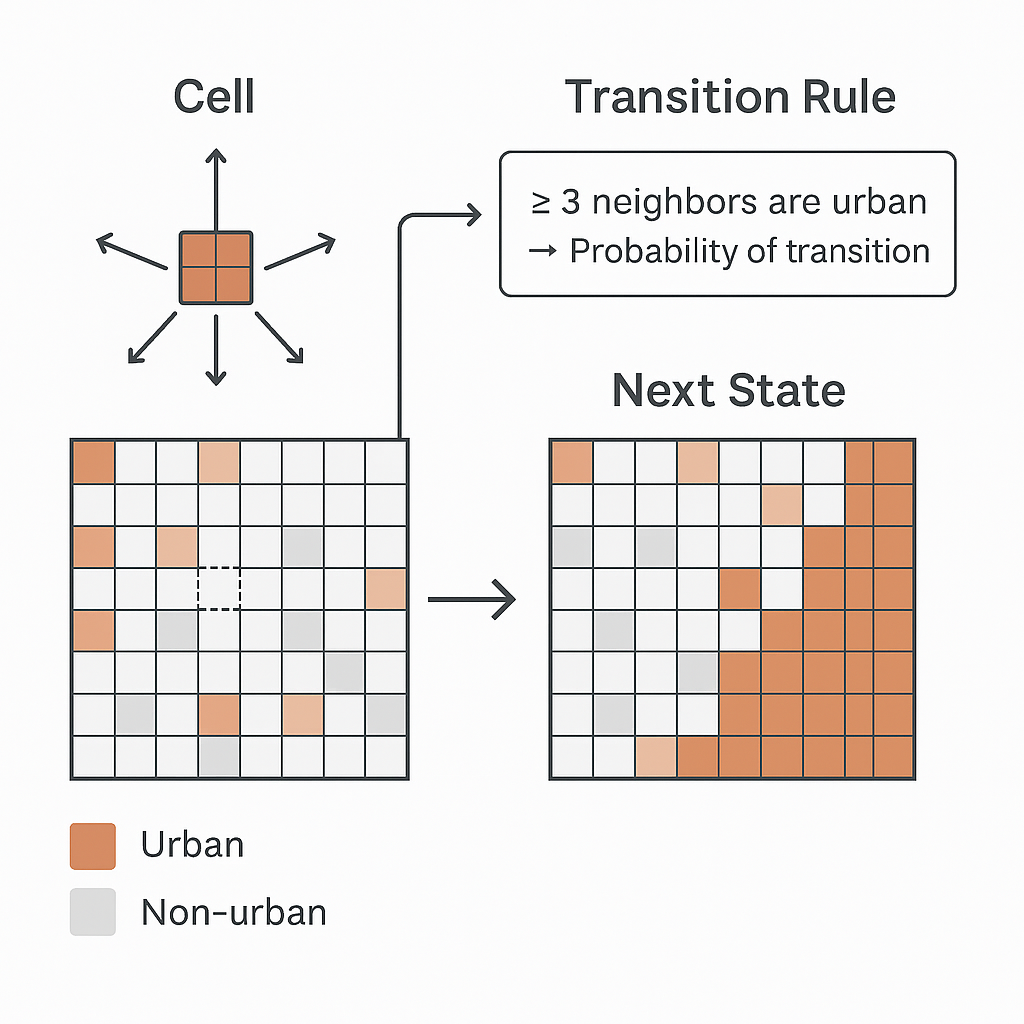
元胞自动机(Cellular Automata, CA)
一、什么是元胞自动机(Cellular Automata, CA) 元胞自动机(CA) 是一种基于离散时间、离散空间与规则驱动演化的动力系统,由 冯诺依曼(John von Neumann) 于1940年代首次提出,用于模…...

智能手表单元测试报告(Unit Test Report)
📄 智能手表单元测试报告(Unit Test Report) 项目名称:Aurora Watch S1 模块版本:Firmware v1.0.4 测试阶段:模块开发完成后的单元测试 报告编号:AW-S1-UTR-2025-001 测试负责人:赵磊(软件架构师) 报告日期:2025-xx-xx 一、测试目的 通过对智能手表关键功能模块进…...