5月31日day41打卡
简单CNN
知识回顾
- 数据增强
- 卷积神经网络定义的写法
- batch归一化:调整一个批次的分布,常用与图像数据
- 特征图:只有卷积操作输出的才叫特征图
- 调度器:直接修改基础学习率
卷积操作常见流程如下:
1. 输入 → 卷积层 → Batch归一化层(可选) → 池化层 → 激活函数 → 下一层
- Flatten -> Dense (with Dropout,可选) -> Dense (Output)
这里相关的概念比较多,如果之前没有学习过复试班强化班中的计算机视觉部分,请自行上网检索视频了解下基础概念,也可以对照我提供的之前的讲义学习下。
计算机视觉入门
作业:尝试手动修改下不同的调度器和CNN的结构,观察训练的差异。
一、数据增强
在图像数据预处理环节,为提升数据多样性,可采用数据增强(数据增广)策略。该策略通常不改变单次训练的样本总数,而是通过对现有图像进行多样化变换,使每次训练输入的样本呈现更丰富的形态差异,从而有效扩展模型训练的样本空间多样性。
常见的修改策略包括以下几类
- 几何变换:如旋转、缩放、平移、剪裁、裁剪、翻转
- 像素变换:如修改颜色、亮度、对比度、饱和度、色相、高斯模糊(模拟对焦失败)、增加噪声、马赛克
- 语义增强(暂时不用):mixup,对图像进行结构性改造、cutout随机遮挡等
此外,在数据极少的场景长,常常用生成模型来扩充数据集,如GAN、VAE等。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集:仅进行必要的标准化,保持数据原始特性,标准化不损失数据信息,可还原
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform # 测试集不使用增强
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
注意数据增强一般是不改变每个批次的数据量,是对原始数据修改后替换原始数据。其中该数据集事先知道其均值和标准差,如果不知道,需要提前计算下。
二、 CNN模型
卷积的本质:通过卷积核在输入通道上的滑动乘积,提取跨通道的空间特征。所以只需要定义几个参数即可
- 卷积核大小:卷积核的大小,如3x3、5x5、7x7等。
- 输入通道数:输入图片的通道数,如1(单通道图片)、3(RGB图片)、4(RGBA图片)等。
- 输出通道数:卷积核的个数,即输出的通道数。如本模型中通过 32→64→128 逐步增加特征复杂度
- 步长(stride):卷积核的滑动步长,默认为1。
# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)上述定义CNN模型中:
- 使用三层卷积+池化结构提取图像特征
- 每层卷积后添加BatchNorm加速训练并提高稳定性
- 使用Dropout减少过拟合
可以把全连接层前面的不理解为神经网络的一部分,单纯理解为特征提取器,他们的存在就是帮助模型进行特征提取的。
上述定义CNN模型中:
- 使用三层卷积+池化结构提取图像特征
- 每层卷积后添加BatchNorm加速训练并提高稳定性
- 使用Dropout减少过拟合
可以把全连接层前面的不理解为神经网络的一部分,单纯理解为特征提取器,他们的存在就是帮助模型进行特征提取的。
2.1 batch归一化
Batch 归一化是深度学习中常用的一种归一化技术,加速模型收敛并提升泛化能力。通常位于卷积层后。
卷积操作常见流程如下:
- 输入 → 卷积层 → Batch归一化层(可选) → 池化层 → 激活函数 → 下一层
- Flatten -> Dense (with Dropout,可选) -> Dense (Output)
其中,BatchNorm 应在池化前对空间维度的特征完成归一化,以确保归一化统计量基于足够多的样本(空间位置),避免池化导致的统计量偏差
旨在解决深度神经网络训练中的内部协变量偏移问题:深层网络中,随着前层参数更新,后层输入分布会发生变化,导致模型需要不断适应新分布,训练难度增加。就好比你在学新知识,知识体系的基础一直在变,你就得不断重新适应,模型训练也是如此,这就导致训练变得困难,这就是内部协变量偏移问题。
通过对每个批次的输入数据进行标准化(均值为 0、方差为 1),想象把一堆杂乱无章、分布不同的数据规整到一个标准的样子。
- 使各层输入分布稳定,让数据处于激活函数比较合适的区域,缓解梯度消失 / 爆炸问题;
- 因为数据分布稳定了,所以允许使用更大的学习率,提升训练效率。

深度学习的归一化有2类:
- Batch Normalization:一般用于图像数据,因为图像数据通常是批量处理,有相对固定的 Batch Size ,能利用 Batch 内数据计算稳定的统计量(均值、方差 )来做归一化。
- Layer Normalization:一般用于文本数据,本数据的序列长度往往不同,像不同句子长短不一,很难像图像那样固定 Batch Size 。如果用 Batch 归一化,不同批次的统计量波动大,效果不好。层归一化是对单个样本的所有隐藏单元进行归一化,不依赖批次。
ps:这个操作在结构化数据中其实是叫做标准化,但是在深度学习领域,习惯把这类对网络中间层数据进行调整分布的操作都叫做归一化 。
2.2 特征图
卷积层输出的叫做特征图,通过输入尺寸和卷积核的尺寸、步长可以计算出输出尺寸。可以通过可视化中间层的特征图,理解 CNN 如何从底层特征(如边缘)逐步提取高层语义特征(如物体部件、整体结构)。MLP是不输出特征图的,因为他输出的一维向量,无法保留空间维度
特征图就代表着在之前特征提取器上提取到的特征,可以通过 Grad-CAM方法来查看模型在识别图像时,特征图所对应的权重是多少。-----深度学习可解释性
2.3 调度器
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)
ReduceLROnPlateau调度器适用于当监测的指标(如验证损失)停滞时降低学习率。是大多数任务的首选调度器,尤其适合验证集波动较大的情况
这种学习率调度器的方法相较于之前只有单纯的优化器,是一种超参数的优化方法,它通过调整学习率来优化模型。
常见的优化器有 adam、SGD、RMSprop 等,而除此之外学习率调度器有 lr_scheduler.StepLR、lr_scheduler.ExponentialLR、lr_scheduler.CosineAnnealingLR 等。
可以把优化器和调度器理解为调参手段,学习率是参数
注意,优化器如adam虽然也在调整学习率,但是他的调整是相对值,计算步长后根据基础学习率来调整。但是调度器是直接调整基础学习率。
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始使用CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_cnn_model.pth')
# print("模型已保存为: cifar10_cnn_model.pth")
@浙大疏锦行
相关文章:
5月31日day41打卡
简单CNN 知识回顾 数据增强卷积神经网络定义的写法batch归一化:调整一个批次的分布,常用与图像数据特征图:只有卷积操作输出的才叫特征图调度器:直接修改基础学习率 卷积操作常见流程如下: 1. 输入 → 卷积层 → Batch…...
)
“粽”览全局:分布式系统架构与实践深度解析(端午特别版)
第一部分:引言——技术世界的“端午”第二部分:分布式系统概述——粽子节点初探第三部分:核心技术详解——技术“粽子”大解构 粽叶篇:通信协议糯米篇:一致性算法馅料篇:任务调度与计算包扎篇:系…...
STM32G4 电机外设篇(一) GPIO+UART
目录 一、STM32G4 电机外设篇(一) GPIOUART1 GPIO1.1 STM32CUBEMX 配置以及Keil代码1.2 代码和实验现象 2 UART2.1 STM32CUBEMX 配置以及Keil代码2.2 代码和实验现象 附学习参考网址欢迎大家有问题评论交流 (* ^ ω ^) 一、STM32G4 电机外设篇࿰…...

代理IP在云计算中的应用:技术演进与场景实践
一、技术融合的必然性:代理IP与云计算的协同效应 在数字化转型的浪潮中,云计算已成为企业IT架构的核心底座,而代理IP技术则作为网络访问的关键基础设施,两者在技术演进路径上呈现出深度融合的趋势。云计算的弹性资源池与代理IP的…...
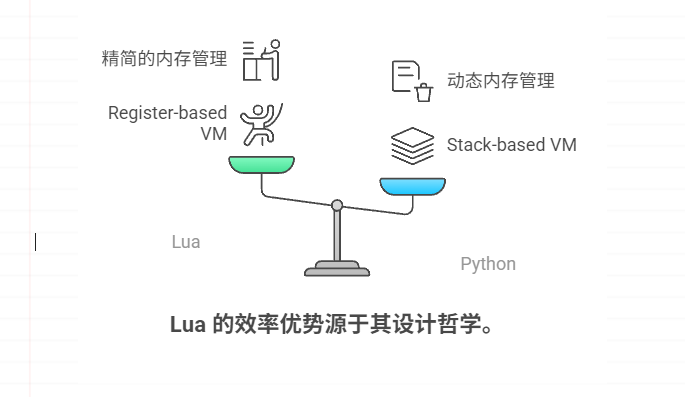
Lua 的速度为什么比 Python 快
Lua 的执行速度通常比 Python 快,主要原因在于其解释器设计轻量、虚拟机效率高、内存管理策略更为精简,以及语言本身对动态特性的控制较严。其中,Lua 使用了 register-based 的虚拟机架构,而 Python(CPython࿰…...
【iOS】方法交换
方法交换 method-swizzling是什么相关API方法交换的风险method-swizzling使用过程中的一次性问题在当前类中进行方法交换类方法的方法交换 方法交换的应用 method-swizzling是什么 method-swizzling的含义是方法交换,他的主要作用是在运行的时候将一个方法的实现替…...

跑步相关术语解释
老婆一直问我PB是啥意思,写个文章解释下。 1. 成绩类 PB (Personal Best):个人最好成绩,指在特定距离(如10K、全马)中的最快完赛时间 。PW (Personal Worst)࿱…...

数据结构:线性表的基本操作与链式表达
个人主页 文章专栏 成名之作——赛博算命之梅花易数的Java实现 陆续回三中,忘回漏回滴滴~感谢各位大佬的支持 一.线性表的定义和基本操作 1.1定义 线性表是具有相同数据类型的n个数据元素的有序数列,n为表长 第一个元素叫表头元素,除了他…...
C++:设计模式--工厂模式
更多内容:XiaoJ的知识星球 目录 1.简单工厂模式1.1 简单工厂1.2 实现步骤1.3 实现代码1.4 优缺点 2.工厂模式2.1 工厂模式2.2 实现步骤2.3 实现代码2.4 优缺点 3.抽象工厂模式3.1 抽象工厂模式3.2 实现步骤3.3 实现代码3.4 优缺点 1.简单工厂模式 . 1.1 简单工厂 …...

【前端优化】使用speed-measure-webpack-plugin分析前端运行、打包耗时,优化项目
记录下 项目安装speed-measure-webpack-plugin 打包分析: 修改vue.config.js文件 speed-measure-webpack-plugin进行构建速度分析,需要包裹整个 configureWebpack 配置 const originalConfig {publicPath: /,assetsDir: assets,parallel: true,devS…...
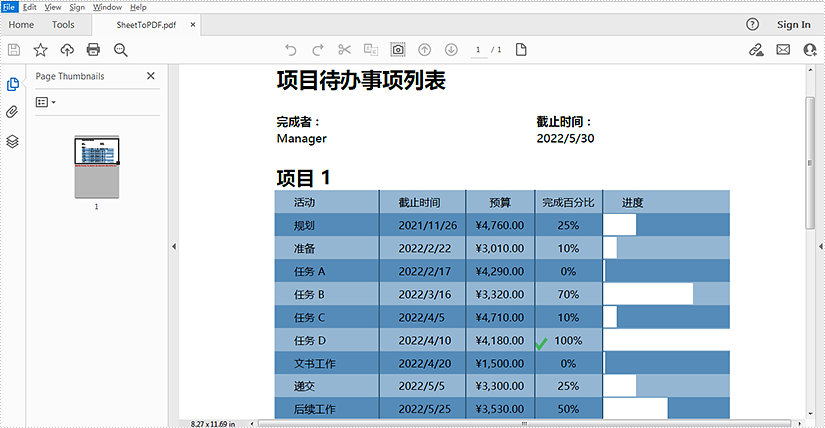
国产化Excel处理组件Spire.XLS教程:如何使用 C# 将 Excel(XLS 或 XLSX)文件转换为 PDF
Excel 是常见的数据处理与呈现工具,但直接共享 Excel 文件可能面临格式错乱、兼容性不足或数据泄露的风险。为了保证文档在不同平台和终端上的稳定展示,开发者常常需要将 Excel 文件转换为 PDF 格式。 本文将详细介绍如何使用 C#和.NET Excel 库——Spi…...
B3623 枚举排列(递归实现排列型枚举)
B3623 枚举排列(递归实现排列型枚举) - 洛谷 题目描述 今有 n 名学生,要从中选出 k 人排成一列拍照。 请按字典序输出所有可能的排列方式。 输入格式 仅一行,两个正整数 n,k。 输出格式 若干行,每行 k 个正整数…...
)
vue-08(使用slot进行灵活的组件渲染)
使用slot进行灵活的组件渲染 作用域slot是 Vue.js 中的一种强大机制,它允许父组件自定义子组件内容的呈现。与仅向下传递数据的常规 props 不同,作用域 slot 为父级提供了一个模板,然后子级可以填充数据。这提供了高度的灵活性和可重用性&am…...

Fine Pruned Tiled Light Lists(精细删减的分块光照列表)
概括 在这篇文章, 我将介绍一种Tiled Light 变体,主要针对AMD Graphics Core Next(GCN)架构进行优化,我们的方法应用于游戏 古墓丽影:崛起 中,特别是我们在通过光列表生成和阴影贴图渲染之间交错进行异步计…...
)
2025-5-29-C++ 学习 字符串(3)
字符串 2025-5-29-C 学习 字符串(3)P3741 小果的键盘题目背景题目描述输入格式输出格式输入输出样例 #1输入 #1输出 #1 输入输出样例 #2输入 #2输出 #2 输入输出样例 #3输入 #3输出 #3 输入输出样例 #4输入 #4输出 #4 输入输出样例 #5输入 #5输出 #5 说明…...

openresty+lua+redis把非正常访问的域名加入黑名单
一、验证lua geoIp2是否缺少依赖 1、执行命令 /usr/local/openresty/bin/opm get anjia0532/lua-resty-maxminddb 执行安装命令报错,缺少Digest/MD5依赖 2、Digest/MD5依赖 yum -y install perl-Digest-MD5 GeoIP2 lua库依赖动态库安装,lua库依赖libmaxminddb实…...

使用Mathematica绘制随机多项式的根
使用ListPlot和NSolve直接绘制: (*返回系数为r和s之间整数的n次随机多项式*) eq[n_, r_, s_] : RandomInteger[{r, s}, {n}] . Array[Power[x, # - 1] &, n] (*返回给定随机多项式的根所对应的笛卡尔坐标*) sol[n_, r_, s_] : {Re[#], Im[#]} & / (x /.…...

IEEE PRMVAI 2025 WS 26:计算机视觉前沿 Workshop 来袭!
宝子们,搞计算机视觉和深度学习的看过来啦!🎉 2025 年 IEEE 第三届模式识别、机器视觉和人工智能国际会议里,Workshop 26 简直是科研宝藏地! 这次 Workshop 聚焦 “Deep learning - based low - level models for comp…...
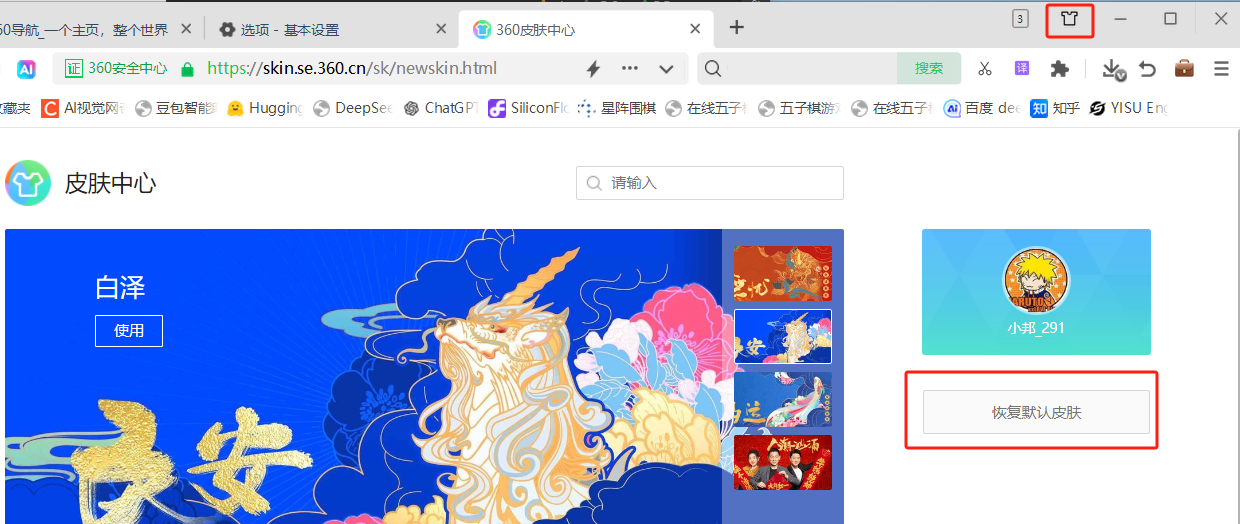
360浏览器设置主题
设置默认主题: 1.右上角有个皮肤按钮 进来后,右边有个回复默认皮肤按钮。 换成彩色皮肤后,找按钮不太好找了。...
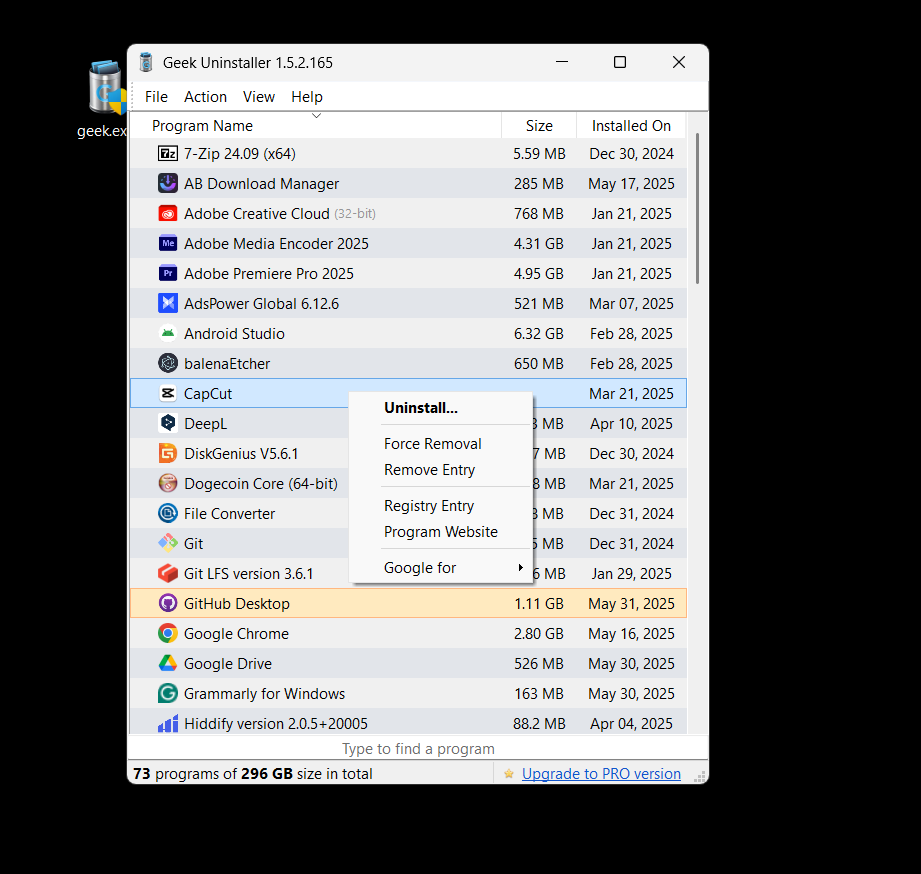
最卸载器——Geek Uninstaller 使用指南
Geek Uninstaller 是一款轻量级的第三方卸载工具,专为 Windows 系统设计,提供比系统默认卸载器更彻底的应用清除能力。它体积小、绿色免安装,使用起来简单直观,但功能却不含糊。 一、为什么要用 Geek Uninstaller? Wi…...

leetcode216.组合总和III:回溯算法中多条件约束下的状态管理
一、题目深度解析与组合约束条件 题目描述 找出所有相加之和为n的k个数的组合,且满足以下条件: 每个数只能使用一次(范围为1到9)所有数字均为唯一的正整数组合中的数字按升序排列 例如,当k3,n9时&#…...
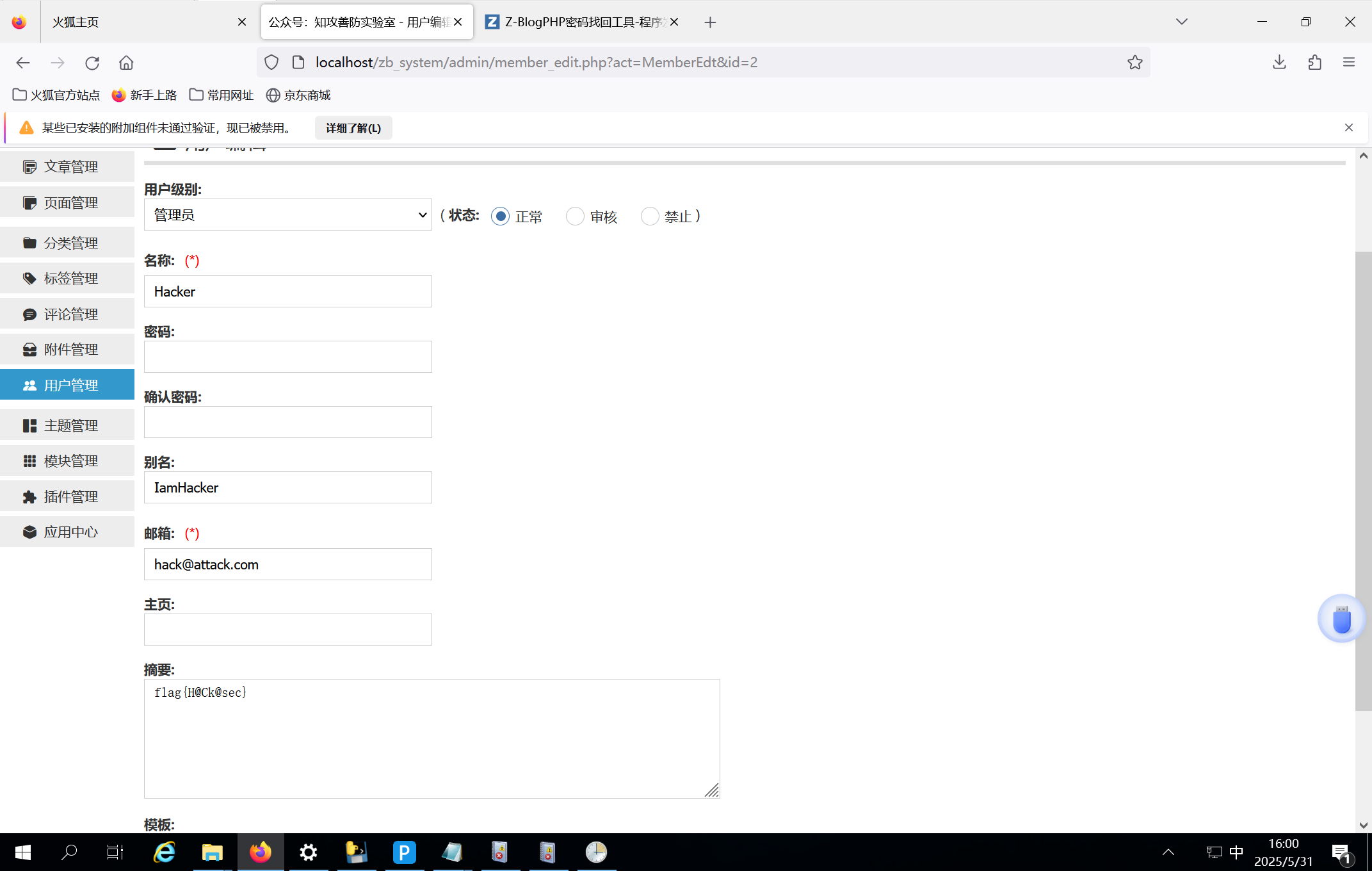
应急响应靶机-web3-知攻善防实验室
题目: 1.攻击者的两个IP地址 2.攻击者隐藏用户名称 3.三个攻击者留下的flag 密码:yj123456 解题: 1.攻击者的两个IP地址 一个可能是远程,D盾,404.php,192.168.75.129 找到远程连接相关的英文,1149代表远程连接成功…...
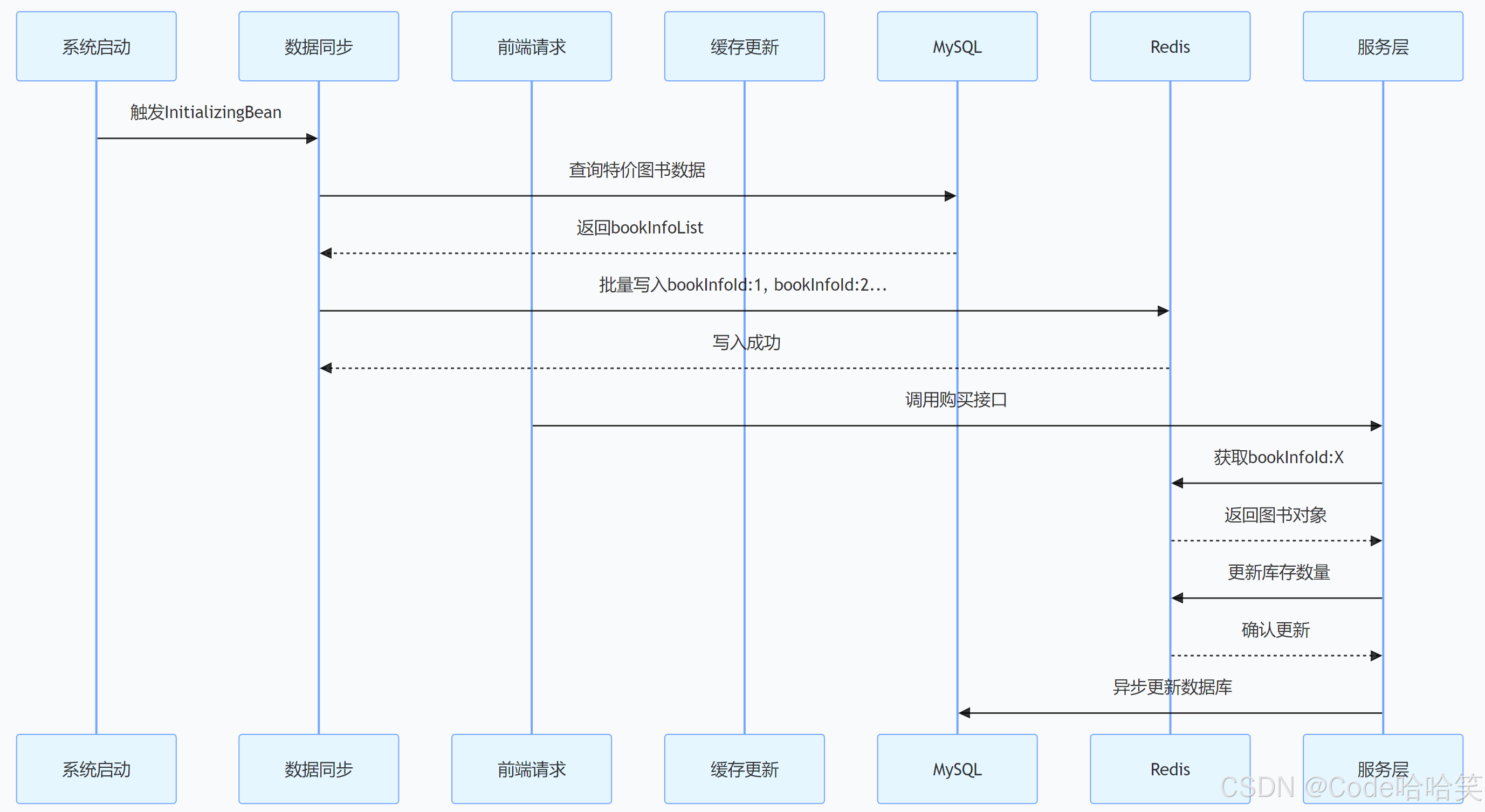
【基于SpringBoot的图书购买系统】Redis中的数据以分页的形式展示:从配置到前后端交互的完整实现
引言 在当今互联网应用开发中,高性能和高并发已经成为系统设计的核心考量因素。Redis作为一款高性能的内存数据库,以其快速的读写速度、丰富的数据结构和灵活的扩展性,成为解决系统缓存、高并发访问等场景的首选技术之一。在图书管理系统中&…...
Jupyter MCP服务器部署实战:AI模型与Python环境无缝集成教程
Jupyter MCP 服务器是基于模型上下文协议(Model Context Protocol, MCP)的 Jupyter 环境扩展组件,它能够实现大型语言模型与实时编码会话的无缝集成。该服务器通过标准化的协议接口,使 AI 模型能够安全地访问和操作 Jupyter 的核心…...
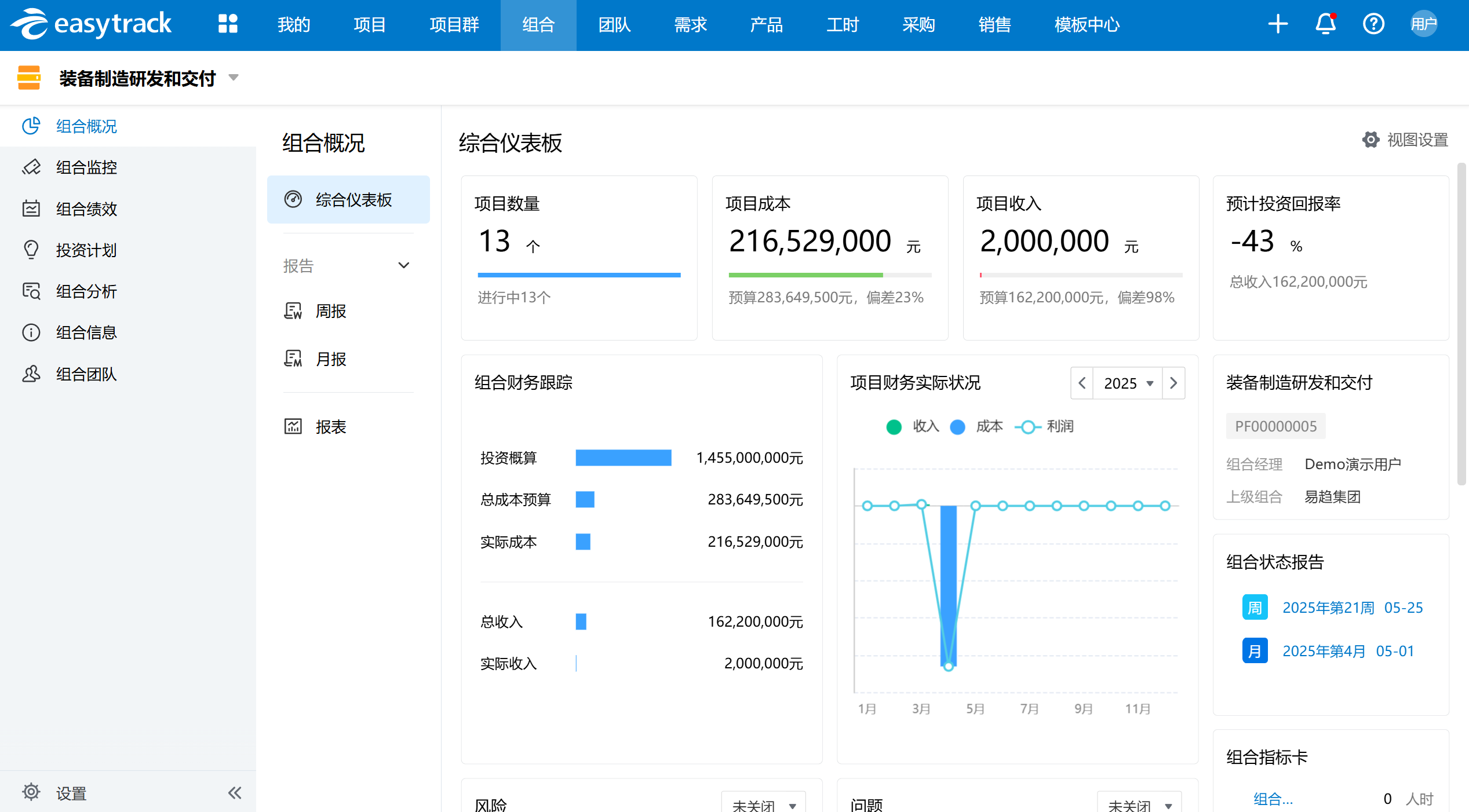
PMO价值重构:从项目管理“交付机器”到“战略推手”
在数字化转型浪潮中,项目管理办公室(PMO)正经历着前所未有的角色蜕变。传统上,PMO往往被视为项目管理的“交付机器”,专注于项目的按时交付和资源分配。然而,随着企业对战略执行的重视,PMO正逐渐…...

如何成为一名优秀的产品经理
一、 夯实核心基础 深入理解智能驾驶技术栈: 感知: 摄像头、雷达(毫米波、激光雷达)、超声波传感器的工作原理、优缺点、融合策略。了解目标检测、跟踪、SLAM等基础算法概念。 定位: GNSS、IMU、高精地图、轮速计等定…...

[SLAM自救笔记0]:开端
📍背景介绍 本人本硕双非,目前研究方向为4D毫米波雷达SLAM与多传感器融合。主攻技术栈是RIO(Radar-Inertial Odometry)与LIO(LiDAR-Inertial Odometry)。 🎯定位方向说明 虽然研究方向偏RIO&…...
零知开源——STM32F407VET6驱动Flappy Bird游戏教程
简介 本教程使用STM32F407VET6零知增强板驱动3.5寸TFT触摸屏实现经典Flappy Bird游戏。通过触摸屏控制小鸟跳跃,躲避障碍物柱体,挑战最高分。项目涉及STM32底层驱动、图形库移植、触摸控制和游戏逻辑设计。 目录 简介 一、硬件准备 二、软件架构 三、…...

[SC]SystemC在CPU和GPU等复杂SoC验证中的应用
SystemC在CPU和GPU等复杂SoC验证中的应用 摘要:SystemC 是一种基于 C++ 的硬件描述和仿真语言,广泛用于系统级设计和验证,特别是在 CPU 和 GPU 等复杂 SoC (System on Chip) 的验证工作中。通过 SystemC,你可以构建硬件模块、定义时序行为、进行系统级仿真,并与 UV…...

鸿蒙OSUniApp导航栏组件开发:打造清新简约的用户界面#三方框架 #Uniapp
UniApp 开发实战:打造符合鸿蒙设计风格的日历活动安排组件 在移动应用开发中,日历和活动安排是非常常见的需求。本文将详细介绍如何使用 UniApp 框架开发一个优雅的日历活动安排组件,并融入鸿蒙系统的设计理念,实现一个既美观又实…...