Python60日基础学习打卡Day39
昨天我们介绍了图像数据的格式以及模型定义的过程,发现和之前结构化数据的略有不同,主要差异体现在2处
- 模型定义的时候需要展平图像
- 由于数据过大,需要将数据集进行分批次处理,这往往涉及到了dataset和dataloader来规范代码的组织
单通道图片的规范写法
# 先继续之前的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt
import warnings
# 忽略警告信息
warnings.filterwarnings("ignore")
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64 # 每批处理64个样本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义模型、损失函数和优化器
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)# from torchsummary import summary # 导入torchsummary库
# print("\n模型结构信息:")
# summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 新增:记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号(从1开始)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):# enumerate() 是 Python 内置函数,用于遍历可迭代对象(如列表、元组)并同时获取索引和值。# batch_idx:当前批次的索引(从 0 开始)# (data, target):当前批次的样本数据和对应的标签,是一个元组,这是因为dataloader内置的getitem方法返回的是一个元组,包含数据和标签。# 只需要记住这种固定写法即可data, target = data.to(device), target.to(device) # 移至GPU(如果可用)optimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始# 统计准确率和损失running_loss += loss.item() #将loss转化为标量值并且累加到running_loss中,计算总损失_, predicted = output.max(1) # output:是模型的输出(logits),形状为 [batch_size, 10](MNIST 有 10 个类别)# 获取预测结果,max(1) 返回每行(即每个样本)的最大值和对应的索引,这里我们只需要索引total += target.size(0) # target.size(0) 返回当前批次的样本数量,即 batch_size,累加所有批次的样本数,最终等于训练集的总样本数correct += predicted.eq(target).sum().item() # 返回一个布尔张量,表示预测是否正确,sum() 计算正确预测的数量,item() 将结果转换为 Python 数字# 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 测试、打印 epoch 结果epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 保留原 epoch 级曲线(可选)# plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)return epoch_test_acc # 返回最终测试准确率之前我们用mlp训练鸢尾花数据集的时候并没有用函数的形式来封装训练和测试过程,这样写会让代码更加具有逻辑-----隔离参数和内容。
- 后续直接修改参数就行,不需要去找到对应操作的代码
- 方便复用,未来有多模型对比时,就可以复用这个函数
这里我们先不写早停策略,因为规范的早停策略需要用到验证集,一般还需要划分测试集
- 划分数据集:训练集(用于训练)、验证集(用于早停和调参)、测试集(用于最终报告性能)。
- 在训练过程中,使用验证集触发早停。
- 训练结束后,仅用测试集运行一次测试函数,得到最终准确率。
测试函数和绘图函数均被封装在了train函数中,但是测试函数和绘图函数在定义train函数之后,这是因为在 Python 中,函数定义的顺序不影响调用,只要在调用前已经完成定义即可。
# 6. 测试模型(不变)
def test(model, test_loader, criterion, device):model.eval() # 设置为评估模式test_loss = 0correct = 0total = 0with torch.no_grad(): # 不计算梯度,节省内存和计算资源for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()avg_loss = test_loss / len(test_loader)accuracy = 100. * correct / totalreturn avg_loss, accuracy # 返回损失和准确率# 7. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试(设置 epochs=2 验证效果)
epochs = 2
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")在PyTorch中处理张量(Tensor)时,以下是关于展平(Flatten)、维度调整(如view/reshape)等操作的关键点,这些操作通常不会影响第一个维度(即批量维度batch_size)
图像任务中的张量形状
输入张量的形状通常为:
(batch_size, channels, height, width)
例如:(batch_size, 3, 28, 28)
其中,batch_size 代表一次输入的样本数量。
NLP任务中的张量形状
输入张量的形状可能为:
(batch_size, sequence_length)
此时,batch_size 同样是第一个维度。
1. Flatten操作
- 功能:将张量展平为一维数组,但保留批量维度。
- 示例:
- 输入形状:
(batch_size, 3, 28, 28)(图像数据) - Flatten后形状:
(batch_size, 3×28×28)=(batch_size, 2352) - 说明:第一个维度
batch_size不变,后面的所有维度被展平为一个维度。
- 输入形状:
2. view/reshape操作
- 功能:调整张量维度,但必须显式保留或指定批量维度。
- 示例:
- 输入形状:
(batch_size, 3, 28, 28) - 调整为:
(batch_size, -1) - 结果:展平为两个维度,保留
batch_size,第二个维度自动计算为3×28×28=2352。
- 输入形状:
总结
- 批量维度不变性:无论进行flatten、view还是reshape操作,第一个维度
batch_size通常保持不变。 - 动态维度指定:使用
-1让PyTorch自动计算该维度的大小,但需确保其他维度的指定合理,避免形状不匹配错误。
彩色图片的规范写法
彩色的通道也是在第一步被直接展平,其他代码一致
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_mlp_model.pth')
# # print("模型已保存为: cifar10_mlp_model.pth")由于深度mlp的参数过多,为了避免过拟合在这里引入了dropout这个操作,他可以在训练阶段随机丢弃一些神经元,避免过拟合情况。dropout的取值也是超参数。
在测试阶段,由于开启了eval模式,会自动关闭dropout。
# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")此时你会发现MLP(多层感知机)在图像任务上表现较差(即使增加深度和轮次也只能达到 50-55% 准确率),主要原因与图像数据的空间特性和MLP 的结构缺陷密切相关。
- MLP 的每一层都是全连接层,输入图像会被展平为一维向量(如 CIFAR-10 的 32x32x3 图像展平为 3072 维向量)。图像中相邻像素通常具有强相关性(如边缘、纹理),但 MLP 将所有像素视为独立特征,无法利用局部空间结构。例如,识别 “汽车轮胎” 需要邻近像素的组合信息,而 MLP 需通过大量参数单独学习每个像素的关联,效率极低。
- 深层 MLP 的参数规模呈指数级增长,容易过拟合
所以我们接下来将会学习CNN架构,CNN架构的参数规模相对较小,且训练速度更快,而且CNN架构可以解决图像识别问题,而MLP不能。
相关文章:

Python60日基础学习打卡Day39
昨天我们介绍了图像数据的格式以及模型定义的过程,发现和之前结构化数据的略有不同,主要差异体现在2处 模型定义的时候需要展平图像由于数据过大,需要将数据集进行分批次处理,这往往涉及到了dataset和dataloader来规范代码的组织…...
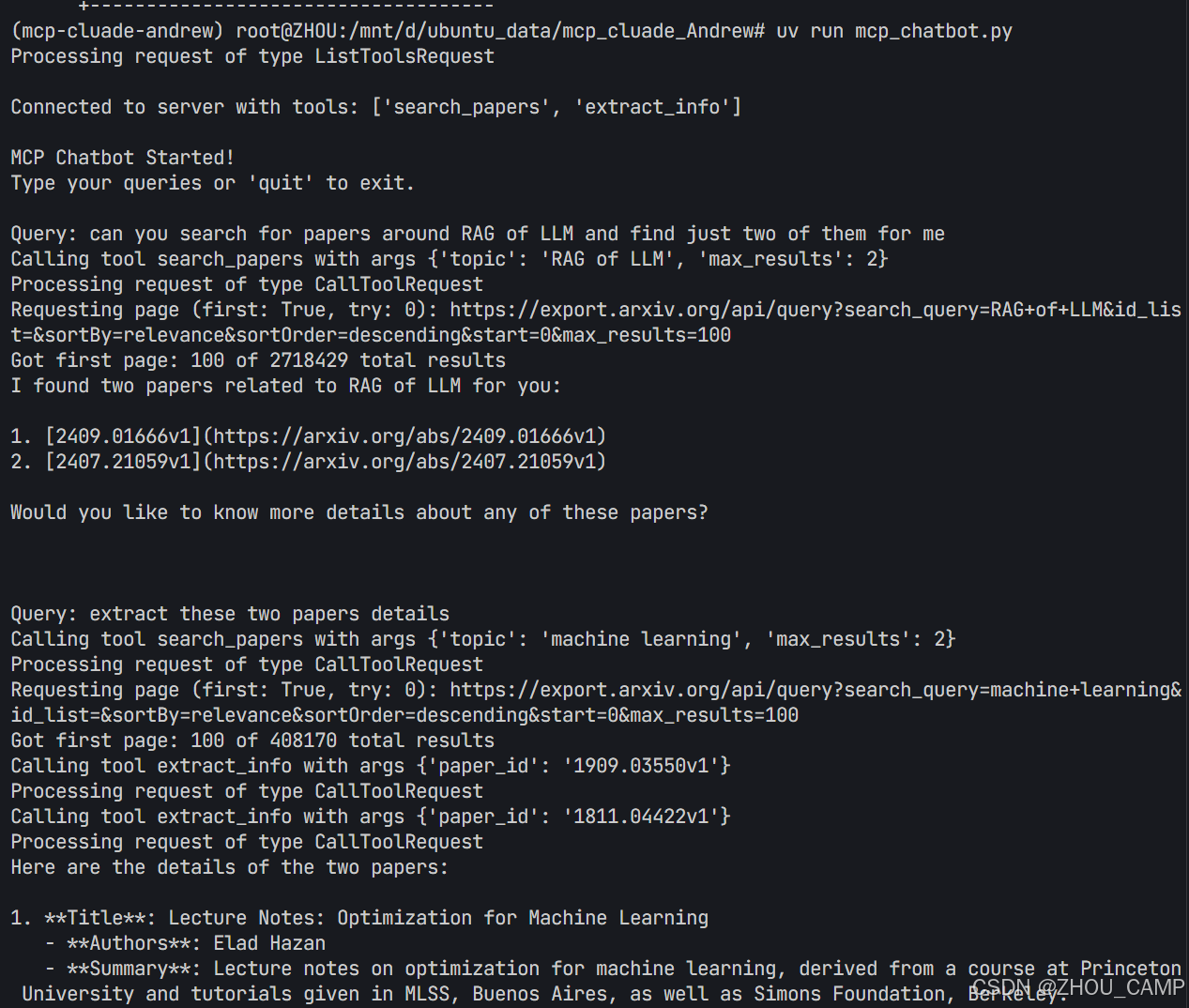
吴恩达MCP课程(3):mcp_chatbot
原课程代码是用Anthropic写的,下面代码是用OpenAI改写的,模型则用阿里巴巴的模型做测试 .env 文件为: OPENAI_API_KEYsk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx OPENAI_API_BASEhttps://dashscope.aliyuncs.com/compatible-mode…...

MySQL访问控制与账号管理:原理、技术与最佳实践
MySQL的安全体系建立在精细的访问控制和账号管理机制上。本文基于MySQL 9.3官方文档,深入解析其核心原理、关键技术、实用技巧和行业最佳实践。 一、访问控制核心原理:双重验证机制 连接验证 (Connection Verification) 客户端发起连接时,MyS…...

AWS 创建VPC 并且添加权限控制
AWS 创建VPC 并且添加权限控制 以下是完整的从0到1在AWS中创建VPC并配置权限的步骤(包含网络配置、安全组权限和实例访问): 1. 创建VPC 步骤: 登录AWS控制台 访问 AWS VPC控制台,点击 创建VPC。 配置基础信息 名称…...

langchain学习 01
dotenv库:可以从.env文件中加载配置信息。 from dotenv import load_dotenv # 加载函数,之后调用这个函数,即可获取配置环境.env里面的内容: deep_seek_api_key<api_key>getpass库:从终端输入password性质的内…...
【清晰教程】查看和修改Git配置情况
目录 查看安装版本 查看特定配置 查看全局配置 查看本地仓库配置 设置或修改配置 查看安装版本 打开命令行工具,通过version命令检查Git版本号。 git --version 如果显示出 Git 的版本号,说明 Git 已经成功安装。 查看特定配置 如果想要查看特定…...
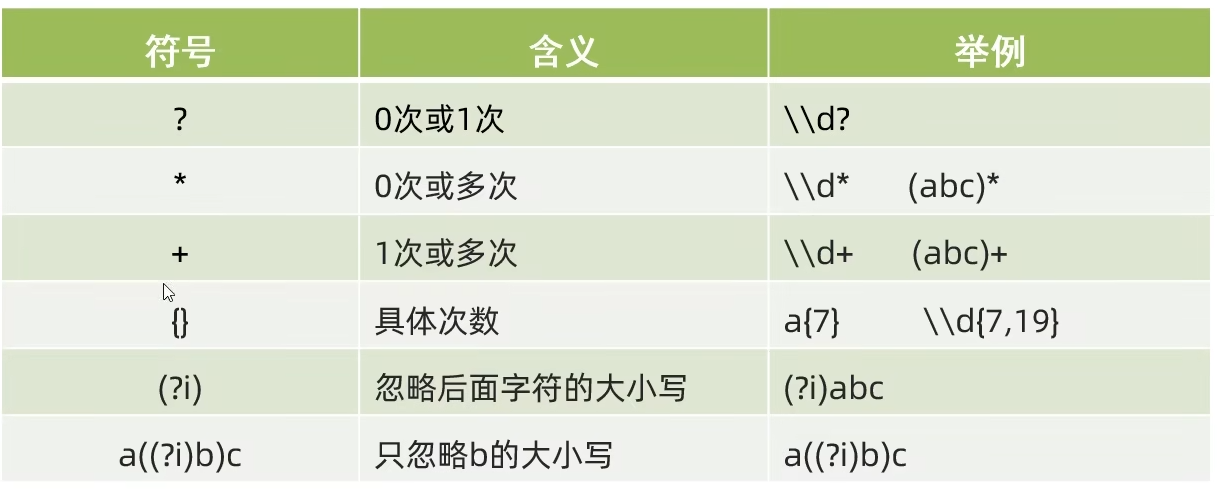
JAVA 常用 API 正则表达式
1 正则表达式作用 作用一:校验字符串是否满足规则作用二:在一段文本中查找满足要求的内容 2 正则表达式规则 2.1 字符类 package com.bjpowernode.test14;public class RegexDemo1 {public static void main(String[] args) {//public boolean matche…...

光电设计大赛智能车激光对抗方案分享:低成本高效备赛攻略
一、赛题核心难点与备赛痛点解析 全国大学生光电设计竞赛的 “智能车激光对抗” 赛题,要求参赛队伍设计具备激光对抗功能的智能小车,需实现光电避障、目标识别、轨迹规划及激光精准打击等核心功能。从历年参赛情况看,选手普遍面临三大挑战&a…...
Python实现P-PSO优化算法优化BP神经网络回归模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在当今数据驱动的时代,回归分析作为预测和建模的重要工具,在科学研究和工业应用中占据着重要…...
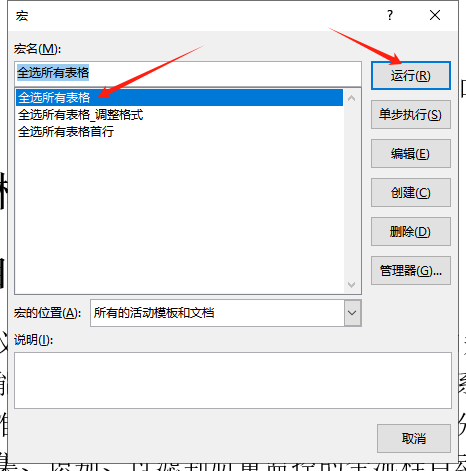
Microsoft的在word中选择文档中的所有表格进行字体和格式的调整时的解决方案
找到宏 创建 并粘贴 使用 Sub 全选所有表格() Dim t As Table an MsgBox("即将选择选区内所有表格,若无选区,则选择全文表格。", vbYesNo, "reboot提醒您!") If an - 6 Then Exit Sub Set rg IIf(Selection.Type wdSelectionIP, …...

C++23:关键特性与最新进展深度解析
文章目录 范围的新功能与增强元组的优化与新特性字符与字符串的转义表示优化std::thread::id的改进与扩展栈踪迹的格式化支持结论 C23作为C标准的最新版本,带来了许多令人瞩目的改进和新特性。从新的范围和元组功能到对字符和字符串转义表示的优化,再到 …...

Rust并发编程实践指南
Rust并发编程实践指南 一、Rust并发编程哲学 mindmaproot((Rust并发))Ownership System▶ 移动语义▶ 借用规则Type Safety▶ Send Trait▶ Sync TraitZero-Cost Abstraction▶ 无运行时开销▶ 编译期检查Fearless Concurrency▶ 数据竞争预防▶ 死锁检测工具二、核心并发模型…...

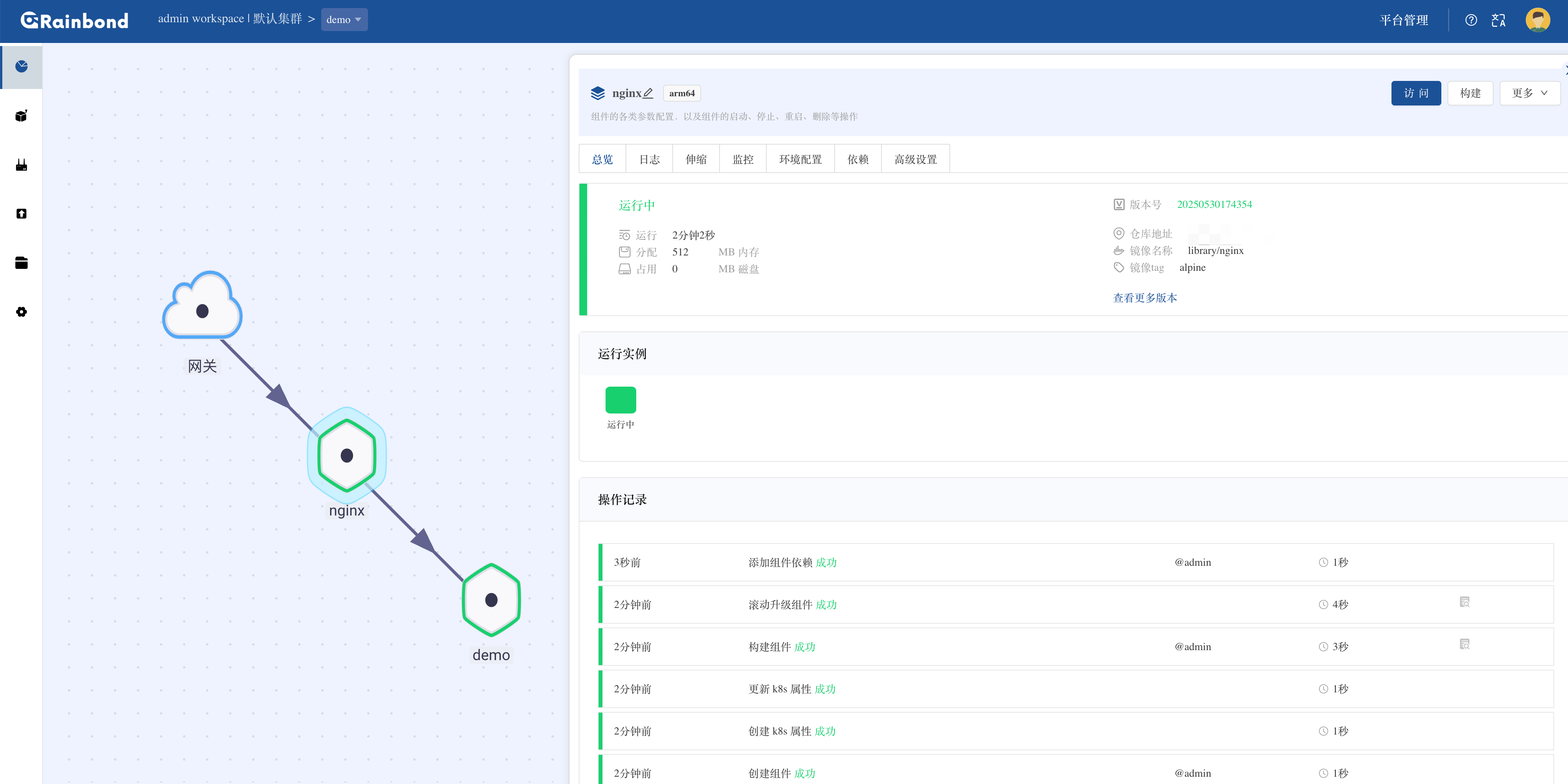
Kubernetes资源申请沾满但是实际的资源占用并不多,是怎么回事?
Kubernetes资源申请沾满但是实际的资源占用并不多是Kubernetes资源管理中的一个常见误解。 K8s资源管理机制 资源请求(Requests) vs 实际使用量 从你的截图可以看到: K8s节点资源状态(第一张图): CPU请求量:13795…...
鲲鹏Arm+麒麟V10 K8s 离线部署教程
针对鲲鹏 CPU 麒麟 V10 的离线环境,手把手教你从环境准备到应用上线,所有依赖包提前打包好,步骤写成傻瓜式操作指南。 一、环境规划# 准备至少两台机器。 架构OS作用Arm64任意,Mac 也可以下载离线包Arm64麒麟 V10单机部署 K8s…...

PGSQL结合linux cron定期执行vacuum_full_analyze命令
VACUUM FULL ANALYZE 详解 一、核心功能 空间回收与重组 完全重写表数据文件,将碎片化的存储空间合并并返还操作系统(普通 VACUUM 仅标记空间可重用)。彻底清理死元组(已删除或更新的旧数据行),解…...

php 中使用MQTT
MQTT 是一种基于发布/订阅模式的 轻量级物联网消息传输协议 ,可以用极少的代码和带宽为联网设备提供实时可靠的消息服务,它广泛应用于物联网、移动互联网、智能硬件、车联网、电力能源等行业。 本文主要介绍如何在 PHP项目中使用composer require php-m…...
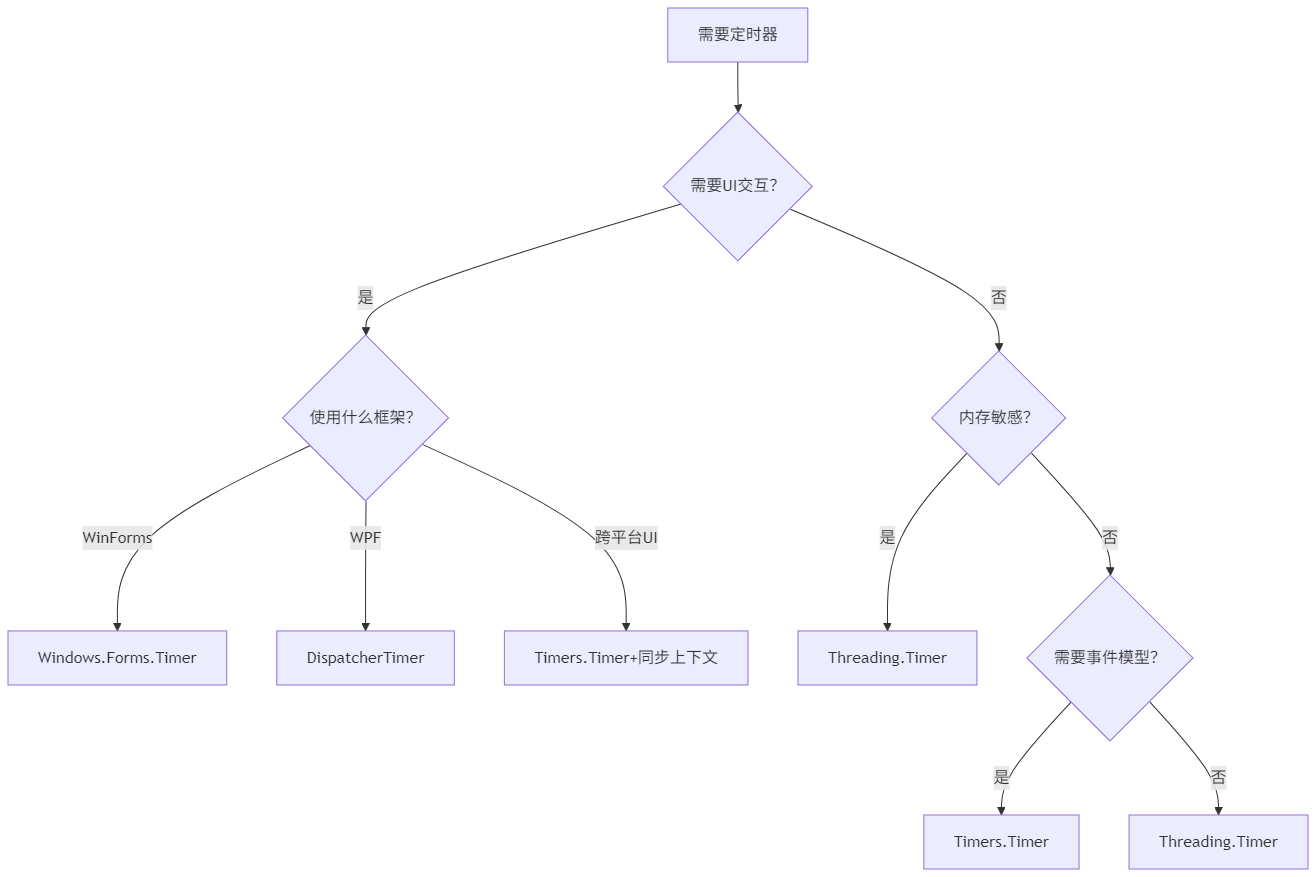
C#定时器深度对比:System.Timers.Timer vs System.Threading.Timer性能实测与选型指南
本文通过真实基准测试揭秘两种常用定时器的性能差异,助你做出最佳选择 一、C#定时器全景概览 在C#生态中,不同定时器适用于不同场景。以下是主流定时器的核心特性对比: 定时器类型命名空间适用场景触发线程精度内存开销依赖框架System.Wind…...

go的select多路复用
传统的方法在遍历管道时,如果不关闭会阻塞而导致 deadlock ,在实际开发中,可能我们不好确定什么关闭该管道。使用select来获取channel里面的数据的时候不需要关闭channel 你也许会写出如下代码使用遍历的方式来实现: for { //…...

深度理解与剖析:前端声明式组件系统
好的,我将根据您的要求,首先进行深度理解与多维思考,然后形成一个全面且有深度的综合性总结,其中包含针对初学者的简洁解释。 1. 核心概念解析:声明式与命令式编程 在深入理解前端的声明式组件系统之前,我…...
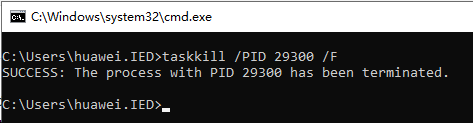
解决8080端口被占问题
文章目录 1. 提出问题2. 解决问题2.1 查看占用8080端口的进程2.2 杀死占用8080端口的进程2.3 测试问题是否已解决3. 实战小结1. 提出问题 运行Spring Boot项目,报错8080端口被占 2. 解决问题 2.1 查看占用8080端口的进程 执行命令:netstat -ano | findstr :8080 2.2 杀死占用…...
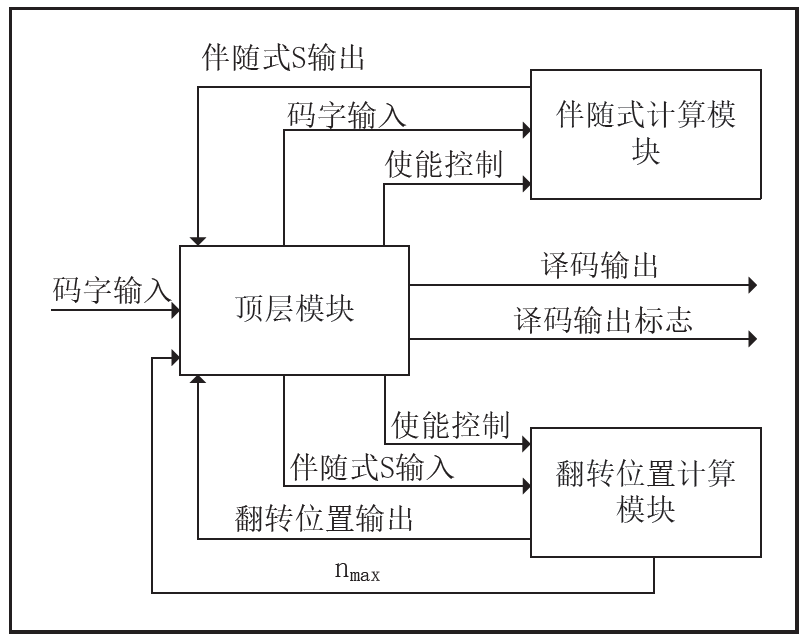
介绍一种LDPC码译码器
介绍比特翻转译码原理以及LDPC码译码器的设计。 1 译码理论 比特翻转(BF)译码算法是硬判决算法的一种。 主要译码思想是:当有一个校验矩阵出错时,BF 算法认为在这个校验矩阵中一定至少存在一个位置的码字信息是错误的࿱…...

3DMAX+Photoshop教程:将树木和人物添加到户外建筑场景中的方法
在本教程中,我将向您展示如何制作室外场景。我不会详细解释每一个细节,而是想快速概述一下我的方法。 在本教程中,我使用了一个相对简单的3D模型,并向您展示了在一些高质量纹理的帮助下可以做什么。此外,我将向您展示…...

【IOS】【OC】【应用内打印功能的实现】如何在APP内实现打印功能,连接本地打印机,把想要打印的界面打印成图片
【IOS】【OC】【应用内打印功能的实现】如何在APP内实现打印功能,连接本地打印机,打印想打印的界面 设备/引擎:Mac(14.1.1)/cocos 开发工具:Xcode 开发语言:OC/C 开发需求:工程中…...
随记 配置服务器的ssl整个过程
第一步 先了解到这个公钥私钥服务器自己可以生成,但是没什么用,浏览器不会信任的,其他人访问不了。所以要一些中间机构颁布的证书才有用。 一般的服务器直接 安装 Certbot 和插件 //CentOS Nginx 用户: sudo yum install epe…...
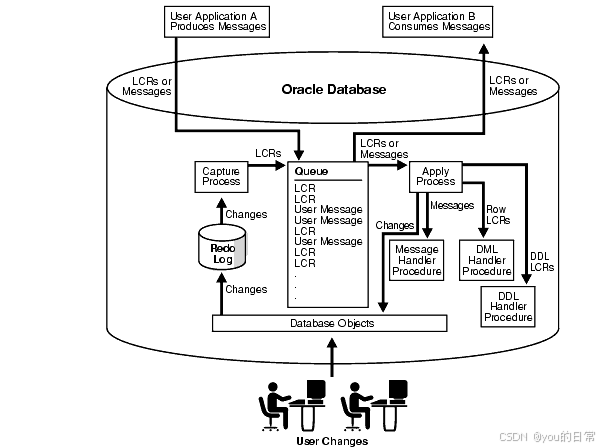
数据库高可用架构设计:集群、负载均衡与故障转移实践
关键词:数据库高可用,HA架构,数据库集群,负载均衡,故障转移,SQL Server Always On,MySQL InnoDB Cluster,高可用性组,读写分离,灾难恢复 在当今瞬息万变的数字化时代,数据的价值日益凸显,数据库作为承载核心业务数据的基石,其可用性直接决定了业务的连续性与用户…...

Correlations氛围测试:文本或图像的相似度热图
1 项目概览:Correlations 是什么? Correlations 是一个交互式 UI 工具,Jina AI 开源项目 Correlations 用于调试和可视化文本或图像向量之间的相似性关系,特别适合:快速把相关内容两两对照,比单纯数字报告更直观。Correlations 把这种快速、主观“氛围检视”做成了可视化…...
从0到1:多医院陪诊小程序开发笔记(上)
概要设计 医院陪诊预约小程序:随着移动互联网的普及,越来越多的医院陪诊服务开始向线上转型, 传统的预约方式往往效率低下,用户需耗费大量时间进行电话预约或现场排队,陪诊服务预约小程序集多种服务于一体,可以提高服…...
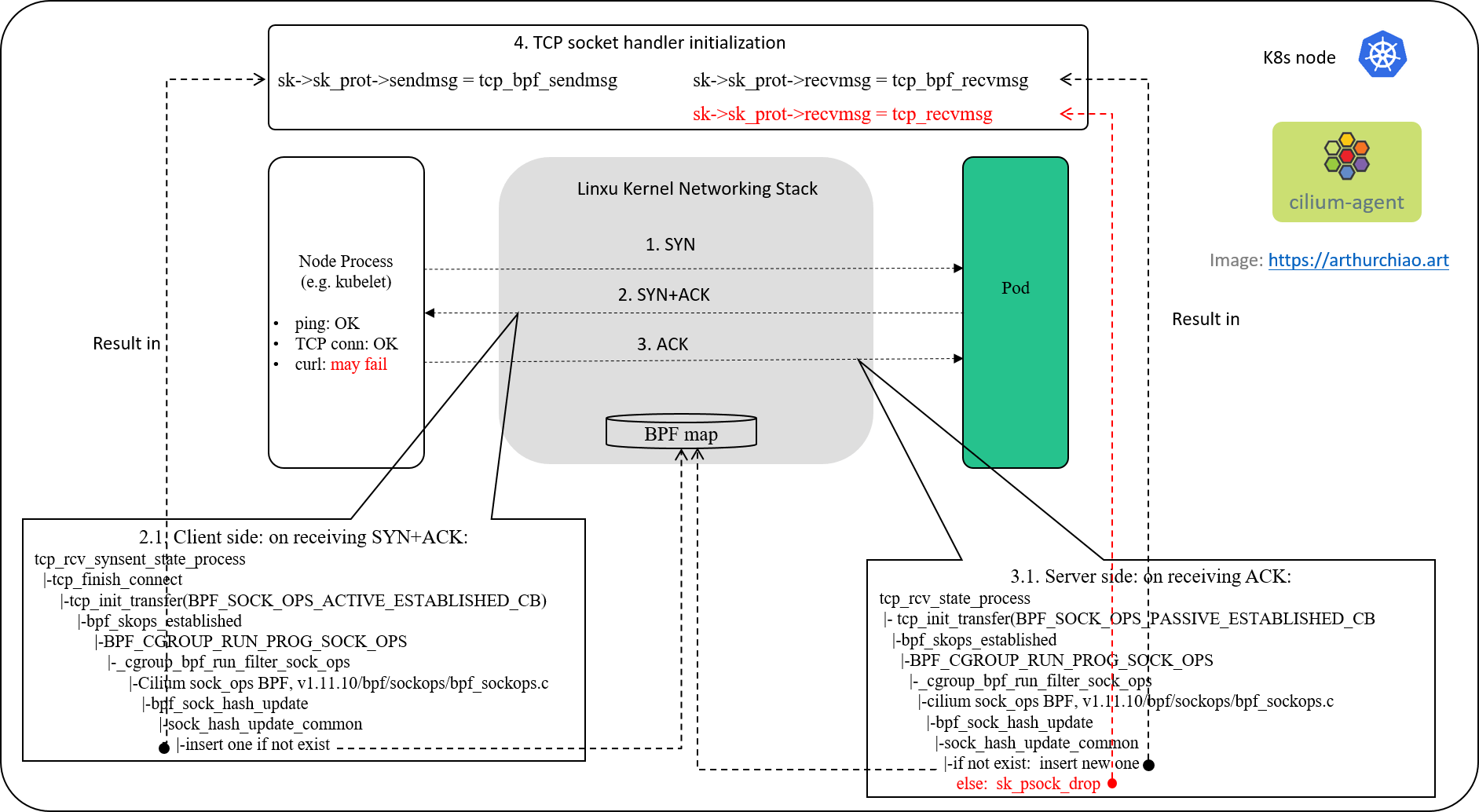
建立连接后 TCP 请求卡住
大家读完觉得有意义记得关注和点赞!!! 这篇文章描述了一个内核和BPF网络问题 以及故障排除步骤,这是一个值得深入研究的有趣案例 Linux 内核网络复杂性。 目录 1 故障报告 1.1 现象:概率健康检查失败 1.2 范围&am…...

尚硅谷redis7 99 springboot整合redis之连接集群
6381宕机,手动shutdown后在redis中,634自动上位变成master结点。 但是在springboot中却没有动态感知道redisCluster的最新集群消息,所以找不到我们要检索的数据。原因是:SpringBoot 2.X版本,Redis默认的连接池采用 Lettuce&#…...
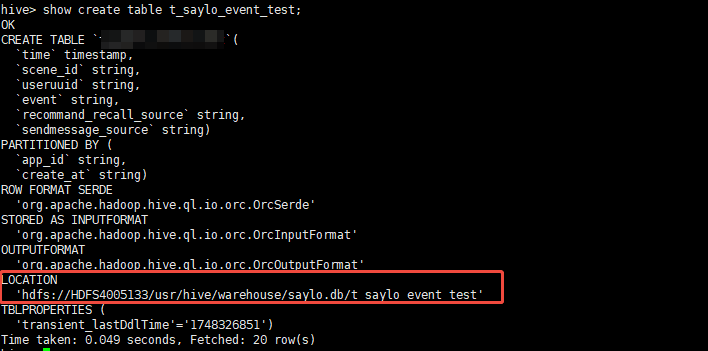
hive 笔记
1. 查看hive表的文件情况 搭建ui界面机器上查看 show create table xxx;得到文件地址 hdfs查看文件情况 hdfs dfs -ls hdfs://HDFS4005133/usr/hive/warehouse/xxx/xxxx/app_idxxx...