GRCh38版本染色体位置转换GRCh37(hg19)
目录
- 方法 1:使用 Ensembl REST API(推荐,适用于少量位点查询)
- 方法 2:使用 UCSC API
- 方法 3:使用 NCBI API 并转换坐标(需要额外步骤)
- 方法 4:使用本地数据库(最可靠,适合批量查询)
- 1、下载 GRCh37 基因注释文件:
- 2、创建 Python 查询脚本:
- 其他
- 注意事项
- Ensembl API 限制:
- 基因组版本差异:
- 基因位置表示:
数据准备:
要获取 GRCh37(hg19)版本的染色体位置,我们需要使用专门针对该基因组版本的数据源。
方法 1:使用 Ensembl REST API(推荐,适用于少量位点查询)
import requests
import timedef get_gene_location_hg19(gene_symbol, max_retries=3):"""获取基因在 GRCh37/hg19 版本的位置"""base_url = "http://grch37.rest.ensembl.org"endpoint = f"/lookup/symbol/homo_sapiens/{gene_symbol}"url = base_url + endpointparams = {"expand": 0,"utr": 0,"content-type": "application/json"}for attempt in range(max_retries):try:response = requests.get(url, params=params, timeout=30)response.raise_for_status()data = response.json()chrom = data['seq_region_name']start = data['start']end = data['end']strand = data['strand']# 返回位置信息(添加chr前缀)return f"chr{chrom}:{start}-{end}"except requests.exceptions.RequestException as e:if attempt < max_retries - 1:wait_time = 2 ** attempt # 指数退避print(f"Attempt {attempt+1} failed. Retrying in {wait_time} seconds...")time.sleep(wait_time)else:raise Exception(f"Failed to get location for {gene_symbol}: {str(e)}")# 测试
print(get_gene_location_hg19("TP53")) # 输出: chr17:7571719-7590868
print(get_gene_location_hg19("BRCA1")) # 输出: chr17:41196312-41277500
方法 2:使用 UCSC API
import requests
import xml.etree.ElementTree as ETdef get_gene_location_ucsc_hg19(gene_symbol):"""使用 UCSC API 获取 hg19 位置"""base_url = "https://api.genome.ucsc.edu"endpoint = f"/getData/track"params = {"genome": "hg19","track": "refGene","gene": gene_symbol,"maxItemsOutput": 1}try:response = requests.get(base_url + endpoint, params=params, timeout=30)response.raise_for_status()data = response.json()if 'refGene' not in data:return f"Gene {gene_symbol} not found"gene_data = data['refGene'][0]chrom = gene_data['chrom'].replace("chr", "")start = gene_data['txStart']end = gene_data['txEnd']return f"chr{chrom}:{start}-{end}"except Exception as e:raise Exception(f"Failed to get location: {str(e)}")# 测试
print(get_gene_location_ucsc_hg19("TP53")) # 输出: chr17:7571719-7590868
方法 3:使用 NCBI API 并转换坐标(需要额外步骤)
import requests
import timedef convert_coordinates_hg38_to_hg19(chrom, start, end):"""将 hg38 坐标转换为 hg19 坐标(需要安装 CrossMap)注意:这需要本地安装 CrossMap 工具"""# 这是一个伪代码示例,实际需要安装 CrossMap 并准备链文件# 安装: pip install CrossMap(或者conda环境安装:onda install -c conda-forge biopython)# 下载链文件: wget http://hgdownload.cse.ucsc.edu/goldenpath/hg38/liftOver/hg38ToHg19.over.chain.gzimport subprocess# 创建 BED 文件bed_content = f"{chrom}\t{start}\t{end}\tfeature"# 运行 CrossMapresult = subprocess.run(["CrossMap.py", "bed", "hg38ToHg19.over.chain.gz", "-"],input=bed_content, text=True, capture_output=True)# 解析结果if result.returncode == 0:output = result.stdout.strip().split('\t')return f"chr{output[0]}:{output[1]}-{output[2]}"else:raise Exception(f"Coordinate conversion failed: {result.stderr}")def get_gene_location_ncbi_hg19(gene_symbol):"""获取基因位置并通过 CrossMap 转换为 hg19"""# 获取 hg38 位置url = f"https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esummary.fcgi?db=gene&term={gene_symbol}[Gene Name] AND human[Organism]&retmode=json"try:response = requests.get(url, timeout=30)response.raise_for_status()data = response.json()gene_id = data["result"]["uids"][0]gene_data = data["result"][gene_id]chrom = gene_data["chromosome"]start = gene_data["genomicinfo"][0]["chrstart"]end = gene_data["genomicinfo"][0]["chrstop"]# 转换为 hg19return convert_coordinates_hg38_to_hg19(chrom, start, end)except Exception as e:raise Exception(f"Failed to get location: {str(e)}")# 注意:此方法需要本地安装 CrossMap 和链文件
方法 4:使用本地数据库(最可靠,适合批量查询)
如果经常需要查询,建议下载 GRCh37 的基因注释文件:
1、下载 GRCh37 基因注释文件:
wget ftp://ftp.ensembl.org/pub/grch37/release-104/gtf/homo_sapiens/Homo_sapiens.GRCh37.87.gtf.gz
gunzip Homo_sapiens.GRCh37.87.gtf.gz
2、创建 Python 查询脚本:
import gzip
import os
import sqlite3
from collections import defaultdict# 创建本地SQLite数据库
def create_gene_db(gtf_path, db_path="genes_hg19.db"):if os.path.exists(db_path):return db_pathconn = sqlite3.connect(db_path)cursor = conn.cursor()# 创建表cursor.execute('''CREATE TABLE genes (gene_id TEXT,gene_name TEXT,chrom TEXT,start INTEGER,end INTEGER,strand TEXT)''')# 创建索引cursor.execute('CREATE INDEX idx_gene_name ON genes (gene_name)')# 解析GTF文件gene_data = defaultdict(lambda: {'start': float('inf'), 'end': float('-inf')})with gzip.open(gtf_path, 'rt') if gtf_path.endswith('.gz') else open(gtf_path) as f:for line in f:if line.startswith('#'):continuefields = line.strip().split('\t')if fields[2] != 'gene':continuechrom = fields[0]start = int(fields[3])end = int(fields[4])strand = fields[6]info = {k: v.strip('"') for k, v in (item.split(' ') for item in fields[8].split(';') if item)}gene_name = info.get('gene_name')gene_id = info.get('gene_id')if gene_name and gene_id:# 更新基因范围if start < gene_data[gene_name]['start']:gene_data[gene_name]['start'] = startif end > gene_data[gene_name]['end']:gene_data[gene_name]['end'] = endgene_data[gene_name].update({'chrom': chrom,'strand': strand,'gene_id': gene_id})# 插入数据库for gene_name, data in gene_data.items():cursor.execute('''INSERT INTO genes (gene_id, gene_name, chrom, start, end, strand)VALUES (?, ?, ?, ?, ?, ?)''', (data['gene_id'], gene_name, data['chrom'], data['start'], data['end'], data['strand']))conn.commit()conn.close()return db_path# 查询函数
def get_gene_location_local(gene_symbol, db_path="genes_hg19.db"):conn = sqlite3.connect(db_path)cursor = conn.cursor()cursor.execute('''SELECT chrom, start, end FROM genes WHERE gene_name = ?''', (gene_symbol,))result = cursor.fetchone()conn.close()if result:chrom, start, end = resultreturn f"chr{chrom}:{start}-{end}"else:return None# 初始化数据库(只需运行一次)
# db_path = create_gene_db("Homo_sapiens.GRCh37.87.gtf.gz")# 查询
print(get_gene_location_local("TP53")) # chr17:7571719-7590868
print(get_gene_location_local("BRCA1")) # chr17:41196312-41277500
其他
下载预处理的基因位置文件,然后解析此文件获取位置信息
wget https://hgdownload.soe.ucsc.edu/goldenPath/hg19/database/refGene.txt.gz
gunzip refGene.txt.gz
注意事项
Ensembl API 限制:
最大每秒15个请求
每小时最多6000个请求
需要添加重试机制和延迟
基因组版本差异:
GRCh37 = hg19
GRCh38 = hg38
确保所有工具和数据库使用一致的版本
基因位置表示:
位置通常是基因的转录起始和终止位置
不同数据库可能有轻微差异(100-1000bp)
对于精确位置需求,请指定特定转录本
对于大多数应用,Ensembl REST API(方法1)是最简单直接的方法,可以快速获取 GRCh37 位置信息。
相关文章:
)
GRCh38版本染色体位置转换GRCh37(hg19)
目录 方法 1:使用 Ensembl REST API(推荐,适用于少量位点查询)方法 2:使用 UCSC API方法 3:使用 NCBI API 并转换坐标(需要额外步骤)方法 4:使用本地数据库(最…...
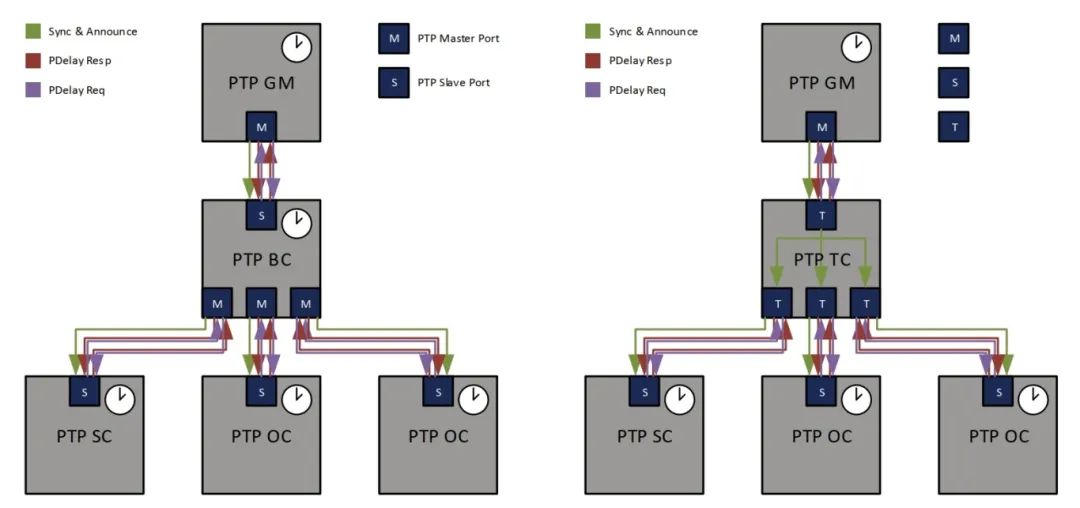
TC/BC/OC P2P/E2E有啥区别?-PTP协议基础概念介绍
前言 时间同步网络中的每个节点,都被称为时钟,PTP协议定义了三种基本时钟节点。本文将介绍这三种类型的时钟,以及gPTP在同步机制上与其他机制的区别 本系列文章将由浅入深的带你了解gPTP,欢迎关注 时钟类型 在PTP中我们将各节…...

解决微信小程序中 Flex 布局下 margin-right 不生效的问题
解决微信小程序中 Flex 布局下 margin-right 不生效的问题 在做微信小程序开发时,遇到了一个棘手的布局问题:在 flex 布局下,给元素设置的 margin-right 不生效,被“吞噬”了。这个问题导致了横向滚动列表的右边距失效࿰…...
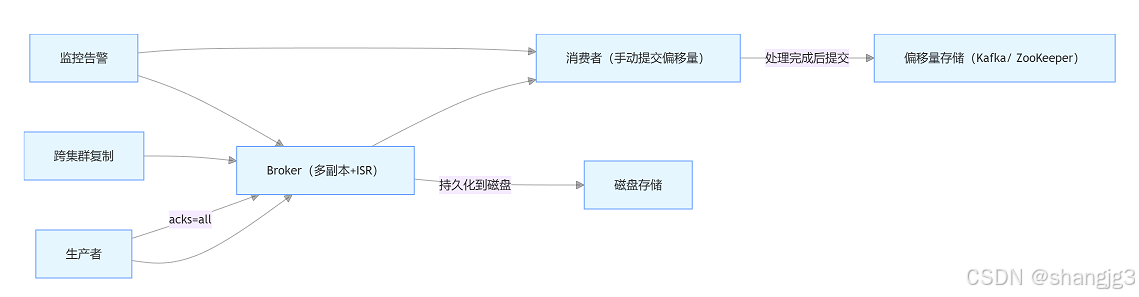
Kafka数据怎么保障不丢失
在分布式消息系统中,数据不丢失是核心可靠性需求之一。Apache Kafka 通过生产者配置、副本机制、持久化策略、消费者偏移量管理等多层机制保障数据可靠性。以下从不同维度解析 Kafka 数据不丢失的核心策略,并附示意图辅助理解。 一、生产者端:…...

使用HTTPS进行传输加密
说明 日期:2025年5月30日 与以纯文本形式发送和接收消息的标准 HTTP 不同,HTTPS 使用SSL/TLS等协议对服务器进行身份验证、加密通信内容和检测篡改。 这样可以防止欺骗、中间人攻击和窃听等攻击。 证书很重要,如果用户主动信任了伪造证书&…...
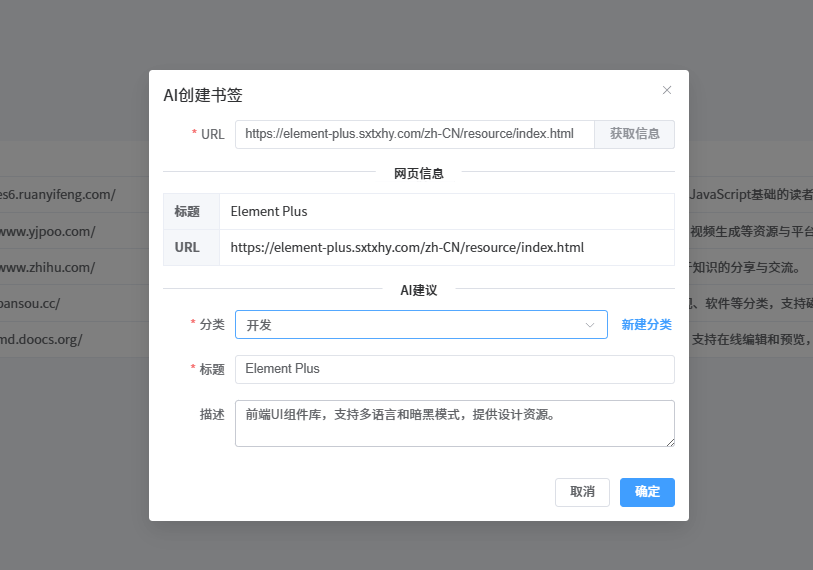
AI书签管理工具开发全记录(八):Ai创建书签功能实现
文章目录 AI书签管理工具开发全记录(八):AI智能创建书签功能深度解析前言 📝1. AI功能设计思路 🧠1.1 传统书签创建的痛点1.2 AI解决方案设计 2. 后端API实现 ⚙️2.1 新增url相关工具方法2.1 创建后端api2.2 创建crea…...
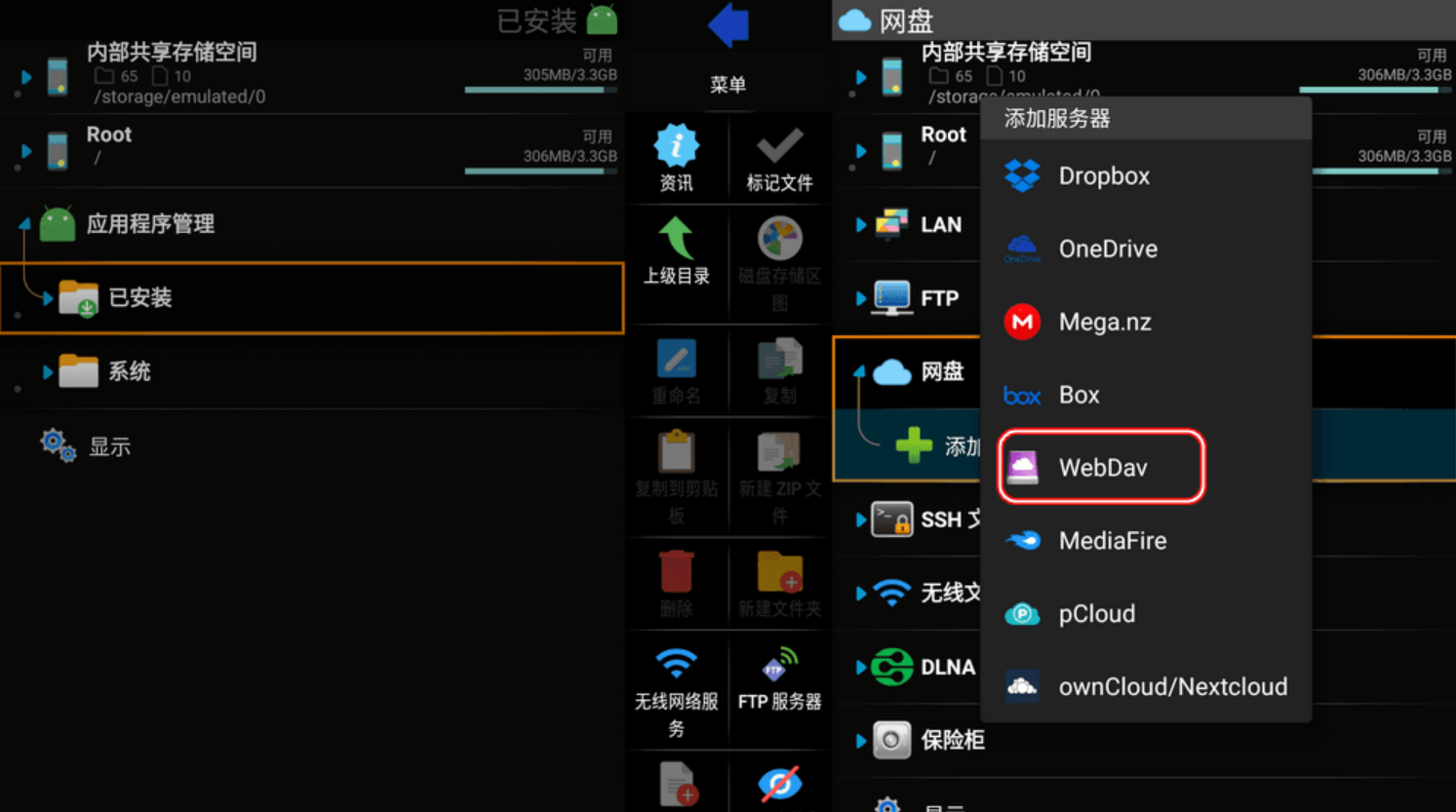
X-plore v4.43.05 强大的安卓文件管理器-MOD解锁高级版 手机平板/电视TV通用
X-plore v4.43.05 强大的安卓文件管理器-MOD解锁高级版 手机平板/电视TV通用 应用简介: X-plore 是一款强大的安卓端文件管理器,它可以在电视或者手机上管理大量媒体文件、应用程序。…...

使用多Agent进行海报生成的技术方案及评估套件-P2P、paper2poster
最近字节、滑铁卢大学相关团队同时放出了他们使用Agent进行海报生成的技术方案,P2P和Paper2Poster,传统方案如类似ppt生成等思路,基本上采用固定的模版,提取相关的关键元素进行模版填充,因此,海报生成的质量…...
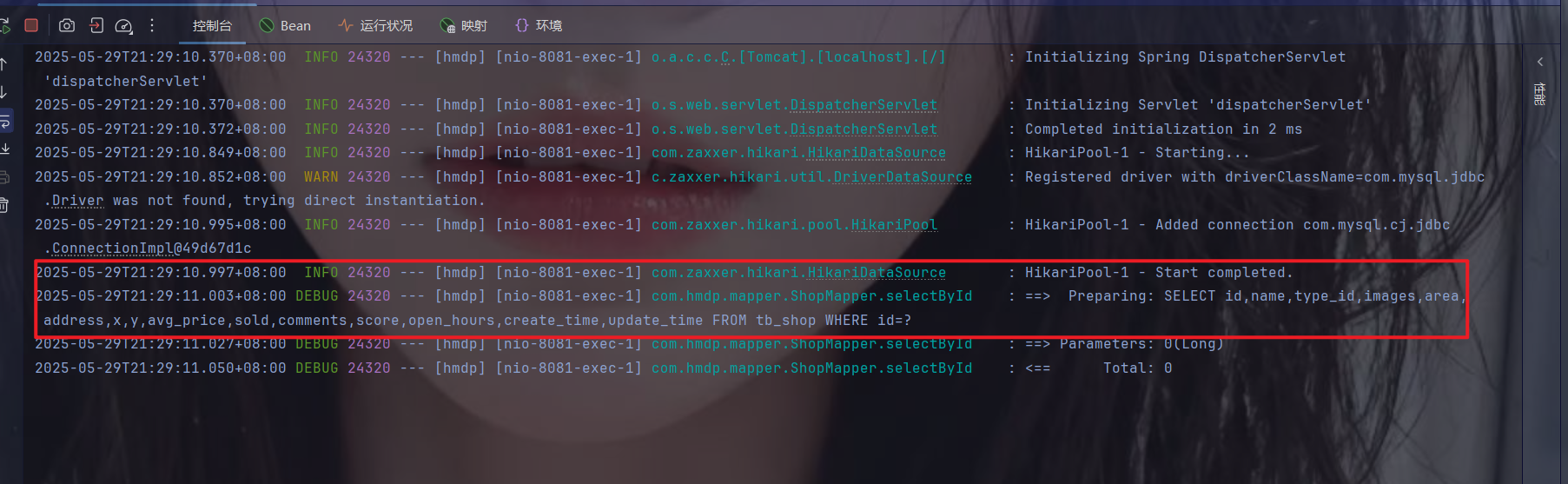
Redis--缓存工具封装
经过前面的学习,发现缓存中的问题,无论是缓存穿透,缓存雪崩,还是缓存击穿,这些问题的解决方案业务代码逻辑都很复杂,我们也不应该每次都来重写这些逻辑,我们可以将其封装成工具。而在封装的时候…...

python:在 PyMOL 中如何查看和使用内置示例文件?
参阅:开源版PyMol安装保姆级教程 百度网盘下载 提取码:csub pip show pymol 简介: PyMOL是一个Python增强的分子图形工具。它擅长蛋白质、小分子、密度、表面和轨迹的3D可视化。它还包括分子编辑、射线追踪和动画。 可视化示例:打开 PyM…...
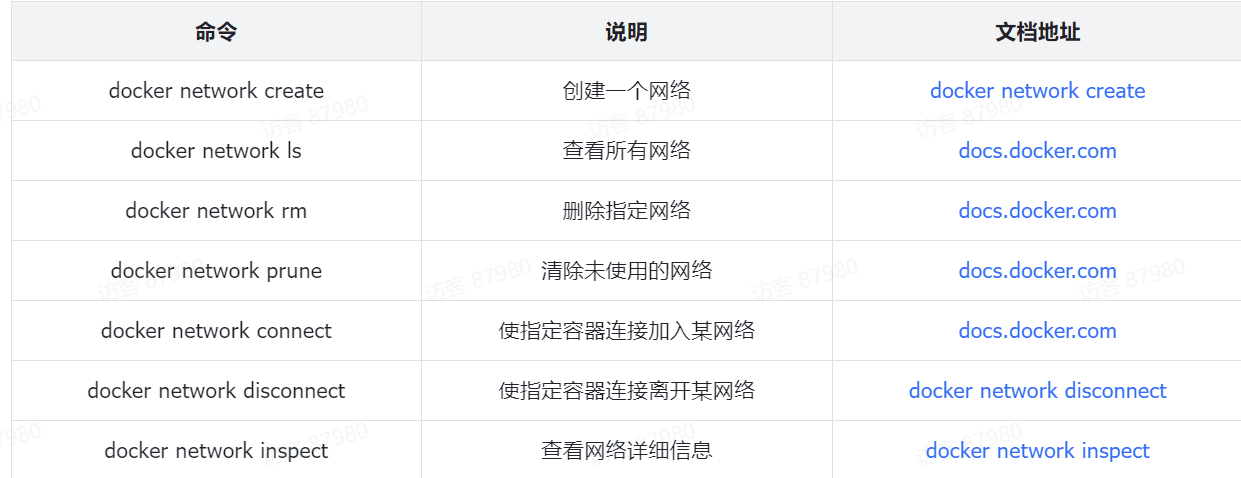
SpringCloud——Docker
1.命令解读 docker run -d 解释:创建并运行一个容器,-d则是让容器以后台进程运行 --name mysql 解释: 给容器起个名字叫mysql -p 3306:3306 解释:-p 宿主机端口:容器内端口,设置端口映射 注意: 1、…...
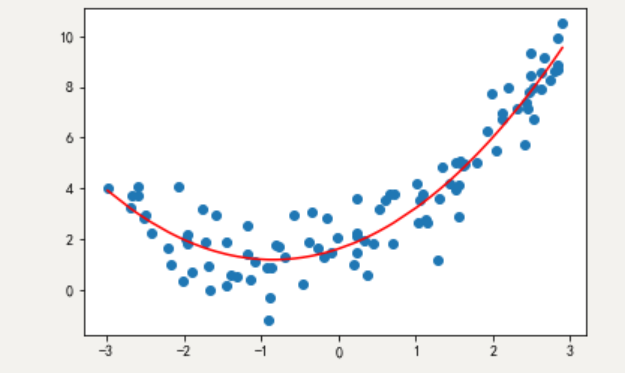
机器学习:欠拟合、过拟合、正则化
本文目录: 一、欠拟合二、过拟合三、拟合问题原因及解决办法四、正则化:尽量减少高次幂特征的影响(一)L1正则化(二)L2正则化(三)L1正则化与L2正则化的对比 五、正好拟合代码…...

运用集合知识做斗地主案例
方法中可变参数 一种特殊形参,定义在方法,构造器的形参列表里,格式:数据类型...参数名称; 可变参数的特点和好处 特点:可以不传数据给它;可以传一个或者同时传多个数据给它;也可以…...

《HelloGitHub》第 110 期
兴趣是最好的老师,HelloGitHub 让你对开源感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣、入门级的开源项目。 github.com/521xueweihan/HelloGitHub 这里有实战项目、入门教程、黑科技、开源书籍、大厂开源项目等,涵盖多种编程语言 Python、…...

使用 Shell 脚本实现 Spring Boot 项目自动化部署到 Docker(Ubuntu 服务器)
使用 Shell 脚本实现 Spring Boot 项目自动化部署到 Docker(Ubuntu 服务器) 在日常项目开发中,我们经常会将 Spring Boot 项目打包并部署到服务器上的 Docker 环境中。为了提升效率、减少重复操作,我们可以通过 Shell 脚本实现自动…...

day023-网络基础与OSI七层模型
文章目录 1. 网络基础知识点1.1 网络中的单位1.2 查看实时网速:iftop1.3 交换机、路由器 2. 路由表2.1 查看路由表的命令2.2 路由追踪命令 3. 通用网站网络架构4. 局域网上网原理-NAT5. 虚拟机上网原理6. 虚拟机的网络模式6.1 NAT模式6.2 桥接模式6.3 仅主机模式 7.…...
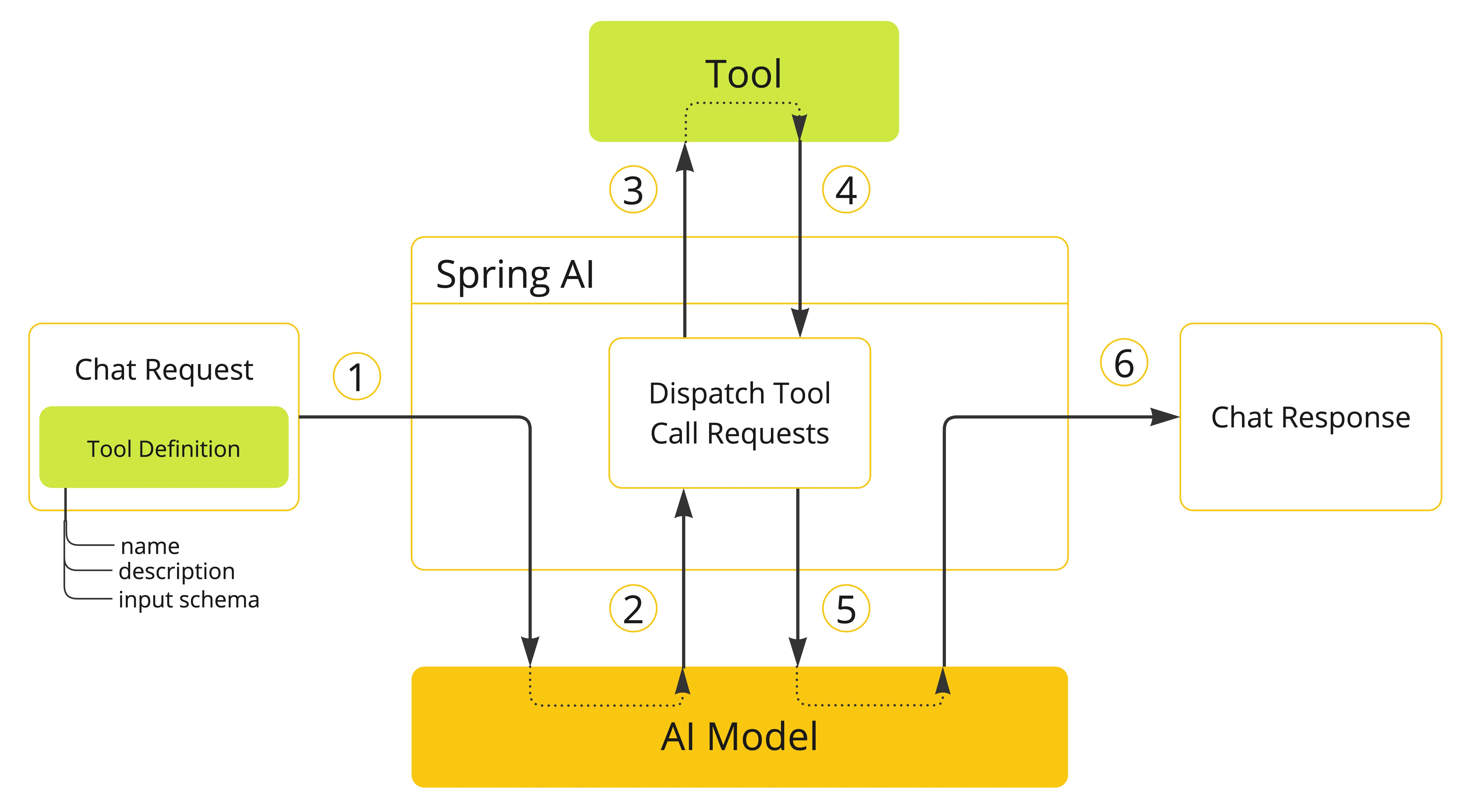
SpringAI系列4: Tool Calling 工具调用 【感觉这版本有bug】
前言:在最近发布的 Spring AI 1.0.0.M6 版本中,其中一个重大变化是 Function Calling 被废弃,被 Tool Calling 取代。Tool Calling工具调用(也称为函数调用)是AI应用中的常见模式,允许模型通过一组API或工具…...

机器人--里程计
教程 轮式里程计视频讲解 里程计分类 ros--odometry 什么是里程计 里程计是一种利用从移动传感器获得的数据来估计物体位置随时间的变化而改变的方法。该方法被用在许多机器人系统来估计机器人相对于初始位置移动的距离。 注意:里程计是一套算法,不…...
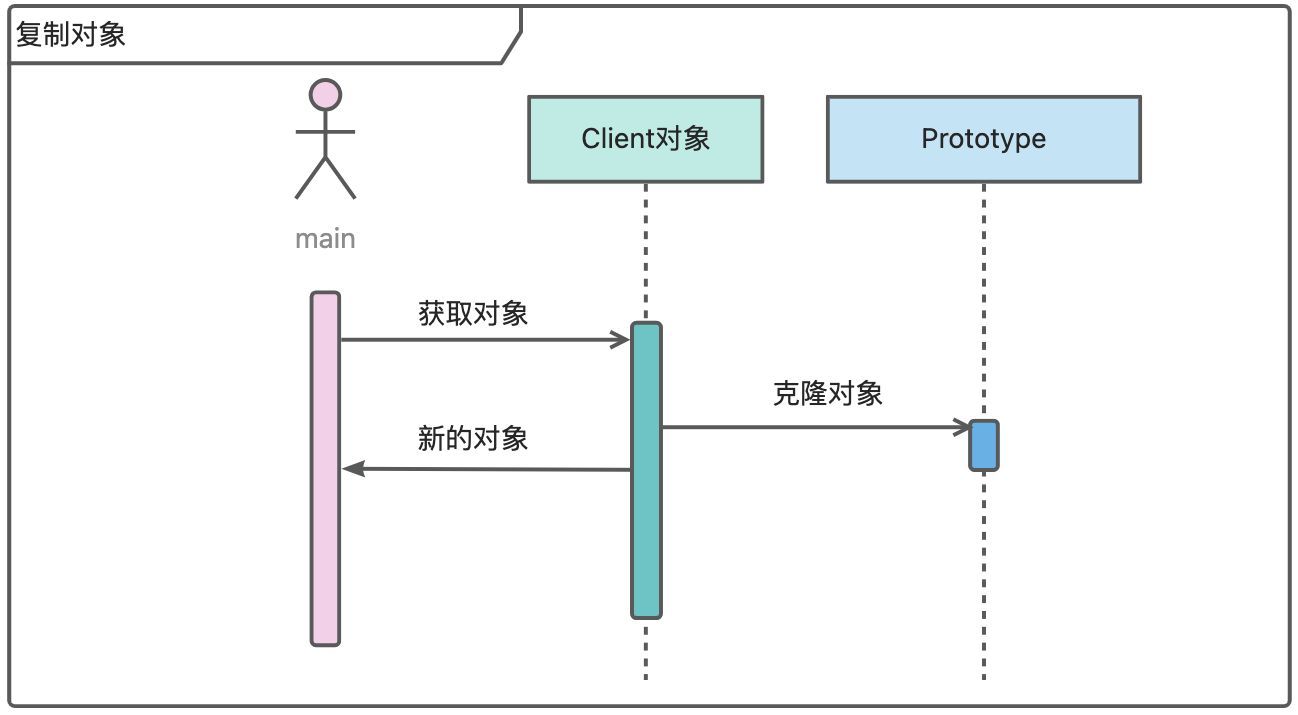
设计模式——原型设计模式(创建型)
摘要 本文详细介绍了原型设计模式,这是一种创建型设计模式,通过复制现有对象(原型)来创建新对象,避免使用new关键字,可提高性能并简化对象创建逻辑。文章阐述了其优点,如提高性能、动态扩展和简…...

react库:class-variance-authority
文章目录 前言一、cva 的核心作用二、代码逐层解析参数详解基础样式(第一个参数):variant:定义颜色/风格变体(如 default、destructive)。size:定义尺寸变体(如 sm、lg)。…...
通过mqtt 点灯
1 解析mqtt 传过来的json 用cjson 解析。 2 类似mvc的结构,调用具体的动作函数 定义设备处理结构体:使用结构体数组映射设备名称与处理函数,实现可扩展的指令分发分离设备逻辑:为每个设备(如 LED、Motor࿰…...

随笔笔记记录5.28
1.setOptMode -opt_leakage_to_dynamic_ratio 调整漏电与动态功耗的优化权重( 1.0 表示仅优化漏电)。 需指定-opt_power_effort(none | low | high),同时使用 2.set_ccopt_property max_source_to_sink_net_length …...
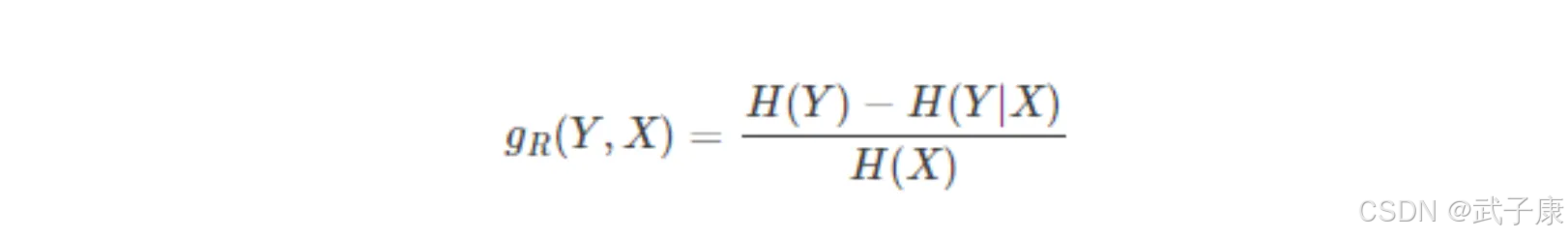
大数据-273 Spark MLib - 基础介绍 机器学习算法 决策树 分类原则 分类原理 基尼系数 熵
点一下关注吧!!!非常感谢!!持续更新!!! 大模型篇章已经开始! 目前已经更新到了第 22 篇:大语言模型 22 - MCP 自动操作 FigmaCursor 自动设计原型 Java篇开…...

基于 Spring Boot + Vue 的墙绘产品展示交易平台设计与实现【含源码+文档】
项目简介 本系统是一个基于 Spring Boot Vue 技术栈开发的墙绘产品展示交易平台,旨在提供一个高效、便捷的在线商城平台,方便用户浏览、选购墙绘产品,并提供管理员进行商品管理、订单管理等功能。系统采用了前后端分离的架构,前…...
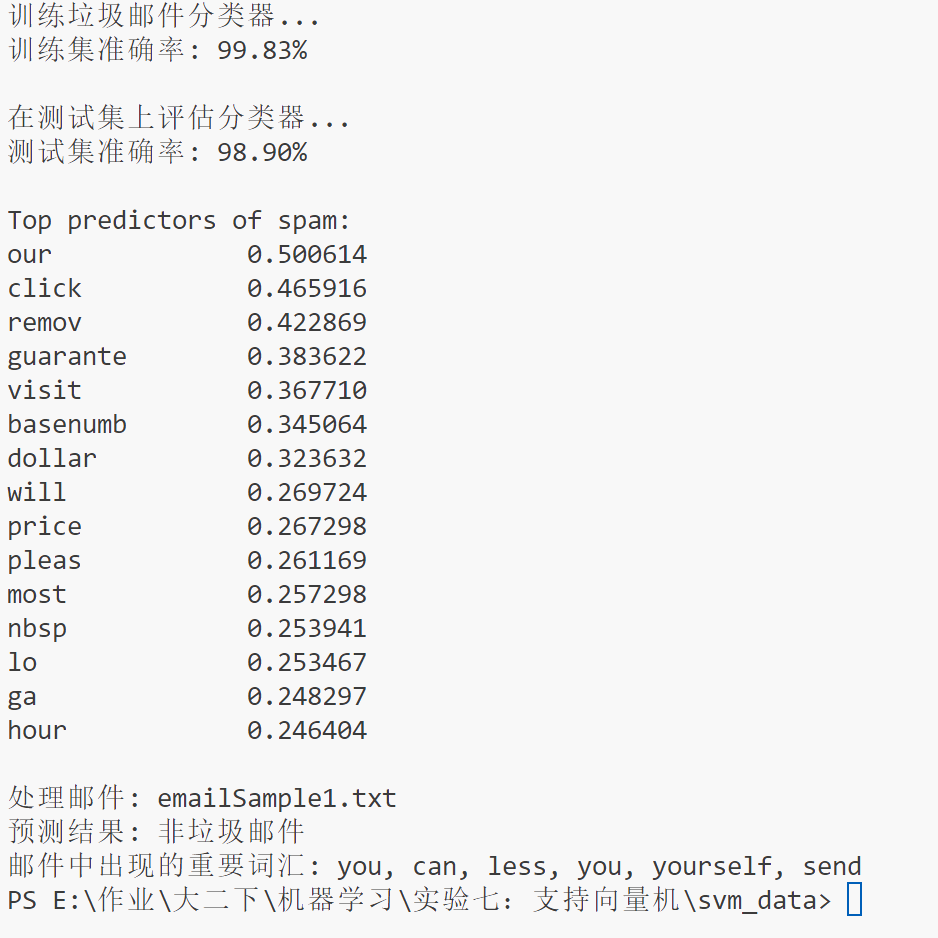
【机器学习】支持向量机
文章目录 一、支持向量机简述1.概念2.基本概念3.算法介绍4.线性可分5.算法流程 二、实验1.代码介绍2.模型流程3.实验结果4.实验小结 一、支持向量机简述 1.概念 支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其…...
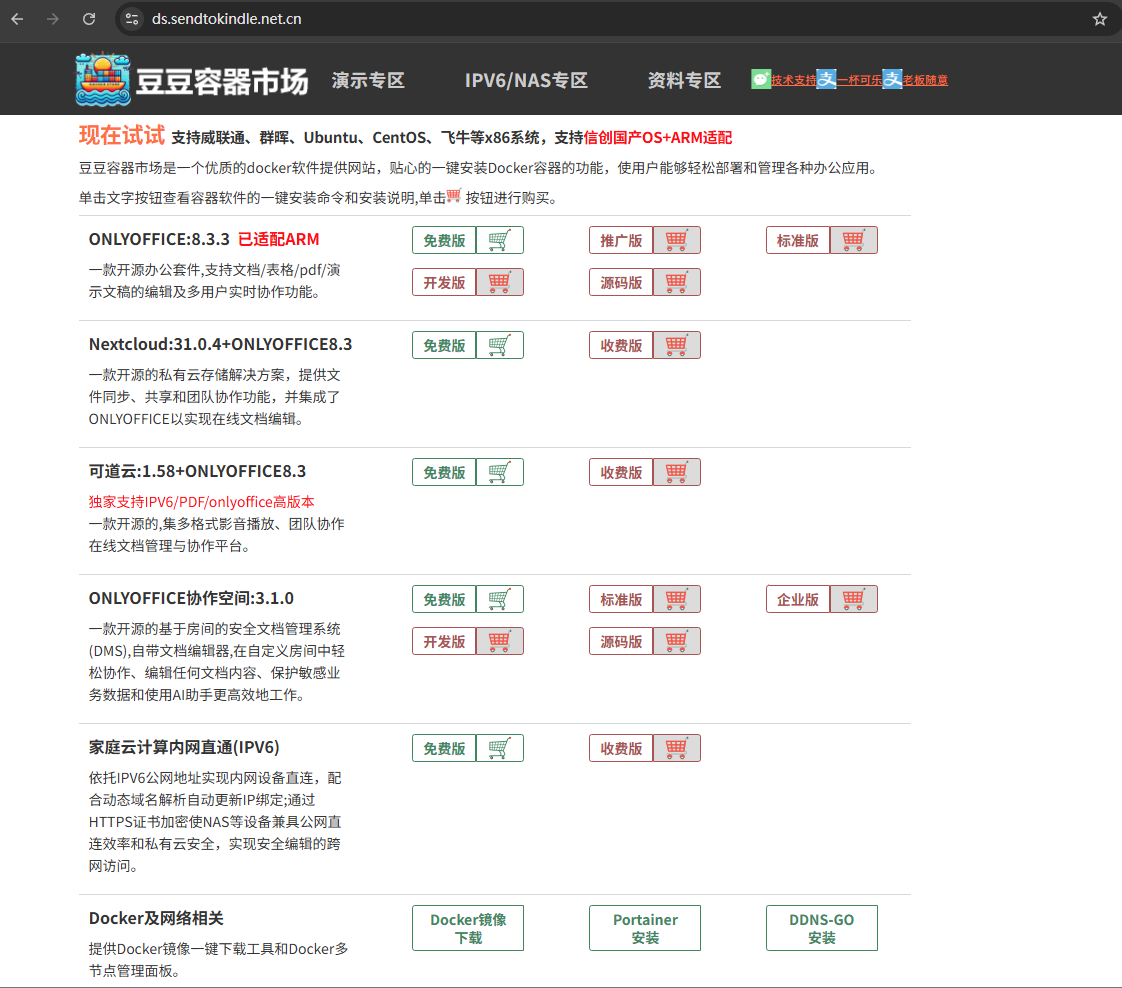
ONLYOFFICE深度解锁系列.4-OnlyOffice客户端原理-真的不支持多端同步
最近很多客户多要求直接部署onlyoffice服务端,还问能否和onlyoffice的客户端进行文件同步,当时真是一脸懵,还有的是老客户,已经安装了onlyoffice协作空间的,也在问如何配置客户端和协作空间的对接。由于问的人太多了,这里统一回复,先说结论,再说原理: 1.onlyoffice document s…...
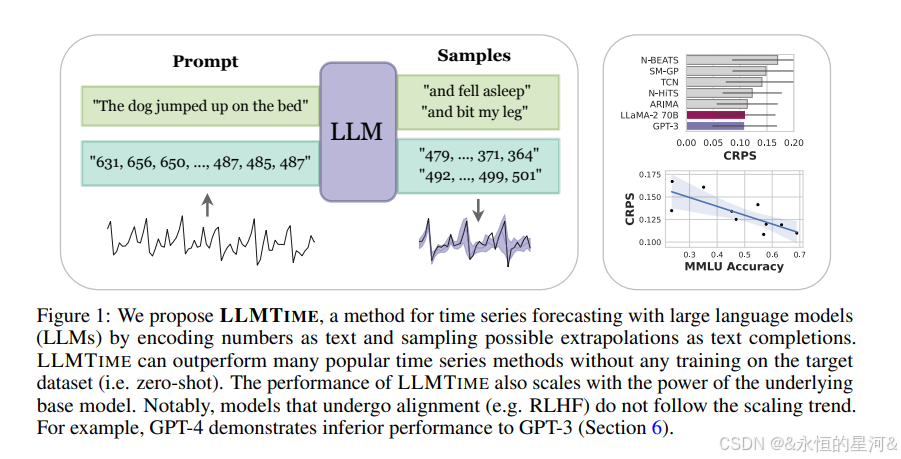
LLMTIME: 不用微调!如何用大模型玩转时间序列预测?
今天是端午节,端午安康!值此传统佳节之际,我想和大家分享一篇关于基于大语言模型的时序预测算法——LLMTIME。随着人工智能技术的飞速发展,利用大型预训练语言模型(LLM)进行时间序列预测成为一个新兴且极具…...
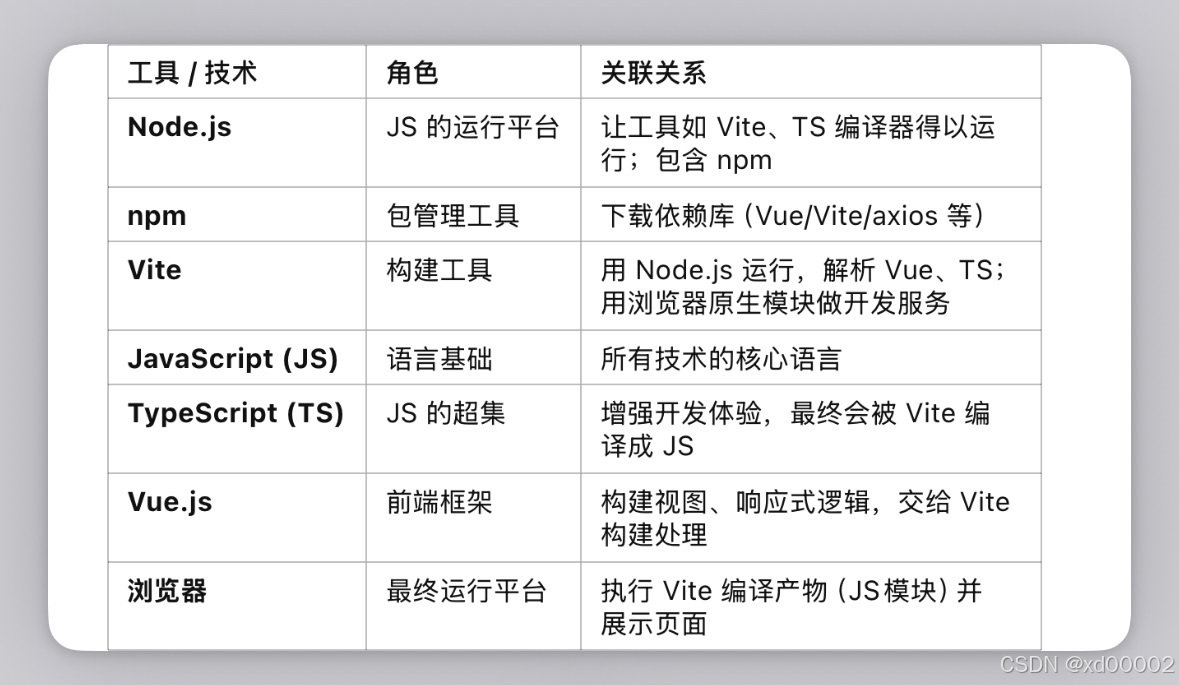
2.从0开始搭建vue项目(node.js,vue3,Ts,ES6)
从“0到跑起来一个 Vue 项目”,重点是各个工具之间的关联关系、职责边界和技术演化脉络。 从你写代码 → 到代码能跑起来 → 再到代码可以部署上线,每一步都有不同的工具参与。 😺😺1. 安装 Node.js —— 万事的根基 Node.js 是…...

MySQL 高可用实现方案详解
MySQL 高可用实现方案详解 一、高可用核心概念 高可用性(High Availability)指系统能够持续提供服务的能力,通常用可用性=正常服务时间/(正常服务时间+故障时间)来衡量,99.99%可用性表示年故障时间不超过52.6分钟。 MySQL实现高可用需要解决以下几个关键问题: 故障自动检测…...
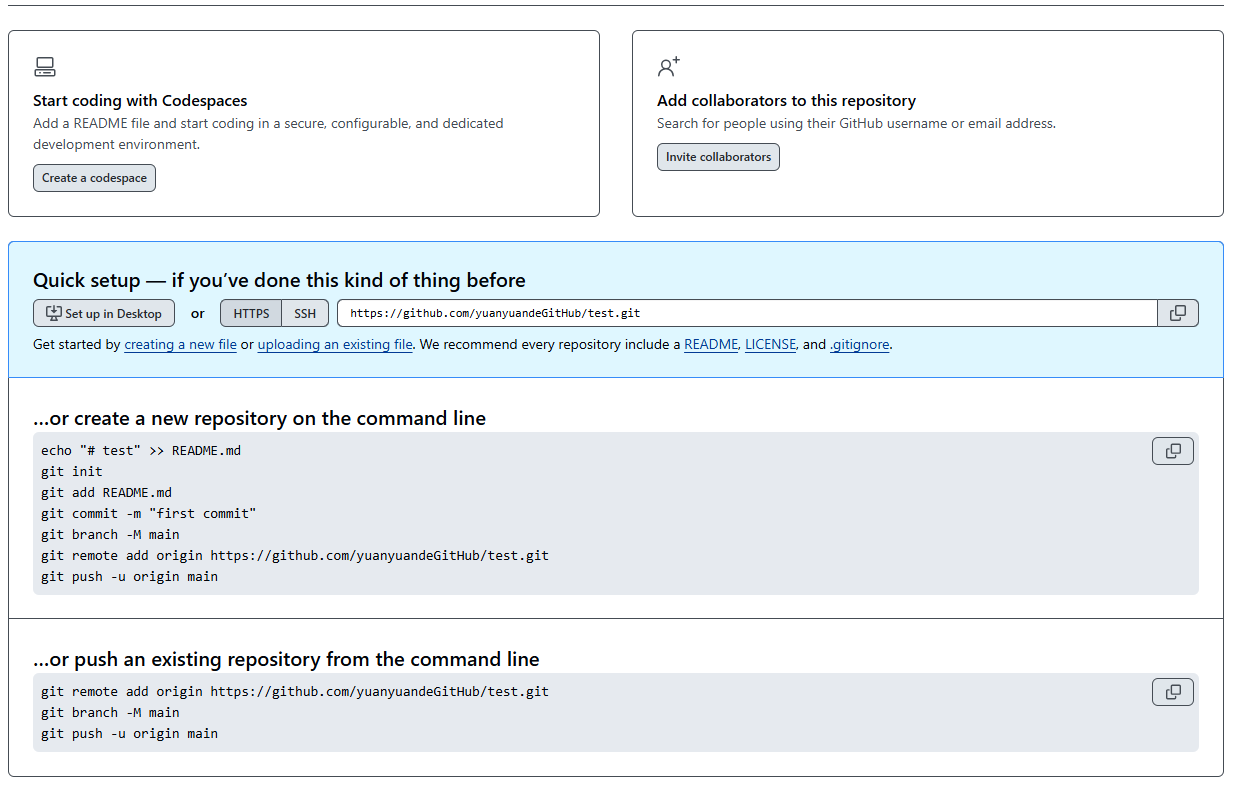
【pycharm】如何连接远程仓库进行版本管理(应用版本)
软件:Pycharm OS:Windows 一、Git基础设置 这里略过Git安装,需要可以参考:windows安装git(全网最详细,保姆教程)-CSDN博客 1. 配置Git 打开GitBash。分次输入下列命令。 git config --…...