【机器学习】支持向量机
文章目录
- 一、支持向量机简述
- 1.概念
- 2.基本概念
- 3.算法介绍
- 4.线性可分
- 5.算法流程
- 二、实验
- 1.代码介绍
- 2.模型流程
- 3.实验结果
- 4.实验小结
一、支持向量机简述
1.概念
支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面,可以将问题化为一个求解凸二次规划的问题。与逻辑回归和神经网络相比,支持向量机,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
2.基本概念
超平面:超平面是SVM中用于分割不同类别数据的决策边界。在线性可分的情况下,SVM试图找到一个超平面,使得不同类别之间的间隔最大化。这个最大间隔确保了模型具有良好的泛化能力,即使面对未知数据也能做出准确的分类
支持向量:支持向量机的核心概念之一是支持向量。在SVM中,支持向量是指距离超平面最近的几个数据点,这些点正是最难分类的数据点,同时也是对决策边界最有影响力的点。如果这些支持向量发生变化,那么超平面的位置也会随之改变,从而影响整个模型的分类效果。
3.算法介绍
在线性可分时,在原空间寻找两类样本的最优分类超平面。在线性不可分时,加入松弛变量并通过使用非线性映射将低维度输入空间的样本映射到高维度空间使其变为线性可分,这样就可以在该特征空间中寻找最优分类超平面。
4.线性可分
对于一个数据集合可以画一条直线将两组数据点分开,这样的数据成为线性可分(linearly separable),如下图所示:
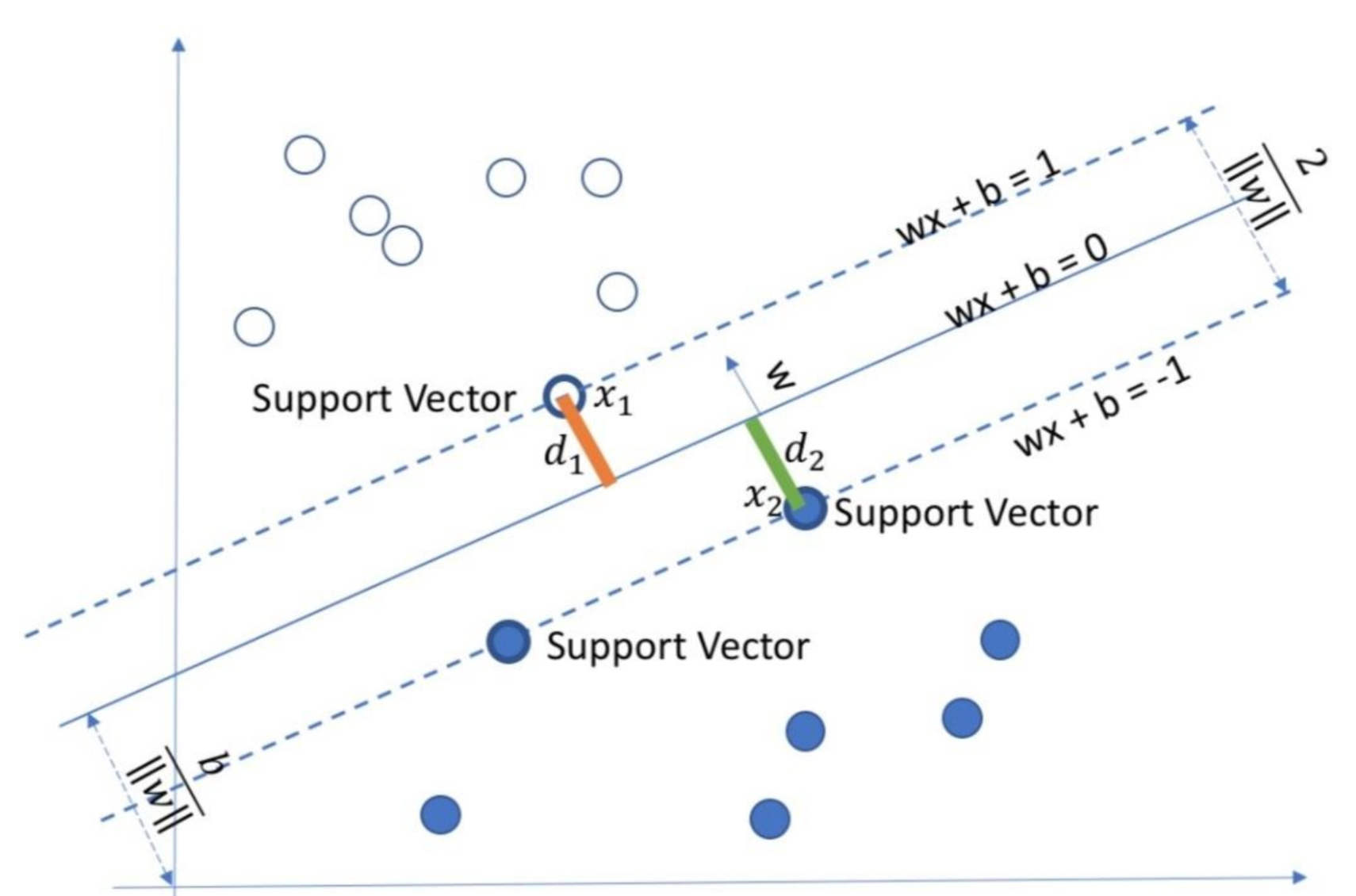
分割超平面:将上述数据集分隔开来的直线成为分隔超平面。对于二维平面来说,分隔超平面就是一条直线。对于三维及三维以上的数据来说,分隔数据的是个平面,称为超平面,也就是分类的决策边界。
间隔:点到分割面的距离,称为点相对于分割面的间隔。数据集所有点到分隔面的最小间隔的2倍,称为分类器或数据集的间隔。论文中提到的间隔多指这个间隔。SVM分类器就是要找最大的数据集间隔。
支持向量:离分隔超平面最近的那些点。
SVM所做的工作就是找这样个超平面,能够将两个不同类别的样本划分开来,但是这种平面是不唯一的,即可能存在无数个超平面都可以将两种样本分开。
Vapnik提出了一种方法,对每一种可能的超平面,我们将它进行平移,直到它与空间中的样本向量相交。我们称这两个向量为支持向量,之后我们计算支持向量到该超平面的距离d,分类效果最好的超平面应该使d最大。
5.算法流程
(1)收集数据
(2)准备数据:需要数值型数据
(3)分析数据:有助于可视化分割超平面
(4)训练算法:SVM的大部分时间都源自训练,该过程主要实现两个参数的调优
(5)测试算法
(6)使用算法:解决分类问题
二、实验
1.代码介绍
def process_email(email_contents):# 转换为小写email_contents = email_contents.lower()# 移除HTML标签、处理URLs、电子邮件地址等email_contents = re.sub(r'<[^<>]+>', ' ', email_contents)email_contents = re.sub(r'(http|https)://[^\s]*', 'httpaddr', email_contents)# ... 其他替换规则 ...# 分词处理words = re.split(r'[@$/#.-:&*+=\[\]?!(){},\'\">_<;% ]', email_contents)# 初始化单词索引列表word_indices = []# 读取词汇表并处理每个单词vocab_list = get_vocab_list()for word in words:# 移除非字母字符并检查单词长度word = re.sub(r'[^a-zA-Z0-9]', '', word)if len(word) < 1:continue# 获取单词在词汇表中的索引if word in vocab_list:word_indices.append(vocab_list[word])return word_indices
功能:将原始邮件文本转换为词汇表中的索引列表。
步骤:
转换为小写,移除 HTML 标签,替换 URL、邮箱地址等特殊格式
按非字母数字字符分割邮件内容
将每个单词映射到词汇表中的索引(如果存在)。
def email_features(word_indices):# 获取词汇表大小vocab_list = get_vocab_list()n = len(vocab_list)# 初始化特征向量x = np.zeros(n)# 设置对应索引的特征为1for idx in word_indices:x[idx-1] = 1 # 词汇表索引从1开始,特征向量索引从0开始return x
功能:将邮件的单词索引列表转换为特征向量(词袋模型)。
实现:
创建一个长度为词汇表大小的向量,每个位置表示一个单词。
如果某个单词在邮件中出现,则对应位置为 1,否则为 0。
def train_spam_classifier():# 加载训练数据data = sio.loadmat('spamTrain.mat')X = data['X'] # 特征矩阵 (4000, 1899)y = data['y'].ravel() # 标签向量# 训练SVM分类器(线性核,C=0.1)clf = svm.SVC(C=0.1, kernel='linear')clf.fit(X, y)# 计算训练集准确率p = clf.predict(X)print(f'训练集准确率: {np.mean(p == y) * 100:.2f}%')return clfdef test_spam_classifier(clf):# 加载测试数据data = sio.loadmat('spamTest.mat')Xtest = data['Xtest']ytest = data['ytest'].ravel()# 计算测试集准确率p = clf.predict(Xtest)print(f'测试集准确率: {np.mean(p == ytest) * 100:.2f}%')
功能:使用 SVM 训练分类器并评估性能。
关键点:
数据格式:X 是 4000×1899 的矩阵(4000 封邮件,1899 个特征)。
SVM 参数:
C=0.1:控制正则化强度,较小的值减少过拟合。
kernel=‘linear’:线性核适合高维稀疏数据(如文本)。
def top_predictors(clf):# 获取词汇表和SVM权重vocab_list = get_vocab_list()weights = clf.coef_[0]# 获取权重排序后的索引(降序)indices = np.argsort(-weights)# 打印前15个预测能力最强的词汇print('\nTop predictors of spam:')for i in range(15):for word, idx in vocab_list.items():if idx == indices[i] + 1:print(f'{word:15} {weights[indices[i]]:.6f}')break
功能:找出对预测垃圾邮件贡献最大的词汇。
原理:
SVM 的线性权重表示每个特征(单词)对分类的重要性。
权重越大,该单词越可能指示邮件是垃圾邮件。
def classify_new_email(clf, email_filename):# 读取邮件内容并预处理with open(email_filename, 'r') as f:email_contents = f.read()# 预处理邮件 → 特征向量 → 预测word_indices = process_email(email_contents)x = email_features(word_indices)prediction = clf.predict(x.reshape(1, -1))print(f'\n处理邮件: {email_filename}')print(f'预测结果: {"垃圾邮件" if prediction[0] == 1 else "非垃圾邮件"}')
功能:对新邮件进行分类预测。
流程:
读取邮件文本。
通过 process_email 转换为单词索引。
通过 email_features 转换为特征向量。
使用训练好的 SVM 模型预测类别。
2.模型流程
1.数据准备:
vocab.txt:包含 1899 个常用单词的词汇表。
spamTrain.mat 和 spamTest.mat:预提取的特征矩阵和标签。
2.训练阶段:
加载训练数据 → 训练 SVM 模型 → 评估训练集准确率。
3.测试阶段:
加载测试数据 → 评估测试集准确率。
4.预测阶段:
对新邮件进行预处理 → 提取特征 → 预测类别。
3.实验结果
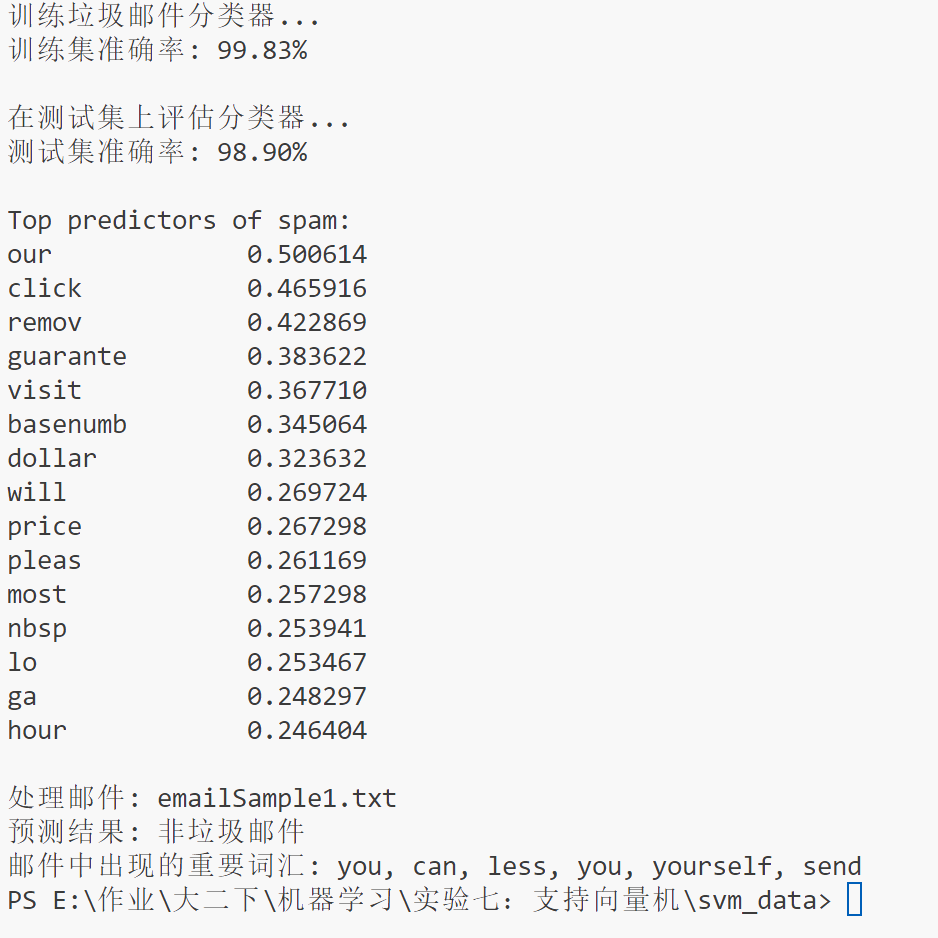
训练集准确率(99.83%)
在用于训练模型的数据集(spamTrain.mat 中提供的数据 )上,模型预测正确的样本数占总样本数的比例高达 99.83% 。这表明模型在学习训练数据的模式和规律方面表现极为出色,能够很好地对训练集中的垃圾邮件和非垃圾邮件进行区分。
测试集准确率(98.90%)
在未参与模型训练的测试数据集(spamTest.mat 中的数据 )上,模型预测正确的比例为 98.90% 。测试集准确率是衡量模型泛化能力的重要指标,说明模型在面对新的、未见过的数据时,也能较为准确地判断邮件是否为垃圾邮件。
与训练集准确率对比
测试集准确率略低于训练集准确率,但差距不大,这是比较理想的情况。一定程度的差距是正常的,因为训练集和测试集数据存在差异,只要差距不显著,就表明模型没有严重的过拟合问题,泛化性能良好。
Top predictors of spam
列出了对判断邮件是否为垃圾邮件贡献最大的词汇及其对应的权重。权重反映了该词汇在 SVM 模型决策过程中的重要性,权重越大,说明该词汇越倾向于指示邮件是垃圾邮件。
比如 “our” 权重为 0.500614 ,“click” 权重为 0.465916 ,意味着在模型看来,邮件中出现这些词时,更有可能是垃圾邮件。像 “click” 常出现在垃圾广告邮件诱导用户点击链接的场景中,“guarante”也常出现在虚假承诺的垃圾推销邮件里。
对新邮件的分类结果(emailSample1.txt )
预测结果:判断 emailSample1.txt 为非垃圾邮件 。这是模型基于对该邮件文本进行预处理、特征提取后,通过已训练的 SVM 分类器进行预测得到的结论。
重要词汇:列出了邮件中出现的部分重要词汇,这些词汇在模型判断过程中具有一定作用。虽然它们整体上没有让模型判定该邮件为垃圾邮件,但这些词汇的出现情况也是模型决策的依据之一 。
4.实验小结
本次实验运用 SVM 构建垃圾邮件分类器。训练集准确率达 99.83% ,测试集准确率为 98.90% ,模型展现出良好的学习与泛化能力。通过合理设置 SVM 参数,结合有效的文本预处理及特征提取,使其能精准捕捉垃圾邮件特征。
从关键预测词汇看,“click”“guarante” 等高频于垃圾邮件场景的词权重较高,为模型判断提供依据。对新邮件emailSample1.txt 的成功分类,验证了模型实际应用的有效性。但仍可在特征工程、参数调优上深入探索,进一步提升模型性能与适应性。
相关文章:
【机器学习】支持向量机
文章目录 一、支持向量机简述1.概念2.基本概念3.算法介绍4.线性可分5.算法流程 二、实验1.代码介绍2.模型流程3.实验结果4.实验小结 一、支持向量机简述 1.概念 支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其…...
ONLYOFFICE深度解锁系列.4-OnlyOffice客户端原理-真的不支持多端同步
最近很多客户多要求直接部署onlyoffice服务端,还问能否和onlyoffice的客户端进行文件同步,当时真是一脸懵,还有的是老客户,已经安装了onlyoffice协作空间的,也在问如何配置客户端和协作空间的对接。由于问的人太多了,这里统一回复,先说结论,再说原理: 1.onlyoffice document s…...
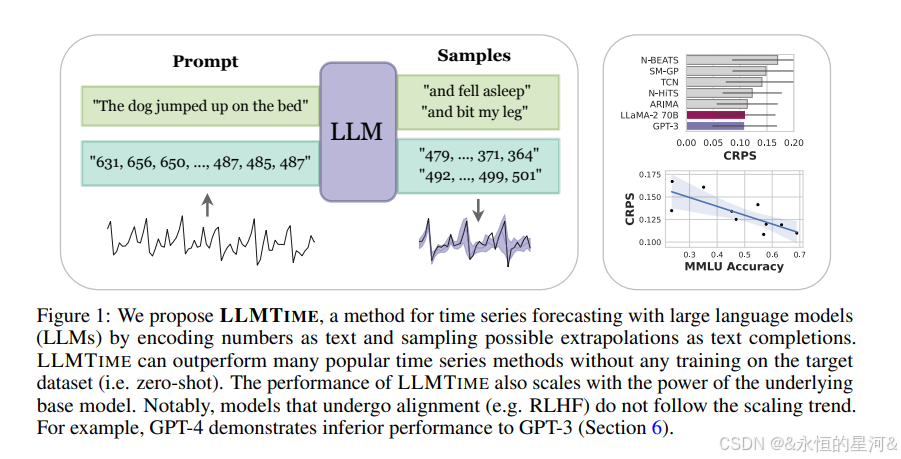
LLMTIME: 不用微调!如何用大模型玩转时间序列预测?
今天是端午节,端午安康!值此传统佳节之际,我想和大家分享一篇关于基于大语言模型的时序预测算法——LLMTIME。随着人工智能技术的飞速发展,利用大型预训练语言模型(LLM)进行时间序列预测成为一个新兴且极具…...
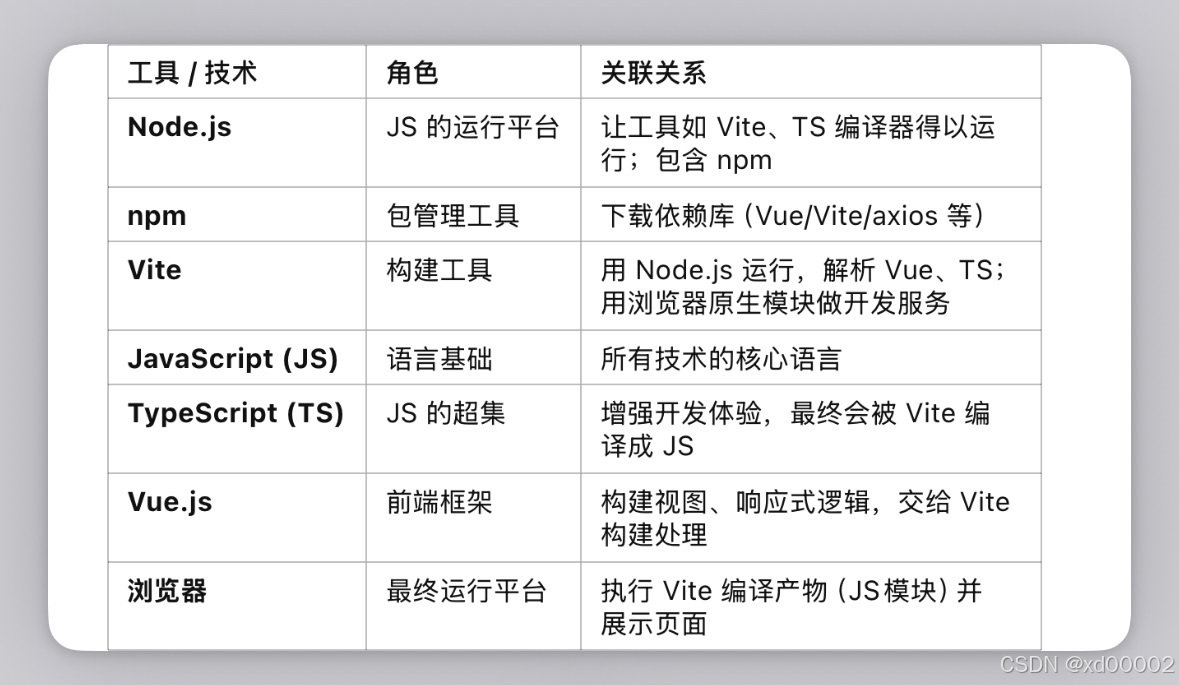
2.从0开始搭建vue项目(node.js,vue3,Ts,ES6)
从“0到跑起来一个 Vue 项目”,重点是各个工具之间的关联关系、职责边界和技术演化脉络。 从你写代码 → 到代码能跑起来 → 再到代码可以部署上线,每一步都有不同的工具参与。 😺😺1. 安装 Node.js —— 万事的根基 Node.js 是…...

MySQL 高可用实现方案详解
MySQL 高可用实现方案详解 一、高可用核心概念 高可用性(High Availability)指系统能够持续提供服务的能力,通常用可用性=正常服务时间/(正常服务时间+故障时间)来衡量,99.99%可用性表示年故障时间不超过52.6分钟。 MySQL实现高可用需要解决以下几个关键问题: 故障自动检测…...
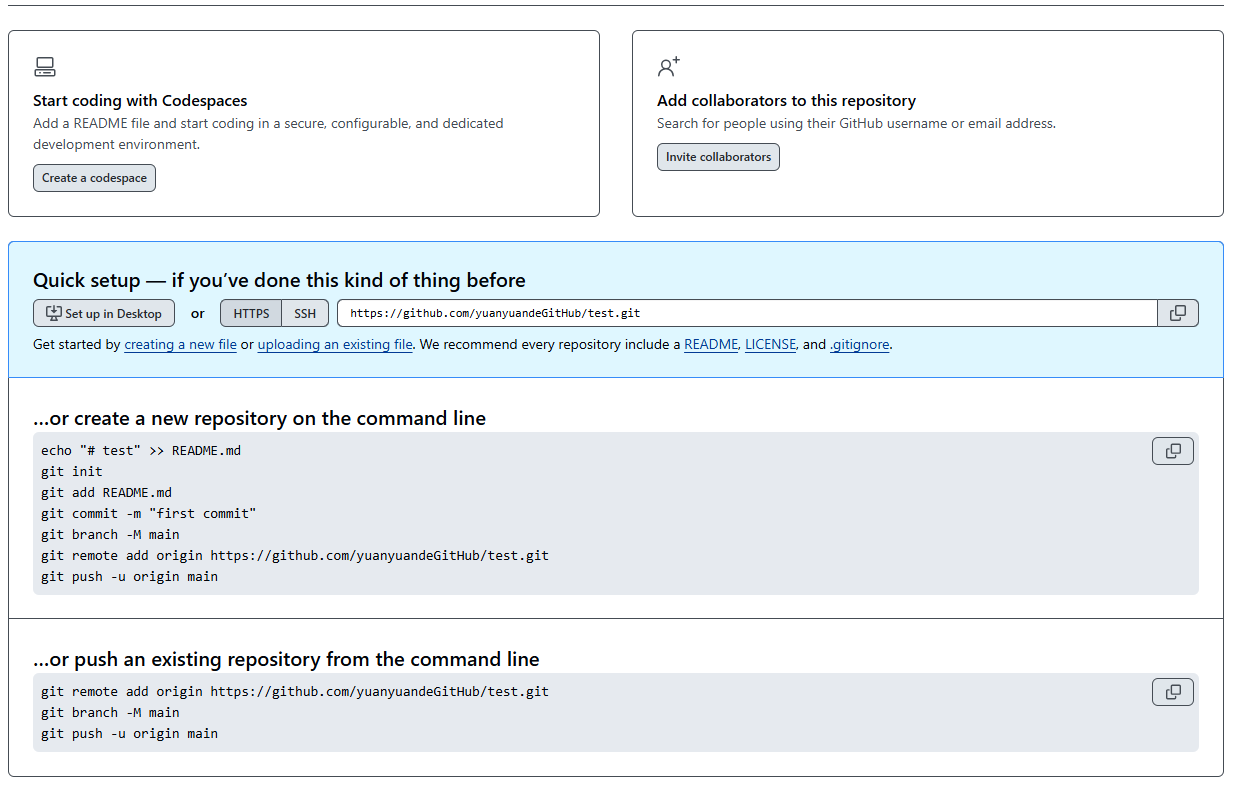
【pycharm】如何连接远程仓库进行版本管理(应用版本)
软件:Pycharm OS:Windows 一、Git基础设置 这里略过Git安装,需要可以参考:windows安装git(全网最详细,保姆教程)-CSDN博客 1. 配置Git 打开GitBash。分次输入下列命令。 git config --…...

linux 1.0.7
用户和权限的含义与作用 linux中的用户和文件 用户的权限是非常重要的 而且有些程序需要使用管理员身份去执行 这些都是非常重要的 不可能让所有的人拥有所有的权限 这样的工具可以避免非法的手段来修改计算机中的数据 linux之所以安全还是权限管理做的很棒 每个登录的用户都有…...

【Rust 轻松构建轻量级多端桌面应用】
使用 Tauri 框架构建跨平台应用 Tauri 是一个基于 Rust 的轻量级框架,可替代 Electron,用于构建高性能、低资源占用的桌面应用。其核心优势在于利用系统原生 WebView 而非捆绑 Chromium,显著减小应用体积。 安装 Tauri 需要先配置 Rust 环境…...
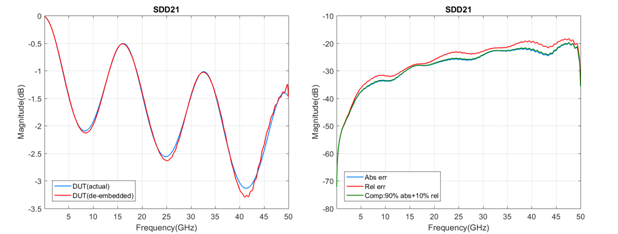
IEEE P370:用于高达 50 GHz 互连的夹具设计和数据质量公制标准
大多数高频仪器,如矢量网络分析仪 (VNA) 和时域反射仪 (TDR),都可以在同轴接口的末端进行非常好的测量。然而,复杂系统中使用的互连很少具有同轴接口。用于表征这些设备的夹具的设计和实施会对测…...

青少年编程与数学 02-020 C#程序设计基础 09课题、面向对象编程
青少年编程与数学 02-020 C#程序设计基础 09课题、面向对象编程 一、概述1. 对象(Object)2. 类(Class)3. 封装(Encapsulation)4. 继承(Inheritance)5. 多态(Polymorphism…...
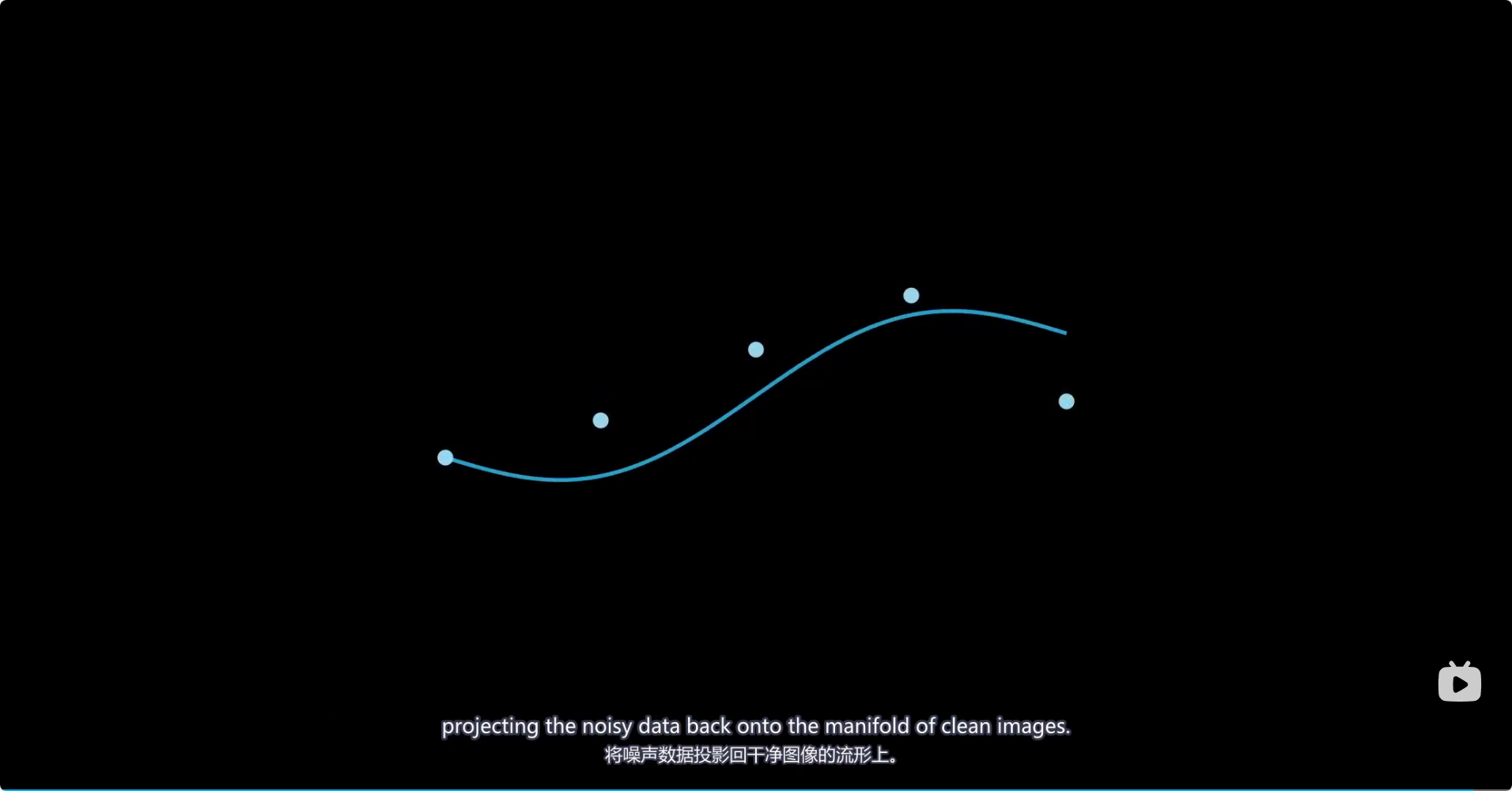
Denoising Autoencoders 视频截图 DAEs简单实现 kaggle 去噪编码器
https://www.bilibili.com/video/BV1syzrYaEtw Denoising Autoencoders (DAEs) 是一种无监督学习模型,属于自动编码器(Autoencoder)的一种扩展形式。它们的目标是通过训练神经网络来学习数据的鲁棒表示(robust representation&a…...

GoogLeNet网络模型
GoogLeNet网络模型 诞生背景 在2014年的ImageNet图像识别挑战赛中,一个GoogLeNet的网络架构大放异彩,与VGG不同的是,VGG用的是3*3的卷积,而GoogLeNet从1*1到7*7的卷积核都用,也就是使用不同大小的卷积核组合。 网络…...
)
LeetCode Hot100 (贪心)
121. 买卖股票的最佳时机 题意 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从…...

仿真科普|弥合市场需求断层,高性能仿真,“性能”与“安全”如何兼得?
2025年3月,塔塔科技(Tata Technologies)确认曾在去年遭受勒索软件组织“猎手国际”(Hunters International)的攻击,1.4TB工程数据被窃取,涉及航空发动机热障涂层工艺参数等超过 73 万份文件。 X…...

工业控制核心引擎高性能MCU——MM32F5370
RAMSUN提供的MM32F5370搭载180MHz Arm China Star-MC1处理器,集成DSP、FPU与三角函数加速单元(CORDIC),轻松应对复杂算法需求。其技术亮点包括: 超高精度PWM:8通道208ps级高精度PWM输出,满足储能…...
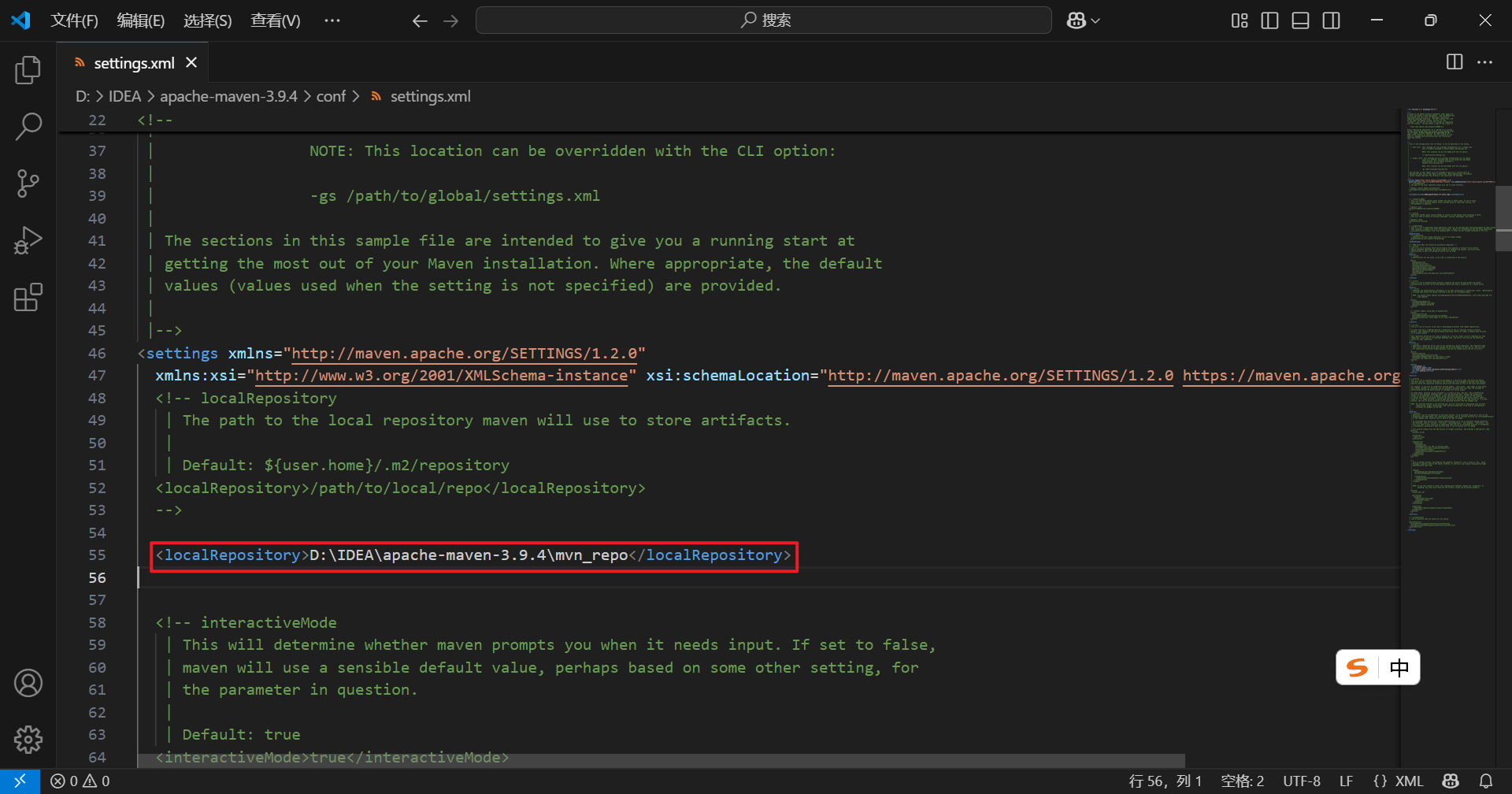
Maven---配置本地仓库
目录 5. 5.1在Maven路径下新建文件夹用于本地仓库存储 5.2 复制本地仓库路径 5.3 找到配置文件路径,使用VSCode方式打开 5.4 新增一行代码 5.5 复制本地仓库路径,设置存储路径 5.1在Maven路径下新建文件夹用于本地仓库存储 5.2 复制本地仓库路径 5…...

vue中events选项与$on监听自定义事件他们的区别与不同,以及$emit与$on之间通信和mounted生命周期钩子函数有哪些作用和属性
events 选项确实曾经被用于监听事件,但它主要用于早期版本的 Vue.js(1.x)中,用于组件之间的通信。在 Vue 2.x 中,events 选项已经被废弃,取而代之的是更强大的 $emit 和 $on 方法。 使用$emit来监听自定义…...

【C++ 】智能指针:内存管理的 “自动导航仪”
目录 一、引入 二、智能指针的两大特性: 1、RAII 特点: 好处: 2、行为像指针 三、智能指针起初的缺陷:拷贝问题 四、几种智能指针的介绍。 1、C98出现的智能指针——auto_ptr auto_ptr解决上述拷贝构造的问题:…...
设备制造行业项目管理难点解析,如何有效解决?
在设备制造行业,项目管理是企业运营的核心环节,直接影响项目交付效率、成本控制和盈利能力。然而,由于行业特性复杂、项目周期长、涉及部门多,企业在实际操作中常常面临诸多管理痛点。金众诚工程项目管理系统,依托金蝶…...

浅谈 PAM-2 到 PAM-4 的信令技术演变
通信信令技术演进:从 PAM-2 到 PAM-4 在当今数字化高速发展的时代,数据传输需求呈爆炸式增长,行业对通信带宽的要求愈发严苛。为顺应这一趋势,通信信令技术不断革新,曾经占据主导地位的不归零(NRZÿ…...
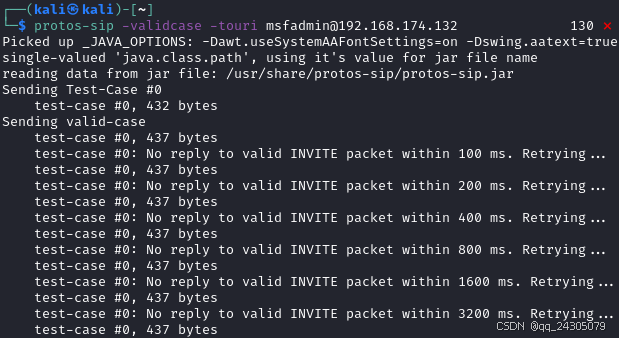
Protos-SIP:经典 SIP 协议模糊测试工具!全参数详细教程!Kali Linux教程!
简介 该测试套件的目的是评估会话发起协议 (SIP) 实现的实现级别安全性和稳健性。 Protos-SIP 是一款专为 SIP 协议模糊测试(Fuzzing)设计的工具,最初由 OUSPG(Oulu University Secure Programming Group)开发&#…...
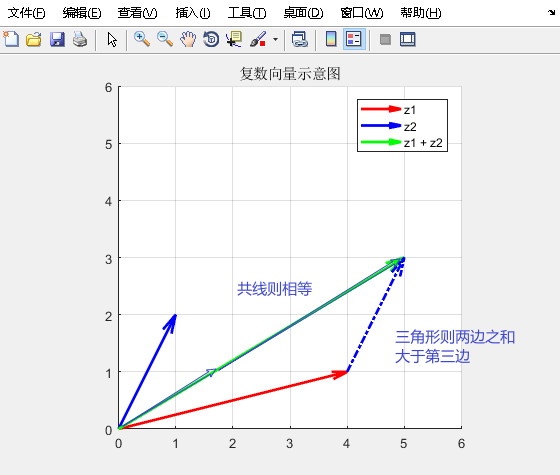
复数三角不等式简介及 MATLAB 演示
复数三角不等式简介及 MATLAB 演示 1. 复数三角不等式简介 复数三角不等式(Complex Triangle Inequality)是复数的一种重要性质,它类似于普通的三角不等式,但适用于复数空间。具体来说,复数三角不等式可以描述复数之…...
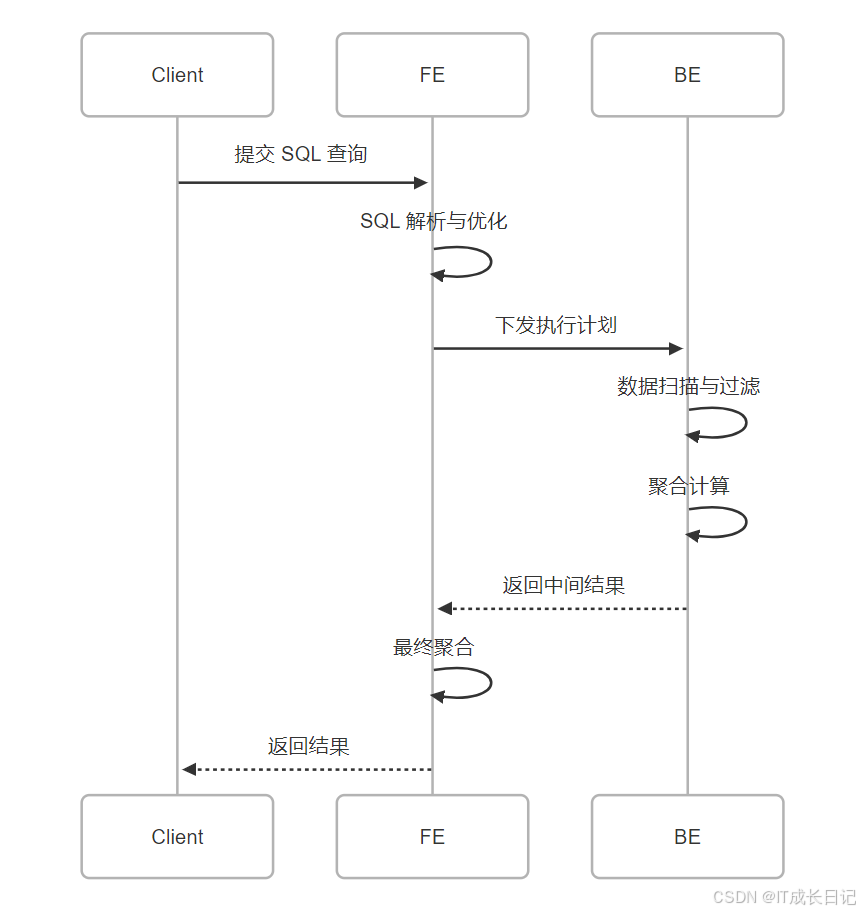
【Doris基础】Apache Doris 基本架构深度解析:从存储到查询的完整技术演进
目录 1 引言 2 Doris 架构全景图 2 核心组件技术解析 2.1 Frontend 层(FE) 2.2 Backend 层(BE) 3 数据存储与复制机制 3.1 存储架构演进 3.2 副本复制策略 4 查询处理全流程解析 4.1 查询生命周期 5 高可用设计 5.1 F…...
程序人生-hellohelloo
计算机系统 大作业 题 目 程序人生-Hello’s P2P 专 业 计算机与电子通信 学 号 2023111976 班 级 23L0504 学 生 孙恩旗 指 导 教 师 刘宏伟 计算机科…...
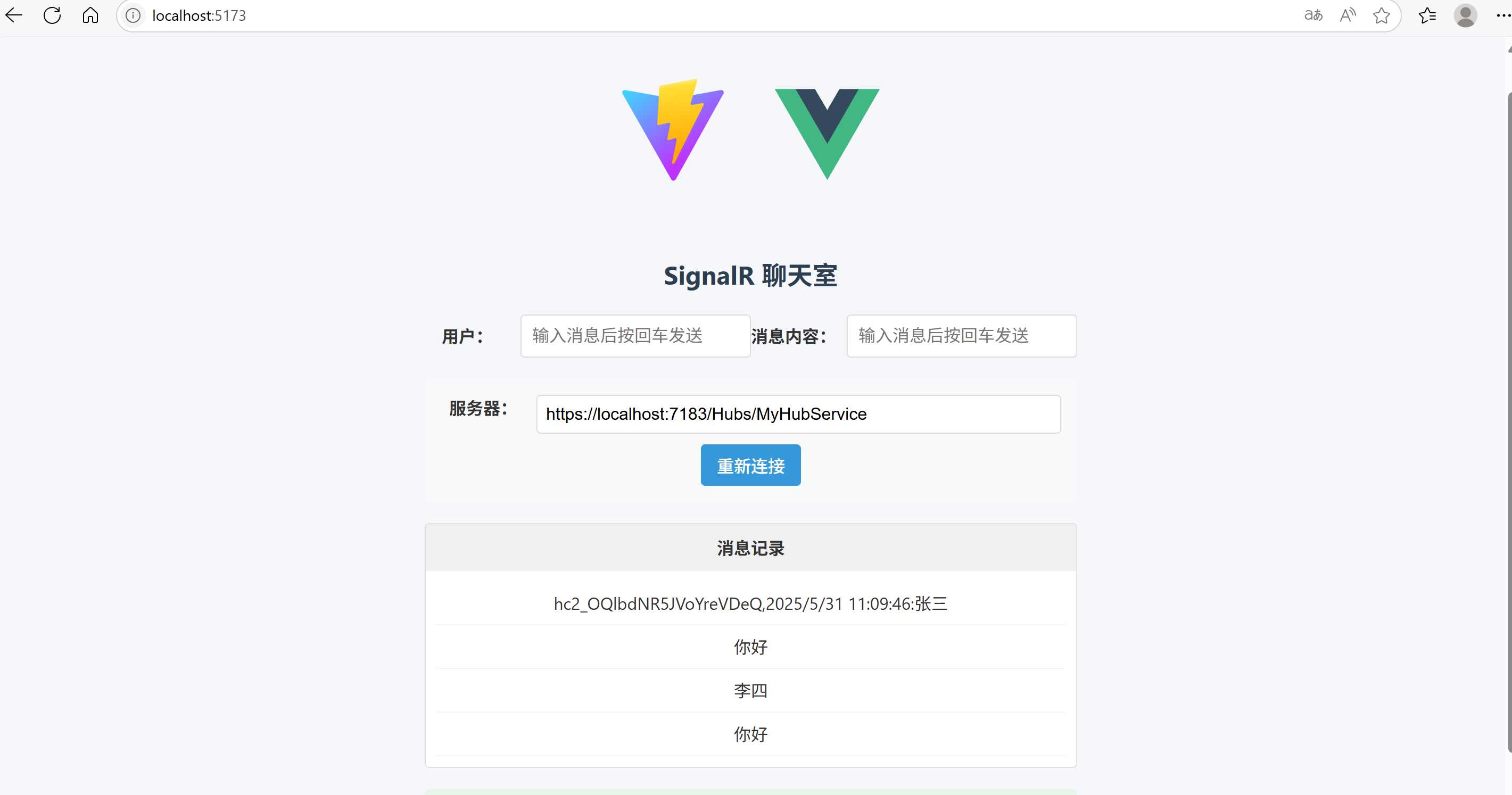
ASP.NET Core SignalR的基本使用
文章目录 前言一、SignalR是什么?在 ASP.NET Core 中的关键特性:SignalR 工作原理简图: 二、使用步骤1.创建ASP.NET Core web Api 项目2.添加 SignalR 包3.创建 SignalR Hub4.配置服务与中间件5.创建控制器(模拟服务器向客户端发送消息)6.创建…...
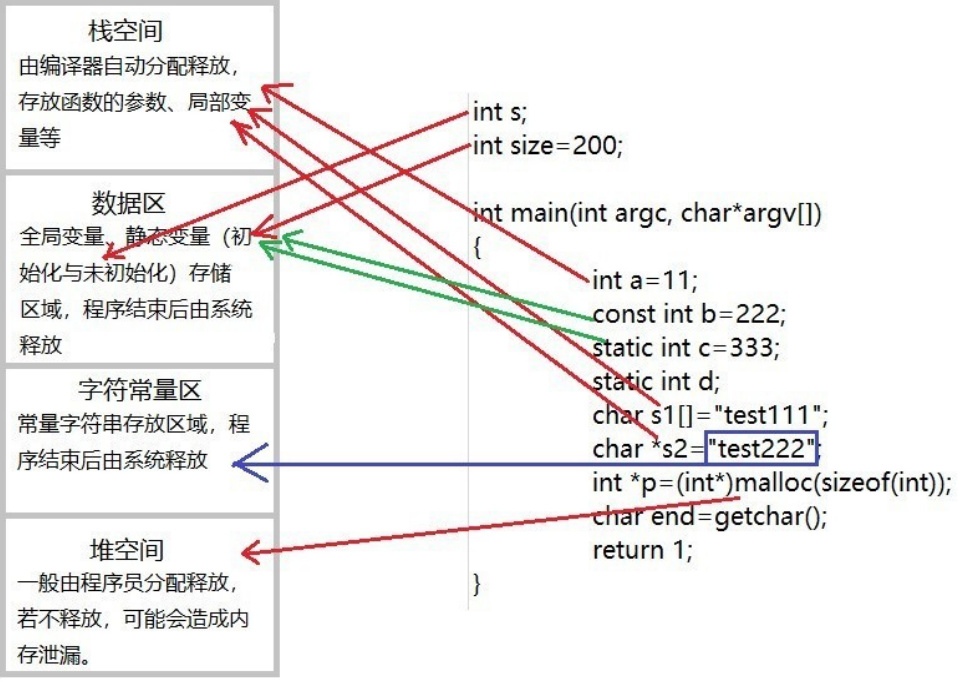
【C语言】讲解 程序分配的区域(新手)
目录 代码区 数据区 堆区 栈区 常量区 重点比较一下堆区与 栈区 总结: 前言: C语言程序的内存分配区域是理解其运行机制的重要部分。根据提供的多条证据,我们可以总结出C语言程序在运行时主要涉及以下五个关键内存区域: 代…...

【脚本 完全参数化的通用 APT 源配置方案-Debian/Ubuntu】
通过脚本在 Debian/Ubuntu 系统上一键切换 APT 源 如Dockerfile中 使用某个源(比如 aliyun) 假设你的目录结构是: . ├── Dockerfile └── switch-apt-source.shFROM ubuntu:22.04# 把脚本拷贝到镜像中 COPY switch-apt-source.sh /us…...

数据集笔记:SeekWorld
提出了一项新任务:地理定位推理(Geolocation Reasoning) 该任务要求模型在感知视觉信息的同时,推理出图像中视觉语义所隐含的高级逻辑关系,从而确定图像的拍摄地点 TheEighthDay/SeekWorld at main 构建了一个基于规则…...

LeetCode 算 法 实 战 - - - 移 除 链 表 元 素、反 转 链 表
LeetCode 算 法 实 战 - - - 移 除 链 表 元 素、反 转 链 表 第 一 题 - - - 移 除 链 表 元 素方 法 一 - - - 原 地 删 除方 法 二 - - - 双 指 针方 法 三 - - - 尾 插 第 二 题 - - - 反 转 链 表方 法 一 - - - 迭 代方 法 二 - - - 采 用 头 插 创 建 新 链 表 总 结 &a…...
:pipeline构建历史展示包名和各阶段间传递参数)
Jenkins实践(10):pipeline构建历史展示包名和各阶段间传递参数
Jenkins实践(10):构建历史展示包名和pipeline各阶段间传递参数 1、构建历史展示包名 参考:https://blog.csdn.net/fen_fen/article/details/148167868 1.1、方法说明 Jenkins版本:Jenkins2.452 通过修改 currentBuild.displayName 和 currentBuild.description 实现: …...