GoogLeNet网络模型
GoogLeNet网络模型
诞生背景
在2014年的ImageNet图像识别挑战赛中,一个GoogLeNet的网络架构大放异彩,与VGG不同的是,VGG用的是3*3的卷积,而GoogLeNet从1*1到7*7的卷积核都用,也就是使用不同大小的卷积核组合。
网络模型架构
在GoogLeNet中,基本的卷积块被称为Inception块。
Inception模块
Inception块参数详解
输入为224×224×3三通道的图像。
路径1:
(1)输入为224×224×3,卷积核数量为64个;卷 积核的尺寸大小为1×1×3;步幅为1(stride=1), 填充为0(padding=0);卷积后得到shape为 224×224×64的特征图输出。
路径2:
(1)输入为224×224×3,卷积核数量为96个;卷 积核的尺寸大小为1×1×3;步幅为1(stride = 1), 填充为0(padding=0);卷积后得到shape为 224×224×64的特征图输出。
(2)输入为224×224×64,卷积核数量为128个; 卷积核的尺寸大小为3×3×64;步幅为1(stride = 1),填充为1(padding=1);卷积后得到shape 为224×224×128的特征图输出。
路径3:
(1)输入为224×224×3,卷积核数量为16个;卷积核 的尺寸大小为1×1×3;步幅为1(stride = 1),填充为 0(padding=0);卷积后得到shape为224×224×16的 特征图输出。
(2)输入为224×224×16,卷积核数量为32个;卷积 核的尺寸大小为5×5×16;步幅为1(stride = 1),填 充 为 2 ( padding=2 ) ; 卷 积 后 得 到 shape 为 224×224×32的特征图输出。
路径4:
(1)输入为224×224×3,池化核的尺寸大小为3×3; 步幅为1(stride = 1),填充为1(padding=1);池 化后得到shape为224×224×3的特征图输出。
(2)输入为224×224×3,卷积核数量为32个;卷积核 的尺寸大小为1×1×3;步幅为1(stride = 1),填充为 0(padding=0);卷积后得到shape为224×224×32的 特征图输出。
通道合并:
路径1的到输出为:224×224×64
路径2的到输出为:224×224×128
路径3的到输出为:224×224×32
路径4的到输出为:224×224×32
最终通道合并为64+128+32+32=256,最终的输出为: 224×224×256
整个网络模型架构
| 阶段 | 层号 | 操作 | 参数 / 配置 | 输出尺寸(H×W×C) | 对应论文描述 |
|---|---|---|---|---|---|
| 输入层 | - | 图像输入 | 224×224 RGB,均值预处理 | 224×224×3 | 摘要 / 引言部分 |
| 初始卷积 | Conv1 | 7×7 卷积,步长 2,填充 3 | 64 个滤波器 | 112×112×64 | 引言中 “7×7 卷积层” |
| 初始池化 | Pool1 | 3×3 最大池化,步长 2,填充 1 | - | 56×56×64 | 引言中 “最大池化层” |
| 降维卷积 | Conv2 | 并行分支: ① 1×1 卷积 ② 1×1 卷积→3×3 卷积 | 分支①:64 通道 分支②:64→192 通道 | 56×56×256 | 引言中 “3×3 卷积(含 1×1 降维)” |
| Inception 组 1 | Inception 2a | 4 分支并行: ① 1×1 卷积 ② 1×1→3×3 卷积 ③ 1×1→5×5 卷积 ④ 池化→1×1 | ①64 ②96→128 ③16→32 ④32 通道 | 56×56×256 | 论文第 4 节 “第一组 Inception 模块” |
| Inception 2b | 4 分支并行(通道数调整) | ①128 ②128→192 ③32→96 ④64 通道 | 56×56×480 | 同上 | |
| 降采样 | Pool2 | 3×3 最大池化,步长 2,填充 1 | - | 28×28×480 | 组间池化,降低尺寸 |
| Inception 组 2 | Inception 3a | 4 分支并行(通道数调整) | ①192 ②96→208 ③16→48 ④64 通道 | 28×28×512 | 论文第 4 节 “第二组 Inception 模块” |
| Inception 3b | 4 分支并行(通道数调整) | ①160 ②112→224 ③24→64 ④64 通道 | 28×28×512 | 同上 | |
| 降采样 | Pool3 | 3×3 最大池化,步长 2,填充 1 | - | 14×14×512 | 组间池化,降低尺寸 |
| Inception 组 3 | Inception 4a | 4 分支并行(通道数调整) 后接辅助分类器 1 | ①128 ②128→256 ③24→64 ④64 通道 辅助分类器:平均池化 + 1×1 卷积 + FC | 14×14×512 | 论文第 4 节 “第三组 Inception 模块” |
| Inception 4b | 4 分支并行(通道数调整) 后接辅助分类器 2 | ①112 ②144→288 ③32→64 ④64 通道 辅助分类器:同上 | 14×14×528 | 同上,辅助分类器缓解梯度消失 | |
| Inception 4c | 4 分支并行(通道数调整) | ①256 ②256→320 ③32→128 ④128 通道 | 14×14×832 | 同上 | |
| 降采样 | Pool4 | 3×3 最大池化,步长 2,填充 1 | - | 7×7×832 | 组间池化,降低尺寸 |
| Inception 组 4 | Inception 5a | 4 分支并行(通道数调整) | ①256 ②320→384 ③32→128 ④128 通道 | 7×7×896 | 论文第 4 节 “第四组 Inception 模块” |
| Inception 5b | 4 分支并行(通道数调整) | ①384 ②384→448 ③48→128 ④128 通道 | 7×7×1088 | 同上 | |
| 全局池化 | GlobalPool | 全局平均池化 | - | 1×1×1024 | 引言中 “全局平均池化替代全连接层” |
| 分类器 | Dropout | 随机丢弃 70% 神经元 | - | 1×1×1024 | 论文第 5 节 “Dropout 层” |
| FC | 全连接层 + Softmax | 1024→1000 通道(ImageNet 类别数) | 1×1×1000 | 论文第 5 节 “线性层 + Softmax” |
环境准备
首先在本地中的某个盘符新建一个文件夹,就叫GoogLeNet吧,作为项目的根目录。
然后新建一个python文件,就叫plot.py吧,往里面写入以下代码,用于下载数据集:
# FashionMNIST里面包含了许多数据集
from click.core import batch
from spacy.cli.train import train
from torchvision.datasets import FashionMNIST
from torchvision import transforms # 处理数据集,归一化
import torch.utils.data as Data
import numpy as np
import matplotlib.pyplot as plt# 下载FashionMMIST数据集
train_data = FashionMNIST(root="./data", # 指定数据集要下载的路径train=True,# 要训练集# 将数据进行归一化操作transform=transforms.Compose([transforms.Resize(size=224), # 调整数据的大小transforms.ToTensor() # 将数据转换为tensor]),download=True # 开启下载
)# 加载数据集集
train_loader = Data.DataLoader(dataset=train_data,# 要加载的数据集batch_size=64 ,# 批量数据大小shuffle=True, # 打乱数据顺序num_workers=0, # 加载数据线程数量
)# 绘制出训练集
for step,(b_x,b_y) in enumerate(train_loader):if step > 0:breakbatch_x = b_x.squeeze().numpy() # 将四维张量移除第一维,将数据转换为numpy格式batch_y = b_y.numpy() # 将张量数据转成numpy格式class_label = train_data.classes # 训练集标签
print("class_label,",class_label)# 绘图
plt.figure(figsize=(12,5))
for ii in np.arange(len(batch_y)):plt.subplot(4,16,ii+1)plt.imshow(batch_x[ii, : , :],cmap=plt.cm.gray)plt.title(class_label[batch_y[ii]],size=10)plt.axis('off')plt.subplots_adjust(wspace=0.05)plt.show()
执行上述代码后,就会开始下载所需要的数据集文件,只不过下载的速度比较慢,然后下载完成,项目的根目录会多出data文件夹,以下是data的目录结构:
--data--FashionMNIST--raw # 该文件夹下就存放数据集文件
模型搭建
创建model.py文件,用于构建模型代码。
import torch
from torch import nn
from torchsummary import summary# 定义一个通用的Inception模块
class Inception(nn.Module):"""in_channels:输入通道数c1:路线1的卷积c2:元组,路线2中有两层卷积c3:元组,路线3中有两层卷积c4:路线4的卷积"""def __init__(self,in_channels,c1,c2,c3,c4):super(Inception,self).__init__()self.ReLU = nn.ReLU() # 定义激活函数 ReLU# 路线1 单1*1卷积层self.p1_1 = nn.Conv2d(in_channels=in_channels,out_channels=c1,kernel_size=1)# 路线2 单1*1卷积层,3*3的卷积self.p2_1 = nn.Conv2d(in_channels=in_channels,out_channels=c2[0],kernel_size=1)self.p2_2 = nn.Conv2d(in_channels=c2[0],out_channels=c2[1],kernel_size=3,padding=1)# 路线3 单1*1卷积层,5*5的卷积self.p3_1 = nn.Conv2d(in_channels=in_channels,out_channels=c3[0],kernel_size=1)self.p3_2 = nn.Conv2d(in_channels=c3[0],out_channels=c3[1],kernel_size=5,padding=2)# 路线4 3*3最大池化,单1*1卷积# stride的默认参数与kernel_size的值一致,而kernel_size的默认值是1self.p4_1 = nn.MaxPool2d(kernel_size=3,padding=1,stride=1)self.p4_2 = nn.Conv2d(in_channels=in_channels,out_channels=c4,kernel_size=1)def forward(self,x):# x为输入大小p1 = self.ReLU(self.p1_1(x)) # 路线1p2 = self.ReLU(self.p2_2(self.ReLU(self.p2_1(x)))) # 路线2p3 = self.ReLU(self.p3_2(self.ReLU(self.p3_1(x)))) # 路线3p4 = self.ReLU(self.p4_2(self.p4_1(x))) # 路线4# 最后进行通道融合 dim=1表示在通道的基础上进行融合return torch.cat((p1,p2,p3,p4),dim=1)# 定义GoogLeNet网络模型
class GoogLeNet(nn.Module):def __init__(self,Inception):super(GoogLeNet,self).__init__()# 定义第一块网络层,相当于封装了部分网络层self.b1 = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3),nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2,padding=1))# 定义第二块网络层self.b2 = nn.Sequential(nn.Conv2d(in_channels=64,out_channels=64,kernel_size=1),nn.ReLU(),nn.Conv2d(in_channels=64,out_channels=192,kernel_size=3,padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2,padding=1))# 定义第三块网络层self.b3 = nn.Sequential(Inception(192,64,(96,128),(16,32),32),Inception(256,128,(128,192),(32,96),64),nn.MaxPool2d(kernel_size=3,stride=2,padding=1))# 定义第四块网络层self.b3 = nn.Sequential(Inception(480,192,(96,208),(16,48),64),Inception(512,160,(112,224),(24,64),64),Inception(512,128,(128,256),(24,64),64),Inception(512,112,(128,288),(32,64),64),Inception(528,256,(160,320),(32,128),128),nn.MaxPool2d(kernel_size=3,stride=2,padding=1))# 定义第五块网络层self.b5 = nn.Sequential(Inception(832,256,(160,320),(32,128),128),Inception(832,384,(192,384),(48,128),128),nn.AdaptiveAvgPool2d((1,1)), # 全局平均池化nn.Flatten(), # 平展层nn.Linear(1024,10) # 全连接层)# 参数初始化 避免模型不收敛for m in self.modules(): # 遍历模型的每一层if isinstance(m,nn.Conv2d): # 如果当前层是卷积层nn.init.kaiming_normal_(m.weight,mode="fan_out",nonlinearity='relu') # 使用凯明初始化方式if m.bias is not None: # 如果偏置b存在nn.init.constant_(m.bias,0) # 将b置为0elif isinstance(m,nn.Linear): # 如果当前层是全连接层nn.init.normal_(m.weight,0,0.01) # 使用正太分布初始化,将权重w置为0,标准差为0.01if m.bias is not None: # 如果参数b存在nn.init.constant_(m.bias,0) # 将b置为0# 定义前向传播def forward(self,x):x = self.b1(x)x = self.b2(x)x = self.b3(x)x = self.b4(x)x = self.b5(x)return x# 定义主函数,进行模型测试(仅测试)
if __name__ == "__main__":device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = GoogLeNet(Inception).to(device)print(summary(model,(1,224,224)))
打个简单的比方,训练网络模型,就好比解方程,为了得到这个方程的极值点,训练的过程就好比是找准一个方向,不断的朝这个方向靠近,使得方程的值不断减小,最终达到极值点,而不收敛,就是,不论你怎么跑,方程的解都不减小。即达不到最后的极值点.在loss上就表现为稳定性的比较大。跟迭代不收敛或者系统不稳定差不多,上下波动不能趋近一个定值。
收敛的意思是指某个值一直在往我们所期望的阈值靠,就拿深度学习中loss损失来做示例,如下一张图是loss在每轮训练时的一个曲线图,可以看到loss一直从一开始的1.8在往1.0降,1.0就是我们期望的阈值,而1.8是最开始loss最大损失值。
模型训练
创建一个model_train.py 文件
import copy
import timeimport torch
from torchvision.datasets import FashionMNIST
from torchvision import transforms
import torch.nn as nn
import torch.utils.data as Data
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltfrom model import GoogLeNet# 处理训练集核数据集
def train_val_data_process():# 加载数据集train_data = FashionMNIST(root="./data",# 数据集所在路径train=True, # 要训练集# 将数据进行归一化操作transform=transforms.Compose([transforms.Resize(size=224), # 修改数据的大小transforms.ToTensor() # 将数据转成Tensor格式]),download=True # 开启加载)# 随机 划分训练集 和 验证集train_data,val_data = Data.random_split(train_data, # 要划分的数据集[round(0.8*len(train_data)), # 划分80%给训练集round(0.2*len(train_data)) # 划分20%给验证集])# 加载训练集数据train_dataloader = Data.DataLoader(dataset=train_data,# 要加载的训练集batch_size=32,# 每轮的训练批次数shuffle=True,# 打乱数据顺序num_workers=2,# 加载数据线程数量)# 加载验证集数据val_dataloader = Data.DataLoader(dataset=val_data,# 要加载的验证集batch_size=32,# 每轮的训练批数shuffle=True,# 打乱数据顺序num_workers=2,# 加载数据集的线程数量)return train_dataloader,val_dataloader# 模型训练
def train_model_process(model,train_dataloader,val_dataloader,num_epochs):# model:需要训练的模型,train_dataloader:训练集数据,val_dataloader:验证集数据,num_epochs:训练轮数# 指定设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 定义优化器optimizer = torch.optim.Adam(model.parameters(),lr=0.001)# 定义交叉熵损失函数criterion = nn.CrossEntropyLoss()# 将模型放入到设备中进行训练model.to(device)# 复制当前模型的参数best_model_wts = copy.deepcopy(model.state_dict())# 初始化参数,记录模型的的精确度和损失值best_acc = 0.0 # 最高精确度train_loss_all = [] # 训练集的总损失train_acc_all = [] # 训练集的总精度val_loss_all = [] # 验证集的总损失val_acc_all = [] # 验证集的总精度since = time.time() # 记录开始训练的时间# 开始训练模型 每轮参数for epoch in range(num_epochs):print("Epoch {}/{}".format(epoch,num_epochs-1))print("-"*10)# 初始化参数,记录本轮的模型的损失之和精度train_loss = 0.0 # 训练的损失train_corrects = 0 # 训练的准确度val_loss = 0.0 # 验证集的损失val_corrents = 0 # 验证集的准确度train_num = 0 # 本轮训练集的数量val_num = 0 # 本轮验证集的数量# 取出每轮中的数据集进行训练for step,(b_x,b_y) in enumerate(train_dataloader):b_x = b_x.to(device) # 将训练集数据放入到设备当中b_y = b_y.to(device) # 将标签数据放入到设备当中model.train() # 开启模型训练模式# 将每批次中的标签数据放入到模型中,进行前向传播output = model(b_x)# 查找每一行中最大值对应的行标,即预测值pre_lab = torch.argmax(output,dim=1)# 计算当前批次的损失值(模型的输出,标签)loss = criterion(output,b_y)# 每批次训练完后,将梯度初始化成0optimizer.zero_grad()# 反向传播计算loss.backward()# 更新参数optimizer.step()# 本批次损失值的累加train_loss += loss.item() * b_x.size(0)# 如果模型预测的结果正确,本批次的准确度+1train_corrects += torch.sum(pre_lab == b_y.data)# 本此次的训练数据累加train_num += b_y.size(0)# 取出每轮中的数据进行验证for step,(b_x,b_y) in enumerate(val_dataloader):# 将数据和标签分别放入到设备中b_x = b_x.to(device)b_y = b_y.to(device)model.eval() # 设置模型为评估模式# 前向传播,输入一个批次,输出该批次的对应的预测值output = model(b_x)# 查找每一行中最大值对应的行标,即预测值pre_lab = torch.argmax(output,dim=1)# 计算本此次的损失函数loss = criterion(output,b_y)# 本批次的损失函数累加val_loss += loss.item() * b_x.size(0)# 如果预测正确,那就本批次的精度度累加val_corrents += torch.sum(pre_lab==b_y.data)# 当前用于验证的样本数累加val_num += b_x.size(0)# 计算每轮次的损失值和准确率train_loss_all.append(train_loss / train_num) # 本轮训练集的loss值train_acc_all.append(train_corrects.double().item() / train_num) # 本轮训练集的准确率val_loss_all.append(val_loss / val_num) # 本轮验证集的loss值val_acc_all.append(val_corrents.double().item() / val_num) # 本轮验证集的准确率print("{} train loss:{:.4f} train acc: {:.4f}".format(epoch, train_loss_all[-1], train_acc_all[-1]))print("{} val loss:{:.4f} val acc: {:.4f}".format(epoch, val_loss_all[-1], val_acc_all[-1]))# 寻找最高准确度 和 模型的权重参数if val_acc_all[-1] > best_acc:best_acc = val_acc_all[-1] # 最高准确度best_model_wts = copy.deepcopy(model.state_dict()) # 最佳模型参数# 计算训练耗时time_use = time.time() - sinceprint("训练耗费的时间:{:.0f}m{:.0f}s".format(time_use//60,time_use%60))# 将最佳的模型参数保存torch.save(best_model_wts,"best_model.pth") # .pth是权重文件的后缀,如果相对路径不行,就改为绝对路径# 保存训练好的模型参数train_process = pd.DataFrame(data={"epoch":range(num_epochs),"train_loss_all":train_loss_all,"train_acc_all":train_acc_all,"val_loss_all":val_loss_all,"val_acc_all":val_acc_all})return train_process# 定义绘图的函数,绘制loss和准确度
def matplot_acc_loss(train_process):plt.figure(figsize=(12,4))# 绘制训练集和验证集的损失值图像plt.subplot(1,2,1) # 一行两列,第一列plt.plot(train_process['epoch'],train_process.train_loss_all,"ro-",label="train loss")plt.plot(train_process['epoch'],train_process.val_acc_all,"bs-",label="val loss")plt.legend() # 图例plt.xlabel("epoch") # x轴标签plt.ylabel("loss") # y轴标签# 绘制训练集和验证集的准确度图像plt.subplot(1,2,2) # 一行两列,第二列plt.plot(train_process['epoch'],train_process.val_loss_all,"ro-",label="train acc")plt.plot(train_process['epoch'],train_process.val_acc_all,"bs-",label="va acc")if __name__ == '__main__':# 实例化自定义模型类model = GoogLeNet()# 加载数据集train_dataloader,val_dataloader = train_val_data_process()# 训练模型train_process = train_model_process(model,train_dataloader,val_dataloader,20)# 绘制图像matplot_acc_loss(train_process)
模型训练完毕后,会生成最佳模型参数文件:
best_model.pth
模型测试
创建一个model_test.py文件,用于模型的测试
import torch
import torch.utils.data as Data
from numpy.random import shuffle
from torchvision import transforms
from torchvision.datasets import FashionMNISTfrom model import GoogLeNet,Inception# 加载要训练的数据
def test_data_process():# 加载测试集数据test_data = FashionMNIST(root="./data",# 指定数据集要下载的路径train=False,# 不要训练集数据# 数据归一化操作transform=transforms.Compose([transforms.Resize(size=224), # 将数据转成224*224大小transforms.ToTensor(),# 将数据转成Tensor格式]),download=True # 加载数据)# 通过DataLoader加载器 来加载数据test_dataloader = Data.DataLoader(dataset=test_data,# 要加载的数据batch_size=1, # 每轮训练的批次数shuffle=True, # 打乱数据集num_workers=0, # 加载数据集的线程数量)return test_dataloader# 测试模型
def test_model_process(model,test_dataloader):# 指定设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 将模型放入设备中model.to(device)# 初始化模型训练的每轮参数test_correct = 0.0 # 准确度test_num = 0 # 测试样本数量# 只进行前向传播with torch.no_grad(): # 将梯度设置为0for test_data_x,test_data_y in enumerate(test_dataloader): # 遍历每轮次# 由于上面设置批次为1,所以这里就不需要循环批次了test_data_x = test_data_x.to(device) # 将测试数据放入到设备中test_data_y = test_data_y.to(device) # 将标签数据放入到设备中# 模型切换成评估模式model.eval()# 前向传播 将测试数据放入到模型中output = model(test_data_x)# 查找每一行中最大值的行标pre_lab = torch.argmax(output,dim=1)# 模型预测的结果 将pre_lab 与 标签数据 进行比较# 如果预测正确,则加1test_correct += torch.sum(pre_lab==test_data_y.data)# 测试样本数量累加test_num += test_data_y.size(0)# 计算最终测试的准确率 每轮的准确度 / 总样本数量test_acc = test_correct.double().item() / test_numprint("测试模型的准确率为:",test_acc)if __name__ == '__main__':# 加载模型model = GoogLeNet(Inception)# 模型具体的训练过程device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载训练好的模型最佳参数model.load_state_dict(torch.load('best_model.pth',map_location=device))# 加载测试的数据集test_dataloader = test_data_process()# 开始测试# test_model_process(model, test_dataloader) # 简略测试# 模型具体的训练过程# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 将模型放入到设备当中model = model.to(device)# 数据的类别classes = ('T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot')# 梯度设置为0with torch.no_grad():# 遍历测试集中的 测试数据 和 标签for b_x,b_y in test_dataloader:# 将数据和标签移动到与模型相同的设备b_x = b_x.to(device)b_y = b_y.to(device)# 将模型设置为评估模式model.eval()# 将数据放入到模型中,得出预测结果output = model(b_x)# 获取最大值的行标pre_lab = torch.argmax(output,dim=1)# 取出张量中的下标result = pre_lab.item()label = b_y.item()print("预测结果为:",classes[result],"标签为:",classes[label])猫狗分类
利用自己的训练集来进行模型训练,实现猫狗分类
环境搭建
将上面刚刚搭建好的GoogLeNet项目,复制一份,就叫GoogLeNet-1吧。
数据集准备和划分
本地已经准备好了data_cat_dog的自定义数据集文件夹,里面均为图片。执行以下脚本,可以实现训练集的数据划分。
data_cat_dog的自定义数据集获取地址禁止私自搬运和商用,后果自负,仅限学习使用
新建一个data_partitioning.py文件,并写入以下代码:
import os
from shutil import copy
import randomdef mkfile(file):if not os.path.exists(file):os.makedirs(file)# 获取data文件夹下所有文件夹名(即需要分类的类名)
file_path = 'data_cat_dog'
flower_class = [cla for cla in os.listdir(file_path)]# 创建 训练集train 文件夹,并由类名在其目录下创建5个子目录
mkfile('data/train')
for cla in flower_class:mkfile('data/train/' + cla)# 创建 验证集val 文件夹,并由类名在其目录下创建子目录
mkfile('data/test')
for cla in flower_class:mkfile('data/test/' + cla)# 划分比例,训练集 : 测试集 = 9 : 1
split_rate = 0.1# 遍历所有类别的全部图像并按比例分成训练集和验证集
for cla in flower_class:cla_path = file_path + '/' + cla + '/' # 某一类别的子目录images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称num = len(images)eval_index = random.sample(images, k=int(num * split_rate)) # 从images列表中随机抽取 k 个图像名称for index, image in enumerate(images):# eval_index 中保存验证集val的图像名称if image in eval_index:image_path = cla_path + imagenew_path = 'data/test/' + clacopy(image_path, new_path) # 将选中的图像复制到新路径# 其余的图像保存在训练集train中else:image_path = cla_path + imagenew_path = 'data/train/' + clacopy(image_path, new_path)print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing barprint()print("processing done!")
执行以上代码,就可以划分猫和狗的训练集和测试集,然后本地项目中会多个以下文件:
--data--test--cat--dog--train--cat--dog
数据集加载
重写model_train.py文件中的部分代码
import copy
import timeimport torch
from torchvision.datasets import ImageFolder # 加载自己的数据集
from torchvision import transforms
import torch.nn as nn
import torch.utils.data as Data
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltfrom model import GoogLeNet# 处理训练集核数据集
def train_val_data_process():# ======(修改的部分开始)=============================ROOT_TRAIN = r'data\train' # 数据集的路径# 定义归一化方法 计算均值和方差 其中的数值来自于下面的数据集归一化部分的mean和variance两个值normalize = transforms.Normalize([0.162,0.151,0.138],[0.058,0.052,0.048])# 定义数据集处理方法变量train_transform = transforms.Compose( # 对数据集进行操作[transforms.Resize((224,224)),# 修改数据集的大小为 224*224transforms.ToTensor(), # 将数据修改为tensor格式normalize # 数据归一化] )# 加载数据集 ImageFolder()为第三方库导入的包train_data = ImageFolder(ROOT_TRAIN, # 读取数据集的路径transform = train_transform # 处理数据的方法)# ======(修改的部分结束)=============================# 随机 划分训练集 和 验证集train_data,val_data = Data.random_split(train_data, # 要划分的数据集[round(0.8*len(train_data)), # 划分80%给训练集round(0.2*len(train_data)) # 划分20%给验证集])# 加载训练集数据train_dataloader = Data.DataLoader(dataset=train_data,# 要加载的训练集batch_size=32,# 每轮的训练批次数shuffle=True,# 打乱数据顺序num_workers=2,# 加载数据线程数量)# 加载验证集数据val_dataloader = Data.DataLoader(dataset=val_data,# 要加载的验证集batch_size=32,# 每轮的训练批数shuffle=True,# 打乱数据顺序num_workers=2,# 加载数据集的线程数量)return train_dataloader,val_dataloader# 模型训练
def train_model_process(model,train_dataloader,val_dataloader,num_epochs):# model:需要训练的模型,train_dataloader:训练集数据,val_dataloader:验证集数据,num_epochs:训练轮数# 指定设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 定义优化器optimizer = torch.optim.Adam(model.parameters(),lr=0.001)# 定义交叉熵损失函数criterion = nn.CrossEntropyLoss()# 将模型放入到设备中进行训练model.to(device)# 复制当前模型的参数best_model_wts = copy.deepcopy(model.state_dict())# 初始化参数,记录模型的的精确度和损失值best_acc = 0.0 # 最高精确度train_loss_all = [] # 训练集的总损失train_acc_all = [] # 训练集的总精度val_loss_all = [] # 验证集的总损失val_acc_all = [] # 验证集的总精度since = time.time() # 记录开始训练的时间# 开始训练模型 每轮参数for epoch in range(num_epochs):print("Epoch {}/{}".format(epoch,num_epochs-1))print("-"*10)# 初始化参数,记录本轮的模型的损失之和精度train_loss = 0.0 # 训练的损失train_corrects = 0 # 训练的准确度val_loss = 0.0 # 验证集的损失val_corrents = 0 # 验证集的准确度train_num = 0 # 本轮训练集的数量val_num = 0 # 本轮验证集的数量# 取出每轮中的数据集进行训练for step,(b_x,b_y) in enumerate(train_dataloader):b_x = b_x.to(device) # 将训练集数据放入到设备当中b_y = b_y.to(device) # 将标签数据放入到设备当中model.train() # 开启模型训练模式# 将每批次中的标签数据放入到模型中,进行前向传播output = model(b_x)# 查找每一行中最大值对应的行标,即预测值pre_lab = torch.argmax(output,dim=1)# 计算当前批次的损失值(模型的输出,标签)loss = criterion(output,b_y)# 每批次训练完后,将梯度初始化成0optimizer.zero_grad()# 反向传播计算loss.backward()# 更新参数optimizer.step()# 本批次损失值的累加train_loss += loss.item() * b_x.size(0)# 如果模型预测的结果正确,本批次的准确度+1train_corrects += torch.sum(pre_lab == b_y.data)# 本此次的训练数据累加train_num += b_y.size(0)# 取出每轮中的数据进行验证for step,(b_x,b_y) in enumerate(val_dataloader):# 将数据和标签分别放入到设备中b_x = b_x.to(device)b_y = b_y.to(device)model.eval() # 设置模型为评估模式# 前向传播,输入一个批次,输出该批次的对应的预测值output = model(b_x)# 查找每一行中最大值对应的行标,即预测值pre_lab = torch.argmax(output,dim=1)# 计算本此次的损失函数loss = criterion(output,b_y)# 本批次的损失函数累加val_loss += loss.item() * b_x.size(0)# 如果预测正确,那就本批次的精度度累加val_corrents += torch.sum(pre_lab==b_y.data)# 当前用于验证的样本数累加val_num += b_x.size(0)# 计算每轮次的损失值和准确率train_loss_all.append(train_loss / train_num) # 本轮训练集的loss值train_acc_all.append(train_corrects.double().item() / train_num) # 本轮训练集的准确率val_loss_all.append(val_loss / val_num) # 本轮验证集的loss值val_acc_all.append(val_corrents.double().item() / val_num) # 本轮验证集的准确率print("{} train loss:{:.4f} train acc: {:.4f}".format(epoch, train_loss_all[-1], train_acc_all[-1]))print("{} val loss:{:.4f} val acc: {:.4f}".format(epoch, val_loss_all[-1], val_acc_all[-1]))# 寻找最高准确度 和 模型的权重参数if val_acc_all[-1] > best_acc:best_acc = val_acc_all[-1] # 最高准确度best_model_wts = copy.deepcopy(model.state_dict()) # 最佳模型参数# 计算训练耗时time_use = time.time() - sinceprint("训练耗费的时间:{:.0f}m{:.0f}s".format(time_use//60,time_use%60))# 将最佳的模型参数保存torch.save(best_model_wts,"best_model.pth") # .pth是权重文件的后缀,如果相对路径不行,就改为绝对路径# 保存训练好的模型参数train_process = pd.DataFrame(data={"epoch":range(num_epochs),"train_loss_all":train_loss_all,"train_acc_all":train_acc_all,"val_loss_all":val_loss_all,"val_acc_all":val_acc_all})return train_process# 定义绘图的函数,绘制loss和准确度
def matplot_acc_loss(train_process):plt.figure(figsize=(12,4))# 绘制训练集和验证集的损失值图像plt.subplot(1,2,1) # 一行两列,第一列plt.plot(train_process['epoch'],train_process.train_loss_all,"ro-",label="train loss")plt.plot(train_process['epoch'],train_process.val_acc_all,"bs-",label="val loss")plt.legend() # 图例plt.xlabel("epoch") # x轴标签plt.ylabel("loss") # y轴标签# 绘制训练集和验证集的准确度图像plt.subplot(1,2,2) # 一行两列,第二列plt.plot(train_process['epoch'],train_process.val_loss_all,"ro-",label="train acc")plt.plot(train_process['epoch'],train_process.val_acc_all,"bs-",label="va acc")if __name__ == '__main__':# 实例化自定义模型类model = GoogLeNet()# 加载数据集train_dataloader,val_dataloader = train_val_data_process()# 训练模型train_process = train_model_process(model,train_dataloader,val_dataloader,20)# 绘制图像matplot_acc_loss(train_process)
数据集归一化
在项目的根目录下创建一个py文件,就叫mean_std.py吧,用于计算均值和方差,使数据归一化,符合正太分布
# mean_std.py文件
from PIL import Image
import os
import numpy as np# 文件夹路径,包含所有图片文件
folder_path = 'data_cat_dog'# 初始化累积变量
total_pixels = 0
sum_normalized_pixel_values = np.zeros(3) # 如果是RGB图像,需要三个通道的均值和方差# 遍历文件夹中的图片文件
for root, dirs, files in os.walk(folder_path):for filename in files:if filename.endswith(('.jpg', '.jpeg', '.png', '.bmp')): # 可根据实际情况添加其他格式image_path = os.path.join(root, filename)image = Image.open(image_path)image_array = np.array(image)# 归一化像素值到0-1之间normalized_image_array = image_array / 255.0# print(image_path)# print(normalized_image_array.shape)# 累积归一化后的像素值和像素数量total_pixels += normalized_image_array.sizesum_normalized_pixel_values += np.sum(normalized_image_array, axis=(0, 1))# 计算均值和方差
mean = sum_normalized_pixel_values / total_pixelssum_squared_diff = np.zeros(3)
for root, dirs, files in os.walk(folder_path):for filename in files:if filename.endswith(('.jpg', '.jpeg', '.png', '.bmp')):image_path = os.path.join(root, filename)image = Image.open(image_path)image_array = np.array(image)# 归一化像素值到0-1之间normalized_image_array = image_array / 255.0# print(normalized_image_array.shape)# print(mean.shape)# print(image_path)try:diff = (normalized_image_array - mean) ** 2sum_squared_diff += np.sum(diff, axis=(0, 1))except:print(f"捕获到自定义异常")# diff = (normalized_image_array - mean) ** 2# sum_squared_diff += np.sum(diff, axis=(0, 1))variance = sum_squared_diff / total_pixelsprint("Mean:", mean)
print("Variance:", variance)运行起来也是需要一定的时间。运行完毕后会得到mean和variance两个值。
模型测试
修改model_test.py文件中的部分代码
import torch
import torch.utils.data as Data
from numpy.random import shuffle
from torchvision import transforms
from torchvision.datasets import FashionMNIST
from torchvision.datasets import ImageFolderfrom model import GoogLeNet,Inception# 加载要训练的数据
def test_data_process():#======================修改的部分开始======================ROOT_TRAIN = r'data\train' # 数据集的路径# 定义归一化方法 计算均值和方差normalize = transforms.Normalize([0.162,0.151,0.138],[0.058,0.052,0.048])# 定义数据集处理方法变量test_transform = transforms.Compose( # 对数据集进行操作[transforms.Resize((224,224)),# 修改数据集的大小为 224*224transforms.ToTensor(), # 将数据修改为tensor格式normalize # 数据归一化] )# 加载数据集 ImageFolder()为第三方库导入的包test_data = ImageFolder(ROOT_TRAIN, # 读取数据集的路径transform = test_transform # 处理数据的方法)#======================修改的部分结束======================# 通过DataLoader加载器 来加载数据test_dataloader = Data.DataLoader(dataset=test_data,# 要加载的数据batch_size=1, # 每轮训练的批次数shuffle=True, # 打乱数据集num_workers=0, # 加载数据集的线程数量)return test_dataloader# 测试模型
def test_model_process(model,test_dataloader):# 指定设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 将模型放入设备中model.to(device)# 初始化模型训练的每轮参数test_correct = 0.0 # 准确度test_num = 0 # 测试样本数量# 只进行前向传播with torch.no_grad(): # 将梯度设置为0for test_data_x,test_data_y in enumerate(test_dataloader): # 遍历每轮次# 由于上面设置批次为1,所以这里就不需要循环批次了test_data_x = test_data_x.to(device) # 将测试数据放入到设备中test_data_y = test_data_y.to(device) # 将标签数据放入到设备中# 模型切换成评估模式model.eval()# 前向传播 将测试数据放入到模型中output = model(test_data_x)# 查找每一行中最大值的行标pre_lab = torch.argmax(output,dim=1)# 模型预测的结果 将pre_lab 与 标签数据 进行比较# 如果预测正确,则加1test_correct += torch.sum(pre_lab==test_data_y.data)# 测试样本数量累加test_num += test_data_y.size(0)# 计算最终测试的准确率 每轮的准确度 / 总样本数量test_acc = test_correct.double().item() / test_numprint("测试模型的准确率为:",test_acc)if __name__ == '__main__':# 加载模型model = GoogLeNet(Inception)# 模型具体的训练过程device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载训练好的模型最佳参数model.load_state_dict(torch.load('best_model.pth',map_location=device))# 加载测试的数据集test_dataloader = test_data_process()# 开始测试# test_model_process(model, test_dataloader) # 简略测试# 模型具体的训练过程# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 将模型放入到设备当中model = model.to(device)# 数据的类别classes = ['猫','狗']# 梯度设置为0with torch.no_grad():# 遍历测试集中的 测试数据 和 标签for b_x,b_y in test_dataloader:# 将数据和标签移动到与模型相同的设备b_x = b_x.to(device)b_y = b_y.to(device)# 将模型设置为评估模式model.eval()# 将数据放入到模型中,得出预测结果output = model(b_x)# 获取最大值的行标pre_lab = torch.argmax(output,dim=1)# 取出张量中的下标result = pre_lab.item()label = b_y.item()print("预测结果为:",classes[result],"标签为:",classes[label])模型的推理
随便从网上下载猫或者狗的图像到项目的根目录下,这里就下载猫的图片吧:

图片名就设置为: 7dd98d1001e939010b1f0c1e537c22e836d19614.jpeg
然后增加和修改model_test.py文件中的代码:
import torch
import torch.utils.data as Data
from numpy.random import shuffle
from torchvision import transforms
from torchvision.datasets import FashionMNIST
from torchvision.datasets import ImageFolder
from PIL import Image # 导入第三方库 增加代码from model import GoogLeNet,Inception# 加载要训练的数据
def test_data_process():#======================修改的部分开始======================ROOT_TRAIN = r'data\train' # 数据集的路径# 定义归一化方法 计算均值和方差normalize = transforms.Normalize([0.162,0.151,0.138],[0.058,0.052,0.048])# 定义数据集处理方法变量test_transform = transforms.Compose( # 对数据集进行操作[transforms.Resize((224,224)),# 修改数据集的大小为 224*224transforms.ToTensor(), # 将数据修改为tensor格式normalize # 数据归一化] )# 加载数据集 ImageFolder()为第三方库导入的包test_data = ImageFolder(ROOT_TRAIN, # 读取数据集的路径transform = test_transform # 处理数据的方法)#======================修改的部分结束======================# 通过DataLoader加载器 来加载数据test_dataloader = Data.DataLoader(dataset=test_data,# 要加载的数据batch_size=1, # 每轮训练的批次数shuffle=True, # 打乱数据集num_workers=0, # 加载数据集的线程数量)return test_dataloader# 测试模型
def test_model_process(model,test_dataloader):# 指定设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 将模型放入设备中model.to(device)# 初始化模型训练的每轮参数test_correct = 0.0 # 准确度test_num = 0 # 测试样本数量# 只进行前向传播with torch.no_grad(): # 将梯度设置为0for test_data_x,test_data_y in enumerate(test_dataloader): # 遍历每轮次# 由于上面设置批次为1,所以这里就不需要循环批次了test_data_x = test_data_x.to(device) # 将测试数据放入到设备中test_data_y = test_data_y.to(device) # 将标签数据放入到设备中# 模型切换成评估模式model.eval()# 前向传播 将测试数据放入到模型中output = model(test_data_x)# 查找每一行中最大值的行标pre_lab = torch.argmax(output,dim=1)# 模型预测的结果 将pre_lab 与 标签数据 进行比较# 如果预测正确,则加1test_correct += torch.sum(pre_lab==test_data_y.data)# 测试样本数量累加test_num += test_data_y.size(0)# 计算最终测试的准确率 每轮的准确度 / 总样本数量test_acc = test_correct.double().item() / test_numprint("测试模型的准确率为:",test_acc)if __name__ == '__main__':# 加载模型model = GoogLeNet(Inception)# 指定设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载训练好的模型最佳参数model.load_state_dict(torch.load('best_model.pth',map_location=device))# 加载测试的数据集# test_dataloader = test_data_process()# 开始测试# test_model_process(model, test_dataloader) # 简略测试# 指定设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 将模型放入到设备当中model = model.to(device)# 数据的类别classes = ['猫','狗']# =================新增代码部分开始,到底直接结束=================# 读取刚刚下载到本地猫的图片cat_url = "7dd98d1001e939010b1f0c1e537c22e836d19614.jpeg"image = Image.open(url) # 要预测图片的路径# 定义归一化方法 计算均值和方差normalize = transforms.Normalize([0.162,0.151,0.138],[0.058,0.052,0.048])# 定义数据集处理方法变量test_transform = transforms.Compose( # 对数据集进行操作[transforms.Resize((224,224)),# 修改数据集的大小为 224*224transforms.ToTensor(), # 将数据修改为tensor格式normalize # 数据归一化] )# 对下载的图片进行格式处理 转成torch类型数据image = test_transform(image)# print(image.shape) # torch.Size([3,224,224]) 打印处理后的图片的维度# 添加批次维度 1image = unsqueeze(0)# print(image.shape) # torch.Size([1,3,224,224]) 打印处理后的图片的维度,其中1表示批次,是由unsqueeze(0)得来的# 去除梯度下降with torch.no_grad():model.eval() # 开启验证模式image = image.to(device) # 将图片放入到设备当中output = model(image) # 将图片放入到模型当中pre_lab = torch.argmax(out_put,dim=1) # 标签result = pre_lab.item()# print(pre_lab) # tensor([0],device='cude:0')# print(result) # 0 表示猫print("预测值: ",classes[result])
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
# 将模型放入到设备当中
model = model.to(device)# 数据的类别
classes = ['猫','狗']# =================新增代码部分开始,到底直接结束=================
# 读取刚刚下载到本地猫的图片
cat_url = "7dd98d1001e939010b1f0c1e537c22e836d19614.jpeg"
image = Image.open(url) # 要预测图片的路径# 定义归一化方法 计算均值和方差
normalize = transforms.Normalize([0.162,0.151,0.138],[0.058,0.052,0.048])# 定义数据集处理方法变量
test_transform = transforms.Compose( # 对数据集进行操作[transforms.Resize((224,224)),# 修改数据集的大小为 224*224transforms.ToTensor(), # 将数据修改为tensor格式normalize # 数据归一化]
)# 对下载的图片进行格式处理 转成torch类型数据
image = test_transform(image)
# print(image.shape) # torch.Size([3,224,224]) 打印处理后的图片的维度# 添加批次维度 1
image = unsqueeze(0)
# print(image.shape) # torch.Size([1,3,224,224]) 打印处理后的图片的维度,其中1表示批次,是由unsqueeze(0)得来的# 去除梯度下降
with torch.no_grad():model.eval() # 开启验证模式image = image.to(device) # 将图片放入到设备当中output = model(image) # 将图片放入到模型当中pre_lab = torch.argmax(out_put,dim=1) # 标签result = pre_lab.item()
# print(pre_lab) # tensor([0],device='cude:0')
# print(result) # 0 表示猫
print("预测值: ",classes[result])
相关文章:
GoogLeNet网络模型
GoogLeNet网络模型 诞生背景 在2014年的ImageNet图像识别挑战赛中,一个GoogLeNet的网络架构大放异彩,与VGG不同的是,VGG用的是3*3的卷积,而GoogLeNet从1*1到7*7的卷积核都用,也就是使用不同大小的卷积核组合。 网络…...
)
LeetCode Hot100 (贪心)
121. 买卖股票的最佳时机 题意 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从…...

仿真科普|弥合市场需求断层,高性能仿真,“性能”与“安全”如何兼得?
2025年3月,塔塔科技(Tata Technologies)确认曾在去年遭受勒索软件组织“猎手国际”(Hunters International)的攻击,1.4TB工程数据被窃取,涉及航空发动机热障涂层工艺参数等超过 73 万份文件。 X…...

工业控制核心引擎高性能MCU——MM32F5370
RAMSUN提供的MM32F5370搭载180MHz Arm China Star-MC1处理器,集成DSP、FPU与三角函数加速单元(CORDIC),轻松应对复杂算法需求。其技术亮点包括: 超高精度PWM:8通道208ps级高精度PWM输出,满足储能…...
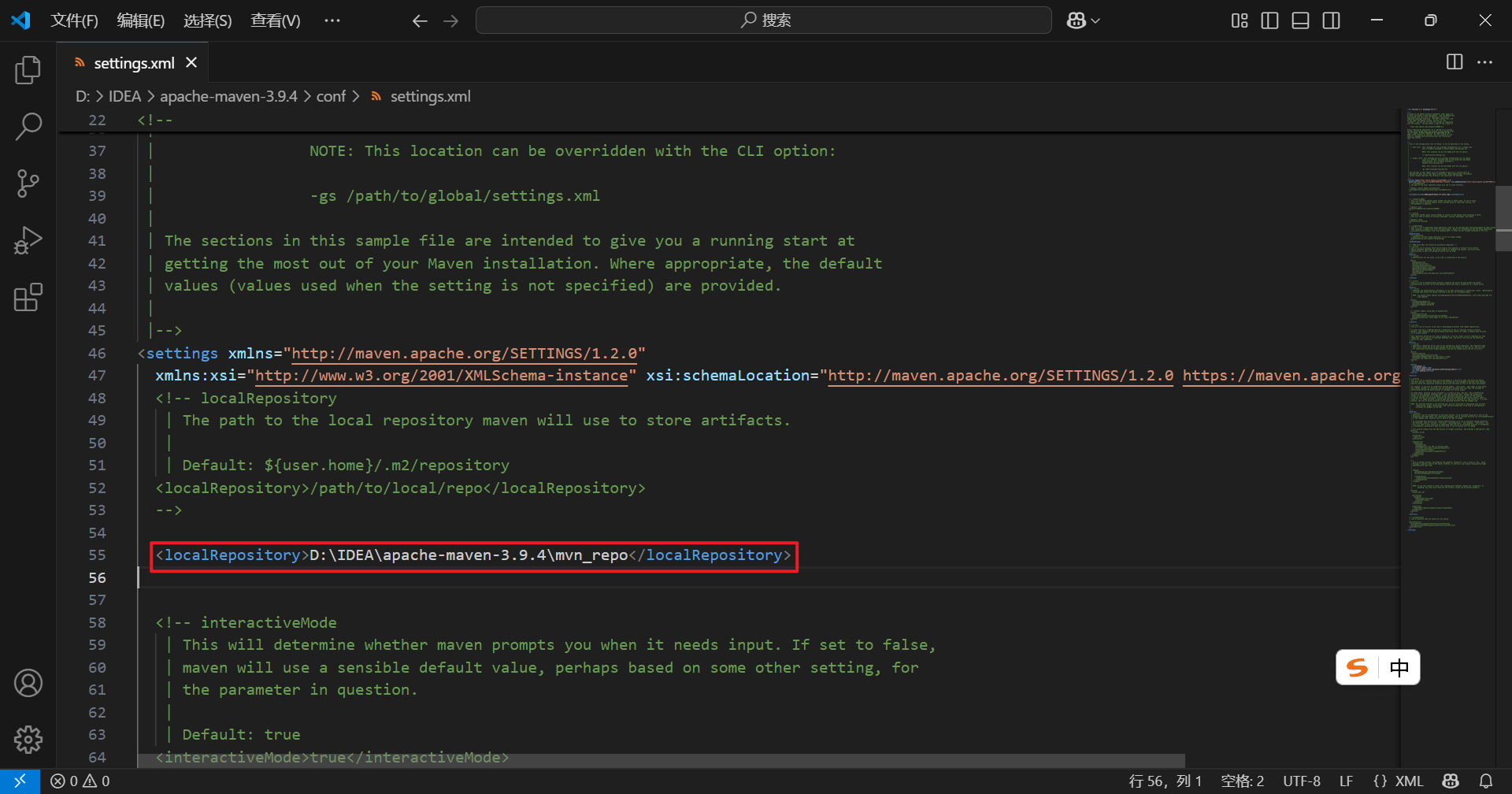
Maven---配置本地仓库
目录 5. 5.1在Maven路径下新建文件夹用于本地仓库存储 5.2 复制本地仓库路径 5.3 找到配置文件路径,使用VSCode方式打开 5.4 新增一行代码 5.5 复制本地仓库路径,设置存储路径 5.1在Maven路径下新建文件夹用于本地仓库存储 5.2 复制本地仓库路径 5…...

vue中events选项与$on监听自定义事件他们的区别与不同,以及$emit与$on之间通信和mounted生命周期钩子函数有哪些作用和属性
events 选项确实曾经被用于监听事件,但它主要用于早期版本的 Vue.js(1.x)中,用于组件之间的通信。在 Vue 2.x 中,events 选项已经被废弃,取而代之的是更强大的 $emit 和 $on 方法。 使用$emit来监听自定义…...

【C++ 】智能指针:内存管理的 “自动导航仪”
目录 一、引入 二、智能指针的两大特性: 1、RAII 特点: 好处: 2、行为像指针 三、智能指针起初的缺陷:拷贝问题 四、几种智能指针的介绍。 1、C98出现的智能指针——auto_ptr auto_ptr解决上述拷贝构造的问题:…...
设备制造行业项目管理难点解析,如何有效解决?
在设备制造行业,项目管理是企业运营的核心环节,直接影响项目交付效率、成本控制和盈利能力。然而,由于行业特性复杂、项目周期长、涉及部门多,企业在实际操作中常常面临诸多管理痛点。金众诚工程项目管理系统,依托金蝶…...

浅谈 PAM-2 到 PAM-4 的信令技术演变
通信信令技术演进:从 PAM-2 到 PAM-4 在当今数字化高速发展的时代,数据传输需求呈爆炸式增长,行业对通信带宽的要求愈发严苛。为顺应这一趋势,通信信令技术不断革新,曾经占据主导地位的不归零(NRZÿ…...
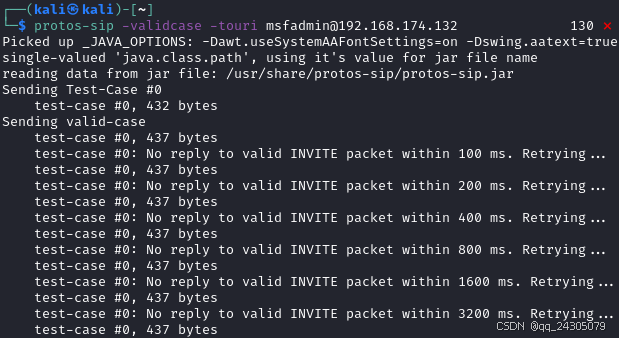
Protos-SIP:经典 SIP 协议模糊测试工具!全参数详细教程!Kali Linux教程!
简介 该测试套件的目的是评估会话发起协议 (SIP) 实现的实现级别安全性和稳健性。 Protos-SIP 是一款专为 SIP 协议模糊测试(Fuzzing)设计的工具,最初由 OUSPG(Oulu University Secure Programming Group)开发&#…...
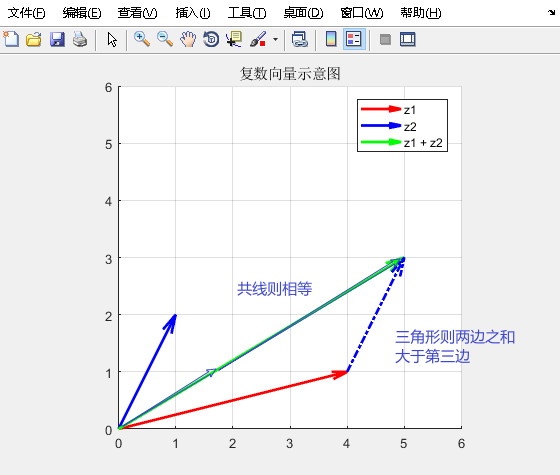
复数三角不等式简介及 MATLAB 演示
复数三角不等式简介及 MATLAB 演示 1. 复数三角不等式简介 复数三角不等式(Complex Triangle Inequality)是复数的一种重要性质,它类似于普通的三角不等式,但适用于复数空间。具体来说,复数三角不等式可以描述复数之…...
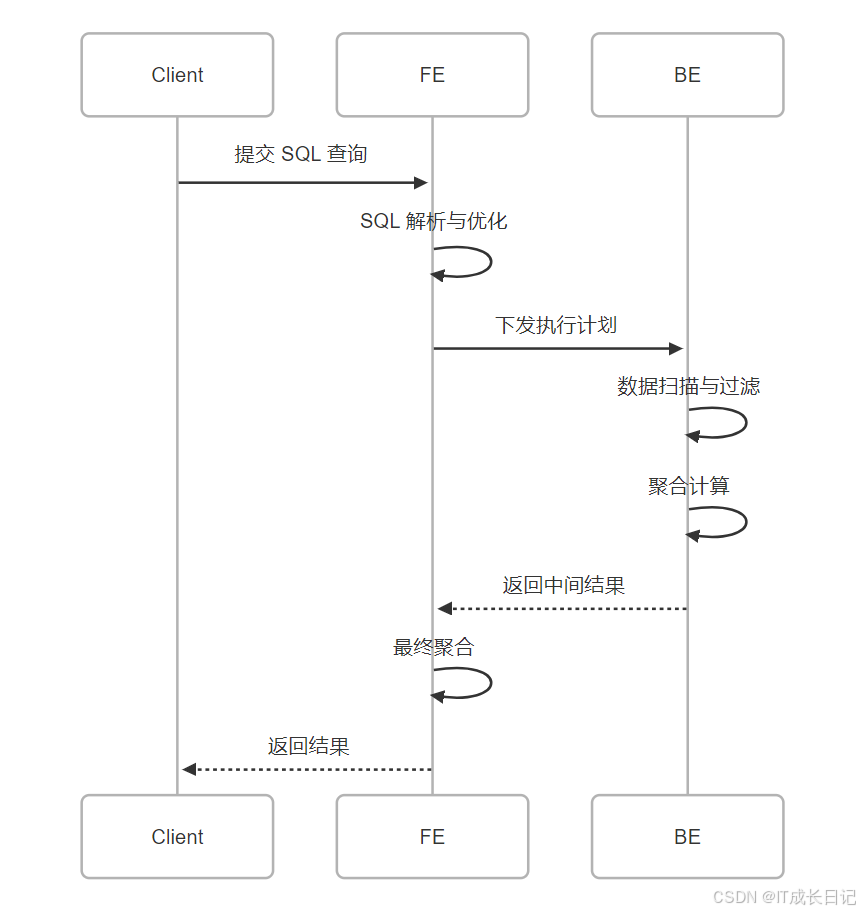
【Doris基础】Apache Doris 基本架构深度解析:从存储到查询的完整技术演进
目录 1 引言 2 Doris 架构全景图 2 核心组件技术解析 2.1 Frontend 层(FE) 2.2 Backend 层(BE) 3 数据存储与复制机制 3.1 存储架构演进 3.2 副本复制策略 4 查询处理全流程解析 4.1 查询生命周期 5 高可用设计 5.1 F…...
程序人生-hellohelloo
计算机系统 大作业 题 目 程序人生-Hello’s P2P 专 业 计算机与电子通信 学 号 2023111976 班 级 23L0504 学 生 孙恩旗 指 导 教 师 刘宏伟 计算机科…...
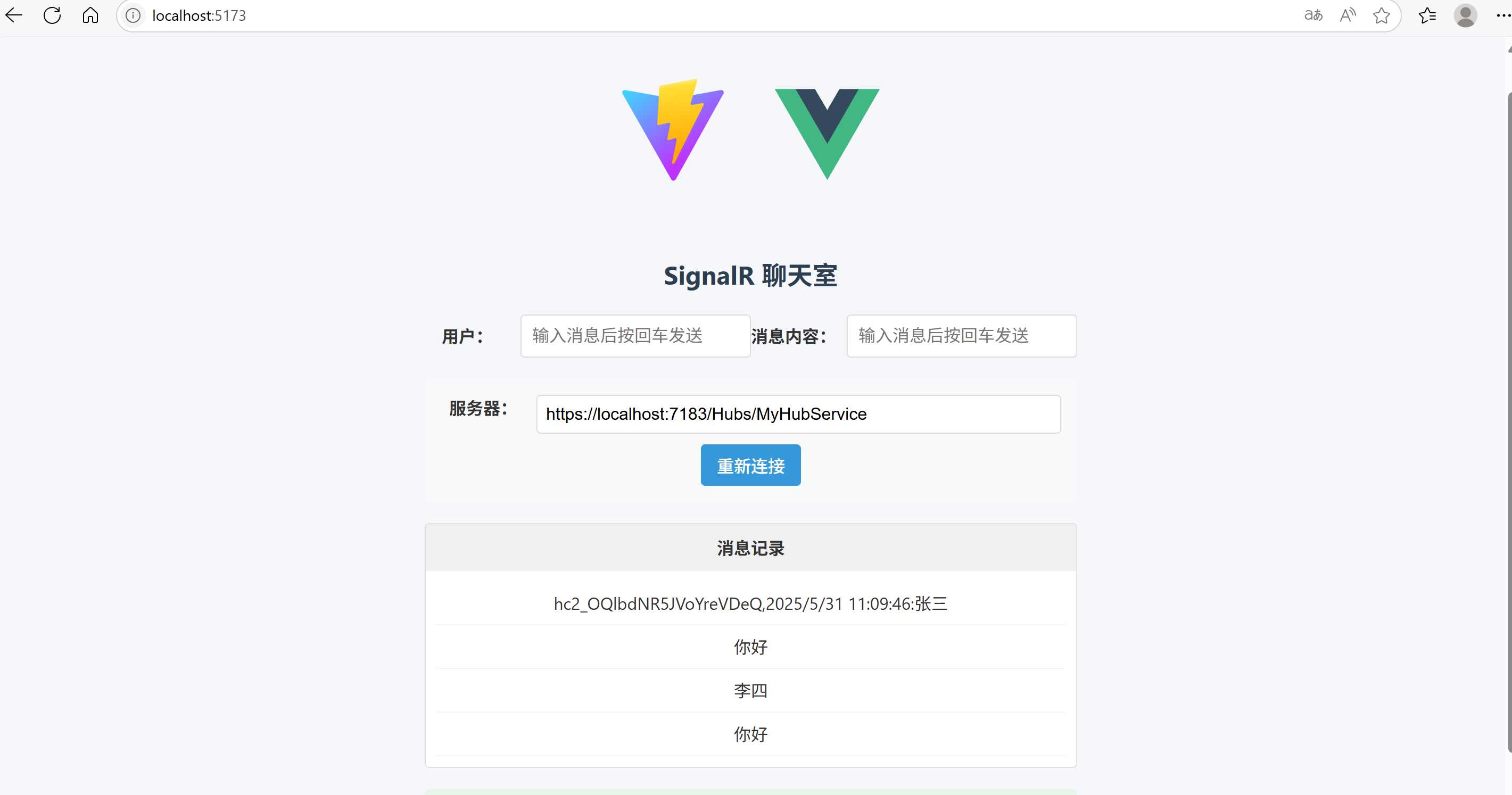
ASP.NET Core SignalR的基本使用
文章目录 前言一、SignalR是什么?在 ASP.NET Core 中的关键特性:SignalR 工作原理简图: 二、使用步骤1.创建ASP.NET Core web Api 项目2.添加 SignalR 包3.创建 SignalR Hub4.配置服务与中间件5.创建控制器(模拟服务器向客户端发送消息)6.创建…...
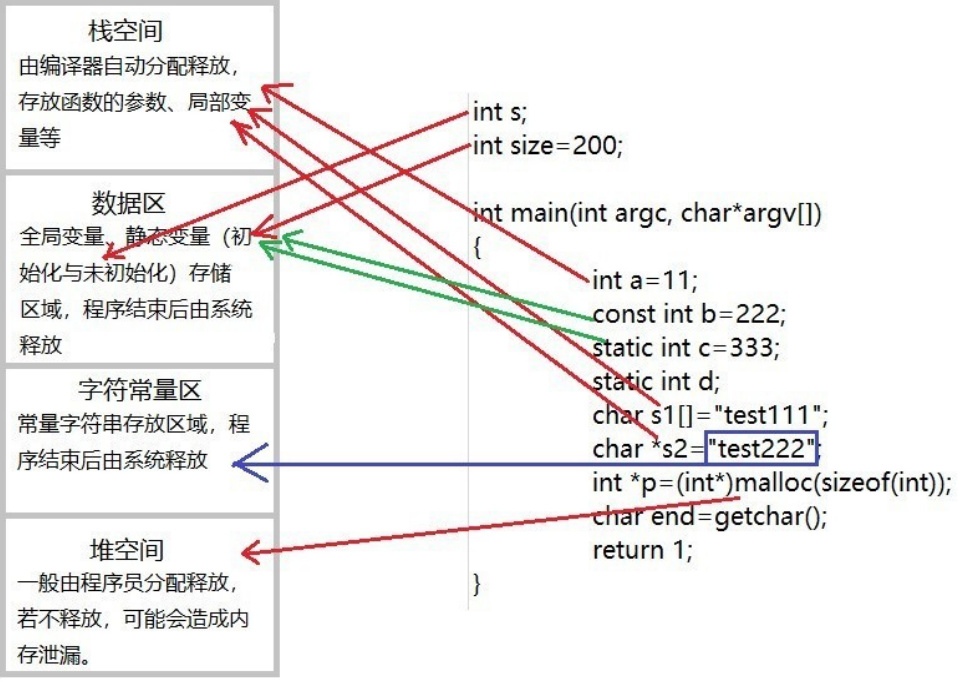
【C语言】讲解 程序分配的区域(新手)
目录 代码区 数据区 堆区 栈区 常量区 重点比较一下堆区与 栈区 总结: 前言: C语言程序的内存分配区域是理解其运行机制的重要部分。根据提供的多条证据,我们可以总结出C语言程序在运行时主要涉及以下五个关键内存区域: 代…...

【脚本 完全参数化的通用 APT 源配置方案-Debian/Ubuntu】
通过脚本在 Debian/Ubuntu 系统上一键切换 APT 源 如Dockerfile中 使用某个源(比如 aliyun) 假设你的目录结构是: . ├── Dockerfile └── switch-apt-source.shFROM ubuntu:22.04# 把脚本拷贝到镜像中 COPY switch-apt-source.sh /us…...

数据集笔记:SeekWorld
提出了一项新任务:地理定位推理(Geolocation Reasoning) 该任务要求模型在感知视觉信息的同时,推理出图像中视觉语义所隐含的高级逻辑关系,从而确定图像的拍摄地点 TheEighthDay/SeekWorld at main 构建了一个基于规则…...

LeetCode 算 法 实 战 - - - 移 除 链 表 元 素、反 转 链 表
LeetCode 算 法 实 战 - - - 移 除 链 表 元 素、反 转 链 表 第 一 题 - - - 移 除 链 表 元 素方 法 一 - - - 原 地 删 除方 法 二 - - - 双 指 针方 法 三 - - - 尾 插 第 二 题 - - - 反 转 链 表方 法 一 - - - 迭 代方 法 二 - - - 采 用 头 插 创 建 新 链 表 总 结 &a…...
:pipeline构建历史展示包名和各阶段间传递参数)
Jenkins实践(10):pipeline构建历史展示包名和各阶段间传递参数
Jenkins实践(10):构建历史展示包名和pipeline各阶段间传递参数 1、构建历史展示包名 参考:https://blog.csdn.net/fen_fen/article/details/148167868 1.1、方法说明 Jenkins版本:Jenkins2.452 通过修改 currentBuild.displayName 和 currentBuild.description 实现: …...
从头认识AI-----循环神经网络(RNN)
前言 前面我们讲了传统的神经网络,如MLP、CNN,这些网络中的输入都被单独处理,没有上下文之间的信息传递机制,这在处理序列数据(如语音、文本、时间序列)时很鸡肋: 如何理解一句话中“前后文”的…...

配置远程无密登陆ubuntu服务器时无法连接问题排查
配置远程无密登陆ubuntu服务器时无法连接问题排查 登陆端排查服务器端登陆排查 登陆端排查 ssh -v 用户名Ubuntu服务器IP可能日志输出 debug1: Authentications that can continue: publickey,password服务器端登陆排查 sudo tail -f /var/log/auth.log可能日志输出 Authen…...

5.31 数学复习笔记 22
前面的笔记,全部写成一段,有点难以阅读。现在改进一下排版。另外,写笔记实际上就是图一个放松呢,关键还是在于练习。 目前的计划是,把讲义上面的高数例题搞清楚之后,大量刷练习册上面的题。感觉不做几本练…...

kafka学习笔记(三、消费者Consumer使用教程——使用实例及及核心流程源码讲解)
1.核心概念与架构 1.1.消费者与消费者组 Kafka消费者是订阅主题(Topic)并拉取消息的客户端实例,其核心逻辑通过KafkaConsumer类实现。消费者组(Consumer Group)是由多个逻辑关联的消费者组成的集合。 核心规则 同一…...

鸿蒙 Form Kit(卡片开发服务)
Form Kit(卡片开发服务) 鸿蒙应用中,Form / Card / Widget 都翻译为“卡片” Form Kit(卡片开发服务)提供一种界面展示形式,可以将应用的重要信息或操作前置到服务卡片,以达到服务直达、减少跳转…...
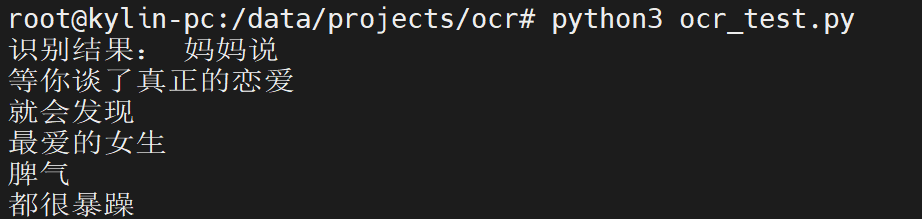
算力卡上部署OCR文本识别服务与测试
使用modelscope上的图像文本行检测和文本识别模型进行本地部署并转为API服务。 本地部署时把代码中的检测和识别模型路径改为本地模型的路径。 关于模型和代码原理可以参见modelscope上这两个模型相关的页面: iic/cv_resnet18_ocr-detection-db-line-level_damo iic…...
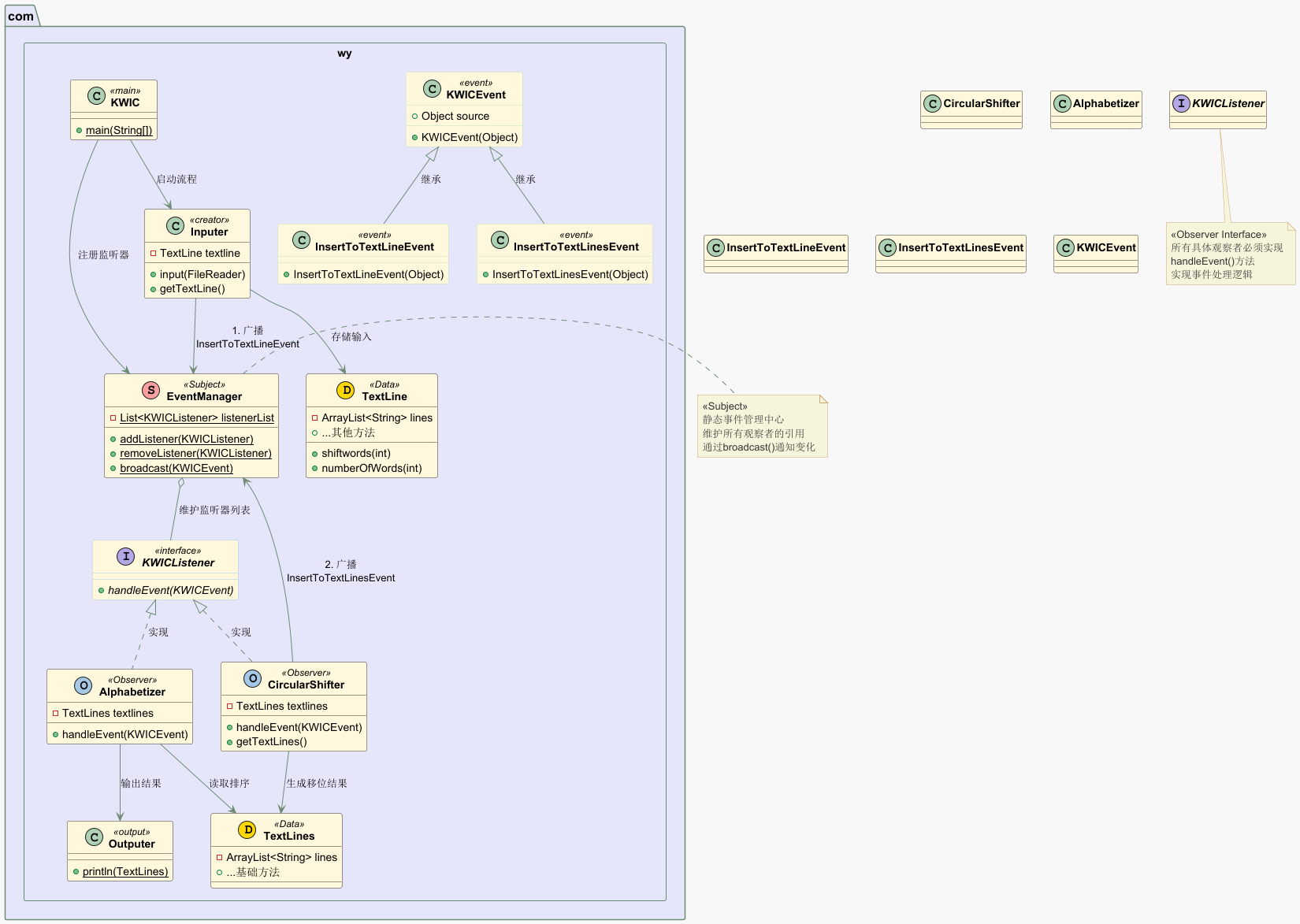
KWIC—Implicit Invocation
KWIC—Implicit Invocation ✏️ KWIC—Implicit Invocation 文章目录 KWIC—Implicit Invocation📝KWIC—Implicit Invocation🧩KWIC🧩核心组件🧩ImplementationScheme⚖️ 隐式调用 vs 显式调用对比 🌟 总结 &#x…...
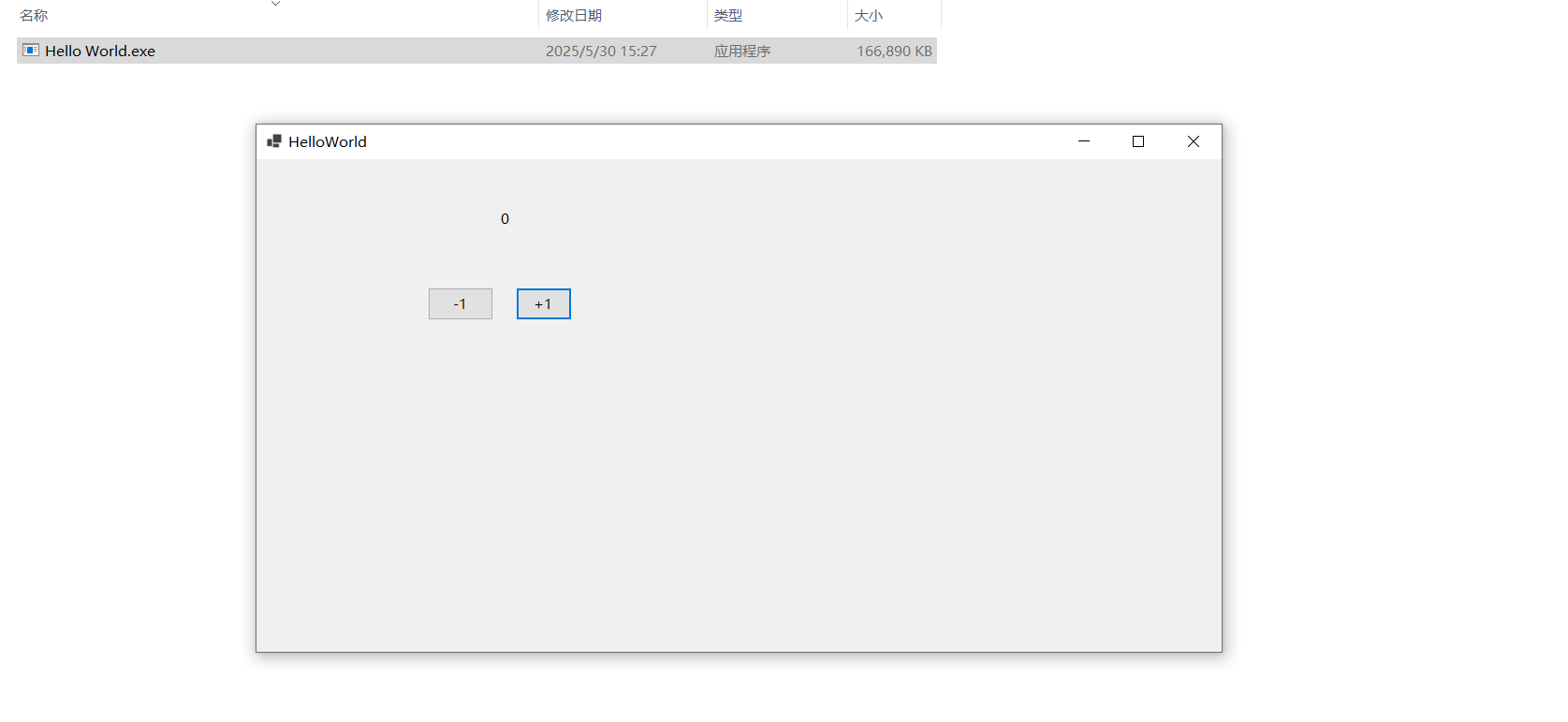
Visual Studio 2022 发布独立的 exe 文件
我们在用 Visual Studio 2022 写好一个 exe 程序之后,如果想把这个拿到其他地方运行,需要把 exe 所在的文件夹一起拿过去。 编译出来的 exe 文件需要其他几个文件一同放在同一目录才能运行,原因在于默认情况下,Visual Studio 是把…...
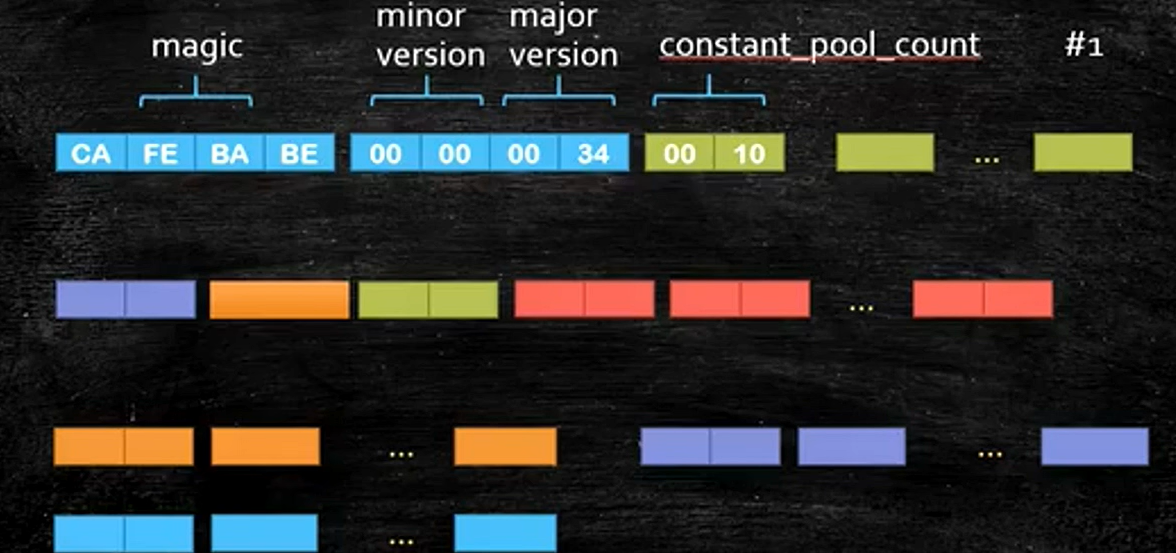
11.4java语言执行浅析4
编译成字节码(.class 文件) 使用 javac 命令将源代码编译为 Java 字节码(bytecode) 它不是机器码,而是 JVM 能理解的中间语言(字节码),具有平台无关性。 编译过程简要࿱…...

Excel 操作 转图片,转pdf等
方式一 spire.xls.free(没找设置分辨率的方法) macOs开发Java GUI程序提示缺少字体问题解决 Spire.XLS:一款Excel处理神器_spire.xls免费版和收费版的区别-CSDN博客 官方文档 Spire.XLS for Java 中文教程 <dependency><groupI…...

说说 Kotlin 中的 Any 与 Java 中的 Object 有何异同?
在 Kotlin 中 Any 类型和 Java 中的 Object 类都是所有类型的根类型。 1 基本定义 Kotlin 中的 Any 和 Any?: Any:是所有非空类型的根类型;Any?:是所有可空类型的根类型; Java 中的 Object: 是所有类…...