kafka学习笔记(三、消费者Consumer使用教程——使用实例及及核心流程源码讲解)

1.核心概念与架构
1.1.消费者与消费者组
Kafka消费者是订阅主题(Topic)并拉取消息的客户端实例,其核心逻辑通过KafkaConsumer类实现。消费者组(Consumer Group)是由多个逻辑关联的消费者组成的集合。
- 核心规则
-
同一分区独占性: 一个分区(
Partition)只能被同一消费者组内的一个消费者消费,但不同消费者组可同时消费同一分区,实现广播模式。 -
负载均衡与容错: 通过动态分区分配(
Rebalance)实现消费者增减时的负载均衡,支持水平扩展和容错恢复。
- 消息投递模式
-
点对点模式: 所有消费者属于同一组,消息被均匀分配给组内消费者,每条消息仅被消费一次。
-
发布/订阅模式: 消费者属于不同组,消息广播到所有组,每个组独立消费全量数据。
消费者与消费者组的这种模式可以让整体的消费能力具备横向伸缩性,可以增加或减少消费者的个数来提高或降低整体的消费能力。注:消费者个数不能大于分区数。
1.2.核心类与组件
| 类名 | 作用 |
|---|---|
KafkaConsumer | 消费者入口类,封装所有消费逻辑(线程不安全,需单线程操作) |
ConsumerNetworkClient | 网络通信层,管理与 Broker 的 TCP 连接和请求发送/接收 |
Fetcher | 消息拉取核心逻辑,处理消息批次、反序列化、异常重试 |
SubscriptionState | 维护订阅状态(主题、分区分配、消费偏移量等) |
ConsumerCoordinator | 消费者协调器,负责消费者组管理、心跳发送、分区再平衡(Rebalance) |
Deserializer | 反序列化器接口,将字节数组转换为 Java 对象 |
2.基础消费者示例
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class BasicKafkaConsumer {public static void main(String[] args) {// 1. 配置消费者属性Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group"); // 消费者组IDprops.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); // 当无提交offset时,从最早的消息开始props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); // 自动提交偏移量props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); // 每秒自动提交// 2. 创建消费者实例try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {// 3. 订阅主题(支持多个主题和正则表达式)consumer.subscribe(Collections.singletonList("test-topic"));// 4. 持续拉取消息while (true) {// poll()参数为等待时间(毫秒),返回消息集合ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理消息System.out.printf("Received message: topic=%s, partition=%d, offset=%d, key=%s, value=%s%n",record.topic(),record.partition(),record.offset(),record.key(),record.value());}}}}
}
3.源码及核心功能解析
3.1.订阅主题和分区
3.1.1. 订阅主题
在上面#2中的代码实例中的注释2中,使用subscribe()方法订阅了一个主题。消费者通过 subscribe() 方法订阅一个或多个主题,Kafka会自动将主题的分区分配给消费者组内的各个消费者。这是最常见的消费方式,适用于动态分区分配场景。
核心特点:
- 自动负载均衡: 消费者组内的消费者会分摊主题的分区(例如:3个分区被2个消费者分配为2+1)。
- 支持分区再平衡(Rebalance): 当消费者加入或离开组时,Kafka会自动重新分配分区。
- 依赖消费者组(Group ID): 通过
group.id标识消费者组,同一组的消费者共享分区。
代码实例:
// 订阅单个主题
consumer.subscribe(Collections.singletonList("test-topic"));// 订阅多个主题
consumer.subscribe(Arrays.asList("topic1", "topic2"));// 使用正则表达式订阅(匹配所有以 "logs-" 开头的主题)
consumer.subscribe(Pattern.compile("logs-.*"));
适用场景:
- 需要动态扩展消费者数量(水平扩展)。
- 分区数量固定或动态变化时(如新增分区)。
- 消费者需要自动故障恢复(如某个消费者宕机,其他消费者接管分区)。
分区分配策略:
通过 partition.assignment.strategy 配置:
-
RangeAssignor(默认): 按范围分配分区(可能导致不均衡)。
-
RoundRobinAssignor: 轮询分配分区(更均衡)。
-
StickyAssignor: 尽量保持分配粘性,减少Rebalance时的分区变动。
3.1.2.直接订阅分区
消费者通过 assign() 方法直接指定要消费的分区,绕过消费者组管理,需手动管理分区偏移量。
核心特点:
- 无消费者组协调: 不依赖 group.id,消费者独立运行。
- 完全手动控制: 需自行指定分区和起始偏移量。
- 不支持自动再平衡: 分区增减或消费者故障时需手动处理。
代码示例:
// 分配指定主题的特定分区
TopicPartition partition0 = new TopicPartition("test-topic", 0);
TopicPartition partition1 = new TopicPartition("test-topic", 1);
consumer.assign(Arrays.asList(partition0, partition1));// 指定从某个offset开始消费
consumer.seek(partition0, 100); // 从offset=100开始
consumer.seekToBeginning(Collections.singleton(partition1)); // 从最早开始
consumer.seekToEnd(Collections.singleton(partition1)); // 从最新开始
适用场景:
- 需要精确控制消费特定分区(如按业务逻辑分区)。
- 消费者组管理不适用时(如单消费者消费所有分区)。
- 测试或调试场景下手动控制消费位置。
3.1.3.取消订阅
适用KafkaConsumer中的unsubscribe()方法来取消主题和分区的订阅。
代码实例:
consumer.unsubscribe()
如果将
subscribe(Collection)或assign(Collection)中的集合参数设置为空集合,那么作用与unsubscribe()等同。
3.2.消息拉取
poll() 方法是消息消费的核心入口,其内部实现涉及 网络通信、消息批量拉取 、分区状态管理 、反序列化 、位移提交 等多个关键步骤。以下从源码层面逐层解析 poll() 方法的完整流程:
3.2.1.poll()方法源码解析
// KafkaConsumer.poll() 方法定义
public ConsumerRecords<K, V> poll(Duration timeout) {// 1. 检查线程安全性(确保单线程调用)acquireAndEnsureOpen();try {// 2. 记录开始时间(用于超时控制)long startMs = time.milliseconds();long remainingMs = timeout.toMillis();// 3. 主循环:处理消息拉取、心跳、Rebalance 等do {// 3.1 发送心跳(维持消费者组活性)coordinator.poll(timeRemaining(remainingMs, startMs));// 3.2 拉取消息(核心逻辑在 Fetcher 中)Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();if (!records.isEmpty()) {// 3.3 返回拉取到的消息(退出循环)return new ConsumerRecords<>(records);}// 3.4 计算剩余等待时间remainingMs = timeRemaining(remainingMs, startMs);} while (remainingMs > 0);return ConsumerRecords.empty();} finally {release();}
}
3.2.2.核心子流程解析
-
发送心跳(
coordinator.poll())
消费者通过ConsumerCoordinator维持与GroupCoordinator的心跳,确保消费者组活性。关键源码路径:
ConsumerCoordinator.poll()→pollHeartbeat()→sendHeartbeatRequest()// ConsumerCoordinator.poll() 核心逻辑 public void poll(long timeoutMs) {// 1. 处理未完成的异步请求(如心跳、JoinGroup 等)client.poll(timeoutMs, time.milliseconds(), new PollCondition() {@Overridepublic boolean shouldBlock() {return !coordinatorUnknown(); // 是否等待响应}});// 2. 检查是否需要触发 Rebalanceif (needRejoin()) {joinGroupIfNeeded(); // 触发 Rebalance}// 3. 周期性发送心跳pollHeartbeat(time.milliseconds()); }心跳机制:
-
心跳间隔: 由
heartbeat.interval.ms控制(默认 3 秒)。 -
会话超时: 由
session.timeout.ms控制(默认 10 秒)。若超时未心跳,消费者被踢出组。
-
-
消息拉取(
fetcher.fetchedRecords())
Fetcher 负责从 Broker 拉取消息并解析。其内部维护一个completedFetches队列缓存已拉取但未处理的消息批次。源码路径:
Fetcher.fetchedRecords()→parseCompletedFetches()→parseRecord()→deserializeRecord()// Fetcher.fetchedRecords() 核心逻辑 public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {Map<TopicPartition, List<ConsumerRecord<K, V>>> drainedRecords = new HashMap<>();int recordsRemaining = maxPollRecords; // 单次 poll 最大记录数(默认 500)// 1. 遍历已完成的拉取请求(completedFetches)while (recordsRemaining > 0 && !completedFetches.isEmpty()) {CompletedFetch completedFetch = completedFetches.peek();// 2. 解析消息批次(MemoryRecords → RecordBatch)MemoryRecords records = completedFetch.records();for (RecordBatch batch : records.batches()) {// 3. 遍历批次内的每条消息for (Record record : batch) {// 4. 反序列化消息(调用 Deserializer)K key = keyDeserializer.deserialize(record.topic(), record.key());V value = valueDeserializer.deserialize(record.topic(), record.value());// 5. 构建 ConsumerRecordConsumerRecord<K, V> consumerRecord = new ConsumerRecord<>(record.topic(),record.partition(),record.offset(),record.timestamp(),TimestampType.forCode(record.timestampType()),record.serializedKeySize(),record.serializedValueSize(),key,value,record.headers(),record.leaderEpoch());// 6. 按分区缓存消息drainedRecords.computeIfAbsent(partition, p -> new ArrayList<>()).add(consumerRecord);recordsRemaining--;}}completedFetches.poll();}return drainedRecords; }关键设计:
- 批量拉取: Kafka 按批次(
RecordBatch)拉取消息,减少网络开销。 - 零拷贝优化:
MemoryRecords直接操作ByteBuffer,避免内存复制。 - 反序列化延迟: 反序列化在消息实际被消费时进行(而非拉取时)。
- 批量拉取: Kafka 按批次(
-
位移提交(
maybeAutoCommitOffsetsAsync())
若启用自动提交(enable.auto.commit=true),消费者会在poll()后异步提交位移。源码路径:
KafkaConsumer.maybeAutoCommitOffsetsAsync()→commitOffsetsAsync()// KafkaConsumer 自动提交逻辑 private void maybeAutoCommitOffsetsAsync() {if (autoCommitEnabled) {// 1. 计算距离上次提交的时间间隔long now = time.milliseconds();if (now - lastAutoCommitTime >= autoCommitIntervalMs) {// 2. 提交所有分区的位移commitOffsetsAsync(subscriptions.allConsumed());lastAutoCommitTime = now;}} }// 异步提交位移 private void commitOffsetsAsync(final Map<TopicPartition, OffsetAndMetadata> offsets) {coordinator.commitOffsetsAsync(offsets, new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {if (exception != null) {log.error("Async auto-commit failed", exception);}}}); }自动提交配置:
-
提交间隔: 由
auto.commit.interval.ms控制(默认 5 秒)。 -
提交内容: 提交所有已消费分区的 offset + 1(确保至少一次语义)。
-
3.2.3.网络通信
所有网络请求(拉取消息、心跳、位移提交)由 ConsumerNetworkClient 管理,其核心机制为 异步请求-响应模型。
-
请求发送
// ConsumerNetworkClient.send() 方法 public RequestFuture<ClientResponse> send(Node node,AbstractRequest.Builder<?> requestBuilder,long timeoutMs ) {// 1. 构建请求对象long now = time.milliseconds();ClientRequest clientRequest = client.newClientRequest(node.idString(),requestBuilder,now,true,timeoutMs,null);// 2. 将请求加入队列(非阻塞)unsent.put(node, clientRequest);return clientRequest.future(); } -
响应处理
// ConsumerNetworkClient.poll() 方法 public void poll(long timeout, long now, PollCondition pollCondition) {// 1. 发送所有未完成的请求sendAllRequests();// 2. 轮询网络通道(Selector),接收响应client.poll(timeout, now, new PollCondition() {@Overridepublic boolean shouldBlock() {return pollCondition.shouldBlock() || hasPendingRequests();}});// 3. 处理已完成的响应handleCompletedSends();handleCompletedReceives();handleDisconnections();handleConnections();handleTimedOutRequests(); }关键机制:
-
请求队列:
unsent缓存待发送的请求。 -
响应回调: 每个请求关联一个
RequestFuture,在响应到达时触发回调。
-
3.3.反序列化
3.3.1.核心接口
Kafka 的反序列化通过 org.apache.kafka.common.serialization.Deserializer 接口实现,所有反序列化器必须实现该接口。
接口定义:
public interface Deserializer<T> extends Closeable {// 配置反序列化器(从消费者配置中读取参数)void configure(Map<String, ?> configs, boolean isKey);// 核心反序列化方法T deserialize(String topic, byte[] data);// 反序列化方法(带Headers)default T deserialize(String topic, Headers headers, byte[] data) {return deserialize(topic, data);}// 关闭资源@Overridevoid close();
}
3.3.2.源码级执行流程
-
消费者初始化阶段
当创建 KafkaConsumer 时,会通过 ConsumerConfig 加载配置,并初始化key.deserializer和value.deserializer。关键源码路径:
KafkaConsumer#initialize()→ConsumerConfig#getConfiguredInstance()// 源码片段:ConsumerConfig.java public static <T> T getConfiguredInstance(String key, Class<T> t) {String className = getString(key);try {Class<?> c = Class.forName(className, true, Utils.getContextOrKafkaClassLoader());return Utils.newInstance(c, t); // 反射创建实例} catch (ClassNotFoundException e) {// 处理异常...} }// KafkaConsumer 构造函数中初始化反序列化器 this.keyDeserializer = config.getConfiguredInstance(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, Deserializer.class); this.valueDeserializer = config.getConfiguredInstance(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, Deserializer.class);// 调用 configure() 方法 Map<String, Object> configs = config.originals(); this.keyDeserializer.configure(configs, true); // 标记为 key 反序列化器 this.valueDeserializer.configure(configs, false); // 标记为 value 反序列化器 -
消息拉取与反序列化
当调用poll()方法拉取消息后,Kafka 会遍历每条消息,使用反序列化器将字节数组转换为 Java 对象。关键源码路径:
KafkaConsumer#poll()→Fetcher#parseRecord()→ConsumerRecord#toRecord()// 源码片段:ConsumerRecord.java public static <K, V> ConsumerRecord<K, V> toRecord(/* 参数省略 */) {// 反序列化 KeyK key = keyDeserializer != null ? keyDeserializer.deserialize(topic, headers, keyBytes) : null;// 反序列化 ValueV value = valueDeserializer != null ? valueDeserializer.deserialize(topic, headers, valueBytes) : null;return new ConsumerRecord<>(topic, partition, offset, timestamp, timestampType,key, value, headers, leaderEpoch); } -
线程安全与生命周期
-
线程安全: 每个 KafkaConsumer 实例持有独立的反序列化器实例,因此反序列化器无需考虑线程安全。
-
生命周期: 反序列化器的
close()方法在消费者关闭时被调用。
-
3.3.3.自定义反序列化器实现
- 实现 Deserializer 接口
假设需要反序列化 JSON 数据:public class JsonDeserializer<T> implements Deserializer<T> {private ObjectMapper objectMapper = new ObjectMapper();private Class<T> targetType;@Overridepublic void configure(Map<String, ?> configs, boolean isKey) {// 从配置中获取目标类型(如 User.class)String configKey = isKey ? "key.type" : "value.type";String typeName = (String) configs.get(configKey);try {this.targetType = (Class<T>) Class.forName(typeName);} catch (ClassNotFoundException e) {throw new KafkaException("Class not found: " + typeName, e);}}@Overridepublic T deserialize(String topic, byte[] data) {if (data == null) return null;try {return objectMapper.readValue(data, targetType);} catch (IOException e) {throw new SerializationException("Error deserializing JSON", e);}}@Overridepublic void close() {// 清理资源(可选)} } - 消费者配置
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class.getName()); props.put("value.type", "com.example.User"); // 自定义参数传递
3.4.消费者拦截器
Kafka 支持通过 ConsumerInterceptor 拦截消息处理流程:
public interface ConsumerInterceptor<K, V> extends Configurable {// 在消息返回给用户前拦截ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records);// 在位移提交前拦截void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets);
}
- KafkaConsumer会在poll()方法返回之前调用拦截器的onConsume()方法来对消息进行定制化处理。
- KafkaConsumer会在提交完消费者位移之后调用拦截器的onCommit(),可以使用和这个方法来记录跟踪所提交的位移信息。
消费者也有连接链的概念,跟生产者一样也是按照
inerceptor.classes参数配置连接链的执行顺序。
配置方式:
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, "com.example.MyConsumerInterceptor");
相关文章:
kafka学习笔记(三、消费者Consumer使用教程——使用实例及及核心流程源码讲解)
1.核心概念与架构 1.1.消费者与消费者组 Kafka消费者是订阅主题(Topic)并拉取消息的客户端实例,其核心逻辑通过KafkaConsumer类实现。消费者组(Consumer Group)是由多个逻辑关联的消费者组成的集合。 核心规则 同一…...

鸿蒙 Form Kit(卡片开发服务)
Form Kit(卡片开发服务) 鸿蒙应用中,Form / Card / Widget 都翻译为“卡片” Form Kit(卡片开发服务)提供一种界面展示形式,可以将应用的重要信息或操作前置到服务卡片,以达到服务直达、减少跳转…...
算力卡上部署OCR文本识别服务与测试
使用modelscope上的图像文本行检测和文本识别模型进行本地部署并转为API服务。 本地部署时把代码中的检测和识别模型路径改为本地模型的路径。 关于模型和代码原理可以参见modelscope上这两个模型相关的页面: iic/cv_resnet18_ocr-detection-db-line-level_damo iic…...
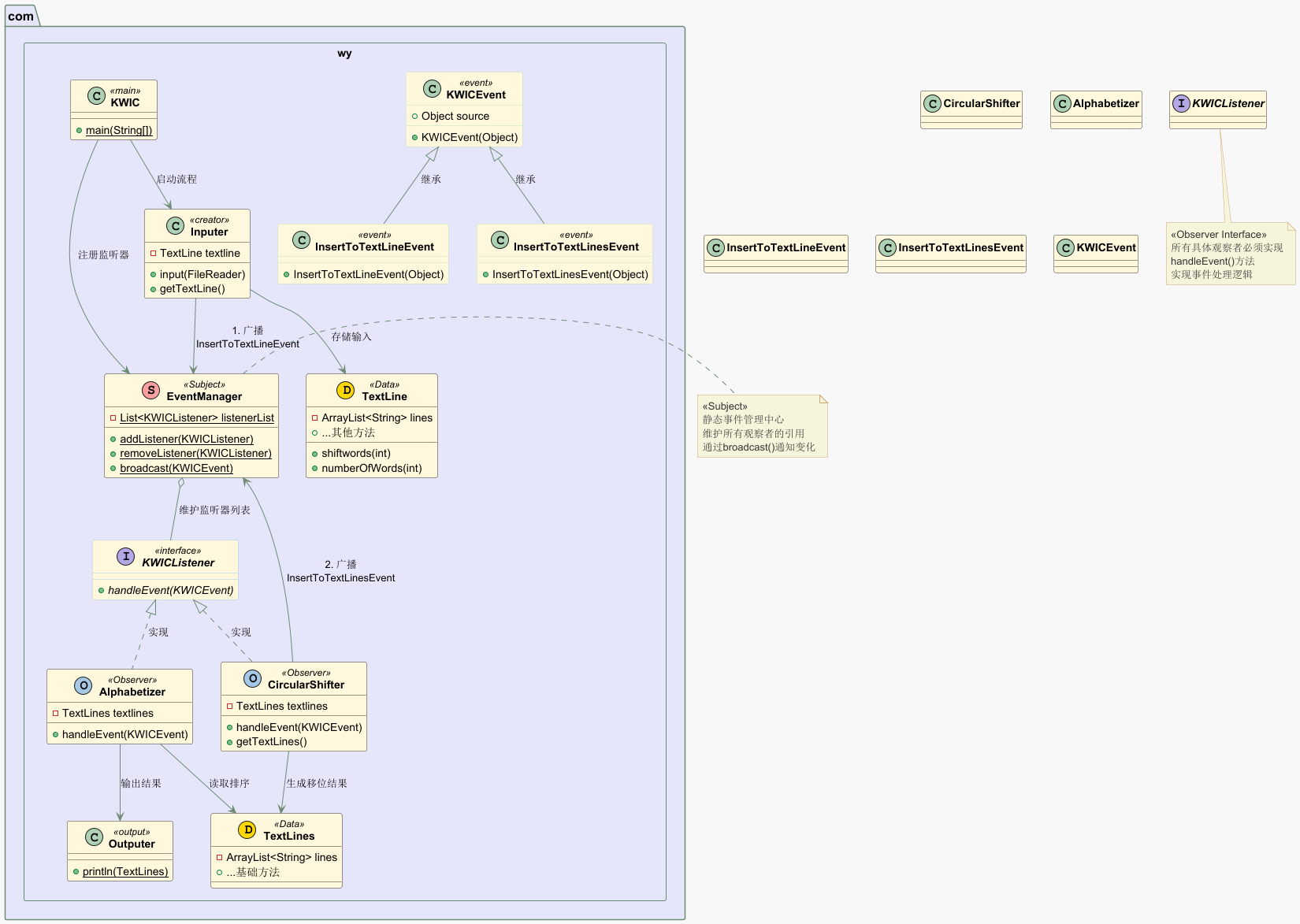
KWIC—Implicit Invocation
KWIC—Implicit Invocation ✏️ KWIC—Implicit Invocation 文章目录 KWIC—Implicit Invocation📝KWIC—Implicit Invocation🧩KWIC🧩核心组件🧩ImplementationScheme⚖️ 隐式调用 vs 显式调用对比 🌟 总结 &#x…...
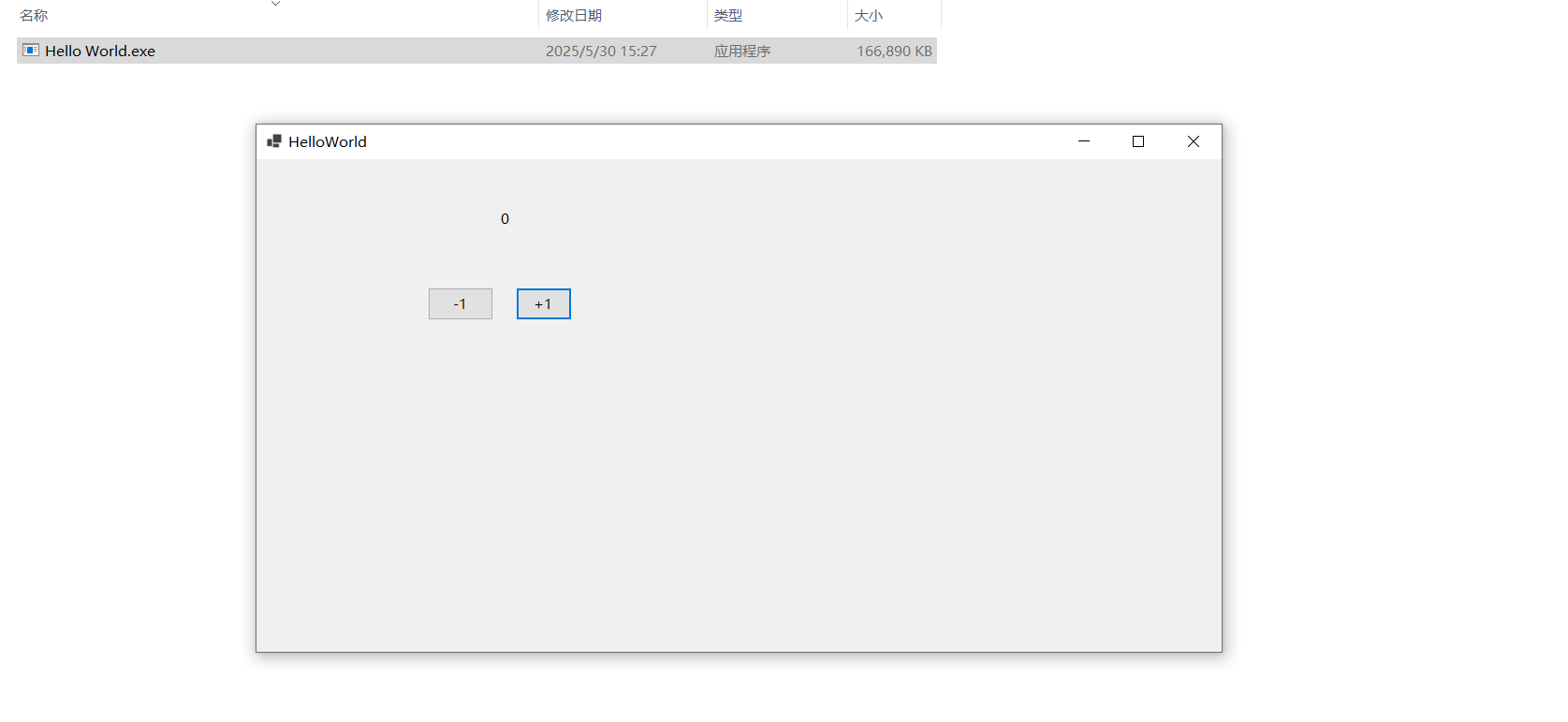
Visual Studio 2022 发布独立的 exe 文件
我们在用 Visual Studio 2022 写好一个 exe 程序之后,如果想把这个拿到其他地方运行,需要把 exe 所在的文件夹一起拿过去。 编译出来的 exe 文件需要其他几个文件一同放在同一目录才能运行,原因在于默认情况下,Visual Studio 是把…...
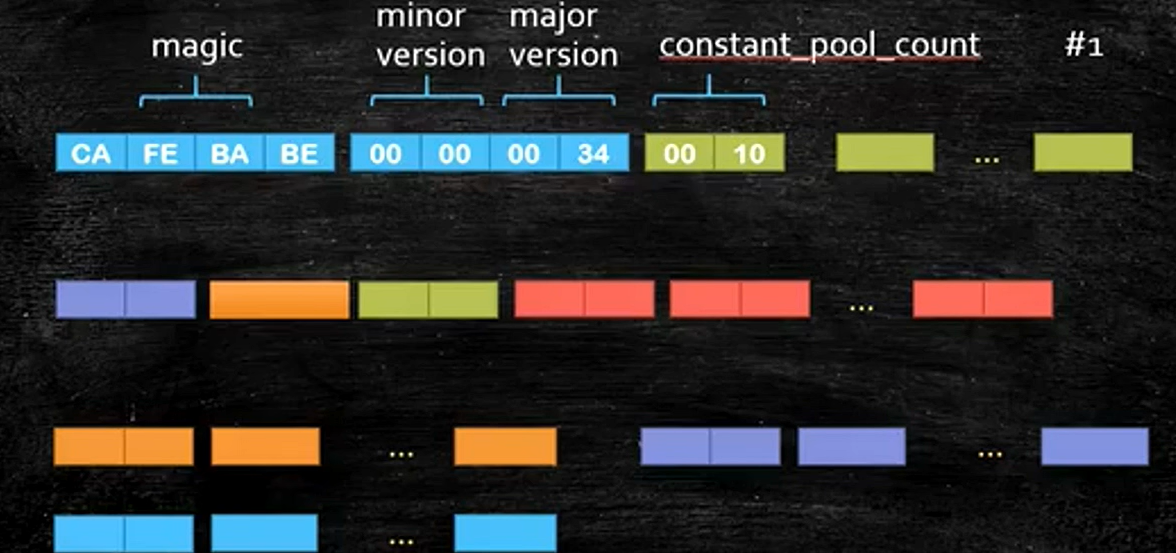
11.4java语言执行浅析4
编译成字节码(.class 文件) 使用 javac 命令将源代码编译为 Java 字节码(bytecode) 它不是机器码,而是 JVM 能理解的中间语言(字节码),具有平台无关性。 编译过程简要࿱…...

Excel 操作 转图片,转pdf等
方式一 spire.xls.free(没找设置分辨率的方法) macOs开发Java GUI程序提示缺少字体问题解决 Spire.XLS:一款Excel处理神器_spire.xls免费版和收费版的区别-CSDN博客 官方文档 Spire.XLS for Java 中文教程 <dependency><groupI…...

说说 Kotlin 中的 Any 与 Java 中的 Object 有何异同?
在 Kotlin 中 Any 类型和 Java 中的 Object 类都是所有类型的根类型。 1 基本定义 Kotlin 中的 Any 和 Any?: Any:是所有非空类型的根类型;Any?:是所有可空类型的根类型; Java 中的 Object: 是所有类…...

python分配方案数 2023年信息素养大赛复赛/决赛真题 小学组/初中组 python编程挑战赛 真题详细解析
python分配方案数 2023全国青少年信息素养大赛Python编程挑战赛复赛真题解析 博主推荐 所有考级比赛学习相关资料合集【推荐收藏】1、Python比赛 信息素养大赛Python编程挑战赛 蓝桥杯python选拔赛真题详解...
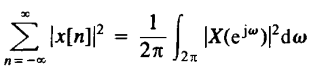
《信号与系统》第 5 章 离散时间傅里叶变换
5.0 引言 这一章将介绍并研究离散时间傅里叶变换,这样就完整地建立了傅里叶分析方法。 5.1 非周期信号的表示:离散时间傅里叶变换 5.1.1 离散时间傅里叶变换的导出 在第4章看到:一个连续时间周期方波的傅里叶级数可以看成一个包络函数的采…...

动态IP与区块链:重构网络信任的底层革命
在数字经济蓬勃发展的今天,网络安全与数据隐私正面临前所未有的挑战。动态IP技术与区块链的深度融合,正在构建一个去中心化、高可信的网络基础设施,为Web3.0时代的到来奠定基础。 一、技术碰撞:动态IP与区块链的天然契合 动态I…...

目前主流图像分类模型的详细对比分析
以下是目前主流图像分类模型的详细对比分析,结合性能、架构特点及应用场景进行整理: 一、主流模型架构分类与定量对比 模型名称架构类型核心特点ImageNet Top-1准确率参数量(百万)计算效率典型应用场景ResNetCNN残差连接解决梯度…...

uniapp使用Canvas生成电子名片
uniapp使用Canvas生成电子名片 工作中有生成电子名片的一个需求,刚刚好弄了发一下分享分享 文章目录 uniapp使用Canvas生成电子名片前言一、上代码?总结 前言 先看效果 一、上代码? 不对不对应该是上才艺,哈哈哈 <template…...

世冠科技亮相中汽中心科技周MBDE会议,共探汽车研发数字化转型新路径
近日,中汽中心2025年科技周MBDE前沿应用主题会议在天津成功举办。本次会议以“智汇津门共探MBDE前沿应用新征程”为主题,聚焦基于模型的数字工程(MBDE)方法论在汽车复杂系统研发中的创新实践与跨领域协同,旨在推动行业…...
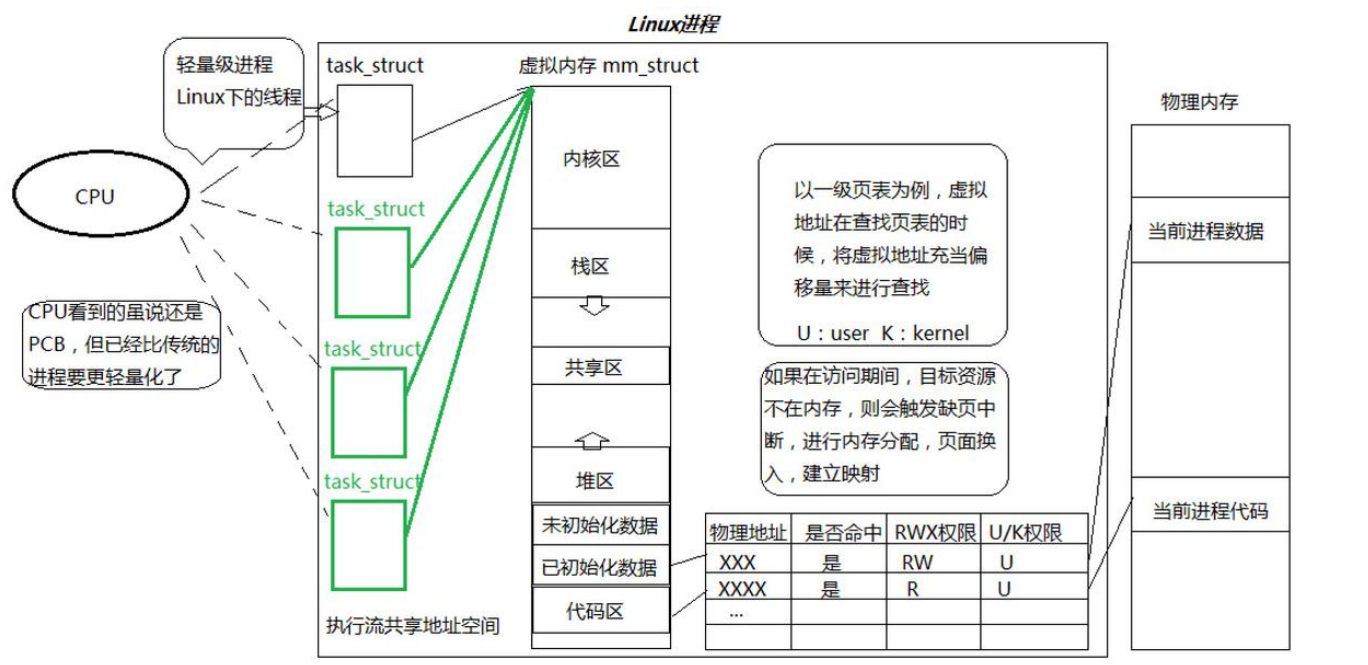
Linux笔记---线程
1. 线程的介绍 1.1 线程的概念 基本定义: 线程(Thread)是操作系统能够进行运算调度的最小单位。它被包含在进程(Process)之中(或者说是进程的一部分、对进程的划分),是进程中的实际…...

MCP架构深度解析:从基础原理到核心设计
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 持续学习,不断…...

【监控】pushgateway中间服务组件
Pushgateway 是 Prometheus 生态中的一个中间服务组件,以独立工具形式存在,主要用于解决 Prometheus 无法直接获取监控指标的场景,弥补其定时拉取(pull)模式的不足。 其用途如下: 突破网络限制࿱…...
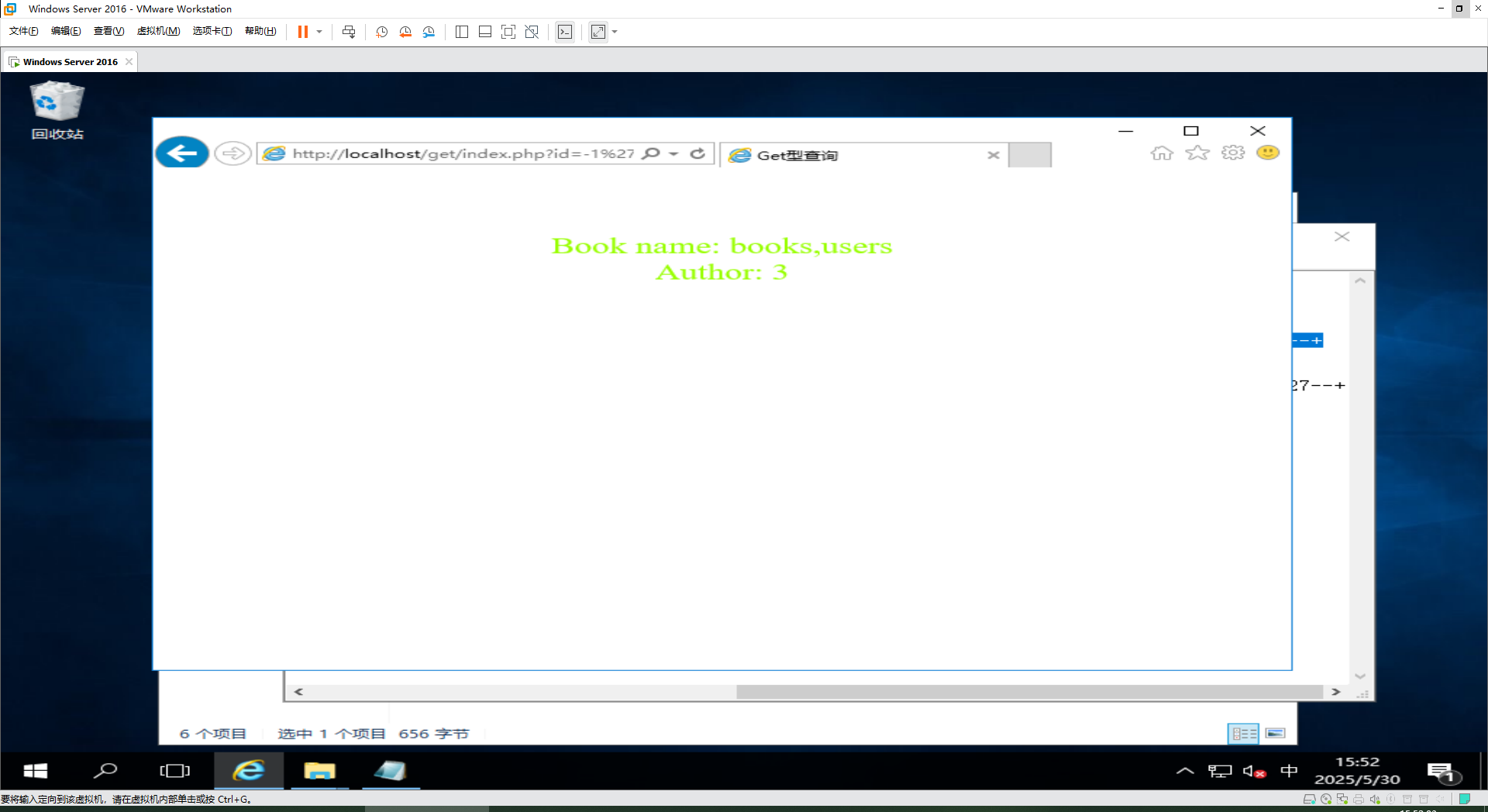
数据库暴露--Get型注入攻击
1.背景知识 1.1Post、Get的对比 特性GET 方法POST 方法HTTP 方法类型GETPOST数据位置URL 查询字符串(?key=value)请求体(Request Body)数据可见性明文显示在 URL 和浏览器历史中不可见(除非开发者工具查看)数据长度限制受 URL 长度限制(通常约 2048 字符)无明确限制(…...

AI炼丹日志-26 - crawl4ai 专为 AI 打造的爬虫爬取库 上手指南
点一下关注吧!!!非常感谢!!持续更新!!! Java篇: MyBatis 更新完毕目前开始更新 Spring,一起深入浅出! 大数据篇 300: Hadoop&…...
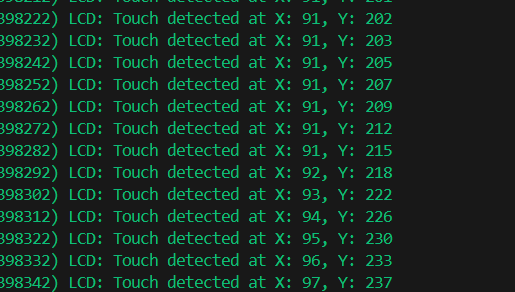
ESP32-idf学习(四)esp32C3驱动lcd
一、前言 屏幕是人机交互的重要媒介,而且现在我们产品升级的趋势越来越高大尚,不少产品都会用lcd来做界面,而esp32c3在一些项目上是可以替代主mcu,所以驱动lcd也是必须学会的啦 我新买的这块st7789,突然发现是带触摸…...

【python】uv管理器
uv是一个速度极快的 Python 包和项目管理器,用 Rust 编写。 安装 安装uv之前,确保你的电脑不需要安装了python 在Windows下,可以使用官方的脚本直接安装 powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.…...

关于Web安全:7. WebShell 管理与持久化后门
一、菜刀马 菜刀马(ChinaZ WebShell) 是一种与“中国菜刀(ChinaZ)”客户端配合使用的 WebShell 木马,广泛应用于 Web 渗透测试中,主要使用 PHP/ASP/JSP 等语言编写。 它的本质是一个一句话木马࿰…...

音视频中的复用器
🎬 什么是复用器(Muxer)? 复用器(muxer)是负责把音频、视频、字幕等多个媒体流打包(封装)成一个单一的文件格式的组件。 💡 举个形象的例子: 假设你有两样东…...
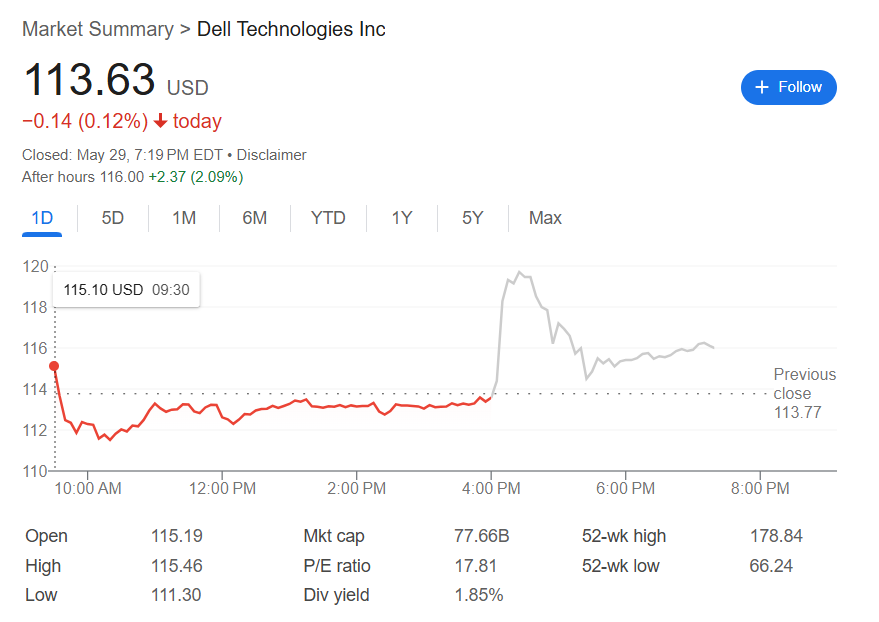
戴尔AI服务器订单激增至121亿美元,但传统业务承压
戴尔科技121亿美元的AI服务器订单,不仅超过了公司整个2025财年的AI服务器出货量,更让其AI订单积压达到144亿美元的历史高位。 戴尔科技最新财报显示,AI服务器需求的爆炸式增长正在重塑这家老牌PC制造商的业务格局,但同时也暴露出…...

远程线程注入
注入简单来说就是让别人的程序执行 你想要让他执行的dll #include<iostream> #include<Windows.h> using namespace std;char szBuffer[] "C:\\Users\\20622\\source\\repos\\Dll1\\Debug\\test.dll"; //dll路径void RemoteThreadInject(DWORD Pid,PCH…...
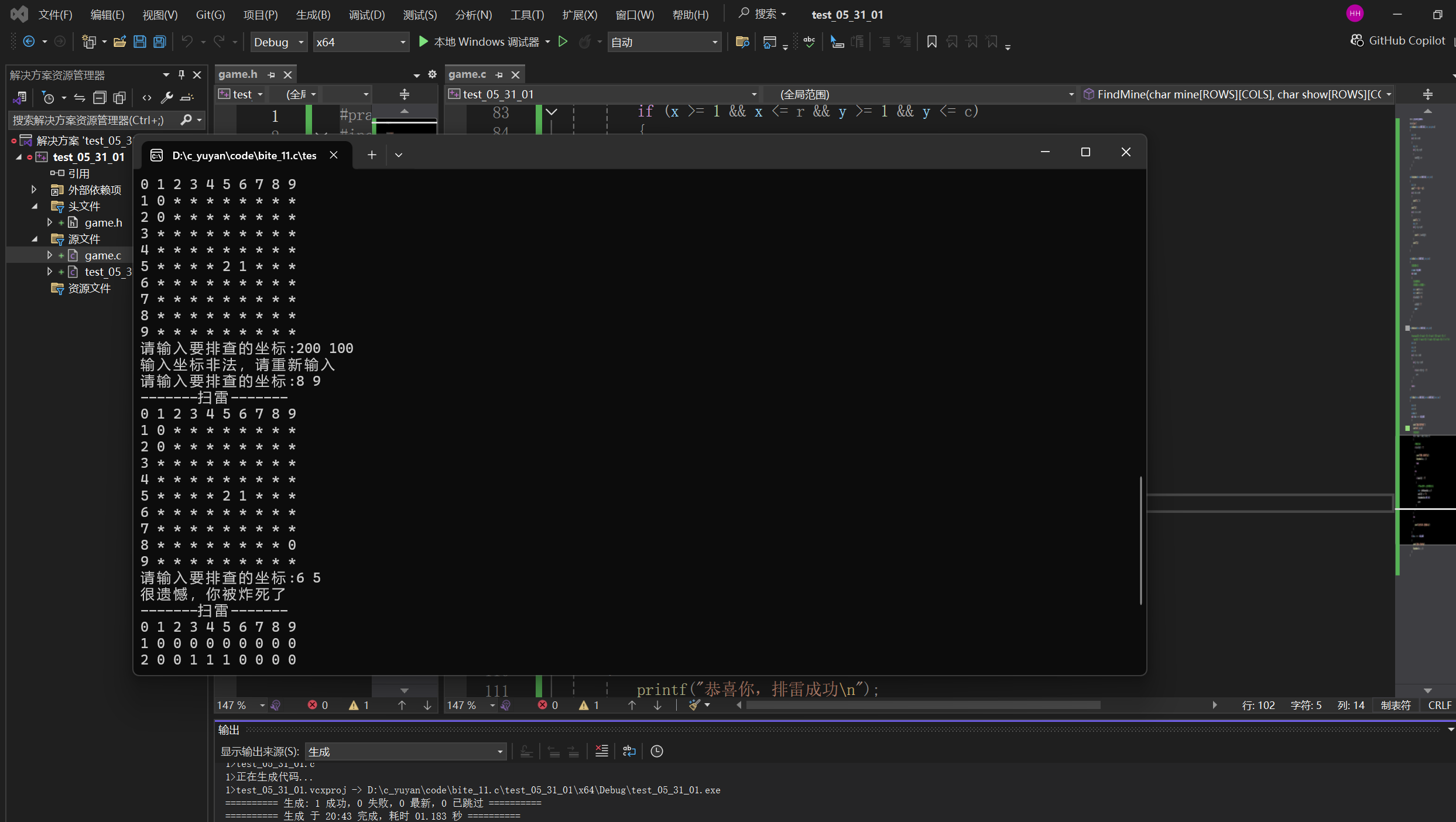
如何手搓扫雷(待扩展)
文章目录 一、扫雷游戏分析与设计1.1 扫雷游戏的功能说明1.2 游戏的分析和设计1.2.1 数据结构的分析1.2.2 文件结构设计 二、扫雷游戏的代码实现三、扫雷游戏的扩展总结 一、扫雷游戏分析与设计 扫雷游戏网页版 1.1 扫雷游戏的功能说明 使用控制台(黑框框的程序&a…...
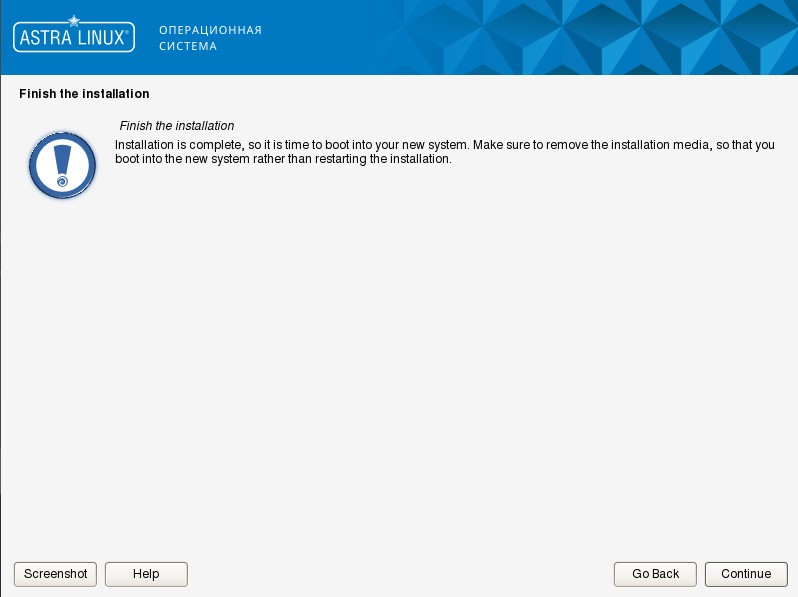
俄军操作系统 Astra Linux 安装教程
安装 U盘制作 Rufus 写盘工具:https://rufus.ie/ Astra Linux ISO 镜像文件:https://dl.astralinux.ru/astra/stable/2.12_x86-64/iso/ 准备一个8g以上的u盘,打开Rufus写盘工具,选择下载的iso镜像,写入u盘ÿ…...

第三方软件评测机构如何助力软件品质提升及企业发展?
第三方软件评测机构与软件开发者及使用者无直接关联,它们提供全方位的检测和公正的评价服务。这样的评测可以展现客观的成效,对提升软件的品质具有显著影响,且在软件产业中发挥着至关重要的角色。 评测的客观性 独立第三方机构与软件开发者…...
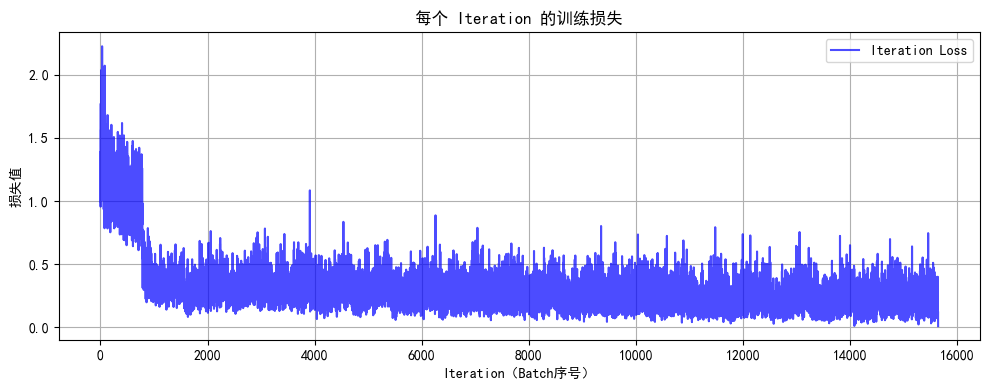
Python打卡训练营Day40
DAY 40 训练和测试的规范写法 知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业&#x…...
)
【仿生系统】爱丽丝机器人的设想(可行性优先级较高)
非程序化、能够根据环境和交互动态产生情感和思想,并以微妙、高级的方式表达出来的能力 我们不想要一个“假”的智能,一个仅仅通过if-else逻辑或者简单prompt来模拟情感的机器人。您追求的是一种更深层次的、能够学习、成长,并形成独特“个性…...